1. Introduction
Vision sensors have advantages of flexibility and high-precision. Distributed vision sensors (DVS) are always used due to their wider fields of view (FOVs). Calibration is an important step for most camera applications. Calibration of a DVS typically has two stages: the intrinsic calibration which can be done separately and the global calibration which calculates the relative poses of the camera frames and the global coordinate frame (GCF). Then the information extracted from each camera can be integrated into the GCF. Generally, the coordinate frame of the reference camera is selected as GCF. However, vision sensors are usually widely distributed to have a better coverage. As two adjacent cameras usually have small or no overlapping FOV, the global calibration of DVS becomes of prime importance.
DVS can be calibrated by high-precision 3D measurement equipment. Lu
et al. [
1] constructed a measurement system and achieved calibration of non-overlapping DVS using two theodolites and a planar target. Calibration methods without expensive equipment have also been investigated. Peng
et al. [
2] proposed an approach omitting translation vectors between cameras, due to the loss of depth information during the camera projection [
3]. It assumes that all the cameras have approximately the same optical center. However, this assumption is not appropriate when the relative distances between cameras are not small in comparison with the distances to the captured scene. In addition, feature detection and matching, such as scale invariant feature transform (SIFT) [
4] is not reliable in insufficient textural environments due to lack of enough distinctive feature points [
2].
Global calibration methods for DVS with overlapping FOV cannot be applied in the case of non-overlapping FOV. Most of the global calibration methods for DVS with non-overlapping FOV are based on mirror reflections [
5,
6,
7], rigidity constraints of calibration targets [
8,
9,
10], movements of the platform [
11] and the auxiliary camera [
12]. For general distributed vision sensors, it is hard to make sure that each camera has a clear sight of the targets through mirror reflections, especially in complex environments. Liu
et al. [
9] proposed a global calibration method by placing multiple targets in front of the vision sensors at least four times. Bosch
et al. [
10] use a poster to determine the relative poses of multiple cameras in two steps. It requires that different parts of the poster are observed by at least two cameras at the same time, so that SIFT features can be utilized. However, it is not flexible to use a long one-dimensional target [
8], rigidly-connected targets [
9] or a large area poster [
10] for the calibration of widely distributed cameras. Pagel [
11] achieved extrinsic calibration of a multi-camera rig with non-overlapping FOV by moving the platform. However, it required that at least two adjacent targets be visible and two cameras can see the target at the same time. Sun
et al. [
12] used an auxiliary camera to observe all the sphere targets. However, all the targets can hardly been observed by one camera at the same time due to widely distribution of the vision sensors.
Structure from motion [
13] solves similar problems as that in the global calibration of DVS. The difference is that the global calibration transforms local coordinate frames into GCF, while structure from motion estimates the locations of 3D points from multiple images [
14]. Fitzagibbon
et al. [
15] recover the 3D scene structure together with 3D camera positions from a closed image sequence. Compared with open sequences, the closed image sequence contains additional constraints. Zhang
et al. [
16] propose an incremental motion estimation algorithm to deal with long image sequences.
Generally, one calibration target is selected as the reference target. Compared with employing the auxiliary camera to capture all the targets in one image, capturing neighboring pairs of targets is more suitable for widely distributed cameras. The relative poses between neighboring pairs of the targets can be solved separately. Then the relative poses between each target and the reference target can be achieved by chainwise coordinate transformations. However, the error accumulates with increasing times of transformations. When dealing with DVS that provides a vision of the surrounding scene just as [
2,
11], vision sensors are always configured in ring-topologies to have a better coverage of the surroundings. The first sensor adjoins the end to form a closed chain. Thus a closed image sequence of neighboring targets can be acquired by the auxiliary camera.
Line features are more stable than point features in detection and matching [
17]. The principle of perspective projection indicates that an infinite scene line is mapped onto an image plane as a line terminating in a vanishing point. Vanishing points and vanishing lines are the distinguish features of perspective projection [
18]. Xu
et al. [
19] proposed a pose estimation method based on vanishing lines of a T-shaped target. Wang [
20] used a target with three equally spaced parallel lines to estimate the rotation matrix by moving the target into at least three different positions. Wei
et al. [
21,
22] calibrated a line-structured vision sensor and a binocular vision sensor by a planar target with several parallel lines. Two mutually orthogonal groups of parallel lines are common in urban environments, such as crossroads, facades of architectures and so on. They can be used as the calibration targets. Even if they are absent in the scene, targets with two mutually orthogonal groups of parallel lines can be employed.
In this paper, we focus on the calibration of widely distributed cameras in ring-topologies. A planar target with two mutually orthogonal groups of parallel lines is allocated to each camera. The vanishing line of the target plane is obtained from two vanishing points. Then the relative pose between each camera and its corresponding target is initialized and refined based on vanishing features and the known line length. A closed image sequence of neighboring pairs of calibration targets is acquired by repeated operations of the auxiliary camera. Then the relative poses between two adjacent targets can be obtained and the transformation matrix from each target to the reference target is initialized in a chainwise manner. In order to adjust the accumulated error due to the chain of transformations, a global calibration method is proposed to optimize relative poses of the targets based on the constraint of the ring-type structure. Finally, using the targets as media, the optimal relative poses between each camera and the reference camera are obtained.
The rest of the paper is organized as follows: preliminary work is introduced in
Section 2. The proposed global calibration method is described in
Section 3. Accuracy analysis of different factors’ effects is given in
Section 4. Synthetic data, simulation images and real data experiments are carried out in
Section 5. The conclusions are given in
Section 6.
4. Accuracy Analysis of Different Factors’ Effects
In this section, analysis of several factors’ effects on the accuracy of the proposed method is performed by synthetic data experiments. The auxiliary camera’s intrinsic parameters are fx = fy = 512, u0 = 512, v0 = 384. The image resolution is 1024 pixel × 768 pixel.
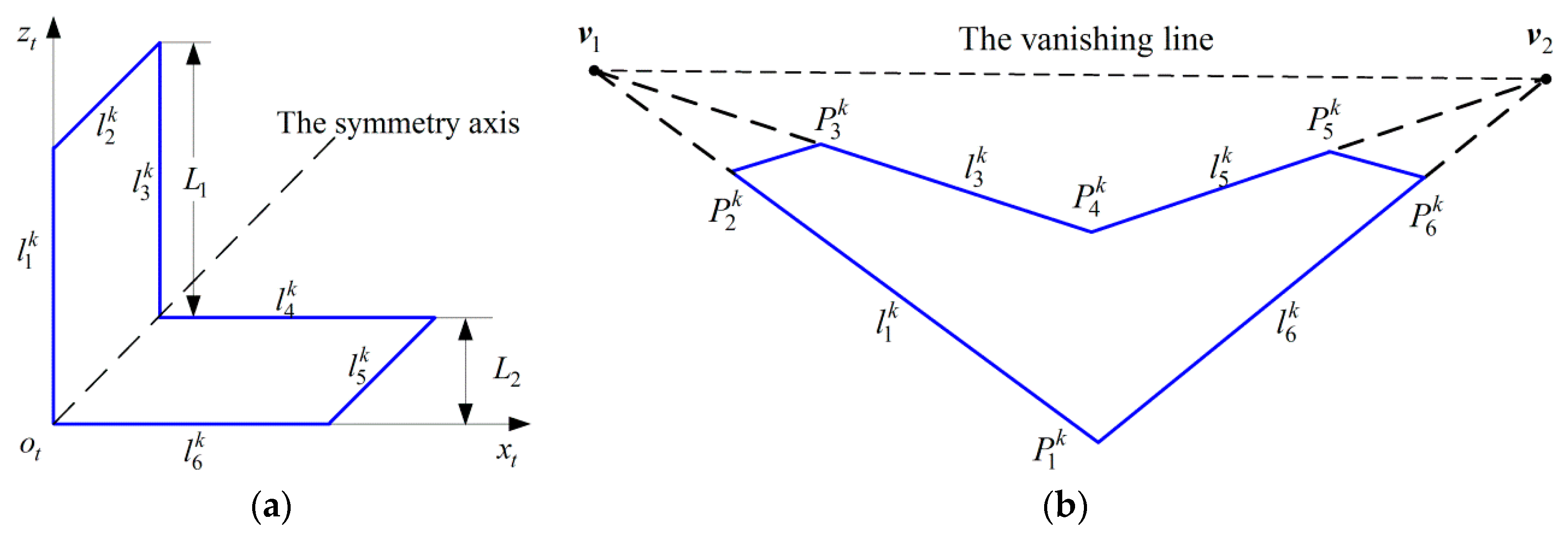
The cameras’ positions are represented by the coordinates of the cameras’ origins in ECF. The cameras’ orientations are denoted by the Euler angles (φ, θ, ϕ) from ECF to CCF. Targets are placed on the ground for convenience. The targets’ positions are represented by the coordinates of the targets’ origins in ECF. The targets’ orientations are denoted by the yaw angle φ from positive z-axis of ECF to the symmetry axis of the target.
dR and dt denote the 2-norm of rotation vector and translation vector differences between the calculation results and the real data. The RMS errors of dR, dt are used to evaluate the accuracy. The number of points that emulate feature lines is equal to the line length in pixels. Gaussian noise with zero mean and different noise levels is added to the image coordinates of the points of feature lines. Analysis of the factors’ effects is shown as follows.
4.1. Accuracy vs. the Pitch Angle of Camera Relative to the Target
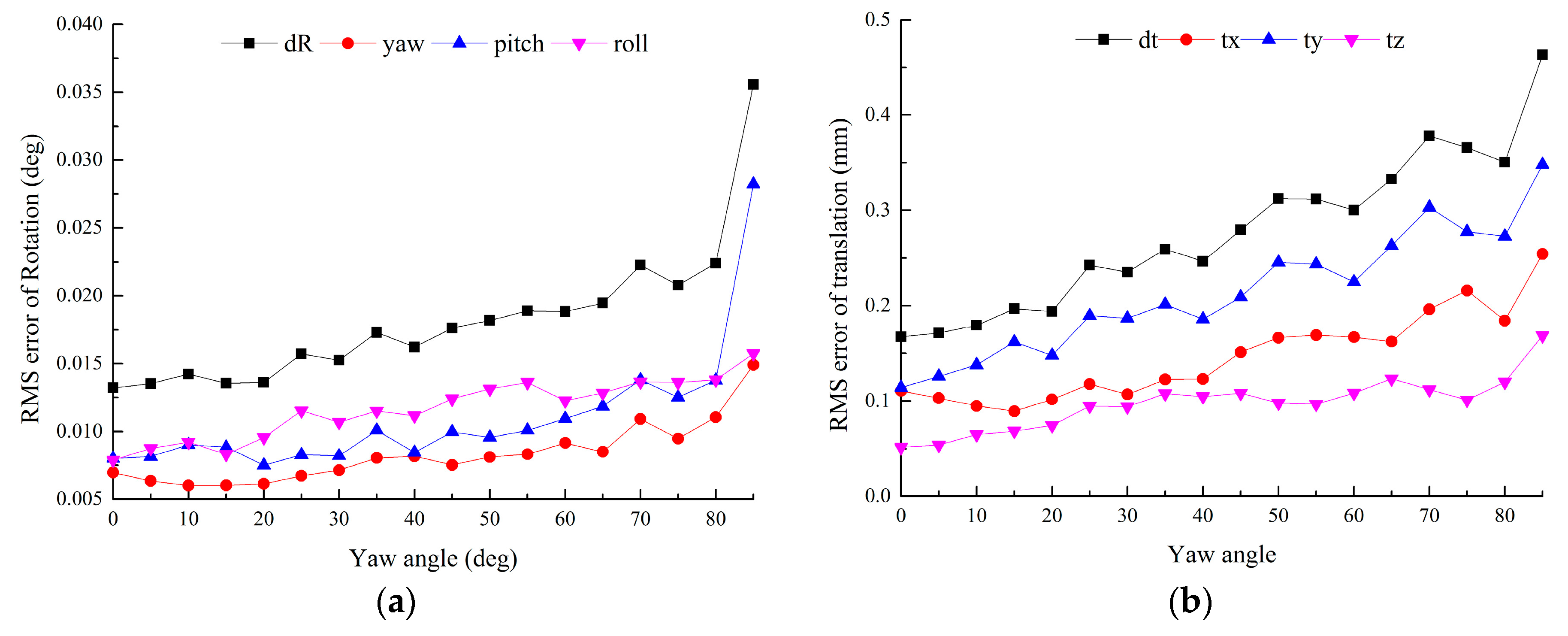
The image sequence is acquired by the auxiliary camera. The pitch angle of the auxiliary camera relative to the target plane is one of the factors affecting the calibration accuracy. In this experiment, two adjacent targets are captured by the auxiliary camera at different pitch angles. The targets’ positions in ECF are [−450, 0, 300]T and [450, 0, 300]T, respectively. The yaw angles of the targets relative to ECF are −18° and 18°, respectively. Two targets are symmetric about the plane yeoeze. The optical axis of the auxiliary camera lies in the symmetry plane yeoeze. The error of obtained by Equation (22) is used to evaluate the effect of the pitch angle. Gaussian noise with σ = 0.2 pixel is added. L1 = 500 mm, L2 = 200 mm. For each level of pitch angle θ, 100 independent trials are performed.
From
Figure 3, the RMS errors of rotation and translation are roughly U-shape. When θ→−90°, the optical axis of the auxiliary camera is perpendicular to the target plane. The vanishing points approximate to infinity, which leads to higher errors. When θ→0°, the number of the extracted feature points decreases, also leads to higher errors. It is ideal to capture pair targets when θ = −40°.
4.2. Accuracy vs. the Yaw Angle Difference between Two Adjacent Targets
In this experiment, ∆φ denotes the yaw angle difference between the symmetry axes of two adjacent targets. ∆φ varies according to the cameras’ distribution. We also use the error of calculated by Equation (22) to evaluate the effect of ∆φ.
The positions of the two targets are same with those in
Section 4.1, while ∆φ varies from 0 to 85°. The two targets remain symmetric about the plane
yeoeze and the auxiliary camera lies in the symmetry plane. Gaussian noise with σ = 0.2 pixel is added.
L1 = 500 mm,
L2 = 200 mm. For each level, 100 independent trials are performed.
From
Figure 4, both the error of rotation and translation rise with the increasing of ∆φ. When ∆φ > 80°, the errors increase sharply. This is because when ∆φ→90°, a group of parallel lines of each target are parallel to the image plane, thus the vanishing points approximate to infinity, which leads to great errors, so it is necessary to avoid ∆φ→90° during the calibration.
4.3. Accuracy vs. the Distance of Parallel Lines
In this experiment, we also use the error of
obtained by Equation (22) to evaluate the effect of the parallel line distances. The poses of the targets are same with those in
Section 4.1. The pitch angle of the auxiliary camera relative to the target plane is set to −40°. L
1 = 500 mm, L
2 varies from 100 mm to 400 mm. Gaussian noise with different levels is added to the image points. For each distance level, 100 independent trials are performed.
From
Figure 5, it can be seen that the error increases linearly with the noise level and decreases with the increasing distance of parallel lines. This is because the difference among slopes of intersecting lines goes up with the increasing distance of parallel lines. Calculation error of vanishing points is inversely proportional to the difference among the slopes of intersecting lines, which have been proven in [
21].
5. Experimental Results
5.1. Experiment of a Use-Case
Numerous situations require a system that provides a real-time view of the surroundings [
28]. One of the typical cases is the operations on aerial vehicles. In this experiment, eight cameras are used to simulate a DVS mounted on an unmanned aerial vehicle (UAV), as shown in
Figure 6. The proposed method is compared with other typical methods by both synthetic data and images simulated by 3ds Max software.
The intrinsic parameters of eight cameras are
fx =
fy = 796.44,
u0 = 512,
v0 = 384. The intrinsic parameters of the auxiliary camera and the image resolution are same with those in
Section 4. The positions and orientations of the cameras are listed in
Table 2. Each target is placed on the ground in its corresponding camera’s FOV. All the targets have the same size,
L1 = 500 mm,
L2 = 200 mm.
5.1.1. Description of the Calibration Methods
There are many calibration methods for multiple cameras. Here five typical methods are described as follows and summarized in
Table 3:
Method 1: This method is similar to the proposed method, except that corner points
are extracted by the corner extraction engine of the J. Bouguet Camera Calibration Toolbox [
23], rather than the intersections of feature lines.
Method 2: This method is similar to the proposed method, except that planar checkerboards with 12 × 12 grids are used as the calibration targets. The side length of each square is 50 mm.
Method 3: The calibration targets and the extraction of corner points are same with the proposed method. Instead of capturing neighboring target pairs, the auxiliary camera captures all the targets in one image frame, so the relative poses between targets can be computed directly.
Method 4: This method is similar to Method 3, except that corner points are obtained by the corner extraction method used in Method 1.
Method 5: This method is similar to Method 3, except that planar checkerboards of Method 2 are used as the calibration targets.
In order to illustrate the effect of the global calibration, there are two sub-methods called chainwise calibration method and global calibration method. The only difference between the two sub-methods is whether to use the global optimization in
Section 3.3 or not.
(2 ≤
k ≤
M) of the chainwise method are obtained directly from multiple coordinate transformations by Equation (23), while the global calibration method is based on an additional global optimization by Equation (25).
5.1.2. Synthetic Data Experiment
In this experiment, the RMS error of
(2 ≤
k ≤ 8) is used to evaluate the accuracy. Gaussian noise with σ = 0.2 pixel is added. For each method, 100 independent trials are performed. From
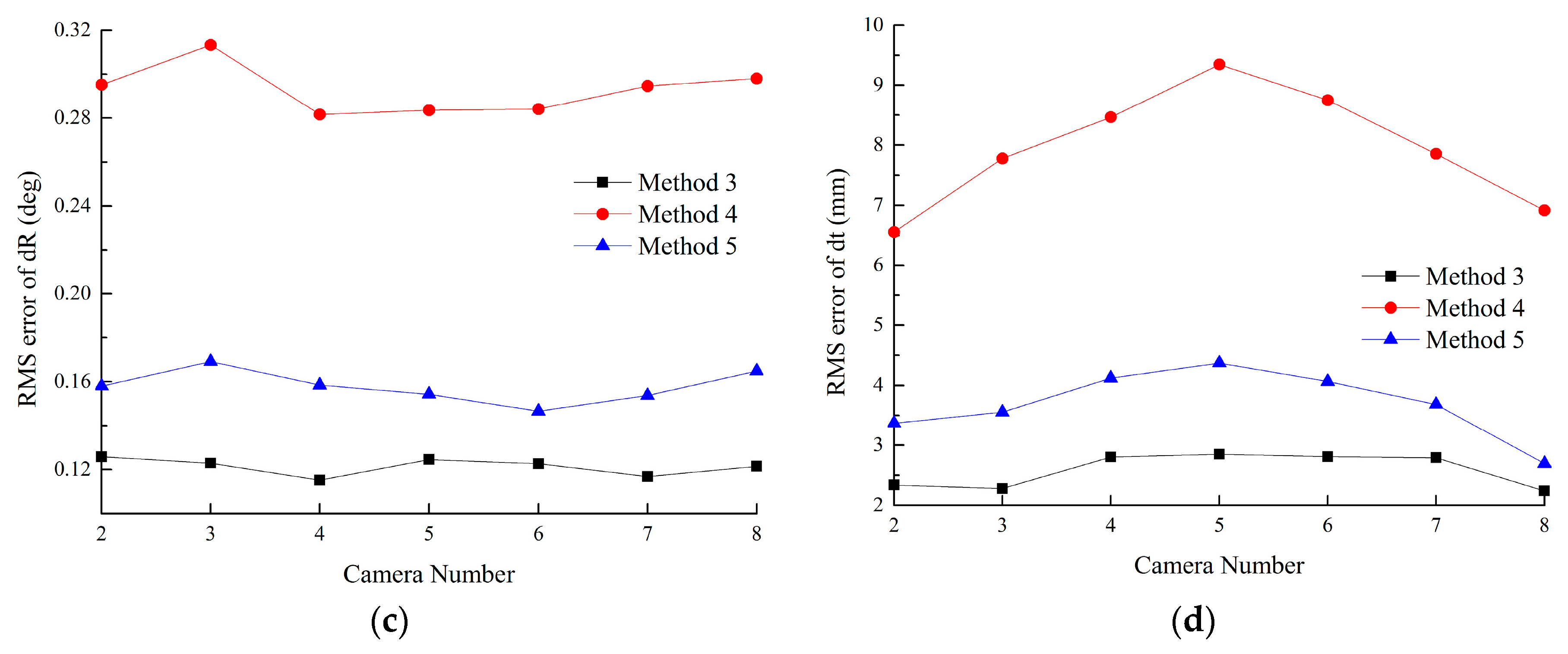
Figure 7, the proposed method outperforms Methods 1–5.
Figure 7a,b show that the error accumulates with the coordinate transformations, and peaks at camera 5, due to the maximum times of transformations. The methods based on the constraint of ring-topologies can effectively reduce the accumulated error, especially for cameras which are far away from the reference.
Methods 3–5 do not suffer from the accumulated error issue because all the targets are visible in one image frame. However, due to limitations of image resolutions, the accuracy of the pose estimation decreases with the increasing number of the targets observed in one image.
Compared with lines-feature algorithms, points-feature algorithms are more sensitive to the image noise.
Figure 7 shows that Methods 1 and 4 are worse than other methods, respectively. Further discussion is given in
Section 5.3.
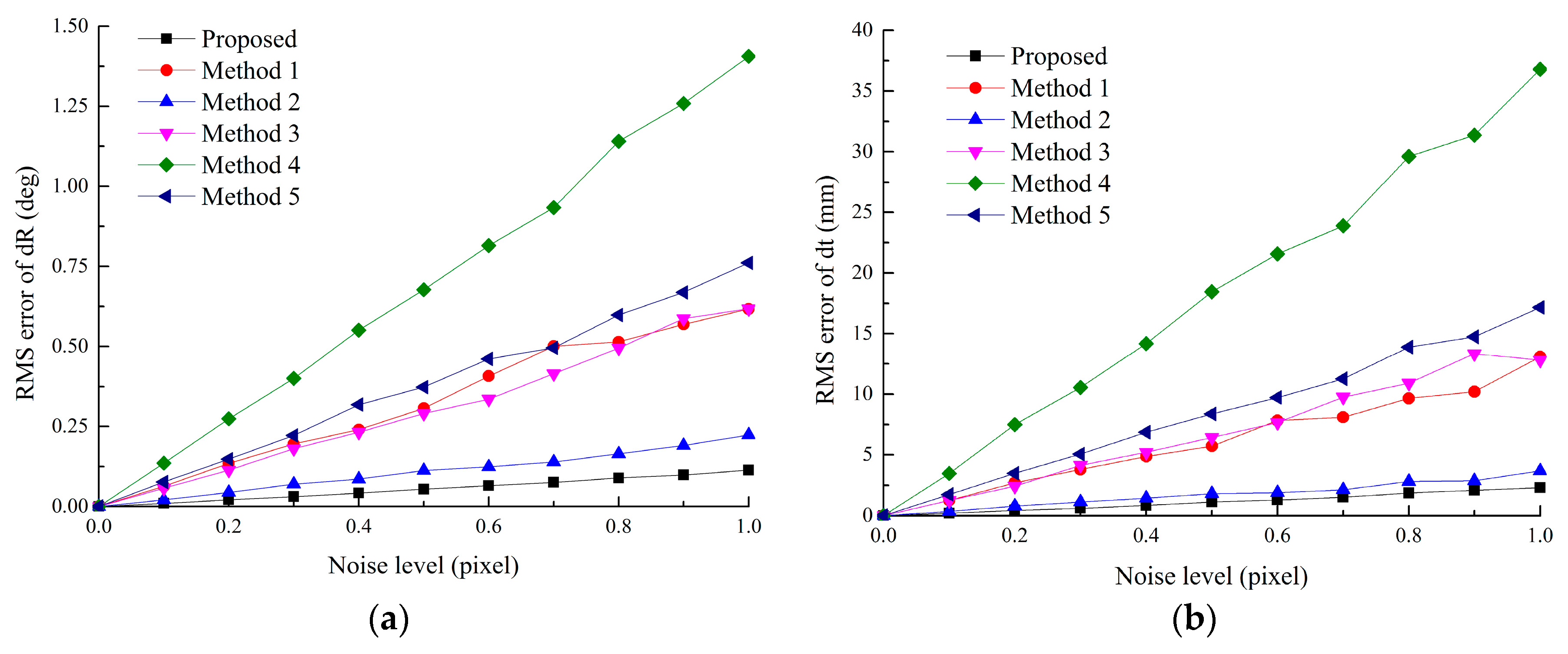
5.1.3. Accuracy vs. the Image Noise Level
In this experiment, the RMS error of
(2 ≤
k ≤ 8) is used to evaluate the effect of the noise level. Synthetic data is same with those in
Section 5.1.2. Gaussian noise from 0.0 to 1.0 pixel is added. For each noise level, 100 independent trials are performed.
From
Figure 8, the RMS error increases linearly with the noise level. It also shows that the proposed method is superior to other methods. If the noise level of the real DVS is less than 0.5 pixels, the RMS errors of rotation and translation of all the cameras are less than 0.05 deg and 1.1 mm, respectively, which is acceptable for common applications.
5.1.4. Experiments Based on Simulation Images
As shown in
Figure 9, we use the 3ds Max software to simulate image sequences. The parameters of the cameras and the targets are same with those in
Section 5.1.2. The feature lines are obtained based on feature points extracted by Steger’s method [
25]. The error of
(2 ≤
k ≤ 8) is used to evaluate the accuracy.
Figure 10 shows that errors of rotation and translation accumulate with the increasing times of coordinate transformations. The proposed method can reduce the accumulated error due to multiple coordinate transformations. Further discussion is given in
Section 5.3.
5.2. Real Data Experiment
As shown in
Figure 11a, eight targets are located in an area about 1200 mm × 1200 mm. As the relative poses of the cameras with non-overlapping FOV are mainly determined by the relative poses of the targets, the RMS errors of point pair distances between eight targets are used as calibration errors in the real experiments.
The distance of point pair and is computed according to the calibration result, and is called measurement distances, dm. The targets are also calibrated similarly by a calibrated Canon 60D digital camera. The distances of the same point pairs can be obtained in the same way and are used as the ground truth dt, due to its relatively high accuracy.
Distance error can be computed by . For the proposed method, Methods 1, 3 and 4, RMS error of and is used to evaluate the accuracy. For Methods 2 and 5, five point pairs are randomly selected and the RMS error of distance error is computed as the calibration error.
The auxiliary camera is a 1/3-in Sony CCD image sensor (ICX673) with a 3.6 mm lens. The image resolution is 720 pixel × 432 pixel. Target parameters are
The image resolution of the Canon device is 1920 pixel × 1280 pixel. The intrinsic parameters of the sensors are calibrated using Bouguet’s calibration toolbox [
23], as shown in
Table 4.
Figure 12 also shows that the proposed method achieves the best accuracy. The RMS error of point pair distances between target 5 and the reference target of the proposed method and Methods 1–5 are 0.465 mm, 0.828 mm, 3.94 mm, 3.83 mm, 1.92 mm and 21.6 mm, respectively. The proposed method is superior to other methods.
5.3. Discussion
Due to the restriction of image resolutions, the accuracy of the pose estimation decreases with the increasing number of the targets observed in one image. There exists a trade-off between the available features of target projections and the accumulated error from the chain of transformations. The experimental results show that the accumulated error can be effectively adjusted from the constraint of ring-topologies. For the vision sensor such as the Sony CCD sensor, capturing all the targets is not a wise choice. The benefits of direct calculation of the relative poses of the targets are cancelled out by the rise of feature extraction errors.
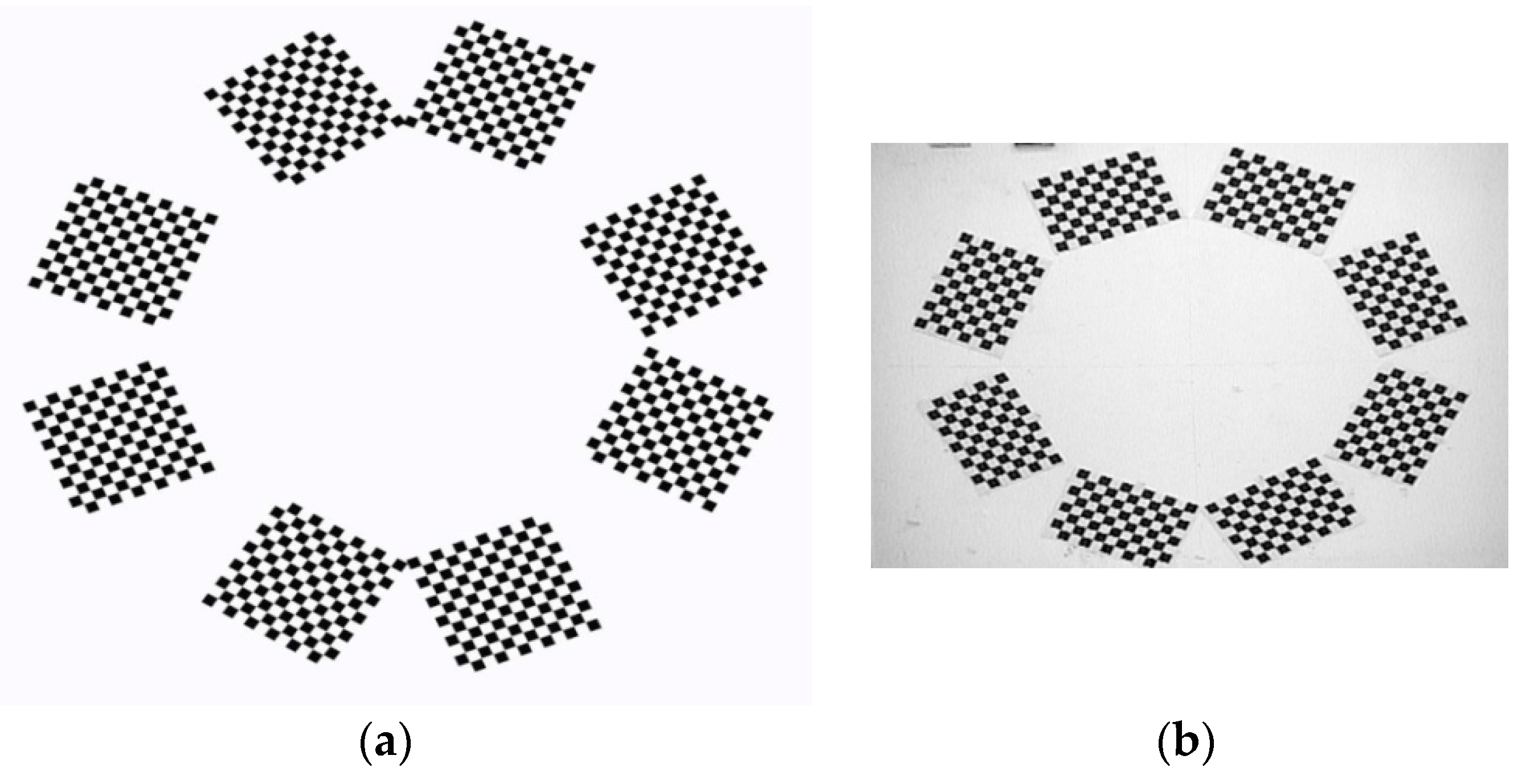
Moreover, it is not convenient to capture all the targets in some applications, because the auxiliary camera should be far away from the widely distributed targets. As shown in
Figure 11b, in order to capture all the checkerboards in one image frame, the targets are pasted on the wall.
The results of simulation images show that the accuracy of Methods 2 and 5 is close to or even better than the proposed method. However, Methods 2 and 5 achieve the worst accuracy in the real experiments.
Figure 13 shows that simulation images are very sharp and clear, which greatly benefit the corner extraction of checkerboards. However, real images could not be so ideal.
These results indicate that the proposed method is accurate and robust, especially when dealing with real images. Methods 2 and 5 are not stable against the image quality. However, there is a gap among the results of synthetic data, simulation images and real experiments. There may be some reasons for this.
Firstly, there is a measurement error during the feature extraction. In our method, the line extraction algorithm is a common-used method with acceptable accuracy and good generality. Line extraction algorithms with higher accuracy contribute to improve the accuracy, which will be further studied in the future. Secondly, the targets used in real experiments are printed on paper. They may not be strictly planar, which also leads to measurement errors.
In addition, the Sony CCD vision sensor is not a professional high-precision vision sensor, which is usually used for security cameras and radio controlled vehicles. High-resolution vision sensors can be used to improve the accuracy.
6. Conclusions
In this article, we have developed a new global calibration method for vision sensors in ring-topologies. Line-based calibration targets are placed in each camera’s FOV. Firstly, the relative poses of cameras and targets are initialized and refined based on the principle of vanishing features and the known line length. Next, in order to overcome small or no overlapping FOV between adjacent cameras, an auxiliary camera is used to capture neighboring targets. The relative poses of the targets is initialized in a chainwise manner, followed by nonlinear optimization to minimizing the squared distances between the observed feature lines and the re-projected corner points. Then the transformation matrix between each camera and the reference camera is determined.
The factors that affect the calibration accuracy are analyzed by synthetic data experiments. Synthetic data, simulation images and real data experiments all demonstrate that the proposed method is accurate and robust to image noise. The accumulated error can be adjusted effectively based on the constraint of ring-topologies. Real data experiments indicates that the measurement accuracy of the farthest camera by the proposed method is about 0.465 mm in an area about 1200 mm × 1200 mm.
The poses of targets need not be known previously and can be adjusted according to the distribution of cameras. It does not need to place the targets into different positions, one placement is enough. Our method is simple and flexible and can be applied to different configurations of multiple cameras. It is well suited for the on-site calibration of widely distributed cameras.
In this paper, we focus on the calibration of DVS in ring-topologies, which contains additional constraint. When dealing with DVS in open-topologies, accumulated errors cannot be adjusted. In addition, vanishing points approximate to infinity when feature lines are parallel to the image plane, which leads to higher errors, so the angle between parallel lines and the image plane should be in a certain range to avoid vanishing points approximate to infinity.
Restricted by hardware conditions, experiments using eight sensors mounted on an UAV are temporarily lacking. We plan to apply our method for the calibration of multiple vision sensors mounted on the vehicle in the future. Methods based on the feature lines in both indoor and outdoor environments instead of planar targets will also be investigated.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}