
Cross View Gait Recognition Using Joint-Direct Linear Discriminant Analysis

Abstract
:1. Introduction
2. Proposed Framework
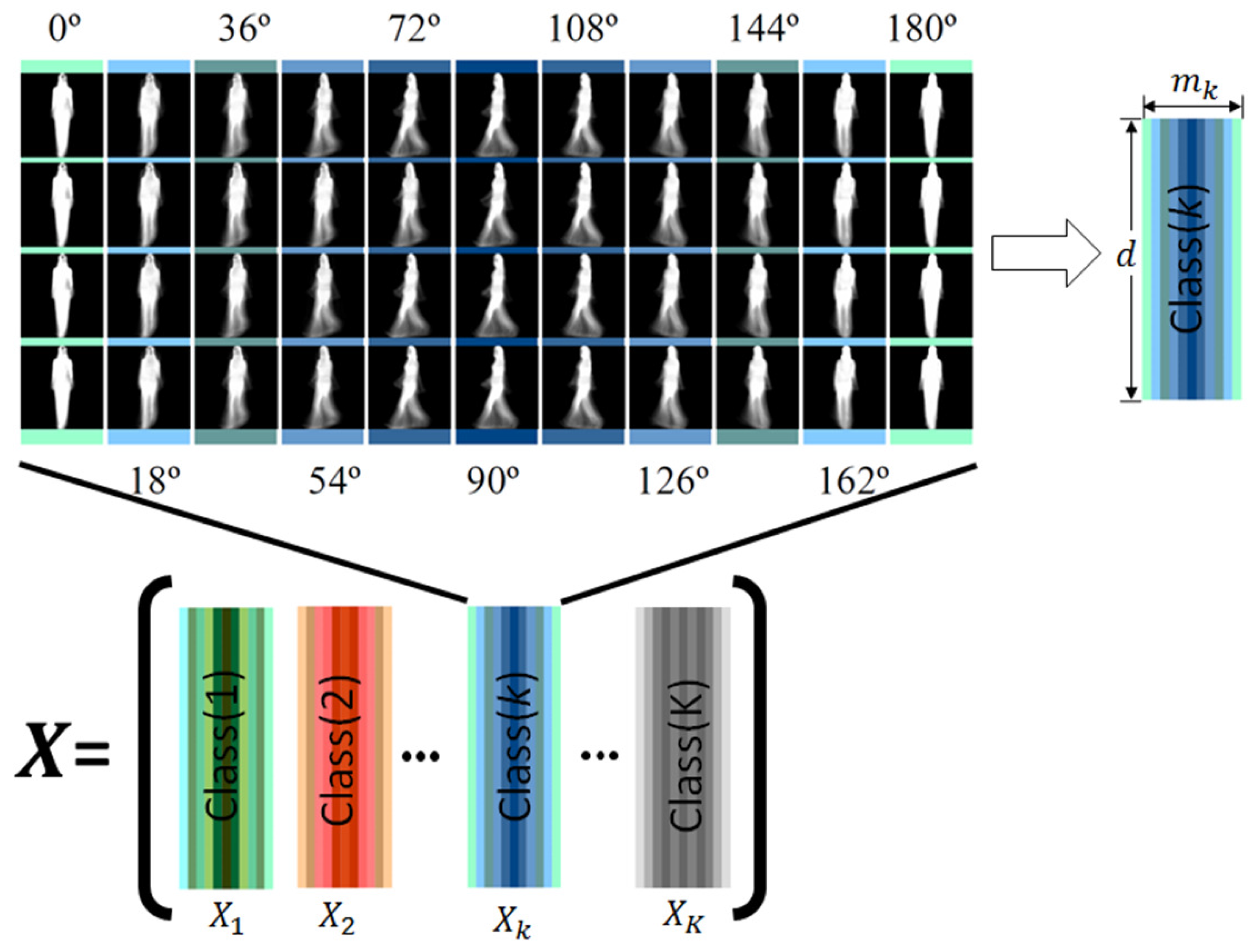
2.1. Computation of GEIs
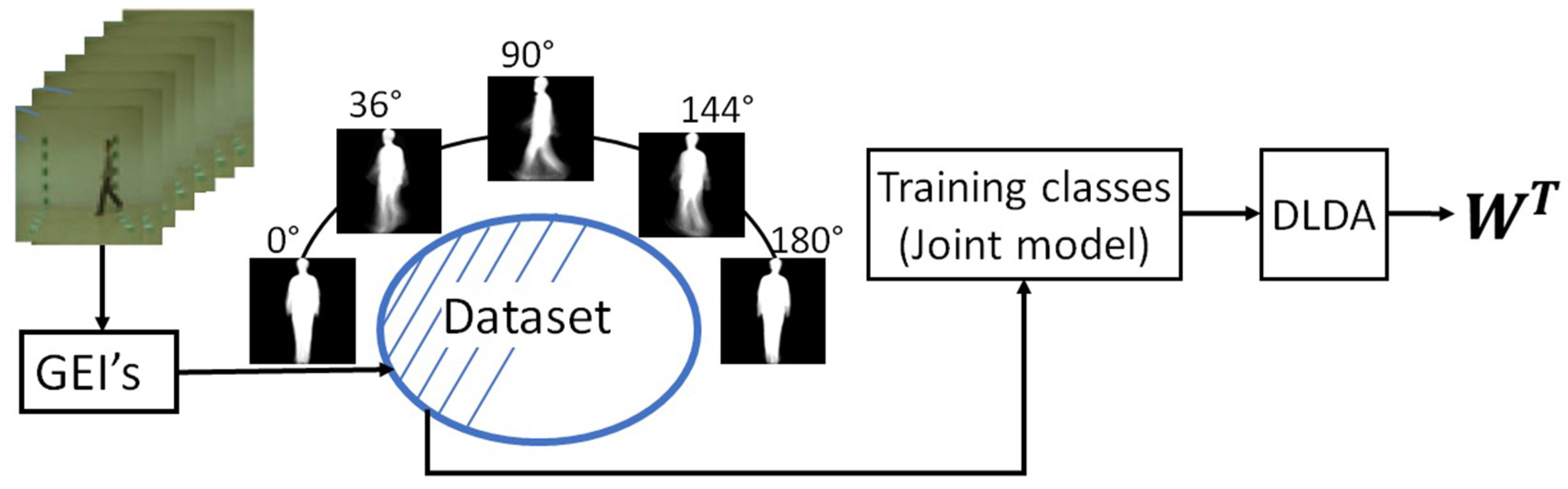
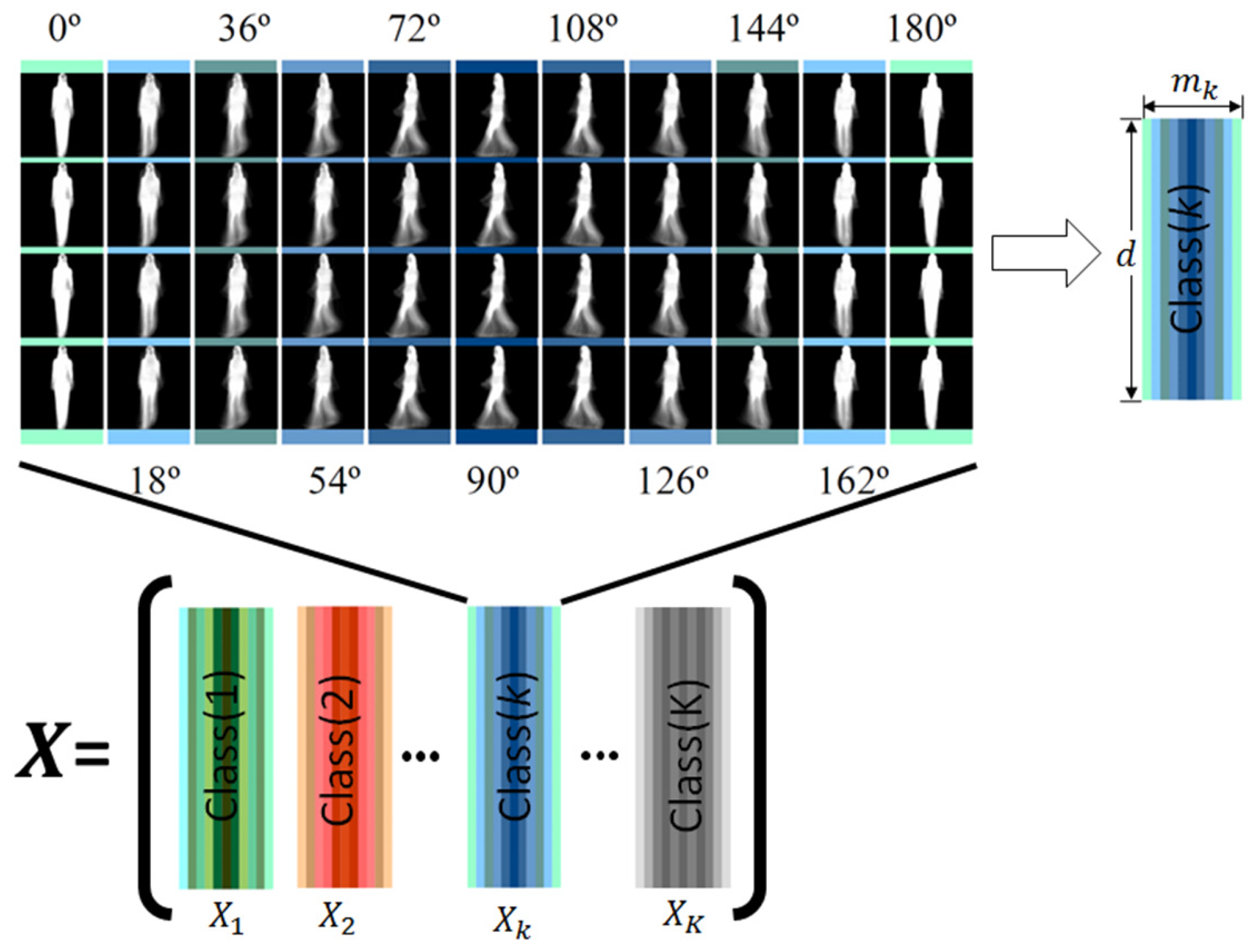
2.2. Joint Model Estimation
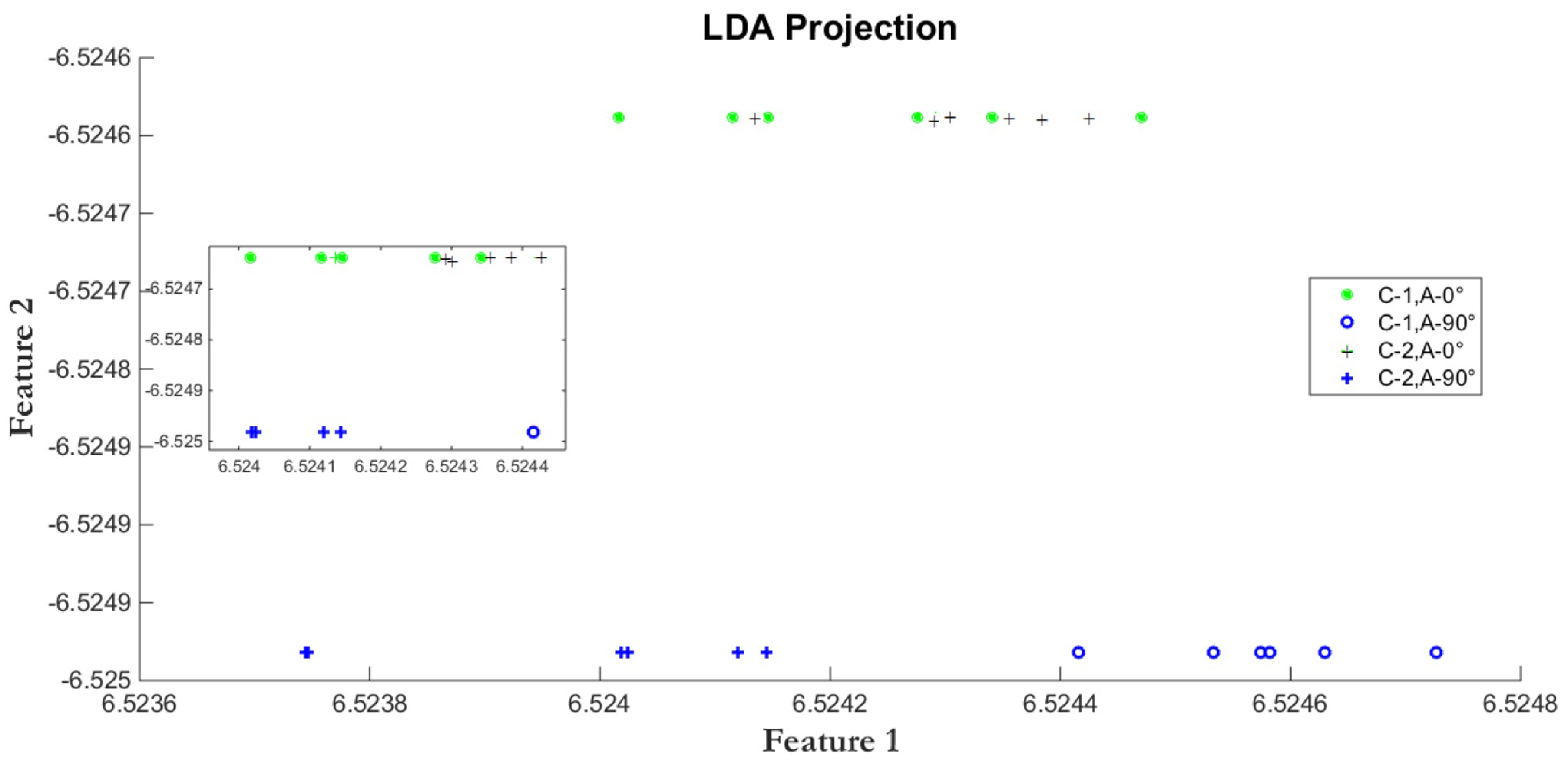
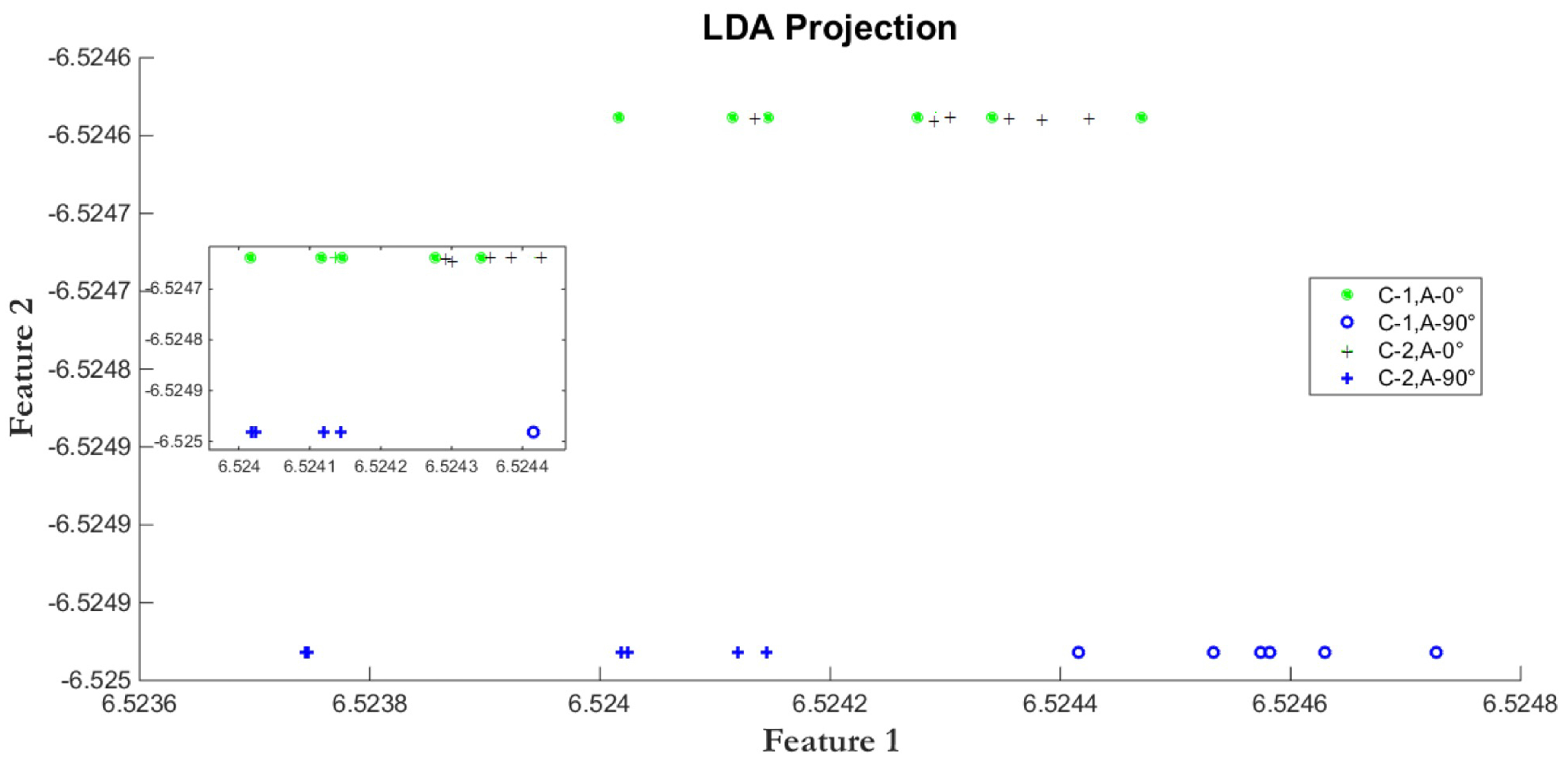
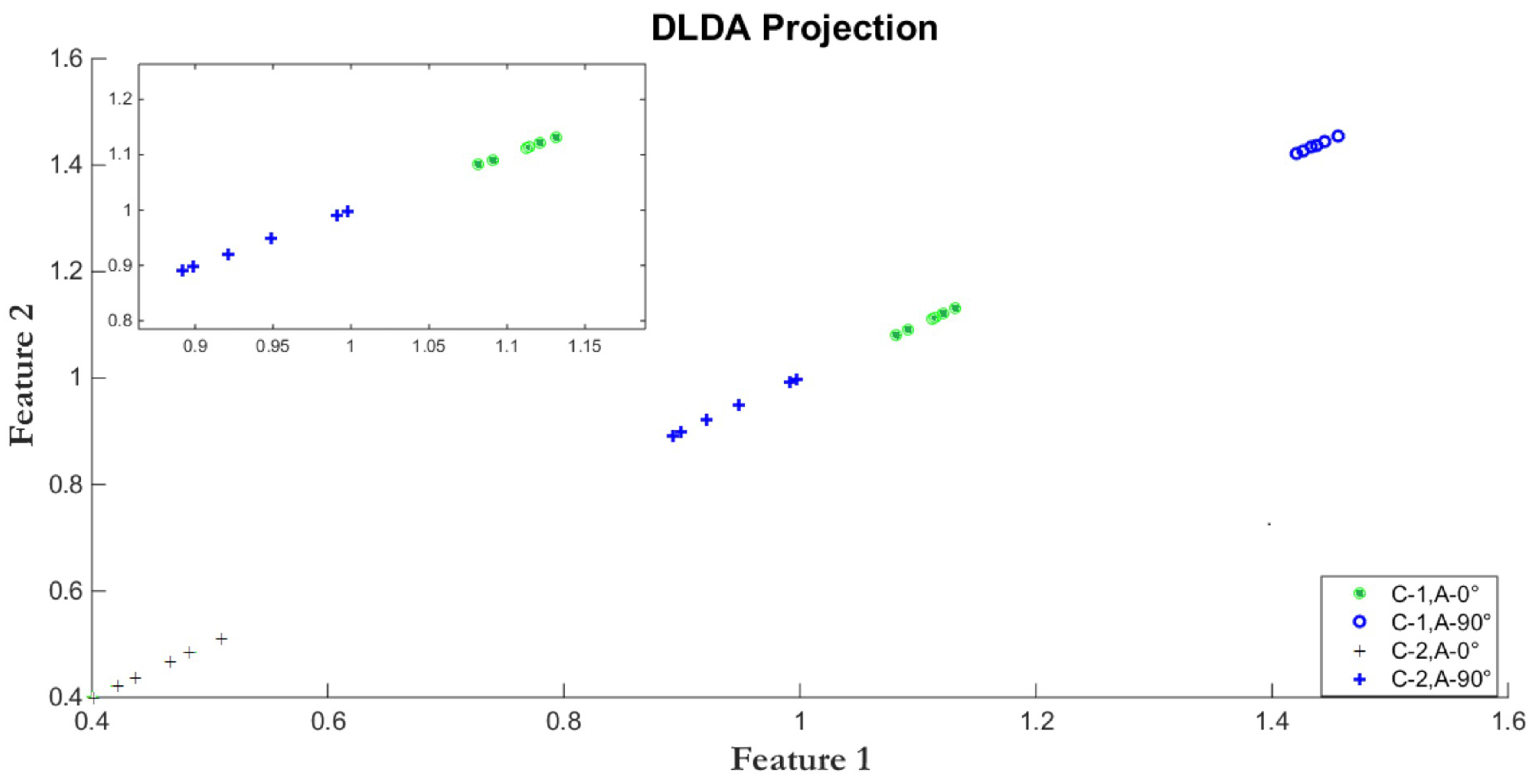
2.3. Direct Linear Discriminant Analysis
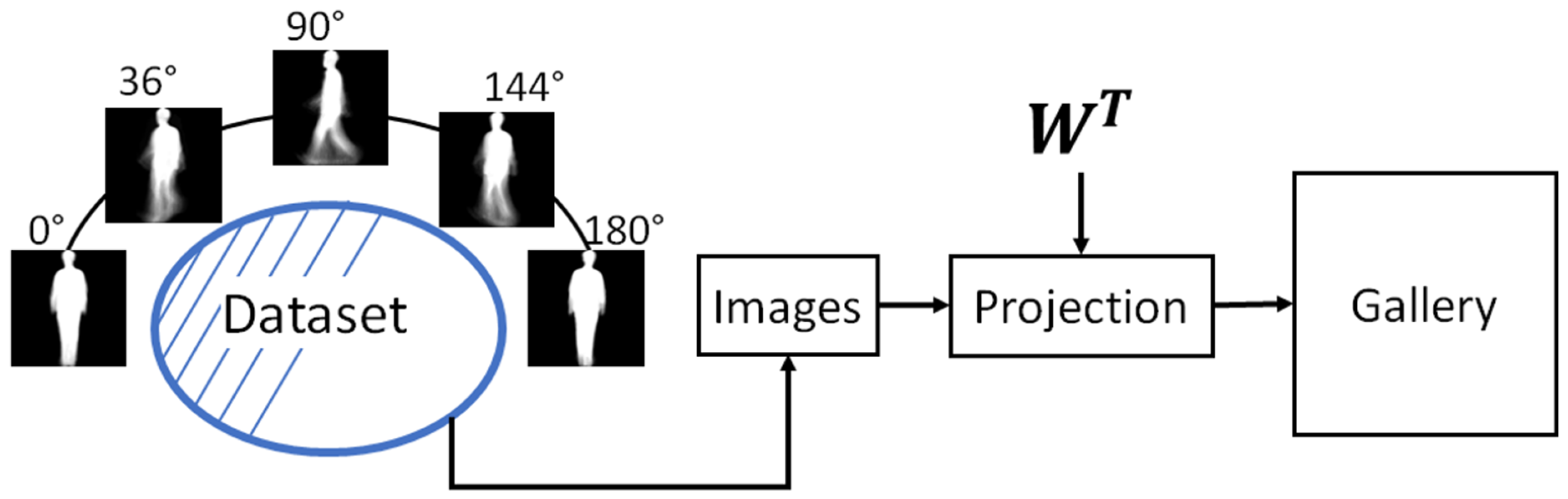
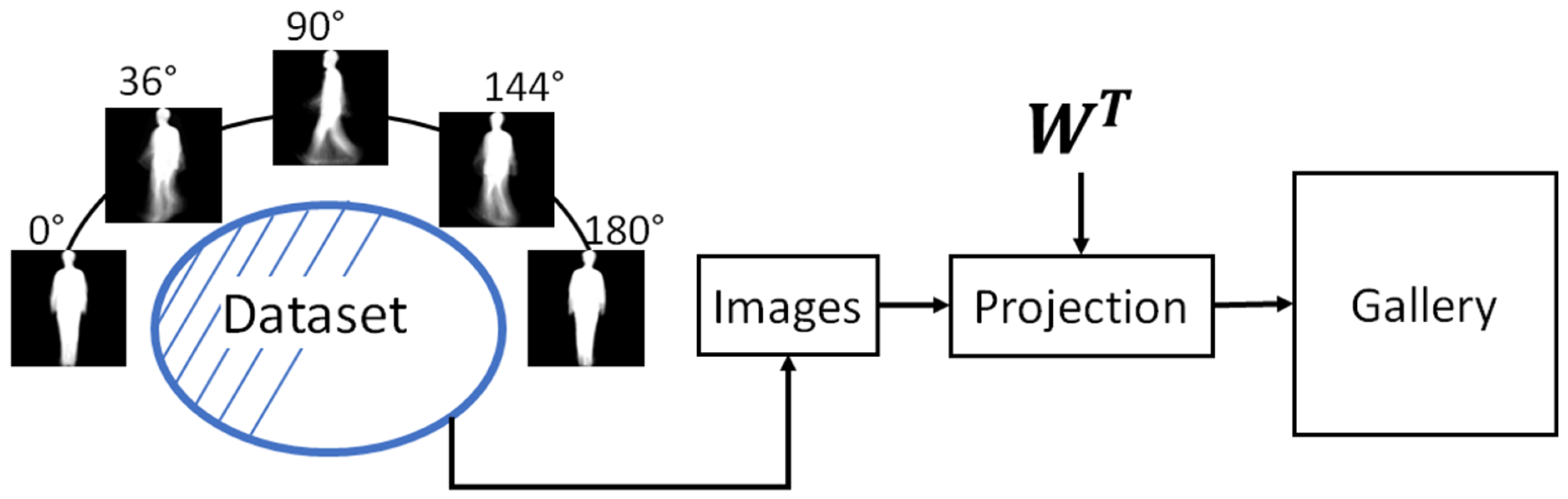
2.4. Gallery Estimation
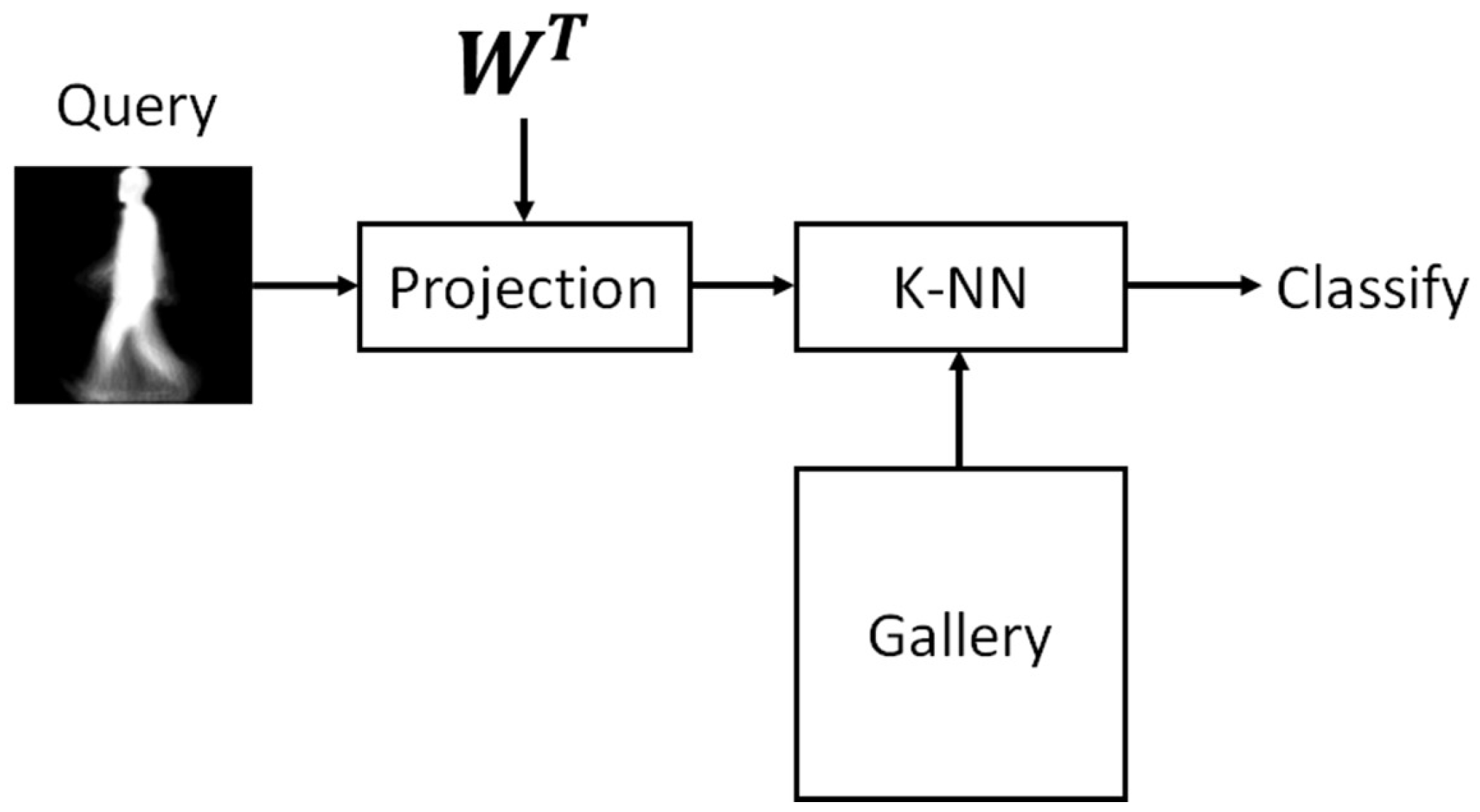
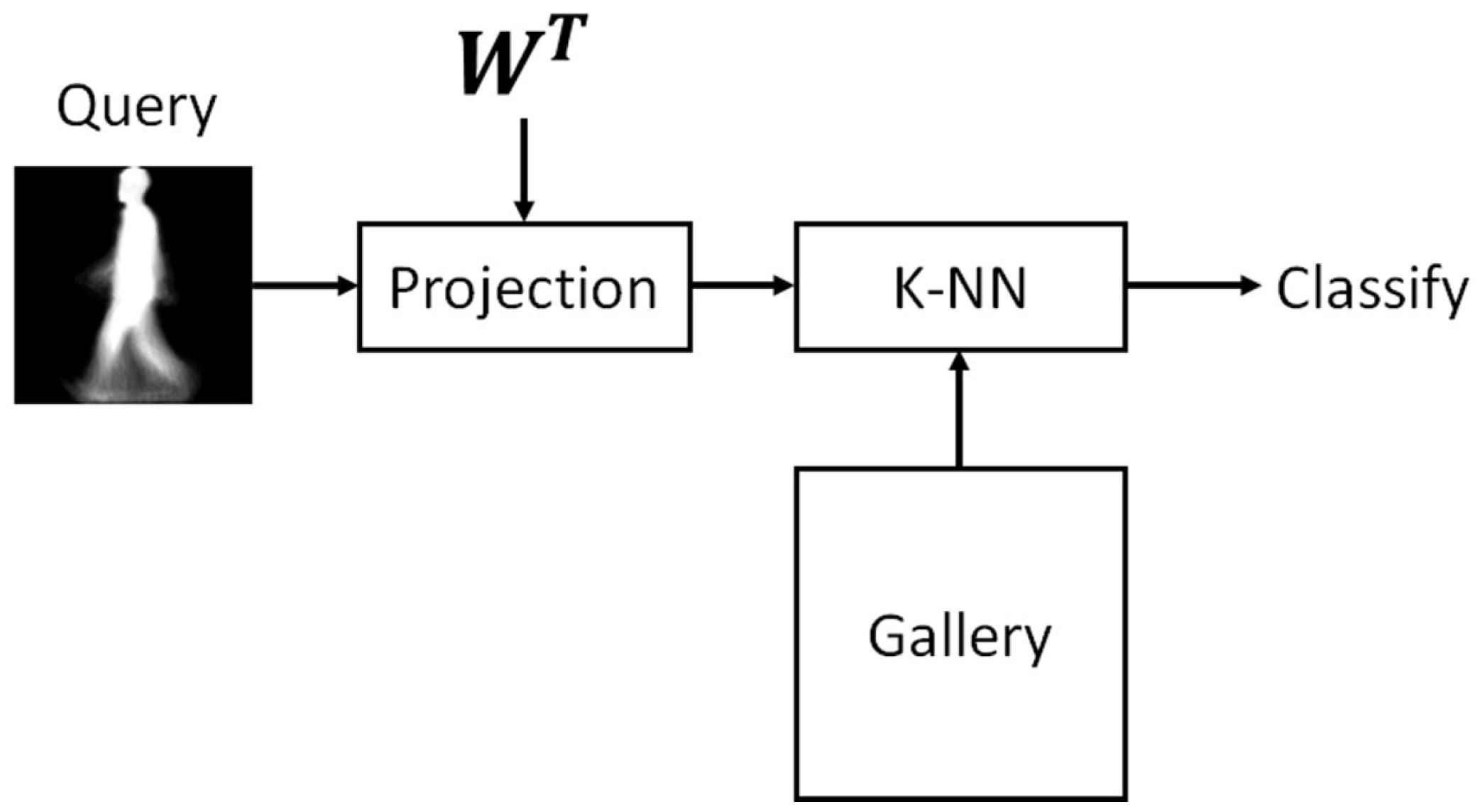
2.5. Classification Stage
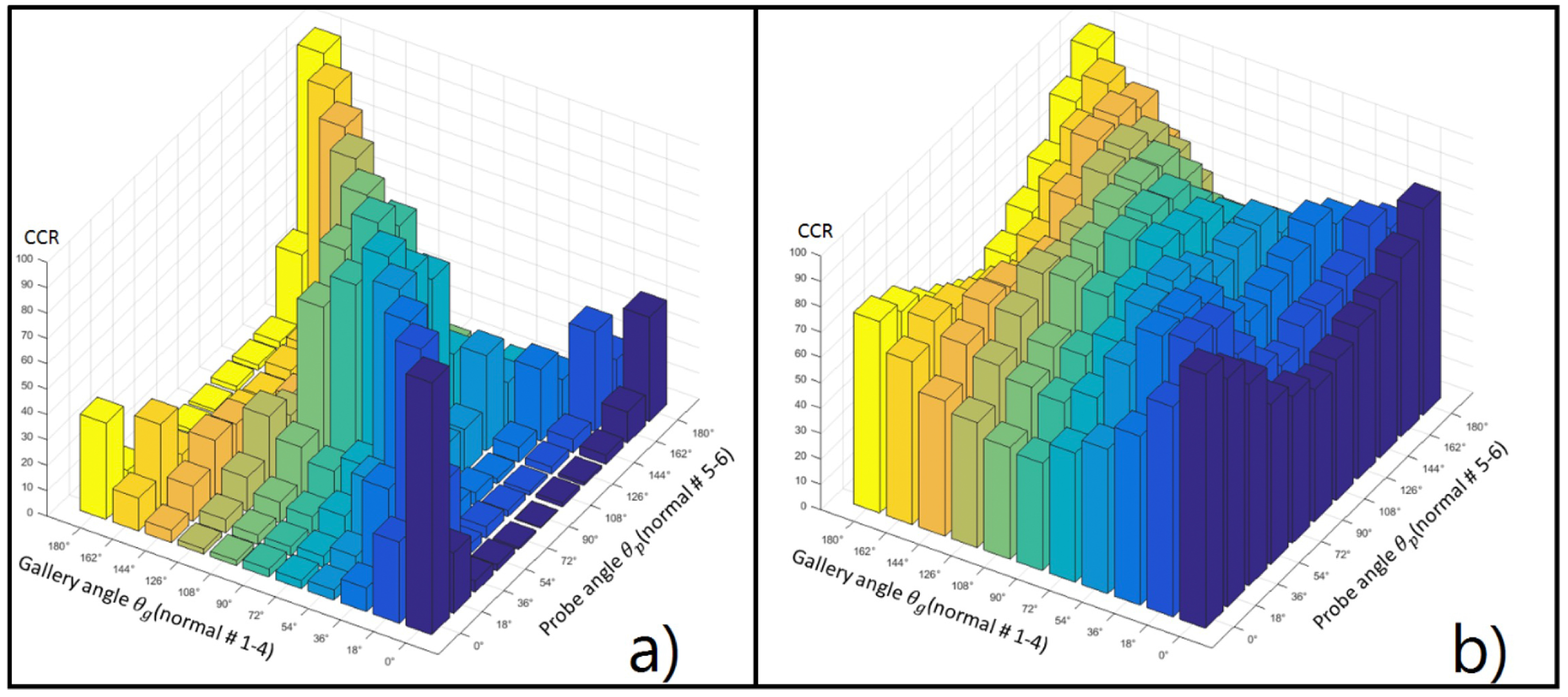
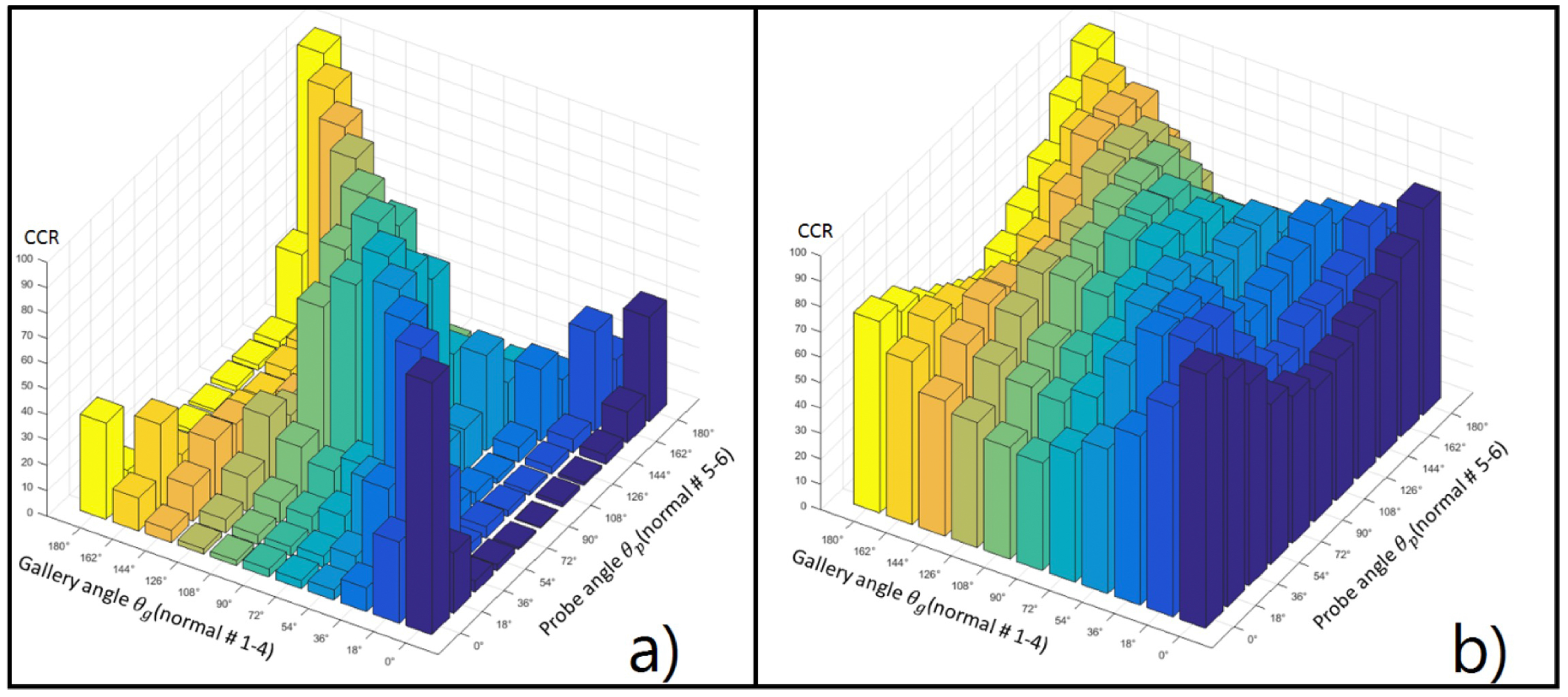
3. Evaluation Results
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Nixon, M.S.; Tan, T.; Chellappa, R. Human Identification Based on Gait; Springer Science & Business Media: New York, NY, USA, 2010; Volume 4. [Google Scholar]
- Hamouchene, I.; Aouat, S. Efficient approach for iris recognition. Signal Image Video Process. 2016, 10, 1361–1367. [Google Scholar] [CrossRef]
- Benitez-Garcia, G.; Olivares-Mercado, J.; Sanchez-Perez, G.; Nakano-Miyatake, M.; Perez-Meana, H. A sub-block-based eigenphases algorithm with optimum sub-block size. Knowl. Based Syst. 2013, 37, 415–426. [Google Scholar] [CrossRef]
- Lee, W.O.; Kim, Y.G.; Hong, H.G.; Park, K.R. Face recognition system for set-top box-based intelligent TV. Sensors 2014, 14, 21726–21749. [Google Scholar] [CrossRef] [PubMed]
- Ng, C.B.; Tay, Y.H.; Goi, B.M. A review of facial gender recognition. Pattern Anal. Appl. 2015, 18, 739–755. [Google Scholar] [CrossRef]
- Chaudhari, J.P.; Dixit, V.V.; Patil, P.M.; Kosta, Y.P. Multimodal biometric-information fusion using the Radon transform. J. Electr. Imaging 2015, 24, 023017. [Google Scholar] [CrossRef]
- Cai, J.; Chen, J.; Liang, X. Single-sample face recognition based on intra-class differences in a variation model. Sensors 2015, 15, 1071–1087. [Google Scholar] [CrossRef] [PubMed]
- Bashir, K.; Xiang, T.; Gong, S. Gait recognition without subject cooperation. Pattern Recognit. Lett. 2010, 31, 2052–2060. [Google Scholar] [CrossRef]
- Liu, D.X.; Wu, X.; Du, W.; Wang, C.; Xu, T. Gait Phase Recognition for Lower-Limb Exoskeleton with Only Joint Angular Sensors. Sensors 2016, 16, 1579. [Google Scholar] [CrossRef] [PubMed]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D.J. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef]
- Bodor, R.; Drenner, A.; Fehr, D.; Masoud, O.; Papanikolopoulos, N. View-independent human motion classification using image-based reconstruction. Image Vis. Comput. 2009, 27, 1194–1206. [Google Scholar] [CrossRef]
- Krzeszowski, T.; Kwolek, B.; Michalczuk, A.; Świtoński, A.; Josiński, H. View independent human gait recognition usingmarkerless 3D humanmotion capture. In Proceedings of the 2012 International Conference on Computer Vision and Graphics, Warsaw, Poland, 24–26 September 2012; pp. 491–500.
- Han, J.; Bhanu, B. Individual recognition using gait energy image. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 316–322. [Google Scholar] [CrossRef] [PubMed]
- Makihara, Y.; Sagawa, R.; Mukaigawa, Y.; Echigo, T.; Yagi, Y. Gait recognition using a view transformation model in the frequency domain. In Computer Vision–ECCV 2006; Springer: New York, NY, USA, 2006; pp. 151–163. [Google Scholar]
- Yu, S.; Tan, D.; Tan, T. A Framework for Evaluating the Effect of View Angle, Clothing and Carrying Condition on Gait Recognition. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR 2006), Hong Kong, China, 20–24 August 2006; Volume 4, pp. 441–444.
- Zhang, Z.; Troje, N.F. View-independent person identification from human gait. Neurocomputing 2005, 69, 250–256. [Google Scholar] [CrossRef]
- Zhao, G.; Liu, G.; Li, H.; Pietikainen, M. 3D gait recognition using multiple cameras. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR 2006), Southampton, UK, 10–12 April 2006; pp. 529–534.
- Liu, N.; Lu, J.; Tan, Y.P. Joint Subspace Learning for View-Invariant Gait Recognition. IEEE Signal Process. Lett. 2011, 18, 431–434. [Google Scholar] [CrossRef]
- Kusakunniran, W.; Wu, Q.; Zhang, J.; Li, H. Gait Recognition Under Various Viewing Angles Based on Correlated Motion Regression. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 966–980. [Google Scholar] [CrossRef]
- Jean, F.; Bergevin, R.; Albu, A.B. Computing and evaluating view-normalized body part trajectories. Image Vis. Comput. 2009, 27, 1272–1284. [Google Scholar] [CrossRef]
- Martín-Félez, R.; Xiang, T. Gait Recognition by Ranking. In Computer Vision—ECCV 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7572, pp. 328–341. [Google Scholar]
- Kale, A.; Chowdhury, A.; Chellappa, R. Towards a view invariant gait recognition algorithm. In Proceedings of the IEEE Conference on Advanced Video and Signal Based Surveillance, Miami, FL, USA, 21–22 July 2003; pp. 143–150.
- Muramatsu, D.; Shiraishi, A.; Makihara, Y.; Yagi, Y. Arbitrary view transformation model for gait person authentication. In Proceedings of the 2012 IEEE Fifth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 23–27 September 2012; pp. 85–90.
- Chapelle, O.; Keerthi, S.S. Efficient algorithms for ranking with SVMs. Inf. Retr. 2010, 13, 201–215. [Google Scholar] [CrossRef]
- Liu, N.; Tan, Y.P. View invariant gait recognition. In Proceedings of the 2010 IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 1410–1413.
- Sugiyama, M. Dimensionality Reduction of Multimodal Labeled Data by Local Fisher Discriminant Analysis. J. Mach. Learn. Res. 2007, 8, 1027–1061. [Google Scholar]
- Chen, L.F.; Liao, H.Y.M.; Ko, M.T.; Lin, J.C.; Yu, G.J. A new LDA-based face recognition system which can solve the small sample size problem. Pattern Recognit. 2000, 33, 1713–1726. [Google Scholar] [CrossRef]
- Tao, D.; Li, X.; Wu, X.; Maybank, S. General Tensor Discriminant Analysis and Gabor Features for Gait Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1700–1715. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Yang, J. A direct LDA algorithm for high-dimensional data—With application to face recognition. Pattern Recognit. 2001, 34, 2067–2070. [Google Scholar] [CrossRef]
- Mansur, A.; Makihara, Y.; Muramatsu, D.; Yagi, Y. Cross-view gait recognition using view-dependent discriminative analysis. In Proceedings of the 2014 IEEE International Joint Conference on Biometrics (IJCB), Clearwater, FL, USA, 29 September–2 October 2014; pp. 1–8.
- Portillo, J.; Leyva, R.; Sanchez, V.; Sanchez, G.; Perez-Meana, H.; Olivares, J.; Toscano, K.; Nakano, M. View-Invariant Gait Recognition Using a Joint-DLDA Framework. In Trends in Applied Knowledge-Based Systems and Data Science, Proceedings of the 29th International Conference on Industrial Engineering and Other Applications of Applied Intelligent Systems (IEA/AIE 2016), Morioka, Japan, 2–4 August 2016; Springer: Cham, Switzerland, 2016; pp. 398–408. [Google Scholar]
- Lv, Z.; Xing, X.; Wang, K.; Guan, D. Class energy image analysis for video sensor-based gait recognition: A review. Sensors 2015, 15, 932–964. [Google Scholar] [CrossRef] [PubMed]
- Juric, M.B.; Sprager, S. Inertial sensor-based gait recognition: A review. Sensors 2015, 15, 22089–22127. [Google Scholar]
- Kusakunniran, W.; Wu, Q.; Li, H.; Zhang, J. Multiple views gait recognition using view transformation model based on optimized gait energy image. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops (ICCV Workshops), Kyoto, Japan, 27 September–4 October 2009; pp. 1058–1064.
- Kusakunniran, W.; Wu, Q.; Zhang, J.; Li, H. Support vector regression for multi-view gait recognition based on local motion feature selection. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 974–981.
- Kusakunniran, W.; Wu, Q.; Zhang, J.; Li, H. Multi-view gait recognition based on motion regression using multilayer perceptron. In Proceedings of the 20th International Conference on Pattern Recognition (ICPR), Istanbul, Turkey, 23–26 August 2010; pp. 2186–2189.
- Sharma, A.; Kumar, A.; Daume, H., III; Jacobs, D.W. Generalized multiview analysis: A discriminative latent space. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2160–2167.
- Yan, S.; Xu, D.; Yang, Q.; Zhang, L.; Tang, X.; Zhang, H.J. Discriminant analysis with tensor representation. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 526–532.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 0° | 18° | 36° | 54° | 72° |
|---|---|---|---|---|---|
| GMLDA [37] | 2% | 2% | 1% | 2% | 4% |
| DATER [38] | 7% | 8% | 18% | 59% | 96% |
| CCA [25] | 2% | 3% | 5% | 6% | 30% |
| VTM [14] | 17% | 30% | 46% | 63% | 83% |
| MvDA [30] | 17% | 27% | 36% | 64% | 95% |
| JDLDA(1) | 16% | 21% | 32% | 50% | 84% |
| JDLDA(2) | 20% | 25% | 37% | 58% | 94% |
| Probe Angle (Normal Walking #5–6) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0° | 18° | 36° | 54° | 72° | 90° | 108° | 126° | 144° | 162° | 180° | ||
| Gallery angle (normal #1–4) | 0° | 99.2 | 31.9 | 9.3 | 4.0 | 3.2 | 3.2 | 2.0 | 2.0 | 4.8 | 12.9 | 37.9 |
| 18° | 23.8 | 99.6 | 39.9 | 8.9 | 4.4 | 3.6 | 3.6 | 5.2 | 13.7 | 33.5 | 10.9 | |
| 36° | 4.4 | 37.9 | 97.6 | 29.8 | 11.7 | 6.9 | 8.1 | 13.3 | 23.4 | 13.3 | 2.0 | |
| 54° | 2.4 | 3.6 | 29.0 | 97.2 | 23.0 | 16.5 | 21.4 | 29.0 | 21.4 | 4.8 | 1.2 | |
| 72° | 0.8 | 4.4 | 7.3 | 21.8 | 97.2 | 81.5 | 68.1 | 21.0 | 5.6 | 3.6 | 1.6 | |
| 90° | 0.4 | 2.4 | 4.8 | 17.7 | 82.3 | 97.6 | 82.3 | 15.3 | 5.2 | 3.6 | 1.2 | |
| 108° | 1.6 | 1.6 | 2.0 | 16.9 | 71.4 | 87.9 | 95.6 | 37.1 | 6.0 | 2.0 | 2.0 | |
| 126° | 1.2 | 2.8 | 6.0 | 37.5 | 33.5 | 22.2 | 48.0 | 96.8 | 26.6 | 4.4 | 2.0 | |
| 144° | 3.6 | 5.2 | 28.2 | 18.5 | 4.4 | 1.6 | 3.2 | 43.1 | 96.4 | 5.6 | 2.8 | |
| 162° | 12.1 | 39.1 | 15.7 | 2.4 | 1.6 | 0.8 | 0.8 | 2.4 | 5.2 | 98.4 | 28.6 | |
| 180° | 41.1 | 19.8 | 8.1 | 3.2 | 2.0 | 0.8 | 1.6 | 3.6 | 12.5 | 51.2 | 99.6 | |
| Probe Angle (Normal Walking #5–6) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0° | 18° | 36° | 54° | 72° | 90° | 108° | 126° | 144° | 162° | 180° | ||
| Gallery angle (normal #1–4) | 0° | 100.0 | 92.3 | 71.4 | 58.1 | 52.4 | 46.8 | 45.2 | 52.4 | 54.4 | 66.9 | 81.5 |
| 18° | 91.1 | 100.0 | 98.0 | 85.9 | 74.2 | 61.7 | 66.9 | 70.6 | 68.5 | 74.2 | 77.0 | |
| 36° | 82.1 | 96.8 | 99.2 | 97.6 | 89.1 | 80.2 | 78.6 | 83.5 | 80.2 | 76.2 | 65.7 | |
| 54° | 68.3 | 83.9 | 95.6 | 98.4 | 94.8 | 91.9 | 91.1 | 86.7 | 79.0 | 64.5 | 54.0 | |
| 72° | 58.1 | 69.8 | 87.9 | 94.4 | 98.8 | 98.8 | 94.8 | 87.1 | 69.0 | 54.4 | 51.2 | |
| 90° | 50.8 | 56.5 | 73.4 | 86.3 | 96.4 | 98.4 | 98.0 | 89.9 | 69.4 | 53.6 | 49.2 | |
| 108° | 51.6 | 59.3 | 78.2 | 86.7 | 95.2 | 97.6 | 98.8 | 97.6 | 86.7 | 65.3 | 52.8 | |
| 126° | 52.4 | 68.1 | 81.9 | 87.9 | 87.5 | 89.1 | 97.6 | 99.2 | 96.4 | 79.0 | 62.5 | |
| 144° | 62.2 | 69.0 | 80.6 | 84.3 | 70.6 | 73.4 | 89.9 | 98.0 | 98.0 | 89.1 | 70.6 | |
| 162° | 73.6 | 79.8 | 78.2 | 64.5 | 60.5 | 58.5 | 60.1 | 83.1 | 91.5 | 98.4 | 88.7 | |
| 180° | 87.8 | 81.0 | 66.5 | 53.2 | 53.6 | 45.6 | 48.0 | 61.3 | 72.6 | 89.9 | 99.6 | |
| Probe Angle (Normal Walking #5–6) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0° | 18° | 36° | 54° | 72° | 90° | 108° | 126° | 144° | 162° | 180° | ||
| Gallery angle (normal #1–4) | 0° | 99.0 | 43.1 | 10.5 | 2.9 | 1.9 | 1.7 | 1.6 | 2.2 | 5.4 | 18.8 | 39.8 |
| 18° | 51.7 | 98.7 | 63.2 | 14.7 | 7.6 | 4.7 | 4.6 | 7.0 | 14.2 | 34.3 | 22.6 | |
| 36° | 19.0 | 71.4 | 97.7 | 57.3 | 22.1 | 12.6 | 12.3 | 18.8 | 24.7 | 24.3 | 10.1 | |
| 54° | 7.4 | 17.1 | 56.1 | 96.8 | 43.1 | 33.2 | 37.4 | 37.8 | 26.4 | 9.2 | 3.9 | |
| 72° | 3.2 | 6.4 | 18.2 | 43.0 | 96.5 | 76.4 | 57.2 | 33.3 | 12.4 | 5.4 | 2.8 | |
| 90° | 1.8 | 3.9 | 10.0 | 31.2 | 75.3 | 96.7 | 87.3 | 30.7 | 10.8 | 3.8 | 2.2 | |
| 108° | 2.5 | 4.4 | 11.0 | 35.2 | 58.8 | 88.0 | 95.7 | 61.1 | 20.7 | 5.4 | 2.9 | |
| 126° | 3.8 | 7.5 | 21.6 | 39.1 | 40.1 | 35.5 | 60.5 | 96.4 | 70.8 | 14.6 | 5.6 | |
| 144° | 8.5 | 13.1 | 27.4 | 26.1 | 11.2 | 8.5 | 19.6 | 73.3 | 97.0 | 25.0 | 11.4 | |
| 162° | 21.4 | 36.4 | 24.5 | 7.4 | 4.6 | 3.6 | 4.1 | 9.4 | 23.7 | 97.1 | 51.6 | |
| 180° | 42.6 | 23.5 | 9.2 | 3.4 | 2.2 | 2.3 | 2.9 | 5.5 | 12.7 | 55.8 | 98.7 | |
| Probe Angle (Normal Walking #5–6) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0° | 18° | 36° | 54° | 72° | 90° | 108° | 126° | 144° | 162° | 180° | ||
| Gallery angle (normal #1–4) | 0° | 99.9 | 80.9 | 45.4 | 21.9 | 14.7 | 11.1 | 10.1 | 14.0 | 23.4 | 45.9 | 66.4 |
| 18° | 92.2 | 100 | 97.3 | 62.9 | 36.6 | 23.8 | 24.8 | 35.5 | 45.4 | 63.5 | 57.1 | |
| 36° | 65.4 | 97.4 | 98.8 | 95.4 | 73.0 | 50.8 | 52.1 | 61.0 | 60.5 | 54.7 | 38.6 | |
| 54° | 35.0 | 65.5 | 94.4 | 98.7 | 91.0 | 82.0 | 80.3 | 73.4 | 61.6 | 34.1 | 21.6 | |
| 72° | 19.0 | 33.4 | 65.1 | 88.5 | 98.8 | 98.0 | 90.2 | 74.4 | 42.7 | 22.7 | 15.6 | |
| 90° | 14.4 | 19.8 | 38.4 | 71.9 | 97.5 | 99.1 | 98.1 | 74.2 | 41.1 | 16.6 | 12.3 | |
| 108° | 15.5 | 22.9 | 45.3 | 75.1 | 92.1 | 98.0 | 98.7 | 96.3 | 72.2 | 28.6 | 16.8 | |
| 126° | 23.8 | 36.7 | 60.9 | 71.9 | 79.0 | 80.6 | 95.7 | 98.5 | 94.8 | 61.0 | 30.4 | |
| 144° | 34.8 | 48.3 | 63.0 | 62.4 | 48.3 | 49.0 | 76.5 | 95.3 | 98.7 | 83.6 | 49.1 | |
| 162° | 53.4 | 64.4 | 52.6 | 30.9 | 22.3 | 19.1 | 25.3 | 54.4 | 80.8 | 99.0 | 87.3 | |
| 180° | 73.9 | 51.0 | 30.5 | 14.9 | 11.7 | 10.0 | 11.6 | 21.0 | 38.5 | 83.4 | 99.7 | |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Portillo-Portillo, J.; Leyva, R.; Sanchez, V.; Sanchez-Perez, G.; Perez-Meana, H.; Olivares-Mercado, J.; Toscano-Medina, K.; Nakano-Miyatake, M. Cross View Gait Recognition Using Joint-Direct Linear Discriminant Analysis. Sensors 2017, 17, 6. https://doi.org/10.3390/s17010006
Portillo-Portillo J, Leyva R, Sanchez V, Sanchez-Perez G, Perez-Meana H, Olivares-Mercado J, Toscano-Medina K, Nakano-Miyatake M. Cross View Gait Recognition Using Joint-Direct Linear Discriminant Analysis. Sensors. 2017; 17(1):6. https://doi.org/10.3390/s17010006
Chicago/Turabian StylePortillo-Portillo, Jose, Roberto Leyva, Victor Sanchez, Gabriel Sanchez-Perez, Hector Perez-Meana, Jesus Olivares-Mercado, Karina Toscano-Medina, and Mariko Nakano-Miyatake. 2017. "Cross View Gait Recognition Using Joint-Direct Linear Discriminant Analysis" Sensors 17, no. 1: 6. https://doi.org/10.3390/s17010006