
Belief Interval of Dempster-Shafer Theory for Line-of-Sight Identification in Indoor Positioning Applications

Abstract
:1. Introduction
2. Proposed Framework
2.1. The Features of RSS
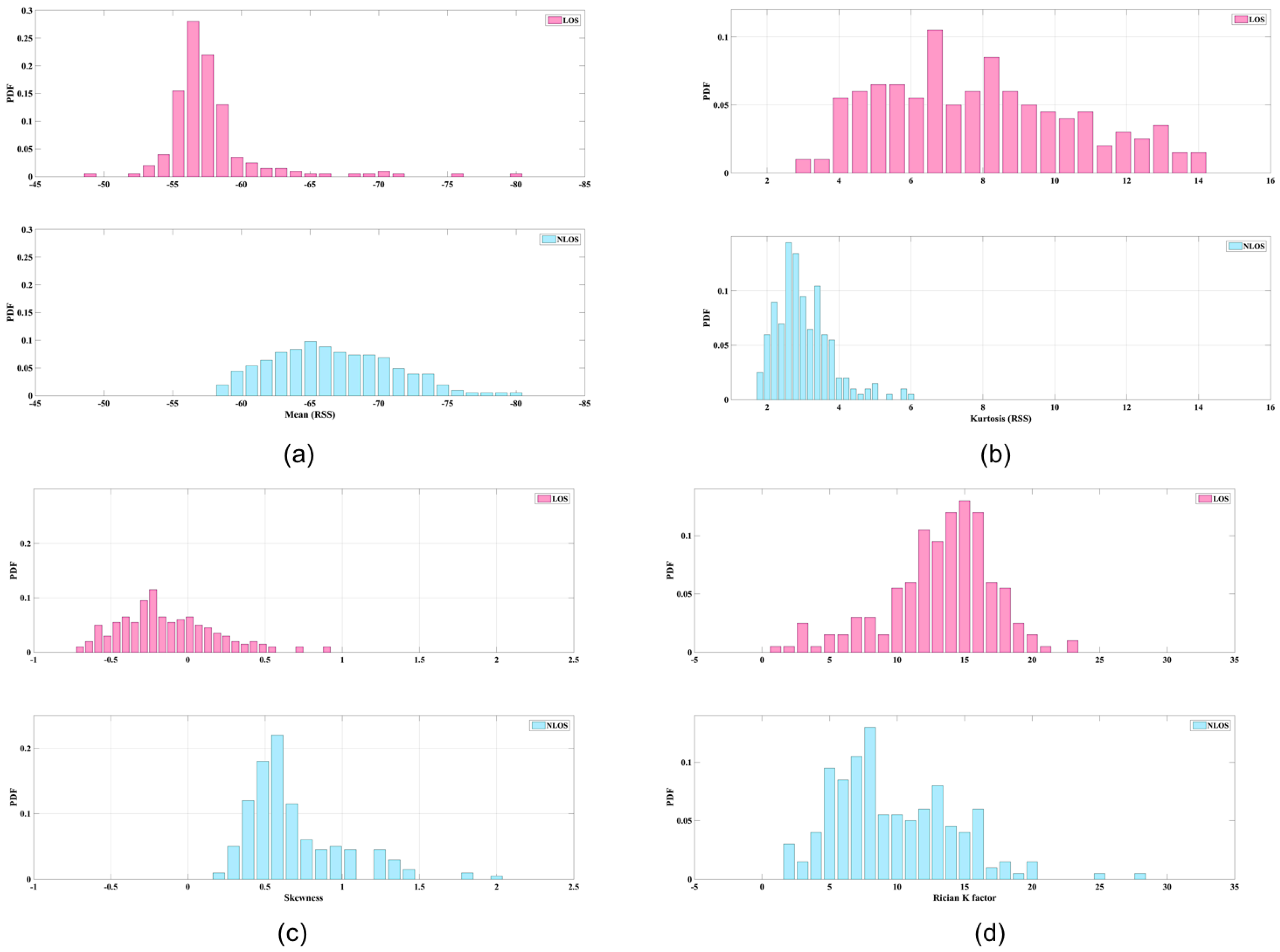
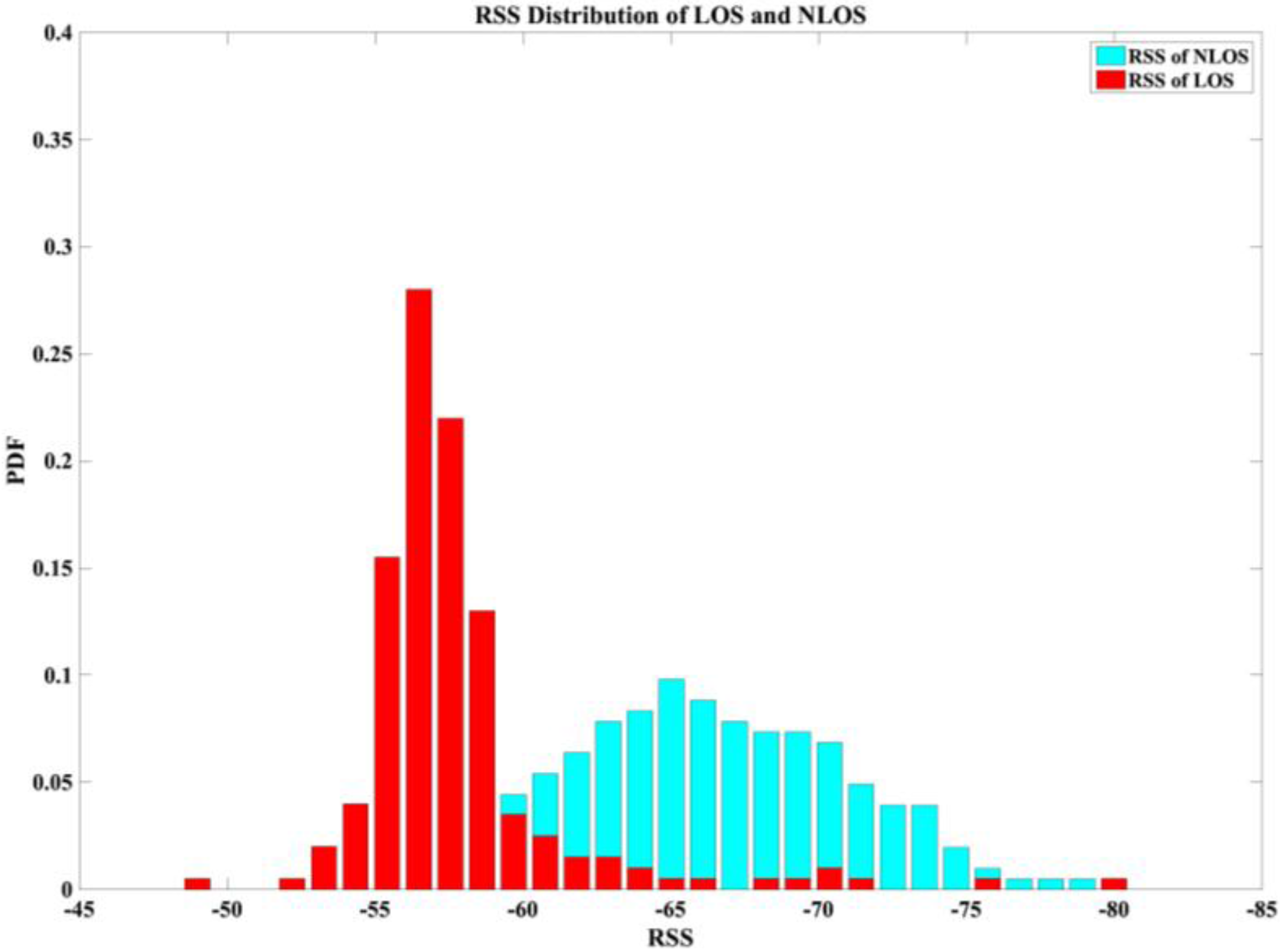
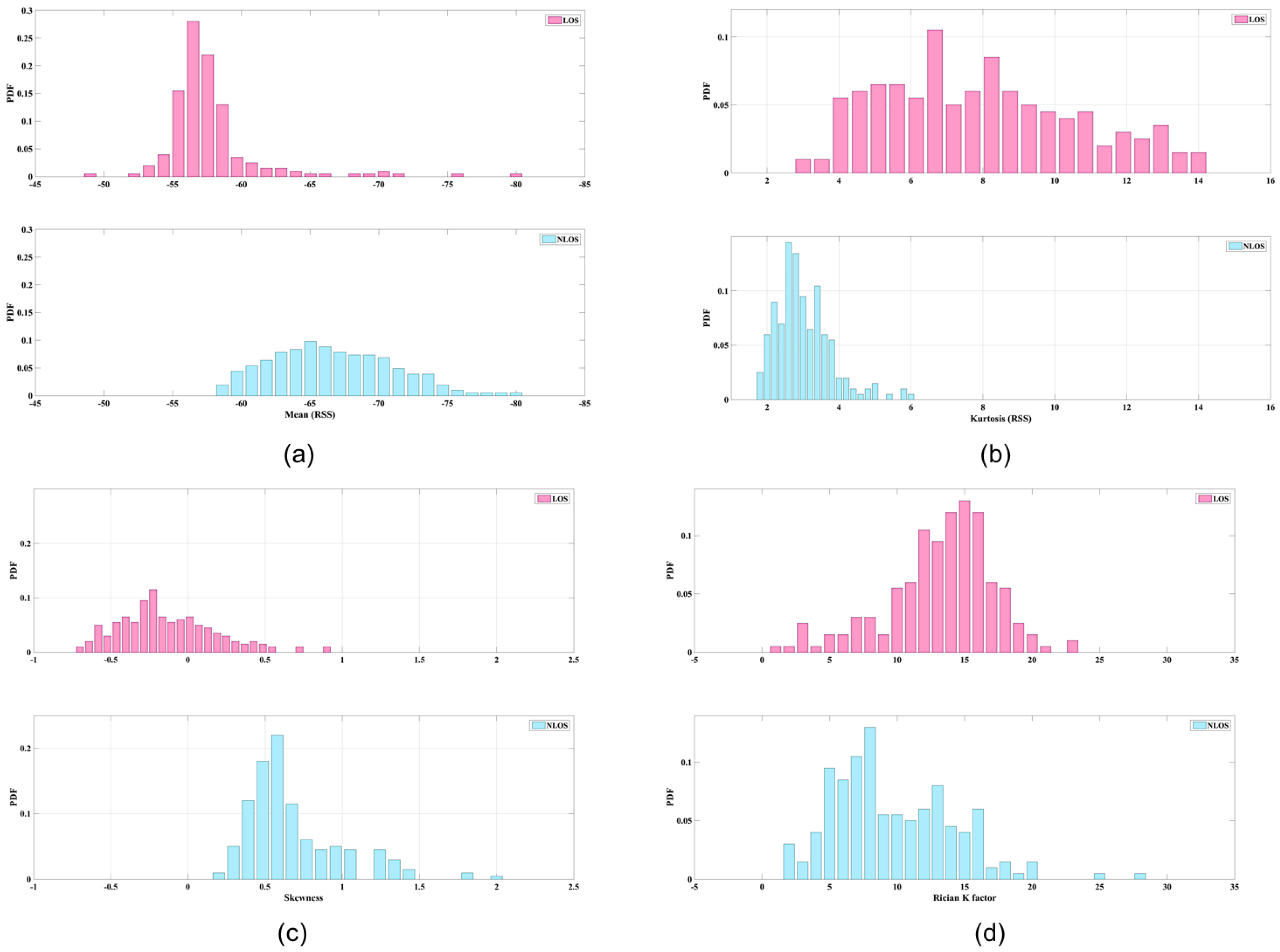
- Mean and standard deviation ( are derived from RSS data. The average strength levels of these two types of data can be categorized for some situations. Figure 2a illustrates the mean values of LOS and NLOS conditions; the clarity of the data is striking. The maximum LOS value is greater than the maximum NLOS value.
- Kurtosis () is used to measure the sharpness of the peak of the probability distribution. The measurements of RSS in LOS conditions are more centralized than those derived from NLOS conditions, because the dominant LOS signal has a stronger energy presentation. Figure 2b shows an example of the kurtosis data. Because of the representation of numbers at the peaks of probability distributions, the figure is based on the number of samples. If fewer samples had been collected, it would be difficult to ascertain the different conditions.
- Skewness (S) is used to measure the asymmetry of the probability distribution. Because of multipath considerations, LOS signals tend to decay following a Rayleigh distribution, whereas NLOS signals tend to follow a Rician distribution. Accordingly, the skewness of a Rayleigh distribution is a generally larger than that of a Rician distribution; hence, a typical LOS measurement should have lower skewness than a typical NLOS measurement. Figure 2c shows an example of skewness data.
- Rician K factor ( is defined as the ratio of power of the direct path to the power of other scattered paths. An empirical study demonstrated a positive relationship between the Rician K factor and an LOS signal [23]. The probability density function of the Rician K factor is defined as follows:where is a first class zeroth-order modified Bessel function, is signal envelope, and is defined as equal to . According to our test, the results of which are shown in Figure 2d, the centralized Rician K factor of an LOS value is larger than that of an NLOS value.
- Log mean () is used primarily for NLOS mitigation. According to our observations, the relationship of RSS and log mean can be illustrated clearly.
2.2. Basic Principles of Dempster-Shafer Theory
2.3. Belief Interval Comparison
3. System Design
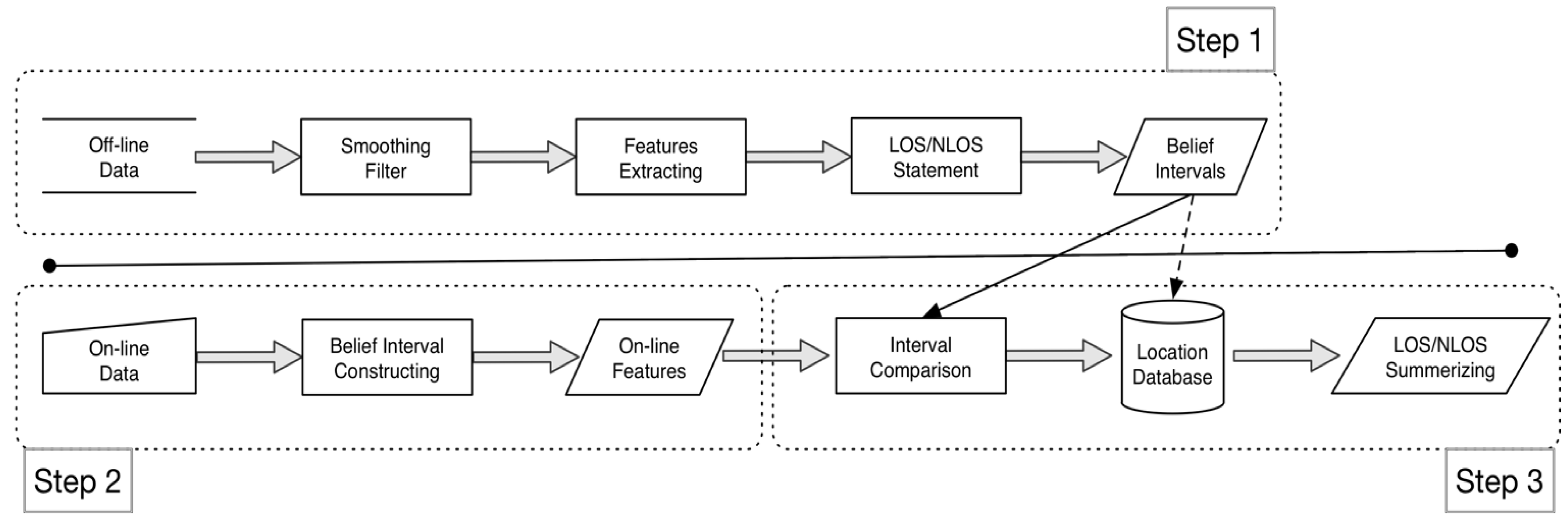
- Step 1.
- In the office system phase, like the fingerprint method, we record four directions of RSS signals in a time period at each location, the direction back to the beacon is the collection of NLS, the other three directions are arranged to the collection of LOS.
- Compute the basic assignments of feature f for each location p, that is , and . Accordingly, transfer the assignments to the Belief Interval of LOS and NLOS, that are and respectively.
- Step 2.
- In the online system phase, the user’s position will be predicted by holding the phone, and receive a series of RSS values. Then, derive the online Belief Interval of LOS and NLOS, that is , t is the time period t.
- Step 3.
- In the belief interval comparison phase, the system compared the online interval to the offline intervals by the proposed method of , where are two comparing intervals. The prediction location is obtained by the following equation:where S is set of locations in the field experiment.
3.1. The Offline System Phase
3.2. The Online System Phase
3.3. The Belief Interval Comparison
- Case 1.
- The exclusion case: According to Figure 3, no intersection exists between two belief intervals; hence, , then < 0.
- Case 2.
- The overlapping case: Equation (24) can be derived as follows:where in this case.
- Case 3.
- The inclusion case: According to Figure 3, exists in this case; thus, Equation (24) can be derived as follows:
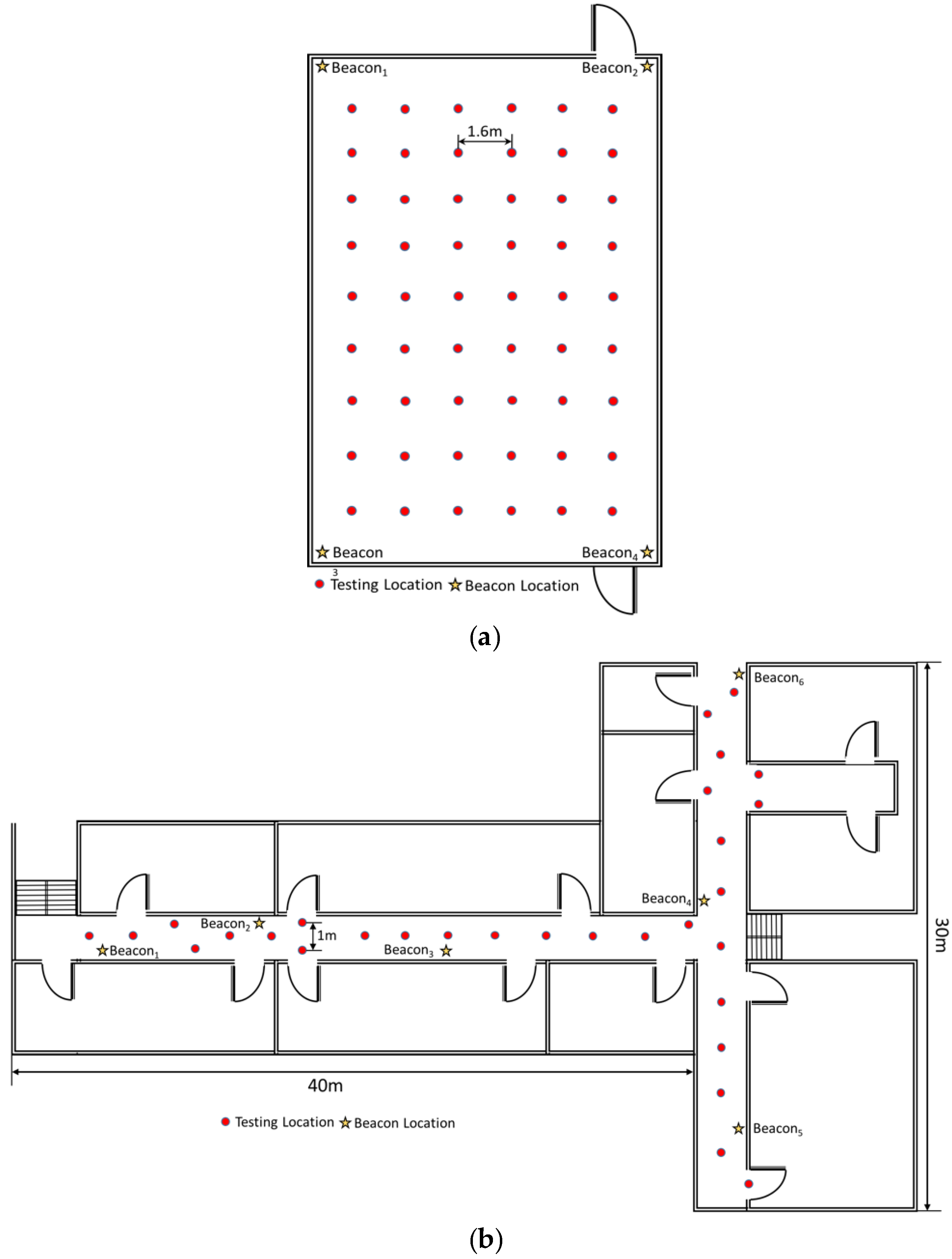
4. Experiments and Discussions
4.1. Experiment Environment Initialization
4.2. The Comparisons on the Distinct Features
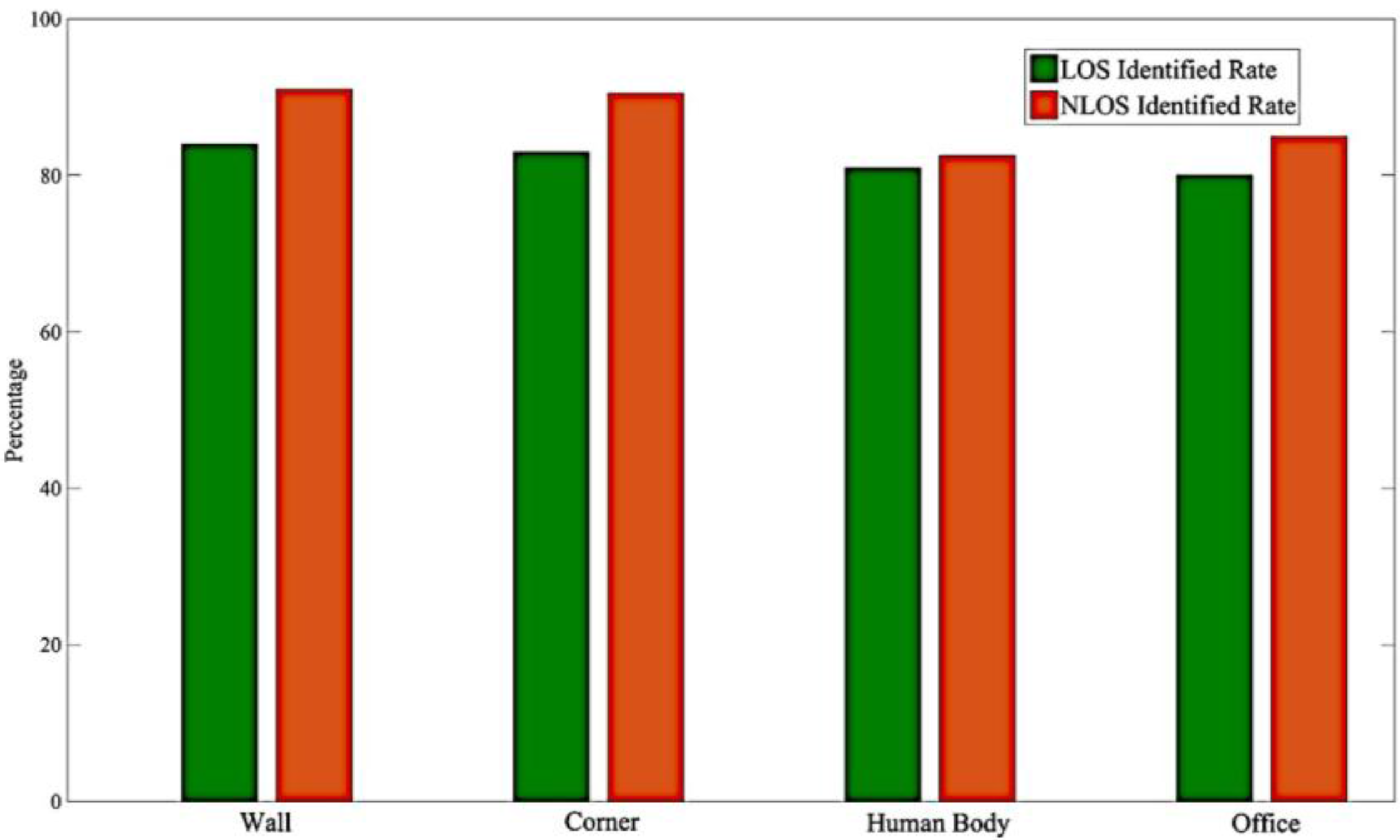
4.3. The Comparisons on the Distinct Situations
4.4. The Robust Testing
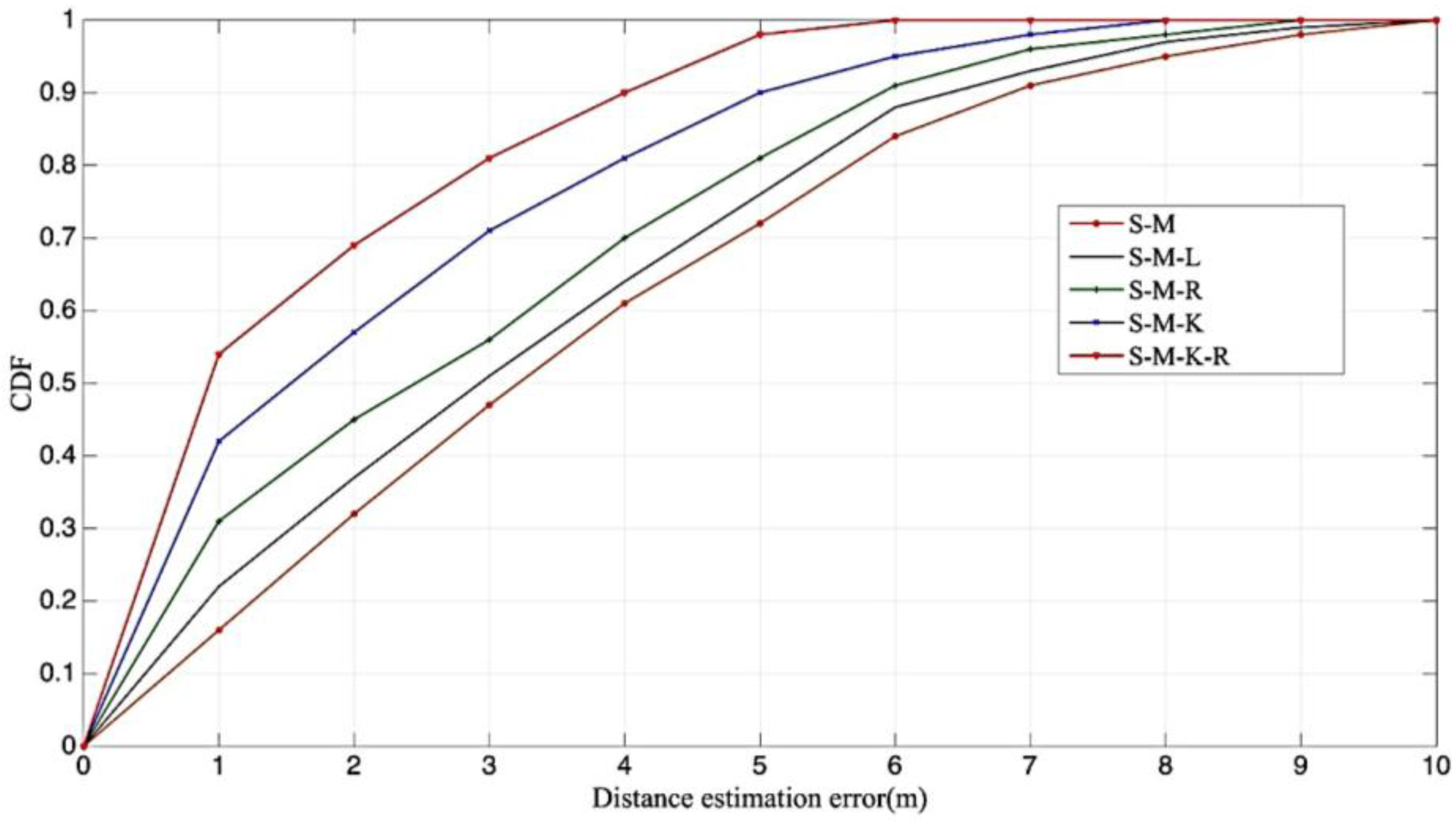
4.5. The Comparisons on the Distinct Models
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Wymeersch, H.; Lien, J.; Win, M.Z. Cooperative Localization in wireless networks. Proc. IEEE Ultra Wide Bandwidth (UWB) Technol. Emerg. Appl. 2009, 97, 427–450. [Google Scholar] [CrossRef]
- Wen, X.; Tao, W.; Own, C.-M.; Pan, Z. On the Dynamic RSS Feedbacks of Indoor Fingerprinting Database for the Localization Reliability Improvement. Sensors 2016, 16, 1278. [Google Scholar] [CrossRef] [PubMed]
- Suwansantisuk, W.; Win, M.Z. Multipath Aided Rapid Acquisition: Optimal Search Strategies. IEEE Trans. Inf. Theory 2007, 53, 174–193. [Google Scholar] [CrossRef]
- Win, M.Z.; Pinto, P.C.; Shep, L.A. A Mathematical Theory of Network Interference and Its Applications. Proc. IEEE Ultra Wide Bandwidth Technol. Emerg. Appl. 2009, 97, 205–230. [Google Scholar] [CrossRef]
- Win, M.Z.; Chrisikos, G.; Sollenberger, N.R. Performance of Rake Reception in Dense Multipath Channels: Implications of Spreading Bandwidth and Selection Diversity Order. IEEE J. Sel. Areas Commun. 2000, 18, 1516–1525. [Google Scholar] [CrossRef]
- Xiao, Z.; Wen, H.; Markham, A. Non-Line-of-Sight Identification and Mitigation Using Received Signal Strength. IEEE Trans. Wirel. Commun. 2015, 14, 1689–1702. [Google Scholar] [CrossRef]
- Liu, K.; Meng, Z.; Own, C.-M. Gaussian Process Regression Plus Method for Localization Reliability Improvement. Sensors 2016, 16, 1193. [Google Scholar] [CrossRef] [PubMed]
- Rappaport, T. Wireless Communications: Principles and Practice, 2nd ed.; Prentice-Hall: Englewood Cliffs, NJ, USA, 2002. [Google Scholar]
- Mucchi, L.; Marcocci, P. A New parameter for UWB Indoor Channel Profile Identification. IEEE Trans. Wirel. Commun. 2009, 8, 1597–1602. [Google Scholar] [CrossRef]
- Borrans, J.; Hatractk, P.; Mandayam, N. Decision Theoretic Framework for NLOS Identification. In Proceedings of the IEEE 48th Vehicular Technology Conference, Ottawa, OT, Canada, 21–21 May 1998. [Google Scholar]
- Yu, K.; Guo, Y.J.; Member, S. Statistical NLOS Identification Based on AOA, TOA and Signal Strength. IEEE Trans. Commun. 2009, 58, 274–286. [Google Scholar] [CrossRef]
- Wymeersch, H.; Marano, S. A Machine Learning Approach to Ranging Error Mitigation for UWB Localization. IEEE Trans. Commun. 2006, 60, 1719–1728. [Google Scholar] [CrossRef]
- Zhou, Z.; Yang, Z.; Wu, C.; Shangguan, L.; Cai, H.; Liu, Y. WiFi-Based Indoor Line-of-Sight Identification. IEEE Trans. Wirel. Commun. 2015, 14, 6125–6136. [Google Scholar] [CrossRef]
- Nurminen, H.; Talvitie, J.; Ali-Loytty, S.; Muller, P.; Lohan, E.S.; Piche, R.; Renfors, M. Statistical Path Loss Parameter Estimation and Positioning Using RSS Measures in Indoor Wireless Networks. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation, New South Wales Sydney, Australia, 13–15 November 2012. [Google Scholar]
- Wang, B.; Chen, Q.; Yang, L.T.; Chao, H.-C. Indoor Smartphone Localization via Fingerprint Crowdsourcing: Challenges and Approaches. IEEE Wirel. Commun. 2016, 23, 82–89. [Google Scholar] [CrossRef]
- Wang, B.; Zhou, S.; Yang, L.T.; Mo, Y. Indoor positioning via subarea fingerprinting and surface fitting with received signal strength. Pervasive Mob. Comput. 2015, 23, 43–58. [Google Scholar] [CrossRef]
- Wang, B.; Zhou, S.; Liu, W.; Mo, Y. Indoor localization based on curve fitting and location search using received signal strength. IEEE Trans. Ind. Electron. 2015, 62, 572–582. [Google Scholar] [CrossRef]
- Mazuelas, S.; Bahillo, A.; Lorenzo, R.M.; Fenandez, P.; Lago, F.A.; Garcia, E.; Blas, J.; Abril, E.J. Robust Indoor Positioning Provided by Real-Time RSSI Values in Unmodified WLAN Networks. Signal Process 2009, 3, 821–831. [Google Scholar] [CrossRef]
- Tseng, K.K.; Pan, J.S.; Wei, W. The Evolutionary Random Interval Fingerprint for a More Secure Wireless Communication. Mob. Inf. Syst. 2013, 9, 281–294. [Google Scholar] [CrossRef]
- Chen, P. A Non-Line-of-Sight Error Mitigation Algorithm in Location Estimation. In Proceedings of the WCNC. 1999 IEEE Wireless Communications and Networking Conference, New Orleans, LA, USA, 21–24 September 1999. [Google Scholar]
- Li, X. An Iterative NLOS Mitigation Algorithm for Location Estimation in Sensor Network. In Proceedings of the 15th IST Mobile Wireless Communication Summit, Myconos, Greece, 19–23 June 2006. [Google Scholar]
- Nawaz, S.; Trigoni, N. Convex Programming based Robust Localization in NLOS Prone Cluttered environments. In Proceedings of the 10th International Conference IPSN, Chicago, IL, USA, 12–14 April 2011. [Google Scholar]
- Tepedelenlioglu, C.; Abdi, A.; Giannakis, G.B. The Ricean K factor: Estimation and Performance Analysis. IEEE Trans. Wirel. Commun. 2003, 2, 799–810. [Google Scholar] [CrossRef]
- Shafer, G. A mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar]
- Bloch, I. Some Aspect of Dempster-Shafer Evidence Theory for Classification of Multi-modality Medical Images Taking Partial Volume Effect into Account. Pattern Recognit. Lett. 1996, 17, 905–916. [Google Scholar] [CrossRef]
- Dymova, L.; Sevastjanov, P. An Interpretation of Intuitionistic Fuzzy Sets in Terms of Evidence Theory: Decision Making Aspect. Knowl. Based Syst. 2010, 23, 772–782. [Google Scholar] [CrossRef]
- Tomas, B.C.; Manducht, T.R. Bilateral Filtering for Gray and Color Images. In Proceedings of the 16th International Conference on Computer Vision, Bombay, India, 7 January 1998. [Google Scholar]
- Kundu, S. Min-transitivity of Fuzzy Leftness Relationship and Its Application to Decision Making. Fuzzy Sets Syst. 1997, 86, 357–367. [Google Scholar] [CrossRef]
- Suykens, J.; Vandewalle, J. Least Squares Support Vector Machine Classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Snelson, E.L. Flexible and Efficient Gaussian Process Models for Machine Learning. Ph.D. Dissertation, Gatsby Computer Neuroscience Unit University College London, London, UK, 2007. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Joint Sets | Mean (M) | Kurtosis (K) | Rician K Factor (R) | Log-Mean (L) |
|---|---|---|---|---|
| S-M | √ | |||
| S-M-L | √ | √ | ||
| S-M-R | √ | √ | ||
| S-M-K | √ | √ | ||
| S-M-K-R | √ | √ | √ |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Zhao, T.; Li, S.; Own, C.-M. Belief Interval of Dempster-Shafer Theory for Line-of-Sight Identification in Indoor Positioning Applications. Sensors 2017, 17, 1242. https://doi.org/10.3390/s17061242
Wu J, Zhao T, Li S, Own C-M. Belief Interval of Dempster-Shafer Theory for Line-of-Sight Identification in Indoor Positioning Applications. Sensors. 2017; 17(6):1242. https://doi.org/10.3390/s17061242
Chicago/Turabian StyleWu, Jinwu, Tingyu Zhao, Shang Li, and Chung-Ming Own. 2017. "Belief Interval of Dempster-Shafer Theory for Line-of-Sight Identification in Indoor Positioning Applications" Sensors 17, no. 6: 1242. https://doi.org/10.3390/s17061242
APA StyleWu, J., Zhao, T., Li, S., & Own, C.-M. (2017). Belief Interval of Dempster-Shafer Theory for Line-of-Sight Identification in Indoor Positioning Applications. Sensors, 17(6), 1242. https://doi.org/10.3390/s17061242