1. Introduction
Communication signal recognition is of great significance for several daily applications, such as operator regulation, communication anti-jamming, and user identification. One of the main objectives of signal recognition is to detect communication resources, ensuring safe, stable, timely, and reliable data exchange for communications. To achieve this objective, automatic modulation classification (AMC) is indispensable because it can help users identify the modulation mode within operating bands, which benefits communication reconfiguration and electromagnetic environment analysis. Besides this, AMC plays an essential role in obtaining digital baseband information from the signal when only limited knowledge about the parameters is available. Such a technique is widely used in both military and civilian applications, e.g., intelligent cognitive radio and anomaly detection, which have attracted much attention from researchers in the past decades [
1,
2,
3,
4,
5,
6].
Existing AMC algorithms can be divided into two main categories [
3], namely, likelihood-based (LB) methods and feature-based (FB) methods. LB methods require calculating the likelihood function of received signals for all modulation modes and then making decisions in accordance with the maximum likelihood ratio test [
3]. Even though LB methods usually obtain high accuracy and minimize the probability of mistakes, such methods suffer from high-latency classification or require complete priori knowledge, e.g., clock frequency offset. Alternatively, a traditional FB method consists of two parts, namely, feature extraction and classifier, where the classifier identifies digital modulation modes in accordance with the effective feature vectors extracted from the signals. Unlike the LB methods, the FB methods are computationally light but may not be theoretically optimal. To date, several FB methods have been validated as effective for the AMC problem. For instance, they successfully extract features from various time domain waveforms, such as cyclic spectrum [
4], high-order cumulant [
6], and wavelet coefficients. Afterwards, a classifier is used for final classification based on features mentioned above. With the development of learning algorithms, performances have been improved, such as with the shallow neural network [
7] and decision tree for the support vector machine (SVM). Recently, deep learning has been widely applied to audio, image, and video processing, facilitating applications such as facial recognition and voice discrimination [
8]. However, few works have been done based on deep learning in the field of communication.
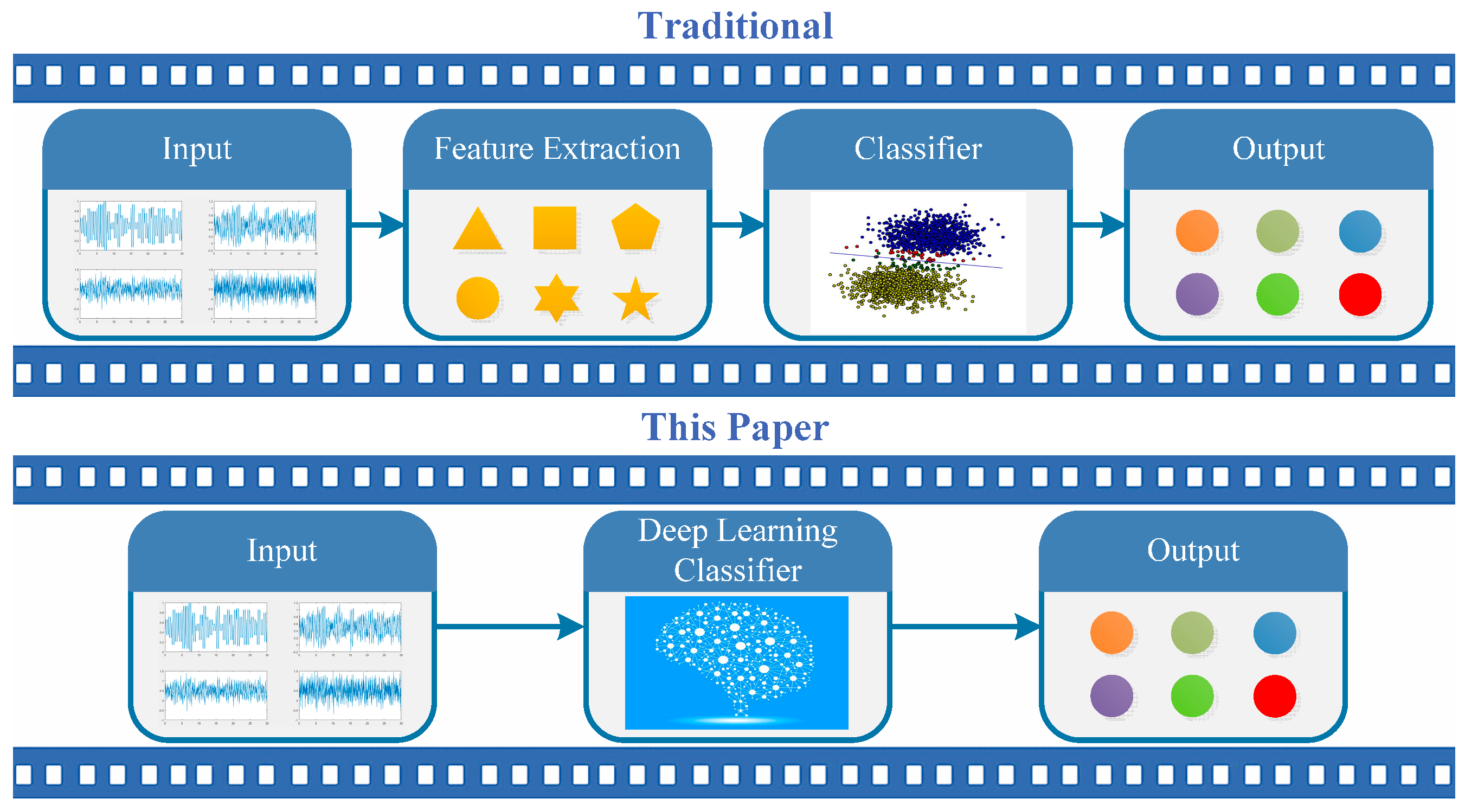
Although researchers have developed various algorithms to implement AMC of digital signals, there are no representative data sets in the field of communication. Meanwhile, these methods are suitable for complex communication equipment and struggle in real-world applications where channels are variable and difficult to predict, because (1) their samples are purely theoretical without the information of real geographical environment; (2) they usually separate feature extraction and the classification process so that information loss is inevitable; and (3) they employ handcrafted features which contribute to the lack of characterization capabilities. In this paper, we propose to realize AMC using convolutional neural networks (CNNs) [
9], long short-term memory (LSTM) [
10], and a fusion model to directly process the time domain waveform data, which is collected with various signal-to-noise ratios (SNRs) based on a real geographical environment.
CNNs exploit spatially local correlation by enforcing a local connectivity pattern between neurons of adjacent layers. The convolution kernels are also shared in each sample for the rapid expansion of parameters caused by the fully connected structure. Sample data are still retained in the original position after convolution such that the local features are well preserved. Despite its great advances in spatial feature extraction, CNNs cannot model the changes in time series well. As is known to us, the temporal property of data is important for AMC applications. As a variant of the recurrent neural network (RNN), LSTM uses the gate structure to realize information transfer in the network in time sequence, which reflects the depth in time series. Therefore, LSTM has a superior capacity to process the time series data.
This paper proposes a heterogeneous deep model fusion (HDMF) method to solve the AMC problem in a unified framework. The framework is shown in
Figure 1. Different from using conventional methods, we solve feature extraction and classification in a unified framework, i.e., based on end-to-end deep learning. In addition, high-performing filters can be obtained based on a learning mechanism. This improvement helps the communication system achieve a much lower computational complexity during testing when compared with the training process. As a further result, an accurate classification performance can be achieved due to its high capacity for feature representation. We use CNNs and LSTM to process the time domain waveforms of the modulation signal. Eleven types of single-carrier modulation signal samples (e.g., MASK, MFSK, MPSK, and MQAM) with additive white Gaussian noise (AWGN) and a fading channel are generated under various signal-to-noise ratios (SNRs) based on an actual geographical environment. Two kinds of HDMFs based on the serial and parallel modes are proposed to increase the classification accuracy. The results show that HDMFs achieve much better results than the single CNN or LSTM method, when the SNR is in the range of 0–20 dB. In summary, the contributions are as follows:
- (1)
CNNs and LSTM are fused based on the serial and parallel modes to solve the AMC problem, thereby leading to two HDMFs. Both are trained in the end-to-end framework, which can learn features and make classifications in a unified framework.
- (2)
The experimental results show that the performance of the fusion model is significantly improved compared with the independent network and also with traditional wavelet/SVM models. The serial version of HDMF achieves much better performance than the parallel version.
- (3)
We collect communication signal data sets which approximate the transmitted wireless channel in an actual geographical environment. Such datasets are very useful for training networks like CNNs and LSTM.
The rest of this paper is organized as follows:
Section 2 briefly introduces related works.
Section 3 introduces the principle of the digital modulation signal and deep learning classification methods.
Section 4 presents the experiments and analysis.
Section 5 summarizes the paper.
3. Heterogeneous Deep Model Fusion
3.1. Communication Signal Description
The samples in this paper were collected via a realistic process with due consideration for the communication principle and real geographical environment. The received signal in the communication system can be expressed as follows:
where
is the efficient signal from the transmitter,
represents the transmitted wireless channel on the basis of the actual geographical environment, and
denotes the AWGN. The communication signal in general is divided into three parts to start with.
3.1.1. Modulation Signal Description
The digital modulation signal
from the transmitter can be expressed as follows:
where
and
are the amplitudes of the in-phase and quadrature channel, respectively;
stands for the carrier frequency;
is the initial phase of the carrier; and
represents the digital sampling pulse signal. In the case of ASK, FSK, and PSK,
is zero. In accordance with the digital baseband information, ASK, FSK, and PSK change
,
, and
in the range of
,
, and
, respectively, over time. By contrast, QAM fully utilizes the orthogonality of the signal. After dividing the digital baseband into
and
channels, the information is integrated into two identical frequency carriers with phase difference of 90° using the ASK modulation mode, which significantly improves the bandwidth efficiency.
The sampling rate of data is 20 times as much the carrier frequency and 60 times as much as the symbol rate; in other words, a symbol period contains three complete carrier waveforms and a carrier period is made of 20 sample dots. Meanwhile, the carrier frequency scope is broadband, in the frequency range of 20 MHz to 2 GHz.
3.1.2. Radio Channel Description
The Longley-Rice model (LR) is an irregular terrain model for radio propagation. We use this method for predicting the attenuation of communication signals for a point-to-point link. LR is proposed for different scenarios and heights of channel antennas in the frequency range of 20 MHz to 20 GHz. This model applies statistics to modify the characterization of the channel, which depends on the variables of each scenario and environment. It determines variation in the signal by the prediction method based on atmospheric changes, topographic profile, and free space. The variations are deformed under actual situation information, such as permittivity, polarization direction, refractive index, weather pattern, and so on, which have deviations that contribute to the attenuation of the signal. The attenuation can be roughly divided into three kinds according to transmission distance as follows:
where
,
, and
represent the transmission distances in the range of line-of-sight, diffraction, and scatter, respectively. The value of
is determined by the real geographic coordinates of communication users.
As one of the most common types of noise, AWGN is always true whether or not the signal is in the communication system. The power spectrum density is a constant at all frequencies, and the noise amplitude obeys the Gauss distribution.
3.2. CNNs
CNNs are a hierarchical neural network type that contain convolution, activation, and pooling layers. In this study, the input of the CNN model is the data of the signal time domain waveform. The difference among the classes of modulation methods is deeply characterized by the stacking of multiple convolutional layers and nonlinear activation. Different from the CNN models in the image domain, we use a series of one-dimensional convolution kernels to process the signals.
Each convolution layer is composed of a number of kernels with the same size. The convolution kernel is common to each sample; thus, each kernel can be called a feature extraction unit. This method of sharing parameters can effectively reduce the number of learning parameters. Moreover, the feature extracted from convolution remains in the original signal position, which preserves the temporal relationship well within the signal. In this paper, rectified linear unit (ReLU) is used as the activation function. We do not use the pooling layer for dimensionality reduction because the amount of signal information is relatively small.
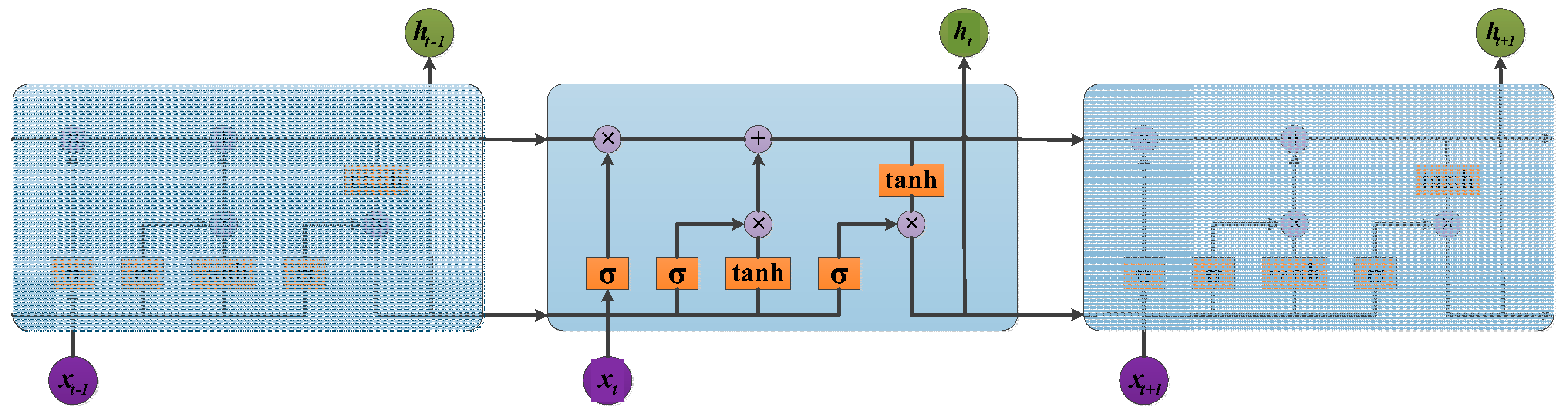
3.3. LSTM
Traditional RNNs are unable to connect information as the gap grows. The vanishing gradient can be interpreted as like the process of forgetting in the human brain. LSTM overcomes this drawback using gate structures that optimize the information transfer among memory cells. The particular structures in memory cells include the input, output, and forget gates. An LSTM memory cell is shown in
Figure 2.
The iterating equations are as follows:
where
is the weight matrix;
is the bias vector;
,
, and
are the outputs of the input, forget, and output gates, respectively;
and
are the cell activations and cell output vectors, respectively; and
and
are nonlinear activation functions.
Standard LSTM usually models the temporal data in the backward direction but ignores the forward temporal data, which has a positive impact on the results. In this paper, a method based on bidirectional LSTM (Bi-LSTM) is exploited to realize AMC. The core concept is to use a forward and a backward LSTM to train a sample simultaneously. Similarly, the architecture of the Bi-LSTM network is designed to model time domain waveforms from past and future.
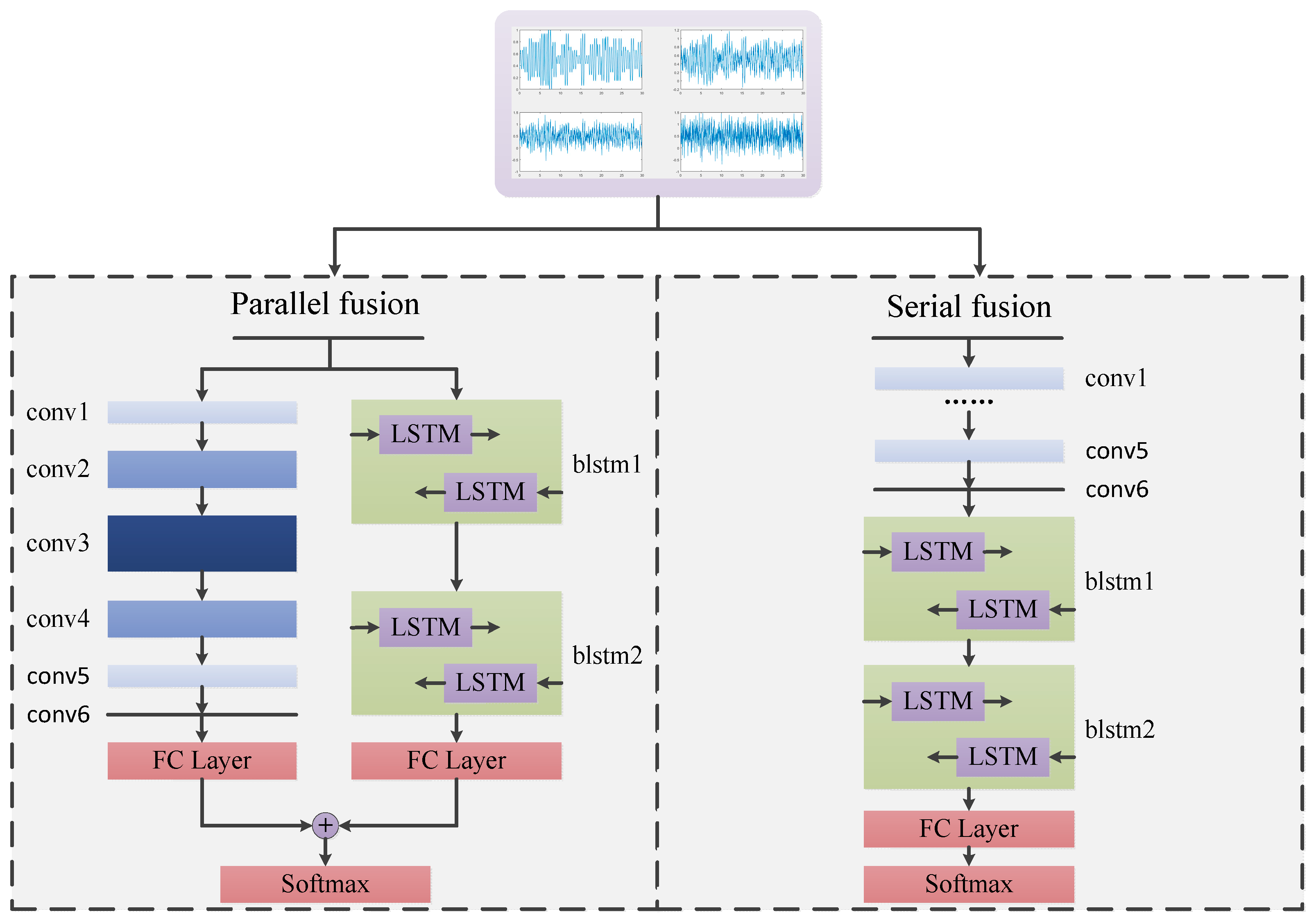
3.4. Fusion Model Based on CNN and LSTM
The HDMFs are established based on the fusion model in serial and parallel ways to enhance the classification performance. The specific structure of the fusion model is shown in
Figure 3.
The modulated communication signal has local special change features. Meanwhile, the data has temporal features similar to voice and video. The fusion models exploit complementary advantages on the basis of these two features.
The six layers of CNNs are used to characterize the differences between the digital modulation modes in the fusion model. The kernel numbers of the convolutional layers are different for each layer. The number of convolutional kernels in the first three layers increases gradually, which transforms single-channel into multichannel signal data. Such a transformation also helps to obtain effective features. Conversely, the number of convolutional kernels in the remaining layers reduces gradually. Finally, the result is restored to single-channel data. Although the data format is the same as the original signal, local features of the signal are extracted by multiple convolution kernels. This leads to the representation for the final classification based on CNNs. The remaining part of the fusion model uses the two-layer Bi-LSTM network to learn the temporal correlation of signals. The output of the upper Bi-LSTM is used as the input for the next layer.
The parallel fusion model (HDMF). The two networks are used to train samples simultaneously. The output of each network is then transformed into an 11-dimensional feature vector by the full connection layer. The resulting feature vectors represent the judgment of the modulation modes of the training samples by the two networks. We then combine the two vectors based on the sum operation as:
and
The loss function of the parallel fusion model consists of two parts, which are balanced by the given parameters.
In Algorithm 1, we show the optimization of the parallel fusion model.
The serial fusion method (HDMF). This is similar to the encoder–decoder framework. In this study, the encoding process is implemented by CNNs; afterwards, LSTM decodes the corresponding information. The features are extracted by the two networks, from simple representation to complex concepts. The upper convolutional layers can extract features locally. Then, the Bi-LSTM layers learn temporal features from these representations.
For both kinds of fusion models, the final feature vectors are the probabilistic output of the softmax layer. The fusion models are trained in the end-to-end way even when different neural networks are used to address the AMC problem.
| Algorithm 1. Training HDMF (parallel) |
| 1: Initialize the parameters in CNN, in LSTM, , in the loss layer, the learning rate , and the number of iterations . |
| 2: While the loss does not converge, do |
| 3: |
| 4: Compute the total loss by . |
| 5: Compute the backpropagation error for each by . |
| 6: Update parameter by |
| 7: Update parameters and by . |
| 8: Update parameter by . |
| 9: End while |
3.5. Communication Signal Generation and Backpropagation
The geographic simulation environment is shown in
Figure 4; it was based on this environment that we collected our datasets. We captured the unmanned aerial vehicle communication signal dataset, which was developed by us based on Visual Studio, and MATLAB. These functions were integrated into a unified format. In Algorithm 2, we show the process of communication signal generation.
Detailed descriptions of the datasets are shown in
Table 1.
| Algorithm 2. Communication signal generation |
| 1: Open the real geographic environment through the control in Visual Studio. |
| 2: Real-time track transmission and simulation of unmanned aerial vehicle (UAV) flight. |
| 3: Add the latitude and longitude coordinates of the radiation and the height of the antenna. |
| 4: Build an LR channel model based on the parameters of coordinate, climate, and terrain, etc. |
| 5: Generation of baseband signals randomly and in order to generate various modulation signals by MATLAB. |
| 6: The communication between Visual Studio and MATLAB is by means of a User Datagram Protocol (UDP), and the real sample data is generated and finally stored. |
We used TensorFlow [
38] to implement our deep learning models. The experiments were done on a PC with an Nvidia GTX TITAN X GPU graphics card (Nvidia, Santa Clara, CA, USA), an Intel Core i7-6700K CPU (Nvidia, Santa Clara, CA, USA), and a 32 GB DDR4 SDRAM. The version of Cuda is 5.1. The Adam method [
39] was used to solve our model with a 0.001 learning rate. The iterations are as follows:
where
and
are the first and second moment estimations of the gradient, which represent the estimation of
and
, respectively;
and
are the corrections of
and
, respectively, which can be regarded as the unbiased estimation of expectation;
is the dynamic constraint of learning rate; and
,
,
, and
are constants.
The fundamental loss and the softmax functions are defined as follows:
where
is the input,
is the corresponding truth label, and
is the input for the softmax layer. The gradient of backpropagation [
40] is calculated as follows:
where
if
, and
if
.
4. Results
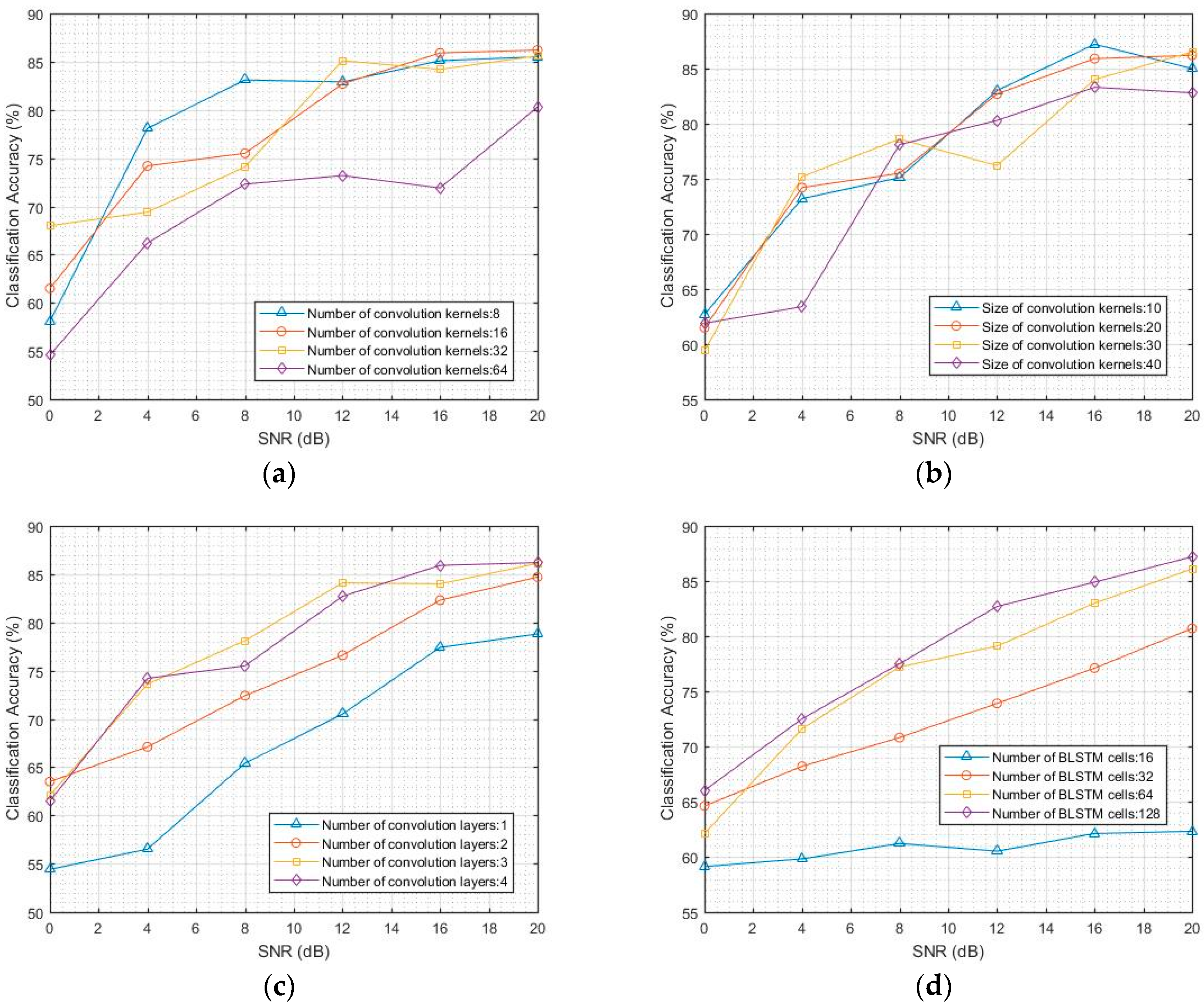
4.1. Classification Accuracy of CNN and LSTM Models
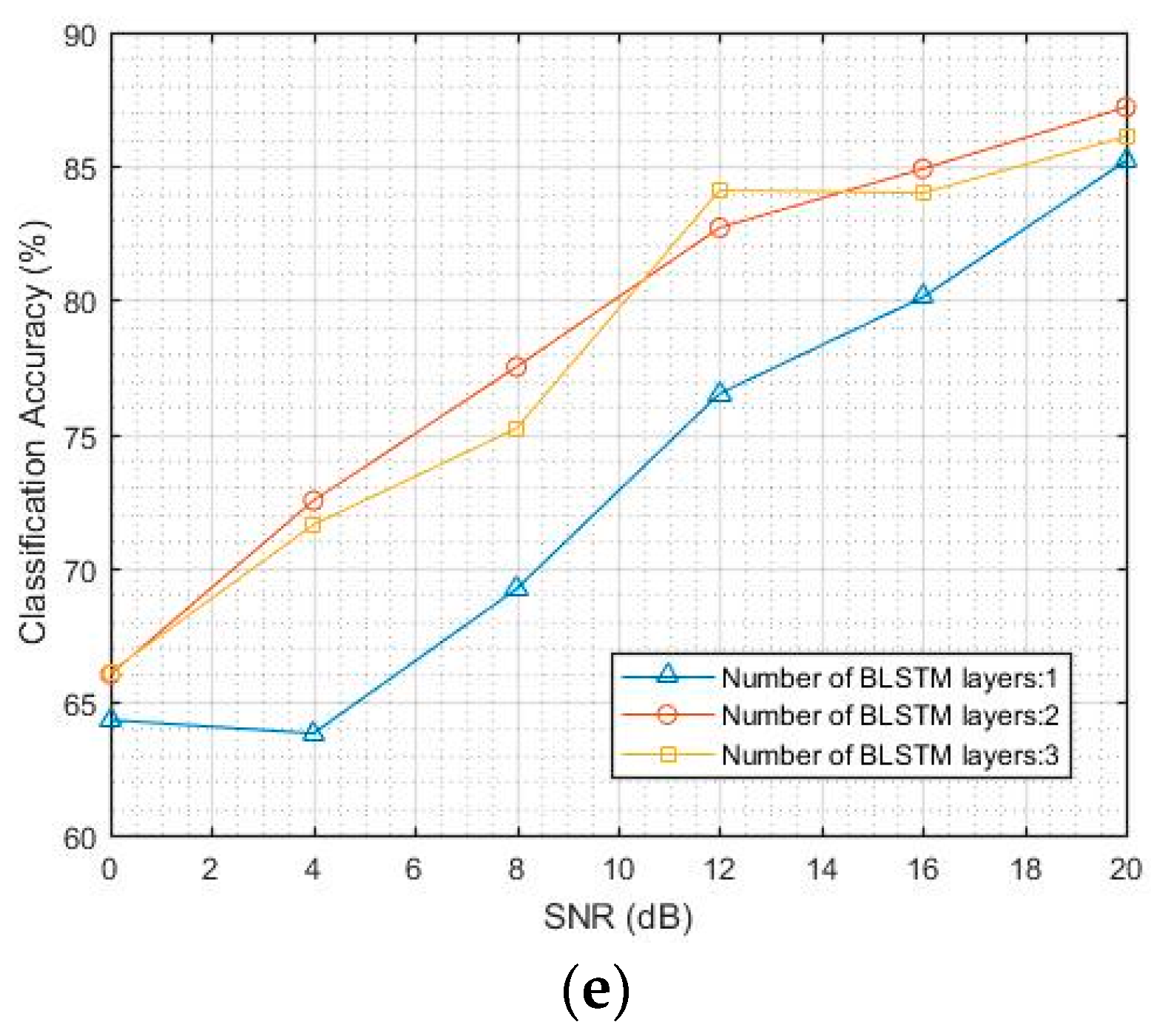
Using CNNs and LSTM to solve the AMC problem, the classification accuracies of CNNs are here reported for varying convolution layer depth from 1 to 4, number of convolution kernels from 8 to 64, and size of convolution kernels from 10 to 40. The classification accuracies of Bi-LSTM were tested with varying layer depth from 1 to 3 and number of memory cells from 16 to 128. The Bi-LSTM used in the fusion model contained two layers. The number of convolution layers was 6. The number of convolution kernels in the first three layers was 8, 16, and 32, and the size of the convolution kernel was 10. The number of convolution kernels in the remaining layers was 16, 8, and 1, and the size of the convolution kernel was 20. The Bi-LSTM model consisted of two layers with 128 memory cells.
For SNR from 0 dB to 20 dB, the classification accuracy of CNN and Bi-LSTM models is shown in
Figure 5. The samples with SNR below 0 dB were not considered in this study. The classification results of the CNN models are shown in
Figure 5a–c. The average classification accuracy of the CNN model for AMC can reach 75% for SNR from 0 dB to 20 dB. An excess of convolution kernels in each layer reduces the classification accuracy. The performance is better when the number of convolution kernels is from 8 to 32. The CNN models with convolution kernels of size 10 to 40 have more or less the same classification accuracy. Increasing the number of convolution layers from 1 to 3 results in a performance boost. The classification results of the Bi-LSTM models are shown in
Figure 5d,e. The results show that the Bi-LSTM model is more suitable for AMC than the CNN model. The average classification accuracy of Bi-LSTM is 77.5%, which is 1.5% higher than that of the CNN model. The performance is better when the number of memory cells is from 32 to 128 than when the number is outside this range. The Bi-LSTM models with more than 2 hidden layers have essentially the same classification accuracy.
The training parameters and computational complexity of CNNs are shown in
Table 2. The results reveal that the proportion of samples with training parameters is reasonable and that our CNNs achieve much lower computational complexity during testing.
4.2. Comparison of Classification Accuracy between the Deep Learning Models and the Traditional Method
We have compared five methods, including both traditional and deep learning methods, based on the same data sets. The classification performance is as follows.
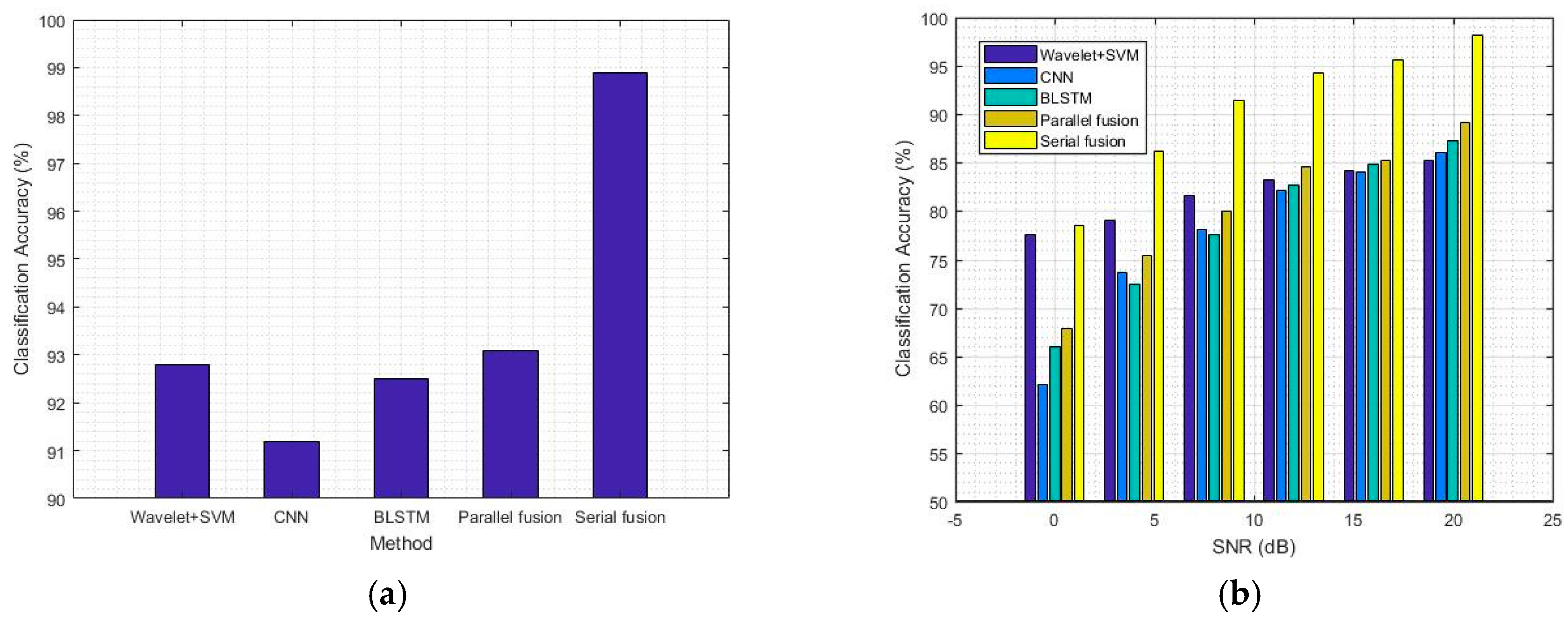
The modified classifiers are established based on the fusion model in serial and parallel modes to increase the classification accuracy. As a result, we compare the classification accuracy of the methods on the basis of deep learning with the traditional method using wavelet and SVM classifiers. The results are shown in
Table 3 and
Table 4 and
Figure 6. The results reveal that the fusion methods have a significant effect on improving classification accuracy. The average classification accuracy of the parallel fusion model is 93% without noise, which is equal to that of the traditional method. The classification accuracy of the parallel fusion model is 2% higher than that of the CNN model and 1% higher than that of the Bi-LSTM model. Moreover, the average classification accuracy of the serial fusion model is 99% without noise, which is 6% higher than that of the parallel fusion model. In fact, the fusion methods are more beneficial to the classification accuracy when the SNR is from 0 dB to 20 dB compared with in the noise-free situation. When the SNR is from 0 dB to 20 dB, the average classification accuracy of the serial fusion method is 91%, which is 11% higher than that of the parallel fusion method.
The performances of the classifiers show that deep learning achieves high classification accuracy for AMC. Waveform local variation and temporal features can be used to identify modulation modes. In comparison with CNN and Bi-LSTM, the performance of the HDMF methods is improved significantly because the classifiers can recognize the two features simultaneously. However, the performance of the serial fusion is considerably higher than that of the parallel fusion because the parallel method belongs to decision-level fusion. The fusion can be viewed as a simple voting process for results. The serial method belongs to feature-level fusion, which combines the feature information to obtain the classification results.
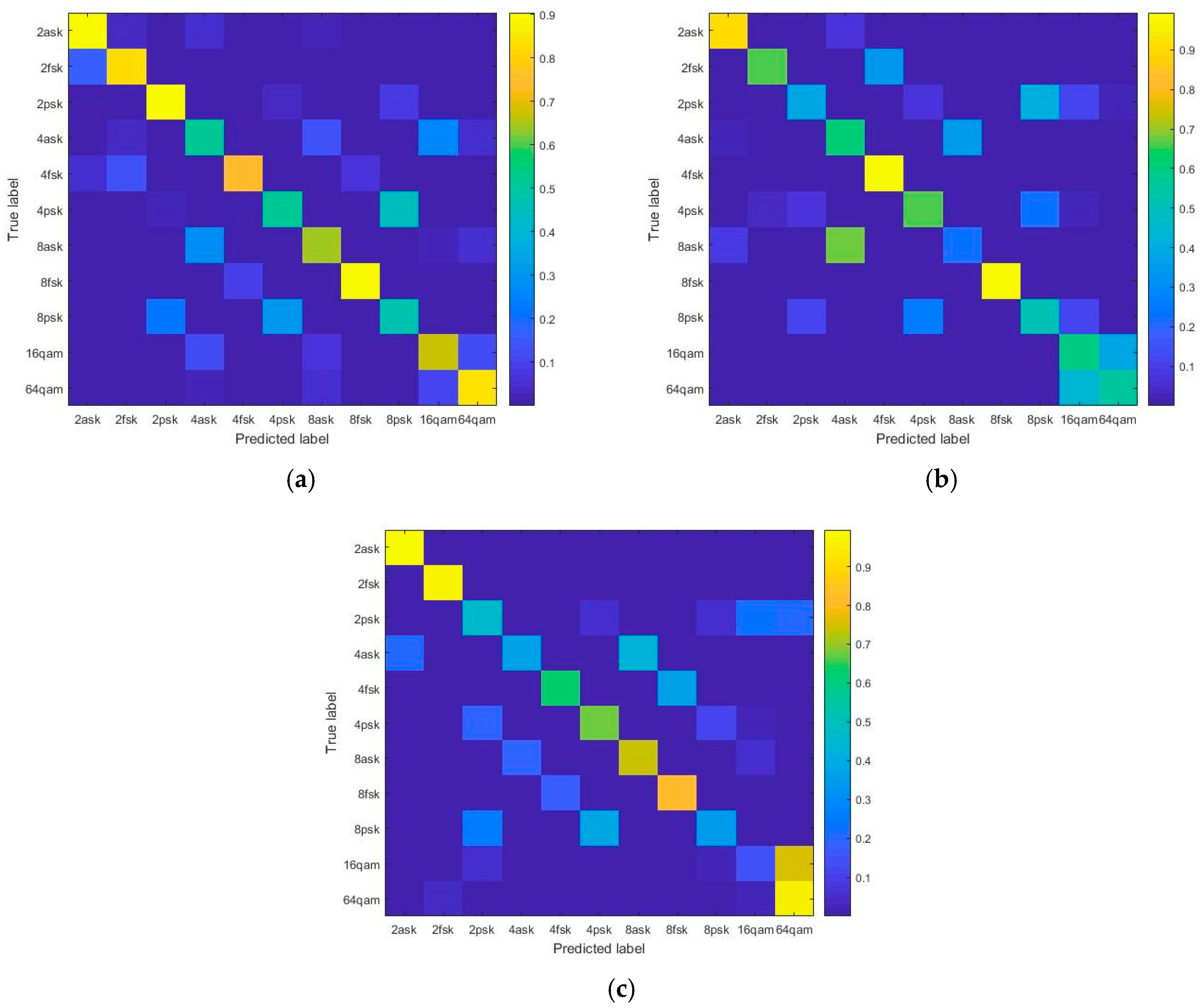
In this study, the modulation mode of the samples includes two forms, namely, within-class and between-class modes. The probability matrices show the identification results of the modulation modes by the serial fusion model when the SNR is 20, 10, and 0 dB, respectively; the results are shown in
Figure 7. When the SNR is 20 dB, a profound discrepancy is observed between the different modulation modes. The probability result does not have the error. The decrease of SNR, PSK, and QAM is prone to misclassification within class, caused by the subtle differences in the M-ary phase mode. Since the waveform variances of the carrier phase appear only once in each symbol period, such change is difficult to obtain in real time. Moreover, the waveform variances caused by phase offset might be neglected, attenuating and interfering under some circumstances. By contrast, the variances of amplitude and frequency are relatively stable. Furthermore, QAM can be considered as a combination of ASK and PSK in practice, which means that the waveforms have the amplitude and phase variances simultaneously. The classifier can detect the different types of variances even when the result is incorrect at low SNR. Therefore, only within-class misclassifications occur in the results.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}