1. Introduction
Alcoholic beverages, like wine and beer, are important products in many countries with a considerable economic impact in the industry. The final product quality must be ensured for which many analytical methods have been researched. Some beverages are internationally recognized by their qualities, thus special protection is applied to avoid fraud. This demands increasingly sensitive, cheap, fast, and accurate non-destructive sensors for characterization and verification. As can be seen in [
1,
2,
3,
4], the most used non-destructive analytical technique is vibrational spectroscopy (near-infrared, mid-infrared, and Raman), although other methods are also applied, like electronic tongues [
5,
6] and nuclear magnetic resonance (NMR) [
7,
8].
Haptic sensors using pressure (firmness testers) have been used from some time in food science and technology [
9,
10]. Obviously, these systems are not suitable for liquid analysis and rigid container non-destructive analysis. However, a system that is based on the mechanical vibrational excitation of liquid samples can circumvent the limitations of pressure based tactile sensors. Although stress and surface waves have been used previously for nondestructive testing of wood [
11] and watermelons [
12,
13,
14], as far as we know, this is the first time that such a sensing approach for the chemical composition study of liquid foods is proposed.
Other acoustic techniques work generally in the frequency range of 1–100 MHz [
15], but this one analyzes audible sounds that are produced by ticking vibrations in order to improve the penetrating properties of the sensor, thus avoiding the large attenuation of high frequency ultrasounds.
A more direct approach to the determination of physicochemical properties of fruit can be seen in [
16]. They obtain the properties of fruit by correlation between the results of direct destructive determination of its chemical components and previous measurements of ultrasonic response of the same fruit. However, in acoustic spectroscopy, the measured sound parameters are attenuation and sound velocity, instead of the spectral response of the material. The use of sound that is generated by very low energy vibrations presents many advantages. It is non-destructive, can be used with intact containers, and it is penetrating enough to explore large volumes of liquid. The analysis of the spectral characteristics of each sample can be made with powerful free or commercial software. Finally, no special coupling or immersed probes are necessary as in the case of ultrasound testing.
The main innovation of this work is the proof that acoustic spectroscopy of liquids, placed the native container with unbroken seal, combined with powerful data mining algorithms, can provide the composition of ternary water-fructose-ethanol mixtures while using a very simple and cost effective experimental setup. Audible sound is able to penetrate most sample containers, so that some limitations of other methods, mainly optical ones, are eliminated. The spectral analysis of resonant mechanical vibrations can be used to study the chemical composition of liquid foods, and not only the mechanical properties of solid foods, like ripeness or texture.
2. Material and Methods
A new haptic sensing technique is presented in this work bioinspired by vibrational touch performance related with certain resonances. This new method performs a direct study of the spectral signatures of vibrational resonances inside a cavity in order to detect the chemical substances in liquids. The experimental system was composed by a mechanical clock as a ticking source, and an isolating platform made from polyethylene foam, a piezoelectric microphone with flat response between 20 Hz and 20 kHz, a resonating cavity made from polypropylene, and the fluid sample. Spectral information in the audible sound frequency range, as obtained from the vibrational absorption bands of the liquid sample inside a reference container, is analyzed by a heuristic classification algorithm. The liquid sample is placed on the surface of cylindrical box that is acting like a mechanical resonator excited by a stable ticking source from a mechanical clock. In an abstract sense, this bioinspired vibrational method can be seen as a cheap and powerful alternative to the previously cited optical and nuclear resonance techniques.
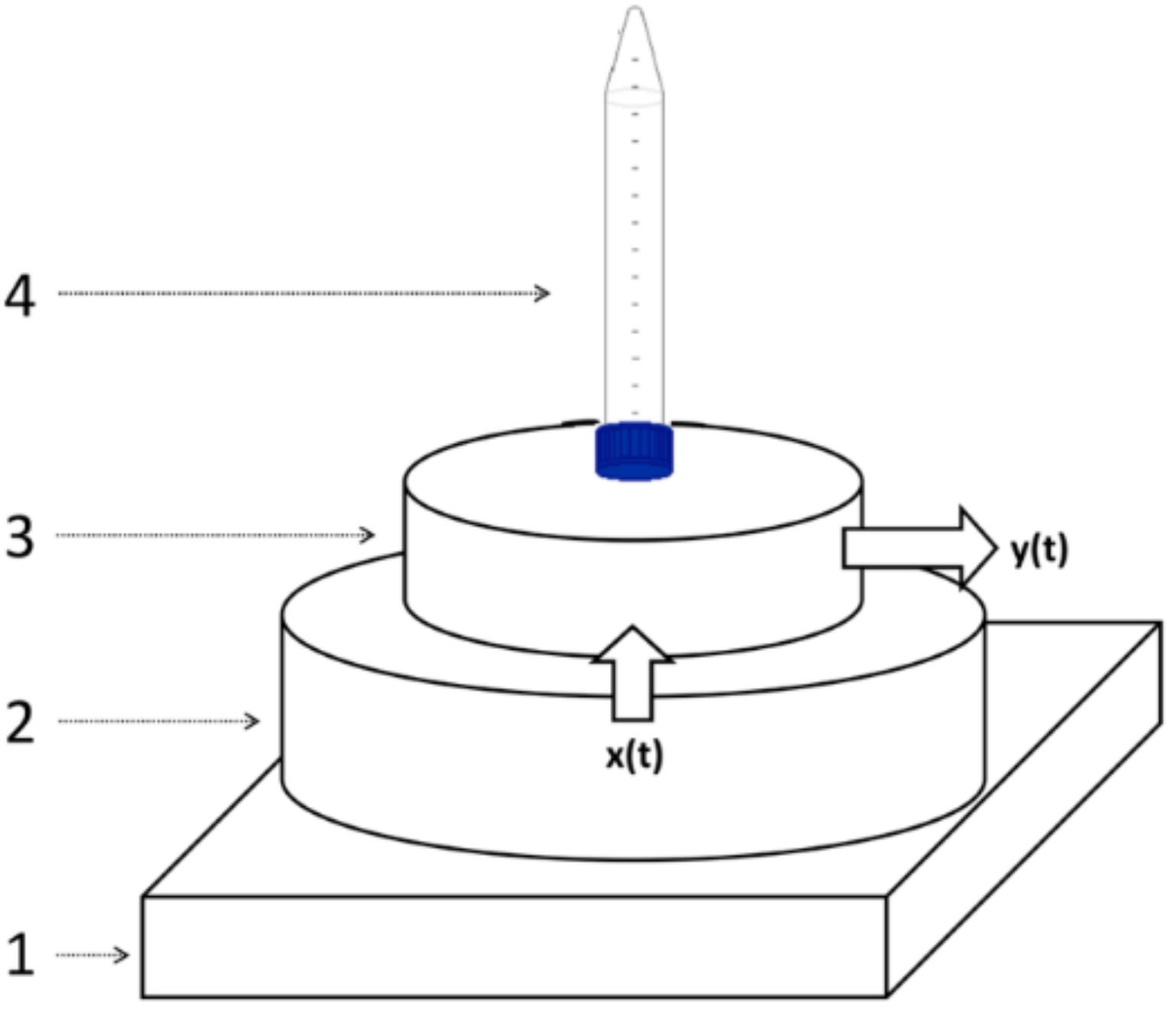
Figure 1 shows the schematic diagram of the experimental setup. The element number 1 represents the polyethylene platform which reduces the influence of the contact support in the acoustic output picked up by the microphone. Box 2 plots the ticking source which generates the input signal
x(t) on the resonating cavity. This cavity has a diameter of 15 cm. Box 3 depicts the resonating cavity which includes the piezoelectric microphone that picks up the output
y(t). The fluid sample (element 4 in the
Figure 1) was placed on the upper surface of the resonator 3. Each audio recording had a duration of 30 s, which was a very good compromise between accuracy, precision and measuring time. This recording time was long enough to eliminate the errors due to the fluctuation of the ticking source from one pulse to another (changes among different spectra from the same sample were below 1%), but short enough to make this technique practical. Obviously, the longer the recording time, the better the spectral precision due to fluctuation averaging.
The microphone was connected to a PC sound card. The measurements were taken with a recording rate of 44,100 Hz by means of the Praat software [
17].
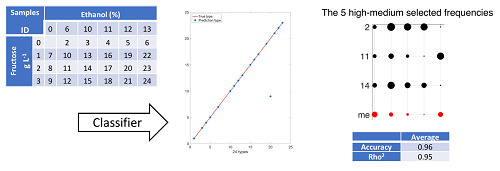
The experiments have been carried out with a set of 23 samples of water solutions with different concentrations of ethanol and fructose. The volume of each sample was 50 mL. Distilled water was used as solvent. Pharmaceutic grade 96% ethanol and food grade pure fructose (>99%) were used for the liquid samples.
The concentrations of ethanol and fructose were:
Ethanol: 0, 6, 10, 11, 12, and 13% by volume.
Fructose: 0, 1, 2, and 3 g/L.
For ethanol volume measurement, polypropylene beakers that are compliant with the ISO 7056 norm were used. In case of real drinks, we would use the native container. We decided to use the polypropylene beakers because the water solutions were prepared as simulated beverages for the experiment. The beakers were new and sterile when used, so no pretreatment or washing procedure was applied. The beakers had a screw cap of plastic. The beaker volume was 50 mL with marks every 10 mL. For finer volume determination, new and sterile medical plastic syringes were used.
The fructose mass for the samples were determined by means of an analytical balance (Ohaus Adventurer, OHAUS Corporation, Parsippany, NJ, USA) with a readability of 0.01 g.
First, samples of ethanol and water were prepared and then fructose was added. The samples were sealed in identical new sterile volume marked polypropylene tubes with polyethylene screw caps. Samples were numbered as the
Table 1 shows and they were kept in a box for a week before measurements were performed to ensure that complete dilution was achieved, and no bubbles were found inside.
The 23 samples were numbered with numeric labels from sample 2 to sample 24. The
Table 1 registers the composition of each sample. The numerical label 1 would correspond to the sample that was composed by pure water. Because we want to emulate alcoholic beverages and substitutes, we have not included the plain water in the experiments.
All of the measurements were done during the same day with careful manipulation of the samples in order to avoid the formation of bubbles or wall drops. Each measurement takes 30 s and they were taken in a consecutive way. The clock ticking sounds were monitored in order to assure their precision by means of the Tickoprint Android App. No anechoic chamber was used for the recordings, but a quiet laboratory room. The noise level was measured with the same system without samples at regular intervals in order to ensure that all sound recordings were made in the same conditions. The acoustical response of samples to the resonant ticking sounds was recorded by means of the Praat software program during 30 s with a sampling rate of 44,100 kHz.
Each measurement was fragmented in different 6 s intervals ([1–6], [2–7], [3–8], …, [24–29]). The input data of the classification algorithm are the spectra of the audio measurements of 6 s in duration. The experiment was carried out with 24 audio measurements of each of the 23 samples of different composition. That means a total of 24 × 23 = 552 audio measurements. The power spectrum of every interval was made using the default Praat options. The power spectrum (or power spectral density) is calculated as:
where,
In the discrete case, a single approximation is:
considering a finite window of
and a signal sampled at discrete times
for a total measurement period
[
18].
Then, a cepstral smoothing of 100 Hz and a decimation procedure were applied in order to reduce the number of points to a reasonable size (1310 points) without losing the main peak structure of the spectra.
The cepstrum is the result of taking the inverse Fourier transform (IFT) of the logarithm of the estimated spectrum of a signal. Generally, the power cepstrum is used in human speech applications, which is defined as:
The cepstral smoothing algorithm averages the spectrum data while using the cepstral results and selecting a frequency interval in Hz [
19].
In summary, the classification algorithm will process 552 input data, each of them being a spectrum that is defined by 1310 values in the frequency range 20 Hz–22.05 kHz.
3. Algorithm for Clustering Problem
The spectral information from the vibrational absorption bands of liquid samples is analyzed by the Grouping Genetic Algorithm (GGA) in order to determine the chemical composition of the liquid mixtures in a completely non-destructive method. The algorithm performs a classification according to the spectral response to the vibrational stimulation from the ticking source. The GGA is a modified Genetic Algorithm (GA) for solving clustering and grouping problems. This section provides a brief overview of GA and GGA.
3.1. The Genetic Algorithm as Evolutionary Algorithm
The Genetic Algorithm belongs to the evolutionary optimization algorithms category. Optimization techniques are generally applied to solve problems where it is not possible to find the optimal solution due to the existence of opposing criteria. It is extremely difficult to obtain the optimal solution and, in general, we do not know if there is a single optimal solution, several solutions, and how many solutions are close enough to the optimum, being that these are much easier to find than the optimal one. The objective is to find a suitable solution, enough nearby to the optimal one, with a limited execution time. We are not interested to find exactly the optimal solution after unacceptable computing time. The characteristic 'evolutionary' means that the algorithm analyzes and processes solutions across several stages, so solutions go through an evolutionary process from the first stage to the last one.
The GA is bio-inspired in the Charles Darwin theory or theory of evolution by natural selection. A population of individuals fighting for survival corresponds to a set of solutions of the optimization problem. Individuals with better fitness will be survive with higher probability than others having worse aptitudes. So, the survival of individuals depends on their fitness and chance in life. The passing of time makes the species to conform to the environment, as the GA will find better solutions of the optimization problem after several generations. The fitness function that is used in this paper to carry out the classification of spectra data is the Extreme Learning Machine (ELM). We discuss the ELM in the following section of the paper.
The
Figure 2 represents the general flow chart of the GA, where a complete cycle depicts a generation of the evolutionary process. Each one executes operations of: fitness computing, selection, recombination or crossover, and mutation. The process starts with an initial population composed of random solutions. Each solution is characterized by a fitness value, which is a measurement/degree of how well it solves the optimization problem: a solution with better fitness value means that it is closer to the unknown optimal solution than others with weaker fitness value. Due to the initial solutions being randomly created, most of them are sure very far from any optimal solution. The algorithm evaluates each solution of the initial population in order to register their fitness values.
After the initial evaluation, the algorithm generates new solutions as offspring the current population. The method to create a new solution is usually based on the contents of two existing solutions, inspired on the creation of offspring from the genetic makeup of their parents in real live. The GA adjustment to solve a particular problem determines the specific rules of parental selection and recombination with a consistent pattern in the encoding solution.
As Darwinian Theory, there is a small probability of unexpected mutation. The GA models the mutation as a random modification in a piece of the solution code. After recombination and mutation, the fitness value of the offspring is calculated. Then, the offspring is added to the current population, therefore the population size increases to living together in an environment with restricted resources. The environmental selection controls the population size discarding some solutions. There are different discard methods, GA usually applies tournaments. Solutions with better fitness will generally win the tournaments, but it also depends on chance.
A new generation starts, and the execution comes back to the parental selection for recombination and following operations. The process finished when some stop conditions matches. Stop conditions for GA usually consist of a maximum number of generations or reaching the convergence of population.
3.2. The Grouping Genetic Algorithm
The GGA is a modified genetic algorithm for solving clustering and grouping problems [
20,
21,
22,
23]. The expression ’grouping’ refers to a technique that takes advantage of special encoding strategies and searching operators in order to obtain compact hierarchical arrangements in grouping-based problems with a high performance in terms of a hierarchy-dependent metric [
24].
The solution coding of a GGA has two different sections: ‘assignment part’ and ‘grouping part’. Both sections are arrays of elements. The information about the classification is not only inside the content of array, also in the length of the arrays. The length of the assignment part is the size of elements to classify. The length of the grouping part matches with the number of groups. Note that the length of the solutions is variable, because each solution could consider different number of groups.
The
Figure 3 shows a simple example of solution coding. This individual has four groups (length of the grouping part is four), named 2, 3, 4, and 6 (content of the array). It is not required using consecutive numbers to identify categories, neither starting at 1. The content of the assignment part array is the group or type which is associated each element. If the element is not yet classified, the array stores a zero value in the array. In this way, the example in
Figure 3 indicates that the first element is not yet associated to any group, whereas the second, third, and last elements of the array are assigned to group 2, the forth is typed as class 4, and so on.
The code of a solution is formed by two parts: assignment part and grouping part. The grouping part collects the different groups of the solution. The value that is stored in the assignment array represents the group that is classified the corresponding element of the array.
The GGA keeps the general flow process described in
Figure 2 for GA because GGA is a modification of this. However, the recombination and mutation operations have different characteristics than GA. The mutation of an individual can be understood as a recombination with a random individual, so we explain more in detail only the crossover operator.
Figure 3 represents an example of recombination of individual A and B in the GGA. For clear explanation, the coding of all cases emphasizes the assignment and grouping parts with a vertical line separating the arrays.
The recombination operation begins taking a copy of individual A as the offspring. Then, a fragment of the grouping part of the individual B is randomly selected. The example in the
Figure 4 considers the sub-array [
15,
17] of individual B. Only the new content of this sub-array is added over the offspring. The example gets the group number 5 because the class 11 is already in the copy. The next step consists of copying to the offspring the complete sets of elements in the individual B associated to the added groups. In
Figure 4, all elements of the individual B belonging to the class number 5 are updated in the offspring. Finally, the grouping part could be re-written in ascending order.
The new offspring is a modified copy of the predecessor A. This copy is added some new groups of the individual B and reassigned the elements belonging to the new groups, like the predecessor B.
3.3. The Fitness Function: The Extreme Learning Machine
An effective fitness function of the GGA presents two major properties: the regressor is as accurate as possible, and the evaluation process is as fast as possible in order to not exceed the total processing time of the algorithm. The Extreme Learning Machine (ELM) matches both requirements: it is a simple machine learning algorithm that achieves a good generalization performance with extremely fast speed [
25]. ELM has revealed its good performance in large dataset multi-label classification applications as well as in regression applications [
26,
27]. It is a generalization of a Single hidden Layer Feedforward Network (SLFN) [
28,
29,
30,
31,
32,
33]. To give a brief description of the essence of the ELM algorithm, we use the same notation as [
27], who provides a descriptive figure with the same symbols. Consider the training data set that is formed by N samples with the format:
where
xj is the input vector of sample
jth,
yj is the corresponding class of
xj. The single hidden layer of ELM is composed by L nodes, each one has an activation function G (
aj,
bj,
x) where
aj is the associated connection weight vector and
bj is the bias. The parameters
aj and
bj are randomly assigned. The hidden layer output matrix
H is defined as:
The algorithm must compute the output weight vector
β as:
where
H† stands for the Moore-Penrose inverse of matrix H and Y correspond to the class labels of the training data set:
The output of the ELM is the optimal weight β˜ of the network, where β˜ is the least-squares solution of β.
The fitness function is applied to an individual by calculating through the ELM the correct classification rate of each of the groups of its grouping part on the training dataset. The best rate is assigned as a fitness value to the individual and the classification rates of the rest of the groups are discarded. The best classification rate determines the features selection that classifies the individual with the best accuracy among all the groups in its grouping part. The features selection is identified by the group with the best classification rate of the grouping part. The rest of the groups have no interest for the solution.
3.4. Statistical Analysis
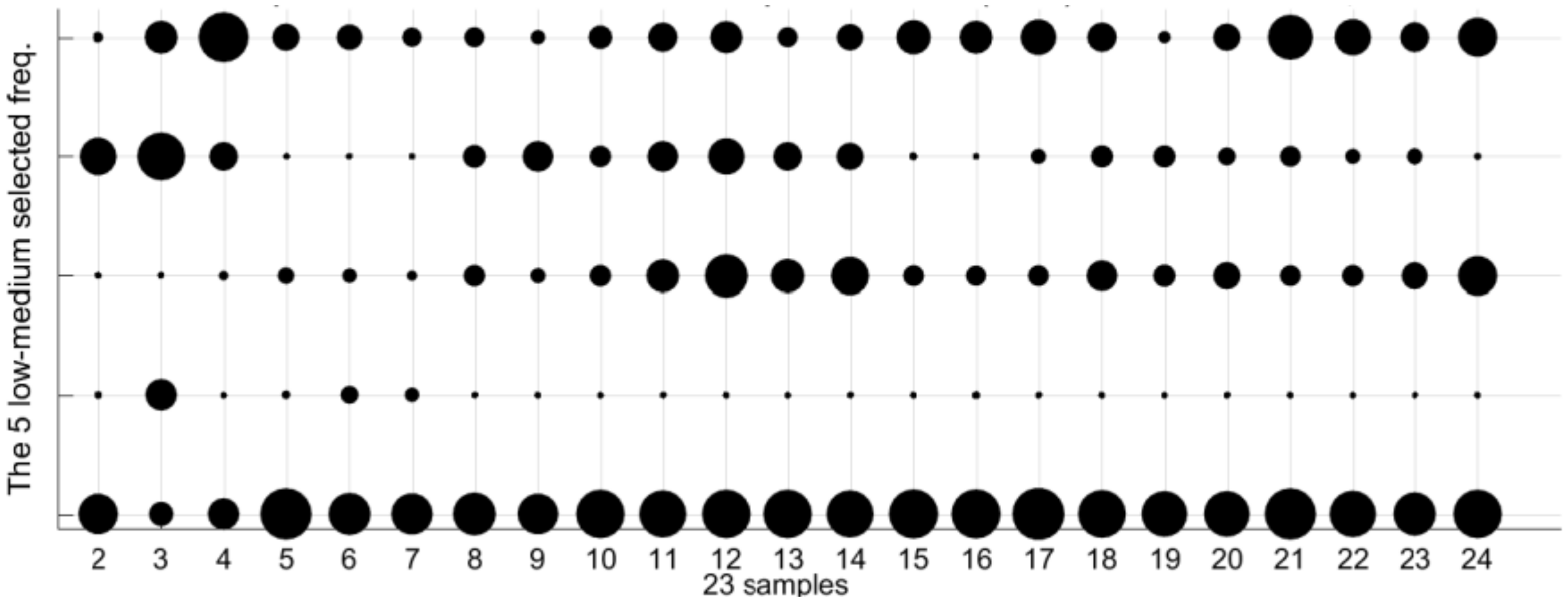
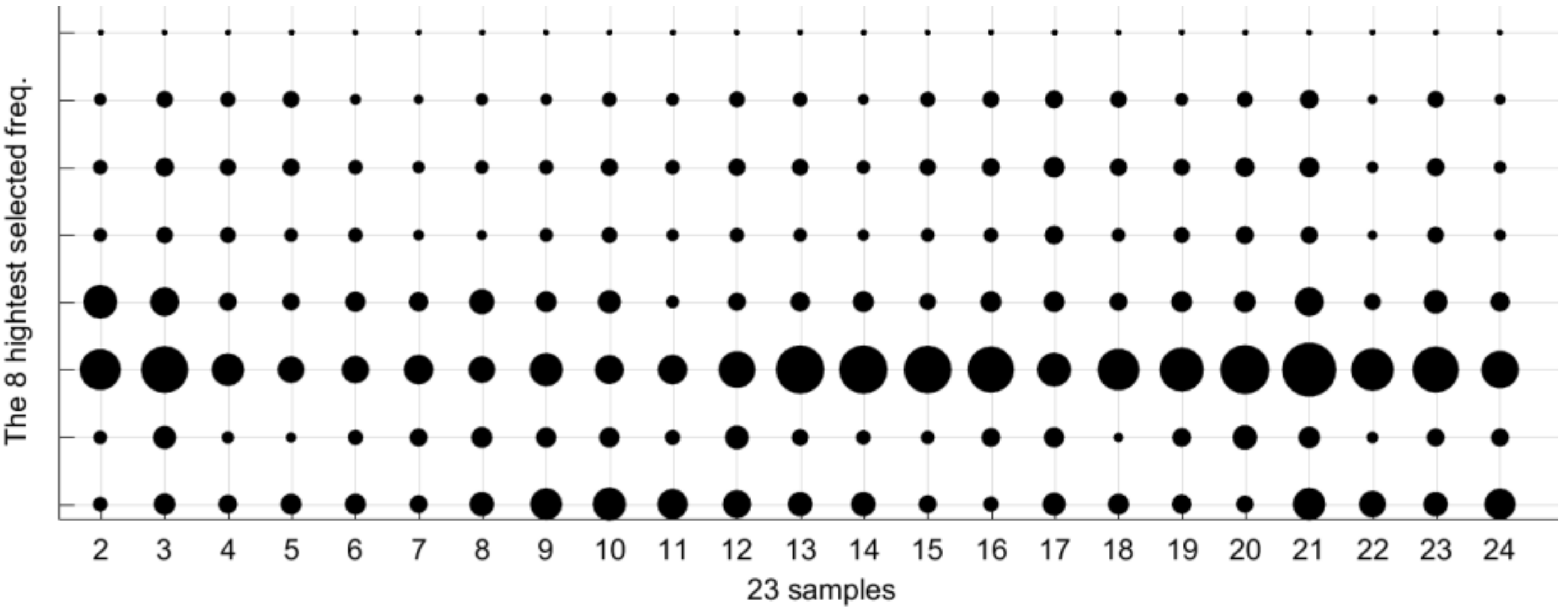
As mentioned before, the spectral data sets have 1310 values along the frequency range 20 Hz–22.05 kHz. The classification by 1310 characteristics is far from being achievable. The objective of the GGA is to slash the number of features that are capable to classify samples within any composition of
Table 1. The algorithm must solve a wrapper feature selection [
34] where the GGA minimizes the output regressor. The solution is characterized by unknown group of features in size and composition. The reduced set of characteristics determined by the GGA among the 1310 must be able to classify any spectrum of the evaluation data set (unknown by the training data set) according to the types defined in
Table 1. We want to select a limited number of attributes, around 40 or 50 features, which are able to perform the classification not worse than 90% successful.
The training, testing, and validation sets are disjoint sets formed from the 552 data. The training set is generally made up of 80% of the total data, the test data set contains between 10% and 15% and the evaluation set consists of the rest of the data (5–10%). We have performed the experiments with training, test and evaluation data set sizes of 80%, 15%, and 5%, respectively. The GGA trains first with a more numerous set, and then it tests with the testing set getting solutions for the selection of a set of attributes. The final solution is applied in the validation set in order to evaluate the accuracy of the solution provided as classifying criteria.
The population size of the GGA is fixed to N
ind = 50 individuals. The selection procedure of the GGA is based on tournament selection. The tournament selection operator has provided very good results in previous applications [
35,
36], and its implementation is quite easy. An offspring population of size 0.5 N
ind is obtained by applying crossover and mutation operators over the N
ind ones. The round of tournament is carried out with the merged population that is formed by parents and offspring, based on the best fitness values of the fighters. The foe is chosen at random for every tournament. The N
ind individuals with more won tournaments survive for the next generation.
The algorithm runs until any of two stopping conditions holds: convergence of the population or maximum number of generations
Gmax has been reached. The convergence is estimated by comparing the fitness of the best solution in the population
fbest with the average fitness of the population
faverage. We use a value of epsilon = 0.001 to carry out the comparison of the following equation:
The maximum number of generations Gmax must be set in such a way that the algorithm is able to find out quality solutions, within a reasonable computation time. In our work, we have established Gmax = 100.
5. Conclusions
We have described a new haptic sensor that is based on vibration to determine the chemical composition of liquid mixtures according to their composition of ethanol and fructose in a non-invasive way with minimal cost. The analyzed spectrum range is 20 Hz–22.05 kHz. The spectral information from the vibrational absorption bands of liquid samples is analyzed by a Grouping Genetic Algorithm. An Extreme Learning Machine implements the fitness function that is able to select a reduced set of frequencies from the acoustical response spectrum of the samples to resonant ticking sounds. It is enough to analyze the response of the spectrum at a few frequencies instead of studying the whole spectrum.
The experiments have been performed with 552 measurements belonging to 23 samples of water, ethanol, and fructose mixtures (50 mL) of distilled water with a concentration of ethanol of 0%–13% by volume and fructose 0–3 g/L. The work concluded that less than 40 frequencies are enough to process the characterization with accuracy greater than 80%. After 20 iterations, the average accuracy of the operation is 96%, any of them with accuracy better than 82%. The method can differentiate up to 1 g/L of fructose and 1% ethanol by volume in liquids samples with an error lower than 10%.
The optimization algorithm provides several solutions with similar quality. The solution is not unique. Also, it is important to note that if the number of types is modified, the set of selected frequencies in the solutions will be also changed. In other words, each frequency has a different contribution to the characterization result. Future research will be orientated to analyze other chemicals substances, more complex mixtures, and to improve the accuracy of the sensor.

 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



