1. Introduction
Currently, vehicle observation streaming mass data access is a research hotspot in smart cities [
1,
2,
3]. When the size of vehicles is n, the frequency of streaming data access is n per second. With the rapid increase in the number of vehicles in urban cities, the frequency of data access is raised exponentially. Sensor networks produce continuous real-time and time-ordered data, called streaming data [
4]. As analyzed by Choong, the characteristics of streaming data are unbounded data size, structured or semi-structured, time ordered and an unfixed data unit [
5]. Along with the application of sensor data, the study of processing sensor data requires more work. The study of streaming data access has great practical value. Streaming data appears regularly in our lives, such as in cell phone positioning, video surveillance, and air sensor monitoring so on. Accessing the streaming data is difficult, so the efficient real-time processing of data is hard to achieve [
6]. As the number of sensors increases, the efficient real-time processing of data becomes more difficult [
7].
Currently, there are several vehicle monitoring networks, for example, the Shenzhen taxi network, the Wuhan taxi network, the Taiyuan bus network and the New York taxi network. The number of vehicles in the Shenzhen taxi network is 25,000, the number of vehicles in Wuhan is 12,000, the number of vehicles in Taiyuan is 2300 and the number of vehicles in New York is 33,000. Vehicles locate and send a message every 60 s in the Shenzhen taxi network and every 30 s in the Wuhan taxi network, Taiyuan bus network and New York taxi network. Moreover, the numbers of vehicles in these sensor networks are growing at a certain rate. To access the streaming data of taxis or buses, there are many techniques available, such as high-performance databases, cache mechanisms, distributed data storage centers and other efficient access algorithms [
8,
9,
10].
The mass data access methods can be divided into direct data storage methods and indirect data filtering methods. In direct data storage methods, a distributed database is provided with good performance, substantial storage, high scalability and high availability characteristics. MongoDB [
11], Redis [
12], HBase [
13] and Cassandra [
14] are widely used distributed databases, where MongoDB is a lightweight, stable and easy to recover and high performance database [
15]. In indirect data filtering methods, Lin proposed two strongly consistent data access algorithms, including poll-each-read and callback [
16]. Kumar proposed a new proxy level web caching mechanism that takes into account the aggregate patterns observed in user object requests [
17]. Tian proposed a novel probabilistic caching mechanism for media on-demand systems based on peer-to-peer with less workload imposed on the server [
18]. However, these streaming data access methods cannot fully support the massive number of sensors, such as the one hundred thousand level number of sensors. The frequency of data access per second is approximately 60 thousand in the Taiyuan BeiDou (BD) bus network. MongoDB supports the data insertion capability of 300 milliseconds with sixty thousand records per second with five shards in superior configuration. When meeting the data frequency of one hundred and twenty thousand records per second, MongoDB is unable to function properly. The whole time of such a size of data access is approximately one hour or endless, as it is unable to handle such a volume of sensor data. In addition, there is valuable information in streaming sensor data, such as the abnormal data containing null values, too large values and too small values. Extracting the valuable information is essential to access the streaming data based on the characteristics of streaming data [
19]. However, little attention is paid to abnormal data access. Hence, the cleaning of streaming data is rarely involved in whole data access. In general, there are two problems with existing streaming data access: (1) it is unable to handle such volumes of sensor data due to limited computing capability; (2) it is unable to achieve efficient data cleaning of streaming data with no proper data cleaning mechanism and a limited computing environment.
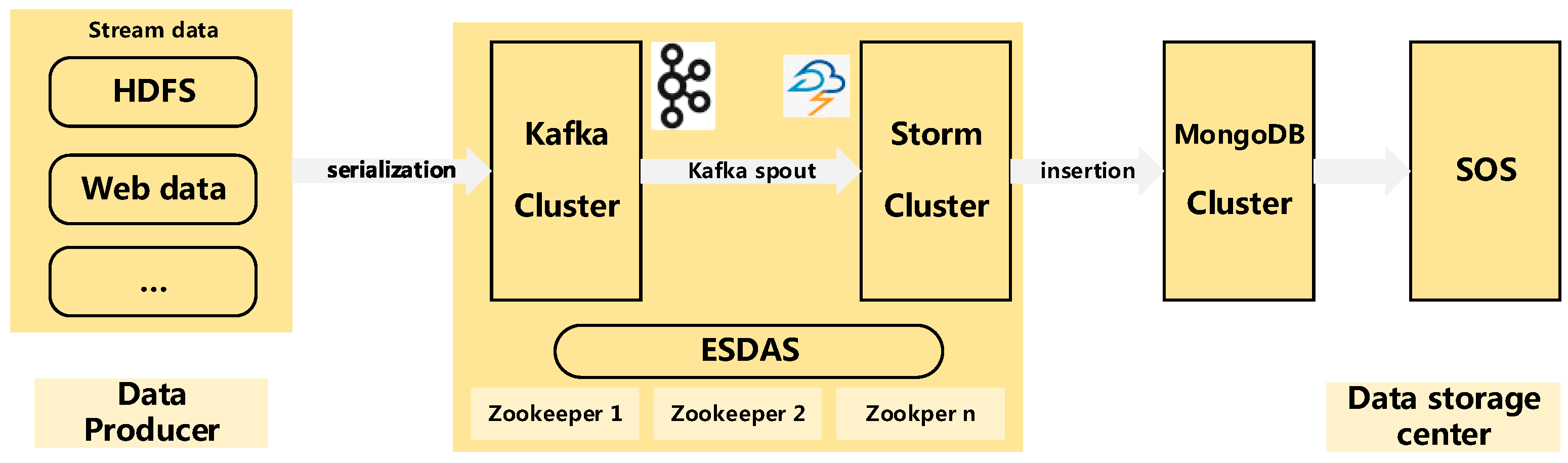
Apache Storm, developed by the Apache software foundation [
20], is a distributed fault-tolerant and real-time streaming processing framework [
21]. Storm has been effectively used for a broad variety of applications, including various data analytics, machine learning tasks, and continuous computation tasks [
22]. Considering the characteristics of spatio-temporal streaming data, we proposed efficient streaming spatio-temporal data access based on Apache Storm (ESDAS) to achieve real-time streaming mass spatio-temporal vehicle data access and customized, flexible, and multi-level data cleaning. In real-time streaming mass spatio-temporal vehicle data access, the evaluation between MongoDB and ESDAS has been achieved, and the efficiency of ESDAS in speed insertion is approximately three times higher than that of MongoDB, as shown in
Section 3.3. In real-time streaming mass spatio-temporal vehicle data cleaning, the filtered bus aggregation mapping with a speeding bolt, a suid bolt, a geographical position bolt, and a route bolt have been achieved in
Section 3.2.
By designing an appropriate data spout/topology algorithm to access the spatio-temporal vehicle data and a comprehensive metadata model, the study achieves real time spatio-temporal data access and cleaning, achieved through experiments. In addition, the Taiyuan BD bus network is selected as the experimental network. As the consumption time of data insertion is approximately ten seconds in the current environment, which cannot meet the real-time data access demand, and valuable information is wasted, the study is meaningful and significant. The paper is organized as follows: we describe the streaming data access methodology in
Section 2, where the streaming data access algorithm is also described. Experiments based on the bus data are performed, and the performance of the proposed method is evaluated in
Section 3. Finally,
Section 4 discusses the metrics of the proposed method and potential future directions.
3. Experiments
Section 3.1 describes the BD buses network and the experimental environment, and
Section 3.2 describes the data access result of ESDAS with different bolts such as the speeding bolt, geological bolt, suid bolt, and route bolt.
Section 3.3 describes the performance evaluation of ESDAS for five thousand, ten thousand, thirty thousand, and fifty thousand records per second.
3.1. BD Bus Network and Experimental Environment
In our study, the BD bus network is chosen as the experimental dataset. After the U.S. global positioning system and the Russian Global Navigation Satellite System, the Chinese BD satellite navigation system is the third oldest satellite navigation system in the world. Meanwhile, the positioning accuracy of the China BD satellite navigation system is generally equal to that of GPS [
34]. The TAX408BD sensor fixed on Taiyuan buses is a product module with a small volume, high sensitivity, and low power consumption that is easy to integrate. Widely used in the fields of shipping, road traffic monitoring, vehicle monitoring, vehicle navigation, handheld tracking and goods tracking, the bus sensor has features such as high precision in real time, three-dimensional positioning, three-dimensional velocity, and timing capability [
34]. The inserted data sample is as follows: (lon”: “112.58497”, “lat”: “37.58712”, “suid”: “100”, “speed”: “0”, “vdesc”:“103 route number”, “plate”:” A81893”).
In our experimental environment, the distributed computing clusters have been established. In the cluster, five computers have been employed with the same configuration. The configuration of each node is an i7 4720HQ (6 M cache, eight cores, 2.60 GHz, 5 GT/s) with 8 gigabytes of Random Access Memory. They are connected to 40 GB/s InfiniBand. The Storm environment contains one nimbus node and four supervisor nodes (Worker nodes). The Nimbus is responsible for distributing code in a cluster, assigning tasks to nodes, and monitoring host failures. The Supervisor is responsible for monitoring the work of the assigned host on the work node; starting and stopping the Nimbus has been assigned to the work process. The Worker is a specific process to address Spout/Bolt logic, according to the topology parameter submitted in conf.setNumWorkers. In this way, the numbers of supervisor nodes and worker nodes are the same.
The 52° North SOS [
29] is applied in the experiment. The SOS provides a data access layer through a Data Access Object paradigm. Three overwritten Data Access Object classes contain InsertObservationDAO. InsertObservationDAO can be inherited to provide the capability of accessing observations in the persistent layer. The Apache Storm 2.0 and Apache Kafka 0.8.2.0 clusters provide strong data access capabilities, and the resource consumption of the clusters is displayed in real time via the main page “
http://localhost:8080”.
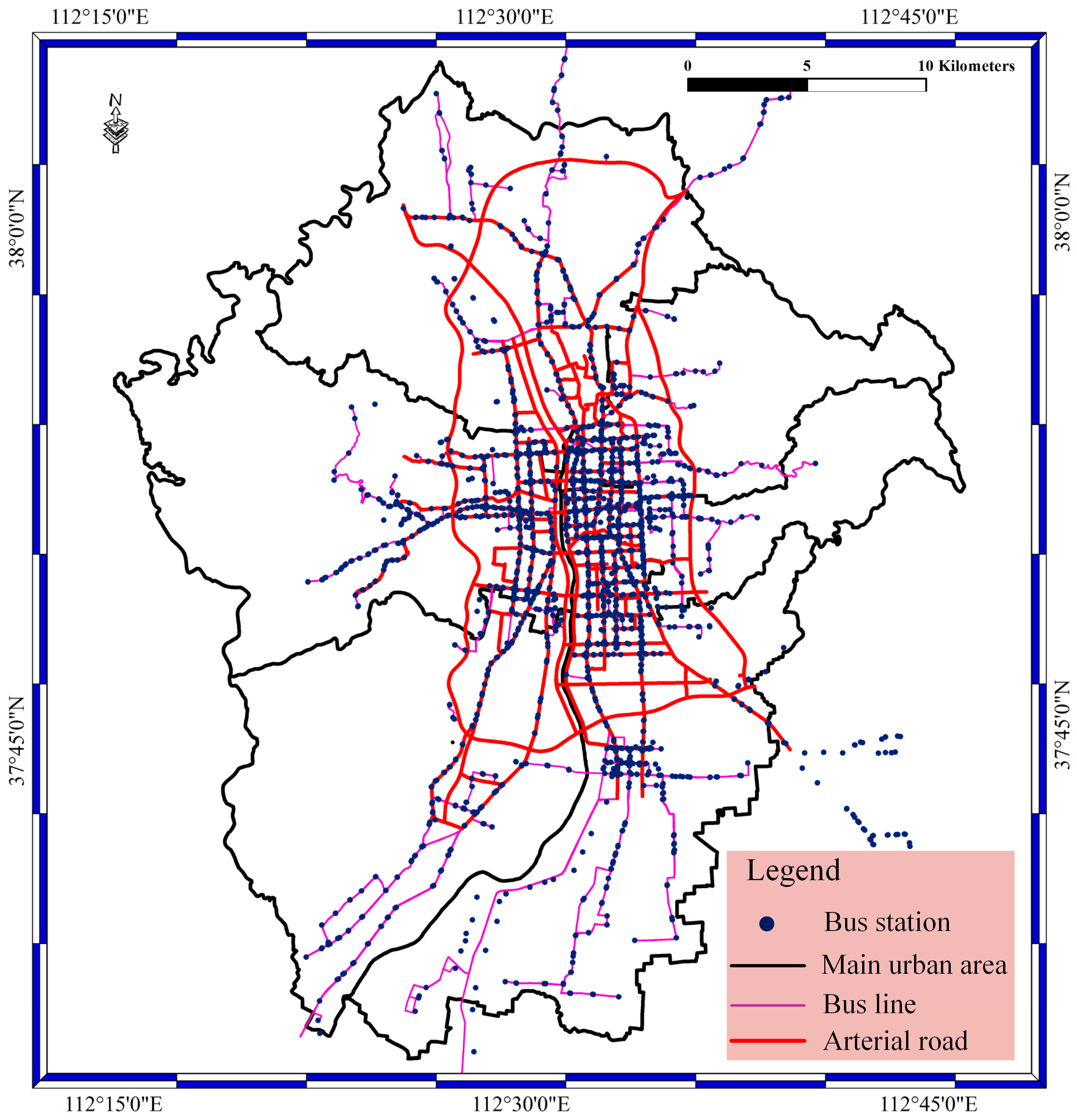
Figure 5 shows the main city area in Taiyuan City. Red lines stand for arterial roads; the pink lines stand for bus lines; the black lines stand for the main urban areas; and the red spots stand for bus stations. The area of Taiyuan City is 1400 square kilometers, and the main city area is 400 square kilometers. The main city area of Taiyuan is surrounded by different mountains and is located on a plain of the mountains. The main city area contains six areas, the Caoping area, Xinghualing area, Wanbolin area, Yingze area, Xiaodain area, and Jingyuan area. The data scale of BD vehicle streaming data should be described in detail. The bus network in Taiyuan contains approximately 2300 buses, and the number of buses is increasing. There are approximately 800 bus stations, 400 bus lines, and 100 arterial roads in the city; each bus sends a location every 10 s; and the size of generated data is 12.67 million locations every day. The most difficult thing is to access the 2300 buses at the same time with short data latency.
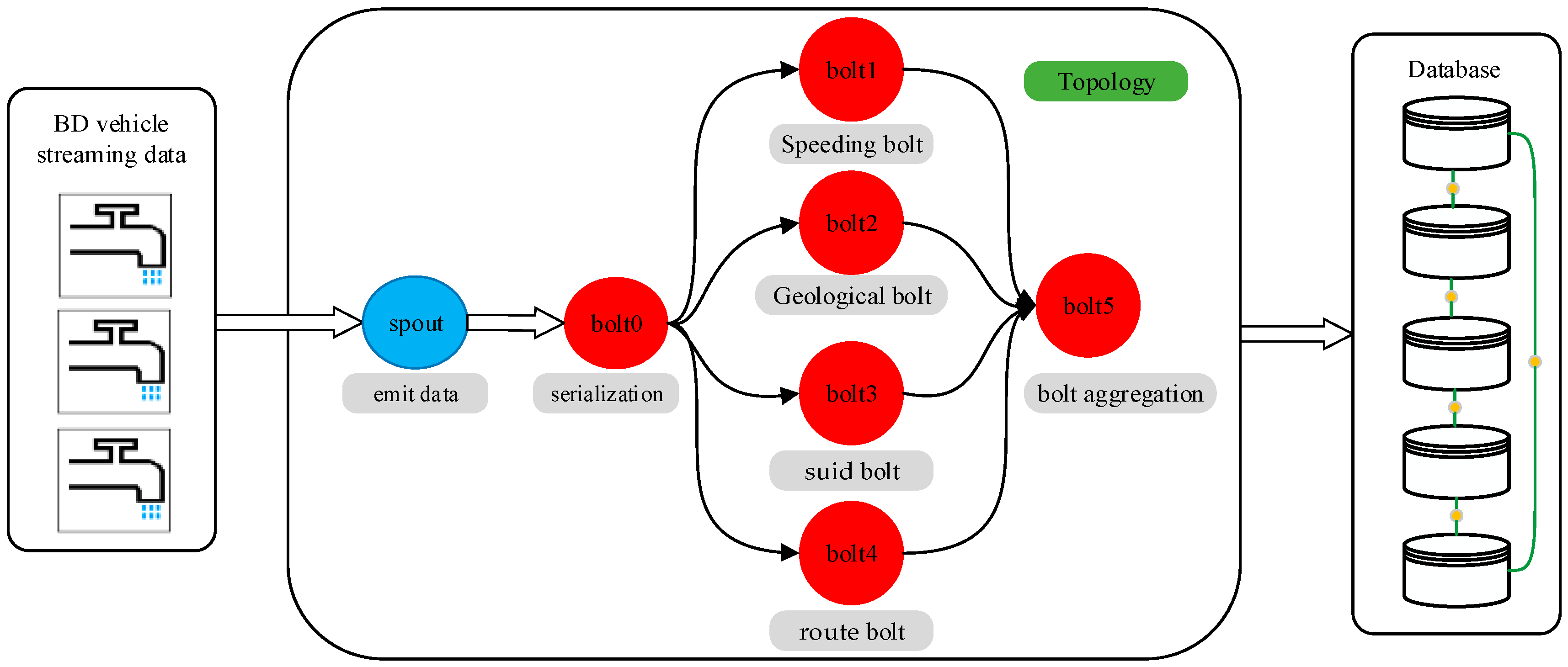
3.2. Data Access Result with Different Bolts
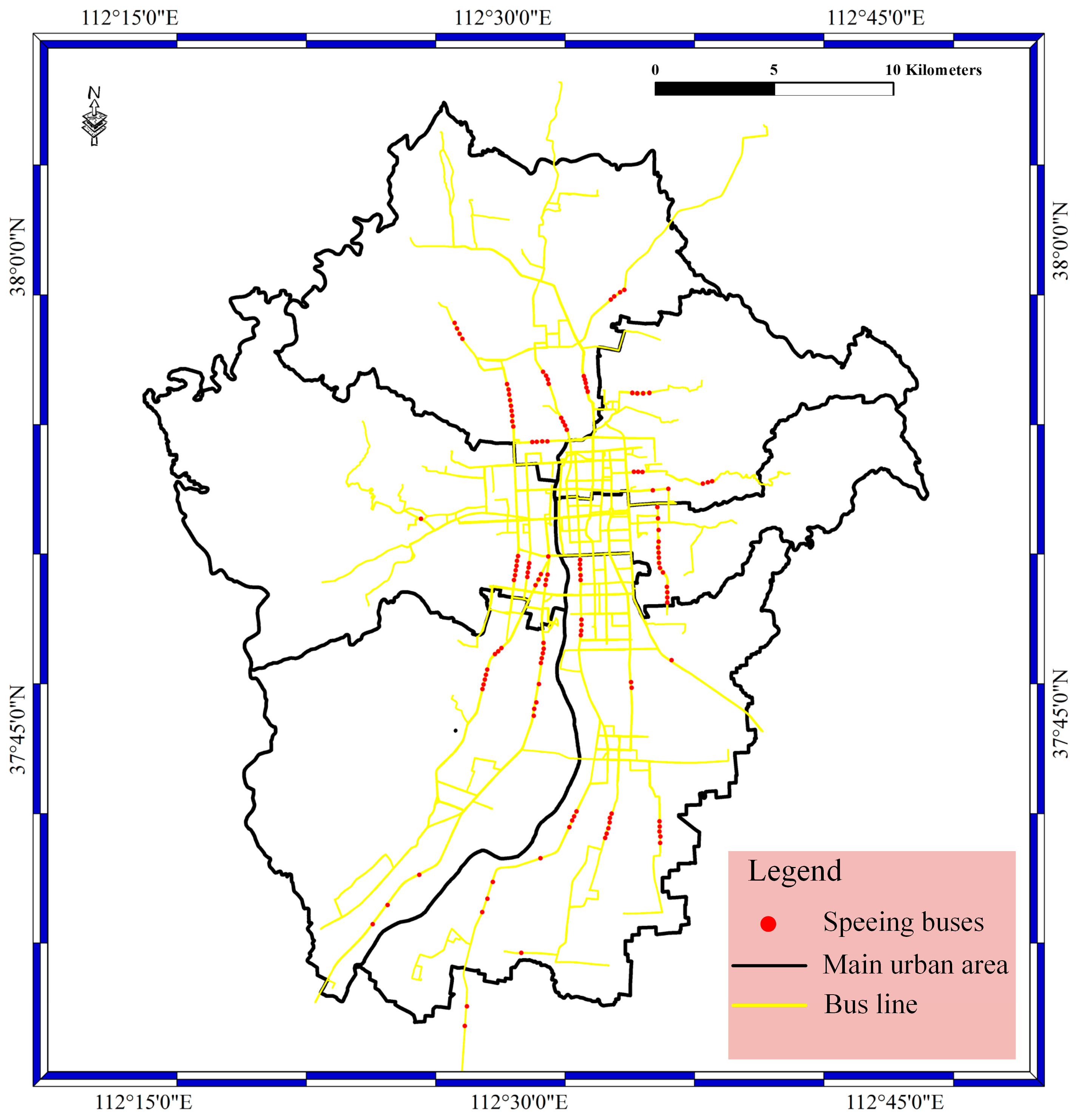
In the data access phase, BD vehicle streaming data are inserted into the Storm cluster at a high frequency and undergo data filtering. Therefore, the stored data contains the filtered data and unfiltered data. In this section, the filtered bus aggregation mapping with the speeding bolt, suid bolt, geographical position bolt, and route bolt have been achieved. In our experiments, the filtered data contain different speed data, location error data, license plate number error data, and route error data. In the speed bolt, the velocity threshold is 30 km/h, which means the bus is speeding when the velocity is greater than or equal to 30 km/h. The speeding data locations in the main urban area of Taiyuan City are shown in
Figure 6. As shown in the figure, the red spots stand for the speeding buses; the yellow lines stand for bus lines; and the black lines stand for the main urban area. Most of the speeding buses are distributed in the main urban area and on the main roads in Taiyuan City.
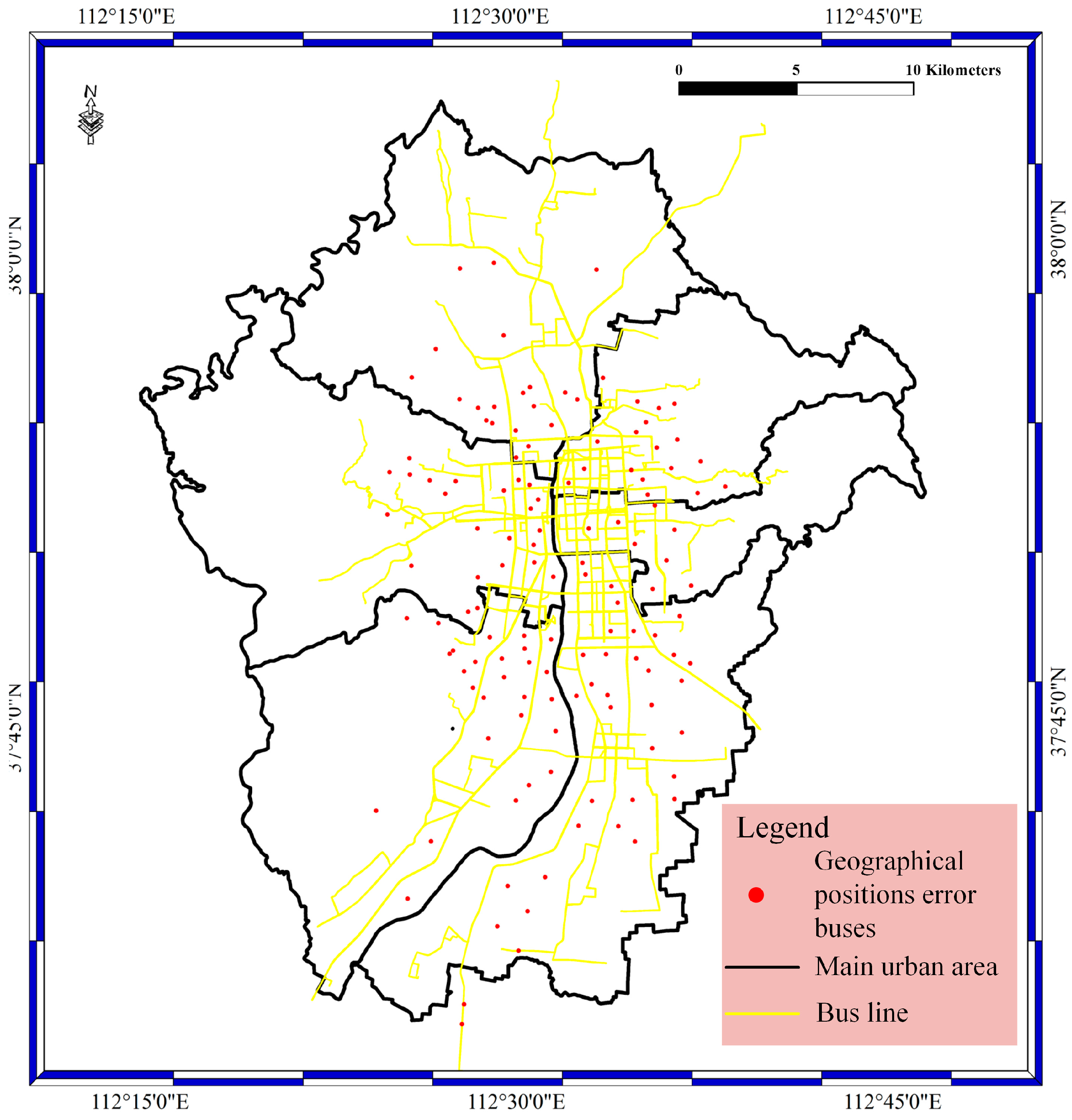
For the geological bolt, the geographical position data are filtered with the specified filter rule. Geographical position filtering is achieved by a judgment of if the geographical position is near the bus lines or near the urban area. In this bolt, the filtering occurs by judging if the distance between the geographical positions and bus lines is greater than or equal to the specified value. In our experiments, the value is set to 10 m, with consideration of system error and random error in geographical positions. In the bolt, the execute method is implemented, and the judgment phase is carried out. The prepare method is used to catch the data from the spout phase.
Figure 7 shows the geographical position error results of the geological bolt phase. The red spots stand for the geographical position error of buses, as well as the geographical position error of buses located far from the main roads instead of on the main roads.
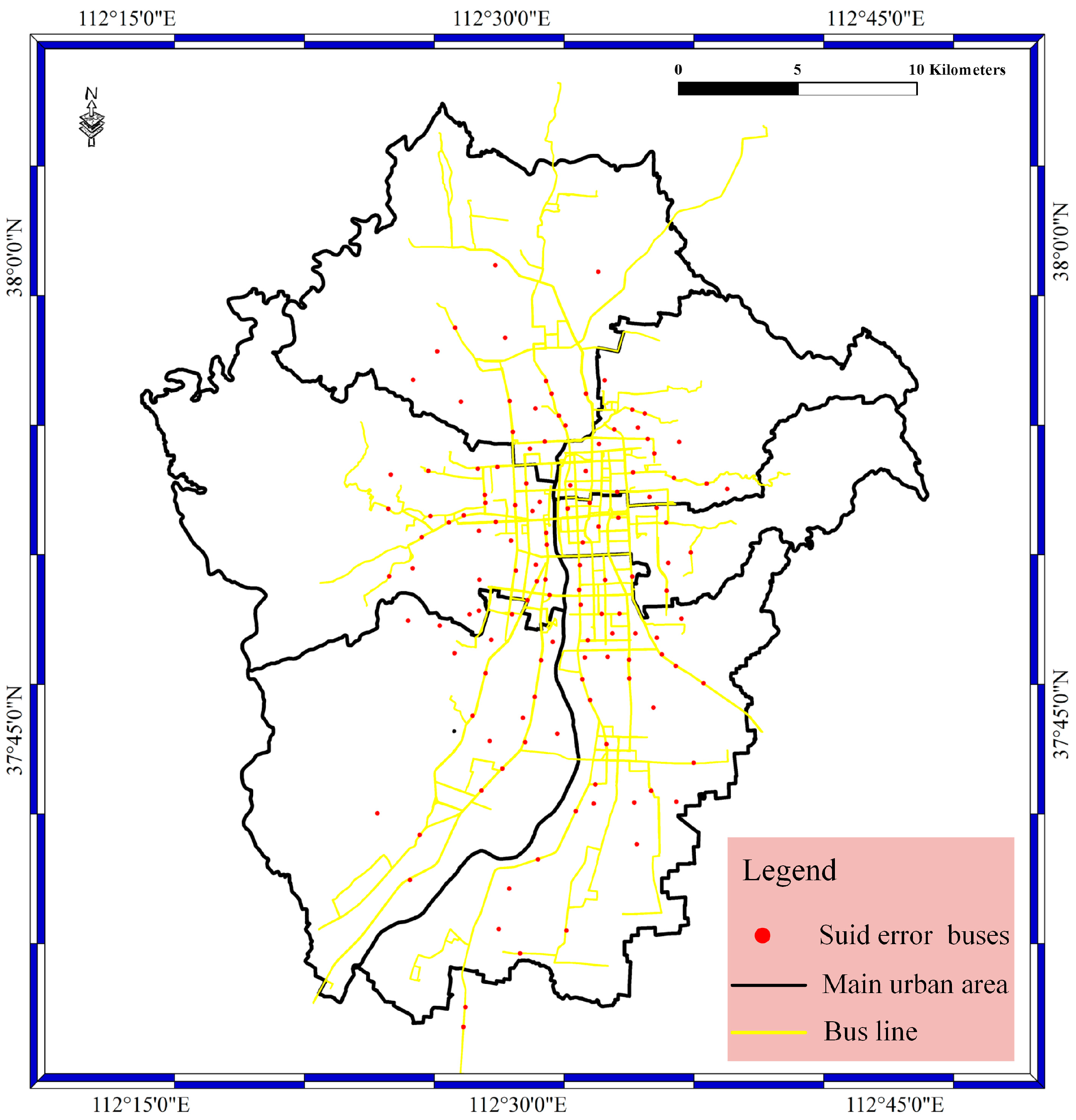
For the suid bolt as shown in
Figure 8, the bolt is designed to filter the BD vehicle streaming data. The suid refers to the license plate number. In the suid bolt phase, the buses without correct license plate numbers are filtered out based on whether the license plate number is in the bus license plate number database. The bus license plate number database was constructed before the experiment. In this way, the license plate number error result is determined in the suid bolt. The red spots stand for the buses with false license plate numbers. In addition, most of the buses with false license plate numbers are located on the bus lines, and a small number of spots are located in the main urban area.
3.3. Performance Evaluation
In the performance evaluation phase, the data access for the Taiyuan BD vehicle streaming data is evaluated. Different data sizes are evaluated in this phase, and four bolts are tested, the speeding bolt, suid bolt, geographical position bolt, and route bolt. The function of the aggregate bolt is to integrate the bolt results and insert the bolt results into the data storage center. In our experiment, the Storm and Kafka clusters are employed, and different data insertion frequencies are tested to validate the feasibility and the efficiency of the ESDAS. In this section, the performance is evaluated, and the result has been shown in
Section 3.2.
In this phase, we employ four kinds of Taiyuan BD bus location data with different insertion frequencies. Taken the speeding bolt test as example, we employ Taiyuan BD location buses data with five thousand, ten thousand, thirty thousand, and fifty thousand records per second. The data sample is described in
Section 3.1. Data of different frequencies are inserted and filtered through ESDAS. The consumption time of the speeding bolt and MongoDB has been compared for different data volumes.
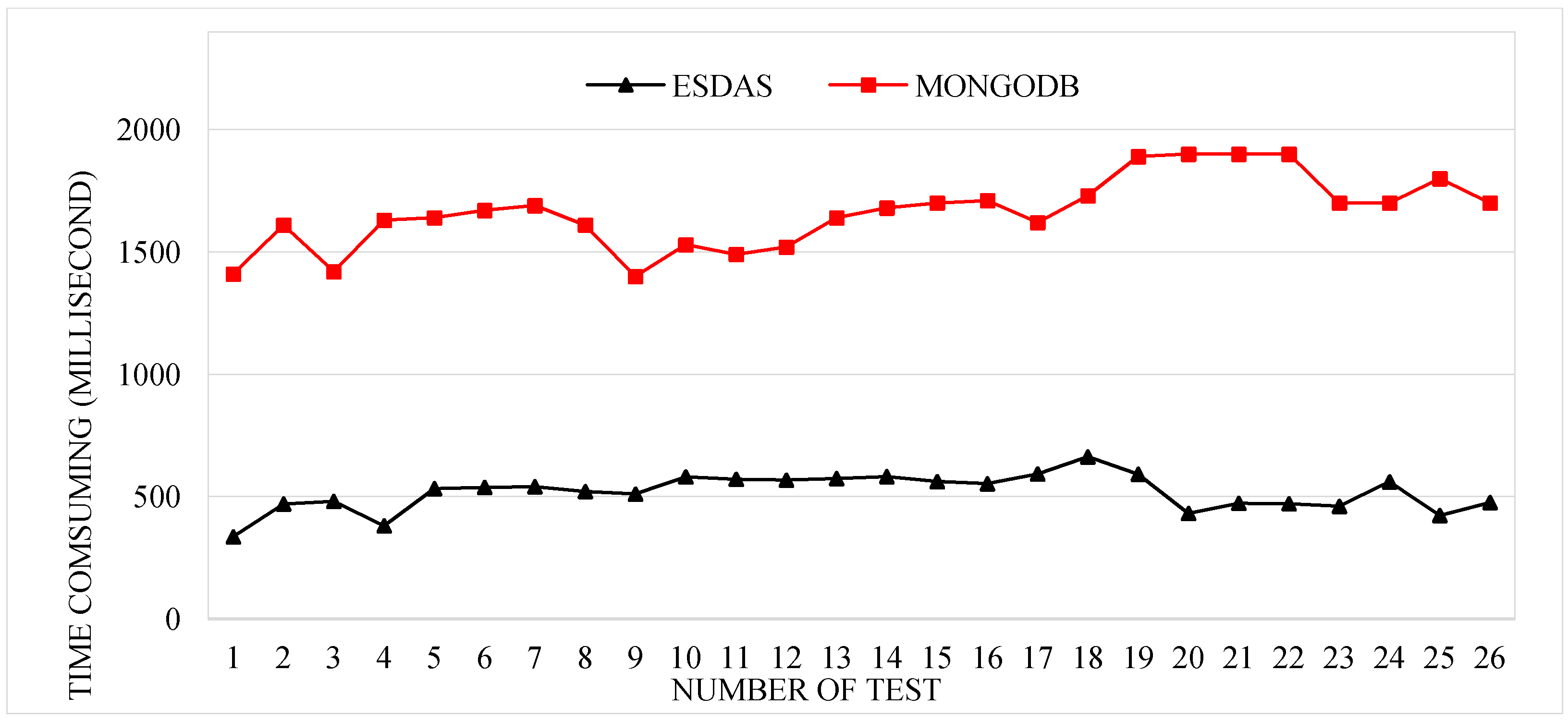
Figure 9 shows the consumption times for ESDAS and MongoDB. The consumption time of ESDAS for the speeding bolt is approximately 300 milliseconds, and that for MongoDB is approximately 1300 milliseconds. The efficiency of ESDAS in the speeding bolt is approximately 3 times higher than that of MongoDB.
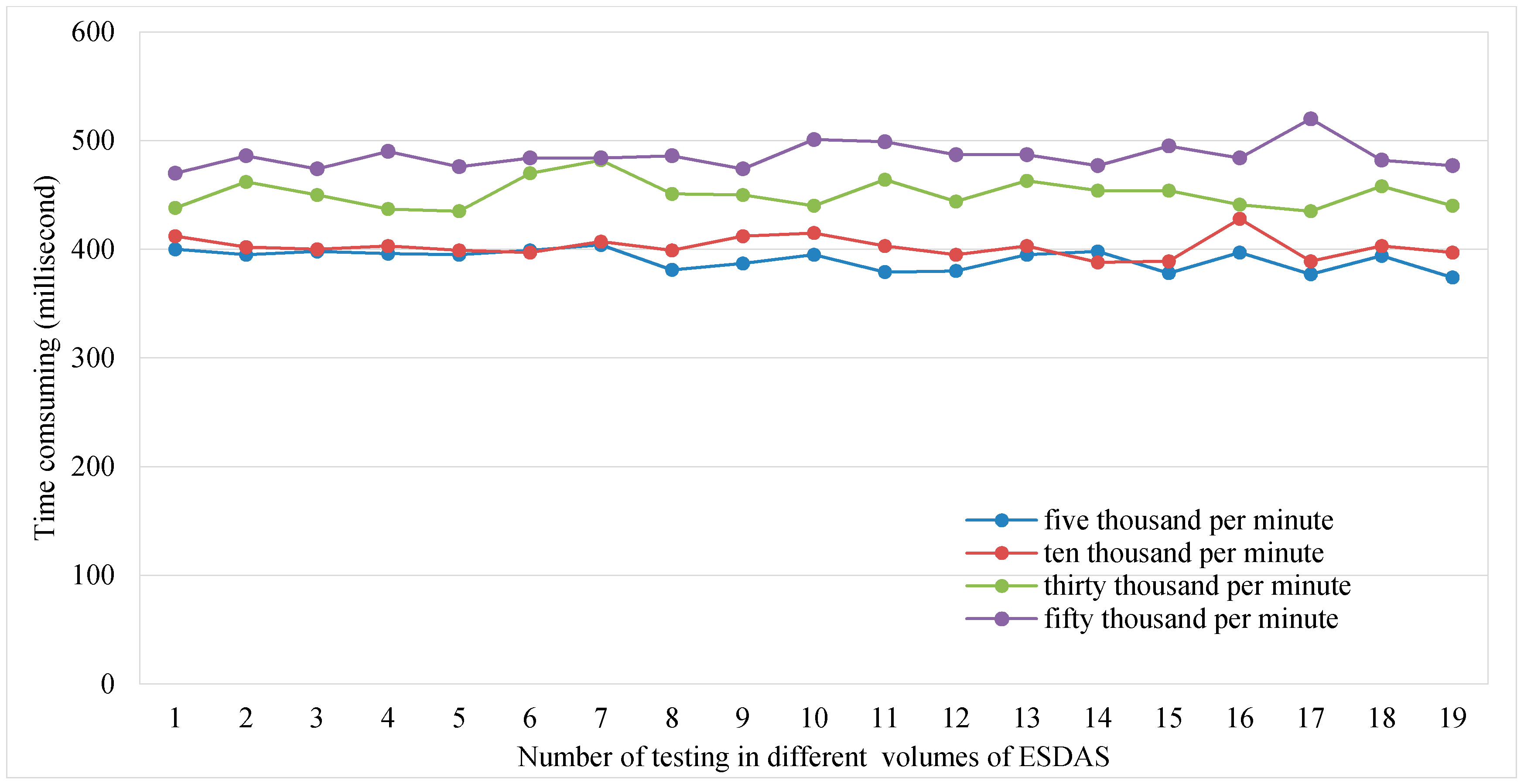
Figure 10 shows the consumption time of ESDAS for the different data volumes of five thousand, ten thousand, thirty thousand, and fifty thousand records per second. For the different data volumes, the consumption times are different. The consumption time is evaluated approximately 20 times. The mean consumption time of ESDAS for five thousand records per second is approximately 400 ms, the consumption time for ten thousand records per second is approximately 600 ms, the consumption time for thirty thousand records per second is approximately 500 ms, and the consumption time for fifty thousand records per second is approximately 700 ms.
For the suid bolt phase, the consumption times for ESDAS and MongoDB are evaluated. The suid bolt result has been described in
Section 3.2. In the five thousand, ten thousand, thirty thousand, and fifty thousand records per second cases, the consumption time is evaluated.
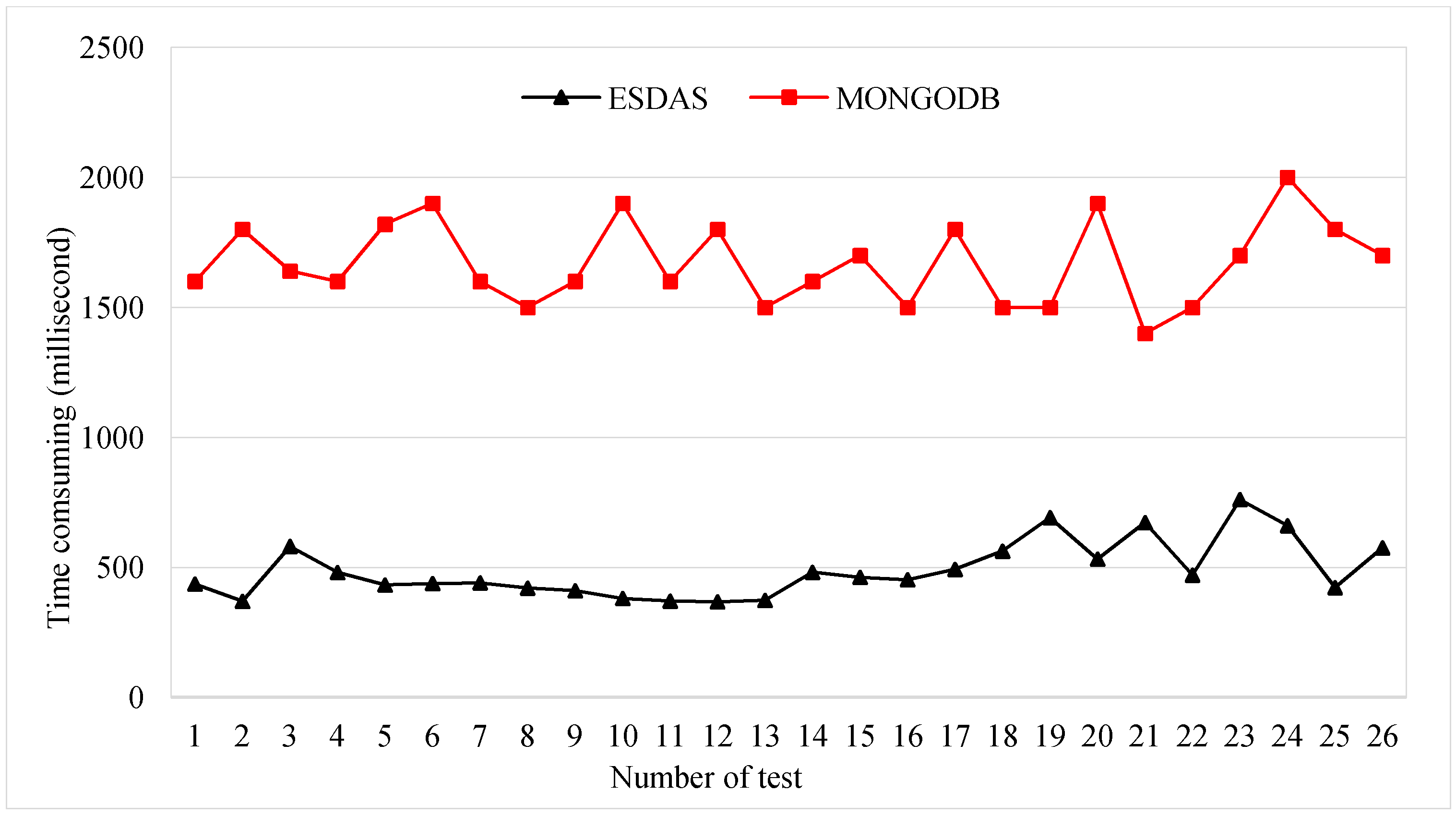
Figure 11 shows the consumption time for the suid bolt for ESDAS and MongoDB in the ten thousand records per second case. The mean consumption time of ESDAS for the suid bolt is approximately 400 ms, and the consumption time of MongoDB is approximately 1800 ms. The efficiency of ESDAS for the suid bolt is approximately three times higher than that of MongoDB.
Similar to the speeding bolt and suid bolt, the performance evaluation of the route bolt and geological bolt can be achieved at several times. In the rest of the experiments, the consumption time for the route bolt is approximately 700 ms for fifty thousand records per second, and the consumption time for MongoDB is approximately 2400 ms. Therefore, the efficiencies for the route bolt and geological bolt are similar to those for the speeding bolt and suid bolt.
In conclusion, the data access results with different bolts have been shown in
Section 3.2. The states of the filtered bus aggregations are different with different bolts. Most filtered buses for the speeding bolt are distributed on the main roads, and the most filtered buses for the geological bolt are distributed away from the roads and bus lines. For the suid bolt, most filtered buses are distributed in a uniform distribution. In terms of efficiency, the consuming time for ESDAS is much less than MongoDB in data with five thousand per second, ten thousand per second, thirty thousand per second, and fifty thousand records per second cases. Through the performance evaluation achieved in experiments, the efficiency of ESDAS in mass spatio-temporal vehicle data access is about three times higher than MongoDB.
Compared with other mass spatio-temporal data access methods as presented in Introduction Section, ESDAS has two advantages: (1) compared with direct storage methods, ESDAS can achieve real-time streaming mass spatio-temporal vehicle data access for the higher data insertion capability in five thousand per second, ten thousand per second, thirty thousand per second, and fifty thousand records per second cases as achieve in
Section 3.3; (2) compared with indirect data filtering way, ESDAS can achieve customized, flexible, and multi-level data filtering as achieved in
Section 3.2.
4. Conclusions
The streaming mass spatio-temporal data access is a hot study area in high efficient and unified access in smart city. In our study, we proposed the ESDAS method to achieve real-time streaming mass spatio-temporal vehicle data access and data cleaning as achieved in
Section 3.2 and
Section 3.3. In
Section 3.2, the raw streaming data are made customized, flexible, and multi-level data filtering, and the filtered buses aggregation mappings with speeding bolt, suid bolt, geographical positions bolt, and route bolt have been achieved. In
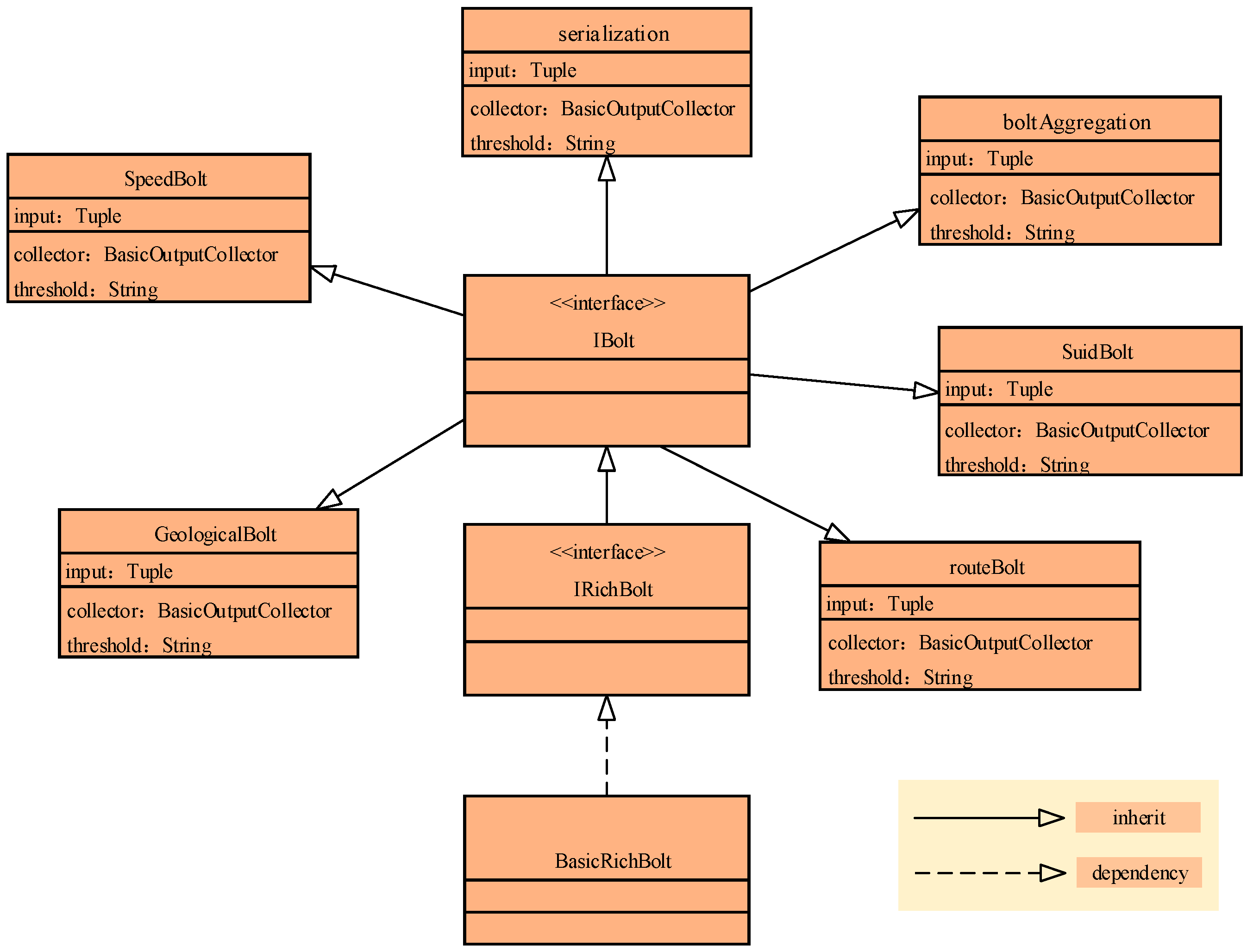
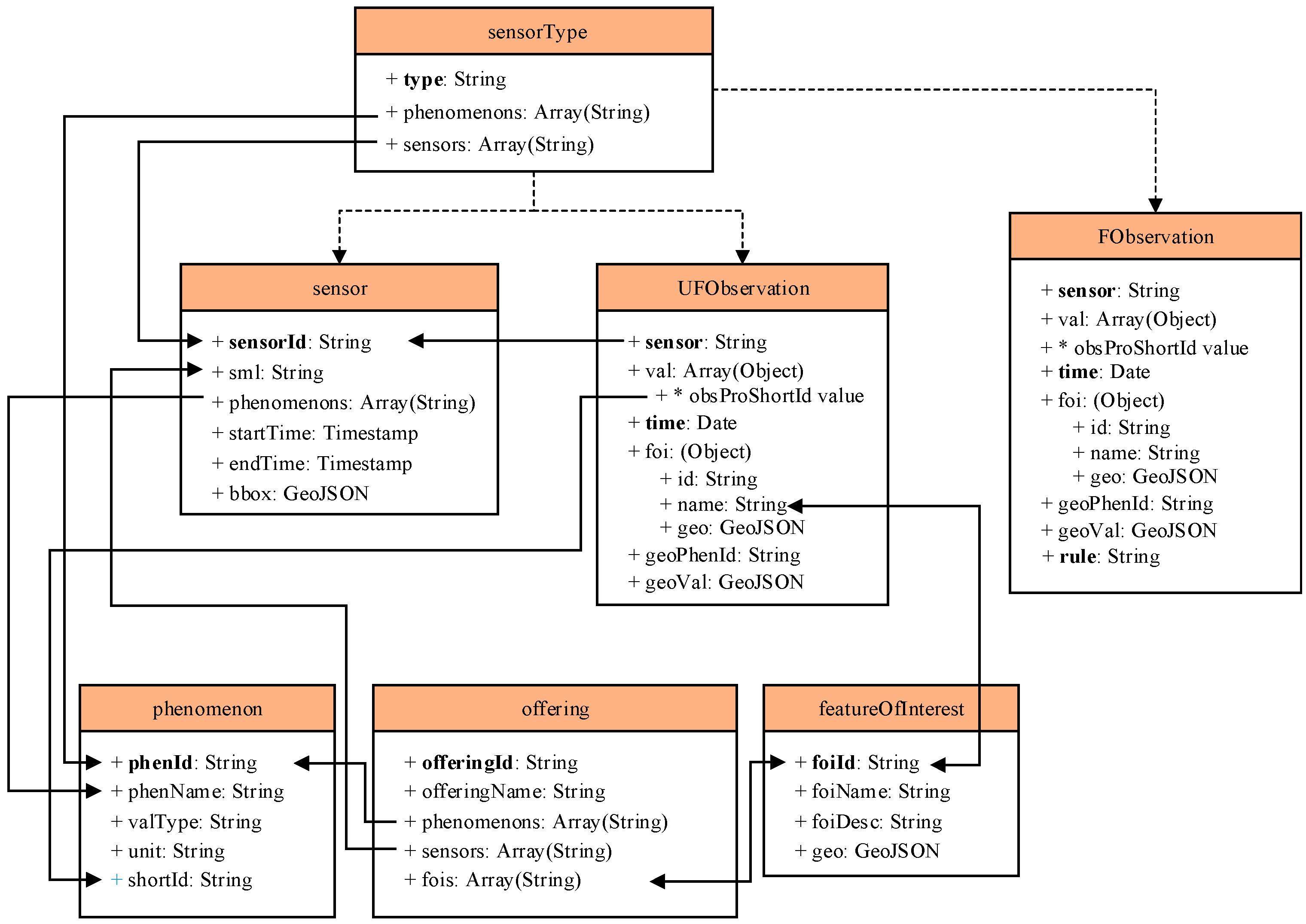
Section 3.3, the efficiency of ESDAS in mass spatio-temporal vehicle data access is about three times higher than MongoDB. Through integrating the SOS, the ESDAS works in web service form. The spout/bolt workflow of topology in ESDAS is illustrated in
Section 2.1 and the tables design in MongoDB for streaming raw data and filtered data is described in detail. In addition, the interface extending for speeding, geological, suid, route bolts are showed in
Section 2.2. The data filtering result of speeding bolt, geological bolt, and suid bolt are presented with different buses aggregation form. The efficient streaming mass data access can be applied in the traffic planning, bus feature mining, congestion prediction, and better transport management in smart city. In future work, on one hand, other bolts such as average velocity bolt, abnormal velocity bolt, maximum latitude and longitude bolt, minimum latitude and longitude and other bolts; on the other hand, other streaming data processing framework such as Apache S4 [
35], Spark [
36] will be applied to make the performance comparison.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










