1. Introduction
In recent years, services provided by computing devices have shifted from proprietary computing services to flexible services focusing on human need. Different kinds of small devices with computing power and communications capabilities have grown in popularity. Computer systems are closely linked to human users by natural interaction methods. Thus, how to recognize human activities is an important part of supporting technology for these computer systems.
At present, two of the major identification methods are based on vision sensors and wearable sensors. Identification methods, which are based on computer vision, use images taken with cameras, and these images are intuitive and understandable. Many public places are provided with 24-h video monitoring equipment, providing a rich source of data for gesture recognition. Meanwhile, as an often-considered subject in computer science, computer vision technology has accumulated plenty of research results. However, since the human body is particular, and activity is ambiguous, diversiform, and different in space and time, it is difficult to get a higher recognition rate with computer vision-based methods. At the same time, there are some limitations of the camera. For example, the use of cameras is limited by factors such as light conditions and install locations. Alternatively, due to the rapid development of electronic technology, physical sensors have the characteristics of small dimensions, high precision, and low cost. So, activity recognition based on wearable sensors has become more and more popular.
Currently, wearable sensors-based human activity recognition plays an important role in disease prevention, rehabilitative training, daily health monitoring, and many other fields. With respect to disease prevention, Sazonov et al. [
1] propose a novel methodology for automatic recognition of postures and activities in patients with stroke by a wearable shoe-based device. Iosifidis et al. [
2] extend the independent living of older persons in the early stages of dementia by identifying human eating and drinking activities. Amft et al. [
3] use on-body sensors for automatic dietary monitoring aimed at lowering the health risks for many chronic diseases, including obesity. In the field of rehabilitative training, it has been pointed out that we can apply automatic recognition of human activities in monitoring the daily life of elderly people [
4], fall detection for the elderly [
5] and motor symptoms in Parkinson’s disease [
6]. In daily healthy monitoring, Zhu et al. apply a wearable system in the constant monitoring of physiological parameters of infants such as heart rate, pulse, invasive blood pressure, and early gastric cancer (EGC) [
7]. In addition, as the universal value for a healthy life, automatic classification of daily activities is used for the promotion of health-enhancing physical activities and a healthier lifestyle [
8].
Most of the existing works utilize mean value, variance, fast Fourier transform (FFT), and wavelet transform (WT) as feature extraction tools in a wearable sensors-based activity recognition system. The methods described above are applied to signals which have great linearity and stationarity. However, the output signal of wearable sensors manifest properties such as nonlinearity and non-stationarity [
9]. If we use simple filtering operations, such as band-pass or low-pass filtering, sometimes we may destroy sharp features of movement patterns in the activity signals. Thus, Hilbert-Huang transform (HHT) is introduced to solve these problems for dealing with nonlinear and non-stationary signals. At this point, state-of-the-art works [
9,
10,
11] have discussed the application of empirical mode decomposition (EMD) in activity recognition. In these works, all the intrinsic mode functions (IMFs) or part of them are selected as features. These features were then combined with other time-domain features to derive some statistics from them. However, these works do not consider using the Hilbert spectral analysis to further process these IMFs and instead use the physical quantities from Hilbert spectral analysis as inputs for the classifier.
According to a further investigation, we find that when we apply features extracted from EMD to activity recognition, there are still some manifest weaknesses. The classification results obtained from extracted features by EMD or combinations of EMD and other non-HHT approaches are significantly dependent on the type of activities. That is to say, by using these features for classification, the performance matrix shows remarkable fluctuation among different kinds of human activities (such as walking, lying, running, etc.). Therefore, we propose that some other useful features of HHT should be explored and utilized for activity recognition to improve the effect of classification. Therefore, in this paper, we present a multi-features extraction method based on HHT to improve the effect of activity recognition. The extracted multi-features include IA and IF obtained from EMD, as well as IE and MS derived from Hilbert spectral analysis. To evaluate the proposed approach, we perform two groups of experiments by using the physical activity monitoring for aging people dataset 2 (PAMAP2) as input signals and utilizing the back propagation (BP) neural network as a classifier. The effect of combining multi-features vs. a single-feature are investigated and discussed in the scenario of a dependent subject. The experimental results show that combined multi-features instantaneous energy density, marginal spectrum, instantaneous amplitude, and instantaneous frequency (IE-MS-IA-IF) can further improve the performance. Finally, we test the effect of multi-features combination in the scenario of an independent subject. The experimental results show that we achieve four performance indexes: recall, precision, F-measure, and accuracy to 0.9337, 0.9417, 0.9353, and 0.9377 respectively, which are all better than related works tested on the same dataset.
The rest of this paper is structured as follows. In
Section 2, an extensive review of feature extraction and classification algorithm is presented.
Section 3 introduces the public dataset and data preprocessing method we use in this study, and
Section 4 describes the activity recognition methodology in detail and analyzes the degree of stationarity (DS) for activity data. In
Section 5, the classification methods and parameters setting of BP neural network are introduced. Next, we present the results obtained from experiments and compare the performance measures with relevant work in
Section 6. Then, the limitation and future work are discussed in
Section 7. Finally, the paper is summarized in
Section 8.
4. The Feature Extraction Method Based on HHT
It is known to us that only when processed data has stationarity, linearity, and periodicity, can those data be converted to frequency domain by FT. Then, the frequency characteristic can be obtained. The data processed by WT can be non-stationary, but it is required to be linear. However, most of the data we meet in real life is nonlinear. What is worse, only a few of them can be approximately seen as linear data. So, both WT and FT have their own limitations. To overcome the above limitation, Huang proposed HHT [
16] to process a nonlinear and non-stationary signal, which has been proven to be effective in practical engineering. Besides, HHT presents the results of feature extraction in time-frequency-energy space and the results contain physical meaning, which makes it easier for us to understand. In this section, we will briefly introduce the HHT algorithm and analyze the stationarity of the activity data.
4.1. A Brief Introduction to HHT
The steps of HHT algorithm are shown as follows and the detailed introduction to each step is described in the corresponding subsection.
- Step 1
EMD. The EMD method is needed to decompose the raw signal into several IMFs to which the HT can be applied. Then the raw signal can be denoted by the sum of IMFs and residue.
- Step 2
HT. Using the HT extend the real signal IMFs into the complex plane. Next, the IA and IF can be derived based on the result of HT.
- Step 3
Hilbert spectral analysis. The Hilbert spectrum can be deduced according to the relationship among IF, IA and time. The final result of this step is to show the frequency-time distribution of signal amplitude and we can analyze the localized features of signal from it.
- Step 4
The derivation of IE, MS, and DS. Based on the Hilbert spectrum, we can get the results of IE, MS, and DS. Furthermore, we can analyze the characteristics and stationarity of different activity data.
4.2. EMD
According to [
16], if we directly use HT to convert activity data, the obtained IF may be negative. That is to say, the IF will lose physical meaning. To avoid this situation, HHT decomposes raw data to several IMFs by using the EMD method. IMF needs to have two characteristics:
In the whole dataset, the number of extrema and the number of zero-crossings must be equal or differ by no more than one.
At any time points, the average value of the envelope defined by the local maxima and the local minima equals zero.
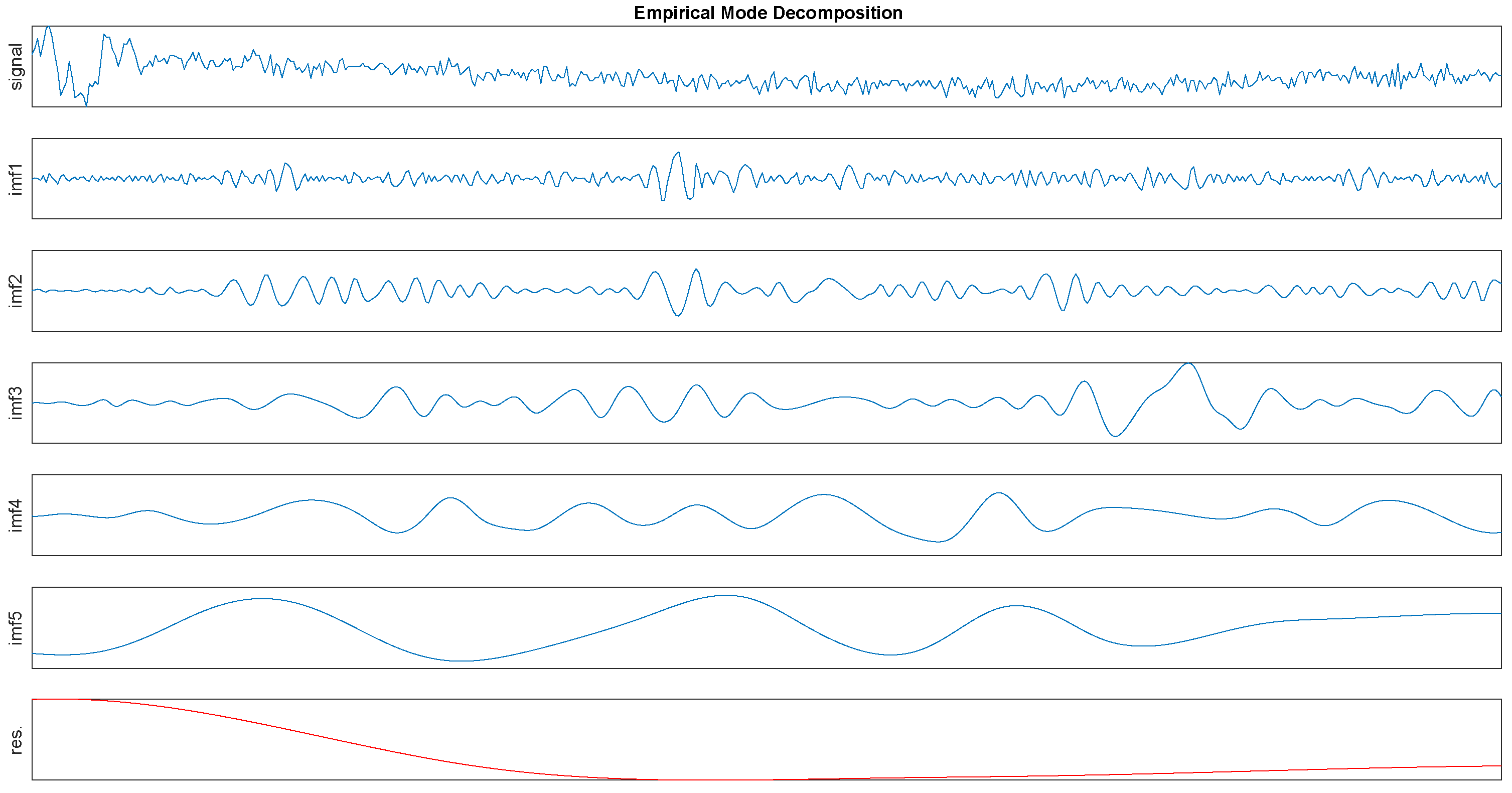
In order to give a intuitive impression first, the EMD process is shown in
Figure 2. Then we will give a detailed interpretation of this algorithm as follows.
We identify all extrema of a signal, then use cubic spline interpolation to connect all the local maxima and repeat this method to process all the local minima. The constructed upper and lower envelops will cover all the data between them. The mean of these two envelops is calculated and denoted as
. Besides, a new component
can be obtained from the difference between the raw data and
, denoted by
However, in reality,
is always not an IMF because of the overshoots and undershoots, which can generate new extrema and influence this process. Thus, in order to get a better result, the sifting process will be repeated several times. In the second sifting process, the result of the first sifting process
serves as the raw data, then we repeat above steps until the result can be regarded as an IMF. The first IMF component can be designated as
where
is the first IMF component and the
k means the sifting times.
Moreover, we can eliminate
from the raw data and designate the rest of the data as
Then we regard the
as the raw data and repeat using the above sifting process. This mentioned process is iterative and IMFs
can be obtained. The whole algorithm will stop until the residue is too small to continue or it becomes a monotonic function from which no more IMF can be extracted. Finally, the raw data
can be denoted by
where the
is the raw signal,
is the
IMF and
is the residue. The EMD algorithm (Algorithm 1) also can be expressed as follows.
| Algorithm 1 EMD algorithm |
Input: The raw data ,
Output: The IMFs , and the residue - 1:
Subfunction for IMF component - 2:
loop - 3:
Using cubic spline interpolation to respectively connect all the local maxima and minima. - 4:
Calculate the mean of these two envelops and denote it as m. - 5:
A new component - 6:
if the new component h is a IMF then - 7:
- 8:
else - 9:
and repeat the loop. - 10:
end if - 11:
end loop - 12:
End Subfunction - 13:
- 14:
Main function - 15:
call Subfunction - 16:
The rest of the data - 17:
while the do not meet the stop criteria do - 18:
- 19:
and call Subfunction - 20:
- 21:
- 22:
end while - 23:
End Main function
|
4.3. HT
The HT of a signal is the same as the convolution of a signal with the function
. In order to get the instantaneous features of activity data, we use the HT to convert each IMF component:
where
indicates the IMF that will be converted,
is the result after transform. Next,
can be derived on this basis.
Moreover, the IA
and instantaneous phase
about
can be obtained.
The IF
is defined as the derivative of instantaneous phase
.
4.4. Hilbert Spectral Analysis
The Hilbert spectrum
can be deduced according to the relationship among IF
, IA
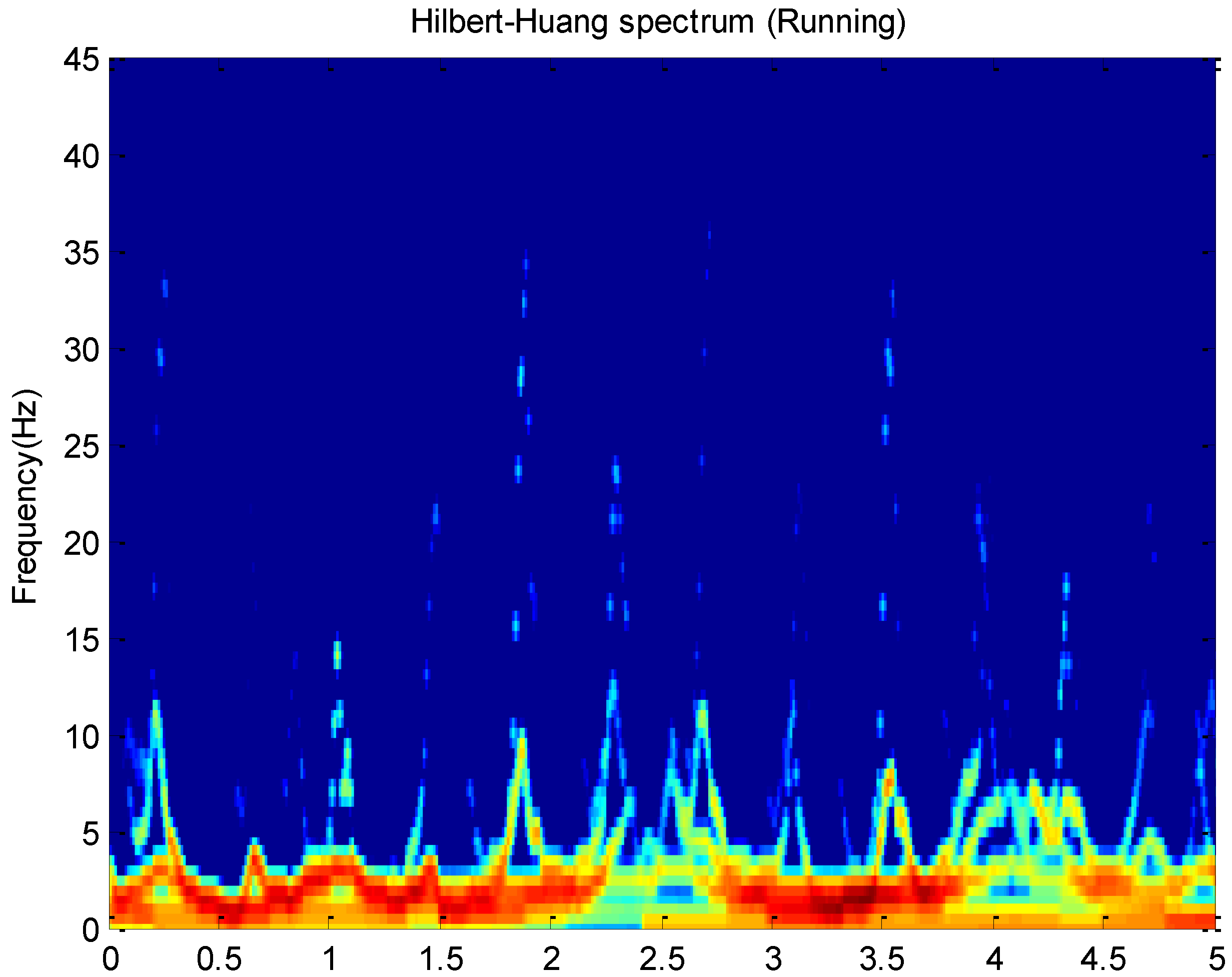
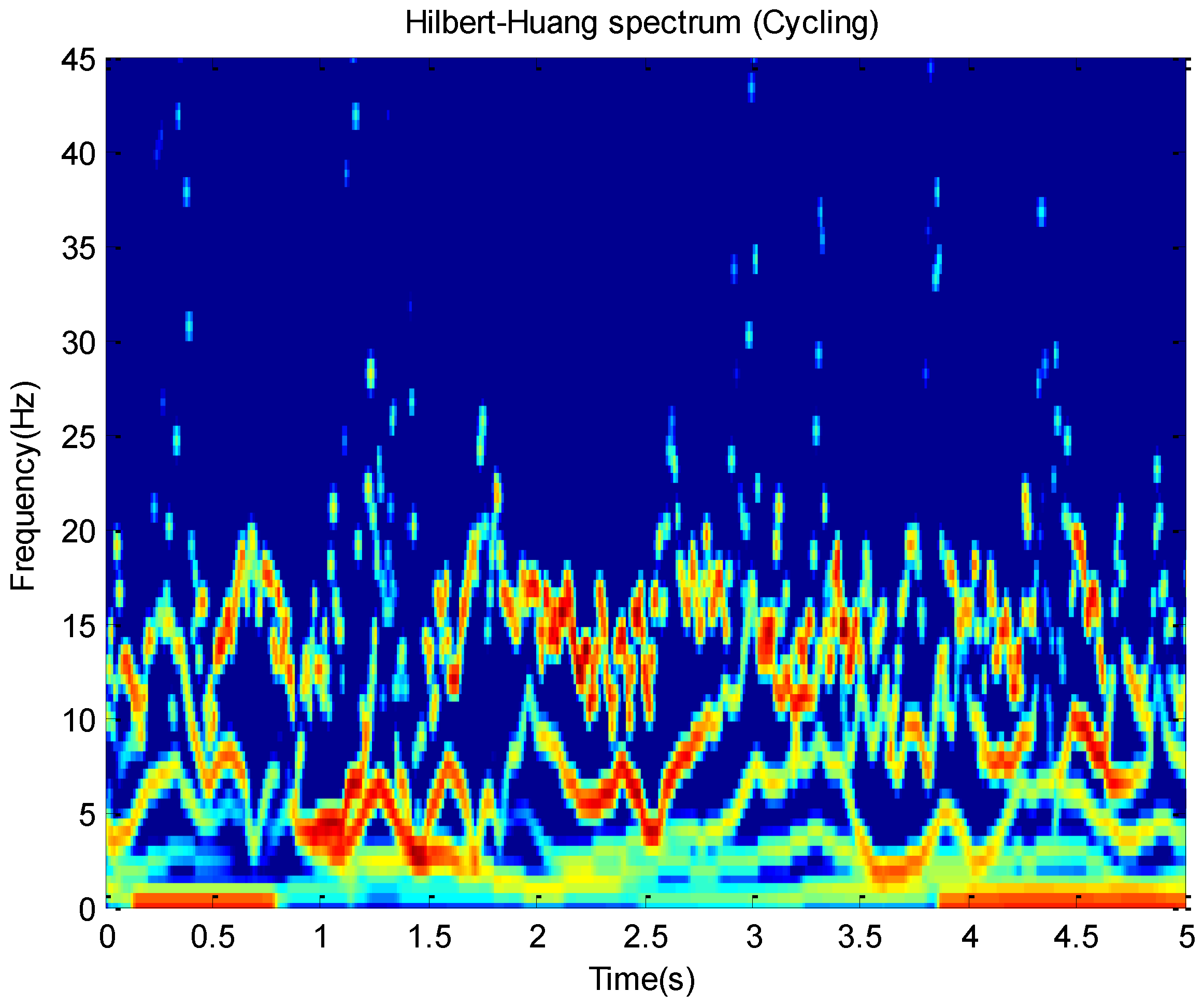
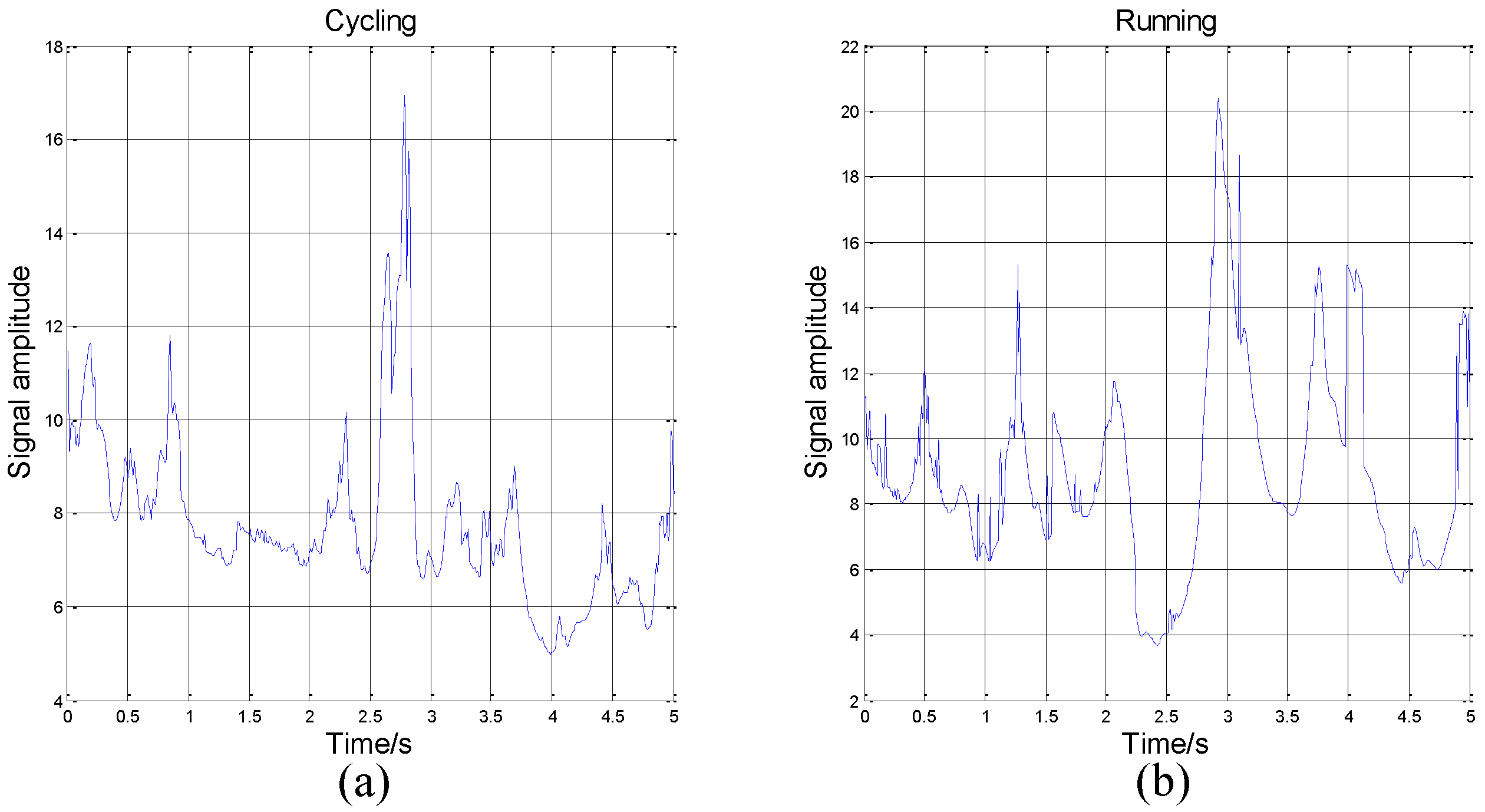
and time. For example, this paper plots Hilbert spectrums about running and cycling in
Figure 3 and
Figure 4. These activity data all come from the
x-axis of the accelerometer on the wrist.
The Hilbert spectrum in the colour map format for the activity data is given in
Figure 3 and
Figure 4. The energy of each IMF was plotted as a skeleton line. In order to give a intuitive feeling on IE, the Hilbert spectrum in the smoothed format is obtained by using
weighted Gaussian filter. As we can see from the above figure, the energy of the activity running is concentrated mainly in the 0–5 Hz frequency region while the energy of activity cycling is dispersedly distribute in 0–25 Hz frequency region. This can reflect the exercise intensity of these activities. At the same time, some features about energy can be deduced.
4.5. IE and MS
Based on the Hilbert spectrum
, we can get definitions about MS and IE. Then, we denote them as
and
respectively.
According to the above analysis, we can use HHT to convert each piece of data and get their IE. These activity data all come from the
z-axis of the accelerometer on the wrist. The IE of activity 1 to activity 6 is shown in
Figure 5.
As we can see in
Figure 5, in some time periods, the numerical value and variation range of IE differ from activity to activity. On one hand, from the view of numerical value, the IE of lying is around 0.2 when the IE of cycling is around 80. On the other hand, from the view of variation range, the peak-to-peak value of lying only 0.1. If we plot lying and cycling in one figure, we will find that the numerical value of lying is nearly a constant.
On the contrary, the peak-to-peak value of cycling can be more than 100. That is to say, cycling is more drastic than lying, which conforms to our intuitive feeling. Meanwhile, it also conforms to Huang’s theory that physical quantities such as IF, MS, and IE gained by HHT have practical meanings. So, we think HHT is more suitable for activity recognition.
However, in some time periods, the IE of two activities can be similar in numerical value and variation range. In this paper, we use the mean and the variance of IE as eigenvalues. The trend of signals’ amplitude may be different, but the mean and variance of IE can be same. So, if we only use one sensor to recognize activity, the judge result may be wrong. The comparison is shown in
Figure 6.
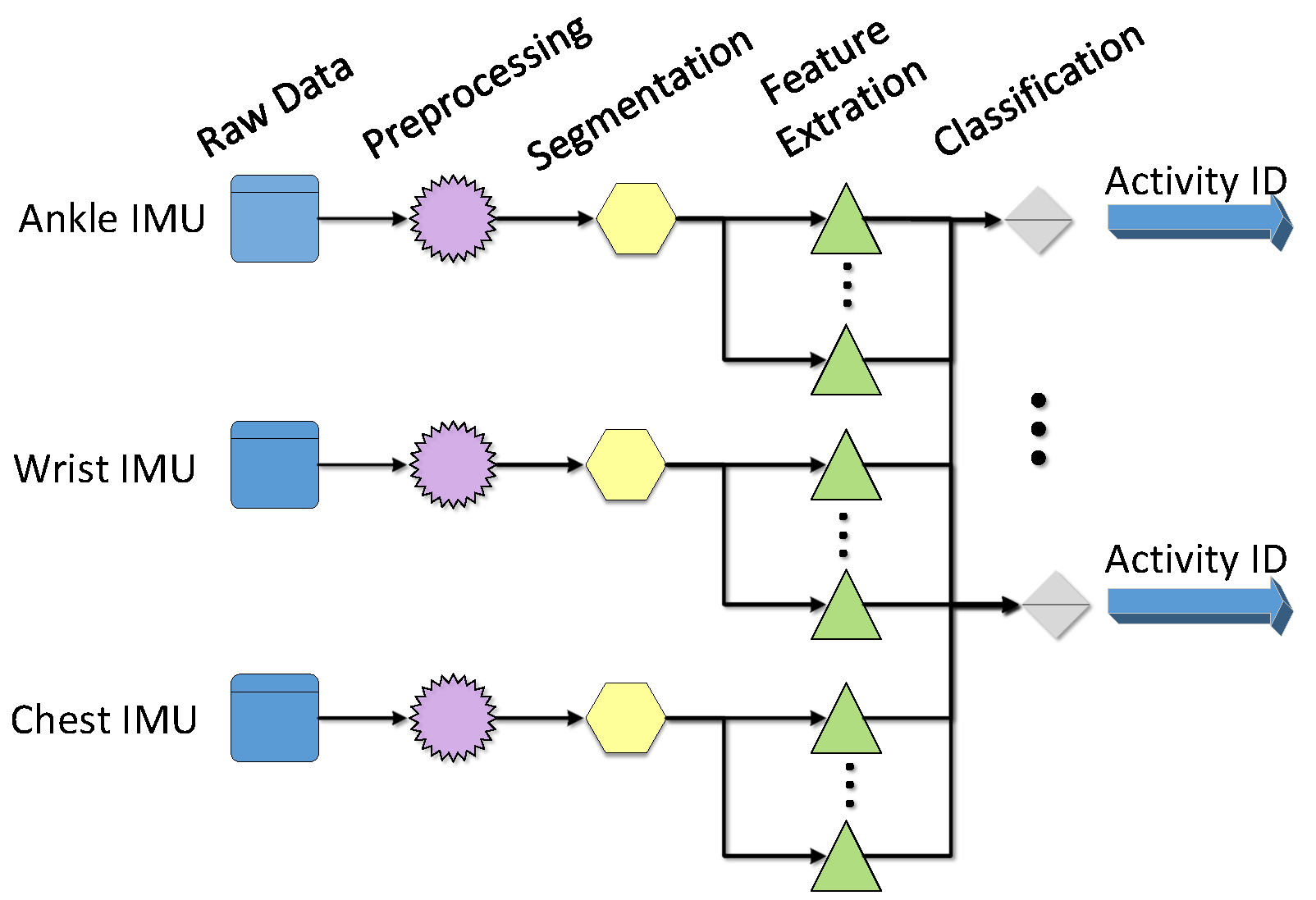
In the athletic process, the exercise intensity will decrease when the participant feels tired. This will cause the feature of the activity to be similar to the features of other activities, which will affect the results of machine judgement. However, different body parts have different reactions during movement. The reaction of the same body part in different activities is similar, but we can solve the problem by adding sensors. Thus, this paper analyzes activity data from 3D accelerometers on the chest, wrist, and ankle. For an example, we consider IE as a feature, according to the above analysis, we can get the mean and the variance of IE to classify activities. Then, in total, we can get 18 eigenvalues from three sensors (each sensor has 6 eigenvalues, the mean and the variance of IE in x, y, z axis).
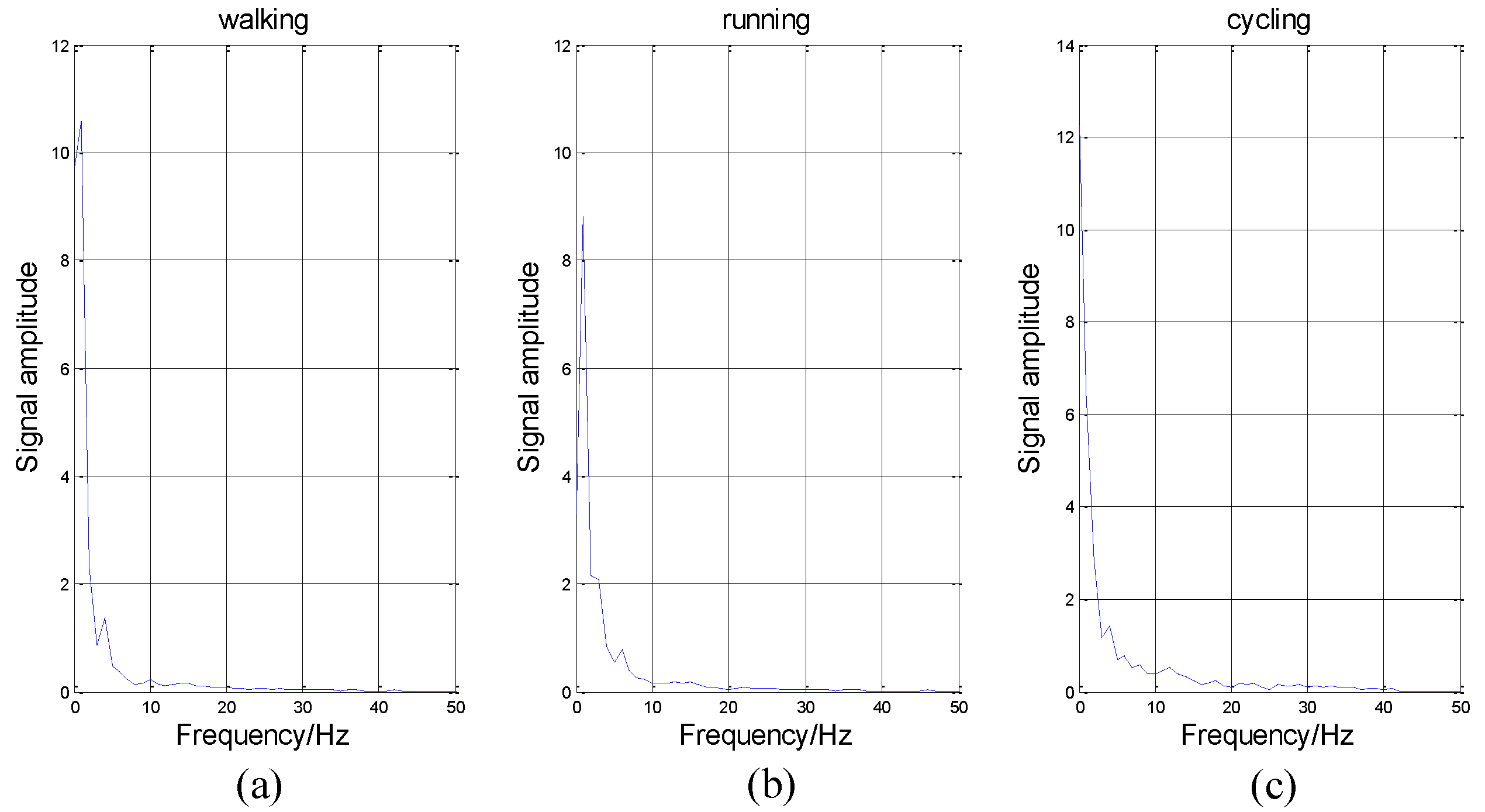
In addition to IE, there are many other features, such as IF, IA, and MS. We introduce them briefly. Firstly, MS represents the value of energy in each frequency. As shown in
Figure 7, the abscissa axis represents frequency and the vertical axis represents energy intensity.
As shown in
Figure 7, the variation tendency of these curves is similar. The energy in low frequency is much larger than that in high frequency, which conforms to our intuitive feeling that these activities are low-frequency-actions. It is impossible for people to perform these actions hundreds of times per second. Thus, in
Figure 7, the energy is nearly equal to zero in high frequency.
The IF and the IA can greatly represent the instantaneous features of a signal. However, for one signal, we can get hundreds of (and even thousands of) eigenvalues about the IF and the IA. It will be difficult for the neural network to train such a large classification network. At the same time, it will need to spend lots of time finishing this work. Therefore, we also consider to use the mean and variance of them in our classification.
4.6. DS
This paper has mentioned several signal processing methods, including FT, STFT, and FFT which all require that the processed signal be stationary. However, this requirement is often ignored by researchers for simplification. Meanwhile, it is extremely difficult to meet the original definition of stationary signal. If we use that definition to judge a signal, nearly all signals will be considered as non-stationary signals.
So, Huang proposes a different definition for stationarity based on HHT [
16]:
Among them, is the mean of the MS, is the DS of a signal.
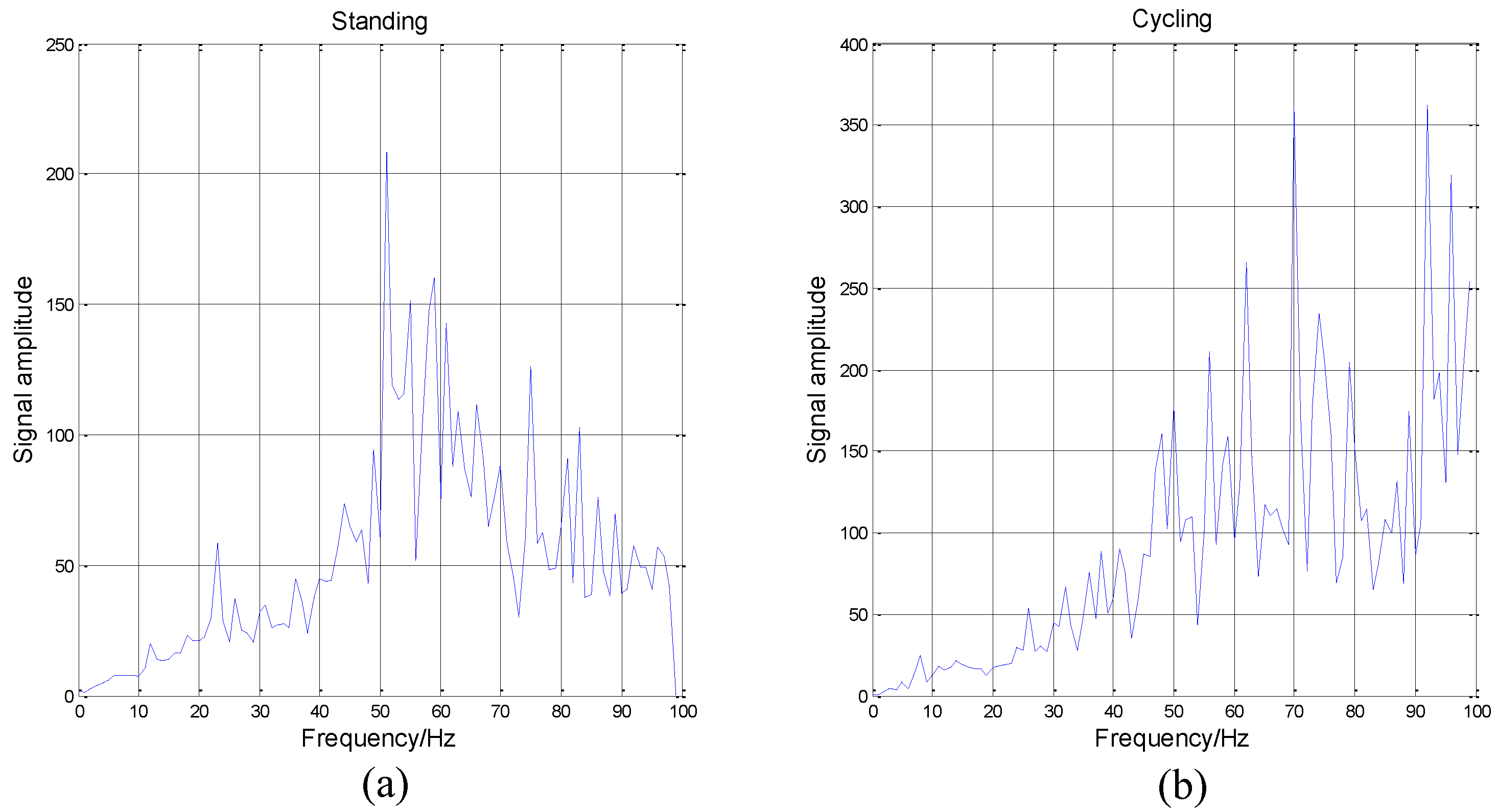
If a signal is stationary, the Hilbert spectrum will not be a function of time, and the will be zero. On the contrary, the higher the index value is, the more non-stationary the signal is. We analyze the data coming from the accelerometer located on the wrist as an example.
It can be seen from
Figure 8 that the cycling data is highly non-stationary. The DS will increase when the frequency increases. Besides, the data of standing is the most non-stationary when the frequency is between 50 Hz to 60 Hz. Then, the overall DS of standing is also poor. Because of these obvious differences among different activities and activity data’s high non-stationarity, we determine that HHT is suitable for activity recognition.
5. Activity Classification
The above extracted features will be used as the inputs to this part, that is, the classification. Artificial neural networks are important methods of classification in the field of activity recognition, as proven by the work in [
46,
47,
48]. Thus, in our work, the BP neural network is employed as the classifier to validate the extracted features.
5.1. Artificial Neural Network
A BP neural network is a multi-layers feed-forward neural network. According to statistics, 80% to 90% of the neural network models use the BP network or its extensions. Meanwhile, they are often used as a classifier in the field of activity recognition [
49].
BP neural networks were proposed by Rumelhart and Mcclelland in 1986 [
50]. From the aspect of structure, it is a typical multi-layers forward neural network with one input layer, several hidden layers, and an output layer. The full connection mode is adopted between the layers and a mutual connection does not exist between neurons in the same layer. The main characteristics of the BP neural networks are signal forward transmission, error backward propagation, and supervised learning. Moreover, it has been theoretically proven that a three-layer network with one hidden layer can approximate any nonlinear function [
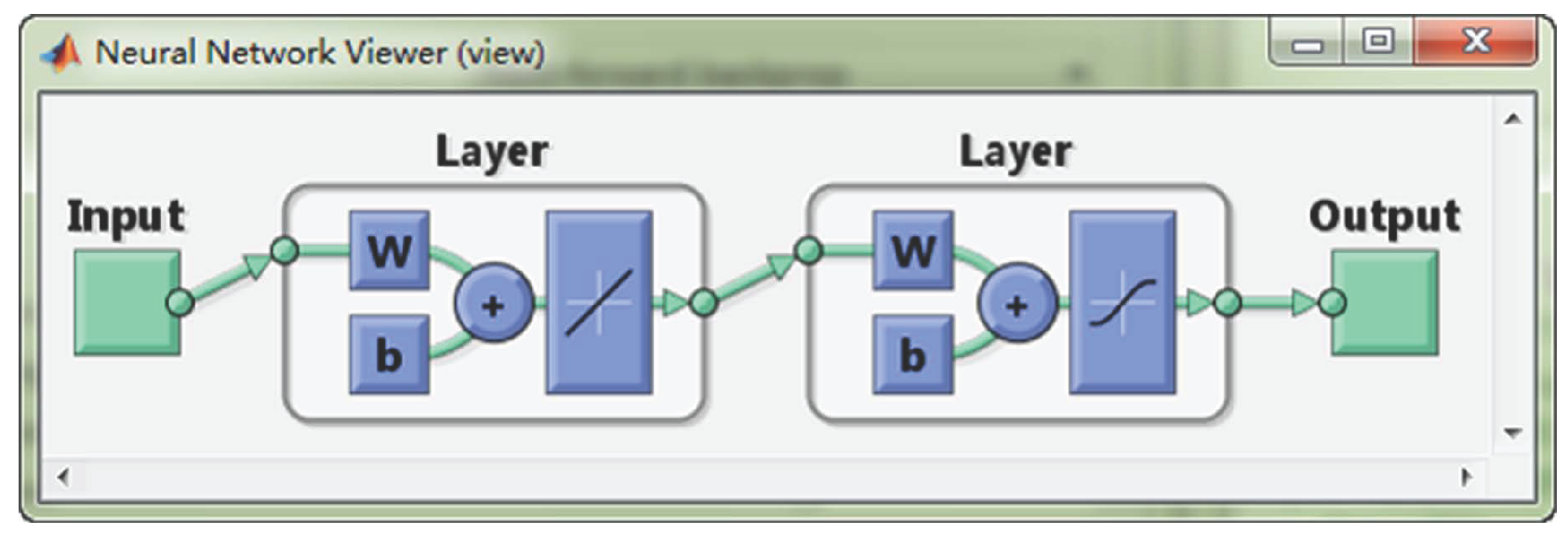
51]. A typical three-layer BP neural network is shown in
Figure 9.
5.2. The Learning Algorithm Based on a BP Neural Network [52]
As shown in
Figure 9 above, the structure of a three-layer BP neural network is demonstrated. The specific implementation steps of this supervised algorithm are given. The situation of more than one hidden layer can be derived based on this algorithm. Hereby, the BP neural network algorithm is shown as follows.
Step 1 Network initialization. The initial parameters of network should be set. For example, setting the weights of the input layer to the hidden layer, the hidden layer to the output layer as any small random number, and setting the initial threshold value.
Step 2 Training samples collection. According to the rules of supervised learning, both the input vector and the corresponding output vector should be provided.
Step 3 Output calculation. Calculating the output from the input layer to the hidden layer and the output layer.
For each neuron in the input layer: the input is , the output is , i is the total number of neurons in the input layer.
For each neuron in the hidden layer: the input is , the output is , j is the total number of neurons in the hidden layer.
For each neuron in the output layer: the input is , the output is , k is the total number of neurons in the output layer.
In the above equations, is the weight from the ith input layer to the jth hidden layer. is the weight from the jth hidden layer to the kth output layer. and are transfer functions. There are many kinds of transfer functions which can be selected.
Step 4 Weight adjustment. According to the error, the BP neural network adjusts the weights from the output layer nodes to the hidden layer nodes and the weights from the hidden layer nodes to the input layer nodes. The network error function is defined as
In Equation (
15),
represents inverse direction of the gradient of the error function in the
Tth training.
For the weight
from the output layer to the hidden layer, the adjusting formula is
In Equation (
16),
η is the learning rate,
,
d is the desired output.
For the weight
from the hidden layer to the input layer, the adjusting formula is
In Equation (
17),
is the error in the output node
k.
Step 5 Iterative loop. Return to Step 2 and iteratively operate until the error meets the requirements.
5.3. Parameters Setting
The feature vector will be used as input to the neural network. In this paper, the activity is classified according to which types of activity are taking place, the corresponding element will be set as 1, and the remaining elements will be zero. For instance, suppose there are five kinds of activities in total. If an unknown activity is classified as the second kind of activity, then the output value will be [0, 1, 0, 0, 0]. Therefore, the number of neurons in the output layer and the number of activity types will remain the same. Besides, the number of neurons in the hidden layer can make a great difference to the performance of the BP neural network. If the number of neurons is too few, the network cannot fully describe the relationship between input and output. On the contrary, if the number of neurons is too large, it will lead to the network needing to take a longer time to learn. What is worse, the classification results may turn out poorly. So, it is important to choose a suitable parameter as the number of neurons in the hidden layer. For a three-layer neural network, there are some common empirical formulas. The empirical formula selected in this paper is as follows:
where
m represents the number of neurons in the hidden layer,
x represents the number of neurons in the input layer, and
y represents the number of neurons in the output layer. The number obtained by this formula is usually not an integer, therefore, the number of neurons is selected from two integers that are near to the calculated results.
The neural network toolbox in
MATLAB [
53] is used to classify activities. The learning rate is set to 0.1. The Trainlm function is selected as the training function, which uses the Levenberg-Marquardt algorithm to update the weights. Moreover, it is the fastest back propagation algorithm in this toolbox. Because the output value of the neural network is 0 or 1, the hidden layer chooses the logsig function as the transfer function since it can map the input values on the
interval to the
interval. In addition, the output layer selects the purelin function as the transfer function. The performance evaluation index is the mean square error, that is, reducing the mean square error to the acceptable range through iterative learning.
5.4. Feature Selection
As we mentioned in section4, a raw signal can be decomposed to several IMFs and their IA and IF can be obtained. It can be seen from the
Figure 2 that the first IMF has the highest frequency and the penultimate signal has the lowest frequency. We regard the first two IMFs as high frequency noise. Usually, daily activities belong to the low frequency motion and the energy of them located at low frequency band [
9]. Meanwhile, the number of IMFs from decomposition is a variable, in order to ensure these features can be obtained. The presented method considers the mean and variance of the third and the fourth IMFs as features to be selected. Then based on all IA and IF, the Hilbert spectrum and relevant physical quantities such as IE, MS, DS can be deduced. There are some relevant papers using EMD to do the feature extraction [
9,
10,
11], but they only consider using the mean and variance of all or part of IA and IF. However, according to the above analysis from
Figure 5, the IE can be an obvious feature for activity recognition. So based on their work, besides using the IA and IF, we also discuss the effect when the mean and variance of IE and MS as features.
6. Results
This section introduces how to use the features of HHT for activity recognition. Moreover, we discuss some different conditions upon experiment, including using each feature independently, combining some of them, and analyzing the effect of two scenarios: dependent subjects and independent subjects. In addition, we make some comparisons with relevant work.
6.1. Performance Measures
In order to compare our results with [
54], this paper uses same performance measures: recall, precision, F-measure and accuracy, which are also commonly used in the field of classification. Firstly, we introduce the concept of confusion matrix, that is a matrix where each column of this matrix represents the activities in a annotated (or target) class while each row represents the activities in an recognized (or output) class. Moreover, we represent the element in the
ith row and
jth column as
, the sum of all elements in the
ith row as
, and the sum of all elements in the
jth column as
. Then let
C be the total number of activity classes and
N be the total number of samples of all activities. Based on these notations, we can clearly define these performance measures as follows.
6.2. Recognition Performance When Only Using IE as Feature
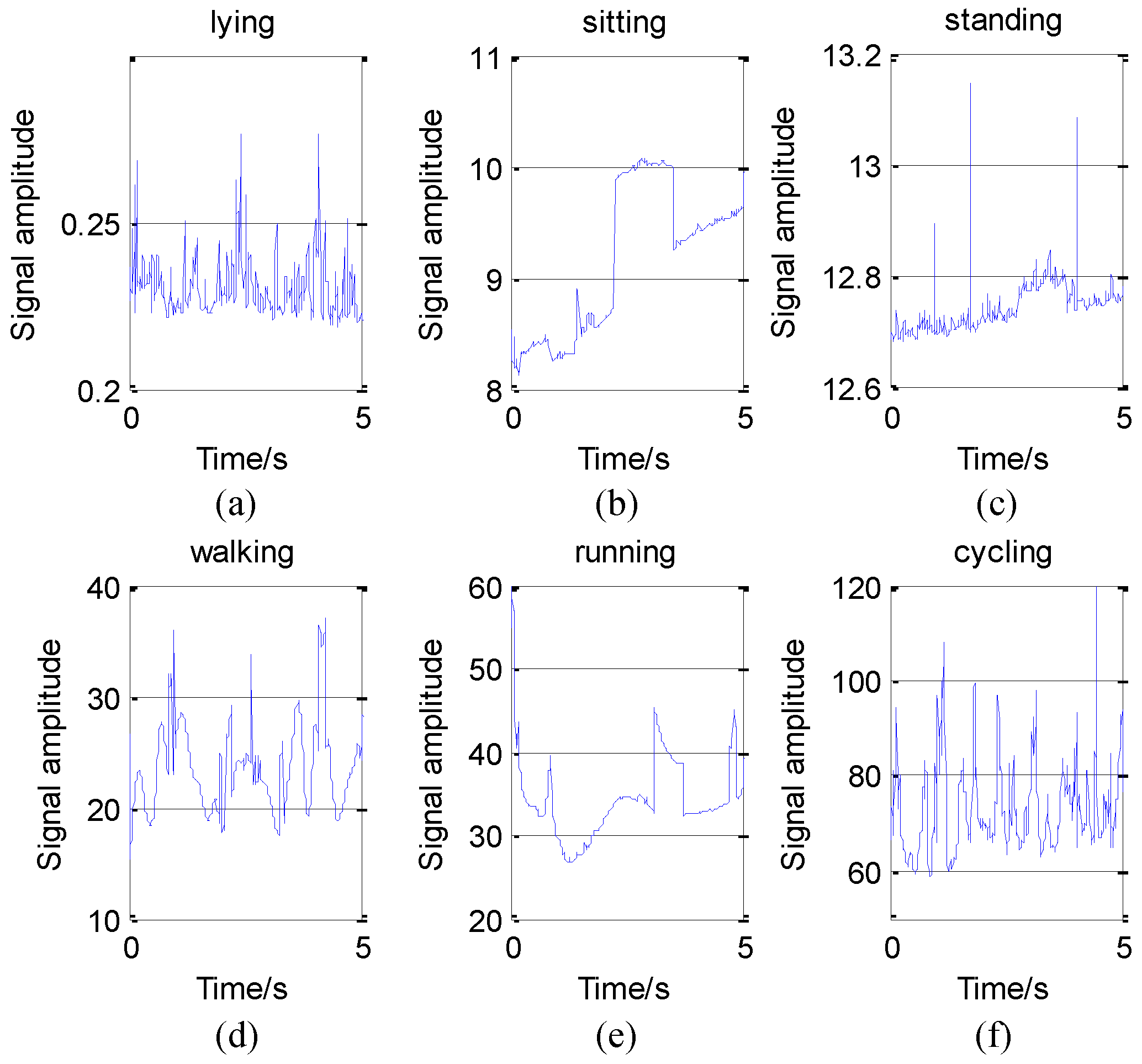
As described in the previous sections, this paper uses three wearable sensors to collect activity data. Then, these data are divided into several segments for every 5.12 s. Each sensor collects data from its x, y, and z axes. This paper classifies 12 activities which include most common activities in daily life. It is important, because we can provide useful guidelines to users if we can recognize these activities accurately.
We divide each subject’s activity data that have been preprocessed into two parts: one half for training the neural network and the other half for testing the training effect. For each data segment, we can get several eigenvalues. Then, we use training data to train the neural network and use testing data to evaluate the classification accuracy. According to Equation (
18), the structure of neural network in this experiment is 18-14-12. The three numbers represent the number of neurons in the input layer, the hidden layer, and the output layer, respectively. The confusion matrix of training data is shown in
Table 4.
Using the trained neural network to classify the data of the other parts, testing data, the confusion matrix is obtained in
Table 5.
Based on the above two confusion matrices, Equations (
20)–(23), we can obtain the performance measures for these two conditions in
Table 6.
In our real life, however, only the untrained data needs to be classified, thus, the results of
Table 5 are more practical and our focus is on trying to improve the performance measures of testing data. Therefore, in the next subsections, we will discuss the activity recognition from this perspective.
6.3. Recognition Performance of Other Features of HHT
Through the experiment, the effect of three different types of features on activity recognition is analyzed. The first feature is the mean and variance of IE, which we have discussed in
Section 6.2. The second feature is the mean and variance of MS and the third one is the mean and the variance of IA and IF. We use the data coming from the accelerometers of three sensors. The accelerometer has three (
x,
y,
z) axis, so when the IE or MS is considered as a feature for activity recognition, the number of eigenvalues is 18. Then, a raw signal can always be decomposed into several IMFs and the total number of IMFs is variable. Therefore, for each signal, the third and the fourth IMFs are selected and this the reason we have illustrated this in
Section 5.4. Next, the IA and IF of each IMFs are extracted as features. Thus, when we use the IA and IF as feature, 72 eigenvalues can be obtained in total.
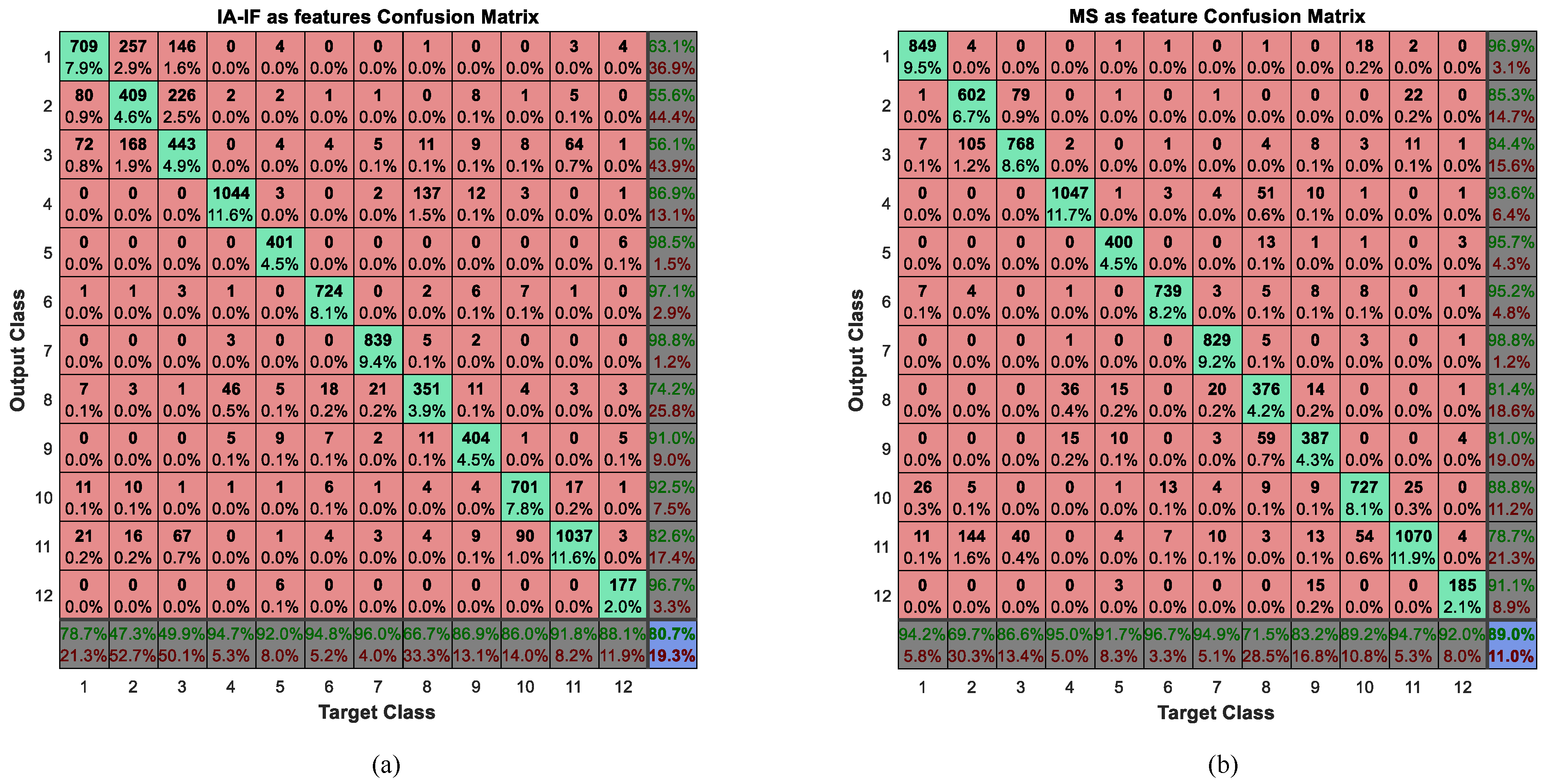
In this experiment, the structure of a neural network is 18-14-12 when the IE or MS was considered as a feature for activity recognition. If the features are IF and IA, the structure of the neural network is 72-29-12. The three numbers represent the number of neurons in the input layer, the hidden layer, and the output layer respectively. The confusion matrices obtained by using MS, IA and IF as features are shown in
Figure 10.
As we can seen from
Figure 10, the judge error between the second activity sitting and the third activity standing is huge, especially when using IA and IF as features, the correct rates are less than 50%. Maybe this is the reason that these two activities be seen as the same activity in the [
54]. Meanwhile, we have discussed these activities in
Figure 5. The features of them are very similar, which leads us to conclude that it is difficult to distinguish them. In addition, from the results of the confusion matrix, we can intuitively draw the conclusion that the effect of IA and IF is much worse than IE or MS in the activity recognition. To compare and evaluate these three types of features, we calculate their performance measures, as shown in
Table 7.
As we predicted, the results shows that the effect of IE and MS are roughly equivalent. The precision and accuracy of IE are a little better than that of MS while the recall and F-measure of MS are relatively better than that of IE. From the previous analysis, the figures of the MS among different activities sometimes looks very similar, nevertheless, we know that, according to the classification results, the neural network can still clearly find these differences and classify them correctly. However, when the IF and IA are considered as features for activity recognition, the performance measures are rather poor. The error rate of some activities is very high, and it is difficult to apply it to real life. We maintain that the IF and IA are instantaneous features, which describe the characteristics of a signal at a certain time, but there are too many eigenvalues to put them all into classification. Thus, we use the mean and variance to process these eigenvalues and use them as inputs to the BP neural network. However, this process eliminates the instantaneous feature and leads to steps which aim to stop the instantaneous feature becoming meaningless. This results in the effect of IA and IF being unsatisfactory. It will be better if we put all instantaneous features into classification without considering time consumption and network magnitude, but it is difficult to process hundreds of, and even thousands of eigenvalues. However, for the IA and IF, the correct rates of some activities like cycling are higher than the other two methods. Therefore, we infer that this method may have a special characteristic which can help improve the performance measures of the other two methods and we consider combining these features in the next subsection.
6.4. Recognition Performance of Multi-Features Combination
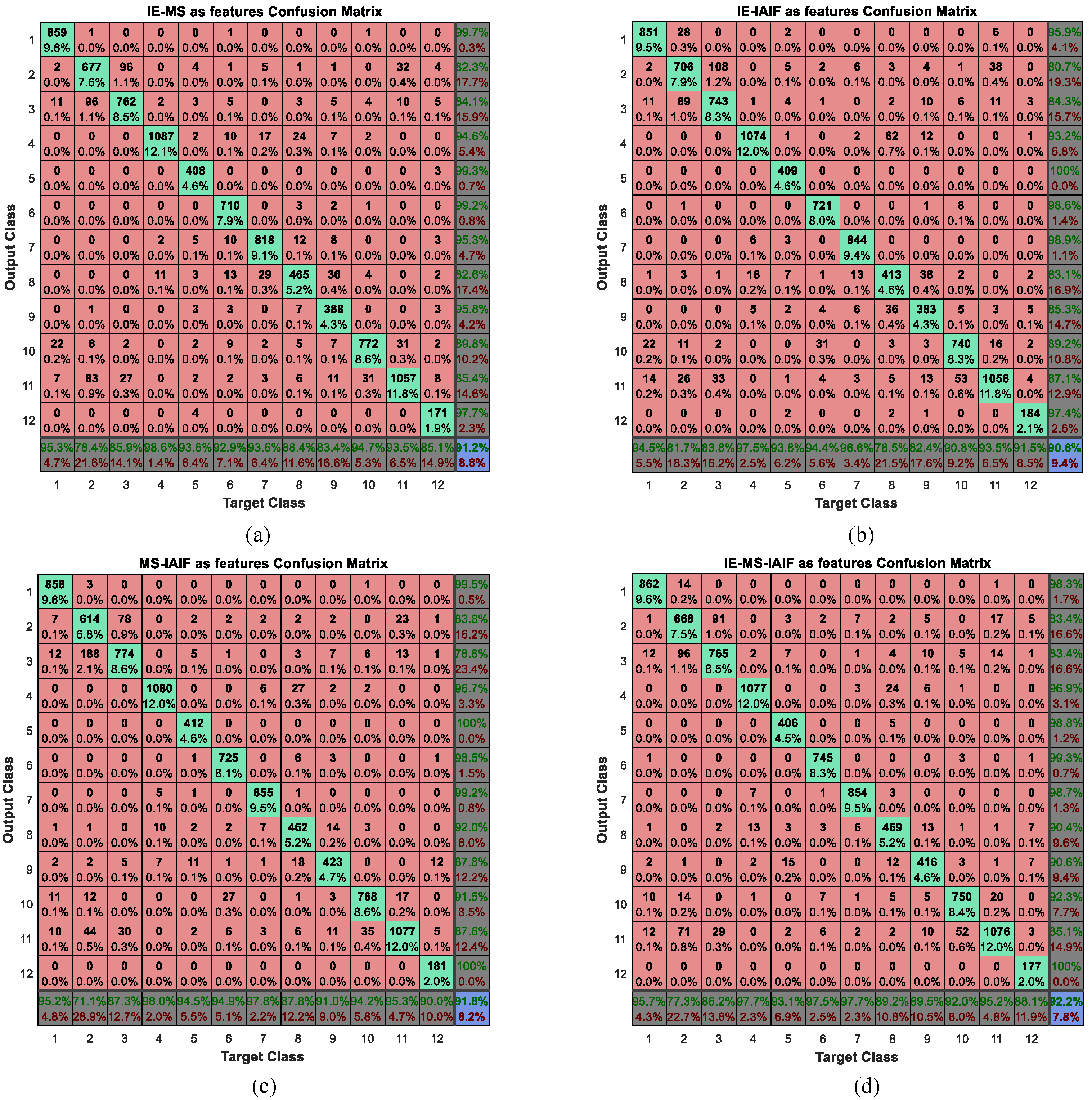
According to the analysis of above subsection, we can get relatively satisfied recognition results when using IE or MS as features. In order to further improve the performance of activity recognition, we consider combining these features both pairwise and by combing all four. Thus, we will have four different types of feature groups including IE-MS, IE-IAIF, MS-IAIF, and IE-MS-IAIF. Then, we take these feature groups as inputs to the BP neural network. The corresponding confusion matrix of each type of feature group can be gained. In this experiment, the structure of the neural network is 90-32-12 when the IE-IAIF or MS-IAIF was considered as a feature for activity recognition. If the features are the IE-MS, the structure of the neural network is 36-20-12 and if the features are the IE-MS-IAIF, the structure of the neural network is 108-36-12. The three numbers represent the number of neurons in the input layer, the hidden layer, and the output layer respectively. We plot their confusion matrices in
Figure 11.
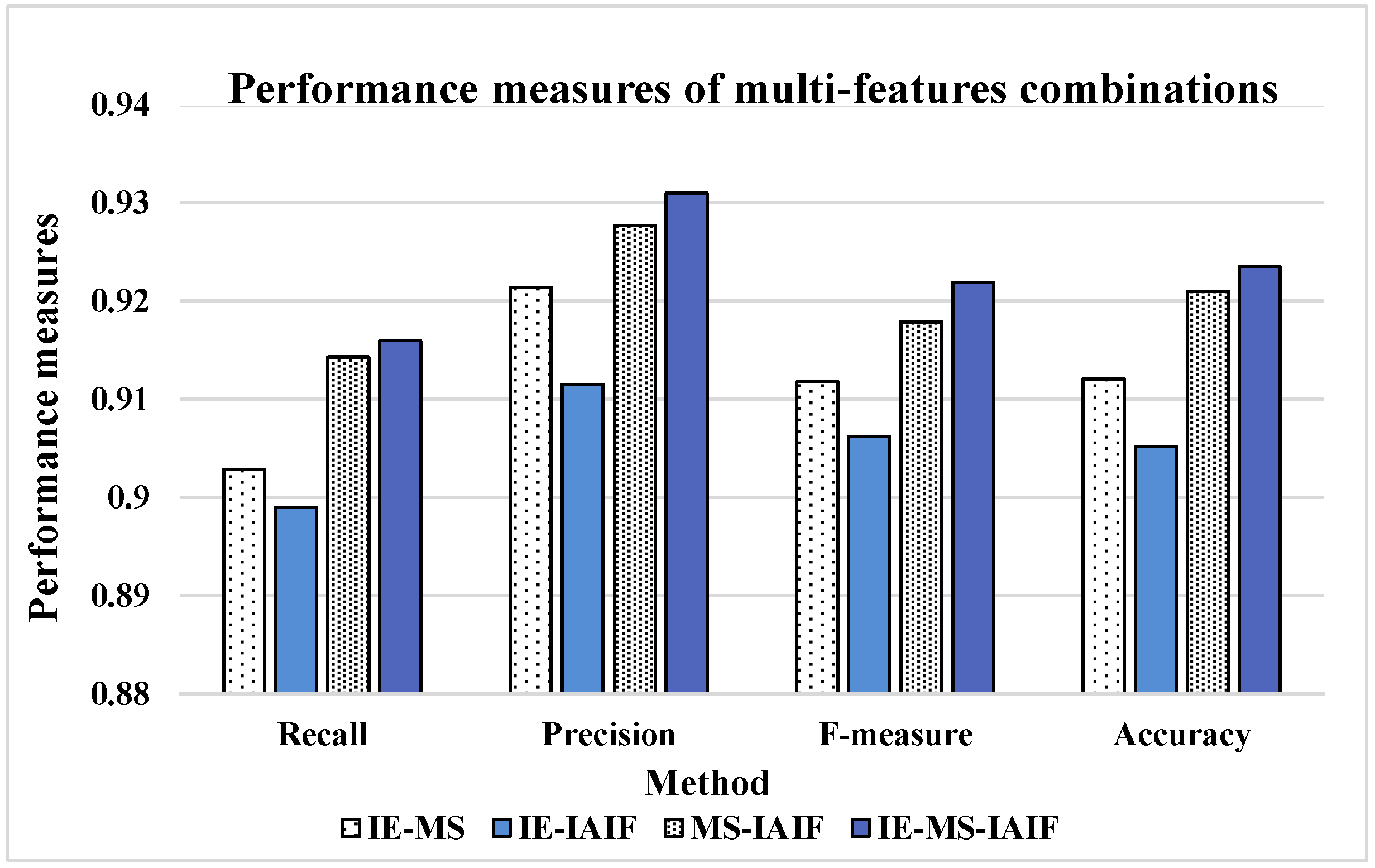
To intuitively compare the effect of these feature groups, we calculate their performance measures and show the results in
Figure 12.
It can be seen from the results that nearly all the numbers in
Figure 12 are bigger than 0.9 while all the numbers in
Table 7 are less than 0.9, so the performance of each feature group is better than that of an individual feature. Thus, we believe that multi-features combination can further improve the performance of activity recognition. In addition, when we use each feature separately, the performance measures of IE and MS are much better than that of IAIF. However, when we combine these features in pairs, the MS-IAIF rather than IE-MS shows the best performance. We think that IE and MS may contain many similar characteristics which mean that it is difficult for these two features to play a complementary role for each other. At the same time, according to the above analysis, the correct rate of some activities using IAIF as a feature is better than the condition of using MS. Thus, IAIF can provide some special characteristics for MS to improve the performance. Moreover, it shows the best results when we combine all three features together, but it only a little bit better than the results of MS-IAIF.
6.5. Recognition Performance of Independent Subject
In the above discussion, each type of activity data is composed of all subjects’ corresponding data and we divide these data into two parts: training data and testing data. However, in our daily life, people focus more on pursuing personalized experience and use the tailor-made devices. Thus, the independent subject validation is important for the activity recognition system. In this subsection, the effect of the presented method in the scenario of independent subject is analyzed. We use the same data preprocessing method as in the scenario of the dependent subject and process each subject’s data independently. That is to say, we will separately divide each subject’s data into two parts without mixing them with any other subjects’ data. According to the analysis of the previous subsection, the feature IE-MS-IAIF shows the best performance in the scenario of dependent subject; therefore, we also use this feature as an example to do the experiment. Besides, in this dataset, only five subjects (including subject ID 1, 2, 5, 6, and 8 ) finish all 12 activities that we want to classify. All other datasets have some missed activity type that mean they cannot be used. As for the data of subject ID 6, the duration of its activity, rope jumping, is less than 3 s, which is too short to use. Thus, in this experiment, we have data from four subjects and we show the results of them in
Table 8.
In order to integrate their respective results into an overall performance measures we propose the definition of overall performance measures which is denoted by
where
represents overall performance measures that are composed of four specific indexes,
is performance measures of the
ith subject that is also composed of four indexes, and they are illustrated in Equations (
24) and (
25). In addition,
m is the total number of subjects, which is 4 in this experiment,
is the sample number of
ith subject, and
N is the total number of all samples. Then, we can get the complete results of this experiment in
Table 8.
As we can see from the
Table 8, performance measures differ from individual to individual because everyone has their own behaviour characteristic. Some people like subject ID 2 may make a big move during an action, which makes each activity can be easily distinguished, while some people like subject ID 5 may make smaller movements, which introduces difficulties to activity recognition. This is the challenge that we face in our daily life. Besides, the more important reason for this phenomenon is that the duration of some of subject ID 5’s activities is too short. This results in the sample size of these activities being small and affects the classification performance of the BP neural network. However, it is not a problem for practical application because the user can supply enough activity data for the algorithm. Thus, we can focus more on the results of the other three subjects. An overall-PM2 is calculated which does not concern the result of subject ID 5. All four performance measures of Overall-PM1 are bigger than 0.91 while those of Overall-PM2 are bigger than 0.93. In the meantime, as for the sample size, although the duration of some activities of subject ID 5 are only about 1 min, the four indexes can be satisfied. For any subject, most of the activities’ durations are less than 3 min, which is short. Nevertheless, the results show relatively high performance. Thus, the presented method can realize accurate activity recognition with a small amount of training data and we can believe that if we can give enough data as inputs, the results can be further improved.
6.6. Comparing with Relevant Work
Many related works [
29,
30,
31,
32,
33,
34,
35,
36,
37] discuss the classification methods for activity recognition. In these papers, several classification approaches are introduced at the same time. Then, the author can determine a relatively good method according to some specific evaluation indexes. In addition, we used fuzzy classification [
55] and the FFT algorithm to process other datasets before, and good classification results are gained with the proposed methods. Moreover, the dataset we use in this paper is from the experiment of [
54]. In the work [
54], the authors propose both dataset and benchmark for different methods of human activity recognition. Therefore, in order to evaluate our work, we make a comparison of the classification results with the outcome presented in [
54]. In that paper, independent subject evaluation is done with leave-one-subject-out (LOSO) 9-fold cross-validation and dependent subject is done with standard 9-fold cross-validation. According to the previous analysis, the scenario of an independent subject is more common and practical, which allows a device to be more suitable for a specific user. Thus, we compare our results of the independent subject in
Table 8 with the results from [
54] which uses LOSO 9-fold cross-validation. Meanwhile, the activity recognition experiment we undertook is described as all the activity recognition tasks in that paper, so the corresponding results of the task are selected.
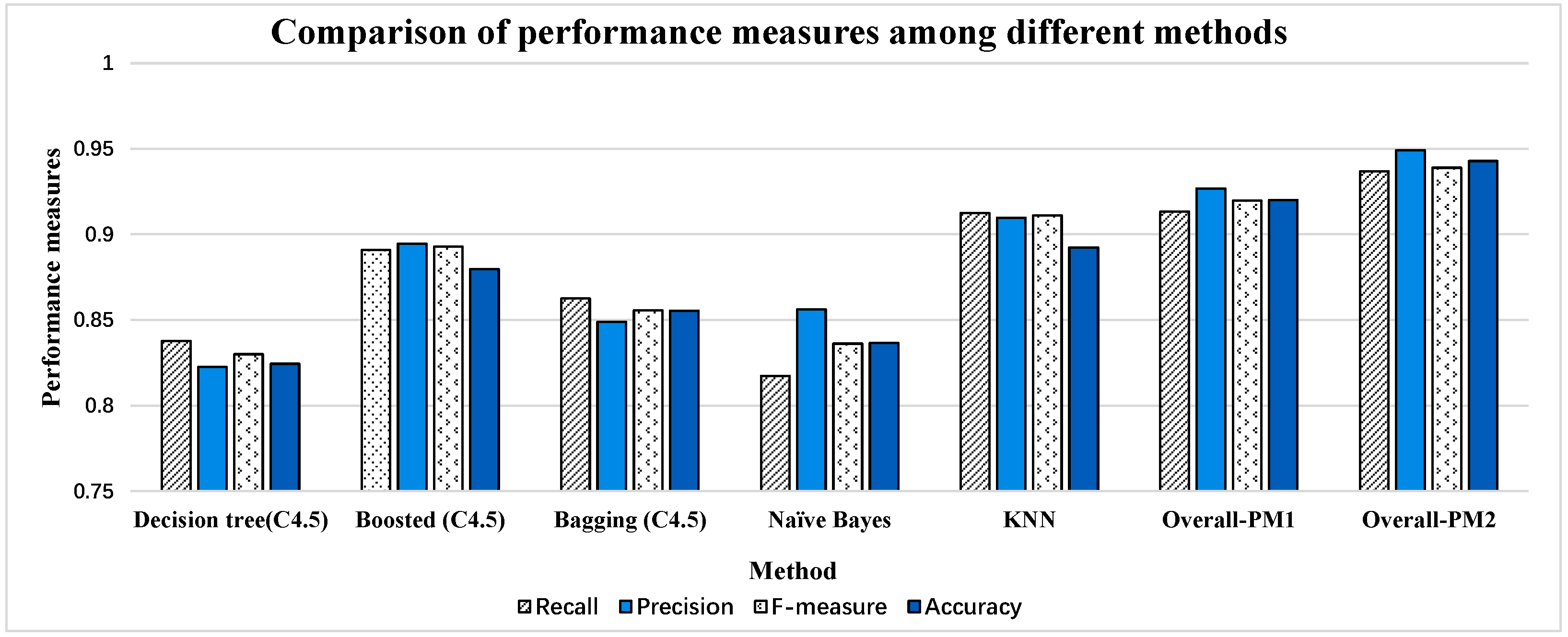
It can be seen form the
Figure 13 that the performance measures of the first four methods are all less than 0.9. KNN shows the best results in [
54] which has a similar effect (slightly lower) to the results of Overall-PM1. If we do not consider subject ID 5 because of the sample size, Overall-PM2 has outperformed KNN significantly. There are some differences between the ways we preprocess the dataset. Besides, different classifiers are used to classify activities. However, the effectiveness of the HHT is remarkable. Especially, when the processed data in activity dataset are nonlinear and non-stationary (it can be seen in
Figure 8), and HHT has obtained a very good effect processing this type of data in other areas [
22,
23,
24,
25,
26,
27,
28]. Hence, the proposed method is verified to be valuable and practical in activity recognition and it can effectively make up the shortcoming of traditional methods when processing activity data.
7. Limitation and Future Work
Before we summarize the paper, current limitations of the proposed method should be pointed out to direct our future works.
Firstly, although the PAMAP2 dataset we used in this paper is well known for activity recognition and benchmarking, the dataset still contains null values and missing data fields due to packet loss in signal collection or the misuse of sensors by practitioners. To the best of our knowledge, how to deal with missing data is another critical issue for activity data processing based on body-worn sensors. In this paper, we only conduct a set of simple dropping policies to deal with the problem. For example, if there are missing data from one sensor in a certain time point, we will drop all data which are collected from three sensors in this time point. These policies are simple to facilitate our experimental study on feature extraction. Nevertheless, our means for missing data will break the continuity of activity data, or may reduce the recognition accuracy. Accordingly, in our future works, we plan to evaluate the influence of missing data to feature extraction for activity recognition, and to investigate some useful methods like interpolation or prediction, with the objective to fix the problem of missing data and improve recognition effect.
Another limitation of our work is that, due to the limitation of time and space, we do not conduct a detailed study on the impact of sensor numbers on the proposed feature extraction approach. In the view of beauty and comfort considerations, however, people are inclined to wear fewer sensors. Thus, it is important to explore the relationship between recognition results and the number of sensors. Moreover, we can find a tradeoff between them based on the relationship. We will also investigate a possible future research task, to integrate other various classification tools (beyond BP neural network) with the proposed feature extraction methods. As we mentioned in
Section 2.2, many kinds of classifiers are widely used in activity recognition. It is valuable to study the effects of the proposed methods with different classifiers.
8. Conclusions
In this paper, a feature extraction method based on HHT has been proposed for activity recognition since the activity data are non-stationary and nonlinear. The experimental results show that our approach is capable of handling this problem and three conclusions can be drawn.
Firstly, In addition to the features (IA and IF) from EMD, we also use two other related features (IE and MS) from Hilbert spectral analysis. In the scenario of dependent subjects, the effect of multi-features combination and single-feature are discussed. The comparison results show further performance improvement with multi-features combination. At the same time, the highest performance measures can be obtained when we combine all three features together, that is, using IE-MS-IAIF as features.
Secondly, in the scenario of the independent subject, the four overall performance indexes: recall, precision, F-measure, and accuracy can reach 0.9337, 0.9417, 0.9353, and 0.9377 respectively. The experimental results from two scenarios show that our method is both suitable for the scenario of independent subject and dependent subject.
Finally, compared with relevant paper, the relatively high performance of the presented method demonstrated that the effectiveness of the HHT is remarkable and it can make up the shortcoming of traditional methods when the processed data are nonlinear and non-stationary.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}