Embedded Processing and Compression of 3D Sensor Data for Large Scale Industrial Environments


Abstract
1. Introduction
1.1. Related Work
1.2. Main Contributions
2. Materials and Methods
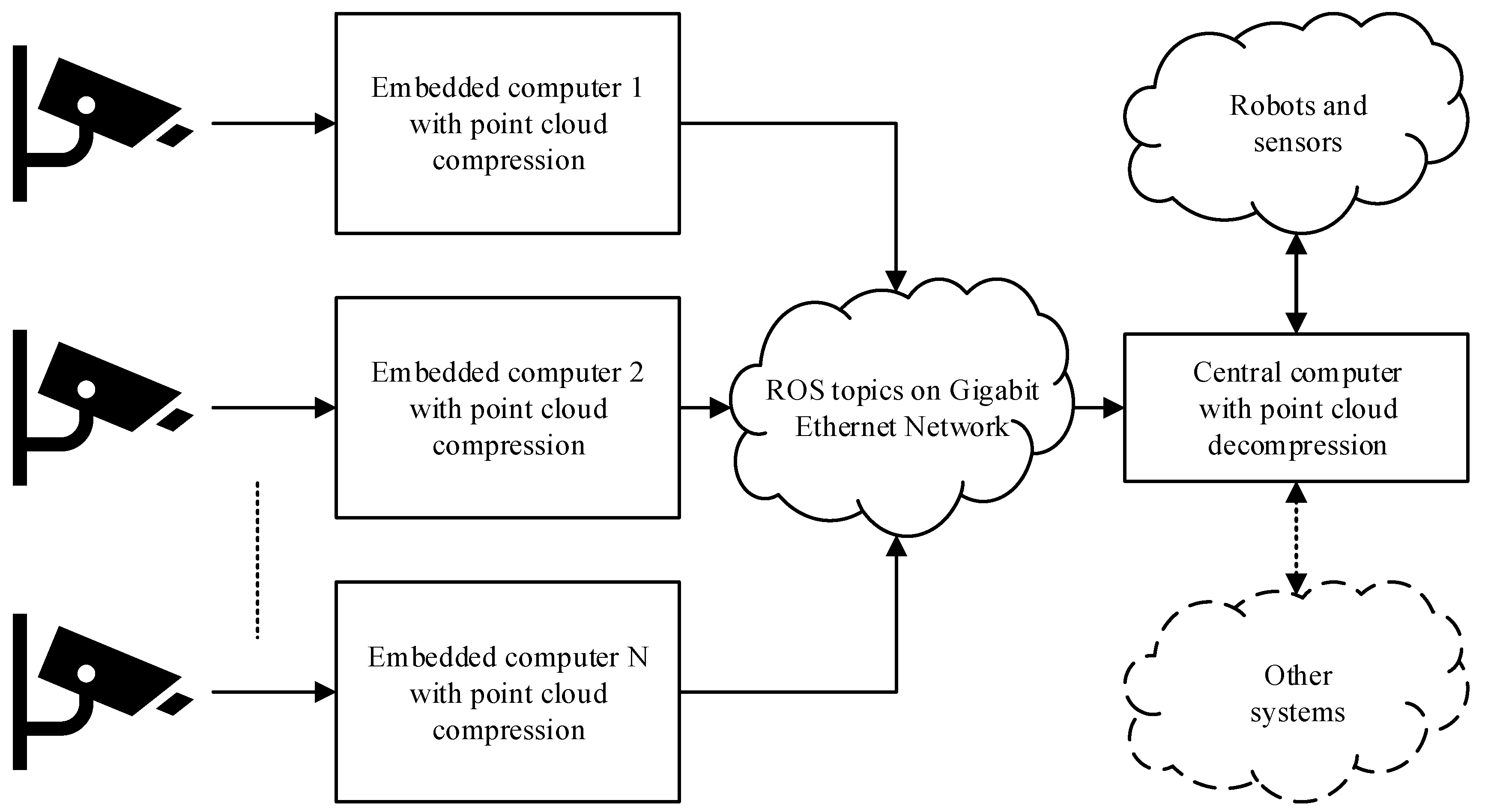
2.1. Problem Formulation and Motivation
2.2. Point Cloud Preprocessing
2.3. Data Representation
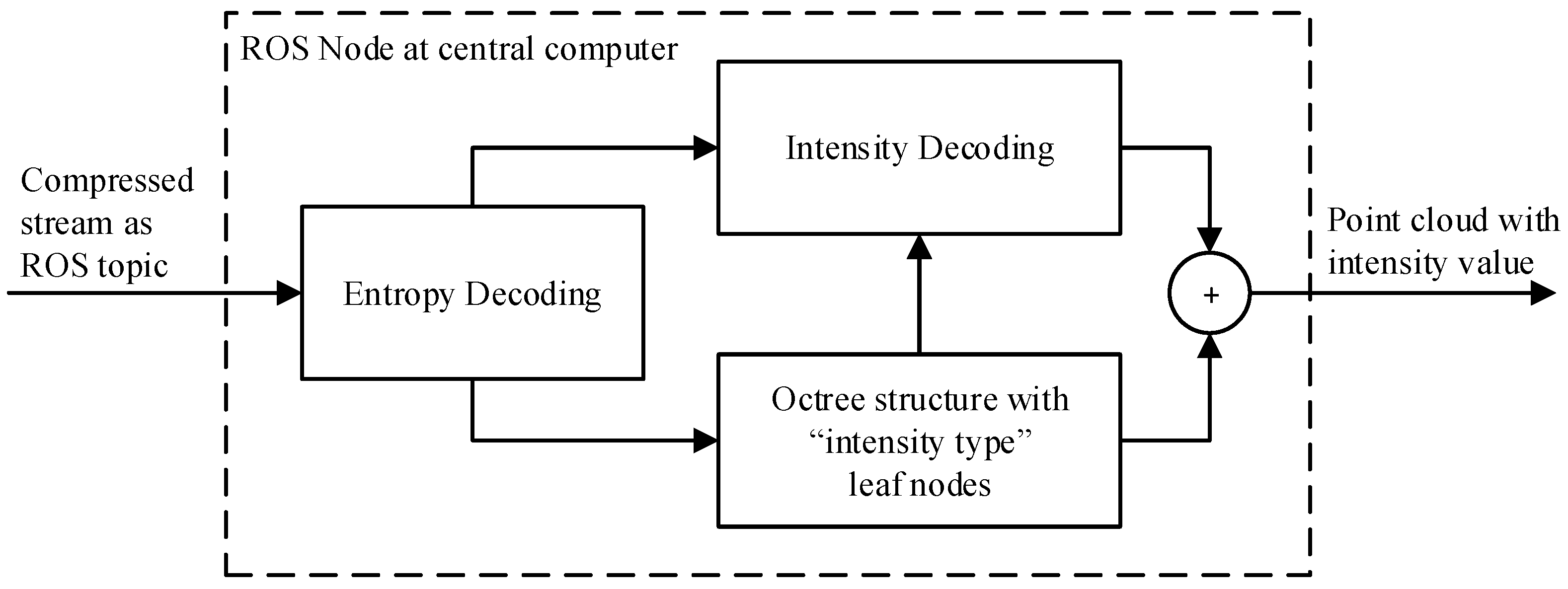
2.4. Compression
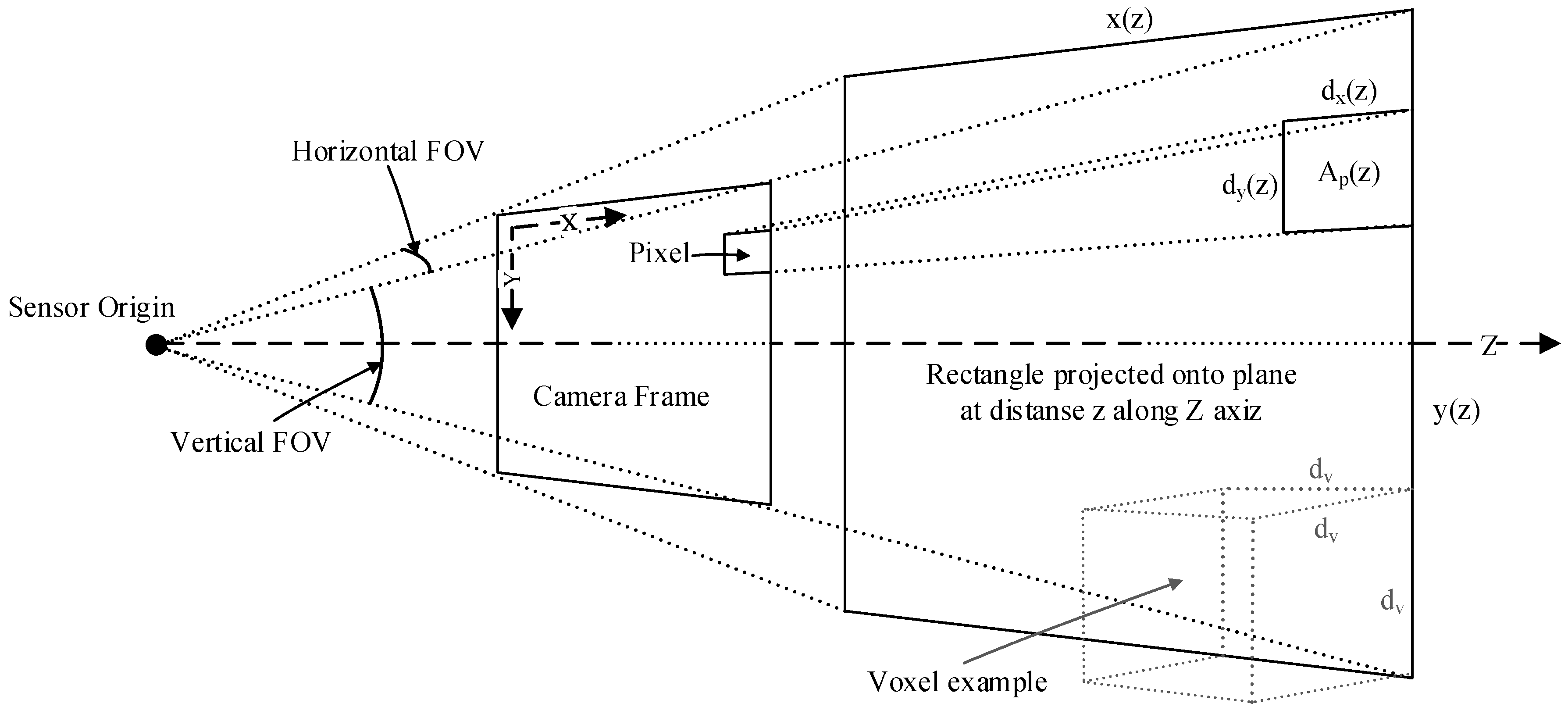
2.5. Voxel Intensity Value Computation
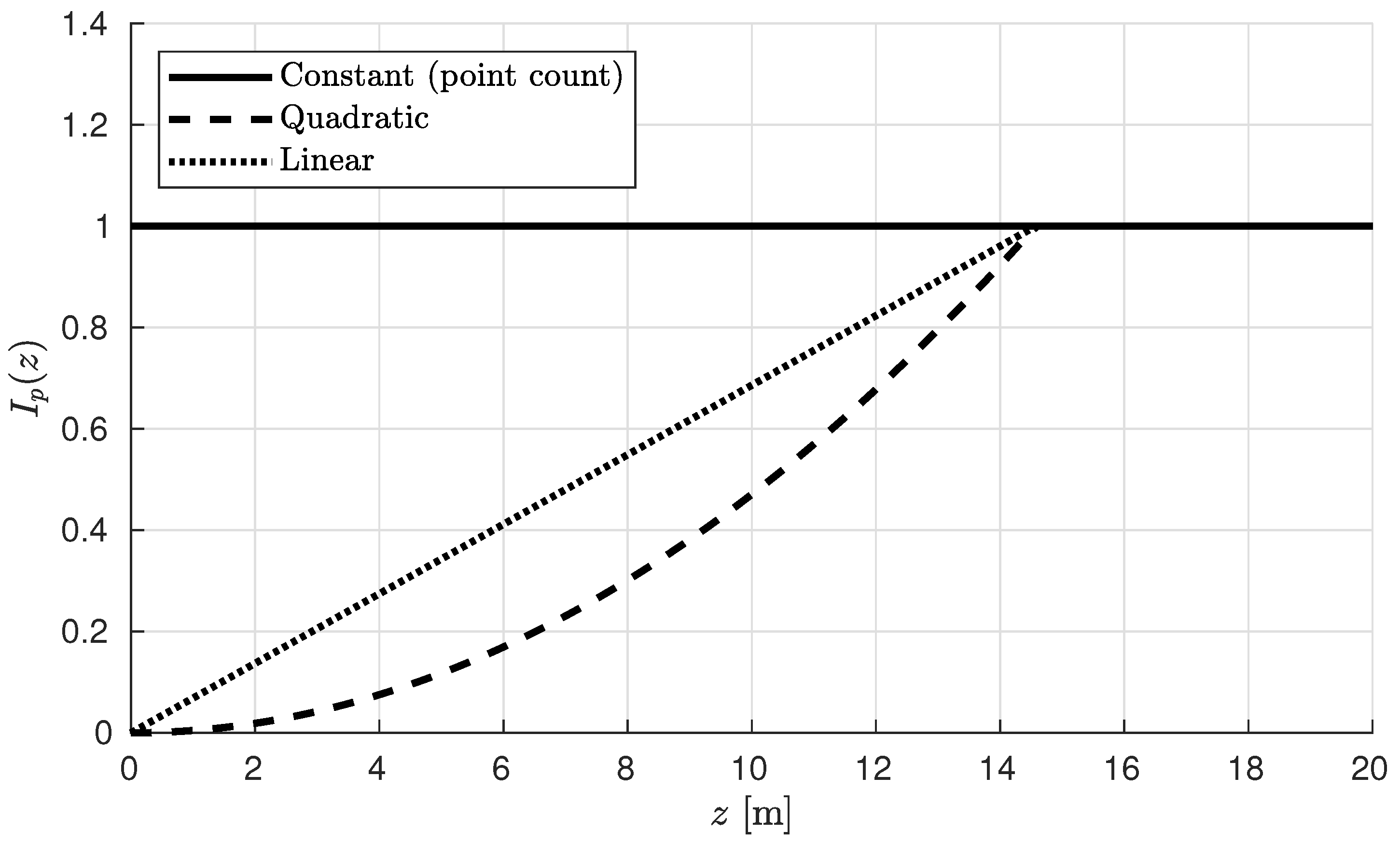
2.5.1. Counting Points
2.5.2. Point Value Based on Quadratic Distance
2.5.3. Point Value Based on Linear Distance
2.5.4. Voxel Intensity
2.6. Decompression and Denoising
2.7. Experimental Setup
2.8. Multisensor Setup
3. Results
3.1. Preprocessing
3.2. Compression
3.3. Frequency and Bandwidth
3.4. Denoising
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Dybedal, J.; Hovland, G. Optimal placement of 3D sensors considering range and field of view. In Proceedings of the 2017 IEEE International Conference on Advanced Intelligent Mechatronics (AIM), Munich, Germany, 3–7 July 2017; pp. 1588–1593. [Google Scholar] [CrossRef]
- Kammerl, J.; Blodow, N.; Rusu, R.B.; Gedikli, S.; Beetz, M.; Steinbach, E. Real-time compression of point cloud streams. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 778–785. [Google Scholar] [CrossRef]
- Martin, G.N.N. Range encoding: An algorithm for removing redundancy from a digitised message. In Proceedings of the Video and Data Recording Conference, Southampton, UK, 24–27 July 1979; pp. 24–27. [Google Scholar]
- Moreno, C.; Chen, Y.; Li, M. A dynamic compression technique for streaming kinect-based Point Cloud data. In Proceedings of the 2017 International Conference on Computing, Networking and Communications (ICNC), Santa Clara, CA, USA, 26–29 January 2017; pp. 550–555. [Google Scholar] [CrossRef]
- Chen, S.; Tian, D.; Feng, C.; Vetro, A.; Kovačević, J. Fast Resampling of Three-Dimensional Point Clouds via Graphs. IEEE Trans. Signal Process. 2018, 66, 666–681. [Google Scholar] [CrossRef]
- Thanou, D.; Chou, P.A.; Frossard, P. Graph-based compression of dynamic 3D point cloud sequences. IEEE Trans. Image Process. 2016, 25, 1765–1778. [Google Scholar] [CrossRef] [PubMed]
- Schoenenberger, Y.; Paratte, J.; Vandergheynst, P. Graph-based denoising for time-varying point clouds. arXiv, 2015; arXiv:cs.CV/1511.04902. [Google Scholar]
- Hornung, A.; Wurm, K.M.; Bennewitz, M.; Stachniss, C.; Burgard, W. OctoMap: An efficient probabilistic 3D mapping framework based on octrees. Auton. Robot 2013, 34, 189–206. [Google Scholar] [CrossRef]
- Kaldestad, K.B.; Hovland, G.; Anisi, D.A. 3D Sensor-Based Obstacle Detection Comparing Octrees and Point clouds Using CUDA. Model. Identif. Control 2012, 33, 123–130. [Google Scholar] [CrossRef]
- Ueki, S.; Mouri, T.; Kawasaki, H. Collision avoidance method for hand-arm robot using both structural model and 3D point cloud. In Proceedings of the 2015 IEEE/SICE International Symposium on System Integration (SII), Nagoya, Japan, 11–13 December 2015; pp. 193–198. [Google Scholar] [CrossRef]
- Quigley, M.; Conley, K.; Gerkey, B.P.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 17 May 2009. [Google Scholar]
- Dybedal, J. SFI-Mechatronics/wp3_compressor and SFI-Mechatronics/wp3_decompressor: First Release. Available online: https://zenodo.org/record/2554855#.XFUDPMQRWUk (accessed on 1 February 2019).
- Hermann, A.; Drews, F.; Bauer, J.; Klemm, S.; Roennau, A.; Dillmann, R. Unified GPU voxel collision detection for mobile manipulation planning. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 4154–4160. [Google Scholar] [CrossRef]
- Rusu, R.B.; Cousins, S. 3D is here: Point Cloud Library (PCL). In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011. [Google Scholar]
- Wiedemeyer, T.; IAI Kinect2. 2014–2015. Available online: https://github.com/code-iai/iai_kinect2 (accessed on 23 January 2018).
- Aalerud, A.; Dybedal, J.; Ujkani, E.; Hovland, G. Industrial Environment Mapping Using Distributed Static 3D Sensor Nodes. In Proceedings of the 2018 14th IEEE/ASME International Conference on Mechatronic and Embedded Systems and Applications (MESA), Oulu, Finland, 2–4 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Ujkani, E.; Dybedal, J.; Aalerud, A.; Kaldestad, K.B.; Hovland, G. Visual Marker Guided Point Cloud Registration in a Large Multi-Sensor Industrial Robot Cell. In Proceedings of the 2018 14th IEEE/ASME International Conference on Mechatronic and Embedded Systems and Applications (MESA), Oulu, Finland, 2–4 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Aalerud, A.; Dybedal, J.; Hovland, G. Automatic Calibration of an Industrial RGB-D Camera Network using Retroreflective Fiducial Markers. Sensors 2018. submitted. [Google Scholar]
- Maimone, A.; Fuchs, H. Reducing interference between multiple structured light depth sensors using motion. In Proceedings of the IEEE Virtual Reality, Costa Mesa, CA, USA, 4–8 March 2012; pp. 51–54. [Google Scholar] [CrossRef]
- Kunz, A.; Brogli, L.; Alavi, A. Interference measurement of kinect for xbox one. In Proceedings of the 22nd ACM Conference on Virtual Reality Software and Technology—VRST’16, Munich, Germany, 2–4 November 2016; ACM Press: New York, NY, USA, 2016; pp. 345–346. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N | X | Y | Z | RotZ | RotY | RotX |
|---|---|---|---|---|---|---|
| 1 | 7.798 | 0.496 | 4.175 | 40.170 | 0.639 | −136.170 |
| 2 | 1.729 | 0.501 | 4.135 | −45.253 | 2.063 | −141.490 |
| 3 | 9.522 | 5.275 | 4.353 | 88.439 | −0.072 | −143.461 |
| 4 | 0.553 | 4.995 | 4.353 | −89.208 | −0.495 | −145.591 |
| 5 | 8.879 | 9.192 | 4.194 | 126.733 | −1.311 | −139.272 |
| 6 | 0.559 | 9.136 | 4.145 | −121.458 | −0.487 | −137.562 |
| Measurement | Original | Cropped |
|---|---|---|
| Number of Points | 217,088 | 37,108 ± 293 |
| Size (KiB) | 3392 | 579.8 ± 4.6 |
| Ratio | 1:1 | 1:5.85 ± 0.05 |
| Measurement | Cropped | Compressed |
|---|---|---|
| Number of Points | 37,108 ± 293 | 17,771 ± 118 |
| Size (KiB) | 579.8 ± 4.6 | 14.31 ± 0.20 |
| Bytes per Point | 16 | 0.82 ± 0.01 |
| Compression Ratio | 1:1 | 1:40.5 ± 0.5 |
| Measurement | Cropped | Compressed |
|---|---|---|
| Number of Points | 37,574 ± 313 | 33,321 ± 243 |
| Size (KiB) | 587.1 ± 0.49 | 26.08 ± 0.17 |
| Bytes per Point | 16 | 0.80 ± 0.01 |
| Compression Ratio | 1:1 | 1:22.5 ± 0.1 |
| Measurement | Compression (@ max. FPS ) | Compression (@ 20 Hz) | Decompression (@ 20 Hz) |
|---|---|---|---|
| FPS | HZ | HZ | HZ |
| Bandwidth | KiB/s | KiB/s | KiB/s |
| Cycle Time | ms | ms | ms |
| CPU load | 100% | 80% | 14% |
| Memory | MiB | 60 MiB | MiB |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dybedal, J.; Aalerud, A.; Hovland, G. Embedded Processing and Compression of 3D Sensor Data for Large Scale Industrial Environments. Sensors 2019, 19, 636. https://doi.org/10.3390/s19030636
Dybedal J, Aalerud A, Hovland G. Embedded Processing and Compression of 3D Sensor Data for Large Scale Industrial Environments. Sensors. 2019; 19(3):636. https://doi.org/10.3390/s19030636
Chicago/Turabian StyleDybedal, Joacim, Atle Aalerud, and Geir Hovland. 2019. "Embedded Processing and Compression of 3D Sensor Data for Large Scale Industrial Environments" Sensors 19, no. 3: 636. https://doi.org/10.3390/s19030636
APA StyleDybedal, J., Aalerud, A., & Hovland, G. (2019). Embedded Processing and Compression of 3D Sensor Data for Large Scale Industrial Environments. Sensors, 19(3), 636. https://doi.org/10.3390/s19030636