Based on previous discussion, we expect to introduce a market scheme in ESNs to accomplish optimal resource allocation by economic theory. However, it is not so straightforward to apply ESNs with an interdisciplinary theory. Thus, we focus on the methods in economics, whose research targets are humans or firms. One common principle for both human networks and ESNs is that people (or devices) respond to incentives. The motivation is that each individual intends to maximize its payoffs and minimize the cost. This is the interaction of these fields. Therefore, we expect to model the environment of ESNs or IoT as a market with multiple agents, where a resource is able to be allocated according to economic theory.
3.1. Multi-Agent Environments and Agent-Based Modelling
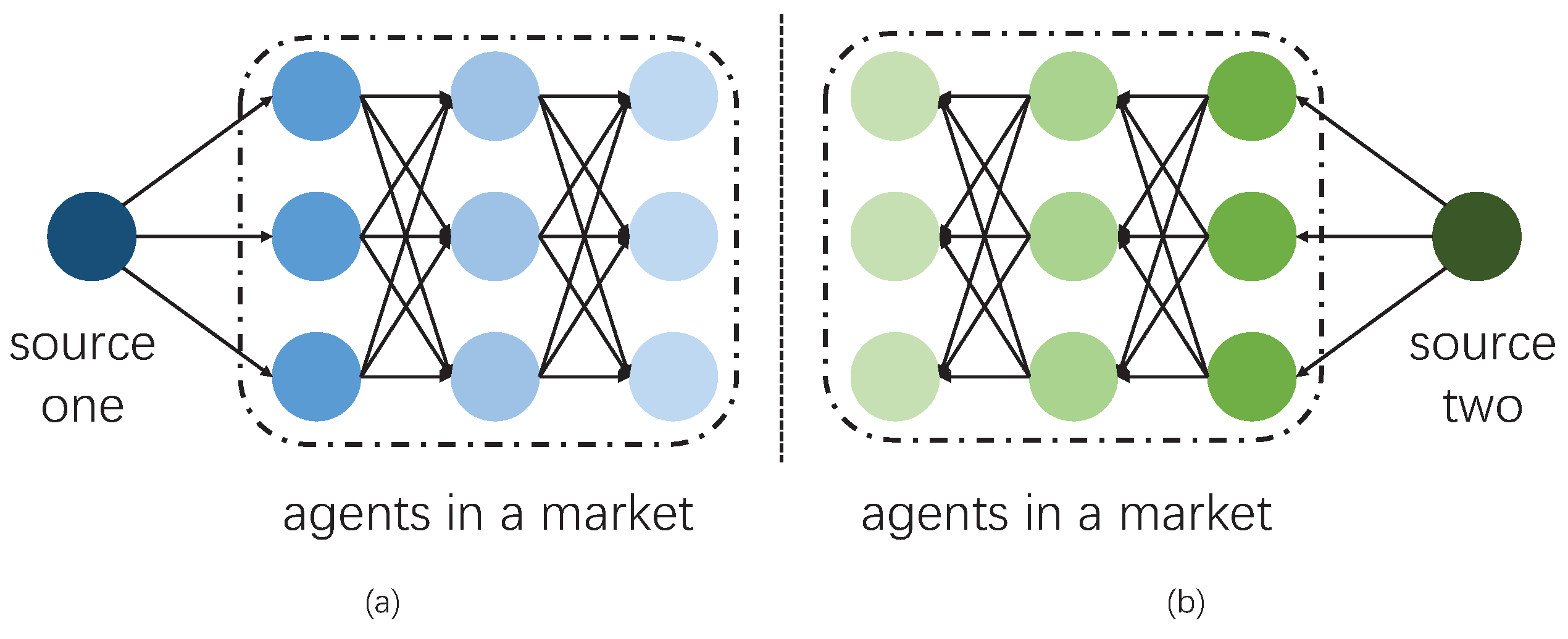
One distinguishing feature of ESNs or IoT is that it connects a variety of nodes or devices. If every node is connected to the rest, the full-connect network is redundant and inefficient, since not all links are required. Meanwhile, some links may exist in an uneconomic way. Therefore, the topology management technique is required to maximize the efficiency of the networks. From the perspective of nodes or agents, this is a problem of decision making, which involves a variety of factors. Thus, we regard this environment as a multi-agent situation, and we analyze it considering decision making problems.
Typically, two standard directions to study multi-agent environments are discussed. One way is from a macro perspective, which is common in a variety of studies. Researchers and designers plan to build a comprehensive model so that every node or agent shall obey. For example, traffic laws are designed to improve traffic efficiency and to reduce accidents, if everyone obeys. Macro methods are relatively straightforward to apply. Most such methods are based on observation, such as recording data towards a certain phenomenon. Afterwards, data analyzing algorithms are applied for pattern recognition. The target models are designed according to this pattern, which ignores details to some extent. On the other hand, a micro method focuses on the basic rules for each agent. With a careful design, each agent is equipped with certain actions and capabilities, such as interactions with others or with environments. The advantages of micro methods or agent-based modelling lie in its flexibility. To sum up, macro methods are basically based on observation and data, thus unseen situations cannot be learned. Whereas micro methods can create a vast array of situations—including unrealistic ones—to improve the robustness.
The key challenge for agent-based modelling is the design of rules. In natural environments, the habits of creatures are relatively stable, and can be described by observation and analysis. This description, however, is not identical to the true patterns. Further experiments are required in order to discover intrinsic correlations and causations. Rules for agents in artificial systems are also difficult. However, once they are settled approximately optimally, they will contain flexible capability to demonstrate and verify a variety of scenarios.
Fortunately, one reasonable clue for designing rules is that people respond to incentives. This is common to any natural system. People or other creatures tend to the choice for less anxiety. In other words, agents face decision making problems in order to maximize their payoffs. This target motivates us to tend to decision theory and relevant methods, such as game theory and reinforcement learning.
3.2. Game Theory and Reinforcement Learning
Applying game theory to solve a resource allocation problem is commonly studied. The key motivation of such research is the existence of the conflict between players or agents. Game theory provides a mathematical solution for a variety of game problems. It extracts models from the real world, considering main factors and ignoring details. The outcomes of any combination of strategies are determined statistically, which may involve the participation and knowledge of humans. By solving different models, game theory solutions are capable of addressing a range of problems in our daily lives, explaining its popularity. Game theory focuses on problems of decision making. It provides a solution for players to follow in order to maximize their payoffs. One major assumption in game theory is that people are rational. This is reasonable, because rational people respond to incentives. In other words, they try to maximize their outcomes. Thus, each player tries to choose the optimal strategy to obtain maximized payoffs. Mathematically, each player
i tries to find a strategy that satisfies
where
is the strategy or action of player
i, and
is the payoffs for player
i. Equation (
5) indicates that the best choice for player
i is the one maximizes
, given the strategy of opponent
j.
On the other hand, the second fundamental assumption in game theory is that knowledge is common for all players. This assumption seems too strong and impractical in the real world. For instance, two competitive firms may pay great attention to protecting their secrets. Furthermore, even if the knowledge is accessible, determining the values of each outcomes is also costly. This is a critical point, since the values may define the games (according to game theory), which further affects the strategies. Therefore, game theory requires an expensive participation of humans, which may not be directly applicable for practical scenarios.
Fortunately, reinforcement learning—being a branch of machine learning—requires no transparent knowledge. The idea of reinforcement learning originates from psychology and trial-and-error methods. Agents can learn and improve a behavior by interacting with environments and other agents. Reinforcement learning shares natural similarities with game theory, both of which target the problems of decision making. The major advantages of reinforcement learning over game theory is its flexibility and robustness. Specifically, reinforcement learning methods can directly learn from the real event, without extracting models, which decreases the gap between real events and games. Meanwhile, no participation of humans is involved in order to determine the outcomes of certain combinations of strategies. Agents with reinforcement learning methods will learn the outcome if they reach there. Furthermore, games may vary according to different outcomes, leading to different solutions. Thus, a particular game and the following solutions have to be designed towards a certain event. Nevertheless, reinforcement learning methods may be insensitive to particular payoffs. Thus, a general algorithm is able to cover a variety of similar games. Therefore, reinforcement learning methods are more practical and suitable for our market model.
Reinforcement learning considers a Markov decision process (MDP). At each state
at time
t, an agent has to choose an action
according to some policy
so that her rewards
are maximized. One main challenge is that high immediate rewards have no guarantee of optimal global rewards. For instance, a good move in chess cannot ensure the final outcome. Therefore, agents have to take the ability of taking future rewards into consideration. One direct strategy is to discount future rewards so that they are comparable with immediate ones. Thus, the target of reinforcement learning is
where
γ is the discount factor. As a branch of machine learning, reinforcement learning aims to build intelligent thinking machines to replace the work of humans to some degree. Therefore, we only need to equip agents with reinforcement learning methods and to introduce them as a game. After the training process, they will learn a pure or a mixed strategy against their opponents and the environment to obtain the optimal rewards.
It seems that the most popular model-free reinforcement learning method is Q-learning. It is capable of both immediate reward and future reward situations. The general updated rule of Q-learning is
where the current state and action are denoted by
and
, whereas
and
denote those in the next time period
.
γ is the discount factor, as mentioned previously.
α is the learning rate and
r is the reward after action
is taken. Equation (
7) suggests that agents back-propagate the future outcomes, and choose based on the prediction.
Another efficient reinforcement learning method is called learning automata (LA), taking the standard form as
where
is the feedback received at time
t, which is similar to the function of rewards. LA is a model of probability, which means actions are taken with respect to
p. Different LA methods, such as Linear Reward-Inaction (
) or Linear Reward-
ϵPenalty (
) methods are distinguished by the values of
and
.
One minor problem of applying Q-learning methods to estimate users’ patterns is that Q values are not direct probability. Thus, we apply softmax to converge typical Q-learning into probabilities, as
where
τ controls the sharpness of the obtained distribution. Thus, we can apply both Q-learning and LA methods to estimate users’ patterns, which is an expression of probability.
Another advantage of reinforcement learning which is also a central concern is the balance of exploration and exploitation. Agents should be able to stick to the best option, since it maximized their rewards. Simultaneously, they should be able to discover potential higher rewards. This is extremely important for a dynamic environment, such as our real world. It equips reinforcement learning adaptability, so that its robustness is improved. Q-learning methods introduce a method or softmax to deal with the tradeoff, whereas LA does not suffer from this problem, since it naturally applies probability to guide policies.
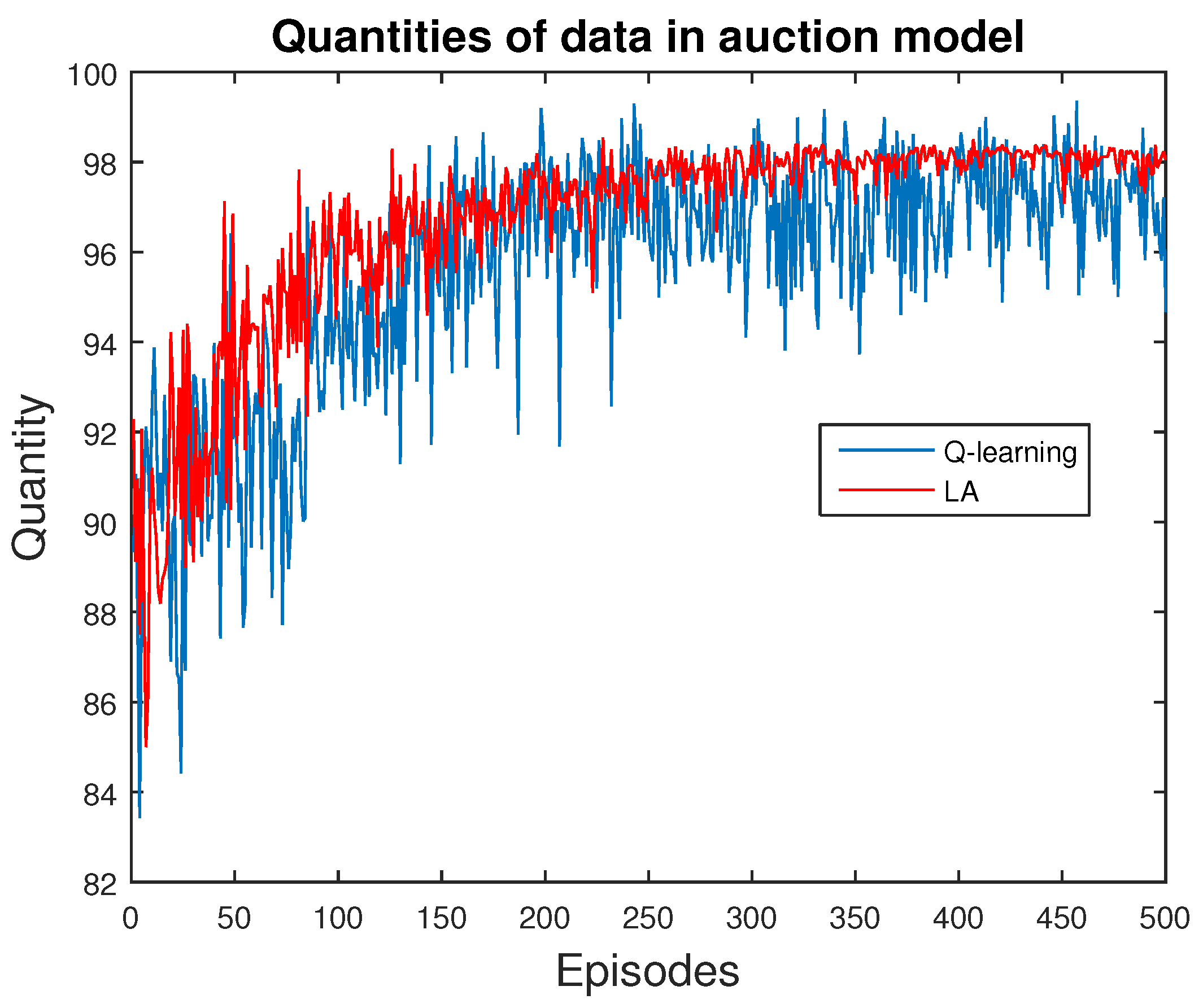
Meanwhile, we can apply reinforcement learning methods to study resource allocation, as the role of game theory. Since we regard the ESNs as a multi-agent environment and we plan to apply an ABM method to study them, we are motivated to equip each single agent with reinforcement learning methods. This is natural and reasonable, since in any multi-agent environment, each agent intends to maximize their payoffs with the lowest cost. Reinforcement learning methods provide them the opportunity of such purpose. This means that if rules are designed according to reinforcement learning methods, resources can be organized according to the choices of each individual, which is similar to the outcomes of a free market. Therefore, we expect to apply price scheme to guide resource allocation, as in economics.
Even though game theory ignores some details when it abstracts models from actual situations, it is still effective and useful to guide resource allocation. Meanwhile, even though a solid proof that reinforcement learning methods can handle game theoretic problems may not exist, they are still capable of solving games. Thus, reinforcement learning methods can be a valid by solution from game theory. Therefore, we design specific games for scenarios such as competition or cooperation to demonstrate the scenarios among agents in ESNs, and to prove the efficiency of applying reinforcement learning methods to allocate resources.
3.3. Applying Reinforcement Learning to Estimate Users’ Patterns
Since users’ patterns are unknown (even to users themselves), supervised learning methods, such as support vector machine (SVM), are inapplicable, since the loss function cannot be calculated. This is also because of the inability to label training data. Meanwhile, one interesting advantage of reinforcement learning is its ability to handle uncertain environments. This motivates us to apply reinforcement learning methods to estimate users’ patterns. It is natural for humans and other creatures to discover the mysterious world by interaction. Thus, we borrow a similar idea to describe users’ patterns by providing users with massive data and observing the interactions. For internet applications, this can be achieved by recording users’ internet behaviors, such as searching and using web pages and apps.
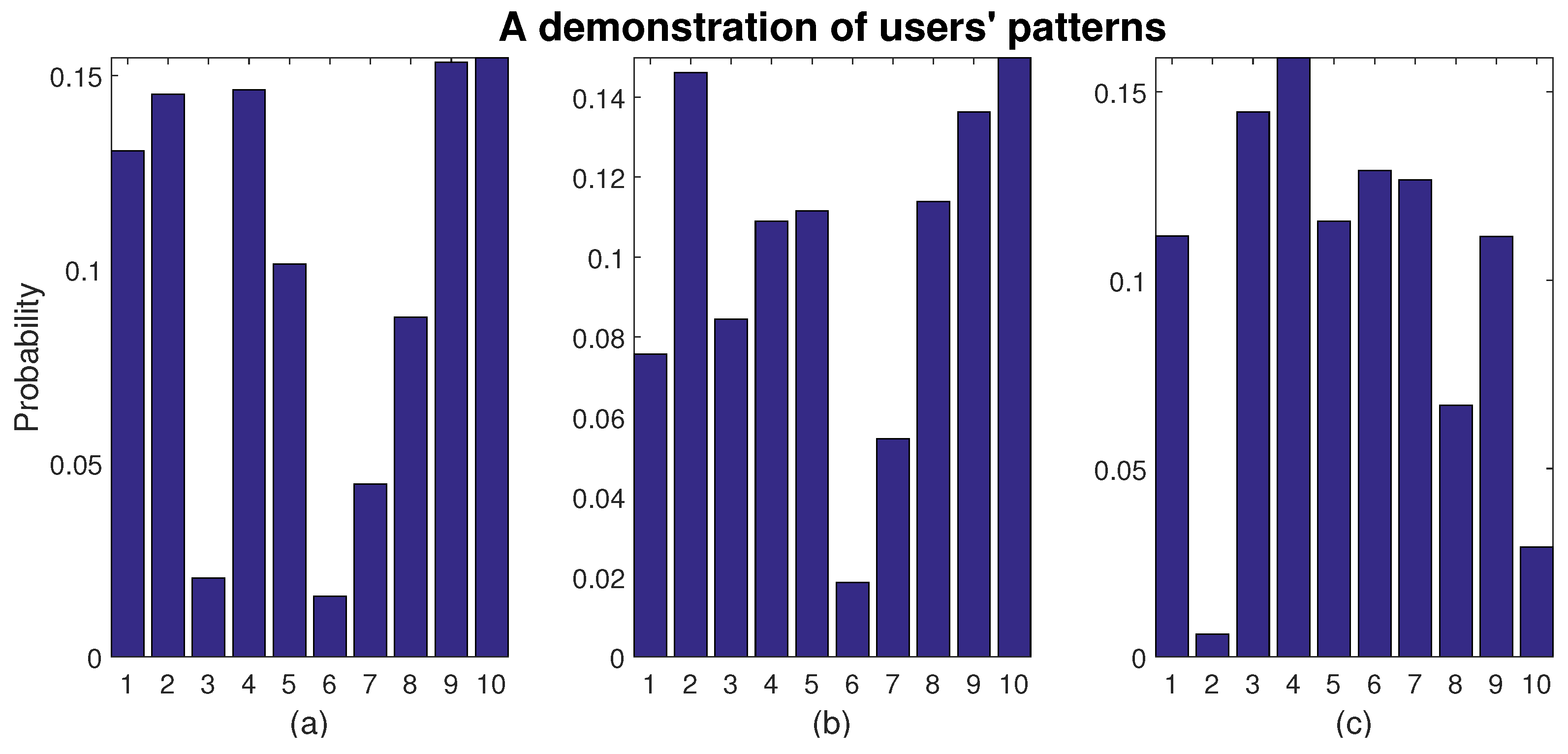
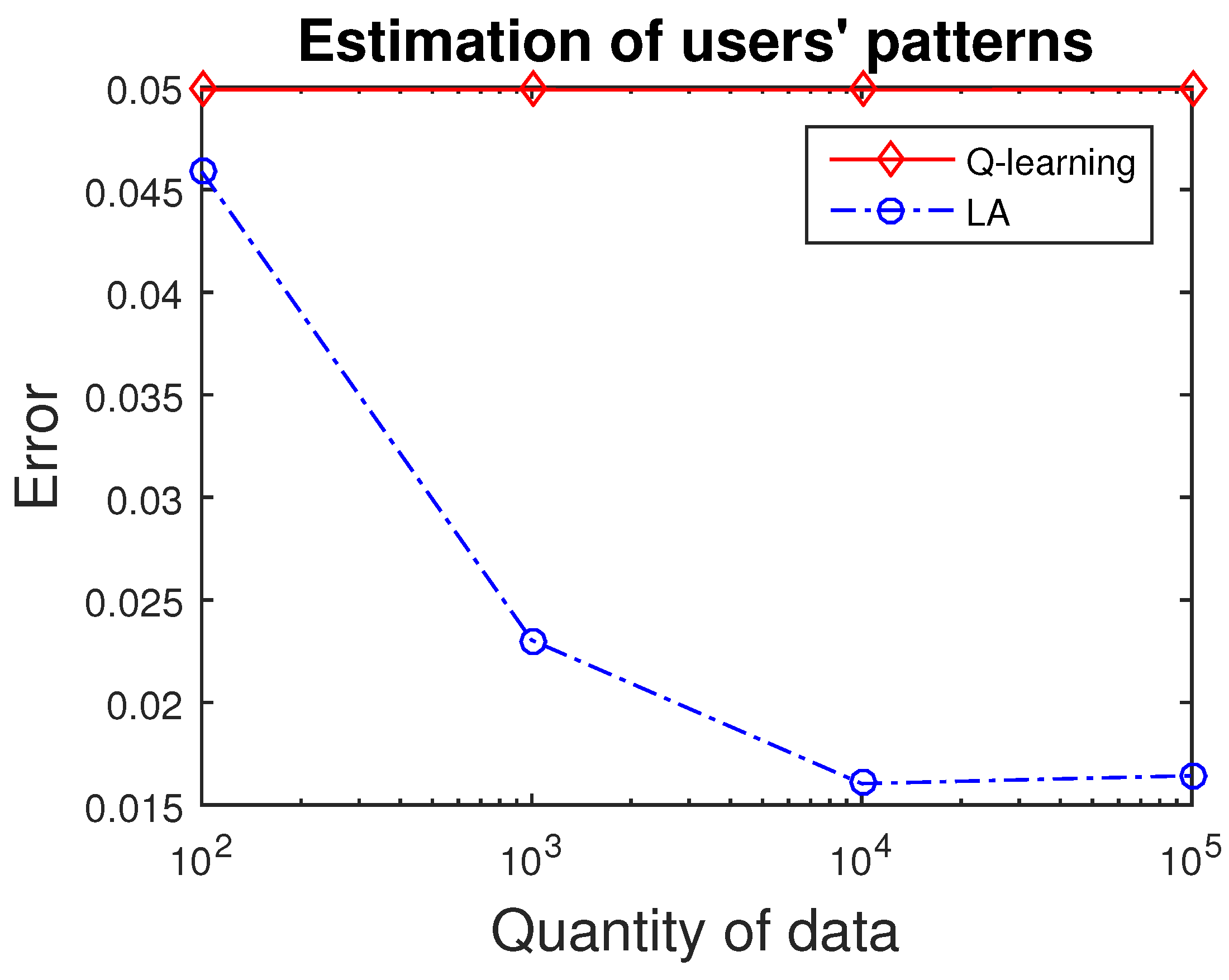
Specifically, we initialize a set of probability, and we introduce each agent with data within categories of N. Each agent can choose whether to receive, based on his own preferences. If he receives, he obtains a reward of , otherwise . Thus, our probability model is updated according to reinforcement learning methods, and the positive stimulation will increase the value of a certain category and restrain that of the others. We compare the differences between our model with true values of users’ patterns, as estimation error. Notice that the true values are only applied to validate our outcome, instead of being applied to guide our algorithms, because they are actually inaccessible. The dilemma of exploration and exploitation is automatically handled, since the policies of actions are designed according to a probability. This means that even though agents tend to choose the action with highest probability, they still have opportunities to explore.
If the data set is large enough, users’ patterns—which are typically stable over a period of time—can be estimated. Meanwhile, due to the fact that reinforcement learning methods are mostly online, they can handle dynamic situations, which means that even if a huge alteration occurs and patterns are changed, the new patterns can be re-estimated without adaption of the algorithms.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}