
History-Based Response Threshold Model for Division of Labor in Multi-Agent Systems


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Problem Description
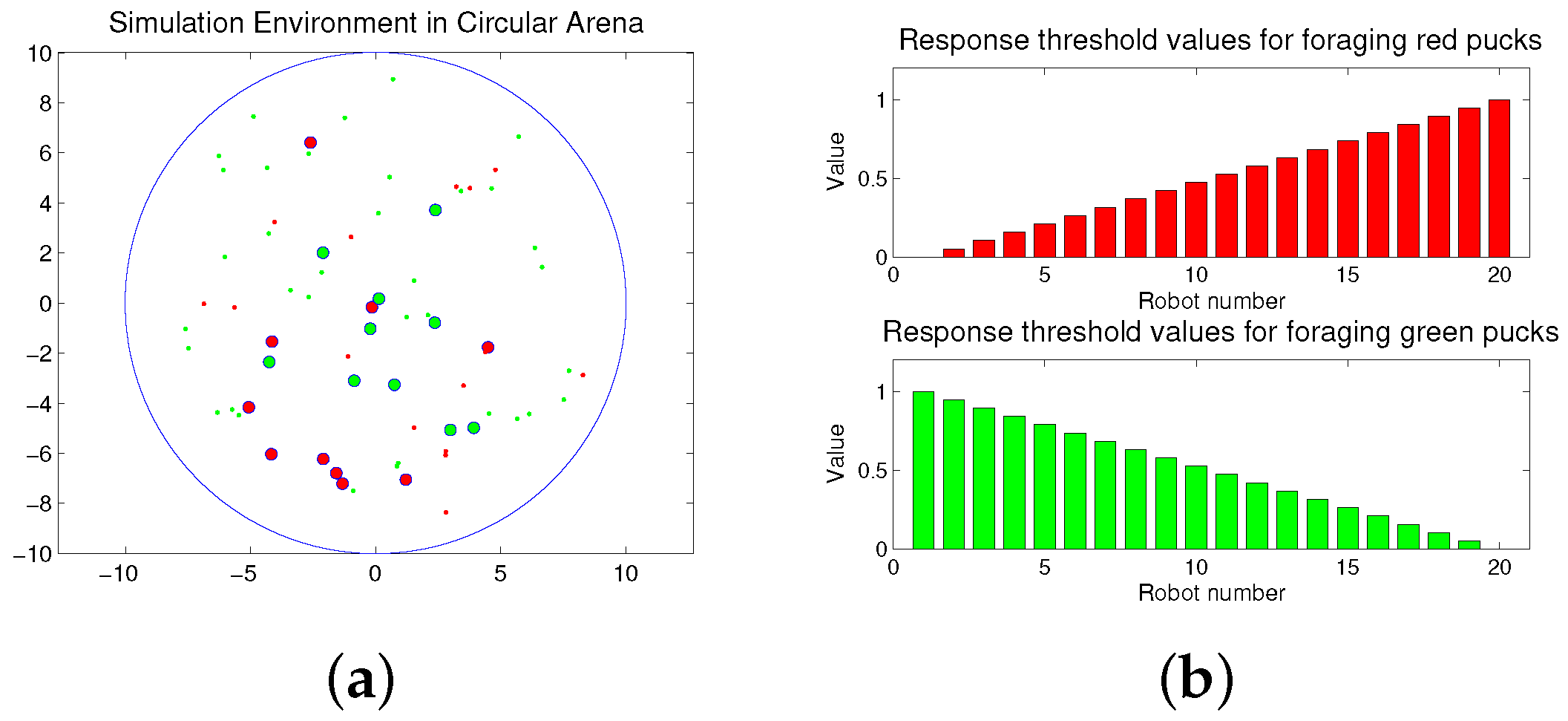
2.1. Task Scenario
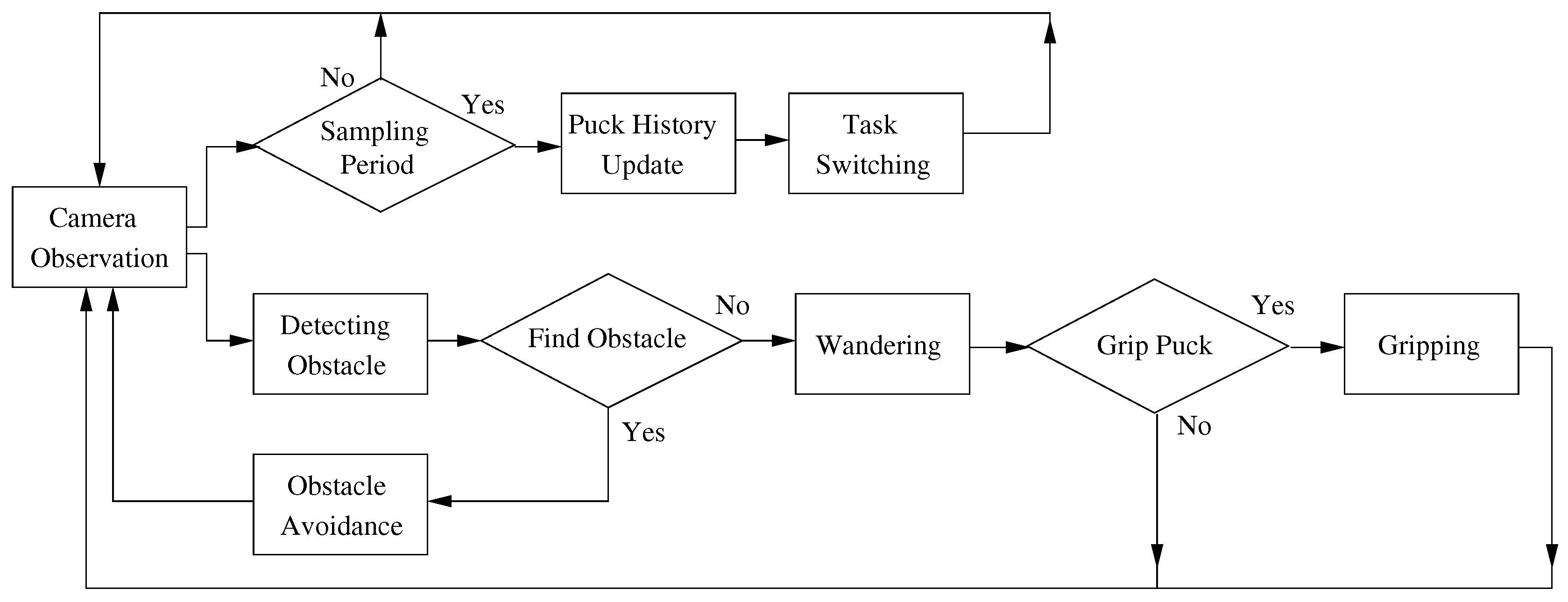
2.2. Robot Behaviors
2.2.1. Observation
2.2.2. Obstacle Avoidance
2.2.3. Wandering
2.2.4. Gripping
2.2.5. Task Switching
3. Proposed Method
3.1. Modeling
3.2. Task Switching Algorithm
4. Experimental Results
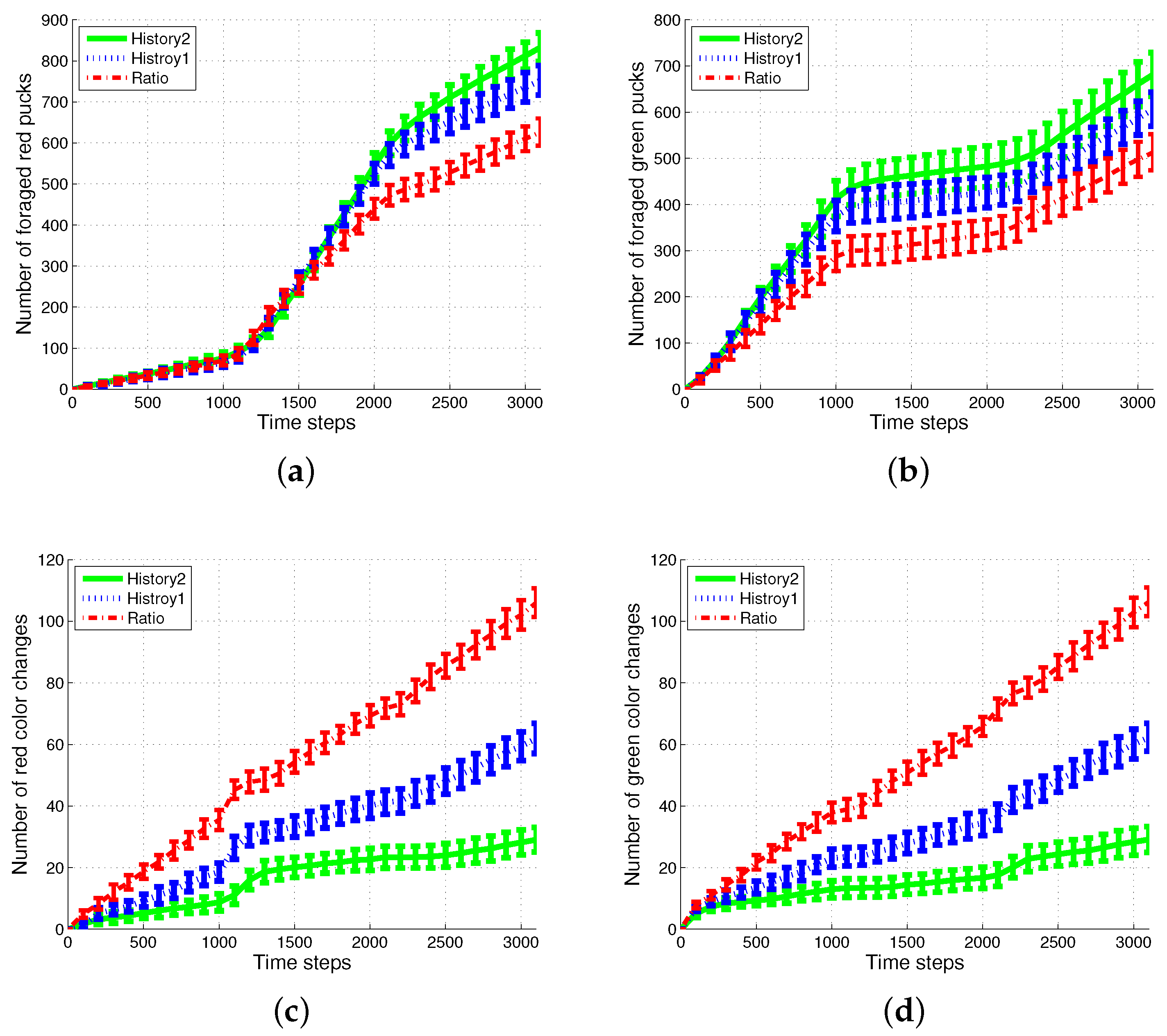
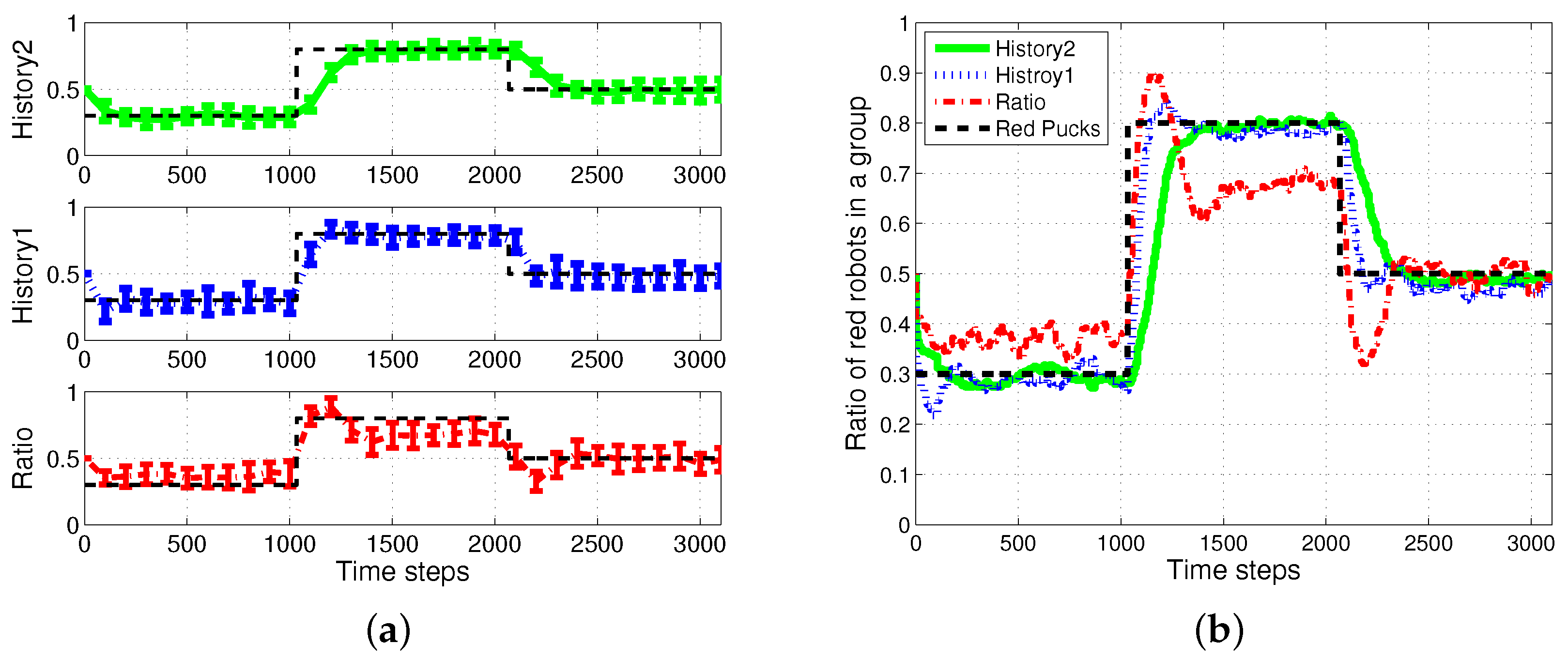
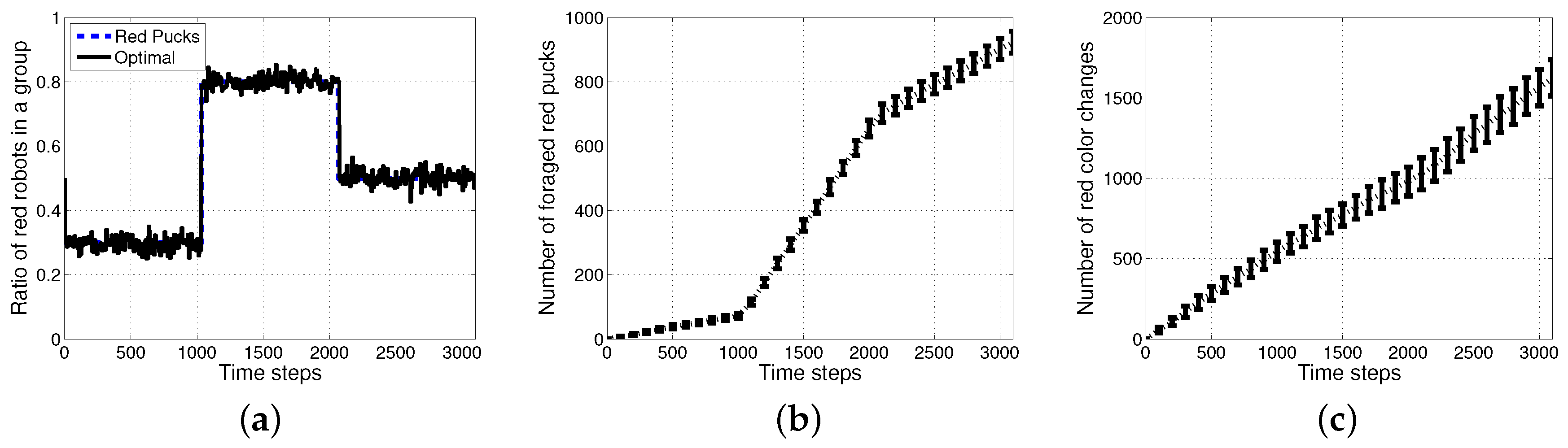
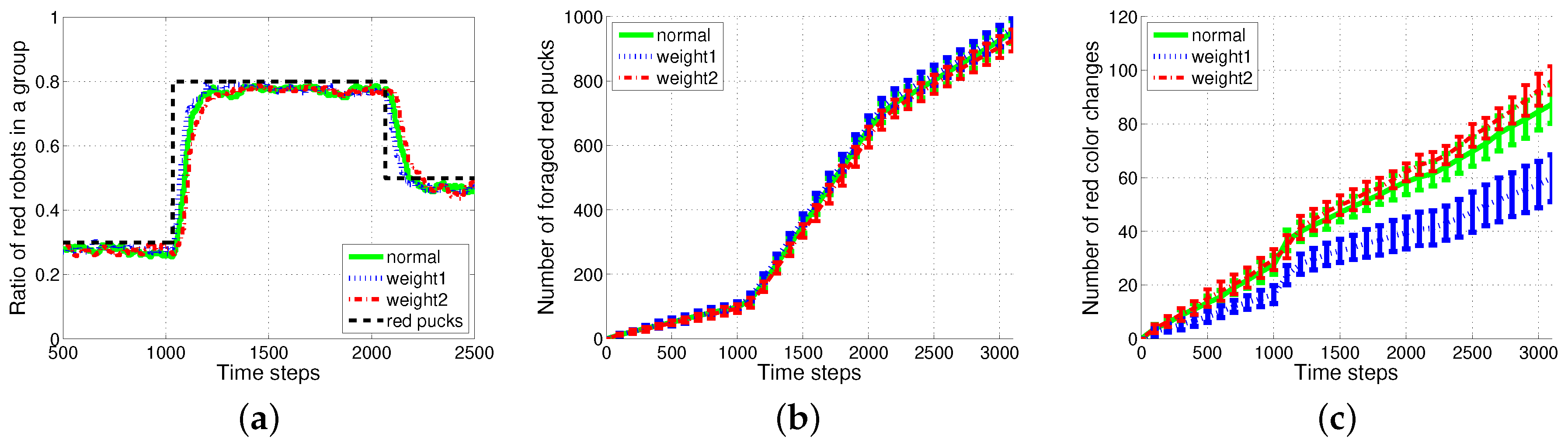
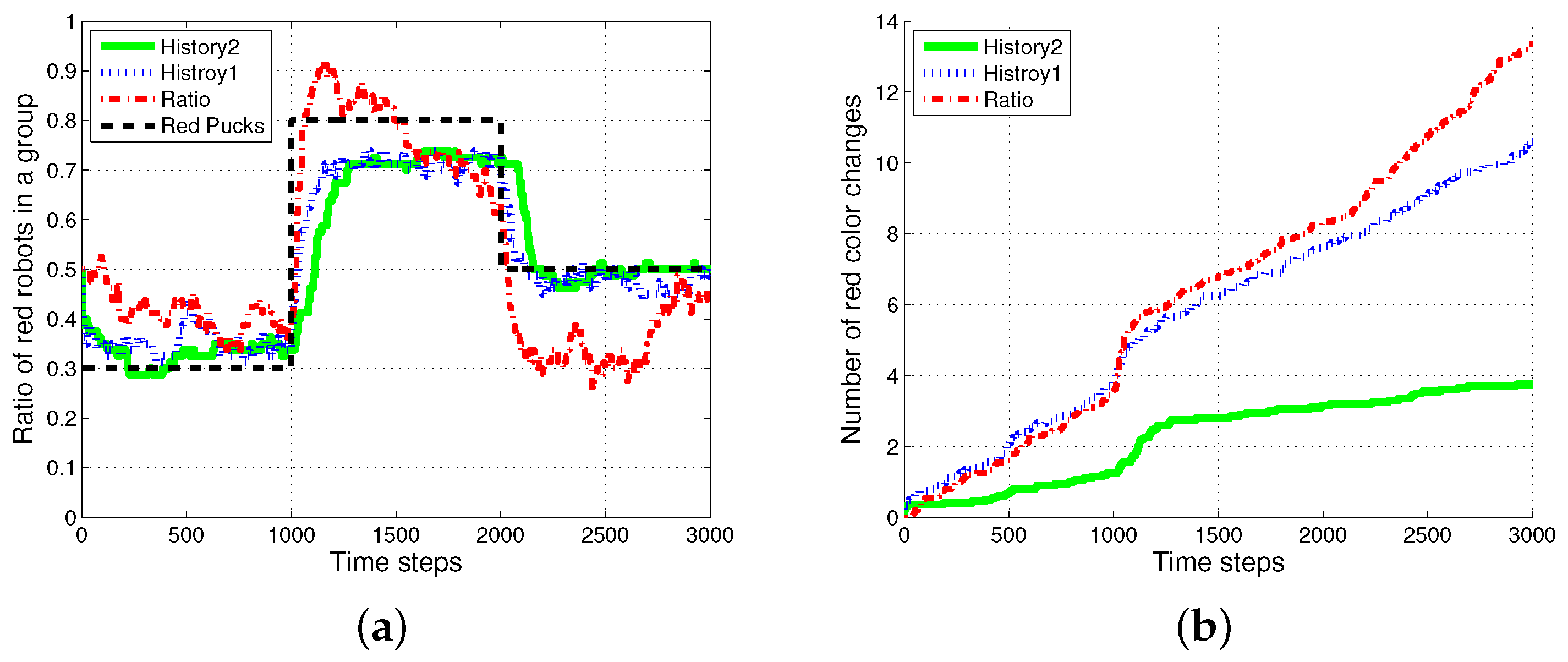
4.1. Result with Changes in Task Demands
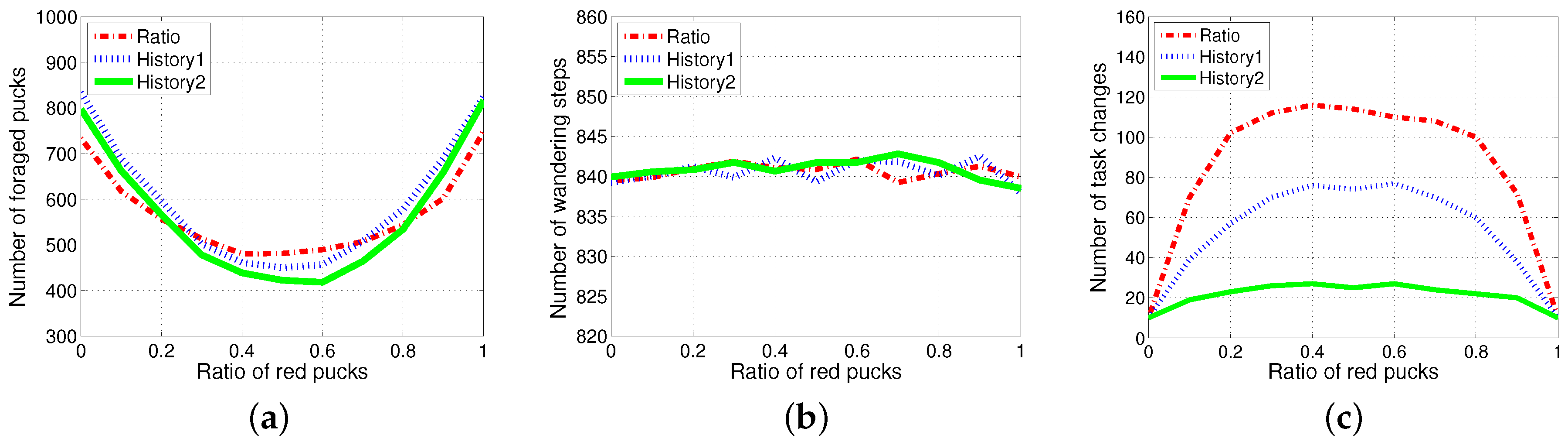
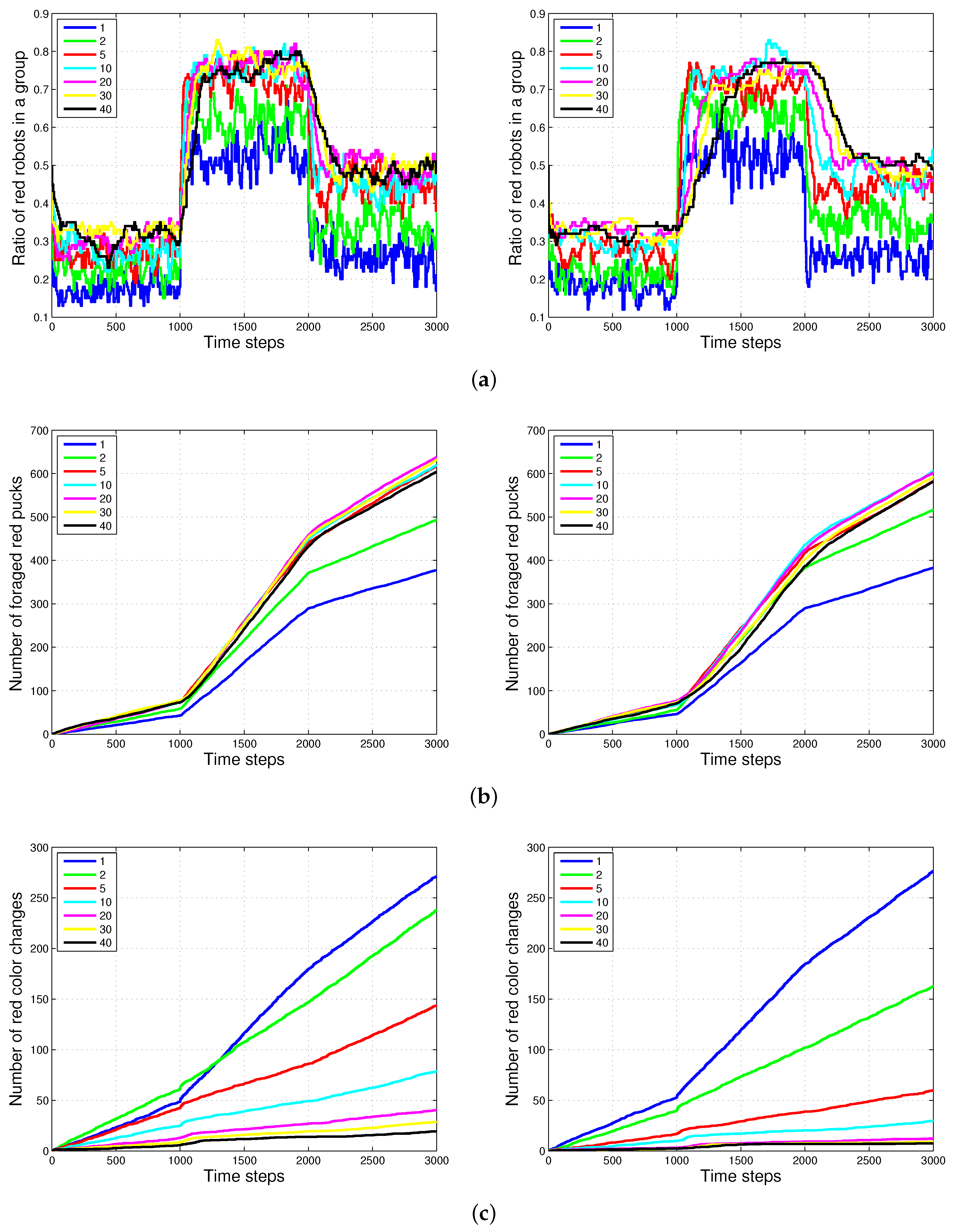
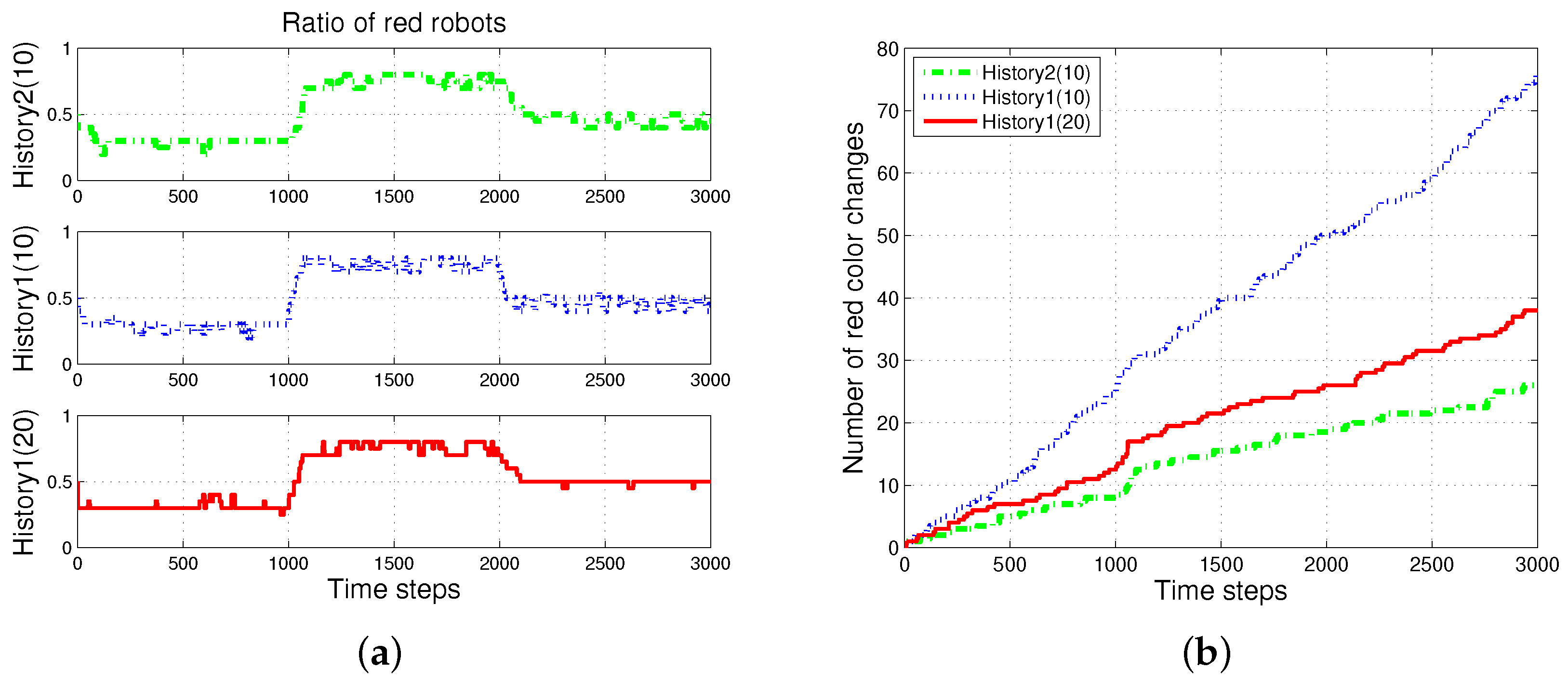
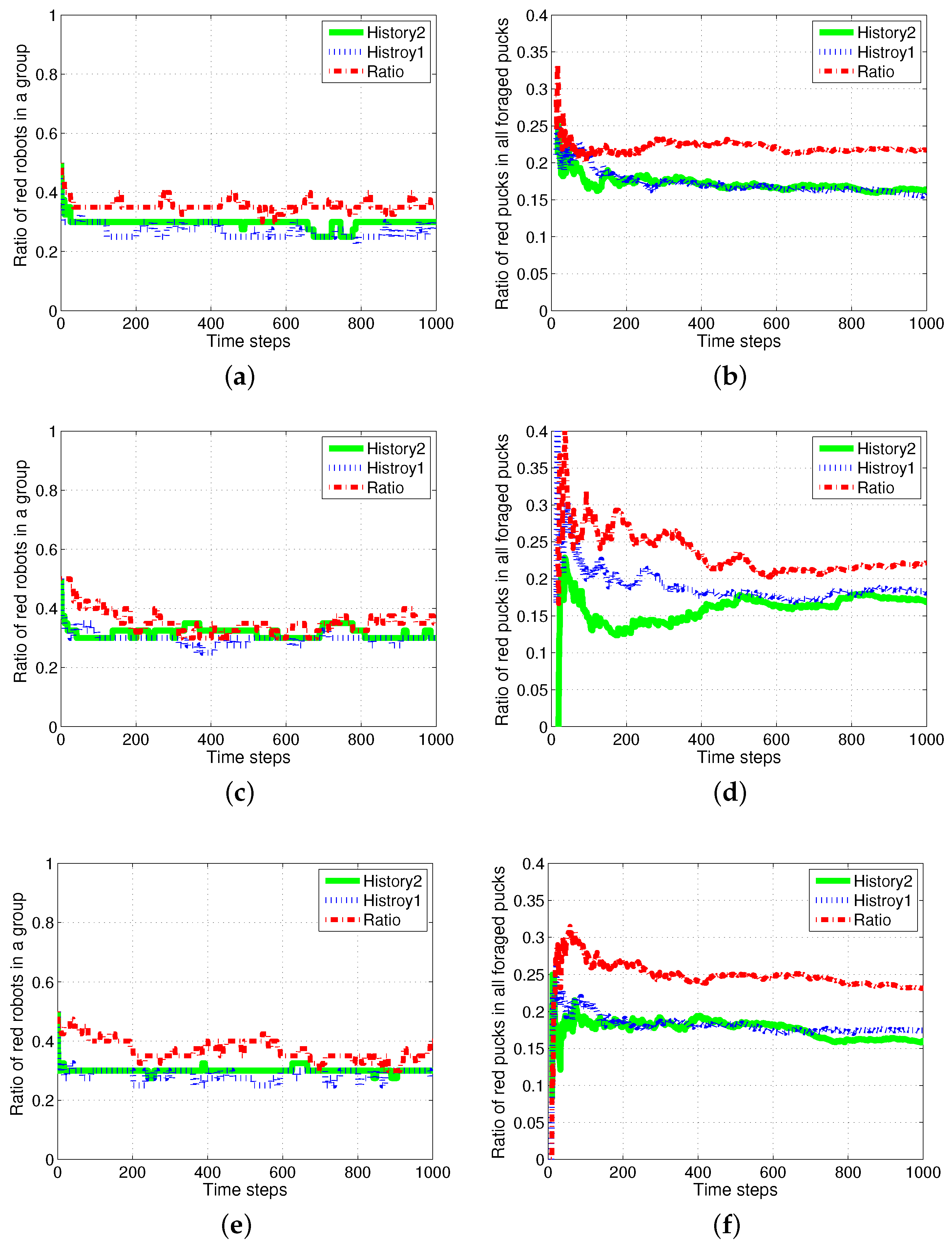
4.2. Results with Changes in the Size of Puck History
4.3. Results with Changes in Vision Sampling Period
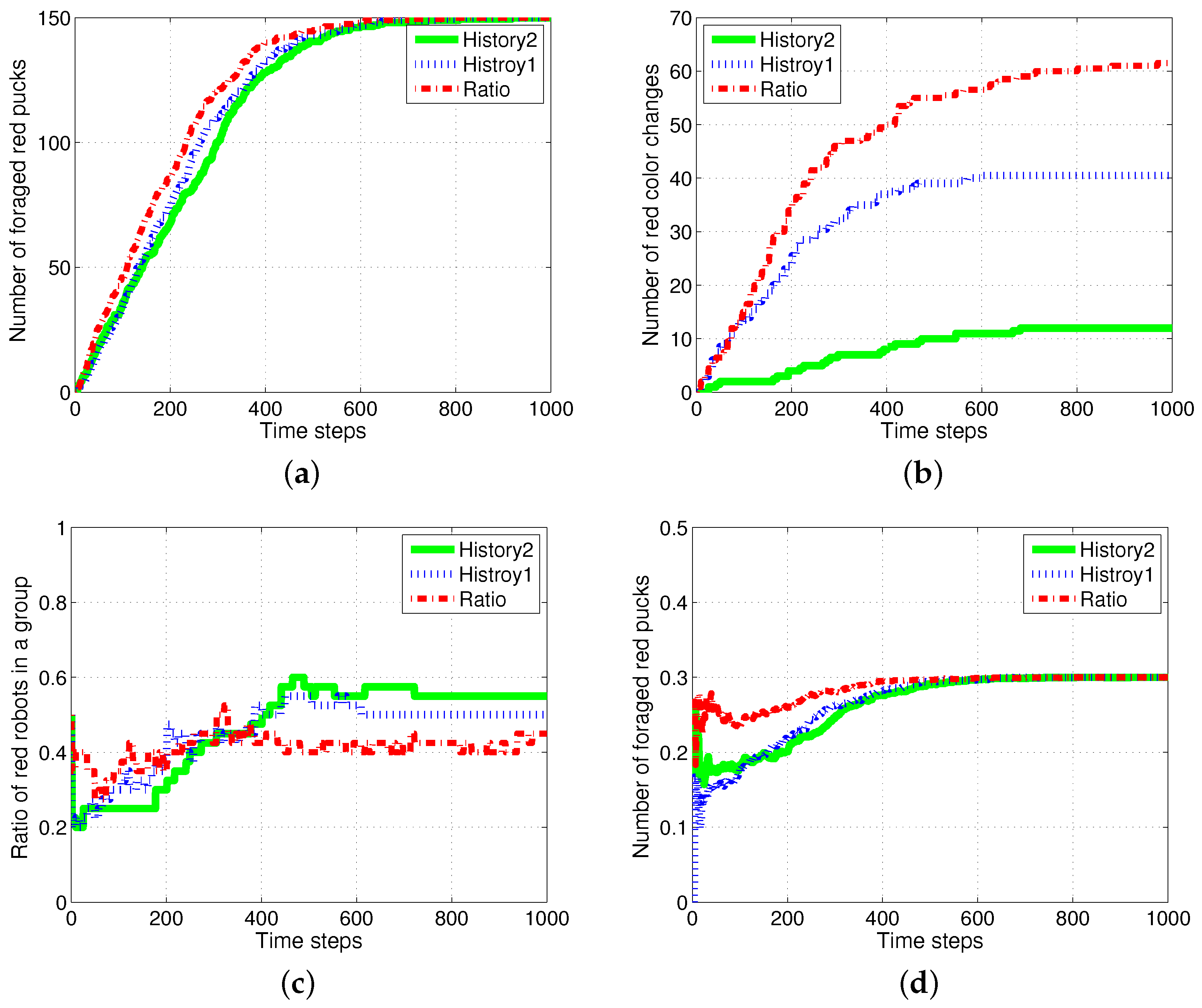
4.4. Results with a Fixed Number of Tasks
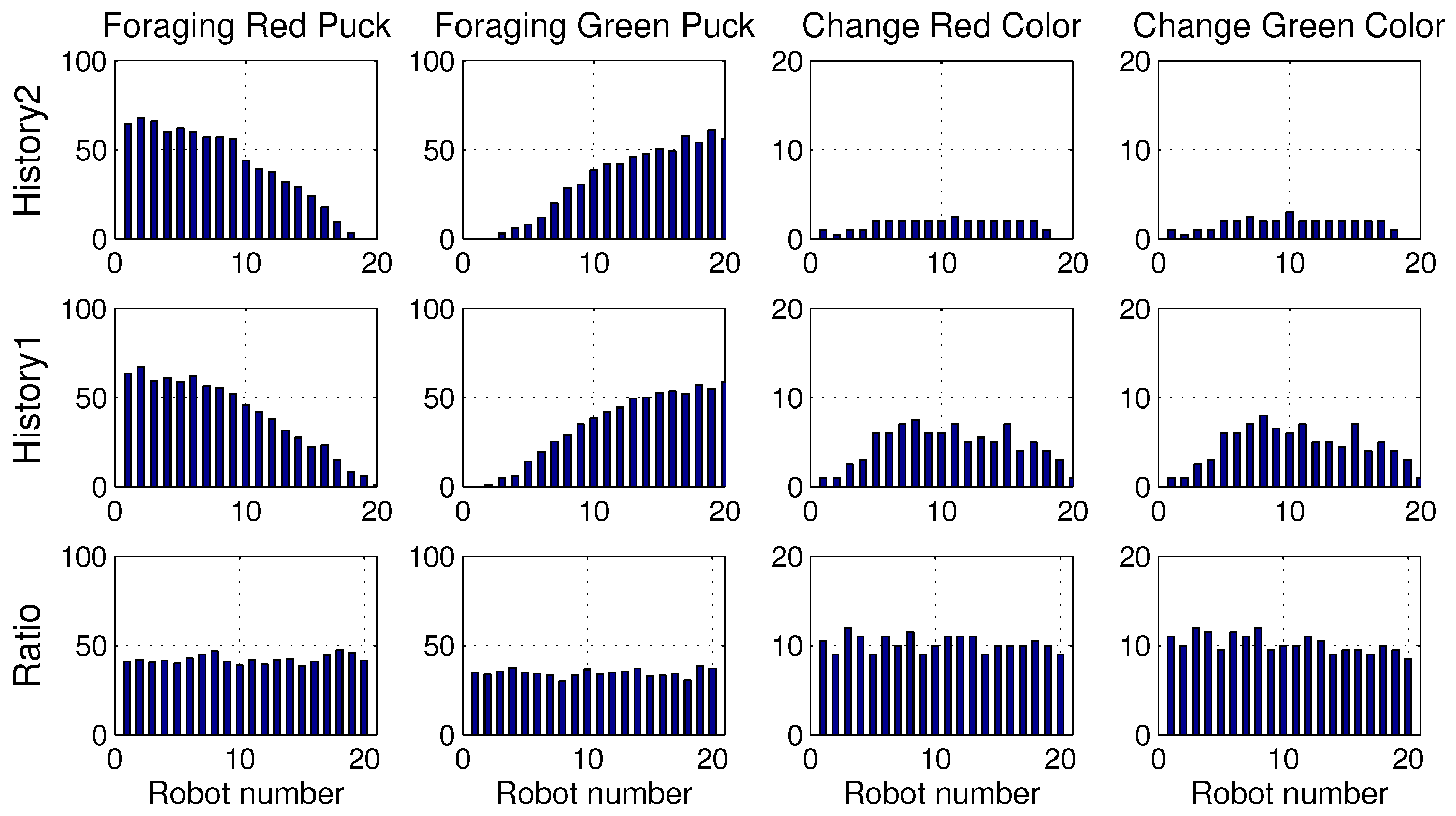
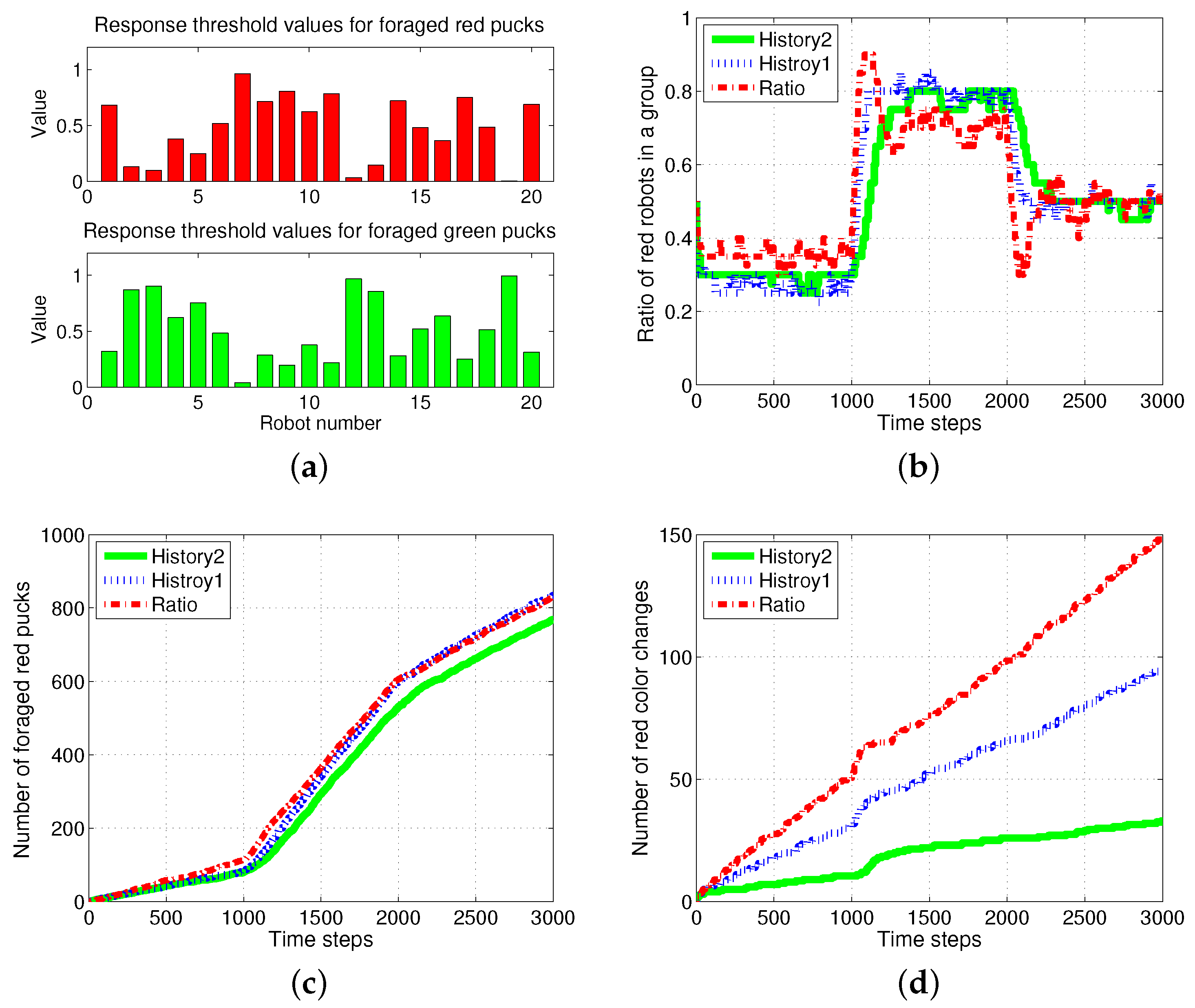
4.5. Results with Changes of Threshold Distribution
4.6. Drawback of Specialization in the Foraging Task
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lerman, K. A Model of Adaptation in Collaborative Multi-Agent Systems. Adapt. Behav. 2004, 12, 187–197. [Google Scholar] [CrossRef]
- Walker, J.H.; Wilson, M.S. Task allocation for robots using inspiration from hormones. Adapt. Behav. 2011, 19, 208–224. [Google Scholar] [CrossRef]
- Jin, L.; Li, S. Distributed Task Allocation of Multiple Robots: A Control Perspective. IEEE Trans. Syst. Man Cybern. Syst. 2016. [Google Scholar] [CrossRef]
- Cao, Y.U.; Fukunaga, A.S.; Kahng, A. Cooperative mobile robotics: Antecedents and directions. Auton. Robot. 1997, 4, 7–27. [Google Scholar] [CrossRef]
- Hu, J.; Xie, L.; Xu, J.; Xu, Z. Multi-agent cooperative target search. Sensors 2014, 14, 9408–9428. [Google Scholar] [CrossRef] [PubMed]
- Erbas, M.; Winfield, A.; Bull, L. Embodied imitation-enhanced reinforcement learning in multi-agent systems. Adapt. Behav. 2013, 22, 31–50. [Google Scholar] [CrossRef]
- Krieger, M.J.; Billeter, J.B.; Keller, L. Ant-like task allocation and recruitment in cooperative robots. Nature 2000, 406, 992–995. [Google Scholar] [PubMed]
- Lerman, K.; Galstyan, A. Mathematical model of foraging in a group of robots: Effect of interference. Auton. Robot. 2002, 13, 127–141. [Google Scholar] [CrossRef]
- Pini, G.; Brutschy, A.; Pinciroli, C.; Dorigo, M.; Birattari, M. Autonomous task partitioning in robot foraging: An approach based on cost estimation. Adapt. Behav. 2013, 21, 118–136. [Google Scholar] [CrossRef]
- Robinson, A. Dietary supplements for reproductive conditioning of Crassostrea gigas kumamoto (Thunberg). I. Effects on gonadal development, quality of ova and larvae through metamorphosis. J. Shellfish Res. 1992, 11, 437. [Google Scholar]
- Detrain, C.; Pasteels, J. Caste differences in behavioral thresholds as a basis for polyethism during food recruitment in the ant, Pheidole pallidula (Nyl.)(Hymenoptera: Myrmicinae). J. Insect Behav. 1991, 4, 157–176. [Google Scholar] [CrossRef]
- Calderone, N.W.; Page, R.E., Jr. Temporal polyethism and behavioural canalization in the honey bee. Apis Mellifera. Anim. Behav. 1996, 51, 631–643. [Google Scholar] [CrossRef]
- Visscher, K.P.; Dukas, R. Honey bees recognize development of nestmates’ ovaries. Anim. Behav. 1995, 49, 542–544. [Google Scholar] [CrossRef]
- Theraulaz, G.; Bonabeau, E.; Denuebourg, J. Response threshold reinforcements and division of labour in insect societies. Proc. R. Soc. Lond. B Biol. Sci. 1998, 265, 327–332. [Google Scholar] [CrossRef]
- Sundstrom, L. Sex allocation and colony maintenance in monogyne and polygyne colonies of Formica truncorum (Hymenoptera: Formicidae): The impact of kinship and mating structure. Am. Nat. 1995, 146, 182–201. [Google Scholar] [CrossRef]
- Wilson, E.O. The relation between caste ratios and division of labor in the ant genus Pheidole (Hymenoptera: Formicidae). Behav. Ecol. Sociobiol. 1984, 16, 89–98. [Google Scholar] [CrossRef]
- Arkin, R.C.; Balch, T.; Nitz, E. Communication of behavorial state in multi-agent retrieval tasks. In Proceedings of the 1993 IEEE International Conference on Robotics and Automation, Atlanta, GA, USA, 2–6 May 1993; pp. 588–594. [Google Scholar]
- Matarić, M.J. Learning social behavior. Robot. Auton. Syst. 1997, 20, 191–204. [Google Scholar] [CrossRef]
- Krieger, M.J.; Billeter, J.B. The call of duty: Self-organised task allocation in a population of up to twelve mobile robots. Robot. Auton. Syst. 2000, 30, 65–84. [Google Scholar] [CrossRef]
- Labella, T.H.; Dorigo, M.; Deneubourg, J.L. Division of labor in a group of robots inspired by ants’ foraging behavior. ACM Trans. Auton. Adapt. Syst. 2006, 1, 4–25. [Google Scholar] [CrossRef]
- Goldingay, H.; Mourik, J.V. Distributed Sequential Task Allocation in Foraging Swarms. In Proceedings of the 2013 IEEE 7th International Conference on Self-Adaptive and Self-Organizing Systems (SASO), Philadelphia, PA, USA, 9–13 September 2013; pp. 149–158. [Google Scholar]
- Campo, A.; Dorigo, M. Efficient multi-foraging in swarm robotics. In Advances in Artificial Life; Springer: Berlin/Heidelberg, Germany, 2007; pp. 696–705. [Google Scholar]
- Yang, Y.; Zhou, C.; Tian, Y. Swarm robots task allocation based on response threshold model. In Proceedings of the 4th International Conference on Autonomous Robots and Agents (ICARA), Wellington, New Zealand, 10–12 February 2009; pp. 171–176. [Google Scholar]
- Lerman, K.; Jones, C.; Galstyan, A.; Matarić, M.J. Analysis of dynamic task allocation in multi-robot systems. Int. J. Robot. Res. 2006, 25, 225–241. [Google Scholar] [CrossRef]
- Castello, E.; Yamamoto, T.; Nakamura, Y.; Ishiguro, H. Task allocation for a robotic swarm based on an adaptive response threshold model. In Proceedings of the 2013 13th International Conference on Control, Automation and Systems (ICCAS), Gwangju, Korea, 20–23 October 2013; pp. 259–266. [Google Scholar]
- Jones, C.; Mataric, M. Adaptive division of labor in large-scale minimalist multi-robot systems. In Proceedings of the 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 27–31 October 2003; Volume 2, pp. 1969–1974. [Google Scholar]
- Ikemoto, Y.; Miura, T.; Asama, H. Adaptive division of labor control for robot group. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; pp. 2409–2414. [Google Scholar]
- Goldberg, D.; Mataric, M.J. Design and evaluation of robust behavior-based controllers for distributed multi-robot collection tasks. In Robot Teams: From Diversity to Polymorphism; Taylor & Francis: Oxford, UK, 2001. [Google Scholar]
- Jevtić, A.; Gutiérrez, A. Distributed bees algorithm parameters optimization for a cost efficient target allocation in swarms of robots. Sensors 2011, 11, 10880–10893. [Google Scholar] [CrossRef] [PubMed]
- Zedadra, O.; Jouandeau, N.; Seridi, H.; Fortino, G. Multi-Agent Foraging: State-of-the-art and research challenges. Complex Adapt. Syst. Model. 2017, 5, 3. [Google Scholar] [CrossRef]
- Yan, Z.; Jouandeau, N.; Cherif, A.A. A survey and analysis of multi-robot coordination. Int. J. Adv. Robot. Syst. 2013, 10, 399. [Google Scholar] [CrossRef]
- Vaughan, R.T.; Gerkey, B.P.; Howard, A. On device abstractions for portable, reusable robot code. In Proceedings of the 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 27–31 October 2003; Volume 3, pp. 2421–2427. [Google Scholar]
- Pinciroli, C. The Swarmanoid Simulator; UniversitéLibre de Bruxelles: Bruxelles, Belgium, 2007. [Google Scholar]
- Giagkos, A.; Wilson, M.S. Swarm intelligence to wireless ad hoc networks: Adaptive honeybee foraging during communication sessions. Adapt. Behav. 2013, 21, 501–515. [Google Scholar] [CrossRef]
- Dorigo, M.; Floreano, D.; Gambardella, L.M.; Mondada, F.; Nolfi, S.; Baaboura, T.; Birattari, M.; Bonani, M.; Brambilla, M.; Brutschy, A.; et al. Swarmanoid: A novel concept for the study of heterogeneous robotic swarms. IEEE Robot. Autom. Mag. 2013, 20, 60–71. [Google Scholar] [CrossRef]
- Michail, P.; Dimitrios, P.; Filippo, N.; Michel, C. Intelligent algorithms based on data processing for modular robotic vehicles control. WSEAS Trans. Syst. 2014, 13, 242–251. [Google Scholar]
- Halász, A.; Hsieh, M.A.; Berman, S.; Kumar, V. Dynamic redistribution of a swarm of robots among multiple sites. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; pp. 2320–2325. [Google Scholar]
- Hsieh, M.A.; Halász, Á.; Berman, S.; Kumar, V. Biologically inspired redistribution of a swarm of robots among multiple sites. Swarm Intell. 2008, 2, 121–141. [Google Scholar] [CrossRef]
- Lee, W.; Kim, D. Adaptive division of labor in multi-robot system with minimum task switching. Simulation 2014, 8, 10. [Google Scholar]
- Lee, W.; Kim, D. Local Interaction of Agents for Division of Labor in Multi-agent Systems. In International Conference on Simulation of Adaptive Behavior; Springer: Berlin/Heidelberg, Germany, 2016; pp. 46–54. [Google Scholar]
- Lichocki, P.; Tarapore, D.; Keller, L.; Floreano, D. Neural networks as mechanisms to regulate division of labor. Am. Nat. 2012, 179, 391–400. [Google Scholar] [CrossRef] [PubMed]















© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, W.; Kim, D. History-Based Response Threshold Model for Division of Labor in Multi-Agent Systems. Sensors 2017, 17, 1232. https://doi.org/10.3390/s17061232
Lee W, Kim D. History-Based Response Threshold Model for Division of Labor in Multi-Agent Systems. Sensors. 2017; 17(6):1232. https://doi.org/10.3390/s17061232
Chicago/Turabian StyleLee, Wonki, and DaeEun Kim. 2017. "History-Based Response Threshold Model for Division of Labor in Multi-Agent Systems" Sensors 17, no. 6: 1232. https://doi.org/10.3390/s17061232
APA StyleLee, W., & Kim, D. (2017). History-Based Response Threshold Model for Division of Labor in Multi-Agent Systems. Sensors, 17(6), 1232. https://doi.org/10.3390/s17061232