Super-Resolution for “Jilin-1” Satellite Video Imagery via a Convolutional Network



Abstract
:1. Introduction
1.1. Traditional Super-Resolution Algorithms
1.2. Super-Resolution with a Convolutional Neural Network
1.3. Formatting of Mathematical Components
- (1)
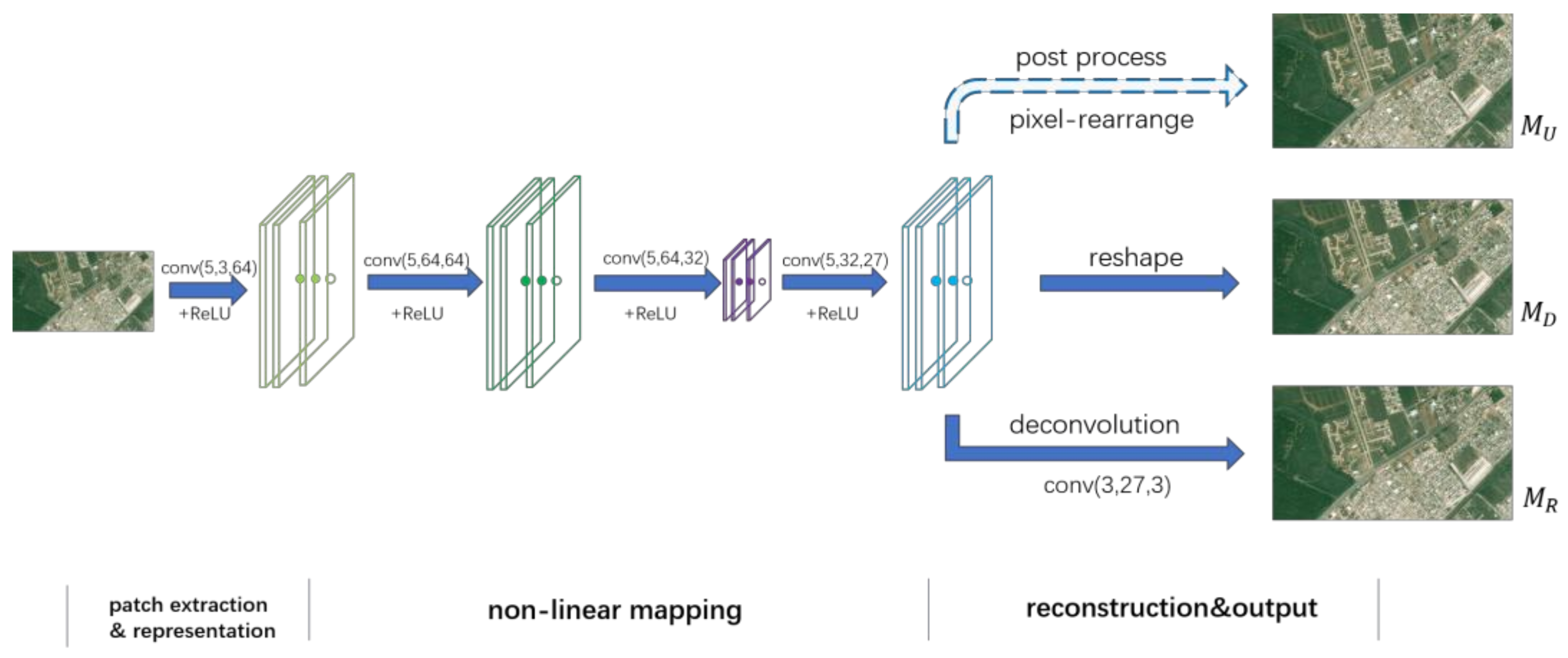
- We propose a five-layer end-to-end network structure without any pre-processing and post-processing for the sake of simplicity. As opposed to outputting a high-dimensional feature layer directly and post-processing as in ESPCN, we place a reshape or deconvolution layer at the end of the network to retain the distribution of ground objects within the image.
- (2)
- We employ a different strategy for the loss function: unlike other CNN algorithms that simply calculate loss via output and ground truth images, we create a joint loss by combining output and high-dimensional features of a non-linear mapping network. This operation can take into account layers before and after magnification, which facilitates a more precise mapping relationship between LR and HR images.
- (3)
- In training, we use satellite video data themselves rather than other images to construct training set. This strategy contributes to the consistency between training and testing images in terms of image content statistics, thus enabling the practicality of the algorithm.
2. Methods
2.1. Network Structure
2.2. Loss Function
2.3. Evaluation Index
3. Experiments and Results
3.1. Dataset and Experimental Settings
3.2. Results
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Freeman, W.T.; Pasztor, E.C.; Carmichael, O.T. Learning low-level vision. Int. J. Comput. Vis. 2000, 40, 25–47. [Google Scholar] [CrossRef]
- Chang, H.; Yeung, D.-Y.; Xiong, Y. Super-resolution through neighbor embedding. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2004, Washington, DC, USA, 27 June–2 July 2004; pp. 275–282. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Chen, C.; Ma, J.; Wang, Z.; Wang, Z.; Hu, R. SRLSP: A Face Image Super-Resolution Algorithm Using Smooth Regression With Local Structure Prior. IEEE Trans. Multimed. 2016, 19, 27–40. [Google Scholar] [CrossRef]
- Jiang, J.; Ma, J.; Chen, C.; Jiang, X.; Zheng, W. Noise Robust Face Image Super-Resolution through Smooth Sparse Representation. IEEE Trans. Cybern. 2016, 47, 3991–4002. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.; Guo, F.; Yu, H.; Chen, C. Fast Single Image Super-Resolution via Self-Example Learning and Sparse Representation. IEEE Trans. Multimed. 2014, 16, 2178–2190. [Google Scholar] [CrossRef]
- Lu, T.; Xiong, Z.; Zhang, Y.; Wang, B.; Lu, T. Robust Face Super-Resolution via Locality-Constrained Low-Rank Representation. IEEE Access 2017, 5, 13103–13117. [Google Scholar] [CrossRef]
- Yue, L.; Shen, H.; Li, J.; Yuan, Q.; Zhang, H.; Zhang, L. Image super-resolution: The techniques, applications, and future. Signal Process. 2016, 128, 389–408. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. Comput. Vis. 2014, 8689, 184–199. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. arXiv, 2016; arXiv:1609.04802. [Google Scholar]
- Ren, H.; El-Khamy, M.; Lee, J. Image Super Resolution Based on Fusing Multiple Convolution Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1050–1057. [Google Scholar]
- Dahl, R.; Norouzi, M.; Shlens, J. Pixel Recursive Super Resolution. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5449–5458. [Google Scholar]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Bosch, M.; Gifford, C.M.; Rodriguez, P.A. Super-Resolution for Overhead Imagery Using DenseNets and Adversarial Learning. arXiv, 2017; arXiv:1711.10312. [Google Scholar]
- Caballero, J.; Ledig, C.; Aitken, A.; Acosta, A.; Totz, J.; Wang, Z.; Shi, W. Real-time video super-resolution with spatio-temporal networks and motion compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2848–2857. [Google Scholar]
- Tao, X.; Gao, H.; Liao, R.; Wang, J.; Jia, J. Detail-Revealing Deep Video Super-Resolution. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4482–4490. [Google Scholar]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. Learning Low Dimensional Convolutional Neural Networks for High-Resolution Remote Sensing Image Retrieval. Remote Sens. 2017, 9, 489. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Area | Video Duration | Frame Size (Pixels) | Filming Date | Side Swivel Angle |
|---|---|---|---|---|
| Durango (Mexico) | 31 s | 1600 × 900 | 3 February 2016 | Unknown |
| Long Beach (USA) | 22 s | 3840 × 2160 | 3 April 2017 | 3.0424 |
| Tianjin (China) | 25 s | 3840 × 2160 | 23 April 2017 | 21.1707 |
| Kabul (Afghanistan) | 15 s | 3840 × 2160 | 23 February 2017 | −2.5611 |
| Testing Images | Bicubic | SCSR | SRCNN “Jilin-1” | SRCNN “Yang91” | |||
|---|---|---|---|---|---|---|---|
| Kabul (Afghanistan) (1) | 31.88 | 34.15 | 26.85 | 34.03 | 35.78 | 36.23 | 35.82 |
| Kabul (Afghanistan) (2) | 34.48 | 36.70 | 27.59 | 36.56 | 38.08 | 38.37 | 38.09 |
| Kabul (Afghanistan) (3) | 36.65 | 38.61 | 27.76 | 38.68 | 39.60 | 39.88 | 39.67 |
| Long Beach (USA) (1) | 34.92 | 37.35 | 29.54 | 37.38 | 38.18 | 39.01 | 38.81 |
| Long Beach (USA) (2) | 37.96 | 40.83 | 30.84 | 40.53 | 41.23 | 42.09 | 41.74 |
| Long Beach (USA) (3) | 37.06 | 39.50 | 31.33 | 39.02 | 40.09 | 40.82 | 40.58 |
| Tianjin (China) (1) | 34.91 | 37.15 | 30.63 | 36.88 | 38.14 | 38.52 | 38.00 |
| Tianjin (China) (2) | 35.57 | 37.76 | 31.90 | 37.34 | 38.53 | 38.74 | 38.58 |
| Durango (Mexico) | 31.04 | 32.83 | 22.41 | 32.88 | 33.00 | 33.19 | 33.18 |
| Testing images | Bicubic | SCSR | SRCNN “Jilin-1” | SRCNN “Yang91“ | |||
|---|---|---|---|---|---|---|---|
| Kabul (Afghanistan) (1) | 0.99368 | 0.99808 | 0.95539 | 0.99809 | 0.99873 | 0.99888 | 0.99874 |
| Kabul (Afghanistan) (2) | 0.98469 | 0.99165 | 0.92958 | 0.99242 | 0.99414 | 0.99465 | 0.99423 |
| Kabul (Afghanistan) (3) | 0.99480 | 0.99792 | 0.94538 | 0.99838 | 0.99870 | 0.99884 | 0.99873 |
| Long Beach (USA) (1) | 0.98189 | 0.99135 | 0.94770 | 0.99201 | 0.99277 | 0.99449 | 0.99409 |
| Long Beach (USA) (2) | 0.99199 | 0.99525 | 0.95648 | 0.99271 | 0.99606 | 0.99725 | 0.99695 |
| Long Beach (USA) (3) | 0.98908 | 0.99420 | 0.95111 | 0.99511 | 0.99530 | 0.99634 | 0.99611 |
| Tianjin (China)(1) | 0.98544 | 0.99839 | 0.97092 | 0.99833 | 0.99465 | 0.99521 | 0.99452 |
| Tianjin (China)(2) | 0.98735 | 0.99410 | 0.96997 | 0.99416 | 0.99543 | 0.99572 | 0.99544 |
| Durango (Mexico) | 0.97333 | 0.99622 | 0.86040 | 0.98767 | 0.98273 | 0.98649 | 0.98647 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, A.; Wang, Z.; Wang, L.; Ren, Y. Super-Resolution for “Jilin-1” Satellite Video Imagery via a Convolutional Network. Sensors 2018, 18, 1194. https://doi.org/10.3390/s18041194
Xiao A, Wang Z, Wang L, Ren Y. Super-Resolution for “Jilin-1” Satellite Video Imagery via a Convolutional Network. Sensors. 2018; 18(4):1194. https://doi.org/10.3390/s18041194
Chicago/Turabian StyleXiao, Aoran, Zhongyuan Wang, Lei Wang, and Yexian Ren. 2018. "Super-Resolution for “Jilin-1” Satellite Video Imagery via a Convolutional Network" Sensors 18, no. 4: 1194. https://doi.org/10.3390/s18041194
APA StyleXiao, A., Wang, Z., Wang, L., & Ren, Y. (2018). Super-Resolution for “Jilin-1” Satellite Video Imagery via a Convolutional Network. Sensors, 18(4), 1194. https://doi.org/10.3390/s18041194