
A Type of Low-Latency Data Gathering Method with Multi-Sink for Sensor Networks


Abstract
:
1. Introduction
2. Related Works
2.1. Random Mobility
2.2. Fixed Mobility
2.3. Controlled Mobility
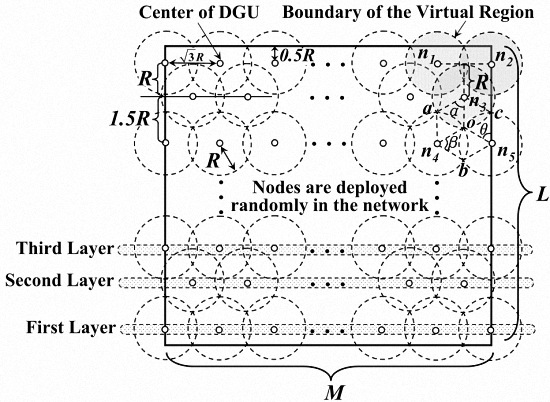
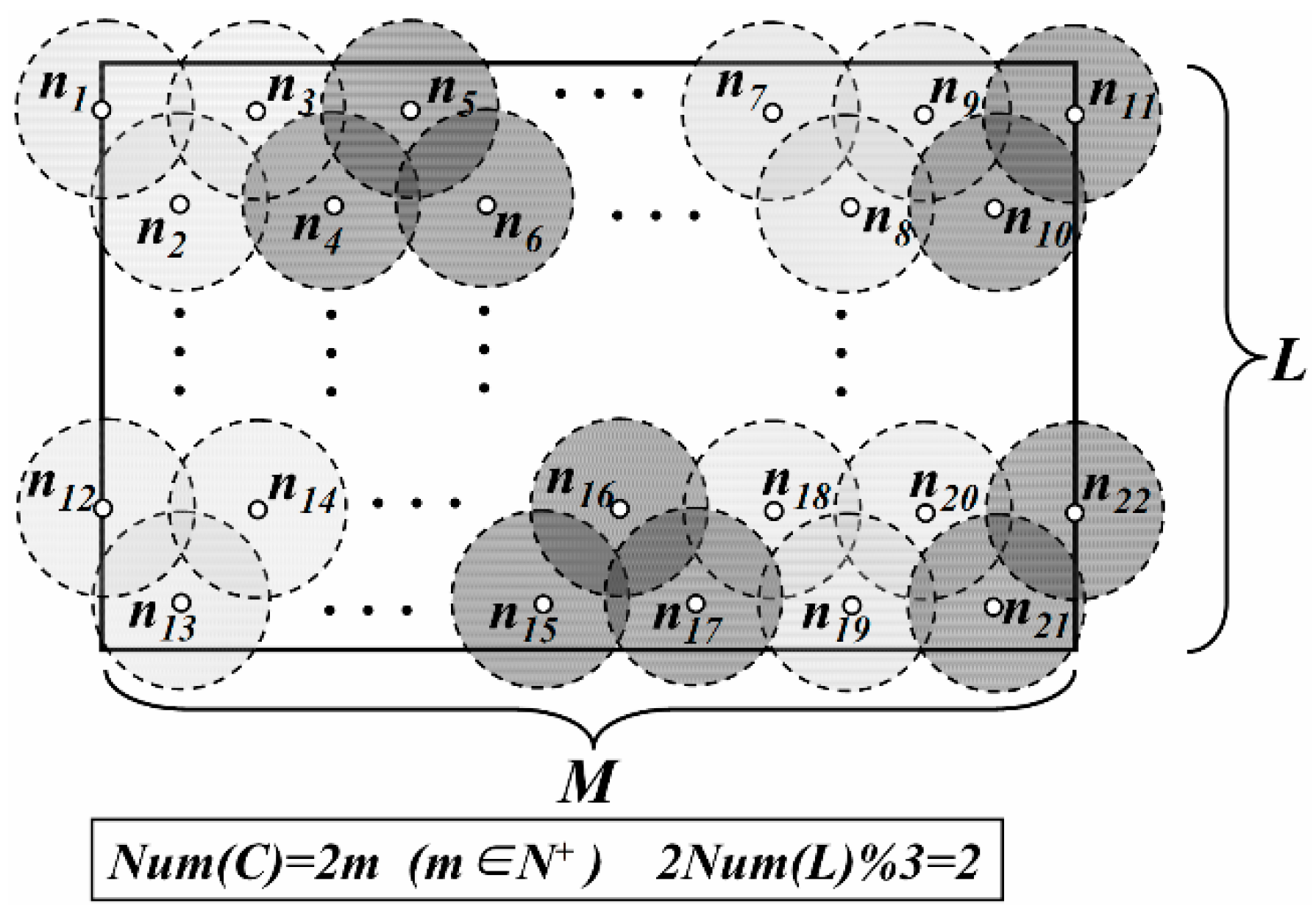
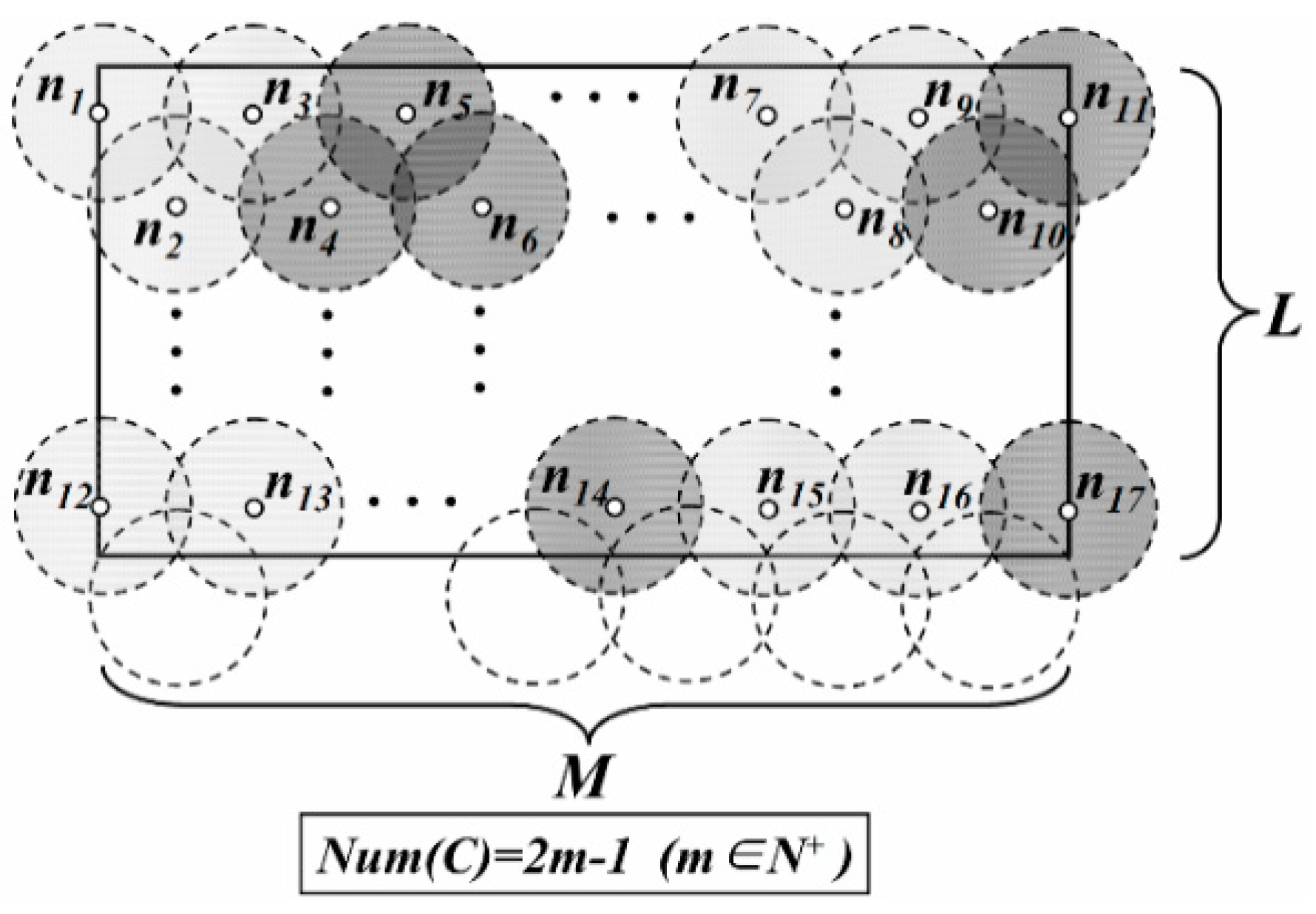
3. Network Model
- (1)
- Nodes are in static and high-density deployment. Total number and density of them is defined as n and ρ respectively.
- (2)
- All nodes except the Sink have the same initial energy E0. The transmission power as well as the sensing radius of each node is also adjustable.
- (3)
- There are several mobile Sinks in the network whose energy and storage space are unlimited.
4. Data Gathering with the Help of Multi-Sink
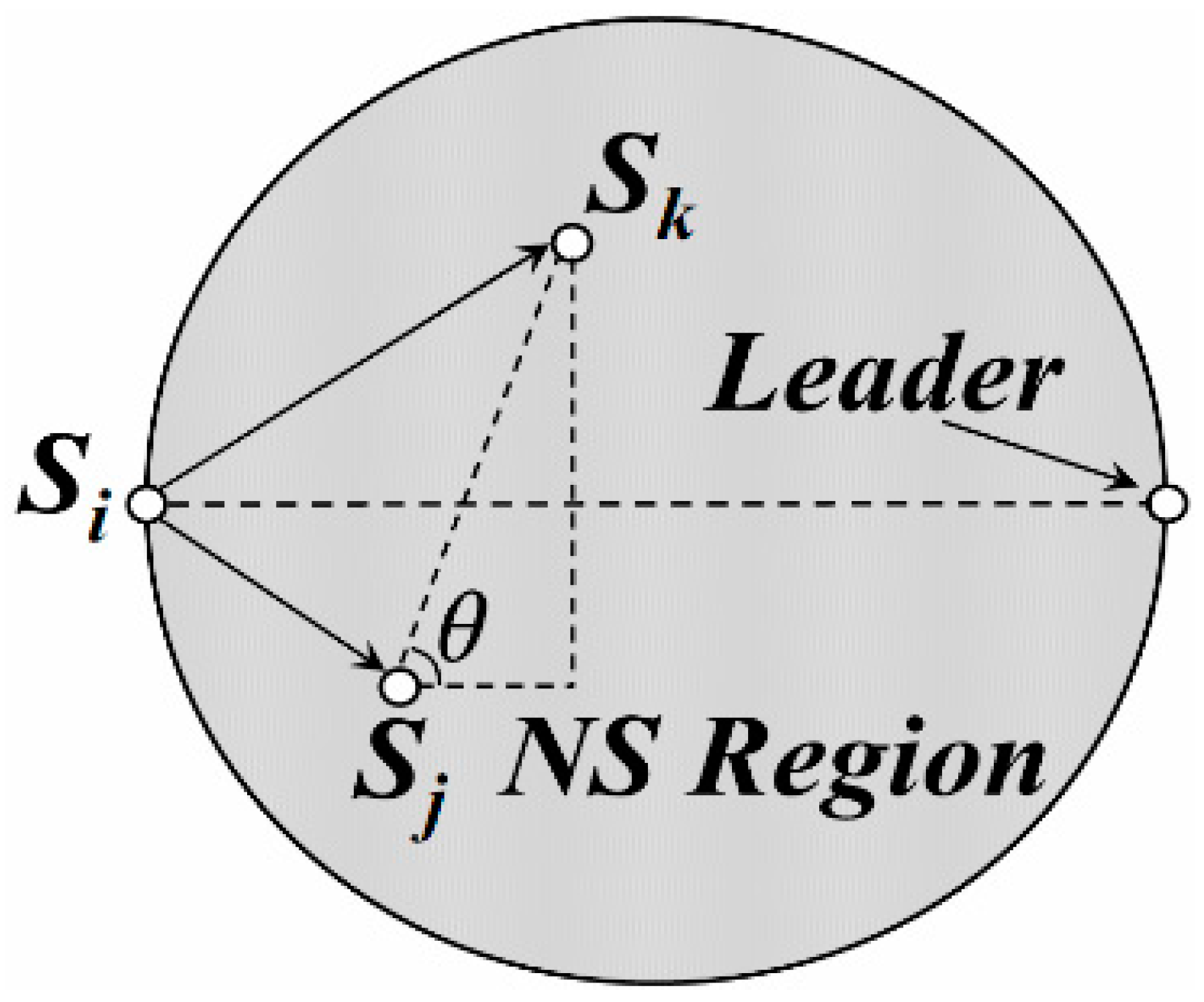
4.1. Leader Selection Strategy in DGA
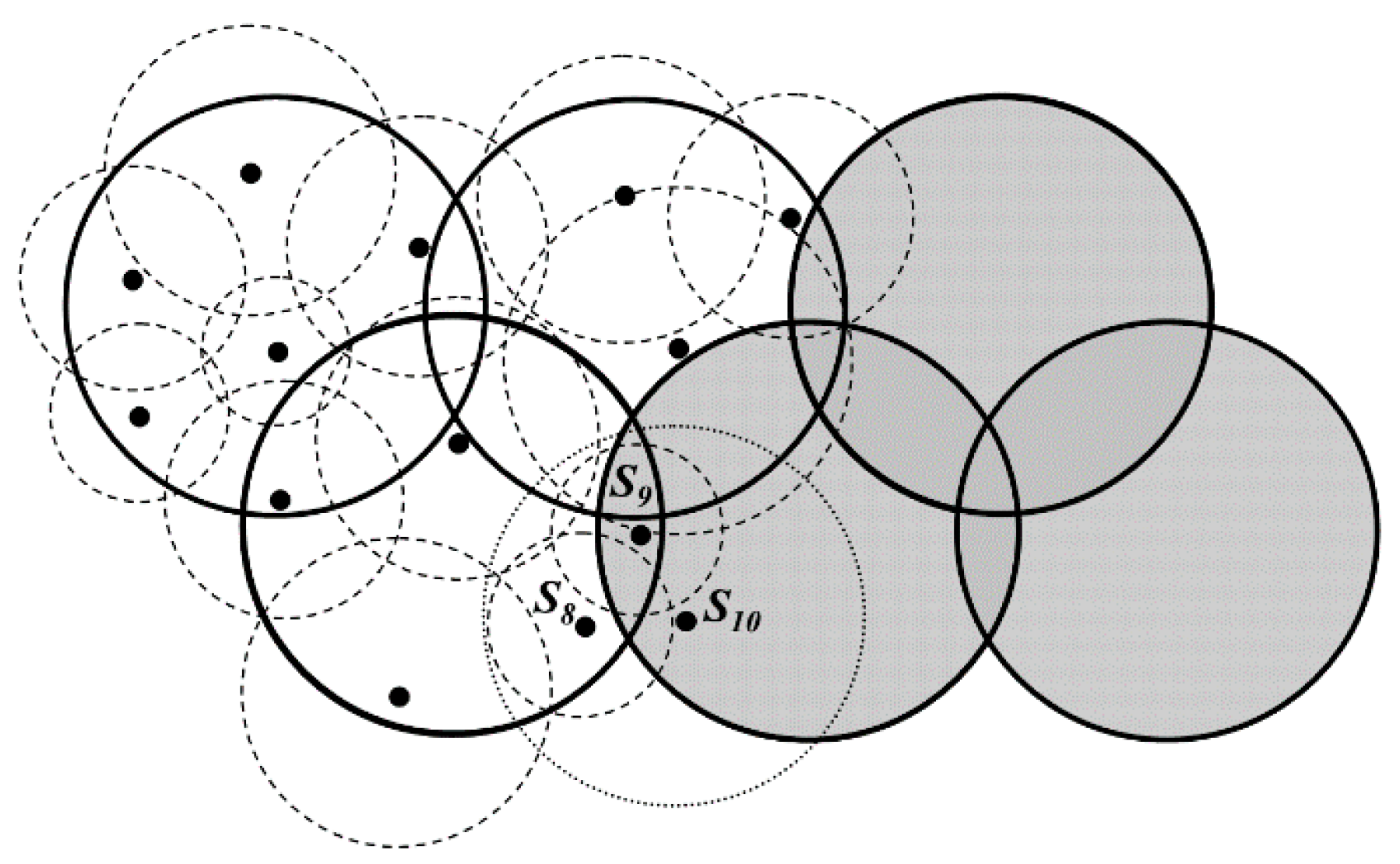
4.2. Redundancy Reduction on Data Gathering
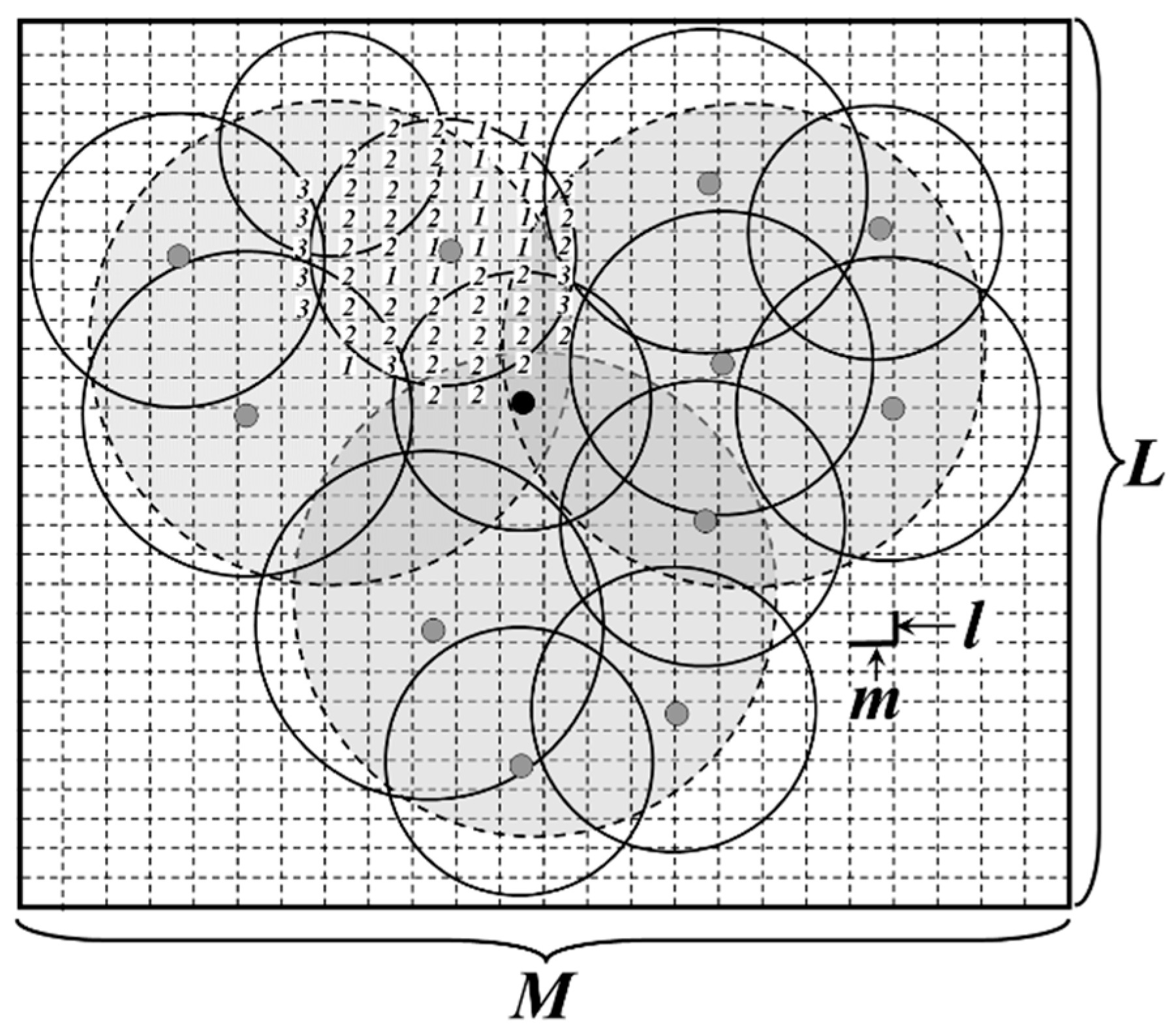
4.2.1. Active Node Selection in Each DGA
4.2.2. Sensing Radius Adjustment
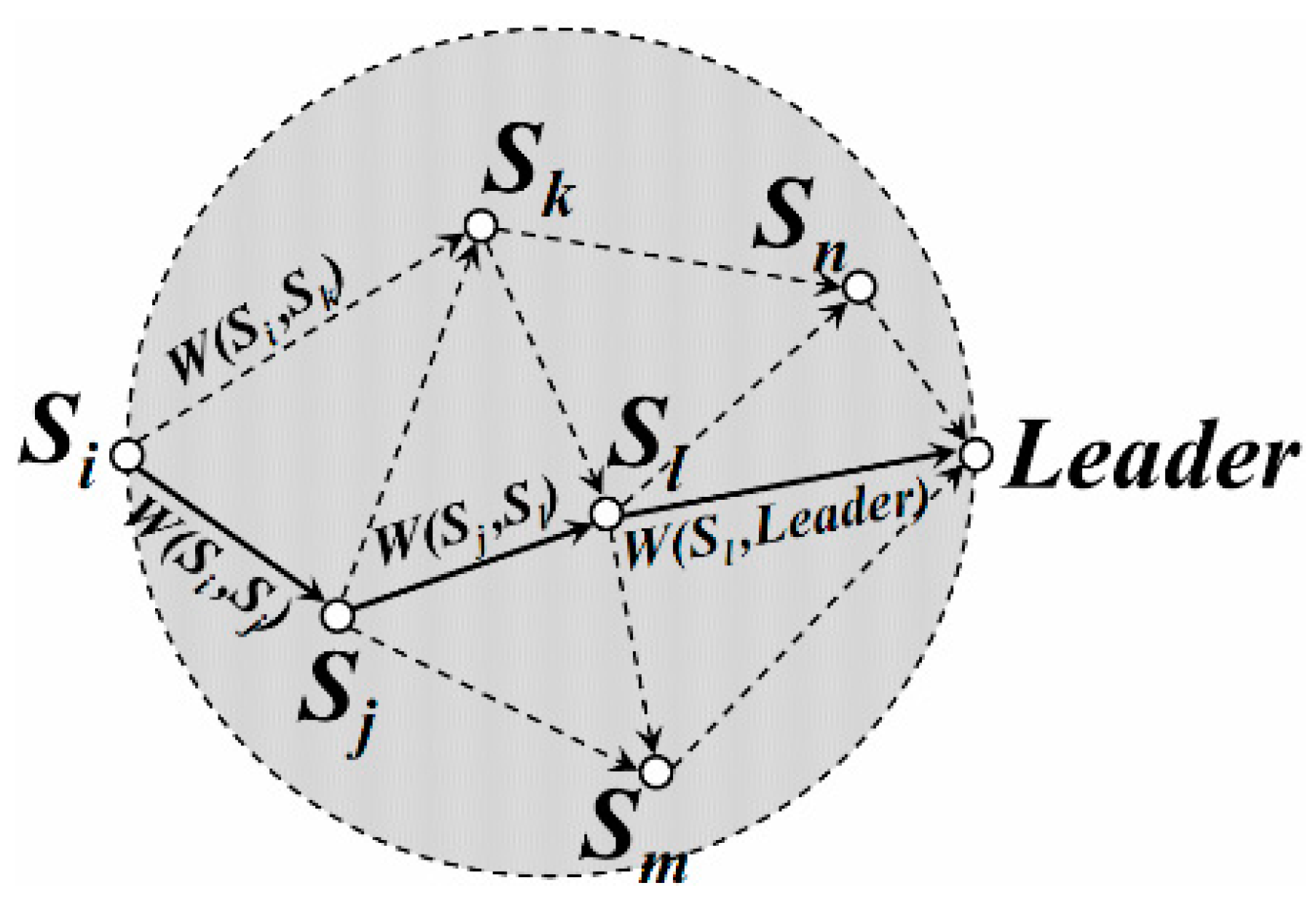
4.3. Energy Efficient Path for Data Transmission in DGA
4.4. Moving Path for Multi-Sink
- Case 1:
- If the DGA is composed of a single DGU, the traverse point is just the center of this DGU. As point Z shows in Figure 12.
- Case 2:
- If there are only two DGUs in the DGA, it is known that two leaders exist in this DGA (just Si and Sj in Figure 12). It is assumed that, Z’ is the TP of this DGA while ki and kj are the data being uploaded from the leaders to the mobile Sink. So, total energy consumption for Si and Sj on data uploading could be described as follows.To get the minimum value of ET(Si) + ET(Sj), the optimal location of Z’ could also be calculated with the help of the partial derivative, as shown in (19), X(Si),Y(Si) and X(Sj),Y(Sj), are the coordinates of Si and Sj respectively.
- Case 3:
- If there are three DGUs in the DGA (e.g., Sl, Sm and Sn are the leaders), the coordinates of its TP (e.g., Z’’) could be calculated out by Formula (20).
- Constraint 1:
- There are k mobile Sinks in the network.
- Constraint 2:
- For a Sink at DGAi, the next TP of it could only be selected from the TPs in the neighbors DGA.
- Constraint 3:
- During one data gathering period T, each Sink should move to each TP once and only once.
5. Simulation Results
5.1. Network Coverage and Redundancy
- Case 1:
- Nodes are deployed randomly in the network without doing any optimization.
- Case 2:
- Nodes in the network carry out sleep scheduling strategy after being deployed.
- Case 3:
- Nodes in the network execute both of the sleep scheduling and the sensing radius adjustment algorithms.
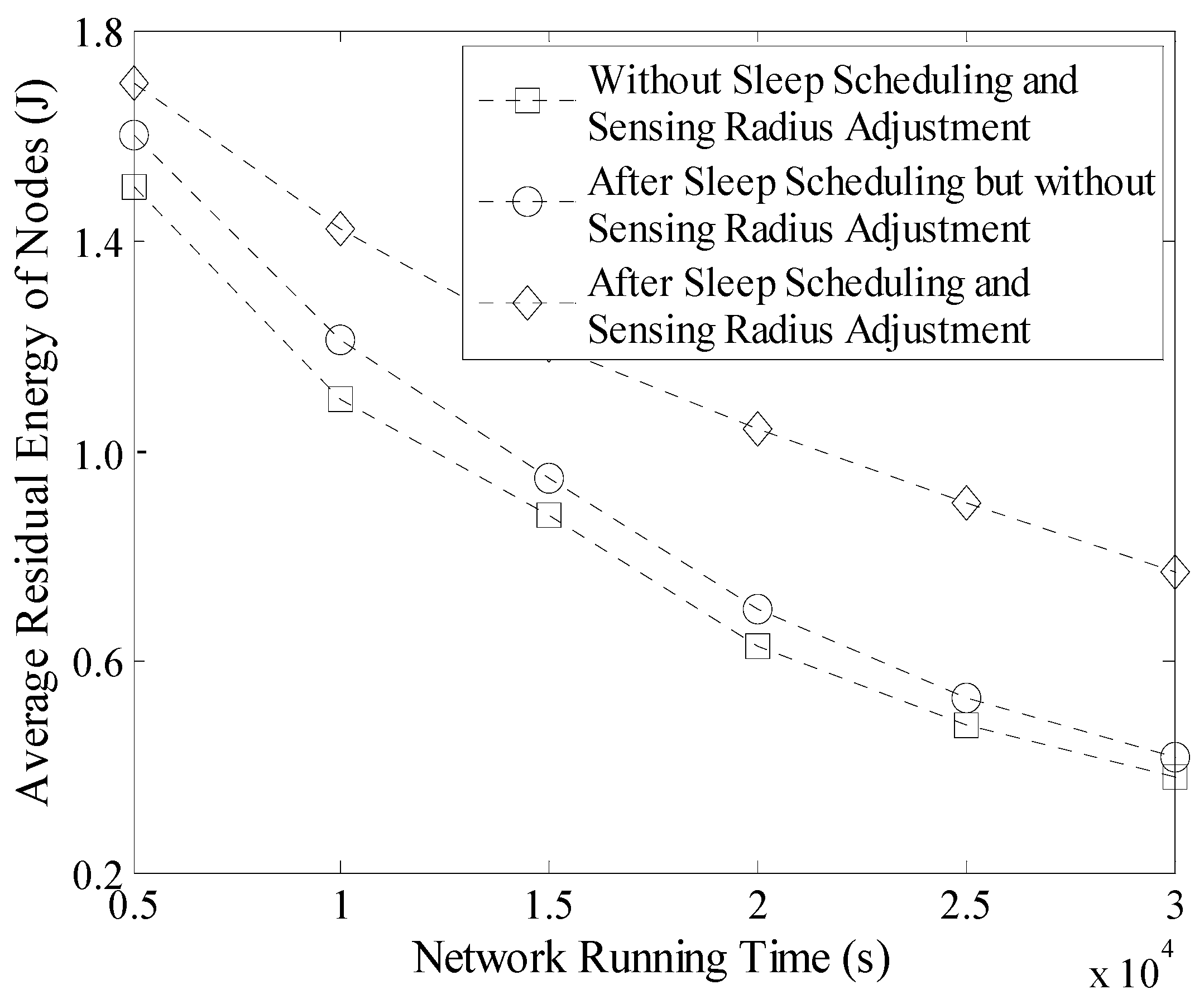
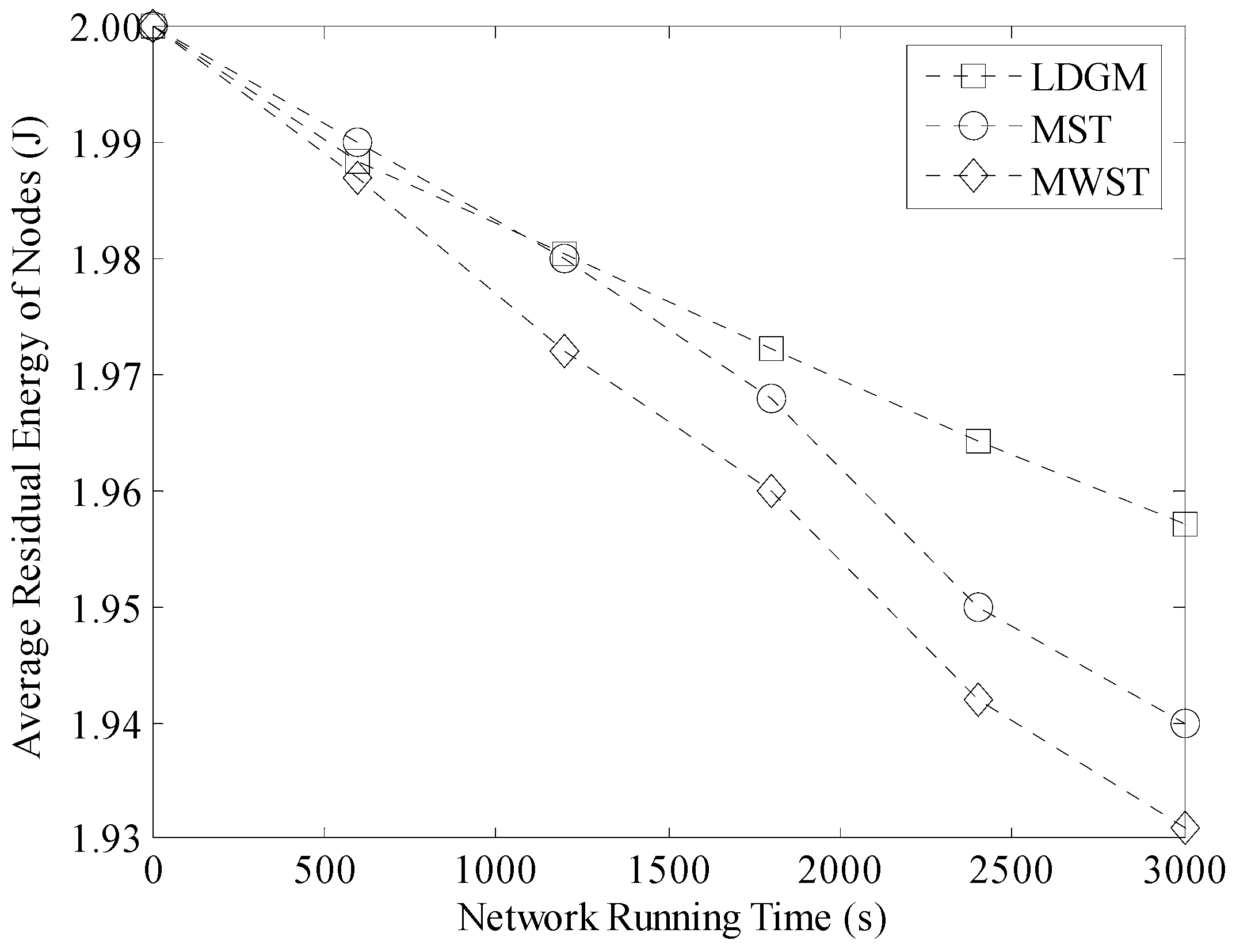
5.2. Average Residual Energy of Nodes
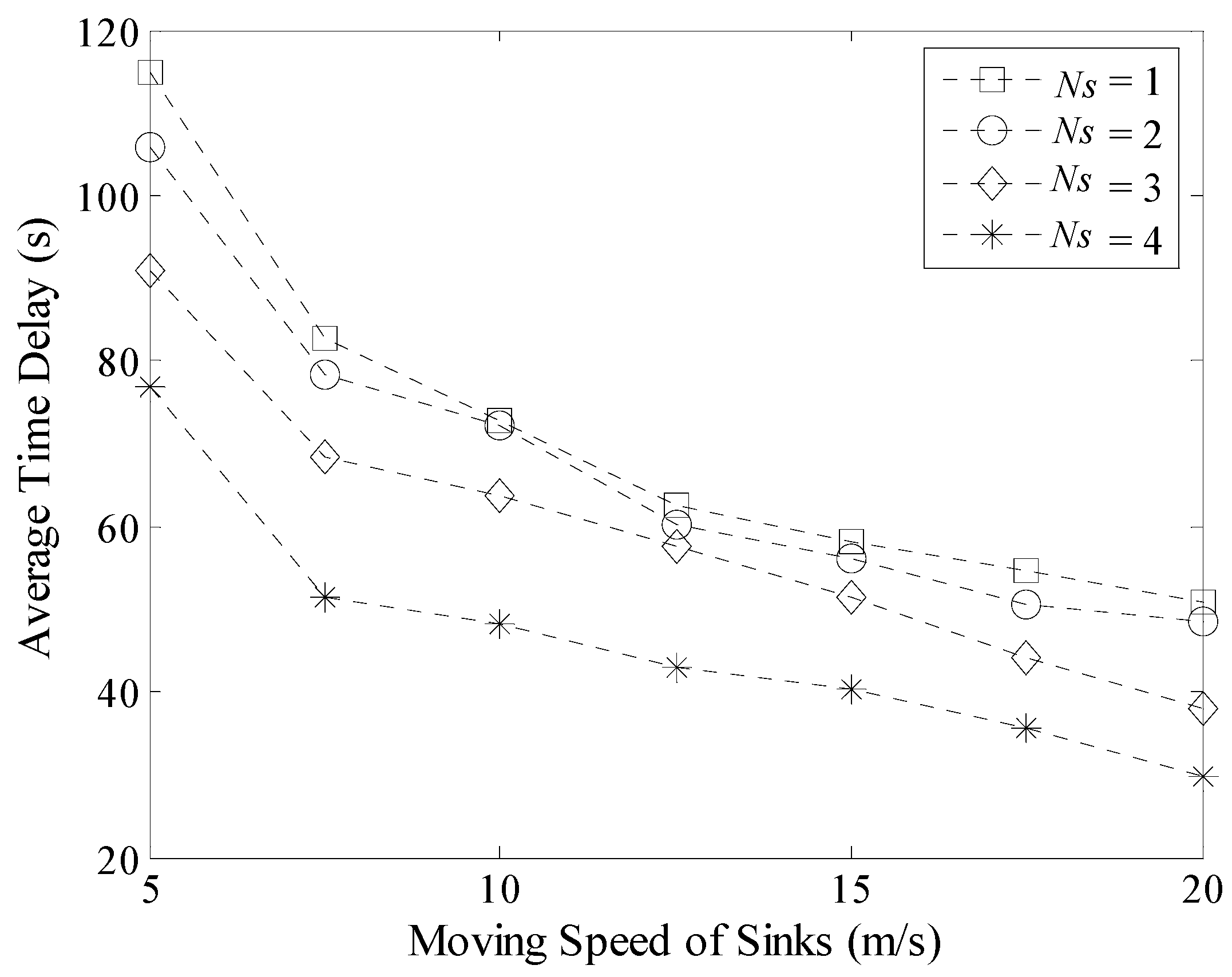
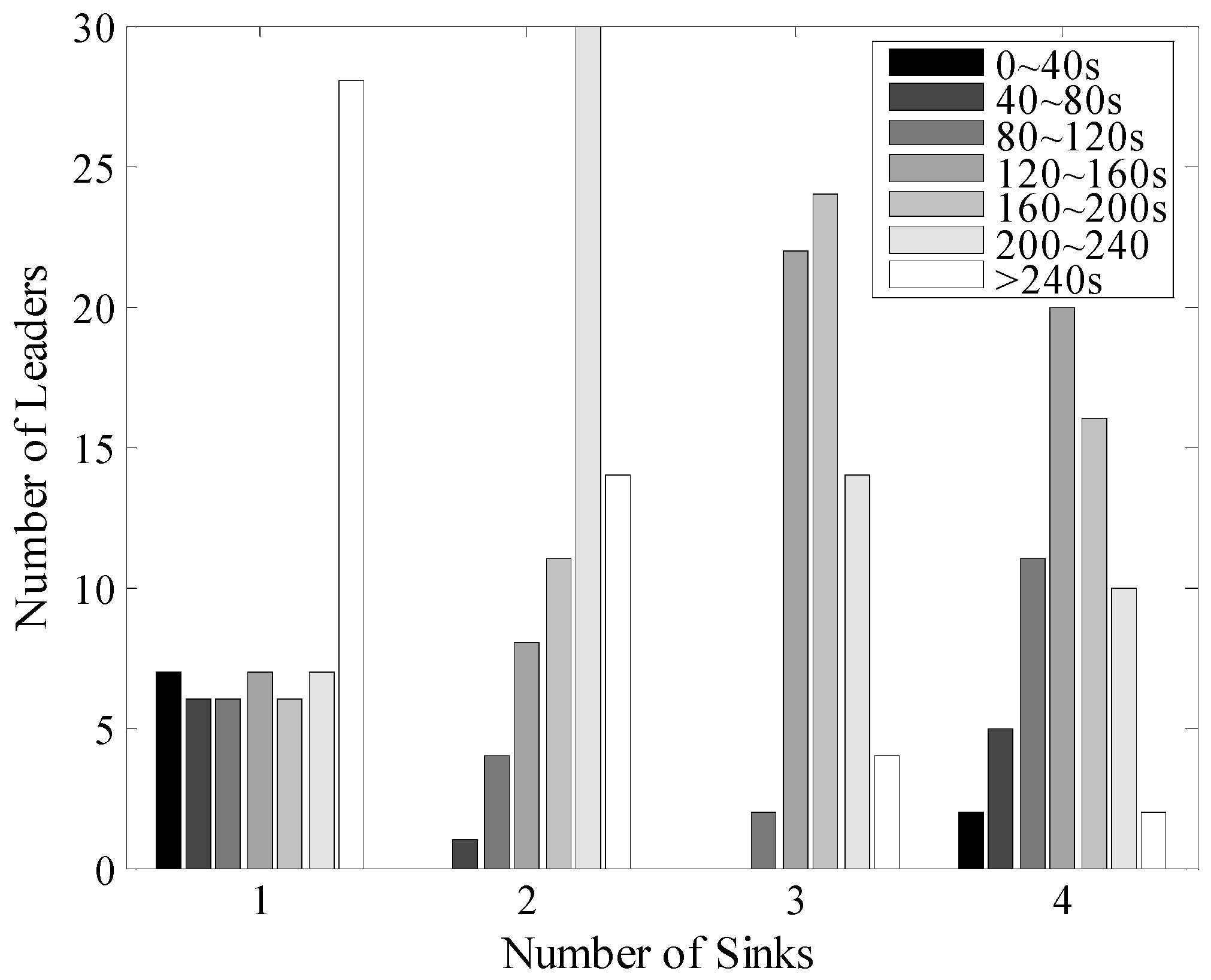
5.3. Time Delay in Data Gathering
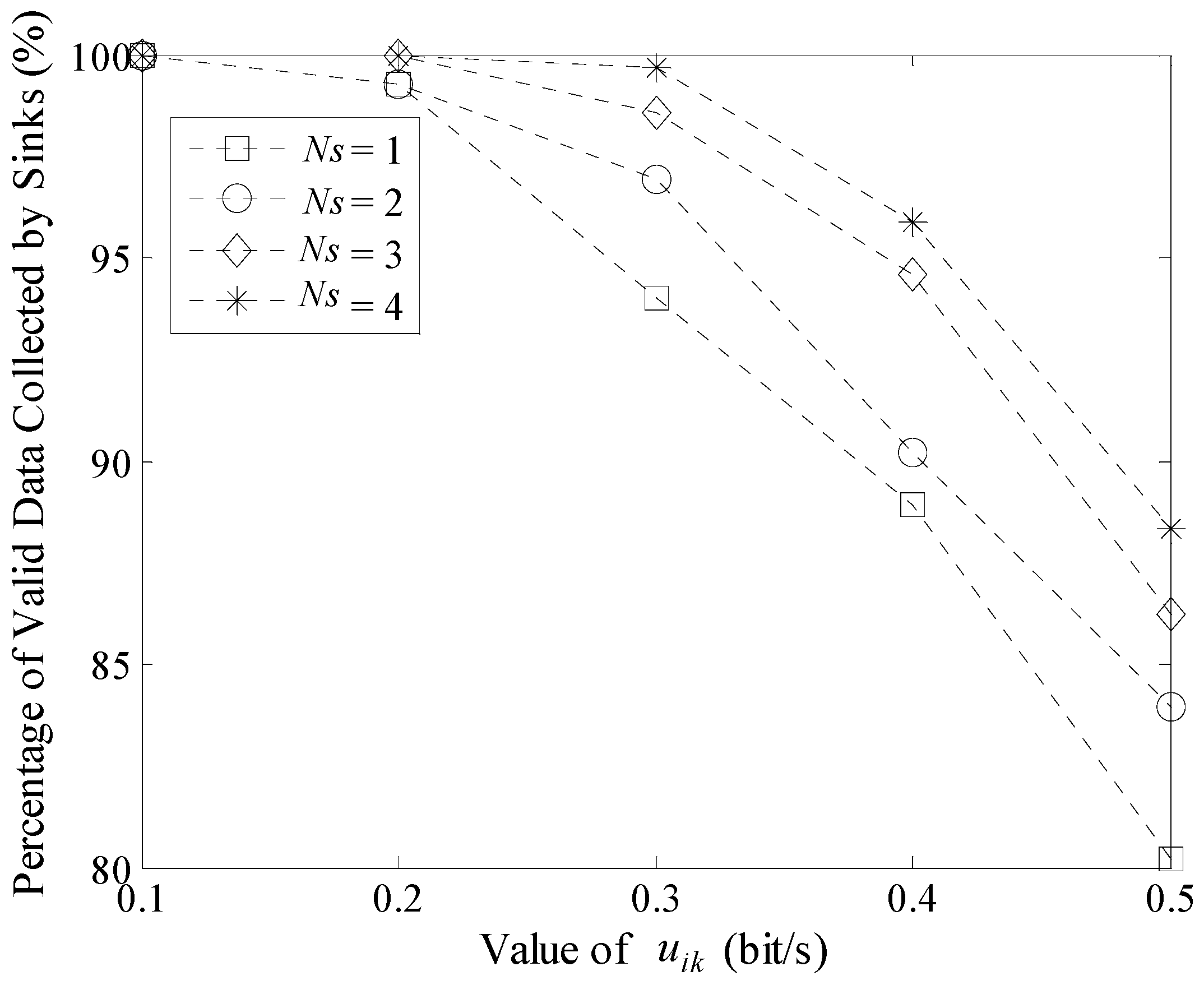
5.4. Efficiency of Data Gathering
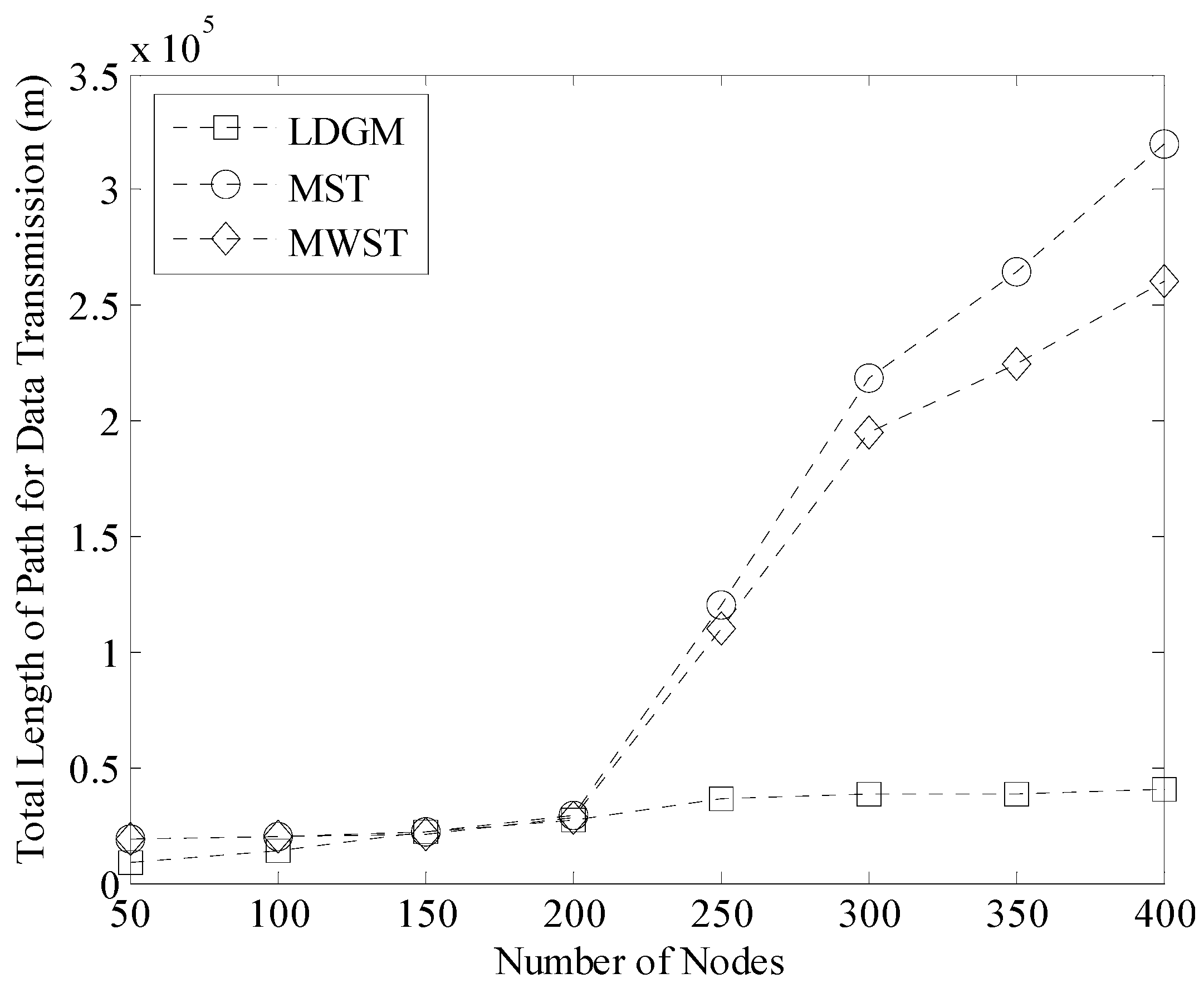
5.5. Costs on Data Gathering
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Francesco, M.D.; Das, S.K.; Anastasi, G. Data Collection in Wireless Sensor Networks with Mobile Elements: A Survey. ACM Trans. Sens. Netw. 2011, 8, 72–102. [Google Scholar] [CrossRef]
- Mammu, A.S.K.; Hernandez-Jayo, U.; Sainz, N.; de la Iglesia, I. Cross-Layer Cluster-Based Energy-Efficient Protocol for Wireless Sensor Networks. Sensors 2015, 15, 8314–8336. [Google Scholar] [CrossRef] [PubMed]
- Salarian, H.; Chin, K.; Naghdy, F. An Energy-Efficient Mobile-Sink Path Selection Strategy for Wireless Sensor Networks. IEEE Trans. Veh. Technol. 2014, 63, 2407–2419. [Google Scholar] [CrossRef]
- De Freitas, E.P.; Heimfarth, T.; Vinel, A.; Wagner, F.R.; Pereira, C.E.; Larsson, T. Cooperation among Wirelessly Connected Static and Mobile Sensor Nodes for Surveillance Applications. Sensors 2013, 13, 12903–12928. [Google Scholar] [CrossRef] [PubMed]
- Shen, J.; Tan, H.; Wang, J.; Wang, J.; Lee, S. A Novel Routing Protocol Providing Good Transmission Reliability in Underwater Sensor Networks. J. Internet Technol. 2015, 16, 171–178. [Google Scholar]
- Xie, S.; Wang, Y. Construction of Tree Network with Limited Delivery Latency in Homogeneous Wireless Sensor Networks. Wirel. Personal Commun. 2014, 78, 231–246. [Google Scholar] [CrossRef]
- Abba, S.; Lee, J.A. An Autonomous Self-Aware and Adaptive Fault Tolerant Routing Technique for Wireless Sensor Networks. Sensors 2015, 15, 20316–20354. [Google Scholar] [CrossRef] [PubMed]
- Lai, Y.; Xie, J.; Lin, Z.; Wang, T.; Liao, M. Adaptive Data Gathering in Mobile Sensor Networks Using Speedy Mobile Elements. Sensors 2015, 15, 23218–23248. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.S.; Sinha, P.; Koksal, C.E. Joint energy management and resource allocation in rechargeable sensor networks. In Proceedings of the IEEE International Conference on Information and Communication, San Diego, CA, USA, 15–19 March 2010.
- Rao, J.; Biswas, S. Network-Assisted Sink Navigation for Distributed Data Gathering: Stability and Delay-Energy Tradeoffs. Comput. Commun. 2010, 33, 160–175. [Google Scholar] [CrossRef]
- Liang, W.; Schweitzer, P.; Xu, Z. Approximation algorithms for capacitated minimum spanning forest problems in wireless sensor networks with a mobile Sink. IEEE Trans. Comput. 2013, 62, 1932–1944. [Google Scholar] [CrossRef]
- Nahas, H.A.; Deogun, J.S.; Manley, E.D. Proactive mitigation of impact of wormholes and sinkholes on routing security in energy-efficient wireless sensor networks. Wirel. Netw. 2009, 15, 431–441. [Google Scholar] [CrossRef]
- Gao, S.; Zhang, H.; Das, S.K. Efficient data collection in wireless sensor networks with path-constrained mobile Sinks. IEEE Trans. Mob. Comput. 2011, 10, 592–608. [Google Scholar] [CrossRef]
- Abo-Zahhad, M.; Ahmed, S.M.; Sabor, N.; Sasaki, S. Mobile Sink-Based Adaptive Immune Energy-Efficient Clustering Protocol for Improving the Lifetime and Stability Period of Wireless Sensor Networks. IEEE Sens. J. 2015, 15, 4576–4586. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Z.; Xia, F.; Yuan, W.; Lee, S. An Energy Efficient Stable Election-Based Routing Algorithm for Wireless Sensor Networks. Sensors 2013, 13, 14301–14320. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Fonoage, M.I.; Cardei, M. Improving network lifetime with mobile wireless sensor networks. Comput. Commun. 2010, 33, 409–419. [Google Scholar] [CrossRef]
- Ren, X.; Liang, W. Delay-tolerant data gathering in energy harvesting sensor networks with a mobile sink. In Proceedings of the IEEE Global Communication Conference, Anaheim, CA, USA, 3–7 December 2012.
- Chakrabarti, A.; Sabharwal, A.; Aazhang, B. Communication power optimization in a sensor network with a path-constrained mobile observer. ACM Trans. Sensor Netw. 2006, 2, 297–324. [Google Scholar] [CrossRef]
- Heinzelman, W.R.; Chandrakasan, A.P.; Balakrishnan, H. Energy efficient communication protocol for wireless sensor networks. In Proceedings of the 33rd Hawaii International Conference on System Sciences, Hawaii, HI, USA, 4–7 January 2000.
- Smaragdakis, G.; Matta, I.; Bestavros, A. SEP: A Stable Election Protocol for Clustered Heterogeneous Wireless Sensor Networks. In Proceedings of the International Workshop on Sensor and Actor Network Protocols and Applications, Boston, MT, USA, 22 August 2004.
- Wang, J.; Zhang, Z.; Shen, J.; Xia, F.; Lee, S. An Improved Stable Election based Routing Protocol with Mobile Sink for Wireless Sensor Networks. In Proceedings of the IEEE International Conference on Green Computing and Communications, Beijing, China, 20–23 August 2013.
- Nikolidakis, S.A.; Kandris, D.; Vergados, D.D.; Douligeris, C. Energy efficient routing in wireless sensor networks through balanced clustering. Algorithms 2013, 6, 29–42. [Google Scholar] [CrossRef]
- Kandris, D.; Tsioumas, P.; Tzes, A.; Nikolakopoulos, G.; Vergados, D.D. Power conservation through energy efficient routing in wireless sensor networks. Sensors 2009, 9, 7320–7342. [Google Scholar] [CrossRef] [PubMed]
- Upadhyayula, S.; Gupta, S.K.S. Spanning Tree Based Algorithms for Low Latency and Energy Efficient Data Aggregation Enhanced Converge-Cast (DAC) in Wireless Sensor Networks. Ad Hoc Netw. 2007, 5, 626–648. [Google Scholar] [CrossRef]
- Sia, Y.K.; Goh, H.G.; Liew, S.Y.; Gan, M.L. Spanning Multi-Tree Algorithm for node and traffic Balancing in multi-sink wireless sensor networks. In Proceedings of the 12th IEEE International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015.
- Santos, A.C.; Duhamel, C.; Belisário, L.S. Heuristics for designing multi-sink clustered WSN topologies. Eng. Appl. Artif. Intell. 2016, 50, 20–31. [Google Scholar] [CrossRef]
- Ghosh, K.; Das, P.K.; Neogy, S. KPS: A Fermat Point Based Energy Efficient Data Aggregating Routing Protocol for Multi-Sink Wireless Sensor Networks. In Advanced Computing and System for Security; Springer India: Kolkata, India, 2016; Volume 1, pp. 203–221. [Google Scholar]
- Gavalas, D.; Venetis, I.E.; Konstantopoulos, C.; Pantziou, G. Energy-efficient multiple itinerary planning for mobile agents-based data aggregation in WSNs. Telecommun. Syst. 2016. [Google Scholar] [CrossRef]
- He, L.; Pan, J.; Xu, J. A progressive approach to reducing data collection latency in wireless sensor networks with mobile elements. IEEE Trans. Mob. Comput. 2013, 12, 1308–1320. [Google Scholar] [CrossRef]
- Mehrabi, A.; Kim, K. Maximizing Data Collection Throughput on a Path in Energy Harvesting Sensor Networks Using a Mobile Sink. IEEE Trans. Mob. Comput. 2015, 15, 690–704. [Google Scholar] [CrossRef]
- Khan, M.; Gansterer, W.; Haring, G. Static vs. mobile sink: The influence of basic parameters on energy efficiency in wireless sensor networks. Comput. Commun. 2013, 36, 965–978. [Google Scholar] [CrossRef] [PubMed]
- Jain, S.; Shah, R.C.; Brunette, W.; Borriello, G.; Roy, S. Exploiting Mobility for Energy Efficient Data Collection in Sensor Networks. Mob. Netw. Appl. 2006, 11, 327–339. [Google Scholar] [CrossRef]
- Chen, T.S.; Tsai, H.W.; Chang, Y.H.; Chen, T.C. Geographic converge cast using mobile Sink in wireless sensor networks. Comput. Commun. 2013, 36, 445–458. [Google Scholar] [CrossRef]
- Yu, F.; Park, S.; Lee, E.; Kim, S.H. Elastic Routing: A novel Geographic Routing for Mobile Sinks in Wireless Sensor Networks. IET Commun. 2010, 4, 716–727. [Google Scholar] [CrossRef]
- Xing, G.; Wang, T.; Jia, W.; Li, M. Rendezvous Design Algorithms for Wireless Sensor Networks with a Mobile Base Station. In Proceedings of the 9th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Hong Kong, China, 27–30 May 2008.
- Somasundara, A.A.; Kansal, A.; Jea, D.D.; Estrin, D.; Srivastava, M.B. Controllably Mobile Infrastructure for Low Energy Embedded Networks. IEEE Trans. Mob. Comput. 2006, 5, 958–973. [Google Scholar] [CrossRef]
- Han, S.W.; Jeong, I.S.; Kang, S.H. Low Latency and Energy Efficient Routing Tree for Wireless Sensor Networks with Multiple Mobile Sink. J. Netw. Comput. Appl. 2013, 36, 156–166. [Google Scholar] [CrossRef]
- Lin, L.; Shroff, N.B.; Stikant, R. Asymptotically optimal energy-aware routing for multi-hop wireless networks with renewable energy sources. IEEE/ACM Trans. Netw. 2007, 15, 1021–1034. [Google Scholar] [CrossRef]
- Luo, J.; Panchard, J.; Piorkowski, M.; Grossglauser, M.; Hubaux, J. MobiRoute: Routing towards a Mobile Sink for Improving Lifetime in Sensor Networks. In Proceedings of the International Conference on Distributed Computing in Sensor Systems, San Francisco, CA, USA, 18–20 June 2006.
- Somasundara, A.; Ramamoorthy, A.; Srivastava, M. Mobile Element Scheduling for Efficient Data Collection in Wireless Sensor Networks with Dynamic Deadlines. In Proceedings of the 25th IEEE International Real-Time Systems Symposium, Lisbon, Portugal, 5–8 December 2004.
- Kinalis, A.; Nikoletseas, S.; Patroumpa, D.; Rolim, J. Biased Sink Mobility with Adaptive Stop Times for Low latency Data Collection in Sensor Networks. Inf. Fusion 2014, 15, 56–63. [Google Scholar] [CrossRef]
- So, A.M.C.; Ye, Y. On solving coverage problems in a wireless sensor network using voronoi diagrams. In Proceedings of the First Workshop on Internet and Network, Hong Kong, China, 15–17 December 2005.

































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Symbol | Value | Unit |
|---|---|---|---|
| Network Size | M × L | 100 × 100~200 × 200 | m2 |
| Radius of DGU | R | 5~20 | m |
| Number of Nodes | N | 100~800 | |
| Number of Mobile Sinks | Ns | 1–4 | |
| Weight Coefficient | α | 0.2 | |
| Weight Coefficient | β | 0.8 | |
| Adjustable Parameter | λ1 | 2 × 10−6 | J/(m2·s) |
| Sensing Rate | uik | 0.05~0.5 | bit/(m2·s) |
| Data Collection Rate of the Mobile Sink | v’ | 100 | Kbps |
| Moving Speed of the Mobile Sink | v | 5–20 | m/s |
| Initial Energy of Nodes | E0 | 2.0 | J |
| Threshold of the Residual Energy | Eth | 0.7 | J |
| Buffer Size of One Node | Cache | 4 | KB |
| Energy Consumption of Sending and Receiving Circuit | Eelec | 50 | nJ·b−1 |
| Energy Consumption of Amplifier in Free-Space Model | μfs | 10 | pJ·(b/m2)−1 |
| Energy Consumption of Amplifier in Multi-Path Fading Model | μamp | 0.0013 | pJ·(b/m4)−1 |
| Number of Nodes | N = 100 | N = 200 | N = 300 | N = 400 |
|---|---|---|---|---|
| Coverage Rate | 0.798059 | 0.970983 | 0.988334 | 0.999804 |
| Number of Nodes | N = 500 | N = 600 | N = 700 | N = 800 |
| Coverage Rate | 0.995491 | 0.996863 | 0.999902 | 1.000000 |
| Number of Nodes | N = 100 | N = 200 | N = 300 | N = 400 |
|---|---|---|---|---|
| Coverage Rate | 0.374174 | 0.5835 | 0.717433 | 0.826786 |
| Number of Nodes | N = 500 | N = 600 | N = 700 | N = 800 |
| Coverage Rate | 0.904532 | 0.946486 | 0.955843 | 0.973194 |
| Value of λ2 | Number of Active Nodes | Rs(Si) after Amended | Number of Nodes with Different Rs(Si) |
|---|---|---|---|
| 6.4 × 10−5 | 252 (Initial Value of Rs(Si) is 8 m) | 7 m | 155 |
| 6 m | 51 | ||
| 5 m | 11 | ||
| 4.9 × 10−5 | 284 (Initial Value of Rs(Si) is 7 m) | 6 m | 179 |
| 5 m | 28 | ||
| 4 m | 3 | ||
| 3.6 × 10−5 | 317 (Initial Value of Rs(Si) is 6 m) | 5 m | 168 |
| 4 m | 22 | ||
| 3 m | 2 | ||
| 2.5 × 10−5 | 382 (Initial Value of Rs(Si) is 5 m) | 4 m | 182 |
| 3 m | 12 | ||
| 2 m | 0 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sha, C.; Qiu, J.-m.; Li, S.-y.; Qiang, M.-y.; Wang, R.-c. A Type of Low-Latency Data Gathering Method with Multi-Sink for Sensor Networks. Sensors 2016, 16, 923. https://doi.org/10.3390/s16060923
Sha C, Qiu J-m, Li S-y, Qiang M-y, Wang R-c. A Type of Low-Latency Data Gathering Method with Multi-Sink for Sensor Networks. Sensors. 2016; 16(6):923. https://doi.org/10.3390/s16060923
Chicago/Turabian StyleSha, Chao, Jian-mei Qiu, Shu-yan Li, Meng-ye Qiang, and Ru-chuan Wang. 2016. "A Type of Low-Latency Data Gathering Method with Multi-Sink for Sensor Networks" Sensors 16, no. 6: 923. https://doi.org/10.3390/s16060923