Novel Descattering Approach for Stereo Vision in Dense Suspended Scatterer Environments

Abstract
:1. Introduction
2. Imaging Model
- The illumination source is known and close to the cameras. This is feasible since the cameras and the light source are installed in the head of the robot.
- The input image I is given in the actual scene radiance values. The radiance maps can be recovered by inverting the acquisition response curve proposed by Debevec and Malik [42].
2.1. Single View Modeling in Scatterers Environment
2.2. Stereo Modeling in Suspended Scatterer Environment
3. Backscattering and Fog Removal
3.1. Non-Uniform Backscattering Removal
3.1.1. Light Compensation
3.1.2. Saturated Backscattering Estimation
3.2. Defogging
3.2.1. DCP-Based Defogging
3.2.2. Normalization-Based Image Correction
4. Stereo Vision Results
4.1. Experimental Setup
- In the first setting, the stereo baseline is 10 cm. The light is put under the cameras. The light source and cameras are not coaxial. The experiment was conducted in a booth with dimensions of 3 × 1.5 × 1.6 m3. We utilized a steam generator to generate the steam using pure water inside the cabin. The generated steam’s temperature is 100–120 °C. Our system is able to produce steam as dense as an attenuation coefficient of 1.15 m−1.
- In the second setup, the stereo vision is the same as the previous configuration. However, the light source is placed above the cameras and coaxial to cameras. This experiment was done in a room with dimensions of 6 × 4 × 2.5 m3. To generate fog in such a big room, we utilized a fog machine (CHAMP-1500W, Joongang Special Lights, Seoul, Korea) that uses oil.
4.2. Stereo Results from Synthetic Images
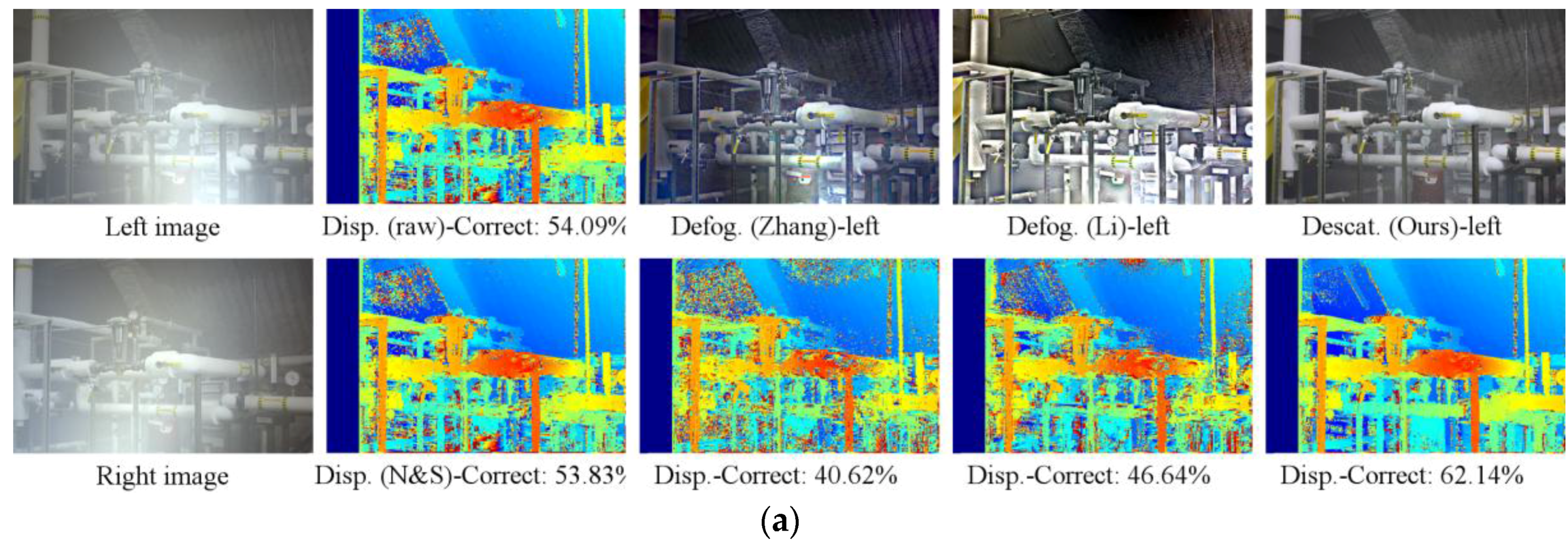
4.3. Stereo Vision Results from Real Images
5. Verification with Robot Manipulation
5.1. The Robot System of the Manipulator
5.2. Manipulation Experiment in Foggy Condition
5.2.1. Experiment Environment
5.2.2. Experiment Results
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Polarization-Based Backscattering Removal


References
- Starr, J.W.; Lattimer, B.Y. Evaluation of Navigation Sensors in Fire Smoke Environments. Fire Technol. 2014, 50, 1459–1481. [Google Scholar] [CrossRef]
- Massot-Campos, M.; Oliver-Codina, G. Optical Sensors and Methods for Underwater 3D Reconstruction. Sensors 2015, 15, 31525–31557. [Google Scholar] [CrossRef] [PubMed]
- Chi, S.; Xie, Z.; Chen, W. A Laser Line Auto-Scanning System for Underwater 3D Reconstruction. Sensors 2016, 16, 1534. [Google Scholar] [CrossRef] [PubMed]
- Narasimhan, S.G.S.G.; Nayar, S.K.S.K.; Bo Sun, B.; Koppal, S.J. Structured light in scattering media. In Proceedings of the Tenth IEEE International Conference on Computer Vision, Beijing, China, 15–21 October 2005; pp. 420–427. [Google Scholar]
- Bianco, G.; Gallo, A.; Bruno, F.; Muzzupappa, M. A Comparative Analysis between Active and Passive Techniques for Underwater 3D Reconstruction of Close-Range Objects. Sensors 2013, 13, 11007–11031. [Google Scholar] [CrossRef] [PubMed]
- Bräuer-Burchardt, C.; Heinze, M.; Schmidt, I.; Kühmstedt, P.; Notni, G. Underwater 3D Surface Measurement Using Fringe Projection Based Scanning Devices. Sensors 2016, 16, 13. [Google Scholar] [CrossRef] [PubMed]
- Bodenmann, A.; Thornton, B.; Ura, T. Generation of High-resolution Three-dimensional Reconstructions of the Seafloor in Color using a Single Camera and Structured Light. J. Field Robot. 2016. [Google Scholar] [CrossRef]
- Scharstein, D.; Szeliski, R. A Taxonomy and Evaluation of Dense Two-Frame Stereo Correspondence Algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Scharstein, D.; Hirschmüller, H.; Kitajima, Y.; Krathwohl, G.; Nešić, N.; Wang, X.; Westling, P. High-resolution stereo datasets with subpixel-accurate ground truth. Lect. Notes Comput. Sci. 2014, 8753, 31–42. [Google Scholar]
- Lazaros, N.; Sirakoulis, G.C.; Gasteratos, A. Review of Stereo Vision Algorithms: From Software to Hardware. Int. J. Optomechatronics 2008, 2, 435–462. [Google Scholar] [CrossRef]
- Tippetts, B.; Lee, D.J.; Lillywhite, K.; Archibald, J. Review of stereo vision algorithms and their suitability for resource-limited systems. J. Real-Time Image Process. 2013, 11, 5–25. [Google Scholar] [CrossRef]
- Faugeras, O.; Viéville, T.; Theron, E.; Vuillemin, J.; Hotz, B.; Zhang, Z.; Moll, L.; Bertin, P.; Mathieu, H.; Fua, P.; et al. Real-time Correlation-Based Stereo: Algorithm, Implementations and Applications. In Research Report RR-2013; INRIA: Versailles, Yvelines, France, 1993. [Google Scholar]
- Mühlmann, K.; Maier, D.; Hesser, J.; Männer, R. Calculating Dense Disparity Maps from Color Stereo Images, an Efficient Implementation. Int. J. Comput. Vis. 2002, 47, 79–88. [Google Scholar] [CrossRef]
- Yoon, K.J.; Kweon, I.S. Adaptive support-weight approach for correspondence search. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 650–656. [Google Scholar] [CrossRef] [PubMed]
- Hosni, A.; Bleyer, M.; Gelautz, M.; Rhemann, C. Local stereo matching using geodesic support weights. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 2093–2096. [Google Scholar]
- Hosni, A.; Rhemann, C.; Bleyer, M.; Rother, C.; Gelautz, M. Fast cost-volume filtering for visual correspondence and beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 504–511. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef]
- Kolmogorov, V.; Zabih, R. Computing Visual Correspondence with Occlusions via Graph Cuts. In Proceedings of the Eighth IEEE International Conference on Computer Vision, 2001, (ICCV 2001), Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar] [CrossRef]
- Sun, J.; Zheng, N.N.; Shum, H.Y. Stereo matching using belief propagation. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 787–800. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient belief propagation for early vision. Int. J. Comput. Vis. 2006, 70, 41–54. [Google Scholar] [CrossRef]
- Schechner, Y.Y.; Narasimhan, S.G.; Nayar, S.K. Polarization-based vision through haze. Appl. Opt. 2003, 42, 511–525. [Google Scholar] [CrossRef] [PubMed]
- Treibitz, T.; Schechner, Y.Y. Instant 3Descatter. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR′06), Stanford, CA, USA, 17–22 June 2006; pp. 1861–1868. [Google Scholar]
- Treibitz, T.; Schechner, Y.Y. Active polarization descattering. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 385–399. [Google Scholar] [CrossRef] [PubMed]
- McCartney, E.J. Optics of the Atmosphere: Scattering by Molecules and Particles; Wiley: Hoboken, NJ, USA, 1976. [Google Scholar]
- Tan, R.T. Visibility in bad weather from a single image. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, Alaska, 23–28 June 2008. [Google Scholar]
- Fattal, R. Single Image Dehazing. ACM Trans. Graphics 2008, 27, 72. [Google Scholar] [CrossRef]
- Nishino, K.; Kratz, L.; Lombardi, S. Bayesian defogging. Int. J. Comput. Vis. 2012, 98, 263–278. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010. [Google Scholar] [CrossRef]
- Negru, M.; Nedevschi, S.; Peter, R.I. Exponential Contrast Restoration in Fog Conditions for Driving Assistance. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2257–2268. [Google Scholar] [CrossRef]
- Chen, C.; Do, M.N.; Wang, J. Robust Image and Video Dehazing with Visual Artifact Suppression via Gradient Residual Minimization; Springer: Berlin, Germany, 2016; pp. 576–591. [Google Scholar]
- Lee, S.; Yun, S.; Nam, J.-H.; Won, C.S.; Jung, S.-W. A review on dark channel prior based image dehazing algorithms. EURASIP J. Image Video Process. 2016, 2016. [Google Scholar] [CrossRef]
- Zhu, Q.; Mai, J.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [PubMed]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Zhang, J.; Cao, Y.; Wang, Z. Nighttime haze removal based on a new imaging model. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4557–4561. [Google Scholar]
- Li, Y.; Tan, R.T.; Brown, M.S. Nighttime Haze Removal with Glow and Multiple Light Colors. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Los Alamitos, CA, USA, 7–13 December 2015; pp. 226–234. [Google Scholar]
- Caraffa, L.; Tarel, J.-P. Combining Stereo and Atmospheric Veil Depth Cues for 3D Reconstruction. IPSJ Trans. Comput. Vis. Appl. 2014, 6, 1–11. [Google Scholar] [CrossRef]
- Roser, M.; Dunbabin, M.; Geiger, A. Simultaneous underwater visibility assessment, enhancement and improved stereo. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014. [Google Scholar]
- Li, Z.; Tan, P.; Tan, R.T.; Zou, D.; Zhou, S.Z.; Cheong, L.-F. Simultaneous video defogging and stereo reconstruction. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4988–4997. [Google Scholar]
- Negahdaripour, S.; Sarafraz, A. Improved stereo matching in scattering media by incorporating a backscatter cue. IEEE Trans. Image Process. 2014, 23, 5743–5755. [Google Scholar] [CrossRef] [PubMed]
- Schechner, Y.Y.; Karpel, N. Recovery of Underwater Visibility and Structure by Polarization Analysis. IEEE J. Ocean. Eng. 2005, 30, 570–587. [Google Scholar] [CrossRef]
- Debevec, P.E.; Malik, J. Recovering high dynamic range radiance maps from photographs. In Proceedings of the 24th Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH′97), Los Angeles, CA, USA, 3–8 August 1997; pp. 369–378. [Google Scholar]
- Kim, H.; Jin, H.; Hadap, S.; Kweon, I. Specular reflection separation using dark channel prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Oregon, Portland, 25–27 June 2013. [Google Scholar]
- Hirschmüller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Criminisi, A.; Blake, A.; Rother, C.; Shotton, J.; Torr, P.H.S. Efficient Dense Stereo with Occlusions for New View-Synthesis by Four-State Dynamic Programming. Int. J. Comput. Vis. 2007, 71, 89–110. [Google Scholar] [CrossRef]
- Giakos, G.C. Active backscattered optical polarimetric imaging of scattered targets. In Proceedings of the 21st IEEE Instrumentation and Measurement Technology Conference (IEEE Cat. No. 04CH37510), Como, Italy, 18–20 May 2004; pp. 430–432. [Google Scholar]
- Gilbert, G.D.; Pernicka, J.C. Improvement of Underwater Visibility by Reduction of Backscatter with a Circular Polarization Technique. Appl. Opt. 1967, 6, 741. [Google Scholar] [CrossRef] [PubMed]
- Lewis, G.D.; Jordan, D.L.; Roberts, P.J. Backscattering target detection in a turbid medium by polarization discrimination. Appl. Opt. 1999, 38, 3937. [Google Scholar] [CrossRef] [PubMed]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Uniform Fog | Non-Uniform Fog | ||
|---|---|---|---|---|
| Descat (%) | Defog (%) | Descat (%) | Defog (%) | |
| Adirondack | 67.10 | 52.79 | 30.84 | 42.73 |
| Backpack | 76.69 | 72.13 | 43.84 | 51.1 |
| Cable | 61.72 | 40.37 | 15.90 | 19.33 |
| Classroom1 | 85.87 | 64.49 | 10.04 | 24.79 |
| Flowers | 44.82 | 48.63 | 19.04 | 14.56 |
| Motorcycle | 76.22 | 71.86 | 43.32 | 58.35 |
| Pipes | 66.96 | 58.78 | 49.19 | 49.68 |
| Recycle | 67.23 | 53.2 | 15.59 | 25.43 |
| Shelves | 47.45 | 40.44 | 24.88 | 35.63 |
| Storage | 61.77 | 54.75 | 33.81 | 33.21 |
| Sword1 | 77.84 | 68.87 | 39.73 | 50.75 |
| Sword2 | 42.21 | 27.99 | 6.85 | 11.82 |
| Average | 64.66 | 54.53 | 27.75 | 34.78 |
| Lighting | Corrupted Image (%) | [40] (%) | [35] (%) | [36] (%) | Proposed Method (%) |
|---|---|---|---|---|---|
| Setup 1—uniform | 33.12 | 33.03 | 25.12 | 34.30 | 47.84 |
| Setup 2—uniform | 26.39 | 37.29 | 23.04 | 32.82 | 46.16 |
| Setup 1—non-uniform | 23.70 | 19.37 | 22.25 | 25.70 | 25.99 |
| Lighting | Corrupted Image (%) | [35] (%) | [36] (%) | Proposed Method (%) |
|---|---|---|---|---|
| Setup 1—uniform | 28.09 | 31.31 | 45.46 | 64.66 |
| Setup 2—uniform | 19.49 | 26.99 | 41.89 | 55.53 |
| Setup 1—non-uniform | 24.94 | 29.14 | 34.57 | 34.78 |
| Resolution | Zhang et al. [35] (ms) | Li et al. [36] (ms) | Ours (ms) | |
|---|---|---|---|---|
| Descat | Defog | |||
| 780 × 580 | 17,470 | 20,520 | 34 | 860 |
| Specification | Uint | ERB-115 | ERB-145 | PRL-120 |
|---|---|---|---|---|
| Max Speed | °/s | 72 | 72 | 25 |
| Nominal Torque | Nm | 7 | 35 | 216 |
| Max Torque | Nm | 19 | 64 | 372 |
| Max rotation angle | ° | 340 | 340 | 360 |
| Weight | kg | 1.8 | 3.9 | 3.6 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, C.D.T.; Park, J.; Cho, K.-Y.; Kim, K.-S.; Kim, S. Novel Descattering Approach for Stereo Vision in Dense Suspended Scatterer Environments. Sensors 2017, 17, 1425. https://doi.org/10.3390/s17061425
Nguyen CDT, Park J, Cho K-Y, Kim K-S, Kim S. Novel Descattering Approach for Stereo Vision in Dense Suspended Scatterer Environments. Sensors. 2017; 17(6):1425. https://doi.org/10.3390/s17061425
Chicago/Turabian StyleNguyen, Chanh D. Tr., Jihyuk Park, Kyeong-Yong Cho, Kyung-Soo Kim, and Soohyun Kim. 2017. "Novel Descattering Approach for Stereo Vision in Dense Suspended Scatterer Environments" Sensors 17, no. 6: 1425. https://doi.org/10.3390/s17061425