Reinforcement Learning-Based Data Forwarding in Underwater Wireless Sensor Networks with Passive Mobility

Institute of Meteorology and Oceanography, National University of Defense Technology, Nanjing 211101, China
*
Author to whom correspondence should be addressed.
Sensors 2019, 19(2), 256; https://doi.org/10.3390/s19020256
Submission received: 17 December 2018
/
Revised: 4 January 2019
/
Accepted: 5 January 2019
/
Published: 10 January 2019
(This article belongs to the Collection Smart Ocean: Emerging Research Advances, Prospects and Challenges)
Abstract
:Data forwarding for underwater wireless sensor networks has drawn large attention in the past decade. Due to the harsh underwater environments for communication, a major challenge of Underwater Wireless Sensor Networks (UWSNs) is the timeliness. Furthermore, underwater sensor nodes are energy constrained, so network lifetime is another obstruction. Additionally, the passive mobility of underwater sensors causes dynamical topology change of underwater networks. It is significant to consider the timeliness and energy consumption of data forwarding in UWSNs, along with the passive mobility of sensor nodes. In this paper, we first formulate the problem of data forwarding, by jointly considering timeliness and energy consumption under a passive mobility model for underwater wireless sensor networks. We then propose a reinforcement learning-based method for the problem. We finally evaluate the performance of the proposed method through simulations. Simulation results demonstrate the validity of the proposed method. Our method outperforms the benchmark protocols in both timeliness and energy efficiency. More specifically, our method gains 83.35% more value of information and saves up to 75.21% energy compared with a classic lifetime-extended routing protocol (QELAR).
1. Introduction
Nowadays, marine surveillance, water contamination detection and monitoring, and oceanographic data collection are indispensable to the exploration, protection and exploitation of aquatic environment [1]. Because of the huge amount of unexploited resources in the ocean, there is an urgent need for research in the field of sensors and sensor networks [2]. Underwater Wireless Sensor Networks (UWSNs) has become a main approach to gain information from previously inaccessible waters. Traditional wireless sensor networks (WSNs) consist of a large number of sensor nodes randomly distributed in a detection field, and these nodes are usually either stationary or moving in limited ranges. However, in many practical scenarios, the movement of nodes is relatively large, such as nodes in UWSNs, delay-tolerant networks, vehicular networks, etc. Nodes in UWSNs can be categorized as stationary nodes and moving nodes. Stationary nodes are anchored to the water bottom while moving nodes can move in a preset velocity, such as Autonomous Underwater Vehicles (AUVs). Nevertheless, only a few researchers take passive mobility of nodes into account. More specifically, nodes may move along internal currents or vortices. Underwater nodes have no access to GPS signals, and the network topology is completely time varying due to irregular mobilities of water currents, which is essentially different from terrestrial WSNs. Meanwhile, due to dynamic topology changes and poor communication conditions underwater, data packets cannot be delivered to the sink nodes deployed on the water surface rapidly.
A major challenge of UWSNs is real-time requirements. For instance, fishery surveillance and real-time monitoring of precious assets such as petroleum pipelines. Specifically, report delay of sea properties such as temperatures may lead to serious loss of temperature sensitive sea animals, e.g., sea cucumbers, because they dissolve fast in high temperatures. Moreover, the detection of leakages of coal oil in early stage prevents water contamination and further resource waste. Therefore, we adopt the concept of the value of information (VoI) which evaluates information in terms of timeliness [3]. Additionally, UWSNs are energy constrained due to the fact that they cannot be recharged or replaced, so their ability to route data diminishes when sensor nodes run out of energy. Network lifetime remains the performance bottleneck which perhaps is one main obstacle in the wide scale deployment of wireless sensor networks [4,5]. In this case, energy consumption is also a fundamental issue in UWSNs.
In conclusion, it is significant to consider the timeliness and energy consumption of data forwarding in UWSNs, along with the passive mobility of sensor nodes. Motivated by the timeliness demand and the energy constraint of UWSNs, we aim to explore data forwarding in UWSNs with passive mobility, jointly considering the timeliness of packets and the energy consumption of the sensor nodes. Due to irregular dynamics of water, the node movement is unpredictable, i.e., the future status has little relevance to its historical trajectories. Consequently, the determination of the relay node of a sensor node depends on its current status and its neighborhood relationship. A reinforcement learning method is proposed in this paper. To the best of knowledge, we are the first to jointly consider timeliness and energy consumption of data forwarding in UWSNs with passive mobility.
The main contributions of this paper are as follows. We first formulate the problem of data forwarding, by jointly considering timeliness and energy consumption under a novel passive mobility model for UWSNs. We then propose a reinforcement learning-based method for the problem. We finally evaluate the performance of the proposed method through simulations. Experimental results demonstrated the validity of the proposed method and they also demonstrated the efficiency, compared with two benchmark methods.
The rest of this paper is organized as follows. Section 2 will review the related work of the proposed method. Section 3 will introduce the preliminaries, including the system model, notations and problem definitions, and the proposed method. Section 4 will show the simulation results. Section 5 will present the discussion of the simulation results and the look out for future work.
2. Related Work
Data forwarding for underwater wireless sensor networks has drawn a lot of attention in the past decade. There are several kinds of routing protocols that aim to improve energy efficiency, timeliness and adaptability to node mobility of UWSNs. In this section, we review the related work on this topic.
Lloret et al. have pointed out the urgent need and significance of UWSNs [1,2]. To satisfy the demand of timeliness of UWSNs, a lot of research was dedicated to decreasing the latency of data forwarding. Bassagni et al. [6] devised a forwarding method named Multi-modAl Reinforcement Learning-based RoutINg (MARLIN) protocol. The MARLIN strategy selects the best relay node along with the best communication channel, and it can be configured to seek reliable routes to the final destination, or to provide faster packet delivery. Gjanci et al. [3] proposed a Greedy and Adaptive AUV Path-finding (GAAP) heuristic. The GAAP strategy proposed a heuristic algorithm which aims to find the path of the AUV so that the value of information of the data delivered to sink nodes is maximized. It showed that the GAAP strategy delivers much more value of information than Random Selection (RS), Lawn Mower (LM) and Traveling Sales Man (TSP) strategies do. Nevertheless, the advantage of the GAAP strategy over the TSP strategy decreases with the network size which enables TSP strategy to collect more packets, and the average end-to-end delay of GAAP strategy is higher than TSP strategy.
Meanwhile, many energy-efficient forwarding methods are devised to prolong the network lifetime. Hu et al. [7] proposed a Q-Learning-based Energy-Efficient and Lifetime-Aware Routing (QELAR) Protocol for Underwater Sensor Networks. QELAR adopted Q-Learning algorithm which defines the residual energy of sensor nodes as the reward function. Therefore, in QELAR protocol, sensor nodes select the node with the most residual energy as the relay node, thus the network lifetime can be prolonged. However, QELAR did not constrain the end-to-end delay, which resulted in longer delay when the number of sensor nodes was increasing. Coutinho et al. [8] devised an Energy Balancing Routing (EnOR) Protocol for Underwater Sensor Networks. The EnOR protocol adopted the idea of balancing the energy consumption among neighboring nodes in the forward set by rotating the priority of them so as to extend the network lifetime. However, a large candidate set results in high delay because the link quality of the high priority nodes is usually low given the long distance between the sender and the high priority nodes. In addition, Jin et al. [9] proposed a Q-Learning-based Delay-Aware Routing (QDAR) Algorithm to Extend the Lifetime of Underwater Sensor Networks. It took both timeliness and energy efficiency into account by defining delay-related cost and energy-related cost.
Moreover, several studies of mobility of sensor nodes dealt with topology changes due to node mobility. For instance, Liu et al. [10] proposed an Opportunistic Forwarding Algorithm based on Irregualar Mobility (OFAIM). OFAIM aims to maximize the network delivery ratio of UWSNs in a 3-D mobility model due to irregular movement. However, there are only sensor nodes but no sink nodes in the scenario of OFAIM, and no descriptions of how the data will be retrieved from underwater sensors.
Additionally, there are some approaches that reduce energy consumption in consideration of node mobility. Forster et al. [11] proposed a Role-Free Clustering with Q-Learning (CLIQUE) for WSNs, which determines the selection of cluster heads without control overhead. The number of hops to reach mobile sink nodes and the residual energy of sensor nodes are jointly adopted as the reward function, thus enhancing the energy efficiency. However, CLIQUE assumed that sensor nodes uniformly disseminate data without consideration of the limited storage of sensor nodes. Webster et al. [12] invented a clustering protocol for UWSNs based on the mobility model proposed by Caruso et al. [13], which aims to minimize the overall energy consumption.
We distinguish our work from the above-mentioned ones as follows. Existing studies dealt with either energy consumption or timeliness of data forwarding in stationary topology, or simply considered energy consumption in dynamic topologies. None of these studies jointly considered all of them. Therefore, we propose a data forwarding method in joint consideration of timeliness and energy efficiency in UWSNs with passive mobility.
3. Materials and Methods
3.1. Preliminaries and Notations
3.1.1. System Model
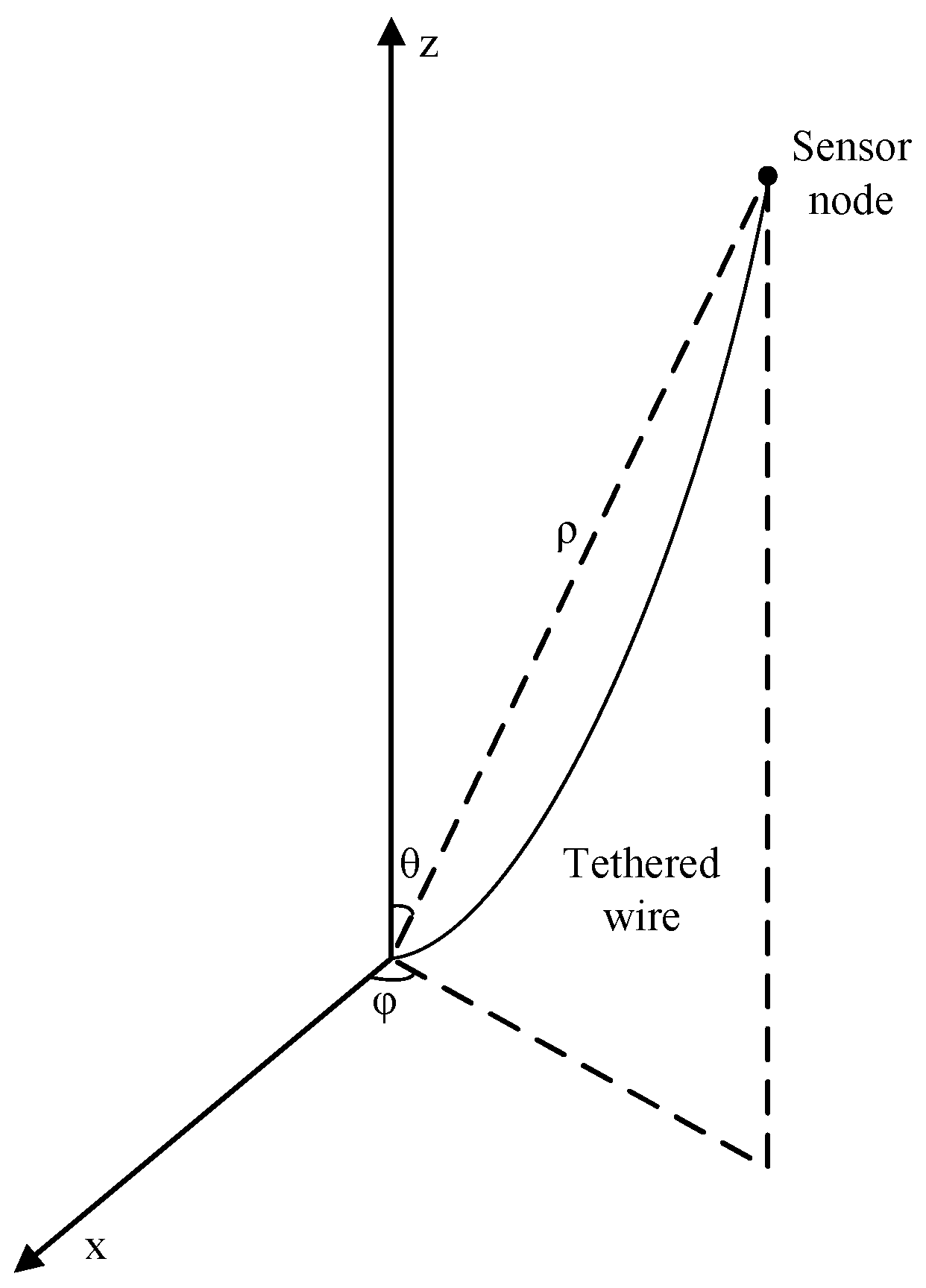
The UWSN is represented by an undirected graph at time slot t, where V is the set of sensor nodes and is the set of links between pairs of nodes within the communication range of each other at time slot t. As depicted in Figure 1, N sensor nodes are tethered to the water bottom via wires, and move passively due to internal currents or vortices.
The moving region is a semi-sphere with a radius of while the communication range of sensor is denoted by . denotes the 3D-coordinate of at time slot t, which is expressed as . If , then is a bidirectional link and is a neighbor of . denotes the set of neighbors of at time slot t.
Meanwhile, we have M sink nodes deployed on the water surface and the set of sink nodes are denoted by S. Additionally, denotes the set of sink nodes which are within the communication range of . Sink node is mounted on an autonomous draft so that can hold its position. In addition, they are equipped with acoustic modems for sensors and RF modems for satellites, along with access to GPS localization. Data packets are periodically generated and denotes the set of packets in at time slot t while denotes the p-th packet in at time slot t. Sensor nodes learn to forward packets to sink nodes in terms of Value of Information and the energy consumption of sensor nodes. Packets are supposed to be received by sink nodes via multi-hop relays.
In order to leverage the broadcast property of the wireless channel, each packet is acknowledged implicitly. Specifically, after transmitting a packet, the sender starts listening to the channel. If it overhears the packet being retransmitted within a certain period of time, the packet is regarded as successfully transmitted; otherwise, the packet is considered to be lost and the sensor node will learn to retransmit it, which will be described in detail in Section 4.
3.1.2. Underwater Movement Model
The movement model is shown in Figure 2. We assume that the moving speed of is denoted as obeys the normal distribution and its actual value range is . denotes the movement direction of at time slot t, where and obey uniform distributions and , respectively. The next location of from its current location will be:
when , where denotes the length of the tethering wire of , the node is held still by its tethered wire and can be written as in spherical coordinates. Otherwise, is defined by Formula (1).
3.1.3. Value of Information
Immediate detection of regions of interest in early stage can provide sufficient time to take corresponding actions. Hence, we adopt the concept of value of information which evaluates information in terms of timeliness. Hence, the later a packet is forwarded to the sink, the lower its value is. Therefore, the of a packet can be expressed as Equation (2),
where represents the p-th packet in at time slot t, indicates the living time duration of packet since it is generated, is the decay factor, k is the discount coefficient and is the maximum life of the packet, i.e., time to live.
is a key factor of the decision making of a sensor node as to which packet should be relayed. If the living duration of a packet approaches its , it will be discarded immediately.
3.1.4. Energy Consumption
Each sensor node has its battery capacity, and with adjustable transmission power. The energy consumption of a sensor mainly includes the energy consumed on the sensor module, its processor module and its communication module, among which the communication module consumes the most energy. Hence, the energy consumption of a sensor node can be approximated by the communication energy consumption while ignoring its other energy consumptions. According to the typical model of energy consumption of free-space spherical wave, the energy consumption of a sensor node is:
where is the data volume that a sensor node receives or transmits, in bit; is the circuit energy consumption of emitting or receiving per bit data, in J/bit; is the minimum energy of signal per bit that can be received by sensor nodes or sink nodes successfully, in ; d is the communication distance, in meter.
3.1.5. Forwarding Orientation
In order to prolong the longevity of UWSNs, it is significant to adopt an energy-efficient forwarding method. Inspired by the murmuration of a swarm of swallows, Pearce et al. [14] proposed a biotic model, the Hybrid Projection Model, which defines the murmuration via two metrics: the opacity and the orientation.
As can be seen in Figure 3, the orientation is mathematically defined as average accumulation of vectors created by the neighbors of a node, which can be calculated by Equation (4),
where denotes the vector of orientation, is the number of neighbors of within its communication range and denotes the vector from to its j-th neighbor at time slot t. The orientation can be acquired locally via the Received Signal Strength (RSS) and Arrival of Angle (AoA) of the broadcasting packets from neighborhood.
The length of denotes the absolute value of the orientation and the orientation direction is denoted by the direction of . Nodes with large orientation values are generally located on the edge of a neighborhood. Otherwise, they are near the centers of their neighborhoods and nodes with lower orientation values are more likely to be the relay node. It has been proved that determining the forwarding direction via orientation metric is energy-efficient [12]. Moreover, there is no requirement for localization when using the orientation metric, which is very suitable for underwater sensors due to their inaccessibility to GPS signals. Therefore, we adopt the orientation metric to determine data forwarding direction.
3.2. Problem Definition
Given a UWSN at time slot t. As mentioned above, we ascertain the objective as minimizing the energy consumption of data forwarding with maximal Value of information within a given monitoring duration T. Therefore, we aim to solve the problem of data forwarding by jointly considering timeliness and energy consumption.
As shown in Equation (6), represents the candidate packet which has the highest value of information in at time slot t. Furthermore, if is able to forward data to any neighbor at time slot t, will be delivered. In Equation (7), each sensor node has limited energy and is out of use when its residual energy hits the bottom at 0. The living time of packets cannot exceed the maximum living duration as shown in Equation (8). In Equation (9), the moving range of each sensor node is limited to the length of its tethered wire .
3.3. Data Forwarding Method
In our scenario, the sensor nodes are dynamically moving due to water flow. In addition, the environment and neighborhood topology of each sensor node keep changing. We adopt a reinforcement learning-based method by which sensor nodes can distributively learn from the changing environments to forward data. This section describes the data forwarding method in detail. Specifically, we present the learning model, the learning method to choose a relay and the algorithm for packet forwarding.
3.3.1. Data Forwarding Procedure
The procedure of data forwarding mainly contains the following three stages, as can be seen in Algorithm 1.
- (1)
- In the beginning of each time slot, each sensor node and sink node broadcasts its beacon signal, e.g., the identifier, orientation and residual energy. Therefore, each sensor node knows its neighbors.
- (2)
- When hears the beacon signal from , it adds to the set of its available sink nodes . Similarly, if can hear the beacon signal of sensor node , will add to the set of its neighbors . Additionally, the distance and orientation of each neighbor or reachable sink node can be acquired locally via the Received Signal Strength (RSS) and Arrival of Angle (AoA) of the beacon signal, respectively. If cannot hear from any sink nodes or sensor nodes, will wait until the next time slot coming.
- (3)
- Sensor node selects the reachable sink node or next relay node by the algorithm RelaySelect which performs a learned choice of a relay node. The RelaySelect algorithm will be introduced in detail in the third subsection.
| Algorithm 1 DataForwarding(). |
|
3.3.2. Q-Learning Model
Q-Learning is a model-free reinforcement learning technique, based on agents taking actions and receiving rewards from the environment in response to actions [11]. Each action is evaluated a Q-value due to its fitness. In the learning process, the agent calculates the reward of each potential action and updates the Q-value by which the real action can be determined. Q-Learning has been widely adopted in wireless ad hoc communications. The main challenge is the modeling of the Q-Learning process and the definition of Q-values.
Given the set of states of an agent, a reward is received in state after the agent takes action at time slot t.
To evaluate how good an action is at a state, the Q-value of action at time slot t, , is updated as follows:
where is the reward of taking action at time slot t, is the expected fitness at time slot , is the learning discount factor and represents the transition probability from state to .
In order to determine the optimal action, the action with the highest Q-value from state to at time slot t can be acquired as follows:
For each state , the optimal action can be greedily acquired by updating the Q-value.
3.3.3. Learning to Forward
If transmits a packet to a relay node or a sink node, the state of at time slot turns to 1, . Otherwise, . The action in our scenario is which denotes the action of forwarding packet to . Then, the reward of of taking action to next state is described as . Lastly, the Q-value is updated to which indicates the fitness of forwarding packet to at time slot t.
In our data forwarding scenario, each sensor node is an independent learning agent and actions are options of a relay node or a sink node within its communication range. The following describes details of the model solution, including time, actions, transmission probabilities, rewards, and Q-values.
Agents Agents are underwater sensor nodes.
Time A handling a packet p is associated with a time slot defined by the sequential number of time slots.
Actions Actions refer to the joint selection of a packet in the node’s cache and of a relay node in its neighborhood. The set of available actions is , where is the action of forwarding packet to relay node .
Transmission Probabilities Denote the probability of transmission from to at time slot t as . Meanwhile, the transmission probability from the current relay node to the next potential relay node is denoted by . is computed by while is computed by and sent to in the header of the broadcast packet in each round. The transmission probabilities can be calculated via the orientation metric by Equation (12), as follows.
Note that is the prediction from the current time slot t because the topology at time slot cannot be ascertained yet due to the node mobility.
Rewards The rewards mainly consist of two aspects, energy consumption and VoI, as shown in Equation (13),
where represents the reward of transmitting packet to , denotes the VoI of packet , and represents the residual energy of after transmission, at time slot t.
Q-values Q-values represent the goodness of actions and agents aim to learn the actual fitness of potential actions. We initialize the Q-values as shown in Equation (14),
where refers to the Q-value of in response to the action of choosing as the relay node, denotes the VoI of packet to be transmitted, and represents the residual energy of , in the beginning.
Algorithm 2 describes the learning process of in each time slot as well as the corresponding determination of the packet to forward and its relay node.
If sink node is within the transmission range of , transmits the packet with the largest VoI in its cache to directly. Otherwise, to identify an optimal forwarding decision, learns the value of function and updates the Q-value. Based on this value determines the optimal forwarding action . Each node starts with no knowledge of its surrounding environment. Broadcasting and listening in neighborhood, sensor nodes iteratively acquire and update their knowledge over time. Function in Equation (15) is approximated via Equation (13) based on the localization and neighborhood at time slot t The Q-values can be updated as shown in Equation (15),
where is the reward of transmitting packet to at time slot , and is approximated via Equation (13) based on the localization and neighborhood at time slot t. Additionally, represents the probability of transmission from to and is the learning factor. In the learning process, sensor nodes calculate the reward of each potential relay node and update the Q-value. Finally, sensor nodes acquire the Q-table by which the most appropriate relay node can be determined.
| Algorithm 2 RelaySelect(). |
|
In our method, each sensor node has to ascertain its neighborhood and then selects the relay node in its neighborhood. Specifically, we have to execute two rounds of calculation for each sensor node in each time slot: (1) the determination of neighbor nodes within the sensor’s communication range; (2) the selection of the neighbor node with highest Q-value. In the first round of calculation, it takes a complexity of to calculate the distances between sensor nodes. In the second round, the complexity depends on the size of the neighborhood of sensor nodes. In the most complicated case, all the sensor nodes in the same neighborhood, i.e., , we need to calculate times of Q-value of the neighbor nodes of . Therefore, it takes a complexity of at most to select relay nodes of all the sensor nodes. Since the number of time slots is constant, the complexity of our method can be ascertained as .
4. Results
In this section, we evaluate the performance of our proposed method compared with two well-known routing protocols: (i) QELAR, a machine learning-based protocol designed for minimizing and balancing node energy consumption [7]; (ii) DBR, a data forwarding method for UWSNs based on the depth of the sender [15]. It is worth mentioning that we use the total residual energy of sensor nodes, Value of Information and the ratio of packet delivery to sink nodes as the main metrics of performance evaluation.
4.1. Experimental Setup
The region of interests cover a space of 1000 m × 1000 m × 1000 m. We assume that the anchors are randomly deployed at the bottom and the length of tethering wires are also randomly generated, while the sink nodes are stationary at (333, 333, 1000) m and (666, 666, 1000) m. We consider UWSNs with different sizes of 10 and 100 sensor nodes, respectively. The sensors use Orthogonal Frequency-division Multiplexing (OFDM) modulation which allows simultaneous transmission from several users.
The simulation parameters are shown in Table 1. Each sensor node has a communication range of 300 m with initial energy of 100 J. The packets are set to the length of 1000 bit with the of 10 time slots. Sensor nodes move passively at a maximum speed of 100 m per time slot. The coefficient of energy consumption and are set to and , respectively. The decaying factor of VoI, i.e., , is set as , while the learning discount factor is set as 1, which speeds up the learning rate. All simulation results are acquired with runs of 100 times.
4.2. Simulation Metrics
Data forwarding performance is assessed through the following three metrics.
Value of Information defined as the VoI of packets acquired by the sink nodes within the monitoring duration.
Residual Energy defined as the total residual energy of sensor nodes within the monitoring duration.
Packet Delivery Ratio defined as the fraction of packets received by the sink nodes within the monitoring duration.
4.3. Simulation Results
In this section, we illustrate the results from simulations. All results are obtained by averaging over 100 simulation times.
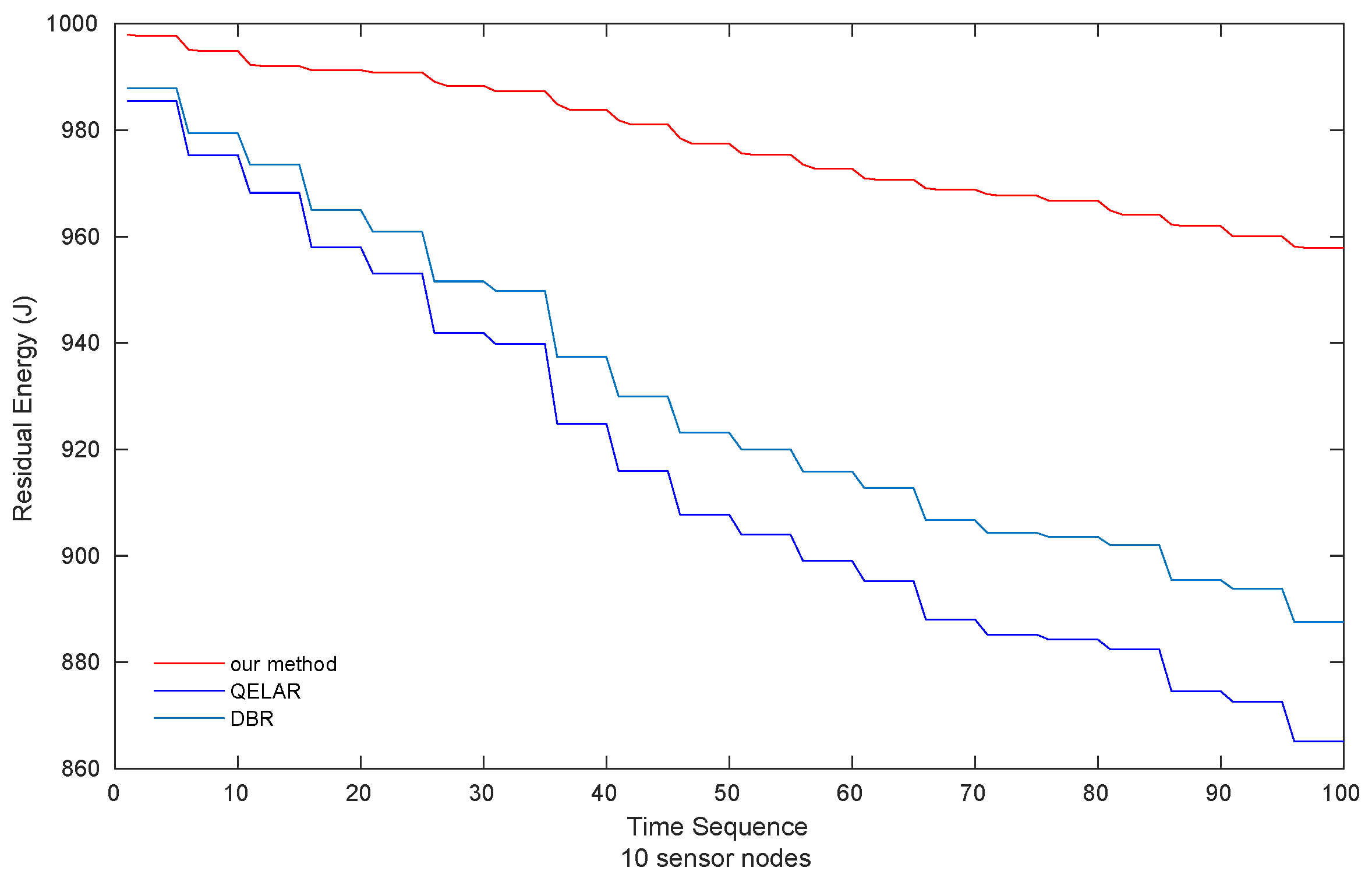
(1) Value of Information As can be seen in Figure 4, the value of information acquired by sink nodes in the scenario of 10 sensor nodes is presented. Our method gains the highest VoI, and higher than QELAR and DBR, respectively. QELAR comes in the second place while DBR obtains the lowest VoI among the three methods.
Moreover, as shown in Figure 5, the VoI acquired by our method performs better as the network size increases, which is and higher than QELAR and DBR, respectively. When forwarding data, QELAR and DBR choose the earliest packet in the cache. Not surprisingly, DBR achieves the lowest VoI because the forwarding decision of DBR depends on the accessibility of neighbors with smaller depths. Specifically, compared with QELAR and our method, sensor nodes have to wait longer for the qualified neighbors, which leads to more decay of the VoI of packets. Our proposed method performs the highest VoI, because our method explicitly takes VoI into account in its reward function (Section 4), which leads to the choice of the packet with largest VoI in the sensor cache.
(2) Residual Energy The results of residual energy of QELAR, DBR and our method with 10 sensor nodes is indicated in Figure 6. The residual energy of QELAR is the lowest while our method consumes the smallest energy among the three methods. More specifically, our method consumes and of the energy consumed by QELAR and DBR, respectively.
As shown in Figure 7, our method still consumes the least energy among the three methods when the network size increases, only and of the energy consumption of QELAR and DBR, respectively. That is mainly because by choosing packets and relay nodes smartly, our method achieves excellent performance in energy consumption. Our method always selects the latest packets in the cache while QELAR always selects the earliest packets. Moreover, in our method, earlier packets may have been discarded due to TTL constraint when the latter packets are forwarded, which leads to the avoidance of forwarding too many early packets in the cache, compared with QELAR. Therefore, the energy consumption of our method is much lower than that of QELAR.
(3) Packet Delivery Ratio The packet delivery ratio (PDR) of QELAR, DBR and our method can be seen in Table 2. DBR achieves higher PDR than other two methods in both scenarios. Because packets are forwarded towards sensor nodes with less depths, the packets are either staying in a sensor node or approaching the water surface, which prevents the packets from being forwarded repeatedly between several sensor nodes and trapped in a certain region. Therefore, DBR decreases the repeating forwarding between sensor nodes and increases the PDR. The PDR to sink nodes of our method in scenarios of 10 and 50 sensor nodes are 66.36% and 71.64%, respectively. Our method achieves a PDR slightly lower than QELAR does, mainly because more packets with earlier generation time in the cache are discarded due to the maximum living duration.
5. Discussion and Conclusions
In this paper, we proposed the data forwarding method in joint consideration of VoI of packets and energy consumption, with passive mobility of sensors in UWSNs. We explicitly take both VoI and energy consumption into account in its reward function, thus reducing the energy consumption as well as enhancing the timeliness of data forwarding in UWSNs. In our method, the Q-value of the same sensor node can be different along the time, thus avoiding the same node acting as a relay node until the depletion of its battery. Meanwhile, packets with larger value of information have higher priority to be transmitted so as to realize better timeliness. Although the packet delivery ratio of our method is relatively lower, our proposed method achieves much higher timeliness and consumes less energy than DBR and QELAR in the circumstance of dynamical topology change due to the passive mobility of sensor nodes. Given that the timeliness and energy consumption were more significant than the delivery ratio in our scenario, our method enhances the performance of UWSNs. In our scenario, the sink nodes are stationary and the performance of data collection may be different if the sink nodes are moving on the surface of the detection region. As a future work, we will study how the movement of sink nodes can influence the data collection of UWSNs. Additionally, recent studies of harvesting ambient energy of UWSNs has drawn large attention. For instance, the kinetic energy of underwater currents can be harvested to prolong the lifetime of UWSNs. Therefore, we intend to carry out the research of energy harvesting-aware data forwarding in UWSNs with passive mobility in the future.
Author Contributions
J.F. conceived and designed the experiments; H.C. performed the experiments; C.D. visualized the simulation results; H.C. wrote the paper.
Funding
This work was supported by the National Natural Science Foundation of China (61371119).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lloret, J. Underwater sensor nodes and networks. Sensors 2013, 13, 11782–11796. [Google Scholar] [CrossRef] [PubMed]
- Garcia, M.; Sendra, S.; Atenas, M.; Lloret, J. Underwater wireless ad-hoc networks: A survey. In Mobile Ad Hoc Networks: Current Status and Future Trends; CRC Press: Boca Raton, FL, USA, 2011; Chapter 14; pp. 379–411. [Google Scholar]
- Gjanci, P.; Petrioli, C.; Basagni, S.; Phillips, C.; Boloni, L.; Turgut, D. Path Finding for Maximum Value of Information in Multi-Modal Underwater Wireless Sensor Networks. IEEE Trans. Mobile Comput. 2018, 17, 404–418. [Google Scholar] [CrossRef]
- Liang, W.; Xu, W.; Ren, X.; Jia, X.; Lin, X. Maintaining Sensor Networks Perpetually Via Wireless Recharging Mobile Vehicles. In Proceedings of the 39th Annual IEEE Conference on Local Computer Networks, Edmonton, AB, Canada, 8–11 September 2014; pp. 270–278. [Google Scholar]
- Ma, Y.; Liang, W.; Xu, W. Charging Utility Maximization in Wireless Rechargeable Sensor Networks by Charging Multiple Sensors Simultaneously. IEEE/ACM Trans. Netw. 2018, 26, 1591–1604. [Google Scholar] [CrossRef]
- Basagni, S.; Valerio, D.; Gjanci, P.; Petrioli, C. Finding MARLIN: Exploiting Multi-Modal Communications for Reliable and Low-latency Underwater Networking. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Atlanta, GA, USA, 1–4 May 2017; pp. 1701–1709. [Google Scholar]
- Hu, T.; Fei, Y. QELAR: Q-Learning-based Energy-Efficient and Lifetime-Aware Routing Protocol for Underwater Sensor Networks. IEEE Trans. Mob. Comput. 2010, 9, 796–809. [Google Scholar]
- Coutinho, R.; Boukerche, A.; Vieira, L.; Loureiro, A. EnRO: Energy Balancing Routing Protocol for Underwater Sensor Networks. In Proceedings of the IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- Jin, Z.; Ma, Y.; Su, Y.; Li, S.; Fu, X. A Q-Learning-Based Delay-Aware Routing Algorithm to Extend the Lifetime of Underwater Sensor Networks. Sensors 2017, 17, 1660. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Liu, Y. On Exploring Data Forwarding Problem in Opportunistic Underwater Sensor Network Using Mobility-Irregular Vehicles. IEEE Trans. Veh. Technol. 2015, 64, 4712–4727. [Google Scholar] [CrossRef]
- Forster, A.; Murphy, A. CLIQUE: Role-Free Clustering with Q-Learning for Wireless Sensor Networks. In Proceedings of the IEEE International Conference on Distributed Computing Systems (ICDCS), Montreal, QC, Canada, 22–26 June 2009; pp. 441–449. [Google Scholar]
- Webster, R.; Munasinghe, K.; Jamalipour, A. Murmuration Inspired Clustering Protocol for Underwater Wireless Sensor Networks. In Proceedings of the IEEE International Conference on Communications (ICC), Kansas, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Caruso, A.; Paparella, F.; Viera, L.; Erol, M.; Gerla, M. The Meandering Current Mobility Model and its Impact on Underwater Mobile Sensor Networks. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Phoenix, AZ, USA, 13–18 April 2008; pp. 221–225. [Google Scholar]
- Pearce, D.; Miller, A.; Rowlands, G.; Turner, M. Role of projection in the control of bird flocks. Proc. Natl. Acad. Sci. USA 2014, 111, 10422–10426. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yan, H.; Shi, Z.; Cui, J. DBR: Depth-Based Routing for Underwater Sensor Networks. In NETWORKING 2008 Ad Hoc and Sensor Networks, Wireless Networks, Next Generation Internet; Springer: Berlin/Heidelberg, Germany, 2008; Volume 4982, pp. 72–86. [Google Scholar]
Figure 1.
An Underwater Wireless Sensor Network (UWSN) with passive mobility.

Figure 2.
Movement model of sensor nodes.

Figure 3.
Orientation of sensor nodes.

Figure 4.
Value of Information obtained by sink nodes (10 sensor nodes).

Figure 5.
Value of Information obtained by sink nodes (50 sensor nodes).

Figure 6.
Residual energy of sensor nodes (10 sensor nodes).

Figure 7.
Residual energy of sensor nodes (50 sensor nodes).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Simulation Parameters.
| Name | Value |
|---|---|
| 300 m | |
| 1000 bit | |
| 100 J | |
| J/bit | |
| 100 m per time slot | |
| 10 time slots | |
| 0.5 | |
| k | 1 |
| 1 |
Table 2.
Packet Delivery Ratio.
| PDR() | DBR | QELAR | Our Method |
|---|---|---|---|
| PDR(10) | |||
| PDR(50) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Chang, H.; Feng, J.; Duan, C. Reinforcement Learning-Based Data Forwarding in Underwater Wireless Sensor Networks with Passive Mobility. Sensors 2019, 19, 256. https://doi.org/10.3390/s19020256
AMA Style
Chang H, Feng J, Duan C. Reinforcement Learning-Based Data Forwarding in Underwater Wireless Sensor Networks with Passive Mobility. Sensors. 2019; 19(2):256. https://doi.org/10.3390/s19020256
Chicago/Turabian StyleChang, Haotian, Jing Feng, and Chaofan Duan. 2019. "Reinforcement Learning-Based Data Forwarding in Underwater Wireless Sensor Networks with Passive Mobility" Sensors 19, no. 2: 256. https://doi.org/10.3390/s19020256
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.