1. Introduction
Internet of Things (IoT) has become a significant part of our daily life over the past few years. A huge number of sensors or intelligent devices have been integrated together to interconnect people with the physical world, which also generates massive sensing data. Data generated by IoT devices are collected, disseminated, and exchanged among different people, business, and societies. With the development of IoT, the amount of data generated by organizations or individuals is increasing dramatically [
1].
Although the massive data generated in the IoT environment is of significant value, exploring and using the extraordinary value of IoT data will increase the risk of privacy breach [
2]. To obtain profits, the collection, storage, and reuse of our personal data poses a serious threat to our privacy. Consequently, researchers are faced with the challenge of ensuring the utility of data while preserving privacy. Various techniques have been developed to protect data privacy. Generally, these techniques for data privacy can be grouped based on the stages of big data life cycle, as follows [
3].
Data generation: In the data generation phase, access restriction, and falsifying data techniques are used.
Data storage: The approaches in the data storage phase are mainly based on encryption techniques.
Data processing: Anonymization techniques as well as clustering, classification, and association rule mining-based techniques are used in the data processing phase.
In this paper, we will focus on the protection of big data privacy in the data storage phase of the big data life cycle. In the IoT environment, the sensing data generated by various sensors and devices will be collected and uploaded to cloud servers, where cloud servers can provide massive storage and cloud computing services. We know that encryption techniques are used for the protection of big data privacy in the data storage phase. When a large amount of encrypted data is stored in cloud servers, the first consideration is confidentiality of the data, which can be ensured by secure and efficient encryption schemes. However, when the data user wants to retrieve the data containing a specific keyword, the cloud server cannot respond to the data user’s retrieval request, because it cannot decrypt the encrypted data. All these problems can be solved by searchable encryption schemes [
4,
5], such as searchable symmetric encryption [
6], public key encryption with keyword search [
7], etc. The searchable encryption scheme mainly includes three entities—data owner, data user, and cloud server. The data owner outsources the encrypted data to the cloud server. The data user queries the encrypted data containing a specific keyword to the cloud server. The cloud server stores and retrieves the encrypted data.
In existing searchable encryption schemes, the data user can access all the data owned by the data owner, which can result in a privacy breach for the data owner. On the one hand, the data owner may be willing to share the data with some specific data users, but not with other data users. On the other hand, the data owner may be willing to share specific data with the data user, but not willing to share other data. Therefore, the data user accesses all the data owned by the data owner, which can result in a privacy breach for the data owner. Furthermore, additional information in the data owned by the data owner can also result in a privacy breach for the data owner. Privacy is subjective, and different people have different privacy needs. For example, the hidden text in a typical Word file includes a lot of sensitive personal information [
8]. However, this additional information, which may disclose the privacy of the data owner, is useless for some data users. In data mining, data preprocessing is used to transform raw data into an understandable format [
9]. In natural language processing, text feature extraction is used to transform a list of words into a feature set that is usable by a classifier [
10]. In speech recognition and image recognition, feature extraction is a key step [
11,
12]. It means that this additional information may be discarded by the data user in the feature extraction phase. In summary, the data user accessing all the data owned by the data owner will result in a privacy breach for the data owner, but will not improve the utility of the data.
In this paper, we will propose a searchable encryption scheme for personalized privacy protection in IoT-based big data. The main contributions of our proposed scheme are as follows:
In our proposed scheme, the data owner generates the file features at different levels, and uploads the encrypted file features to the cloud server.
The proposed scheme makes a trade-off between ensuring the utility of the data and preserving the privacy, and meets the different privacy needs of different individuals.
The rest of this paper is as follows.
Section 2 discusses the recent searchable encryption scheme.
Section 3 presents necessary notations and definitions.
Section 4 formalizes the searchable encryption scheme for meeting the personalized privacy needs in big data and presents main security definition.
Section 5 describes the detailed construction of our proposed scheme.
Section 6 discusses the security of our proposed scheme.
Section 7 performs real time experimental results and makes a comparison of our proposed scheme with the existing schemes. The last section is the conclusion of this paper.
2. Related Work
Several different searchable encryption schemes have been proposed to allow the data user to retrieve the encrypted data [
4,
5]. In this section, we give a simple review on the existing work of the searchable encryption schemes.
In 2000, Song et al. [
6] first proposed a searchable encryption scheme based on the symmetric encryption algorithm, which is called searchable symmetric encryption (SSE). However, their scheme has the following limitations: it is not proven to be a secure searchable encryption scheme; the distribution of the underlying plaintexts is vulnerable to statistical attacks; and the search time is linear to the length of the document collection. To overcome these limitations, Goh et al. [
13] and Chang and Mitzenmacher [
14] deployed a masked index table for SSE and introduced the notion of security for indexes. Curtmola et al. [
15] generalized the security definitions of SSE and proposed two SSE schemes which are secure under the new security definitions. The search time of their schemes is linear to the number of documents. Subsequently, several SSE schemes were proposed for improvement. For example, Cash et al. [
16] proposed an SSE scheme that supports conjunctive search and general Boolean queries on outsourced symmetrically encrypted data; Salam et al. [
17] proposed a privacy-preserving data storage and retrieval system in cloud computing; Li et al. [
18] proposed three different SSE schemes that can guard against a coercer by using the deniable encryption idea; Soleimanian et al. [
19] proposed an SSE scheme to be publicly verifiable.
Although SSE schemes have high efficiency, they suffer from complicated secret key distribution. To resolve this problem, Boneh et al. [
7] introduced a searchable encryption scheme based on public key cryptography, namely public key encryption with keyword search (PEKS). Waters et al. [
20] showed that the PEKS schemes based on bilinear map could be applied to build encrypted and searchable auditing logs. However, the bilinear pairing operation is very complicated. Di et al. [
21] introduced a PEKS scheme without bilinear pairing. The original PEKS scheme in [
7] requires a secure channel to transmit the trapdoors. To overcome this limitation, Baek et al. [
22] proposed a new PEKS scheme without requiring a secure channel. Byun et al. [
23] introduced the off-line keyword-guessing attack (KGA) and pointed out that the original PEKS scheme in [
7] was susceptible to KGA. Rhee et al. [
24] proposed the notion of trapdoor indistinguishability and showed that trapdoor indistinguishability is a sufficient condition for preventing outside KGAs. Jeong et al. [
25] showed that constructing secure PEKS schemes against inside KGA is impossible under the original PEKS framework in [
7]. Xu et al. [
26] proposed a PEKS scheme to against inside KGA. More recently, various improved PEKS schemes have been proposed. For example, Liang et al. [
27] proposed a searchable attribute-based proxy re-encryption system to achieve privacy-preserving keyword search and encrypted data sharing as well as keyword update; Chen et al. [
28] proposed a dual-server PEKS scheme to against inside KGA launched by the malicious server; Yang et al. [
29] proposed a semantic key word searchable proxy re-encryption scheme for secure cloud storage using lattice-based cryptographic primitives; Wu et al. [
30] designed an efficient and secure searchable encryption protocol using the trapdoor permutation function for cloud-based IoT; Yin et al. [
31] proposed a ciphertext-policy attribute-based searchable encryption scheme to achieve keyword-based search and fine-grained access control over encrypted data.
Table 1 shows a simple comparison of some existing searchable encryption schemes. In the design of searchable encryption scheme, privacy is a key concern. However, in all the existing searchable encryption schemes, the data user can access all the data owned by the data owner, which can result in a privacy breach for the data owner.
3. Preliminaries
A summary of the notations used in this paper is presented in
Table 2.
The set of all binary strings of length n is denoted as , and the set of all finite binary strings is denoted as .
An index table (or dictionary) denotes the data structure of the form . Given a , the matching the is returned.
A function is negligible if for every positive polynomial and all sufficiently large , . We similarly write to mean that there exists a negligible function such that for all sufficiently large .
The following basic cryptographic primitives can be found in [
32].
A symmetric encryption scheme is a tuple of probabilistic, polynomial-time (PPT) algorithms, where takes the security parameter as input, and outputs a secret key k; takes a key k and a message as input, and outputs a ciphertext ; takes a key k and a ciphertext c as input, and outputs m if .
For any symmetric encryption scheme , any adversary A and any value for the security parameter, the chosen-plaintext attack (CPA) indistinguishability experiment is defined as:
A random key k is generated by running .
The adversary A is given input and oracle access to , and outputs a pair of messages , of the same length.
A random bit is chosen, and then a ciphertext is computed and given to A. c is called the challenge ciphertext.
The adversary A continues to have oracle access to , and outputs a bit .
The output of the experiment is defined to be 1 if , and 0 otherwise. In the case , we say that A succeeded.
Definition 1. A symmetric encryption scheme is CPA-secure if for all PPT adversaries A there exists a negligible function such thatwhere the probability is taken over the random coins used by A, as well as the random coins used in the CPA indistinguishability experiment. For any adversary A and any value for the security parameter, the computational Diffie-Hellman (CDH) experiment is defined as:
Run to obtain output , where is a cyclic group of order q (with bit length ) and g is a generator of .
Randomly choose a, .
A is given , q, g, , and outputs .
The output of the experiment is defined to be 1 if , and 0 otherwise.
Definition 2. The CDH problem is hard relative to if for all PPT adversaries A there exists a negligible function such that 4. System Model
The searchable encryption scheme for personalized privacy protection mainly includes three entities, i.e., the data owner, the data user, and cloud server. The data owner outsources the encrypted file features to the cloud server. The data user queries the encrypted file features containing a specific keyword to the cloud server. The cloud server stores and retrieves the encrypted file features. As the existing searchable encryption schemes, in this paper, the data owner is considered fully trusted. The data user is considered malicious, which means it may attempt to learn more information than it can retrieve. The cloud server is considered honest but curious in the sense that it may try to learn as much information as possible from the stored encrypted data and correctly execute the searchable encryption protocol.
Given n files , , and a non-negative integer l, let denote the file feature of at level l. Specially, let , i.e., the file feature of at level 0 is still .
Let denote the number of the file feature level (FFL). The data owner wishes to store the file features set on the cloud server. The objectives of the data owner are as follows:
For , , the file feature are stored on the cloud server such that the confidentiality of is preserved.
The data user queries for a keyword w and an FFL l to retrieve all authorized file features such that for a given in a secure and efficient way.
4.1. Formal Definition
The searchable encryption scheme for meeting the personalized privacy needs consists of the following algorithms:
: This algorithm is run by the data owner. It takes the security parameter as input, and outputs the global parameter .
: This algorithm is run by the data owner and the data user, respectively. It takes the global parameter as input, and outputs public/private key pairs and for the data owner and the data user, respectively.
: This algorithm is run by the data owner. It takes the file features set , the data user’s public key and the data owner’s private key as input, and outputs the encrypted file features set and the encrypted index set .
: This algorithm is run by the data user. It takes a keyword w, an FFL l, the data owner’s public key , and the data user’s private key as input, and outputs the trapdoor .
: This algorithm is performed interactively between the cloud server and the data user. It takes the encrypted file features set , the encrypted index set , and the trapdoor as input, and outputs all authorization file features such that for a given .
4.2. Security Definition
The searchable encryption scheme for meeting the personalized privacy needs must satisfy the index indistinguishability and the trapdoor indistinguishability under chosen keyword-FFL pair attack. As per literature [
15], we define two challenge-response games
and
between the adversary A and the challenger C to show the index indistinguishability and the trapdoor indistinguishability under chosen keyword-FFL pair attack, respectively.
The adversary A plays with the challenger C and attempts to distinguish an encrypted index of the given keyword-FFL pair from some encrypted indexes. If A wins , then A has obtained some useful information from some encrypted indexes.
:
- Setup:
Challenger C runs and to generate the global parameter and the public/private key pairs and of the data owner and the data user respectively, and sends , and to A.
- Adaptive query:
The adversary A makes the following queries to C:
- -
The adversary A adaptively selects the keyword-FFL pair for the encrypted index query. C responds with .
- -
The adversary A adaptively selects the keyword-FFL pair for the trapdoor query. C responds with .
- Challenge:
The adversary A sends two challenged keyword-FFL pairs , to C. C picks a random number and sends the encrypted index of the keyword-FFL pair to A.
- Guess:
The adversary A outputs and wins the game if .
Definition 3. We say the searchable encryption scheme for meeting the personalized privacy needs satisfies the index indistinguishability under chosen keyword-FFL pair attack if for all PPT adversaries A there exists a negligible function such that Adversary A plays with challenger C and attempts to distinguish a trapdoor of the given keyword-FFL pair from some trapdoors. If A wins , then A has obtained some useful information from some trapdoors.
:
- Setup:
C runs and to generate the global parameter and the public/private key pairs and of the data owner and the data user respectively, and sends , and to A.
- Adaptive query:
A makes the following queries to C:
- -
Adversary A adaptively selects the keyword-FFL pair for the encrypted index query. C responds with .
- -
Adversary A adaptively selects the keyword-FFL pair for the trapdoor query. C responds with .
- Challenge:
Adversary A sends two challenged keyword-FFL pairs , to C. C picks a random number and sends the trapdoor of the keyword-FFL pair to A.
- Guess:
Adversary A outputs and wins the game if .
Definition 4. We say the searchable encryption scheme for meeting the personalized privacy needs satisfies the trapdoor indistinguishability under chosen keyword-FFL pair attack if for all PPT adversaries A there exists a negligible function such that 5. Proposed Scheme
In this section, we present our proposed searchable encryption scheme for meeting the personalized privacy needs. It consists of the following algorithms.
is run by the data owner. It takes the security parameter as input, and performs the following:
Choose a cyclic group of prime order q and a generator g of .
Choose a symmetric encryption scheme .
Choose two collision-resistant hash functions and .
Set the global parameter .
is run by the data owner and the data user, respectively. It takes the global parameter as input, and performs the following:
Randomly select two elements and in as the private keys of the data owner and the data user, respectively.
Compute and in as the public keys of the data owner and the data user, respectively.
is run by the data owner. It takes the file features set , the data user’s public key and the data owner’s private key as input, and performs the following:
Compute .
For , , randomly select as the identifier of , run algorithm to generate the encryption key of , and compute , , .
Create the index table such that for every and .
Given an FFL , create the keyword set of the file features set .
For , compute .
For , compute .
For , construct the set of the authorized FFL of the file . In other words, implies the date user has authorization to access the file feature .
Create the index table such that for every .
Send and to the cloud server.
is run by the data user. It takes a keyword w, an FFL l, the data owner’s public key and the data user’s private key as input, and performs the following:
Compute .
Compute .
is performed interactively between the cloud server and the data user. It takes the encrypted file features set , the encrypted index set and the trapdoor as input, and performs the following:
The cloud server: Given , search to obtain the set and send to the data user.
The data user: Given , create two index tables and such that , for every , where and () are randomly selected in . Send to the cloud server and store .
The cloud server: Given , create the index table such that for every in and send to the data user.
The data user: Given and , compute for every in .
Remark 1. Please note that , then , . Thus, , , , , for every , where , , . Therefore, our proposed scheme is correct.
Given an FFL , creating the keyword set of the file features subset means that , must be text. Thus, our proposed scheme works for all file types including text, audio, image, video, etc. as long as there exists an FFL such that the file feature of the file at is text.
If the authorized FFL set of the ordinal file is only created by the data owner, then the data user cannot access to the unauthorized file features, thus our proposed scheme meets the different privacy needs of different individuals.
Our proposed scheme can be extended to the multi-user scenario. Let and be the number of the data owners and the data users, respectively. In the multi-user scenario, the public/private key pairs are first generated for every data owner and the data user; the file features stored on the cloud server is an -ary vector, where the i-th element is the encrypted file features set of the i-th data owner; the index stored on the cloud server is an matrix, where the i-th row and j-th column element is the encrypted index set that the i-th data owner created for the j-th data user.
It is obvious that our proposed scheme needs increasing storage space when is getting bigger. In particular, our proposed scheme has similar storage space to the existing searchable encryption schemes when .
6. Security Analysis
In this section, we show that our proposed scheme satisfies the index indistinguishability and the trapdoor indistinguishability under chosen keyword-FFL pair attack.
Theorem 1. If is CPA-Secure and the CDH problem is hard relative to , then our proposed scheme satisfies the index indistinguishability under chosen keyword-FFL pair attack.
Proof. If there exists a PPT, and adversary A wins , then there exists a simulator B such that or .
In the setup phase, C runs and to generate the global parameter , and the public/private key pairs and of the data owner and the data user respectively. Then, C sends , and to A.
In the adaptive query phase, assume A makes queries to C adaptively. The q-th query can be:
- -
A adaptively selects the keyword-FFL pair for the encrypted index query. C responds with , where is the authorized FFL set of , , , , .
- -
A adaptively selects the keyword-FFL pair for the trapdoor query. C responds with , where .
In the challenge phase, A sends two challenged keyword-FFL pairs , to C. C picks a random number and sends the encrypted index of the keyword-FFL pair to A, where , , and .
In the guess phase, A outputs its guess indicating whether the challenge is the encrypted index of or .
From the perspective of A,
and
are random values in
for every
and
. Please note that
. Then the information obtained by the adversary A in
was the same as the information obtained by a simulator
B in the CPA indistinguishability experiment
and in the CDH experiment
. Thus, if A wins
then
or
, i.e.,
Therefore, our proposed scheme satisfies the index indistinguishability under chosen keyword-FFL pair attack if
is CPA-Secure and the CDH problem is hard relative to
. □
Similarly, we can prove the following theorem:
Theorem 2. If is CPA-Secure and the CDH problem is hard relative to , then our proposed scheme satisfies the trapdoor indistinguishability under chosen keyword-FFL pair attack.
7. Performance Analysis
As shown in
Table 3, we present a comprehensive comparison of the computation cost between our proposed scheme and some existing searchable encryption schemes. The notations used in
Table 3 are as follows:
: Time cost for a bilinear pairing.
: Time cost for a hash function.
: Time cost for an exponentiation operation in .
: Time cost for a multiplication operation in .
: Time cost for an encryption process of .
: Time cost for a decryption process of .
To meet the basic security level for comparison, SHA-256 and AES-256 is selected as the collision-resistant hash function and the symmetric encryption scheme, respectively. The cyclic group of order q is generated by a point on an elliptic curve , where q and p are the 256-bits and 521-bits prime numbers, respectively. To evaluate the efficiency of the five schemes, we perform our experiments on a computer with 2.4 GHz Intel Core i7 and 8 GB RAM.
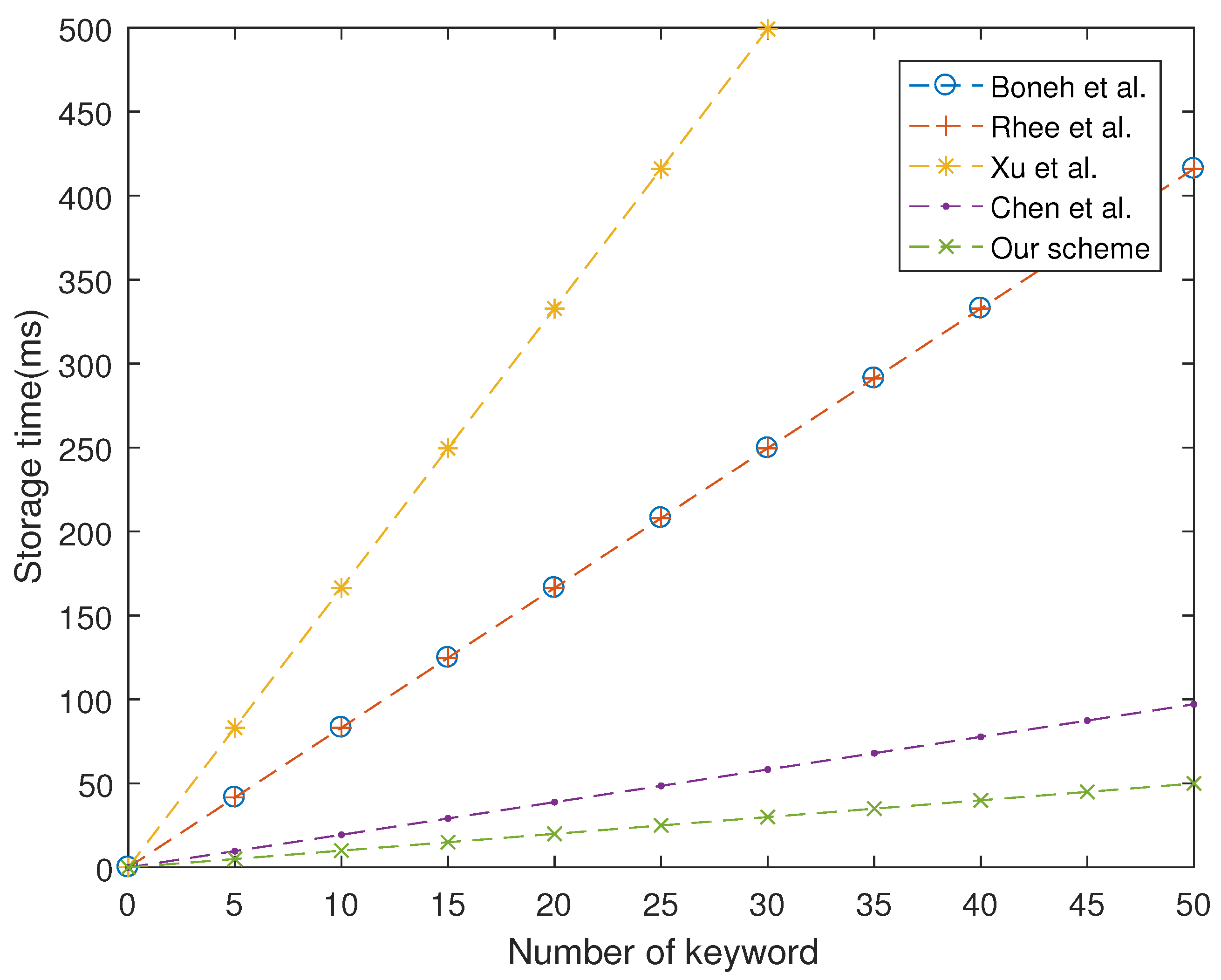
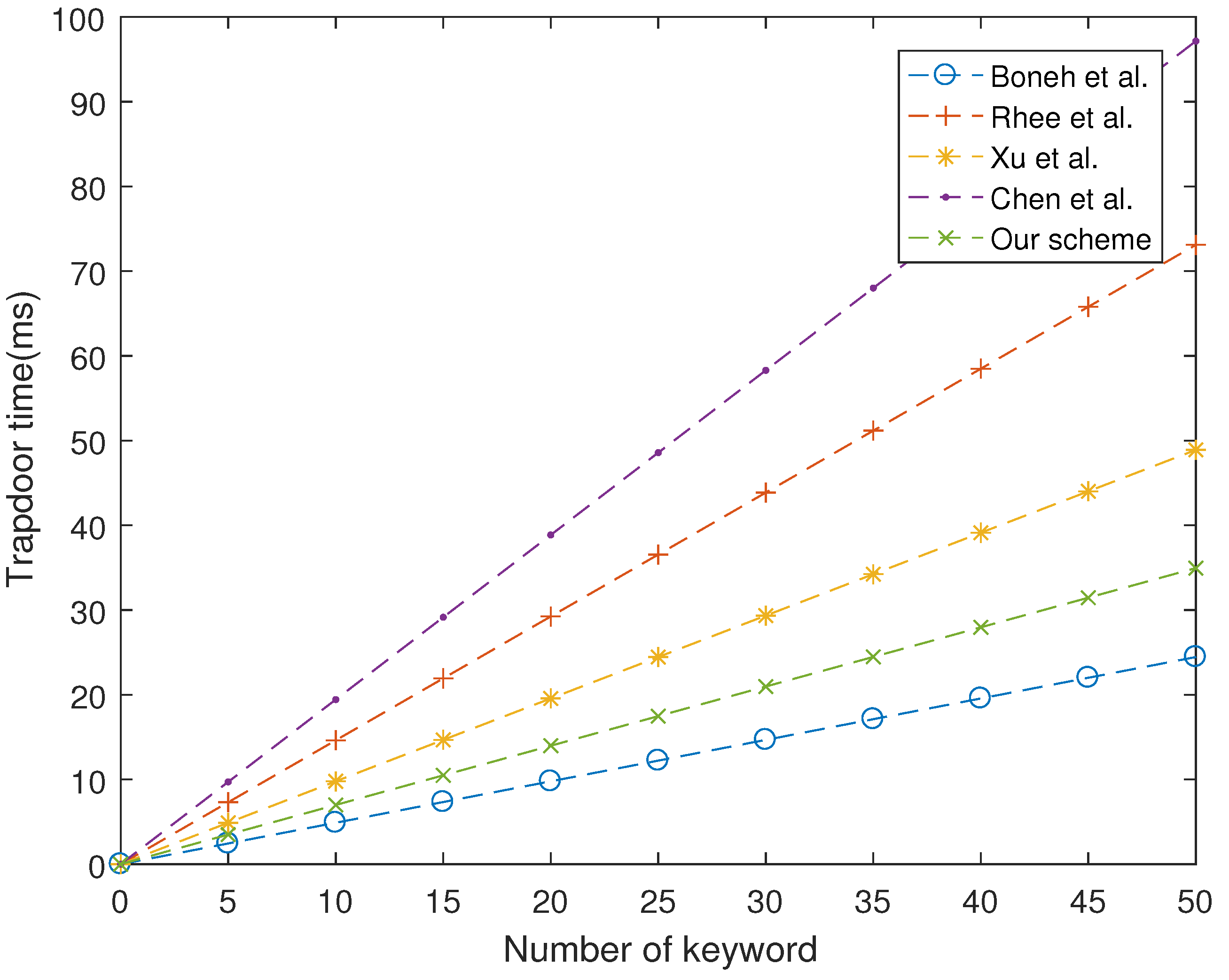
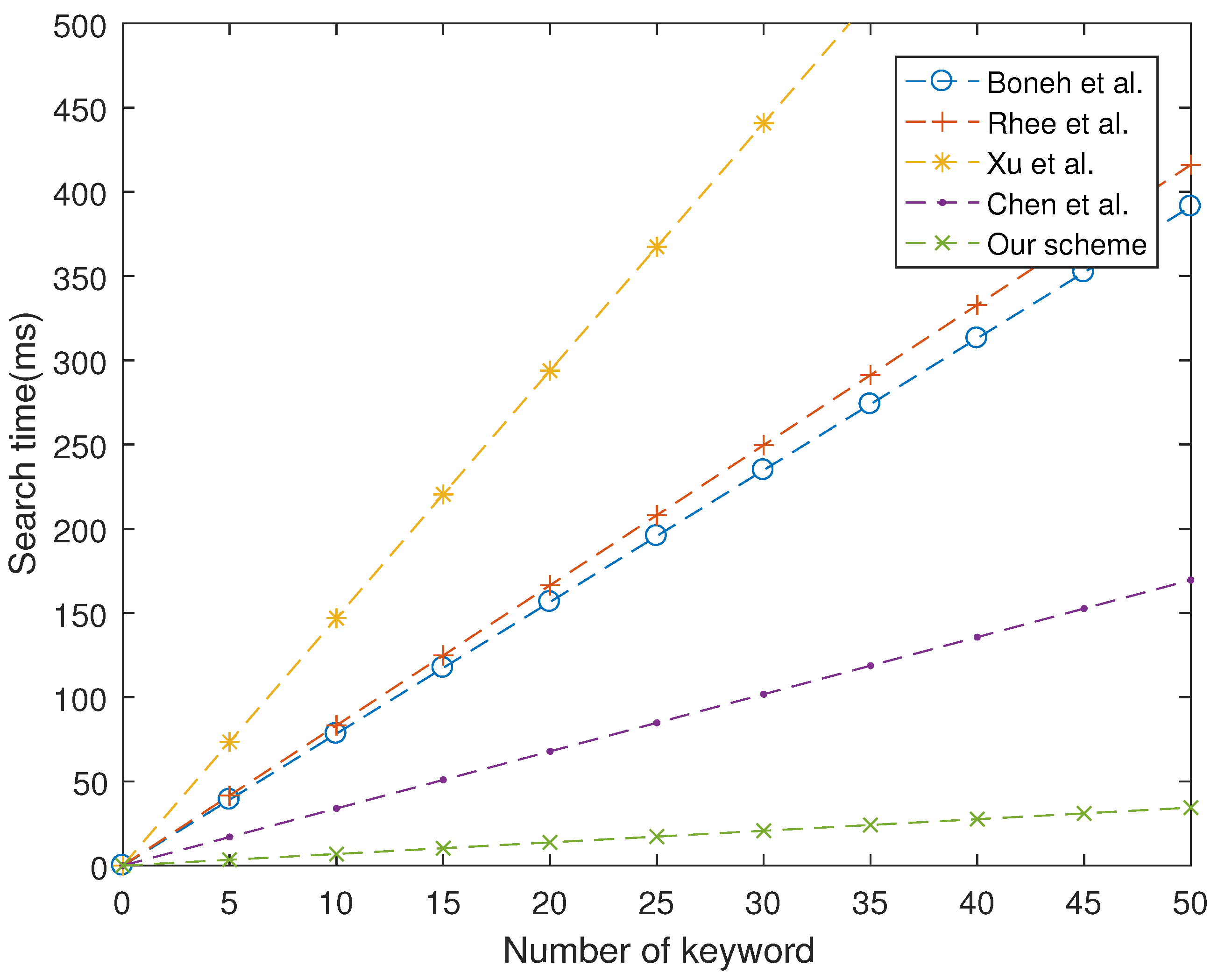
As shown in
Figure 1,
Figure 2 and
Figure 3, our proposed scheme is the most efficient in storage phase and search phase. In trapdoor phase, our proposed scheme has a higher computational cost than that of Boneh et al. [
7], although it is still lower than other schemes. In summary, the performance of our proposed scheme is more efficient than four schemes studied in [
7,
24,
26,
28].
8. Conclusions
In this paper, we have proposed a searchable encryption scheme for meeting personalized privacy needs. Our proposed scheme mainly includes three entities, i.e., the data owner, the data user, and cloud server. The data owner outsources the encrypted file features to the cloud server. The data user queries the encrypted file features containing a specific keyword to the cloud server. The cloud server stores and retrieves the encrypted file features. Compared with the existing searchable encryption schemes, our proposed scheme works for all file types including text, audio, image, video, etc., and meets different privacy needs of different individuals at the expense of high storage cost. We also show that our proposed scheme satisfies index indistinguishability and trapdoor indistinguishability under chosen keyword-FFL pair attack. In other words, our proposed scheme is secure against inside KGA. Performance analysis shows that our proposed scheme is efficient in storage phase, trapdoor phase, and search phase.
Considering the decreasing costs of storage, storage cost is not a problem if , i.e., the number of the FFL is small in our proposed scheme. However, storage cost is still a problem if is too large in our proposed scheme. Thus, choosing an appropriate is an important work in the future.







{kind=link}
{kind=link}
{kind=link}