1. Introduction
Wireless Sensor Network (WSN) is an important technology used in different applications. The sensor nodes used in WSN are usually small battery-operated devices. These sensor nodes are installed in the field to collect the physical information. After deployment, the nodes batteries cannot be replaced. The lifetime of the WSNs ends when the batteries of these sensor nodes are empty [
1]. As a result, the WSNs sensor nodes always meet a severe energy problem. The network lifetime can be increased by cutting down the usage of available resources or by energy harvesting [
2,
3,
4,
5,
6]. Different schemes and strategies have been designed to reduce the energy consumption of sensor nodes. In these designed approaches, the cluster-based approaches [
7,
8,
9,
10,
11,
12,
13,
14] are the most efficient and reliable way to save the energy resources of WSNs.
The cluster-based framework is a hierarchal structure in which sensor nodes fall into a local structure called clusters [
8,
9,
10,
11,
12], which consist of a Cluster Head (CH) and a few root nodes. When these root nodes are in a cluster, they are called Cluster Member Nodes
. The
convey the sensed information through a CH, which manages the information of
in its cluster by allocating transmission slots for each of them [
15]. All the CHs then form the communication backbone of the network at a higher hierarchical level. In hierarchical clustering protocols [
9,
10,
11,
12], CHs perform various extra tasks compared with
, such as node association, authentication, data aggregation, data fusion, and task assignments [
16]. Therefore, it is logical that the CHs would usually have much higher energy consumption as compared to the root nodes. To prevent CHs from early dying and to increase the network lifetime, the energy consumption within the network needs to be balanced by equally distributing the energy and data load among all the CHs.
The previously designed cluster-based [
17,
18] routing protocols randomly pick the CH node. These randomly selected CHs are not optimal in number. Consequently, this creates imbalance and uneven clusters in the network. Additionally, when the size of the cluster is greater, the pressure on CH for aggregating and receiving information also increases. The CHs which are in charge of large clusters expend more energy in comparison with the CHs of small clusters which create an unbalanced energy situation leads to end the network lifetime very earlier [
19,
20]. Controlling the size of the cluster is also important for balancing the load. In the proposed mechanism, we use the Markov chain model [
21] to select an optimal number of CHs in the network according to the number of available sensor nodes for optimal resource utilization. In this designed framework, we also limit the number of
in a cluster to divide the energy overhead and other CH-related responsibilities.
In current cluster-based protocols [
22,
23], once a sensor node gets the CH status message from all the selected CHs, in a moment, it assesses their received signal strengths. Then nodes join themselves with the CH, which has the strongest received signal strength among them [
24,
25]. Whenever a member node links itself to a CH which is selected on the basis of received signal strength and this CH positioned backward compared to its route of transmission towards the BS, back transmission occurs. This type of data transmission contributes to extending the general path length traveled by the locally collected data. In this paper, we present a node association strategy through which every member node compares the received signal strengths by all the CHs. If the received response by any CH is greater as compared to the other CHs, then it computes a midpoint towards the BS from both the CHs. The node then associates itself with a CH having a strong signal strength and located at a lesser distance from the BS. Otherwise, it joins the CH which is at the lesser distance from the BS.
The sensor nodes are deployed in the sensing area through a distributed algorithm [
7,
11]. Consequently, the distribution of nodes in the sensing field is not even. The current clustering protocols [
7,
8,
9,
10,
11,
12] utilize the distributed algorithm for CH selection that increase the computational overhead and also causes the resources to drain very quickly. We use Markov Bi-directional Chain Model (MBCM) [
21,
26] to equally divide the sensing area into clusters, and to examine the behavior of the cluster formation process. We also used this formulation [
21,
26] for optimal CH selection and to analyze the stochastic characteristics of the MOCHs in the sense of the mean value, the probability mass function (PMF), the standard deviation (SD), and the coefficient of variation (COV) for the optimal selection of CHs. Through this formulation [
21,
26], the obtained CHs are optimal in number and well-distributed all across the network, which leads to higher energy efficiency, better fairness among nodes, and prolonged the network lifetime. In our proposed clustering protocol, each sensor node consumes energy equally by revolving the CH’s responsibility between all the sensor nodes. In MOCHs, the CHs are centrally selected by the BS based on the residual energy and distance of each node from the BS. The optimal number of CHs is selected by the BS because the BS is more reliable and equipped with high-speed processors than a CH and root nodes [
27]. Only a defined number of
are joined with a CH to equally distribute the energy and data load over the network. The main contributions of our method are defined as follows:
When the CH positioned backward compared to its direction of transmission towards the BS, back transmission occurs. This type of data transmission contributes to extending the general path length traveled by the locally collected data, which leads to a decrease the lifetime of the network. We define a simple but effective strategy for the node association to its CHs to tackle the problem of backward transmission.
The recently designed clustering protocols [
8,
9,
10,
11,
12], randomly select the CHs through a distributed algorithm which generates unequal clusters with uneven cluster size in the network; these unstable clusters create an unbalanced energy situation that leads to the end the network lifetime being much earlier. The proposed model centrally selects the optimal number of CHs by restricting the number of
in the cluster and guarantees the longer network lifetime.
The proposed model also deals with non-associated which affect the network stability and also drain the available power resources.
The remainder of the paper is organized as follows:
Section 2 describes the related work and background. We discussed the methodology, the details of Markov bi-directional chain model, and motivations in
Section 3. The network model, node deployment strategy and the working of the proposed clustering protocol with phases in a round are discussed in detail in
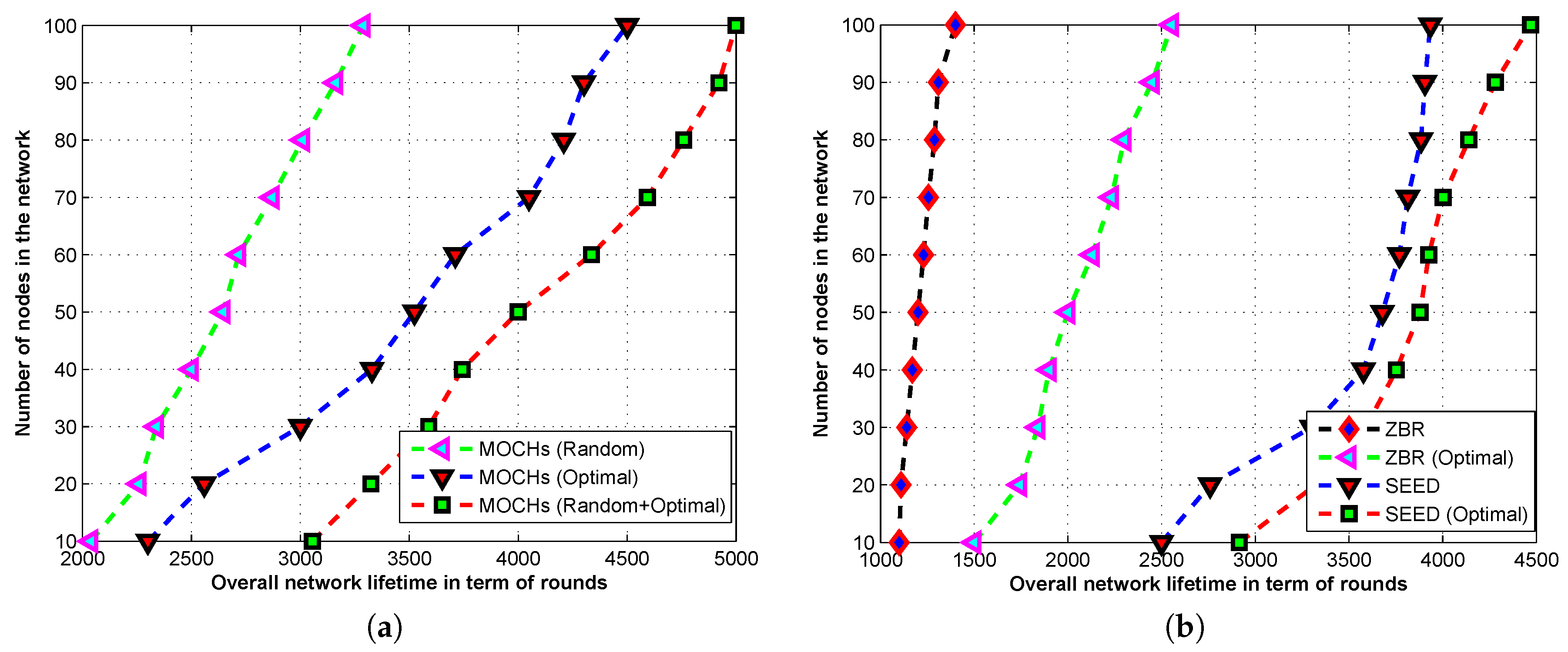
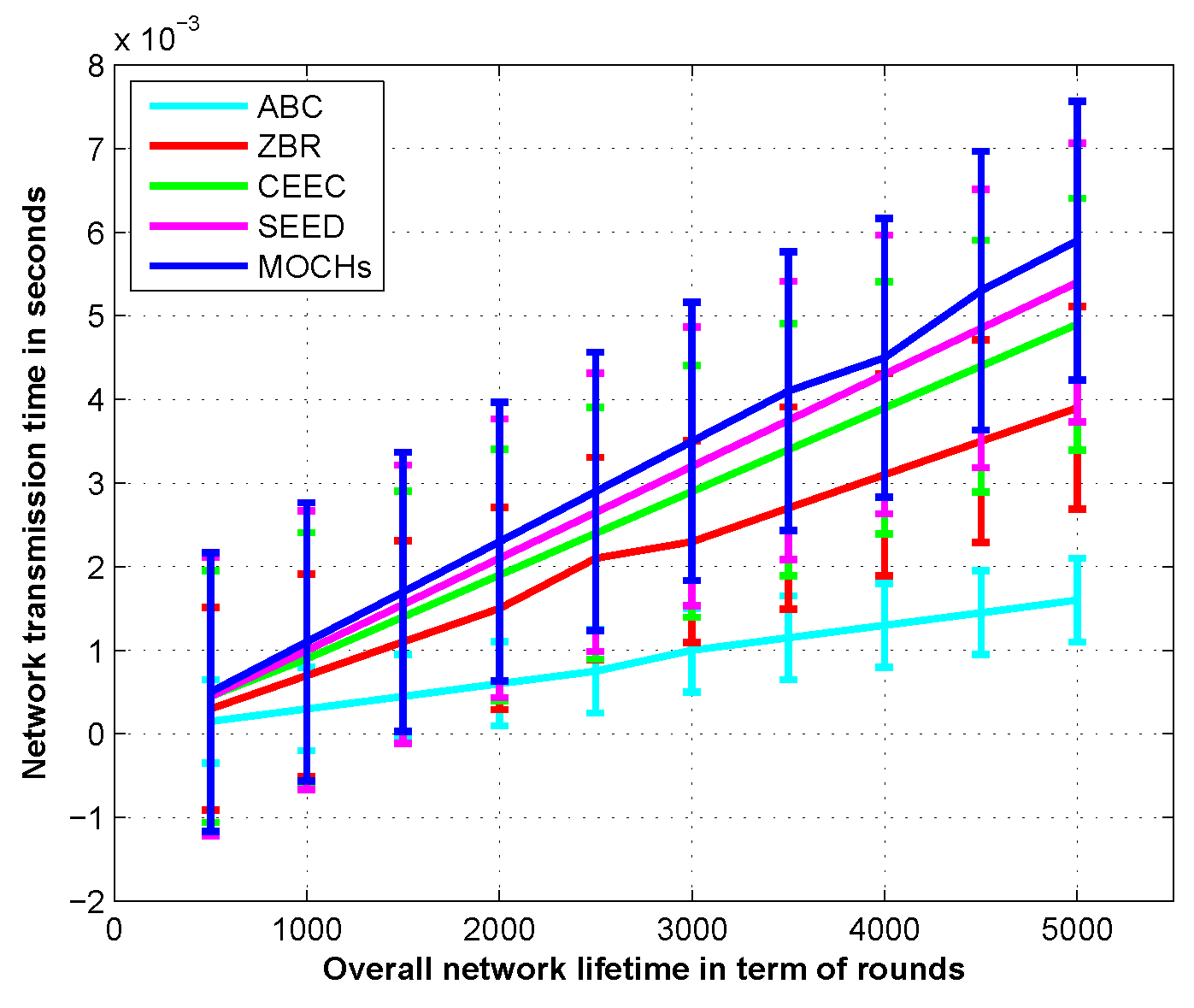
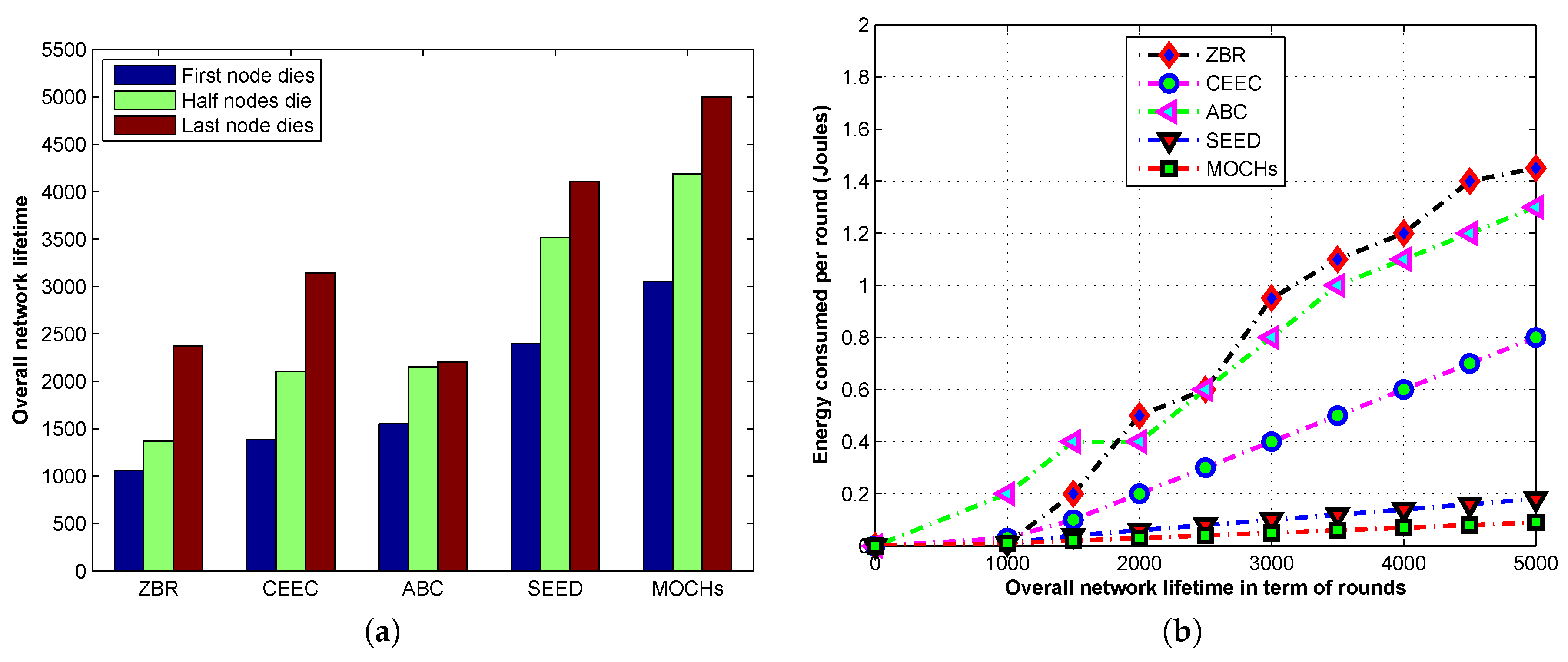
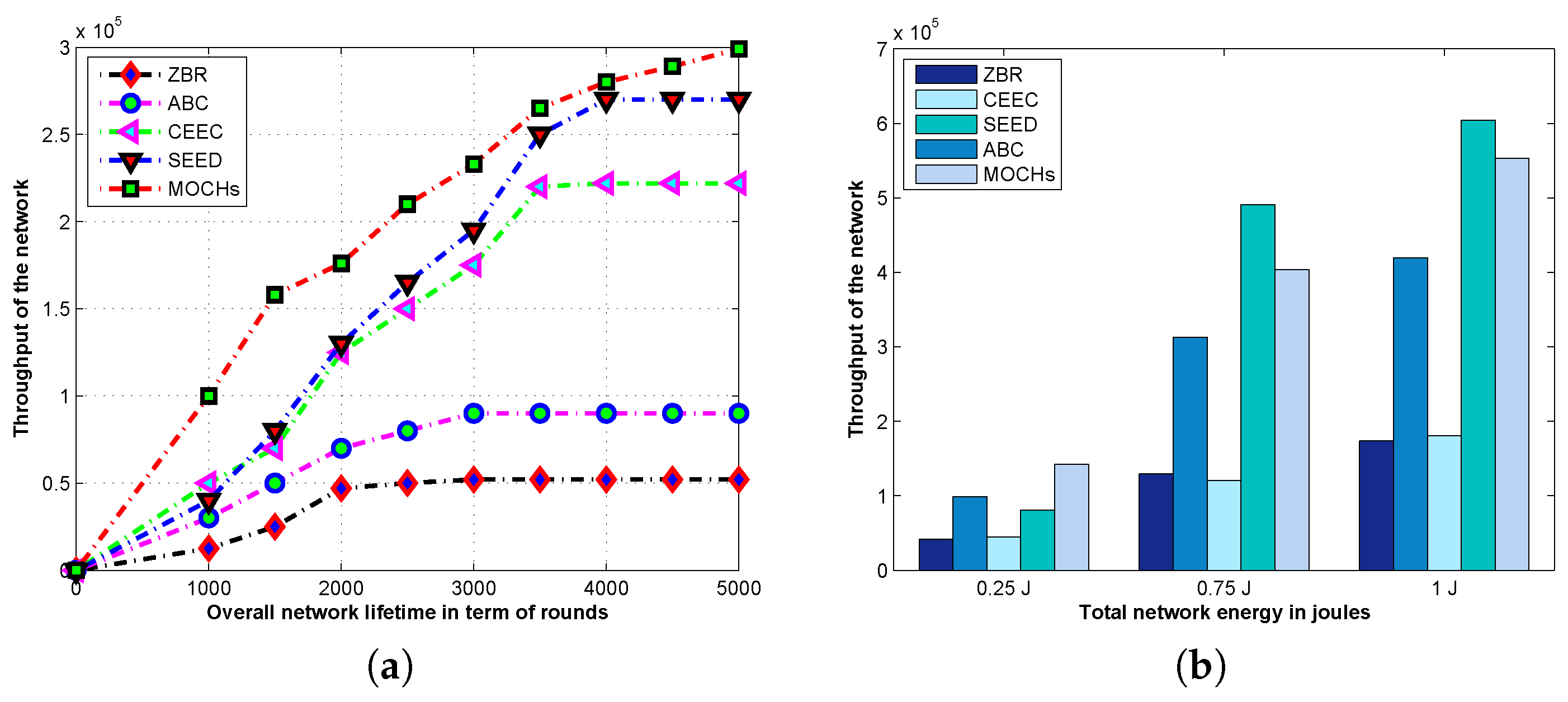
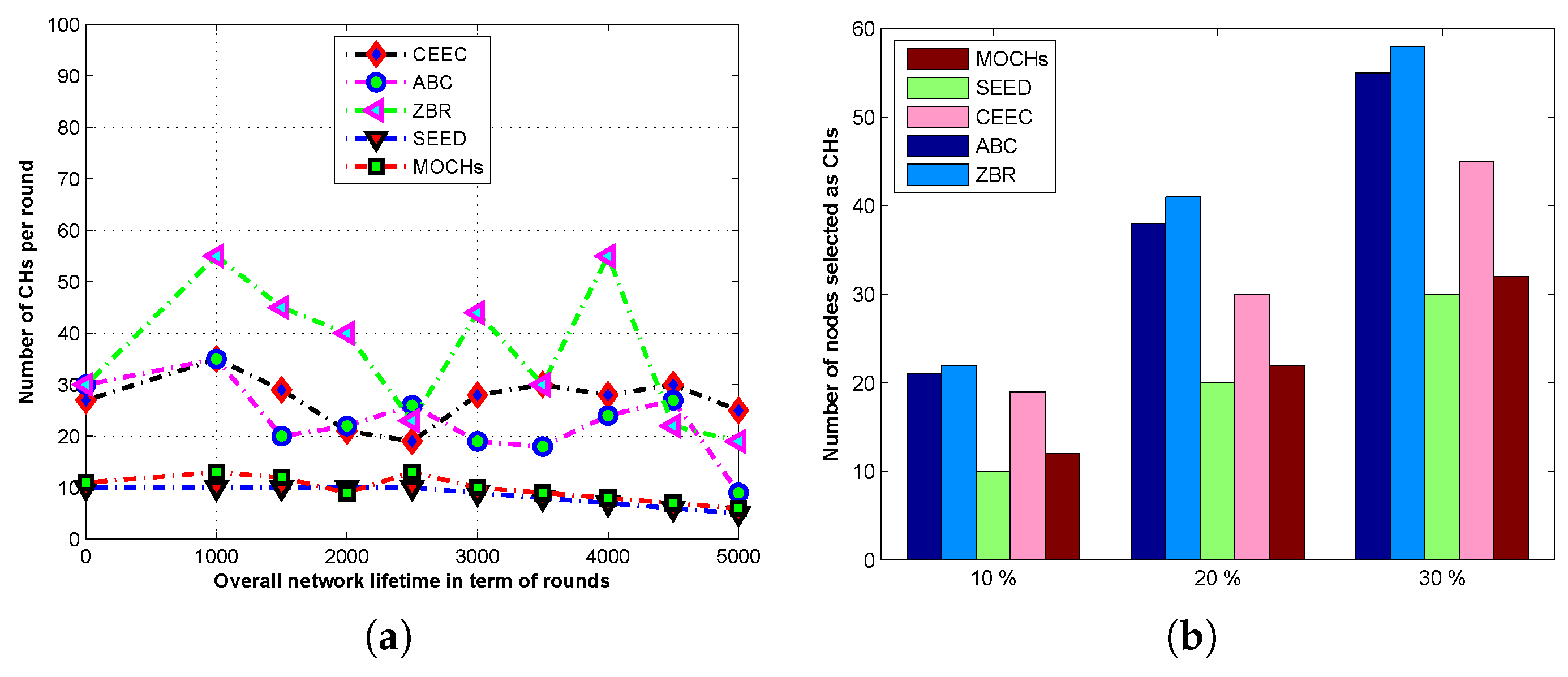
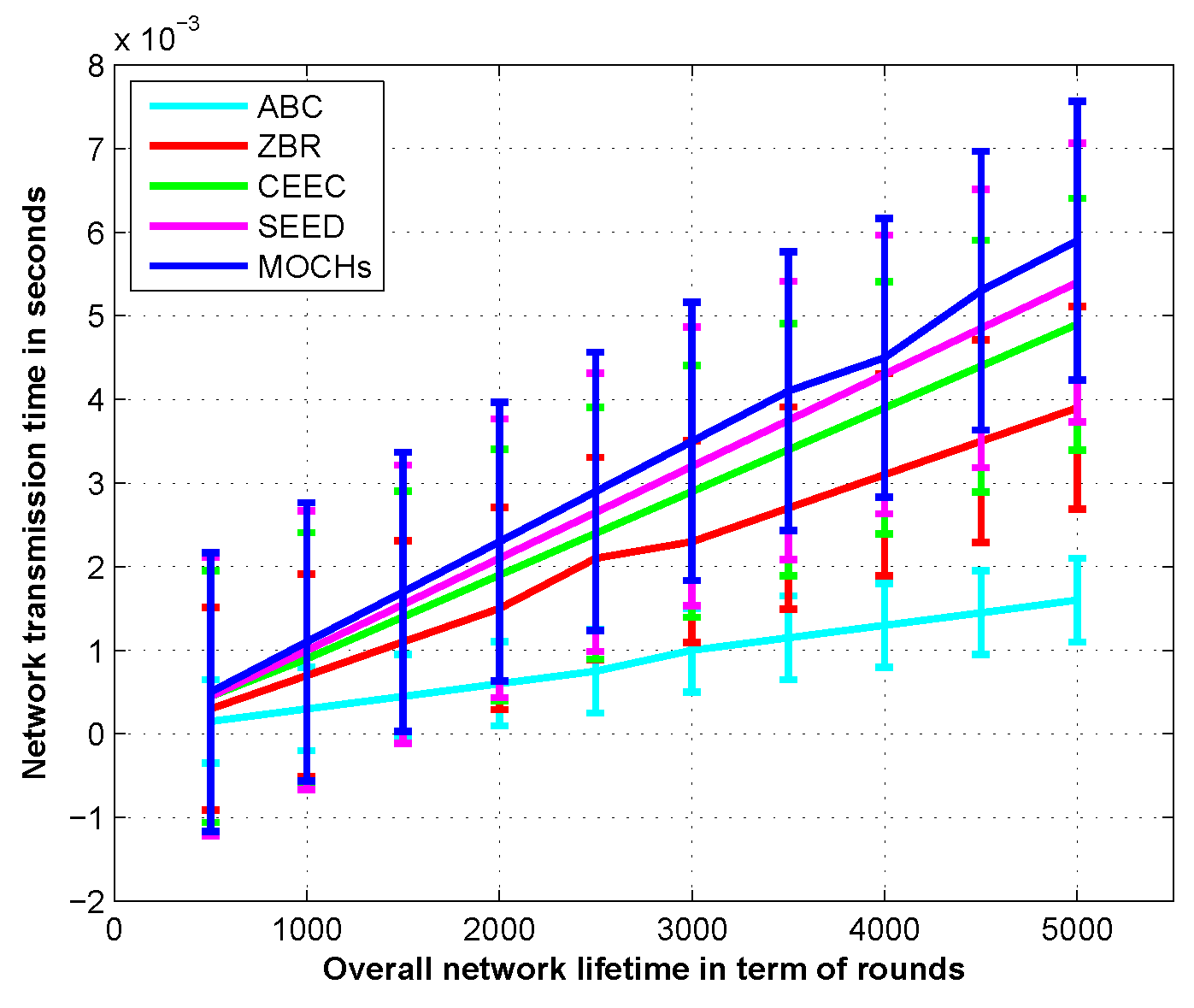
Section 4. Evaluation measures and simulation results for the lifetime of the network, the network stability, the messages towards the BS, the CH selection, and the transmission time of the network are discussed in
Section 5. Finally, the conclusion is drawn in
Section 6.
4. The Proposed Clustering Protocol
In this section, first, we explain the network model of our proposed clustering protocol. We assume that there are N sensor nodes, which are uniformly dispersed in a square region of area 100 m × 100 m. In the literature, different techniques are used to minimize the energy consumption and also some methods are applied to find out main sources of energy drainage in the network. We believe that in the clustering routing protocol the optimal number of CHs selections also takes part in increasing the stability of the network. The size of the cluster should be controlled because sometimes the over populated clusters also lead to depleting the available resources. In our defined model, initially, all of the nodes in the network individually check their suitability for CH selection. Then the BS decides and finalizes the nominated CHs on the basis of selection criteria. The BS is working as a central entity, which reserved the rights of elimination and recommendation. We also keep a balance between the cluster size by defining a criterion in which maximum eleven and minimum six can jointly form a cluster. In case the maximum limit exceeds, the remainder of the nodes, joint with the other CH.
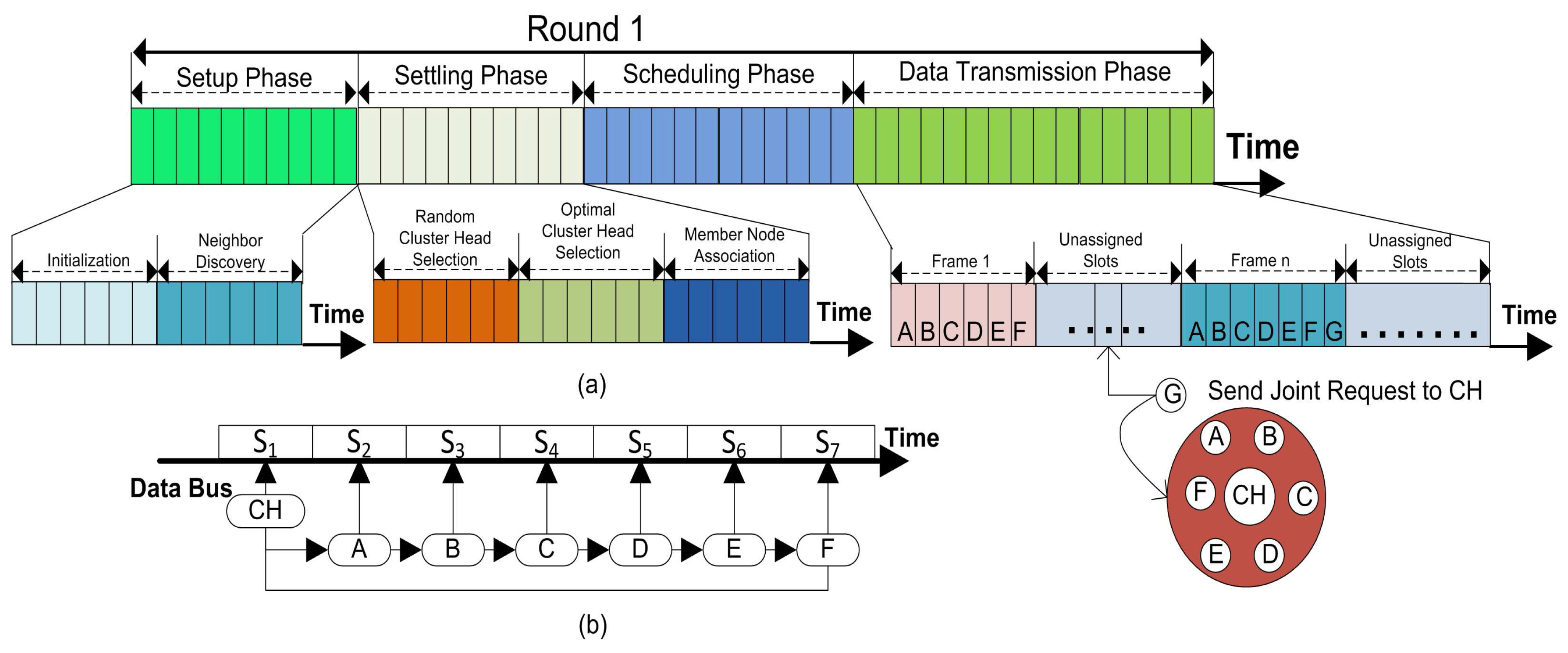
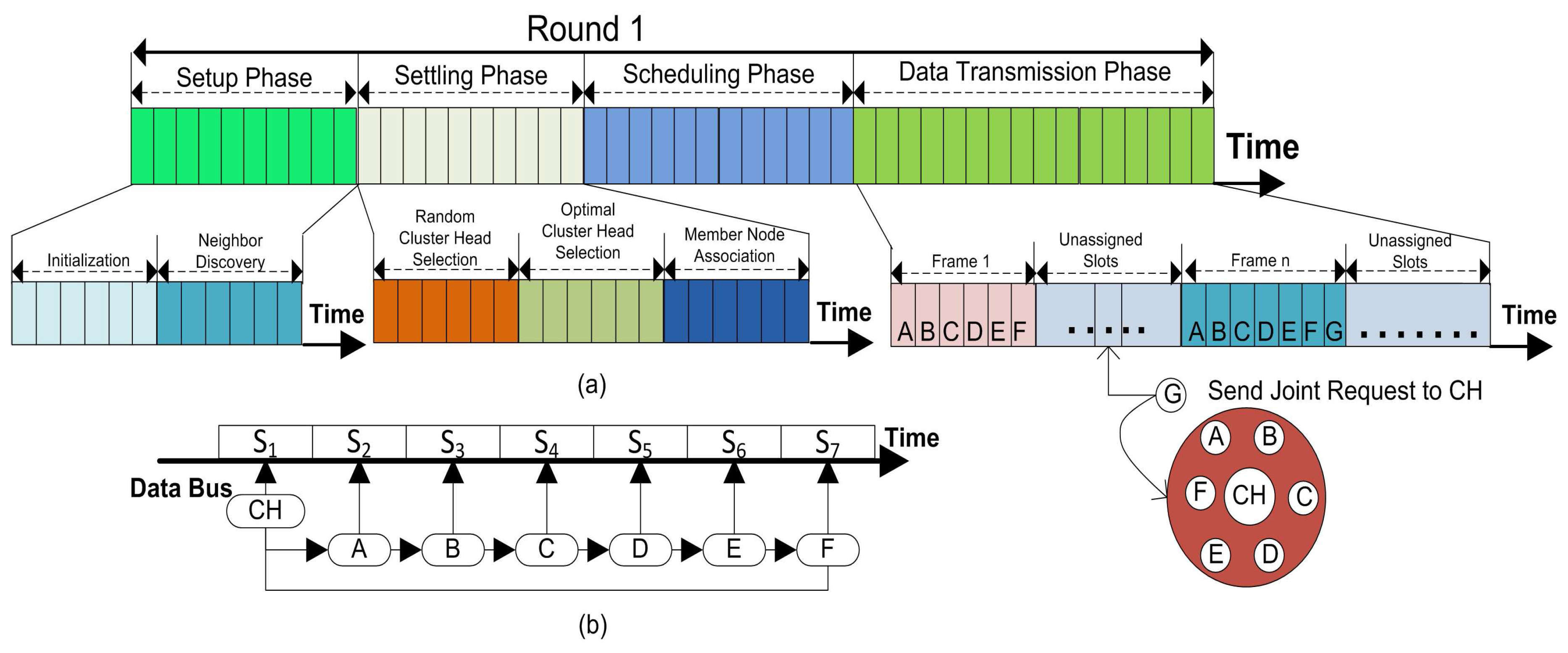
We partitioned the working of our proposed method function into rounds. Every round is then further separated into four phases such as; (1) setup phase; (2) settling phase; (3) scheduling phase and (4) data transmission phase. Whereas, the random and the optimal number of CHs selections provide a way for load balancing and the uneven energy distribution problem as well as help in keeping the stability of the network. For the third and fourth phases included in the overall energy consumption of the network, more details concerning each of the phase are explained in the next subsections.
4.1. Network Model of the Proposed Method
We assume a sensing network in which N sensing nodes are deployed independently and uniformly in a two-dimensional area
A(x,y), and the BS is located outside the field area. We are unaware about the prior knowledge of the area; in this situation, random node distribution could be a more effective strategy. In our designed WSN, we use the following random distribution algorithm to deploy the nodes in the sensing area:
where
λ is the node density and
is the area of the sensing field. In our designed network, nodes collect the information from the surroundings, and convey this information to the BS with the help of concerned CHs. So, in this way, there are three types of nodes in the network like field nodes, CH nodes, and the BS.
Let N is the set of field nodes, and CHs is the set of the cluster head nodes. Where,
and
is the maximum number of nodes.
, where
is the maximum number of
. Each field node is able to set up a link to the other field nodes or CH depending upon the situation. Through the above discussion, we have found this connectivity parameter:
The , and . Here, b is either a member node or a CH. If b is a CH, then a is a member node. The quality of links is directly related to the received signal strength and the distance.
4.2. Markov Chain Model for Resolving the Optimal Cluster Formation and CH Selection Problems
The nodes in the sensing field are installed through a distributed algorithm. Therefore, the distribution of nodes in the sensing field is not even. The previously designed clustering protocols [
7,
8,
9,
10,
11,
12] use the distributed clustering algorithm for CH selection, which increases the computational overhead on all the nodes. Another problem is that optimum numbers of CHs are also not assured through this distributed algorithm. If the selected number of CHs should not be optimal, this causes the resources to deplete very quickly. The number of CHs selected by using randomized schemes [
7,
8,
9,
10,
11], is not guaranteed to be equal to the expected optimal value. To analyze the clustering properties, and to address the problems in cluster formation, we employed a bi-dimensional Markov chain model [
21,
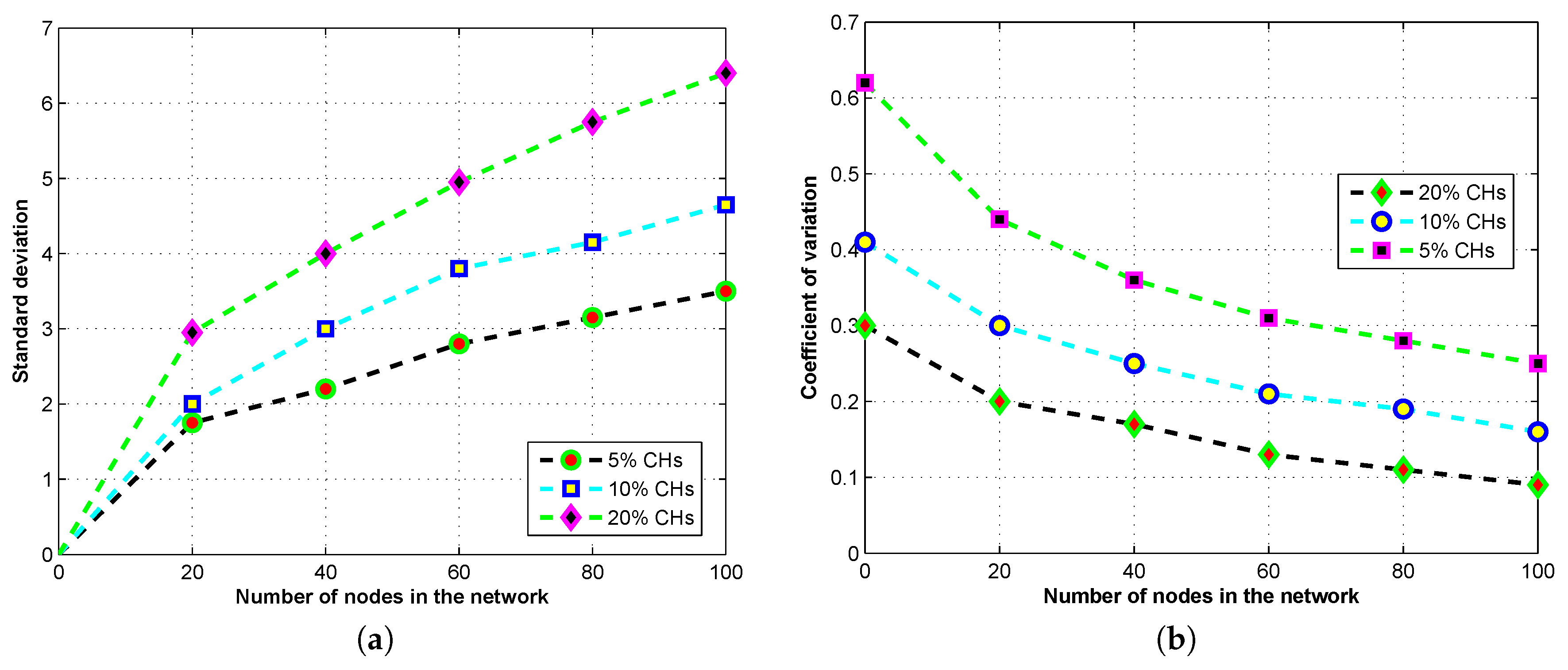
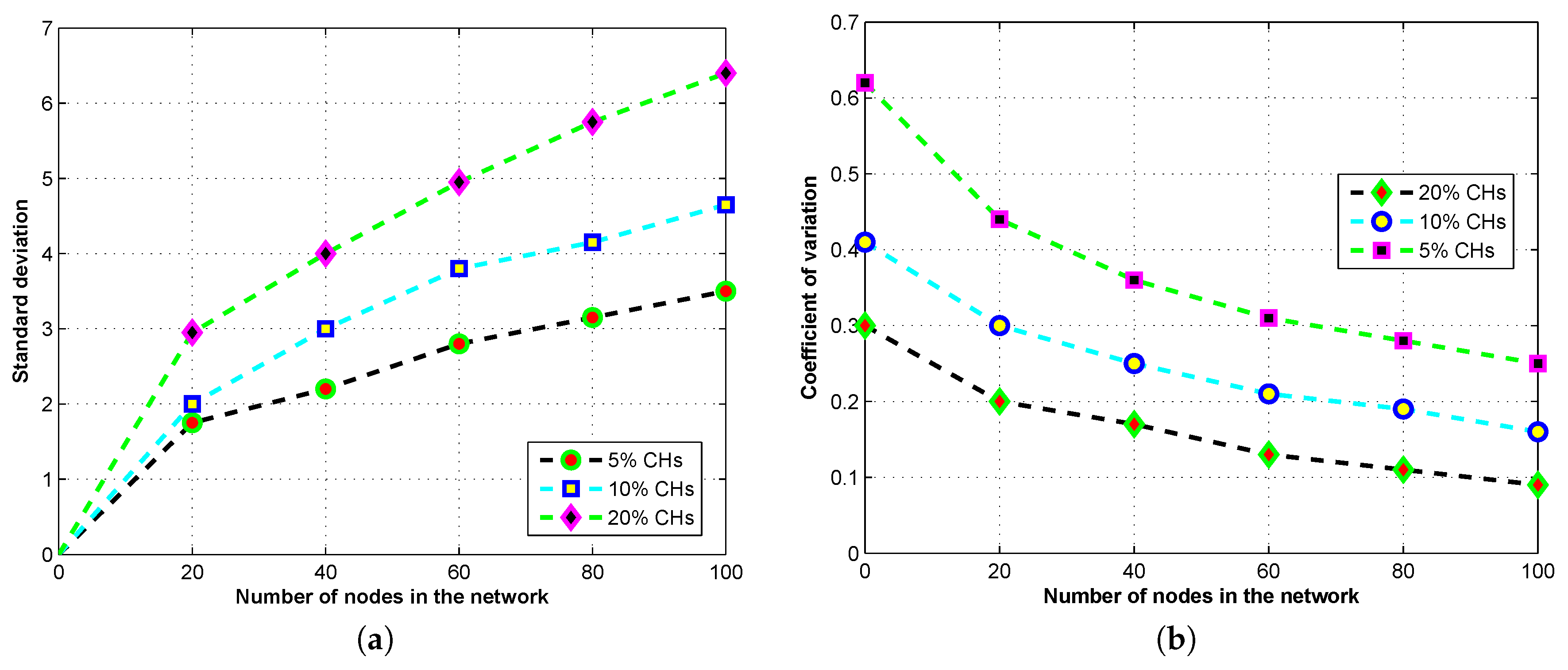
26] to inspect their cluster-forming behavior. We use the Markov model to analyze the stochastic properties of MOCHs for the number of CHs in terms of the PMF, the mean, the SD, and the COV of the number of CHs. Through this formulation, the obtained CHs are optimal in number and well-distributed across the network, which leads to higher energy efficiency and better fairness among nodes, and prolonged the network lifetime.
Suppose that denotes a stochastic process to signify the selected number of CHs at a specific time instant t. As the process of CHs selection starts from the beginning of each round, an integer scale t and a discrete time instants are selected in the beginning of two successive rounds. We express that is the round at a time instant t, and is a stochastic procedure signifies the period of a scheme at a time instant t, which is . We also suppose another integer , which denotes . The state space of this model is: , , , as this process holds the Markov property.
To analyze the clustering properties of the proposed model, we utilize these measures: the distribution of CHs in every round, the average selected CHs in every round, the SD of the number of CHs, and the COV of the number of CHs. The target is the optimal number of CHs; the optimal number of CHs allows and guarantees the minimum energy consumption in the network. The SD calculates the variations in the target values, and the COV estimates the distribution of the average number of CHs related to the number of CHs. Let CH is a random variable indicates the total number of CHs in a round. We use the bi-directional Markov chain model stationary distribution and one-step transition probabilities [
26] to estimate the PMF for the CHs as follows:
where
π denotes staionary distribution, P is one step transition probablity matrix, and f signifies a factor matrix,
are elements of the factor matrix. Additionally, depending upon the PMF of the number of CHs, we are able to estimate the average number of CHs
, the COV
, and the SD
:
Furthermore, we also consider the case if no CH is selected, then the other phases of this round will be omitted, and the next round will start. By using such enhancement, the CH selection and cluster formation process (the settling phase) becomes more effective and practical. Consequently, we exclude the cases with no CH selected in the network and we get these statistical properties given as:
The SD and COV for the number of CHs are given as:
By utilizing the Markov chain model, we perform a stage-based stochastic analysis of our model to analyze the performance of MOCHs with better granularity. The conditional PMF of the number of CHs for a stage
x is given as:
By using the Equation (
10), we are able to estimate the SD, and the COV for the optimal number of CHs at each step.
4.3. Setup Phase
This is the first phase of our proposed model which is divided into two parts. In the first part, the initialization of the network takes place and in the second part, the neighbor discovery is completed. The details of setup phase are given below.
4.3.1. Initialization
At the start of the network, the sensor nodes are randomly installed in the sensing area. During the nodes installation procedure, some points also take into consideration to avoid premature exhaustion of the network because once the nodes are employed in the field, there is no any possibility to change their batteries or their locations. The density of nodes in a specific area, the transmission distance, and the number of relaying nodes also affect the network stability.
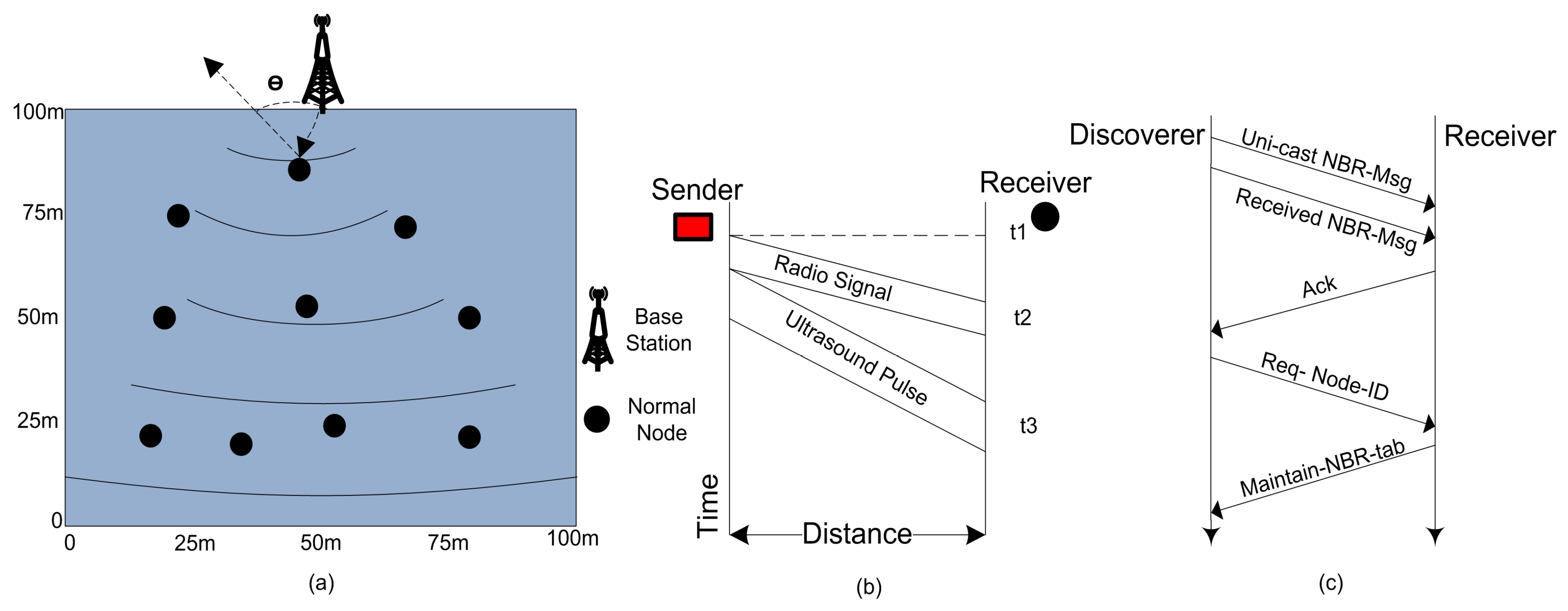
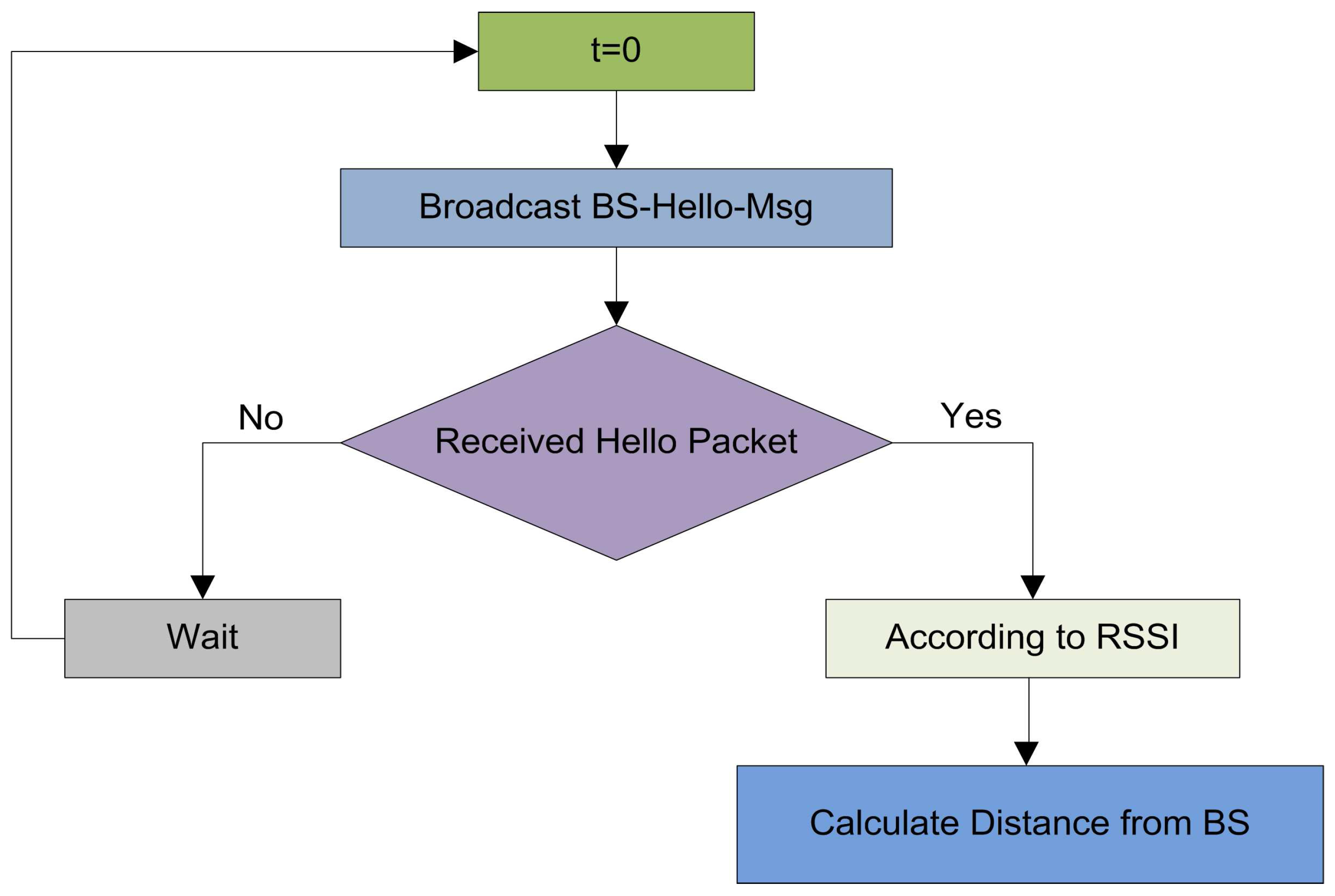
In the initialization phase, the BS broadcast a
-
-
at a certain power level. This message contains the coordinates of the BS. When this message is received by the sensor nodes, the nodes can estimate the distance of the BS according to the received signal strength indication. The illustration of the network initialization is given in
Figure 1.
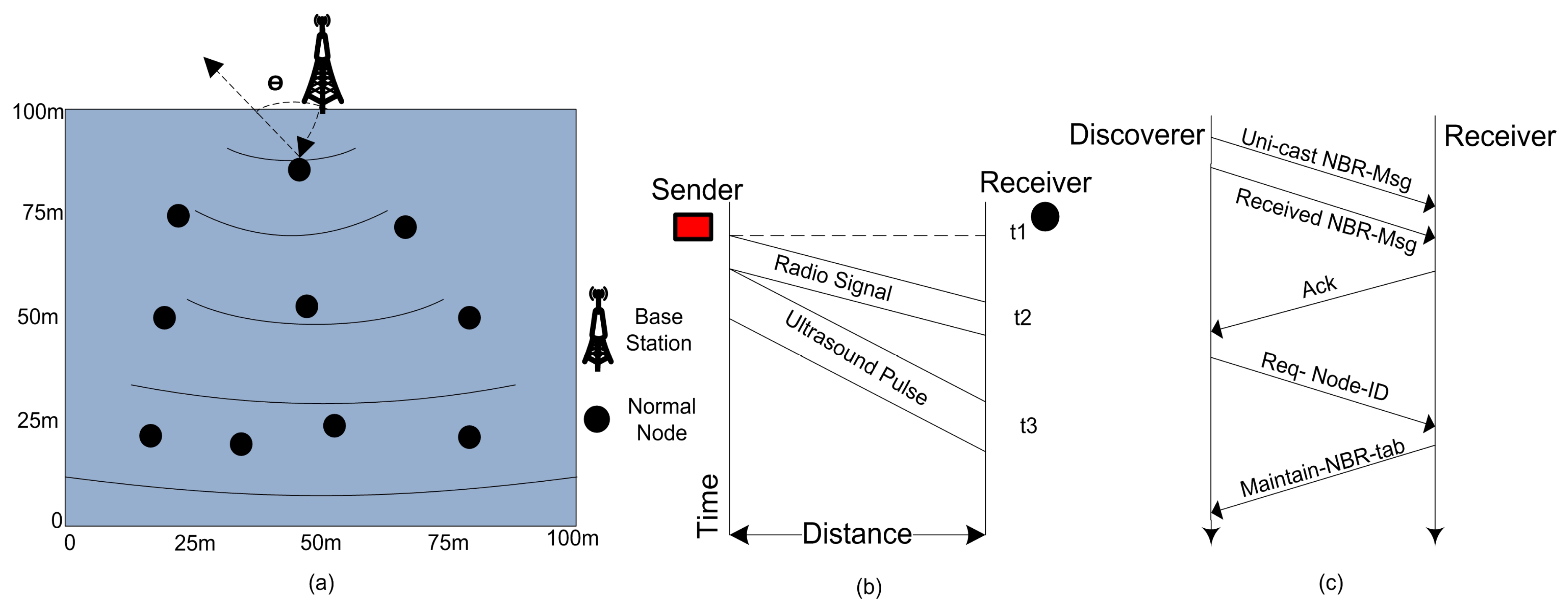
The received signal strength indication is utilized to compute the distance of one node from another. The strength of a signal fades as long it propagates from sender nodes towards the receiver nodes as revealed in
Figure 2. A radio propagation model can be used to estimate the distance between two nodes on the basis of receiving signal.
Lemma 1. The initialization of the network is stabilized in finite time.
Proof. The proof of this Lemma is given in Section 4 of [
40] in Lemma 4. ☐
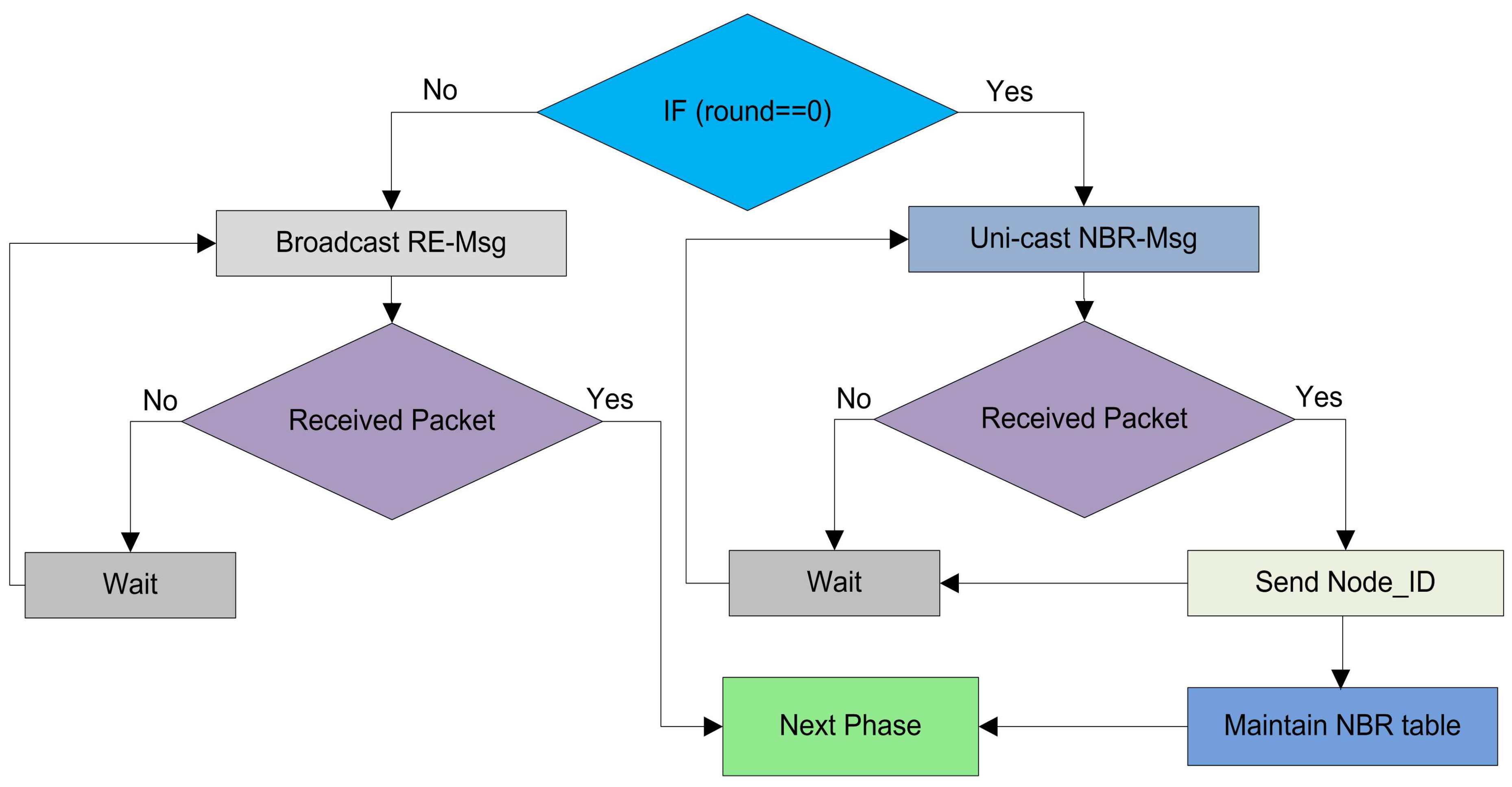
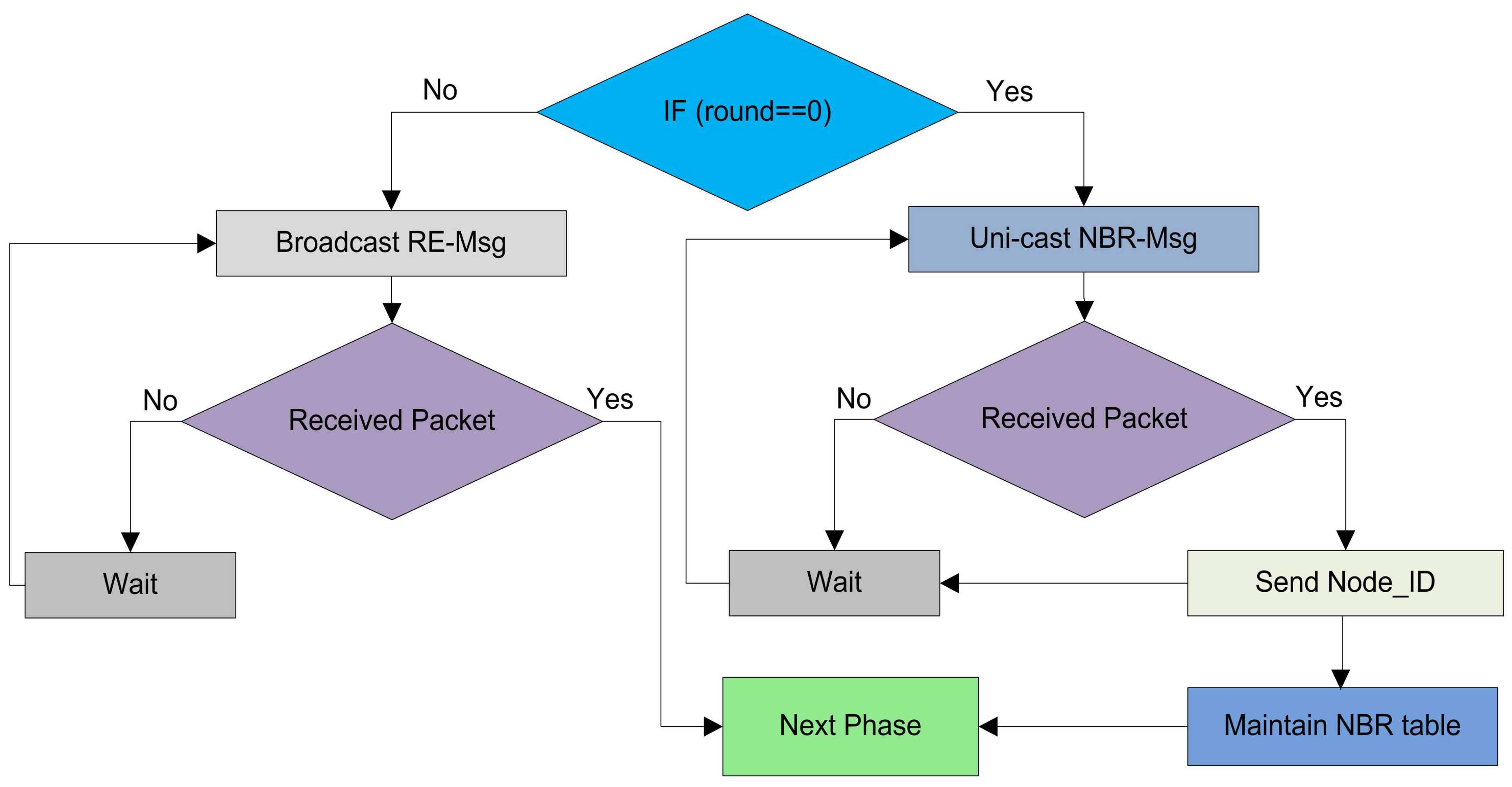
4.3.2. Neighbor Discovery
The main purpose of neighbor discovery is that in the beginning no reliable infrastructure is found among the
for communication, and data exchange becomes crucial for WSNs. The setup phase starts with every round with the aim to upgrade the system. When all the
in a network become familiar about some coordinates related to them, like: received signal strengths, and the node IDs, the probability of successful communications between nodes increases. We use a
NBR-Msg exchange method to inform neighbor nodes with the node IDs, the link status, and all other coordinates of the neighbor nodes in a network as depicted in
Figure 3.
The other reason for neighbor discovery is that the sensor nodes in the network decide themselves to be CHs at the beginning of every round with a certain probability. They disseminate their status as a CH -- on intra-cluster transmission range. The nodes which are not elected as a CH receive a message from closer CHs. They send a joint request -- to concern CH. A number of sensor nodes in the network do not receive any CH status announcement from any of the CH. These sensor nodes wait for the CH status message for a predefined time slot and then these nodes become self-generating force CHs. These self-generated CHs can directly communicate with the BS either these nodes are placed close or far away from the BS. These force CHs consume additional energy during their communication to forward data. To triumph over this problem, we employ a simple strategy to handle with these non-associated nodes in our proposed clustering protocol. If a node does not receive any CH announcement message -- it sends a request to CH through the closest neighbor. Then this non-associated node will forward its sensed data to its next neighbor node towards the BS with the help of a CH node. There is no need to send data directly to the BS. The neighbor node will forward this packet to its associated CH.
Lemma 2. After the initialization, all the nodes in network discover their neighbors in finite time.
Proof. All the nodes in the network spend a finite time to set the variable to themselves, here the is the initialization time. For any node j in the network, we suppose that the node j has the minimum number of neighbors i and satisfies , where, the is the initialization time of node i and is the time taken by node i to discover j neighbor nodes. As the j has the finite number of neighbors i, then node i chooses j and sets the variable to j in a finite time. As the node i spends a finite time to set the variable of itself and at maximum waits for all the other nodes in the network to discover their neighbors in a finite time. ☐
4.4. Settling Phase
After the setup phase, the settling phase starts in which the whole network is divided into clusters. The details of the settling phase are given in the next subsection.
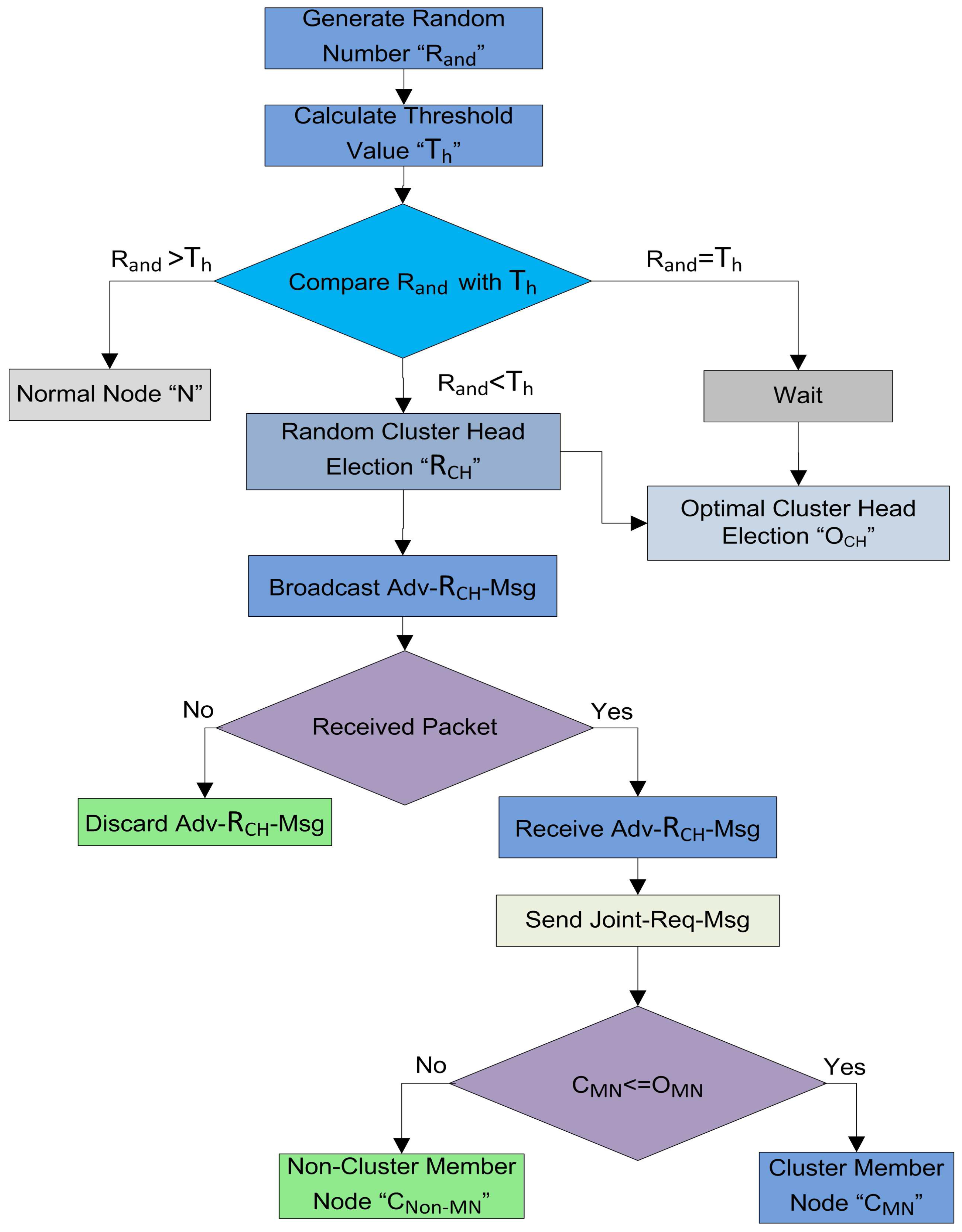
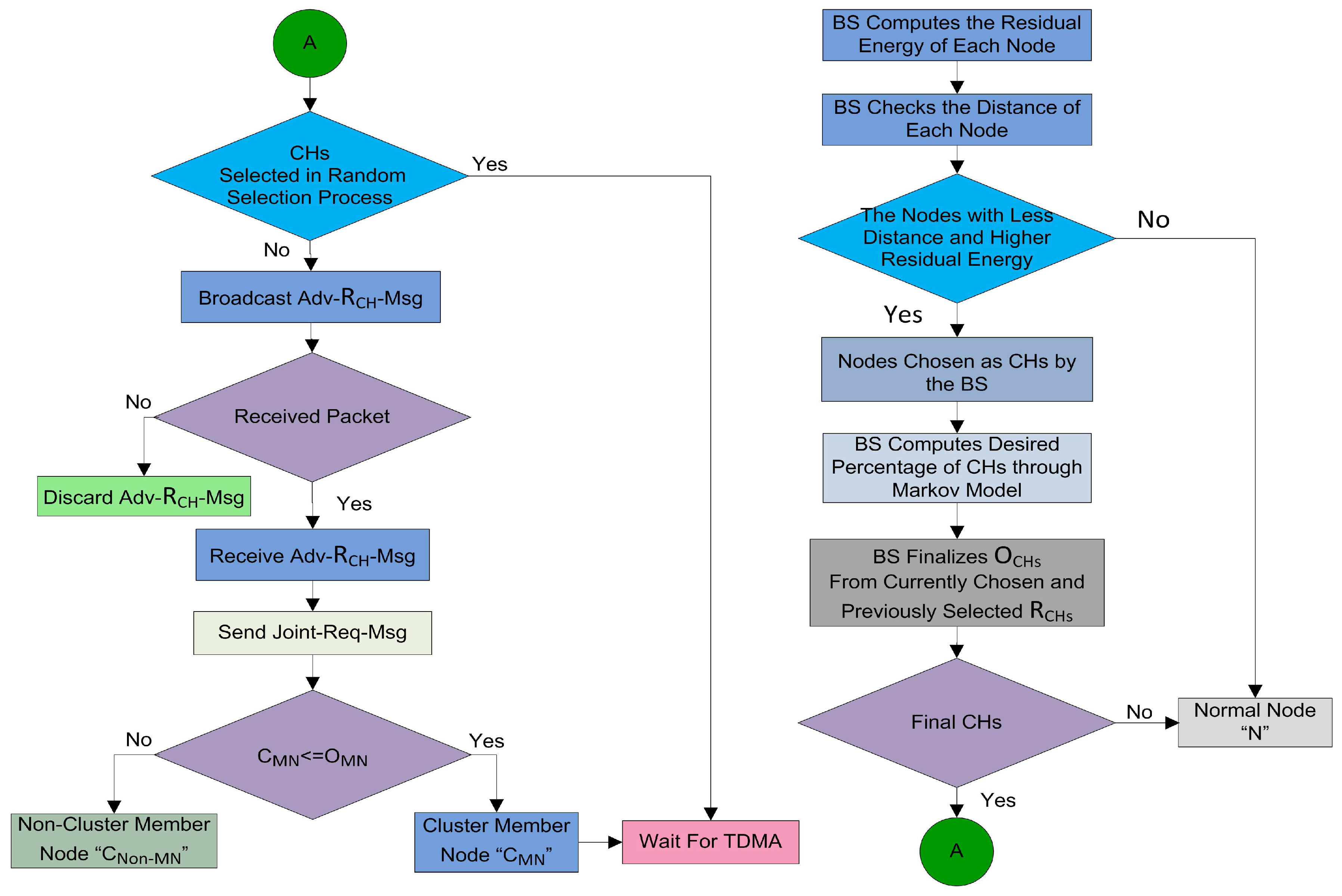
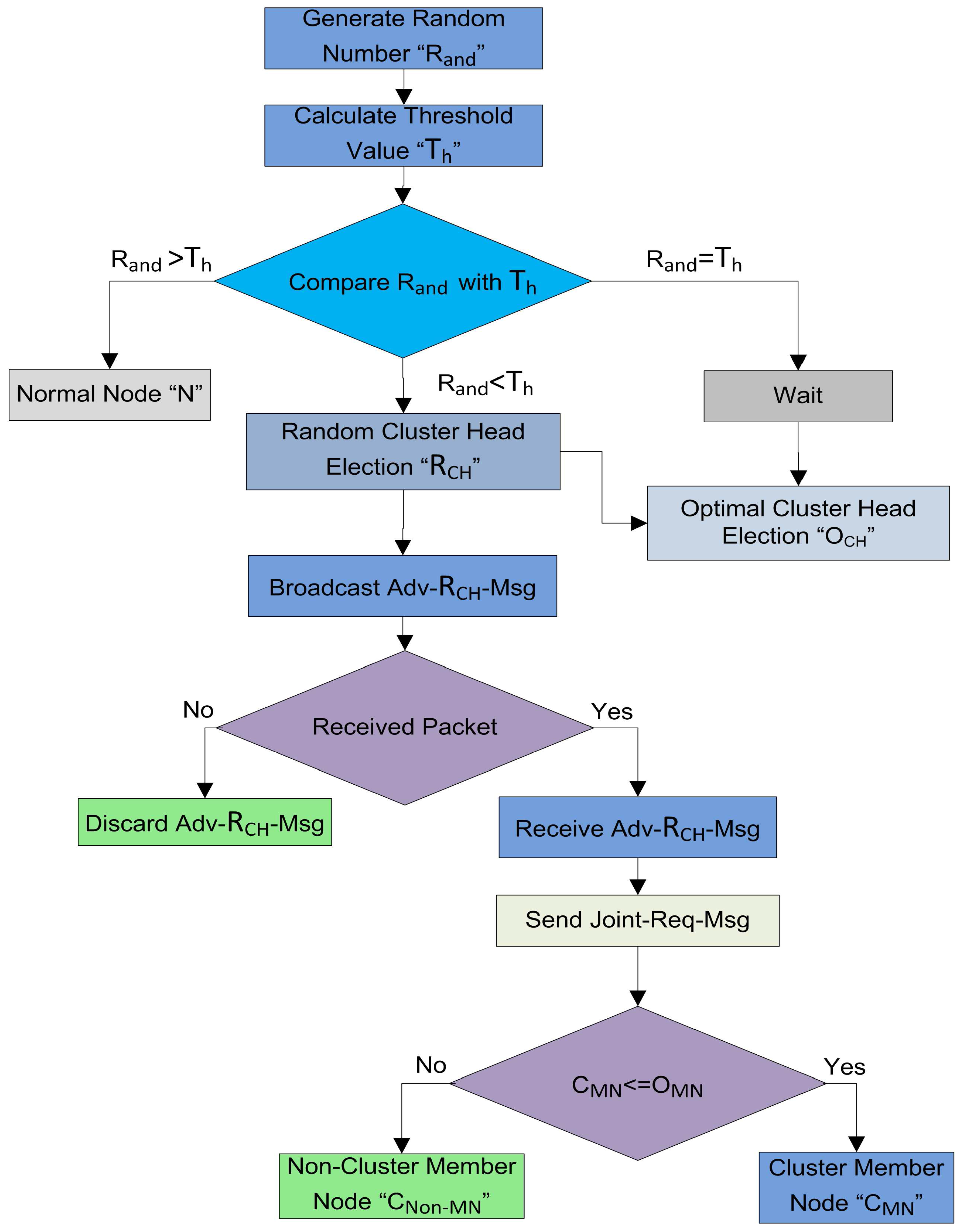
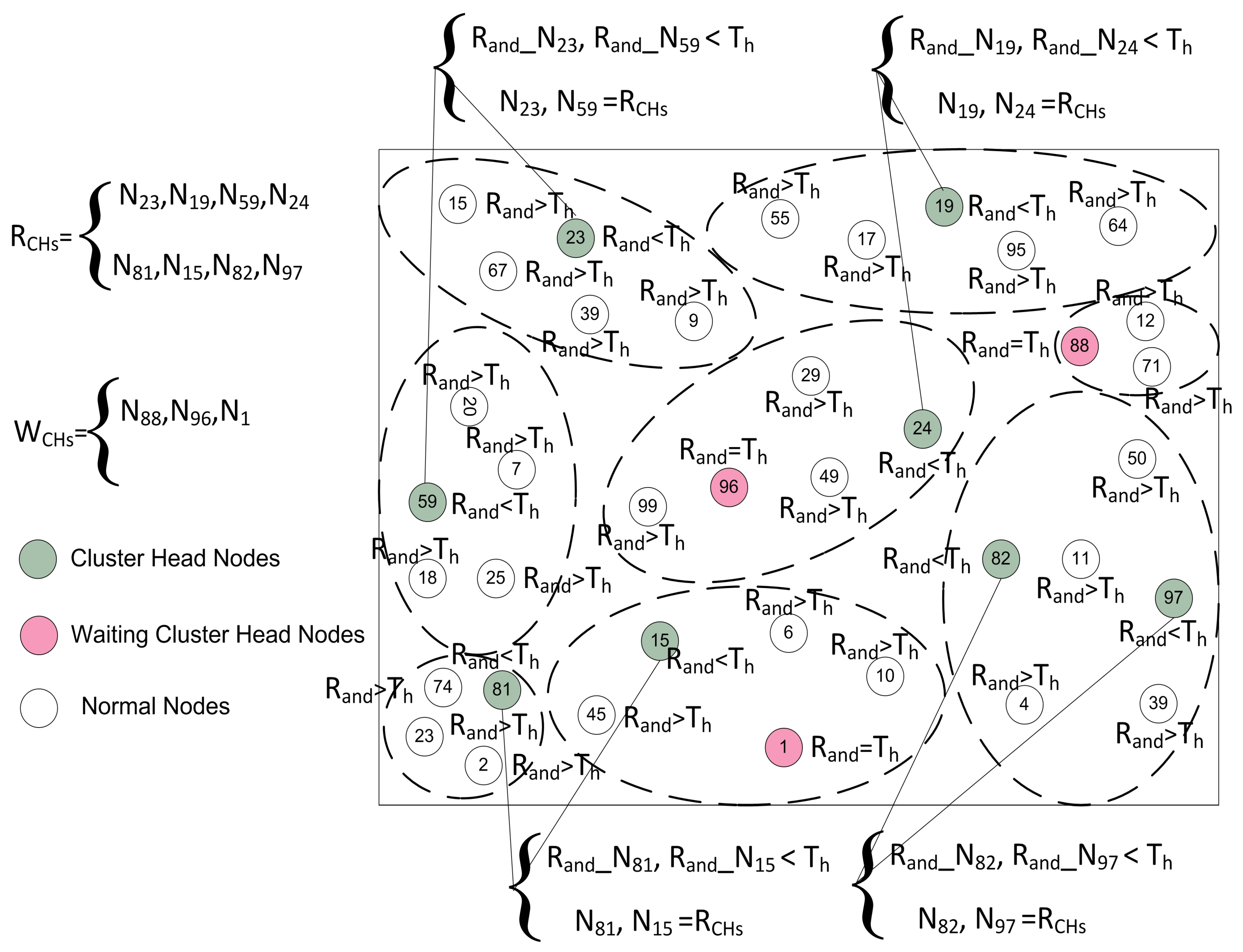
4.4.1. Random CH Selection
In this phase, every node elects itself as a local CH on the basis of certain probability. In SEED [
11], every node in the network selects itself as CH on the basis of the desired percentage of CHs for the whole network. Each node chooses a random number
from zero to one, then it calculates the threshold
. The node compares the self-generated random number
with the calculated
. If the selected random number
is less than or equal to threshold
, then this specific node becomes a CH for the current round. Firstly, in our proposed protocol the CHs are selected by following the random procedure. The detail of the random CH selection process of our model is shown in
Figure 4.
The threshold
calculating formula for MOCHs is defined as follows:
where,
P is the desired percentage of CHs,
r is the current round,
is a node i, and
G is the set of nodes that have not been CHs in the previous
rounds. After calculating the threshold, each node in the network generates a random number
and calculates its status for the current round on the basis of the generated number. The random selection of CHs is made by each node itself on the basis of following three cases:
- Case 1
: The node cannot be designated as a CH for the current round and this node is nominated as a root node ”N”.
- Case 2
: In this case, the node checks whether it remained CH or not in the previous round. The node verifies its status through the list G, which contains all the names of the root nodes in the previous round. If its name is present in the list G, then it declares its status as a for the current round.
- Case 3
: In this scenario, the node becomes a and waits for the decision of the BS for finalizing the optimal number of .
After the random CH selection process, the nodes which are selected as
advertise their status message as
-
-
on their intra-cluster communication range. The nodes which receive this advertisement message, send the
-
-
to these
. When the
receives this joint request, it checks the number of
. If the number of
are less than the pre-defined number, then
add this node as a
for this round. The complete random CH selection and random cluster formation procedures are defined in
Figure 5.
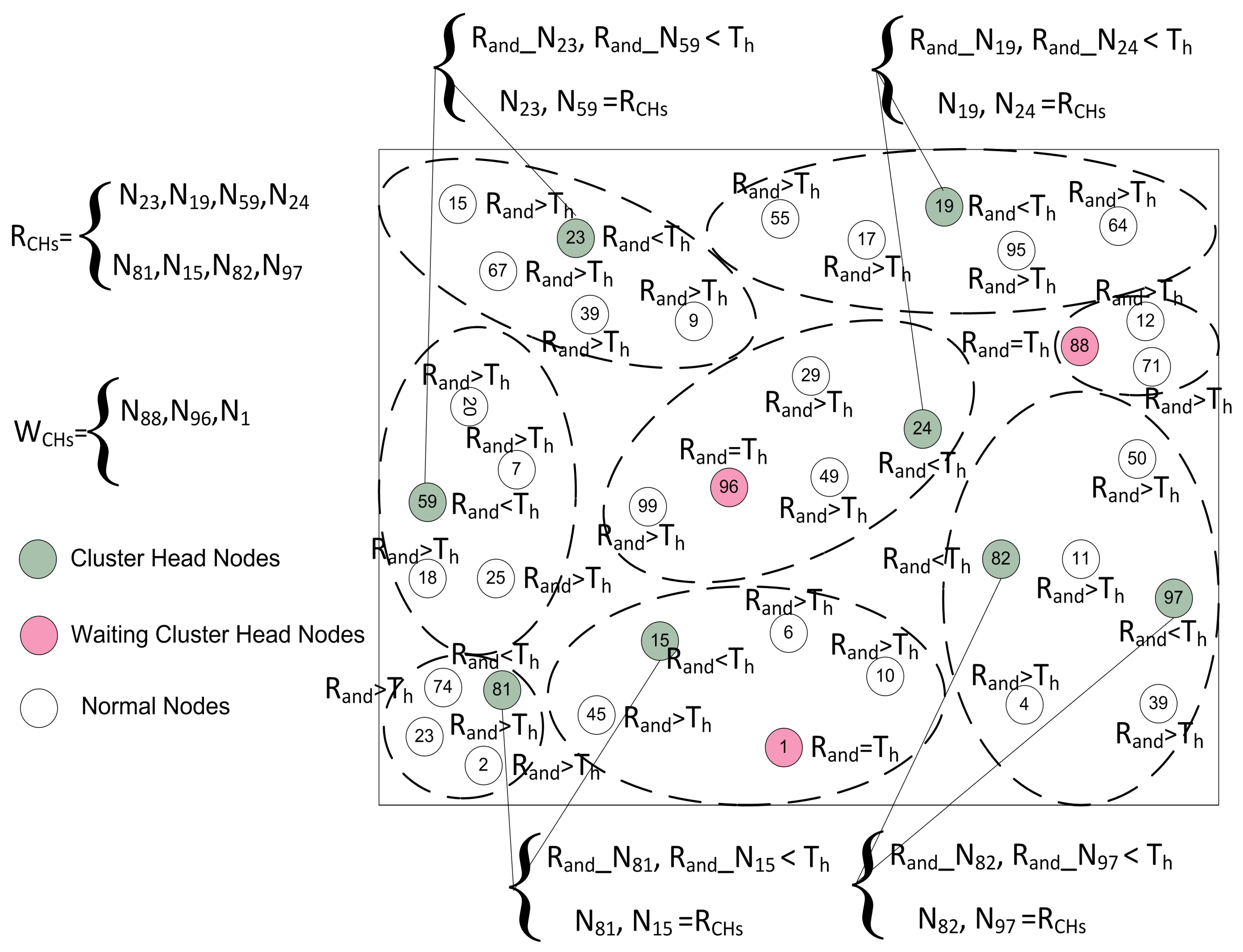
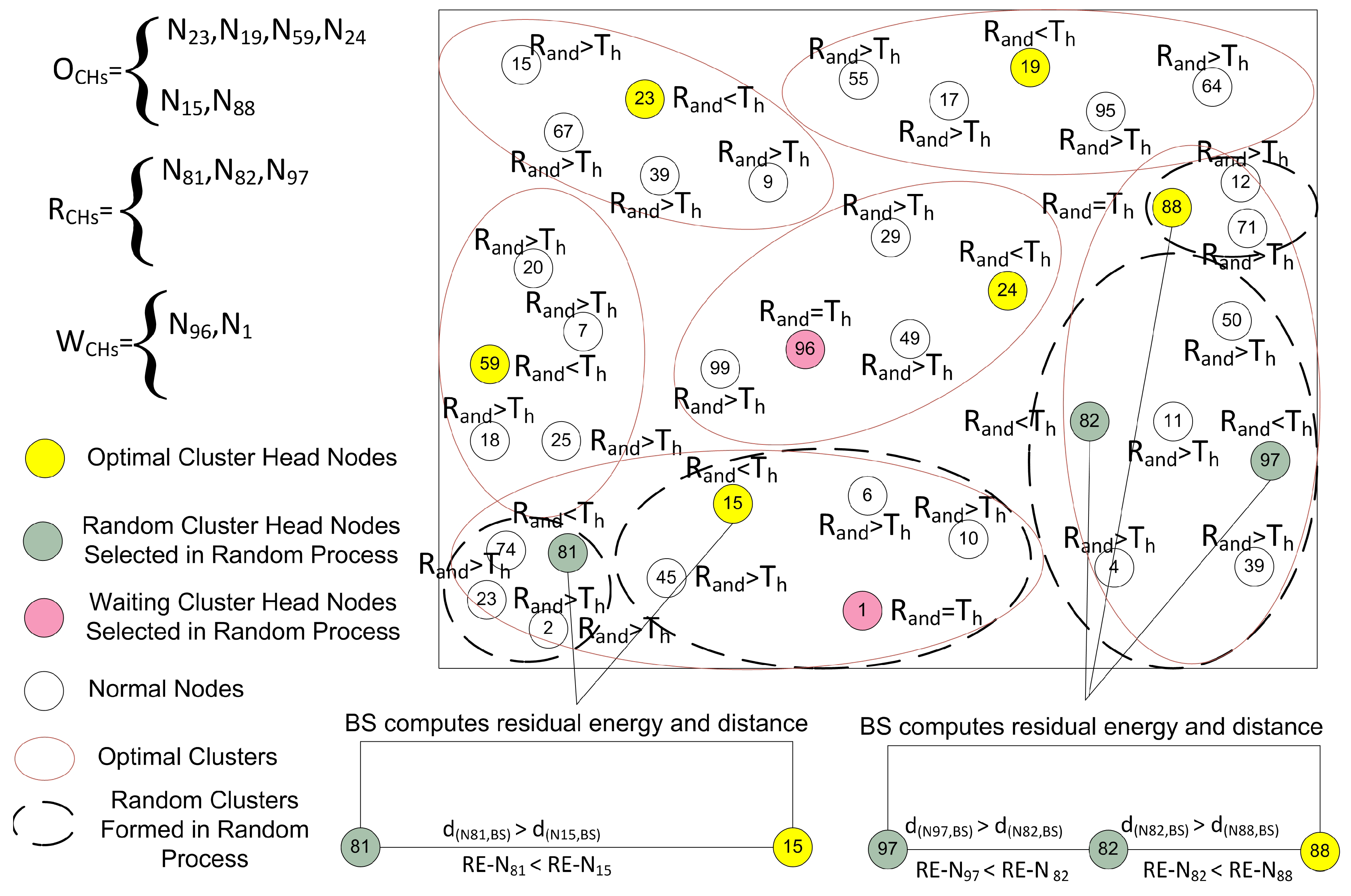
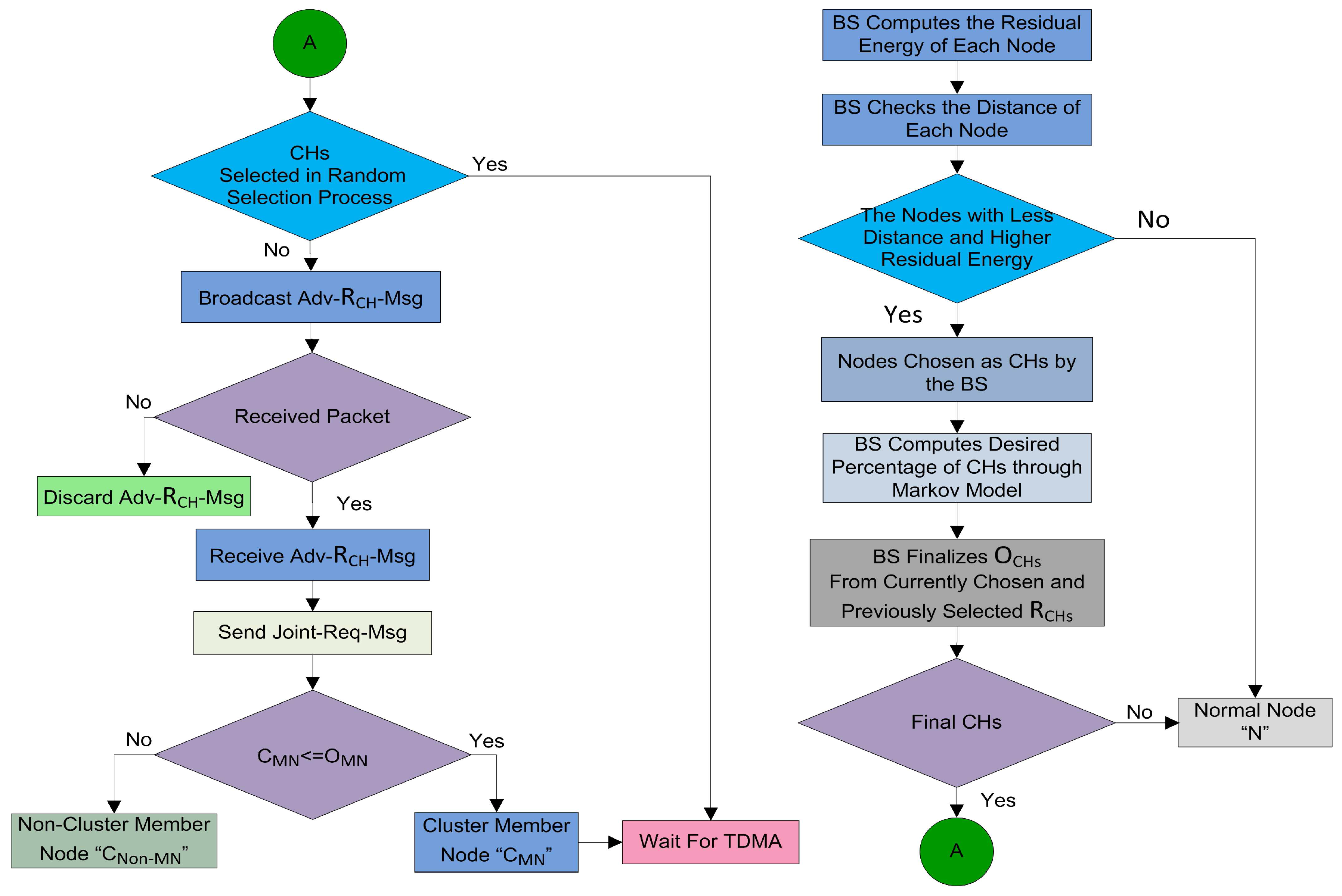
4.4.2. Optimal Number of CH Selection
Proper and careful utilization of the available resources can also help in increasing the lifetime of the network. The first step in this way is that the selection of CHs should be proper. An uneven number of CHs in every round can be a waste of resources. As defined earlier, the CH is responsible for collecting, fusing, and sending data of
. So, each step in the cluster formation consumes the power of the nodes. After the random selection of the CHs, it is essential to check whether the selected number of CHs are meeting the optimality criteria or not. In this step, the BS is involved to verify the number of CHs selected in the random selection process as demonstrated in
Figure 6. The selection of CHs through a random selection process is not optimal because the CHs are selected through the distributed algorithm. So, there is a need to optimize the resources of the network. It is necessary to check if the resources are consumed in a balanced way or not. To supervise all this CH selection and cluster formation process, we engage the BS to supervise and to certify all these selection procedures. The decisions of BS are more reliable, as the BS is enriched with high-speed processors and storage capabilities as compared to root nodes [
9]. The BS is not just following a single criterion, it also takes into account the distance, remaining energy, the average energy of the network, and member nodes for CH selection. Before proceeding to the next phase, the BS makes sure that the selected CHs in a random process are optimized or not. The BS calculates the optimal number of CHs through the Markov model [
26] using Equation (
4) according to the number of sensor nodes in the network. The BS is the central entity; it can reject an already selected CH in the random selection process as revealed in
Figure 6. After that, there are three cases for finalizing the optimal number of CHs as discussed below:
- Case 1
: The BS discards some and all the waiting to achieve the optimal value.
- Case 2
: The BS selects some new from the waiting CHs equal to the optimal value. If the are not enough, then the BS can also select some new CHs equal to the optimal number from the root nodes.
- Case 3
: The BS allows the process to move to the next phase.
where,
represent optimal CHs,
express the randomly selected CHs, and
express the waiting CHs. According to the first order radio energy model [
11], to attain a suitable Signal to Noise Ratio (SNR) in transmitting a
l-bit message over a distance
d, the energy spent by the radio is given as:
Where,
is the energy consumed per bit to run the transmitter or the receiver circuit,
and
depend on the transmitter amplifier model we use, and
d is the distance between the sender and the receiver. We assume that the radio channel is symmetric such that the energy required to transmit a message from node A to node B is the same as the energy required to transmit a message from node B to node A for a given SNR. The energy consumed by a CH for aggregating and sending data to the BS is computed as:
where,
K is the number of clusters in a network of
N nodes. As we discuss earlier, that the BS has unlimited resources. Therefore, these calculations and computations cannot affect the network lifetime. When the BS gets the
, then it ensures that the already selected
are near to the optimal number or not. If the network is uniformly divided into clusters on the basis of selected
, then the BS allows the system to move on the next phase. Otherwise, it picks a few nodes with higher residual energy and lesser communication distance according to the calculated optimal number through the Markov model. In the first round, the BS selects the CHs on the basis of communication distance from the entire network. However, in the other rounds the sensor nodes, including CHs send their residual energy information with the data packets. As the rounds proceed, each node consumes energy in sensing, transmission, and reception. At the end of each round the
and CHs calculate their remaining energy and send this information to the BS with the data packets. Now, the BS is well aware of the remaining energies of all the
and the CHs at the end of every round. So, the BS uses this information for selecting the
for the next round. As a result, after each round the BS updates the residual energy information of each node in the network. Finally, the
are selected on the basis of remaining energy and communication distance. If sometimes the nodes selected through this criterion are less than an optimal number, then the CHs from the
list and the
list with higher residual energy are preferred to be selected as
. The optimal CH selection, and cluster formation procedures are shown in
Figure 7.
4.4.3. Association of Cluster Members (ACM) and Cluster Formation (CF)
In current clustering architecture, a sensor node obtains the CH status messages from the chosen CHs. It evaluates their received signal strengths. Then this node joints with a CH which has the strongest received signal strength among them. Whenever a node associates itself with a CH on the basis of receiving signal strengths, then the following major points of concern arise:
If CH positioned backward compared to its direction of transmission towards the BS, back transmission occurs. This type of data transmission contributes to extending the general path length traveled by the locally collected data.
The sizes of clusters become non-uniform ensuring the non-uniform overhead on the CHs.
To solve the association problems, we consider a specific scenario in which a member node
N receives the
status message
-
-
from two
, e.g.,
and
. Then the node locates its distance
from the BS, and determines a midpoint
. Afterward, the node compares the value of received signal from both the CHs at this midpoint. Since at this midpoint the strength of the signal from
is greater than the
. As a result, the node
N sends a joint request
-
-
to the
. The node
N is situated at the lesser distance from
as compared to
, but the node joins the
to omit the back transmission. To join with
is beneficial for the node to save the energy. To understand this, we develop the following mathematical expressions:
where,
H is a line joining
and a point
Q, while
Q is a point on the line between
and the BS and
X is the distance between point
Q and midpoint
.
where,
, by adding the Equations (
13) and (
14), we have:
After substituting,
We can note from Equation (
18) that the distance of the node from BS
is constant, and
is directly related to
. If we minimize this
, then, we can attain our objective which is equivalent to
. Consequently, if a member node selects the CH closer to the midpoint towards the BS, than the squared distance of their communication is smaller, which means that the energy utilization is minimized for that node, leading to increasing the network lifetime. The energy consumption of a node in a cluster formation process is:
So, the total energy consumed for dividing the whole network into clusters is:
The WSN nodes have inbuilt resource limitations, so, the clustering procedure is commonly adopted for WSN applications to accomplish the energy efficiency. Clustering is an efficient method to organize the WSN nodes into hierarchal groups. This hierarchal structure is adopted at different layers like the Network layer or the Data Link layer according to the system requirement. Clustering improves the system performance by reducing the local network traffic, the long-distance communication, and the routing information of root nodes. The proposed model also adopts clustering due to the following reasons:
Clustering facilitates in reducing the cost of topology maintenance as a reaction to dynamic topology changes.
In a clustered structure, the topology reconfiguration is only performed on the CH level and it does not affect root nodes.
Clustering also minimizes the overhead generated due to dynamic topology adaptation.
Clustering allows resource utilization optimization which is successfully used to save time and energy.
Lemma 3. The time and data packet exchange complexity of MOCHs for cluster formation in a round is . While the time and the message exchange complexity of the proposed scheme for dividing the whole network into random clusters during a round with N number of nodes is .
Proof. After the selection of optimal number of CHs, the election process is completed. Each of the sensor nodes either sends or receives a message. The nodes which are selected as CHs for this round advertise their status as CHs, while the send a -- to their associated CHs merely. Therefore, the data packet exchange complexity of a node during a round is . Thus, the information exchange complexity of the proposed model for developing clusters in a round is . In the cluster formation procedure, each sensor node in the sensing field needs to process nodes despite the fact that in severe cases to become a . This entire process is completed in a predefined time slot. The time complexity of a round for selecting a CH is the . Consequently, the time complexity of cluster formation in a round of the proposed scheme is . ☐
Lemma 4. The time complexity of MOCHs for selecting a CH in a round is . While the time complexity of the proposed scheme for the whole network with N number of nodes is .
Proof. In a random CH selection process of MOCHs, all the nodes in the network generate a random number
between 0 and 1. Then these nodes compare this generated number
with the threshold value
, pre-computed by employing the Equation (
10). If the randomly generated number
of a node is less than the threshold value computed by Equation (
10), in this case that node elects itself as a CH for this current round. This entire course of action for random CH selection is completed during a predefined time slot. Consequently, the time complexity of a single node for selecting it as a CH is
. Accordingly, the time complexity of selecting CHs in a round for the proposed model is
. ☐
4.4.4. Dealing with Non-Associated Cluster Members (NACM)
Some sensor nodes in the network are not receiving a CH advertisement message from any CH. These nodes wait for a specific time slot for the CH advertisement message and after that predefined time slot, these nodes start sending their data directly to the BS. In the literature of WSN [
7,
8,
9,
10,
11], these self-generated CHs are known as
. These self-generated force CHs are a waste of system resources, because all the time in a round these force CHs repeatedly send their information to the BS which affects the network stability. We also define a strategy to deal with these force CHs and we named them Non-Associated Cluster Members (NACM). In MOCHs, if a node does not receive any CH advertisement message, it will send a data forwarding request to the CH of its closest neighbor node. The requested CH will assign a data slot for this
node at the request. Then the neighbor node will forward the data of this
node during the assigned slot as shown
Figure 8. The energy consumption of a
node to forward a data packet of
l bits is:
Here,
is the distance between a field node and its neighbor (NBR). The energy consumption of a neighbor node to receive a data packet of
l bits is:
4.5. Scheduling Phase (SP)
Once all the sensor nodes are structured into clusters, each CH creates a schedule for the in its cluster. This allows the radio components of each to be turned off during all the time slots except its transmit time, thus this action minimizes the energy dissipated by the individual sensors.
Thus, overall energy consumption in SP is computed as in [
11]:
There are two modes of communication like Ready-to-receive and Time Division Multiple Access (TDMA). In the Ready-to-receive mode, the nodes remain active all the time to send its data. Thus consumes a lot of energy resources. While in the second mode, the nodes, after receiving their time slots, turn into sleeping mode and set the right time to awake for communication. In the sleeping mode, the sensor nodes save a lot of energy. We adopted the TDMA mode for our proposed model because it saves the energy resources and also it is designed for communication over shortest path on established links in awake up mode.
Lemma 5. In the MOCHs, TDMA slot allocation time and message exchange complexity are for each node and for the entire network with nodes is . Where N is number of member nodes and is the set of optimal number of CHs.
Proof. After cluster formation process, each CH in the network sends a TDMA slot to each member node. So, the message exchange complexity of one node is O(1). Therefore, the message exchange complexity for TDMA slot allocation in MOCHs algorithm is . After receiving this TDMA schedule each sends an acknowledgment message to the CH. This whole procedure is done during a predefined time period. The time complexity of one node is O(1). Thus, the time complexity for TDMA slot allocation in MOCHs algorithm is . ☐
4.6. Data Transmission (DT) phase
The data transmission phase starts after the time slots are allocated to every associated
in the network. This phase is the most important phase in the lifetime of the network because nodes in this phase send their sensed data to their relevant CH which aggregates and forwards this correlated data to the BS. The total energy consumed by all the nodes for transmitting and receiving a full-length data packet containing
F frames is calculated in a similar way as in [
11]:
After computing the energy consumed in each phase of a round, finally, we calculate the energy consumed by all the nodes during a complete round as:
In recent cluster-based protocols [
9,
10,
12,
27], the CHs convey their data to the BS through relay nodes. Most of the times the CHs towards the BS are chosen as relay nodes. In this case, the CHs sensing their area and also working as the head nodes. The CHs are ordinary nodes with no extra resources and when these ordinary nodes are working as CHs their energy consumption increase. However, when these nodes are selected as relay nodes to forward the data of backward CH nodes, these nodes exhaust their power resources very quickly. The CH nodes, which are closer to the BS are most of the time run out of batteries making the network unstable much earlier. In MOCHs, the CHs collect all the information from their
and then they directly convey collected information to the BS.
Lemma 6. All the sensed data packets in the network sensed by the arrive at the CHs.
Proof. The root nodes, which receives a CH status message --, send their -- to the concern CHs. The CHs then accept their request and these root nodes become the . After cluster formation, the CH sends a TDMA slot to each node individually in which send their packets to the CHs. So, each member node in the network sends one data packet to the CH. Hence, all the nodes in the network send all the sensed data packets to the CHs. ☐




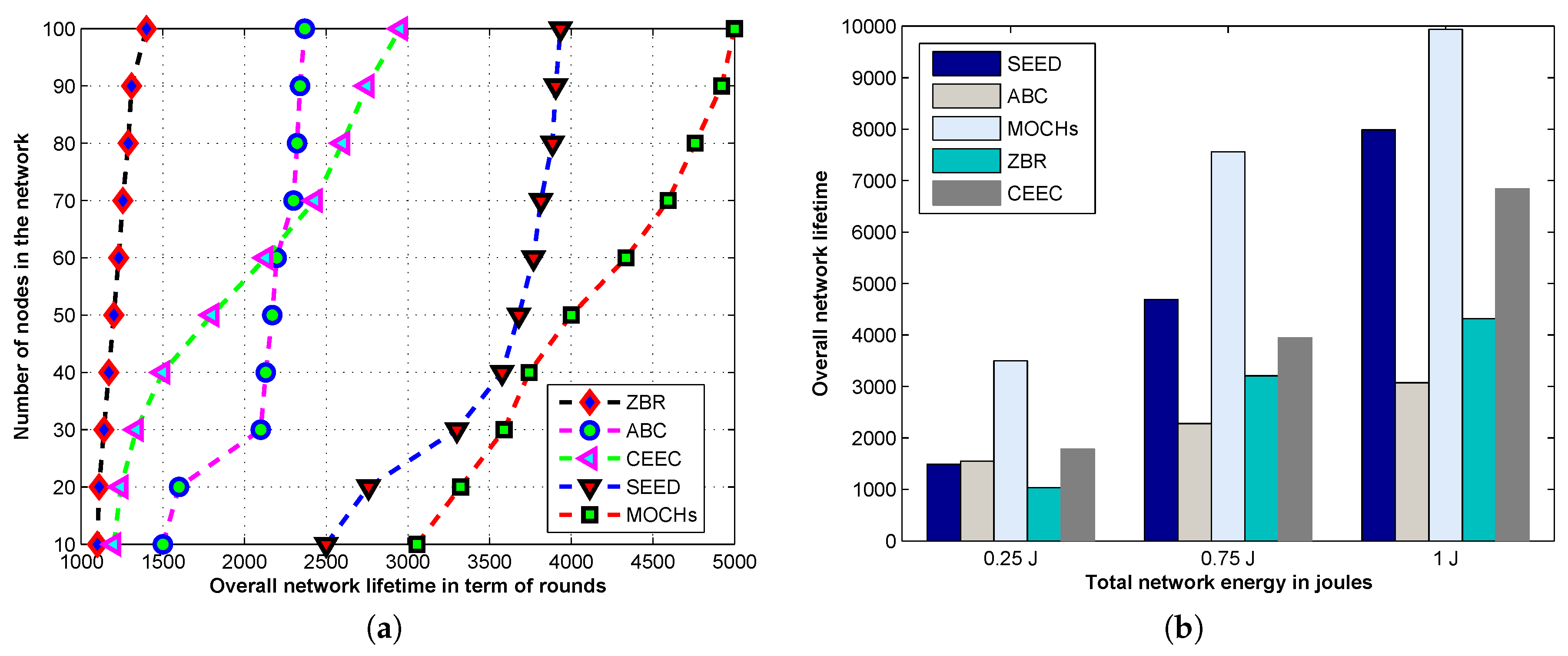
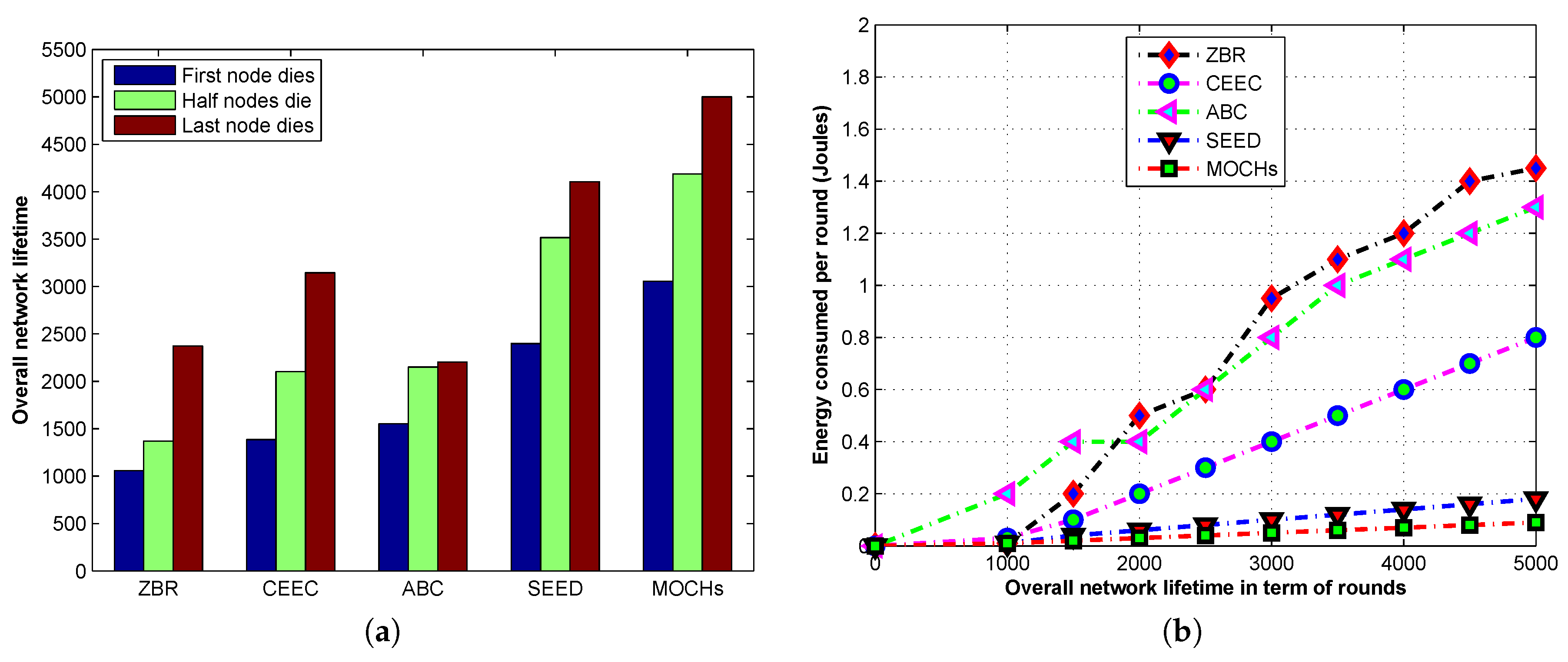
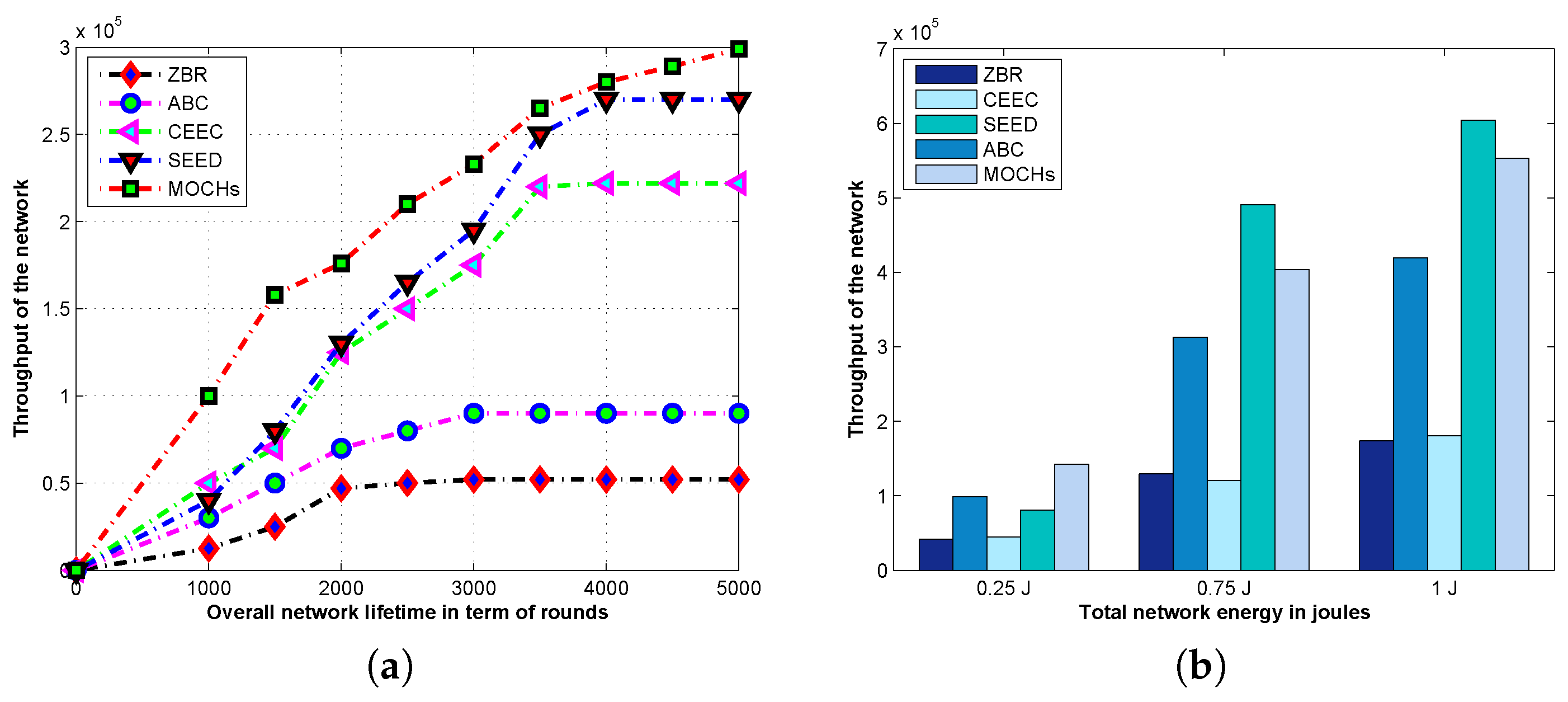
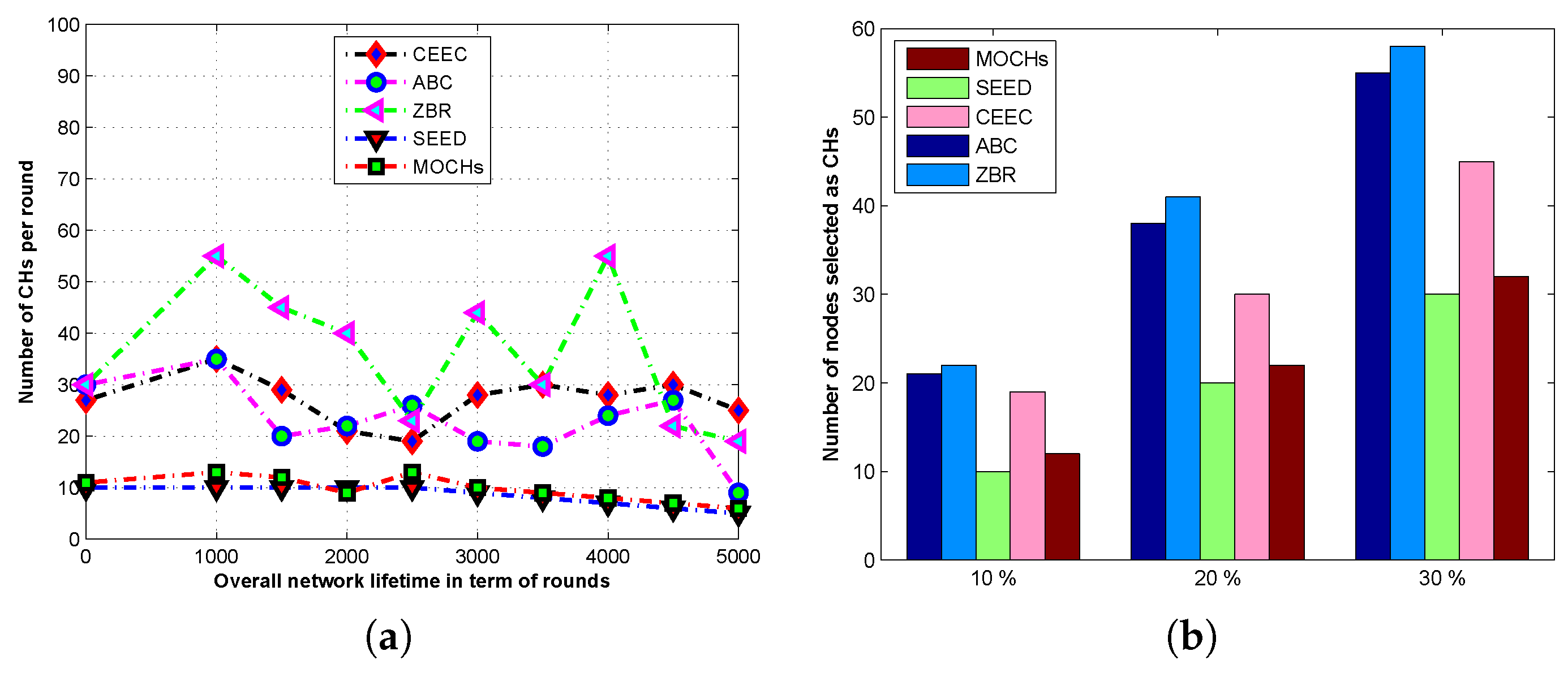

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}