Traffic Estimation for Large Urban Road Network with High Missing Data Ratio



1
Department of Automatic Control and Systems Engineering, University of Sheffield, Sheffield S1 3JD, UK
2
Department of Computer Science, University of Sheffield, Sheffield S1 4DP, UK
*
Author to whom correspondence should be addressed.
Sensors 2019, 19(12), 2813; https://doi.org/10.3390/s19122813
Submission received: 29 May 2019
/
Revised: 18 June 2019
/
Accepted: 20 June 2019
/
Published: 24 June 2019
(This article belongs to the Section Intelligent Sensors)
Abstract
:Intelligent transportation systems require the knowledge of current and forecasted traffic states for effective control of road networks. The actual traffic state has to be estimated as the existing sensors does not capture the needed state. Sensor measurements often contain missing or incomplete data as a result of communication issues, faulty sensors or cost leading to incomplete monitoring of the entire road network. This missing data poses challenges to traffic estimation approaches. In this work, a robust spatio-temporal traffic imputation approach capable of withstanding high missing data rate is presented. A particle based approach with Kriging interpolation is proposed. The performance of the particle based Kriging interpolation for different missing data ratios was investigated for a large road network comprising 1000 segments. Results indicate that the effect of missing data in a large road network can be mitigated by the Kriging interpolation within the particle filter framework.
1. Introduction
Intelligent Transportation Systems (ITS) require accurate knowledge of traffic states for effective traffic monitoring and control. Traffic states are usually estimated from noisy sensor measurements [1] using various approaches, which can typically be subdivided into model based approaches, data driven approaches or streaming-data-driven [2]. An overview of the different modelling methodologies is given in Refs. [3,4]. These modelling methodologies include microscopic, macroscopic and mesoscopic approaches. Microscopic traffic models [3,4,5,6] describe the motion of each individual vehicle with a high level of detail. Hao et al. [7,8] recently proposed a model predictive control (MPC) termed urban cell transmission model (UCTM) for optimal switching of traffic lights at intersections based on the predicted traffic.
In macroscopic models [9,10], traffic state is represented by aggregating behaviour of the traffic, usually in terms of the average speed and the average density over a given period of time. Mesoscopic models [3] employ some features of microscopic and macroscopic approaches by utilising varying levels/degrees of detail to model traffic behaviour. This is achieved by modelling some locations with aggregated measurements as in macroscopic and the remaining locations are modelled down to the details of individual vehicles as is done in the case of microscopic.
Macroscopic models are sufficient to produce acceptable estimation accuracy when compared to the computational overhead of the microscopic models. Hence, they are the preferred choice for most practical purposes such as traffic control/management, road pricing and changes in infrastructure. Most traffic estimation approaches are model based [2], while the new trend is to develop data driven approaches [11].
Data driven methods rely on historical data or streaming/real-time data. Within the last decade, there has been growing interest in applying Kriging to traffic state prediction; for directional traffic volume using global position system (GPS) data [12], annual average traffic count interpolation using origin-destination data [13], estimating annual average daily traffic [14,15], traffic volume prediction [16,17], and traffic volume imputation [18].
Kriging is one of the most flexible data driven methods originally employed in geo-statistics or spatio-temporal analysis. Kriging exploits the spatial dependence (either covariance or variogram) using a weighted sum of observed data points to interpolate the values at locations of interest. It was initially used for copper mining by Krige [19] and was developed further by Matheron [20]. Since then, it has been applied in other fields such as spatial analysis and computer experiments. In the recent times, the method has been applied in traffic prediction [12].
One of the major challenges faced in traffic prediction is the issue of missing or sparse data. Traffic measurements are generally captured with different types of sensors and transmitted through communication infrastructure for processing and utilisation. These infrastructures are subject to failure and malfunction occasionally leading to incomplete/missing data, sometimes more than 40% [21]. The problem of sparse data is caused by the high cost of installing and managing traffic measurement devices making them impractical to cover all locations needed for effective observation of the full road network.
To address these challenges, researchers resorted to various methods and approaches such as missing data imputation [22], compressive sensing and historical averages [23], and Kriging interpolation [16]. In Ref. [24], a particle filter (PF) with the stochastic compositional model (SCM) is developed to estimate traffic states in motorways. Boundary measurements (inflow and outflow) were used to estimate the traffic state within the segments. The study reported that missing boundary measurements affected the estimated accuracy. A solution to the problem of missing data in particle filter measurement update was proposed in our previous work [25]. Here Kriging methods were used to interpolate the missing data which is subsequently used for the computation of the PF likelihood for traffic state estimation.
This work extends the approach of [25] for a larger road network of several kilometres with 1000 segments under the influence of missing data and/or sensor failure. The task of training such large segments would be resource intensive, hence the reduced measurement space, proposed in Ref. [26], was used to select the most influential segments in the road network. The drawback of Ref. [26] is that the most influential segments are selected based on only available measurements without considering any missing values. This would mean that if some interconnected segments have missing data, they would not be used leading to information loss. To address this, we propose a new approach, that combines the benefits of both approaches ([25,26]) in a single framework. First, the most probable segments are selected using the column based matrix decomposition (CBMD). Second, when there are missing measurements in the segments, Kriging is used to estimate the measurements before the measurement update step (see Section 5.3).
The present work differs from Refs. [12,16] in the following ways. Whereas [12,16] employed Kriging for predicting vehicular speed, our approach used Kriging to estimate missing vehicular flow and speed measurements which is then applied to the computation of measurement update step for particle filter estimation. In addition, our approach combines speed and vehicular flow estimation unlike the former which predicted only speed. The approaches used in Refs. [12,16] are similar, the only difference being that the former proposes the use of alternate distance metric called Approximate Road Distance Network (ARDN) to replace the Euclidean distance metric.
The contribution of this work is twofold: (i) A robust spatio-temporal traffic imputation that can withstand higher missing data proportion via information exchange between correlated segments. (ii) the use of Kriging and particle filter to address the effects of high missing/sparse data. A Column based matrix decomposition is used to select most influential segments in large road network and then imputing any missing measurements in the selected segments using Kriging.
The rest of the paper is organised as follows. Section 2 discusses some related work followed by the presentation of traffic flow and measurement model used in this work in Section 3. A background theory of random sets, covariance and variograms, which is the building block of Kriging is presented in Section 4. Recursive Bayesian estimation and particle filters (PF) are presented in Section 5. The proposed method was discussed in Section 5.3. Results and discussion are presented in Section 6.2 with conclusions being drawn in Section 7.
2. Related Work
A review of three different missing data imputation methods was presented by Ref. [27]. These include interpolation, prediction and statistical learning. The interpolation method imputes missing measurement at the particular location by averaging all historical measurements at that location at similar times of day. Prediction methods use a deterministic mathematical description to model the relationship between historical and future data. The statistical methods on the other hand treats the traffic as a random variable and tries to capture stochastic nature of the traffic pattern into the imputation algorithm.
In Refs. [28,29,30], a multi-resolution approximation using linear combinations of basis functions was proposed to address computational complexity of large datasets. The novelty in Ref. [28] lies in the use of multiple basis functions computed at lower resolutions closer to observation locations and then combining them to capture the different covariance functions with varying properties. The solution is achieved by dividing the spatial domain recursively into small regions and smaller sub-regions until the fine-scale dependencies are captured.
Nychka et al. [28] used radial basis functions (RBF) and special type of Gaussian Markov random field (GMRF) called spatial autoregressive (SAR) model to model the spatial correlation among the coefficients while Katzfuss et al. [30] automatically determines the appropriate basis/covariance function. Whereas in Ref. [29], it was assumed that the sub-domains are independent, Ref. [30] assumed depended sub-domains and performed full-scale approximation. As the computations are done locally in parallel, it is possible to fuse multisensor data sources, in which case, the different covariance functions are used for each data source. While both mentioned that the approach could be extended to non-stationary functions, it was not implemented nor was there a derivation for such. The different methods on missing traffic data imputation considered small road network in the range of a few kilometres.
3. Model Formulation
Consider a general discrete time state space system of a form,
where is a nonlinear function of the target state vector , represents a nonlinear relationship between sensor output and target state vector affected by a measurement noise . In addition, is the probability density function of the new state given the previous state , and is the likelihood function of the measurement given the state .
3.1. Stochastic Compositional Traffic Flow Model
In this work, a stochastic compositional model (SCM) [31] is considered for modelling of a motorway/freeway vehicle traffic evolution expressed as in Equation (1). This extended cell-transition model incorporates traffic speed and uses forward and backward waves to describe the complex relationship between traffic behaviour especially for a large road network. SCM utilises sending and receiving functions which models the stochastic nature of traffic state evolution. The vehicles that are able to leave a cell are represented by receiving functions while those that are allowed to enter a cell are determined by the receiving functions. The receiving functions are usually less than or equal to the sending functions to obey the law of conservation of vehicles.
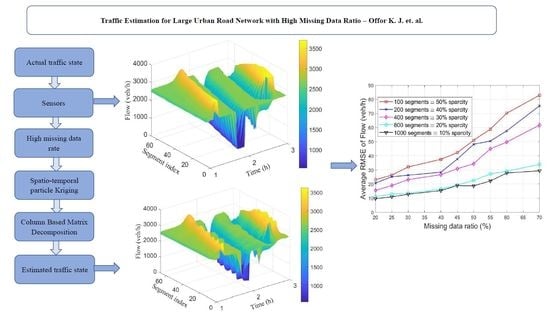
In the SCM, the road network is divided into a given number of cells, n, also called segments. Each segment has a length and number of lanes as shown in Figure 1, where . At any given time period k, a certain number of vehicles crosses the boundary between two segments i and . The number of vehicles in a given cell i within the same time period k is represented by with their average speed given by .
The overall state vector at time k is given by where is the local state vector at segment i. Equations (3)–(5) models traffic state evolution within the cells.
where , called inflow represents the number of vehicles entering the first cell with average speed , , called outflow represents the number of vehicles leaving the last segment with average speed . The inflow and outflow vehicles with their average speeds are called the boundary conditions and are supplied to the model at the beginning.
3.2. Measurement Model
Consider the road network shown in Figure 1 divided into different segments with n boundaries. The traffic state at a boundary is sampled at discrete time steps , , to give . The measurements at all the boundaries are collected into a matrix given by . The relationship between the sampling interval and the state update time step Equation (1) is such that sampling interval is split into q state update time steps. That is, . The measurement model and noise is represented by Equation (6) with error = . With the assumption of Gaussian noise, can be expressed as:
4. Random Sets, Covariances and Variograms
4.1. Random Set
Let be a non-stationary set of m measurements , in our case average vehicle speeds or vehicle counts , observed in segments at locations , where . Note that location of each sensor is uniquely defined by the segment topology (Figure 1). Then, according to Equation (7),
the random set of variables can be approximated by a Gaussian process which is uniquely defined by the drift, i.e., the mean field , and the corresponding covariance . Individual samples of the set Equation (7) can be also expressed as
with drift and residual . Based on the degree to which the moments, in our case mean and variance of the random set are dependent (or independent) on a spatial relationship between points , the 1st or the 2nd-order of stationarity can be recognised. While, the 1st-order stationary random set assumes a constant mean , the 2nd-order stationary random field assumes a linear drift between the increments . In the rest of this sequel, we assume that the random set is intrinsic and stationary on the 2nd-order.
4.2. Covariance
By assuming that random variables are 2nd-order stationary and isotropic, the covariance function in Equation (7) reads as follows:
The role of covariance function is to model the correlation between measurements and observed at locations and based on their separation distance called a lagh. Since the correlation between two random variables solely depends on their spatial distance, and not at all on their location, the lag can be conveniently expressed as an Euclidean norm, defined as . Above statements can be summarised into the following equalities, i.e., the isotropy assumptions:
For a straight stretch of motorway (Figure 1) this is equivalent to the path length through the road network.
The process of covariance function modelling requires to find a covariance curve that has the best fit to the empirical data Equation (9), possibly being a subject to constraints. The covariance models to choose from include exponential, spherical, Gaussian, linear or power model [14]. In this work, the best fit for the dataset was achieved by the exponential model depicted in Figure 2a and given by
where a is the nugget, b is the range and c is still.
As can be observed in Figure 2a, observe that the covariance function decreases with distance, so it can be thought of as a similarity function.
5. Recursive Bayesian Estimation
5.1. Bayesian Estimation
Consider a general discrete time state space system represented as in Equations (1) and (2). The goal of Bayesian estimation is to infer the state variable as defined in Section 3.1 with the available sensor measurements . By using the Bayesian framework, this estimation problem relates to the recursive evaluation of the probability density function (PDF) in two consecutive steps, the prediction and the measurement update of the state vectors.
The prediction state density of state is calculated from the prior PDF by using Chapman-Kolmogorov equation
Equation (14) follows the 1st order Markov property which assumes that only depends on state and at time k and respectively. The measurement update is computed from the prior distribution of Equation (14) and measurements by a Bayesian formula which results in
The 1st order Markov property for Equation (15) implies that only depends on measurement at time k.
5.2. Particle Filter
Arguably, the most popular algorithm for nonlinear recursive estimation is the particle filter (PF), extensively evaluated in Ref. [32]. PF represents any arbitrary probability density function by samples or particles , where is the number of particles, i.e.,
The particles are used to form an approximative distribution as
where is an approximated distribution, is a the Dirac delta function and the weights of the particles satisfying . The time update of the Bayesian recursion Equation (1) is in case of PF evaluated as
The particles in above Equation (18) are sampled from proposal distribution , i.e., . Proposal distribution is very often defined by the state transition PDF, that is . In this case, the weights updates result to
The measurement update (2) is computed by a Equation (15), which can be in terms of the particles represented as
Similarly, the particle filter weights are updated as
The denominator in Equations (15) and (21) is only a normalising factor independent of thus can be safety omitted if the distribution is numerically normed as shown by Equations (20) and (21).
The MC recursion tempt to degrade over time as all relative weights would tend to zero except for one that tends to one. Therefore, when particle depletion ratio reaches 0.5 a Sampling Importance Resampling (SIR) or Sampling Importance Sampling (SIS) techniques are applied in the recursion.
5.3. Missing Measurement Interpolation and Improved Likelihood Computation
For a large road network with many segments, using all the measurements in the particle filter measurement update step becomes computationally intensive. Column based matrix decomposition approach similar (as earlier stated in Section 1) to the work of [26] is employed to select the most probable segments that would give acceptable accuracy.
The idea is to select m most influential segments from all available segments n using CBMD and then estimating missing measurements (if any) of the most influential segments using Kriging for improved particle likelihood computation. Let represent a set of all segments or measurement locations in a given time period, where the rows, k is number of time instances at which the measurements were taken and columns n number of road segments.
The goal of CBMD is to approximate the measuremtns with a subset of measurements where is a subset of the measurements using singular value decomposition (SVD) as Ref. [33]:
where is the transformation matrix that expresses every column of all measurement in terms of the basis in . Having computed the SVD, the right singular matrix is used to assign a probability to each selected location according to:
where is the ith element of the jth right singular vector and r is the rank of the matrix. From the probabilities computed, m locations with the highest probabilities are chosen as the reduced measurement to approximate the entire network which is used in computing the particle filter likelihood during the measurement update step.
The likelihood function term in Equation (21), is computed when a new measurement arrives. The performance of the PF degrades substantially when there is a missing measurement. For the multivariate Gaussian distribution, the PDF is given by:
where is the covariance matrix of the measurement data, is the determinant of and is the difference between the PF predicted value () and measurement (), given by:
The measurement matrix can be expressed as,
where represents the value estimated by Kriging (when measurement is not available). Note that the sampling time index is split into q update time indices as mentioned in Section 3.2. The measurement update state of the PF is performed only when ≡. The modified particle method is presented in Algorithm 1.
| Algorithm 1 Particle Filter for Traffic State Estimation with Kriging Estimated Measurements [24] |
|
5.4. Missing Data Estimation via Kriging Models
The underlying idea of Kriging is to obtain the response , interpreted as a random variable positioned at the location , by interpolating random variables from Equation (7), i.e., observations , at locations . The Kriging predictor incorporates the covariance structure among the observation points into the weights for predicting as a linear combination:
In order to assess the accuracy of the Kriging prediction w.r.t the real (true) value an error is declared
The following criteria, evaluated in terms of mean and variance of the prediction error Equation (29), apply to any type of Kriging interpolation:
Kriging weights are chosen such that the mean squared prediction error Equation (31), also known as Kriging variance or Kriging error is minimised as over all Equation (31) subject to the unbiased conditions of Equations (30) and (32) by a Lagrange multiplier to give,
where matrix is the covariance between the individual samples and column vector is a covariance function between samples and the point to interpolate.
6. Performance Evaluation
A road network with 1000 segments was simulated using SUMO software [34] to validate the proposed method. The segments are spaced 0.5 km apart and measurements (number of vehicles crossing each segment boundary with their average speed) taken every second. Traffic signs were installed at some locations to model the effect of congestion.
This is an extension of the previous work [25] where a smaller number segments was considered. The aggregate traffic flow and speed were sampled every 60 s and the results collected over a period of 10,800 s (3 h). Two types of vehicles, bus and passenger car was defined with the parameters as in Table 1.
The vehicles were added randomly into the network through the inflow boundary every one second and they travel through the network until they get to the last boundary when they leave the network. As a vehicle crosses each induction loop, it is counted with its speed. The average speed of the vehicles arriving at an induction loop over a period is recorded as the average speed. The entire statistics, flow, occupancy, and speed are collected in an output file for further processing.
6.1. Simulation Design
To simulate different scenarios such as congestion and free flow, (i) the number of lanes were decreased from 3 to 2, and (ii) the rate of vehicle injection into the network is varied at different time periods. Figure 3 and Figure 4 show the spatio-temporal evolution of the traffic and their corresponding average speed, respectively, for a 100 segment section. The average speed of the vehicles varies around 100 km/h when the flow was around 2000 veh/h. Between time interval [1.5 h, 1.7 h], the flow was increased slightly to cause congestion, this resulted to a decrease in the average speed as can be seen in the first spike from Figure 4.
Observe that the effect was felt more close to the inflow boundary. The vehicles’ speed increases marginally as they move into the network. Between time interval [1.6 h, 1.9 h] the flow was decreased leading to increase in the average speed. Finally, the number of lanes in segments 10 to 14 were reduced from 3 to 2 between time interval [2.4 h, 2.4 h] while maintaining vehicle injection rate. This results to substantive decrease in speed as can be seen (cone-shaped) in Figure 4. As the vehicles leave the segments with closed lanes, there is increase in their speed again.
6.2. Results and Discussion
In order to test the prediction accuracy for different levels of sparsity, a statistical measure namely the root mean squared error (RMSE), was computed. Note, is the ground truth or actual measurement, is the estimated value and is number of independent Monte Carlo runs. The measurements at some boundaries were randomly removed each time and then estimated using the proposed method. Different missing data rates (from 10, 20, …, 70%) were investigated by randomly removing measurements at some locations using leave one out cross validation. This was repeated for 100 Monte Carlo runs and the average value used.
Figure 5 and Figure 6 show the average estimation error for the different missing data ratios and the number of segments. It would be observed that the prediction error increases with the missing data rate. This is expected as less data is available for the computation. This effect could be reduced further by incorporating a mechanism known as multi resolution approach [30].
The plots also show that the higher the number of segments used, the better the accuracy. This could be attributed to the fact that there is better information exchange within the network and hence, on average, more segments with available data are used for the higher dimensional segments scenario. This is in agreement with [35] where estimation accuracy in the presence of sparse sensor data was improved by exchanging particle weights between segments. For instance, a 10 segment network with 70% missing data ratio will result to using only 3 data points to estimate the remaining 7 missing locations. The chances of these 3 locations correlating with the other 7 is lower compared to when 30 out of 100 data points are available.
Figure 7 and Figure 8 show the spatio-temporal evolution of the traffic flow and the corresponding average speed for the 100 segment scenario.
The number of vehicles crossing each boundary in space and their associated average speed is represented by the colour bar.Compared to the ground truth shown in Figure 3 and Figure 4, it is evident that estimated number of vehicles crossing segment boundaries and the associated speeds have been estimated with a good accuracy. Observe also that the estimated flow and speed captured the periods where there is drop in number of vehicles and decrease in speed.
7. Conclusions
This paper presented a traffic estimation for a large road network with different missing data ratios. The computational overhead of the large network was addressed by using a method called reduced measurement space proposed by [26] to select the most influential and information rich segments in the road network. These are subsequently used in the particle filter measurement update step. Missing data in the selected segments are imputed using Kriring. A 1000-segment road network was simulated using SUMO. Different missing data ratios ranging from 10% to 70% were tested for different sizes of road network ranging from 100 to 1000 segments.
The results indicate that considering a larger number of segments would reduce the overall estimation error even when the missing data ration is high. From the foregoing results and discussion, it is recommended that the best estimation accuracy would be obtained when the entire road network is considered at once. The effects of computational overhead could further be reduced by using a distributed approach with a central control unit.
Author Contributions
Ideas/conceptualisation, L.S.M., K.J.O.; methodology, L.S.M., K.J.O. and L.V.; software: particle filter/traffic models, L.S.M.; Kriging/sparsity, K.J.O.; implementation, K.J.O., L.S.M. and L.V.; validation, K.J.O., L.V.; formal analysis, K.J.O., L.S.M. and L.V.; investigation, K.J.O.; writing—original draft preparation, K.J.O.; writing—review and editing, L.V., L.S.M., K.J.O.; visualisation, K.J.O.
Funding
The authors acknowledge the support from the SETA project funded from the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 688082 and the Tertiary Education Trust Fund (TETFund, Nigeria). The APC was funded by Department of Automatic Control and Systems Engineering, University of Sheffield.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Ferrara, A.; Sacone, S.; Siri, S. State estimation in freeway traffic systems. In Freeway Traffic Modelling and Control. Advances in Industrial Control; Springer International Publishing: Cham, Switzerland, 2018; pp. 169–190. [Google Scholar]
- Seo, T.; Bayen, A.M.; Kusakabe, T.; Asakura, Y. Traffic state estimation on highway: A comprehensive survey. Annu. Rev. Control 2017, 43, 128–151. [Google Scholar] [CrossRef] [Green Version]
- Hoogendoorn, S.P.; Bovy, P.H.L. Generic gas-kinetic traffic systems modeling with applications to vehicular traffic flow. Transp. Res. Part B 2001, 35, 317–336. [Google Scholar] [CrossRef]
- Papageorgiou, M.; Ben-Akiva, M.; Bottom, J.; Bovy, P.H.L.; Hoogendoorn, S.P.; Hounsell, N.B.; Kotsialos, A.; Mcdonald, M. ITS and traffic management. In Handbooks in Operations Research and Management Science; Elsevier: Amsterdam, The Netrerlands, 2007; Chapter 11; Volume 14. [Google Scholar]
- Pipes, L.A. An operational analysis of traffic dynamics. J. Appl. Phys. 1953, 24, 274–281. [Google Scholar] [CrossRef]
- Gipps, P.G. A behavioural car-following model for computer simulation. Transp. Res. Part B Methodol. 1981, 15, 105–111. [Google Scholar] [CrossRef]
- Hao, Z.; Boel, R.; Li, Z. Model based urban traffic control, part I: Local model and local model predictive controllers. Transp. Res. Part C Emerg. Technol. 2018, 97, 61–81. [Google Scholar] [CrossRef]
- Hao, Z.; Boel, R.; Li, Z. Model based urban traffic control, part II: Local model and local model predictive controllers. Transp. Res. Part C Emerg. Technol. 2018, 97, 23–44. [Google Scholar] [CrossRef]
- Messmer, A.; Papageorgiou, M. METANET: A macroscopic simulation program for motorway networks. Traffic Eng. Control 1990, 31, 466–470. [Google Scholar]
- Daganzo, C.F. The cell transmission model: A dynamic representation of highway traffic consistent with the hydrodynamic theory. Transp. Res. Part B 1994, 28, 269–287. [Google Scholar] [CrossRef]
- Lu, H.-P.; Sun, Z.-Y.; Qu, W.-C. Big data-driven based real-time traffic flow state identification and prediction. Discret. Dyn. Nat. Soc. 2015, 2015, 1–11. [Google Scholar] [CrossRef]
- Braxmeier, H.; Schmidt, V.; Spodarev, E. Kriged road-traffic maps. In Interfacing Geostatistics and GIS; Pilz, J., Ed.; Springer: Heidelberg, Germany, 2009; Chapter 9; pp. 105–119. [Google Scholar]
- Lowry, M. Spatial interpolation of traffic counts based on origin-destination centrality. J. Transp. Geogr. 2014, 36, 98–105. [Google Scholar] [CrossRef]
- Wang, X.; Kockelman, K.M.; Murray, W.J. Forecasting network data: Spatial interpolation of traffic counts from Texas data. Transp. Res. Rec. 2009, 2105, 100–108. [Google Scholar] [CrossRef]
- Gastaldi, M.; Gecchele, G.; Rossi, R. Estimation of annual average daily traffic from one-week traffic counts. A combined ANN-Fuzzy approach. Transp. Res. Part C Emerg. Technol. 2014, 47, 86–99. [Google Scholar] [CrossRef]
- Zou, H.; Yue, Y.; Li, Q.; Yeh, O.G.A. An improved distance metric for the interpolation of link-based traffic data using kriging: A case study of a large-scale urban road network. Int. J. Geogr. Inf. Sci. 2012, 26, 667–689. [Google Scholar] [CrossRef]
- Song, Y.; Wang, X.; Wright, G.; Thatcher, D.; Wu, P.; Felix, P. Traffic volume prediction with segment-based regression Kriging and its implementation in assessing the impact of heavy vehicles. IEEE Trans. Intell. Transp. Syst. 2019, 20, 234–243. [Google Scholar] [CrossRef]
- Yang, H.; Yang, J.; Han, L.D.; Liu, X.; Pu, L.; Chin, S.-M.; Hwang, H.-L. A Kriging based spatiotemporal approach for traffic volume data imputation. PLoS ONE 2018, 13, 1–11. [Google Scholar] [CrossRef]
- Krige, D.G. A statistical approach to some basic mine problems on the Witwatersrand. J. Chem. Metall. Soc. S. Min. Afr. 1951, 52, 119–139. [Google Scholar]
- Matheron, G. Principles of geostatistics. Econ. Geol. 1963, 58, 1246–1266. [Google Scholar] [CrossRef]
- Zhang, Y. A comparative study of three multivariate short-term freeway traffic flow forecasting methods with missing data. J. Intell. Transp. Syst. 2016, 20, 205–218. [Google Scholar] [CrossRef]
- Ladino, A.; Kibangou, Y.; Fourati, H.; Canudas de Wit, C. Travel time forecasting from clustered time series via optimal fusion strategy. In Proceedings of the 2016 European Control Conference (ECC), Aalborg, Denmark, 29 June–1 July 2016. [Google Scholar]
- Hawes, M.; Amer, H.M.; Mihaylova, L. Traffic state estimation via a particle filter with compressive sensing and historical traffic data. In Proceedings of the 2016 19th International Conference on Information Fusion (FUSION), Heidelberg, Germany, 5–8 July 2016; pp. 735–742. [Google Scholar]
- Mihaylova, L.; Boel, R.; Hegyi, A. Freeway traffic estimation within particle filtering framework. Automatica 2007, 43, 290–300. [Google Scholar] [CrossRef] [Green Version]
- Offor, K.J.; Hawes, M.; Mihaylova, L.S. Short term traffic flow prediction with particle methods in the presence of sparse data. In Proceedings of the 2018 21st International Conference on Information Fusion (FUSION), Cambridge, UK, 10–13 July 2018; pp. 1205–1212. [Google Scholar]
- Hawes, M.; Amer, H.M.; Mihaylova, L. Traffic state estimation via a particle filter over a reduced measurement space. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017. [Google Scholar]
- Li, Y.; Li, Z.; Li, L. Missing traffic data: Comparison of imputation methods. IET Intell. Transp. Syst. 2014, 8, 51–57. [Google Scholar] [CrossRef]
- Nychka, D.; Bandyopadhyay, S.; Hammerling, D.; Lindgren, F. A multiresolution Gaussian process model for the analysis of large spatial datasets. J. Comput. Graph. Stat. 2015, 24, 579–599. [Google Scholar] [CrossRef]
- Katzfuss, M.; Hammerling, D. Parallel inference for massive distributed spatial data using low-rank models. Stat. Comput. 2017, 27, 363–375. [Google Scholar] [CrossRef]
- Katzfuss, M. A multi-resolution approximation for massive spatial datasets. J. Am. Stat. Assoc. 2017, 112, 201–214. [Google Scholar] [CrossRef]
- Boel, R.; Mihaylova, L. A compositional stochastic model for real-time freeway traffic simulation. Transp. Res. Part B Methodol. 2006, 40, 319–334. [Google Scholar] [CrossRef]
- Gustafsson, F. Particle filter theory and practice with positioning applications. IEEE Aerosp. Electron. Syst. Mag. 2010, 25, 53–82. [Google Scholar] [CrossRef]
- Mitrovic, N.; Asif, M.T.; Dauwels, J.; Jaillet, P. Low-dimensional models for compressed sensing and prediction of large-scale traffic data. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2949–2954. [Google Scholar] [CrossRef]
- Behrisch, M.; Bieker, L.; Erdmann, J.; Krajzewicz, D. SUMO—Simulation of urban mobility—An overview. In Proceedings of the SIMUL 2011, The Third International Conference on Advances in System Simulation, Barcelona, Spain, 23–28 Oktober 2011; pp. 63–68. [Google Scholar]
- Mihaylova, L.; Hegyi, A.; Gning, A.; Boel, R.K. Parallelized particle and Gaussian sum particle filters for large-scale freeway traffic systems. IEEE Trans. Intell. Transp. Syst. 2012, 13, 36–48. [Google Scholar] [CrossRef]
Figure 1.
Stochastic compositional model (SCM) road network showing segments and measurement points [31].
Figure 1.
Stochastic compositional model (SCM) road network showing segments and measurement points [31].
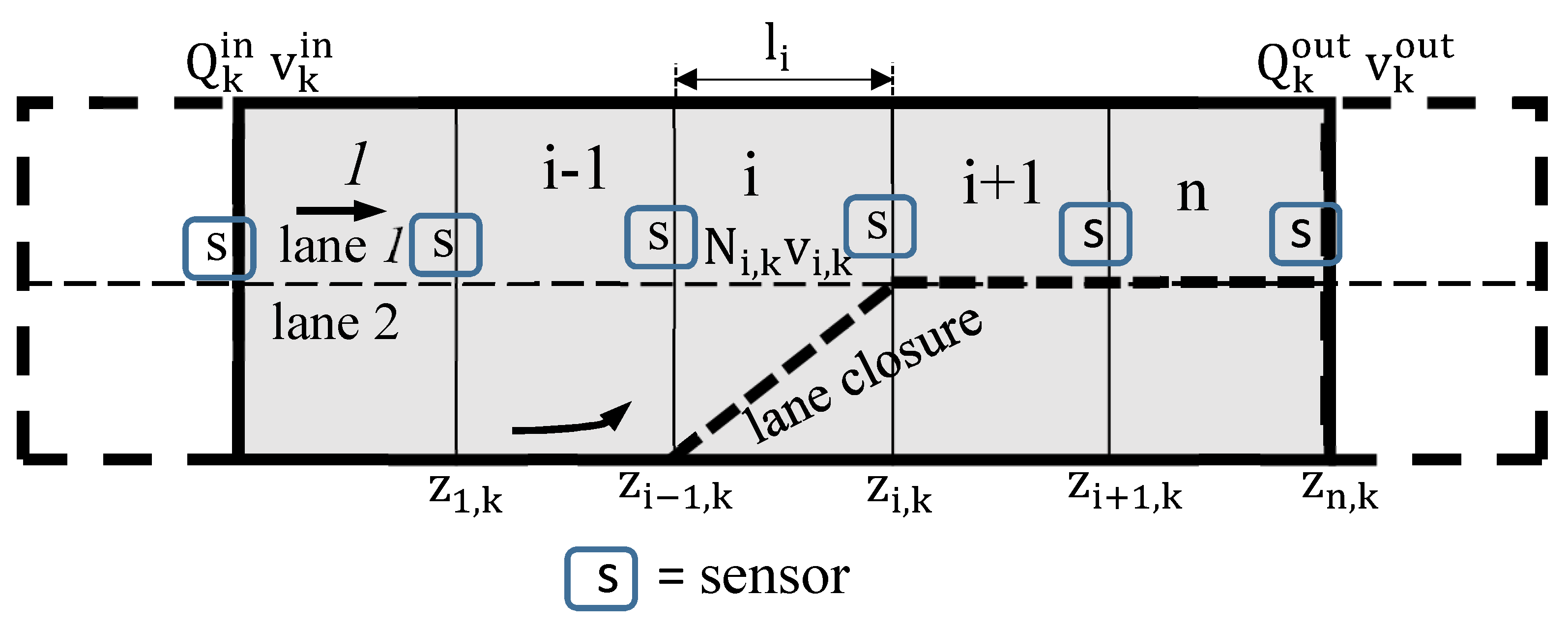
Figure 2.
Covariance and variogram models.

Figure 3.
Spatio-temporal evolution of traffic flow for the 100 segment.
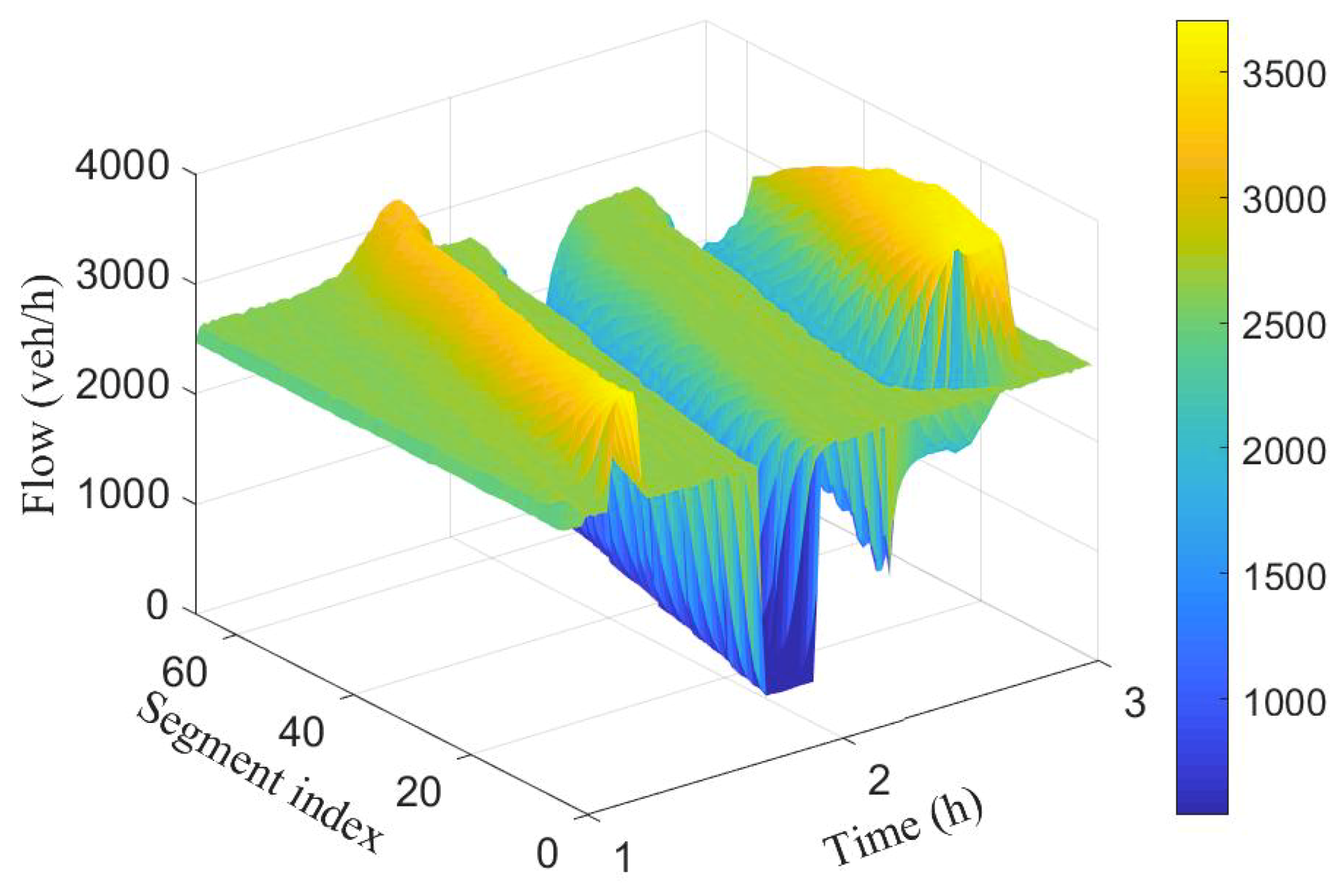
Figure 4.
Spatio-temporal evolution of traffic speed for the 100 segment.

Figure 5.
RMSE of speed at different missing data ratios.

Figure 6.
RMSE of flow at different missing data ratios.

Figure 7.
Estimated flow for the 100 segment with 30% missing data.

Figure 8.
Estimated speed for the 100 segment with 30% missing data.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
SUMO simulation parameters.
| Car | Bus | |
|---|---|---|
| Max speed | 25 m/s | 20 m/s |
| Acceleration | 1.0 m/s | 0.8 m/s |
| Deceleration | 4.5 m/s | 4.5 m/s |
| Sigma (driver perfection) | 0.5 | 0.5 |
| Length | 5 m | 10 m |
| Minimum Separation | 2.5 m | 3 m |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Offor, K.J.; Vaci, L.; Mihaylova, L.S. Traffic Estimation for Large Urban Road Network with High Missing Data Ratio. Sensors 2019, 19, 2813. https://doi.org/10.3390/s19122813
AMA Style
Offor KJ, Vaci L, Mihaylova LS. Traffic Estimation for Large Urban Road Network with High Missing Data Ratio. Sensors. 2019; 19(12):2813. https://doi.org/10.3390/s19122813
Chicago/Turabian StyleOffor, Kennedy John, Lubos Vaci, and Lyudmila S. Mihaylova. 2019. "Traffic Estimation for Large Urban Road Network with High Missing Data Ratio" Sensors 19, no. 12: 2813. https://doi.org/10.3390/s19122813
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.