5.1. Experiments Settings
We build the wireless network using CC2530 ZigBee nodes, which are based on the IEEE 802.15.4 standard and operate in the 2.4 GHz frequency band. RPs are set up uniformly in the monitoring area. Two different experiments are performed to evaluate the proposed approach, respectively for the outdoor environment and the indoor environment.
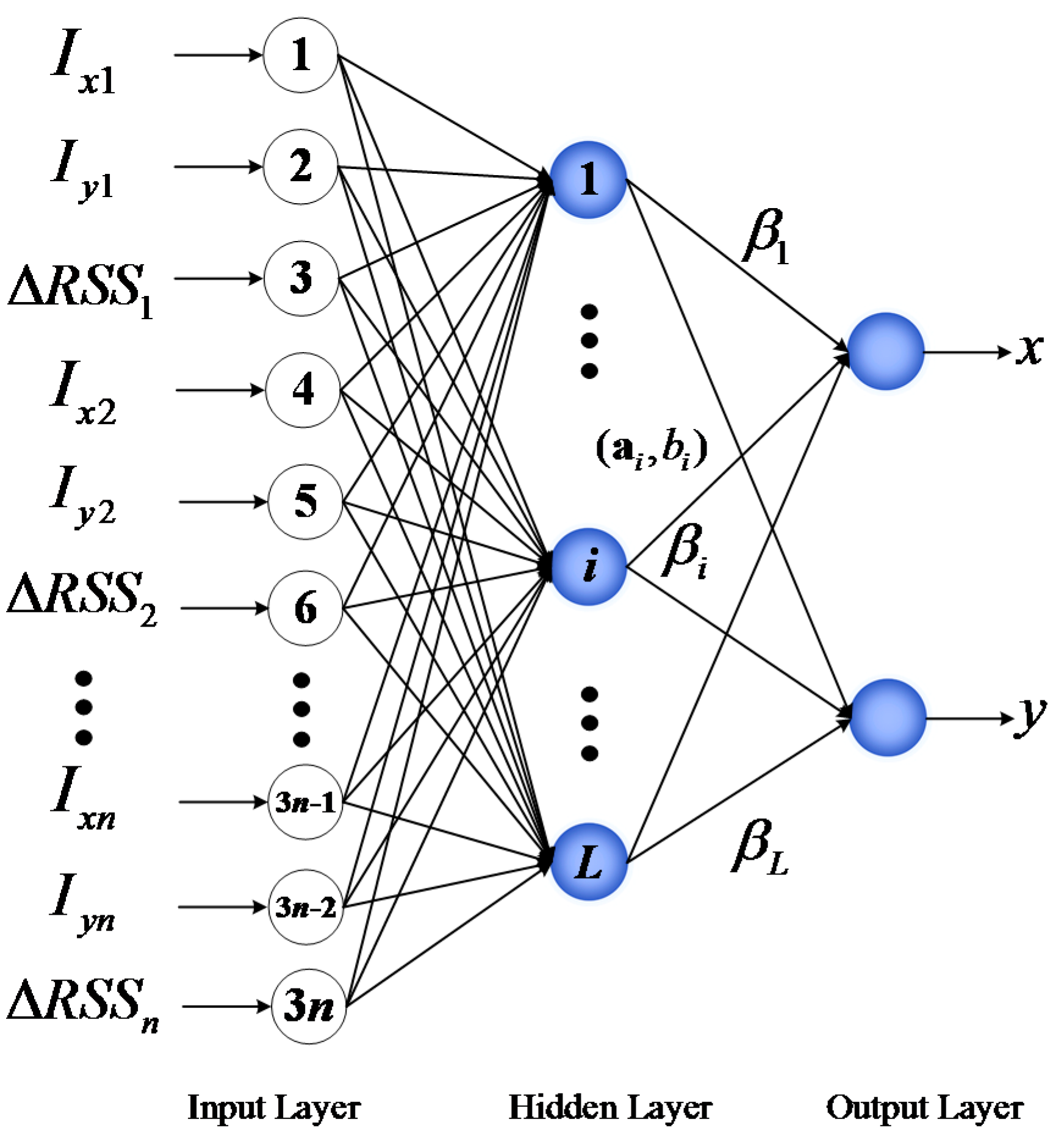
In the experiments, we choose the weighted
K-nearest neighbor (WKNN), SVM, and BPNN for comparison to verify the performance of the proposed PGFE-ELM. As mentioned in
Section 4.1, we set
and
in the following experiments for the two situations in
Figure 3a,b. After data collection, the localization algorithms are carried out in Matlab 2012a environment running in an Inter i5 3.2 GHz CPU and 4G RAM. In addition, we use the following localization accuracy (17) as the evaluation criteria:
where
is the predicted coordinates, and
is the real coordinates of the
ith testing point (TP), and
z is the number of the TPs.
In the performance evaluation processes, the data from RPs is used for training and the data from TPs is used for testing. Each RP provides one training sample, and each TP provides one testing sample. It should be noted that we use the same person to collect the training data and the testing data. The RSS are sampled at the 5-min interval in the working days, and the RSS values of all the RPs and TPs are collected 100 times, and the average values of these RPs and TPs consist of the training dataset and the testing dataset, respectively.
5.2. Experimental Performance Evaluation for Outdoor Environment
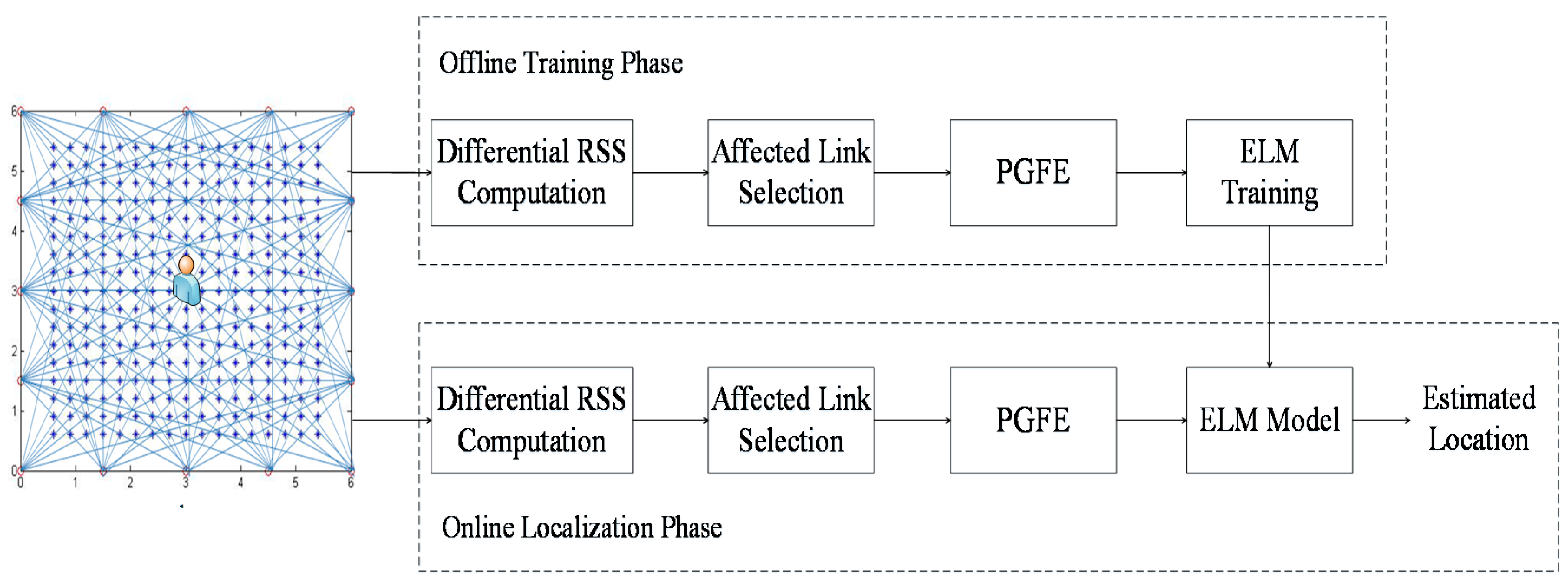
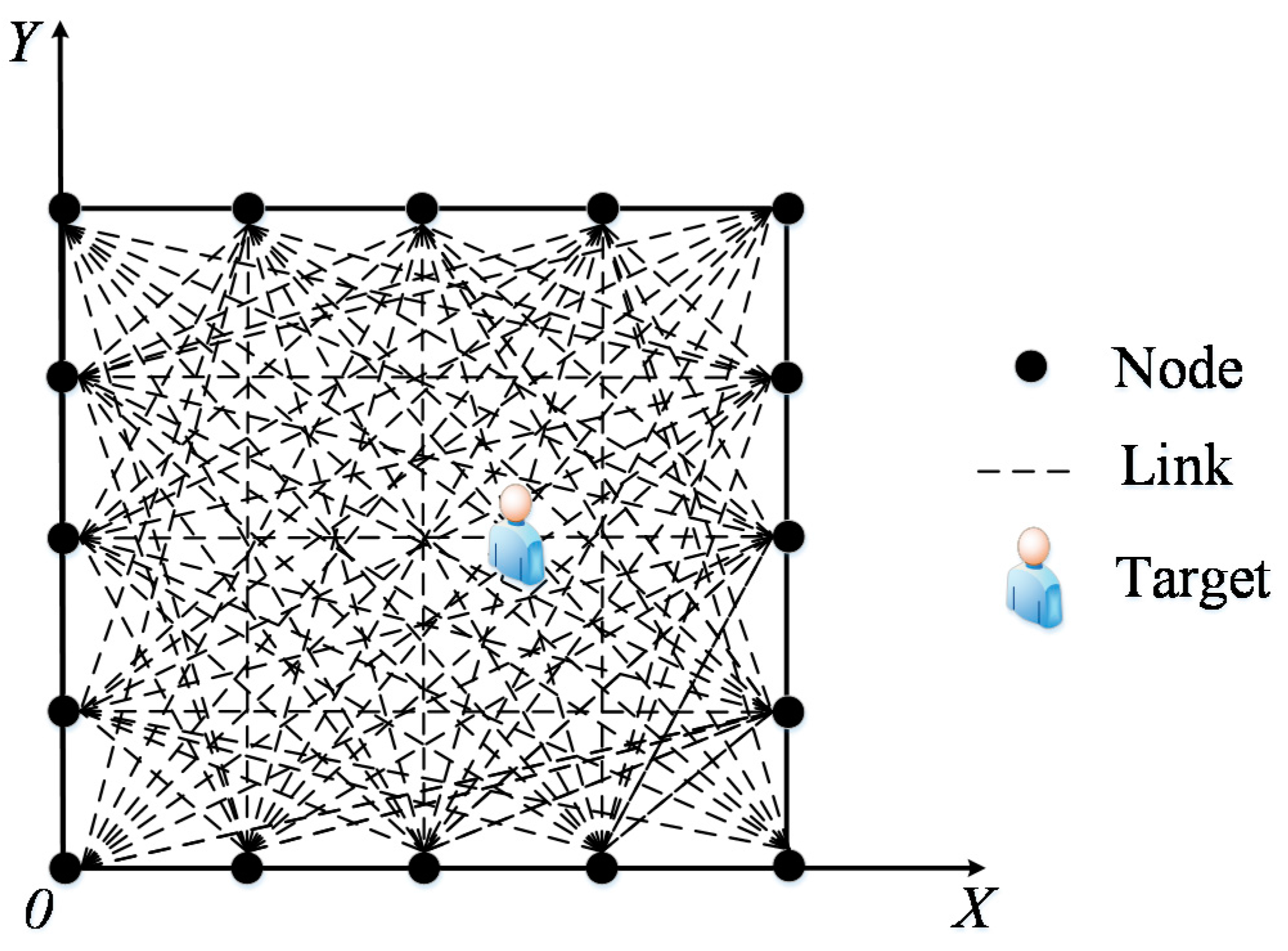
The outdoor environment experiment was set up on the campus of the University of Science and Technology Beijing. As shown in
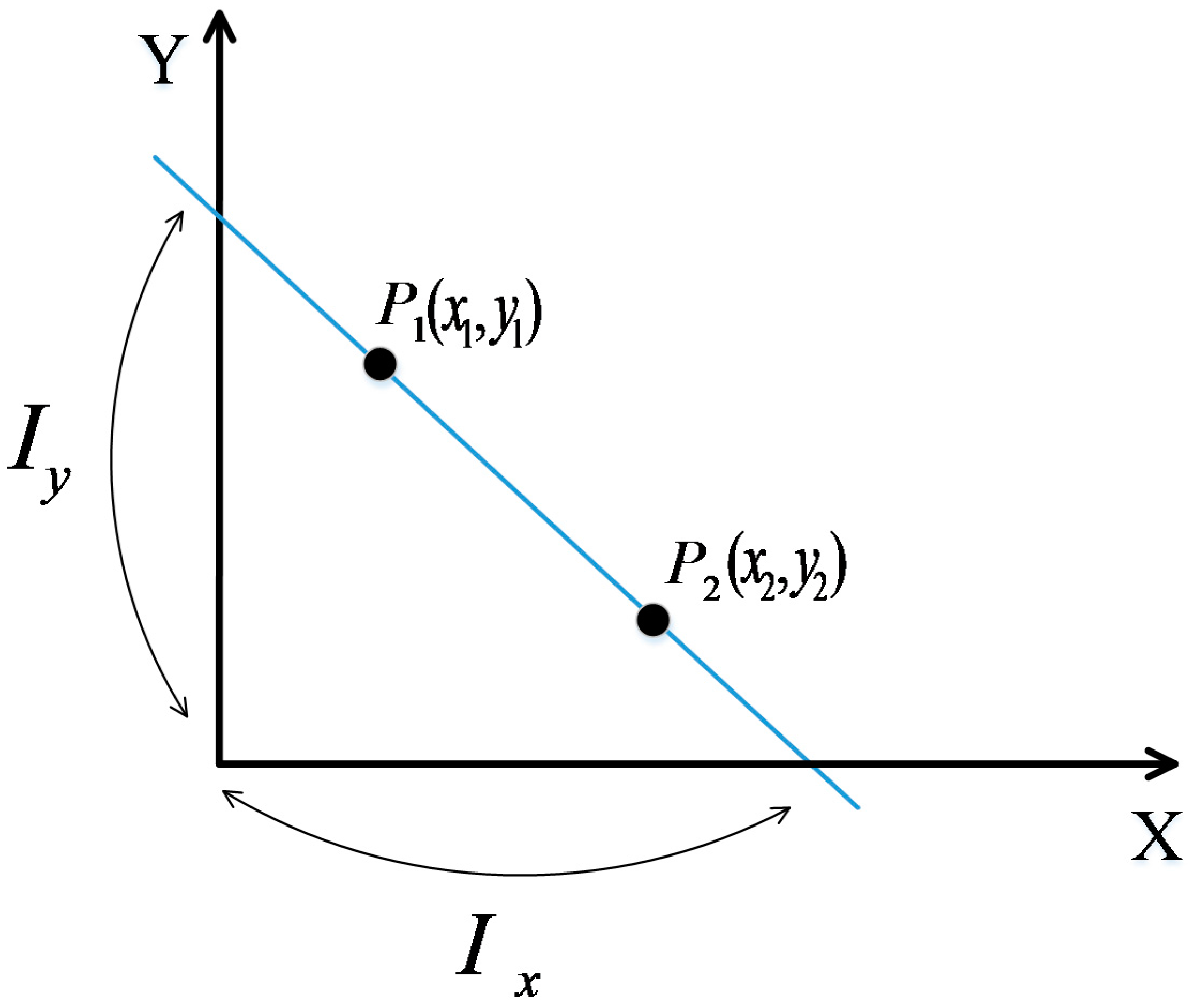
Figure 6, the monitoring area is a 6 m × 6 m square, with 16 nodes placed along its boundary and the adjacent node distances of 1.5 m. In the experiments, for two RP distribution scenarios are examined, one with 0.3 m space between adjacent RPs (i.e., 0.3 m RP spaced scenario) and another one with 0.6 m space between adjacent RPs (i.e., 0.6 m RP spaced scenario). In the first scenario, there are 289 RPs in total, whereas in the second scenario there are 81 RPs in total. In order to implement the proposed PGFE-ELM, we build a coordinate system for the monitoring area, in which the x-axis and the y-axis overlap the two edges of the monitoring area (see
Figure 7).
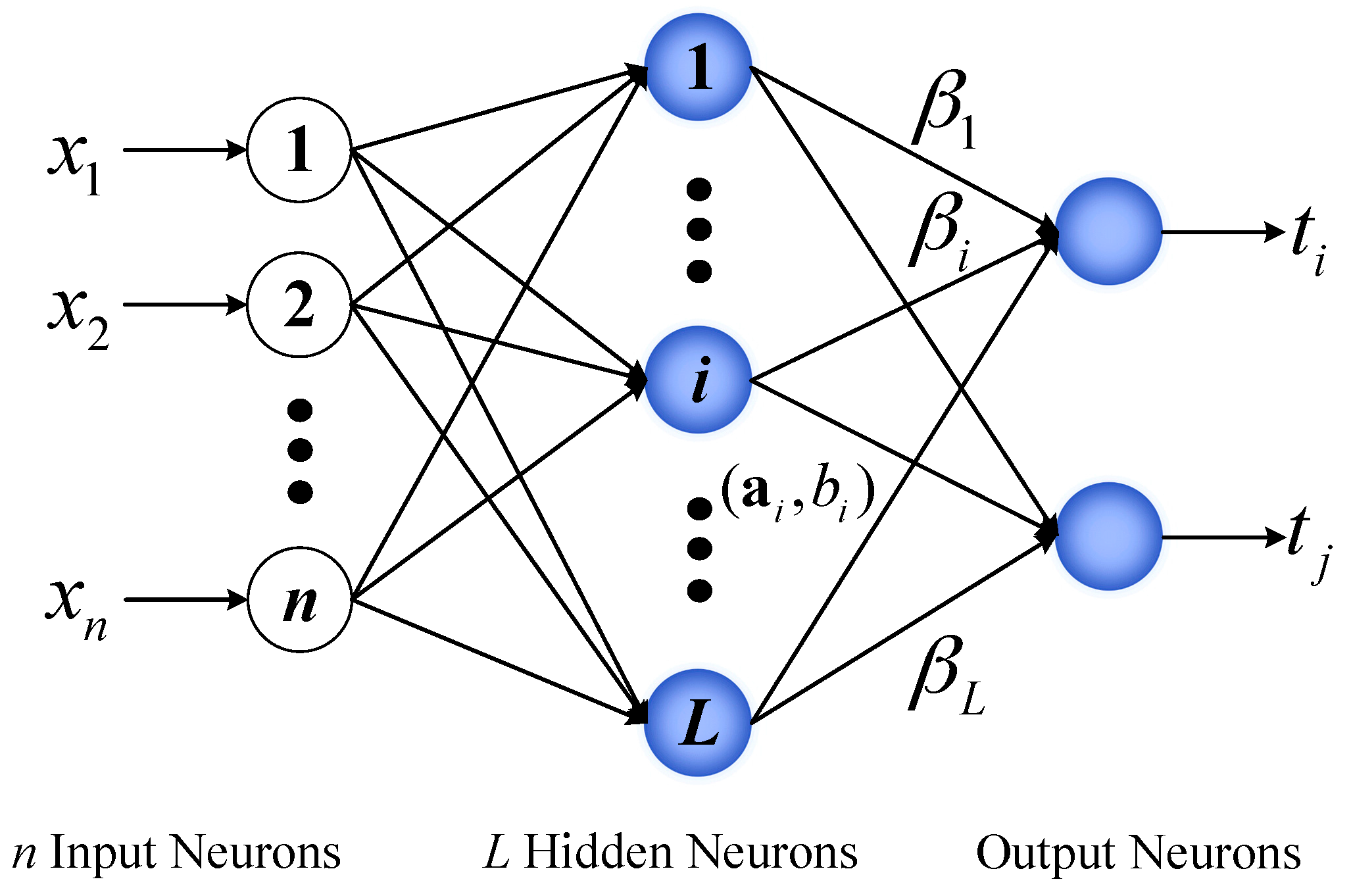
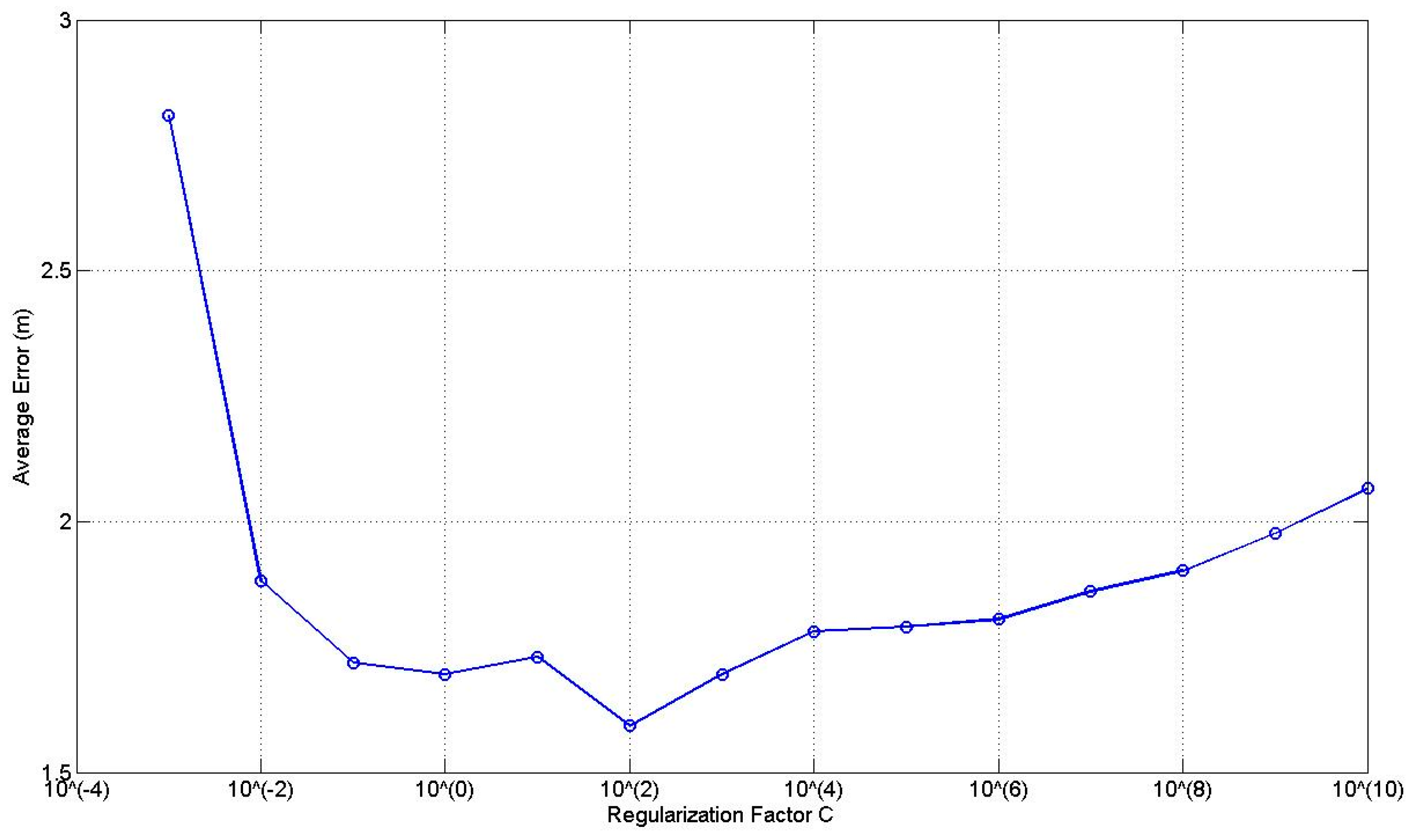
There are two tuning parameters in ELM (sigmoid function is used as the activation function), i.e., the regularization factor
C and the number of hidden nodes
L.
Figure 8 illustrates the average error curve using all the links at the 0.3 m RP spaced scenario with respect to
C given
L = 10. It can be found that the average error curve presents a parabolic shape with the increase of
C and obtains the smallest average error when
C = 10
2. Therefore, we choose
C = 10
2 in the following experiments.
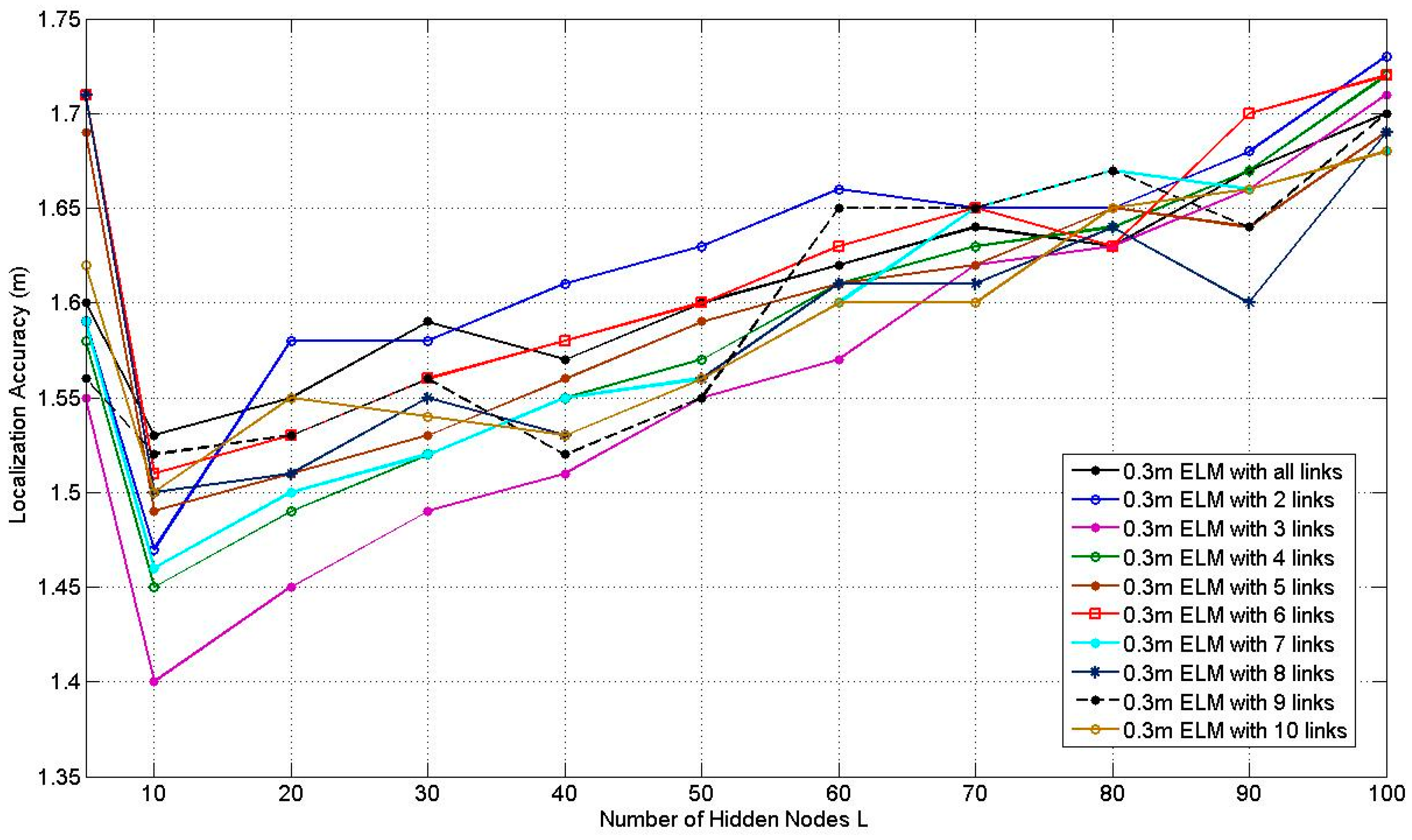
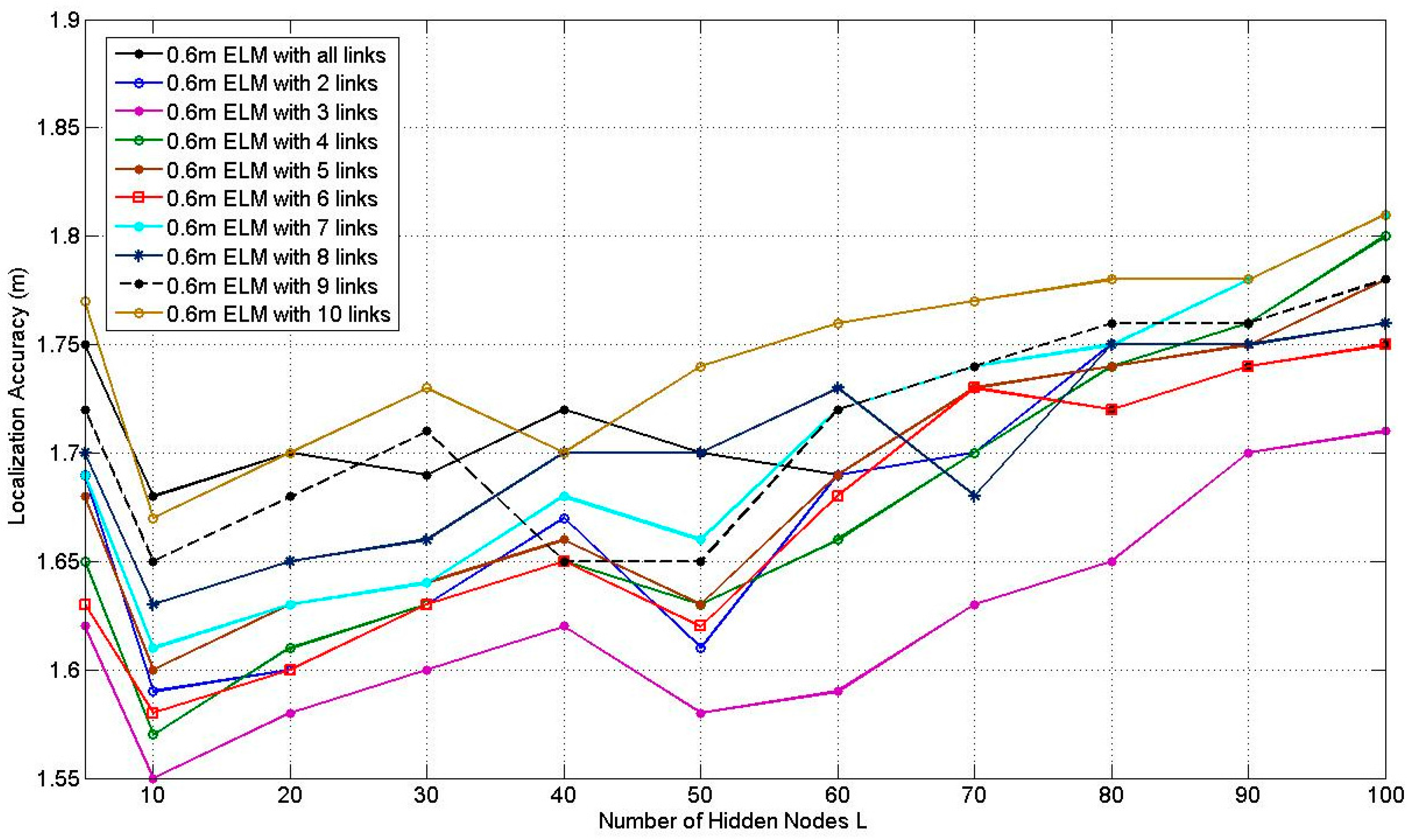
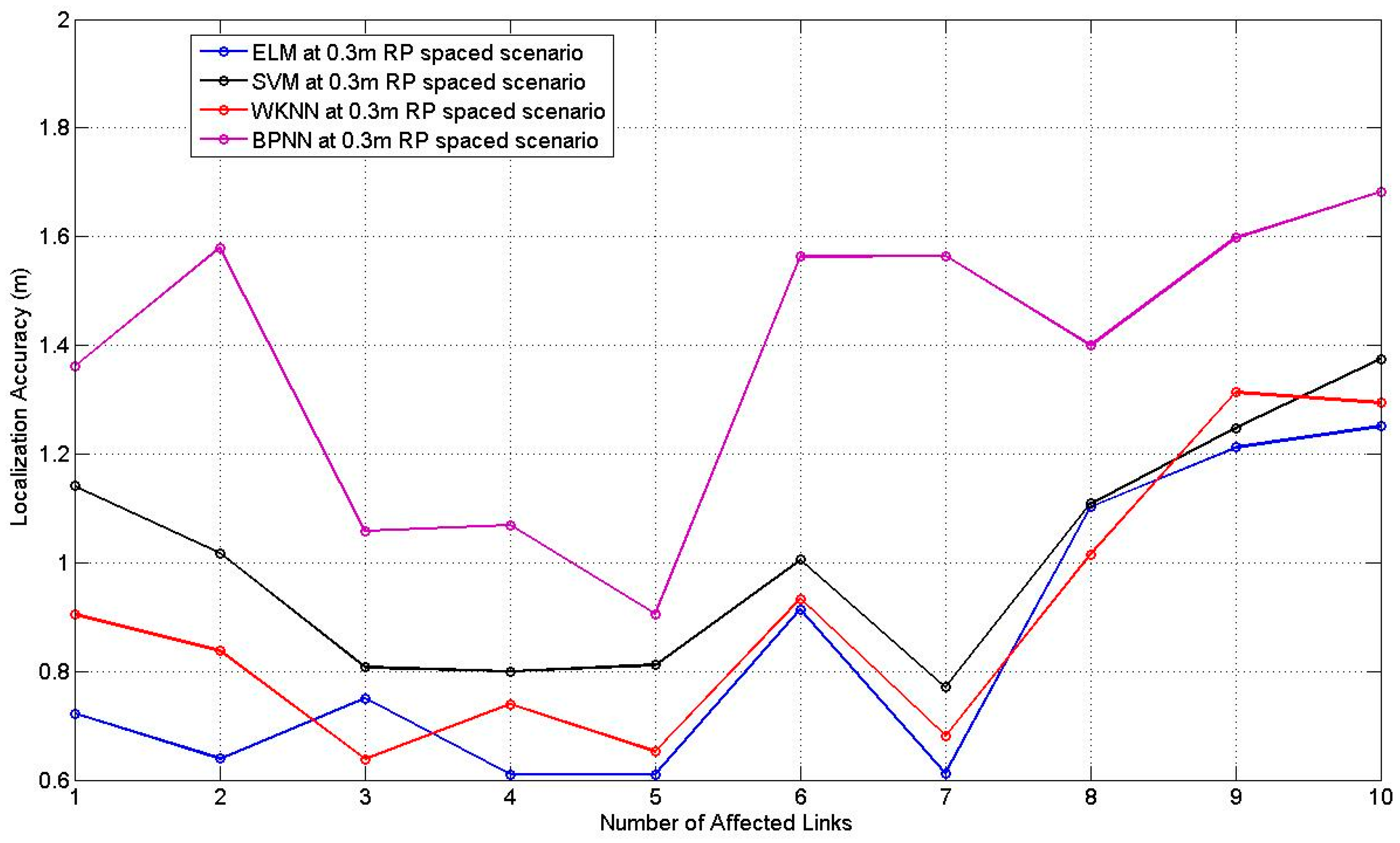
Figure 9 illustrates how the average localization accuracy of PGFE-ELM changes with the increase of the number of hidden nodes from 5 to 100, for the 0.3 m RP spaced scenario with the number of the affected links from 2 to 10 and all the affected links. According to
Figure 9, it can be found that the best average localization accuracies can be achieved when
L = 10, no matter how many affected links are selected. The situation when
L = 10 with 3 selected affected links can obtain the best average localization accuracy, which equals to 1.40 m.
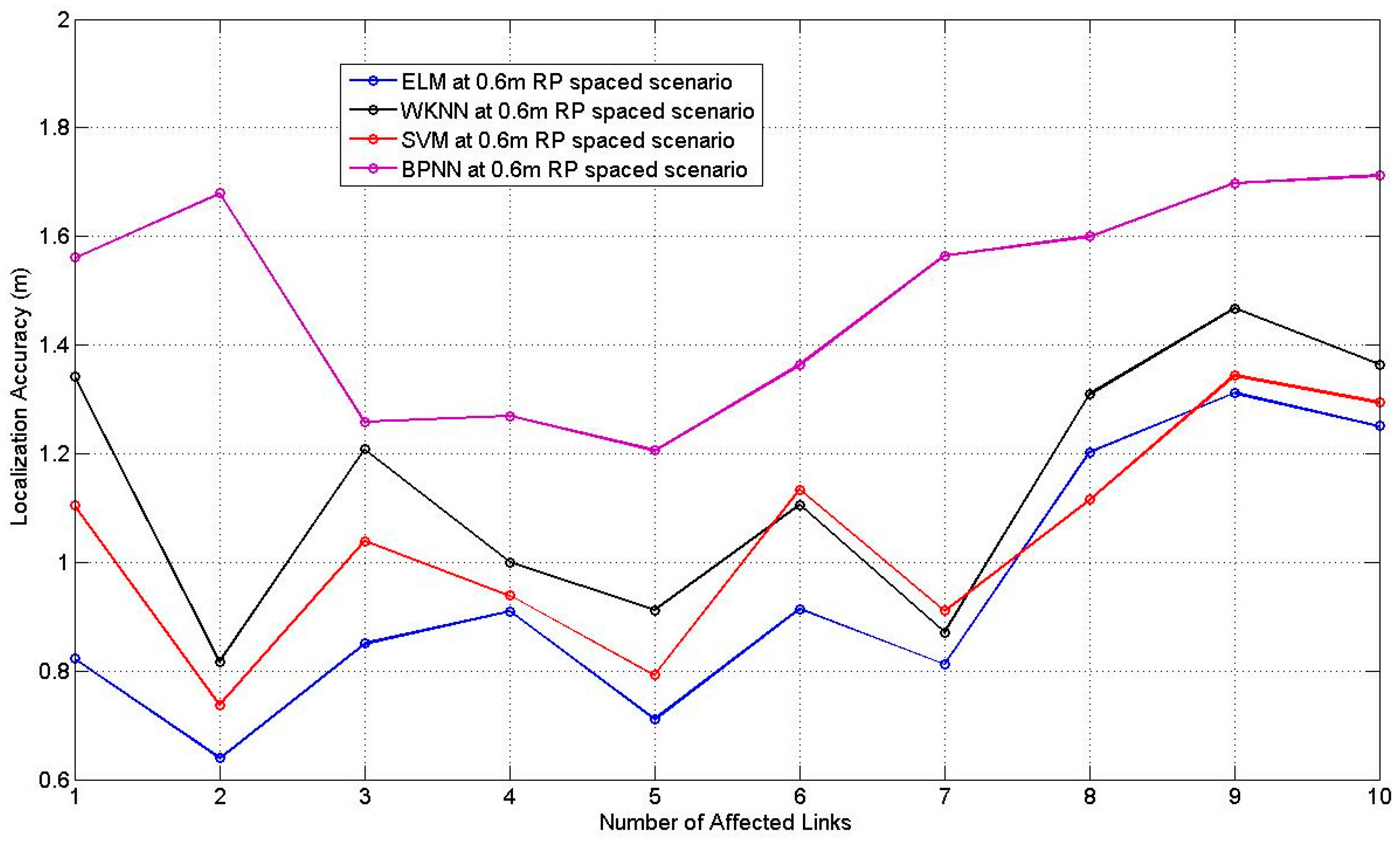
Figure 10 illustrates the average localization accuracy of PGFE-ELM when the RP is 0.6 m spaced scenario. Similar to
Figure 9, the corresponding best average localization accuracies are obtained when
L = 10. The situation when
L = 10 with 3 affected links can obtain the best average localization accuracy, which equals to 1.55 m. Comparing
Figure 9 and
Figure 10, we can find that the average localization accuracies of most situations in
Figure 9 with the 0.3 m RP spaced scenario are better than the corresponding situations in
Figure 10. Whereas the average localization accuracies of in
Figure 10 with the 0.6 m RP spaced scenario is worse but with less calibration overhead.
Normally the affected link is identified by comparing the differential RSS measurement with a predefined threshold. However, due to the uncertainties of the experimental environments, such threshold may introduce false detection. Differently, PGFE-ELM compares the differential RSS measurements of all the links and selects the given number of affected links from the most significant ones. As it is difficult to know the optimal number of the affected links in PGFE-ELM, we examine this by experiments.
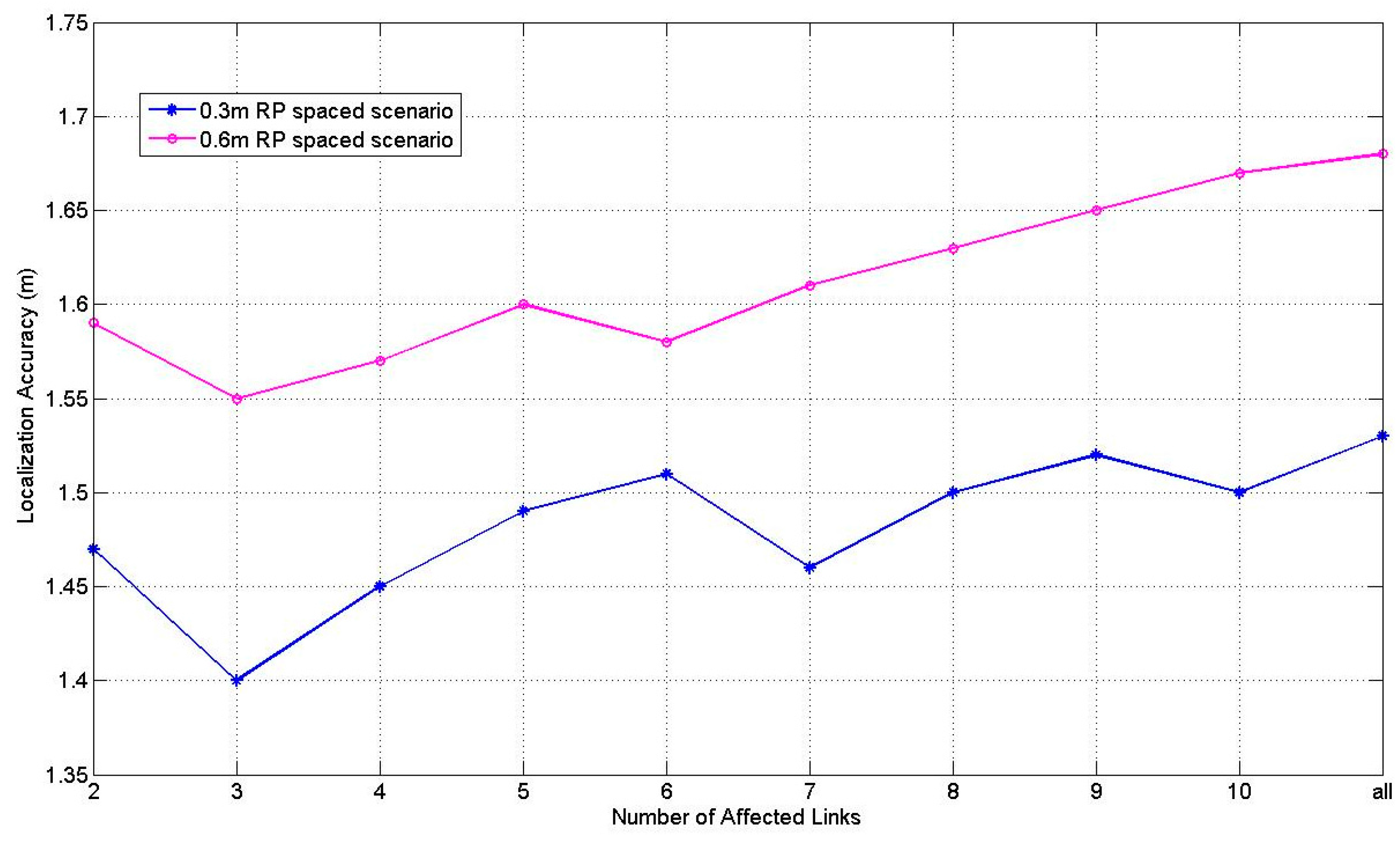
Figure 11 illustrates the comparison results of PGFE-ELM accuracy versus the number of affected links with the number of hidden nodes 10 which is showed best performance in
Figure 9 and
Figure 10. We can find that PGFE-ELM achieves the best localization accuracy in both of the two RP spaced scenarios when the number of affected links is set as 3. The main reasons are that: if the assigned number of the affected links is set as 2, the number of links may be not enough for estimating the target location; whereas if the assigned number of the affected links is too large, some links may be identified as affected links incorrectly and subsequently degrade the localization performance.
There is only one tuning parameter in WKNN, i.e., the number of neighbors
K.
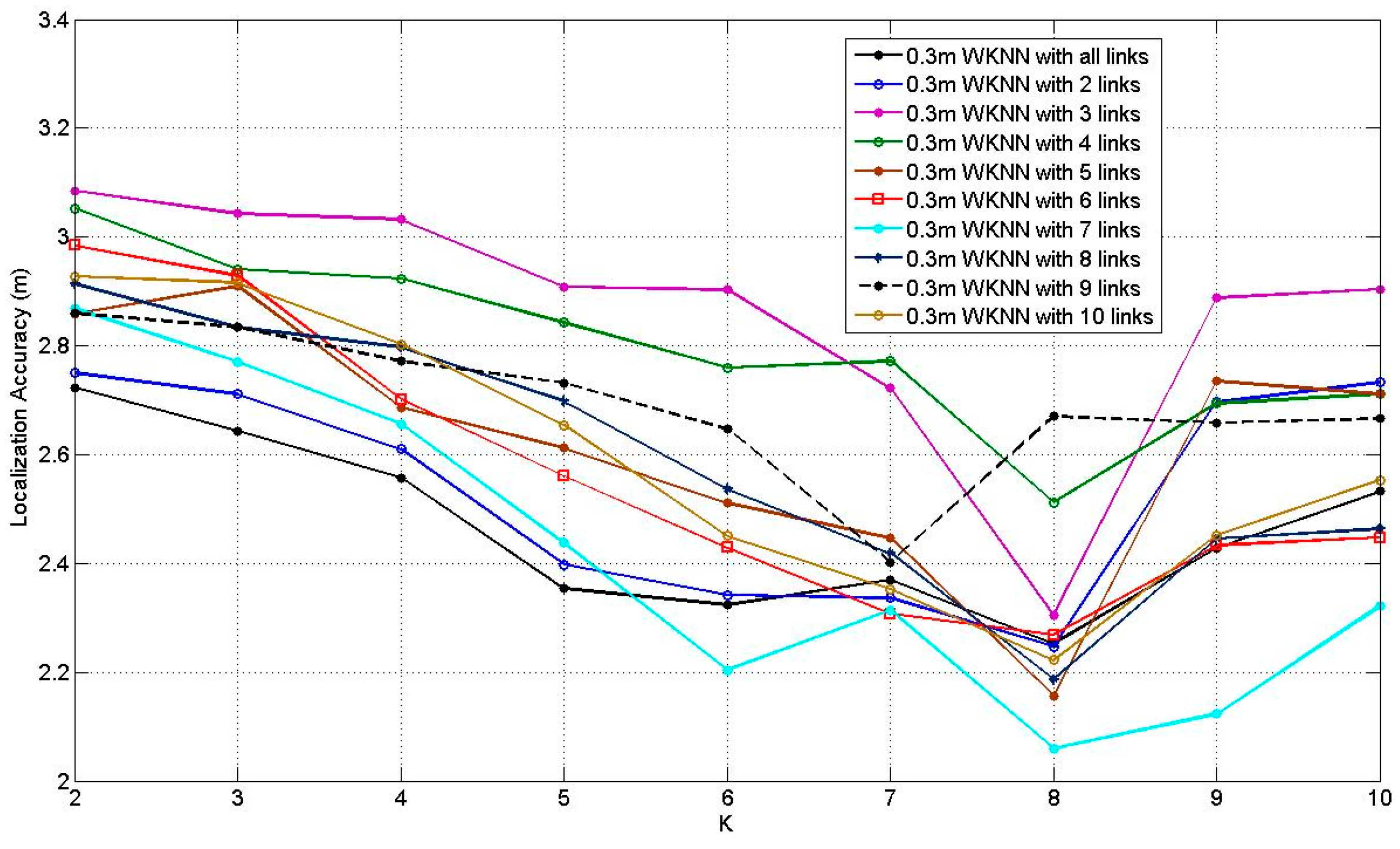
Figure 12 illustrates the how the average localization accuracy of WKNN at 0.3 m RP spaced scenario changes when
K increases from 2 to 10, with the number of the affected links from 2 to 10 and all the affected links. According to
Figure 12, it can be found that all the curves present the downtrends before
K = 8 and most of them rise after
K = 8. The situation of
K = 8 with 7 affected links obtains the best average localization accuracy, which equals to 2.06 m.
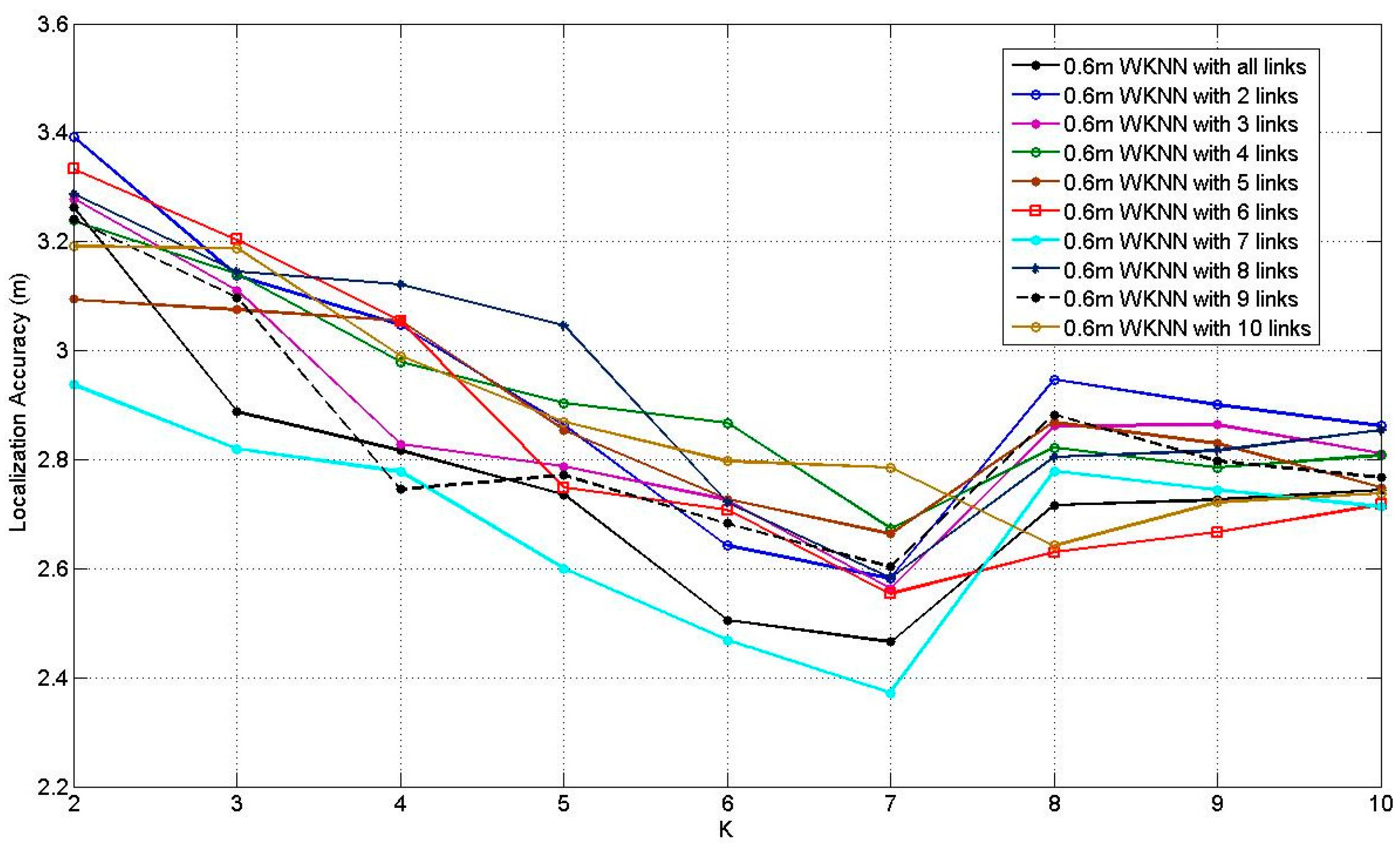
Figure 13 illustrates the results of WKNN at 0.6 m RP spaced scenario, when increasing
K from 2 to 10. Similar to
Figure 12, all the curves present the downtrends before
K = 7 and most of them rise after
K = 7. The situation of
K = 8 with 7 affected links obtains the smallest error, which equals to 2.37 m. Similar to ELM, in the 0.3 m RP spaced scenario, WKNN can achieve better average localization accuracy compared with the 0.3 m RP spaced scenario.
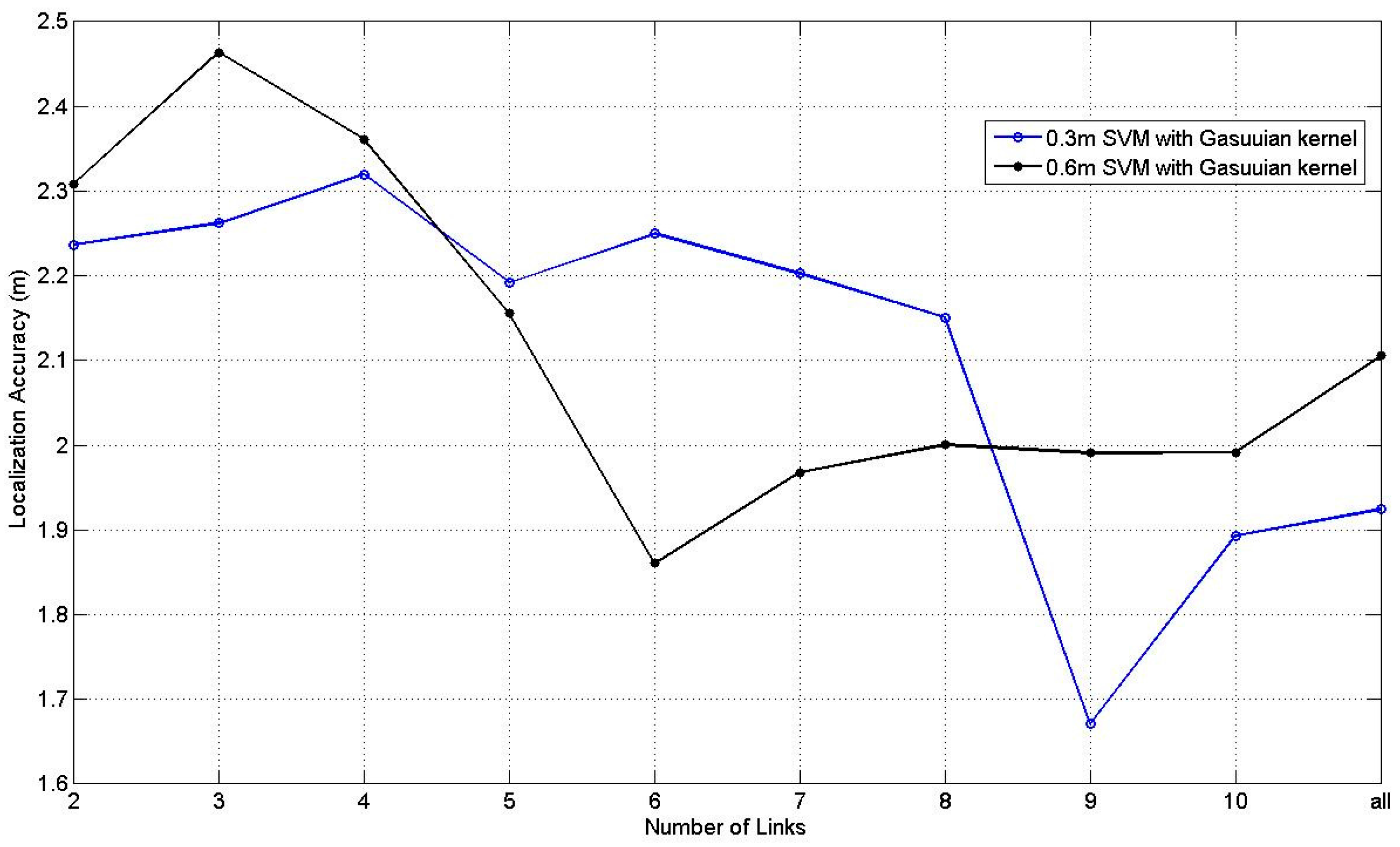
Figure 14 illustrates the results of SVM with Gaussian kernel at 0.3 m and 0.6 m RP spaced scenarios s with the number of the affected links changing from 2 to 10 and all the affected links. All the parameters in SVM are obtained through the cross validation. According to
Figure 14, it can be found that the situation of 0.6 RP spaced scenario is relatively smoother than the situation of 0.3 m RP spaced scenario with tiny fluctuation, and situation with 9 affected links at 0.3 m RP spaced scenario obtains the best average localization accuracy, which equals to 1.67 m.
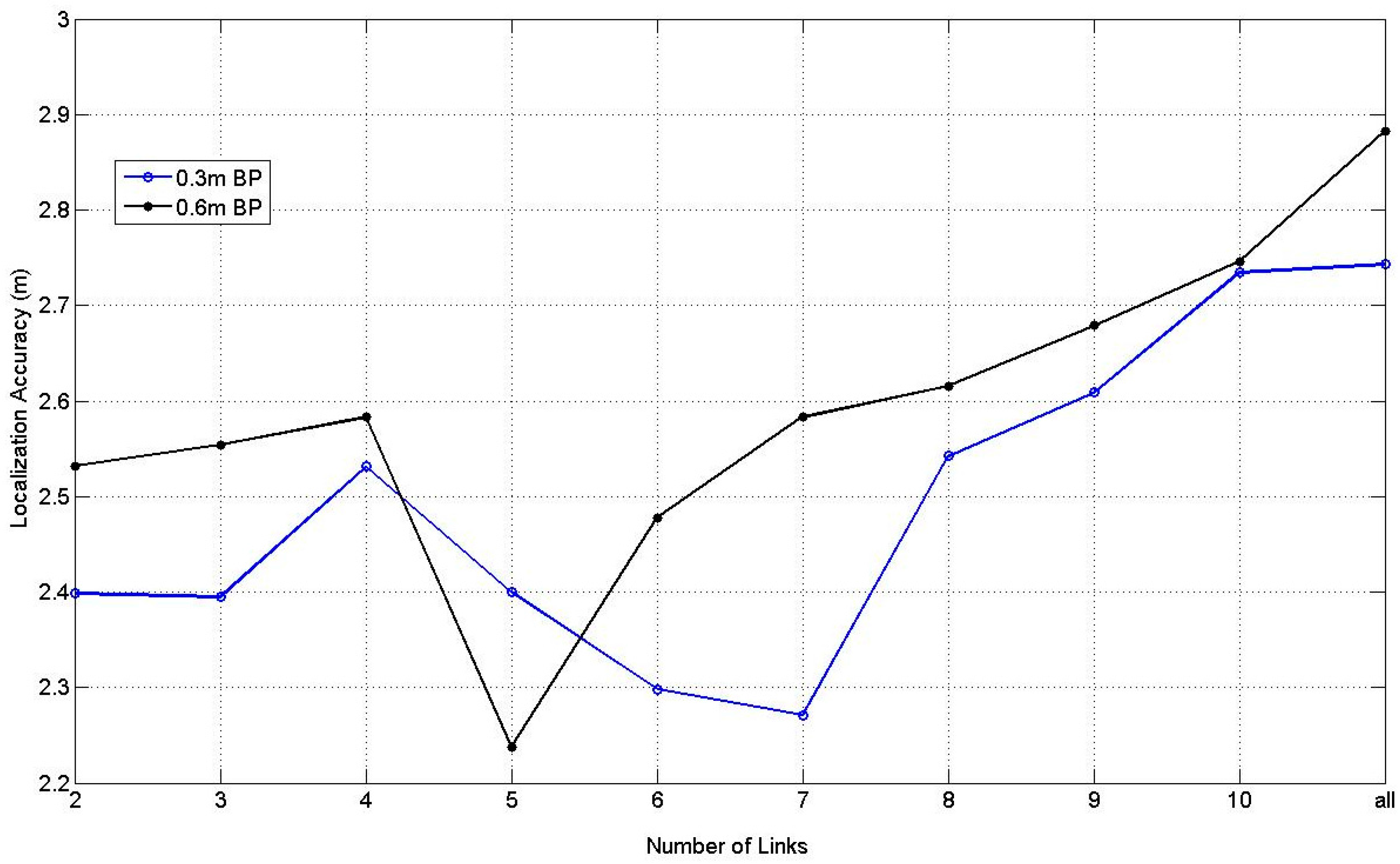
Figure 15 illustrates the results of BPNN with one hidden layer and 10 hidden nodes at 0.3 m and 0.6 m RP spaced scenarios with the changing of the number of the affected links from 2 to 10 and all the affected links. In
Figure 15, the situation with 5 affected links at 0.6 m spaced scenario obtains the best average localization accuracy, which equals to 2.23 m.
Table 1 and
Table 2 demonstrate the time consumption of ELM, WKNN, SVM and BPNN with 3, 5, 7, 9 and all links at 0.3 m RP spaced scenario and 0.6 m RP spaced scenario, respectively. We can find that obviously ELM is much faster than other machine learning approaches, especially in training time. For example, ELM is thousands of times faster than SVM and hundreds of times faster than BPNN at 0.3 m RP spaced scenario. Furthermore, the testing time of ELM equals to or is close to 0 s in most situations. Evidently, in terms of time consumption, with the increase of data quantity, the advantage of ELM will be more significant.
Furthermore, the best and worst localization accuracy among TPs in different situations is listed in
Table A1,
Table A2,
Table A3,
Table A4 and
Table A5 in the
Appendix A, respectively. For ELM and BPNN, the number of hidden nodes
L is set as 10; for WKNN,
K is set as 8 in the 0.3 m scenario and 7 in the 0.6 m scenario. We can find that in some situations, the best localization accuracy of ELM and SVM are even under 0.1 m. In addition, the worst localization accuracy in different situations of ELM is about 3 m, and other approaches can be high as 5 m. These results indicate that ELM is more robust than other machine learning approaches.
According to the above figures and tables, we can find that the results of the 0.3 m RP spaced scenario of all the four machine learning approaches are better than their corresponding results of the 0.6 m RP spaced scenario in most situations, which indicates that 0.3 m between adjacent RPs is more suitable than the case with 0.6 m. Furthermore, if we use all the affected links in the experiment, all the situations cannot obtain their own best average localization accuracies, which indicates that choosing the appropriate number of the affected links is important and can reduce the computation burden of the models and improve the localization accuracy efficiently. Finally, we also can find that all of the localization accuracy of PGFE-ELM in different situations is much better than WKNN, SVM, and BPNN, which shows its excellent generalization performance. It should note that the best average localization accuracy of these approaches is 1.40 m, which is achieved by PGFE-ELM with the 0.3 m RP spaced.
In order to verify the validity of the proposed PGFE, we perform the experiment using the original dataset only with the differential RSS values.
Table 3 lists the comparison results of the four machine learning approaches with and without PGFE in the situation of 3 affected links of the 0.3 m RP spaced scenario. It can be found that the results with PGFE are much better than the corresponding ones without PGFE, WKNN and SVM can achieve about 1 m improvement when PGFE is used.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















