
Pedestrian Detection and Tracking from Low-Resolution Unmanned Aerial Vehicle Thermal Imagery

Abstract
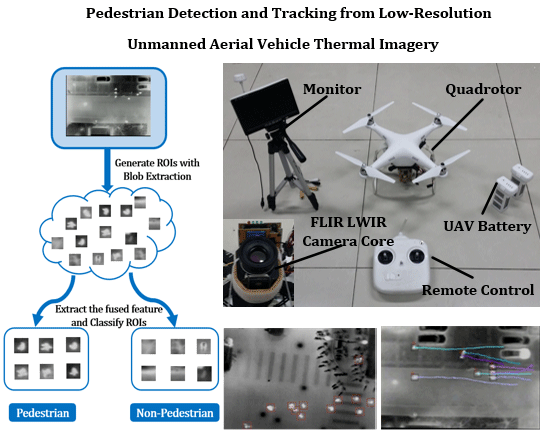
:
1. Introduction
2. Related Work
2.1. Pedestrian Detection
2.2. Pedestrian Tracking
3. Pedestrian Detection and Tracking
3.1. Pedestrian Detection
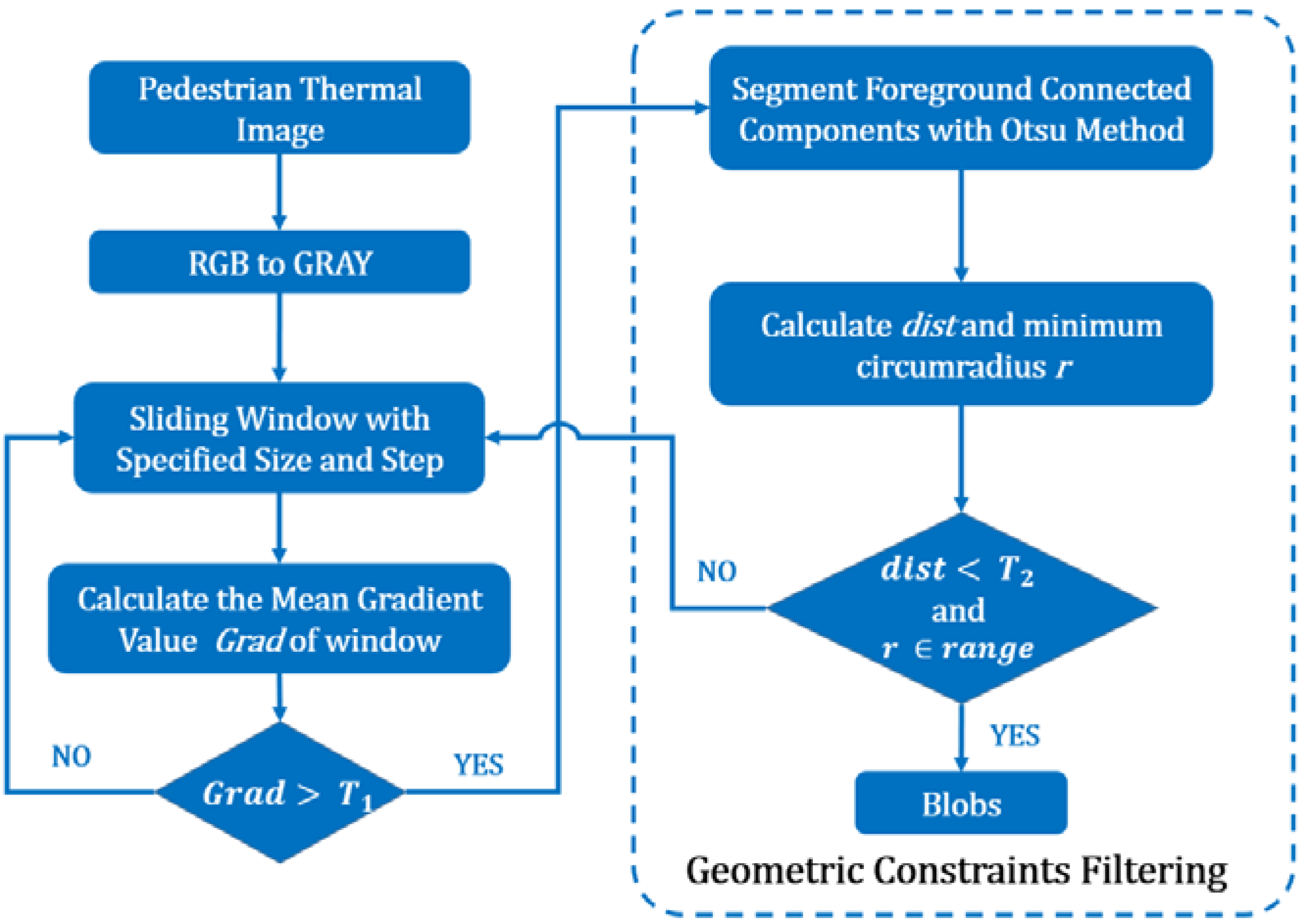
3.1.1. Blob Extraction
- (1)
- Central location: According to the properties of a typical top-down view thermal image of a human, the distance between the centroid and center of the ROI should not be large. Therefore, the Euclidean distance between the centroid and center is calculated and then compared to a threshold () to filter ROIs (see Equation (4)):where and are the centroid and center of a square ROI, respectively.
- (2)
- Minimum circumscribed circle: Because the scales of most of the pedestrian objects in top-view thermal images are similar, the pedestrian ROIs should not exceed a certain range. Therefore, by comparing the minimum circumradius r of a pedestrian connected component to a predefined, we could eliminate too large or too small blobs and some rectangle regions. This method will further help filter the false ROIs.
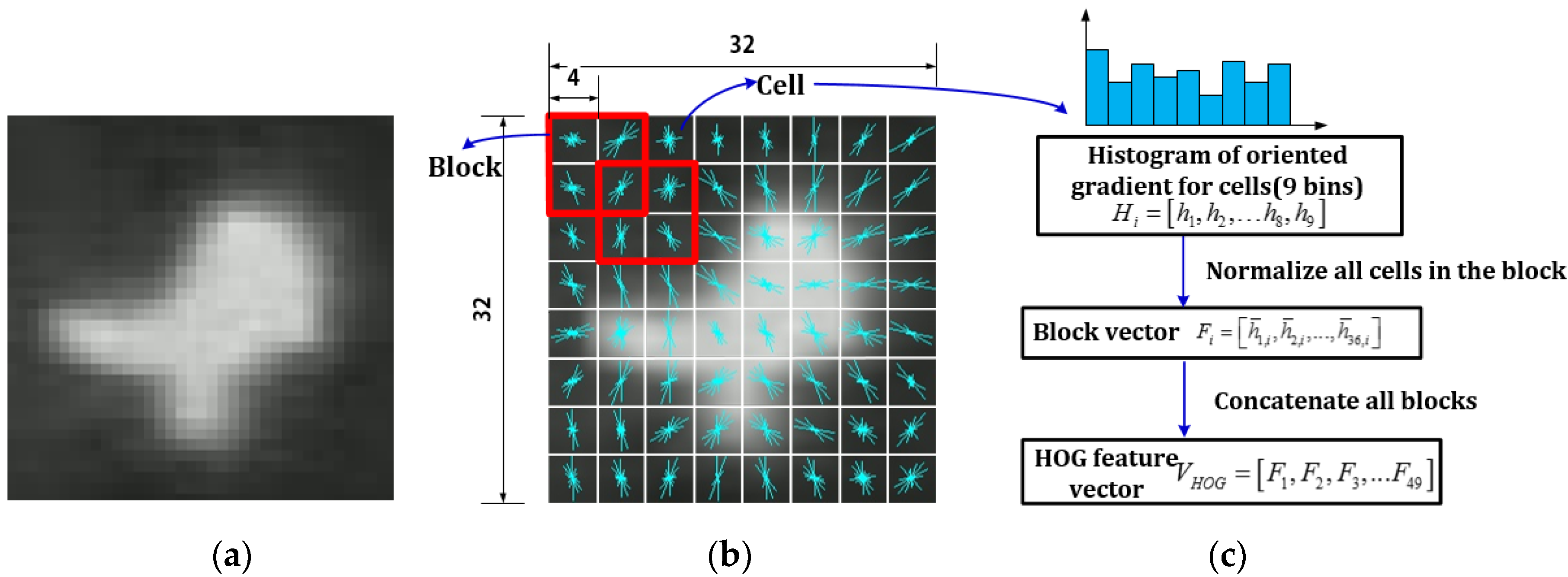
3.1.2. Blob Classification
3.2. Pedestrian Tracking
3.2.1. Video Registration
- (1)
- Detecting the stationary feature as the control points;
- (2)
- Establishing correspondence between feature sets to obtain the coordinates of the same stationary point;
- (3)
- Setting up the transformation model from the obtained point coordinate;
- (4)
- Warping the current frame to the reference frame using the transformation model.
3.2.2. Pedestrian Tracking
- (1)
- Once one pedestrian object is detected in the current frame, input the center coordinate of the object into the feature tracker;
- (2)
- Applying the pyramidal Lucas–Kanade feature tracker to estimate the displacement between consecutive frames, the estimated displacement then is used to predict the coordinate of the object in the next frame;
- (3)
- Around the predicted coordinate, a search region is determined. In the search region, a secondary detection is conducted to accurately find the pedestrian localization.
4. Experiments for Pedestrian Detection and Tracking
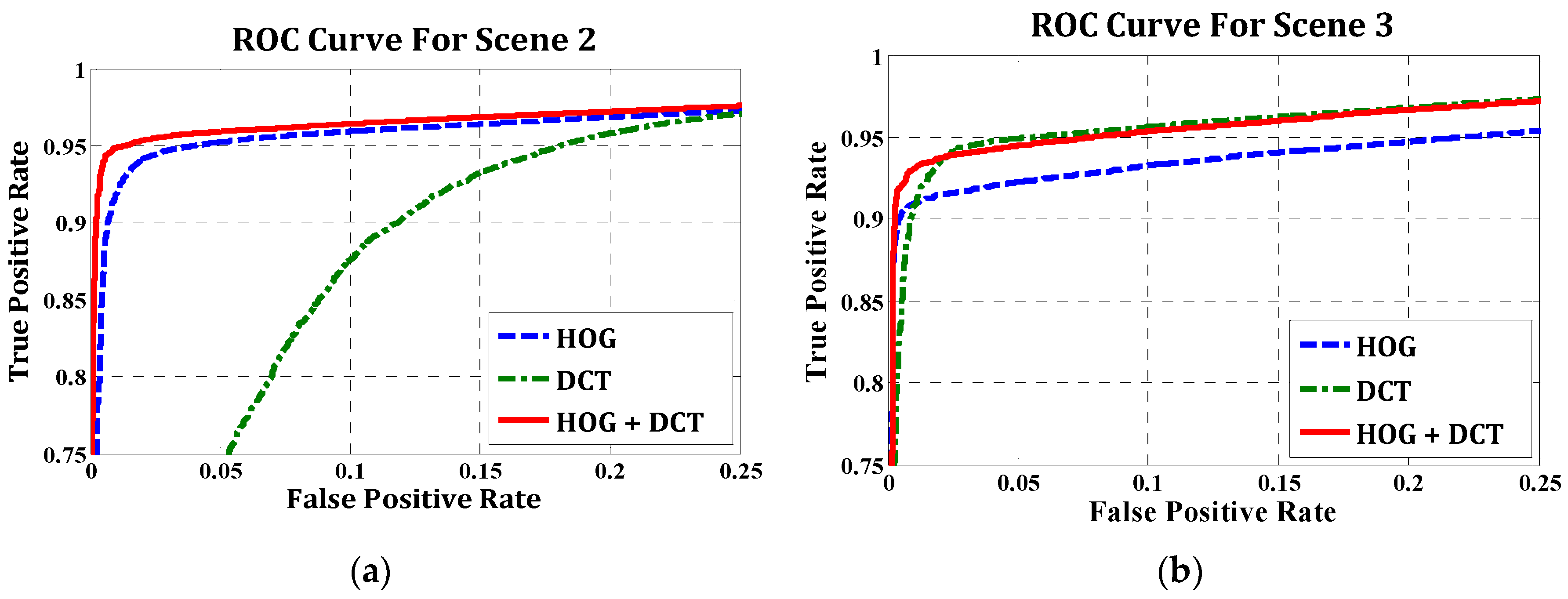
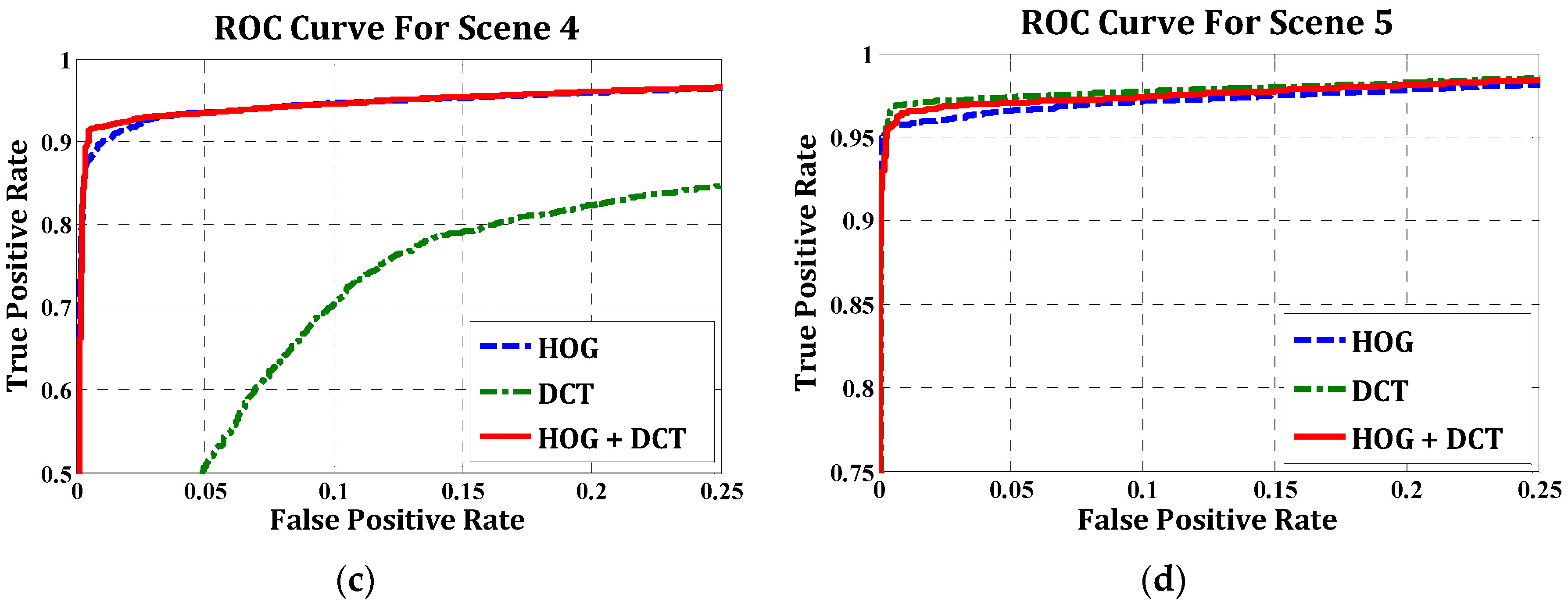
4.1. Evaluation for Pedestrian Detection
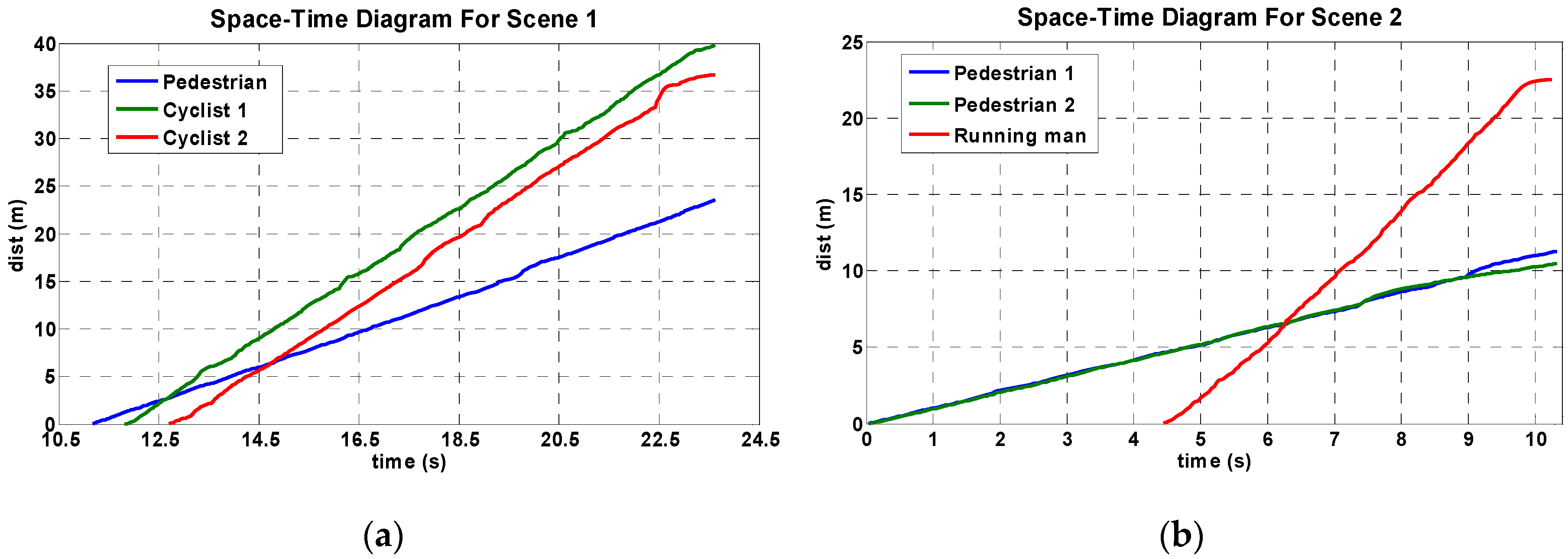
4.2. Evaluation for Pedestrian Tracking
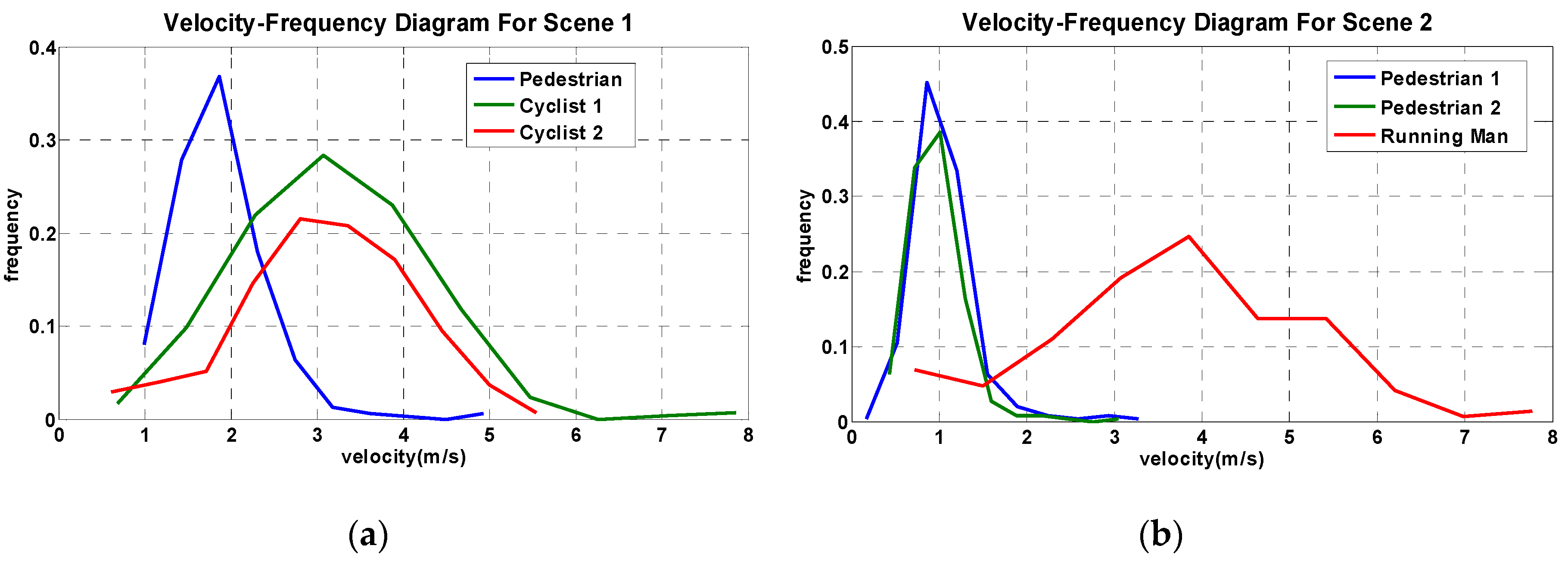
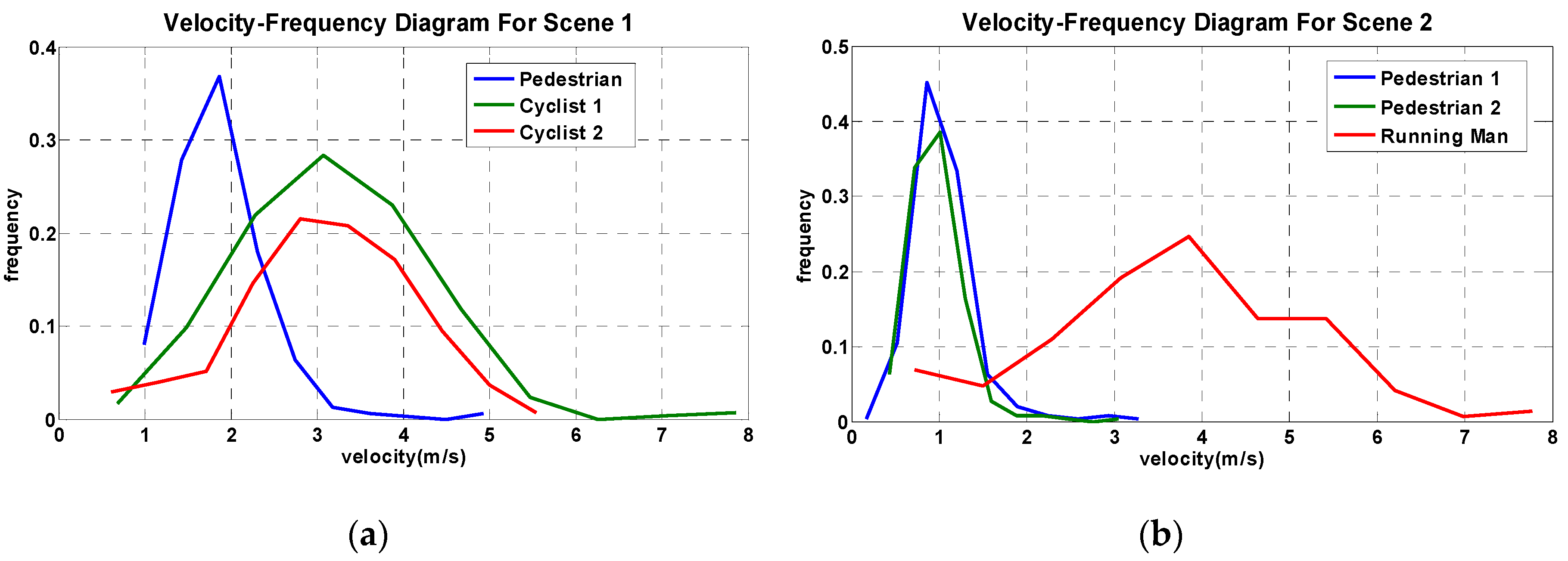
5. Pedestrian Tracking and Velocity Estimation
6. Discussion
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| UAVs | Unmanned Aerial Vehicles |
| SVM | Support Vector Machine |
| HOG | Histogram of Oriented Gradient |
| DCT | Discrete Cosine Transform |
| ROI | Region of Interest |
| CSM | Contour Saliency Map |
References
- Geronimo, D.; Lopez, A.M.; Sappa, A.D.; Graf, T. Survey of Pedestrian Detection for Advanced Driver Assistance Systems. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1239–1258. [Google Scholar] [CrossRef] [PubMed]
- Oreifej, O.; Mehran, R.; Shah, M. Human identity recognition in aerial images. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 709–716.
- Gaszczak, A.; Breckon, T.P.; Han, J. Real-time people and vehicle detection from UAV imagery. In Proceedings of the Intelligent Robots and Computer Vision XXVIII: Algorithms and Techniques, San Francisco, CA, USA, 24 January 2011; pp. 536–547.
- Portmann, J.; Lynen, S.; Chli, M.; Siegwart, R. People detection and tracking from aerial thermal views. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1794–1800.
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; pp. 886–893.
- Bouguet, J. Pyramidal Implementation of the Lucas Kanade Feature Tracker Description of the Algorithm. Available online: http://robots.stanford.edu/cs223b04/algo_tracking.pdf (accessed on 24 March 2016).
- Enzweiler, M.; Gavrila, D.M. Monocular Pedestrian Detection: Survey and Experiments. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2179–2195. [Google Scholar] [CrossRef] [PubMed]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: An Evaluation of the State of the Art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Davis, J.W.; Keck, M.A. A Two-Stage Template Approach to Person Detection in Thermal Imagery. In Proceedings of the Seventh IEEE Workshops on Application of Computer Vision, Breckenridge, CO, USA, 5–7 January 2005; pp. 364–369.
- Dai, C.; Zheng, Y.; Li, X. Pedestrian detection and tracking in infrared imagery using shape and appearance. Comput. Vis. Image Underst. 2007, 106, 288–299. [Google Scholar] [CrossRef]
- Leykin, A.; Hammoud, R. Pedestrian tracking by fusion of thermal-visible surveillance videos. Mach. Vis. Appl. 2008, 21, 587–595. [Google Scholar] [CrossRef]
- Miezianko, R.; Pokrajac, D. People detection in low resolution infrared videos. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Anchorage, AK, USA, 23–28 June 2008; pp. 1–6.
- Jeon, E.S.; Choi, J.-S.; Lee, J.H.; Shin, K.Y.; Kim, Y.G.; Le, T.T.; Park, K.R. Human Detection Based on the Generation of a Background Image by Using a Far-Infrared Light Camera. Sensors 2015, 15, 6763–6788. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.H.; Choi, J.-S.; Jeon, E.S.; Kim, Y.G.; Le, T.T.; Shin, K.Y.; Lee, H.C.; Park, K.R. Robust Pedestrian Detection by Combining Visible and Thermal Infrared Cameras. Sensors 2015, 15, 10580–10615. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.Y.; He, Z.X.; Zhang, S.Y.; Liang, D. Robust pedestrian detection in thermal infrared imagery using a shape distribution histogram feature and modified sparse representation classification. Pattern Recognit. 2015, 48, 1947–1960. [Google Scholar] [CrossRef]
- Xu, F.; Liu, X.; Fujimura, K. Pedestrian detection and tracking with night vision. IEEE Trans. Intell. Transp. Syst. 2005, 6, 63–71. [Google Scholar] [CrossRef]
- Ge, J.; Luo, Y.; Tei, G. Real-Time Pedestrian Detection and Tracking at Nighttime for Driver-Assistance Systems. IEEE Trans. Intell. Transp. Syst. 2009, 10, 283–298. [Google Scholar]
- Qi, B.; John, V.; Liu, Z.; Mita, S. Use of Sparse Representation for Pedestrian Detection in Thermal Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Columbus, OH, USA, 23–28 June 2014; pp. 274–280.
- Teutsch, M.; Mueller, T.; Huber, M.; Beyerer, J. Low Resolution Person Detection with a Moving Thermal Infrared Camera by Hot Spot Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Columbus, OH, USA, 23–28 June 2014; pp. 209–216.
- Sidla, O.; Braendle, N.; Benesova, W.; Rosner, M.; Lypetskyy, Y. Towards complex visual surveillance algorithms on smart cameras. In Proceedings of the IEEE 12th International Conference on Computer Vision Workshops (ICCV Workshops), Kyoto, Japan, 27 September–4 October 2009; pp. 847–853.
- Benfold, B.; Reid, I. Stable multi-target tracking in real-time surveillance video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 20–25 June 2011; pp. 3457–3464.
- Xiao, J.; Yang, C.; Han, F.; Cheng, H. Vehicle and Person Tracking in Aerial Videos. In Multimodal Technologies for Perception of Humans; Stiefelhagen, R., Bowers, R., Fiscus, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 203–214. [Google Scholar]
- Bhattacharya, S.; Idrees, H.; Saleemi, I.; Ali, S.; Shah, M. Moving Object Detection and Tracking in Forward Looking Infra-Red Aerial Imagery. In Machine Vision Beyond Visible Spectrum; Hammoud, R., Fan, G., McMillan, R.W., Ikeuchi, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 221–252. [Google Scholar]
- Miller, A.; Babenko, P.; Hu, M.; Shah, M. Person Tracking in UAV Video. In Multimodal Technologies for Perception of Humans; Stiefelhagen, R., Bowers, R., Fiscus, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 215–220. [Google Scholar]
- Fernandez-Caballero, A.; Lopez, M.T.; Serrano-Cuerda, J. Thermal-Infrared Pedestrian ROI Extraction through Thermal and Motion Information Fusion. Sensors 2014, 14, 6666–6676. [Google Scholar] [CrossRef] [PubMed]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. I-511–I-518.
- A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66.
- Hafed, Z.; Levine, M. Face Recognition Using the Discrete Cosine Transform. Int. J. Comput. Vis. 2001, 43, 167–188. [Google Scholar] [CrossRef]
- Vaidehi, V.; Babu, N.T.N.; Avinash, H.; Vimal, M.D.; Sumitra, A.; Balmuralidhar, P.; Chandra, G. Face recognition using discrete cosine transform and fisher linear discriminant. In Proceedings of the 11th International Conference on Control Automation Robotics & Vision (ICARCV), Singapore, 7–10 December 2010; pp. 1157–1160.
- Shastry, A.C.; Schowengerdt, R.A. Airborne video registration and traffic-flow parameter estimation. IEEE Trans. Intell. Transp. Syst. 2005, 6, 391–405. [Google Scholar] [CrossRef]
- Shi, J.; Tomasi, C. Good Features To Track. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 21–23 June 1994; pp. 593–600.
- Tomasi, C. Detection and Tracking of Point Features. Tech. Rep. 1991, 9, 9795–9802. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The CLEAR MOT metrics. J. Image Video Process. 2008, 2008. [Google Scholar] [CrossRef]
- Sun, W.; Wu, X.; Wang, Y.; Yu, G. A continuous-flow-intersection-lite design and traffic control for oversaturated bottleneck intersections. Transp. Res. Part C Emerg. Technol. 2015, 56, 18–33. [Google Scholar] [CrossRef]
- Ma, X.; Wu, Y.J.; Wang, Y.; Chen, F.; Liu, J. Mining smart card data for transit riders’ travel patterns. Transp. Res. Part C Emerg. Technol. 2013, 36, 1–12. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Resolution | Flying Altitude | Scenario | Date/Time | Temperature |
|---|---|---|---|---|---|
| Scene 1 | 720 × 480 | 40–70 m | Multi-scene | April/Afternoon, Night | 10 °C–15 °C |
| Scene 2 | 720 × 480 | 50 m | Road | 20 January/20:22 p.m. | 5 °C |
| Scene 3 | 720 × 480 | 60 m | Road | 19 January/19:46 p.m. | 6 °C |
| Scene 4 | 720 × 480 | 40 m | Road | 8 April/23:12 p.m. | 14 °C |
| Scene 5 | 720 × 480 | 50 m | Road | 8 July/16:12 p.m. | 28 °C |
| Dataset | # Pedestrian | # TP | # FP | # FN | Precision | Recall |
|---|---|---|---|---|---|---|
| Scene 1 | 1320 | 1228 | 78 | 92 | 94.03% | 93.03% |
| Scene 2 | 9214 | 8216 | 686 | 998 | 92.30% | 89.17% |
| Scene 3 | 10,029 | 9255 | 344 | 774 | 96.41% | 92.28% |
| Scene 4 | 5094 | 4322 | 396 | 772 | 91.61% | 84.84% |
| Scene 5 | 3175 | 2923 | 197 | 252 | 93.69% | 92.06% |
| Dataset | # Images | # Training | # Test | Training Blobs | Test Blobs |
|---|---|---|---|---|---|
| # Positives/Negatives | # Positives/Negatives | ||||
| Scene 1 | No Training | ||||
| Scene 2 | 2783 | 544 | 2239 | 2347/9802 | 8339/35,215 |
| Scene 3 | 2817 | 512 | 2305 | 2098/938 | 9237/4097 |
| Scene 4 | 1446 | 365 | 1081 | 1560/881 | 4473/2817 |
| Scene 5 | 1270 | 340 | 930 | 734/966 | 2984/4572 |
| Dataset | k | Range | α | β | ||
|---|---|---|---|---|---|---|
| Scene 2 | 3.5 | 3 | 29 | (9, 16) | 10 | 3 |
| Scene 3 | 4 | 2 | 25 | (7, 14) | 10 | 3 |
| Scene 4 | 3 | 2 | 35 | (12, 19) | 10 | 3 |
| Scene 5 | 5 | 2 | 27 | (8, 15) | 10 | 3 |
| Dataset | Resolution | Flying Altitude | Scenario | Date/Time | Temperature |
|---|---|---|---|---|---|
| Sequence 1 | 720 × 480 | 50 m | Road | 20 January/20:22 p.m. | 5 °C |
| Sequence 2 | 720 × 480 | 50 m | Road | 20 January/20:32 p.m. | 5 °C |
| Sequence 3 | 720 × 480 | 45 m | Plaza | 13 April/16:12 p.m. | 18 °C |
| Sequence | # Frames | # | # | # | # | MOTA |
|---|---|---|---|---|---|---|
| Sequence 1 | 635 | 3404 | 374 | 193 | 0 | 0.8334 |
| Sequence 1 KLT | 635 | 3404 | 379 | 956 | 5 | 0.6063 |
| Sequence 2 | 992 | 4957 | 161 | 597 | 0 | 0.8471 |
| Sequence 2 KLT | 992 | 4957 | 198 | 1637 | 4 | 0.6290 |
| Sequence 3 | 1186 | 3699 | 318 | 0 | 0 | 0.9140 |
| Sequence 3 KLT | 1186 | 3699 | 104 | 1367 | 5 | 0.6010 |
| Dataset | # Pedestrian | # TP | # FP | # FN | Precision | Recall |
|---|---|---|---|---|---|---|
| Scene 2 | 9214 | 8545 | 29,684 | 669 | 22.35% | 92.74% |
| Scene 3 | 10,029 | 9633 | 3187 | 396 | 75.14% | 96.05% |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Wu, X.; Yu, G.; Xu, Y.; Wang, Y. Pedestrian Detection and Tracking from Low-Resolution Unmanned Aerial Vehicle Thermal Imagery. Sensors 2016, 16, 446. https://doi.org/10.3390/s16040446
Ma Y, Wu X, Yu G, Xu Y, Wang Y. Pedestrian Detection and Tracking from Low-Resolution Unmanned Aerial Vehicle Thermal Imagery. Sensors. 2016; 16(4):446. https://doi.org/10.3390/s16040446
Chicago/Turabian StyleMa, Yalong, Xinkai Wu, Guizhen Yu, Yongzheng Xu, and Yunpeng Wang. 2016. "Pedestrian Detection and Tracking from Low-Resolution Unmanned Aerial Vehicle Thermal Imagery" Sensors 16, no. 4: 446. https://doi.org/10.3390/s16040446