Design of an Elliptic Curve Cryptography Processor for RFID Tag Chips

Abstract
: Radio Frequency Identification (RFID) is an important technique for wireless sensor networks and the Internet of Things. Recently, considerable research has been performed in the combination of public key cryptography and RFID. In this paper, an efficient architecture of Elliptic Curve Cryptography (ECC) Processor for RFID tag chip is presented. We adopt a new inversion algorithm which requires fewer registers to store variables than the traditional schemes. A new method for coordinate swapping is proposed, which can reduce the complexity of the controller and shorten the time of iterative calculation effectively. A modified circular shift register architecture is presented in this paper, which is an effective way to reduce the area of register files. Clock gating and asynchronous counter are exploited to reduce the power consumption. The simulation and synthesis results show that the time needed for one elliptic curve scalar point multiplication over GF(2163) is 176.7 K clock cycles and the gate area is 13.8 K with UMC 0.13 μm Complementary Metal Oxide Semiconductor (CMOS) technology. Moreover, the low power and low cost consumption make the Elliptic Curve Cryptography Processor (ECP) a prospective candidate for application in the RFID tag chip.1. Introduction
Radio frequency identification (RFID) is an auto identification technology. Nowadays, it is widely used for identification control, chain management, wireless sensor networks (WSNs) and other applications. With the rapid development of the Internet of Things (IOT) and WSN, the demand on security-related RFID systems has grown fast [1]. These RFID applications require low-power and low-cost implementations of security mechanisms.
Recently, symmetric key cryptography, such as Advanced Encryption Standard (AES), has been suggested that it might not be preferable for RFID systems, since the number of RFID tags can be very large in WSNs and there is a potential risk involved in storing numerous symmetric keys. To satisfy security and system requirements, it is proved that a suitable public key cryptography scheme is necessary. Due to the fact that the traditional public key cryptography adds high overhead to the RFID tag chip, it has been considered to be unsuitable for a long time. For instance, passive RFID tags obtain energy from radio frequency signals, the power supply is limited. Therefore, these tags cannot utilize the energy-demanding cryptographic algorithms, such as the well-known RSA cryptography. Nevertheless, Elliptic Curve Cryptography (ECC), proposed by Koblitz [2], has been employed in many applications recently due to its numerous advantages over traditional public key cryptography schemes. The main advantage is that in utilizing the smaller key sizes, ECC can offer the similar security level as RSA [3]. For example, the security of 163-bit ECC is considered equivalent to 1024-bits RSA [4]. This feature makes it highly suited for implementation in RFID tag chips and being used in WSNs extensively.
The security of ECC is based on the difficulty of elliptic curve discrete logarithm problem (ECDLP) and the underlying operation in the elliptic curve cryptosystems is scalar point multiplication. The point multiplication can be performed by finite field arithmetic computations such as field addition, field multiplication, field squaring, and inversion. A number of hardware implementations for elliptic curve cryptography have been suggested in literatures, but only a few of them are aimed for RFID. Most implementations focus on speed and are based on the field-programmable gate array (FPGA) technology [5–9].
There are several implementations of scalar point multiplication in the literatures targeting RFID tag chips [10–13]. These implementations are different from coordinate systems (e.g., affine, projective, and mixed), basis (e.g., polynomial basis, normal basis), curves, architectures or algorithms. Most of these implementation efforts are concentrated on reducing the register number of elliptic curve cryptography processor without considering the practical applications, such as the transaction time. Generally, the total transaction time of RFID is required less than 300 ms [14]. However, most papers for RFID show that the time consumption to finish one point multiplication is over or close to 300 ms. Some papers just deliver a single ECC processor without involving the interfaces for other modules in a RFID tag chip, such as ROM, RAM and system controller. Low power consumption is an essential requirement for passive RFID tag chips. However, most related papers only focus on how to reduce the area of ECC processor for RFID tag chips. It has been ignored for a long time to reduce the power consumption with various low power techniques.
In this paper, we present an efficient implementation of Elliptic Curve Cryptography Processor (ECP) targeting RFID tag chips. First of all, the architecture of the RFID tag chip with ECP is described. Later on, we analyze different algorithms for scalar point multiplication and inversion, which are underlying operations in the elliptic curve cryptosystem. A new inversion algorithm is adopted and it needs fewer registers to store variables than the traditional methods. Then, we design a compact and efficient modular arithmetic logic unit (MALU). The modified circular shift register architecture is presented in this paper. We optimize the primary architecture and it shows an effective way to reduce the area of register files. In this paper, a new method of coordinates swapping is proposed which can reduce the complexity of the controller and shorten the time of iterative calculation effectively. In order to achieve low power consumption, clock gating and asynchronous counters are extensively used in our design. Finally, we perform an evaluation of our design and make comparisons with previous works.
The proposed design requires less clock cycles to finish one scalar point multiplication. The total time spent on scalar point multiplication is nearly 176.7 K clock cycles. The compact ECP needs only the area of 0.12 mm2 with UMC 0.13 μm technology and the power consumption is 20.1 μW at the clock frequency of 847.5 KHz. All of these characteristics make the ECP design very attractive for RFID tag chips.
The rest of the paper is organized as follows: Section 2 presents the architecture of the RFID tag chip with our proposed ECP, and in Section 3, the ECC algorithms are analyzed and optimized. Section 4 presents the implementation design for the different modular arithmetic logic units. In Sections 5 and 6, the modified register array and the structure of ECP command controller are presented. In Section 7, the low power strategies are presented. Result analysis and comparison are carried out in Section 8. Finally, we conclude this paper in Section 9.
2. The Architecture of the RFID Tag Chip with ECP
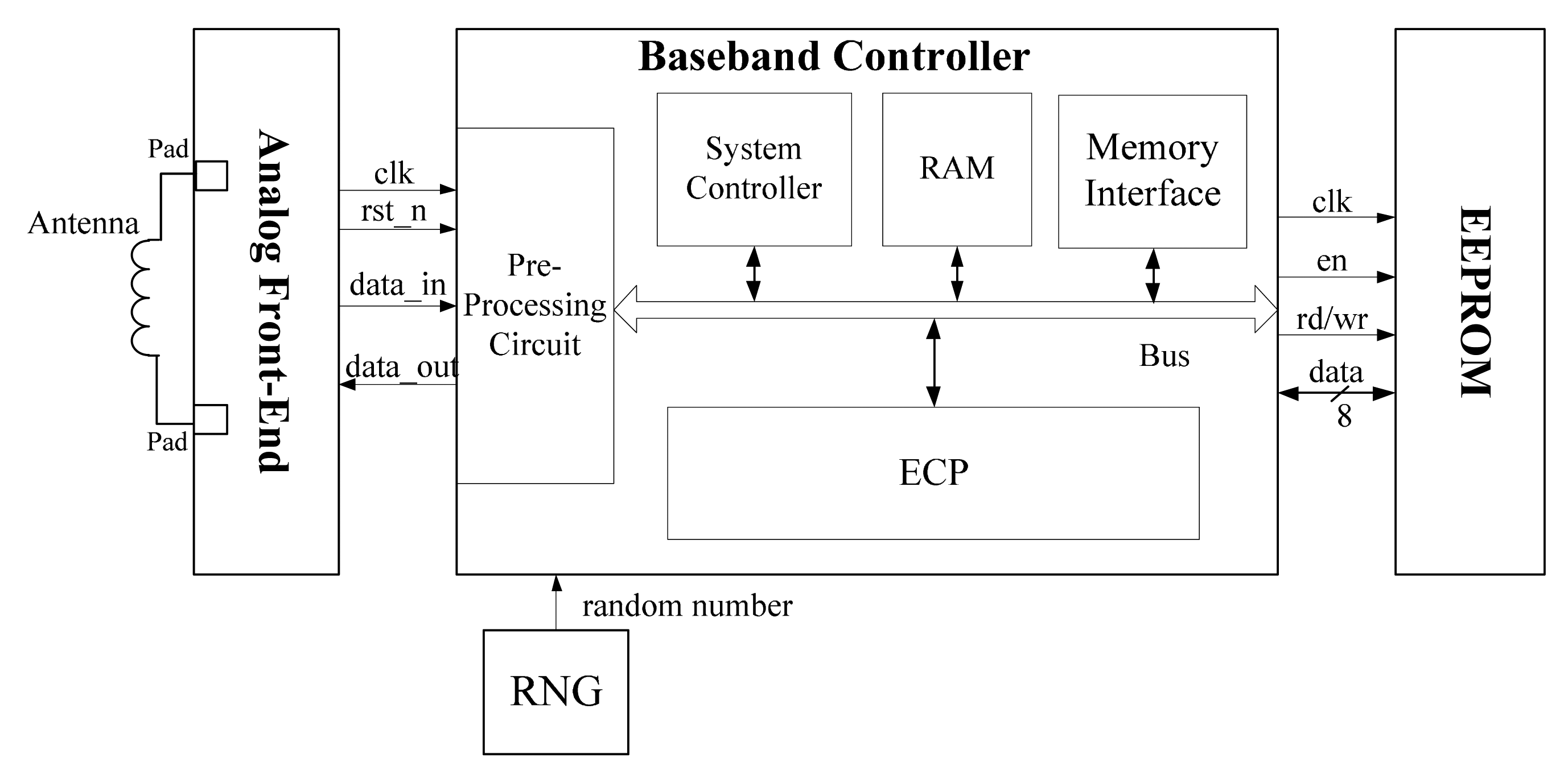
A typical ECP-embedded RFID tag chip can be divided into four parts [15], including Analog Front End (AFE), Random Number Generator (RNG), EEPROM and Digital Baseband Controller, as illustrated in Figure 1. AFE accomplishes the detailed functions of physical layer according to the RFID protocol, including carrier signal demodulation, modulation, power supply, clock generation, and reset signal generation. Random numbers generated from RNG will be used in elliptic curve digital signature algorithm (ECDSA). RNG can make sure the randomness property of each authentication so that the data in the authentication is unpredictable. EEPROM is used for storing private or public information, such as the private key, base point of elliptic curve (EC) and the EC equation parameters. Baseband Controller, utilizing the streamline bus structure, integrates the pre-processing circuit, RAM block, system controller, memory interface and ECP into one unit.
After the AFE demodulates a frame sent by the reader, then the pre-processing circuit will check the validation of the frame and extract the useful information from the frame. If the frame is legitimate, the RAM block will store the frame data into the memory arrays through the bus. When the phase of data receiving is over, the system controller will read the related information through the bus and load them into the ECP unit for further calculation. When the initialization of EC parameters has been fulfilled, the system controller will inform the ECP to start related calculation and wait for the signals from the ECP before entering the responding phase.
In this paper, the structure of the ECP is suitable for Elliptic Curves (ECs) in binary extension field of GF(2m), which means the value of m can be any legitimate value. However, for better discussion, m is set to 163, and the reduction polynomial is shown as follows:
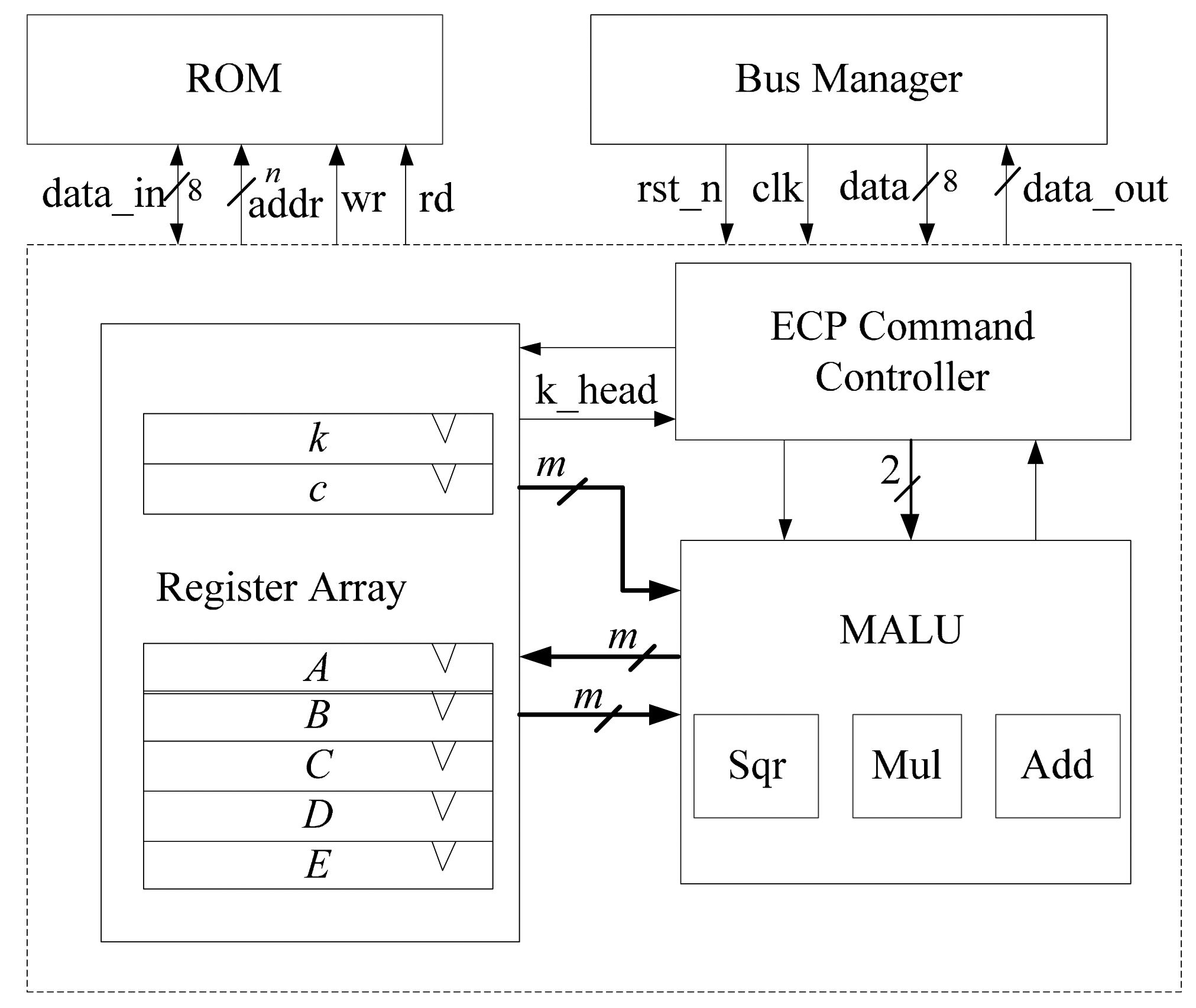
As shown in Figure 2, we propose a structure of the ECP, composed of register array, MALU and ECP command controller. The ECP performs the scalar point multiplication, inversion and any other ECC calculations and returns the results of the calculations via the bus. In our implementation, the ECP loads the private key k, ECs parameter c and base point P(x,y) into register array from ROM and executes the scalar point multiplication or other operations. After finishing the calculation, it outputs the results for further use.
3. Scalar Point Multiplication
3.1. Arithmetic Analysis
Scalar point multiplication, Q = k·P, is the underlying operation in the elliptic curve cryptosystems. P is the base point of ECs and k is a scalar used as private key. The resultant point Q will be used as a public key. According to ECDLP, if k is significantly large then it is very hard to retrieve k when the values of P and Q are given. The scalar point multiplication can be executed by point additions and point doublings, both of which involve many basic field arithmetic operations. In this paper, the EC is set as a generic Koblitz curve with the form of Equation (2), which is widely used in ECC, and the basic arithmetic operations are performed in the Galois field (GF). The GFs are either prime field GF(p) or extension binary field GF(2m). The GF(2m) design is easier for hardware implementation and is adopted in this paper.
There are two commonly used algorithms for scalar point multiplication, namely Binary Method [16] and Montgomery Ladder Method [17]. Binary Method is a basic scalar point multiplication method, also called double and add method, as shown in Algorithm 1. The scalar point multiplication iterates through every bit of k. In each iteration, the point doubling is performed. When the particular bit of k is one, the point addition is also performed. It means that the execution time of one scalar point multiplication is correlated to the hamming weight of the key k, and then the Simple Power Analysis (SPA) attacks become a threat to reveal the key value through recording power traces over time.
| Algorithm 1. Binary Method for scalar point multiplication. |
| Input : k and P, k = (km−1,km−2,…k0)2, ki∈{0,1} |
| Output : Q = k·P |
| 1 : set Q←0 |
| 2 : for i from m−1to 0 do |
| 3 : Q←2Q |
| 4 : if ki =1 then Q←Q + P |
| 5 : return Q |
Montgomery ladder method is one of the most commonly used algorithms to perform scalar point multiplication. The advantage of this method is that only the x-coordinate is used for point doubling and point addition in affine coordinates. Hence, the number of field operations and register variables can be reduced in each iteration. However, in affine coordinates, two inversion operations are needed in each iteration. As a result, at least 2 m field inversions should be performed to finish one scalar point multiplication, as shown in Algorithm 2, which leads to huge time consumption and is conflict with RFID real-time requirement. Therefore, we introduce the López-Dahab projective coordinate [18].
| Algorithm 2. Montgomery Ladder Method in affine coordinates. |
| Input : P,k, where P = (x,y)∈ GF(2m), k = [kt−1 ⋯ k1,k0]∈ Z+ |
| Output : Q = kP = (x1,y1) |
| 1 : if k = 0 or x = 0 then return Q = (0,0) and stop |
| 2 : set x1←x, x2←x2+b/x2 |
| 3 : for i = t−2 decreto 0 do |
| if ki=1, set |
| else set |
| 4 : set r1←x1+x,r2←x2+x |
| 5 : set |
| 6 : return Q(x1,y1) |
| Algorithm 3. Montgomery ladder algorithm in López-Dahab coordinates. |
| Input : P, k,where P = (x,y)∈GF(2m),k = [kt−1⋯k1,k0]∈Z+ |
| Output : Q = kP = (x1,y1) |
| 1: if k = 0 or x = 0 then return Q = (0,0) and stop |
| 2: set X1←x,Z1←1,X2←x4+b,Z2←x2 |
| 3: for i=t−2 decreto 0 do |
| if ki = 1, set (X1,Z1) = Madd(X1,Z1,X2,Z2) |
| (X2,Z2)= Mdouble(X2, Z2) |
| else set (X2,Z2)=Madd(X2,Z2,X1,Z1) |
| (X1,Z1)=Mdouble(X1,Z1) |
| 4 : set Q(x1,y1)=Mxy(X1,Z1,X2,Z2) |
| 5 : return Q(x1,y1) |
| Note : |
In projective coordinates, X-coordinate and Z-coordinate are used in each iteration, but the inversion operation is avoided. Only one inversion operation is performed in the conversion from projective coordinates to affine coordinates, as shown in Algorithm 3. It will dramatically reduce the time cost of the calculation. In the affine coordinates, because the inversion operation is performed in each iteration, 6 m-bit register variables are needed in the calculation of each iteration, which is the same number of m-bit registers as the method in the projective coordinates. Compared to Binary method, Montgomery ladder method performs point addition and point doubling in each iteration regardless of the value of ki. It offers intrinsic protection against SPA and Timing Analysis (TA) [19].
In general, the scalar point multiplication can be divided into 4 basic computing elements in GF(2m), namely multiplication, addition, inversion and squaring. The inversion operation can be performed by multiplication and squaring. In this paper, we combine the adder, squarer and multiplier into one design unit called MALU.
3.2. Inversion Algorithm
In the end of Algorithm 3, Mxy(X1, Z1, X2, Z2) means the conversion from projective coordinates to affine coordinates. It requires only one inversion operation in Algorithm 3. As inversion is a complicated operation, the Fermat's Little Theorem provides a simple method to perform inversion as follows [20]:
According to Equation (3), in the binary extension field of GF(2163), a total of 161 multiplications and 162 squarings are needed in one inversion operation. The previous Itoh-Tsujii (IT) algorithm is an effective scheme to reduce the number of multiplication operation in one inversion [21]. Algorithm 4 shows the inversion operation with the IT method. It is based on the following decomposition:
| Algorithm 4. Inversion with IT method over GF(2163). | |
| Input : A∈GF(2163) | |
| Output : T =A−1=A2m−2 where m =163 | |
| 1: B ← A2 | 2: T ← B×A, |
| 3: B ←T22 | 4: T ← B×T, |
| 5: B ←T2 | 6: T ← B×A, |
| 7: B ←T25 | 8: T ← B×T, |
| 9: B ←T210 | 10: B ← B×T, |
| 11: B ←T220 | 12: T ← B×T, |
| 13: B ←T240 | 14: T ← B×T, |
| 15: B ← T2 | 16: T ← B×A, |
| 17: B ← T281 | 18: T ← B×T, |
| 19: T ← T2 | |
Recently, a new Dimitrov-Järvinen (DJ) algorithm for inversion was introduced [22]. The new DJ method is based on the ingenious decomposition as follows [23]:
From Equations (4) and (5), in the binary extension field of GF(2163), IT method and DJ method both require 9 multiplications and 162 squarings. In the implementation of these two methods, IT method needs three 163-bit register variables, but DJ method only needs two 163-bits register variables. Our design has implemented the DJ method in projective coordinate system with only one inversion operation. The inversion algorithm with DJ method is shown in Algorithm 5.
| Algorithm 5. Inversion with the Dimitrov-Järvinen (DJ) method over GF(2163). | |
| Input : A∈GF(2163) | |
| Output :T =A−1=A2m−2 where m =163 | |
| 1: A ← A2 | 2: T ← A2, |
| 3: A ← A×T | 4: T ← T2, |
| 5: A ← A×T | 6: T ← A23, |
| 7: A ← A×T | 8: T ← T23, |
| 9: A ← A× T | 10: T ← A29, |
| 11: A ← A×T | 12: T ← T29, |
| 13: A ← A×T | 14:T ← A227, |
| 15: A ← A×T | 16 :T ← T227, |
| 17 : A ← A×T | 18:T ← A281, |
| 19:T ← A×T | |
4. Modular Arithmetic Logic Unit (MALU)
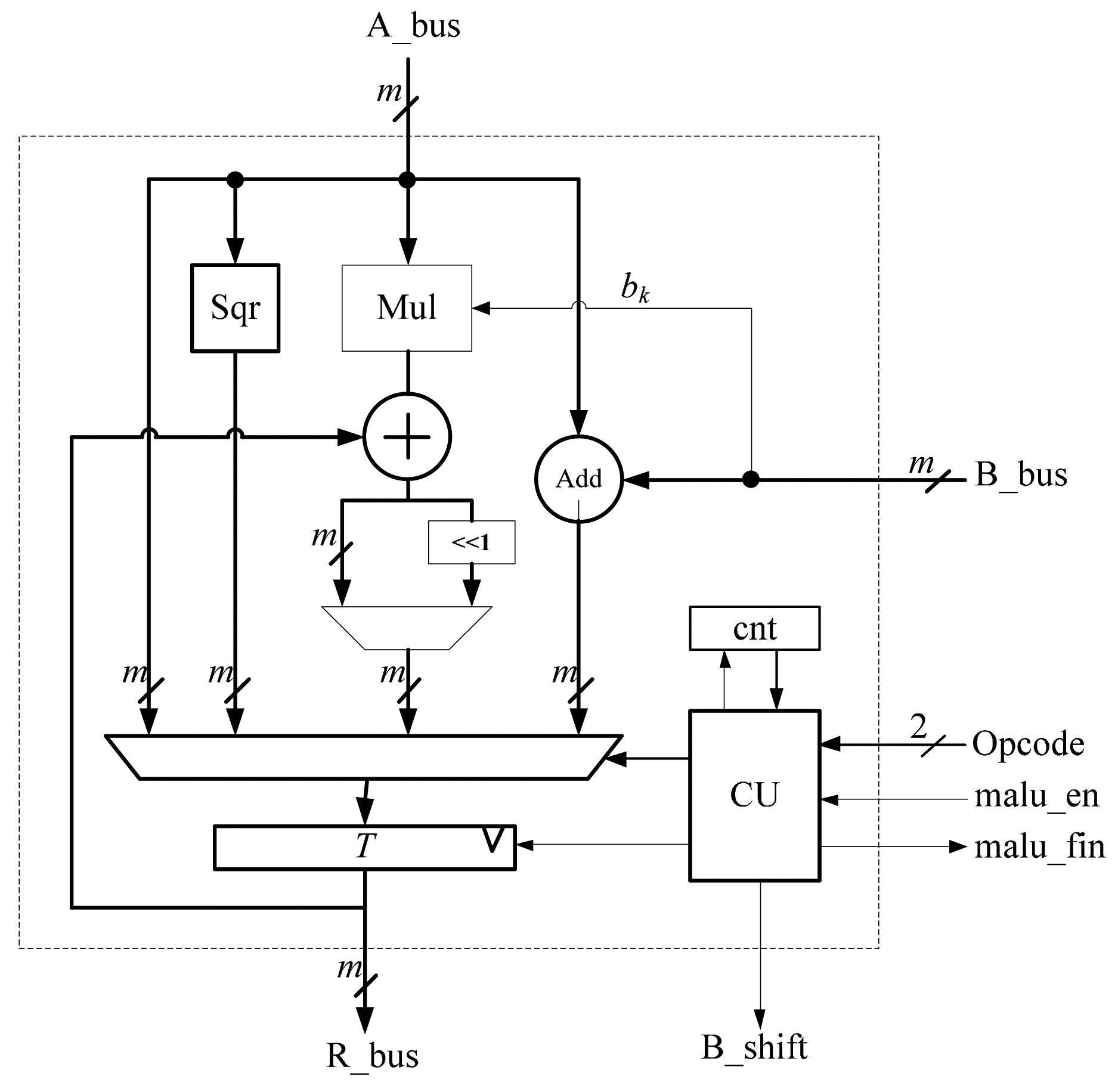
The MALU shown in Figure 3 performs the GF(2m) field operations, namely the multiplication, addition, squaring and inversion. The inversion operation can be performed by multiplications and squarings. The MALU contains 5 units, an adder unit, multiplier unit, squarer unit, controller unit and register T. The MALU is designed to execute 4 basic commands, namely ADD, SQR, MUL and INV. The operands for these commands are stored in the register array. Opcode is used to select which operation to be performed. When the signal of malu_en is valid and the MALU gets the input operands through the bus of A_bus and B_bus, the MALU will make proper operation according to the value of Opcode.
For addition, the field addition operation adds A and B, provided by A_bus and B_bus. It can be simply obtained by a bit-wise XOR operation. For squaring, the field squaring operation needs only one operand provided by A_bus. Addition and squaring operations can be efficiently performed in the MALU with a latency of one clock cycle.
Multiplication is more complex. By using the bit-serial multiplier, one operand is provided by A_bus. The multiplier requires the most significant bit (MSB) bk of B_bus for the multiplicand. The signal B_shift is used for multiplication and is provided to Reg_B in the register array. In the field of GF(2m), when the multiplication is performed, B_shift will be valid for m clock cycles, and the register Reg_B will shift to the left m times. The counter in the MALU is used to count the number of clock cycle for multiplication. It will take m clock cycles to finish one multiplication operation with the bit-serial multiplier.
After each command is executed, the MALU will provide a signal called malu_fin to inform up-level ECP for further computing. The register T serves as a medium for restoring the results of 4 basic commands and is responsible for exchanging data with register Reg_A through R_bus.
4.1. Adder Unit
For two elements, A=(am–1,am–2,…,a0)∈GF(2m) and B=(bm–1,bm–2,…,b0)∈GF(2m), field addition in the binary extension field of GF(2m) can be simply obtained by a bit-wise XOR addition operation as . Therefore, the Adder Unit is implemented in our design using 163 XOR gates with one clock cycle output latency.
4.2. Squarer Unit
We represent A(x)∈GF(2m) in polynomial basis as follows:
Squaring in GF(2m) can be calculated as follows:
In the field of GF(2163), m=163, the field arithmetic is implemented as polynomial arithmetic modulo F(x). Using the equivalence in Equation (8), it can reduce the double-sized result with the reduction polynomial.
From Equations (7) and (8), we can get the results as follows:
Therefore, without huge area requirements, squaring in GF(2m) can be efficiently implemented as a combinational logic circuit to output the result in one clock cycle. There are total 247 XOR gates in the squaring circuit. The operand comes from A_bus and the result can be saved in register T. The squarer unit is shown in Figure 4.
4.3. Multiplier Unit
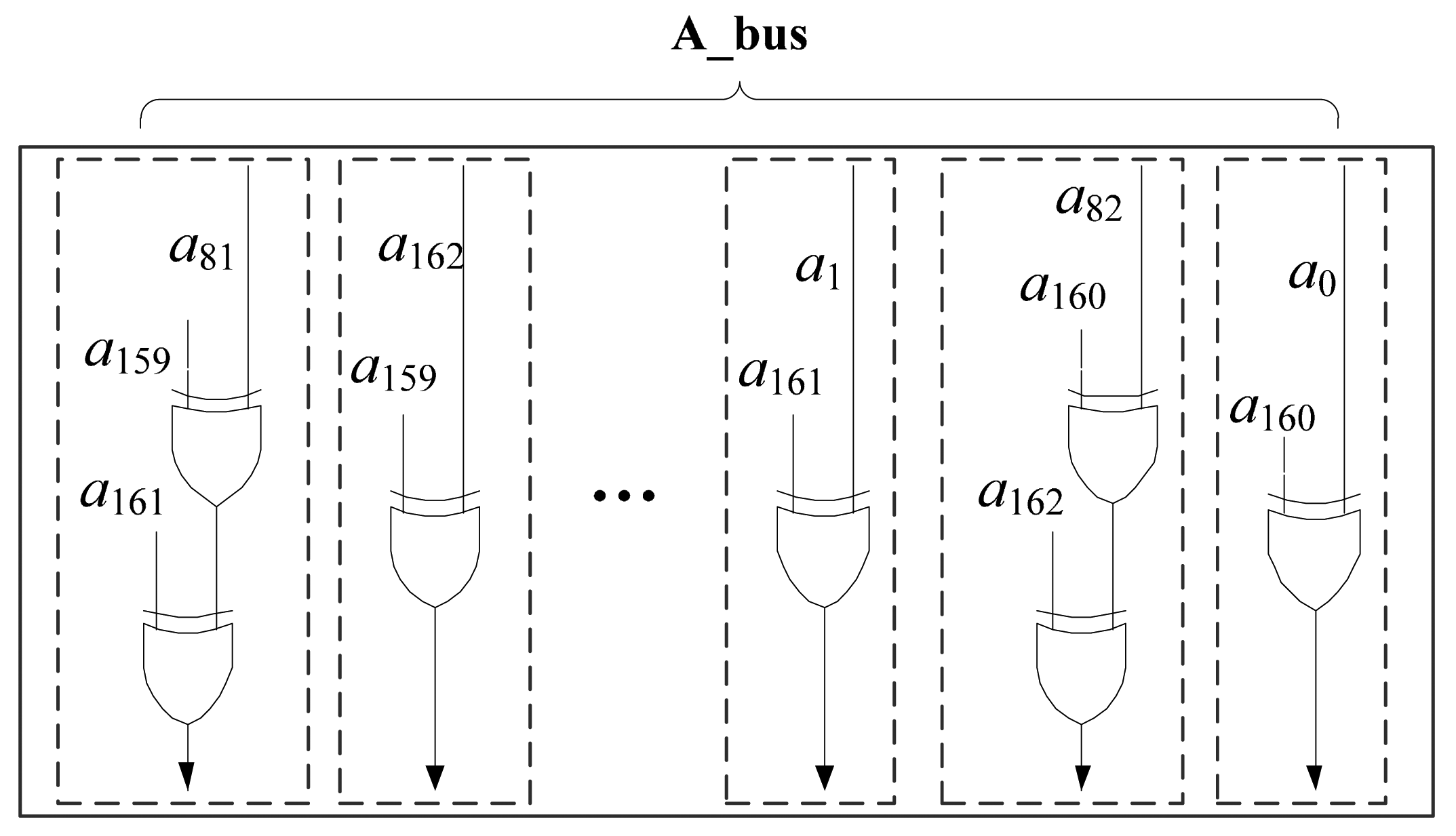
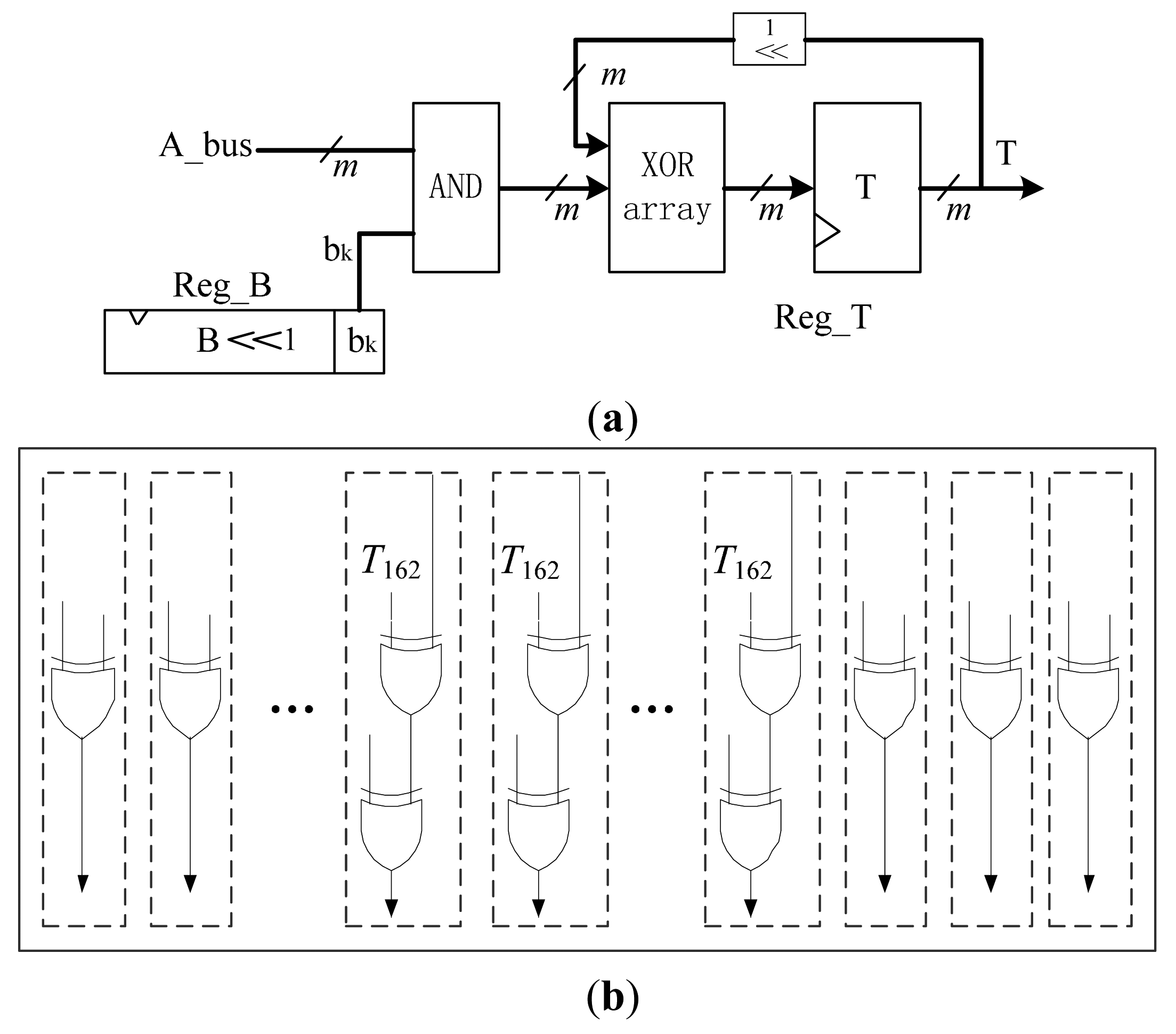
The multiplier unit is the biggest component in the MALU. As the low-power and low-cost requirements of RFID, it is necessary to optimize the design of multiplier unit. Bit-serial multipliers are proved to be the most efficient scheme that can reduce area consumption and maintain good performance [11]. It will take m clock cycles to finish one multiplication operation. We implement the Bit-serial multipliers as Algorithm 6, and the structure is shown in Figure 5. The operand A can be enabled onto the A_bus, directly from the Register Array. The individual bit of bi comes from the MSB of B_bus which is directly from a 163-bits cyclic shift-register Reg_B in the Register Array. The XOR array is based on the reduction polynomial and is composed of 166 XOR gates. Therefore, there are total 163 AND gates, 166 XOR gates and a 163-bits shifter-register T in the bit-serial multiplier circuit. The register T is also used to store the results of addition and squaring.
| Algorithm 6. Bit-serial multiplication in the field of GF(2163). | |
| Input :, , where ai,bi ∈ {0,1} | |
| Output : T = A·B mod , where c ∈ {0,1} | |
| 1 : T←0 | |
| 2 : for i = m−1 down to 0 do | |
| T←bi·A(x) + T·x + tm−1·F(x) | |
| 3 : Return T | |
5. Register Array
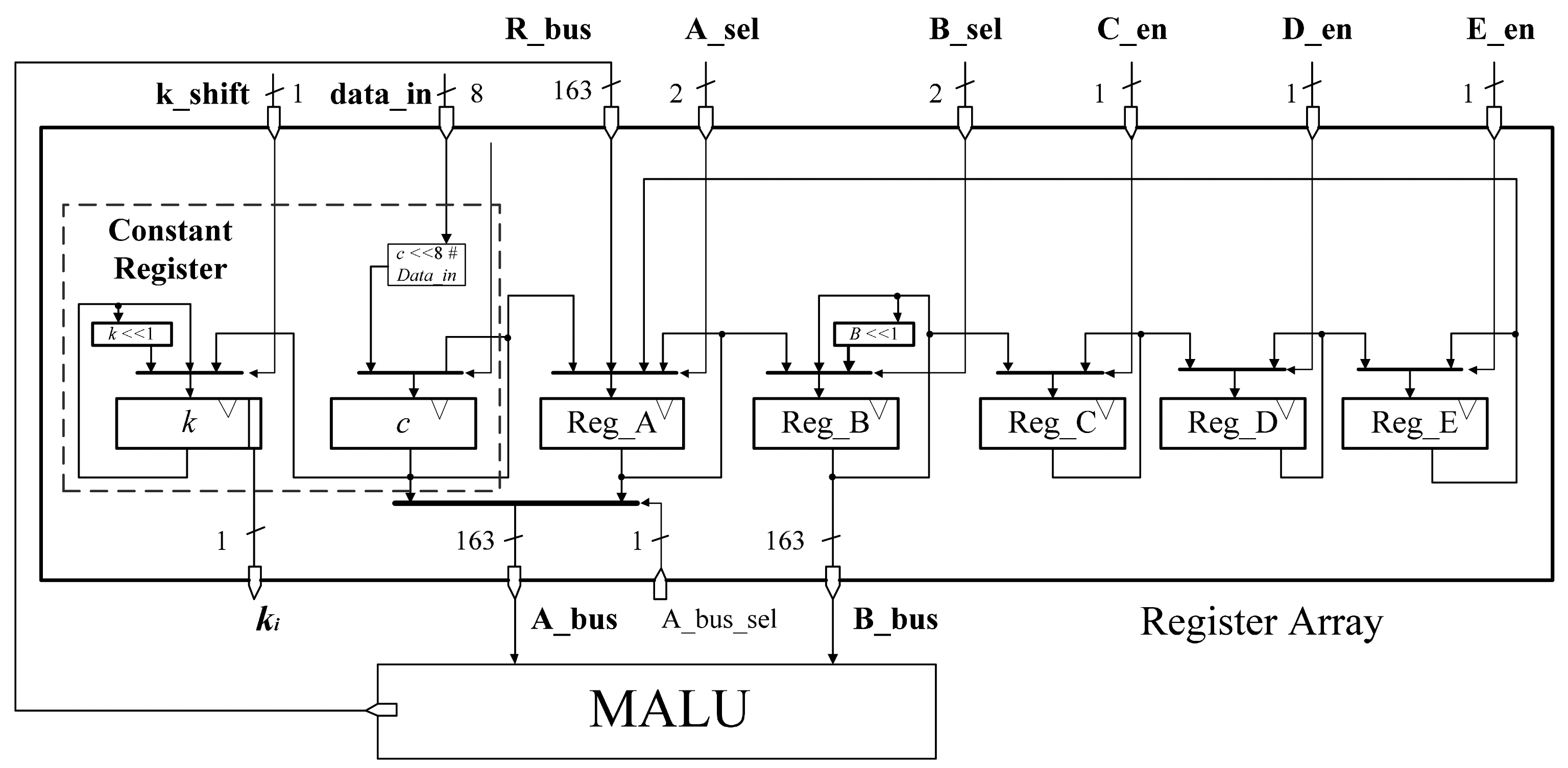
The architecture of the register array file is shown in Figure 6. This circular shift register architecture has been proved to be an effective method to reduce the area consumption of register files [10]. We modify the primary architecture and make it fit for our whole design. In [10], the calculation that converting projective coordinates to affine coordinates is not involved and the register k is set in their controller module. Therefore, there are only six registers needed in their register file. In our register file, there are seven registers including register k. Register k and register c are the constant registers. Reg_A, Reg_B, Reg_C, Reg_D, Reg_E are used to store temporary variables of the calculation. Register c has an 8-bit I/O through which data coming from external ROM or RAM can be loaded and stored. These external data can be private key k, ECs parameter c, or the coordinates of base point P(x,y). When the ECP needs some constant parameters for calculation, register c will load those parameters. After the private key k is loaded into register c from the external ROM, register k will load the key value from register c immediately. After finishing the data preparation of part 2 in Algorithm 3, the register k can be shifted by one bit to the left according to the iteration calculation of part 3 in Algorithm 3 and provides the ki value for ECP command controller.
The whole register array is a circular shift register file. Each register is independently controlled by ECP command controller for efficient management. Furthermore, Reg_B is a circular shift register which can be shifted by one bit to the left. The data in Reg_A and Reg_B will input to MALU through A_bus and B_bus for the calculation based on opcode. Reg_C, Reg_D, Reg_E can only be updated by the preceding register, as the original scheme. To reduce the power consumption, clock gating, as a low power strategy, is applied to the circular shift register. Compared to the primary architecture, we integrate the register of private key k and the register of constant c into the register array. It makes our ECP become more compact and efficient.
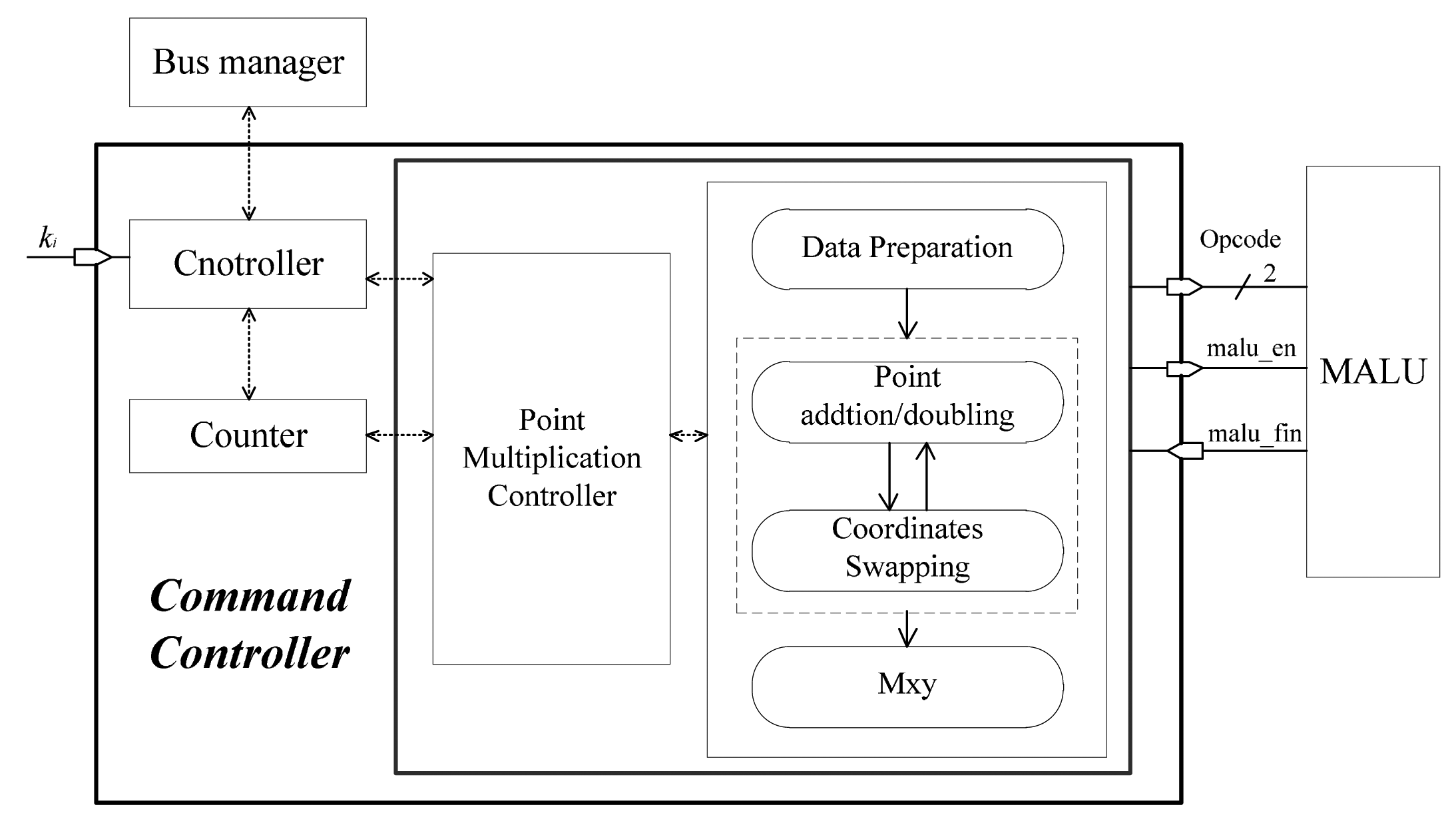
6. ECP Command Controller
The ECP command controller, as shown in Figure 7, executes data preparation, point addition, point doubling, and the Mxy according to Algorithm 3. The data preparation is carried out simply by transferring (x,y) into (X1, Z1, X2, Z2), from the affine coordinates to the López-Dahab projective coordinates. The Mxy part involves the final calculations for converting projective coordinates to affine coordinates. The routines implemented in the ECP command controller are collected in Figure 8.
According to part 3 of Algorithm 3, the ECP command controller takes in the most significant bit (MSB) of the shift register k from register array. No matter if ki = 0 or ki = 1, a point addition and a point doubling are performed in one iterative calculation. Figure 8 shows that five registers are needed to store temporary variables in the calculation of point addition and point doubling. The base point coordinate x and EC parameter c will be loaded into the constant register c from the external ROM when they are needed.
In the iterative calculation of the part 3 of Algorithm 3, when ki = 1, point addition and point doubling are performed as follows:
When ki = 0, point addition and point doubling are performed as follows:
According to Equations (9) and (11), when ki changes from 1 to 0, the terms X1Z2Z1X2 and X1Z2 + Z1X2 will remain unchanged. When ki = 0, before the calculation of point addition and point doubling, X1 and Z1 will be swapped with X2 and Z2. Therefore, X1, Z1, X2, Z2 will be stored in Reg_C, Reg_D, Reg_A, Reg_B respectively. The outputs to point addition are saved in X2, Z2 (Reg_A, Reg_B) and the outputs to point doubling are saved in X1, Z1 (Reg_C, Reg_D). As the updated result value of X1, Z1, X2, Z2 are stored in Reg_C, Reg_D, Reg_A, Reg_B respectively, a coordinate swapping is still needed to swap X1, Z1 with X2, Z2, in the end of point doubling. Therefore, the final results of X1, Z1, X2, Z2 are stored in Reg_A, Reg_B, Reg_C, Reg_D, respectively.
Consequently, the point addition and point doubling can be repeated in the iterative calculation in the part 3 of Algorithm 3 without the involvement of ki bits. However, when ki = 0, it needs extra coordinates swapping operations. By the way of coordinates swapping, it is easy to implement the controller and decrease the complexity. In addition, it can shorten the time of iterative calculation effectively.
As Figure 8 shows, in data preparation, it needs three squaring and one field addition. Six multiplications, five squaring and three field additions are performed in the calculation of one point addition and point doubling. In the phase of converting projective coordinates to affine coordinates, including an inversion operation, there are total of 19 multiplications, 163 squaring and 6 field additions. Assuming H(k) = 163, the hamming weight of private k, point multiplication will take approximately 163.9 K clock cycles without clock cycles of controlling. When the base point coordinate P(x, y) or EC parameter c is utilized as one operand, the constant register requires a read operation, and the operation will take 21 clock cycles. The final simulation result shows that point multiplication will take 176.7 K clock cycles based on our whole design scheme.
7. Low Power Strategies
As the energy provided for passive RFID tag comes from radio frequency signals, low power consumption is an essential requirement for passive RFID tag chip. The operation distance of RFID systems depends on the maximum of the dynamic power of tag chip. Clock-gating and asynchronous counters are adopted in the design of our ECC processor to minimize power consumption.
Clock gating is a popular technique used in many synchronous circuits for reducing dynamic power dissipation [24]. Clock gating saves power by adding more logic to a circuit to prune the clock tree. Pruning the clock disables portions of the circuitry so that the flip-flops in them do not have to switch states. The used clock gating cells come from UMC standard cell library in 0.13 μm CMOS technology.
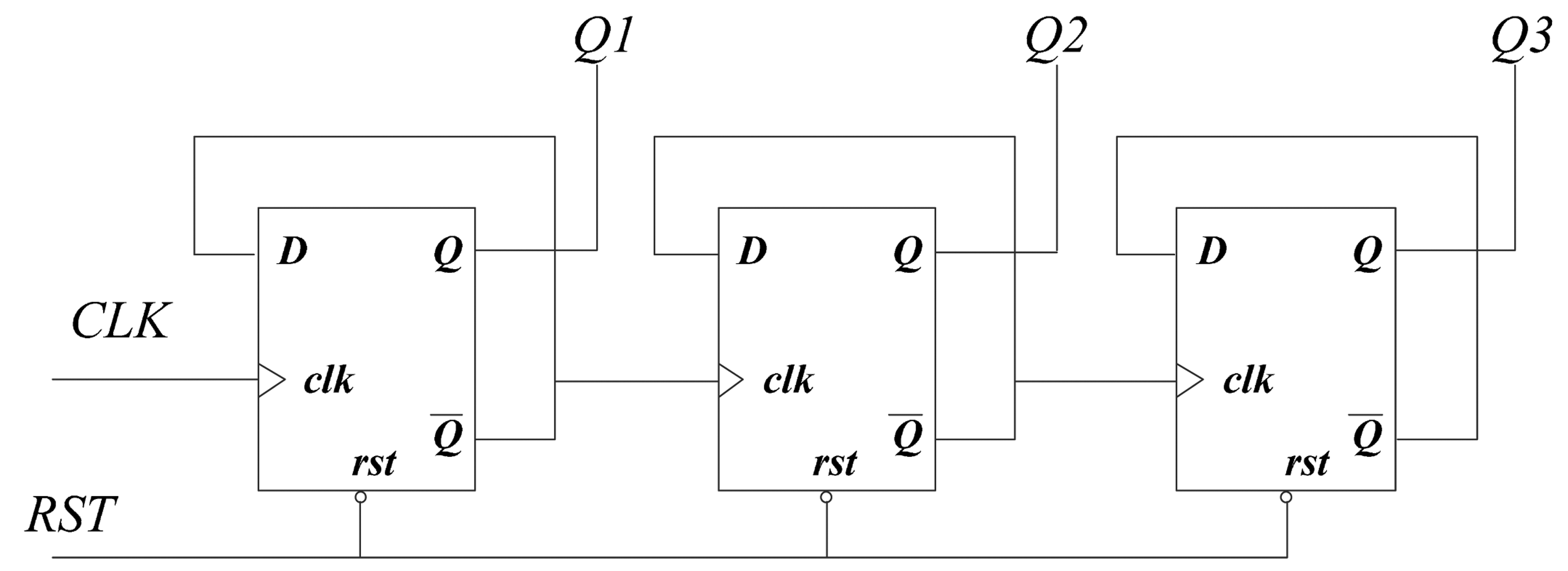
Many counters are used in the design of ECC processor. Using synchronous counter might bring in large power consumption, since every bit of the registers would be triggered on each of the clock edges. For asynchronous counter, as shown in Figure 9, only the first flip-flop would be triggered by clk. The subsequent flip-flops are triggered by the former flip-flops. Therefore, the unnecessary switches in registers can be minimized as well as reducing the dynamic power. As the ECC processor for RFID tag works at a low clock frequency, there is no need to use synchronous counters. Compared to synchronous counter, asynchronous counters with more than 4-bit flip-flops structure can reduce the power consumption by 50% at least [25].
8. Result and Comparison
8.1. Result Analysis
The proposed design has been conducted in Verilog HDL. We synthesized our processor using a low leakage power library of UMC 0.13 μm (fsc0l_d_generic_core_tt1p2v25c.db). For synthesis, we used the EDA tool of Design Complier. Gate equivalent (GE) can provide meaningful comparisons of area among different technologies. The area of two inputs NAND is 5.12 μm2 in fsc0l lib. Table 1 shows the gate count of every component of our ECP. The controller and the MALU have the area of 918 GE and 3591 GE respectively. The register array (9342 GE) dominates the gate area and occupies 67% area of the whole design.
Power consumption is one of the most important factors for passive RFID tag chip. We used EDA tools of VCS and Power Compiler to get the estimation of average power at the gate level. First, the Value Change Dump (VCD) files were generated in VCS. Then, VCD files were translated to Switching Activity Interchange Format (SAIF) files, which were used in Power Complier to get average power consumptions. The carrier frequency of ISO/IEC 14443 standard is 13.56 MHz [26], so the source clock frequency provided by AFE is 13.56 MHz.When the ECP is applied to the RFID tag chip, the ECP will be under the control of the baseband. The work clock of ECP comes from the baseband. The source clock may be divided by 2n, and the divided clock will be provided for the ECP, where n = 0, 1, 2, 3, 4, 5, 6. Figure 10 and Table 2 show the ECP's power consumption, time and energy for one scalar point multiplication at different work frequencies and the power consumption can be effectively reduced by decreasing the operation frequency. Because of the adoption of low power strategies, such as clock gating and asynchronous counter, it can save about 15% power consumption at the same work clock frequency. In order to compare the frequency power benefits, Figure 11 shows the normalized time, power and energy for one scalar point multiplication under different work frequencies.
The simulation result of a certain scalar point multiplication demonstrates that the time needed for one calculation is 176.7 K clock cycles. Taking the ISO/IEC 14443 standard as an example [26], the AFE will extract a clock with the frequency of 13.56 MHz, so the total time consumption is nearly 13.1 ms.
As the ISO 14443 standard specified, the frame waiting time (FWT) defines the maximum time for a RFID tag to start its response frame after the end of a reader frame, as shown in Figure 12. The FWT is calculated by the following formula:
Both the power consumption and the calculation time prove that our proposed ECP can meet the demands of real-time and resource-constraint for the applications of RFID tag chips. The layout of the ECP is shown in Figure 13. The largest module is the register array, followed by the MALU module, and the ECP command controller is the smallest module. The overall area of the ECP processor is 349 μm × 358 μm.
8.2. Comparisons
Table 3 shows the comparison with the related works. The ECP can work at different clock frequencies according to the real-time and power requirements of different RFID systems. The number of clock cycles for one scalar point multiplication is 176.7 K and it is much less than the design of [10–13].
The MALU in the design of [10] has an 8-bit adder and an 8-bit multiplier. Therefore, the squaring operation uses the same logic as the multiplication, hence, each squaring requires m clock cycles. In our design, there is a specialized squarer unit and the squaring operation requires only one clock cycle. Moreover, the design of [10] assumes that the coordinate conversion to the affine coordinate system and the calculation of Y-coordinate value are performed on a reader or back-end system, hence, the inversion operation has not been implemented in [10]. If the inversion is performed in the design of [10], another 163-bit register should be added. The area of one bit register composed of D-type flip-flops is about 8 GE in UMC 0.13 μm technology. In fact, the coordinate conversion is necessary in a complete ECP of the RFID tag chip for encryption and decryption applications, such as ECDSA [29]. Due to the adoption of the DJ method, one 163-bit register is saved in the inversion operation of our design. As a result, the number of 163-bit register is the same as [10], but the coordinate conversion is implemented in our scheme. The design of [10] can acquire the trades-offs between the gate area and the number of clock cycles depending on the digit sizes, but the time cost for one scalar point multiplication is about 240 ms, it can hardly satisfy the transaction time requirements of some RFID systems.
The literature [12] has adopted the same method and structure as [10] does. The ECs parameters are fixed that can be very helpful to reduce the area, but it is not compatible in different RFID systems. In our design, the register c of register array can load in different ECs parameters. Moreover, the EC in [12] is a kind of binary Edwards curve, which is a special elliptic curve. The binary Edwards curves have not been recommended by NIST standards [30] and are not widely used in cryptosystems. The Koblitz curve is widely used and is adopted in our design.
In [11], the ECP has been implemented in an affine coordinate system, with the disadvantage that it requires one inversion to be computed in each iteration. As a result, it needs much more clock cycles than our work for one scalar point multiplication. Moreover, the ECs parameter c in [11] is fixed. Hence, the design of [11] cannot be used in other Koblitz curves when the parameter c is changed. In [11], it does not achieve a much better result than ours or other works. Finally, in [13], the scalar point multiplication is done in 297 K clock cycles and the area is 13.2 K GE. The gate area of our design is slightly larger than [13], but the number of clock cycles is much less than [13].
Due to the adoption of clock gating and asynchronous counter, the power consumption is smaller than all the other designs at the same clock frequency. With the power and the time to finish one scalar point multiplication, we can get the energy consumption demonstrating that our design can satisfy the low-power requirement of RFID tag chips. The low number of clock cycles needed for one scalar point multiplication makes it suitable for real-time applications of RFID tag chips. Although the gate area of our design is slightly larger than [12,13], our design achieves a good trade-off between the real-time requirement and the constrained resource.
9. Conclusions
A design of Elliptic Curve Cryptography processor based on Koblitz curves for the RFID tag chip is presented in this paper. We employ Montgomery Ladder algorithm for scalar point multiplication which is the underlying operation in the elliptic curve cryptography. A new DJ method is exploited for inversion operation and it requires fewer registers to store variables than the traditional methods. A preferable MALU for our ECP design is presented in detail. In the iterative calculation of point addition and point doubling, a new coordinates swapping method is proposed. It can reduce the complexity of the ECP command controller and shorten the time of iterative calculation effectively. The modified circular shift register file is introduced to reduce the complexity of system. Some low power strategies, such as clock gating and asynchronous counter are adopted, saving about 15% power consumption.
Our design was synthesized with UMC 0.13 μm CMOS technology at different frequencies. Compared to other reported results, our architecture acquires good trade-offs of clock cycle number, gate area, power consumption and energy. On the aspects of power consumption and time cost, our design shows better performance. According to the implementation results, the ECP area is 0.12 mm2, and the power consumption can be reduced to 20.1 μW at the clock frequency of 847.5 KHz, which can meet the demands of real-time, low-power, and resource-constraints for the applications of RFID tag chips and WSNs.
Acknowledgments
This work is supported by the National Natural Science Foundation of China (Grant No.61306038 and No.61376031), ChenGuang Project of science and technology for Wuhan youths (No.2013072304010829) and the Fundamental Research Funds for the Central Universities (HUST: 2013TS050).
Author Contributions
All authors have contributed to the presented work. Zilong Liu, Dongsheng Liu and Xuecheng Zou proposed the architecture and scheme. Zilong Liu and Jian Cheng conducted the implementation and wrote the manuscript. Hui Lin has contributed to algorithm analysis. All authors have read and revised the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Atzori, L.; Morabito, G. The internet of things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar]
- Koblitz, N. Elliptic curve cryptosystems. Math. Comput. 1987. [Google Scholar]
- Koblitz, N.; Menezes, A.; Vanstone, S. The state of elliptic curve cryptography. Des. Codes Cryptogr. 2000, 19, 173–193. [Google Scholar]
- National Security Agency. The Case for Elliptic Curve Cryptography. Available online: http://www.nsa.gov/business/programs/elliptic_curve.shtml (accessed on 15 September 2014).
- Mahdizadeh, H.; Masoumi, M. Novel architecture for efficient FPGA implementation of elliptic curve cryptographic Processor over GF(2163). IEEE Trans. Very Large Scale Integr. 2013, 21, 2330–2333. [Google Scholar]
- Gustavo, D.; Jeanm, P.D.; Jose, L.I. Efficient elliptic curve point multiplication using digit-serial binary field operation. IEEE Trans. Ind. Electron. 2013, 60, 217–225. [Google Scholar]
- Järvinen, K. Optimized FPGA-based elliptic curve cryptography processor for high-speed applications. Integr. VLSI J. 2011, 44, 270–279. [Google Scholar]
- Dimitrov, V.S.; Järvinen, K.U.; Jacobson, M.J.; Chan, W.F.; Huang, Z. Provably sublinear point multiplication on Koblitz curves and its hardware implementation. IEEE Trans. Comput. 2008, 57, 1469–1481. [Google Scholar]
- Azarderakhsh, R.; Masoleh, A.R. High-Performance implementation of point multiplication on Koblitz curves. IEEE Trans. Circuits Syst. II Exp. Briefs. 2013, 60, 41–45. [Google Scholar]
- Lee, Y.K.; Sakiyama, K.; Batina, L.; Verbauwhede, I. Elliptic-curve-based security processor for RFID. IEEE Trans. Comput. 2008, 57, 1514–1527. [Google Scholar]
- Kumar, S.; Paar, C. Are standards compliant elliptic curve cryptosystems feasible on RFID? Proceedings of Workshop on RFID Security, Graz, Austria, 12–14 July 2006; pp. 12–14.
- Kocabas, U.; Fan, J.; Verbauwhede, I. Implementation of binary Edwards curves for very-constrained devices. Proceedings of 2010 the 21st International Conference on Application-Specific Systems Architectures and Processor (ASAP), Rennes, France, 7–9 July 2010; pp. 185–191.
- Hein, D.; Wolkerstorfer, J.; Felber, N. ECC is Ready for RFID-A Proof in Silicon. In Selected Areas in Cryptography; Roberto, M.A., Liam, K., Eds.; Springer: Heidelberg, Germany, 2009; Volume 5381, pp. 401–413. [Google Scholar]
- Wang, D.M.; Ding, Y.Y.; Zhang, J.; Hu, J.G.; Tan, H.Z. Area-Efficient and ultra-low-power architecture of RSA Processor for RFID. Electron. Lett. 2012, 48, 1185–1187. [Google Scholar]
- Nainan, S.; Romin, P.; Tanvi, S. RFID Technology Based Attendance Management System. Int. J. Comput. Sci. Issue 2013, 10, 516–521. [Google Scholar]
- Menezes, A.; Oorschot, A.V.; Vanstone, S. Handbook of Applied Cryptography; CRC Press Inc.: Boca Raton, FL, USA, 1997. [Google Scholar]
- Montgomery, P. Speeding the pollard and elliptic curve method of factorization. Math. Comput. 1987, 48, 243–264. [Google Scholar]
- López, J.; Dahab, R. Fast Multiplication on elliptic curves over GF(2m) without precomputation. In Cryptographic Hardware and Embedded Systems; Cetin, K.K., Christof, P., Eds.; Springer: Heidelberg, Germany, 1999; Volume 1717, pp. 316–327. [Google Scholar]
- Joye, M.; Yen, S.M. The Montgomery Powering Ladder. In Cryptographic Hardware and Embedded Systems; Burton, S.K., Cetin, K.K., Eds.; Springer: Heidelberg, Germany, 2002; Volume 2523, pp. 291–302. [Google Scholar]
- Burton, D.M. Elementary Number Theory; Tata McGraw-Hill Education: Noida, India, 2006. [Google Scholar]
- Itoh, T.; Tsujii, S. A fast algorithm for computing multiplicative inverses in GF(2m) using normal bases. Inf. Comput. 1988, 78, 171–177. [Google Scholar]
- Dimitrov, V.; Järvinen, K. Another look at inversions over binary fields. Proceedings of 2013 21st IEEE Symposium on Computer Arithmetic (ARITH), Austin, TX, USA, 7–10 April 2013; pp. 211–218.
- Reza, A.; Kimmo, U.J.; Mechran, M.K. Efficient algorithm and architecture for elliptic curve cryptography for extremely constrained secure applications. IEEE Trans. Circuits Syst. I Regul. Pap. 2014, 61, 1144–1155. [Google Scholar]
- Wu, Q.; Pedram, M.; Wu, X. Clock-Gating and its application to low power design of sequential circuits. IEEE Trans. Circuits Syst. I Fundam. Theory Appl. 2000, 47, 415–420. [Google Scholar]
- Wei, D.; Zhang, C.; Cui, Y.; Chen, H.; Wang, Z. Design of a low-cost low-power baseband-processor for UHF RFID tag with asynchronous design technique. Proceedings of the 2012 IEEE International Symposium on Circuits and Systems (ISCAS), Seoul, Korea, 20–23 May 15.
- Identification Cards—Contactless Integrated Circuit(s) Cards—Proximity Cards, Part 1: Physical Characteristics, ISO/IEC 14443-1, December 1999.
- Ferreira, J.; Filipe, P.; Cunha, G.; Silva, J. Cloud terminals for ticketing systems. Proceedings of the Fifth International Conferences on Advanced Service Computing, Valencia, Spain, 27–31 May 2013; pp. 19–25.
- Markantonakis, K.; Mayes, K.; Sauveron, D.; Askoxylakis, I.G. Overview of security threats for smart cards in the public transport industry. Proceedings of the 2008 IEEE International Conference on e-Business Engineering, Xi'an, China, 22–24 October 2008; pp. 506–513.
- Johnson, D.; Menezes, A.; Vanstone, S. The elliptic curve digital signature algorithm (ECDSA). Int. J. Inf. Secur. 2001, 1, 36–63. [Google Scholar]
- National Institute of Standards and Technology. Recommended Elliptic Curves for Federal Government Use. Available online: http://csrc.nist.gov/groups/ST/toolkit/documents/dss/NISTReCur.pdf (accessed on 15 September 2014).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ecp_con | MALU | Reg_array | |
|---|---|---|---|
| Cell Area (μm2) | 4702.7 | 18385.9 | 47831.1 |
| Area (Gates) | 918 | 3591 | 9342 |
| Freq (KHz) | 13,560 | 6780 | 3390 | 1695 | 847.5 | 423 | 212 |
| Power (μW) | 253 | 129 | 68.6 | 36.7 | 20.1 | 11.2 | 6.27 |
| Time (ms) | 13.1 | 26.1 | 52.2 | 104.5 | 208.5 | 417.7 | 833.5 |
| Energy (μJ) | 3.31 | 3.37 | 3.58 | 3.83 | 4.19 | 4.68 | 5.23 |
| Ref. | Freq.(KHz) | Power (μW) | Cycles | Time (ms) | ECP Area (gates) | Core Size (μm2) | Energy * (μJ) | Technology |
|---|---|---|---|---|---|---|---|---|
| This Work | 13,560 | 253 | 176.7 K | 13.1 | 13.8 K | 124,942 | 3.3 | UMC 0.13 μm |
| 1,690 | 36.7 | 104.5 | 3.8 | |||||
| 847.5 | 20.1 | 208.5 | 4.2 | |||||
| 423 | 11.2 | 417.7 | 4.7 | |||||
| [10] | 1,130 | 36.63 | 275.8 K | 244.08 | 12.5 K | N.A. | 8.9 | UMC 0.13 μm |
| 590 | 21.55 | 144.8 K | 245.49 | 14.1 K | 5.3 | |||
| 411 | 15.75 | 101.2 K | 246.19 | 14.7 K | 3.9 | |||
| 323 | 12.08 | 78.5 K | 243.17 | 15.4 K | 2.9 | |||
| [11] | 13,560 | N.A. | 376.9 K | 31.8 | 15 K | N.A. | N.A. | AMI 0.35 μm |
| [12] | 400 | 7.3 | 219.1 K | 547.87 | 11.7 K | N.A. | 3.9 | UMC 0.13 μm |
| [13] | 847.5 | 83 | 350.4 | 219,897 | 29.1 | UMC 0.18 μm | ||
| 106 | 10.8 | 297 K | 2801.9 | 13.2 K | 30.2 | |||
| 106 | 54.7 | 2801.9 | N.A. | 153.2 | AMS 0.35 μm | |||
*Energy consumption for one scalar point multiplication.
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Liu, D.; Zou, X.; Lin, H.; Cheng, J. Design of an Elliptic Curve Cryptography Processor for RFID Tag Chips. Sensors 2014, 14, 17883-17904. https://doi.org/10.3390/s141017883
Liu Z, Liu D, Zou X, Lin H, Cheng J. Design of an Elliptic Curve Cryptography Processor for RFID Tag Chips. Sensors. 2014; 14(10):17883-17904. https://doi.org/10.3390/s141017883
Chicago/Turabian StyleLiu, Zilong, Dongsheng Liu, Xuecheng Zou, Hui Lin, and Jian Cheng. 2014. "Design of an Elliptic Curve Cryptography Processor for RFID Tag Chips" Sensors 14, no. 10: 17883-17904. https://doi.org/10.3390/s141017883
APA StyleLiu, Z., Liu, D., Zou, X., Lin, H., & Cheng, J. (2014). Design of an Elliptic Curve Cryptography Processor for RFID Tag Chips. Sensors, 14(10), 17883-17904. https://doi.org/10.3390/s141017883