Visual Odometry and Place Recognition Fusion for Vehicle Position Tracking in Urban Environments



Abstract
:1. Introduction
2. Related Work
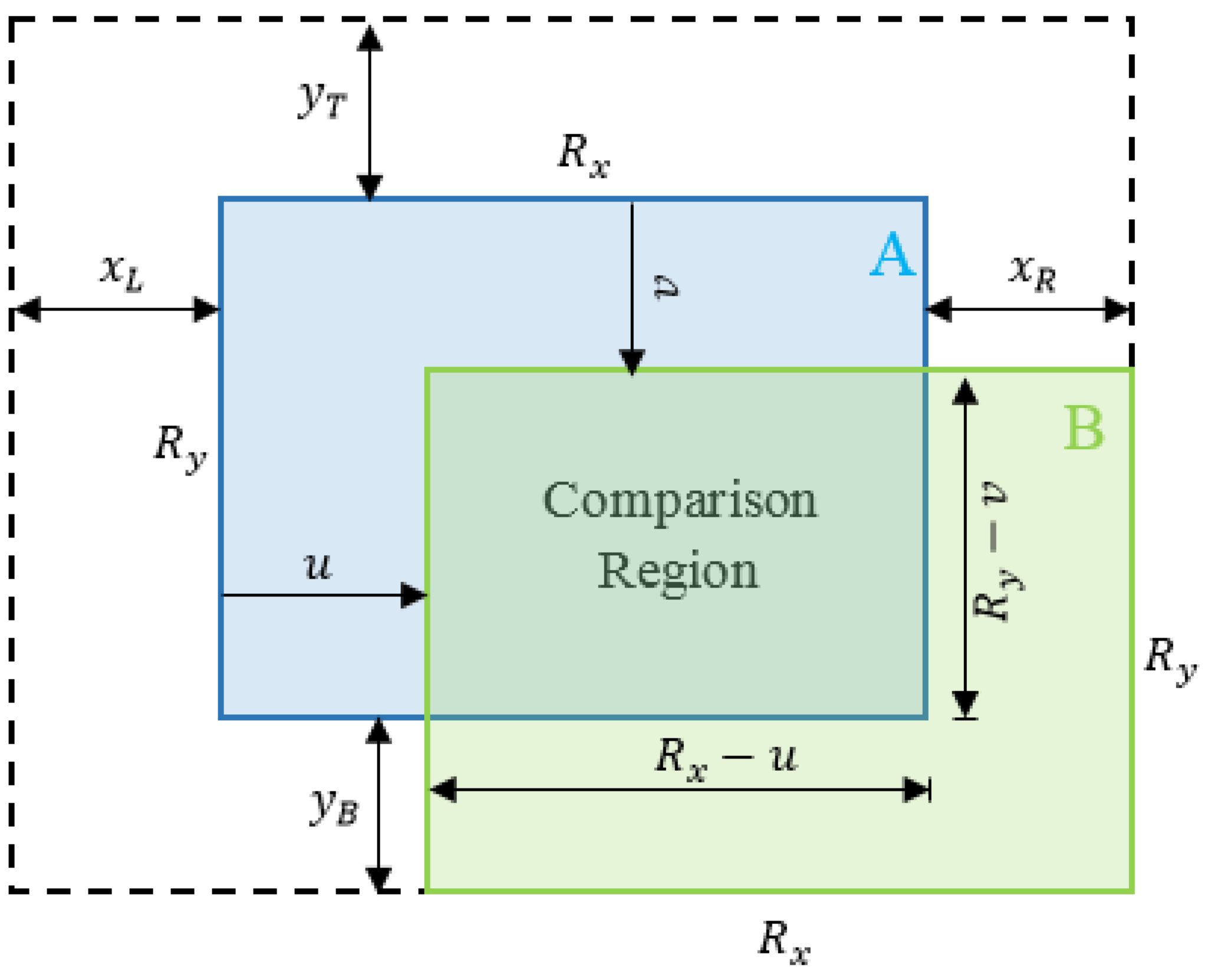
3. Appearance-Based Global Positioning System
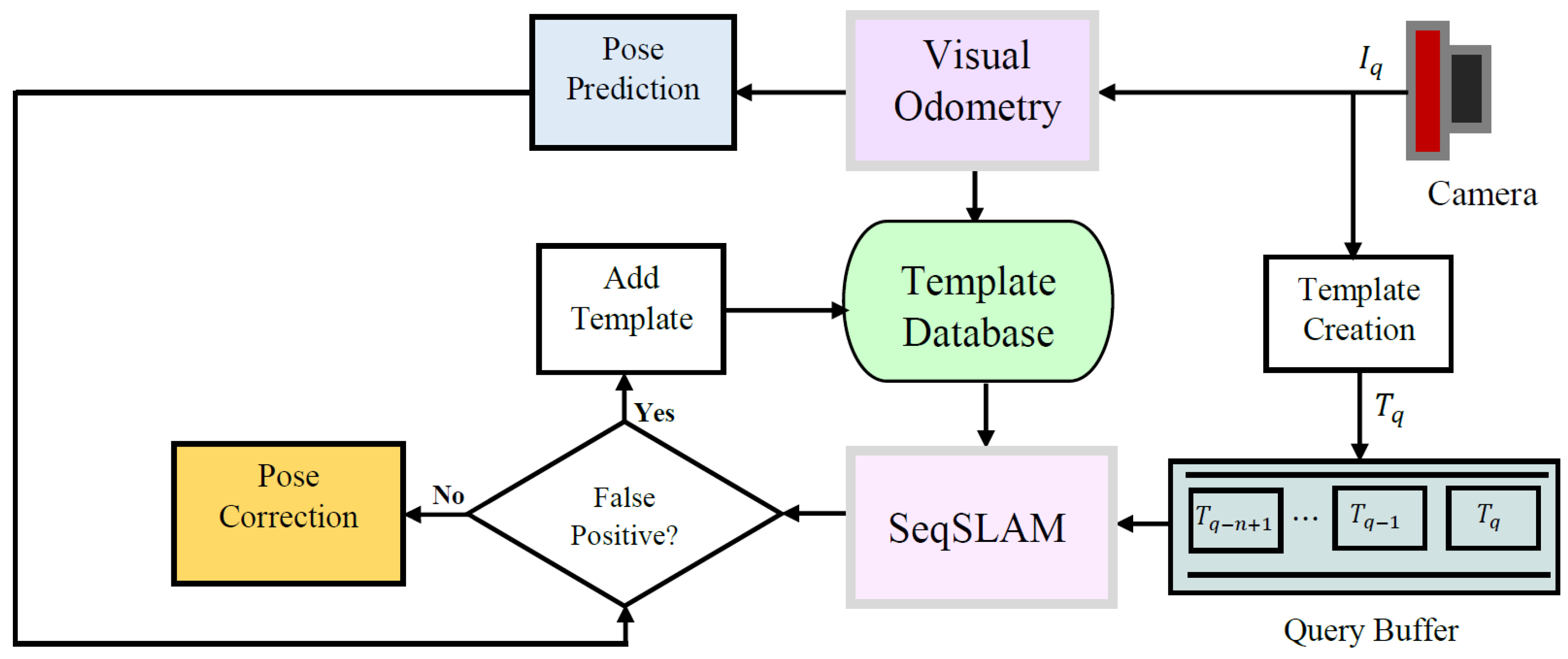
4. Proposed Approach
4.1. Position Tracking
4.1.1. Visual Odometry System
4.1.2. State Prediction and Uncertainty Estimation
4.2. Loop Closure-Based Measurement Update
4.3. False Positives Filtering
| Algorithm 1: False positives filtering. |
 |
4.4. Filtering-Based Fusion of Visual Odometry and SeqSLAM
4.5. Unscented Kalman Filter
5. Experiments and Results
5.1. The Experimental Dataset and Parameters
5.1.1. The Experimental Dataset
5.1.2. Parameters
5.2. Results
5.2.1. Accuracy Evaluation
5.2.2. Fusion Method Evaluation
5.3. Timing and Storage
5.4. Discussion
6. Conclusions
Author Contributions
Conflicts of Interest
Abbreviations
| GPS | Global Positioning System |
| SfM | Structure from Motion |
| VO | Visual Odometry |
| SeqSLAM | Sequence SLAM |
| SLAM | Simultaneous Localization and Mapping |
| KF | Kalman Filter |
| UKF | Unscented Kalman Filter |
| FP | False positive |
| FN | False negative |
| probability density function |
References
- Milford, M.J.; Wyeth, G.F. SeqSLAM: Visual route-based navigation for sunny summer days and stormy winter nights. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), St. Paul, MN, USA, 14–18 May 2012; pp. 1643–1649. [Google Scholar]
- Milford, M. Vision-Based Place Recognition: How Low Can You Go? Int. J. Robot. Res. 2013, 32, 766–789. [Google Scholar] [CrossRef]
- Bonardi, F.; Ainouz, S.; Boutteau, R.; Dupuis, Y.; Savatier, X.; Vasseur, P. PHROG: A multimodal Feature for Place Recognition. Sensors 2017, 17, 1167. [Google Scholar] [CrossRef] [PubMed]
- Stone, T.; Mangan, M.; Ardin, P.; Webb, B. Sky segmentation with ultraviolet images can be used for navigation. In Proceedings of the Robotics: Science and Systems X (RSS), University of California, Berkeley, CA, USA, 12–16 July 2014. [Google Scholar]
- Sünderhauf, N.; Shirazi, S.; Dayoub, F.; Upcroft, B.; Milford, M. On the performance of convnet features for place recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 4297–4304. [Google Scholar]
- Sünderhauf, N.; Neubert, P.; Protzel, P. Are We There Yet? Challenging SeqSLAM on a 3000 km Journey Across All Four Seasons. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Workshop on Long-Term Autonomy, Chemnitz, Germany, 15 January 2013. [Google Scholar]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Cummins, M.; Newman, P. FAB-MAP: Probabilistic localization and mapping in the space of appearance. Int. J. Robot. Res. 2008, 27, 647–665. [Google Scholar] [CrossRef]
- Cummins, M.; Newman, P. Appearance-only SLAM at large scale with FAB-MAP 2.0. Int. J. Robot. Res. 2011, 30, 1100–1123. [Google Scholar] [CrossRef]
- Badino, H.; Huber, D.; Kanade, T. Visual topometric localization. In Proceedings of the IEEE Intelligent Vehicles Symposium, Baden-Baden, Germany, 5–9 June 2011; pp. 794–799. [Google Scholar]
- Baatz, G.; Köser, K.; Chen, D.; Grzeszczuk, R.; Pollefeys, M. Leveraging 3D City Models for Rotation Invariant Place-of-Interest Recognition. Int. J. Comput. Vis. 2012, 27, 315–334. [Google Scholar] [CrossRef]
- Oh, S.; Tariq, S.; Walker, B.; Dellaert, F. Map-Based Priors for Localization. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sendai, Japan, 28 September–2 October 2004. [Google Scholar]
- Milford, M. Visual Route Recognition with a Handful of Bits. Proceedings of Robotics: Science and Systems (RSS), Sydney, Australia, 9–13 July 2012; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Clipp, B.; Lim, J.; Frahm, J.-M.; Pollefeys, M. Parallel, real-time visual SLAM. In Proceedings of the IEEE/RSJ International Conference on IROS, Taipei, Taiwan, 18–22 October 2010; pp. 3961–3968. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Geiger, A.; Ziegler, J.; Stiller, C. Stereoscan: Dense 3D reconstruction in real-time. In Proceedings of the IEEE Intelligent Vehicles Symposium, Baden-Baden, Germany, 5–9 June 2011; pp. 963–968. [Google Scholar]
- Kaess, M.; Ni, K.; Dellaert, F. Flow separation for fast and robust stereo odometry. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. Dtam: Dense tracking andmapping in real-time. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Ranganathan, A.; Dellaert, F. Online probabilistic topological mapping. IJRR 2011, 30, 755–771. [Google Scholar] [CrossRef]
- Paul, R.; Newman, P. FAB-MAP 3D: Topological mapping with spatial and visual appearance. In Proceedings of the IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 2649–2656. [Google Scholar]
- Kaess, M.; Johannsson, H.; Roberts, R.; Ila, V.; Leonard, J.J.; Dellaert, F. iSAM2: Incremental smoothing and mapping using the bayes tree. Int. J. Robot. Res. 2012, 31, 217–236. [Google Scholar] [CrossRef] [Green Version]
- Mei, C.; Sibley, G.; Cummins, M.; Newman, P.; Reid, I. RSLAM: A System for Large-Scale Mapping in Constant-Time Using Stereo. Int. J. Comput. Vis. 2011, 94, 198–214. [Google Scholar] [CrossRef]
- Brubaker, M.A.; Geiger, A.; Urtasun, R. Map-Based Probabilistic Visual Self-Localization. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 652–665. [Google Scholar] [CrossRef] [PubMed]
- Floros, B.L.G.; van der Zander, B. Openstreetslam: Global vehicle localization using openstreetmaps. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Karlsruhe, Germany, 6–10 May 2013; pp. 1054–1059. [Google Scholar]
- Hentschel, M.; Wagner, B. Autonomous robot navigation based on OpenStreetMap geodata. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems, Funchal, Portugal, 19–22 September 2010; pp. 1645–1650. [Google Scholar]
- Chu, H.; Mei, H.; Bansal, M.; Walter, M.R. Accurate vision-based vehicle localization using satellite imagery. arXiv, 2015; arXiv:1510.09171. [Google Scholar]
- Majdik, A.L.; Verda, D.; Albers-Schoenberg, Y.; Scaramuzza, D. Micro air vehicle localization and position tracking from textured 3d cadastral models. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 920–927. [Google Scholar]
- Pepperell, E.; Corke, P.; Milford, M. Towards Persistent Visual Navigation Using SMART. In Proceedings of the Australasian Conference on Robotics and Automation (ARAA), Sydney, Australia, 2–4 December 2013. [Google Scholar]
- Kümmerle, R.; Grisetti, G.; Strasdat, H.; Konolige, K.; Burgard, W. G2o: A general framework for graph optimization. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Thrun, S.; Burgard, W.; Fox, D. Probabilistic Robotics; MIT Press: Cambridge, MA, USA, 2005; Volume 1. [Google Scholar]
- Scaramuzza, D.; Fraundorfer, F. Visual odometry (tutorial). IEEE Robot. Autom. Mag. 2011, 18, 80–92. [Google Scholar] [CrossRef]
- Kneip, L.; Furgale, P. OpenGV: A unified and generalized approach to real-time calibrated geometric vision. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1–8. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Dingfu, Z.; Dai, Y.; Hongdong, L. Reliable scale estimation and correction for monocular visual odometry. In Proceedings of the IEEE Intelligent Vehicles Symposium, Gothenburg, Sweden, 19–22 June 2016; pp. 490–495. [Google Scholar]
- Thrun, S.; Fox, D.; Burgard, W.; Dellaert, F. Robust Monte Carlo Localization for Mobile Robots. Artif. Intell. 2001, 128, 99–141. [Google Scholar] [CrossRef]
- Ouerghi, S.; Boutteau, R.; Tlili, F.; Savatier, X. CUDA-based SeqSLAM for Real-Time Place Recognition. In Proceedings of the 25th International Conference on Computer Graphics, Visualization and Vision (WSCG), Plzen, Czech Republic, 29 May–2 June 2017. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | Distance up to | Traveled Distance (m) |
|---|---|---|
| A | 1160.1 | |
| B | 1204.8 | |
| 00 | C | 2566.1 |
| D | 3023.3 | |
| E | 3636.3 | |
| F | 3707 |
| Parameter | Value | Description |
|---|---|---|
| , | Template size | |
| Q | 10 | Query sequence length |
| P | pixels | Patch normalization size |
| Shift offsets |
| Sequence | Method | Mean Position Error (m) | (%) of Trajectory |
|---|---|---|---|
| 00 | VO+SeqSLAM | 7.98 | 0.2 |
| VO | 14.26 | 0.39 | |
| 05 | VO+SeqSLAM | 5.59 | 0.25 |
| VO | 9.02 | 0.41 | |
| 06 | VO+SeqSLAM | 3.43 | 0.27 |
| VO | 6.54 | 0.53 |
| Sequence | Method | Position Error (m) | Heading Error (deg) |
|---|---|---|---|
| 00 | VO+SeqSLAM | 4.5 | 2.5 |
| VO | 16.71 | 9.96 | |
| 05 | VO+SeqSLAM | 1.37 | 2.85 |
| VO | 14.29 | 6.03 | |
| 06 | VO+SeqSLAM | 3.93 | 1.31 |
| VO | 18.03 | 3.55 |
| Sequence | Fusion Method | Mean Position Error (m) | (%) of Trajectory |
|---|---|---|---|
| 00 | EKF | 7.98 | 0.2 |
| UKF | 7.96 | 0.2 | |
| 05 | EKF | 5.59 | 0.25 |
| UKF | 5.62 | 0.25 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouerghi, S.; Boutteau, R.; Savatier, X.; Tlili, F. Visual Odometry and Place Recognition Fusion for Vehicle Position Tracking in Urban Environments. Sensors 2018, 18, 939. https://doi.org/10.3390/s18040939
Ouerghi S, Boutteau R, Savatier X, Tlili F. Visual Odometry and Place Recognition Fusion for Vehicle Position Tracking in Urban Environments. Sensors. 2018; 18(4):939. https://doi.org/10.3390/s18040939
Chicago/Turabian StyleOuerghi, Safa, Rémi Boutteau, Xavier Savatier, and Fethi Tlili. 2018. "Visual Odometry and Place Recognition Fusion for Vehicle Position Tracking in Urban Environments" Sensors 18, no. 4: 939. https://doi.org/10.3390/s18040939
APA StyleOuerghi, S., Boutteau, R., Savatier, X., & Tlili, F. (2018). Visual Odometry and Place Recognition Fusion for Vehicle Position Tracking in Urban Environments. Sensors, 18(4), 939. https://doi.org/10.3390/s18040939