
A Distributed Learning Method for ℓ 1 -Regularized Kernel Machine over Wireless Sensor Networks

Abstract
:1. Introduction
2. Preliminaries and Problem Statement
2.1. Kernel Minimum Mean Squared Error Estimation
2.2. Alternating Direction Method of Multipliers
2.3. Problem Statement
3. Distributed -Regularized KMSE Machine
3.1. Derivation and Solution of the -Regularized KMSE Machine
3.2. Collaboration Method between Neighboring Nodes
3.3. Distributed Learning Algorithm for the -Regularized KMSE Machine
| Algorithm 1: L1-DKMSE |
| Input: Initialize the training set for node , iterations , , and , choose the Radial Basis Function (RBF) as the kernel function, and initialize the kernel parameter and the regularization parameter . |
| Output: the sparse model . |
| Repeat: |
| Step 1: each node obtains its sparse model by iterations of Equations (27)–(29) using its training examples. Then, it broadcasts its sparse model to its one-hop neighboring nodes in . |
| Step 2: each node receives and adds the key examples in to its local training set. |
| Step 3: each node predicts its local training examples by using and then computes and using Equations (23) and (24), respectively. |
| Step 4: If the models on each node are all stable, stop; otherwise, increment () and return to Step 1. |
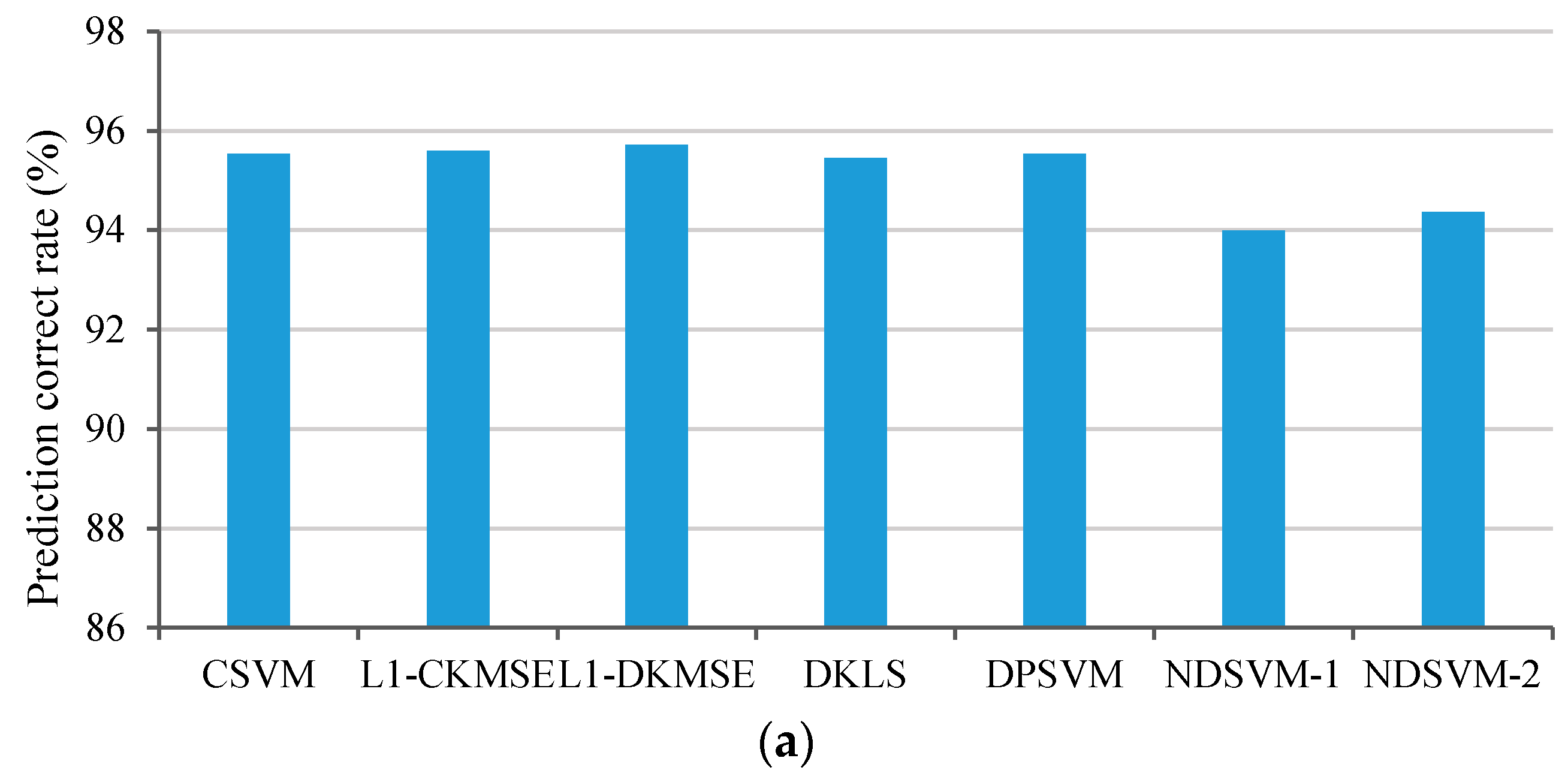
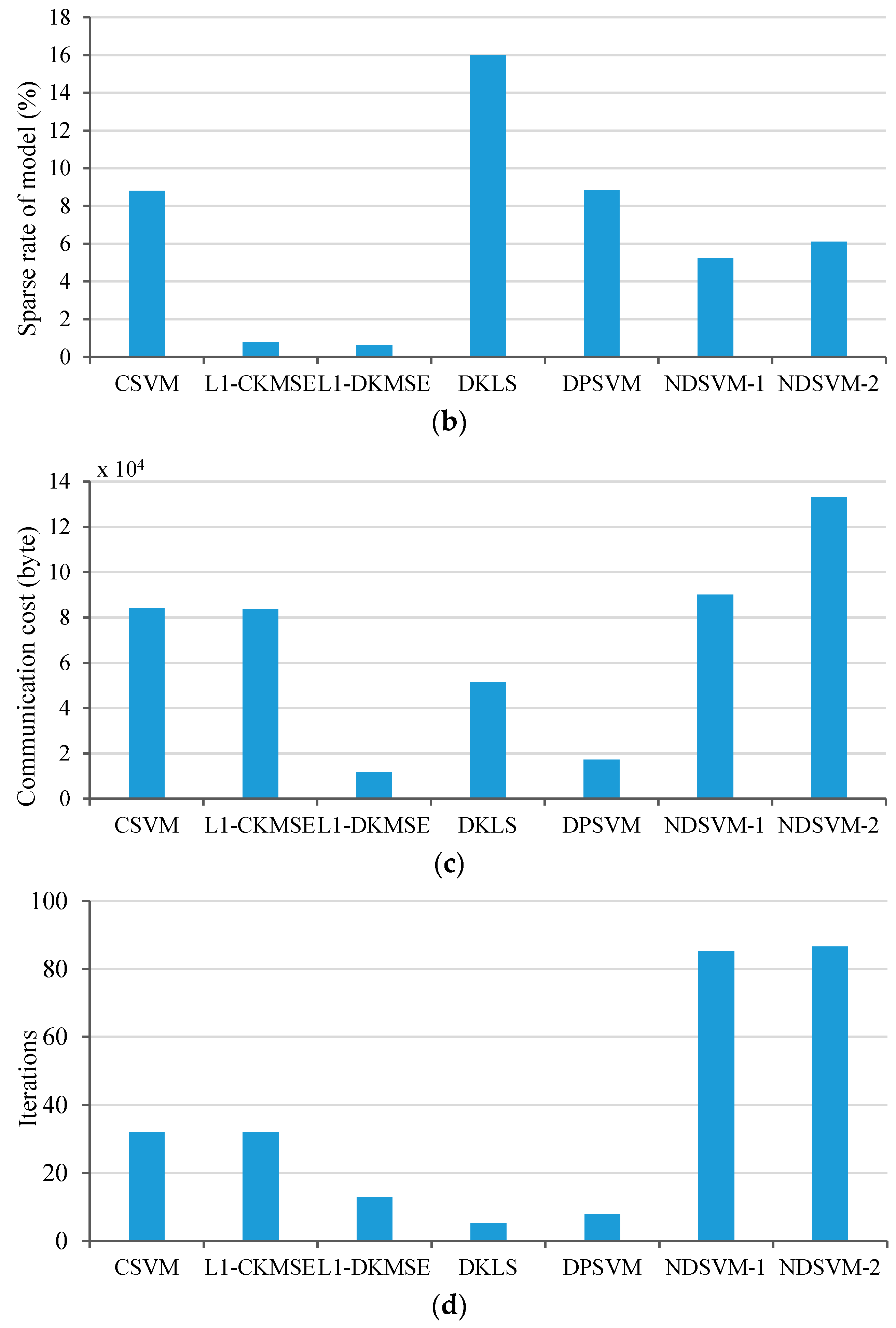
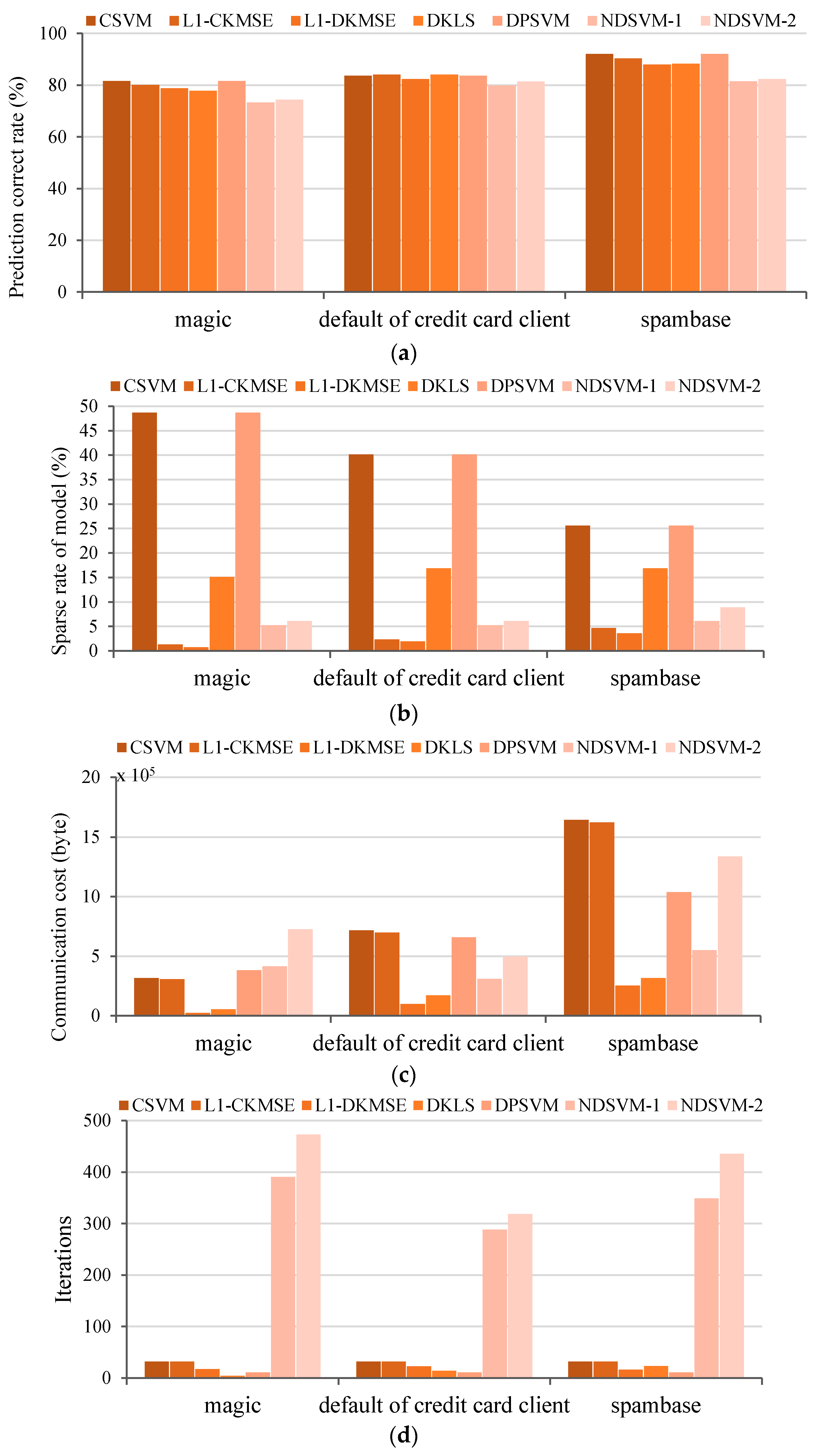
4. Numerical Simulations
4.1. Synthetic Dataset
4.2. UCI Datasets
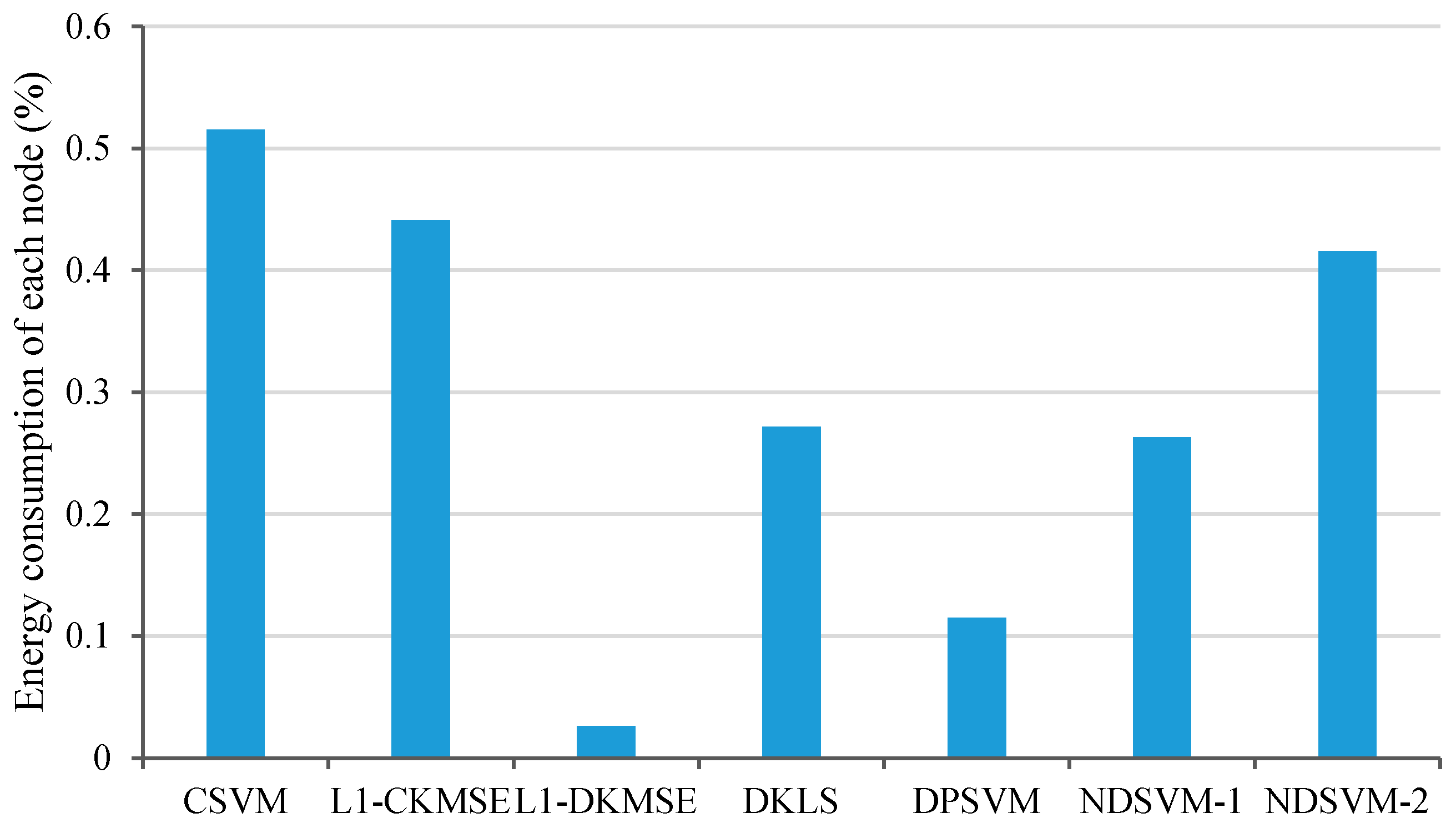
5. Experiment on Test Platform
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Arora, A.; Dutta, P.; Bapat, S.; Kulathumani, V.; Zhang, H.; Naik, V.; Mittal, V.; Cao, H.; Demirbas, M.; Gouda, M.; et al. A line in the sand: A wireless sensor network for target detection, classification, and tracking. Comput. Netw. 2004, 46, 605–634. [Google Scholar] [CrossRef]
- Frigo, J.; Kulathumani, V.; Brennan, S.; Rosten, E.; Raby, E. Sensor network based vehicle classification and license plate identification system. In Proceedings of the 6th International Conference on Networked Sensing Systems (INSS’09), Pittsburgh, PA, USA, 17–19 June 2009; pp. 224–227.
- Taghvaeeyan, S.; Rajamani, R. Portable roadside sensors for vehicle counting, classification, and Speed measurement. IEEE. Trans. Intell. Transp. Syst. 2014, 15, 73–83. [Google Scholar] [CrossRef]
- Yu, C.B.; Hu, J.J.; Li, R.; Deng, S.H.; Yang, R.M. Node fault diagnosis in WSN based on RS and SVM. In Proceedings of the 2014 International Conference on Wireless Communication and Sensor Network (WCSN), Wuhan, China, 13–14 December 2014; pp. 153–156.
- Sajana, A.; Subramanian, R.; Kumar, P.V.; Krishnan, S.; Amrutur, B.; Sebastian, J.; Hegde, M.; Anand, S.V.R. A low-complexity algorithm for intrusion detection in a PIR-based wireless sensor network. In Proceedings of the 5th International Conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP), Melbourne, Australia, 7–10 December 2009; pp. 337–342.
- Raj, A.B.; Ramesh, M.V.; Raghavendra, V.K.; Hemalatha, T. Security enhancement in wireless sensor networks using machine learning. In Proceedings of the IEEE 14th International Conference on High Performance Computing and Communications, Liverpool, UK, 25–27 June 2012; pp. 1264–1269.
- Lv, F.X.; Zhang, J.C.; Guo, X.K.; Wang, Q. The acoustic target in battlefield intelligent classification and identification with multi-features in WSN. Sci. Technol. Eng. 2013, 13, 10713–10721. [Google Scholar]
- Garrido-Castellano, J.A.; Murillo-Fuentes, J.J. On the implementation of distributed asynchronous nonlinear kernel methods over wireless sensor networks. EURASIP J. Wirel. Commun. Netw. 2015, 1, 1–14. [Google Scholar]
- Ji, X.-R.; Hou, C.-Q.; Hou, Y.-B. Research on the distributed training method for linear SVM in WSN. J. Electron. Inf. Technol. 2015, 37, 708–714. [Google Scholar]
- Guestrin, C.; Bodik, P.; Thibaux, R.; Paskin, M. Distributed regression: An efficient framework for Modeling Sensor Network Data. In Proceedings of the International Symposium on Information Processing in Sensor Networks (IPSN’04), Berkeley, CA, USA, 26–27 April 2004; pp. 1–10.
- Predd, J.B.; Kulkarni, S.R.; Poor, H.V. Distributed kernel regression: An algorithm for training collaboratively. In Proceedings of the IEEE Information Theory Workshop, Punta Del Este, Uruguay, 13–17 March 2006; pp. 332–336.
- Predd, J.B.; Kulkarni, S.R.; Poor, H.V. A collaborative training algorithm for distributed learning. IEEE Trans. Inf. Theory 2009, 55, 1856–1870. [Google Scholar] [CrossRef]
- Forero, P.A.; Cano, A.; Giannakis, G.B. Consensus-based distributed linear support vector machines. In Proceedings of the 9th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN’10), Stockholm, Sweden, 12–16 April 2010; pp. 35–46.
- Forero, P.A.; Cano, A.; Giannakis, G.B. Consensus-based distributed support vector machines. J. Mach. Learn. Res. 2010, 11, 1663–1707. [Google Scholar]
- Flouri, K.; Beferull-Lozano, B.; Tsakalides, P. Optimal gossip algorithm for distributed consensus SVM training in wireless sensor networks. In Proceedings of the 16th International Conference on Digital Signal Processin (DSP’09), Santorini, Greece, 5–7 July 2009; pp. 886–891.
- Flouri, K.; Beferull-Lozano, B.; Tsakalides, P. Training a support-vector machine-based classifier in distributed sensor networks. In Proceedings of the 14th European Signal Processing Conference, Florence, Italy, 4–8 September 2006; pp. 1–5.
- Lu, Y.; Roychowdhury, V.; Vandenberghe, L. Distributed parallel support vector machines in strongly connected networks. IEEE Trans. Neural Netw. 2008, 19, 1167–1178. [Google Scholar]
- Scholkopf, B.; Smola, A. Pattern recognition. In Learning with Kernels: Support Vector Machines, Regularization, Optimization and Beyond; MIT Press: Cambridge, MA, USA, 2001; pp. 189–211. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Shawe-Taylor, J.; Cristianini, N. Support vector machines. In An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000; pp. 82–106. [Google Scholar]
- Ruiz-Gonzalez, R.; Gomez-Gil, J.; Gomez-Gil, F.J.; Martínez-Martínez, V. An SVM-based classifier for estimating the state of various rotating components in agro-Industrial machinery with a vibration signal acquired from a single point on the machine chassis. Sensors 2014, 14, 20713–20735. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Chen, X.; Yan, Y.; Wei, W.; Wang, Z.J. Classification of EEG signals using a multiple kernel learning support Vector machine. Sensors 2014, 14, 12784–12802. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Wu, L. Classification of fruits using computer vision and a multiclass support vector machine. Sensors 2012, 12, 12489–12505. [Google Scholar] [CrossRef] [PubMed]
- Shahid, N.; Naqvi, I.H.; Qaisar, S.B. Quarter-sphere SVM: Attribute and spatio-temporal correlations based outlier & event detection in wireless sensor networks. In Proceedings of the IEEE Wireless Communication and Networking Conference: Mobile and Wireless Networks (WCNC 2012), Paris, France, 1–4 April 2012; pp. 2048–2053.
- Qian, L.; Chen, C.; Zhou, H.-X. Application of a modified SVM multi-class classification algorithm in wireless sensor networks. J. China Univ. Metrol. 2013, 24, 298–303. [Google Scholar]
- Bhargava, A.; Raghuvanshi, A.S. Anomaly detection in wireless sensor networks using S-Transform in combination with SVM. In Proceedings of the 5th International Conference on Computational Intelligence and Communication Networks (CICN 2013), Mathura, India, 27–29 September2013; pp. 111–116.
- Liu, Z.; Guo, W.; Tang, Z.; Chen, Y. Multi-sensor data Fusion using a relevance Vector machine based on an ant colony for Gearbox Fault detection. Sensors 2015, 15, 21857–21875. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Zhang, X.; Li, Y. Kernel MSE algorithm: A unified framework for KFD, LS-SVM and KRR. In Proceedings of the International Joint Conference on Neural Networks, Washington, DC, USA, 15–19 July 2001; pp. 1486–1491.
- Boyd, S.; Parikh, N.; Chu, E. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Bertsekas, D.P.; Tsitsiklis, J.N. Iterative methods for nonlinear problems. In Parallel and Distributed Computation: Numerical Methods; Athena Scientific: Belmont, MA, USA, 2003; pp. 224–261. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Classes | Dim. Feature | Size |
|---|---|---|---|
| magic | 2 | 10 | 19,020 |
| default of credit card client | 2 | 24 | 30,000 |
| spambase | 2 | 57 | 4601 |
| Algorithms | Magic | Default of Credit Card Client | Spambase |
|---|---|---|---|
| CSVM | |||
| L1-CKMSE | |||
| L1-DKMSE | |||
| DKLS | |||
| DPSVM | |||
| NDSVM-1 | |||
| NDSVM-2 |
| Algorithms | Amount of Data Sent at Every Turn of Each Node (Byte) | Iterations |
|---|---|---|
| CSVM | 140 | 20 |
| L1-CKMSE | 140 | 20 |
| L1-DKMSE | 26 | 16 |
| DKLS | 312 | 6 |
| DPSVM | 67 | 9 |
| NDSVM-1 | 35 | 85 |
| NDSVM-2 | 51 | 87 |
| 500 mA Load Method | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Voltage (V) | 8.40 | 7.94 | 7.74 | 7.58 | 7.46 | 7.36 | 7.30 | 7.24 | 7.16 | 7.02 | 6.84 | 6.00 |
| Battery capacity (%) | 100 | 90 | 80 | 70 | 60 | 50 | 40 | 30 | 20 | 10 | 5 | 0 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, X.; Hou, C.; Hou, Y.; Gao, F.; Wang, S. A Distributed Learning Method for ℓ 1 -Regularized Kernel Machine over Wireless Sensor Networks. Sensors 2016, 16, 1021. https://doi.org/10.3390/s16071021
Ji X, Hou C, Hou Y, Gao F, Wang S. A Distributed Learning Method for ℓ 1 -Regularized Kernel Machine over Wireless Sensor Networks. Sensors. 2016; 16(7):1021. https://doi.org/10.3390/s16071021
Chicago/Turabian StyleJi, Xinrong, Cuiqin Hou, Yibin Hou, Fang Gao, and Shulong Wang. 2016. "A Distributed Learning Method for ℓ 1 -Regularized Kernel Machine over Wireless Sensor Networks" Sensors 16, no. 7: 1021. https://doi.org/10.3390/s16071021