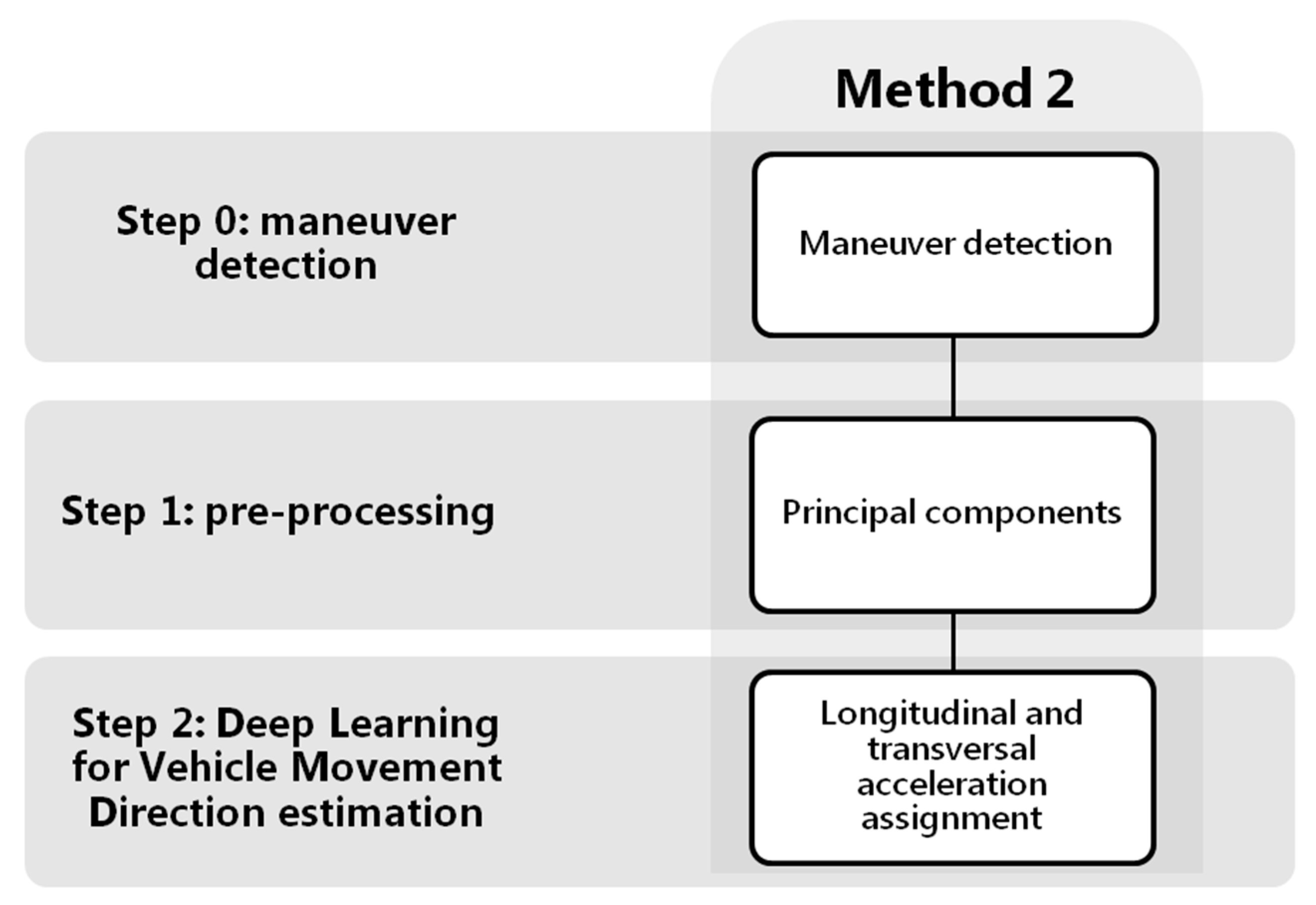
We can see in the diagram of
Figure 5 the first step, common to the two estimation methods, which is the detection of maneuvers using accelerometers (step 0 method 1,
Figure 5). Once the beginning and the end of the specific maneuvers are detected, they will be divided into shorter windows of 10 s with an overlap of 5 s. All the overlapping windows of the maneuvers will be the inputs to the neural network architecture that will be shown later (step 2 method 1,
Figure 5), to classify the acceleration forces according to four classes;
braking,
acceleration,
turn and
mixed. Finally, the most reliable classes will be used in a post-processing algorithm that will allow the VMD to be obtained.
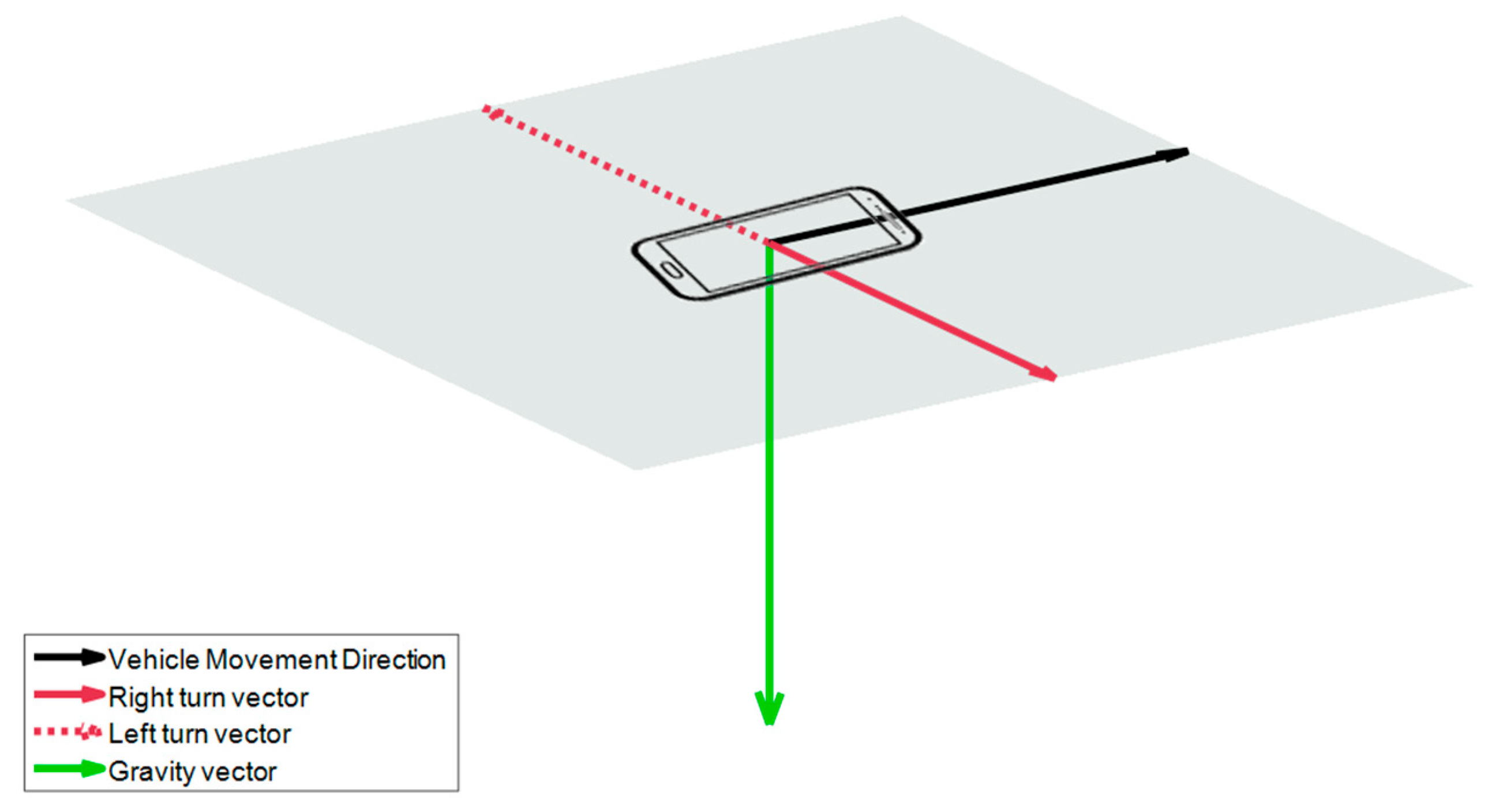
Due to the possible free positions that the driver can carry out the smartphone inside the vehicle, the distribution of the gravity between the tri-axial accelerometers in each journey can be very different, making the model more complex. For it, in this method we analyze different types of pre-processing of the input signals (step 1 method 1,
Figure 5), in order to improve the classification performance. The raw accelerometers will be taken as baseline, and we will compare it with the same signals removing the gravity component of the accelerations; with the accelerations projected to a plane perpendicular to the gravity; and, finally, a simple estimation of the speed has also been made, as proposed by Cervantes-Villanueva [
24], including this information as one more channel to the neural network. We examine this in more depth later.
4.1. Deep Learning Model for Acceleration Classification
Classification of the driving acceleration forces (step 2 method 1,
Figure 5) in
braking,
acceleration,
turn and
mixed is carried out by means of a network architecture with a CNN of two layers, followed by a RNN of three stacked layers, two fully connected (FC) layers to the output, and finally a Softmax layer, as shown in
Figure 6.
The most common interpretation of architecture is that convolutional network layers act as the feature extractor, providing a time-series of feature vectors as input to recurrent networks, that model dynamic information in maneuvers. Ordóñez and Roggen [
18], in the area of activity recognition, also use convolutional networks as a feature extractor. As they explain in their work, in domain 1D each kernel can be understood as a filter that helps us to eliminate outliers, applying them on each sensor or each component of the accelerometers in our case. To increase the deeper representation of the data, two convolutional layers have been used. The first layer has 32 filters and the second layer 64 filters; using ReLU as activation function; and performs max pooling, maximum neighborhood, to reduce the dimensionality.
The reason for adding the recurrent networks to the output of the convolutional networks is to be able to learn and model the temporal information, collected in the feature map at the output of the convolutional. The recurrent networks we used were a GRU, because this type offers very good results for time-series modeling. If our input signals will be the accelerometers recorded with the smartphone (or variations of them), this architecture becomes very powerful for learning the sequential features. In addition, the nodes of the network are memory cells, which will allow us to update the states at each time instant, storing the temporal relationships inside the maneuver. Dong et al. [
14] compared different architectures and emphasized the benefits of using recurring networks, since these act like unfolded network across time steps. The GRU network consists of three stacked layers, and each GRU layer is formed by 128 neurons.
Since our dataset contains a very large number of maneuvers for training, we expect that the use of stacked layers can significantly improve the results. The output of the last GRU layer is used as input to the last three layers of the architecture, consisting of two fully connected layers and finally a Softmax layer, which will provide us the output probabilities from network scores. The model was trained using an Adam optimizer for minimizing the cross-entropy loss function. Trying to prevent overfitting, a dropout technique was added at the output of the recurrent networks layer; we also used weight decay or L2 regularization; and max pooling in the convolutional layers to reduce the computational cost reducing the number of parameters. Several learning rates were tested, selecting a low value of 0.001, since although the optimization took longer, training results were more reliable than with higher rates. Hyperparameter optimization was done through a grid search using 10-fold cross-validation on the training dataset. The resulting hyperparameters were then used to get the results in the test dataset.
Training phase has been processed on a computer with a Nvidia Tesla K80 graphic card (dual GPU card, with 24 GB of GDDR5 memory, 480 GB/s of memory bandwidth and 4992 CUDA cores). However, the testing phase could be done on a smartphone directly, since it requires a more reasonable consumption of resources. The open source software library TensorFlowTM, with Python, was used to build the network.
4.2. Model Evaluation and Interpretability
To evaluate the model, different steps of the procedure have been taken into account. Since the purpose of the method is to obtain a reliable VMD, the most important aim will be to compare if the direction estimated is close to the true driving direction, measuring the difference in degrees. In addition, the number of journeys in which it has been possible to estimate VMD will be an important metric (step 2 in method 1
Figure 5 after applying the post-processing algorithm). For method 1, the number of journeys in which VMD can be estimated will depend on the detection or not of maneuvers associated with braking/decelerations or accelerations by the neural networks; that is to say, that neural architecture predicts such classes.
Another mode of evaluation will be the previous step to obtain the VMD in each of the methods presented (step 2 in method 1
Figure 5 before applying the post-processing algorithm). To do this, the different tests will be compared according to the accuracy obtained in the classifications of acceleration forces. Although at the end of the section, a comparative study based on metrics, such as the precision, the recall, the F1 score or the G mean, has been done, the accuracy will be the fundamental metric. It will be specified by the use of confusion matrices obtained for each class.
Not only has the evaluation of the model been considered, but also the interpretation of the training process in the different layers of the Deep Learning architecture, through techniques that allow visualizing data of high dimensionality, like t-distributed stochastic neighbor embedding (t-SNE) (L. van der Maaten and Hinton [
25]). This interpretation has been done through the visualization of the projection of the feature vectors obtained in the previous layers to the decision making, that is, in the previous layers to the fully connected layer. In particular, the outputs of the second convolutional network and the output of the recurrent networks GRU of three stacked layers have been analyzed. The objective of visualizing the feature projections, in a function of different parameters, is to observe the influence of these parameters in the decisions that are taken in each layer. For example, to analyze aspects such as whether or not the output information of a layer is independent of the position of the mobile, or whether it begins to show or not a capacity for discrimination of the different types of acceleration forces. t-SNE technique converts the high-dimensional Euclidean distances between data points into conditional probabilities, the similarities. To find the low-dimensional data representation, t-SNE tries to minimize the error between the conditional probability in the high-dimensional data points and in the low-dimensional map points. For the calculation of the similarity between points in the low dimensional space, it employs a Student-t distribution.
When using t-SNE, it is important to consider different values of the perplexity parameter, which roughly represents the number of effective nearest neighbors to consider. Depending on the density of data, some values are usually recommended; generally larger datasets require higher perplexity values. Although the typical range for perplexity is between 5 and 50, depending on the selected value, we can see it reflected in a greater number of clusters. Wattenberg et al. [
26] analyzed multiple plots by varying the perplexities. The recommended values by Chaudhary et al. [
25] are in a range between 5 and 50, but may change for each data set. For instance, Wattenberg et al. [
26] advise that for the t-SNE algorithm to operate properly, the perplexity should have a value smaller than the number of points, and also that in order to avoid weird shapes, the algorithm must be iterated until a stable configuration is reached, since strange figures may be because the process has stopped very soon.
4.3. Model Assessment Using Different Pre-Processing Strategies
In this section we present our first results. We have done several tests with different input signals to analyze how this influences classification rates. More specifically, four different approaches have been evaluated:
Raw accelerometer signals, the tri-axial component, without any type of pre-processing. These will be used as a baseline.
Removing the gravity to each component of the accelerometers, to have the force of the driving maneuvers.
Projecting the accelerations to a perpendicular plane to the gravity.
Speed estimation added like a channel to the previous approach.
At the end of this section, we present a comparative analysis of these three pre-processing alternatives using several metrics such as accuracy, precision, recall, F1 score or G mean. As well as evaluating the success rates when calculating the VMDs and the number of journeys where this direction can be estimated. Finally, on a smaller dataset, t-SNE projections will be shown to analyze the influence of certain parameters and visualize how it changes for each strategy.
The total journeys have been divided into several subsets; training, validation and testing. For training and validation, k-fold cross-validation was performed, with a k = 10, using a total of 54,403 journeys. Each maneuver is divided into overlapping windows; therefore, the training/validation set has not been divided according to the number of journeys or maneuvers, but as a function of the number of overlapping windows of each class (to avoid skew problems). As we previously mentioned, for this study there are four classes:
braking;
acceleration;
turn; and,
mixed. A total of 149,157 maneuvers have been used for the training/validation, corresponding to a total of 944,384 overlapping windows already balanced (236,096 of each class), see
Table 1 for the dissection by operating system. Finally, different sets of journeys have been used to test and to visualize the classification process in each part. To evaluate the results of the neural network as well as the success rates in obtaining the VMD, a large set of tests has been used, consisting of a total of 9697 journeys of both operating systems (testing 1 in
Table 1). Because obtaining the projections of the feature vectors in the different parts of the architecture is very expensive computationally, a smaller test set of 297 examples has been used, with journeys of both operating systems also (testing 2 in
Table 1). To test, it has not been necessary to balance the data by class, for this reason the number of overlapping windows by label has not been specified in
Table 1 neither for testing 1 nor for testing 2.
4.3.1. Results with Raw Accelerometers
In this first test raw accelerometer signals [X, Y, Z], without any pre-processing, have been used as input to the network. As mentioned, to evaluate the results we will not only take into account if the estimated VMD is close to the true direction (output results of step 2 in method 1
Figure 5 after applying the post-processing algorithm), but also the confusion matrices with the results of neural network classification will be obtained and compared later according to several metrics (output results of step 2 in method 1
Figure 5 before applying the post-processing algorithm).
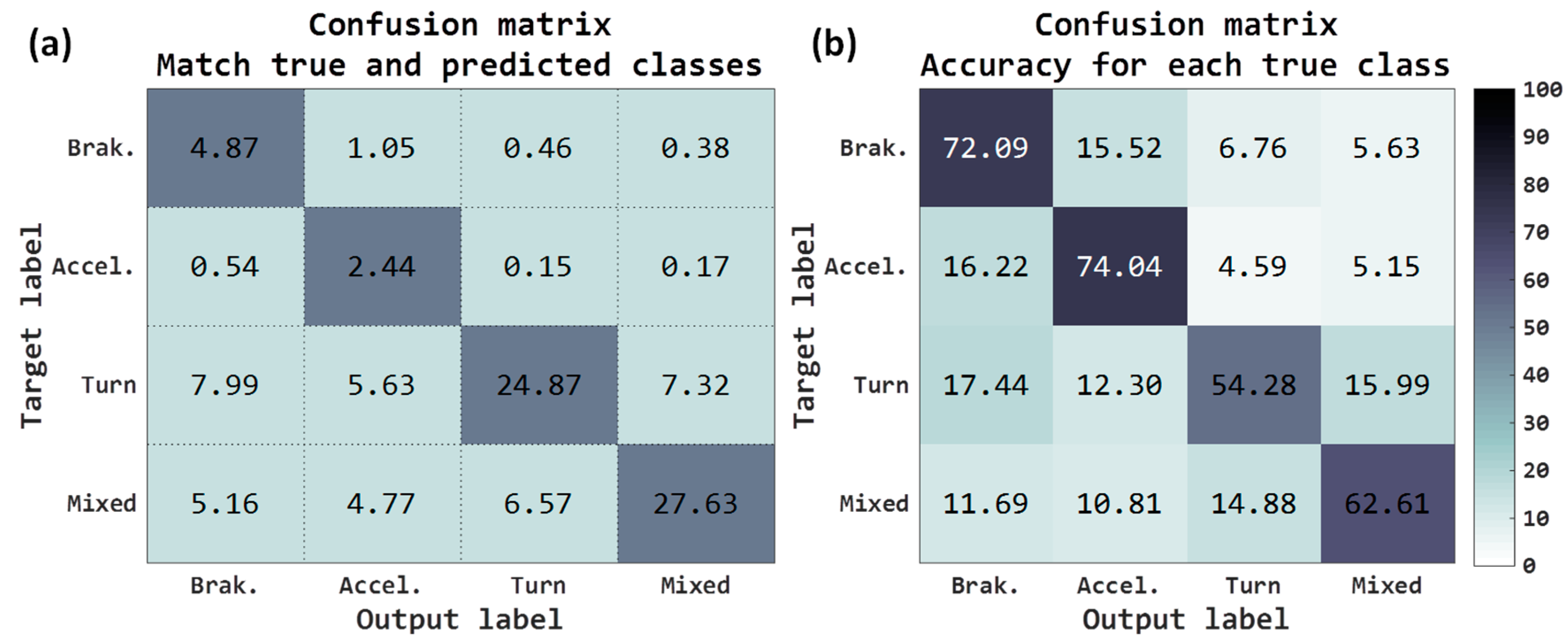
The accuracy metric refers to rate of correctly classified acceleration forces windows. Confusion matrices refer to two criteria, the first matrix (see
Figure 7a) represents the percentage of acceleration forces windows that have been correctly classified and the second matrix (see
Figure 7b) represents the accuracy for each true classes. Both in the first matrix and in the second matrix, the rows are the true class and the columns are the predicted class (output of network).
Total accuracy obtained with the raw accelerometers has been 27.88%, the sum of the main diagonal of the matrix shown in
Figure 7a. As mentioned, the test examples have not been balanced, since it is not necessary, and of the 9697 journey, there are some acceleration forces/classes that are more common along the routes. For example, observing the confusion matrix of
Figure 7a, the classes more usual are the
turn classes (45.81%, sum of the third row) and
mixed classes (44.13%, sum of the fourth row). For instance, in the case of
acceleration, although 1.56% has been correctly classified, it also shows a high error rate with the
braking class, 1.11%. If we observe these same results but depending on the accuracy for each true class,
Figure 7b, in the case of
acceleration the right rate is 47.36% and the error rate with the class of
braking is the 33.53%. The classes with the highest rate have been the
braking where the 57.99% are correctly predicted as braking.
These preliminary results have revealed that none of the classes worked reliably. In any case, it has to be taken into account that these results are predictions at the level of each window, and the results when calculating the VMD along a whole journey with the post-processing algorithm must be higher, since the algorithm performs a consistency with all window decisions. These raw accelerometer results will be used as the baseline.
Later, these outputs of the neural network are used for the post-processing algorithm applied to each journey in order to obtain the VMD. The details of the algorithm (
Vehicle Movement Direction algorithm, post-processing step 2
Figure 5) are the following. Firstly, the probabilities obtained in the corresponding overlapping windows will be added together and the final class will be the one with the greater probability after the addition. Only samples that exceed at least 1.5 times the background noise threshold, estimated for the journey, will participate in the calculation of the VMD. With the samples associated to the “good” mixed events (exceeding certain probabilities) a principal component analysis (PCA) will be made to get the two main directions of greater variability. As a result, most of the acceleration and braking samples must fit to one of the previous directions, and the turn samples to other perpendicular direction (also using samples with a certain probability). Thus, the samples of acceleration and braking that do not shift more than 45 degrees from the direction of the principal component associated previously to the longitudinal direction, will be used for the calculation of the VMD. This is as long as they are in sets of at least three consecutive samples, to avoid possible loose samples that deviate the results. Finally, to estimate the final VMD, the average of the resulting acceleration samples without gravity is calculated. To increase the reliability of the results, a higher probability threshold has been required for journeys of less than 5 min, since longer journeys usually have more maneuvers and, therefore, there is more consistency with more decisions along the route, compensating for possible failures of the network.
Below are the results of the VMD obtained, depending on the number of samples that are used for the estimation, see
Table 2. A minimum of 15 samples is required, obtaining only a success rate of 50.86% and estimating in 87.79% of the test journeys.
It is possible to observe in the previous table,
Table 2, that when demanding more samples to the algorithm of post-processing, the success rate in the directions increases slightly, but reduces the number of journeys where it can be estimated. The results are still very low with only 52.33% of correct directions, demanding 60 or more samples for the calculation, and estimating in 67.67% of test journeys.
4.3.2. Results Removing Gravity from Accelerometer Signals
In this study a pre-processing step is applied to the raw accelerometer signals, before using it as inputs to our Deep Learning architecture. This pre-processing step consists in removing the gravity force from the accelerometer components. For this aim, an estimation of the gravity force has been done, by means of the average of the 3-axis accelerometers in background zones between maneuvers.
The results at the output of the neural network have been the following: final accuracy obtained for the 4 classes has been 59.81%, a gain of 31.93% with respect to baseline. The classes that have improved the most have been (see
Figure 8a) both
brakings as well as
mixed. Observing the accuracy for each true class (
Figure 8b), all have improved the results, outperforming all of them with 50% success.
Although we really have not normalized the inputs, because of the risk of losing the maneuver information in sensor data, by removing the gravity component of the raw signals we have moved the maneuver values to a more appropriate variation range of input to the neural network. Components that do not carry out gravity information could have a mean near to zero, but components with all gravity information could have a mean around ±9.8 m/s2. Removing gravity, we did some kind of “normalization” that could be the cause of this improvement in the classification rates.
The results in the VMD have been (see
Table 3) better than those obtained with raw accelerometers; by obtaining better network classifications, the post-processing algorithm results have increased considerably. Demanding 15 samples, a 71.55% of success rate is obtained, and it is possible to calculate this in the 82.86% of the journeys; 20.69% more than in the baseline. Demanding 60 samples, the results go up to 74.86% success, although the routes where this can be calculated is drastically lowered to 51.93%.
4.3.3. Results Using Horizontal Projection of Acceleration forces
Assuming that the driving maneuvers must be in a plane perpendicular to gravity, if we project the accelerations on this horizontal plane, we could observe only the forces related to driving. So using these horizontal projections could improve the classification rates, with respect to the raw accelerometers or the results obtained by removing the gravity from accelerometers. These projections are the same as those used at
Section 3.2, in order to delimit the maneuvers limits better.
With the components of acceleration projected on the horizontal plane, like input signals to the neural architecture, the total accuracy has been 43.37%, in
Figure 9a, which is 15.49% more than that obtained with raw accelerometers. The results are similar in the case of raw accelerometers removing gravity, slightly lower for the case of the most useful classes such as braking and acceleration and slightly higher for the turns and mixed classes,
Figure 9b.
Maybe the fact that the deceleration and acceleration classes are slightly lower makes the results of the VMD go down a bit, see
Table 4, because the turn class does not help to assign the sign to the VMD properly. Despite the fact that the success rate is lower, the number of journeys where it can be calculated is higher than in the case of raw accelerometers removing gravity, so this solution may be of interest; for example, for 15 samples the rate is 69.76% for the 87.03% of the journeys and in the raw accelerometers removing gravity is 71.55% for the 82.86%. If we increase the samples to 60, the rate is 74.55% for 63.59% of the journeys, while for the other it is 74.86% for the 51.93% of the journeys, that is to say it can be estimated in 11.66% more journeys, failing in 0.31% more.
4.3.4. Results Removing Gravity from Accelerometer Signals and Adding Speed Estimation
The best results have been obtained using as input the raw accelerometers removing the gravity component. In order to try to improve these rates, we have added as additional information the estimation of speed changes analyzing only accelerometer signals. To approximate the speed, we have based this on a technique proposed in Cervantes-Villanueva et al. [
24] where speed is estimated in small windows of one second. For each window, the module of the three axes of the accelerometers is calculated at each instant of time and added, multiplying said result by the sum of the time difference between the samples of said window. Once these values have been calculated for each window, the speed at a given time will be the speed at the previous time instant, plus the difference in speeds between the current window and the previous window. Estimating the value of the speed from the three-axis accelerometers is complex and we really only want the information of sudden changes in speed, so we have normalized this value between 0 and 1, and we have introduced this signal as one more channel to the neural network.
Adding this information to the three previous channels, it seems that the classification rates of the network have not improved, see
Figure 10, only the mixed class has gone up slightly. So the results when calculating the VMD have not been increased either (see
Table 5).
4.4. Comparative Study
In this subsection, we will compare both the results obtained from the output of the neural network based on several metrics, as well as the percentage of success in calculating the VMD.
Five different metrics commonly used in the literature have been used: accuracy, which refers to the rate of correctly classified maneuvers; precision, that refers to the proportion of predictions that have been correctly classified; recall, the rate of true labels predicted; F1 score, harmonic mean of precision and recall; and, G mean, geometric mean. The baseline is the classifier with the raw accelerometers as inputs.
As it is a multi-label problem, for each one of the metrics the corresponding formulas have been applied by labels, calculating the metric for each label as if it were a binary classification problem, and then averaging them. To get the mean, two usual forms have been applied: macro-averaged (
Figure 11b) and micro averaged (
Figure 11c). The main difference is that for macro-averaged, initially the formula of the metric is applied for each class and then these are averaged; and for micro-averaged, firstly it is necessary to add the true positives, false positives, true negatives and false negatives of the six classes and once these four values are obtained, to apply them in the formula of the corresponding metric.
It is possible to observe that the raw accelerometers removing gravity offer the best results compared to other configurations, see
Figure 11, going over most of the metrics to the other inputs. The results adding the information of the speed are similar; therefore, we are going to take only the accelerometers without gravity as the best, since they require less processing. The percentage of right maneuvers classified is 59.81% (accuracy), see
Figure 11a. The ratio of predictions correct are 31.84% and 33.16% for macro and micro precision respectively; and the accuracy for the true labels are 65.76% for macro recall and 59.81% for micro recall. The F1 score and the G mean are, respectively, 35.89% (macro)/42.67% (micro) and 62.67% (macro)/59.81% (micro). The results of classification are acceptable, since, as mentioned, the task of classifying these four classes is quite complex using only accelerometers. We have improved baseline results but they are still insufficient for the accurate classification and do not provide excessively good results, probably for several reasons. One reason may be the previous nature of the classes, which categorizing them into a pure single class becomes complicated because the classes can easily present patterns of other categories. For example, it is extremely tricky to find a pure turn event (almost always these events have some longitudinal force). It is also important to highlight that until selecting the Deep Learning model used, we tested with different Deep Learning architectures consisting of several convolutional layers plus dense layers at the output, without including the recurrent networks. However, the results obtained were worse more than 5% with respect to the final selected model in the raw accelerometer tests. Among the different recurrent networks tested were the long short-term memory (LSTM) and gated recurrent unit (GRU) networks, but the LSTMs showed a result of around 3% lower average compared to the GRUs.
In the following
Table 6 are the results obtained in the estimation of the VMD (percentage of correctly classified journeys) and the number of journeys where it can be calculated, when we require 60 or more samples for each approach. As mentioned, in some cases it may be interesting to obtain the direction in the greatest possible number of journeys or, on the contrary, obtain a higher rate of success despite calculating it in a smaller number of trips. Depending on this criterion, the most appropriate input may vary from projections of accelerations over the horizontal plane or the raw accelerometers without gravity. If we want to increase the reliability, we can demand more samples in the calculation of the VMD, but the percentage of journeys where it is estimated will decrease in all cases.
In order to compare with a baseline system through this new method for estimating VMD based on Deep Learning, we probed other techniques to obtain the VMD based on the idea proposed in Chaudhary et al. [
5]. The article says that when the vehicle begins to move, in that initial movement you can obtain the longitudinal acceleration. This idea is actually more complex, because when the vehicle starts the movement it does not have to move in a straight direction, it can go out turning. So we develop a more complicated method that, when an acceleration maneuver or braking maneuver were detected (after and before a stop situation respectively), we calculated the possible VMD. To detect the stops, we trained a neural network that classified the signal as zones of stops or not, in addition to adding a signal-level consistency in the accelerometers. However the success rate achieved was only 62.98% of accuracy, being able to calculate it in a 67.43% of the journeys, a worse result that those obtained with Deep Learning techniques.
Now we are going to try to interpret the training process in the different layers of the Deep Learning architecture. For that, from a smaller set of journeys, the feature vectors obtained in the outputs of the different network layers have been projected, using the t-SNE algorithm. For this purpose, different values of perplexity have been tested, obtaining 50 as the most optimal to visualize the groups. This perplexity value will also be used for the rest of the tests. The first projection corresponds to the feature vector of the test set obtained at the output of the second convolutional layer; the second projection corresponds to the feature vector of the same test set but at the output of the recurrent networks. These feature vectors have been projected in function on the type of class predicted by the network. In order to see the influence of how gravity is distributed among the three axes and the noise threshold of the journey, these projections have also been shown as a function of them.
In
Figure 12a, we can see these projections when the raw accelerometers are used as input. It is possible to observe how the convolutional network by itself is not able to create four unique clusters associated with the four output categories, although it is already capable of grouping classes of different types that are mixed. On the contrary, the output of the GRU recurrent networks,
Figure 12d, seems indeed to distinguish four big clusters, in spite of the results being not optimal. In
Figure 12b,e, we draw these same projections but as a function of how gravity is distributed between the axis of the accelerometers. Firstly it is worth emphasizing that the most common mobile position for the drivers is when the Z axis receives a great part of gravity, and the mobile is horizontal with respect to the ground. At the output of the convolutional network,
Figure 12b shows that this distribution seems to be very important in network decisions; the X, Y and Z axes appear to be in different groups, except obviously in the case of distributed, when there is no axis that receives most of the gravity. Whereas at the output of the recurrent networks,
Figure 12e, although they appear more mixed, it still seems a decisive parameter. Finally, if we represent it as a function of the noise threshold of the journey, something similar to the output of the convolutional network occurs,
Figure 12c, but not to the GRU,
Figure 12f; it seems that the network is able to discriminate independently of the noise threshold, not perfectly but better than with the gravity distribution.
With the previous results, the importance of the gravity in the decision is highlighted, and this can be one of the reasons why when we eliminate the component of the gravity or we project them to a horizontal plane the rates improve regarding the raw accelerometers. If now we paint these projections of the feature vectors but only at the output of the recurrent networks, for the three remaining strategies: removing gravity (
Figure 13), projecting in the horizontal plane (
Figure 14) and removing gravity and adding the information of the speed (
Figure 15), we can observe the independence with respect to these two parameters, gravity and noise threshold, as well as the input that best groups the clusters into four categories in which we remove the gravity of the raw accelerometers, whether or not we add the speed information.
To summarize this section, this first method has shown its limitations, not being able to estimate the direction in the whole set of routes and obtaining a success rate that does not exceed approximately 75%. Therefore, we propose the following solution, which instead of classifying directly with the acceleration forces, will try to predict the longitudinal and transversal forces.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}