Remaining Useful Life Prognosis for Turbofan Engine Using Explainable Deep Neural Networks with Dimensionality Reduction





Abstract
:1. Introduction
2. Proposed Methodology
2.1. Deep-Stacked Convolutional Bi-LSTM Model
2.1.1. One-Dimensional CNN (1D CNN)
2.1.2. LSTM
2.1.3. Bi-LSTM
2.1.4. Residual Network and Dropout Technique
2.2. Dimensionality Reduction and Explainable Artificial Intelligence
2.2.1. Correlation Analysis and Regularization
2.2.2. Explainable Artificial Intelligence (xAI)
2.3. Proposed Deep Convolutional Bi-LSTM Network Model
3. Experimental Study
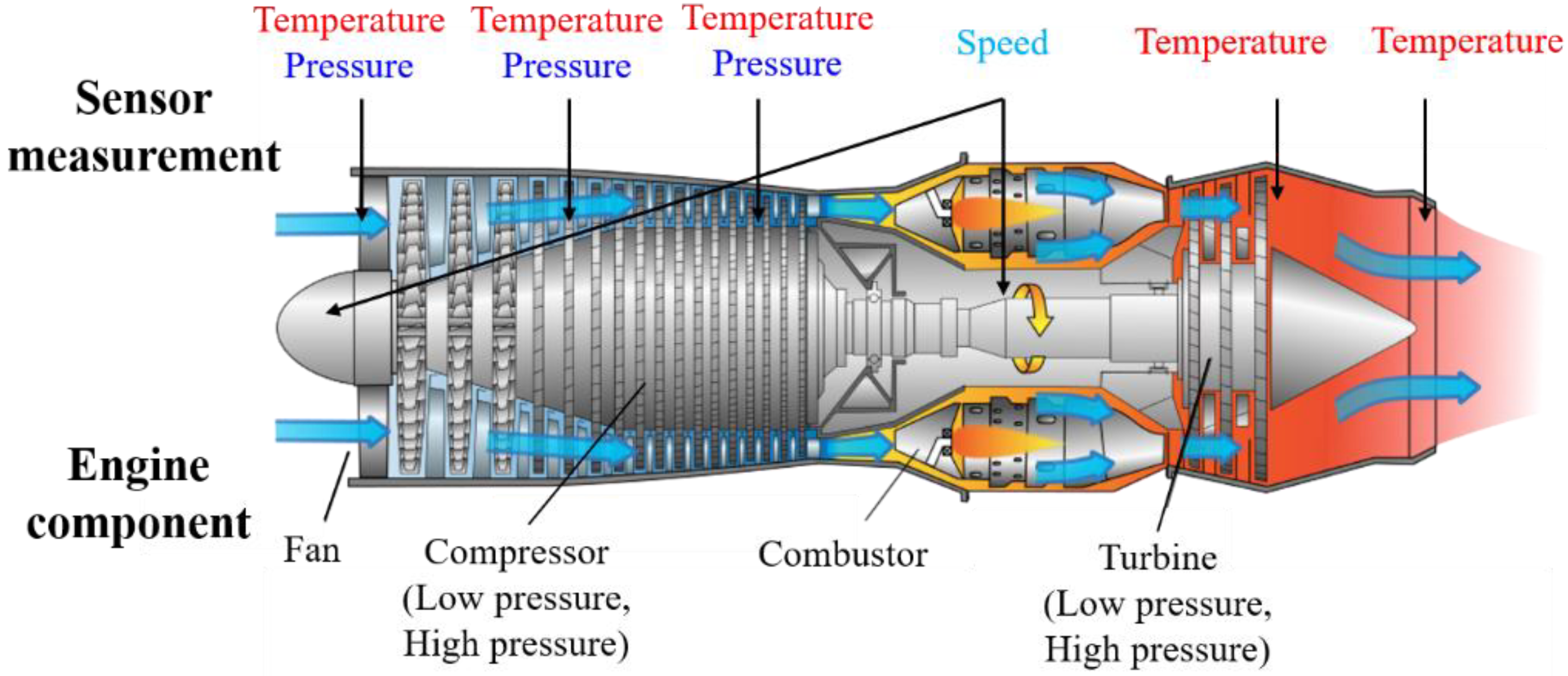
3.1. C-MAPSS Dataset
3.2. Hyperparameter Setup and Evaluation Metrics
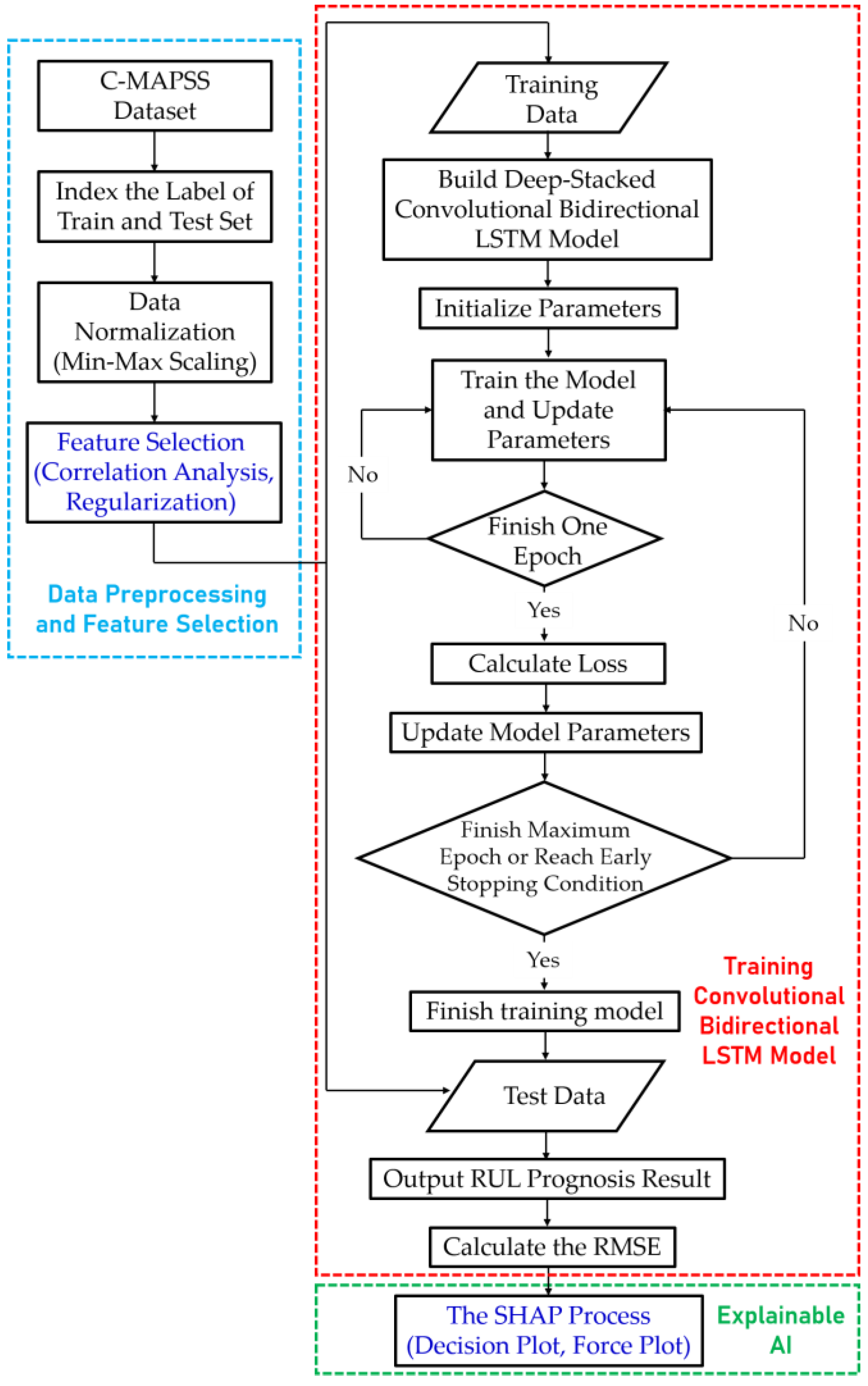
3.3. Flowchart of RUL Prognosis
- The C-MAPSS data are indexed and normalized into a training set and a test set. The data are then processed by correlation analysis and the feature selection technique of L1, L2, and Elastic Net.
- The 21 time-series sensor data are divided into 200 mini batches and trained in the deep-stacked convolutional Bi-LSTM model. The model learns temporal and spatial characteristics with three 1D CNN layers, three LSTM layers, and two Bi-LSTM layers and uses the dropout technique and residual network to prevent overfitting and achieve high accuracy. Each time the epoch is completed on the first parameter, the loss is calculated and the parameter is updated. Learning ends when the maximum 200 epochs are completed or the early stopping condition is satisfied. After training is complete, the final model is determined, and the RUL and error are calculated by applying test data to this model.
- The SHAP algorithm, an explainable AI technique, is applied to the predicted result. The explanation results can be visualized as a decision plot or force plot and used as analysis data.
4. Results and Discussion
4.1. Comparison with Literature
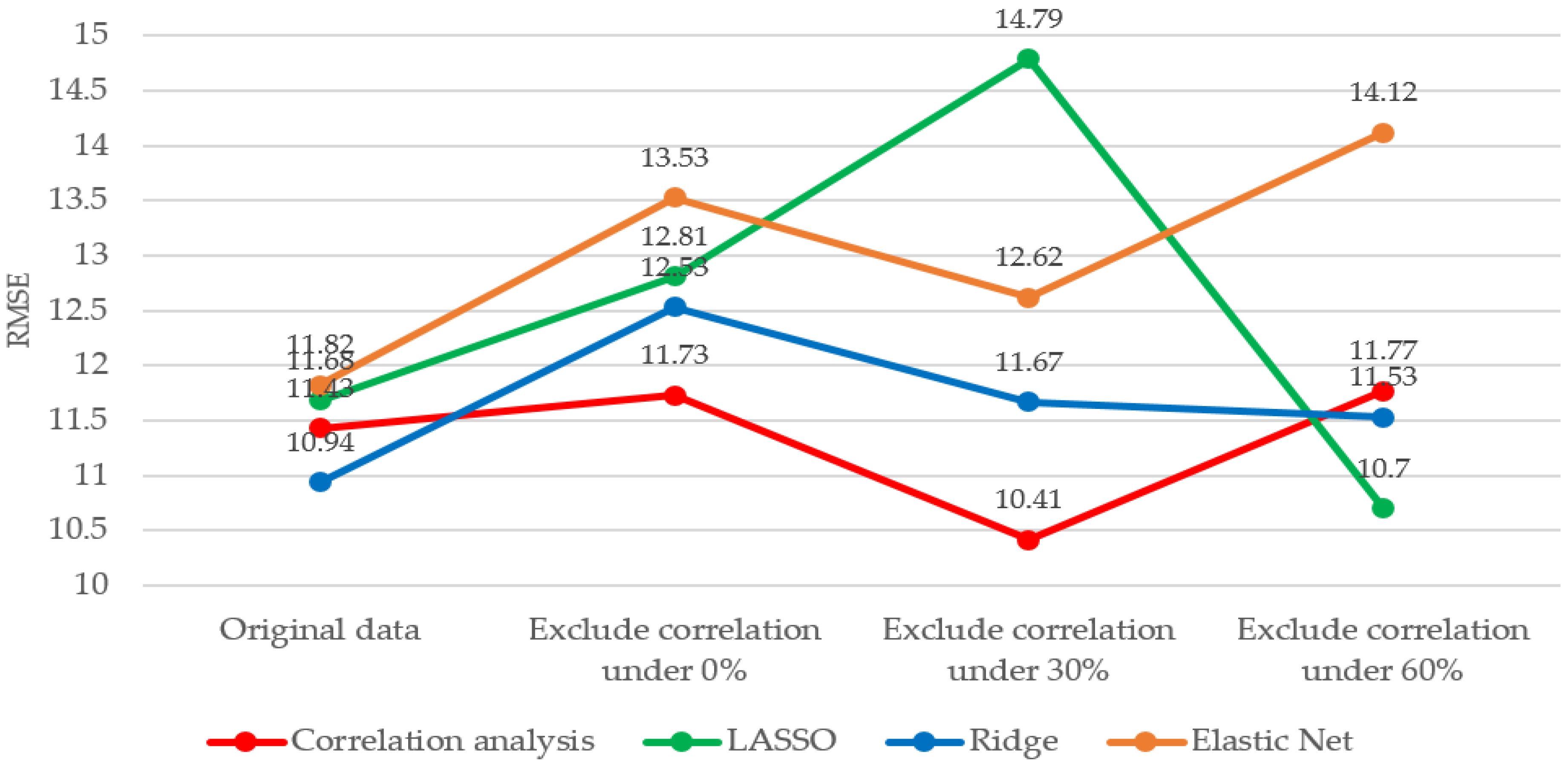
4.2. Analysis of Feature Selection Effect
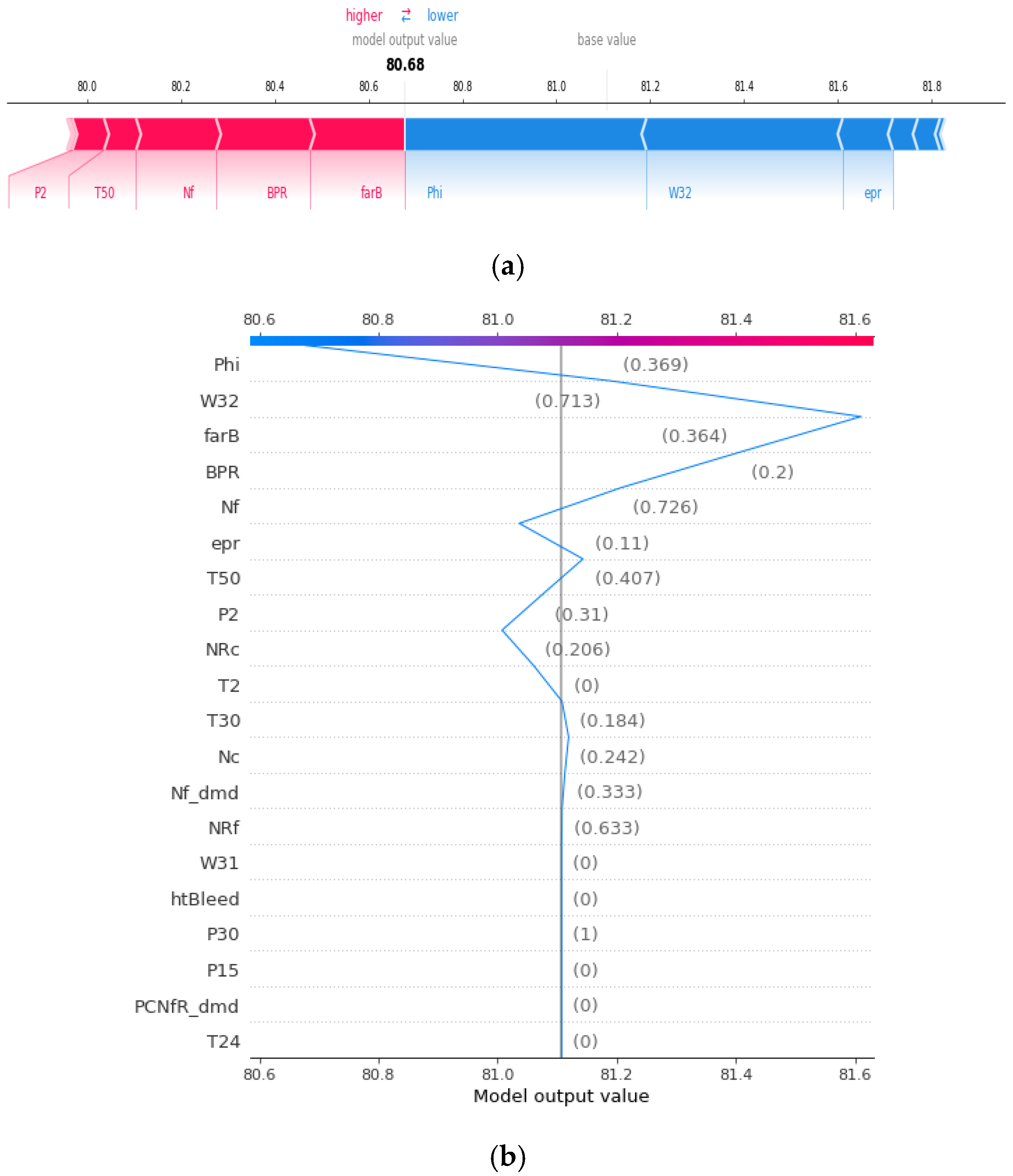
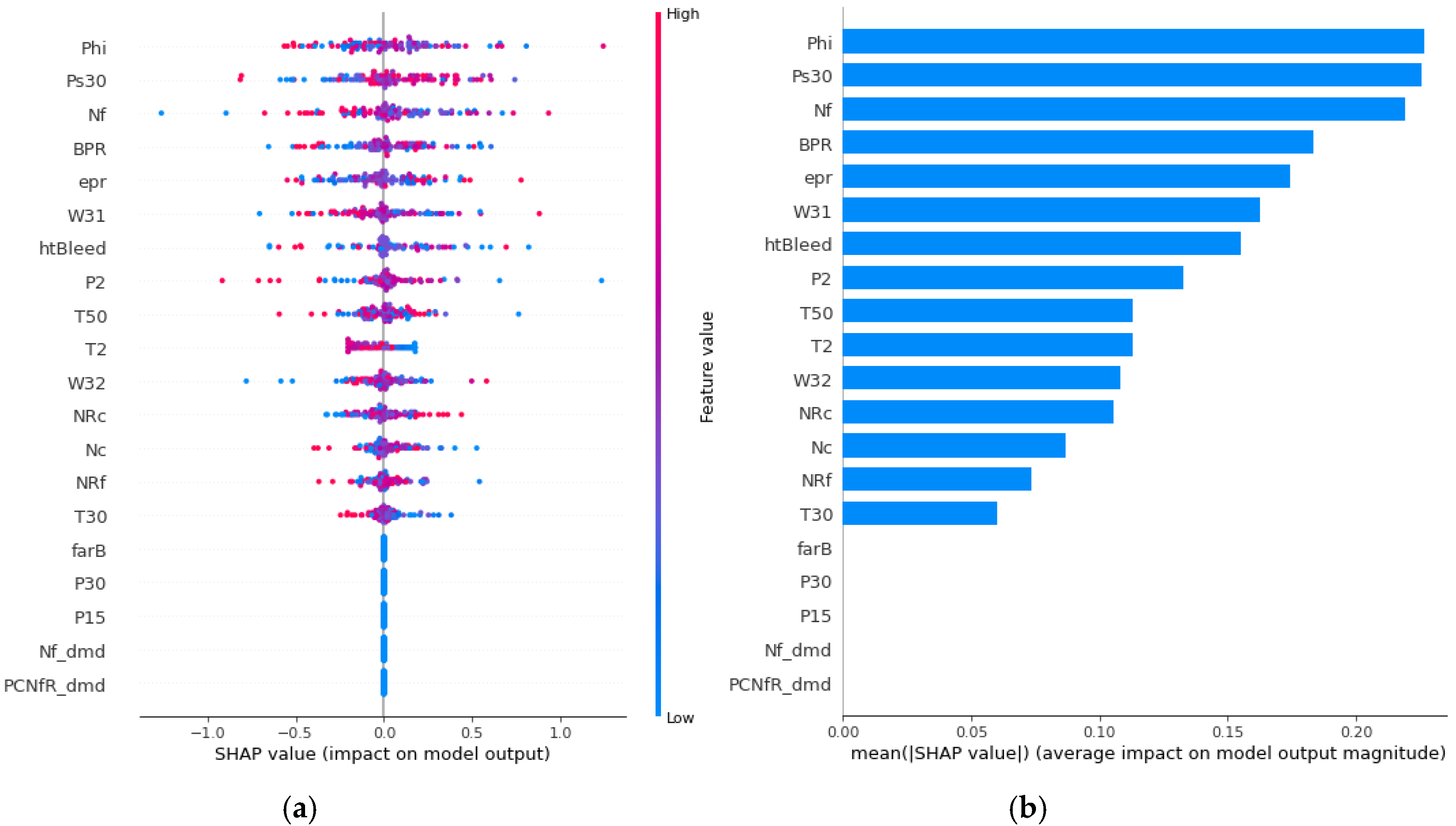
4.3. SHAP Analysis through Visualization
5. Conclusions
- (1)
- The proposed deep learning model performs best in terms of accuracy in prognosis with reference to the benchmarked algorithms. Residual network and dropout techniques contribute toward the prevention of overfitting.
- (2)
- During the feature selection, correlation analysis and regularization are employed to remove irrelevant input sensors or weights. The regularized model can significantly reduce complexity, while maintaining high accuracy.
- (3)
- Use of xAI techniques helps identify primary sensors (i.e., components) influential to the prognosis. The xAI helps specify the “black box” deep learning model, which is surely beneficial for preventive and predictive engine maintenance.
Author Contributions
Funding
Conflicts of Interest
References
- Pintelon, L.; Parodi-Herz, A. Maintenance: An evolutionary perspective. In Complex System Maintenance Handbook, 1st ed.; Springer: London, UK, 2008; pp. 21–48. [Google Scholar]
- Lee, J.; Jin, C.; Liu, Z.; Ardakani, H.D. Introduction to data-driven methodologies for prognostics and health management. In Probabilistic Prognostics and Health Management of Energy Systems, 1st ed.; Springer: Cham, Switzerland, 2017; pp. 9–32. [Google Scholar]
- Djeziri, M.A.; Benmoussa, S.; Zio, E. Review on Health Indices Extraction and Trend Modeling for Remaining Useful Life Estimation. In Artificial Intelligence Techniques for a Scalable Energy Transition, 1st ed.; Springer: Cham, Switzerland, 2020; pp. 183–223. [Google Scholar]
- Kim, N.-H.; An, D.; Choi, J.-H. Prognostics and Health Management of Engineering Systems: An Introduction; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Byington, C.S.; Watson, M.; Edwards, D.; Stoelting, P. A model-based approach to prognostics and health management for flight control actuators. In Proceedings of the 2004 IEEE Aerospace Conference Proceedings (IEEE Cat. No. 04TH8720), Big Sky, MT, USA, 6–13 March 2004; pp. 3551–3562. [Google Scholar]
- Oh, H.; Azarian, M.H.; Pecht, M.; White, C.H.; Sohaney, R.C.; Rhem, E. Physics-of-failure approach for fan PHM in electronics applications. In Proceedings of the 2010 Prognostics and System Health Management Conference, Macau, China, 12–14 January 2010; pp. 1–6. [Google Scholar]
- Zhang, H.; Kang, R.; Pecht, M. A hybrid prognostics and health management approach for condition-based maintenance. In Proceedings of the 2009 IEEE International Conference on Industrial Engineering and Engineering Management, Hong Kong, China, 8–11 December 2009; pp. 1165–1169. [Google Scholar]
- Sun, T.; Xia, B.; Liu, Y.; Lai, Y.; Zheng, W.; Wang, H.; Wang, W.; Wang, M. A novel hybrid prognostic approach for remaining useful life estimation of lithium-ion batteries. Energies 2019, 12, 3678. [Google Scholar] [CrossRef] [Green Version]
- Babu, G.S.; Zhao, P.; Li, X.-L. Deep convolutional neural network based regression approach for estimation of remaining useful life. Lect. Notes Comput. Sci. 2016, 9642, 214–228. [Google Scholar]
- Li, X.; Ding, Q.; Sun, J.-Q. Remaining useful life estimation in prognostics using deep convolution neural networks. Reliab. Eng. Syst. Saf. 2018, 172, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Zheng, S.; Ristovski, K.; Farahat, A.; Gupta, C. Long short-term memory network for remaining useful life estimation. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management (ICPHM), Piscataway, NJ, USA, 19–21 June 2017; pp. 88–95. [Google Scholar]
- Wang, J.; Wen, G.; Yang, S.; Liu, Y. Remaining useful life estimation in prognostics using deep bidirectional lstm neural network. In Proceedings of the 2018 Prognostics and System Health Management Conference (PHM-Chongqing), Chongqing, China, 26–28 October 2018; pp. 1037–1042. [Google Scholar]
- Zhang, A.; Wang, H.; Li, S.; Cui, Y.; Liu, Z.; Yang, G.; Hu, J. Transfer learning with deep recurrent neural networks for remaining useful life estimation. Appl. Sci. 2018, 8, 2416. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Lim, P.; Qin, A.K.; Tan, K.C. Multiobjective deep belief networks ensemble for remaining useful life estimation in prognostics. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2306–2318. [Google Scholar] [CrossRef]
- Ellefsen, A.L.; Bjørlykhaug, E.; Æsøy, V.; Ushakov, S.; Zhang, H. Remaining useful life predictions for turbofan engine degradation using semi-supervised deep architecture. Reliab. Eng. Syst. Saf. 2019, 183, 240–251. [Google Scholar] [CrossRef]
- Al-Dulaimi, A.; Zabihi, S.; Asif, A.; Mohammadi, A. A multimodal and hybrid deep neural network model for remaining useful life estimation. Comput. Ind. 2019, 108, 186–196. [Google Scholar] [CrossRef]
- Li, J.; Li, X.; He, D. A directed acyclic graph network combined with CNN and LSTM for remaining useful life prediction. IEEE Access 2019, 7, 75464–75475. [Google Scholar] [CrossRef]
- Hong, C.W.; Lee, K.; Ko, M.-S.; Kim, J.-K.; Oh, K.; Hur, K. Multivariate Time Series Forecasting for Remaining Useful Life of Turbofan Engine Using Deep-Stacked Neural Network and Correlation Analysis. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Korea, 19–22 February 2020; pp. 63–70. [Google Scholar]
- Saxena, A.; Goebel, K.; Simon, D.; Eklund, N. Damage propagation modeling for aircraft engine run-to-failure simulation. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008; pp. 1–9. [Google Scholar]
- Yu, L.; Liu, H. Feature selection for high-dimensional data: A fast correlation-based filter solution. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 856–863. [Google Scholar]
- Shi, Y.; Miao, J.; Wang, Z.; Zhang, P.; Niu, L. Feature Selection with l2,1−2 Regularization. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 4967–4982. [Google Scholar] [CrossRef] [PubMed]
- Lasheras, F.S.; Nieto, P.J.G.; de Cos Juez, F.J.; Bayón, R.M.; Suárez, V.M.G. A hybrid PCA-CART-MARS-based prognostic approach of the remaining useful life for aircraft engines. Sensors 2015, 15, 7062–7083. [Google Scholar] [CrossRef] [PubMed]
- Yu, W.; Kim, I.Y.; Mechefske, C. Remaining useful life estimation using a bidirectional recurrent neural network based autoencoder scheme. Mech. Syst. Signal Process. 2019, 129, 764–780. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Friendly, M. Corrgrams: Exploratory displays for correlation matrices. Am. Stat. 2002, 56, 316–324. [Google Scholar] [CrossRef]
- Ying, X. An overview of Overfitting and its solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- Gunning, D. Explainable Artificial Intelligence (xai). Available online: https://www.cc.gatech.edu/~alanwags/DLAI2016/(Gunning)%20IJCAI-16%20DLAI%20WS.pdf (accessed on 18 November 2020).
- Ponn, T.; Kröger, T.; Diermeyer, F. Identification and Explanation of Challenging Conditions for Camera-Based Object Detection of Automated Vehicles. Sensors 2020, 20, 3699. [Google Scholar] [CrossRef] [PubMed]
- Dindorf, C.; Teufl, W.; Taetz, B.; Bleser, G.; Fröhlich, M. Interpretability of input representations for gait classification in patients after total hip arthroplasty. Sensors 2020, 20, 4385. [Google Scholar] [CrossRef] [PubMed]
- García, M.V.; Aznarte, J.L. Shapley additive explanations for NO2 forecasting. Ecol. Inform. 2020, 56, 101039. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017, 1st ed.; Curran Associates: Red Hook, NY, USA, 2017; pp. 4765–4774. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. Available online: https://arxiv.org/pdf/1412.6980.pdf (accessed on 18 November 2020).
- Saxena, A.; Celaya, J.; Balaban, E.; Goebel, K.; Saha, B.; Saha, S.; Schwabacher, M. Metrics for evaluating performance of prognostic techniques. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008; pp. 1–17. [Google Scholar]
- Schober, P.; Boer, C.; Schwarte, L.A. Correlation coefficients: Appropriate use and interpretation. Anesth. Analg. 2018, 126, 1763–1768. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | FD001 | FD002 | FD003 | FD004 |
|---|---|---|---|---|
| Number of engines | 100 | 260 | 100 | 249 |
| Number of training samples | 20,631 | 53,579 | 24,270 | 61,249 |
| Number of test samples | 100 | 259 | 100 | 248 |
| Number of the data column | 26 | 26 | 26 | 26 |
| Average life span (cycles) | 206 | 206 | 247 | 245 |
| Operating conditions | 1 | 6 | 1 | 6 |
| Fault conditions | 1 | 1 | 2 | 2 |
| Sensor Number | Symbol | Description | Units | Trend |
|---|---|---|---|---|
| 1 | T2 | Total temperature at fan inlet | °R | ~ |
| 2 | T24 | Total temperature at LPC outlet | °R | ↑ |
| 3 | T30 | Total temperature at HPC outlet | °R | ↑ |
| 4 | T50 | Total temperature at LPT outlet | °R | ↑ |
| 5 | P2 | Pressure at fan inlet | psia | ~ |
| 6 | P15 | Total pressure in bypass-duct | psia | ~ |
| 7 | P30 | Total pressure at HPC outlet | psia | ↓ |
| 8 | Nf | Physical fan speed | rpm | ↑ |
| 9 | Nc | Physical core speed | rpm | ↑ |
| 10 | epr | Engine pressure ratio | -- | ~ |
| 11 | Ps30 | Static pressure at HPC outlet | psia | ↑ |
| 12 | Phi | Ratio of fuel flow to Ps30 | pps/psi | ↓ |
| 13 | NRf | Corrected fan speed | rpm | ↑ |
| 14 | NRc | Corrected core speed | rpm | ↓ |
| 15 | BPR | Bypass ratio | -- | ↑ |
| 16 | farB | Burner fuel-air ratio | -- | ~ |
| 17 | htBleed | Bleed enthalpy | -- | ↑ |
| 18 | Nf_dmd | Demanded fan speed | rpm | ~ |
| 19 | PCNfR_dmd | Demanded corrected fan speed | rpm | ~ |
| 20 | W31 | HPT coolant bleed | lbm/s | ↓ |
| 21 | W32 | LPT coolant bleed | lbm/s | ↓ |
| Architecture Hyperparameters | |||||
| Number of Hidden Layers | Number of Units | Normalization | Activation | Mini Batch | Regularization |
| 8(3, 3, 2) | 128–64–22(15, 14, 13)–128–64–22(15, 14, 13)–256–512 | Min-Max Scaling | ReLu | 200 | Dropout (0.55) |
| Optimization Hyperparameters | |||||
| Algorithm | Validation | Loss | Epochs | Decay | Learning Rate |
| Adam | 5% of train data | RMSE | Early stopping (Max. 200) | 0 | 0.0001 |
| Method | Description | Years | RMSE |
|---|---|---|---|
| MLP [8] | Multilayer Perceptron | 2016 | 37.56 |
| SVR [8] | Support Vector Regression | 2016 | 20.96 |
| RVR [8] | Relevance Vector Regression | 2016 | 23.80 |
| CNN [8] | 2 CNN | 2016 | 18.45 |
| LSTM [10] | 2 LSTM | 2017 | 16.14 |
| DBN [13] | Deep Belief Network | 2017 | 15.21 |
| BLSTM [11] | 2 Bi-LSTM | 2018 | 14.26 |
| RNN [9] | 5 Recurrent layers | 2018 | 13.44 |
| DCNN [9] | 5 CNN | 2018 | 12.61 |
| Bi-LSTM [12] | 2 Bi-LSTM | 2018 | 13.65 |
| Semi-Supervised [14] | RBM + 2 LSTM | 2019 | 12.56 |
| HDNN [15] | 3 CNN/3 LSTM Hybrid | 2019 | 13.02 |
| DAG [16] | (CNN/LSTM Hybrid) + LSTM | 2019 | 11.96 |
| Proposed method | 3 CNN + 3 LSTM + 2 Bi-LSTM | 2020 | 10.41 |
| Algorithm | Original Data (21 Sensors) | Exclude Correlation under 0% (6 Sensors Removed) | Exclude Correlation under 30% (7 Sensors Removed) | Exclude Correlation under 60% (9 Sensors Removed) | Average RMSE |
|---|---|---|---|---|---|
| Correlation Analysis | 11.43 | 11.73 | 10.41 (MSE 108.40, MAE 7.36, MAPE 14.05) | 11.77 | 11.34 |
| LASSO | 11.68 | 12.81 | 14.79 | 10.70 | 12.50 |
| Ridge | 10.94 | 12.53 | 11.67 | 11.53 | 11.67 |
| Elastic Net | 11.82 | 13.53 | 12.62 | 14.12 | 13.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, C.W.; Lee, C.; Lee, K.; Ko, M.-S.; Kim, D.E.; Hur, K. Remaining Useful Life Prognosis for Turbofan Engine Using Explainable Deep Neural Networks with Dimensionality Reduction. Sensors 2020, 20, 6626. https://doi.org/10.3390/s20226626
Hong CW, Lee C, Lee K, Ko M-S, Kim DE, Hur K. Remaining Useful Life Prognosis for Turbofan Engine Using Explainable Deep Neural Networks with Dimensionality Reduction. Sensors. 2020; 20(22):6626. https://doi.org/10.3390/s20226626
Chicago/Turabian StyleHong, Chang Woo, Changmin Lee, Kwangsuk Lee, Min-Seung Ko, Dae Eun Kim, and Kyeon Hur. 2020. "Remaining Useful Life Prognosis for Turbofan Engine Using Explainable Deep Neural Networks with Dimensionality Reduction" Sensors 20, no. 22: 6626. https://doi.org/10.3390/s20226626