1. Introduction
The identification of mobile phones through their built-in components has been extensively investigated by researchers for different electronic components: the internal digital camera [
1], the RF transmission components for various communication standards (e.g., GSM, WiFi) as described in [
2,
3], the microphones [
4,
5] and the accelerometers [
6,
7]. The identification is performed by exploiting tiny physical differences, which characterize electronic components due to the manufacturing process or the use of different materials. These differences can be observed in the digital output generated by the electronic components when they are stimulated by a similar or identical input (e.g., motion pattern stimulus to an accelerometer). Through a statistical analysis of the digital output, it is possible to extract the fingerprints and use machine learning algorithms to classify and identify the devices (e.g., mobile phones). The proposed classification and identification of the devices is based on the fact that physical differences impact the statistical features of the digital output (e.g., variance, kurtosis). Because it is not known a priori which statistical features are more relevant, experimental campaigns are needed in order to identify the most appropriate statistical features.
The identification of mobile phones on the basis of their physical features is an important function in many applications. For example, the correct identification of electronic devices (e.g., mobile phones) is useful in the fight against the counterfeiting and distribution of electronic goods. Many tools and methods to identify counterfeit products are based on visual or augmented inspection techniques, like Scanning Acoustic Microscopy (SAM) and Scanning Electron Microscopy (SEM). Since these methods have an important drawback of requiring expensive tools, some researchers have instead proposed more cost-effective approaches based on the statistical analysis of the digital output of the components [
8].
Another application is related to multi-factor authentication, where the physical properties of the mobile phone can complement or augment authentication methods based on cryptographic means, that is the identification based on a cryptographic key can be combined with the identification based on the physical properties. This approach was used in [
9,
10].
The identification of mobile phones on the basis of their built-in components, like RF transmission components, digital cameras, microphones and accelerometers, has been extensively investigated in the literature. However, no cases on mobile phone identification based on magnetometers have been reported to date. A survey of the different techniques and approaches is presented here.
Mobile phone identification based on the RF fingerprinting has been applied to many different wireless communication standards supported by the mobile phone, like WiFi, GSM, Bluetooth, and so on. In most cases, the RF fingerprinting is implemented by collecting the RF emissions when the mobile phone is transmitting. For example, in the case of GSM or WiFi, the mobile phone emits bursts of traffic, which are repeated with a high frequency. An RF receiver (e.g., a spectrum analyzer or a digitizer) is used to collect the signal in space, downsample it, filter it and then digitize it. The physical differences of the RF transmitter appear in the time series of the digitized collected bursts as small variations between one mobile phone to another. Then, specific statistical features like variance, skewness and kurtosis are extracted from the time series and used as mobile phone fingerprints. This is the approach used for WiFi in [
11] and for GSM in [
12].
A similar approach is based on the processing of the digital output generated by the sensors present in the mobile phone. By following this approach, the observables used for the mobile phone identification are not collected by an external device, but they are collected by the mobile phone itself once the sensors are stimulated in some way. This approach has been used for the internal digital cameras starting from the pioneering work by Lukas et al. [
1]. In a digital camera, several sources of imperfection and noise show up during the various stages of the image acquisition process. Even if the imaging sensor takes a picture of an absolutely uniformly lit scene, the resulting digital image can exhibit small changes in intensity between individual pixels. These changes are due to various hardware imperfections or differences among cameras, which include lens radial distortion, chromatic aberrations, dust on the lens, sensor pattern noise, high-ISO sensitivity noise, white noise and shot noise. Some of these noise components (e.g., high-ISO noise, white noise and shot noise) have a random distribution, and if a large number of frames are used and added or averaged together, these noise components tend to cancel out. This is the case of SPN, which has been widely used to uniquely identify with high accuracy digital cameras and mobile phones, as described in the survey paper [
13]. In this case, the stimulation is the light received by the camera.
Fingerprinting through the built-in microphones characterization of a mobile phone was also investigated in the literature by [
5,
14,
15,
16]. The verification and identification of mobile phones with audio acquisition capability (e.g., mobile phones, tablets, webcams, camcorders, cordless phones) can be achieved by analyzing the response of the audio circuit to a standard stimulus (e.g., a standard tone). Because of the nominal values of the electronic components and the different designs employed by the various manufacturers, the microphones of the different mobile phones introduce a different convolution distortion of the input audio signal (i.e., frequency response), which becomes part of the recorded audio. In general, the authors of the above papers use the MFCC to define the features used for fingerprinting as commonly employed to fingerprint human speakers. Most of the papers use SVMs to classify mobile phones on the basis of the audio recordings.
Mobile identification based on MEMS sensor fingerprinting and, in particular, on accelerometers has been presented mainly in [
6,
17,
18] where the authors describe the experimental identification of mobile phones using their built-in accelerometers and gyroscopes. Data are collected when the phones are subject to repeatable movements performed by a high precision robotic arm, so that a considerable dataset from which are extracted several statistical features is obtained. Then, using an SVM classifier, phones of the same brand and model are identified with an accuracy higher than 90% for some combination of features. Usually, the authors use variance, skewness, kurtosis and entropy-related (e.g., Shannon entropy, log entropy, threshold entropy) features for classification. Results show that, if properly stimulated, built-in accelerometers and gyroscopes can be used to extract fingerprints that allow for a very precise intra-model identification, thus confirming the applicability to anti-counterfeiting and other scenarios.
To our knowledge, no authors have attempted to identify and classify mobile phones on the basis of the built-in magnetometers, which are subject to a motion pattern.
The objective of this paper is to evaluate a technique for mobile phone identification based on the built-in magnetometers of the mobile phone, which are now present in most of the recent models of mobile phones. The technique is based on the stimulation of the magnetometers using a rotating platform with a fixed magnet. A mobile phone is installed on a cost-effective rotating platform spinning at a constant speed. Every time the mobile phone passes in front of the magnet, the magnetic field stimulates the magnetometer of the mobile phone. The digital output of the magnetometer is collected by the mobile phone itself and processed through appropriate statistical tools. In particular, statistical features like variance, skewness and kurtosis are extracted and used as fingerprints. A SVM learning algorithm is used to classify the different mobile phones on the basis of the extracted statistical features. SVMs are used here for their superior performance to other machine learning algorithms, like KNN and naive Bayes. This difference in performance among the machine learning algorithms is reported in the Results section of this paper. For each mobile phone, the experiment is repeated across six different days to ensure consistency in the results. A total of 10 phones from different brands and models or of the same model were used in the experiment. Our experimental evidence shows that inter-model (i.e., different models and brands) classification is possible with great accuracy, but intra-model (i.e., phones with different serial numbers and same model) classification is far more challenging, the resulting accuracy being just slightly better than random guessing.
The remainder of the paper is organized as follows:
Section 2 provides the overall methodology for the fingerprinting data collection, analysis and comparison.
Section 3 shows the results of our tests, while in
Section 4, we wrap-up, make final comments and point to future work.
2. Methodology for Data Acquisition and Processing
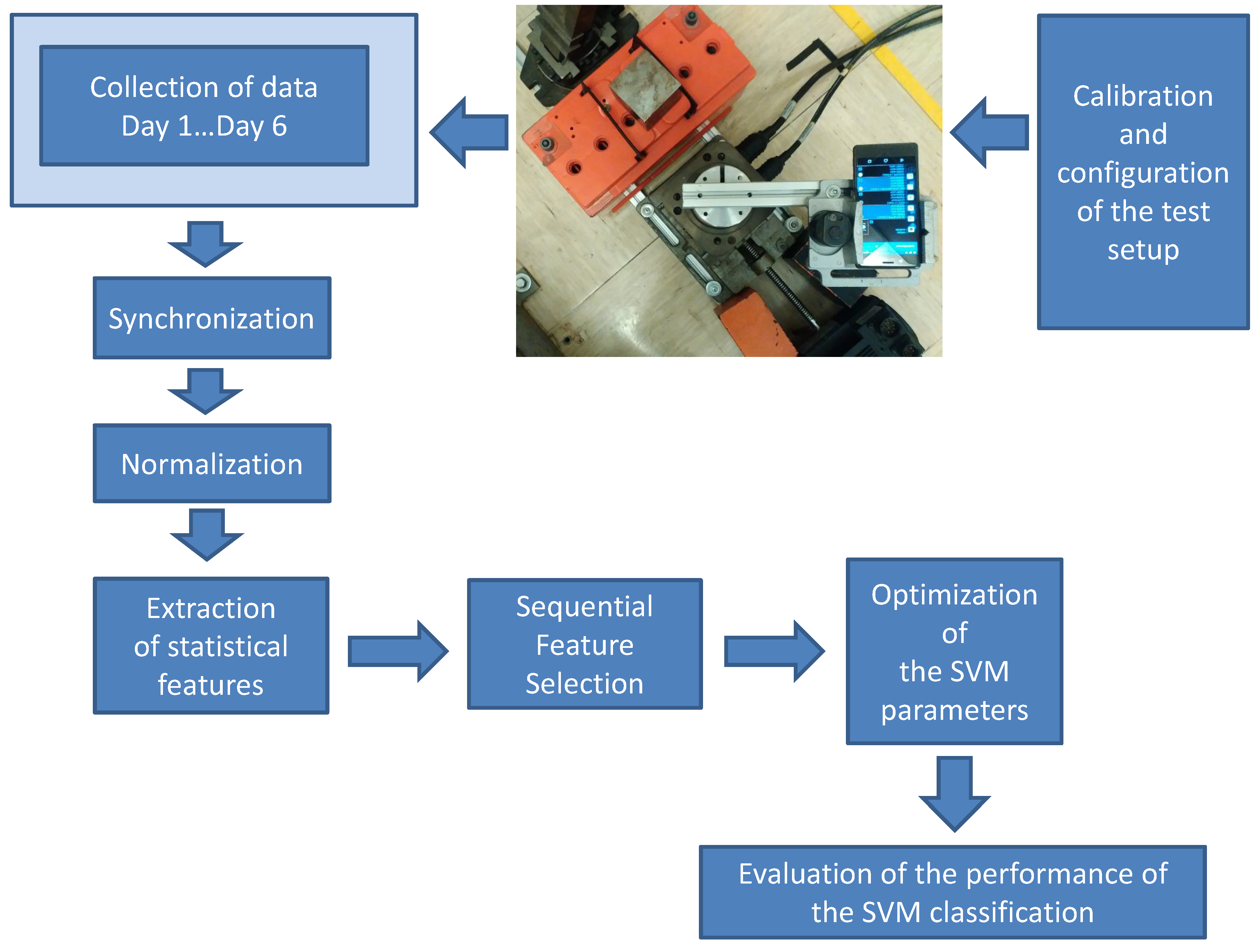
The overall methodology flow used in the paper for the collection of data, processing and analysis is shown in
Figure 1. Each step is described in the following paragraphs.
The initial step is the setup of the test bed where the rotating platform for the definition of the motion pattern is configured. The test bed is illustrated in
Figure 2, where a mobile phone is installed on a cost-effective rotating platform and a magnetic element (an iron cube) is positioned at one extreme of the test bed. The rotating platform rotates the mobile phone with a specific motion pattern. The built-in magnetometer is stimulated by the magnetic element when it passes over it. The magnetic perturbation is collected and analyzed using an Android application installed in the mobile phone. In this experiment, we have used the AndroSensor application, but any other application that is able to record the digital output from the magnetometer can be used.
The application was configured to record the magnetometer digital output with a sampling time of 0.05 s. The motion pattern used in our experiment was as follows: +120 rpm then −120 rpm for 4 s, +150 rpm then −150 rpm for 3 s, +180 rpm then −180 rpm for 2 s. Each mobile phone was kept for 60 s before the start of the motion pattern in a fixed position in front of the magnet. Each mobile phone was subject to this motion pattern. A total of 10 mobile phones was used in the experiments.
Table 1 shows the brand and models of the phones used in the experiment. We note that three phones were from the same brand and model (i.e., HTC One X), while the other phones were from different brands and models.
In each measurement campaign, each mobile phone is subject to 25 repetitions of the motion pattern. This experimental campaign was executed during six different days (even at the distance of a week), so as to ensure that the fingerprints are stable over time. As a consequence, we have a total of 25*6 = 150 motion patterns (henceforth called responses in the rest of this paper), which can be used for classification.
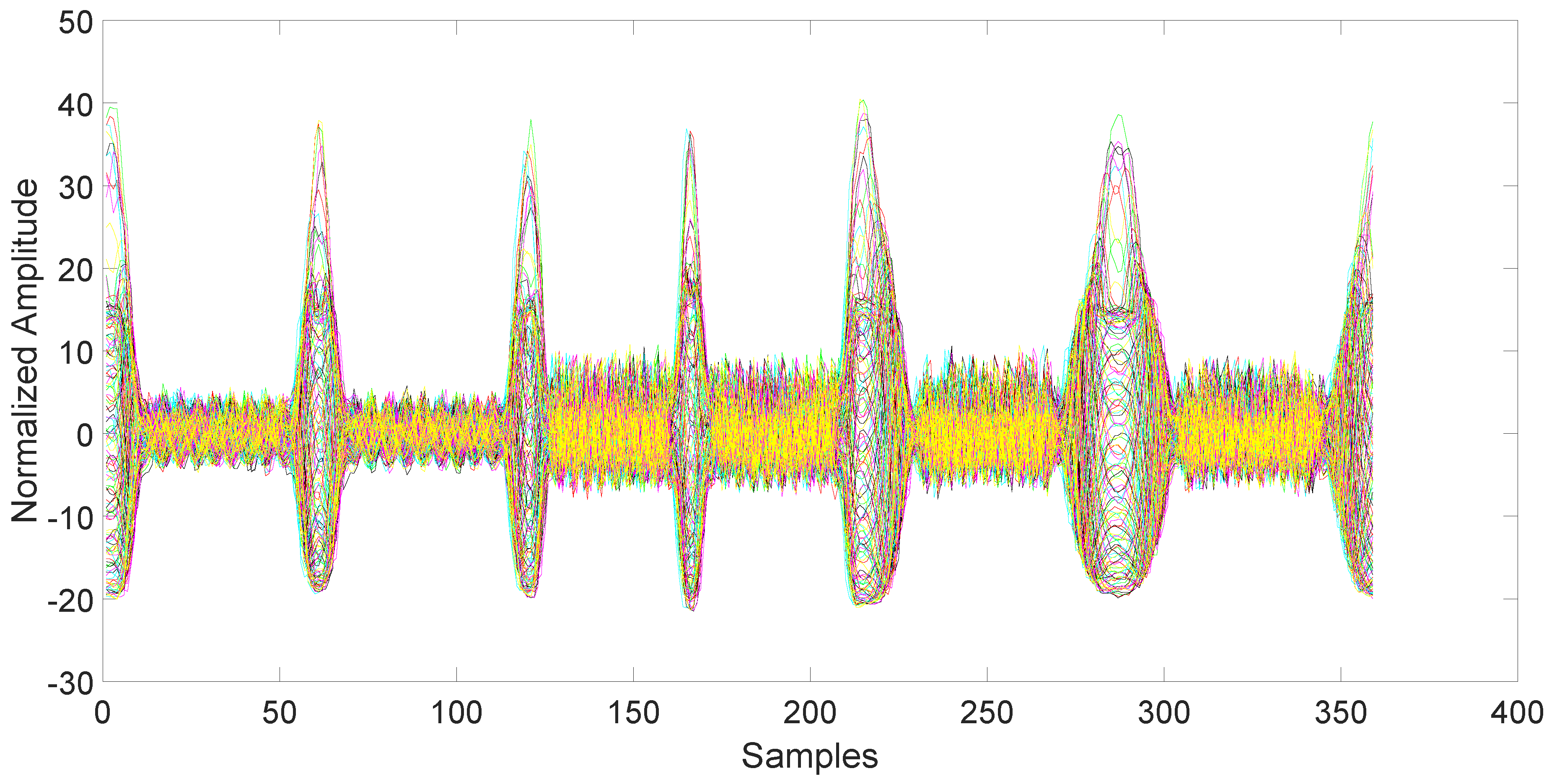
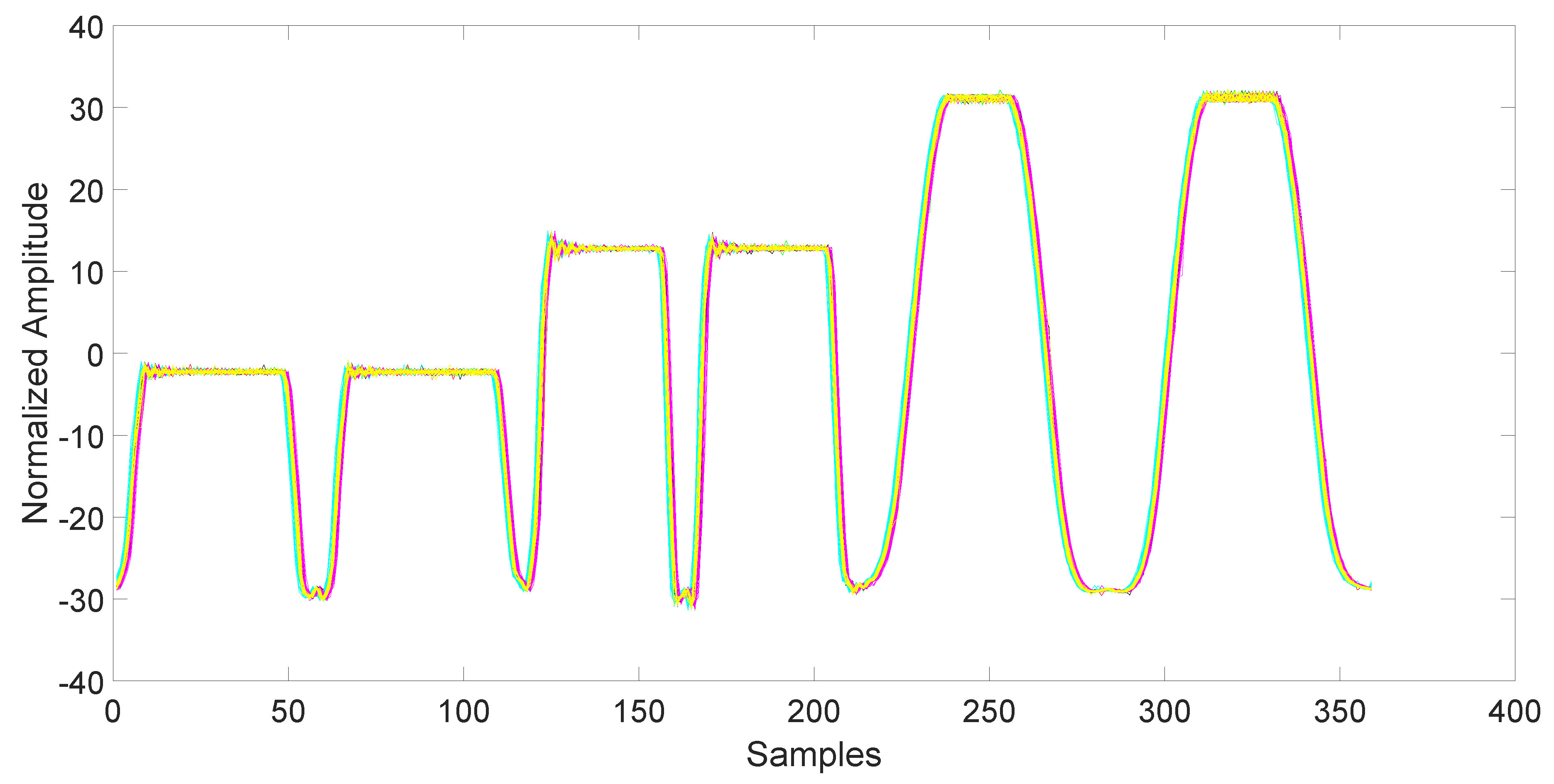
After collection, the data must be synchronized and normalized. This is an important step, since unsynchronized/unnormalized data can introduce a severe bias in the classification. Since the data collected by the magnetometers are particularly noisy (see
Figure 3), the synchronization is done using the related accelerometers data, which are also collected by the AndroSensor application with the same rate (see
Figure 4). The synchronization is performed using the variance trajectory technique. This technique is based on the calculation of the variance on a sliding window of samples, which moves along the response. The variance will increase substantially when the sliding windows meet a sharp rise or fall of the response. The rise of the variance identifies the beginning and the end of the response. This process is applied to all 150 responses gathered in the collection phase. The application of variance trajectory was inspired by its use in RF fingerprinting to detect the start and end of the wireless communication bursts [
11]. After synchronization, the data are normalized. The normalization is carried out by applying the RMS to each single response for each individual mobile phone.
To ensure that the fingerprints are stable over time, the classification through machine learning tools (described later on) is performed on the combination of the 150 collected responses. In other words, the representative set of each phone for classification is made up of 150 responses.
The next step is to extract the statistical features from the 150 responses, which can be seen as time series with specific characteristics of variance or entropy. We follow a similar approach as those proposed in the literature for different built-in components (e.g., RF and accelerometers), where variance, skewness, kurtosis and entropy are calculated for each response.
Table 2 shows the set of statistical features used in our classification problem.
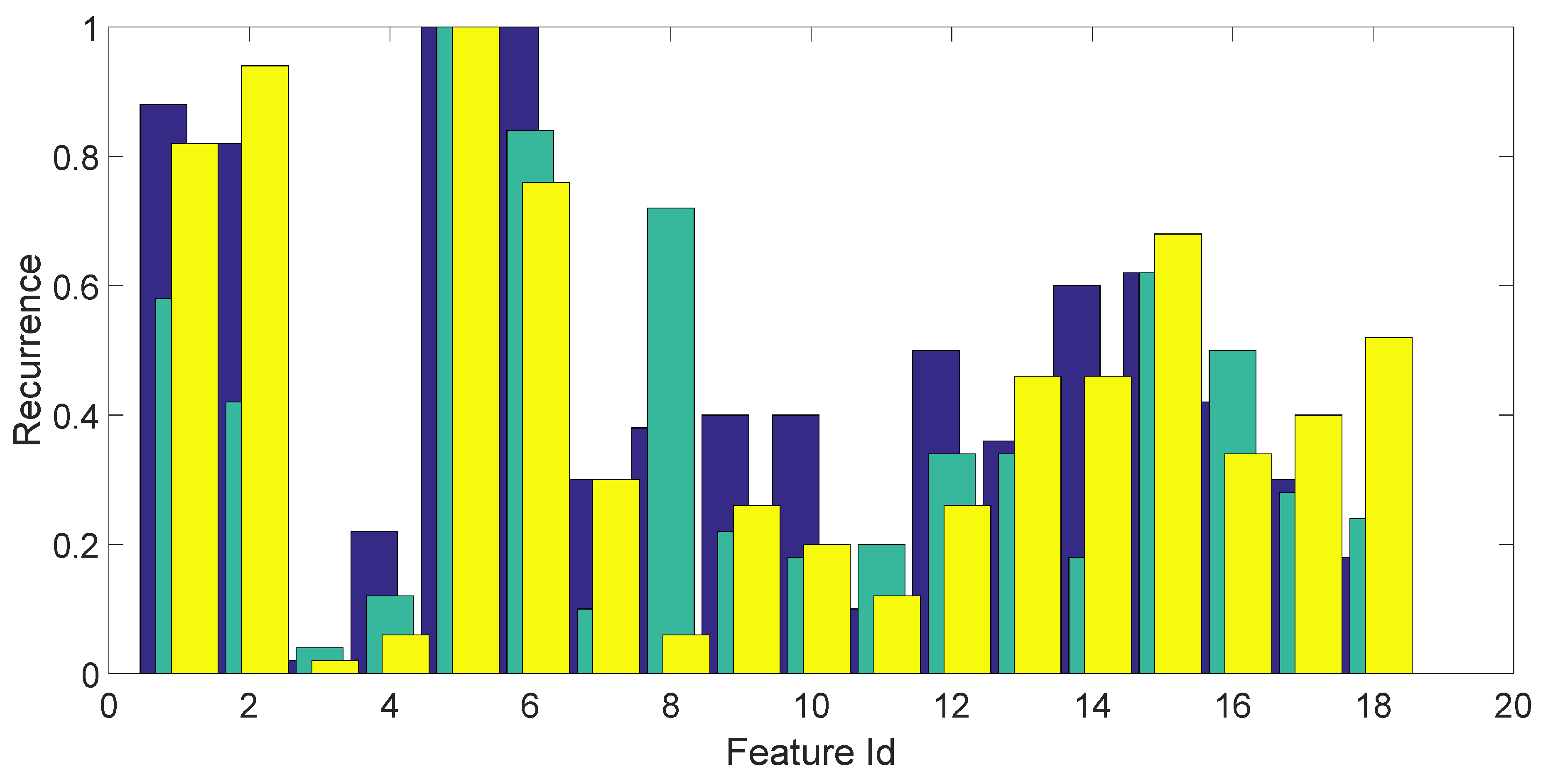
Now, since the resulting set of features is large, it is important to identify the subset of features that are expected to provide the best identification and verification accuracy. The process to achieve this goal is called feature selection. Various approaches to feature selection have been proposed in the literature (see, e.g., [
19]). In this paper, we combine the SFS algorithm with a brute force approach. SFS starts with a single feature or a small set of features and incrementally adds a new feature at the time by measuring the resulting value of a given metric. If the metric improves, the feature is added; otherwise, another feature is checked for inclusion. The process continues until no further improvement of the metric is detected.
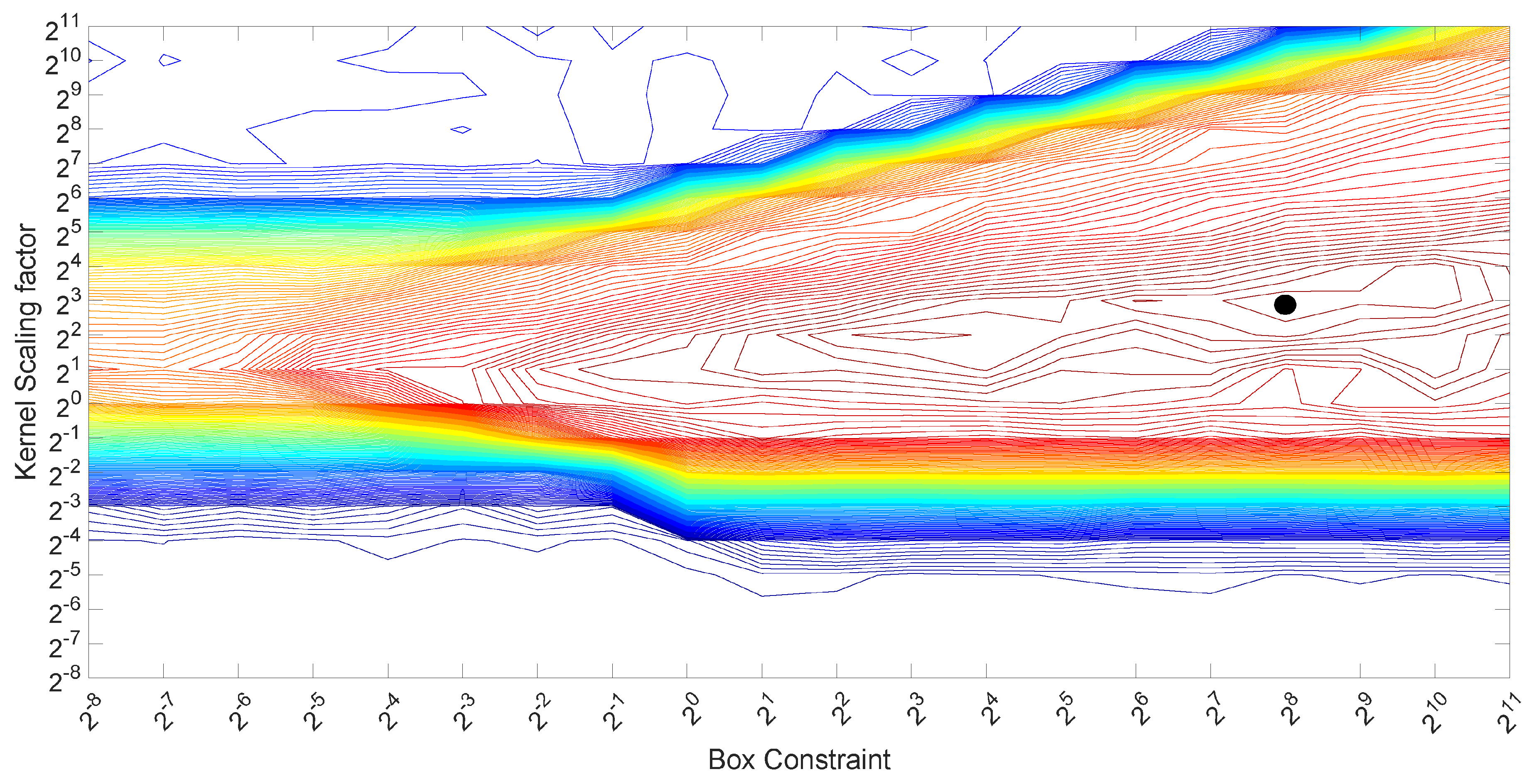
In this paper, a metric based on the overall accuracy of the confusion matrix was used for the SFS algorithm. Moreover, in order to avoid local maxima, a brute force search was also performed to select one or a few sets of combinations of 4 features among all possible combinations (sets of 4 features out of 18, which results in sets of features to check). In the brute force approach, all possible combinations of the 4 features were calculated. Then, the best combination of the 4 features was selected to seed the SFS algorithm, which computed the remaining features to add.
Once the best set of features is selected, the parameters of the machine learning algorithm at hand must be optimized. The execution of SFS is already based on optimal values reported in the literature for the application of SVM to fingerprinting. Yet, since it is the first time that classification of mobile phones based on magnetometers is attempted, the optimization of the parameters is performed specifically for the collected set of responses. As described in
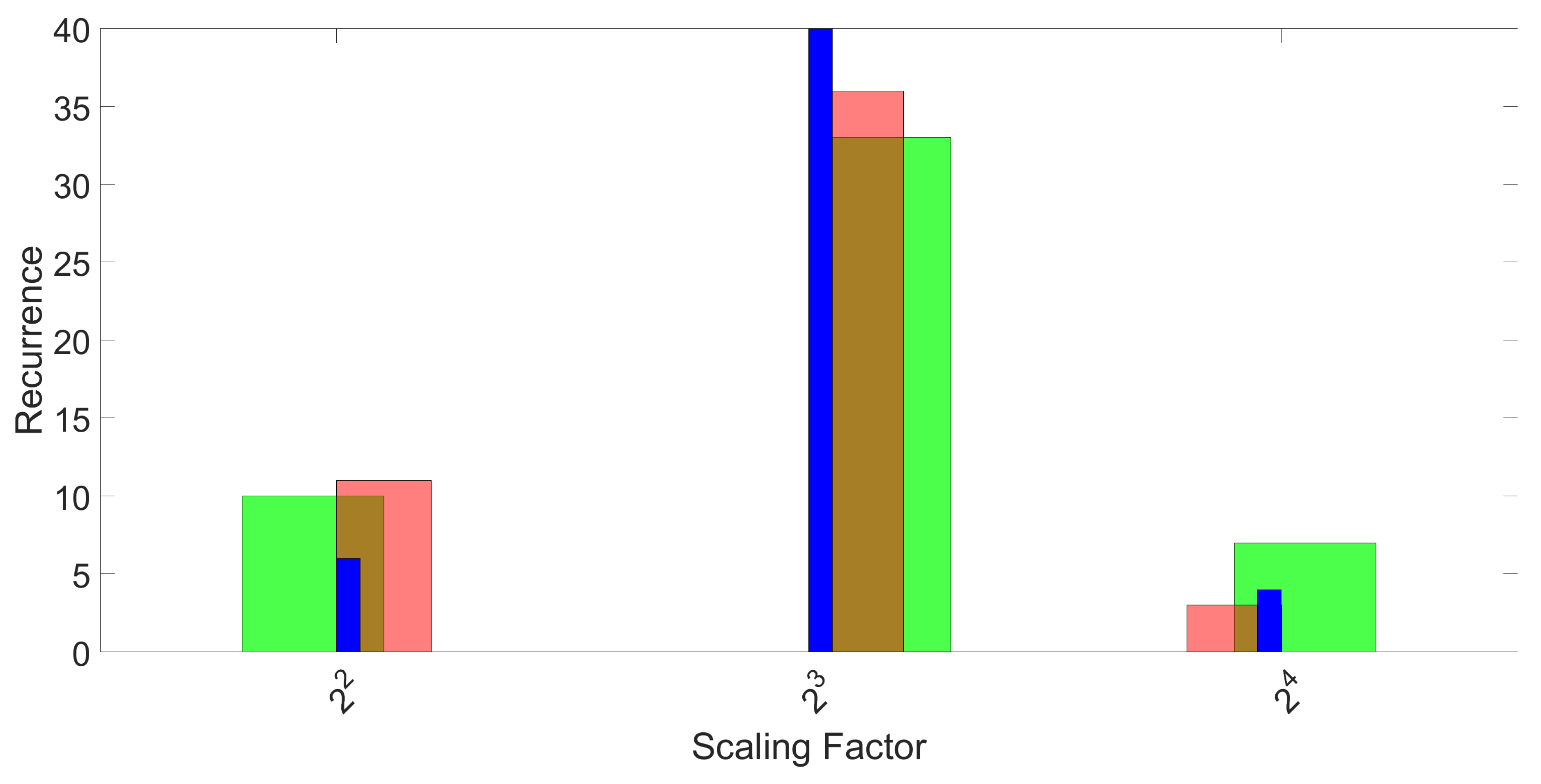
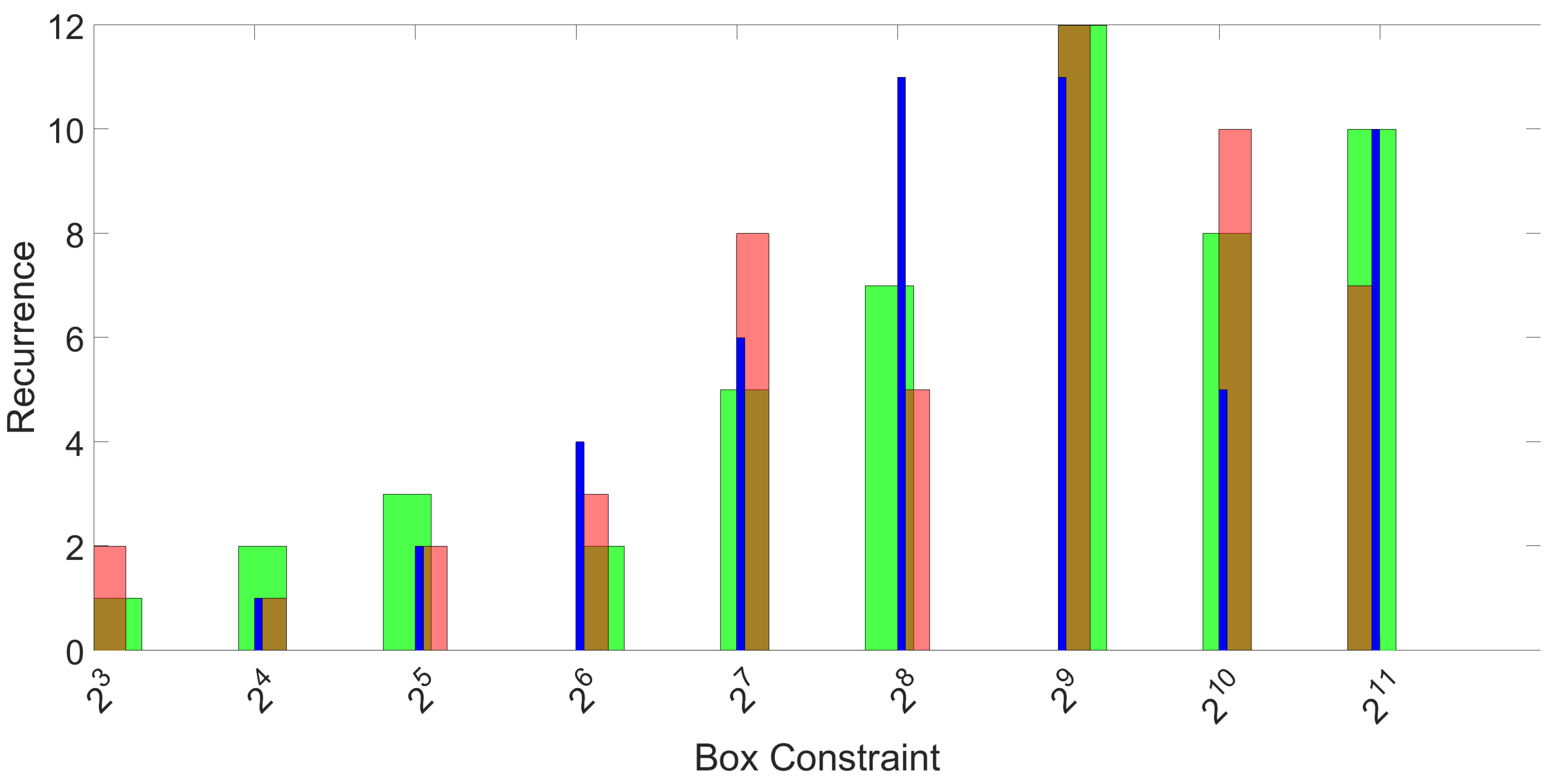
Section 3, a 3-fold approach was used for classification based on machine learning tools, and this process was repeated 50 times. For each repetition and each fold, feature selection and optimization of parameters is performed on the training set only, and classification accuracy is computed only on the test set. The histograms of the recurrence of the selected features, as well as the optimal values of parameters are provided in
Section 3.
The final step is the classification itself, which is done through SVMs, widely adopted in fingerprinting (see [
5,
6,
20]). A comparison with other standard classifiers (KNN, naive Bayes and random forests) is also carried out and reported.
In standard machine learning classification settings, classification performance is measured as follows. A given class is taken as a reference class (usually called the “positive” class), then the following quantities are computed:
is the number of true positive matches, where the machine learning algorithm has correctly identified a sample (e.g., a collected RF signal in our context) as belonging to the positive class;
is the number of true negative matches, where the machine learning algorithm has correctly identified a sample as not belonging to the positive class;
is the number of false positive matches, where the machine learning algorithm has mistakenly identified a sample as belonging to the positive class;
is the number of false negative matches, where the machine learning algorithm has mistakenly identified a sample as not belonging to the positive class.
One of the standard adopted metrics is the accuracy, which is defined as:
where
is the number of true positives and
is the number of true negatives resulting from the application of the SVM machine learning algorithm to the problem of verifying that the collected fingerprints are representative of the same magnetometer evaluated in the training phase (i.e., for verification).
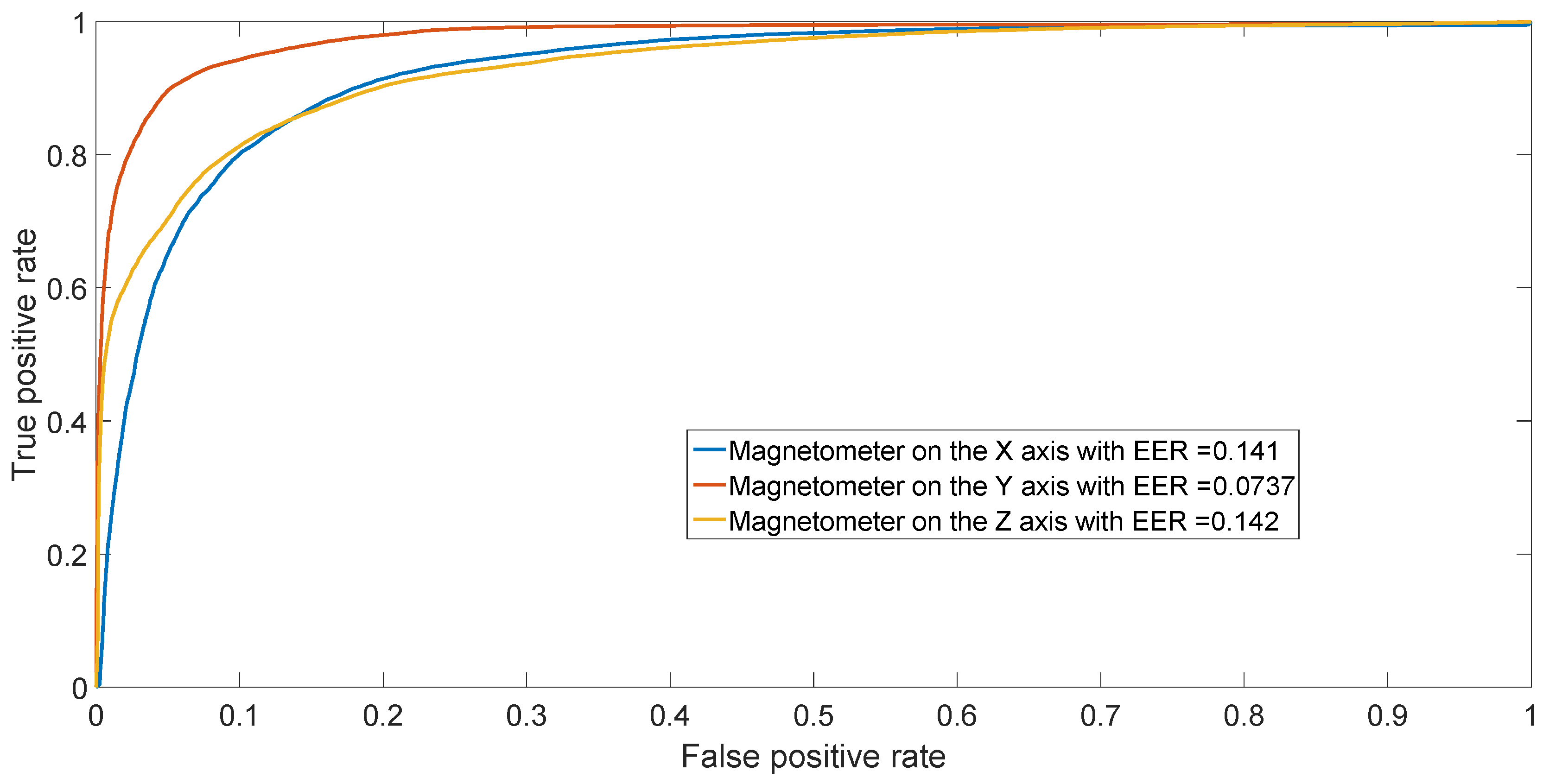
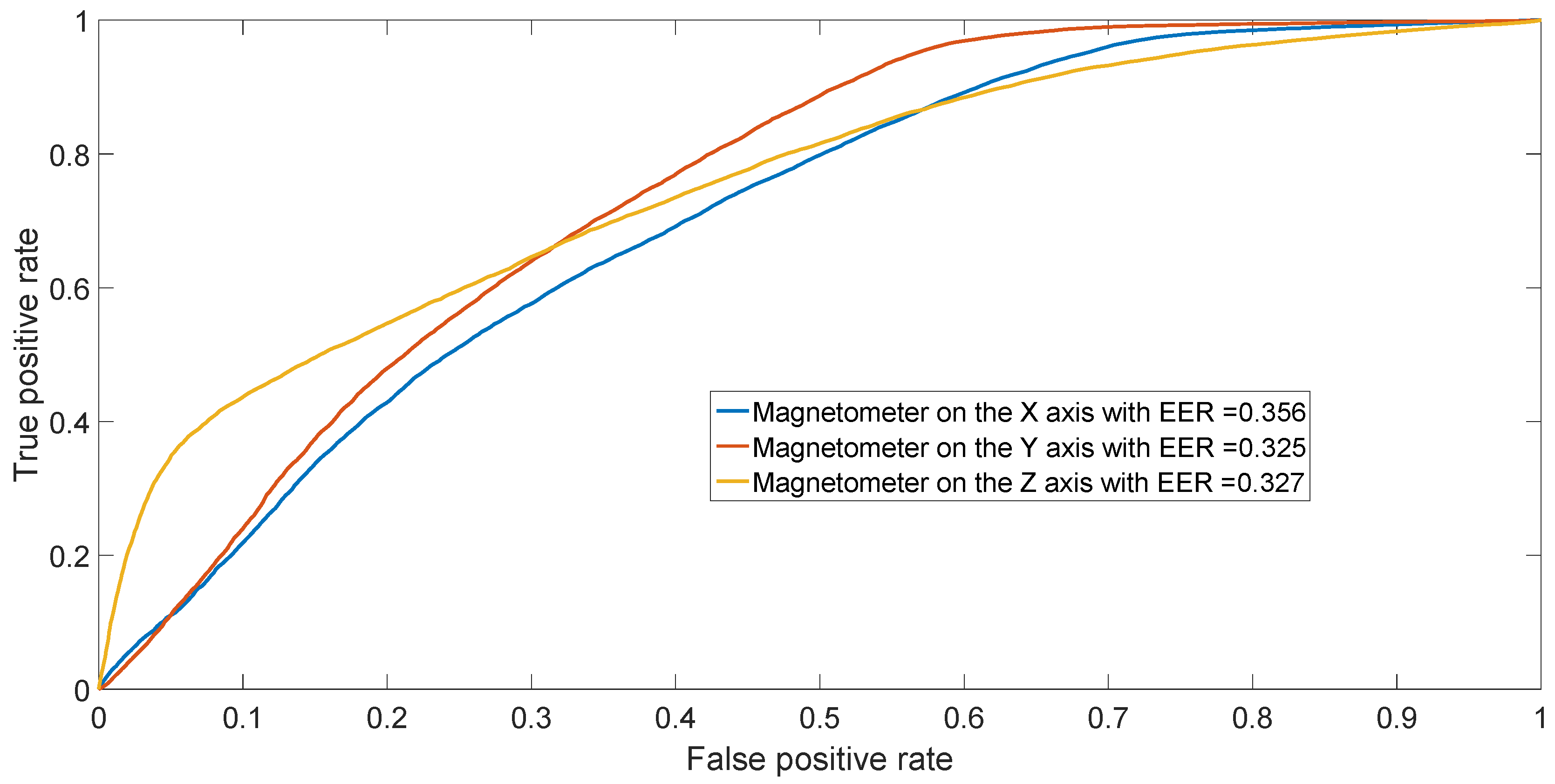
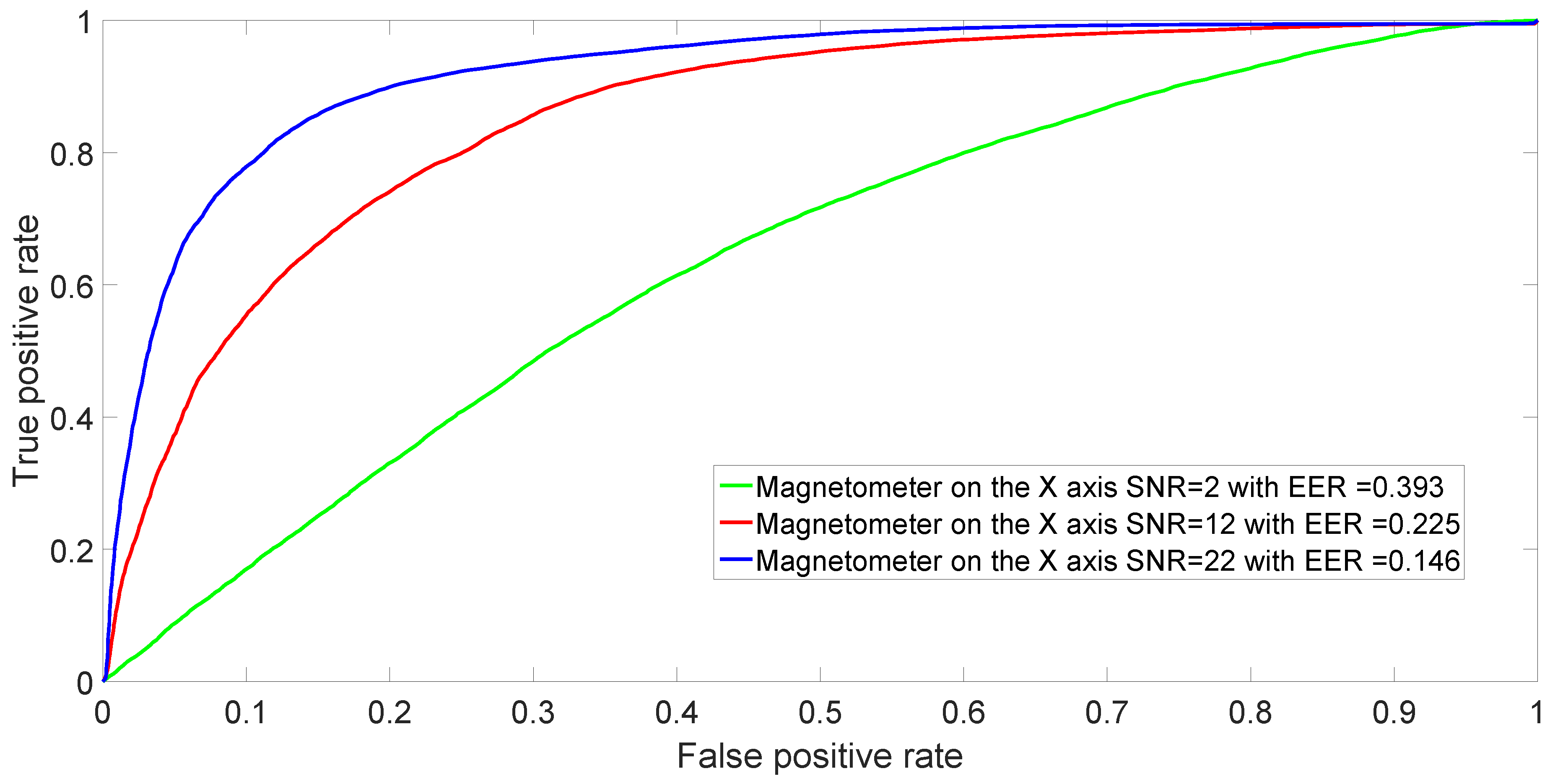
The ROC is generated by plotting the rate vs. rate in a binary classifier system as its discrimination threshold is varied.
The EER corresponds to the condition on the ROC curve where and are equal. In this paper, the value of the EER is calculated for the X-axis. This metric is frequently used as a summary statistic to compare the performance of various classification systems. In general, the lower EER, the better the classification performance.
Finally, the confusion matrix is also used to show the results of the identification process. In the confusion matrix, each column of the matrix represents a predicted class, while each row represents the actual class. As in our experiments we used 10 phones, the confusion matrix has a dimension of 10 × 10. In the confusion matrix, the correct guesses (i.e., true positive or negative) are located in the diagonal of the table, so it is easy to inspect the table for errors, as they will be represented by values outside the diagonal. The overall accuracy can be defined as the sum of the elements on the diagonal over the total sum (which in our case, equals 1500, i.e., 150 responses for 10 phones).


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}