New Multi-Keyword Ciphertext Search Method for Sensor Network Cloud Platforms

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We propose a method for building document vectors, by combing term frequency-inverse document frequency (TF-IDF) with Vector Space Model (VSM) to optimize search efficiency, and we propose an improved quality hierarchical clustering (IQHC) algorithm based on the quality hierarchical clustering algorithm (QHC).
- We incorporated this improved algorithm into a new multi-keyword ranked search method for encrypted sensor data and used the new search method to implement a multi-keyword ciphertext search over encrypted cloud data, based on the improved quality hierarchical clustering algorithm (MCS-IQHC).
- We ran a series of experiments to test the quality of MCS-IQHC, MRSE, and MRSE-HCI methods, and to demonstrate that the proposed method facilitates highly-efficient and accurate multi-keyword ciphertext searching, under the simulated sensor cloud network environment.
2. Related Work
2.1. Quality Hierarchial Clustering Algorithm Analysis
2.2. TF-IDF and VSM
3. Background
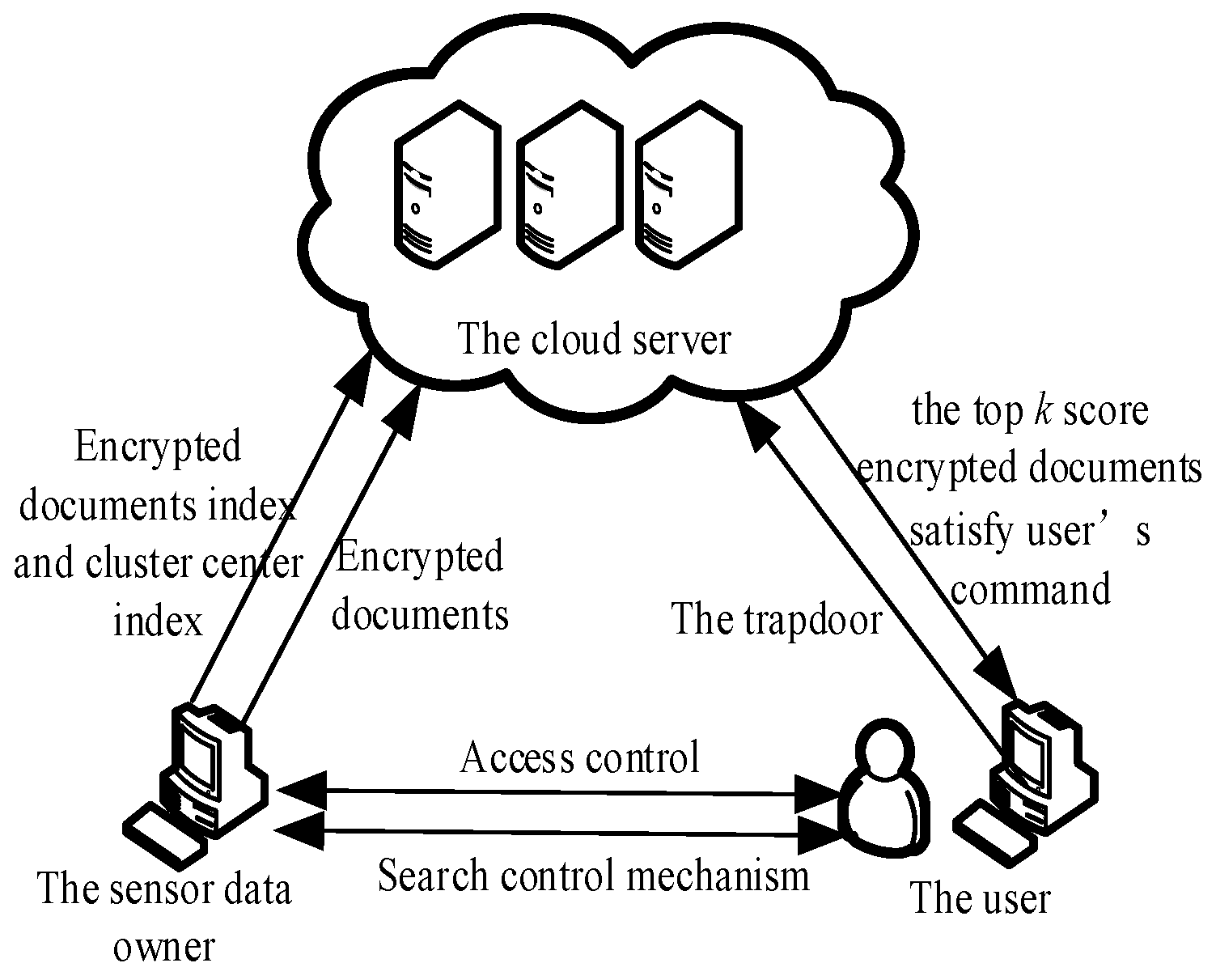
3.1. System Model
3.2. Security Threat Model
4. Multi-Keyword Ciphertext Search Method
4.1. Improved Quality Hierarchical Clustering Algorithm
- Generate n samples of the document vectors G1, G2, …, Gn, Gi = (g1, g2, …, gp)T, (i = 1, 2, ..., n) through TF-IDF and VSM. These vectors all have p dimensions. Standardize the vectors. When n > p, construct a sample matrix. Apply the following transformations to the sample elements:where is the expectation; sj is the standard deviation.
- Obtain a normalized sample matrix M as follows:Determine M’s covariance matrix C, where MT is the transpose matrix of M.
- Apply the Singular Value Decomposition method to solve the characteristic equation (|C-λIp| = 0) of the Sample Covariance Matrix M. Then, obtain p characteristic roots and sort them in descending order. Use contribution rate η from Formula (4), to confirm the number of principal components and mark this value as m. Choose a value for η, the original information is represented by the m principal components. Use each latent root λj (j = 1, 2, …, m), determined by solvingto obtain m unit eigenvectors bj (j = 1, 2, …, m).Rb = λjb,
- Convert the normalized data variables into principal components. P1 is the first principal component, P2 is the second principal component, ..., Pm is the mth principal component. Obtain dimension reduction vectors after replacing the document vectors with the new principal components.
- Set the maximum number of documents in each cluster (denoted as TH), and the minimum threshold value of the correlation value marked as min(S). The Euclidean distance is used to measure the correlation between the documents, and to establish a relationship between each document and cluster center.
- Cluster the document vectors, after a dimension reduction, via the K-means algorithm [18]. k is the number of the clusters. When k is unstable, we add a new cluster center and generate k + 1 new random cluster centers to the clusters. Then, we compare the minimum threshold min(S) of the correlation value with the minimum correlation score min(St), (t = 1, 2, ..., k) in each cluster. If min(St) < min(S), we add a new clustering center and re-cluster. We repeat this process until k is stable, then proceed with Step 7.
- We consider the clustering center set in Step 6 as the first-level cluster center C0, and verify the number of documents in each cluster sequentially. If the number of documents exceeds the pre-set threshold value TH, we divide the cluster into multiple sub-clusters; otherwise, do not divide. Regard any newly divided sub-clusters as a second-level cluster center, and repeat Step 7 until the number of documents in all clusters falls under threshold TH.
- Repeat steps 1–7 until all clusters satisfy the cluster dependency and quantity requirements. The clustering process is complete.
4.2. MCS-IQHC
- Document vector execution. The sensor data owner considers the product of TF and IDF as the value of keywords. In VSM, a vector represents the documents in the upload queue. The value at that position, denotes each dimension of the document vectors. Then, a dictionary Dw and the document vector set D are created.
- Index creation. The IQHC clusters the document vectors and generates a u-bit dictionary Dw. This is implemented by the sensor data owner. The clustering results are used to build a cluster and document index. The length of the document-index and cluster-index vectors are u bits.
- Index encryption. The sensor data owner generates a u-bit random vector S = {0,1}u and two u × u reversible matrices Z1, Z2 as the key, using the KNN [17] query algorithm at random. Each bit of the division vector S is a random variable 0 or 1. Thus, there is approximately the same number of 0 and 1 values in S. Each bit in the matrix Z1 or Z2 is a random integer. Segmentation vector S, serves as a split indicator for segmenting the document index and cluster index. The sensor data owner divides the cluster index vector V into two vectors V’ and V” based on S. This process is random. The ith bit of vectors V’ and V” are denoted by Vi’ and Vi”, (i = 1, 2, ..., u). The transposed matrices Z1T, Z2T are reversible matrices of Z1, Z2, where Z1T, Z2T is used to encrypt V’ and V”. When the ith term in S is 0, then Vi” = Vi’ = Vi, (i = 1, 2, ..., u); or the ith in S is 1 then Vi’ = Vi − Vi”, (i = 1, 2, ..., u); the cluster index is encrypted as Ic = {Z1TV’, Z2TV”} as is the document index Id.
- Document encryption. The sensor data owner chooses a secure symmetric encryption algorithm to encrypt the documents, then sends the encrypted document set De with the encrypted document index Id and the encrypted cluster index Ic to the cloud server.
- Trapdoor generation. The user selects keywords, assigns different values to these keywords on demand, and requests that the cloud server return the first k documents that satisfy the demand. The search request is subsequently constructed and sent to the data owner. After receiving the request, the sensor data owner assigns a value to the requested keyword location, according to the dictionary Dw’, then produces a u-bit search vector Q and encrypts Q with the matrix Z1−1, Z2−1. The search vector Q is then randomly divided into two vectors Q’ and Q” (based on S) by the data owner. The ith bit in Q’ and Q” is denoted as Qi’ and Qi”, (i = 1, 2, ..., u). If the ith bit in S is 0, then Qi’ = Qi − Qi” (i = 1, 2, ..., u); otherwise the ith in S is 1. This results in the relationship Qi” = Qi’ = Qi, (i = 1, 2, ..., u).The search request Q is split into Q’ and Q”; where Q’ and Q” are encrypted by the matrices Z1−1, Z2−1 to obtain the trapdoor Td = {Z1−1Q’, Z2−1Q”}. The sensor data owner then sends Td to the user.
- Search process. The user sends the trapdoor Td to the cloud server. The correlation score which marked as Score [6] is calculated according to the inner product calculated by the cloud server. Formula (6) shows that the inner product of Ic and Td is equal to the inner product of V and Q. The result of the ciphertext state search is the same as the plaintext state search; the encryption does not affect the accuracy of the search results.The cloud server first calculates the inner product of Td and the first-level cluster center in Ic, then it finds the highest-scoring first-level cluster center. The second-stage cluster center with the highest score is determined by calculating the inner product of Td and the previously obtained sub-cluster center of the first-level cluster center, until reaching the final high-score cluster center. Finally, the inner product of Td and Id are used to obtain the top k-scoring encrypted documents and return them to the user.
- Decryption process. The user sends a decryption request to the sensor data owner, then decrypts the document after receiving the decryption key from the owner.
4.3. Security Analysis for MCS-IQHC
5. Experimental Results and Analysis
5.1. Experimental Data and Environmental Configuration
5.2. Experimental Search Efficiency and Accuracy
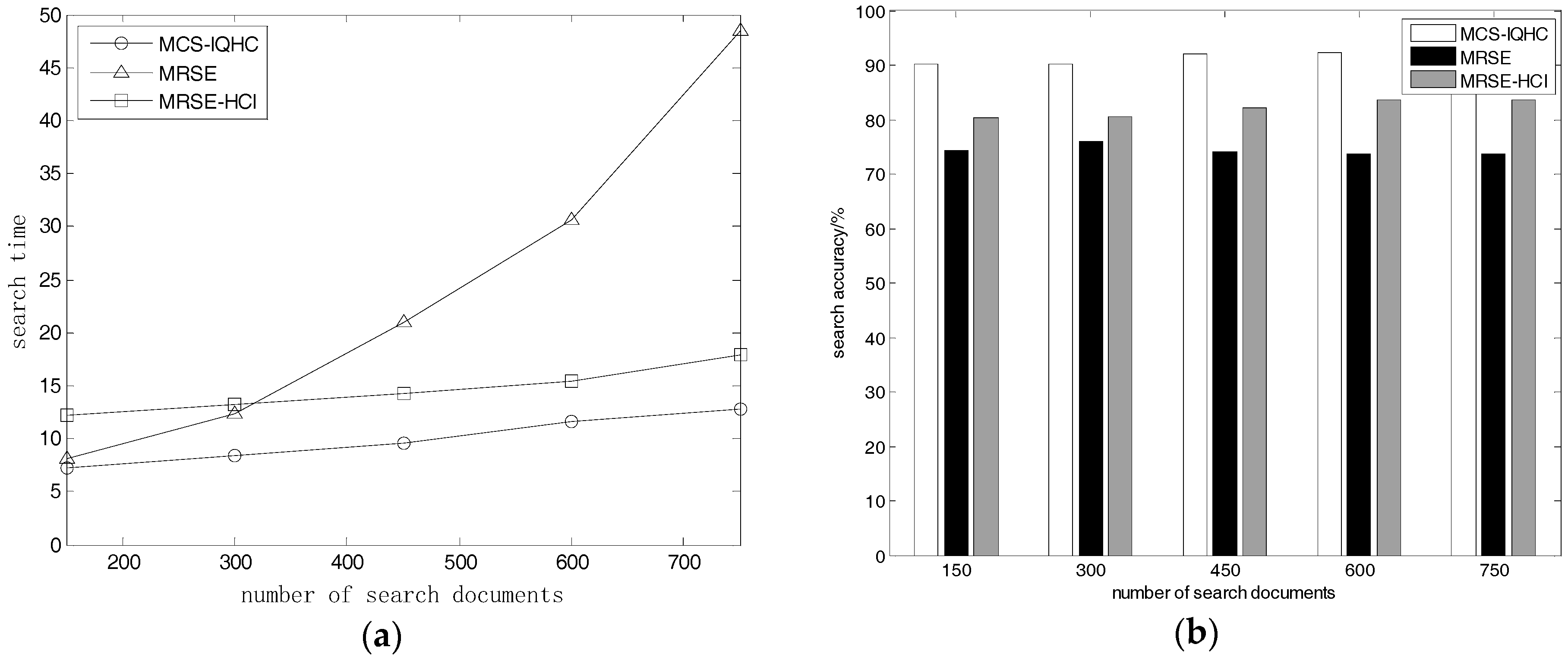
5.2.1. Document Quantity Effects on Search Time and Accuracy
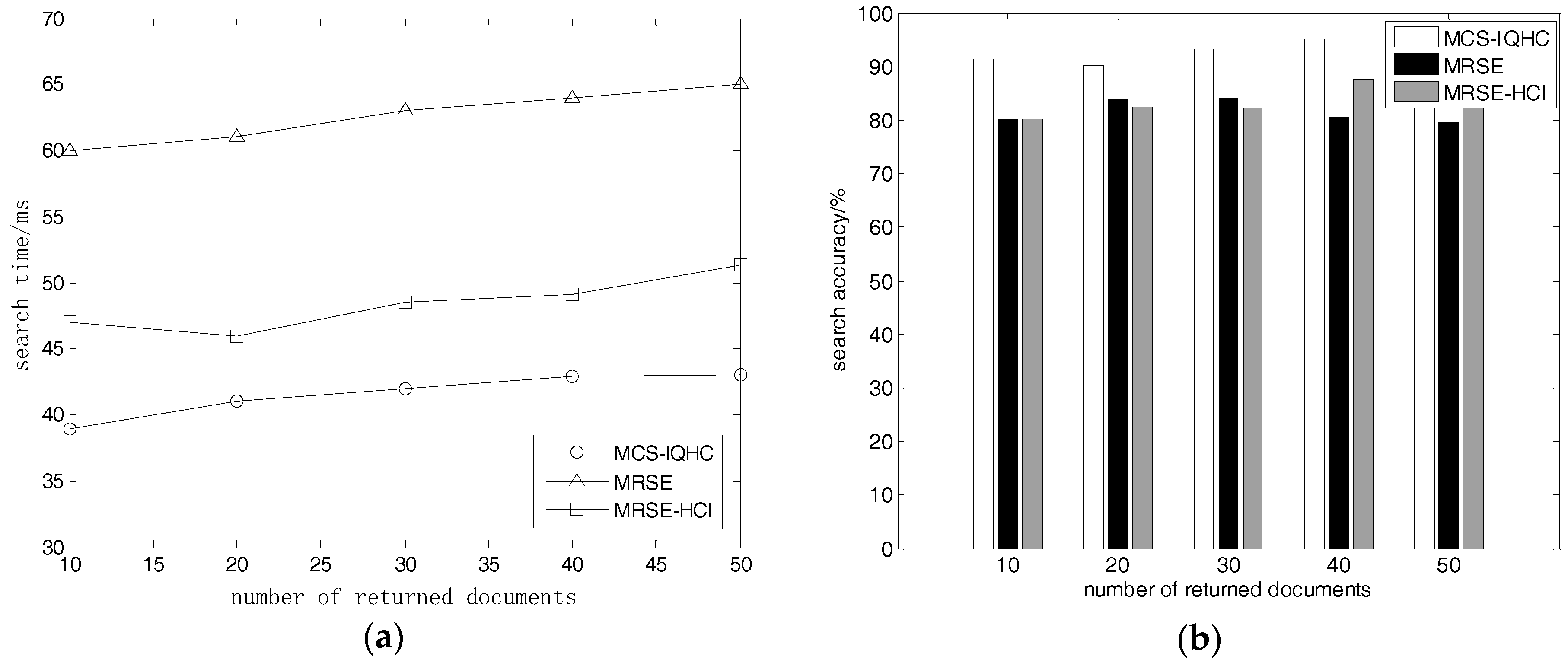
5.2.2. Returned Document Quantity Effects on Search Time and Accuracy
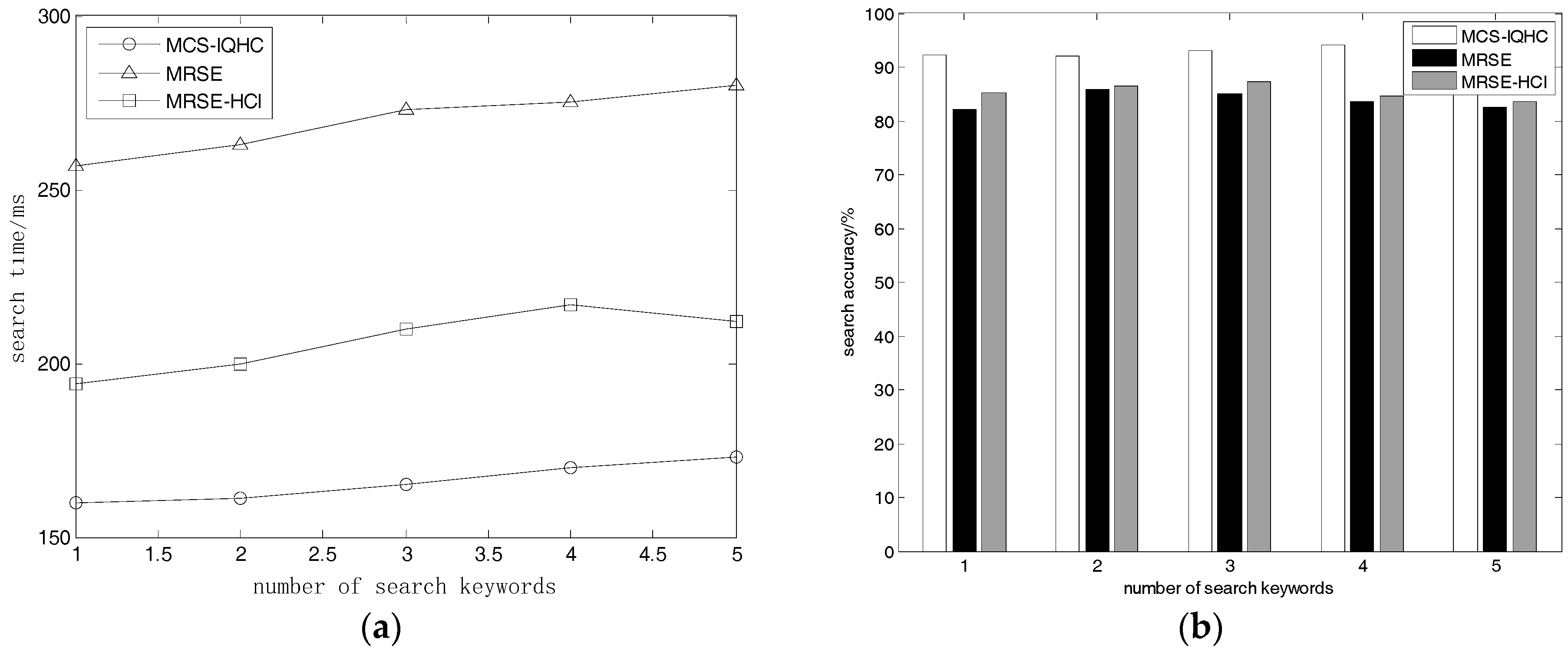
5.2.3. Keyword Quantity Effects on Search Time and Accuracy
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, Y.; Peng, H.; Wang, J. Verifiable Diversity Ranking Search over Encrypted Outsourced Data. Comput. Mater. Cont. 2018, 55, 037–057. [Google Scholar] [CrossRef]
- Wu, C.; Zapevalova, E.; Chen, Y.; Li, F. Time Optimization of Multiple Knowledge Transfers in the Big Data Environment. Comput. Mater. Cont. 2018, 54, 269–285. [Google Scholar]
- Wang, Y. Searchable Encryption Scheme Based on Fuzzy Keyword in Cloud Computing. Master’s Thesis, Xidian University, Xi’an, China, 2014. [Google Scholar]
- Qin, Z.; Bao, W.; Zhao, Y.; Xiong, H. A fuzzy keyword search scheme with encryption in cloud storage. Netinfo Secur. 2015, 15, 7–12. [Google Scholar]
- Cao, N.; Wang, C.; Li, M.; Ren, K.; Lou, W. Privacy-preserving multi-keyword ranked search over encrypted cloud data. In Proceedings of the IEEE INFOCOM 2011, Shanghai, China, 10–15 April 2011; IEEE Press: Piscataway, NJ, USA, 2011; pp. 829–837. [Google Scholar]
- Wang, Y. Secure Rank-Ordered Search of Multi-Keyword in Cloud Storage Platform; Harbin Institute of Technology: Harbin, China, 2015. [Google Scholar]
- Handa, R.; Challa, R. A cluster based multi-keyword search on outsourced encrypted cloud data. In Proceedings of the IEEE International Conference on Computing for Sustainable Global Development, New Delhi, India, 11–13 March 2015; IEEE Press: Piscataway, NJ, USA, 2015; pp. 115–120. [Google Scholar]
- Chen, C.; Zhu, X.; Shen, P.; Hu, J.; Guo, S. An efficient privacy-preserving ranked keyword search method. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 951–963. [Google Scholar] [CrossRef]
- Li, S.; Wang, X. Multi-user verifying completeness and integrity encrypted keyword query in cloud storage. Comput. Eng. Appl. 2016, 52, 132–138. [Google Scholar]
- Lu, H.; Li, X. Multi-Keyword Search Scheme Based on Minhash Function in Secure Cloud Environment. Sci. Technol. Eng. 2015, 15, 89–95. [Google Scholar]
- Guo, Z.; Lin, T. Research on Fast Clustering K-means Algorithm for Large-scale Data. Comput. Appl. Softw. 2017, 34, 43–47. [Google Scholar]
- Kong, Z. The Design and Implementation of Text Classification System Based on VSM; Harbin Institute of Technology: Harbin, China, 2014; pp. 15–17. [Google Scholar]
- Ding, Y.; Xu, Z.; Ye, J.; Choo, K. Secure outsourcing of modular exponentiations under single untrusted programme model. J. Comput. Syst. Sci. 2016, 90, 1–13. [Google Scholar] [CrossRef]
- Wei, Y.; Pasalic, E.; Hu, Y. A New Correlation Attack on Nonlinear Combining Generators. IEEE Trans. Inf. Theory 2011, 57, 6321–6331. [Google Scholar] [CrossRef]
- Wei, Y.; Pasalic, E.; Hu, Y. Guess and Determine Attacks on Filter Generators—Revisited. IEEE Trans. Inf. Theory 2012, 58, 2530–2539. [Google Scholar] [CrossRef]
- Wang, Y.; Pang, H.; Yang, Y.; Ding, X. Secure server-aided top-k monitoring. Inf. Sci. 2017, 420, 345–363. [Google Scholar] [CrossRef]
- Yang, H.; Chang, Y. App-DDoS detection method based on K-means multiple principal component analysis. J. Commun. 2014, 35, 16–24. [Google Scholar]
- Peng, C. Distributed K-Means clustering algorithm based on Fisher discriminant ratio. J. Jiangsu Univ. (Natl. Sci. Ed.) 2014, 35, 422–427. [Google Scholar]
- Wong, W.; Cheung, D.; Kao, B.; Mamoulis, N. Secure KNN computation on encrypted databases. In Proceedings of the ACM Special Interest Group on Management of Data International Conference on Management of Data, Providence, RI, USA, 29 June–2 July 2009; ACM Press: New York, NY, USA, 2009; p. 139152. [Google Scholar]
- Wang, Y.; Pang, H.; Tran, N.; Deng, R. CCA Secure encryption supporting authorized equality test on ciphertexts in standard model and its applications. Inf. Sci. 2017, 414, 289–305. [Google Scholar] [CrossRef]
- Li, L. Text Categorization Corpus (Fudan) Test Corpus. Available online: http://www.nlpir.org/?action-viewnews-itemid-103 (accessed on 1 December 2017).




© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, L.; Wang, Z.; Wang, Y.; Yang, H.; Zhang, J. New Multi-Keyword Ciphertext Search Method for Sensor Network Cloud Platforms. Sensors 2018, 18, 3047. https://doi.org/10.3390/s18093047
Xie L, Wang Z, Wang Y, Yang H, Zhang J. New Multi-Keyword Ciphertext Search Method for Sensor Network Cloud Platforms. Sensors. 2018; 18(9):3047. https://doi.org/10.3390/s18093047
Chicago/Turabian StyleXie, Lixia, Ziying Wang, Yue Wang, Hongyu Yang, and Jiyong Zhang. 2018. "New Multi-Keyword Ciphertext Search Method for Sensor Network Cloud Platforms" Sensors 18, no. 9: 3047. https://doi.org/10.3390/s18093047
APA StyleXie, L., Wang, Z., Wang, Y., Yang, H., & Zhang, J. (2018). New Multi-Keyword Ciphertext Search Method for Sensor Network Cloud Platforms. Sensors, 18(9), 3047. https://doi.org/10.3390/s18093047