Deep Learning Cluster Structures for Management Decisions: The Digital CEO †


Abstract
1. Introduction
2. Research Background
2.1. Cybersecurity
2.2. Deep Learning
2.3. Deep Reinforcement Learning
3. Deep Learning Cluster Structures for Management Decisions
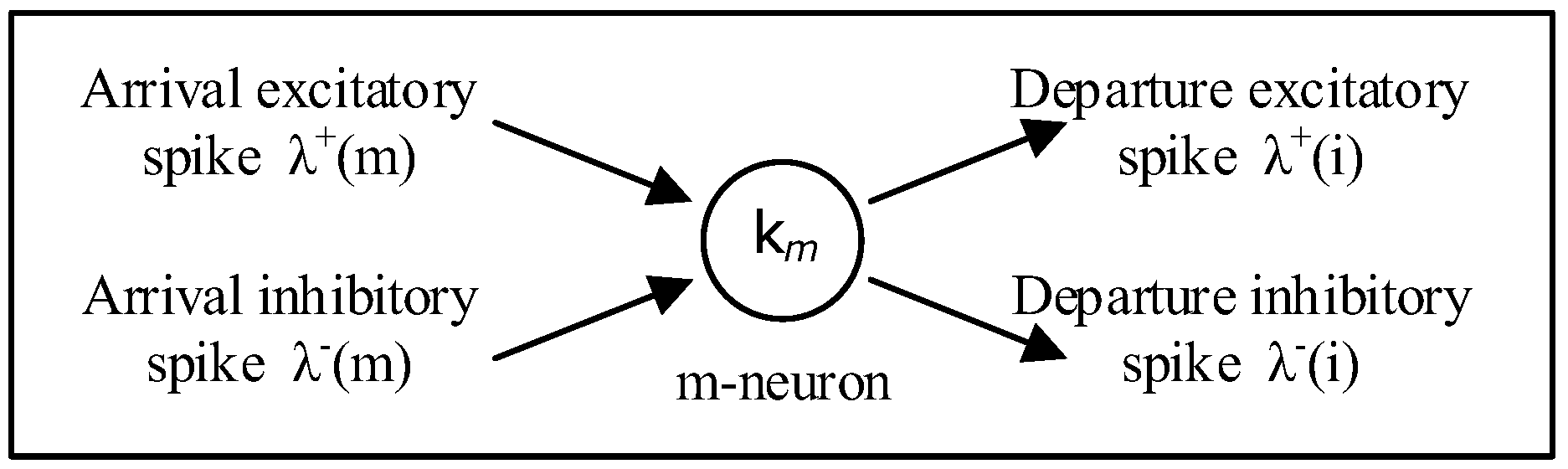
3.1. The Random Neural Network—Reinforcement Learning
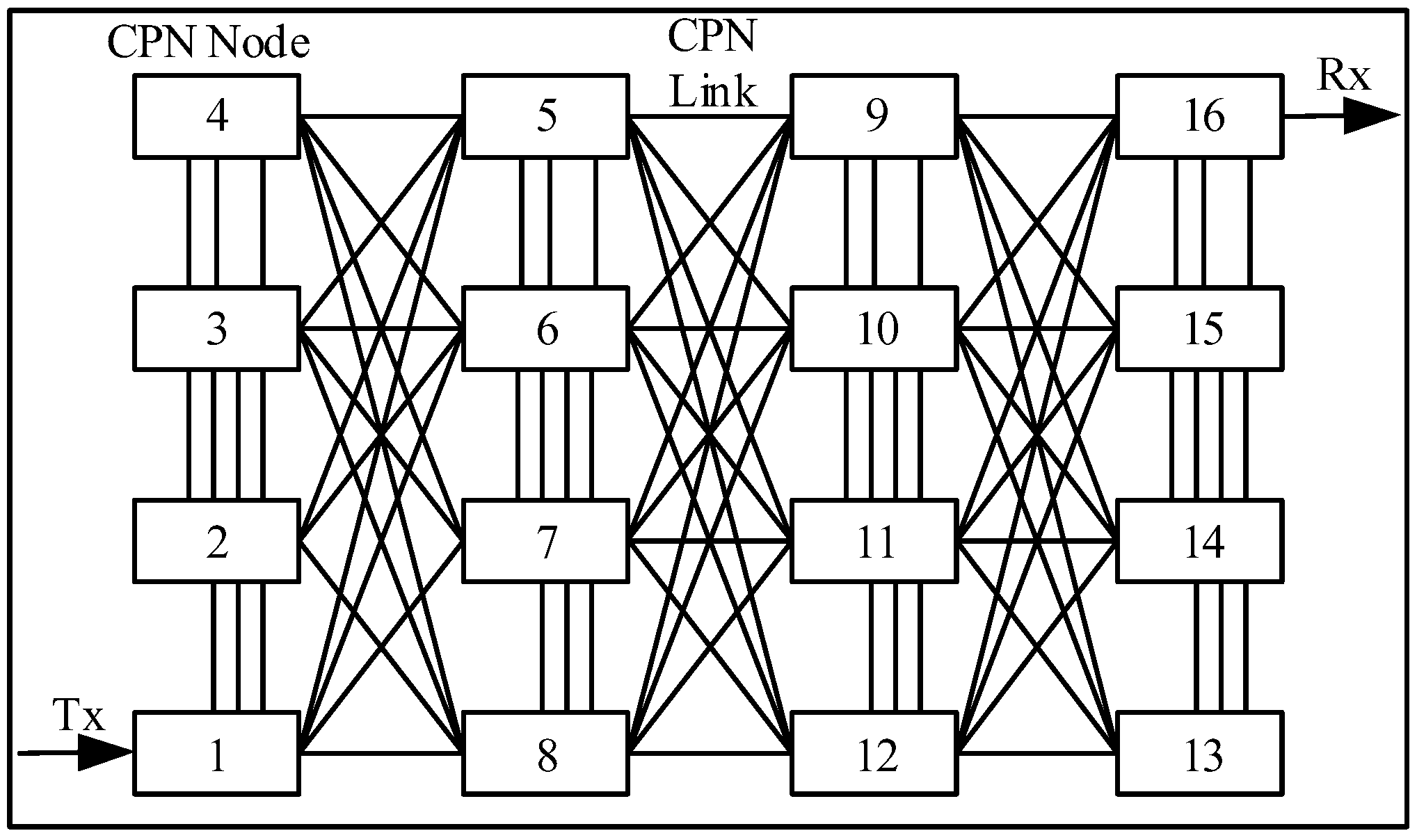
3.2. The Cognitive Packet Network
3.3. Deep Learning Clusters
- I = (idl1, idl2, …, idlu), U-dimensional vector I Є [0,1]U for the input state for the cell u;
- w−(u,c), U × C matrix of weights from the U input cells to the cells in each of the C clusters;
- Y = (ydl1, ydl2, …, ydlc), a C-dimensional vector Y Є [0,1]C for the cell state qc for the cluster c.
3.4. Deep Learning Management Clusters
- Imc = (imc1, imc2, …, imcc), C-dimensional vector Imc Є [0,1]C for the input state for the cluster c;
- w−(c), C-dimensional vector of weights from the C input clusters to the cells in the Management Cluster mc;
- Ymc, a scalar Ymc Є [0,1], the cell state qmc for the Management Cluster mc.
3.5. Deep Learning Cluster Structures
3.5.1. Deep Learning Cluster Model
3.5.2. Deep Learning Clusters
- IQoS = (iQoS1, iQoS2, …, iQoSu) a U-dimensional IQoS Є [0,1]U vector where iQoS1, iQoS2, and iQoSu are the same value for each QoS type;
- w−QoS(u,c) is the U × C matrix of weights of the QoS Deep Learning Cluster;
- YQoS = (yQoS1, yQoS2, …, yQoSc) a C-dimensional vector YQoS Є [0,1]C where yQoS1 is the QoS metric and yQoS2, …, yQoSc are the node’s QoS best routing gates.
- ICyber = (iCyber1, iCyber2, …, iCyberu) a U-dimensional vector ICyber Є [0,1]U where iCyber1, iCyber2, …, iCyberu are the Cyber keys from the CP;
- w−Cyber(u,c) is the U × C matrix of weights of the Cyber Deep Learning Cluster;
- YCyber = (yCyber1, yCyber2, …, yCyberc) a C-dimensional vector YCyber Є [0,1]C where yCyber1, yCyber2, …, yCyberc are the Cyber keys from the DL cluster.
3.5.3. Deep Learning Management Cluster
- Iqmc = (iqmc1, iqmc2, … iqmcc), a C-dimensional vector Iqmc Є [0,1]C with the values of the QoS Metrics for each QoS cluster;
- wqmc−(c) is the C-dimensional vector of weights that represents the Goal = (αDelay, βLoss, γBandwidth);
- Yqmc, a scalar Yqmc Є [0,1] that represents the best QoS metric routing decision to be taken.
- Icmc = (icmc1, icmc2, … icmcc), a C-dimensional vector Icmc Є [0,1]C with the values of the key errors for each Cyber cluster (User, Packet, Node);
- wcmc−(c) is the C-dimensional vector of weights that represents the relevance of each Cyber Cluster;
- Ycmc, a scalar Ycmc Є [0,1] that represents if the packet has passed the Cyber network security.
- ICEOmc, a scalar ICEOmc Є [0,1] with the values of the QoS management cluster;
- wCEOmc− a scalar wCEOmc− Є [0,1] that represents the error of the Cyber management cluster;
- YCEOmc, a scalar YCEOmc Є [0,1] that represents the final routing decision.
4. Implementation
4.1. Quality of Service Deep Learning Cluster
4.2. Cyber Deep Learning Cluster
4.3. Deep Learning Management Cluster
5. Experimental Results
5.1. Cyber Deep Learning cluster results
5.2. Quality of Service Deep Learning Cluster Results (3 × 3 Nodes)
5.3. Deep Learning Management Cluster Results (3 × 3 Nodes)
5.4. Quality of Service Deep Learning Cluster Results (4 × 4 Nodes)
5.5. Deep Learning Management Cluster Results (4 × 4 Nodes)
5.6. Quality of Service Deep Learning Cluster Results (5 × 5 Nodes)
5.7. Deep Learning Management Cluster Results (5 × 5 Nodes)
6. Conclusions
Funding
Conflicts of Interest
Appendix A

References
- Bassett, S.; Bullmore, E. Small-World Brain Networks. Neuroscientist 2007, 12, 512–523. [Google Scholar] [CrossRef] [PubMed]
- Squire, L. Declarative and Nondeclarative Memory: Multiple Brain Systems Supporting Learning and Memory. J. Cogn. Neurosci. 1992, 4, 232–243. [Google Scholar] [CrossRef] [PubMed]
- Grossberg, S. The Link between Brain Learning, Attention, and Consciousness. Conscious. Cogn. 1999, 8, 1–44. [Google Scholar] [CrossRef] [PubMed]
- Ericsson, G. Cyber Security and Power System Communication, Essential Parts of a Smart Grid Infrastructure. IEEE Trans. Power Deliv. 2010, 25, 1501–1507. [Google Scholar] [CrossRef]
- Ten, C.; Manimaran, G.; Liu, C. Cybersecurity for Critical Infrastructures: Attack and Defense Modeling. IEEE Trans. Syst. Man Cybern. A 2010, 40, 853–865. [Google Scholar] [CrossRef]
- Cruz, T.; Rosa, L.; Proença, J.; Maglaras, L.; Aubigny, M.; Lev, L.; Jiang, J.; Simões, P. A Cybersecurity Detection Framework for Supervisory Control and Data Acquisition Systems. IEEE Trans. Ind. Inform. 2016, 12, 2236–2246. [Google Scholar] [CrossRef]
- Wang, Q.; Guo, W.; Zhang, K.; Ororbia, A.; Xing, X.; Liu, X.; Giles, L. Learning Adversary-Resistant Deep Neural Networks. arXiv, 2016; arXiv:1612.01401. [Google Scholar]
- Tuor, A.; Kaplan, S.; Hutchinson, B.; Nichols, N.; Robinson, S. Deep Learning for Unsupervised Insider Threat Detection in Structured Cybersecurity Data Streams; Association for the Advancement of Artificial Intelligence: Menlo Park, CA, USA, 2017; pp. 4993–4994. [Google Scholar]
- Wu, M.; Song, Z.; Moon, Y. Detecting cyber-physical attacks in CyberManufacturing systems with machine learning methods. J. Intell. Manuf. 2017, 1–13. [Google Scholar] [CrossRef]
- Huang, S.; Zhou, C.-J.; Yang, S.-H.; Qin, Y.-Q. Cyber-physical system security for networked industrial processes. Int. J. Autom. Comput. Sci. 2015, 12, 567–578. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep Learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Courville, A.; Vincent, P. Unsupervised Feature Learning and Deep Learning: A Review and New Perspectives. arXiv, 2012; arXiv:1206.5538. [Google Scholar]
- Shao, J.; Zhao, Z.; Su, F.; Cai, A. Progressive framework for deep neural networks: From linear to non-linear. J. China Univ. Posts Telecommun. 2016, 23, 1–7. [Google Scholar]
- Le, Q.; Ngiam, J.; Coates, A.; Lahiri, A.; Prochnow, B.; Ng, A. On optimization methods for Deep Learning. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 265–272. [Google Scholar]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A. Multimodal Deep Learning. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Bekker, A.; Opher, I.; Lapidot, I.; Goldberger, J. Intra-cluster training strategy for Deep Learning with applications to language identification. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Vietri sul Mare, Italy, 13–16 September 2016; pp. 1–6. [Google Scholar]
- Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double Q-Learning. In Proceedings of the Association for the Advancement of Artificial Intelligence Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Lillicrap, T.; Hunt, J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with Deep Reinforcement learning. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016; pp. 1–14. [Google Scholar]
- Mnih, V.; Badia, A.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1928–1937. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1995–2003. [Google Scholar]
- Duan, Y.; Chen, X.; Houthooft, R.; Schulman, J.; Abbeel, P. Benchmarking deep reinforcement learning for continuous control. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1329–1338. [Google Scholar]
- Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; Meger, D. Deep Reinforcement Learning that Matters. In Proceedings of the Association for the Advancement of Artificial Intelligence Conference on Artificial Intelligence, Edmonton, AB, Canada, 13–17 November 2018; pp. 1–26. [Google Scholar]
- Mao, H.; Alizadeh, M.; Menache, I.; Kandula, S. Resource Management with Deep Reinforcement Learning. In Proceedings of the 15th ACM Workshop on Hot Topics in Networks, Atlanta, GA, USA, 9–10 November 2016; pp. 50–56. [Google Scholar]
- Gelenbe, E. Random Neural Networks with Negative and Positive Signals and Product Form Solution. Neural Comput. 1989, 1, 502–510. [Google Scholar] [CrossRef]
- Gelenbe, E. Stability of the Random Neural Network Model. Neural Comput. 1990, 2, 239–247. [Google Scholar] [CrossRef]
- Gelenbe, E. Learning with the Recurrent Random Neural Network. In Proceedings of the IFIP Congress, Madrid, Spain, 7–11 September 1992; Volume 1, pp. 343–349. [Google Scholar]
- Gelenbe, E.; Wu, F. Large scale simulation for human evacuation and rescue. Comput. Math. Appl. 2012, 64, 3869–3880. [Google Scholar] [CrossRef]
- Filippoupolitis, A.; Hey, L.A.; Loukas, G.; Gelenbe, E.; Timotheou, S. Emergency response simulation using wireless sensor networks. In Proceedings of the 1st International Conference on Ambient Media and Systems, Quebec City, QC, Canada, 11–14 February 2008; Volume 21, pp. 1–7. [Google Scholar]
- Gelenbe, E.; Koçak, T. Area-based results for mine detection. IEEE Trans. Geosci. Remote Sens. 2000, 38, 12–24. [Google Scholar] [CrossRef]
- Gelenbe, E.; Sungur, M.; Cramer, C.; Gelenbe, P. Traffic and Video Quality with Adaptive Neural Compression. Multimed. Syst. 1996, 4, 357–369. [Google Scholar] [CrossRef]
- Atalay, V.; Gelenbe, E.; Yalabik, N. The Random Neural Network Model for Texture Generation. Int. J. Pattern Recognit. Artif. Intell. 1992, 6, 131–141. [Google Scholar] [CrossRef]
- Gelenbe, E. Cognitive Packet Network. U.S. Patent 6804201 B1, 12 October 2004. [Google Scholar]
- Gelenbe, E.; Xu, Z.; Seref, E. Cognitive Packet Networks. In Proceedings of the 11th IEEE International Conference on Tools with Artificial Intelligence, Washington, DC, USA, 8–10 November 1999; pp. 47–54. [Google Scholar]
- Gelenbe, E.; Lent, R.; Xu, Z. Networks with Cognitive Packets. In Proceedings of the 8th International Symposium on Modeling, Analysis, and Simulation on Computer and Telecommunication Systems, San Francisco, CA, USA, 29 August–1 September 2000; pp. 3–10. [Google Scholar]
- Gelenbe, E.; Lent, R.; Xu, Z. Measurement and performance of a cognitive packet network. Comput. Netw. 2001, 37, 691–701. [Google Scholar] [CrossRef]
- Gelenbe, E.; Lent, R.; Montuori, A.; Xu, Z. Cognitive Packet Networks: QoS and Performance. In Proceedings of the 10th IEEE International Symposium on Modeling, Analysis, and Simulation on Computer and Telecommunication Systems, Fort Worth, TX, USA, 16 October 2002; pp. 3–9. [Google Scholar]
- Gelenbe, E.; Yin, Y. Deep Learning with random neural networks. In Proceedings of the International Joint Conference on Neural Networks, Vancouver, BC, Canada, 24–29 July 2016; pp. 1633–1638. [Google Scholar]
- Yin, Y.; Gelenbe, E. Deep Learning in Multi-Layer Architectures of Dense Nuclei. arXiv, 2016; arXiv:1609.07160. [Google Scholar]
- Gelenbe, E. G-Networks: A Unifying Model for Neural Nets and Queueing Networks. Ann. Oper. Res. 1994, 48, 433. [Google Scholar] [CrossRef]
- Fourneau, J.M.; Gelenbe, E.; Suros, R. G-Networks with Multiple Class Negative and Positive Customers. In Proceedings of the International Workshop on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems, Durham, NC, USA, 31 January–2 February 1994; pp. 30–34. [Google Scholar]
- Gelenbe, E.; Timotheou, S. Random Neural Networks with Synchronized Interactions. Neural Comput. 2008, 20, 2308–2324. [Google Scholar] [CrossRef] [PubMed]
- Serrano, W.; Gelenbe, E. The Deep Learning Random Neural Network with a Management Cluster. In Proceedings of the International Conference on Intelligent Decision Technologies, Sorrento, Italy, 19 June 2017; pp. 185–195. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Node 4 Initial—Final | Node 5 Initial—Final | Node 9 Initial—Final | Node 16 Initial—Final |
| Delay: 40–40 | Delay: 50–80 | Delay: 90–120 | Delay: 160–160 |
| Loss: 65–65 | Loss: 60–45 | Loss: 40–25 | Loss: 05–05 |
| Bandwidth: 45–45 | Bandwidth: 55–85 | Bandwidth: 95–125 | Bandwidth: 165–165 |
| Node 3 Initial—Final | Node 6 Initial—Final | Node 10 Initial—Final | Node 15 Initial—Final |
| Delay: 30–30 | Delay: 60–70 | Delay: 100–110 | Delay: 150–150 |
| Loss: 70–70 | Loss: 55–50 | Loss: 35–30 | Loss: 10–10 |
| Bandwidth: 35–35 | Bandwidth: 65–75 | Bandwidth: 105–115 | Bandwidth:155–155 |
| Node 2 Initial—Final | Node 7 Initial—Final | Node 11 Initial—Final | Node 14 Initial—Final |
| Delay: 20–20 | Delay: 70–60 | Delay: 110–100 | Delay: 140–140 |
| Loss: 75–75 | Loss: 50–55 | Loss: 30–35 | Loss: 15–15 |
| Bandwidth: 25–25 | Bandwidth: 75–65 | Bandwidth: 115–105 | Bandwidth: 145–145 |
| Node 1 Initial—Final | Node 8 Initial—Final | Node 12 Initial—Final | Node 13 Initial—Final |
| Delay: 10–10 | Delay: 80–50 | Delay: 120–90 | Delay: 130–130 |
| Loss: 80–80 | Loss: 45–60 | Loss: 25–40 | Loss: 20–20 |
| Bandwidth: 15–15 | Bandwidth: 85–55 | Bandwidth: 125–95 | Bandwidth: 135–135 |
| Dimension | ∆ = 0.0 | ∆ = 0.1 | ∆ = 0.2 | ∆ = 0.3 | ∆ = 0.4 |
|---|---|---|---|---|---|
| 1 | 9.7500 × 10−11 | 0.0102 | 0.0409 | 0.0921 | 0.1638 |
| 2 | 9.7537 × 10−11 | 0.0213 | 0.0851 | 0.1915 | 0.3406 |
| 3 | 9.7537 × 10−11 | 0.0326 | 0.1305 | 0.2938 | 0.5226 |
| 4 | 9.7537 × 10−11 | 0.0451 | 0.1806 | 0.4067 | 0.7238 |
| 5 | 9.7537 × 10−11 | 0.0576 | 0.2306 | 0.5195 | 0.9249 |
| 6 | 9.7537 × 10−11 | 0.0715 | 0.2867 | 0.6465 | 1.1519 |
| 7 | 9.7537 × 10−11 | 0.0851 | 0.3414 | 0.7703 | 1.3732 |
| 8 | 9.7537 × 10−11 | 0.1006 | 0.4038 | 0.9119 | 1.6273 |
| 9 | 9.7537 × 10−11 | 0.1153 | 0.4633 | 1.0470 | 1.8698 |
| 10 | 9.7537 × 10−11 | 0.1323 | 0.5321 | 1.2038 | 2.1526 |
| Packet | Goal Number | Goal Description | QoS |
|---|---|---|---|
| 001–020 | - | Network Initialization Packets | |
| 021–022 | 1 | 1 × Delay | Initial Values |
| 023–040 | 1 | 1 × Delay | Final Values |
| 041–042 | 2 | 1 × Loss | Initial Values |
| 043–060 | 2 | 1 × Loss | Final Values |
| 061–062 | 3 | 1 × Bandwidth | Initial Values |
| 063–080 | 3 | 1 × Bandwidth | Final Values |
| 081–082 | 4 | 0.5 × Delay + 0.5 × Loss | Initial Values |
| 083–100 | 4 | 0.5 × Delay + 0.5 × Loss | Final Values |
| 101–102 | 5 | 0.5 × Delay + 0.5 × Bandwidth | Initial Values |
| 103–120 | 5 | 0.5 × Delay + 0.5 × Bandwidth | Final Values |
| 121–122 | 6 | 0.5 × Loss + 0.5 × Bandwidth | Initial Values |
| 123–140 | 6 | 0.5 × Loss + 0.5 × Bandwidth | Final Values |
| 141–142 | 7 | 0.3 × Delay + 0.3 × Loss + 0.3 × Bandwidth | Initial Values |
| 143–160 | 7 | 0.3 × Delay + 0.3 × Loss + 0.3 × Bandwidth | Final Values |
| Cyber DL Cluster | Error | Iteration | QoS DL Cluster | Error | Iteration |
|---|---|---|---|---|---|
| Cyber User | 6.96 × 10−10 | 58 | QoS Delay | 9.59 × 10−10 | 163.67 |
| Cyber Packet | 7.34 × 10−10 | 108 | QoS Loss | 9.16 × 10−10 | 163.14 |
| Cyber Node | 9.94 × 10−10 | 1162.33 | QoS Bandwidth | 9.16 × 10−10 | 135.33 |
| Updates | RNN-RL | QoS Delay | QoS Loss | QoS Bandwidth |
|---|---|---|---|---|
| Initialization | 0 | 4 | 1 | 3 |
| CP 021-160 | 140 | 9 | 1 | 9 |
| Packet | RNN-RL Route | DL Route | Best Route | Goal 1/Reward | 1/Threshold |
|---|---|---|---|---|---|
| 021 | 1-4-9 | 1-4-9 | 1-4-9 | 130.00 | 130.00 |
| 022 | 1-4-9 | 1-4-9 | 1-4-9 | 130.00 | 130.00 |
| 023 | 1-4-9 | 1-4-9 | 1-6-9 | 150.00 | 130.00 |
| 024 | 1-4-9 | 1-4-9 | 1-6-9 | 150.00 | 131.76 |
| 025 | 1-4-9 | 1-4-9 | 1-6-9 | 150.00 | 133.38 |
| 026 | 1-4-9 | 1-4-9 | 1-6-9 | 150.00 | 134.87 |
| 027 | 1-5-9 | 1-4-9 | 1-6-9 | 140.00 | 136.25 |
| 028 | 1-4-9 | 1-4-9 | 1-6-9 | 150.00 | 136.61 |
| 029 | 1-2-6-9 | 1-4-9 | 1-6-9 | 150.00 | 137.84 |
| 030 | 1-6-9 | 1-4-9 | 1-6-9 | 130.00 | 138.97 |
| 031 | 1-6-9 | 1-6-9 | 1-6-9 | 130.00 | 138.02 |
| 040 | 1-6-9 | 1-6-9 | 1-6-9 | 130.00 | 132.99 |
| Packet | RNN-RL Route | DL Route | Best Route | Goal 1/Reward | 1/Threshold |
|---|---|---|---|---|---|
| 081 | 1-4-9 | 1-4-9 | 1-4-9 | 82.50 | 82.50 |
| 082 | 1-4-9 | 1-4-9 | 1-4-9 | 82.50 | 82.50 |
| 083 | 1-4-9 | 1-4-9 | 1-6-9 | 87.50 | 82.50 |
| 084 | 1-5-9 | 1-4-9 | 1-6-9 | 85.00 | 82.97 |
| 085 | 1-6-9 | 1-4-9 | 1-6-9 | 82.50 | 83.17 |
| 086 | 1-6-9 | 1-6-9 | 1-6-9 | 82.50 | 83.10 |
| 087 | 1-6-9 | 1-6-9 | 1-6-9 | 82.50 | 83.04 |
| 088 | 1-6-9 | 1-6-9 | 1-6-9 | 82.50 | 82.99 |
| 089 | 1-6-9 | 1-6-9 | 1-6-9 | 82.50 | 82.94 |
| 090 | 1-6-9 | 1-6-9 | 1-6-9 | 82.50 | 82.90 |
| 091 | 1-6-9 | 1-6-9 | 1-6-9 | 82.50 | 82.86 |
| 100 | 1-6-9 | 1-6-9 | 1-6-9 | 82.50 | 82.64 |
| Packet | RNN-RL Route | DL Route | Best Route | Goal 1/Reward | 1/Threshold |
|---|---|---|---|---|---|
| 141 | 1-4-9 | 1-4-9 | 1-4-9 | 101.66 | 101.66 |
| 142 | 1-4-9 | 1-4-9 | 1-4-9 | 101.66 | 101.66 |
| 143 | 1-4-9 | 1-4-9 | 1-6-9 | 111.66 | 101.66 |
| 144 | 1-4-9 | 1-4-9 | 1-6-9 | 111.66 | 102.58 |
| 145 | 1-4-9 | 1-4-9 | 1-6-9 | 111.66 | 103.42 |
| 146 | 1-4-9 | 1-4-9 | 1-6-9 | 111.66 | 104.18 |
| 147 | 1-5-9 | 1-4-9 | 1-6-9 | 106.66 | 104.89 |
| 148 | 1-6-9 | 1-4-9 | 1-6-9 | 101.66 | 105.06 |
| 149 | 1-6-9 | 1-6-9 | 1-6-9 | 101.66 | 104.71 |
| 150 | 1-6-9 | 1-6-9 | 1-6-9 | 101.66 | 104.40 |
| 151 | 1-6-9 | 1-6-9 | 1-6-9 | 101.66 | 104.12 |
| 160 | 1-6-9 | 1-6-9 | 1-6-9 | 101.66 | 102.60 |
| Variable | Cognitive Packet: 30 G: 1.0 × D + 0.0 × L + 0.0 × B | Cognitive Packet: 85 G: 0.5 × D + 0.5 × L + 0.0 × B | Cognitive Packet: 148 G: 0.3 × D + 0.3 × L + 0.3 × B | |||
|---|---|---|---|---|---|---|
| Cyber Attack | ∆ = 0.0 | ∆ = 0.1 | ∆ = 0.0 | ∆ = 0.1 | ∆ = 0.0 | ∆ = 0.1 |
| Cyber Icmc | 5 × 10−11 | 3.4 × 10−4 | 5 × 10−11 | 3.4 × 10−4 | 5 × 10−11 | 3.4 × 10−4 |
| Cyber Ycmc | 0.9994 | 0.9969 | 0.9994 | 0.9969 | 0.9994 | 0.9969 |
| QoS-Delay Iqmc | 0.6300 | 0.6300 | 0.3150 | 0.3150 | 0.2100 | 0.2100 |
| QoS-Loss Iqmc | 0.0000 | 0.0000 | 0.2625 | 0.2625 | 0.1750 | 0.1750 |
| QoS-Band Iqmc | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.2133 | 0.2133 |
| QoS-Delay Yqmc | 0.1765 | 0.1765 | 0.3000 | 0.3000 | 0.3913 | 0.3913 |
| QoS-Loss Yqmc | 0.9994 | 0.9994 | 0.3396 | 0.3396 | 0.4354 | 0.4354 |
| QoS- Band Yqmc | 0.9994 | 0.9994 | 0.9994 | 0.9994 | 0.3875 | 0.3875 |
| CEO ICEOmc | 0.1000 | 0.1000 | 0.1000 | 0.1000 | 0.9000 | 0.9000 |
| CEO wCEOmc−(c) | 0.0000 | 0.9999 | 0.0000 | 0.9999 | 0.0000 | 0.9999 |
| CEO YCEOmc | 0.9994 | 0.5746 | 0.9994 | 0.5746 | 0.9994 | 0.1305 |
| Routing Decision | RNN-DL Gate-4 Node 6 | DL-Delay Gate-2 Node 4 | RNN-DL Gate-4 Node 6 | DL-Delay Gate-2 Node 4 | RNN-DL Gate-4 Node 6 | DL-Band Gate-2 Node 4 |
| Cognitive Packet | Goal Number | Goal Description | QoS Metric |
|---|---|---|---|
| 000–100 | - | Network Initialization Cognitive Packets | |
| 001–002 | 1 | 1.0 × Delay + 0.0 × Loss + 0.0 × Bandwidth | Initial Values |
| 003–040 | 1 | 1.0 × Delay + 0.0 × Loss + 0.0 × Bandwidth | Final Values |
| 041–042 | 2 | 0.0 × Delay + 1.0 × Loss + 0.0 × Bandwidth | Initial Values |
| 043–080 | 2 | 0.0 × Delay + 1.0 × Loss + 0.0 × Bandwidth | Final Values |
| 081–082 | 3 | 0.0 × Delay + 0.0 × Loss + 1.0 × Bandwidth | Initial Values |
| 083–120 | 3 | 0.0 × Delay + 0.0 × Loss + 1.0 × Bandwidth | Final Values |
| 121–122 | 4 | 0.5 × Delay + 0.5 × Loss + 0.0 × Bandwidth | Initial Values |
| 123–160 | 4 | 0.5 × Delay + 0.5 × Loss + 0.0 × Bandwidth | Final Values |
| 161–162 | 5 | 0.5 × Delay + 0.0 × Loss + 0.5 × Bandwidth | Initial Values |
| 163–200 | 5 | 0.5 × Delay + 0.0 × Loss + 0.5 × Bandwidth | Final Values |
| 201–202 | 6 | 0.0 × Delay + 0.5 × Loss + 0.5 × Bandwidth | Initial Values |
| 203–240 | 6 | 0.0 × Delay + 0.5 × Loss + 0.5 × Bandwidth | Final Values |
| 241–242 | 7 | 0.3 × Delay + 0 × 3Loss + 0.3 × Bandwidth | Initial Values |
| 243–280 | 7 | 0.3 × Delay + 0 × 3Loss + 0.3 × Bandwidth | Final Values |
| Cyber DL Cluster | Error | Iteration | QoS DL Cluster | Error | Iteration |
|---|---|---|---|---|---|
| Cyber User | 6.96 × 10−10 | 58.00 | QoS Delay | 9.34 × 10−10 | 158.67 |
| Cyber Packet | 7.34 × 10−10 | 108.00 | QoS Loss | 9.22 × 10−10 | 152.07 |
| Cyber Node | 9.93 × 10−10 | 1017.87 | QoS Bandwidth | 8.83 × 10−10 | 127.60 |
| Updates | RNN-RL | QoS Delay | QoS Loss | QoS Bandwidth |
|---|---|---|---|---|
| Initialization | 0 | 8 | 6 | 7 |
| CP 001-280 | 280 | 9 | 4 | 9 |
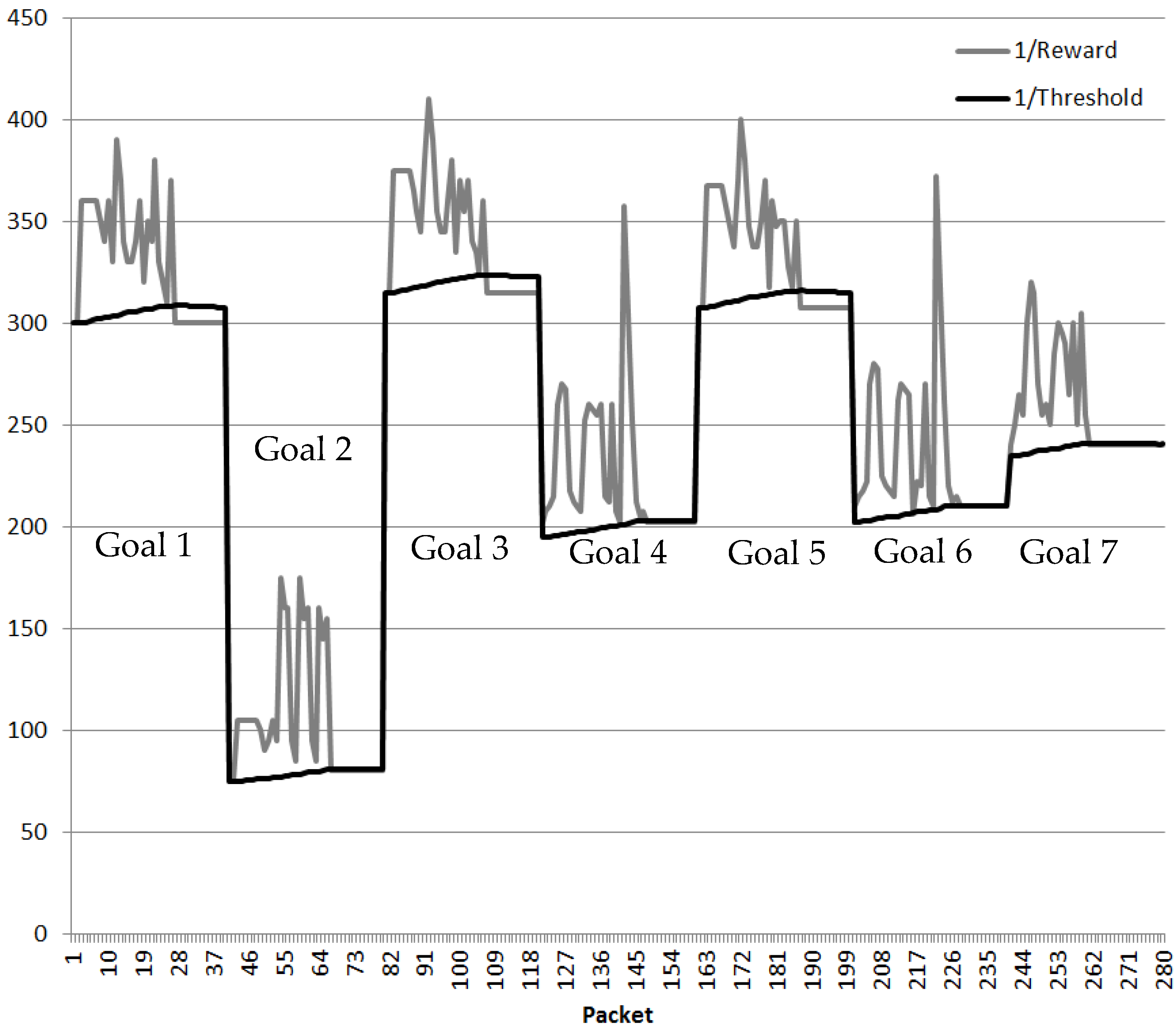
| Packet | RNN-RL Route | DL Route | Best Route | Goal 1/Reward | 1/Threshold |
|---|---|---|---|---|---|
| 001 | 1-5-9-16 | 1-5-9-16 | 1-5-9-16 | 300.00 | 300.00 |
| 002 | 1-5-9-16 | 1-5-9-16 | 1-5-9-16 | 300.00 | 300.00 |
| 003 | 1-5-9-16 | 1-5-9-16 | 1-8-12-16 | 360.00 | 300.00 |
| 004 | 1-5-9-16 | 1-5-9-16 | 1-8-12-16 | 360.00 | 300.50 |
| 005 | 1-5-9-16 | 1-5-9-16 | 1-8-12-16 | 360.00 | 301.00 |
| 006 | 1-5-9-16 | 1-5-9-16 | 1-8-12-16 | 360.00 | 301.49 |
| 007 | 1-5-9-16 | 1-5-9-16 | 1-8-12-16 | 360.00 | 301.98 |
| 008 | 1-6-9-16 | 1-5-9-16 | 1-8-12-16 | 350.00 | 302.47 |
| 009 | 1-7-9-16 | 1-5-9-16 | 1-8-12-16 | 340.00 | 302.88 |
| 010 | 1-2-6-10-16 | 1-5-9-16 | 1-8-12-16 | 360.00 | 303.21 |
| 011 | 1-8-9-16 | 1-5-9-16 | 1-8-12-16 | 330.00 | 303.69 |
| 012 | 1-4-5-10-16 | 1-5-9-16 | 1-8-12-16 | 390.00 | 303.93 |
| 013 | 1-3-5-11-16 | 1-5-9-16 | 1-8-12-16 | 370.00 | 304.61 |
| 014 | 1-5-11-16 | 1-5-9-16 | 1-8-12-16 | 340.00 | 305.15 |
| 015 | 1-6-11-16 | 1-5-9-16 | 1-8-12-16 | 330.00 | 305.46 |
| 016 | 1-7-10-16 | 1-5-9-16 | 1-8-12-16 | 330.00 | 305.69 |
| 017 | 1-2-7-11-16 | 1-5-9-16 | 1-8-12-16 | 340.00 | 305.91 |
| 018 | 1-4-6-12-16 | 1-5-9-16 | 1-8-12-16 | 360.00 | 306.22 |
| 019 | 1-8-10-16 | 1-5-9-16 | 1-8-12-16 | 320.00 | 306.68 |
| 020 | 1-3-6-12-16 | 1-5-9-16 | 1-8-12-16 | 350.00 | 306.80 |
| 021 | 1-5-11-16 | 1-5-9-16 | 1-8-12-16 | 340.00 | 307.18 |
| 022 | 1-4-3-7-12-16 | 1-5-9-16 | 1-8-12-16 | 380.00 | 307.48 |
| 023 | 1-2-8-11-16 | 1-5-9-16 | 1-8-12-16 | 330.00 | 308.07 |
| 024 | 1-6-12-15 | 1-5-9-16 | 1-8-12-16 | 320.00 | 308.27 |
| 025 | 1-7-12-15 | 1-5-9-16 | 1-8-12-16 | 310.00 | 308.39 |
| 026 | 1-3-4-8-12-16 | 1-5-9-16 | 1-8-12-16 | 370.00 | 308.40 |
| 027 | 1-8-12-16 | 1-5-9-16 | 1-8-12-16 | 300.00 | 308.92 |
| 028 | 1-8-12-16 | 1-8-12-16 | 1-8-12-16 | 300.00 | 308.82 |
| 029 | 1-8-12-16 | 1-8-12-16 | 1-8-12-16 | 300.00 | 308.73 |
| 030 | 1-8-12-16 | 1-8-12-16 | 1-8-12-16 | 300.00 | 308.64 |
| 040 | 1-8-12-16 | 1-8-12-16 | 1-8-12-16 | 300.00 | 307.80 |
| Variable | Cognitive Packet: 107 G: 1.0 × D + 0.0 × L + 0.0 × B | Cognitive Packet: 228 G: 0.5 × D + 0.5 × L + 0.0 × B | Cognitive Packet: 341 G: 0.3 × D + 0.3 × L + 0.3 × B | |||
|---|---|---|---|---|---|---|
| Cyber Attack | ∆ = 0.0 | ∆ = 0.1 | ∆ = 0.0 | ∆ = 0.1 | ∆ = 0.0 | ∆ = 0.1 |
| Cyber Icmc | 5 × 10−11 | 3.4 × 10−4 | 5 × 10−11 | 3.4 × 10−4 | 5 × 10−11 | 3.4 × 10−4 |
| Cyber Ycmc | 0.9994 | 0.9969 | 0.9994 | 0.9969 | 0.9994 | 0.9969 |
| QoS-Delay Iqmc | 0.8000 | 0.8000 | 0.4000 | 0.4000 | 0.2666 | 0.2666 |
| QoS-Loss Iqmc | 0.0000 | 0.0000 | 0.2875 | 0.2875 | 0.1916 | 0.1916 |
| QoS-Band Iqmc | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.2716 | 0.2716 |
| QoS-Delay Yqmc | 0.1444 | 0.1444 | 0.2523 | 0.2523 | 0.3361 | 0.3361 |
| QoS-Loss Yqmc | 0.9994 | 0.9994 | 0.3195 | 0.3195 | 0.4132 | 0.4132 |
| QoS- Band Yqmc | 0.9994 | 0.9994 | 0.9994 | 0.9994 | 0.3319 | 0.3319 |
| CEO ICEOmc | 0.1000 | 0.1000 | 0.1000 | 0.1000 | 0.9000 | 0.9000 |
| CEO wCEOmc−(c) | 0.0000 | 0.9999 | 0.0000 | 0.9999 | 0.0000 | 0.9999 |
| CEO YCEOmc | 0.9994 | 0.5746 | 0.9994 | 0.5746 | 0.9994 | 0.1305 |
| Routing Decision | RNN-DL Gate-6 Node 8 | DL-Delay Gate-3 Node 5 | RNN-DL Gate-6 Node 8 | DL-Delay Gate-6 Node 8 | RNN-DL Gate-6 Node 8 | DL-Band Gate-3 Node 5 |
| Cognitive Packet | Goal Number | Goal Description | QoS Metric |
|---|---|---|---|
| 0000–1500 | - | Network Initialization Cognitive Packets | |
| 001–002 | 1 | 1.0 × Delay + 0.0 × Loss + 0.0 × Bandwidth | Initial Values |
| 003–050 | 1 | 1.0 × Delay + 0.0 × Loss + 0.0 × Bandwidth | Final Values |
| Cyber DL Cluster | Error | Iteration | QoS DL Cluster | Error | Iteration |
|---|---|---|---|---|---|
| Cyber User | 7.56 × 10−13 | 62 | QoS Delay | 9.4 × 10−13 | 221.11 |
| Cyber Packet | 8.60 × 10−13 | 125 | QoS Loss | 9.30 × 10−13 | 182.40 |
| Cyber Node | 9.91 × 10−13 | 2128.68 | QoS Bandwidth | 9.30 × 10−13 | 200.71 |
| Updates | RNN-RL | QoS Delay | QoS Loss | QoS Bandwidth |
|---|---|---|---|---|
| Initialization | 0 | 8 | 20 | 7 |
| CP 001-050 | 50 | 1 | 0 | 0 |
| Variable | Cognitive Packet: 034 G: 1.0 × D + 0.0 × L + 0.0 × B | |
|---|---|---|
| Cyber Attack | ∆ = 0.0 | ∆ = 0.1 |
| Cyber Icmc | 5.14 × 10−14 | 3.47 × 10−4 |
| Cyber Ycmc | 0.9994 | 0.9969 |
| QoS-Delay Iqmc | 0.5590 | 0.5590 |
| QoS-Loss Iqmc | 0.0000 | 0.0000 |
| QoS-Band Iqmc | 0.0000 | 0.0000 |
| QoS-Delay Yqmc | 0.1945 | 0.1945 |
| QoS-Loss Yqmc | 0.9994 | 0.9994 |
| QoS- Band Yqmc | 0.9994 | 0.9994 |
| CEO ICEOmc | 0.1000 | 0.1000 |
| CEO wCEOmc−(c) | 0.0000 | 0.9999 |
| CEO YCEOmc | 0.9994 | 0.5746 |
| Routing Decision | RNN-RL Gate-8 Node 10 | DL-Delay Gate-4 Node 6 |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Serrano, W. Deep Learning Cluster Structures for Management Decisions: The Digital CEO. Sensors 2018, 18, 3327. https://doi.org/10.3390/s18103327
Serrano W. Deep Learning Cluster Structures for Management Decisions: The Digital CEO. Sensors. 2018; 18(10):3327. https://doi.org/10.3390/s18103327
Chicago/Turabian StyleSerrano, Will. 2018. "Deep Learning Cluster Structures for Management Decisions: The Digital CEO" Sensors 18, no. 10: 3327. https://doi.org/10.3390/s18103327
APA StyleSerrano, W. (2018). Deep Learning Cluster Structures for Management Decisions: The Digital CEO. Sensors, 18(10), 3327. https://doi.org/10.3390/s18103327