1. Introduction
Every aspect of human daily lives has been penetrated by data fusion. For example, humans can naturally integrate information gathered by organs, like eyes, nose and ears, etc., to make a judgment and a decision. Multi-sensor data fusion, a functional simulation of the procedure of decision-making performed by the human brain, enjoys decades of fame across engineering systems and industries. The fusion of information from sensors with different physical characteristics enhances the understanding of our surroundings and provides the basis for planning, decision-making and the control of autonomous and intelligent machines [
1]. This technique has been widely used in many fields, such as medical diagnosis [
2], image fusion [
3,
4,
5], target tracking and recognition [
6] and device fault diagnosis [
7,
8].
With the development of technology, various types of failures occur frequently, which bring great threats to human life owing to the more and more complicated structure of modern engineering systems. Fault detection and diagnosis have been attracting considerable attention in more recent years. The existing fault diagnosis methods are various. For example, the methods based on the expert system [
9,
10,
11] are developed through the domain experts’ experiences, which lead from long-term practice. In this method, diagnosis is performed by preestablished software or a system that can functionally imitate the process of reasoning and decision-making by experts. This method is simple and understandable in principle, but usually encounters obstacles in practice. On the one hand, this method relies on the experts’ knowledge level too much, which means the diagnosis accuracy is easily affected by this factor. Additionally, knowledge acquisition and rule base establishment, on the other hand, are long and difficult processes. The other methods for fault diagnosis, such as machine learning [
12] and signal processing [
13], are widely used in real applications. The machine learning for fault diagnosis, the neural network, for example, makes use of the historical data from failures to train the neural network algorithm. This method structurally imitates human cognitive ability and is a new method with full potential. However, the factors such as the neural network structure and the training intensity often influence the diagnosis effect. The signal processing method, wavelet transform, for instance, is an effective method for fault diagnosis, but lacks robustness to noise. Sensor data fusion [
14], as a data-driven method, has attracted more and more attention. This method can integrate multi-source information with different physical characteristics to reduce uncertainty. To date, we are able to find more references in fault diagnosis where the multi-sensor fusion technique is used owing to the following reasons:
In comparison with single source data, multi-source information fusion extends the detection range in time and space to enhance the ability of information collection.
A detected fault may have multi-attributes, which need different types sensors to jointly finish the detection task.
Multi-sensors are needed to overcome the complexity and uncertainty of the surroundings. Sensor data fusion contributes to enhancing the robustness and safety of a system.
In practical applications, there are various interferences in the working environment, so information gathered from sensors is uncertain and lacks reliability. Therefore, how to measure and how to process uncertain information are key issues in the sensor fusion system. To address these issues, theories of the uncertainty model and process are introduced, such as fuzzy set theory [
15,
16], evidence theory [
17,
18,
19,
20], D numbers [
21], possibility theory [
22], etc. A working device cannot be analyzed accurately because of its randomicity, complexity and inconstancy. The relationship between the detected feature and the real working state is usually fuzzy and uncertain; on this basis, a number of fault diagnosis methods based on fuzzy set theory are highly researched, such as [
23,
24]. D-S evidence theory, which was first proposed by Dempster [
17] and then developed by Shafer [
18], is able to deal with uncertain information without a prior probability. The mass function, belief function and plausibility function defined in D-S evidence theory can measure uncertain information well; thus, it is flexible and more effective than probability theory. Dempster’s combination rule is effective at reducing uncertainty and focus on the certain information to make a decision. D-S evidence theory has good performance in uncertainty modeling [
25,
26] and data fusion [
27,
28], which contribute to its wide application in the fields of uncertain information processing [
29,
30] and decision-making [
31]. D numbers theory, as a generalization of D-S evidence theory, is also effective at handling uncertain information, such as risk analysis [
32], environmental impact assessment [
33], supplier selection [
21], etc.
Actually, not just the method of modeling and processing is uncertain, but also, the measure of the reliability of information source influences the fusion results. While most of the fusion systems optimistically assume that the information sources are all reliable and pay more attention to uncertainty modeling and fusion methods, however, the performance of the fusion system highly depends on the sensor performance, including accuracy, work efficiency and the ability to understand the dynamic working environment [
34]. Therefore, the procedure to estimate the reliability of each sensor is indispensable. In evidence theory, discounting factors were introduced by Shafer [
18] to account for the reliability of the information sources. Originally, the discounting factors were defined to discount the belief functions. Later, the sensor discounting factor was introduced in [
35] to represent the sensor reliability. Now, we can find more researchers who employ the discounting factor method to measure the reliability of the multi-source information. For example, in [
8], a novel belief entropy [
36] was applied to measure the information volume of the evidence. Then, the discounting coefficients based on this belief entropy, as the reliability of each evidence, are calculated to deal with the evidence conflicts in the application of evidence theory. In [
34], Guo et al. presented a framework for sensor reliability evaluation in classification problems based on evidence theory. In their work, static reliability and dynamic reliability were taken into account in the evaluation process, where a static discounting factor assigned to a sensor was based on the comparison of its original readings and the actual values of data, and the dynamic discounting factor was obtained by adaptive learning and regulation in real-time situations. Similarly, the statistic sensor reliability and dynamic sensor reliability were also taken into consideration in [
7]. Being different from [
34], the static reliability in [
7] was obtained from the evidence sufficiency and evidence importance propose by Fan and Zuo [
37], and the dynamic reliability was generated based on the evidence distance function [
38] and the belief entropy [
36]. This method can be used for conflict management [
39,
40,
41,
42] in D-S evidence theory, as well. Although the discounting factors’ method performs well in some cases, some aspects can be improved to measure the reliability of the sensors more reasonably. Sensor reliability is related to the context of sensor acquisitions. The external factors, such as environmental noises, deceptive behaviors of observed targets, meteorological conditions, and so forth, often affect the performance of the sensors. Therefore, sensor reliability cannot be easily and accurately measured. In other words, a crisp discounting number cannot completely cover the whole complexity and fuzziness of the sensor reliability. Therefore, we deem that it will be more reasonable to model the fuzzy reliability of a sensor. In addition, the existing methods [
7,
8,
31,
41] usually excavate the discounting factors from BPA, which has lost part of the source information; as a result, the obtained discounting factor may not reflect the real situation well.
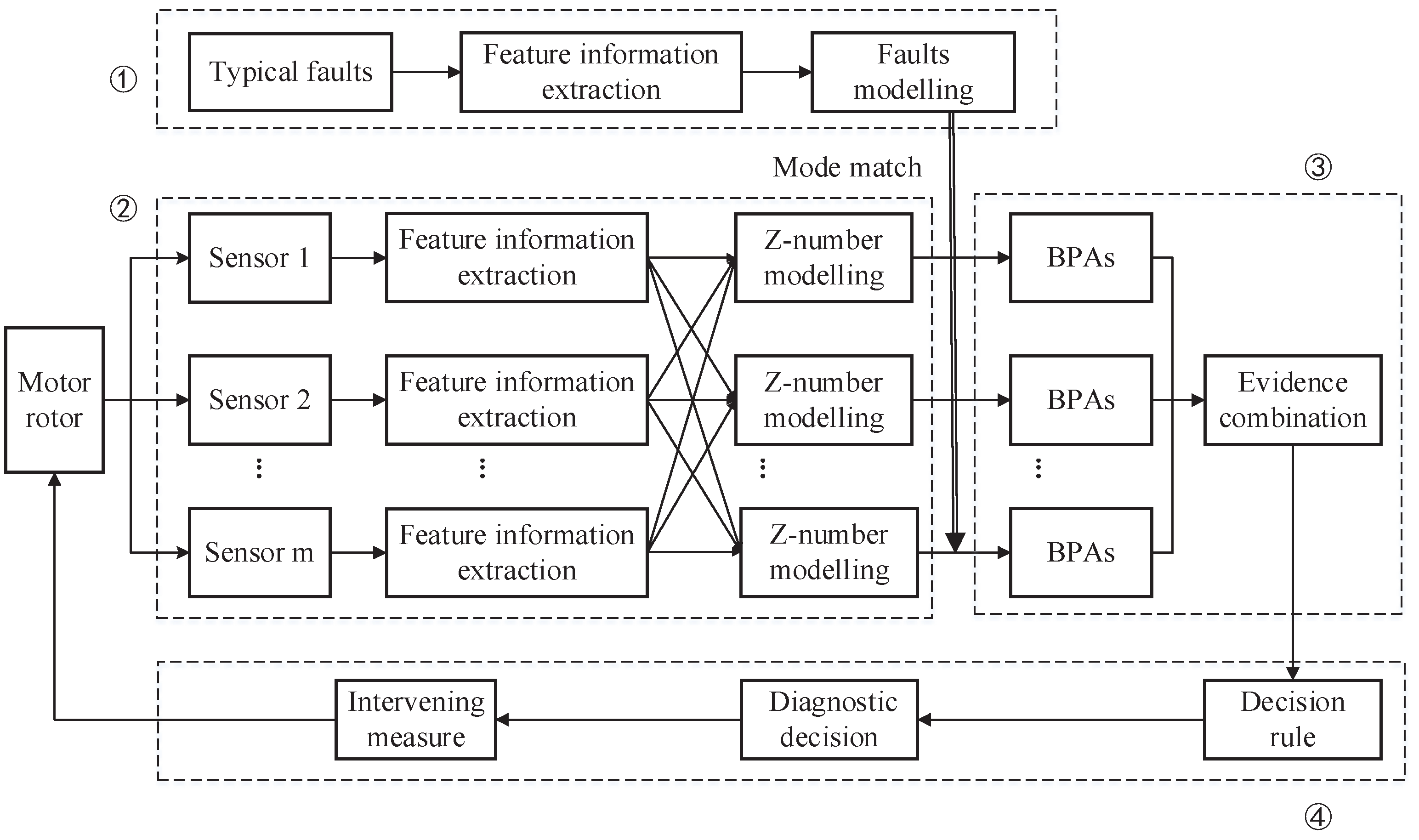
To address the above issues, we propose a new sensor data fusion method based on
Z-numbers and D-S evidence theory. The concept of
Z-number proposed by Zadeh [
43] in 2011 is an ordered pair fuzzy numbers denoted by
. The first component
A is a fuzzy restriction on a value of the variable
X. The second component
B represents a measure of the certainty or reliability of the
A. A
Z-number can take both the fuzziness and the reliability into consideration, which is just suitable for modeling sensor data. In this paper, we propose a data-driven method to dynamically produce
Z-numbers. The fuzzy reliability, which is obtained from the original feature information, can reduce the information lost. Based on the proposed
Z-number model, we conjunctively apply the evidence theory [
17,
18] and the
Z-number [
43] to evidence the combination in fault diagnosis. D-S evidence theory [
17,
18] can establish the relationship between the set and the proposition of fault and is widely used for sensor data fusion in fault diagnosis. For example, for a discernment frame {unbalance, misalignment, the base loose, rotor bending}, uncertain information can be described as “the rotor fault has a belief degree of 70% belonging to the set A = {unbalanced, base loose} and has a belief of 30% belonging to set B = {rotor bending, misalignment}”. By mode matching, we make use of the component
A of a
Z-number to get BPA. The second component, the fuzzy reliability, as a measurement of the reliability of the sensor, can be used to modify the BPA. By fusing the multi-sensor and multi-feature information, the synthesized evidence is obtained for fault diagnosis according to the defined diagnostic rules.
4. An Illustrated Example for Sensor Data Fusion in Fault Diagnosis
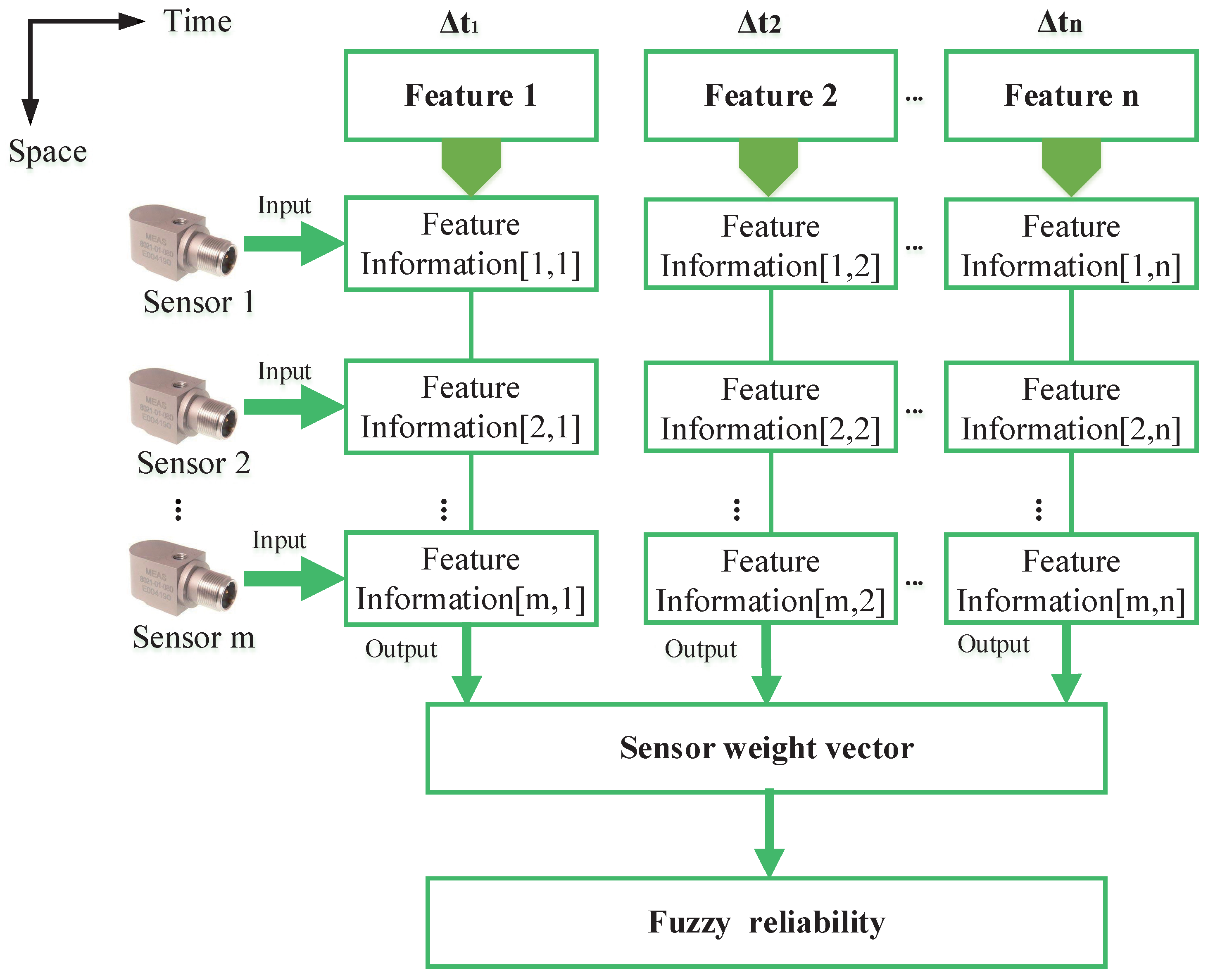
In order to validate the proposed method, a case study of the fault diagnosis of a motor rotor is performed. A total of 900 observations are measured under some typical faults (rotor unbalance, rotor misalignment, Pedestal looseness) to establish fault models. Additionally, 180 measurements of the test mode are used to determine the feature information and the sensor reliability. Suppose there are three types of fault in a motor rotor, which are noted as
. Three vibration acceleration sensors are placed in different installation positions to collect the vibration signal. Acceleration vibration frequency amplitudes at the frequencies of
,
and
are taken as the fault feature variables. The implementations of fault diagnosis are as follows:
Modeling typical faults: As shown in
Table 6, collecting five groups of data under the three failure modes for each fault feature, each group contains 20 measurements. The membership function
of the fault mode F
i with respect to fault feature under
jX
can be obtained based on the method described in
Section 3.1 (
). For example, the membership function of the fault mode F1 with respect to fault feature under
can be noted as:
Modeling the detected sample with the
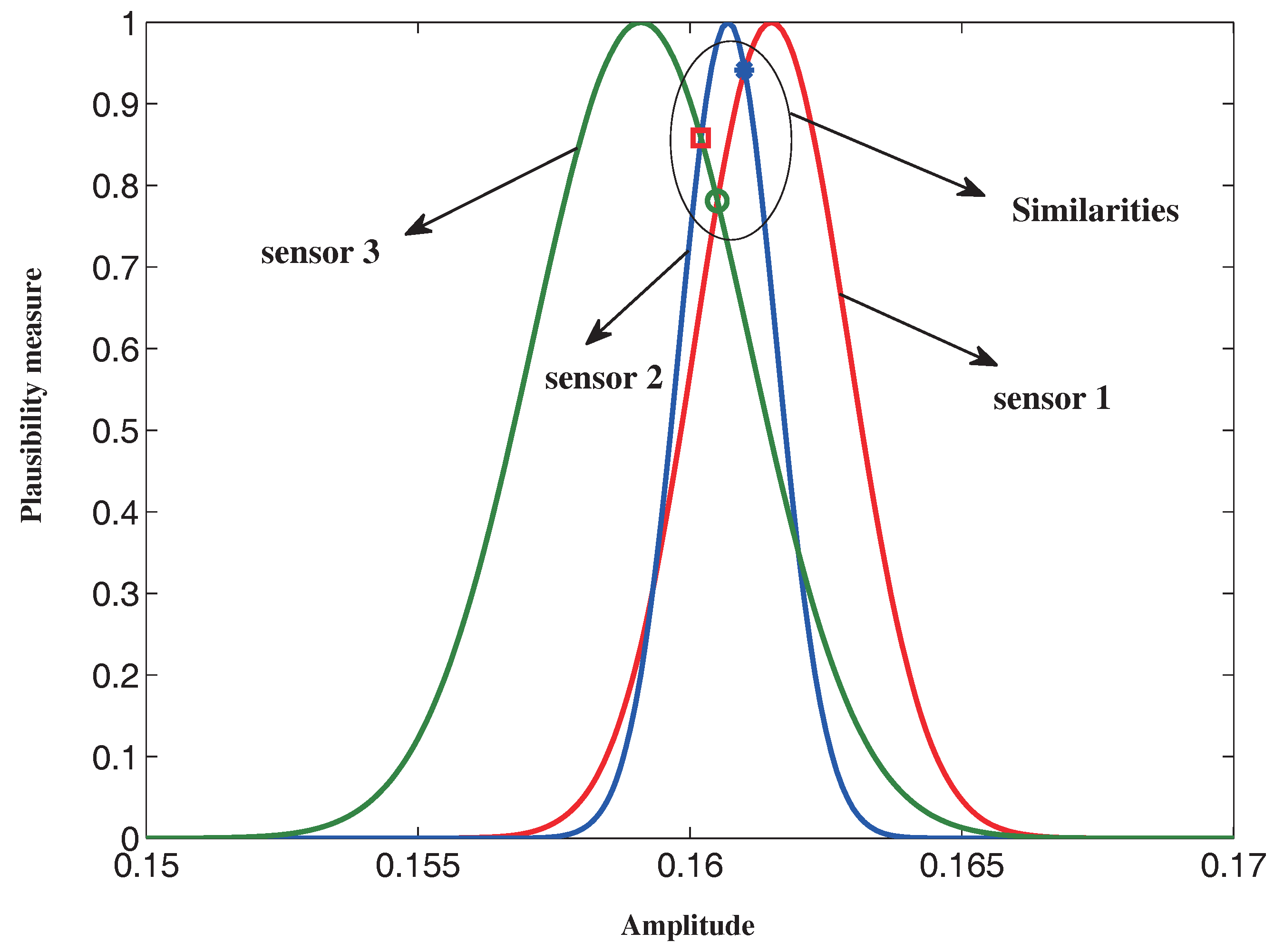
Z-number: Three groups of data for each fault feature are collected from three sensors under a certain working condition, and each group contains 20 measurements. The mean values and variances of the measurements are shown in
Table 7. The similarity matrices with respect to the feature variables under
,
and
are determined with Equations (20) and (21) as follows:
The support degree and credibility degree of the sensors under different features are calculated and shown in
Table 8. The weight vectors are
,
and
. Then, the fuzzy reliability of the three sensors can be calculated as:
,
,
. Consequently, a total of nine
Z-numbers can be determined with the results above.
Model matching and data fusion: Matching the membership function of component
A of the
Z-number with the typical faults to generate BPA, the results are shown in
Table 9. The fuzzy reliabilities of the sensors are defuzzified with Equation (35) to discount the BPAs. The defuzzified reliabilities are
= 0.8477,
= 0.9476,
= 0.83. The modified BPAs shown in
Table 10 can be determined with Equation (34). The fused evidence of the sensors for a certain feature is listed in
Table 10. The averaged evidence of the
,
and
as the final diagnostic evidence is obtained as:
Fault diagnosis and decision-making: Making a judgment for the detected model according to the rules defined in
Section 3.4, the related implementing measures can be performed for the system. The final evidence support for the fault of F2, namely rotor misalignment, is 0.8129, which is larger than 0.6, and the uncertain degrees are all smaller than 0.3. Consequently, the fault type of the motor rotor is identified as misalignment.
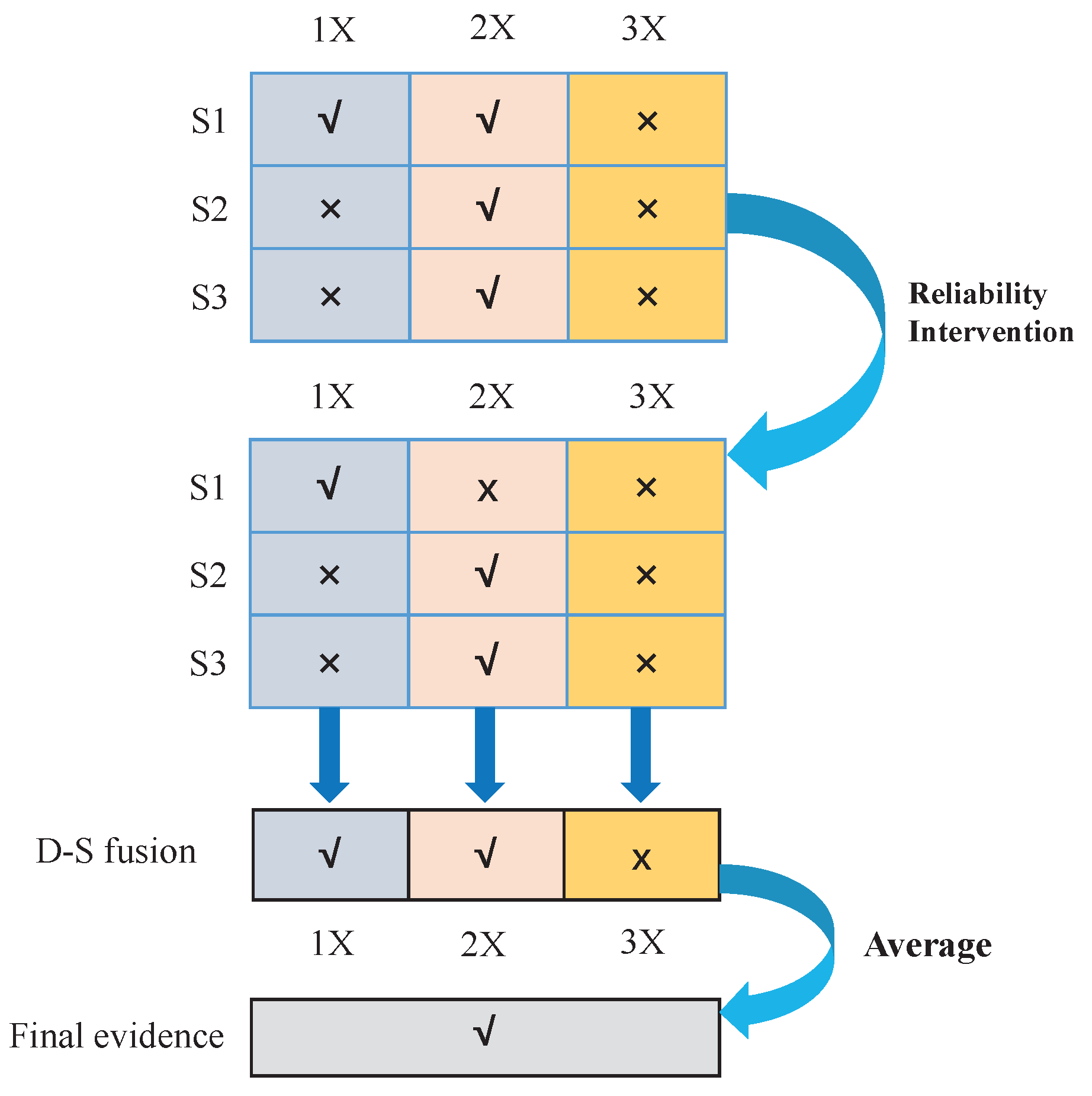
From the experimental result in this section, we come to a conclusion: the proposed sensor data fusion method reaches the achievable result that is not obtained from the method by employment of a single sensor or/and analysis of a single fault feature. For example, as shown in
Table 9, if we only consider one fault feature and only one single sensor, then evidence may not go far enough for determining the fault type. Considering the fault features and employed sensors as two dimensions, before considering the reliability, the diagnostic result can be depicted in
Figure 6, where “√” represents that the related evidence is enough for fault diagnosis, while “×” represents that we cannot make a decision. For example, the BPA obtained from Sensor 1 under
is
The evidence supports that F2 is 0.9399, which exceeds the threshold 0.6; the value of uncertain evidence (compound BPAs) is smaller than 0.3; thus, we can identify that F2 is the fault for the moment. However, with the same sensor, the evidence from the fault feature
is not enough to determine the fault type. Further, with the intervention of the reliability, the modified BPAs give a new diagnostic result. The fusion result of the BPAs of different sensors can be obtained with Dempster’s combination rule. Although the result under
is still insufficient to make a judgment, the mean evidence from the multi-features can make a synthesized judgment for the final decision-making.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}