An Optimized Tightly-Coupled VIO Design on the Basis of the Fused Point and Line Features for Patrol Robot Navigation

1
School of Automation Engineering, Northeast Electric Power University, Jilin 132012, China
2
School of Computer Science, Northeast Electric Power University, Jilin 132012, China
*
Author to whom correspondence should be addressed.
Sensors 2019, 19(9), 2004; https://doi.org/10.3390/s19092004
Submission received: 29 January 2019
/
Revised: 26 April 2019
/
Accepted: 28 April 2019
/
Published: 29 April 2019
(This article belongs to the Special Issue Visual Sensors)
Abstract
:The development and maturation of simultaneous localization and mapping (SLAM) in robotics opens the door to the application of a visual inertial odometry (VIO) to the robot navigation system. For a patrol robot with no available Global Positioning System (GPS) support, the embedded VIO components, which are generally composed of an Inertial Measurement Unit (IMU) and a camera, fuse the inertial recursion with SLAM calculation tasks, and enable the robot to estimate its location within a map. The highlights of the optimized VIO design lie in the simplified VIO initialization strategy as well as the fused point and line feature-matching based method for efficient pose estimates in the front-end. With a tightly-coupled VIO anatomy, the system state is explicitly expressed in a vector and further estimated by the state estimator. The consequent problems associated with the data association, state optimization, sliding window and timestamp alignment in the back-end are discussed in detail. The dataset tests and real substation scene tests are conducted, and the experimental results indicate that the proposed VIO can realize the accurate pose estimation with a favorable initializing efficiency and eminent map representations as expected in concerned environments. The proposed VIO design can therefore be recognized as a preferred tool reference for a class of visual and inertial SLAM application domains preceded by no external location reference support hypothesis.
1. Introduction
When robots operate under an unknown environment, an absolute external location reference such as a Global Positioning System (GPS) may be not available, and the no-prior-knowledge based navigating technology will be highly required. Thus, the individual intelligent robot should have the ability to estimate its own location using the carried sensors, such as Inertial Measurement Units (IMUs), laser radars, cameras, et al. [1,2,3]. For the navigation and perception problems of patrol robots working in the substations, the electromagnetic interferences will influence the signal transmissions, which therefore does not allow for the GPS receiver to assist the patrol robots with continuous and steady signal supports. In contrast to the existing navigation modes performed by dedicated external sensors, the robust solutions mainly lie mainly in utilizing the essential visual functions of cameras to build an environment map in real-time and estimate the position of the robot within the map simultaneously. This problem is called simultaneous localization and mapping (SLAM). It is noteworthy that SLAM may not only contribute to the acquisition and identification of the scene knowledge by some appropriate mode, but that it may also improve navigation performances with steady pose estimates [4]. One of the most significant SLAM results is proposed by Davison A.J., who pioneered the updating of the states of cameras and landmark points by an extended Kalman filter (EKF) and addressed the real-time SLAM problems for practical applications [5]. Klein G. extended the above model using a nonlinear optimization. He explicitly structured the SLAM system in terms of the front-end and the back-end, and improved the matched back-end framework by having the fused global constraints of the state variables be optimal rather than the pure iterations of EKF [6].
The above methods form the basis of feature-based methods for an efficient pose estimation [7,8,9]. Under the simple circumstances where the illumination changes slowly, or the cameras equipped are at a low speed movement, the direct methods are generally simpler to apply in practice, directly recovering the camera motion by minimizing a pixel-level intensities-based measurement error with no need to detect feature points [10,11,12]. Lately, there has been more research in the area of SLAM-based robot localization. In cases where the accurate pose estimates and large-scale scene reconstructions for mapping tasks are desired, the feature-based methods are more suitable for robotic applications.
Some research focuses on eliminating the accumulative positioning errors mainly caused by the incorrect feature points matching among images [13,14]. Actually, considering the fact that the cameras in motion find it difficult to present the expected brilliant images continuously, and in view of the fact that in some cases the cameras are working under the scenes with poor visibility or the ‘understanding’ of scenes can not be achieved in terms of textures, a visual inertial odometry (VIO) scheme is generally preferred, by fusing the inertial recursion (IMUs present) and SLAM calculation (cameras present) in robotics, to satisfy a long-term positioning accuracy and a matched favorable navigation stability in a short-time rapid maneuver.
By a method in which the state of the camera and the state of IMU are either directly incorporated in one state estimator or not, the typical VIO may be classified into a loosely-coupled mode and tightly-coupled mode. A loosely-coupled VIO separately estimates the relative motion by two state estimators, viz., the state of the camera and the state of IMU are separately estimated, and the VIO makes a fusion of these two results. A tightly-coupled VIO fuses raw measurements from the camera and IMU, explicitly estimating the relative motion by one state estimator, and this is generally fulfilled by constructing the joint nonlinear loss functions associated with the state variables. By contrast, the tightly-coupled mode presents a better accuracy and robustness.
For the state estimation, a filter-based method and optimization-based method are both possible [15,16,17,18]. The tightly-coupled mode fully takes into account the coupling between the used sensors. The optimization-based method explicitly incorporates the raw measurements of sensors and globally optimizes the sensor states by one estimator. As a mainstream framework, the tightly-coupled optimization-based VIO has been greatly extended theoretically. In principle, the system state of a VIO is expressed by typically integrating the pose (such as a rotation and translation by IMUs/cameras), velocity and zero bias (such as an inherent gyro bias and accelerometer bias by IMUs). The system state estimation of a VIO can converge to the desired state by optimizing the previously-constructed loss functions with respect to the state. It should also be noted that the initial values of the state variables for the global optimization are given by a system initialization module. To guarantee the long-term and steady availability in cases where limited numbers of feature points or textures are present, some research has been developed to improve the feature extraction pattern by fusing the line features or plane features in the VIO front-end, enabling the cameras to efficiently keep tracking. These solutions are equivalent to exerting some additional constraints to the entire pose estimation tasks [19,20].
The maturation and development of the above techniques underpin a successful robot application in the power patrol inspection. Accordingly, the efficiently initialized VIO permits the robot to perform accurate localization and navigation tasks [21,22]. Based on the above discussion, an optimized VIO system is presented to take into account the problems associated with the initialization efficiency and feature matching results.
The main contributions to this paper are shown in the following aspects.
- First, during the course of a VIO initialization, the constant-velocity constraints are applied to the robots in motion. The consuming time for calculating the camera rotation between frames, is, in consequence, much less than that under the non-restriction conditions, accelerating the acquisition process of the initial state variables (including the pose, velocity, zero bias, etc.) dynamically.
- Second, as a consequence of explicitly taking into account the textures of the electrical equipment in the work volume, the improved VIO characterized by the feature matching in terms of point features and line features enables the camera movement estimation (such as the rotation or translation) to be more accurate and smooth.
- Third, the sparse maps represented by the point features and line features are constructed as expected under the sliding window optimization model. The introduction of this practical optimization model improves the efficiencies of the state estimation and mapping. Additionally, both dataset tests and substation scene tests for the robot routing inspection applications have been conducted, and the detailed evaluation results are given.
The outline of the remainder of the paper is as follows. The following section mainly discusses the VIO anatomy, besides the detailed description of the VIO front-end, including the reprojection errors associated with the points features and line features; additionally, the IMU pre-integration model is given, and the superiority of the fused-point and line feature-matching based method in accurate pose estimates over the direct method and simple point feature-matching based method is numerically proven by multiple sets of simulations. In Section 3, a simplified VIO initialization strategy is proposed and discussed, which subsequently includes a gyro bias estimation, accelerometer bias and gravity estimation, and scale factor and velocity estimation; furthermore, the laboratory test on the comparative time consumption by three typical feature-based visual odometries (VO) is highlighted. The matched state variable optimization tasks in the VIO back-end are emphasized in Section 4; specifically, the sliding window model for the accumulated error reduction and the visual measurement model for the two Jacobian matrix calculations with respect to the reprojection errors defined in Section 2, are respectively established. Section 5 carries out the experiments on dataset tests and real substation scene tests, and presents the main conclusions of this investigation.
2. Overall Description of Tightly-Coupled VIO
The physical structure of VIO can be divided into two parts: an IMU and a monocular camera. The embedded IMU provides the VIO system with an orthogonal 3-axial acceleration and angular rate in the body (robot) coordinate frame. The camera is mounted on the stationary base of the robot, providing the VIO system with sequential image information, by which it estimates the robot pose in the world coordinate frame and which can be further applied to represent and address the structure from motion (SFM) problem [23,24]. The essential part of integrating these two components consists in updating the state variables of the tightly-coupled VIO system as time evolves, so as to efficiently obtain the global optimum solutions of the state variables.
2.1. VIO Anatomy
Denote the world coordinate frame of the VIO system by , which is referred to as the absolute reference used to denote the position and orientation of the objects in the concerned scenes. Denote the IMU coordinate frame (body coordinate frame) and the camera coordinate frame by and , respectively. A transformation between and is represented by a homogeneous transform matrix , where represents the rotation and represents the displacement. Let denote the robot velocity expressed in the world coordinate frame. Denote the gyro bias and accelerometer bias by and , respectively. Figure 1 presents the diagrammatic representation of a VIO state estimator algorithm.
As illustrated, Figure 1 shows how information flows forward from the front-end to the back-end of the process. The VIO front-end collects the manipulated inputs from the IMU and the camera, and after obtaining the raw pose estimates of the robot in motion it turns to the VIO back-end to calculate the initial state vector . As mentioned above, the fused point and line feature-matching based method is conducted for the ideal pose estimates, on basis of the gray images.
The VIO back-end is used to optimize the state vector from . Let:
where represents the scale factor of the monocular camera, and represents the gravity vector expressed in the world coordinate frame. represents the VIO state vector and represents the loss function with respect to . and respectively represent the point features and line features of the images in the world coordinate frame. and are, respectively, the constructed quadratic form functions of the point feature reprojection error and line feature reprojection error. is also a quadratic form function of the IMU error, which in nature denotes the constraints between the current frame and the previous keyframe in terms of a series of variable errors, like the rotation, position, velocity and bias [25]. Minimize the loss function by means of a typical Levenberg-Marquardt iterative calculation to assure the global optimization results, viz., the VIO can put out the globally optimal pose, trajectory, and landmark position in the world coordinate frame.
Note that the relative position and orientation between the camera and the IMU are fixed once the installation is done. Analogously, the transformation relationship between and can be represented by a homogeneous transform matrix , where represents the rotation and represents the displacement. More specifically, essentially has a major impact on the precision and stability of the VIO system, which should therefore be calibrated with some mathematical means beforehand. Referring to the existing well-developed ways [26], the typical hand-eye calibration method is adopted in this paper.
2.2. Reprojection Error of the Camera
As described above, the VIO system fuses the point features and line features derived from the camera images. For the point features, the reprojection error denotes the distance (on the imaging plane) of the projection position of 3-D points from the detected position, minimizing this error by means of identifying the matched transform matrix, which then indicates that the pose optimization process is fully implemented. Suppose is the position of the th feature point in 3-D space and is the detected projection position of on the imaging plane, the constructed reprojection error in terms of the point features can be defined as [27]:
where, is the depth of , and is the intrinsic matrix of the camera. is the Lie algebraic representation of the pose, and it follows that:
For a line segment with the ends , the line reprojection error denotes a sum of point-to-line distances between the projected line segment ends () and the detected line segment ends () on the imaging plane; it follows that [28]:
where, represents the distance between the detected position of and line , similarly, represents the distance between the detected position of and line . The normalized form may be defined as:
where and respectively indicate the corresponding homogeneous coordinates of the two ends of . The graphic interpretation of the point/line feature reprojection error is illustrated by the points and line segments in Figure 2.
2.3. IMU Pre-Integration
The output frequency of the IMUs is generally dozens of times that of the cameras, which then indicates during the course of the data fusion that the VIO collects multiple sets of IMU measurement data in a single sampling interval (between two keyframes).
Let and respectively denote the measured angular rate and acceleration. We have:
where and are the angular rate and acceleration to be estimated. and are white noise. The accelerometer bias and the gyro bias are subject to random walk noise.
The th updated , and can be given by [29]:
where is the time interval between two keyframes. The relative motion between two keyframes can be defined in terms of the pre-integrated , and , shown as follows:
Note that it is supposed that bias and bias are constant during the time interval from to , as indicated in Equations (11)–(13), and for this to be the case they should be initially calibrated in practice. Define the change of (and ) as the disturbance and linearize it with first-order approximation; consequently, we obtain the th state estimates in terms of the ith state estimates and the residual error:
where and are the Jacobian matrices of the pre-integrated measurements with respect to at the sampling point i.
The pose estimation and IMU pre-integration form the front-end tasks of the designed VIO. To evaluate the performances of the VIO, we carry out a set of numerical simulations. Two images () derived from fr1/desk of the TUM RGB-D datasets [30] are arbitrarily designated as the testing samples, the fused point and line feature-matching based method and the simple point feature-matching based method, together with the direct method. are conducted under different optimization strategies, including non-optimization, typical Gauss-Newton (G-N) optimization and Levenberg-Marquardt (L-M) optimization for the first round and convergence achieved respectively. The comparative results are shown in Table 1, in terms of the transform matrix and RMSE (root mean squared error) values.
As in Table 1, since the direct method estimates the robot pose directly by minimizing a pixel-level intensities-based measurement error, which in nature belongs to the optimization problem, when non optimization is adopted the direct method itself is not available at all. For the first-round G-N optimization, the direct method and the simple point feature-matching based method both fail to result in valid estimates, which is mainly because the trust region problem is not fully taken into account during the optimization process, and consequently an oversized step is employed by mistake. By contrast, the fused point and line feature-matching based method presents a better robustness under a wider range of optimization strategies without any load in complexity; specifically, with the L-M optimization conditions its pose estimation precision is generally best (a lower RMSE between the estimated and the true transform matrix given in fr1/desk TUM). The following section concentrates on fulfilling the VIO initialization design for a better state initializing efficiency.
3. VIO Initialization Design
The behavior of the VIO highly depends on the initial values of the system states. A proposed method of initializing the VIO states consists of previously setting a constant velocity for a patrol robot in operation. Moreover, it assumes that the rotation is steadily unchangeable. The simplified solution, therefore, is expected to improve the initializing efficiency of an actual VIO without any decrease in the precision. Quite simply, the accuracy of the estimated gravity is evaluated by reference to its true value (since the magnitude of the true gravity is known), so that the effectiveness of the simplified VIO initializing strategy can be verified. The detailed procedures are shown below.
3.1. Gyro Bias Estimation
Assume that the relative rotation defined in the pre-integration module is constant, and that the velocity difference is zero during the given time interval [i,i + 1], [i + 1,i + 2], …; we have:
Define the residual error by integrating the terms from the camera calculation and gyro pre-integration. It follows that [31]:
where ( is derived from the monocular camera). N is the number of keyframes.
The gyro bias is estimated by minimizing with the L-M calculation. Among some typical feature point methods such as ORB (Oriented Brief) feature, SURF (Speeded Up Robust Features) feature and SIFT (Scale Invariant Feature Transform) feature, the process of feature extraction and matching cost more execution time. To quantitatively illustrate the time taken for each step of the VIO pose estimation, Table 2 presents the comparative time consumption results through three typical feature-based visual odometries (VO) with a computer Lenovo Y510 (Inteli5-4200MQ, 2.5GHz CPU, 8GB RAM, Lenovo Grope, Beijing, China,) under an Ubuntu 16.04 environment. The images that are used are coming from the fr1_xyz of TUM dataset.
As described, the main idea of the VIO initialization lies in calculating the rotation matrix of each frame according to the results from the first two frames on the basis of keeping the rotation constant, rather than repetitively performing a routine feature extraction and feature matching. This is illustrated by the comparative time consumed for the bias estimation in Figure 3; we arbitrarily designate different numbers of the images for testing, and compare the corresponding consumption time by the method in this paper and the typical methods in [22,31]. Clearly, continuously estimating the rotation between the frames reveals its poor efficiency when a larger number of frames are concerned; therefore, the proposed method shows its superiority in dealing with the bias estimation in large-scale scene information.
3.2. Accelerometer Bias and Gravity Estimation
The residual error of relative velocity may be directly defined on the basis of the constant velocity hypothesis with the known , viz., the accelerometer bias is fully taken into account in this case, which is quite different from that adopted in [31]. We define:
Analogously, the estimates of the accelerometer bias and the gravity are solved by forming a least-square problem with manipulated VIO inputs. It is noted that, in view of the VIO computational load, only three keyframes with a strong parallax excitation are used to establish the fewer simultaneous equations, and this simplified scheme is sufficiently accurate to deal with a wider range of accelerometer bias phenomena.
We further optimize the gravity and parameterize it as:
where is the magnitude of the gravity, and is the direction vector of the current gravity . and are two orthogonal bases on the tangent plane and can be easily determined by the Gram-Schmidt process. and are the corresponding 2D components to be estimated. Substitute Equation (20) into Equation (19) and solve it by Singular Value Decomposition (SVD) [32]. This process is iterated several times until converges.
3.3. Scale Factor and Velocity Estimation
The scale uncertainty of the monocular cameras may lead to an ambiguous estimate trajectory. The scale factor s is therefore introduced to represent the position transformation between the camera and IMU, and it follows that [33]:
Substitute Equation (21) into Equation (16) and ignore the accelerometer bias. We have:
Substitute the relative velocity of the pre-integration measurements (expressed in Equation (12)) into Equation (22), and let and respectively denote the time interval between Keyframe 1 to Keyframe 2 and Keyframe 2 to Keyframe 3. Eliminate the unknown, and we can get , similar to [31]. Thus, can be calculated from the residual error equation below:
In Equation (22), so far, the unknown is solvable. For the first (K−1) keyframes, the corresponding velocity can be explicitly calculated. Conversely, the current (the Kth) keyframe should be given by Equation (15).
4. Tightly-Coupled Information Fusion Based on Sliding Window
The VIO system may proceed, in this phase, by realizing the initialization of the variables illustrated above. The core points consist in continuously optimizing the joint loss functions of each error term (including , and ). However, since the front-end of the VIO collects a large amount of input information from the camera and IMU, a heavy emphasis should be placed upon the real-time state estimation of the VIO that has to cope with the potential tracking failures. Considering the computational load in the back-end of the VIO, a practical sliding window scheme is developed to perform the efficient state optimization [34].
4.1. Sliding Window Model
The sliding window in the VIO mainly marginalizes out certain states of the system by a Schur complement, and the reinsertion of these as prior information (the prior term ) would allow the loss functions to be formed and optimized. That is, further supplies the system state with observable constraints. Suppose that the ith system state vector (in terms of discrete moment) is , the matched error terms, can therefore be expressed as:
where and respectively represent the sets of visual and inertial measurements in the current sliding window, and and respectively represent the point features and line features which are observed at least twice in the current sliding window. and respectively represent the information matrix of the point feature reprojection error and line feature reprojection error. and are also information matrices, respectively representing the pre-integration information matrix and bias random walk information matrix. is the robust kernel, piece-wisely expressed as:
where is in the Huber norm ( being a pre-set threshold). and are defined in Equations (18) and (19). Analogously, the definitions of and are also derived from the pre-integration measurements, and we have:
The marginalization result can be denoted as the prior term , and it follows that:
where represents the prior information after marginalization, and represents the Hessian matrix constrained by the pose, landmark position and IMU measurements.
The modified loss function in a linear combination form can therefore be further written as:
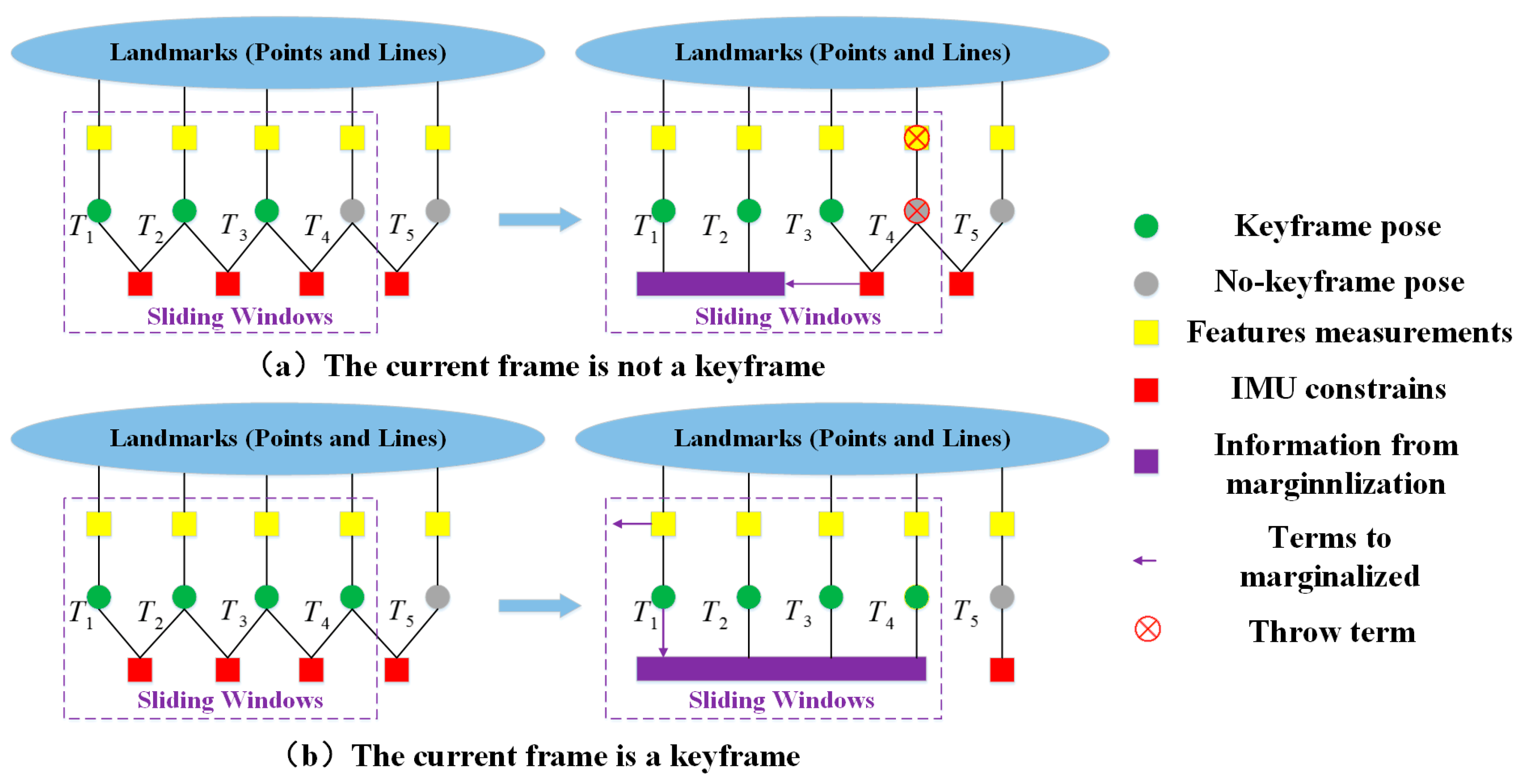
The typical optimization strategy of is similar to Visual-Inertial System (VINS) [35]. Given the frames in the optimization window, the decision-making pattern of the end-back of the VIO is diagrammatically represented in Figure 4. In the figure, the green circle in the figure indicates the pose of the keyframes, the gray circle indicates the pose of the non-keyframes, the yellow square indicates the measurements of the features, the red square indicates the inertial constraints of the IMU, and the purple square and the arrow indicate the information that is marginalized. The red cross indicates the measurements that was discarded. Two cases are discussed: ① if the current inserted frame is not a keyframe, the visual measurement, together with the current pose estimate, would be explicitly neglected, viz., the IMU constraints would only be marginalized out; ② if the current frame is a keyframe, the visual measurement and the pose estimate of the oldest keyframe in the sliding window would be marginalized out and the current keyframe would be kept accordingly.
Owing to the specific forms of the variables to be optimized in the sliding window model, the following work will turn to the definition of the vertices/edges in the graph optimization model by means of a G2o optimization framework and to the estimation of the state variables by means of an L-M iterating calculation [36].
4.2. Visual Measurement Model
For the loss function represented by Equation (31), the optimization means recurrently performing the linear expansion of Equation (31) around the current estimated value, which therefore implies its principal of calculating the Jacobian matrices of the residual functions with respect to the state variables. Specifically, the method chosen to solve the Jacobian matrix of the point reprojection error with respect to the pose should be the typical chain rule [37], which yields:
with
where is the disturbance of the pose, is the coordinate of the landmark in the camera coordinate frame, and and are the focal length parameters in . is an identity matrix.
For the Jacobian matrix of line reprojection error with respect to the pose, let be the Plücker coordinate of the line feature [38], and let the homogeneous coordinates of and be and respectively. We have:
with
where is the direction vector of the line, and is the normal vector of the plane formed by the line and origin point; they are both in the Plücker coordinate frame. In addition to the Jacobian matrices of the point/line reprojection error with respect to the pose, analogously, the Jacobian matrices of the point/line position in space could be formulized as the similar forms to those in Equations (32) and (35), due to the limits of the space. Please see [39] for details.
5. Experimental Section
The experimental observations consist of dataset tests and substation scene tests. The behaviors of the VIO on the datasets largely reflect its actual performances, so the process of evaluating the performances of the designed VIO consists of first testing it in the public datasets.
5.1. Dataset Tests and Analyses
The public dataset European Robotics Challenge (EUROC) [40] provides a series of information (such as images, accelerations and angular rates, etc.) invoking a micro aerial vehicle (MAV) equipped with a stereo camera and an IMU in either ① a cluttered workspace scene or ② an industrial machine hall scene. Moreover, the derived information (11 sequences in total) is classified into three grades: “easy”, “medium” and “difficult”, depending for example on the velocity of the aerial vehicle, the texture status of the scene, or the lighting conditions nearby. Also, EUROC presents the standard trajectories captured by the VICON motion capture system with reliable navigating parameters (so-called ‘Ground Truth’) available to users, including the position, attitude, velocity of the MAV in 3D space and some other inertial data, such as the gyro bias and the accelerometer bias obtained by the IMU. Specifically, the V1_01_easy sequence and the MH_04_difficult sequence are designated as the testing samples, and are therefore more appropriate to reflect the strong information domain coverage. In contrast, the state estimates are compared with those extracted by the existing eminent VIOs, such as OKVIS, VIORB, VINS, etc. One thing that should be noted is that, since EUROC doesn’t explicitly provide the Ground Truth scale, we therefore extract it by collecting the translation results from ORB-SLAM2 and translation references provided by Ground Truth. Once we obtained the translation transformation between the first two keyframes in ORB-SLAM2, the truth scale would be a calculation of the translation transformation to the references. Note also that the EUROC dataset presents the stereo images at 20 Hz with IMU measurements at 200 Hz and a trajectory Ground Truth with a higher updating frequency. Hence, the efficient state estimate comparison can only depend upon the accurate alignment of the timestamps. Among these, the VIO trajectory comparison is fulfilled by means of the evo tool [41], and the position error comparison is conducted by the script that TUM provides.
5.1.1. VIO Initialization Results
The initialization results are illustrated by the convergence procedures of the initialization state with respect to two typical sequences (V1_01_easy and MH_04_difficult) in Figure 5, and the initialization state is constructed of ① the accelerometer bias, ② the gyro bias in orthogonal tri-axes, ③ the condition number (referring to the data adaptation), ④ the scale factor of the monocular camera, and ⑤ the orthogonal tri-axial component of the gravity vector. Quite clearly, all of these five sets of variables converge for . Specifically, the accelerometer bias and gravity vector appear convergent after , and the accelerometer bias converges to almost zero even under the MH_04_difficult sequence circumstances, while in contrast to this the gyro bias appears larger yet, with more stable characteristics; the reasons for this consist in the fact that we merely calculated and corrected the gyro bias by means of the pose transformation directly derived from the camera, whereas the estimations for the accelerometer bias were implicitly performed by the precise least-square iterations. By comparison, the initialization performances for the MH_04_difficult sequence are slightly inferior, because the condition number illustrated in Figure 6c approximately converges until ; by then, the observabilities for the initialization state variables are satisfied. Meanwhile, the estimated scale factor, as shown, may be considered to be a true value for ; the camera trajectory can therefore be recognized as being precisely recovered as expected.
5.1.2. Navigation Performance Evaluations
The feature extraction results are diagrammatically illustrated by Figure 6. As shown, in cases where the scene textures appear clear with an ideal illumination, a large amount of point features and line features are captured as expected (see Figure 6a). Additionally, even though the MH_04_difficult sequence supplies the system with an unstable illumination for representing the MAV in motion circumstances (see Figure 6b), the VIO front-end can still extract enough features and consequently stabilize the dynamic VIO. Here, four representative pictures are selected to describe the scenes that are considered.
The performances of the VIO designed above are diagrammatically given in 3D space, being characterized by absolute positioning errors (APEs). APE is often used as the absolute trajectory error, and the corresponding poses are directly compared between the estimate and reference, and given a pose relation.
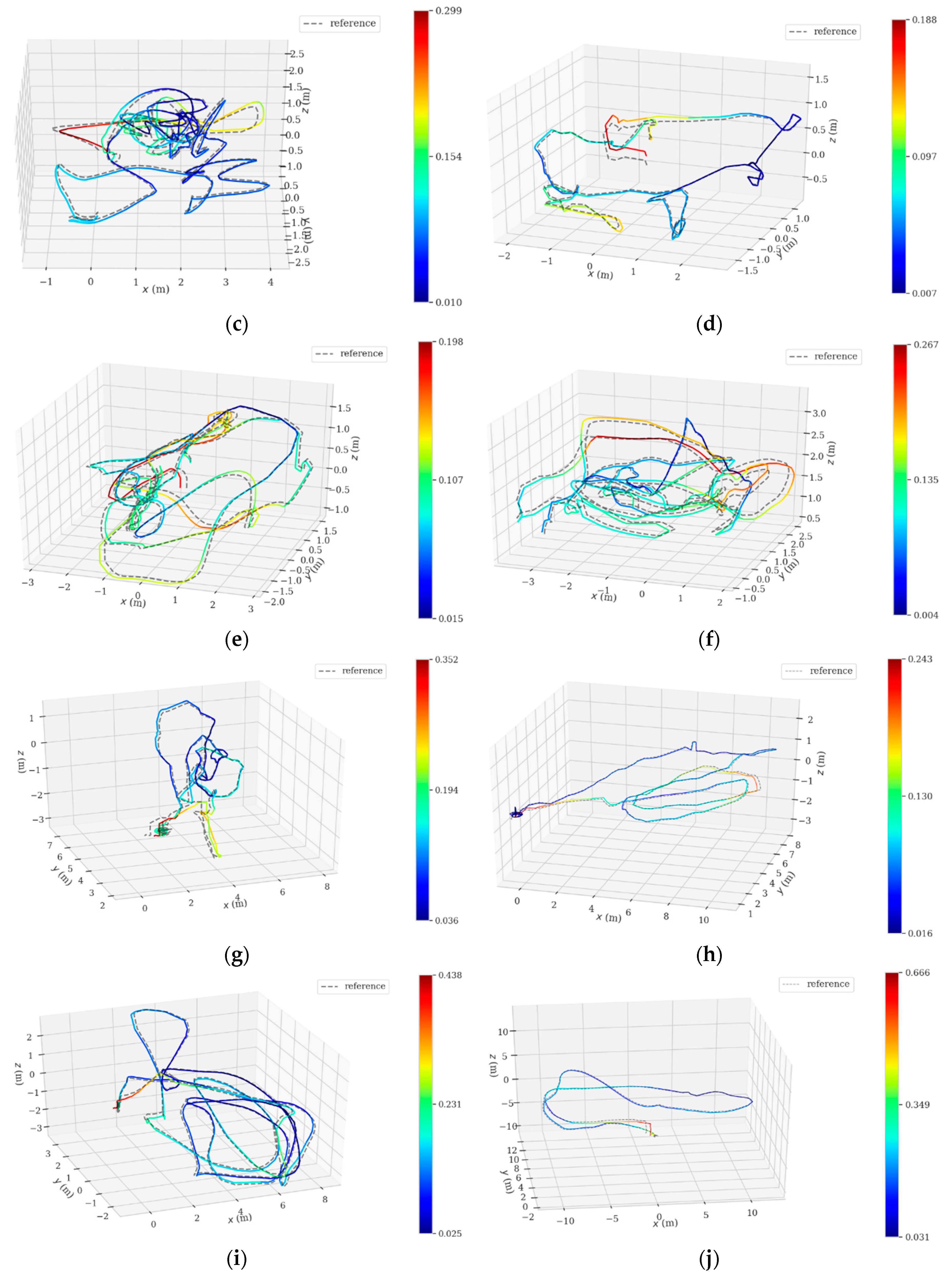
Figure 7a–k corresponds to 11 sequences at different difficulty levels. Furthermore, more detailed analyses related to the two typical sequences (V1_01_easy and MH_04_difficult) are illustrated by planar trajectories, as shown in Figure 8. In Figure 7, the dotted lines represent the Ground Truth trajectories (reference), the color lines represent the estimated trajectories by the designed VIO; the closer the color of the lines approaches to red, the greater the APE, and vice versa. As we can see, the designed VIO presents stable tracking performances for all difficulty levels, even for a fast camera movement or un-ideal illumination circumstances (as V2_03_ difficult and MH_05_difficult denote); no ‘tracking lost’ appears.
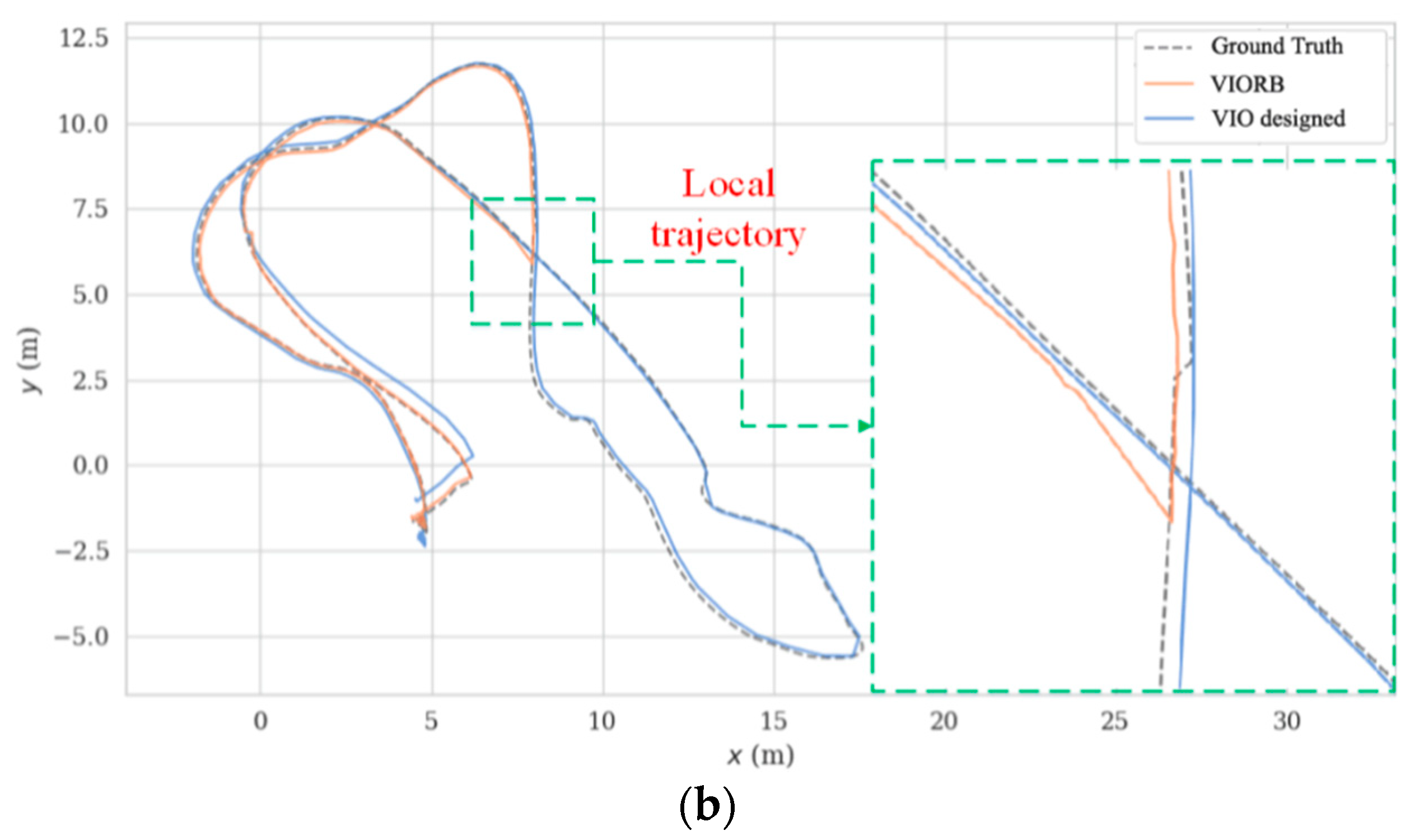
The corresponding trajectory comparisons by VIORB (merely with point-based SLAM) and the designed VIO (with fused point and line based SLAM) are given in Figure 8 with a more detailed APE (see Table 3). Considering the fact that the dynamics of the MAV in space are irregular, the 3D trajectory comparisons, would therefore be insufficiently visible; we are, accordingly, mainly concerned with the projected planar trajectory for further analyses (take typical sequence V1_01_easy and sequence MH_04_difficult, for example). In Figure 8, the dotted lines represent the projected Ground Truth trajectories, and the orange full lines and blue full lines respectively denote the trajectories by VIORB and the designed VIO. Figure 8b shows that the VIORB scheme failed to dynamically track the desired Ground Truth trajectory stably. Quite clearly, the orange full line shows its interruption in tracking, which is mainly caused by a lack of environmental textures. Even though the loop closure detection part could help VIORB by restarting the positioning tracing thread according to the previous scene information, the short-term tracking failures could be never acceptable for the actual robot inspection applications. Compared with VIORB, the generated trajectories by the designed VIO kept close to the Ground Truth trajectories (being collected by Vicon). The amplified local trajectories clearly show its superior performances in precision.
This high precision can also be indicated by the tri-axial APE in the world coordinate frame in Figure 9, and the VIO designed in this paper supplies the combined system with less APE along the X & Y directions in statistics. Two essential enhancements actually facilitate this good result: one is the fused line feature constraints, which further improved the pose transformation precision between the images; the other is the introduced sliding window, which efficiently reduced the data dimension for the back-end optimization. These enhancements are encouragingly achieved with no sacrifices in the VIO operating efficiency.
The corresponding visualized APE distributions are shown in Figure 10a,b, which also statistically shows the max values (red lines), the median values (yellow lines), the min values (green lines) and the concentrated error distributions, being termed ‘mean value domain’ (blue and orange blocks). Here, the remaining points represent the outliers with less weight. As we see, the positioning accuracy by the designed VIO over that by VIORB approaches 4 cm for the V1_01_easy sequence, whose value would be impressively over 16 cm for the MH_04_difficult sequence. Table 3 also gives the detailed APE for the total 11 sequences in terms of the comparison between 5 typical VIOs and the VIO designed in this paper. It can be concluded that the proposed VIO steadily presents its superiorities when dealing with the datasets with different difficulty levels.
5.1.3. Mapping Results
As an illustration of how the point and line features can be fused to support the operations of the VIO front-end, the sparse maps in terms of the fused point and line features for the V1_01_easy sequence and MH_04_difficult sequence are respectively shown in Figure 11. The green lines represent the trajectories of the keyframes, the blue lines represent the selected keyframes for the sliding window optimization, the black points or lines represent the fixed features in 3D space which have been marginalized out, and the red or pink points and lines represent the features which are still in their early optimizing phase. The results indicate that the designed VIO powerfully provides additional structured supports for the typical sparse maps, and this efficient mapping therefore means that it can be recognized as an eminent tool for the solution of scene reconstructions under complex human interaction situations, being preferred for assisting the practical location, navigation and obstacle avoidance tasks.
5.2. Substation Scene Tests and Evaluations
The positioning performances are experimentally assessed to evaluate the universal applicability of the VIO designed in practice. The substation scene tests are conducted based upon campus substation (100 m × 40 m rectangle) observations and subsequent laboratory analyses. Table 4 presents the calibration parameters of the camera and IMU we use.
Let the robot move around the rectangle with a lower constant velocity; the monocular camera embedded simultaneously entered the working state and was set to initialize the state variables by the initialization strategy described in Section 3, once the user workstation obtained the moderate convergent behaviors of the initial state variables. This, then, permitted the robot to perform higher-speed moving tasks (keep walking around the substation). Given the collected information by the user workstation, as shown in Figure 12, the state variables converge for , as we expected. With a controllable constant velocity, it is relatively efficient to initialize a VIO system. Figure 12e also presents an increase in speed for .
The feature extraction results of the VIO front-end in the substation scene is shown in Figure 13; obviously, the VIO front-end is capable of acquiring abundant point and line features even in cases where the illumination changes frequently (the snow diffuse reflection happens). As in Figure 14, the trajectory drawn according to the camera motion is rectangle distributed, which favorably conforms to the planar geometric appearance of the substation. The fused line features is therefore proven to improve the VIO accuracy both for translation and rotation, and to further improve the VIO robustness under the un-ideal illumination environments.
6. Conclusions
An optimized tightly-coupled VIO model which combines an efficient initializing strategy and fused point and line feature matching ideas was employed for navigating and mapping tasks of patrol robots in substations. After exhibiting favorable performances in initializing efficiency, pose estimation and trajectory tracking in a public dataset, this was further experimentally assessed by a campus substation application. It illustrated that, for the feature extraction and matching tasks in the VIO front-end, the fused point and line based method is generally preferred with an L-M optimization strategy; the optimized VIO presents its superiorities even though it is dealing with datasets with different difficulty levels. With respect to the point features and line features, the sparse maps are constructed under the sliding window optimization model, providing the VIO with a necessary location, navigation and obstacle avoidance references. The experimental results showed that a shortened initialization time was derived in practice and that the designed VIO could still accurately fulfill the point and line feature extractions and recover the motion trajectory under un-ideal illumination circumstances. The proposed VIO model therefore fairly meets the SLAM requirements with no external absolute location reference supports.
Author Contributions
L.X., Q.M. and D.C. devised the research and wrote the paper; L.X. and B.M. polished the English expression; Q.M. and H.Y. designed the experiments. All authors have read and approved the final manuscript.
Funding
This research was funded by National Nature Science Foundation of China under Grant 61503073, 61703090, and Natural Research Fund of Science and Technology Department, Jilin Province under Grant 20170101125JC.
Acknowledgments
Special thanks go to Xun Xu, Senior Research Fellow of University of Wollongong, Australia for his cordial help to the successful accomplishment of this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Liang, X.; Chen, H.; Li, Y. Visual Laser-SLAM in Large-Scale Indoor Environments. In Proceedings of the IEEE International Conference on Robotics & Biomimetics, Qingdao, China, 3–6 December 2016; pp. 19–24. [Google Scholar]
- Zhang, Z.; Liu, S.; Tsai, G. PIRVS: An Advanced Visual-Inertial SLAM System with Flexible Sensor Fusion and Hardware Co-Design. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3826–3832. [Google Scholar]
- Teng, Z.J.; Qu, Z.Q.; Zhang, L.Y. Research on Vehicle Navigation BD/DR/MM Integrated Navigation Positioning. J. Northeast Electr. Power Univ. 2017, 37, 98–101. (In Chinese) [Google Scholar]
- Guo, X.L.; Yang, T.T.; Zhang, Y.C. Gesture Recognition Based on Kinect Depth Information. J. Northeast Dianli Univ. 2016, 36, 90–94. (In Chinese) [Google Scholar]
- Davison, A.J.; Reid, I.D.; Molton, N.D. MonoSLAM: Real-Time Single Camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 6, 1052–1067. [Google Scholar] [CrossRef]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 1–10. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Zhou, H.; Zou, D.; Pei, L. StructSLAM: Visual SLAM with Building Structure Lines. IEEE Trans. Veh. Technol. 2015, 64, 1364–1375. [Google Scholar] [CrossRef]
- Benedettelli, D.; Garulli, A.; Giannitrapani, A. Cooperative SLAM Using M-Space Representation of Linear Features. Robot. Auton. Syst. 2012, 60, 1267–1278. [Google Scholar] [CrossRef]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Proceedings of the European Conference on Computer Vision (Computer Vision—ECCV 2014), Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast Semi-Direct Monocular Visual Odometry. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1–8. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef]
- Tian, Y.Y.; Tan, Q.C. Filter Noise Analysis Based on Sub-Pixel Edge Orientation Algorithm. J. Northeast Dianli Univ. 2016, 36, 43–47. (In Chinese) [Google Scholar]
- Hu, J.P.; Li, L.; Xie, Q.; Zhang, D.C. A Novel Segmentation Approach for Glass Insulators in Aerial Images. J. Northeast Electr. Power Univ. 2018, 38, 87–92. (In Chinese) [Google Scholar]
- Weiss, S.; Siegwart, R. Real-Time Metric State Estimation for Modular Vision-Inertial Systems. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 4531–4537. [Google Scholar]
- Ethzasl_sensor_fusion. Available online: https://github.com/ethz-asl/ethzasl_sensor_fusion (accessed on 3 October 2018).
- Falquez, J.M.; Kasper, M.; Sibley, G. Inertial Aided Dense & Semi-Dense Methods for Robust Direct Visual Odometry. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots & Systems, Daejeon, Korea, 9–14 October 2016; pp. 3601–3607. [Google Scholar]
- Leutenegger, S.; Lynen, S.; Bosse, M. Keyframe-Based Visual-Inertial Odometry Using Nonlinear Optimization. Int. J. Robot. Res. 2014, 34, 314–334. [Google Scholar] [CrossRef]
- Gomez-Ojeda, R.; Zuñiga-Noël, D.; Moreno, F.A. PL-SLAM: A Stereo SLAM System through the Combination of Points and Line Segments. arXiv 2017, arXiv:1705.09479, 1–12. [Google Scholar] [CrossRef]
- Hsiao, M.; Westman, E.; Kaess, M. Dense planar-inertial slam with structural constraints. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar]
- Huang, W.; Liu, H. Online Initialization and Automatic Camera-IMU Extrinsic Calibration for Monocular Visual-Inertial SLAM. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 5182–5189. [Google Scholar]
- Qin, T.; Shen, S. Robust Initialization of Monocular Visual-Inertial Estimation on Aerial Robots. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 24–28. [Google Scholar]
- Locher, A.; Havlena, M.; Van Gool, L. Progressive Structure from Motion. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 22–38. [Google Scholar]
- Saputra, M.R.U.; Markham, A.; Trigoni, N. Visual SLAM and structure from motion in dynamic environments: A survey. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardos, J.D. Visual-Inertial Monocular SLAM with Map Reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef]
- Sun, J.; Wang, P.; Qin, Z. Effective Self-Calibration for Camera Parameters and Hand-Eye Geometry Based on Two Feature Points Motions. IEEE/CAA J. Autom. Sin. 2017, 4, 370–380. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, Z.; Zheng, W. Monocular Visual-Inertial SLAM: Continuous Preintegration and Reliable Initialization. Sensors 2017, 17, 2613. [Google Scholar] [CrossRef]
- Zuo, X.; Xie, X.; Liu, Y. Robust Visual SLAM with Point and Line Features. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; pp. 1–8. [Google Scholar]
- Forster, C.; Carlone, L.; Dellaert, F. On-Manifold Preintegration for Real-Time Visual-Inertial Odometry. IEEE Trans. Robot. 2016, 33, 99–120. [Google Scholar] [CrossRef]
- RGB-D SLAM Dataset and Benchmark. Available online: https://vision.in.tum.de/data/datasets/rgbd-dataset (accessed on 11 June 2018).
- Mu, X.; Chen, J.; Zhou, Z. Accurate Initial State Estimation in a Monocular Visual-Inertial SLAM System. Sensors 2018, 18, 506. [Google Scholar]
- Zhou, S.; Yang, F. Inverse Quadratic Eigenvalues Problem for Mixed Matrix and Its Optimal Approximation. J. Northeast Electr. Power Univ. 2018, 38, 85–89. (In Chinese) [Google Scholar]
- Ruotsalainen, L.; Kirkko-Jaakkola, M.; Rantanen, J.; Mäkelä, M. Error Modelling for Multi-Sensor Measurements in Infrastructure-Free Indoor Navigation. Sensors 2018, 18, 590. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, D.; Li, J. Stereo Visual-Inertial SLAM with Points and Lines. IEEE Access 2018, 6, 69381–69392. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Kümmerle, R.; Grisetti, G.; Strasdat, H. G2o: A General Framework for Graph Optimization. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3607–3613. [Google Scholar]
- Qin, T.; Li, P.; Shen, S. Relocalization, Global Optimization and Map Merging for Monocular Visual-Inertial SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1197–1204. [Google Scholar]
- Pumarola, A.; Vakhitov, A.; Agudo, A. PL-SLAM: Real-time Monocular Visual SLAM with Points and Lines. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, Singapore, 29 May–3 June 2017; pp. 1–6. [Google Scholar]
- He, Y.; Zhao, J.; Guo, Y. PL-VIO: Tightly-Coupled Monocular Visual-Inertial Odometry Using Point and Line Features. Sensors 2018, 18, 1159. [Google Scholar] [CrossRef] [PubMed]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC Micro Aerial Vehicle Datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Available online: https://github.com/MichaelGrupp/evo (accessed on 6 December 2018).
- Kasyanov, A.; Engelmann, F.; Stückler, J. Keyframe-Based Visual-Inertial Online SLAM with Relocalization. arXiv 2017, arXiv:1702.02175, 1–8. [Google Scholar]
Figure 1.
Flow chart of a VIO state estimator algorithm.

Figure 2.
The graphic interpretation of the point/line feature reprojection error.

Figure 3.
The time consumed for the bias estimation.

Figure 4.
Decision-making pattern of the sliding window model, (a) the inserted frame is not a keyframe and (b) the inserted frame is a keyframe.
Figure 4.
Decision-making pattern of the sliding window model, (a) the inserted frame is not a keyframe and (b) the inserted frame is a keyframe.

Figure 5.
The convergence procedures of the initialization states for the V1_01_easy & MH_04_difficult sequences, (a) Initialization results of accelerometer bias; (b) Initialization results of gyro bias; (c) Calculation of the condition number; (d) Initialization results of scale factor; (e) Initialization results of gravity vector.
Figure 5.
The convergence procedures of the initialization states for the V1_01_easy & MH_04_difficult sequences, (a) Initialization results of accelerometer bias; (b) Initialization results of gyro bias; (c) Calculation of the condition number; (d) Initialization results of scale factor; (e) Initialization results of gravity vector.

Figure 6.
Feature extraction performances of the VIO front-end: (a) V1_01_easy sequence; (b) MH_04_difficult sequence.
Figure 6.
Feature extraction performances of the VIO front-end: (a) V1_01_easy sequence; (b) MH_04_difficult sequence.

Figure 7.
VIO Performances when dealing with sequences at different difficulty levels. (a) V1_01_ easy sequence; (b) V1_02_ medium sequence; (c) V1_03_ difficult sequence; (d) V2_01_ easy sequence; (e) V2_02_ medium sequence; (f) V2_03_ difficult sequence; (g) MH_01_easy sequence; (h) MH_02_easy sequence; (i) MH_03_medium sequence; (j) MH_04_difficult sequence; (k) MH_05_difficult sequence.
Figure 7.
VIO Performances when dealing with sequences at different difficulty levels. (a) V1_01_ easy sequence; (b) V1_02_ medium sequence; (c) V1_03_ difficult sequence; (d) V2_01_ easy sequence; (e) V2_02_ medium sequence; (f) V2_03_ difficult sequence; (g) MH_01_easy sequence; (h) MH_02_easy sequence; (i) MH_03_medium sequence; (j) MH_04_difficult sequence; (k) MH_05_difficult sequence.



Figure 8.
VIO planar trajectory comparisons, (a) V1_01_easy sequence; (b) MH_04_difficult sequence.


Figure 9.
Tri-axial absolute positioning error, (a) V1_01_easy sequence; (b) MH_04_difficult sequence.
Figure 9.
Tri-axial absolute positioning error, (a) V1_01_easy sequence; (b) MH_04_difficult sequence.

Figure 10.
Absolute positioning error distribution, (a) V1_01_easy sequence; (b) MH_04_difficult sequence.
Figure 10.
Absolute positioning error distribution, (a) V1_01_easy sequence; (b) MH_04_difficult sequence.

Figure 11.
Sparse maps in terms of fused point and line features, (a) V1_01_easy sequence; (b) MH_04_difficult sequence.
Figure 11.
Sparse maps in terms of fused point and line features, (a) V1_01_easy sequence; (b) MH_04_difficult sequence.

Figure 12.
The convergence procedures of the initialization states in the substation scene tests, (a) Initialization results of accelerometer bias; (b) Initialization results of gyro bias; (c) Calculation of the condition number; (d) The initialization results of the gravity vector; (e) The initialization results of velocity.
Figure 12.
The convergence procedures of the initialization states in the substation scene tests, (a) Initialization results of accelerometer bias; (b) Initialization results of gyro bias; (c) Calculation of the condition number; (d) The initialization results of the gravity vector; (e) The initialization results of velocity.


Figure 13.
Feature extractions of the VIO front-end in the substation scene.

Figure 14.
Rectangular trajectory drawn according to the camera motion.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The comparative pose measurement results.
| Simple Point Feature-Matching Based Method | Fused Point and Line Feature-Matching Based Method | Direct Method | ||
|---|---|---|---|---|
| Non optimization | × | |||
| RMSE | 0.7329 | 0.2128 | - | |
| G-N for 1 round | × | × | ||
| RMSE | - | 0.1020 | - | |
| G-N for convergence achieved | ||||
| RMSE | 0.1010 | 0.1009 | 0.2926 | |
| L-M for 1 round | ||||
| RMSE | 0.1320 | 0.1011 | 0.3376 | |
| L-M for convergence achieved | ||||
| RMSE | 0.0601 | 0.0486 | 0.2917 | |
Table 2.
The comparative time consumption results (s).
| Feature Extraction | Descriptor Calculation | Feature Matching | Pose Estimation | Total | |
|---|---|---|---|---|---|
| ORB SURF SIFT | 0.0101 0.0435 0.9228 | 0.0087 0.0095 0.0125 | 0.0118 0.0274 0.0285 | 0.0009 0.0014 0.0012 | 0.0315 0.0818 0.9650 |
Table 3.
The comparative absolute positioning errors in the European Robotics Challenge (EUROC) datasets.
Table 3.
The comparative absolute positioning errors in the European Robotics Challenge (EUROC) datasets.
| Ref. [42] | Ref. [25] | Ref. [18] | Ref. [35] | Ref. [39] | VIO Designed | |
|---|---|---|---|---|---|---|
| V1_01_easy | 0.1167 | 0.0958 | 0.0716 | 0.0544 | 0.0591 | 0.0524 |
| V1_02_medium | 0.1392 | 0.0964 | 0.0912 | 0.0849 | 0.0766 | 0.0724 |
| V1_03_diffcult | 0.1934 | 0.1742 | 0.1597 | 0.1302 | 0.1102 | |
| V2_01_easy | 0.1267 | 0.0858 | 0.1017 | 0.0712 | 0.0502 | 0.0413 |
| V2_02_medium | 0.2049 | 0.1525 | 0.1876 | 0.1638 | 0.0945 | 0.0815 |
| V2_03_diffcult | 0.2588 | 0.2719 | 0.2347 | 0.2609 | 0.2176 | |
| MH_01_easy | 0.2557 | 0.1537 | 0.1647 | 0.1221 | 0.0731 | 0.0513 |
| MH_02_easy | 0.1861 | 0.1595 | 0.1573 | 0.1287 | 0.2327 | 0.0407 |
| MH_03_medium | 0.2176 | 0.1719 | 0.2077 | 0.1365 | 0.1122 | 0.1065 |
| MH_04_diffcult | 0.3037 | 0.3165 | 0.3921 | 0.1894 | 0.1394 | 0.1377 |
| MH_05_diffcult | 0.3509 | 0.2173 | 0.2569 | 0.1546 |
Table 4.
Calibration parameters of camera and IMU.
| Camera Intrinsic | Focal length: pixel, pixel Principal point of photograph: Radial distortion: |
| Camera/IMU Extrinsic | |
| Image parameters | Image resolution: 752 × 480 pixel |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Xia, L.; Meng, Q.; Chi, D.; Meng, B.; Yang, H. An Optimized Tightly-Coupled VIO Design on the Basis of the Fused Point and Line Features for Patrol Robot Navigation. Sensors 2019, 19, 2004. https://doi.org/10.3390/s19092004
AMA Style
Xia L, Meng Q, Chi D, Meng B, Yang H. An Optimized Tightly-Coupled VIO Design on the Basis of the Fused Point and Line Features for Patrol Robot Navigation. Sensors. 2019; 19(9):2004. https://doi.org/10.3390/s19092004
Chicago/Turabian StyleXia, Linlin, Qingyu Meng, Deru Chi, Bo Meng, and Hanrui Yang. 2019. "An Optimized Tightly-Coupled VIO Design on the Basis of the Fused Point and Line Features for Patrol Robot Navigation" Sensors 19, no. 9: 2004. https://doi.org/10.3390/s19092004
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.