
Coordinate-Based Clustering Method for Indoor Fingerprinting Localization in Dense Cluttered Environments


Abstract
:1. Introduction
2. AP Deployment Influence Analysis
2.1. Indoor Wireless Signal Transmission Model
2.2. Database Structure for Indoor Positioning System
2.3. AP Deployment Influence
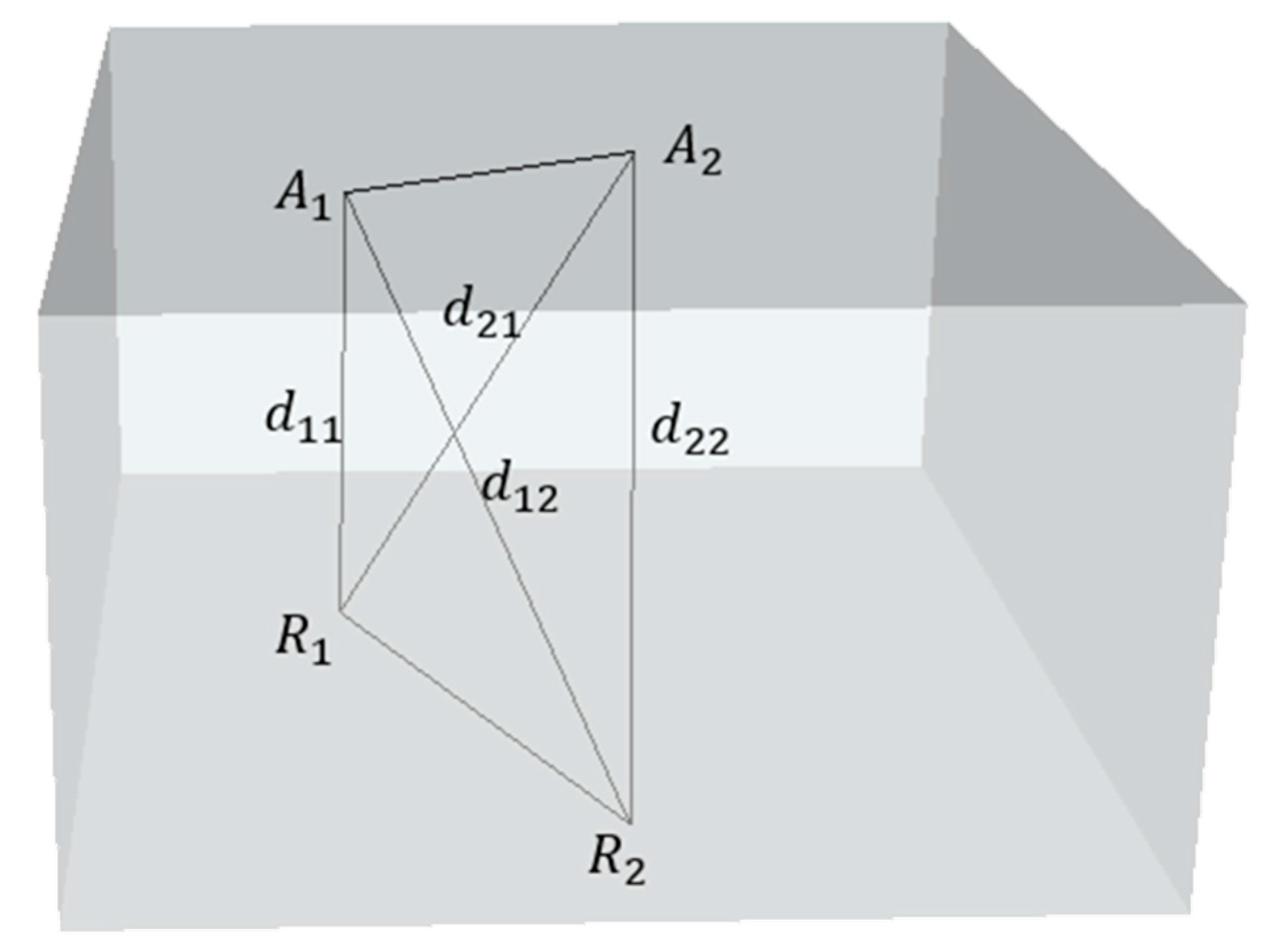
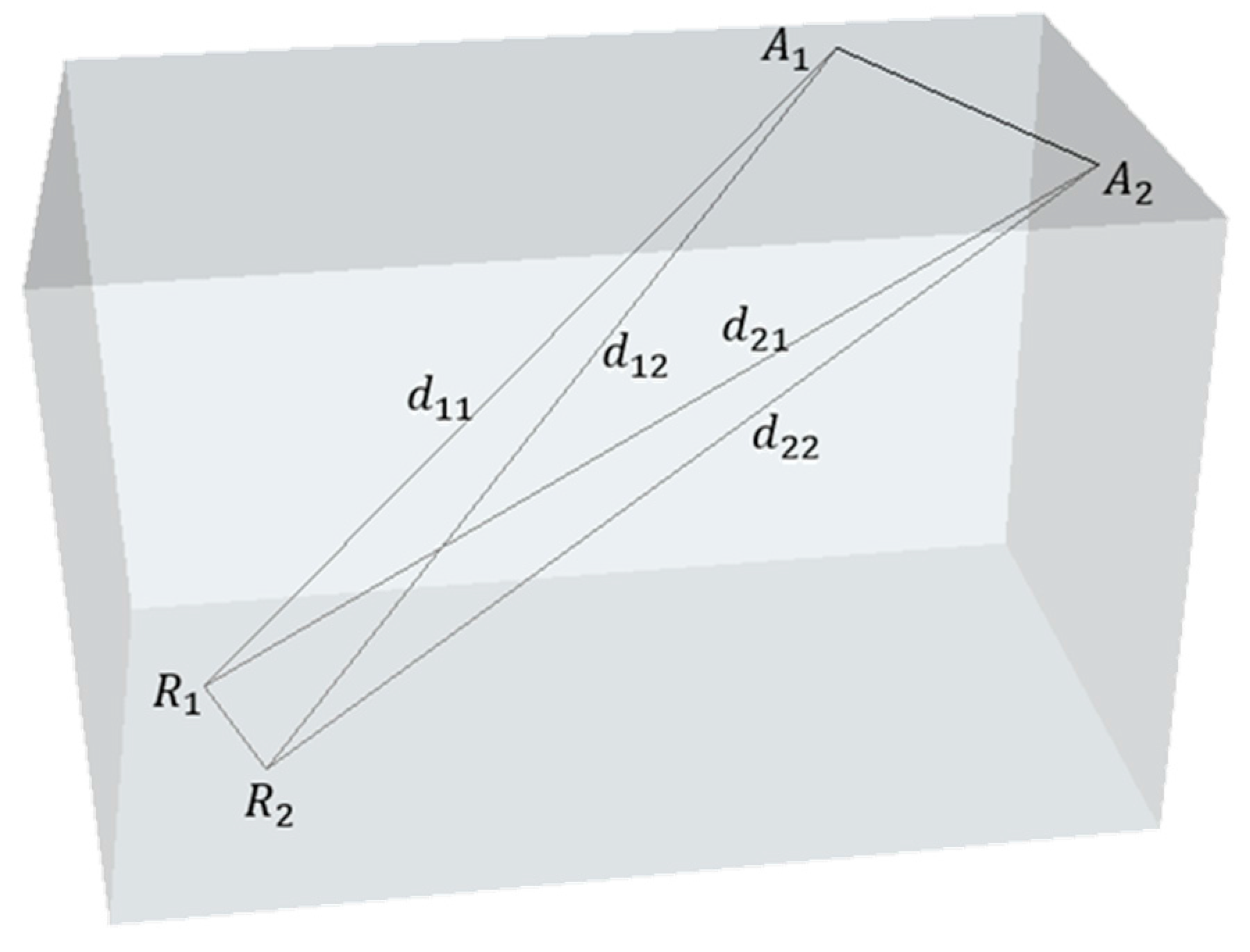
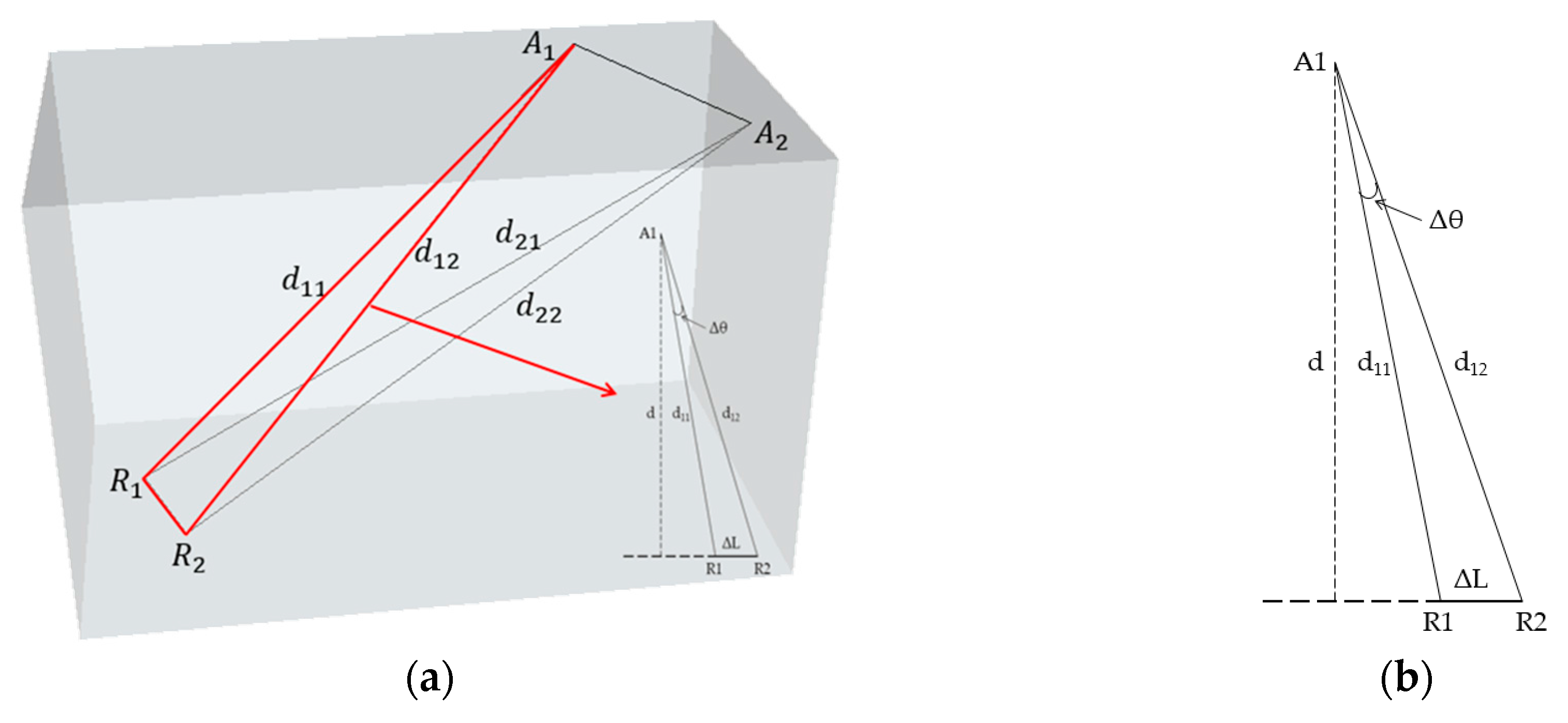
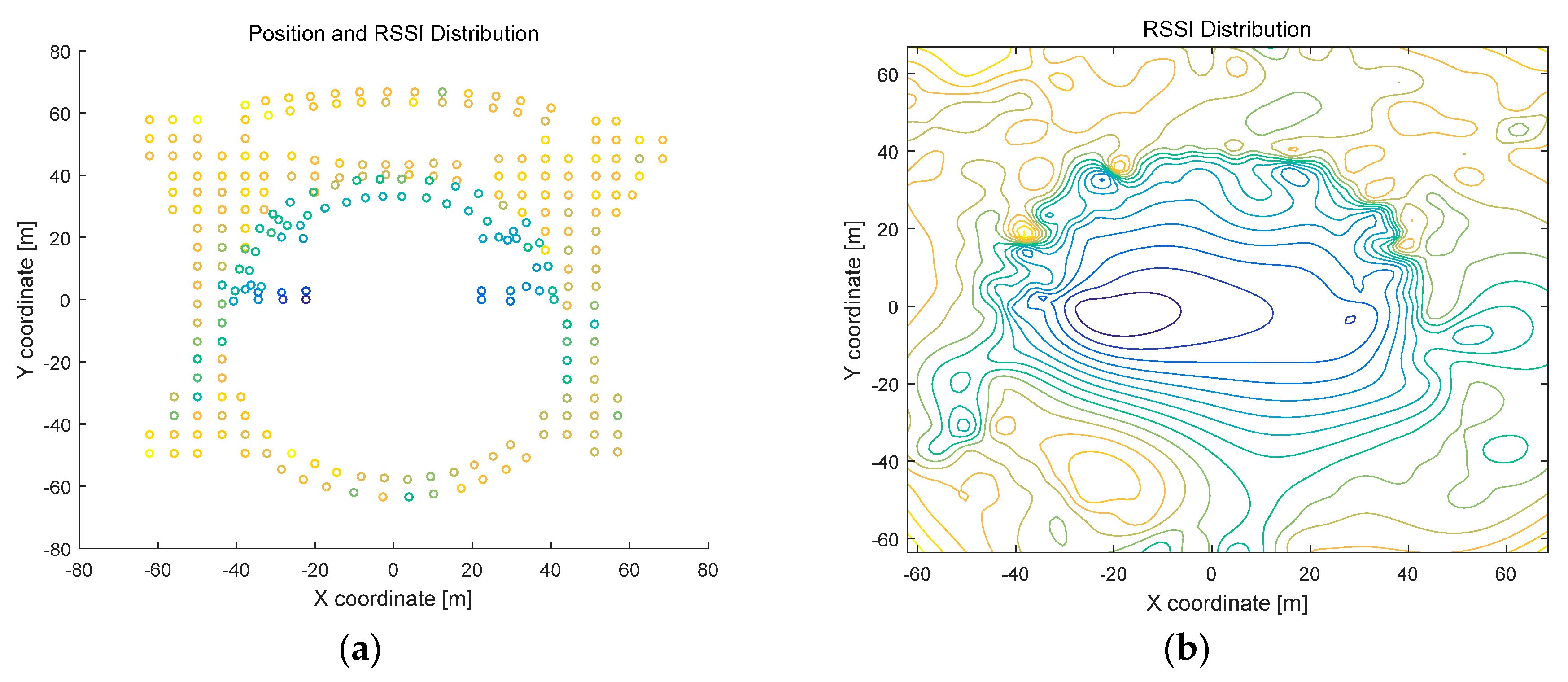
2.3.1. APs Are Close to RPs
2.3.2. APs Are Distant from RPs
2.3.3. Influence Analysis
3. Coordinate-Based Clustering
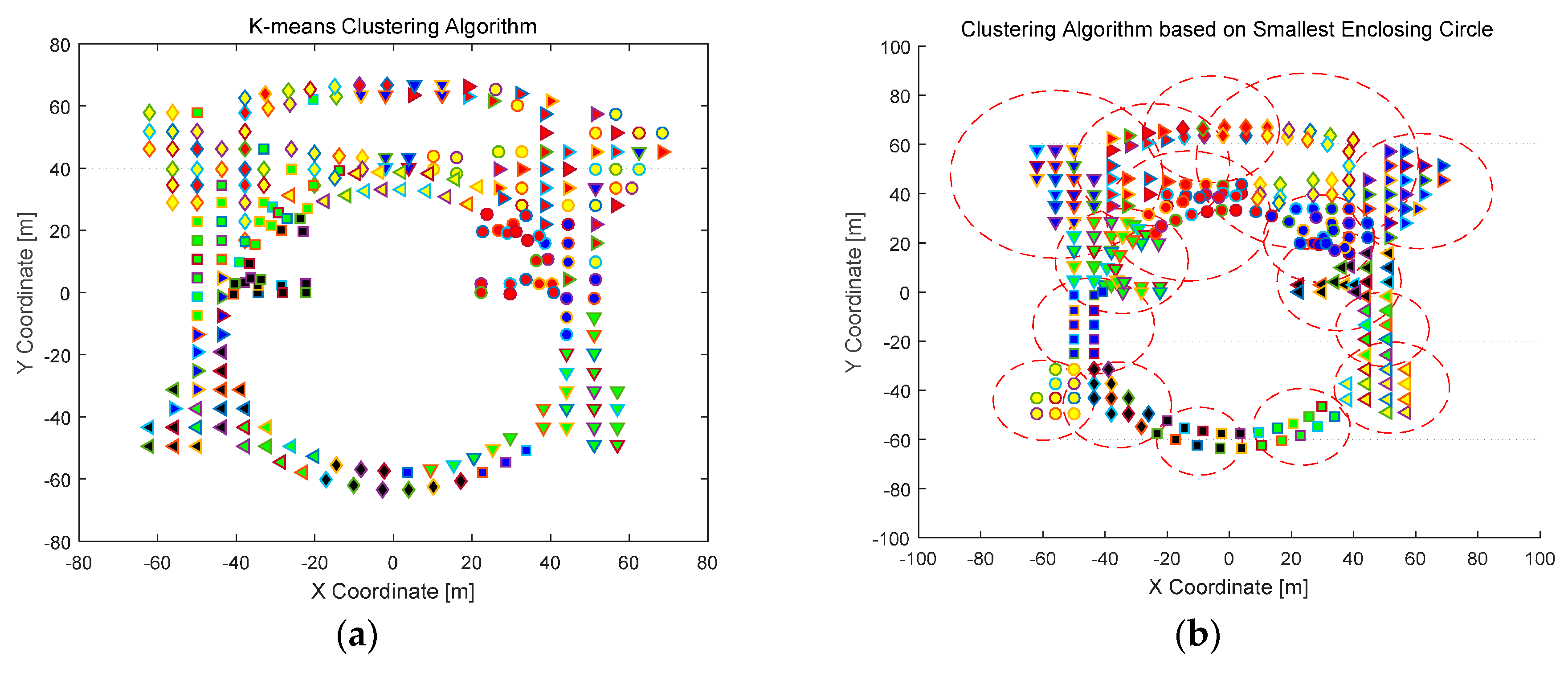
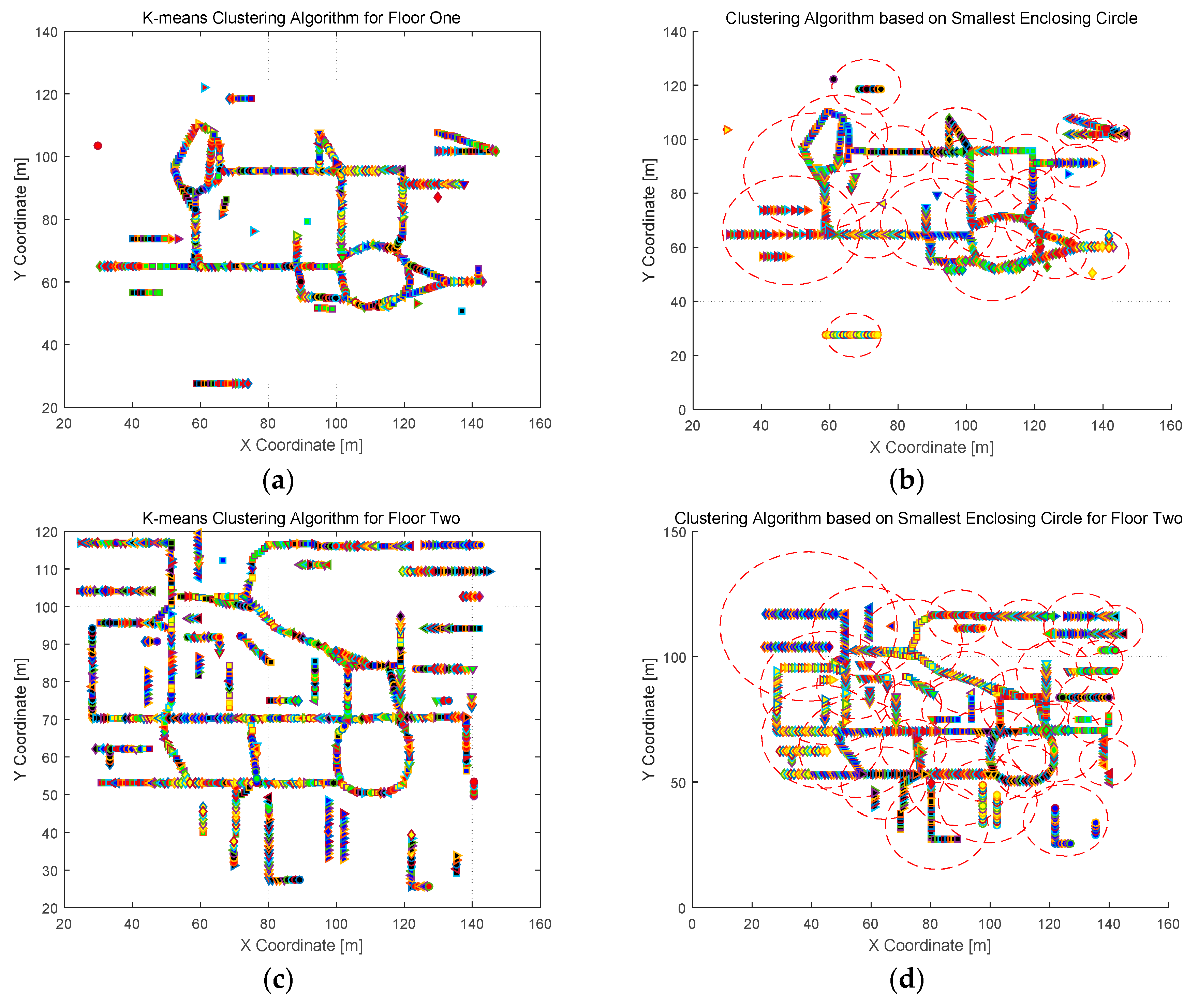
3.1. Grid-Based Clustering
3.2. Smallest-Enclosing-Circle-Based Clustering
3.2.1. Smallest Enclosing Circle Model
3.2.2. Smallest Enclosing Circle Clustering Algorithm
- Step 1.
- Select k points from set P randomly for the initialization of smallest enclosing circle-based algorithm.
- Step 2.
- Calculate the Euclidean distances between remaining points and the selected points in database. Cluster the remaining points into k smallest enclosing circles based on the minimum-distance principle, and update the centers and radiuses of circles based on the theory of SEC.
- Step 3.
- Evaluate the changes of circle centers before and after SEC algorithm, if the center changes are larger than the given threshold, then do Step 2; else do Step 4.
- Step 4.
- Store the centers’ coordinates and RSS information into database for on-line evaluation stage.
| Algorithm 1: Smallest Enclosing Circle (SEC) Clustering Algorithm |
| Initialize: |
| Calculation: |
| Verification: |
4. Measurement Analysis
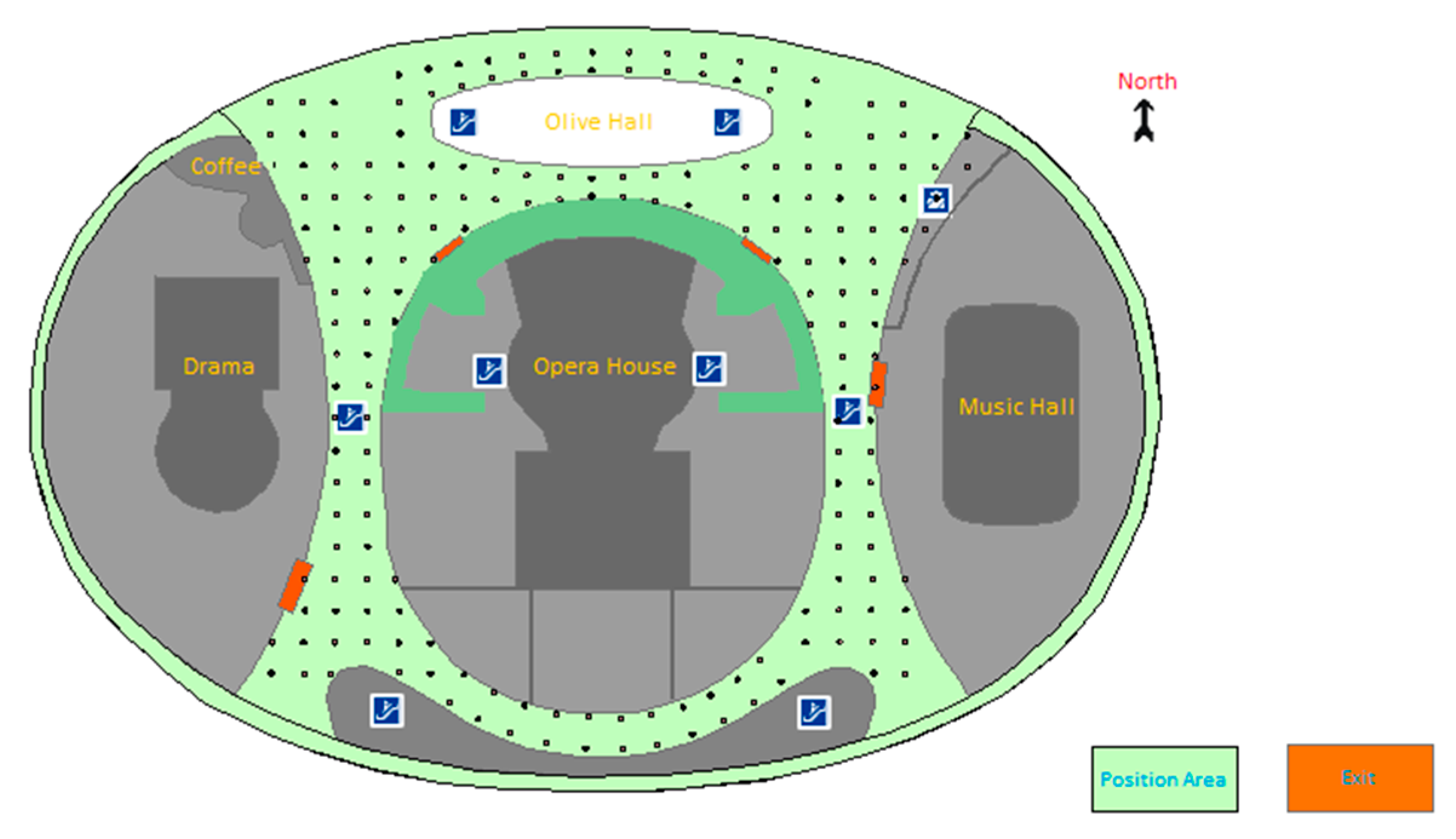
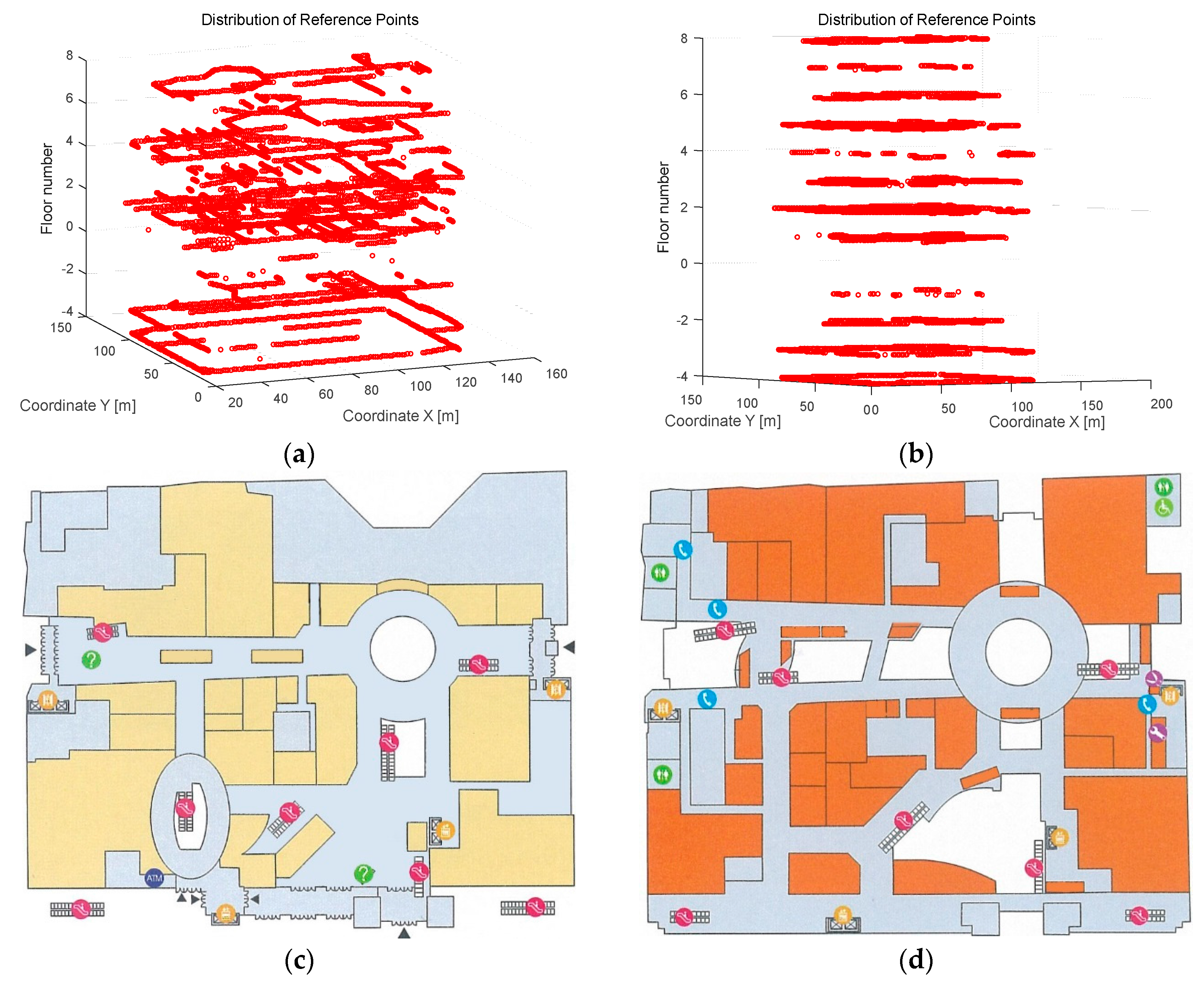
4.1. Experiments Scenario and Implementation
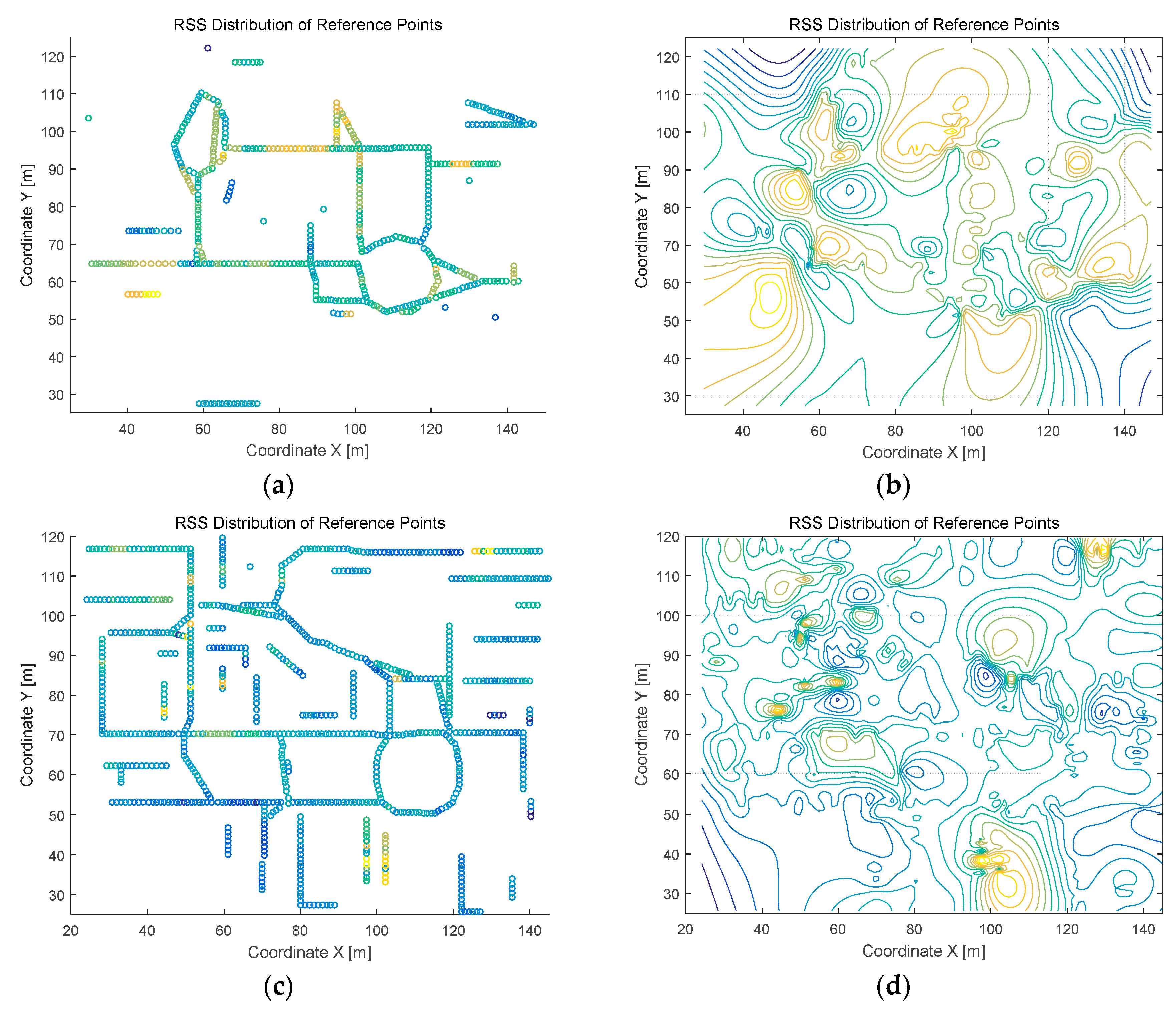
4.2. Measurement Results and Analysis
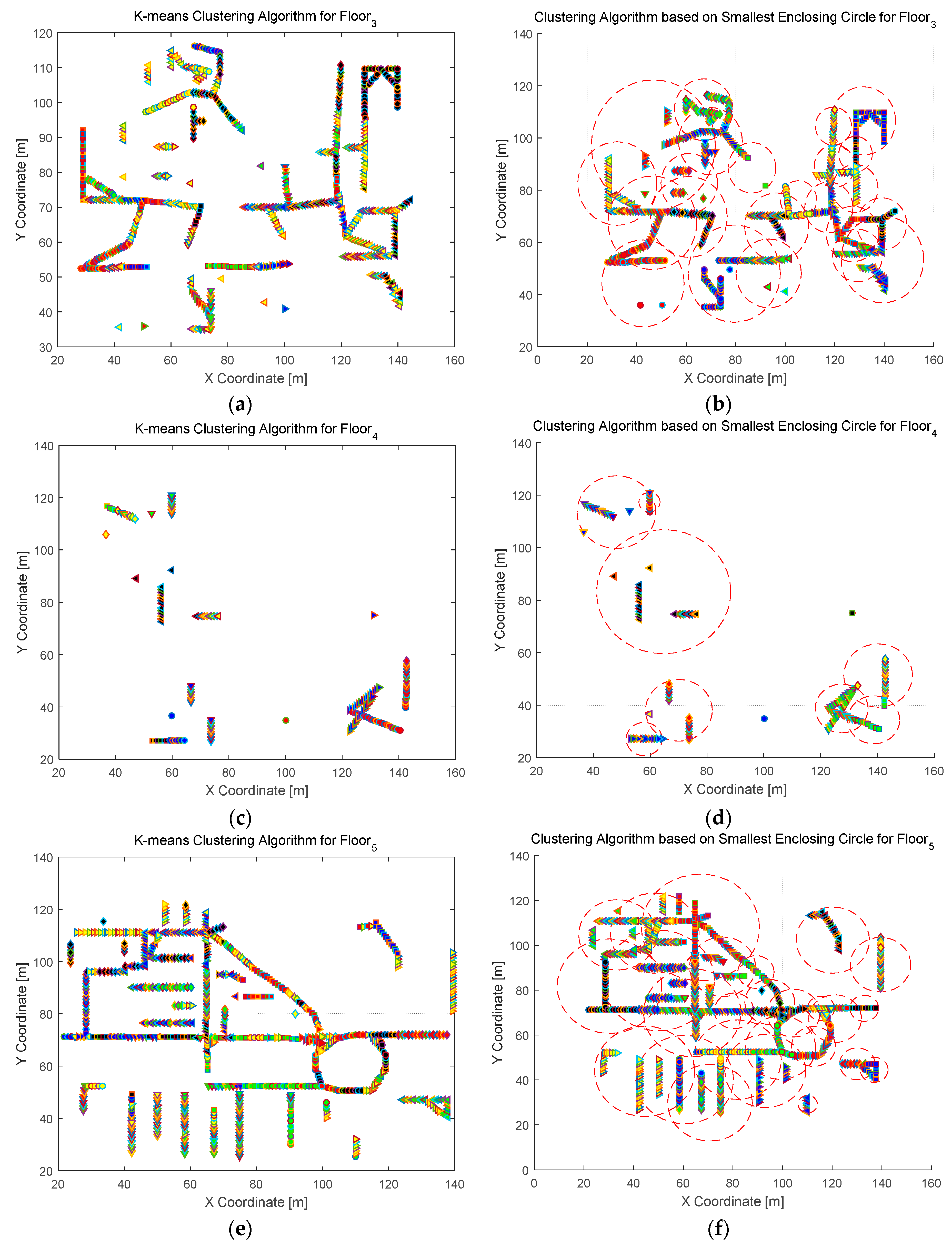
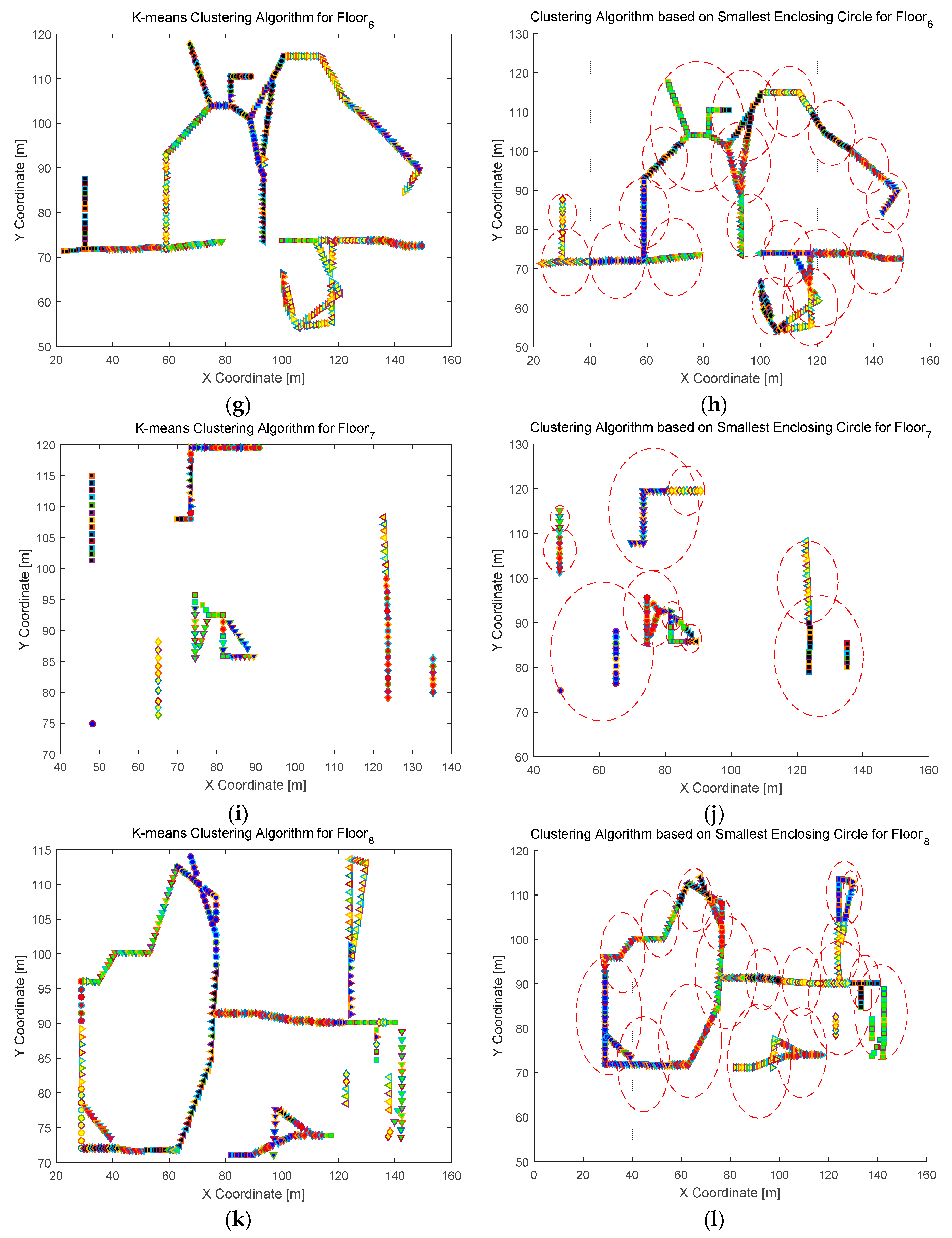
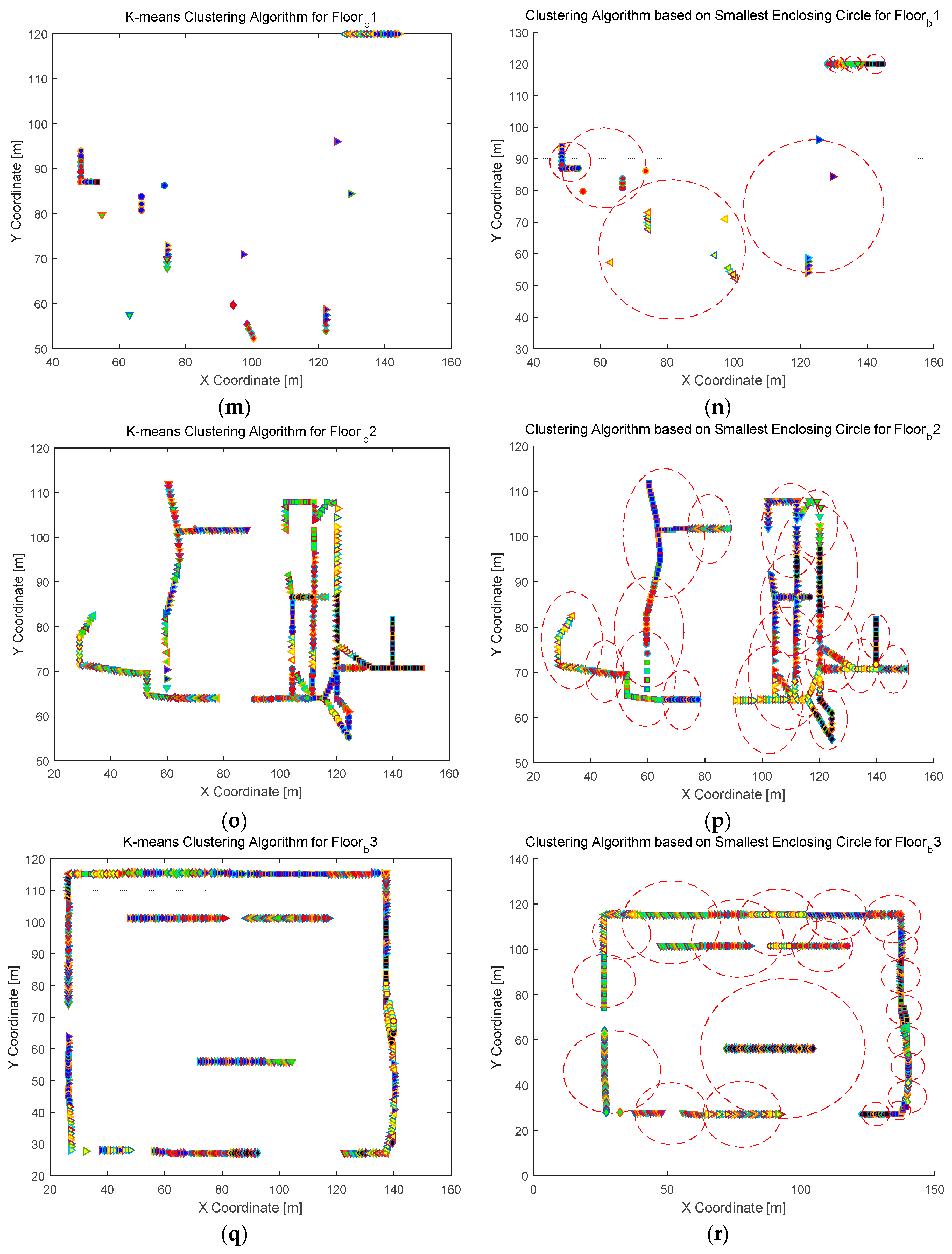
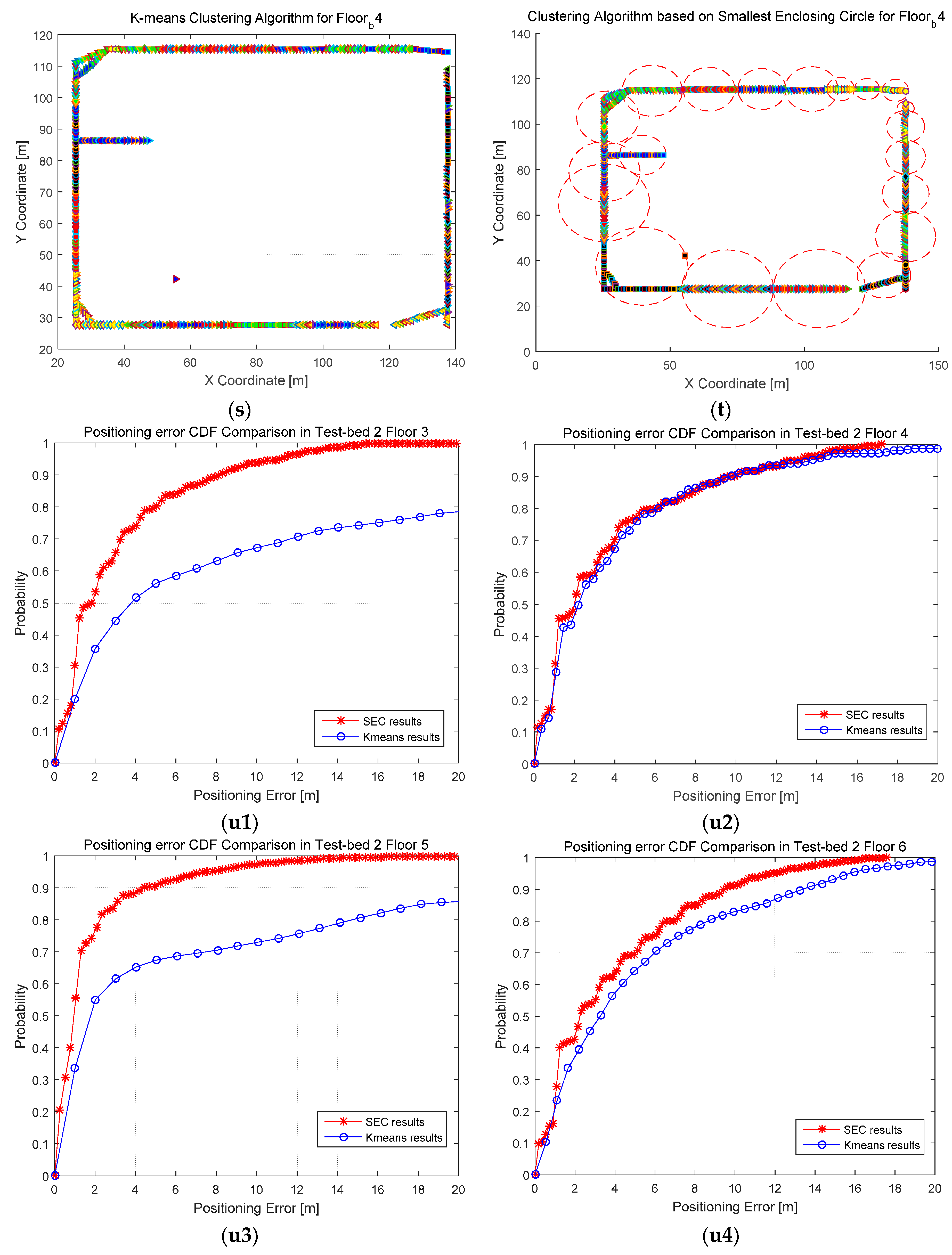
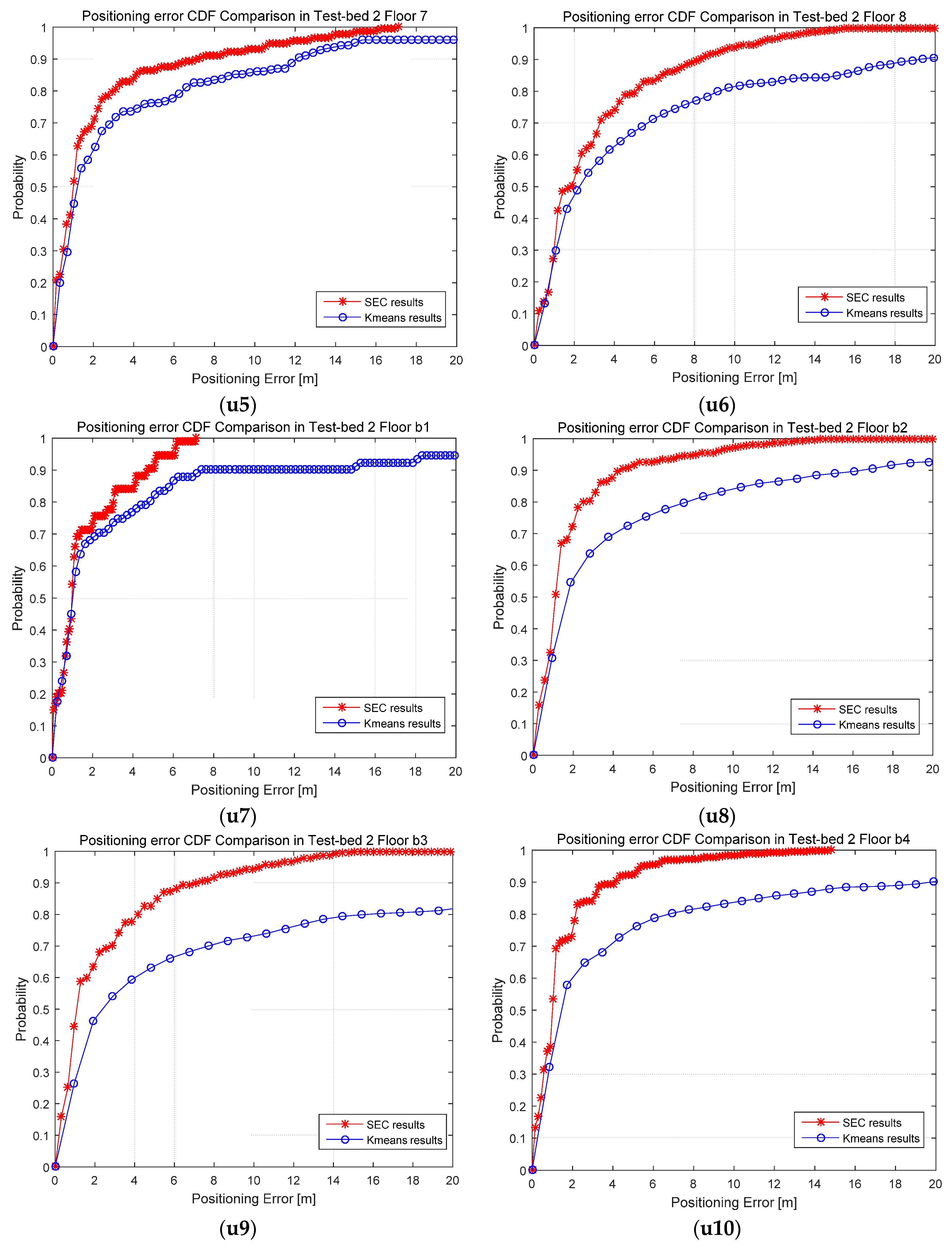
4.2.1. Clustering Results and Analysis
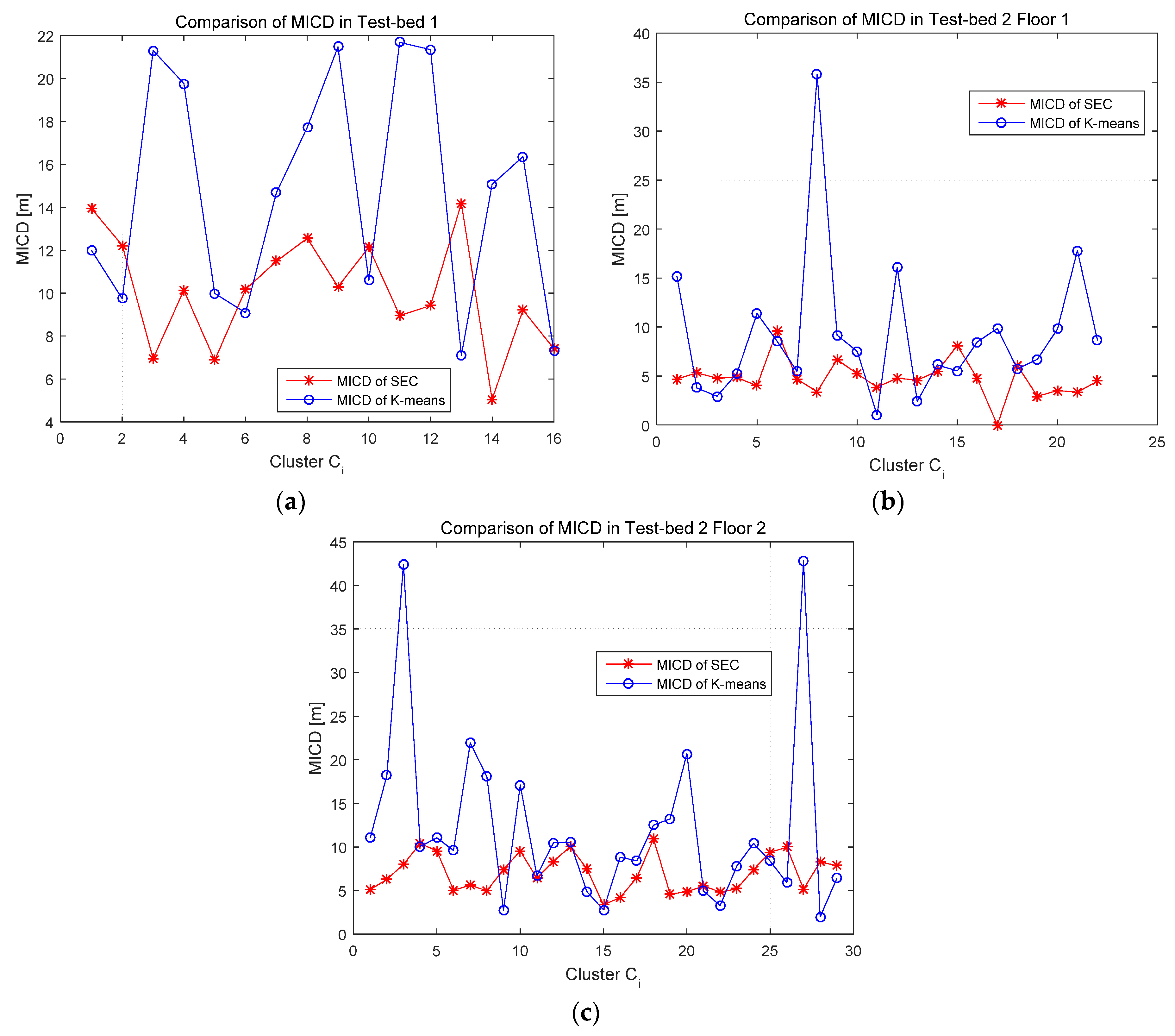
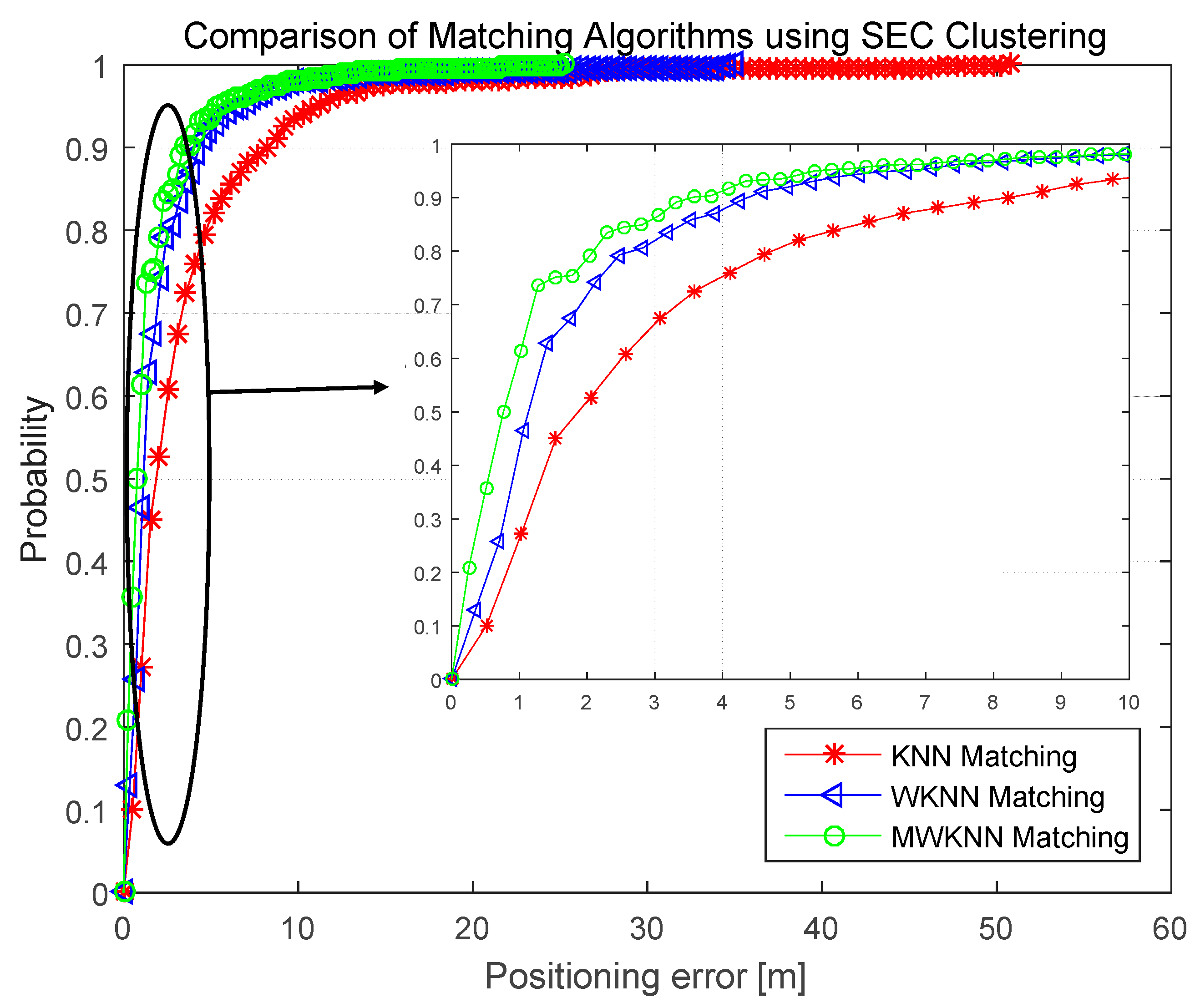
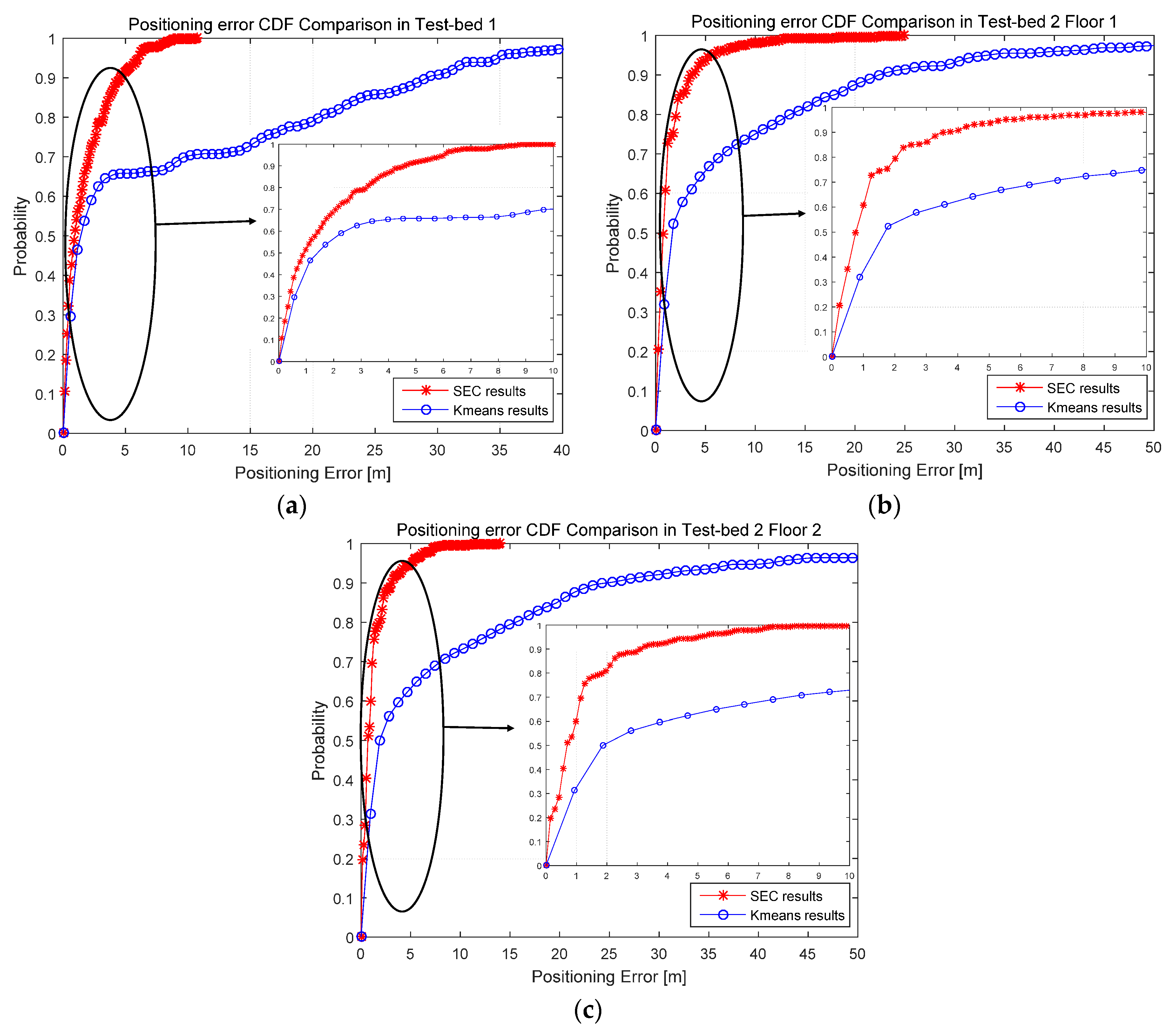
4.2.2. Positioning Accuracy Results and Analysis
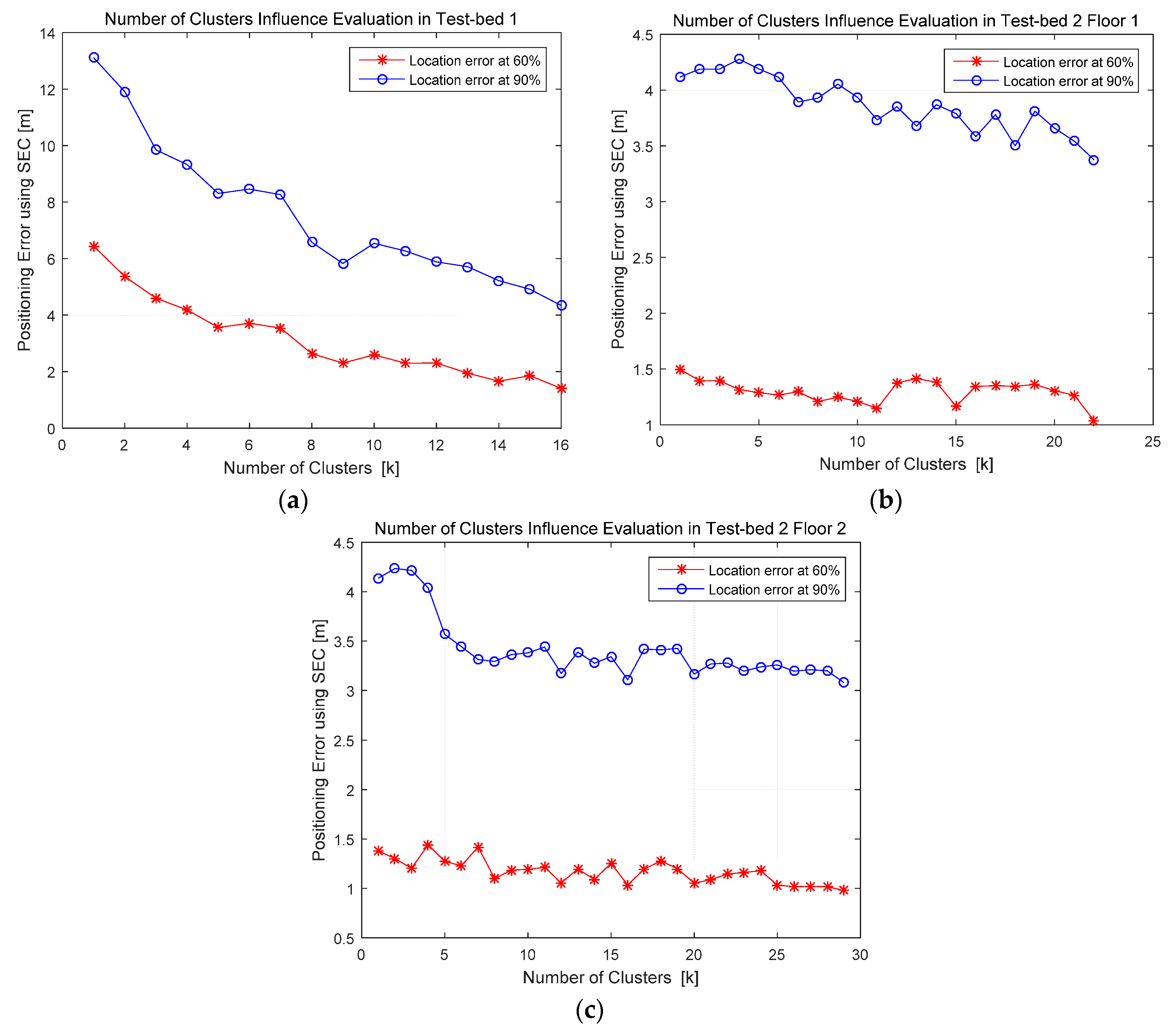
4.2.3. Number of Clusters Evaluation
4.3. Related Works
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A





References
- “Indoor Location in Retail: Where Is the Money?” ABI Research: Location Technologies Market Research. May 2015. Available online: https://www.abiresearch.com/market-research/service/location-technologies/ (accessed on 12 May 2015).
- Deak, G.; Curran, K.; Condell, J. A survey of active and passive indoor localisation systems. Comput. Commun. 2012, 35, 1939–1954. [Google Scholar] [CrossRef]
- Hossain, A.; Soh, W.S. A survey of calibration-free indoor positioning systems. Comput. Commun. 2015, 66, 1–13. [Google Scholar] [CrossRef]
- Koyuncu, H.; Yang, S.H. A survey of indoor positioning and object locating systems. IJCSNS Int. J. Comput. Sci. Netw. Secur. 2010, 10, 121–128. [Google Scholar]
- Liu, H.; Darabi, H.; Banerjee, P.; Liu, J. Survey of wireless indoor positioning techniques and systems. IEEE Trans. Syst. Man Cybern. C Appl. Rev. 2007, 37, 1067–1080. [Google Scholar] [CrossRef]
- Jiang, W.; Li, Y.; Rizos, C. Precise indoor positioning and attitude determination using terrestrial ranging signals. J. Navig. 2015, 68, 274–290. [Google Scholar] [CrossRef]
- Alarifi, A.; Al-Salman, A.; Alsaleh, M.; Alnafessah, A.; Al-Hadhrami, S.; Al-Ammar, M.A.; Al-Khalifa, H.S. Ultra wideband indoor positioning technologies: Analysis and recent advances. Sensors 2016, 16, 707. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Jiang, M.; Liang, J.; Qin, X.; Hu, M.; Peng, T.; Hu, X. 5G WiFi signal-based indoor localization system using cluster k-nearest neighbor algorithm. Int. J. Distrib. Sens. Netw. 2014, 2014. [Google Scholar] [CrossRef]
- Kriz, P.; Maly, F.; Kozel, T. Improving indoor localization using bluetooth low energy beacons. Mob. Inf. Syst. 2016, 2016. [Google Scholar] [CrossRef]
- Cheon, J.; Hwang, H.; Kim, D.; Jung, Y. IEEE 802.15. 4 Zigbee-based time-of-arrival estimation for wireless sensor networks. Sensors 2016, 16, 203. [Google Scholar] [CrossRef] [PubMed]
- Montaser, A.; Moselhi, O. RFID indoor location identification for construction projects. Autom. Constr. 2014, 39, 167–179. [Google Scholar] [CrossRef]
- Gu, Y.; Lo, A.; Niemegeers, I. A survey of indoor positioning systems for wireless personal networks. IEEE Commun. Surv. Tutor. 2009, 11, 13–32. [Google Scholar] [CrossRef]
- Bisio, I.; Lavagetto, F.; Marchese, M.; Sciarrone, A. Performance comparison of a probabilistic fingerprint-based indoor positioning system over different smartphones. In Proceedings of the 2013 International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECTS)—Part of SummerSim 2013 Multiconference, Toronto, ON, Canada, 7–10 July 2013; pp. 161–166.
- Bisio, I.; Lavagetto, F.; Marchese, M.; Sciarrone, A. Smart probabilistic fingerprinting for WiFi-based indoor positioning with mobile devices. Pervasive Mob. Comput. 2016, 31, 107–123. [Google Scholar] [CrossRef]
- Bisio, I.; Lavagetto, F.; Marchese, M.; Sciarrone, A. GPS/HPS-and Wi-fi fingerprint-based location recognition for check-in applications over smartphones in cloud-based LBSs. IEEE Trans. Multimedia 2013, 15, 858–869. [Google Scholar] [CrossRef]
- Bisio, I.; Lavagetto, F.; Marchese, M.; Sciarrone, A. Energy efficient WiFi-based fingerprinting for indoor positioning with smartphones. In Proceedings of the 2013 IEEE Globecom Workshops (GC Wkshps), Atlanta, GA, USA, 9–13 December 2013; pp. 4639–4643.
- Laitinen, E.; Lohan, E.S. On the choice of access point selection criterion and other position estimation characteristics for WLAN-based indoor positioning. Sensors 2016, 16, 737. [Google Scholar] [CrossRef] [PubMed]
- Razavi, A.; Valkama, M.; Lohan, E.S. K-means fingerprint clustering for low-complexity floor estimation in indoor mobile localization. In Proceedings of the Globecom Workshop on Localization and Tracking: Indoors, Outdoors and Emerging Networks, San Diego, CA, USA, 6–10 December 2015; pp. 1–7.
- Huang, Z.; Xia, J.; Yu, H.; Guan, Y.; Chen, J. Clustering combined indoor localization algorithms for crowdsourcing devices: Mining RSSI relative relationship. In Proceedings of the Wireless Communications and Signal Processing (WCSP), Hefei, China, 23–25 October 2014; pp. 1–6.
- Zhang, Z.; Di, X.; Tian, J.; Chen, P. A WLAN planning method for indoor positioning system. In Proceedings of the 2016 International Conference on Information Networking (ICOIN), Kota Kinabalu, Malaysia, 13–15 January 2016; pp. 303–307.
- Du, X.; Yang, K. A Map-assisted WiFi AP placement algorithm enabling mobile device’s indoor positioning. IEEE Syst. J. 2016, PP. [Google Scholar] [CrossRef]
- Laitinen, E.; Lohan, E.S. Access point topology evaluation and optimization based on Cramér-Rao Lower Bound for WLAN indoor positioning. In Proceedings of the 2016 International Conference on Localization and GNSS (ICL-GNSS), Barcelona, Spain, 28–30 June 2016; pp. 1–5.
- Liu, W.; Fu, X.; Deng, Z.; Xu, L.; Jiao, J. Smallest enclosing circle-based fingerprint clustering and modified-WKNN matching algorithm for indoor positioning. In Proceedings of the 2016 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Madrid, Spain, 4–7 October 2016.
- Ilango, M.R.; Mohan, V. A survey of grid based clustering algorithms. Int. J. Eng. Sci. Technol. 2010, 2, 3441–3446. [Google Scholar]
- Chen, J.; Fang, B.X.; Tan, J.L.; Jin, S.C. Index filtering algorithm based on minimum enclosing circle partition. Chin. J. Comput. 2012, 35, 2139–2146. [Google Scholar] [CrossRef]
- Yang, S.L.; Li, Y.S.; Hu, X.X.; Pan, R.Y. Optimization study on k value of k-means algorithm. Syst. Eng. Theory Pract. 2006, 2, 97–101. [Google Scholar]
- Bahl, P.; Padmanabhan, V.N. RADAR: An in-building RF-based user location and tracking system. In Proceedings of the Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies, Tel Aviv, Israel, 26–30 March 2000; Volume 2, pp. 775–784.
- Youssef, M.; Agrawala, A. The Horus WLAN location determination system. In Proceedings of the 3rd International Conference on Mobile Systems, Applications, and Services, Seattle, WA, USA, 6–8 June 2005; pp. 205–218.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition | Mathematical Operators | Definition |
|---|---|---|---|
| RPs in the database, pk is the k-th RP | Integer notation, represents the maximum integer less than A. | ||
| Circle centers in SEC, Ok is the center of k-th circle | Arbitrary notation, represents the selection is random. | ||
| k 1 | Number of clusters, selected as a constant generally | min | Minimum selection notation. |
| Radiuses of SECs, rk is the radius of k-th circle | mid(A, B) | Midpoint calculation, represents the midpoint of the line AB. | |
| SECs, Ck is the k-th circle | dist | Distance calculation, represents the Euclidean distance in this paper. |
| Floor Number | Number of RPs | Number of Hearable APs 1 |
|---|---|---|
| Floor 1 | 504 | 110 |
| Floor 2 | 893 | 133 |
| Floor 3 | 574 | 86 |
| Floor 4 | 140 | 23 |
| Floor 5 | 720 | 115 |
| Floor 6 | 385 | 52 |
| Floor 7 | 131 | 27 |
| Floor 8 | 349 | 37 |
| Floor b1 2 | 54 | 21 |
| Floor b2 | 372 | 57 |
| Floor b3 | 427 | 76 |
| Floor b4 | 400 | 63 |
| Positioning Error | Test-Bed 1 | Test-Bed 2 Floor 1 | Test-Bed 2 Floor 2 |
|---|---|---|---|
| K-means | 2.26 m (60%) | 3.58 (60%) | 3.73 m (60%) |
| 28.35 m (90%) | 21.50 m (90%) | 22.43 m (90%) | |
| SEC | 1.52 m (60%) | 1.07 m (60%) | 0.98 m (60%) |
| 4.67 m (90%) | 3.78 m (90%) | 3.24 m (90%) |
| Related Works | Positioning Accuracy | Experimental Environments |
|---|---|---|
| RADAR [27] | 2.37 m (50%) and 5.93 m (90%) | Real testing environments |
| Horus [28] | 0.86 m and 1.32 m | Test bed 1 (68.2 × 25.9 m2); Test bed 2 (11.8 × 35.9 m2) |
| Works in [21] | 3 m (71%) | 1200 m2 testing environments |
| Our work | 1.52 m (60%) and 3.24 m (90%) | Test-bed 1 (210 × 140 m2); Test-bed 2 (120 × 90 m2) |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Fu, X.; Deng, Z. Coordinate-Based Clustering Method for Indoor Fingerprinting Localization in Dense Cluttered Environments. Sensors 2016, 16, 2055. https://doi.org/10.3390/s16122055
Liu W, Fu X, Deng Z. Coordinate-Based Clustering Method for Indoor Fingerprinting Localization in Dense Cluttered Environments. Sensors. 2016; 16(12):2055. https://doi.org/10.3390/s16122055
Chicago/Turabian StyleLiu, Wen, Xiao Fu, and Zhongliang Deng. 2016. "Coordinate-Based Clustering Method for Indoor Fingerprinting Localization in Dense Cluttered Environments" Sensors 16, no. 12: 2055. https://doi.org/10.3390/s16122055