A Non-Linear Filtering Algorithm Based on Alpha-Divergence Minimization

Global Navigation Satellite System Research Center, Wuhan University, Wuhan 430079, China
*
Author to whom correspondence should be addressed.
Sensors 2018, 18(10), 3217; https://doi.org/10.3390/s18103217
Submission received: 25 August 2018
/
Revised: 15 September 2018
/
Accepted: 16 September 2018
/
Published: 24 September 2018
(This article belongs to the Special Issue Sensor Signal and Information Processing II)
Abstract
:A non-linear filtering algorithm based on the alpha-divergence is proposed, which uses the exponential family distribution to approximate the actual state distribution and the alpha-divergence to measure the approximation degree between the two distributions; thus, it provides more choices for similarity measurement by adjusting the value of during the updating process of the equation of state and the measurement equation in the non-linear dynamic systems. Firstly, an -mixed probability density function that satisfies the normalization condition is defined, and the properties of the mean and variance are analyzed when the probability density functions and are one-dimensional normal distributions. Secondly, the sufficient condition of the alpha-divergence taking the minimum value is proven, that is when , the natural statistical vector’s expectations of the exponential family distribution are equal to the natural statistical vector’s expectations of the -mixed probability state density function. Finally, the conclusion is applied to non-linear filtering, and the non-linear filtering algorithm based on alpha-divergence minimization is proposed, providing more non-linear processing strategies for non-linear filtering. Furthermore, the algorithm’s validity is verified by the experimental results, and a better filtering effect is achieved for non-linear filtering by adjusting the value of .
1. Introduction
The analysis and design of non-linear filtering algorithms are of enormous significance because non-linear dynamic stochastic systems have been widely used in practical systems, such as navigation system [1], simultaneous localization and mapping [2], and so on. Because the state model and the measurement model are non-linear and the state variables and the observation variables of the systems no longer satisfy the Gaussian distribution, the representation of the probability density distribution of the non-linear function will become difficult. In order to solve this problem, deterministic sampling (such as the unscented Kalman filter and cubature Kalman filter) and random sampling (such as the particle filter) are adopted to approximate the probability density distribution of the non-linear function, that is to say, to replace the actual state distribution density function by a hypothetical one [3].
In order to measure the similarity between the hypothetical state distribution density function and the actual one, we need to select a measurement method to ensure the effectiveness of the above methods. The alpha-divergence, proposed by S.Amari, is used to measure the deviation between data distributions and [4]. It can be used to measure the similarity between the hypothetical state distribution density function and the actual one for the non-linear filtering. Compared with the Kullback–Leibler divergence (the KL divergence), the alpha-divergence provides more choices for measuring the similarity between the hypothetical state distribution density function and the actual one. Therefore, we use alpha-divergence as a measurement criterion to measure the similarity between the two distribution functions. Indeed, adjusting the value of parameter in the function can ensure the interesting properties of similarity measurement. Another choice of characterizes different learning principles, in the sense that the model distribution is more inclusive () or more exclusive () [5]. Such flexibility enables -based methods to outperform KL-based methods with the value of being properly selected. The higher the similarity of the two probability distributions and , the smaller the value of alpha-divergence will be. Then, it can be proven that in a specific range of value, can fully represent the properties of when the value of alpha-divergence is minimum.
Because the posterior distribution of non-linear filtering is difficult to solve, given that the posterior probability distribution is , we can use the probability distribution to approximate the posterior probability distribution of non-linear filtering. The approximate distribution is expected to be a distribution with a finite moment vector. This in turn means that a good choice for the approximate distribution is from the exponential family distribution, which is a practically convenient and widely-used unified family of distributions on finite dimensional Euclidean spaces.
The main contributions of this article include:
- We define an -mixed probability density function and prove that it satisfies the normalization condition when we specify the probability distributions and to be univariate normal distributions. Then, we analyze the monotonicity of the mean and the variance of the -mixed probability density function with respect to the parameter when and are specified to be univariate normal distributions. The results will be used in the algorithm implementation to guarantee the convergence.
- We specify the probability density function as an exponential family state density function and choose it to approximate the known state probability density function . After the -mixed probability density function is defined by and , we prove that the sufficient condition for alpha-divergence minimization is when and the expected value of the natural statistical vector of is equivalent to the expected value of the natural statistical vector of the -mixed probability density function.
- We apply the sufficient condition to the non-linear measurement update step of the non-linear filtering. The experiments show that the proposed method can achieve better performance by using a proper value.
2. Related Work
It has become a common method to apply various measurement methods of divergence to optimization and filtering, among which the KL divergence, as the only invariant flat divergence, has been most commonly studied [6]. The KL divergence is used to measure the error in the Gaussian approximation process, and it is applied in the process of distributing updated Kalman filtering [7]. The proposal distribution of the particle filter algorithm is regenerated using the KL divergence after containing the latest measurement values, so the new proposal distribution approaches the actual posterior distribution [8]. Martin et al. proposed the Kullback–Leibler divergence-based differential evolution Markov chain filter for global localization for mobile robots in a challenging environment [9], where the KL-divergence is the basis of the cost function for minimization. The work in [3] provides a better measurement method for estimating the posterior distribution to apply KL minimization to the prediction and updating of the filtering algorithm, but it only provides the proof of the KL divergence minimization. The similarity of the posterior probability distribution between adjacent sensors in the distributed cubature Kalman filter is measured by minimizing the KL divergence, and great simulation results are achieved in the collaborative space target tracking task [10].
As a special situation of alpha-divergence, the KL divergence is easy to calculate, but it provides only one measurement method. Therefore, the studies on the theory and related applications of the KL divergence are taken seriously. A discrete probability distribution of minimum Chi-square divergence is established [11]. Chi-square divergence is taken as a new criterion for image thresholding segmentation, obtaining better image segmentation results than that from the KL divergence [12,13]. It has been proven that the alpha-divergence minimization is equivalent to the -integration of stochastic models, and it is applied to the multiple-expert decision-making system [6]. Amari et al. [14] also proved that the alpha-divergence is the only divergence category, which belongs to both f-divergence and Bregman divergence, so it has information monotonicity, a geometric structure with Fisher’s measurement and a dual flat geometric structure. Gultekin et al. [15] proposed to use Monte Carlo integration to optimize the minimization equation of alpha-divergence, but this does not prove the alpha-divergence minimization. In [16], the application of the alpha-divergence minimization in approximate reasoning has been systematically analyzed, and different values of can change the algorithm between the variational Bayesian algorithm and expectation propagation algorithm. As a special situation of the alpha-divergence (), q-entropy [17,18] has been widely used in the field of physics. Li et al. [19] proposed a new class of variational inference methods using a variant of the alpha-divergence, which is called Rényi divergence, and applied it to the variational auto-encoders and Bayesian neural networks. There are more introductions about theories and applications of the alpha-divergence in [20,21]. Although the theories and applications of alpha-divergence have been very popular, we focus on providing a theory to perfect the alpha-divergence minimization and apply it to non-linear filtering.
3. Background Work
In Section 3.1, we provide the framework of the non-linear filtering. Then, we introduce the alpha-divergence in Section 3.2, which contains many types of divergence as special cases.
3.1. Non-Linear Filtering
The actual system studied in the filtering is usually non-linear and non-Gaussian. Non-linear filtering refers to a filtering that can estimate the optimal estimation problem of the state variables in the dynamic system online and in real time from the system observations.
The state space model of non-linear systems with additive Gaussian white noise is:
where is the system state vector that needs to be estimated; is the zero mean value Gaussian white noise, and its variance is . Equation (1) describes the state transition of the system.
The random observation model of the state vector is:
where is system measurement; is the zero mean value Gaussian white noise, and its variance is . Suppose and are independent of each other and the observed value is independent of the state variables .
The entire probability state space is represented by the generation model as shown in Figure 1. is the system state; is the observational variable, and the purpose is to estimate the value of state . The Bayesian filter is a general method to solve state estimation. The Bayesian filter is used to calculate the posterior distribution , and its recursive solution consists of prediction steps and update steps.
Under the Bayesian optimal filter framework, the system state equation determines that the conditional transition probability of the current state is a Gaussian distribution:
If the prediction distribution of the system can be obtained from Chapman–Kolmogorov, the prior probability is:
When there is a measurement input, the system measurement update equation determines that the measurement likelihood transfer probability of the current state obeys a Gaussian distribution:
According to the Bayesian information criterion, the posterior probability obtained is:
where is the normalized factor, and it is defined as follows:
Unlike the Kalman filter framework, the Bayesian filter framework does not demand that the update structure be linear, so it can use non-linear update steps.
In the non-linear filtering problem, the posterior distribution often cannot be solved correctly. Our purpose is to use the distribution to approximate the posterior distribution without an analytical solution. Here, we use the alpha-divergence measurement to measure the similarity between the two. We propose a method that directly minimizes alpha-divergence without adding any additional approximations.
3.2. The Alpha-Divergence
The KL divergence is commonly used in similarity measures, but we will generalize it to the alpha-divergence. The alpha-divergence is a parametric family of divergence functions, including several well-known divergence measures as special cases, and it gives us more flexibility in approximation [20].
Definition 1.
Let us consider two unnormalized distributions and with respect to a random variable x. The alpha-divergence is defined by:
where , which means is continuous at zero and one.
The alpha-divergence meets the following two properties:
- , if and only if , . This property can be used precisely to measure the difference between the two distributions.
- is a convex function with respect to and .
Note that the term disappears when and are normalized distributions, i.e., . The alpha-divergence in (8) is expressed by:
In general, we can get another equivalent expression of the alpha-divergence when we set :
Alpha-divergence includes several special cases such as the KL divergence, the Hellinger divergence and divergence (Pearson’s distance), which are summarized below.
- As approaches one, Equation (8) is the limitation form of , and it specializes to the KL divergence from to as L’Hôpital’s rule is used:When and are normalized distributions, the KL divergence is expressed as:
- As approaches zero, Equation (8) is still the limitation form of , and it specializes to the dual form of the KL divergence from to as L’Hôpital’s rule is used:When and are normalized distributions, the dual form of the KL divergence is expressed as:
- When , the alpha-divergence specializes to the Hellinger divergence, which is the only dual divergence in the alpha-divergence:where is the Hellinger distance, which is the half of the Euclidean distance between two random distributions after taking the difference of the square root, and it corresponds to the fundamental property of distance measurement and is a valid distance metric.
- When , the alpha-divergence degrades to -divergence:
In the later experiment, we will adapt the value of to optimize the distribution similarity measurement.
4. Non-Linear Filtering Based on the Alpha-Divergence
We first define an -mixed probability density function, which will be used in the non-linear filtering based on the alpha-divergence minimization. Then, we show that the sufficient condition for the alpha-divergence minimization is when and the expected value of the natural statistical vector of is equivalent to the expected value of the natural statistical vector of the -mixed probability density function. At last, we apply the sufficient condition to the non-linear measurement update steps for solving the non-linear filtering problem.
4.1. The -Mixed Probability Density Function
We first give a definition of a normalized probability density function called the -mixed probability density function, which is expressed as .
Definition 2.
We define an α-mixed probability density function:
We can prove that when both and are univariate normal distributions, then is still the Gaussian probability density function.
Suppose that and , so the probability density functions can be expressed as follows:
Then we can combine these two functions with parameter :
where is the mean of the -mixed probability density function; (which can be reduced to ) is the variance of the -mixed probability density function; is a scalar factor, and the expression is as follows:
Therefore, is a normalized probability density function, satisfying the normalization conditions . It is clear that the product of two Gaussian distributions is still a Gaussian distribution, which will bring great convenience to the representation of probability distribution of the latter filtering problem.
At the same time, we can get that the variance of is , which should satisfy the condition that its value is greater than zero. We can know by its denominator when , the value of can take any value on the real number axis; when , the scope of is . Then, it is easy to know that the closer is to , the greater the range of values of .
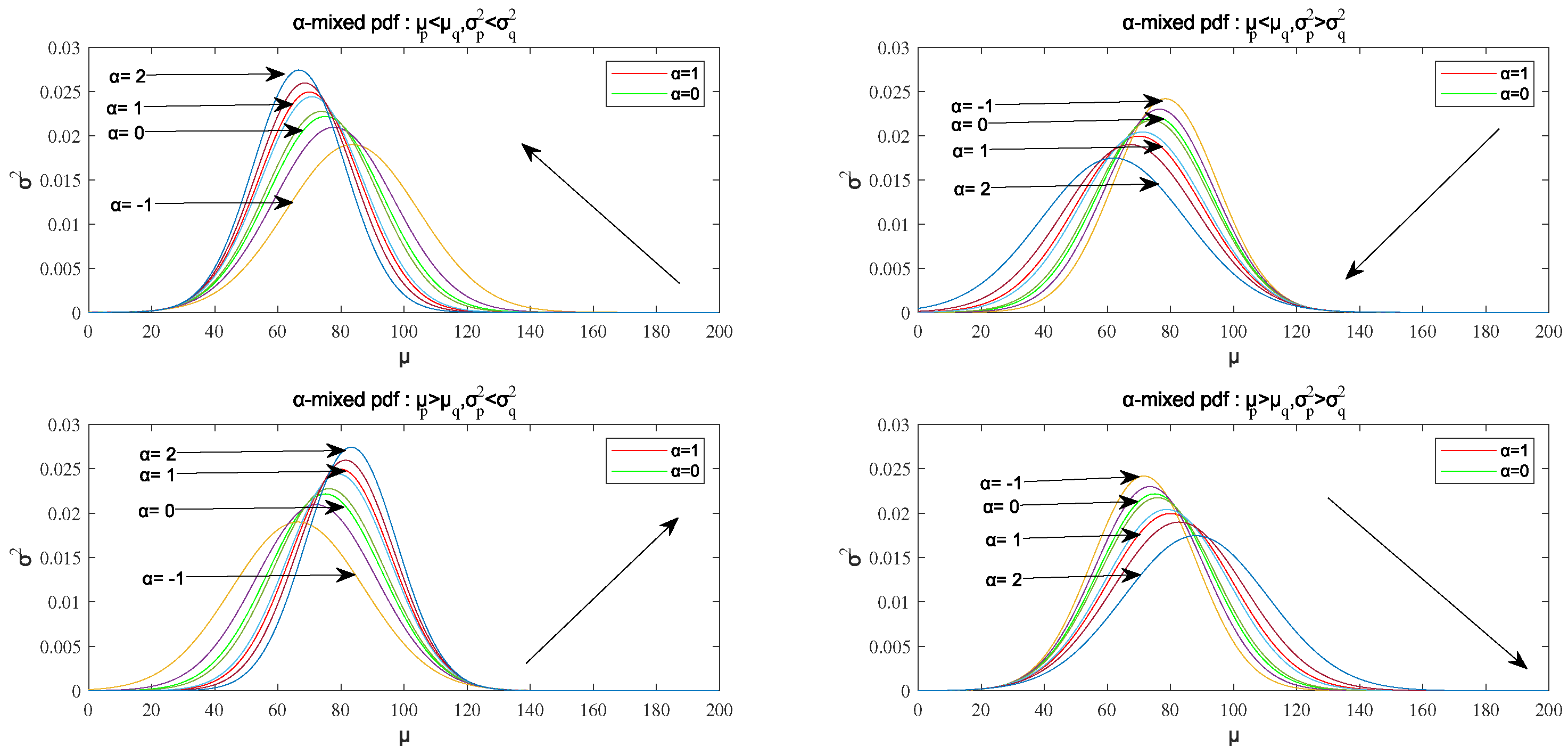
In addition, the influence of the mean and the variance of the two distributions on the mean and variance of the -mixed probability density function can be analyzed to facilitate the solution of the algorithm latter. As for the variance, when , decreases with the increase of ; when , it can be concluded that ; when , increases with the increase of . As for the mean value, when , ; if , . It is clear that if , then increases with the increase of ; if , then decreases with the increase of . The summary of the properties is shown in Table 1.
The monotonicity of the mean and the variance with respect to is shown in Figure 2.
It is clear that when and , decreases with the increase of and decreases with the increase of ; when and , decreases with the increase of and increases with the increase of ; when and , increases with the increase of and decreases with the increase of ; when and , increases with the increase of and increases with the increase of .
When , the -mixed probability density function is the interpolation function of and , so its mean value and the variance are all between and , as shown in Figure 2, and its image curve is also between them.
The above analysis will be used in the algorithm implementation of the sufficient condition in the non-linear filtering algorithm.
4.2. The Alpha-Divergence Minimization
In the solving process of the alpha-divergence minimization, either the posterior distribution itself or the calculation of the maximized posterior distribution is complex, so the approximate distribution with good characterization ability is often used to approximate the true posterior distribution . As a result, a higher degree achieves better approximation. Here, we restrict the approximate distribution to be an exponential family distribution; denote , with good properties, defined as follows:
Here, is a parameter set of probability density function; c(x) and g() are known functions; is a vector composed of natural parameters; is a natural statistical vector. contains enough information to express the state variable x in the exponential family distribution completely; is a coefficient parameter that combines based on parameter set .
In the non-linear filtering, assume the exponential family distribution is ; arbitrary function is , and we use to approximate , measuring the degree of approximation by the alpha-divergence. Therefore, the alpha-divergence of relative to is obtained, defined as:
We state and prove in Theorem 1 that the alpha-divergence between the exponential family distribution and the probability density function of arbitrary state variable is minimum, if and only if the expected value of the natural statistical vector in the exponential family distribution is equal to the expected value of the natural statistical vector in the -mixed probability state density function. In Corollary 1, given , the equivalence condition can be obtained in the case of . In Corollary 2, we conclude that the specialization of the exponential family distribution is obtained after being processed by the Gaussian probability density function.
Theorem 1.
The alpha-divergence between the exponential family distribution and the known state probability density function takes the minimum value; if and only if , the expected value of the natural statistical vector in the exponential family distribution is equal to the expected value of the natural statistical vector in the α-mixed probability state density function, that is:
Proof of Theorem 1.
Sufficient conditions for J minimization are that the first derivative and the second derivative satisfy the following conditions:
First, we derive Equation (22) with respect to , and according to the conditions in the first derivative, the outcome is:
Let the above equation be equal to zero, then:
In addition, since is a probability density function, it satisfies the normalization condition:
Derive in the above equation, and the outcome is:
The first item of Equation (23) can be obtained from Equations (26) and (28), which is the existence conditions of the stationary point for J.
To ensure that Equation (24) can minimize Equation (22), which means the stationary point is also its minimum point, we also need to prove that the second derivative satisfies the condition. Derive in Equation (25); the outcome is:
For the first item, it is easy to prove , and the proof is as follows.
It can be known from Equation (21):
The gradient of Equation (30) with respect to the natural parameter vector is as follows:
Then, consider the matrix formed by its second derivative with respect to the natural parameter vector:
According to the definition of the covariance matrix, the content in the bracket is the covariance matrix of the natural parameter vector with respect to the exponential family probability density function , and for arbitrary probability density distribution , the variance matrix is a positive definite matrix, so < 0; and when , the first item is greater than zero.
The integral of the second item is the secondary moment, so or , and the second item is greater than zero.
To sum up, when , . ☐
Corollary 1.
(See Theorem 1 of [3] for more details) When , , turns into . We can obtain the above theorem under the condition of and obtain the approximate distribution by minimizing the KL divergence, which also proves that the stationary point obtained when the first derivative of its KL divergence is equal to zero also satisfies the condition that its second derivative is greater than zero. The corresponding expectation propagation algorithm is shown as follows:
Corollary 2.
(See Corollary 1.1 of [3] for more details) When the exponential family distribution is simplified as the Gaussian probability density function, its sufficient statistic for , we use the mean and variance of Gaussian probability density function, and the expectation of the corresponding propagation algorithm can use the moment matching method to calculate, so the first moment and the second moment are defined as follows:
The corresponding second central moment is defined as follows:
The complexity of Theorem 1 lies in that both sides of Equation (23) depend on the probability distribution of at the same time. The that satisfies the condition can be obtained by repeated iterative update on . The specific process is shown in Algorithm 1:
| Algorithm 1 Approximation of the true probability distribution . |
| Input: Target distribution parameter of ; damping factor ; divergence parameter ; initialization value of Output: The exponential family probability function
|
In the above algorithms, we need to pay attention to the following two problems: giving an initial value of and selecting damping factors. As for the first problem, we can know that when , the value range of is , according to the analysis of the -mixed probability density function in Section 4.1. Although the value of is greater than one, the value range of is limited under the condition that is unknown in the initial state; when , the value of can take any value on the whole real number axis, so the initial value we can choose is relatively larger, making and . When the value of is greater than one, the mean value of the -mixed probability density function will decrease, and the variance will also decrease, as shown in the upper left of Figure 2.
As for the second question, when , the -mixed probability density function is the interpolation function of and according to the analysis in Section 4.1. The value range in of damping factor is quite reasonable because the two probability density functions are interpolated when the value range of is in (0, 1), and the new probability density function is between the two. According to Equation (36), the smaller of , the closer the new to the old ; the larger of , the closer the new to . The mean value and the variance of is smaller than the real according to the analysis of the first question. Then, we will continue to combine new with to form a -mixed probability density function. Similarly, we clarify that the mean value and the variance of the new are larger than , so the value of we choose should be as close as possible to one.
The convergence of the algorithm can be guaranteed after considering the above two problems, and we can get that meets the conditions. It can be known from Theorem 1 that the approximation of can be obtained to ensure it converges on this minimum point after repeated iterative updates.
4.3. Non-Linear Filtering Algorithm Based on the Alpha-Divergence
In the process of non-linear filtering, assuming that a priori and a posteriori probability density functions satisfy the Assumed Density Filter (ADF), then define the prior parameter as ; the corresponding distribution is prior distribution ; define the posterior parameter as , then the corresponding distribution is posterior distribution .
The prediction of the state variance can be expressed as follows:
The corresponding first moment about the origin of can be obtained from Equation (37a).
By Corollary 2, when the alpha-divergence is simplified to the KL divergence, the corresponding mean value and variance are:
Here, the prior distribution can be obtained.
Similarly, the update steps of the filter can be expressed as follows:
It is clear according to Theorem 1:
Here, , , is the proposal distribution. We choose the proposal distribution as a priori distribution . We define , , so:
An approximate calculation of the mean value and the variance for is conducted:
Since Equation (40) contains on both sides of the equation, we must use Algorithm 1 to conduct the iterative calculation to get the satisfied posterior distribution .
If , the above steps can be reduced to a simpler filtering algorithm, as shown in [3].
5. Simulations and Analysis
According to Theorem 1, when , the non-linear filtering method we proposed is feasible theoretically. In the simulation experiment, the algorithm is validated by taking different values when . We name our proposed method as AKF and compare it with the traditional non-linear filtering methods such as EKF and UKF.
We choose the Univariate Nonstationary Growth Model (UNGM) [22] to analyze the performance of the proposed method. The system state equation is:
The observation equation is:
The equation of state is a non-linear equation including the fractional relation, square relation and trigonometric function relation. is the process noise with the mean value of zero and the variance of Q. The relationship between the observed signal and state in the measurement equation is also non-linear. is the observation noise with the mean value of zero and the variance of R. Therefore, this system is a typical system with non-linear states and observations, and this model has become the basic model for verifying the non-linear filtering algorithm [22,23].
In the experiment, we set Q = 10, R = 1 and set the initial state as .
First, we simulate the system. When , the values of are right for the experiments; here, the value of is two, and the entire experimental simulation time is T = 50. The result of the state estimation is shown in Figure 3, and it can be seen that the non-linear filtering method we proposed is feasible; the state value can be estimated well during the whole process, and its performance is superior to EKF and UKF in some cases.
Second, in order to measure the accuracy of state estimation, the difference between the real state value at each moment and the estimated state value can be calculated to obtain the absolute value; thus, the absolute deviation of the state estimation at each moment is obtained, namely:
As shown in Figure 4, we can see that the algorithm error we proposed is always relatively small where the absolute value deviation is relatively large. It can be seen that our proposed method performs better than other non-linear methods.
In order to measure the overall level of error, we have done many simulation experiments. The average error of each experiment is defined as:
The experimental results are shown in Table 2. We can see that when the estimation of T time series is averaged, the error mean of each AKF is minimum, which indicates the effectiveness of the algorithm, and the filtering accuracy of the algorithm is better than the other two methods under the same conditions. Because the UNGM has strong nonlinearity and we set the variance to the state noise as 10, which is quite large, so the performance differences between EKF, UKF and AKF are rather small.
Then, we analyze the influence of the initial value on the filtering results by modifying the value of process noise. As can be seen from Table 3, AKF’s performance becomes more and more similar to EKF/UKF as the Q becomes smaller.
In the end, we analyze the performance of the whole non-linear filtering algorithm by adjusting the value of through 20 experiments. In order to reduce the influence of the initial value on the experimental results, we take Q = 0.1 and then average the 20 experimental errors. The result is shown in Figure 5. We can see that the error grows as grows in this example, as the noise is relatively small.
6. Conclusions
We have first defined the -mixed probability density function and analyzed the monotonicity of the mean and the variance under different values. Secondly, the sufficient conditions for to find the minimum value have been proven, which provides more methods for measuring the distribution similarity of non-linear filtering. Finally, a non-linear filtering algorithm based on the alpha-divergence minimization has been proposed by applying the above two points to the non-linear filtering. Moreover, we have verified that the validity of the algorithm in one-dimensional UNGM.
Although the filtering algorithm is effective, the alpha-divergence is a direct extension of the KL divergence. We can try to verify that the minimum physical meaning of the alpha divergence is equivalent to the minimum physical meaning of the KL divergence in a further study. The algorithm should be applied to more practical applications to prove its effectiveness. Meanwhile, we can use more sophisticated particle filtering techniques, such as [24,25], to make the algorithm more efficient. Furthermore, the alpha-divergence method described above is applied to uni-modal approximations, but more attention should be paid to multi-modal distributions, which are more difficult and common in practical systems. Furthermore, it is worth designing a strategy to automatically learn the appropriate values.
Author Contributions
Y.L. and C.G. conceived of and designed the method and performed the experiment. Y.L. and S.Y. participated in the experiment and analyzed the data. Y.L. and C.G. wrote the paper. S.Y. revised the paper. J.Z. guided and supervised the overall process.
Funding
This research was supported by a grant from the National Key Research and Development Program of China (2016YFB0501801).
Acknowledgments
The authors thank Dingyou Ma of Tsinghua University for his help.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Grewal, M.S.; Andrews, A.P. Applications of Kalman filtering in aerospace 1960 to the present [historical perspectives]. IEEE Control Syst. 2010, 30, 69–78. [Google Scholar]
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef]
- Darling, J.E.; Demars, K.J. Minimization of the Kullback Leibler Divergence for Nonlinear Estimation. J. Guid. Control Dyn. 2017, 40, 1739–1748. [Google Scholar] [CrossRef]
- Amari, S. Differential Geometrical Method in Statistics; Lecture Note in Statistics; Springer: Berlin, Germany, 1985; Volume 28. [Google Scholar]
- Minka, T. Divergence Measures and Message Passing; Microsoft Research Ltd.: Cambridge, UK, 2005. [Google Scholar]
- Amari, S. Integration of Stochastic Models by Minimizing α-Divergence. Neural Comput. 2007, 19, 2780–2796. [Google Scholar] [CrossRef] [PubMed]
- Raitoharju, M.; García-Fernández, Á.F.; Piché, R. Kullback–Leibler divergence approach to partitioned update Kalman filter. Signal Process. 2017, 130, 289–298. [Google Scholar] [CrossRef] [Green Version]
- Mansouri, M.; Nounou, H.; Nounou, M. Kullback–Leibler divergence-based improved particle filter. In Proceedings of the 2014 IEEE 11th International Multi-Conference on Systems, Signals & Devices (SSD), Barcelona, Spain, 11–14 February 2014; pp. 1–6. [Google Scholar]
- Martin, F.; Moreno, L.; Garrido, S.; Blanco, D. Kullback–Leibler Divergence-Based Differential Evolution Markov Chain Filter for Global Localization of Mobile Robots. Sensors 2015, 15, 23431–23458. [Google Scholar] [CrossRef] [PubMed]
- Hu, C.; Lin, H.; Li, Z.; He, B.; Liu, G. Kullback–Leibler Divergence Based Distributed Cubature Kalman Filter and Its Application in Cooperative Space Object Tracking. Entropy 2018, 20, 116. [Google Scholar] [CrossRef]
- Kumar, P.; Taneja, I.J. Chi square divergence and minimization problem. J. Comb. Inf. Syst. Sci. 2004, 28, 181–207. [Google Scholar]
- Qiao, W.; Wu, C. Study on Image Segmentation of Image Thresholding Method Based on Chi-Square Divergence and Its Realization. Comput. Appl. Softw. 2008, 10, 30. [Google Scholar]
- Wang, C.; Fan, Y.; Xiong, L. Improved image segmentation based on 2-D minimum chi-square-divergence. Comput. Eng. Appl. 2014, 18, 8–13. [Google Scholar]
- Amari, S. Alpha-Divergence Is Unique, Belonging to Both f-Divergence and Bregman Divergence Classes. IEEE Trans. Inf. Theory 2009, 55, 4925–4931. [Google Scholar] [CrossRef]
- Gultekin, S.; Paisley, J. Nonlinear Kalman Filtering with Divergence Minimization. IEEE Trans. Signal Process. 2017, 65, 6319–6331. [Google Scholar] [CrossRef]
- Hernandezlobato, J.M.; Li, Y.; Rowland, M.; Bui, T.D.; Hernandezlobato, D.; Turner, R.E. Black Box Alpha Divergence Minimization. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1511–1520. [Google Scholar]
- Tsallis, C. Possible Generalization of Boltzmann-Gibbs Statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Tsallis, C. Introduction to Nonextensive Statistical Mechanics. Condens. Matter Stat. Mech. 2004. [Google Scholar] [CrossRef]
- Li, Y.; Turner, R.E. Rényi divergence variational inference. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 1073–1081. [Google Scholar]
- Amari, S.I. Information Geometry and Its Applications; Springer: Berlin, Germany, 2016. [Google Scholar]
- Nielsen, F.; Critchley, F.; Dodson, C.T.J. Computational Information Geometry; Springer: Berlin, Germany, 2017. [Google Scholar]
- Garcia-Fernandez, Á.F.; Morelande, M.R.; Grajal, J. Truncated unscented Kalman filtering. IEEE Trans. Signal Process. 2012, 60, 3372–3386. [Google Scholar] [CrossRef]
- Li, Y.; Cheng, Y.; Li, X.; Hua, X.; Qin, Y. Information Geometric Approach to Recursive Update in Nonlinear Filtering. Entropy 2017, 19, 54. [Google Scholar] [CrossRef]
- Martino, L.; Elvira, V.; Camps-Valls, G. Group Importance Sampling for particle filtering and MCMC. Dig. Signal Process. 2018, 82, 133–151. [Google Scholar] [CrossRef]
- Salomone, R.; South, L.F.; Drovandi, C.C.; Kroese, D.P. Unbiased and Consistent Nested Sampling via Sequential Monte Carlo. arXiv, 2018; arXiv:1805.03924. [Google Scholar]
Figure 1.
Hidden Markov Model (HMM).

Figure 2.
The monotonicity of the mean and the variance with respect to .

Figure 3.
State estimation comparison of different non-linear filtering methods.

Figure 4.
RMS comparison at different times.

Figure 5.
The error changes as changes.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The monotonicity of the mean and the variance of the -mixed probability density function.
| Increases with the Increase of | Decreases with the Increase of | ||
|---|---|---|---|
| increases with the increase of | |||
| decreases with the increase of | |||
Table 2.
Average errors of experiments.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|
| EKF | 1.6414 | 1.8434 | 1.8245 | 1.7749 | 1.6666 | 1.3255 | ⋯ |
| UKF | 1.5400 | 1.7703 | 1.6688 | 1.6387 | 1.6241 | 1.2243 | ⋯ |
| AKF | 1.4819 | 1.5921 | 1.4710 | 1.4694 | 1.4389 | 1.1222 | ⋯ |
Table 3.
Influence of the variance Q of state equation noise on experimental error.
| Q | 0.05 | 0.1 | 1 | 10 |
|---|---|---|---|---|
| EKF | 0.2256 | 0.2950 | 0.7288 | 1.7827 |
| UKF | 0.2222 | 0.3002 | 0.7396 | 1.6222 |
| AKF | 0.2167 | 0.2767 | 0.7144 | 1.5244 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Luo, Y.; Guo, C.; Zheng, J.; You, S. A Non-Linear Filtering Algorithm Based on Alpha-Divergence Minimization. Sensors 2018, 18, 3217. https://doi.org/10.3390/s18103217
AMA Style
Luo Y, Guo C, Zheng J, You S. A Non-Linear Filtering Algorithm Based on Alpha-Divergence Minimization. Sensors. 2018; 18(10):3217. https://doi.org/10.3390/s18103217
Chicago/Turabian StyleLuo, Yarong, Chi Guo, Jiansheng Zheng, and Shengyong You. 2018. "A Non-Linear Filtering Algorithm Based on Alpha-Divergence Minimization" Sensors 18, no. 10: 3217. https://doi.org/10.3390/s18103217
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.