Research on the Fusion of Dependent Evidence Based on Rank Correlation Coefficient


School of Automation Engineering, Shanghai University of Electric Power, Shanghai 200090, China
*
Author to whom correspondence should be addressed.
Sensors 2017, 17(10), 2362; https://doi.org/10.3390/s17102362
Submission received: 1 September 2017
/
Revised: 6 October 2017
/
Accepted: 9 October 2017
/
Published: 16 October 2017
(This article belongs to the Special Issue Advances in Multi-Sensor Information Fusion: Theory and Applications 2017)
Abstract
:In order to meet the higher accuracy and system reliability requirements, the information fusion for multi-sensor systems is an increasing concern. Dempster–Shafer evidence theory (D–S theory) has been investigated for many applications in multi-sensor information fusion due to its flexibility in uncertainty modeling. However, classical evidence theory assumes that the evidence is independent of each other, which is often unrealistic. Ignoring the relationship between the evidence may lead to unreasonable fusion results, and even lead to wrong decisions. This assumption severely prevents D–S evidence theory from practical application and further development. In this paper, an innovative evidence fusion model to deal with dependent evidence based on rank correlation coefficient is proposed. The model first uses rank correlation coefficient to measure the dependence degree between different evidence. Then, total discount coefficient is obtained based on the dependence degree, which also considers the impact of the reliability of evidence. Finally, the discount evidence fusion model is presented. An example is illustrated to show the use and effectiveness of the proposed method.
1. Introduction
With the development of science and technology, in order to meet the higher accuracy and system reliability requirements, the information fusion filters for multi-sensor systems have been widely applied [1]. Various methods have been proposed for multi-sensor modeling and sensor data fusion [2,3,4,5,6,7], including night-vision image fusion [8], weighted measurement fusion and Unscented Kalman Filter [9], neural network models [10], fuzzy set theory [11], belief function theory [12], and so on.
The fusion of different uncertain data is an important research topic of modern intelligent multi-sensor systems. Among these methods, Dempster–Shafer evidence theory (D–S theory) has been investigated for many applications in multi-sensor information fusion due to its flexibility in uncertainty modeling [13,14,15]. D–S theory was first proposed by Dempster in 1967 [16], and further developed by Shafer in 1976 [17]. It can not only deal with imprecise information and uncertain information, but also deal with complimentary information and missing information [18,19,20,21]. Therefore, besides multi-sensor information fusion, D–S theory has also been investigated for applications in many fields such as fault diagnosis [22,23], pattern recognition [24,25,26,27,28], multi-source information fusion [29], multiple attribute decision making [30,31,32,33,34,35,36] and risk analysis [37,38,39,40].
In D–S theory, Dempster’s rule plays a vital part in the process of information fusion. However, there is an issue that limits the application of evidence theory. The classical evidence theory is based on the assumption that the evidence is independent of each other [41]. In practice, the dependence is more common. In other words, some elementary item of evidence will be counted twice without considering dependent evidence in the process of information fusion [42]. For example, one expert’s opinion may be affected by another expert’s opinion in an open decision making environment. In addition, there will be dependence between the evidence “grain production” and the evidence “natural disaster” in the agriculture risk analysis system [43]. A mistake will be generated if ignoring dependence between different evidence. To deal with dependent sources of information, many scholars proposed different methods [44]. The existing methods could be divided into two categories [45]: (1) improve the combination rule or (2) modify the original belief structure.
For the first category, the basic idea is to find a new evidence fusion method without considering dependence [45]. Some scholars have proposed their own combination rules. Cattaneo proposed the rules based on an assumption of minimal conflict rather than the independence assumption [46]. However, this method only analyzes the dependence between BBAs (Basic Belief Assignments) and fails to reveal the dependence between information sources. Destercke holds the view that the minimum rule of possibility theory could be generalized to the dependent evidence fusion [47,48]. However, in [18], the author thought this rule didn’t satisfy the fundamental evidence equation. In [42], the cautious rule of combination aiming at reliable sources of evidence and the bold disjunctive rule aiming at unreliable sources of evidence is proposed. Both of them satisfy commutative law, associative law and idempotent law. However, this combination rule was established in the canonical decomposition of BBA. Choenni proposed a dependent evidence fusion method using the idea of joint probability distribution of probability theory [49]. However, this method essentially deals with BBA as a discrete probability distribution and the fusion result is a couple of focal elements rather than BBA. Chebbah et al. proposed a new combination rule that takes consideration of sources’ degree of independence and they also suggest a method to quantify sources’ degree of independence [50].
For the second category, the basic idea is to reduce the repetitive computation of the dependent part of the information sources as far as possible [45]. In this category, there are two research ideas. The first research idea is based on the relevant source evidence model, which is first proposed in [51] by Smets. This paper holds that the reason why the two pieces of evidence are related is that they are obtained from the same source of evidence. The same source of evidence represents the correlation part between the pieces of evidence. Smets proposed a combination method in [51] based on the TBM (transferable belief model). Then, Xiao et al. proposed a combination rule based on the model in [51], and this rule is in the framework of D–S evidence theory. According to this theory, if we know the correlation part of two information sources, and the evidence of the correlation information source is available, this method is effective to deal with dependent evidence. However, this method is not reasonable as it does not care about the significance of the common evidence in some application systems. In addition, how to acquire the common evidence between two dependent pieces of evidence remains a question.
The second research idea is based on the discount evidence model. The main idea of this model is that dependent evidence shouldn’t be given the same weight as independent evidence in the process of information fusion since it provides less effective information [52]. The dependent evidence should be discounted in advance, and the discounting coefficients (or weight) are related to the degree of dependence. Guralnik et al. [53] presented a formal definition of algorithm dependency based on three criteria, i.e., method, sensors and features, and divided evidence into highly dependent, weakly dependent and independent evidence. Yager [54] proposed an interesting approach that makes use of a weighted aggregation of the belief structures where the weights are related to the degree of dependence. It is more practical to be used in real applications; however, how to define the degree of dependence is not addressed. To address this problem, Su et al. [43] presented a strategy of handling dependent evidence at a systematic level, which is able to capture both inner dependence (or interior relationship) and outer dependence (or exterior relationship). For inner dependence, they suggested using the analytic network process (ANP) to derive the degree of dependence. For outer dependence, they proposed a model based on the intersection of influencing factors identified during the information propagating and evaluating process. However, the method is subjective to some extent. For variables with a certain amount of historical data and samples, statistical methods can be used to measure the dependence among information sources. Su et al. [53] suggests using the Pearson correlation coefficient to represent the correlation between evidence. However, the Pearson correlation coefficient presents only a linear correlation between two variables, which is not always the case in real applications. In this paper, we proposed a method to measure the dependence between evidence based on rank correlation coefficient that could remove the limitation of Pearson correlation coefficient.
This paper is organized as follows. In Section 2, the preliminaries on D–S evidence theory, the definition of the discounted BBA and Spearman’s rank correlation coefficient are briefly introduced. In Section 3, the model based on Spearman’s rank correlation coefficient is proposed. In Section 4, an experiment is illustrated to show the rationality of this new method. Finally, the conclusions are given in Section 5.
2. Preliminaries
Some preliminaries are introduced in this section, including Dempster–Shafer evidence theory, the discounted evidence, Pignistic Probability Transformation and Spearman’s rank correlation coefficient.
2.1. Dempster–Shafer Evidence Theory
Definition 1.
Let be a finite nonempty set of N elements that are mutual and exhaustive, and we define Θ as Frame of Discernment [43]. Let be the power set composed of elements of Θ. The Basic Belief Assignment function (BBA) is defined as a mapping from the power set to a number between 0 and 1, , which satisfies the following conditions [43]:
where denotes the Basic Belief Assignment of proposition A.
Definition 2.
(Dempster’s Rule) Let be N independent BBAs in the frame of Discernment of Θ. The result of their combination is denoted as , and calculated as follows [16]:
where K is normalizing factor, calculated as:
Definition 3.
Let m be the BBA on Θ and α be the discount coefficient, the discounted BBA defined as:
Definition 4.
(Pignistic Probability Transformation, PPT) To make a decision after BBA fusion results in acquisition, there are two methods: the first method is decision according to the BBA fusion results, the second method is translating the BBA fusion results to the probability and making decision. In the first method, the information loss may be large, and the second method helps to draw a more accurate result. Based on such consideration, Smets proposed the Pignistic Probability Transformation method [55]. Supposing m is BBA in Θ, let be the Pignistic Probability distribution. The Pignistic Probability Transformation is defined as
where is the cardinality of A, and ∅ is denoted as the empty set.
2.2. Spearman’s Rank Correlation Coefficient
There are all kinds of parameters to evaluate the dependent degree. The article [56] suggests using the Pearson correlation coefficient to represent the correlation between evidence. However, before using the Pearson correlation coefficient, it is necessary to assume that experiment data derived from normal distribution and was equidistant at least within the logical range. The rank correlation coefficient is a parameter-free measure for correlations that may be used to measure the level of agreement between two stochastic variables without making assumptions regarding the parametric structure of the probability distribution of the variables. The rank correlation coefficient, a parameter independent of the distribution, was proposed by Sperman in 1904 and used to measure the correlation between the two variables [57,58].
The basic idea of the Spearman rank correlation coefficient is to use the rank of the variable instead of the specific data for statistical inference [59]. Suppose that the variables x and y have n samples (measured values) denoted as , , where i = 1, 2, ⋯ n. Sorting the sample data from large to small (or from small to large), let , be the position of original data , after arrangment. The Spearman rank correlation coefficient is defined as
where , the is growing with closer and closer to the strict monotonic function. represents becoming a strictly monotone increasing function and represents becoming a strictly monotone decreasing function. If , have no relevance to the distinct monotonic function.
3. Proposed Method
3.1. The Framework of the Proposed Method
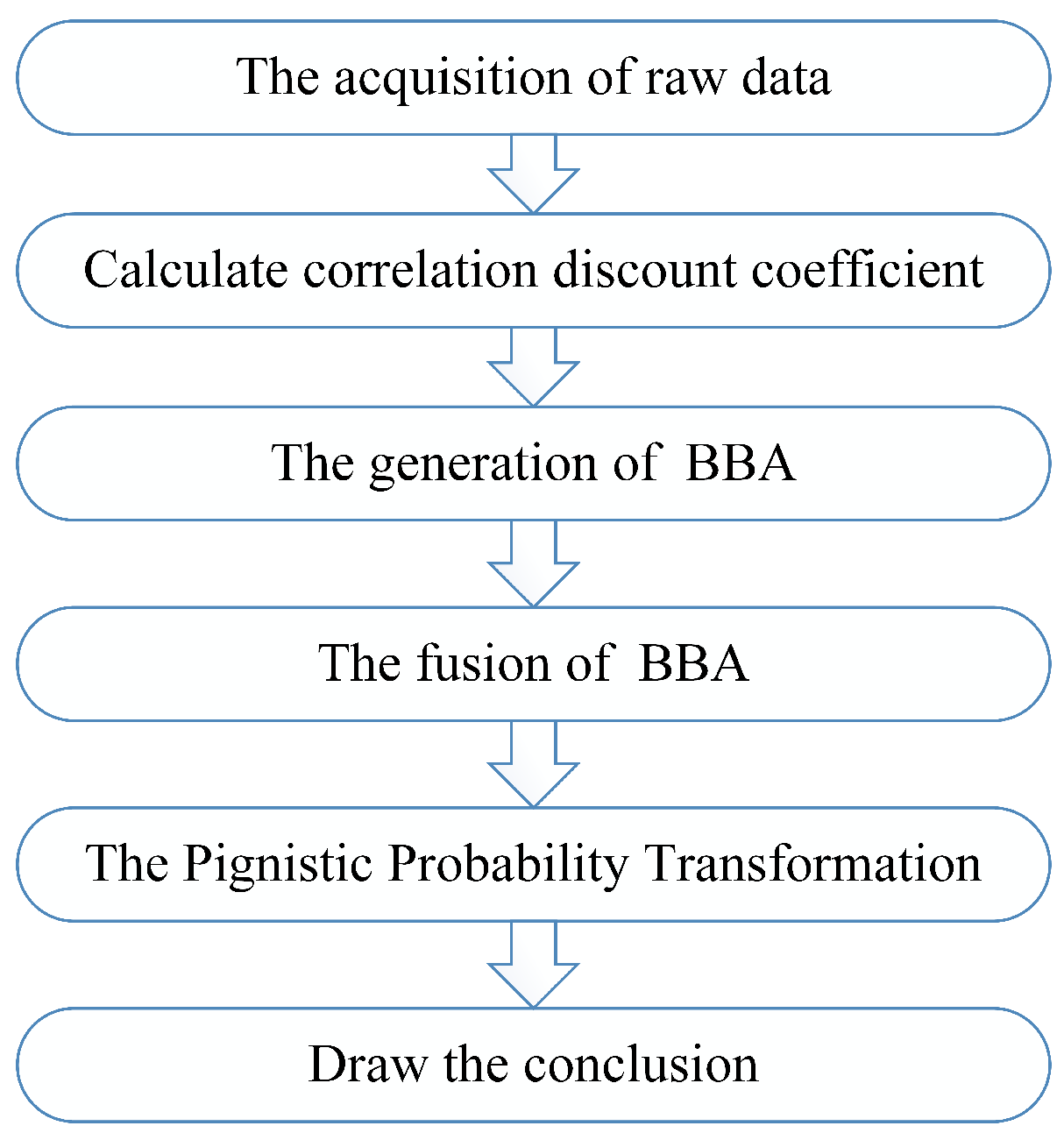
In this section, the method of handling dependent evidence is given in detail in order to fuse dependent sensor data properly. A flowchart of the proposed method is given in Figure 1. From Section 1, we can know that there are two basic directions to handle dependent evidence. One is to modify the Dempster’s combination rule, finding a new evidence fusion method without considering dependence. The other is to reduce the repetitive computation of the dependent part of the information sources as far as possible. Here, we adopt the latter method to establish our evidence fusion model. First, collect sensor data as the raw data to generate BBA. Then, analyze the association between every two sensor information sources and calculate the correlation discount coefficient based on the analysis of sensor data. In addition, fuse the discounted BBA according to Dempster’s combination rule. Finally, a decision conclusion is making by using the method of Pignistic Probability Transformation proposed in [55].
3.2. The Generation of the Correlation Discount Coefficient
Thinking of the need to experience the construction and fusion of BBA from the sensor information source and the final decision making, the analysis of the relevance of the evidence should begin with the initial information source, as the real application involves multi-sensor sources of information, and the relationship between the sensor information source is complex. In order to find a simple and effective representation, this paper adopts the following method:
- Step 1:
- Calculate the Spearman rank correlation coefficient between every two sensor information sources according to Equation (6).
- Step 2:
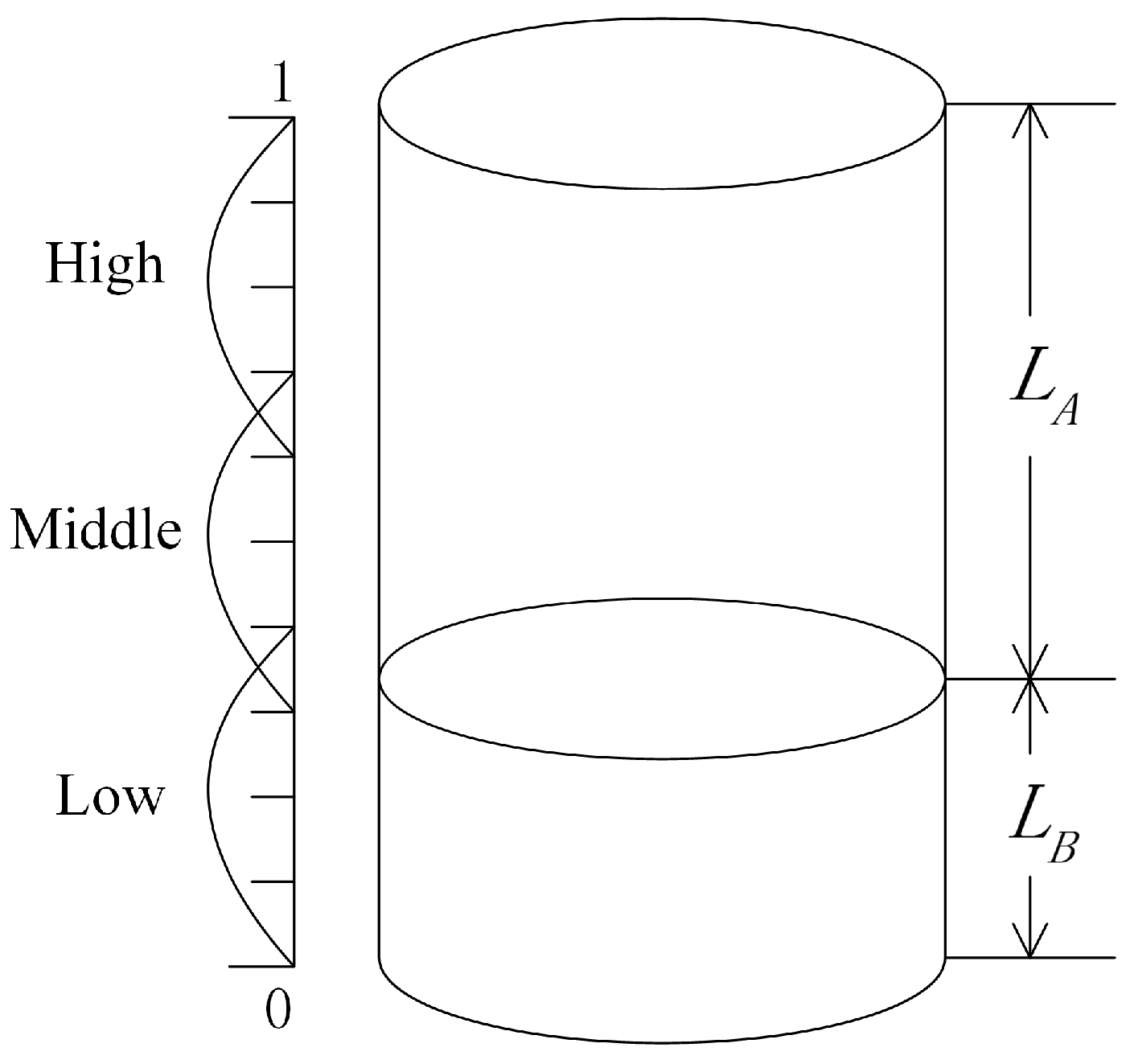
- The correlation between the two sensor information sources can be divided into positive correlation and negative correlation. In other words, rank correlation coefficients are positive or negative, and negative correlation evidence can be regarded as conflict evidence. Calculate the dependence degree between two information sources:Here, is defined as the absolute value of because the positive correlation or negative correlation does not substantially affect the fusion result for the information fusion system based on the D–S evidence theory. To illustrate this problem, there is an example:Suppose that there are two sensors A and B to qualitatively measure the water level. The recognition framework is defined as . As shown in Figure 2, sensor A measures the distance between the top of the well and water surface, denoted as , while sensor B measures the distance between the bottom of the well and water surface, denoted as .Assume that the depth of this well is 1. The interval [0, 0.4], [0.3, 0.7] and [0.6, 1], respectively, represent the statuses of low water level, middle water level and high water level. By analysing the geometric relationship, and satisfy the follow equation:That is, and have a strictly negative correlation relationship, . However, and may have different values for the same water level, and they established the same BBA for the water level. For example, when , , both of the sensors establish the same BBA:In addition, when , , both of the sensors establish the same BBA:In other words, the positive correlation or negative correlation does not substantially affect the fusion result for the information fusion system based on the D–S evidence theory.Supposing that there are M sensor sources, we can then establish dependency matrix D:
- Step 3:
- Calculate the total dependence degree of each sensor information source. The total dependence degree of is defined as
- Step 4:
- Considering that the evidence with strong relevance should be given a smaller discount factor, the correlation discount coefficient is defined as
3.3. Reliability Assessment
In a multi-sensor information fusion system, the global system performance is closely related to each sensor’s reliability. The reliability of the information source refers to the correct rate obtained by direct decision by the information source. The higher reliability evidence helps to draw a more accurate result in the decision-making process. In addition, the higher reliability evidence should be given larger weight in evidence fusion. For the target recognition, it is assumed that there are N groups of training data to establish BBA by and M of them have correct classification results. The reliability of the information source is defined as
3.4. The Fusion of Dependent Evidence
On the basis of the above analyses, the total discounting coefficient of evidence from information source , represented by , can be defined as
Suppose that BBA is established by , whose total discounting coefficient is . The formula of dependent evidence fusion is as follows:
where represents discount calculation with discounting coefficient . (see Equation (4)).
4. Experiment and Discussion
In this paper, Iris Dataset from the machine learning database [60] is used as the data source of the experiment. The dataset contains three types of irises, such as Setosa, Versicolour and Virginica, and each group of irises contains 50 sets of data samples. Each group has four different attributes: SL (Sepal Length), SW (Sepal Width), PL (Petal Length) and PW (Petal Width). These four different attributes can be used as four kinds of information sources to construct BBA.
4.1. Possible Application of the Proposed Evidence Fusion Model
The dependent evidence fusion method in this paper could effectively deal with uncertain information fusion issues existing in the real world. One of the applications of this method could be target recognition. For example, to recognize the enemy aircraft, which could be in the form of a bomber, the Air Early Warning plane or fighter plane, we could first acquire information such as airborne radar signal, infrared signal or the electronic support measure (ESM) information. Different types of enemy aircraft usually have different features in the information. Thus, the type of aircraft could be recognized based on the acquired information. The recognition rate can be improved by combining information from different sensors. The dependence among the sensors is also considered in the proposed method. Similar to the iris example, the airborne radar signal, infrared signal or the ESM information are associated with the iris attributes SL, SW, PL or PW, and the types of enemy aircraft are associated with the iris types Setosa, Versicolour or Virginica.
Another possible application could be fault diagnosis. For example, in a power transformer fault diagnosis system, we want to recognize different fault types including transformer winding, transformer core, arc discharge or transformer insulation aging, and so on. In addition, the corresponding fault symptoms including transformer core earth current, insulation resistance or other symptoms could be acquired to establish different BBAs. Different fault symptoms may be dependent and the fusion method proposed in this article can handle this problem. In other words, the dependent information fusion model based on rank correlation coefficient could be investigated for applications in many fields.
4.2. Experimental Method
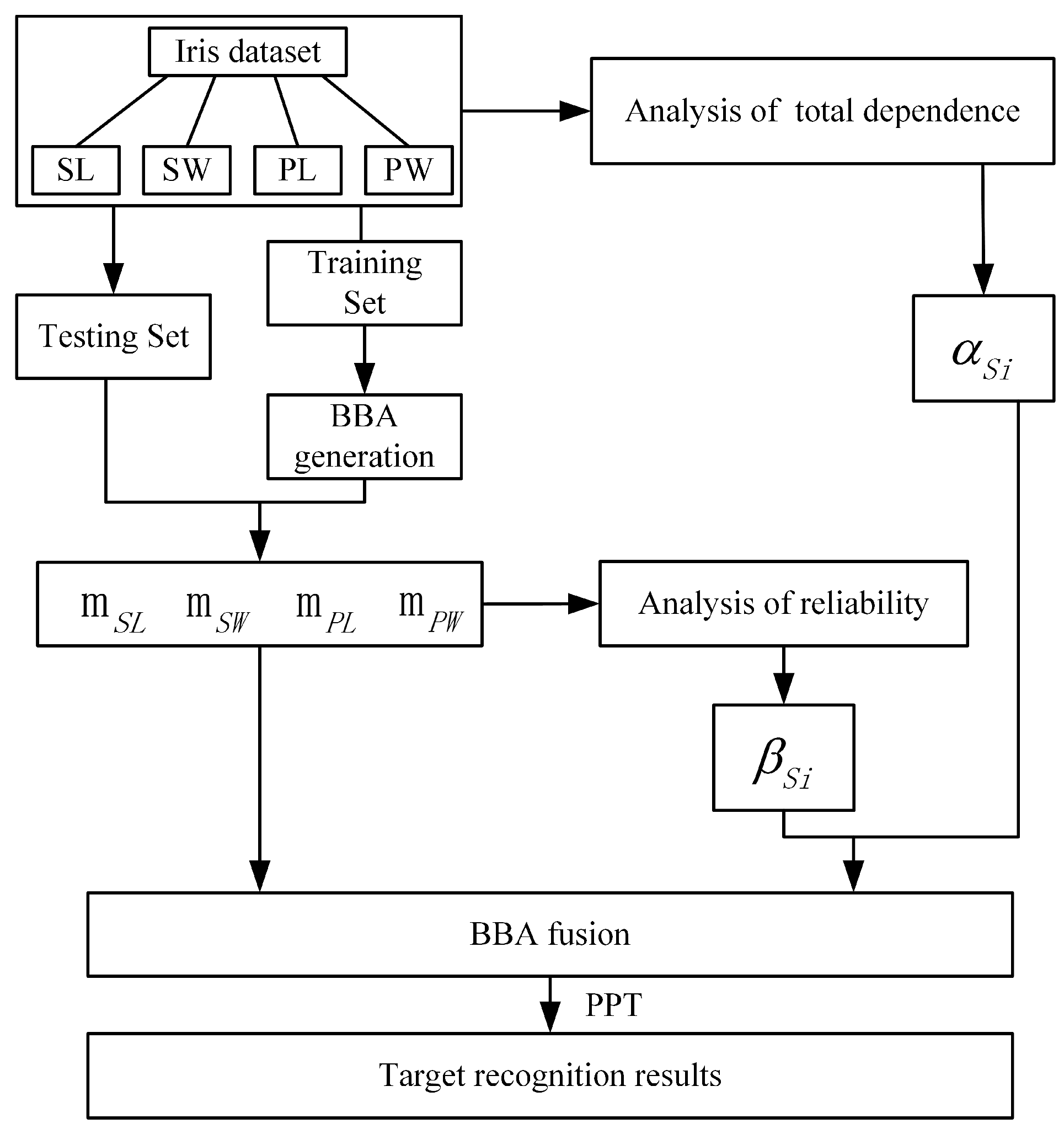
The main procedure of the proposed method to recognize iris class is shown in Figure 3.
In the experiment, some samples were randomly selected as the training set, and the remaining samples were used as test set. The steps are as follows:
- Step 1:
- Calculate the correlation discount coefficient of four attributes. Refer to Section 3.2.
- Step 2:
- Build BBA. Four BBAs were established for SL, SW, PL and PW. The BBA was established according to the article [61].
- Step 3:
- Calculate reliability coefficient , and refer to Section 3.3.
- Step 4:
- Calculate the total discounting coefficient of four attributes according to Equation (15).
- Step 5:
- Model testing. Using the test data, we assume for four cases that the evidence is independent from each other, only considering the dependence between the evidence, only considering the reliability of the evidence, considering both dependence and reliability, and then calculating the recognition accuracy. Then, we increase the proportion of training set data, and repeat the above experiment. In the four cases, the fusion rule as follows:
- Group 1:
- Assume that the evidence is independent from each other
- Group 2:
- Only considering the dependence between the evidence
- Group 3:
- Only considering the reliability of the evidence
- Group 4:
- Considering both dependence and reliability
The method of decision-making after fusion is based on the Pignistic Probability Transformation (PPT) proposed in [55].
4.3. Experimental Procedure
In this section, the correlation of iris data sets is performed. The main procedures are as follows:
- Step 1:
- The first step is to analyse the dependence among SL, SW, PL, and PW attributes. Rank correlation coefficients among attributes of iris data sets are shown in Table 1.Then, we can establish dependency matrix D:Calculate the total dependence degree of each attribute as Equation (12). Results are as follows:Considering that the evidence with strong relevance should be given a smaller discount factor, the correlation discount coefficient is calculated as Equation (13). The results are as follows:
- Step 2:
- Build BBA. Four BBAs were established for SL, SW, PL and PW. The BBA was established according to the article [61].
- Step 3:
- Calculate reliability coefficients of the four attributes as Equation (14). The results are as follows:
- Step 4:
- The total discounting coefficient of the four attributes can be calculated as Equation (15). The results are as follows:After normalization, the total discounting coefficient of the four attributes is
- Step 5:
- Model testing. Based on the above calculation, we begin to test our evidence fusion model. The detailed steps are shown in Section 4.2.
- Step 6:
- Then, we calculate the confidence interval of this experiment. For each piece of evidence, we can acquire a BBA, and suppose its recognition result is A. Then, the Belief function (Bel(A)), defined as a sum of the mass probabilities of all the proper subsets of A, is calculated as follows:
In addition, the Plausibility function ( Pl(A) ), defined as maximum belief of A, is calculated as follows:
Then, the Belief Interval is defined as . Here, calculate the average Bel and Pl of each proportion of testing data.
4.4. Results and Analysis
In four cases, the average classification recognition accuracy test results are shown in Figure 4.
The confidence interval of this experiment as shown in Figure 5.
Comparing Group 1 with Group 3 (or Group 2 with Group 4), it is obvious that the recognition accuracy is significantly improved when considering reliability. However, comparing Group 1 with Group 2 (or Group 3 with Group 4), the recognition accuracy is decreased. In addition, further research shows the reliability coefficients of the four attributes and the correlation coefficients in Table 2.
From Table 2, the reliability coefficient of PW or PL is large, indicating higher reliability. However, the correlation coefficient of PW or PL is small, indicating higher dependence of these two attributes in the whole system. The reliability coefficient of SW is small (lower reliability), while its correlation coefficient is the largest (the most independent attribute in the whole system). In this experiment, a higher recognition accuracy was obtained when using PW or PL attributes. However, there is strong dependence between PW and PL, and the higher recognition accuracy of PW or PL attributes is actually unreasonable for repeating fusion of two similar pieces of evidence. The recognition accuracy will be decreased when considering the effect of dependent evidence. On the other hand, the recognition accuracy will be below actual accuracy if two dependent pieces of evidence that both have low recognition accuracy are fused. In this case, the total recognition accuracy will increase when considering dependent evidence. In the next section, a case study is used to show the effectiveness of the proposed method.
4.5. Further Study
A case study is used to show the effectiveness of the proposed method. Assume that the framework is , and four independent pieces of evidence are R1, R2, R3 and R4. In this case, the correct recognition result is A. As are shown in the following table, and the pieces of evidence R1, R2, and R3 could draw the correct result; however, evidence R4 draws the wrong result (Table 3).
Case1: Combining these four independent pieces of evidence according to the traditional Dempster’s rule:
after PPT, the probability is
The recognition result is A, which is correct by combining four independent pieces of evidence.
Case2: Let us consider another condition: we have the fifth piece of evidence R5, which is the same as R4, that is, . Apparently, R4 is totally dependent on R5, and there may be a mistake if we combine these five pieces of evidence regardless of their association; for example:
after PPT, and the probability is
The recognition result is B; therefore, using traditional Dempster’s rule without considering dependent can draw a wrong result. The reason is that one of the pieces of evidence is totally dependent on another piece of evidence, which means that one of the pieces of evidence has been counted twice.
Case3: By considering the dependent evidence based on the method proposed in Section 3, the correlation discount coefficient could be given as follows:
Then, the fusion rule is
The final result is
The recognition result is A. Thus, the proposed dependent evidence fusion model could improve the decision-making result especially in the fusion of low recognition evidence.
5. Conclusions
With the rapid development of artificial intelligence, the acquisition of information has increasing importance. In industrial applications, the multi-sensor information fusion system based on Dempster–Shafer evidence theory plays a more and more important role in information collection and decision-making. However, the classical evidence theory assumes that the evidence is independent from each other, which is often difficult to establish in practice. To address this issue, this paper analyzes the present researche about dependent evidence fusion. Comparing with all kinds of correlation measurement methods, we select the Spearman’s rank correlation coefficient as the metric to measure dependence existing in evidence. Rank correlation coefficient is a parameter-free measure for correlations, which may be used to measure the level of agreement between two stochastic variables without making assumptions regarding the parametric structure of the probability distribution of the variables. Then, a dependent evidence fusion model based on rank correlation coefficient is established. Finally, an experiment is developed to verify the effectiveness of this model based on iris data sets. Experiment results suggest that considering reliability will improve accuracy of decision-making and considering dependent evidence helps draw more reasonable and robust conclusions. In other words, it is necessary to consider the influence of dependent evidence in information fusion to gain a more credible result.
Acknowledgments
This work was partially supported by the National Natural Science Foundation of China (Grant No. 61503237, Grant No. 61573290), the Shanghai Natural Science Foundation (Grant No. 15ZR1418300), the Shanghai Science and Technology Commission Key Program (Grant No. 15160500800), the Shanghai Key Laboratory of Power Station Automation Technology (No. 13DZ2273800), and the Shanghai Education Commission Excellent Youth Project (Grant No. ZZsdl15144).
Author Contributions
F.S. and X.S. designed and performed the research; F.S. wrote the paper; H.Q. and N.Y. performed the computation; X.S. and F.S. analyzed the data; and W.H. contributed analysis tools. All authors discussed the results and commented on the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Tian, T.; Sun, S.; Li, N. Multi-sensor information fusion estimators for stochastic uncertain systems with correlated noises. Inf. Fusion 2016, 27, 126–137. [Google Scholar] [CrossRef]
- Tang, Y.; Zhou, D.; Xu, S.; He, Z. A weighted belief entropy-based uncertainty measure for multi-sensor data fusion. Sensors 2017, 17, 928. [Google Scholar] [CrossRef] [PubMed]
- Villarrubia, G.; Paz, J.F.D.; Iglesia, D.H.D.L.; Bajo, J. Combining multi-agent systems and wireless sensor networks for monitoring crop irrigation. Sensors 2017, 17, 1775. [Google Scholar] [CrossRef] [PubMed]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Howard, N.; Huang, G.B.; Hussain, A. Fusing audio, visual and textual clues for sentiment analysis from multimodal content. Neurocomputing 2016, 174, 50–59. [Google Scholar] [CrossRef]
- Cambria, E.; White, B. Jumping NLP Curves: A Review of Natural Language Processing Research. IEEE Comput. Intell. Mag. 2014, 9, 48–57. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Gelbukh, A. Aspect extraction for opinion mining with a deep convolutional neural network. Knowl. Based Syst. 2016, 108, 42–49. [Google Scholar] [CrossRef]
- Jin, X.B.; Zheng, H.-J.; Du, J.-J.; Wang, Y.-M. S-Retinex brightness adjustment for night-vision image. 2011, 15, 2571–2576. [Google Scholar]
- Hao, G.; Sun, S.L.; Li, Y. Nonlinear weighted measurement fusion unscented kalman filter with asymptotic optimality. Inf. Sci. 2015, 299, 85–98. [Google Scholar] [CrossRef]
- Alexandridis, A. Evolving RBF neural networks for adaptive soft-sensor design. Int. J. Neural Syst. 2013, 23, 1350029. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Deng, Y.; Wu, J. Fuzzy sensor fusion based on evidence theory and its application. Appl. Artif. Intell. 2013, 27, 235–248. [Google Scholar] [CrossRef]
- Frikha, A.; Moalla, H. Analytic hierarchy process for multi-sensor data fusion based on belief function theory. Eur. J. Oper. Res. 2015, 241, 133–147. [Google Scholar] [CrossRef]
- Deng, X.; Jiang, W.; Zhang, J. Zero-sum matrix game with payoffs of Dempster-Shafer belief structures and its applications on sensors. Sensors 2017, 17, 922. [Google Scholar] [CrossRef] [PubMed]
- Jiang, W.; Hu, W.; Xie, C. A new engine fault diagnosis method based on multi-sensor data fusion. Appl. Sci. 2017, 7, 280. [Google Scholar] [CrossRef]
- Jiang, W.; Zhuang, M.; Xie, C. A reliability-based method to sensor data fusion. Sensors 2017, 17, 1575. [Google Scholar] [CrossRef] [PubMed]
- Dempster, A. Upper and lower probabilities induced by a multivalued mapping. Ann. Math. Stat. 1967, 38, 325–339. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar]
- Cattaneo, M.E.G.V. Belief functions combination without the assumption of independence of the information sources. Knowl. Based Syst. 2011, 52, 299–315. [Google Scholar] [CrossRef]
- Wang, Y.M.; Yang, J.B.; Xu, D.L.; Chin, K.S. On the combination and normalization of interval-valued belief structures. Inf. Sci. Int. J. 2007, 177, 1230–1247. [Google Scholar] [CrossRef]
- Yang, Y.; Han, D. A new distance-based total uncertainty measure in the theory of belief functions. Knowl. Based Syst. 2016, 94, 114–123. [Google Scholar] [CrossRef]
- Deng, Y. Generalized evidence theory. Appl. Intell. 2015, 43, 530–543. [Google Scholar] [CrossRef]
- Cheng, G.; Chen, X.H.; Shan, X.L.; Liu, H.G.; Zhou, C.F. A new method of gear fault diagnosis in strong noise based on multi-sensor information fusion. J. Vib. Control. 2016, 22, 1504–1515. [Google Scholar] [CrossRef]
- Zhang, J.C.; Zhou, S.P.; Li, Y.; Su, Y.S.; Zhang, P.G. Improved D–S evidence theory for pipeline damage identification. J. Vibroeng. 2015, 17, 3527–3537. [Google Scholar]
- Liu, Z.G.; Pan, Q.; Dezert, J.; Martin, A. Adaptive imputation of missing values for incomplete pattern classification. Pattern Recognit. 2016, 52, 85–95. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.G.; Pan, Q.; Dezert, J.; Mercier, G. Credal c-means clustering method based on belief functions. Knowl. Based Syst. 2015, 74, 119–132. [Google Scholar] [CrossRef]
- Denoeux, T. A neural network classifier based on Dempster–Shafer theory. IEEE Trans. Syst. Man Cybern. Syst. 2000, 30, 131–150. [Google Scholar] [CrossRef]
- Kang, B.; Deng, Y.; Sadiq, R.; Mahadevan, S. Evidential cognitive maps. Knowl. Based Syst. 2012, 35, 77–86. [Google Scholar] [CrossRef]
- Wei, D.; Deng, X.; Zhang, X.; Deng, Y.; Mahadevan, S. Identifying influential nodes in weighted networks based on evidence theory. Phys. A Stat. Mech. Its App. 2013, 392, 2564–2575. [Google Scholar] [CrossRef]
- Yager, R.R. Set measure directed multi-Source information fusion. IEEE Tran. Fuzzy Syst. 2011, 19, 1031–1039. [Google Scholar] [CrossRef]
- Yager, R.R. A knowledge-based approach to adversarial decision making. Int. J. Intell. Syst. 2008, 23, 1–21. [Google Scholar] [CrossRef]
- Yang, J.B.; Xu, D.L. Nonlinear information aggregation via evidential reasoning in multiattribute decision analysis under uncertainty. IEEE Tran. Syst. Man Cybern. Syst. 2002, 32, 376–393. [Google Scholar] [CrossRef]
- Yang, J.; Wang, Y.; Xu, D.; Chin, K. The evidential reasoning approach for MADA under both probabilistic and fuzzy uncertainties. Eur. J. Oper. Res. 2006, 171, 309–343. [Google Scholar] [CrossRef]
- Ma, W.; Xiong, W.; Luo, X. A model for decision making with missing, imprecise, and uncertain evaluations of multiple criteria. Int. J. Intell. Syst. 2013, 28, 152–184. [Google Scholar] [CrossRef]
- Yao, S.; Huang, W.Q. Induced ordered weighted evidential reasoning approach for multiple attribute decision analysis with uncertainty. Int. J. Intell. Syst. 2014, 29, 906–925. [Google Scholar] [CrossRef]
- Huang, S.; Su, X.; Hu, Y.; Mahadevan, S.; Deng, Y. A new decision-making method by incomplete preferences based on evidence distance. Knowl. Based Syst. 2014, 56, 264–272. [Google Scholar] [CrossRef]
- Wang, X.; Yang, F.; Li, D.; Zhang, F. Group decision-making method for dynamic cloud model based on cumulative prospect theory. Int. J. Grid Distrib. Comput. 2016, 9, 283–290. [Google Scholar] [CrossRef]
- Yang, J.; Huang, H.Z.; He, L.P.; Zhu, S.P.; Wen, D. Risk evaluation in failure mode and effects analysis of aircraft turbine rotor blades using Dempster–Shafer evidence theory under uncertainty. Eng. Fall. Anal. 2011, 18, 2084–2092. [Google Scholar] [CrossRef]
- Wang, X.; Yang, F.; Wei, H.; Ji, L. A risk assessment model of uncertainty system based on set-valued mapping. J. Intell. Fuzzy Syst. 2016, 31, 3155–3162. [Google Scholar] [CrossRef]
- Ji, L.; Yang, F.; Wang, X. Transformation of possibility distribution into mass function and method of ordered reliability decision. J. Comput. Theor. Nanosci. 2016, 13, 4454–4460. [Google Scholar] [CrossRef]
- Su, X.; Mahadevan, S.; Xu, P.; Deng, Y. Dependence assessment in human reliability analysis using evidence theory and AHP. Risk Anal. 2015, 35, 1296–1316. [Google Scholar] [CrossRef] [PubMed]
- Shafer, G. The problem of dependent evidence. Int. J. Approx. Reason. 2016, 79, 41–44. [Google Scholar] [CrossRef]
- Denoeux, T. Conjunctive and disjunctive combination of belief functions induced by nondistinct bodies of evidence. Artif. Intell. 2008, 172, 234–264. [Google Scholar] [CrossRef]
- Su, X.; Mahadevan, S.; Xu, P.; Deng, Y. Handling of dependence in Dempster–Shafer theory. Int. J. Intell. Syst. 2015, 30, 441–467. [Google Scholar] [CrossRef]
- Su, X.; Han, W.; Xu, P.; Deng, Y. Review of combining dependent evidence. Syst. Eng. Electron. 2016, 38, 1345–1351. [Google Scholar]
- Su, X.; Mahadevan, S.; Han, W.; Deng, Y. Combining dependent bodies of evidence. Appl. Intell. 2016, 44, 634–644. [Google Scholar] [CrossRef]
- Cattaneo, Marco EGV. Combining belief functions issued from dependent sources. In Proceedings of the Third International Symposium on Imprecise Probabilities and Their Application (isipta’03), Lugano, Switzerland, 14–17 July 2003; pp. 133–147. [Google Scholar]
- Destercke, S.; Dubois, D.; Chojnacki, E. Cautious conjunctive merging of belief functions. In Symbolic and Quantitative Approaches to Reasoning with Uncertainty: 9th European Conference, ECSQARU 2007, Hammamet, Tunisia, 31 October 31–2 November 2007; Mellouli, K., Ed.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 332–343. [Google Scholar]
- Destercke, S.; Dubois, D. Idempotent conjunctive combination of belief functions: Extending the minimum rule of possibility theory. Inf. Sci. 2011, 181, 3925–3945. [Google Scholar] [CrossRef] [Green Version]
- Choenni, S.; Blok, H.E.; Leertouwer, E. Handling uncertainty and ignorance in databases: A rule to combine dependent data. In Database Systems for Advanced Applications: 11th International Conference, DASFAA 2006, Singapore, 12–15 April 2006; Li Lee, M., Tan, K.L., Wuwongse, V., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 310–324. [Google Scholar]
- Chebbah, M.; Martin, A.; Ben Yaghlane, B. Combining partially independent belief functions. Decis. Support Syst. 2015, 73, 37–46. [Google Scholar] [CrossRef] [Green Version]
- Smets, P. The concept of distinct evidence. In Proceedings of the 4th Conference on Information Processing and anagement of Uncertainty in Knowledge-based Systems (IPMU), Palma de Mayorca, Spain, 6–10 July 1992; pp. 789–794. [Google Scholar]
- Jiang, H.N.; Xu, X.B.; Wen, C.L. The combination method for dependent evidence and its application for simultaneous faults diagnosis. In Proceedings of the 2009 International Conference on Wavelet Analysis and Pattern Recognition, Baoding, China, 12–15 July 2009; pp. 496–501. [Google Scholar]
- Guralnik, V.; Mylaraswamy, D.; Voges, H. On handling dependent evidence and multiple faults in knowledge fusion for engine health management. In Proceedings of the 2006 IEEE Aerospace Conference, Big Sky, MT, USA, 4–11 March 2006; pp. 9–10. [Google Scholar]
- Yager, R.R. On the fusion of non-independent belief structures. Int. J. Gen. Syst. 2009, 38, 505–531. [Google Scholar] [CrossRef]
- Smets, P.; Kennes, R. The transferable belief model. Artif. Intell. 1994, 66, 191–234. [Google Scholar] [CrossRef]
- Su, X.; Xu, P.; Mahadevan, S.; Deng, Y. On consideration of dependence and reliability of evidence in Dempster–Shafer theory. J. Inf. Comput. Sci. 2014, 11, 4901–4910. [Google Scholar]
- Bishara, A.J.; Hittner, J.B. Testing the significance of a correlation with nonnormal data: Comparison of Pearson, Spearman, transformation, and resampling approaches. Psychol. Methods 2012, 17, 399–417. [Google Scholar] [CrossRef] [PubMed]
- Puth, M.T.; Neuhauser, M.; Ruxton, G.D. Effective use of Spearman’s and Kendall’s correlation coefficients for association between two measured traits. Anim. Behav. 2015, 102, 77–84. [Google Scholar] [CrossRef]
- Zhang, W.Y.; Wei, Z.W.; Wang, B.H.; Han, X.P. Measuring mixing patterns in complex networks by Spearman rank correlation coefficient. Physica A 2016, 451, 440–450. [Google Scholar] [CrossRef]
- UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/datasets/Iris (accessed on 10 August 2017).
- Xu, P.; Deng, Y.; Su, X.; Mahadevan, S. A new method to determine basic probability assignment from training data. Knowl. Based Syst. 2013, 46, 69–80. [Google Scholar] [CrossRef]
Figure 1.
Flowchart of the proposed method.

Figure 2.
Measurement of the water level.

Figure 3.
The main procedure of the proposed method to recognize iris class.

Figure 4.
Average classification recognition accuracy in four cases.

Figure 5.
The confidence intervals of the experiments.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Correlation coefficients among attributes.
| Attribute | SL | SW | PL | PW |
|---|---|---|---|---|
| SL | 1.0000 | −0.1595 | 0.8814 | 0.8344 |
| SW | −0.1595 | 1.0000 | −0.3034 | −0.2775 |
| PL | 0.8814 | −0.3034 | 1.0000 | 0.9360 |
| PW | 0.8344 | −0.2775 | 0.9360 | 1.0000 |
Table 2.
The reliability coefficient and correlation coefficient of four attributes.
| Coefficient | SL | SW | PL | PW |
|---|---|---|---|---|
| reliability coefficient | 0.7267 | 0.5467 | 0.9533 | 0.9600 |
| correlation coefficient | 0.3478 | 0.5746 | 0.3204 | 0.3281 |
Table 3.
Four pieces of evidence and their recognition results.
| Item | BBA | PPT | Recognition Result |
|---|---|---|---|
| R1 | A | ||
| R2 | A | ||
| R3 | A | ||
| R4 | B |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Shi, F.; Su, X.; Qian, H.; Yang, N.; Han, W. Research on the Fusion of Dependent Evidence Based on Rank Correlation Coefficient. Sensors 2017, 17, 2362. https://doi.org/10.3390/s17102362
AMA Style
Shi F, Su X, Qian H, Yang N, Han W. Research on the Fusion of Dependent Evidence Based on Rank Correlation Coefficient. Sensors. 2017; 17(10):2362. https://doi.org/10.3390/s17102362
Chicago/Turabian StyleShi, Fengjian, Xiaoyan Su, Hong Qian, Ning Yang, and Wenhua Han. 2017. "Research on the Fusion of Dependent Evidence Based on Rank Correlation Coefficient" Sensors 17, no. 10: 2362. https://doi.org/10.3390/s17102362
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.