1. Introduction
Wireless sensor networks (WSNs) which are composed of lots of tiny, resource-constrained and cheap sensor nodes are self-organized networks. These nodes are always deployed in distributed mode to perform various applications, such as healthcare monitoring, transportation systems, industry service, and environmental measurement of humidity or temperature data [
1]. In each case, efficient data gathering for target information is one of the primary missions.
In a typical scenario, WSNs have many ordinary sensor nodes and a base station named sink node. The ordinary nodes can only perform simple measurement and communication tasks since they are always equipped with limited power supply and most of the time, it is difficult to replace or recharge the battery. In contrast, the sink node is capable of performing complex operations since it is usually supplied with unlimited resources. Thus how to balance the energy consumption and develop energy efficient data collection protocols is still a research hotspot.
To reduce energy consumption for data gathering in WSNs, distributed source coding (DSC) [
2] was proposed to compress the raw data between the ordinary nodes. DSC-based data collection protocols are composed of two important procedures. The first step is the collection of spatial-temporal correlation properties of the raw data. The second is a coding step which is based on the Slepian-Wolf coding theory. The coding process imposes no communication burden among sensor nodes, but the data correlation of the whole network must be calculated at the sink node before data collection, which results in a relatively high computational cost.
In recent years, compressive sensing has emerged as a new approach for signal acquisition, which can guarantee exact signal reconstruction with a small number of measurements [
3]. Data compression and data collection are integrated into a single procedure in compressive sensing-based data gathering methods. Moreover, the high computational burdens are transferred to the base station. Finally, the incomplete data can be recovered by various complicated reconstruction algorithms at the sink node. Nevertheless, to ensure exact reconstruction, the key point is that the signals are required to be sparse in some base dictionary. Sparse representation expresses signals as sparse linear combinations of the basis. Therefore, dictionary learning for sparse signal representation is one of the core problems of compressive sensing.
The paper presents an ODL-CDG algorithm. The proposed algorithm aims to reduce the energy consumption for data gathering problem in WSNs. How to design ODL-CDG algorithm to be robust to environmental noise is also our objective. The main contributions of this paper can be summarized as follows:
- (1)
Inspired by the periodicity of nature signals, the learned dictionary is constrained with sparse structure where each atom is a sparse linear combination of the base dictionary. We first apply the sparse structured dictionary in the compressive data gathering process.
- (2)
The self-coherence of the learned dictionary is introduced as a penalty during the optimization procedure, which reduces the reconstruction error caused by ambient noise.
- (3)
In respect of the sparse structured dictionary D and the Gaussian observation matrix Φ, it’s theoretically demonstrated that the sensing matrix P = ΦD meets the property of RIP with very high probability. What’s more, the lower bound of necessary number of measurements for exact reconstruction is given.
- (4)
With these consideration, the online dictionary learning algorithm is designed to improve the adaptability of data gathering algorithm for a variety of practical applications. The training data is gathered in parallel with the compressive sensing procedure, which reduces the enormous energy consumption.
The remainder of this paper is organized as follows: in
Section 2, we review the previous works involving dictionary learning and energy-efficient data gathering problem in wireless sensor networks.
Section 3 presents the mathematical formulation of the problem in detail.
Section 4 demonstrates the RIP property of the sensing matrix. In
Section 5, the optimized solution of our proposed ODL-CDG problem is given and the convergence property is also analyzed. In
Section 6, the performances of the ODL-CDG algorithm are verified on synthetic datasets and the real datasets by experimental results. Finally, conclusions are drawn and future work proposed in
Section 7.
2. Related Work
In the past few years, much effort has gone into designing data gathering techniques with the aim of reducing energy consumption in WSNs. Luo et al. [
4] first proposed a complete design for compressive sensing-based data gathering (CDG) in large scale wireless sensor networks. In CDG, the sensor readings are assumed to be spatially correlated. Moreover, the communication cost is reduced and the load balance is achieved simultaneously. Liu et al. [
5] introduced a novel compressed sensing method called expanding window compressed sensing (EW-CS) to improve recovery quality for non-uniform compressible signals. Shen et al. [
6] proposed non-uniform compressive sensing (NCS) for signal reconstruction in the WSNs. The spatio-temporal correlation of the sensed data and the network heterogeneity were both taken into consideration in NCS, which leads to significantly less samples. In [
7], the authors presented a quantitative analysis of the primary energy consumption of WSNs. They pointed out that the compressed sensing and distributed compressed sensing may act as energy efficient sensing approaches in comparison with other compression techniques.
The abovementioned compressive sensing-based data gathering methods can relieve the energy shortage problem and prolong network lifespan. However, these methods have limitations in that the signals are assumed only to be sparsely represented in a specified basis, etc., in a wavelet, Discrete Cosine Transform (DCT) or Fourier basis. Actually, a single predetermined basis may not be able to sparsely represent all types of signals, since there is a wide variety of applications for WSNs.
To adapt to signals of enormous diversity and dynamics, dictionary learning from a set of training signals has received lots of attention. The goal is to train a dictionary that can decompose the signals using a few atoms. The K-SVD [
8] method is one of the well-known dictionary learning algorithms, which can lead to much more compact representation of signals. Duarte et al. [
9] proposed to train the dictionary and optimize the sampling matrix simultaneously. The motivation is to make the mutual coherence between the dictionary and the projection matrix as minimal as possible. Christian et al. [
10] presented a dictionary learning algorithm called IDL which made a trade-off between the coherence of the dictionary to the observations of signal class and the self-coherence of the dictionary atoms. To accelerate the convergence of K-SVD, an overcomplete dictionary was proposed in [
11]. The authors suggested updating the atoms sequentially, thus leading to much better learning accuracy when compared with K-SVD. In [
12], a new dictionary learning framework for distributed compressive sensing application was presented utilizing the data correlation between intra-nodes and inter-nodes, which resulted in improved compressive sensing (CS) performance
However, the case where there is no access to the original data is not taken into account in the above work. What’s more, obtaining the full original data may be costly in wireless sensor networks. That is our motivation to learn the dictionary from a compressive sensing approach. Studer et al. [
13] investigated dictionary learning from sparsely corrupted signals or compressed signals. In [
14], the authors further extended the problem of compressive dictionary learning based on sparse random projections. The idea was coming from their previous paper [
15], where the compressive K-SVD (CK-SVD) algorithm was proposed to learn a dictionary using compressive sensing measurements. Aghagolzadeh et al. [
16] associated the spatial diversity of compressive sensing measurements without additional structural constraints on the learned dictionary, which guaranteed the convergence to a unique solution with high probability.
Nevertheless, the environmental noise is not considered in the methods mentioned above. As analyzed in
Section 3, the reconstruction error caused by environmental noise is positively correlated with the self-coherence of the learned dictionary. Thus, the self-coherence of the learned dictionary is added as a penalty term during the dictionary updating step. The novel dictionary is also imposed by structural constraints.
4. Necessary Guarantees for Signal Reconstruction
Cai et al. [
23] proved that Basis Pursuit algorithm could guarantee the reconstruction of Equation (4) in the following theorem:
Theorem 1. Assume that the measurement matrix Φ satisfies for some . Let θ be a S-spare vector. Then, the recovery error of Equation (4) is bounded by the noise level.
The reconstruction of signals that are sparse in an orthonormal basis is guaranteed by the above theorem. Nevertheless, we mainly stress the problem that signals are not sparse in an orthonormal basis but rather in a redundant dictionary
D ∈
RN×2N, as described in
Section 3.2 and
Section 3.3. For the sake of elaboration convenience, the following two lemmas are given:
Lemma 1. Let entries of Φ ∈
RM×N be independent normal variables with mean zero and variance n−1. Let DΛ, i.e., |Λ| = S,
be the submatrix extracted from columns of the redundant matrix D. Define the isometry constant δΛ =
δΛ(D) and v: = δΛ + δ + δΛδ for 0 < δ < 1. Then:with probability exceeding:where c is a positive constant, in particular c equals 7/18
for the Gaussian matrix Φ. Proof. The proof of lemma 1 can be found in [
24]. □
Lemma 2. The restricted isometry constant of a redundant dictionary D with coherence μ is bounded with: Proof. This can be obtained from the proof [
25]. □
Theorem 2. Assume that the structure of our redundant dictionary is D = ΨΘ = Ψ[
IN×NΣN×N],
where Ψ is the orthogonal base dictionary, i.e., discrete cosine transform (DCT) based ion RN for N = 2
2p+1.
The number of atoms is K = 2
2p+2.
Suppose that the sparsity of the signal is smaller than 2
p−4,
the necessary sampling number that could guarantee signal reconstruction is obtained by:with the constants C1 ≈ 524.33
and C2 ≈ 5.75
. Proof. For t > 0, assume that the local isometry constant of matrix P = ΦΨ is δΛ (P), which is no larger than δΛ (D) + δ + δΛ (D)δ with probability at least 1−e−t. □
By Lemma 1, we obtain that:
Thus the global isometry constant
is bounded over all
possibilities. So:
Using the Stirling formula, and confining the above term to less than
e−t, the following inequation is obtained:
The above theoretical derivation states that δS(P) is less than δS(D) + δ + δS(D)δ with probability at least 1−e−t when .
Let
μ be the coherence of dictionary
D, we assume:
Then combining with Lemma 2, we can obtain:
Thus, defining
δ = 7/33 yields:
As demonstrated by Theorem 1, the necessary number of samples to have
is:
Replacing
S in Equation (21) with 2
S, and plugging
K = 2
2p+2 and
δ = 7/33 into Equation (21), the necessary number of samples is finally available. That is:
6. Simulation
This section presents our simulation results on synthetic data and the real datasets. The performance of the proposed dictionary is compared with a pre-specified dictionary, like the DCT dictionary, and other dictionary learning approaches, such as K-SVD, IDL and CK-SVD.
6.1. Recovery Accuracy
The initial basis Ψ is a 50 × 50 DCT matrix. A set of training signals is generated by a linear combination of the original synthetic data. The process is accomplished by applying a projection matrix Φ with independent and identically distributed Gaussian entries and column normalization. Input parameters to Algorithm 1 are λA = 0.1, λΘ = 0.05, εstop = 0.001 and T = 100.
The performance is evaluated by using the relative reconstruction error, i.e.,
, where
X and
denote the original signal and the reconstructed signal, respectively. Each setting is averaged for 50 trials. The simulation results are presented in
Figure 1 and
Figure 2. In
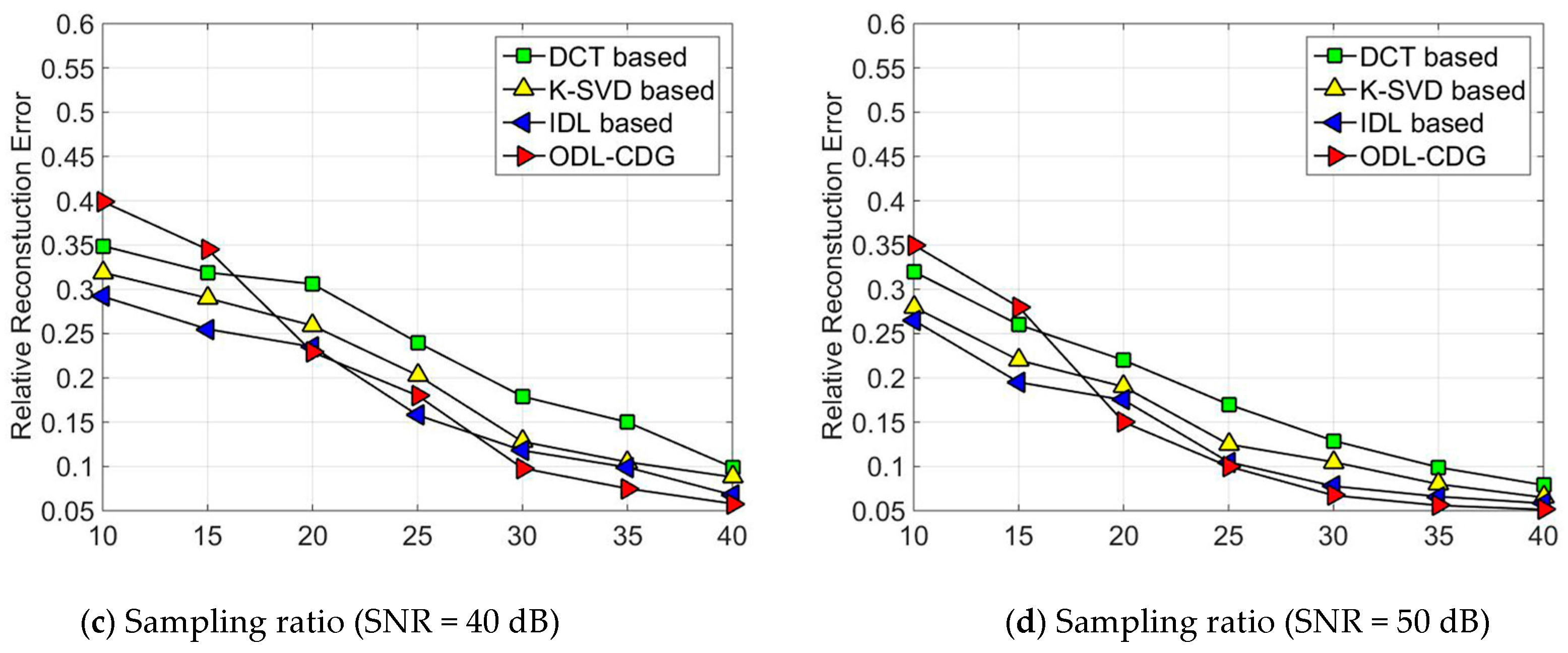
Figure 1, each subgraph corresponds to a certain amount of sampling ratio. The signals are added with white Gaussian noise, which yields the signal-to-noise ratio (SNR) to range from 20 dB to 50 dB. As can been seen from
Figure 1a, ODL has poor performance when the sampling ratio is low, but the ODL dictionary outperforms both the DCT dictionary and the K-SVD method in the relative reconstruction error, when the sampling ratio is high (high than 20%). The fixed dictionary, DCT, is the worst case. That’s because the DCT dictionary using a fixed structure cannot sparsely represent synthetic data of various diversities. In comparison, K-SVD is better than the DCT dictionary. This is because K-SVD can adapt to sparsely represent the synthetic data by training. Since the IDL algorithm trains the dictionary using the self-coherence constraint term, the relative reconstruction error is smaller than DCT and K-SVD. Similar results can be obtained from
Figure 2, where the relative reconstruction errors of DCT, K-SVD, IDL and ODL are obtained with sampling ratios of 10%, 15%, 20%, 25%, 30% and 40%, respectively. As we can see in our simulations, the results of ODL are much worse than DCT, K-SVD, and IDL when the sampling ratios is quite low (less than 10%). But ODL outperforms these algorithms compared by gradually increasing the sampling ratio.
6.2. Impact of Regularization Parameters on Sparse Representation Error
The performance of ODL-CDG algorithm may also be highly influenced by the setting value of regularization parameters
λA and
λΘ. In this experiment, we analyze how the selected regularization parameters affect the sparse representation error. The optimal parameters for ODL-CDG algorithm is determined. The datasets used in this section are collected from the IntelLab [
30]. We select the temperature values and the humidity values of size 54 × 100 between 28 February and 27 March 2004. The time interval is 31 s. We first solve the following sparse representation problem on training data
:
where
S denotes the sparsity of the coefficient
θ.
Then, the sparse representation error of the learned dictionary is evaluated using the root mean square error (RMSE), which is defined as follows:
where
L is the amount of training data. We average the experiment 50 times for every training data vector.
Figure 3 shows the simulation results. In general, the sparse representation error is becoming larger as the parameter
λA gradually increases. That’s because regularization parameter
λA determines the sparsity of the sparse coefficient. To constrain the coefficients to be sparser, we need to increase
λA to a specific threshold. However, as can be seen from
Figure 3, the sparse representation error increases tremendously as
λA exceeds 0.1. In
Figure 4, parameter
λΘ shows that it has the same trend as
λA in impacting the sparse representation error. Based on the above discussion, we set the regularization parameter as a relatively small value, such as
λA = 0.1 and
λΘ = 0.05. These are also the optimal parameter values we set in
Section 6.1.
6.3. Energy Consumption Comparison
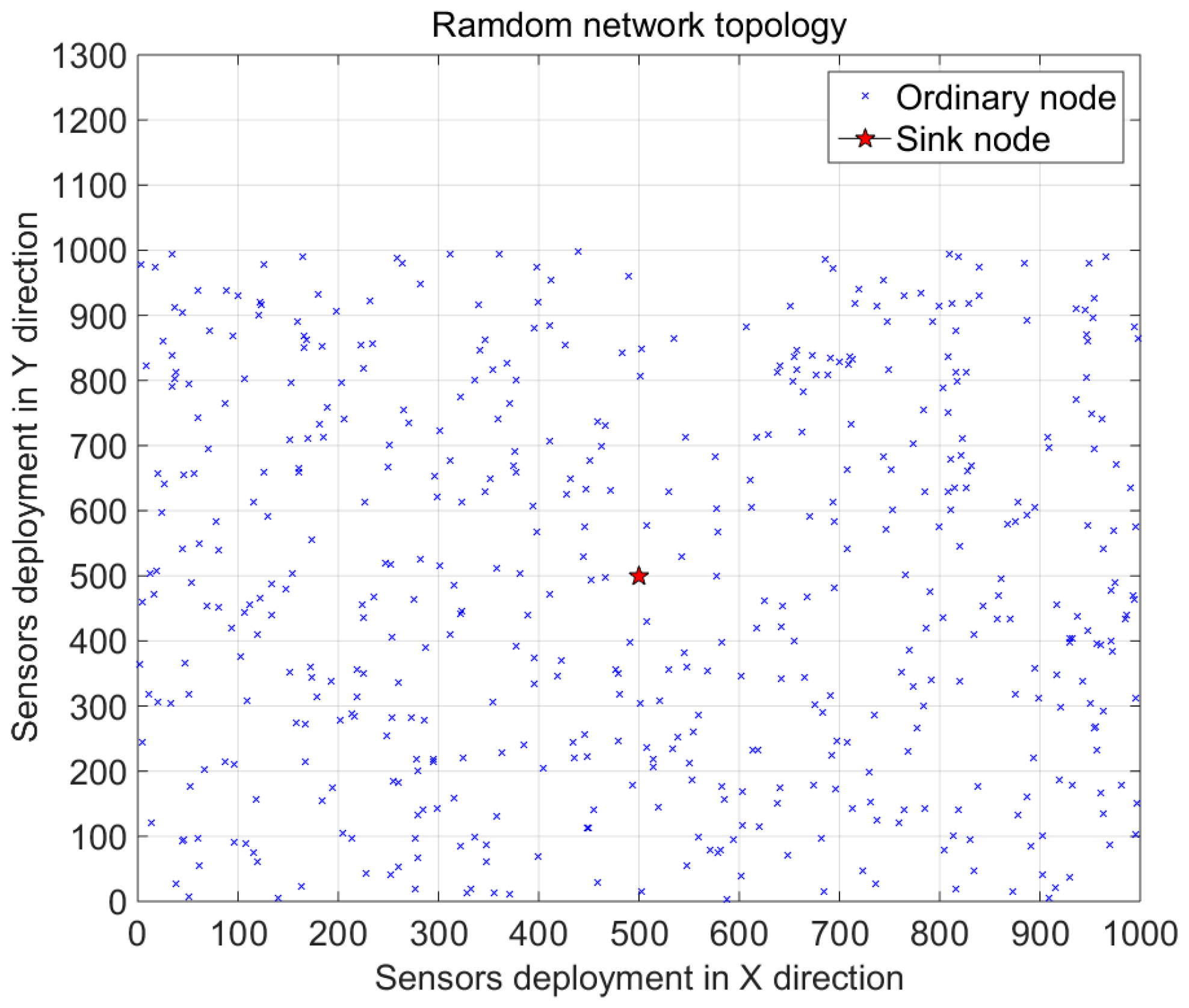
In this subsection, we simulate the energy consumption of the ODL-CDG algorithm. The simulation platform is MATLAB. Suppose 500 nodes are randomly deployed in a 1000 m × 1000 m area and the sink node is deployed in the center. The random topology of these sensor nodes is shown in
Figure 5. The communication range is 50 m and the initial energy is 2 J. The original data used in this section is synthetized of multiple data sets. Thus they cannot be sparsely represented in a predefined dictionary. To evaluate the energy consumption of ODL-CDG, we employ the same energy model in [
31]:
where
Etrans denotes the energy consumption of transmitting
l bits of data to another node within distance
d,
Erec denotes the energy consumption of receiving
l bits of data,
Eelec denotes the energy consumption of the modular circuit, and
Emp denotes the energy consumed by the power amplifying circuit. The parameters input to the ODL-CDG algorithm are the same as in
Section 6.1 and the related parameters are listed in
Table 2.
It is regarded as a successful reconstruction when the relative reconstruction error is smaller than 0.1.
Figure 6 shows the energy consumption of ODL-CDG algorithm compared with other dictionary learning-based data gathering methods. Note that the K-SVD-based data gathering method requires one to access the whole data, so the original training data should be transmitted to the sink node by multi-hop paths. Moreover, the K-SVD dictionary should be updated in time since the synthetized data contains large diversities. Thus, the initial step of dictionary learning before data gathering may consume large amounts of energy. Therefore, the energy consumption of the K-SVD-based data gathering method is significantly larger than that of CK-SVD and the ODL-CDG.
Figure 6 shows that ODL-CDG algorithm achieves the best energy savings. That’s because the dictionary in the ODL-CDG algorithm is learned in the process of compressive data gathering, which greatly reduces the energy consumption for raw data transmission through the entire network. Similarly, the total energy consumption of CK-SVD is enlarged with the increase of successful reconstruction number. But its energy consumption is still high than ODL-CDG as can be seen from
Figure 6. The reason is that the introduced self-coherence penalty term can restrain the reconstruction error in the ODL-CDG algorithm, so the ODL-CDG algorithm should collect much fewer CS measurements than the CK-SVD-based data gathering method for the same reconstruction accuracy.
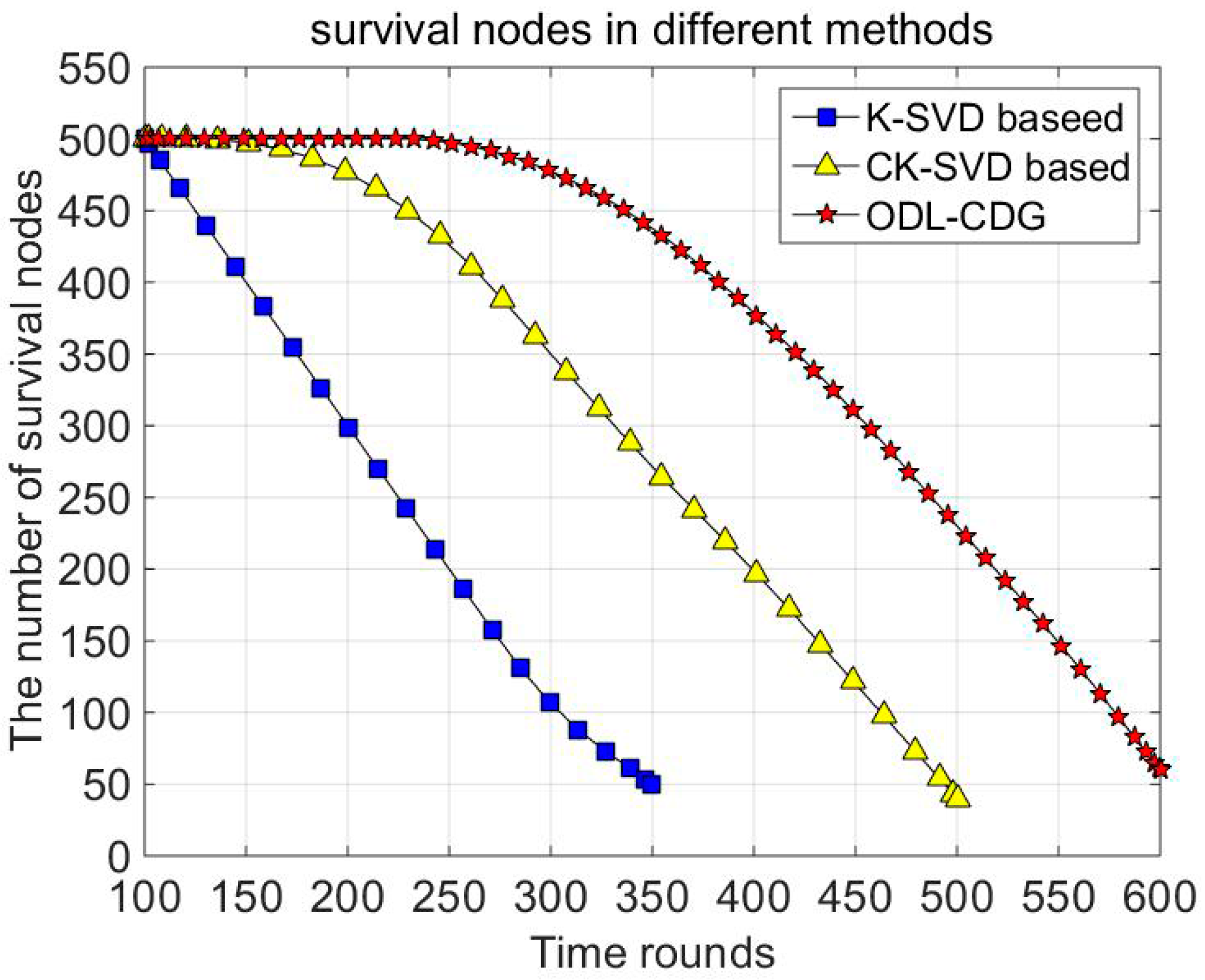
In
Figure 7, the impact of different dictionary learning-based data gathering methods on the lifespan of nodes is studied. The node is supposed to survive when its energy is higher than zero. As can be seen from
Figure 7, the ODL-CDG algorithm outperforms the other methods since the proposed dictionary has better adaptability to various signals. Thus the ODL-CDG algorithm reduces the energy consumption and prolongs the network lifespan.
7. Conclusions and Future Work
In this paper, we propose the ODL-CDG algorithm for energy efficient data collection in WSNs. The training signals for dictionary learning are obtained by a compressive data gathering approach, which greatly reduces the energy consumption. Inspired by the periodicity of natural signals, the learned dictionary is constrained with a sparse structure. To reduce the recovery error caused by environmental noise, the self-coherence of the learned dictionary is also introduced as a penalty term during the dictionary optimization procedure. Simulation results show the online dictionary learning algorithm outperforms both pre-specified dictionaries, like the DCT dictionary, and other dictionary learning approaches, like K-SVD, IDL and CK-SVD. The energy consumption of the ODL-CDG algorithm is significantly less than that of K-SVD-based and CK-SVD-based data gathering methods, which helps to enhance the network lifetime. In the future, we intend to employ other measurement matrices, such as the sparse measurement matrices, to further reduce the energy consumption. What’s more, how to apply the proposed algorithm to real large-scale WSNs is also a potential research direction.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}