
Sound Event Detection by Pseudo-Labeling in Weakly Labeled Dataset



Abstract
:1. Introduction
2. Related Work
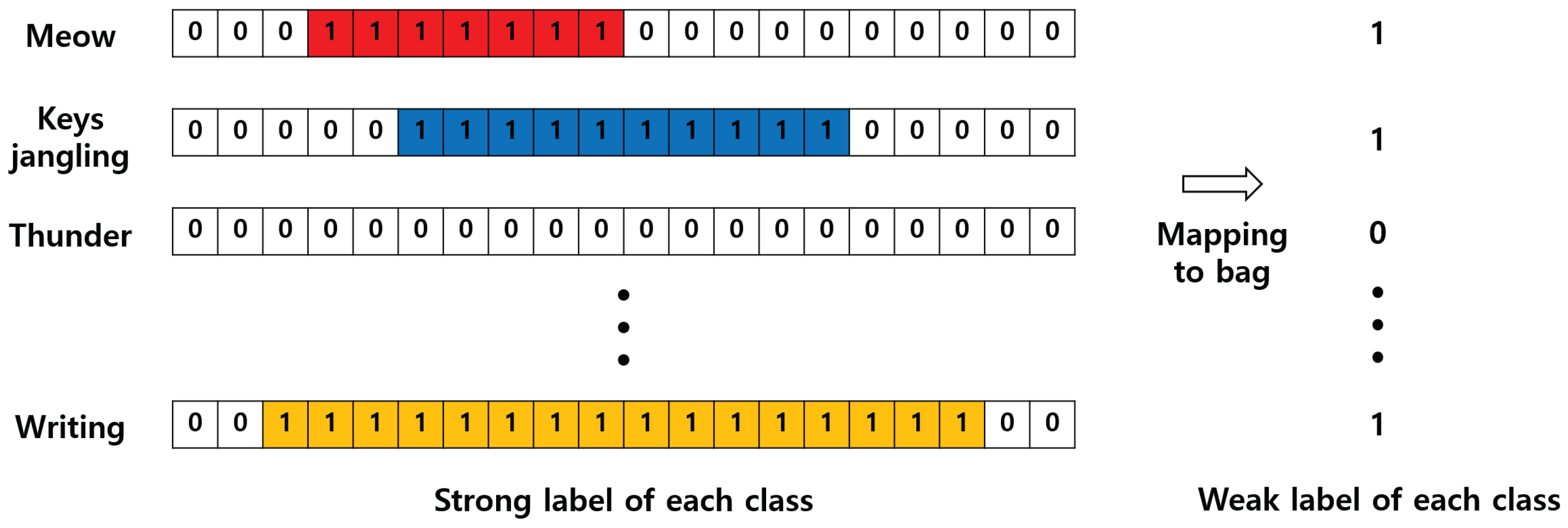
2.1. Multi Instance Learning (MIL)
2.2. Dilated Convolution
2.3. Gated Linear Unit (GLU)
3. Proposed Method
3.1. Extraction Segmentation Mask
3.2. Global Pooling to Predict the Presence or Absence of Target Events
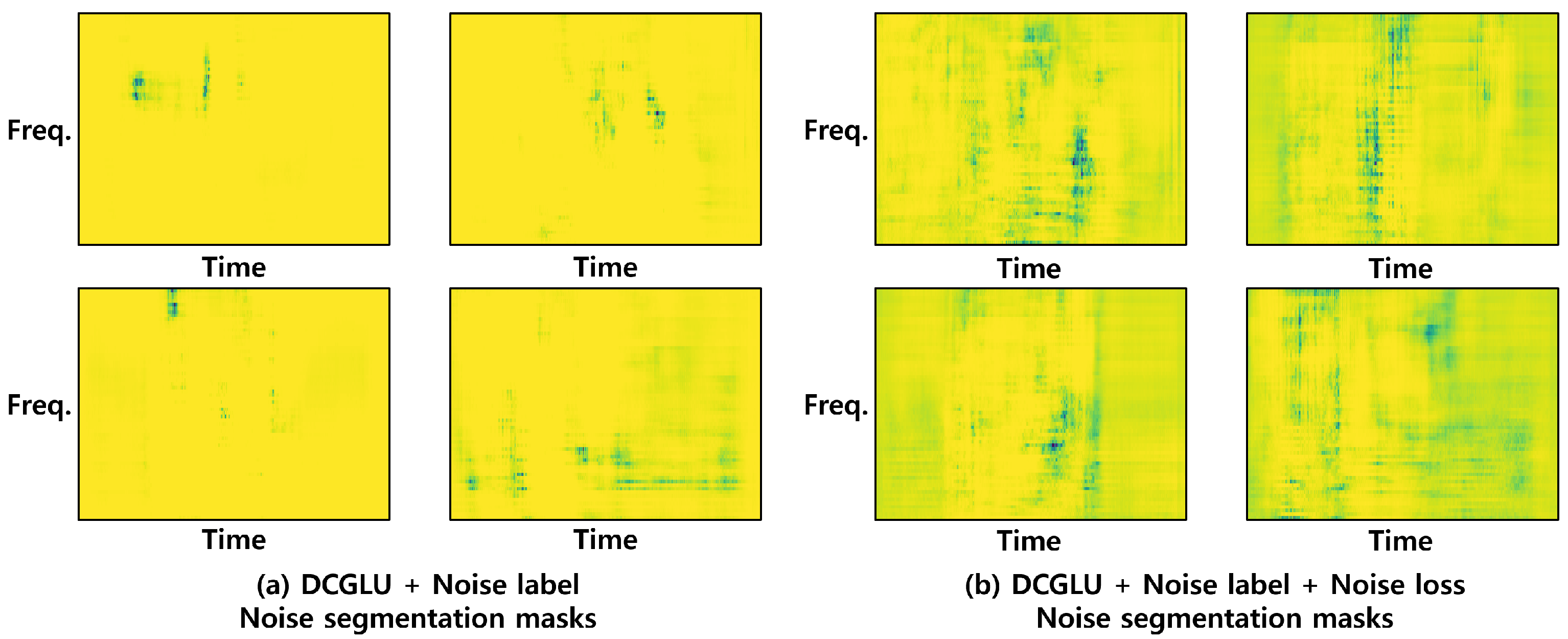
3.3. Noise Label and Noise Loss to Extract Noise Contents
4. Experiment
4.1. Database
4.2. Feature Extraction
4.3. Evaluation and Metric
4.4. Post Processing for Performance Evaluation
4.5. Model
4.6. Ablation Analysis
4.6.1. Effect of Applying GLU
4.6.2. Effect of Applying Dilated Convolution
4.6.3. Effects of Simultaneous Application of GLU and Dilated Convolution (DCGLU)
4.6.4. Change When Noise Label Is Added
4.6.5. Validity of Noise Label and Noise Loss
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dong, L.; Tang, Z.; Li, X.; Chen, Y.; Xue, J. Discrimination of mining microseismic events and blasts using convolutional neural networks and original waveform. J. Cent. South Univ. 2020, 27, 2078–3089. [Google Scholar] [CrossRef]
- Mesaros, A.; Heittola, T.; Virtanen, T.; Plumbley, M.D. Sound event detection: A tutorial. IEEE Signal Process. Mag. 2021, 38, 67–83. [Google Scholar] [CrossRef]
- Xia, X.; Togneri, R.; Sohel, F.; Zhao, Y.; Huang, D. A survey: Neural network-based deep learning for acoustic event detection. Circuits Syst. Signal Process. 2019, 38, 3433–3453. [Google Scholar] [CrossRef]
- Crocco, M.; Cristani, M.; Trucco, A.; Murino, V. Audio surveillance: A systematic review. ACM Comput. Surv. 2016, 48, 1–46. [Google Scholar] [CrossRef]
- Park, S.; Elhilali, M.; Han, D.; Ko, H. Amphibian Sounds Generating Network Based on Adversarial Learning. IEEE Signal Process. Lett. 2020, 27, 640–644. [Google Scholar] [CrossRef]
- Ko, K.; Park, J.; Han, D.; Ko, H. Channel and Frequency Attention Module for Diverse Animal Sound Classification. IEICE Trans. Inf. Syst. 2019, 102, 2615–2618. [Google Scholar] [CrossRef] [Green Version]
- Schröder, J.; Goetze, S.; Grützmacher, V.; Anemüller, J. Automatic acoustic siren detection in traffic noise by part-based models. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 493–497. [Google Scholar]
- Cakır, E.; Parascandolo, G.; Heittola, T.; Huttunen, H.; Virtanen, T. Convolutional recurrent neural networks for polyphonic sound event detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1291–1303. [Google Scholar] [CrossRef] [Green Version]
- Parascandolo, G.; Huttunen, H.; Virtanen, T. Recurrent neural networks for polyphonic sound event detection in real life recordings. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 6440–6444. [Google Scholar]
- Dietterich, T.G.; Lathrop, R.H.; Lozano-Pérez, T. Solving the multiple instance problem with axis-parallel rectangles. Artif. Intell. 1997, 89, 31–71. [Google Scholar] [CrossRef] [Green Version]
- Chou, S.Y.; Jang, J.S.R.; Yang, Y.H. FrameCNN: A weakly-supervised learning framework for frame-wise acoustic event detection and classification. Recall 2017, 14, 55–64. [Google Scholar]
- Kumar, A.; Raj, B. Deep cnn framework for audio event recognition using weakly labeled web data. arXiv 2017, arXiv:1707.02530. [Google Scholar]
- Xu, Y.; Kong, Q.; Wang, W.; Plumbley, M.D. Large-scale weakly supervised audio classification using gated convolutional neural network. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 121–125. [Google Scholar]
- Kong, Q.; Xu, Y.; Sobieraj, I.; Wang, W.; Plumbley, M.D. Sound event detection and time-frequency segmentation from weakly labelled data. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 777–787. [Google Scholar] [CrossRef]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Wang, Y.; Metze, F. A first attempt at polyphonic sound event detection using connectionist temporal classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2986–2990. [Google Scholar]
- Hou, Y.; Kong, Q.; Li, S.; Plumbley, M.D. Sound event detection with sequentially labelled data based on connectionist temporal classification and unsupervised clustering. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 46–50. [Google Scholar]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the ICML 2013 Workshop: Challenges in Representation Learning (WREPL), Atlanta, GA, USA, 16–21 June 2013; Volume 3, p. 896. [Google Scholar]
- Mesaros, A.; Heittola, T.; Virtanen, T. A multi-device dataset for urban acoustic scene classification. arXiv 2018, arXiv:1807.09840. [Google Scholar]
- Fonseca, E.; Plakal, M.; Font, F.; Ellis, D.P.; Favory, X.; Pons, J.; Serra, X. General-purpose tagging of freesound audio with audioset labels: Task description, dataset, and baseline. arXiv 2018, arXiv:1807.09902. [Google Scholar]
- Maron, O.; Lozano-Pérez, T. A framework for multiple-instance learning. Adv. Neural Inf. Process. Syst. 1998, 570–576. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.51.7638&rep=rep1&type=pdf (accessed on 10 November 2021).
- Quellec, G.; Cazuguel, G.; Cochener, B.; Lamard, M. Multiple-instance learning for medical image and video analysis. IEEE Rev. Biomed. Eng. 2017, 10, 213–234. [Google Scholar] [CrossRef]
- Xu, Y.; Mo, T.; Feng, Q.; Zhong, P.; Lai, M.; Eric, I.; Chang, C. Deep learning of feature representation with multiple instance learning for medical image analysis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 1626–1630. [Google Scholar]
- Papandreou, G.; Chen, L.C.; Murphy, K.P.; Yuille, A.L. Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1742–1750. [Google Scholar]
- Wu, J.; Zhao, Y.; Zhu, J.Y.; Luo, S.; Tu, Z. Milcut: A sweeping line multiple instance learning paradigm for interactive image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 256–263. [Google Scholar]
- Naranjo-Alcazar, J.; Perez-Castanos, S.; Zuccarello, P.; Cobos, M. Acoustic scene classification with squeeze-excitation residual networks. ACM Comput. Surv. 2016, 48, 1–46. [Google Scholar] [CrossRef]
- McDonnell, M.D.; Gao, W. Acoustic scene classification using deep residual networks with late fusion of separated high and low frequency paths. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 141–145. [Google Scholar]
- Chen, Y.; Guo, Q.; Liang, X.; Wang, J.; Qian, Y. Environmental sound classification with dilated convolutions. Appl. Acoust. 2019, 148, 123–132. [Google Scholar] [CrossRef]
- Wei, Y.; Xiao, H.; Shi, H.; Jie, Z.; Feng, J.; Huang, T.S. Revisiting dilated convolution: A simple approach for weakly-and semi-supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7268–7277. [Google Scholar]
- Wang, Y.; Hu, S.; Wang, G.; Chen, C.; Pan, Z. Multi-scale dilated convolution of convolutional neural network for crowd counting. Multimed. Tools Appl. 2020, 79, 1057–1073. [Google Scholar] [CrossRef]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Li, Y.; Liu, M.; Drossos, K.; Virtanen, T. Sound event detection via dilated convolutional recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 286–290. [Google Scholar]
- Kolesnikov, A.; Lampert, C.H. Seed, expand and constrain: Three principles for weakly-supervised image segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 695–711. [Google Scholar]
- Kong, Q.; Iqbal, T.; Xu, Y.; Wang, W.; Plumbley, M.D. DCASE 2018 challenge surrey cross-task convolutional neural network baseline. arXiv 2018, arXiv:1808.00773. [Google Scholar]
- Miyazaki, K.; Komatsu, T.; Hayashi, T.; Watanabe, S.; Toda, T.; Takeda, K. Weakly-Supervised Sound Event Detection with Self-Attention. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 66–70. [Google Scholar]
- Mesaros, A.; Heittola, T.; Virtanen, T. Metrics for polyphonic sound event detection. Appl. Sci. 2016, 6, 162. [Google Scholar] [CrossRef]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 142, 29–36. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Proposed Model | Baseline Model | ||||
|---|---|---|---|---|---|
| Layers, Activation Function {Kernel Size, Dilation Rate, Repeat} | Number of Kernel | Output Size {Channel × Time × Frequency} | Layers, Activation Function {Kernel Size, Repeat} | Number of Kernel | Output Size {Channel × Time × Frequency} |
| Input log mel spectrogram | - | 1 × 431 × 64 | Input log mel spectrogram | - | 1 × 431 × 64 |
| Dilated CNN, GLU {3 × 3, 1, 2} | 64 | 32 × 431 × 64 | CNN, ReLU {3 × 3, 2} | 64 | 64 × 431 × 64 |
| Dilated CNN, GLU {3 × 3, 2, 2} | 128 | 64 × 431 × 64 | CNN, ReLU {3 × 3, 2} | 128 | 128 × 431 × 64 |
| Dilated CNN, GLU {3 × 3, 4, 2} | 256 | 128 × 431 × 64 | CNN, ReLU {3 × 3, 2} | 256 | 256 × 431 × 64 |
| Dilated CNN, GLU {3 × 3, 8, 2} | 256 | 128 × 431 × 64 | CNN, ReLU {3 × 3, 2} | 256 | 256 × 431 × 64 |
| CNN, Sigmoid {1 × 1, -, -} | 42 | 42 × 431 × 64 | CNN, Sigmoid {1 × 1, -} | 41 | 41 × 431 × 64 |
| Global Weighted Rank Pooling | - | 42 | Global Weighted Rank Pooling | - | 41 |
| 0 dB | 10 dB | 20 dB | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Models | F1 | AUC | mAP | F1 | AUC | mAP | F1 | AUC | mAP |
| FrameCNN [11] | 0.301 | 0.675 | 0.319 | 0.318 | 0.696 | 0.352 | 0.320 | 0.708 | 0.367 |
| WLDCNN [12] | 0.289 | 0.599 | 0.268 | 0.312 | 0.621 | 0.309 | 0.300 | 0.617 | 0.295 |
| Attention [13] | 0.648 | 0.854 | 0.696 | 0.695 | 0.874 | 0.738 | 0.698 | 0.875 | 0.743 |
| Baseline [14] | 0.423 | 0.844 | 0.492 | 0.463 | 0.874 | 0.568 | 0.471 | 0.881 | 0.591 |
| Baseline + GLU | 0.427 | 0.846 | 0.499 | 0.465 | 0.874 | 0.571 | 0.482 | 0.886 | 0.605 |
| Baseline + Dilated | 0.559 | 0.902 | 0.687 | 0.616 | 0.928 | 0.758 | 0.616 | 0.931 | 0.764 |
| Baseline + GLU + Dilated (DCGLU) | 0.565 | 0.900 | 0.687 | 0.613 | 0.926 | 0.752 | 0.627 | 0.933 | 0.776 |
| DCGLU + Noise label | 0.565 | 0.900 | 0.687 | 0.614 | 0.925 | 0.754 | 0.628 | 0.933 | 0.776 |
| DCGLU + Noise label + Noise loss | 0.597 | 0.910 | 0.721 | 0.645 | 0.933 | 0.785 | 0.659 | 0.940 | 0.802 |
| 0 dB | 10 dB | 20 dB | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Models | F1 | AUC | mAP | F1 | AUC | mAP | F1 | AUC | mAP |
| FrameCNN [11] | 0.143 | 0.621 | 0.064 | 0.155 | 0.638 | 0.069 | 0.158 | 0.648 | 0.071 |
| WLDCNN [12] | 0.105 | 0.576 | 0.126 | 0.146 | 0.598 | 0.155 | 0.121 | 0.589 | 0.135 |
| Attention [13] | 0.117 | 0.781 | 0.218 | 0.129 | 0.799 | 0.235 | 0.137 | 0.802 | 0.242 |
| Baseline [14] | 0.366 | 0.715 | 0.284 | 0.426 | 0.749 | 0.344 | 0.445 | 0.760 | 0.374 |
| Baseline + GLU | 0.366 | 0.713 | 0.286 | 0.425 | 0.745 | 0.351 | 0.452 | 0.758 | 0.383 |
| Baseline + Dilated | 0.514 | 0.823 | 0.473 | 0.560 | 0.849 | 0.526 | 0.575 | 0.857 | 0.545 |
| Baseline + GLU + Dilated (DCGLU) | 0.517 | 0.819 | 0.471 | 0.568 | 0.851 | 0.533 | 0.588 | 0.861 | 0.558 |
| DCGLU + Noise label | 0.516 | 0.819 | 0.471 | 0.570 | 0.851 | 0.536 | 0.587 | 0.861 | 0.559 |
| DCGLU + Noise label + Noise loss | 0.543 | 0.832 | 0.502 | 0.595 | 0.861 | 0.564 | 0.610 | 0.870 | 0.583 |
| Models | Acous. Guitar | Applause | Bark | Base Drum | Burping | Bus | Cello | Chime | Clarinet | Keyboard | Cough | Cowbell | Double Bass | Drawer | Elec. Piano | Fart | Finger Snap | Fire Works | Flute | Glock. | Gong |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FrameCNN [11] | 0.275 | 0.577 | 0.249 | 0.288 | 0.225 | 0.499 | 0.345 | 0.296 | 0.416 | 0.217 | 0.202 | 0.179 | 0.218 | 0.195 | 0.368 | 0.233 | 0.206 | 0.188 | 0.423 | 0.288 | 0.270 |
| WLDCNN [12] | 0.194 | 0.855 | 0.195 | 0.190 | 0.191 | 0.589 | 0.230 | 0.190 | 0.468 | 0.192 | 0.196 | 0.190 | 0.186 | 0.193 | 0.252 | 0.196 | 0.199 | 0.196 | 0.449 | 0.349 | 0.194 |
| Attention [13] | 0.307 | 0.866 | 0.860 | 0.529 | 0.787 | 0.669 | 0.526 | 0.693 | 0.750 | 0.640 | 0.783 | 0.841 | 0.353 | 0.337 | 0.536 | 0.599 | 0.711 | 0.430 | 0.749 | 0.534 | 0.442 |
| Baseline [14] | 0.372 | 0.569 | 0.518 | 0.269 | 0.384 | 0.441 | 0.389 | 0.512 | 0.446 | 0.480 | 0.402 | 0.345 | 0.273 | 0.262 | 0.422 | 0.377 | 0.379 | 0.273 | 0.440 | 0.439 | 0.348 |
| Baseline + GLU | 0.382 | 0.557 | 0.514 | 0.266 | 0.406 | 0.432 | 0.399 | 0.522 | 0.453 | 0.486 | 0.406 | 0.346 | 0.264 | 0.252 | 0.420 | 0.375 | 0.382 | 0.270 | 0.449 | 0.438 | 0.355 |
| Baseline + Dilated | 0.437 | 0.763 | 0.706 | 0.397 | 0.558 | 0.542 | 0.484 | 0.604 | 0.574 | 0.572 | 0.555 | 0.565 | 0.367 | 0.314 | 0.506 | 0.534 | 0.494 | 0.343 | 0.572 | 0.567 | 0.406 |
| Baseline + GLU + Dilated (DCGLU) | 0.429 | 0.746 | 0.734 | 0.399 | 0.560 | 0.517 | 0.486 | 0.646 | 0.609 | 0.574 | 0.566 | 0.589 | 0.368 | 0.312 | 0.510 | 0.533 | 0.505 | 0.336 | 0.602 | 0.582 | 0.405 |
| DCGLU + Noise label | 0.425 | 0.752 | 0.737 | 0.375 | 0.566 | 0.513 | 0.488 | 0.632 | 0.599 | 0.577 | 0.581 | 0.602 | 0.349 | 0.320 | 0.492 | 0.526 | 0.497 | 0.328 | 0.602 | 0.582 | 0.404 |
| DCGLU + Noise label + Noise loss | 0.466 | 0.783 | 0.763 | 0.431 | 0.607 | 0.556 | 0.494 | 0.688 | 0.629 | 0.586 | 0.605 | 0.635 | 0.380 | 0.331 | 0.528 | 0.599 | 0.523 | 0.368 | 0.627 | 0.603 | 0.461 |
| Models | Gunshot | Harmonica | Hihat | Keys | Knock | Laughter | Meow | Microwave | Oboe | Sexophone | Scissors | Shatter | Snare drum | Squeak | Tambourine | Tearing | Telephone | Trumpet | Violin | Writing | Avg. |
| FrameCNN [11] | 0.220 | 0.559 | 0.279 | 0.302 | 0.175 | 0.208 | 0.223 | 0.285 | 0.489 | 0.548 | 0.231 | 0.208 | 0.383 | 0.202 | 0.339 | 0.226 | 0.312 | 0.381 | 0.467 | 0.213 | 0.301 |
| WLDCNN [12] | 0.245 | 0.362 | 0.472 | 0.197 | 0.198 | 0.191 | 0.200 | 0.202 | 0.482 | 0.702 | 0.191 | 0.237 | 0.296 | 0.189 | 0.192 | 0.197 | 0.233 | 0.486 | 0.495 | 0.193 | 0.289 |
| Attention [13] | 0.572 | 0.879 | 0.924 | 0.851 | 0.546 | 0.651 | 0.586 | 0.652 | 0.678 | 0.782 | 0.603 | 0.597 | 0.848 | 0.500 | 0.753 | 0.526 | 0.548 | 0.845 | 0.787 | 0.505 | 0.648 |
| Baseline [14] | 0.398 | 0.532 | 0.515 | 0.506 | 0.327 | 0.424 | 0.463 | 0.360 | 0.487 | 0.511 | 0.404 | 0.429 | 0.497 | 0.362 | 0.649 | 0.444 | 0.388 | 0.502 | 0.438 | 0.378 | 0.423 |
| Baseline + GLU | 0.401 | 0.555 | 0.515 | 0.502 | 0.320 | 0.417 | 0.474 | 0.371 | 0.494 | 0.521 | 0.409 | 0.410 | 0.517 | 0.374 | 0.689 | 0.450 | 0.387 | 0.525 | 0.448 | 0.373 | 0.427 |
| Baseline + Dilated | 0.514 | 0.763 | 0.764 | 0.731 | 0.385 | 0.537 | 0.611 | 0.493 | 0.674 | 0.636 | 0.500 | 0.599 | 0.655 | 0.497 | 0.867 | 0.559 | 0.510 | 0.720 | 0.638 | 0.446 | 0.559 |
| Baseline + GLU + Dilated (DCGLU) | 0.505 | 0.742 | 0.721 | 0.740 | 0.389 | 0.559 | 0.646 | 0.478 | 0.695 | 0.660 | 0.505 | 0.587 | 0.639 | 0.492 | 0.889 | 0.575 | 0.528 | 0.729 | 0.643 | 0.449 | 0.565 |
| DCGLU + Noise label | 0.504 | 0.746 | 0.734 | 0.730 | 0.382 | 0.554 | 0.652 | 0.484 | 0.700 | 0.664 | 0.495 | 0.606 | 0.652 | 0.509 | 0.892 | 0.577 | 0.525 | 0.736 | 0.627 | 0.445 | 0.565 |
| DCGLU + Noise label + Noise loss | 0.546 | 0.790 | 0.765 | 0.752 | 0.407 | 0.588 | 0.675 | 0.528 | 0.730 | 0.690 | 0.524 | 0.642 | 0.695 | 0.544 | 0.892 | 0.610 | 0.573 | 0.746 | 0.657 | 0.477 | 0.597 |
| Models | Acous. Guitar | Applause | Bark | Base Drum | Burping | Bus | Cello | Chime | Clarinet | Keyboard | Cough | Cowbell | Double Bass | Drawer | Elec. Piano | Fart | Finger Snap | Fire Works | Flute | Glock. | Gong |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FrameCNN [11] | 0.136 | 0.343 | 0.111 | 0.046 | 0.071 | 0.262 | 0.206 | 0.157 | 0.227 | 0.071 | 0.064 | 0.049 | 0.072 | 0.061 | 0.191 | 0.077 | 0.055 | 0.061 | 0.228 | 0.132 | 0.142 |
| WLDCNN [12] | 0.000 | 0.544 | 0.000 | 0.000 | 0.000 | 0.417 | 0.113 | 0.000 | 0.358 | 0.000 | 0.000 | 0.000 | 0.002 | 0.000 | 0.075 | 0.060 | 0.000 | 0.000 | 0.283 | 0.114 | 0.000 |
| Attention [13] | 0.069 | 0.233 | 0.076 | 0.065 | 0.154 | 0.189 | 0.170 | 0.163 | 0.231 | 0.036 | 0.051 | 0.070 | 0.026 | 0.008 | 0.127 | 0.077 | 0.057 | 0.023 | 0.217 | 0.072 | 0.110 |
| Baseline [14] | 0.290 | 0.607 | 0.403 | 0.149 | 0.341 | 0.388 | 0.346 | 0.562 | 0.401 | 0.457 | 0.262 | 0.319 | 0.062 | 0.048 | 0.381 | 0.305 | 0.278 | 0.133 | 0.401 | 0.372 | 0.332 |
| Baseline + GLU | 0.296 | 0.596 | 0.392 | 0.151 | 0.337 | 0.365 | 0.347 | 0.545 | 0.415 | 0.453 | 0.265 | 0.315 | 0.054 | 0.046 | 0.352 | 0.305 | 0.272 | 0.125 | 0.423 | 0.358 | 0.317 |
| Baseline + Dilated | 0.418 | 0.740 | 0.637 | 0.265 | 0.493 | 0.520 | 0.463 | 0.629 | 0.589 | 0.552 | 0.476 | 0.507 | 0.266 | 0.186 | 0.505 | 0.507 | 0.462 | 0.241 | 0.539 | 0.462 | 0.388 |
| Baseline + GLU + Dilated (DCGLU) | 0.396 | 0.725 | 0.657 | 0.264 | 0.501 | 0.471 | 0.443 | 0.652 | 0.596 | 0.558 | 0.495 | 0.535 | 0.251 | 0.162 | 0.498 | 0.506 | 0.472 | 0.216 | 0.571 | 0.465 | 0.375 |
| DCGLU + Noise label | 0.388 | 0.731 | 0.662 | 0.245 | 0.500 | 0.469 | 0.448 | 0.639 | 0.602 | 0.554 | 0.500 | 0.515 | 0.232 | 0.164 | 0.472 | 0.499 | 0.469 | 0.223 | 0.575 | 0.469 | 0.384 |
| DCGLU + Noise label + Noise loss | 0.432 | 0.753 | 0.672 | 0.310 | 0.538 | 0.520 | 0.474 | 0.672 | 0.621 | 0.566 | 0.532 | 0.553 | 0.281 | 0.177 | 0.505 | 0.545 | 0.505 | 0.250 | 0.590 | 0.477 | 0.425 |
| Models | Gunshot | Harmonica | Hihat | Keys | Knock | Laughter | Meow | Microwave | Oboe | Sexophone | Scissors | Shatter | Snare drum | Squeak | Tambourine | Tearing | Telephone | Trumpet | Violin | Writing | Avg. |
| FrameCNN [11] | 0.080 | 0.311 | 0.129 | 0.139 | 0.048 | 0.081 | 0.082 | 0.169 | 0.310 | 0.286 | 0.087 | 0.076 | 0.223 | 0.074 | 0.208 | 0.077 | 0.157 | 0.214 | 0.256 | 0.079 | 0.143 |
| WLDCNN [12] | 0.031 | 0.264 | 0.119 | 0.000 | 0.000 | 0.00 | 0.024 | 0.100 | 0.287 | 0.618 | 0.003 | 0.039 | 0.215 | 0.000 | 0.000 | 0.000 | 0.000 | 0.253 | 0.382 | 0.000 | 0.105 |
| Attention [13] | 0.056 | 0.309 | 0.110 | 0.098 | 0.035 | 0.014 | 0.054 | 0.166 | 0.276 | 0.294 | 0.033 | 0.032 | 0.149 | 0.061 | 0.114 | 0.031 | 0.139 | 0.268 | 0.269 | 0.040 | 0.117 |
| Baseline [14] | 0.237 | 0.593 | 0.441 | 0.448 | 0.159 | 0.295 | 0.313 | 0.341 | 0.585 | 0.503 | 0.349 | 0.310 | 0.574 | 0.287 | 0.624 | 0.353 | 0.363 | 0.568 | 0.469 | 0.346 | 0.366 |
| Baseline + GLU | 0.248 | 0.622 | 0.433 | 0.460 | 0.153 | 0.291 | 0.309 | 0.319 | 0.605 | 0.529 | 0.350 | 0.304 | 0.600 | 0.298 | 0.638 | 0.360 | 0.361 | 0.579 | 0.475 | 0.360 | 0.366 |
| Baseline + Dilated | 0.431 | 0.753 | 0.635 | 0.682 | 0.263 | 0.487 | 0.517 | 0.489 | 0.669 | 0.627 | 0.482 | 0.548 | 0.671 | 0.479 | 0.713 | 0.515 | 0.500 | 0.695 | 0.637 | 0.438 | 0.514 |
| Baseline + GLU + Dilated (DCGLU) | 0.424 | 0.743 | 0.612 | 0.695 | 0.261 | 0.509 | 0.568 | 0.480 | 0.693 | 0.646 | 0.503 | 0.531 | 0.677 | 0.500 | 0.724 | 0.520 | 0.501 | 0.716 | 0.641 | 0.427 | 0.517 |
| DCGLU + Noise label | 0.425 | 0.752 | 0.610 | 0.700 | 0.254 | 0.500 | 0.554 | 0.485 | 0.701 | 0.659 | 0.506 | 0.546 | 0.685 | 0.492 | 0.722 | 0.522 | 0.515 | 0.717 | 0.639 | 0.435 | 0.516 |
| DCGLU + Noise label + Noise loss | 0.457 | 0.762 | 0.644 | 0.709 | 0.285 | 0.534 | 0.595 | 0.514 | 0.706 | 0.675 | 0.511 | 0.562 | 0.703 | 0.526 | 0.725 | 0.550 | 0.539 | 0.728 | 0.652 | 0.468 | 0.543 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, C.; Kim, D.; Ko, H. Sound Event Detection by Pseudo-Labeling in Weakly Labeled Dataset. Sensors 2021, 21, 8375. https://doi.org/10.3390/s21248375
Park C, Kim D, Ko H. Sound Event Detection by Pseudo-Labeling in Weakly Labeled Dataset. Sensors. 2021; 21(24):8375. https://doi.org/10.3390/s21248375
Chicago/Turabian StylePark, Chungho, Donghyeon Kim, and Hanseok Ko. 2021. "Sound Event Detection by Pseudo-Labeling in Weakly Labeled Dataset" Sensors 21, no. 24: 8375. https://doi.org/10.3390/s21248375
APA StylePark, C., Kim, D., & Ko, H. (2021). Sound Event Detection by Pseudo-Labeling in Weakly Labeled Dataset. Sensors, 21(24), 8375. https://doi.org/10.3390/s21248375