
Conversational Agents: Goals, Technologies, Vision and Challenges


Abstract
:1. Introduction
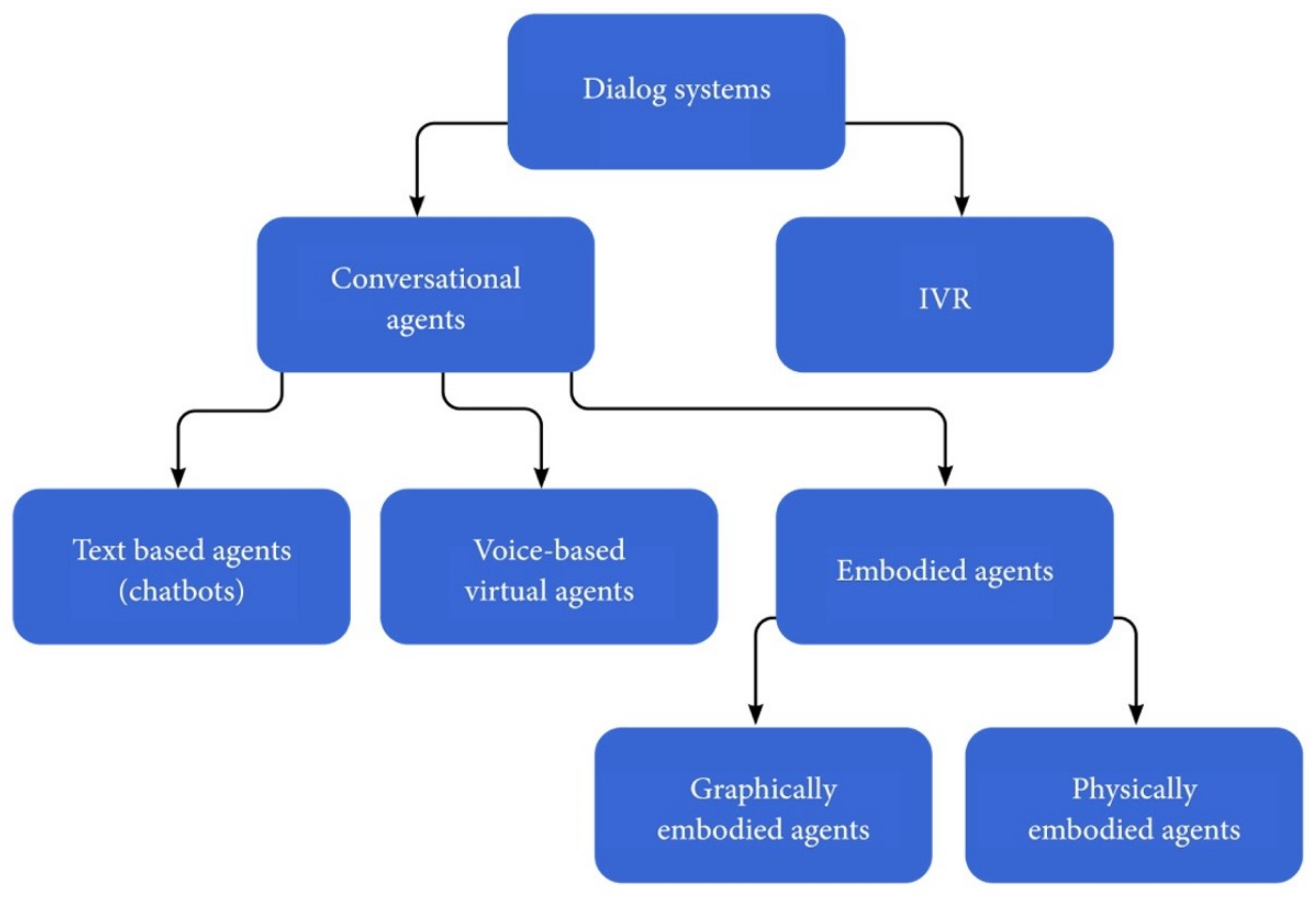
2. Related Definitions and Terms
3. CA’s Design Issues
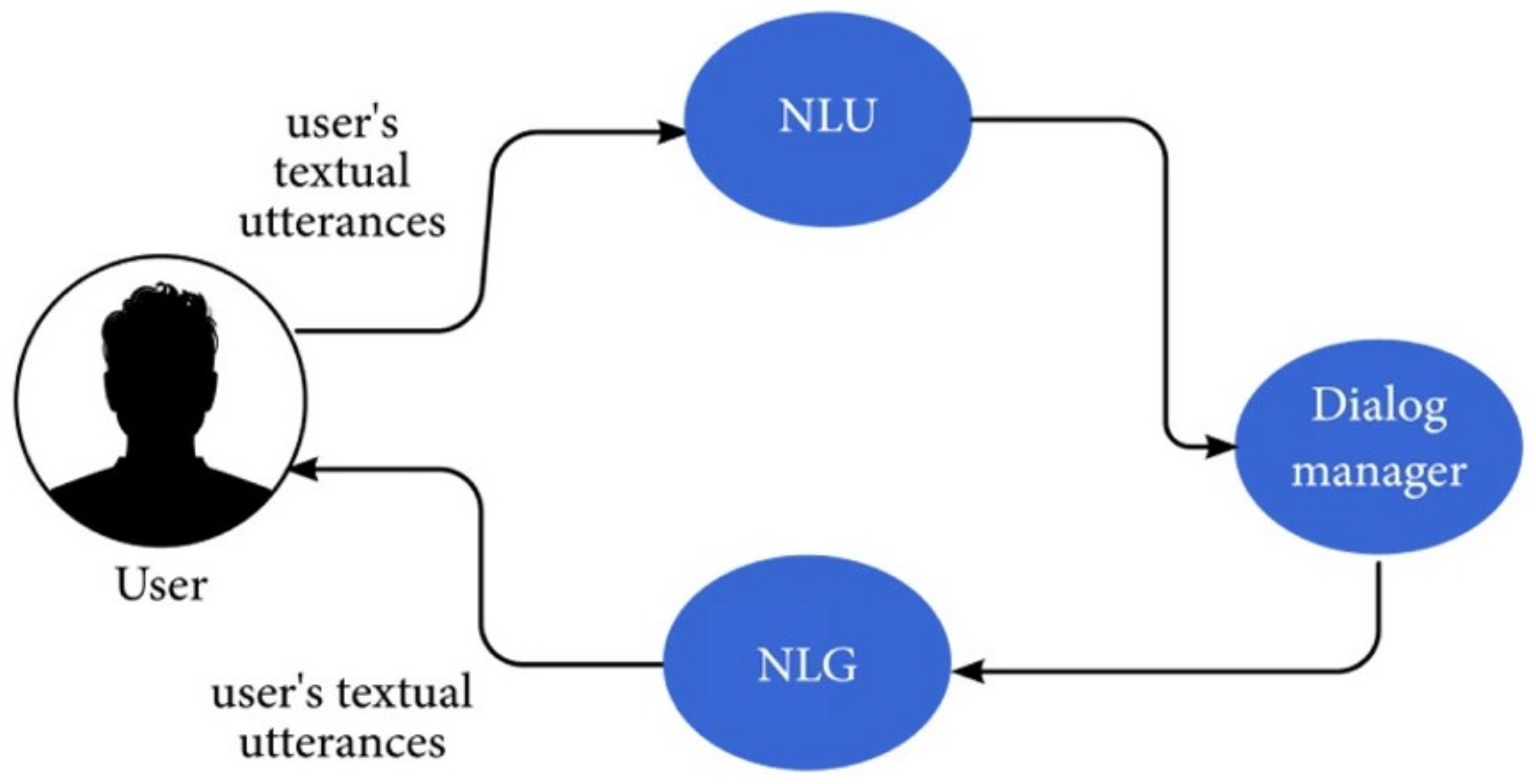
3.1. Text Related Components
- The natural-language-understanding (NLU) component: interprets the words into an internal computer language, called a logical form, which represents the meaning of the text.
- The dialogue manager component: receives the logical form and decides on how to respond. The dialogue manager may also include a module that assists with long-term conversations.
- The natural-language-generation (NLG) component: converts the answer into a text sequence in natural human language.
- Responder—the interface between the user and the CA: transfers and monitors the inputs and the outputs.
- Classifier—the interface between the responder and the graphmaster: normalizes and filters user inputs and processes the graphmaster output.
- Graphmaster—the brain behind the CA: manages the high-level algorithms.
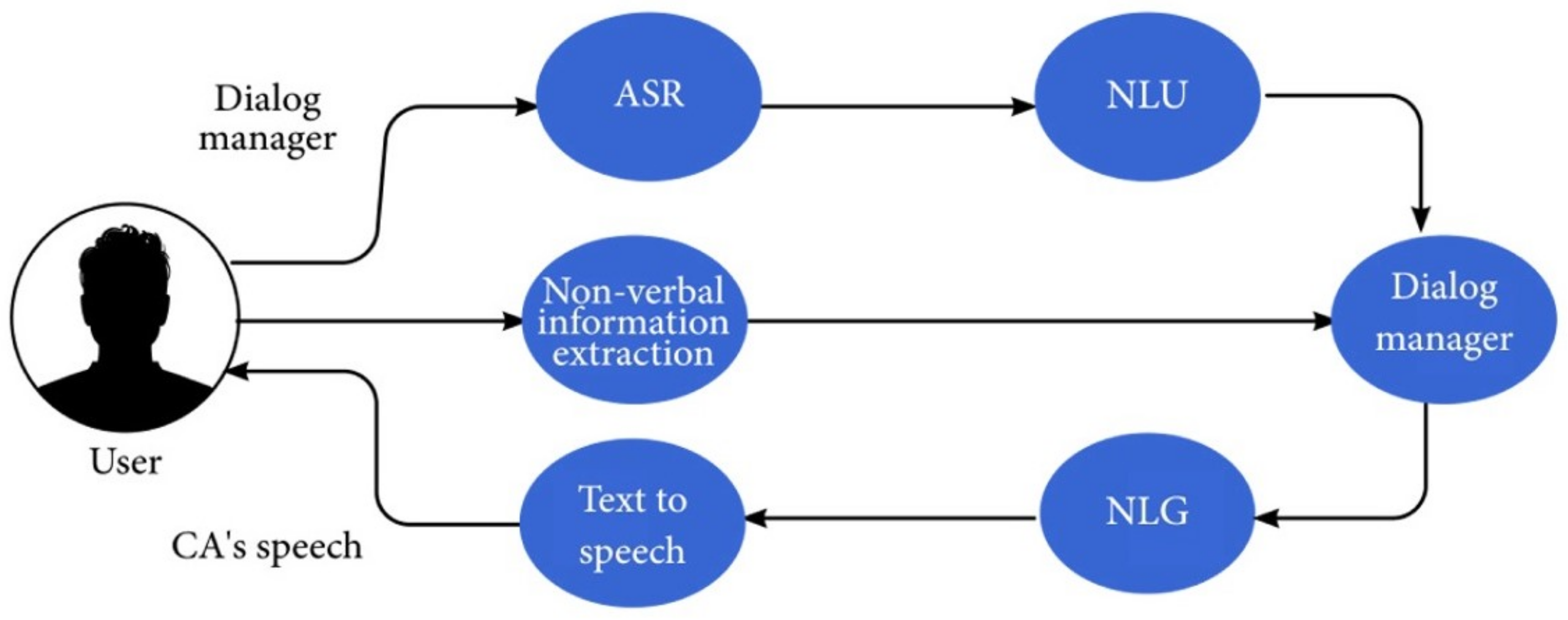
3.2. Voice-Related Components
- An automatic-speech-recognition (ASR) component (speech to text): converts the audio stream to a text representation.
- Non-verbal-information-extraction component: extracts relevant non-verbal information from the audio, such as observing the user’s emotional state or understanding the urgency.
- Text-to-speech component: synthesizes the output waveform that is sent to the speakers.
3.3. Physical-Related Components
- Perception component: receives visual movements and preprocesses them. The preprocessing pipeline consists of four submodules: (1) The body correspondence solver is responsible for performing required operations (such as rotation and scaling) on the observations. (2) The sensory memory receives the transformed positions and buffers them in chronological order. (3) The working memory holds a continuous trajectory for each hand through agent-centric space. (4) The segmenter submodule decomposes the received trajectory into movement segments called guiding strokes.
- The shared-knowledge component is responsible for the representation of motor knowledge. This component consists of a hierarchical structure, starting with the form of single-gesture performances in terms of movement trajectories and leading into less-contextualized motor levels and then toward more context. The motor-representation hierarchy consists of three levels: motor commands, motor programs, and motor schemas.
- The gesture-generator component is invoked by a prior decision to express an intention through a gesture. This component may also be used by a virtual agent that is built on a motor-control engine.
3.4. Task-Related Components
- State tracker: estimates the state of the user’s goal by tracking the information across all turns of the dialogue.
- Policy manager: determines the next set of actions to help reach that goal. The policy manager uses the goal-related information from the state tracker and may communicate with the dialogue manager.
- Action manager: performs the required cyber actions (e.g., hotel reservations, food ordering, and flight booking) and/or the required physical actions to successfully fulfill the user requests.
4. Technologies behind CA Components
4.1. Natural Language Understanding
4.2. The Dialogue Manager
4.3. Natural Language Generation
4.4. End to End Models
4.5. Technologies Specific to Goal-Oriented CAs
5. Human-Related Issues
5.1. Emotional Aspect of Conversations
5.2. The Effect of CA Personality
5.3. Personalized CAs and their Effect on Human Engagements
6. Goals and Applications of Conversational Agents
6.1. Personal Assistants and Open-Domain Conversational Agents
6.2. Educational Applications
Special-Needs Education and Assistance
6.3. Healthcare Conversational Agents
6.4. CAs in the Business Domain
6.5. Influence and Malicious CAs in Social Networks
7. Evaluation Metrics
7.1. Human-Based Evaluation Procedures
7.2. Machine-Evaluation Metrics
7.3. Machine-Learning-Based Evaluation
8. Publicly Available Conversation Datasets
8.1. Datasets for General Purpose CAs
8.2. Datasets for Question Answering
8.3. Datasets for Goal-Oriented CAs
8.4. Datasets for Social Assistance
8.5. Educational Datasets
9. Conclusions and Open Issues
Funding
Conflicts of Interest
Abbreviations
| AGATA | Automatic generation of IAML from text acquisition |
| ASD | Autistic spectrum disorder |
| ASK | Alexa Skills Kit |
| AI | Artificial intelligence |
| AIML | Artificial-intelligence Markup Language |
| ASR | Automatic speech recognition |
| ASRU | Automatic speech recognition |
| B2B | Business to business |
| CA | Conversational agents |
| CCG | Combinatory categorial grammar |
| CFG | Context-free grammar |
| CORGI | Commonsense reasoning by instruction |
| CTGAN | Conditional text generative adversarial network |
| DAN | Deep average network |
| DBN | Dynamic Bayesian network |
| DNN | Deep neural network |
| DSTC | Dialogue-state-tracking Challenge |
| DOAJ | Directory of open-access journals |
| DRL | Deep reinforcement learning |
| DRQN | Deep recurrent QNetwork |
| DSTC | Dialogue system technology challenge |
| ECA | Embodied conversational agent |
| ED | Emotion detection |
| EQ | Emotional quotient |
| FAQ | Frequently asked questions |
| GAN | Generative adversarial network |
| HQ | Hedonic quality |
| HRED | Hierarchical recurrent encoder–decoder |
| IoT | Internet of Things |
| IQ | Intelligence quotient |
| IR | Information retrieval |
| IRIS | Informal response interactive system |
| IS | Information systems |
| ITS | Intelligent tutoring systems |
| IVR | Interactive voice response |
| JA | Joint attention |
| LD | Linear dichroism |
| LIA | Learning by instruction agent |
| LSA | Latent semantic analysis |
| LSTM | Long short-term memory |
| MDP | Markov decision process |
| MDPI | Multidisciplinary Digital Publishing Institute |
| ML | Machine learning |
| MMI | Maximum mutual information |
| MOOC | Massive open online course |
| MT | Machine translation |
| NBT | Neural belief tracking |
| NLG | Natural-language generation |
| NLP | Natural-language processing |
| NLU | Natural-language understanding |
| PCFG | Probabilistic context-free grammar |
| POS | Part-of-speech |
| PBD | Programming-by-demonstration |
| RNN | Recurrent neural network |
| ROUGE | Recall-oriented understudy for gisting evaluation |
| SAR | Socially assistive robotics |
| SCE | Socio-cognitive engineering |
| SGD | Schema-guided dialogue |
| SL | Sign language |
| SQUAD | Stanford question-answering dataset |
| SSA | Sensibleness and specificity average |
| SVM | Support vector machine |
| TF-IDF | Term frequency inverse document frequency |
| TLA | Three-letter acronym |
| UX | User experience |
References
- Bosker, B. Siri Rising: The Inside Story of Siri’s Origins—And Why She Could Overshadow the Iphone. Huffington Post. Available online: https://www.huffpost.com/entry/siri-do-engine-apple-iphone_n_2499165 (accessed on 9 December 2021).
- Adiwardana, D.; Luong, M.T.; So, D.R.; Hall, J.; Fiedel, N.; Thoppilan, R.; Yang, Z.; Kulshreshtha, A.; Nemade, G.; Lu, Y.; et al. Towards a human-like open-domain chatbot. arXiv 2020, arXiv:2001.09977. [Google Scholar]
- Bhat, H.R.; Lone, T.A.; Paul, Z.M. Cortana-intelligent personal digital assistant: A review. Int. J. Adv. Res. Comput. Sci. 2017, 8, 55–57. [Google Scholar]
- Adamopoulou, E.; Moussiades, L. Chatbots: History, Technology, and Applications. Mach. Learn. Appl. 2020, 2, 100006. [Google Scholar] [CrossRef]
- Adamopoulou, E.; Moussiades, L. An overview of chatbot technology. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Neos Marmaras, Greece, 5–7 June 2020; Springer Nature: Cham, Switzerland, 2020; pp. 373–383. [Google Scholar]
- Nuruzzaman, M.; Hussain, O.K. A survey on chatbot implementation in customer service industry through deep neural networks. In Proceedings of the 2018 IEEE 15th International Conference on e-Business Engineering (ICEBE), Xi’an, China, 2–14 October 2018; IEEE: Manhattan, NY, USA, 2018; pp. 54–61. [Google Scholar]
- Borah, B.; Pathak, D.; Sarmah, P.; Som, B.; Nandi, S. Survey of Textbased Chatbot in Perspective of Recent Technologies. In Proceedings of the International Conference on Computational Intelligence, Communications, and Business Analytics, Kalyani, India, 27–28 July 2018; Springer: Cham, Switzerland, 2018; pp. 84–96. [Google Scholar]
- Chen, H.; Liu, X.; Yin, D.; Tang, J. A survey on dialogue systems: Recent advances and new frontiers. Acm Sigkdd Explor. Newsl. 2017, 19, 25–35. [Google Scholar] [CrossRef]
- Jianfeng Gao, M.G.; Li, L. Neural Approaches to Conversational AI. arXiv 2019, arXiv:1809.08267. [Google Scholar]
- Diederich, S.; Brendel, A.B.; Kolbe, L.M. On Conversational Agents in Information Systems Research: Analyzing the Past to Guide Future Work. In Proceedings of the 14th International Conference on Wirtschaftsinformatiks, Siegen, Germany, 24–27 February 2019. [Google Scholar]
- Meyer von Wolff, R.; Hobert, S.; Schumann, M. How may i help you?–state of the art and open research questions for chatbots at the digital workplace. In Proceedings of the 52nd Hawaii International Conference on System Sciences, Honolulu, HI, USA, 8–11 January 2019. [Google Scholar]
- Vishnoi, L. Conversational Agent: A More Assertive Form of Chatbots. 2020. Available online: https://towardsdatascience.com/conversational-agent-a-more-assertive-form-of-chatbots-de6f1c8da8dd (accessed on 9 December 2021).
- Nuseibeh, R. What is a Chatbot? 2018. Available online: https://medium.com/\spacefactor\@m{}rajai_nuseibeh/what-is-a-chatbot-402427354f44 (accessed on 9 December 2021).
- Radziwill, N.; Benton, M. Evaluating Quality of Chatbots and Intelligent Conversational Agents. Softw. Qual. Prof. 2017, 19, 25. [Google Scholar]
- Hussain, S.; Sianaki, O.A.; Ababneh, N. A survey on conversational agents/chatbots classification and design techniques. In Proceedings of the Workshops of the International Conference on Advanced Information Networking and Applications, Matsue, Japan, 27–29 March 2019; pp. 946–956. [Google Scholar]
- Masche, J.; Le, N.T. A review of technologies for conversational systems. In Proceedings of the International conference on Computer Science, Applied Mathematics and Applications, Berlin, Germany, 30 June–1 July 2017; pp. 212–225. [Google Scholar]
- Nimavat, K.; Champaneria, T. Chatbots: An overview types, architecture, tools and future possibilities. Int. J. Sci. Res. Dev. 2017, 5, 1019–1024. [Google Scholar]
- Venkatesh, A.; Khatri, C.; Ram, A.; Guo, F.; Gabriel, R.; Nagar, A.; Prasad, R.; Cheng, M.; Hedayatnia, B.; Metallinou, A.; et al. On Evaluating and Comparing Conversational Agents. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Weizenbaum, J. ELIZA—A computer program for the study of natural language communication between man and machine. Commun. ACM 1966, 9, 36–45. [Google Scholar] [CrossRef]
- Breazeal, C. Social robots: From research to commercialization. In Proceedings of the 2017 ACM/IEEE International Conference on Human-Robot Interaction, Vienna, Austria, 6–9 March 2017; p. 1. [Google Scholar] [CrossRef]
- Gehl, R.W. Teaching to the Turing Test with Cleverbot. J. Incl. Scholarsh. Pedagog. 2014, 24, 56–66. [Google Scholar]
- Hill, J.; Randolph Ford, W.; Farreras, I.G. Real conversations with artificial intelligence: A comparison between human–human online conversations and human–chatbot conversations. Comput. Hum. Behav. 2015, 49, 245–250. [Google Scholar] [CrossRef]
- Lopatovska, I.; Rink, K.; Knight, I.; Raines, K.; Cosenza, K.; Williams, H.; Sorsche, P.; Hirsch, D.; Li, Q.; Martinez, A. Talk to me: Exploring user interactions with the Amazon Alexa. J. Librariansh. Inf. Sci. 2019, 51, 984–997. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, Z.; Fang, Y.; Li, X.; Takanobu, R.; Li, J.; Peng, B.; Gao, J.; Zhu, X.; Huang, M. Convlab-2: An open-source toolkit for building, evaluating, and diagnosing dialogue systems. arXiv 2020, arXiv:2002.04793. [Google Scholar]
- Taskbot, A.P. Alexa Prize Taskbot. 2021. Available online: https://developer.amazon.com/alexaprize (accessed on 9 December 2021).
- Fernandes, A. NLP, NLU, NLG and how Chatbots Work. Available online: https://chatbotslife.com/nlp-nlu-nlg-and-how-chatbots-work-dd7861dfc9df (accessed on 9 December 2021).
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. arXiv 2017, arXiv:1708.05148. [Google Scholar]
- Stoner, D.J.; Ford, L.; Ricci, M. Simulating Military Radio Communications Using Speech Recognition and Chat-Bot Technology; The Titan Corporation: Orlando, FL, USA, 2004; Available online: https://docplayer.net/39136593-Simulating-military-radio-communications-using-speech-recognition-and-chat-bot-technology.html (accessed on 9 December 2021).
- Abdul-Kader, S.A.; Woods, J. Survey on Chatbot Design Techniques in Speech Conversation Systems. Int. J. Adv. Comput. Sci. Appl. 2015, 6, 72–80. [Google Scholar]
- Ramesh, K.; Ravishankaran, S.; Joshi, A.; Chandrasekaran, K. A Survey of Design Techniques for Conversational Agents. In Proceedings of the 2017 ICICCT Information, Communication and Computing Technology, New Delhi, India, 13 May 2017; pp. 336–350. [Google Scholar]
- Ahmad, N.A.; Hamid, M.H.C.; Zainal, A.; Rauf, M.F.A.; Adnan, Z. Review of Chatbots Design Techniques. Int. J. Comput. Appl. 2018, 181, 56–67. [Google Scholar]
- Diederich, S.; Brendel, A.B.; Kolbe, L.M. Towards a Taxonomy of Platforms for Conversational Agent Design. WI 2019. 2019. Available online: https://aisel.aisnet.org/wi2019/track10/papers/1/ (accessed on 9 December 2021).
- Lokman, A.S.; Ameedeen, M.A. Modern Chatbot Systems: A Technical Review. In Proceedings of the Future Technologies Conference (FTC), San Francisco, CA, USA, 25–26 October 2019; pp. 1012–1023. [Google Scholar]
- Azaria, A.; Nivasch, K. SAIF: A Correction-Detection Deep-Learning Architecture for Personal Assistants. Sensors 2020, 20, 5577. [Google Scholar] [CrossRef]
- Saund, E. How Do Conversational Agents Answer Questions? Available online: https://towardsdatascience.com/how-do-conversational-agents-answer-questions-d504d37ef1cc (accessed on 9 December 2021).
- Benzeghiba, M.; De Mori, R.; Deroo, O.; Dupont, S.; Erbes, T.; Jouvet, D.; Fissore, L.; Laface, P.; Mertins, A.; Ris, C.; et al. Automatic speech recognition and speech variability: A review. Speech Commun. 2007, 49, 763–786. [Google Scholar] [CrossRef] [Green Version]
- Yu, D.; Deng, L. Automatic Speech Recognition; Springer Nature: Cham, Switzerland, 2016. [Google Scholar]
- Sadeghipour, A.; Kopp, S. Embodied gesture processing: Motor-based integration of perception and action in social artificial agents. Cogn. Comput. 2011, 3, 419–435. [Google Scholar] [CrossRef] [Green Version]
- Krishnaswamy, N.; Narayana, P.; Wang, I.; Rim, K.; Bangar, R.; Patil, D.; Mulay, G.; Beveridge, R.; Ruiz, J.; Draper, B.; et al. Communicating and acting: Understanding gesture in simulation semantics. In Proceedings of the 12th International Conference on Computational Semantics (IWCS), Montpellier, France, 19–22 September 2017. [Google Scholar]
- Homburg, D.; Thieme, M.S.; Völker, J.; Stock, R. RoboTalk-Prototyping a Humanoid Robot as Speech-to-Sign Language Translator. In Proceedings of the 52nd Hawaii International Conference on System Sciences, Honolulu, HI, USA, 8–11 January 2019. [Google Scholar]
- Singh, S.; Jain, A.; Kumar, D. Recognizing and interpreting sign language gesture for human robot interaction. Int. J. Comput. Appl. 2012, 52. [Google Scholar] [CrossRef]
- Beck, A.; Stevens, B.; Bard, K.A.; Cañamero, L. Emotional body language displayed by artificial agents. Acm Trans. Interact. Intell. Syst. (Tiis) 2012, 2, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Zhao, T.; Eskenazi, M. Towards end-to-end learning for dialog state tracking and management using deep reinforcement learning. arXiv 2016, arXiv:1606.02560. [Google Scholar]
- Noroozi, V.; Zhang, Y.; Bakhturina, E.; Kornuta, T. A Fast and Robust BERT-based Dialogue State Tracker for Schema-Guided Dialogue Dataset. arXiv 2020, arXiv:2008.12335. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Navigli, R. Natural Language Understanding: Instructions for (Present and Future) Use. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 5697–5702. [Google Scholar]
- Inui, N.; Koiso, T.; Nakamura, J.; Kotani, Y. Fully corpus-based natural language dialogue system. In Proceedings of the Natural Language Generation in Spoken and Written Dialogue, AAAI Spring Symposium, Palo Alto, CA, USA, 24–26 March 2003. [Google Scholar]
- Wallace, R.S. The anatomy of ALICE. In Parsing the Turing Test; Springer Nature: Cham, Switzerland, 2009; pp. 181–210. [Google Scholar]
- Marietto, M.d.G.B.; de Aguiar, R.V.; Barbosa, G.d.O.; Botelho, W.T.; Pimentel, E.; França, R.d.S.; da Silva, V.L. Artificial intelligence markup language: A brief tutorial. arXiv 2013, arXiv:1307.3091. [Google Scholar] [CrossRef]
- Agostaro, F.; Augello, A.; Pilato, G.; Vassallo, G.; Gaglio, S. A conversational agent based on a conceptual interpretation of a data driven semantic space. In Proceedings of the Congress of the Italian Association for Artificial Intelligence, Milan, Italy, 21–23 September 2005; pp. 381–392. [Google Scholar]
- Banchs, R.E.; Li, H. IRIS: A chat-oriented dialogue system based on the vector space model. In Proceedings of the ACL 2012 System Demonstrations, Jeju, Korea, 8–14 July 2012; pp. 37–42. [Google Scholar]
- Nijholt, A. Context-Free Grammars: Covers, Normal Forms, And Parsing; Lecture Notes in Computer Science; Springer Science and Business Media: Berlin/Heidelberg, Germany, 1980; Volume 93. [Google Scholar]
- Resnik, P. Probabilistic tree-adjoining grammar as a framework for statistical natural language processing. In Proceedings of the 14th International Conference on Computational Linguistics, Nantes, France, 23–28 August 1992. [Google Scholar]
- Gandhe, A.; Rastrow, A.; Hoffmeister, B. Scalable language model adaptation for spoken dialogue systems. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 907–912. [Google Scholar]
- Azaria, A.; Srivastava, S.; Krishnamurthy, J.; Labutov, I.; Mitchell, T.M. An agent for learning new natural language commands. Auton. Agents Multi-Agent Syst. 2020, 34, 1–27. [Google Scholar] [CrossRef]
- Bocklisch, T.; Faulkner, J.; Pawlowski, N.; Nichol, A. Rasa: Open source language understanding and dialogue management. arXiv 2017, arXiv:1712.05181. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the 18th International Conference on Machine Learning (ICML 2001), Williamstown, MA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Lee, S.; Zhu, Q.; Takanobu, R.; Zhang, Z.; Zhang, Y.; Li, X.; Li, J.; Peng, B.; Li, X.; Huang, M.; et al. ConvLab: Multi-Domain End-to-End Dialog System Platform. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 64–69. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- McTear, M. The Role of Spoken Dialogue in User–Environment Interaction. In Human-Centric Interfaces for Ambient Intelligence; Academic Press: Cambridge, MA, USA, 2010; pp. 225–254. [Google Scholar] [CrossRef]
- Harms, J.G.; Kucherbaev, P.; Bozzon, A.; Houben, G.J. Approaches for dialog management in conversational agents. IEEE Internet Comput. 2018, 23, 13–22. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, A.; Wobcke, W. An agent-based approach to dialogue management in personal assistants. In Proceedings of the 10th International Conference on Intelligent User Interfaces, San Diego, CA, USA, 10–13 January 2005; pp. 137–144. [Google Scholar]
- Moore, R.C.; Dowding, J.; Bratt, H.; Gawron, J.M.; Gorfu, Y.; Cheyer, A. CommandTalk: A spoken-language interface for battlefield simulations. In Proceedings of the Fifth Conference on Applied Natural Language Processing, Washington, WA, USA, 31 March–3 April 1997; pp. 1–7. [Google Scholar]
- Stent, A.; Dowding, J.; Gawron, J.M.; Bratt, E.O.; Moore, R.C. The CommandTalk spoken dialogue system. In Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics, College Park, MA, USA, 20–26 June 1999; pp. 183–190. [Google Scholar]
- MindMeld. Introducing MindMeld. Available online: https://www.mindmeld.com/docs/intro/introducing_mindmeld.html (accessed on 9 December 2021).
- Klopfenstein, L.C.; Delpriori, S.; Ricci, A. Adapting a conversational text generator for online chatbot messaging. In Proceedings of the International Conference on Internet Science, St. Petersburg, Russia, 24–26 October 2018; pp. 87–99. [Google Scholar]
- Building and deploying a chatbot by using Dialogflow (overview). Available online: https://cloud.google.com/solutions/building-and-deploying-chatbot-dialogflow (accessed on 9 December 2021).
- Williams, J.D.; Kamal, E.; Ashour, M.; Amr, H.; Miller, J.; Zweig, G. Fast and easy language understanding for dialog systems with Microsoft Language Understanding Intelligent Service (LUIS). In Proceedings of the 16th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Prague, Czech Republic, 2–4 September 2015; pp. 159–161. [Google Scholar]
- Henderson, M.; Thomson, B.; Young, S. Word-based dialog state tracking with recurrent neural networks. In Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), Philadelphia, PA, USA, 18–20 June 2014; pp. 292–299. [Google Scholar]
- Singh, S.P.; Kearns, M.J.; Litman, D.J.; Walker, M.A. Reinforcement learning for spoken dialogue systems. Adv. Neural Inf. Process. Syst. 1999, 12, 956–962. [Google Scholar]
- Li, J.; Monroe, W.; Ritter, A.; Galley, M.; Gao, J.; Jurafsky, D. Deep Reinforcement Learning for Dialogue Generation. arXiv 2016, arXiv:1606.01541. [Google Scholar]
- Serban, I.V.; Sankar, C.; Germain, M.; Zhang, S.; Lin, Z.; Subramanian, S.; Kim, T.; Pieper, M.; Chandar, S.; Ke, N.R.; et al. A deep reinforcement learning chatbot. arXiv 2017, arXiv:1709.02349. [Google Scholar]
- Reiter, E.; Dale, R. Building Applied Natural Language Generation Systems. Nat. Lang. Eng. 1997, 3, 57–87. [Google Scholar] [CrossRef] [Green Version]
- Gatt, A.; Krahmer, E. Survey of the state of the art in natural language generation: Core tasks, applications and evaluation. J. Artif. Intell. Res. 2018, 61, 65–170. [Google Scholar] [CrossRef]
- Van Deemter, K.; Krahmer, E.; Theune, M. Squibs and Discussions: Real versus Template-Based Natural Language Generation: A False Opposition? Comput. Linguist. 2005, 31, 15–24. [Google Scholar] [CrossRef]
- Wen, T.H.; Gašić, M.; Mrkšić, N.; Su, P.H.; Vandyke, D.; Young, S. Semantically Conditioned LSTM-based Natural Language Generation for Spoken Dialogue Systems. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 1711–1721. [Google Scholar] [CrossRef] [Green Version]
- Tran, V.K.; Nguyen, L.M.; Tojo, S. Neural-based Natural Language Generation in Dialogue using RNN Encoder-Decoder with Semantic Aggregation. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, Saarbrücken, Germany, 15–17 August 2017; Association for Computational Linguistics: Saarbruecken, Germany, 2017; pp. 231–240. [Google Scholar] [CrossRef]
- Juraska, J.; Karagiannis, P.; Bowden, K.; Walker, M. A Deep Ensemble Model with Slot Alignment for Sequence-to-Sequence Natural Language Generation. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 152–162. [Google Scholar] [CrossRef] [Green Version]
- Dušek, O.; Novikova, J.; Rieser, V. Evaluating the state-of-the-art of End-to-End Natural Language Generation: The E2E NLG challenge. Comput. Speech Lang. 2020, 59, 123–156. [Google Scholar] [CrossRef]
- Sordoni, A.; Galley, M.; Auli, M.; Brockett, C.; Ji, Y.; Mitchell, M.; Nie, J.Y.; Gao, J.; Dolan, B. A Neural Network Approach to Context-Sensitive Generation of Conversational Responses. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; pp. 196–205. [Google Scholar]
- Mikolov, T.; Zweig, G. Context dependent recurrent neural network language model. In Proceedings of the 2012 IEEE Spoken Language Technology Workshop (SLT), Miami, FL, USA, 2–5 December 2012; IEEE: Manhattan, NY, USA, 2012; pp. 234–239. [Google Scholar]
- Li, J.; Galley, M.; Brockett, C.; Gao, J.; Dolan, B. A Diversity-Promoting Objective Function for Neural Conversation Models. arXiv 2015, arXiv:1510.03055. [Google Scholar]
- Serban, I.; Sordoni, A.; Bengio, Y.; Courville, A.; Pineau, J. Building end-to-end dialogue systems using generative hierarchical neural network models. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- He, S.; Liu, C.; Liu, K.; Zhao, J. Generating Natural Answers by Incorporating Copying and Retrieving Mechanisms in Sequence-to-Sequence Learning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 199–208. [Google Scholar]
- Qiu, M.; Li, F.L.; Wang, S.; Gao, X.; Chen, Y.; Zhao, W.; Chen, H.; Huang, J.; Chu, W. Alime chat: A sequence to sequence and rerank based chatbot engine. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics; Short Papers, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 2, pp. 498–503. [Google Scholar]
- Ghazvininejad, M.; Brockett, C.; Chang, M.W.; Dolan, B.; Gao, J.; tau Yih, W.; Galley, M. A Knowledge-Grounded Neural Conversation Model. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Ham, D.; Lee, J.G.; Jang, Y.; Kim, K.E. End-to-End Neural Pipeline for Goal-Oriented Dialogue Systems using GPT-2. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Online, 5–10 July 2020; pp. 583–592. [Google Scholar] [CrossRef]
- Kim, J.; Ham, D.; Lee, J.G.; Kim, K.E. End-to-End Document-Grounded Conversation with Encoder-Decoder Pre-Trained Language Model. In Proceedings of the DSTC9 Workshop, Online, 8–9 February 2021. [Google Scholar]
- Das, A.; Kottur, S.; Moura, J.M.; Lee, S.; Batra, D. Learning cooperative visual dialog agents with deep reinforcement learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2951–2960. [Google Scholar]
- Zhang, Z.; Takanobu, R.; Huang, M.; Zhu, X. Recent Advances and Challenges in Task-oriented Dialog System. arXiv 2020, arXiv:2003.07490. [Google Scholar] [CrossRef]
- Kim, A.; Song, H.J.; Park, S.B. A two-step neural dialog state tracker for task-oriented dialog processing. Comput. Intell. Neurosci. 2018, 2018, 5798684. [Google Scholar] [CrossRef]
- Mrksic, N.; Seaghdha, D.O.; Wen, T.H.; Thomson, B.; Young, S.J. Neural Belief Tracker: Data-Driven Dialogue State Tracking. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics; Long Papers, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1777–1788. [Google Scholar] [CrossRef]
- Su, P.H.; Vandyke, D.; Gasic, M.; Kim, D.; Mrksic, N.; Wen, T.H.; Young, S. Learning from real users: Rating dialogue success with neural networks for reinforcement learning in spoken dialogue systems. arXiv 2015, arXiv:1508.03386. [Google Scholar]
- Liu, B.; Lane, I. Iterative policy learning in end-to-end trainable task-oriented neural dialog models. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 482–489. [Google Scholar]
- Clark, L.M.H.; Pantidi, N.; Cooney, O.; Garaialde, P.R.D.D.; Edwards, J.; Spillane, B.; Gilmartin, E.; Murad, C.; Munteanu, C. What Makes a Good Conversation?: Challenges in Designing Truly Conversational Agents. In Proceedings of the 2019 CHI Conference, Glasgow, UK, 4–9 May 2019. [Google Scholar]
- Yang, X.; Aurisicchio, M.; Baxter, W. Understanding Affective Experiences with Conversational Agents. In Proceedings of the 2019 CHI Conference, Glasgow, UK, 4–9 May 2019. [Google Scholar]
- Acheampong, F.A.; Wenyu, C.; Nunoo-Mensah, H. Text-based emotion detection: Advances, challenges, and opportunities. Eng. Rep. 2020, 2, e12189. [Google Scholar] [CrossRef]
- Allouch, M.; Azaria, A.; Azoulay, R.; Ben-Izchak, E.; Zwilling, M.; Zachor, D.A. Automatic detection of insulting sentences in conversation. In Proceedings of the 2018 IEEE International Conference on the Science of Electrical Engineering in Israel (ICSEE), Eilat, Israel, 12–14 December 2018; pp. 1–4. [Google Scholar]
- Schlesinger, A.; O’Hara, K.P.; Taylor, A.S. Let’s talk about race: Identity, chatbots, and AI. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–14. [Google Scholar]
- Sarder, M.A. ECActive Embodied Conversational Agent for Mental Health Intervention. Master’s Thesis, Delft University of Technology, Delft, The Netherlands, August 2018. [Google Scholar]
- Yalçın, Ö.N. Empathy framework for embodied conversational agents. Cogn. Syst. Res. 2020, 59, 123–132. [Google Scholar] [CrossRef]
- Tellols, D.; Lopez-Sanchez, M.; Rodríguez, I.; Almajano, P.; Puig, A. Enhancing sentient embodied conversational agents with machine learning. Pattern Recognit. Lett. 2020, 129, 317–323. [Google Scholar] [CrossRef]
- McLeod, S. Maslow’s Hierarchy of Needs. Simply Psychology. 2007. Available online: https://www.simplypsychology.org/maslow.html (accessed on 9 December 2021).
- Chen, J.; Wu, Y.; Jia, C.; Zheng, H.; Huang, G. Customizable text generation via conditional text generative adversarial network. Neurocomputing 2020, 416, 125–135. [Google Scholar] [CrossRef]
- Zhou, L.; Gao, J.; Li, D.; Shum, H.Y. The design and implementation of xiaoice, an empathetic social chatbot. Comput. Linguist. 2020, 46, 53–93. [Google Scholar] [CrossRef]
- Asghar, N.; Poupart, P.; Hoey, J.; Jiang, X.; Mou, L. Affective neural response generation. In Proceedings of the European Conference on Information Retrieval, Grenoble, France, 26–29 March 2018; pp. 154–166. [Google Scholar]
- Zhou, H.; Huang, M.; Zhang, T.; Zhu, X.; Liu, B. Emotional chatting machine: Emotional conversation generation with internal and external memory. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Chaves, A.P.; Gerosa, M.A. How should my chatbot interact? A survey on human-chatbot interaction design, 2020. arXiv 2020, arXiv:1904.02743. [Google Scholar]
- Zhang, S.; Dinan, E.; Urbanek, J.; Szlam, A.; Kiela, D.; Weston, J. Personalizing Dialogue Agents: I have a dog, do you have pets too? arXiv 2018, arXiv:1709.02349. [Google Scholar]
- Völkel, S.T.; Schödel, R.; Buschek, D.; Stachl, C.; Winterhalter, V.; Bühner, M.; Hussmann, H. Developing a Personality Model for Speech-based Conversational Agents Using the Psycholexical Approach. In Proceedings of the CHI ’20—2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–14. [Google Scholar]
- Roccas, S.; Sagiv, L.; Schwartz, S.H.; Knafo, A. The Big Five Personality Factors and Personal Values. Personal. Soc. Psychol. Bull. 2002, 28, 789–801. [Google Scholar] [CrossRef]
- Feine, J.; Gnewuch, U.; Morana, S.; Maedche, A. A Taxonomy of Social Cues for Conversational Agents. Int. J. Hum.-Comput. Stud. 2019, 132, 138–161. [Google Scholar] [CrossRef]
- Burgoon, J.; Guerrero, L.; Manusov, V. Nonverbal signals. In The SAGE Handbook of Interpersonal Communication; SAGE Publications: Thousand Oaks, CA, USA, 2011; pp. 239–282. [Google Scholar]
- Liao, Y.; He, J. Racial mirroring effects on human-agent interaction in psychotherapeutic conversations. In Proceedings of the 25th International Conference on Intelligent User Interfaces, Cagliari, Italy, 18–20 March 2020; pp. 430–442. [Google Scholar]
- Go, E.; Sundar, S.S. Humanizing chatbots: The effects of visual, identity and conversational cues on humanness perceptions. Comput. Hum. Behav. 2019, 97, 304–316. [Google Scholar] [CrossRef]
- Smith, E.M.; Williamson, M.; Shuster, K.; Weston, J.; Boureau, Y.L. Can You Put it All Together: Evaluating Conversational Agents’ Ability to Blend Skills. arXiv 2020, arXiv:2004.08449. [Google Scholar]
- Ferland, L.; Koutstaal, W. How’s Your Day Look? The (Un)Expected Sociolinguistic Effects of User Modeling in a Conversational Agent. In Proceedings of the CHI EA ’20: Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 482–489. [Google Scholar] [CrossRef] [Green Version]
- Carfora, V.; Massimo, F.D.; Rastelli, R.; Catellani, P.; Piastra, M. Dialogue management in conversational agents through psychology of persuasion and machine learning. Multimed. Tools Appl. 2020, 79, 35949–35971. [Google Scholar] [CrossRef]
- Ajzen, I. The theory of planned behavior. Organ. Behav. Hum. Decis. Process. 1991, 50, 179–211. [Google Scholar] [CrossRef]
- Azoulay, R.; David, E.; Avigal, M.; Hutzler, D. Adaptive Task Selection in Automated Educational Software: A Comparative Study. In Intelligent Systems and Learning Data Analytics in Online Education; Elsevier: Amsterdam, The Netherlands, 2021. [Google Scholar]
- Azevedo, R.; Landis, R.S.; Feyzi-Behnagh, R.; Duffy, M.; Trevors, G.; Harley, J.M.; Bouchet, F.; Burlison, J.; Taub, M.; Pacampara, N.; et al. The effectiveness of pedagogical agents’ prompting and feedback in facilitating co-adapted learning with MetaTutor. In Proceedings of the International Conference on Intelligent Tutoring Systems, Chania, Crete, Greece, 14–18 June 2012; pp. 212–221. [Google Scholar]
- Ueno, M.; Miyazawa, Y. IRT-based adaptive hints to scaffold learning in programming. IEEE Trans. Learn. Technol. 2017, 11, 415–428. [Google Scholar] [CrossRef]
- Winkler, R.; Hobert, S.; Salovaara, A.; Söllner, M.; Leimeister, J.M. Sara, the lecturer: Improving learning in online education with a scaffolding-based conversational agent. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 26 April 2020; pp. 1–14. [Google Scholar]
- Ni, L.; Lu, C.; Liu, N.; Liu, J. Mandy: Towards a smart primary care chatbot application. In Proceedings of the International Symposium on Knowledge and Systems Sciences, Bangkok, Thailand, 17–19 November 2017; pp. 38–52. [Google Scholar]
- Schuetzler, R.M.; Grimes, G.M.; Giboney, J.S.; Nunamaker, J.F., Jr. The influence of conversational agents on socially desirable responding. In Proceedings of the 51st Hawaii International Conference on System Sciences, Big Island, HI, USA, 3–6 January 2018; p. 283. [Google Scholar]
- Colby, K.M. Ten criticisms of parry. ACM SIGART Bull. 1974, 48, 5–9. [Google Scholar] [CrossRef]
- Yin, Z.; Chang, K.h.; Zhang, R. Deepprobe: Information directed sequence understanding and chatbot design via recurrent neural networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 2131–2139. [Google Scholar]
- Liu, H.; Lin, T.; Sun, H.; Lin, W.; Chang, C.W.; Zhong, T.; Rudnicky, A. Rubystar: A non-task-oriented mixture model dialog system. arXiv 2017, arXiv:1711.02781. [Google Scholar]
- Hoy, M.B. Human-Aided Bots. Med. Ref. Serv. Q. 2018, 37, 81–88. [Google Scholar] [CrossRef]
- Azaria, A.; Krishnamurthy, J.; Mitchell, T. Instructable intelligent personal agent. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Li, T.J.J.; Azaria, A.; Myers, B.A. SUGILITE: Creating multimodal smartphone automation by demonstration. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 6038–6049. [Google Scholar]
- Chkroun, M.; Azaria, A. Safebot: A safe collaborative chatbot. In Proceedings of the AAAI Workshops, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Ait-Mlouk, A.; Jiang, L. KBot: A Knowledge graph based chatBot for natural language understanding over linked data. IEEE Access 2020, 8, 149220–149230. [Google Scholar] [CrossRef]
- Paladines, J.; Ramirez, J. A systematic literature review of intelligent tutoring systems with dialogue in natural language. IEEE Access 2020, 8, 164246–164267. [Google Scholar] [CrossRef]
- Paschoal, L.N.; Krassmann, A.L.; Nunes, F.B.; de Oliveira, M.M.; Bercht, M.; Barbosa, E.F.; de Souza, S.d.R.S. A Systematic Identification of Pedagogical Conversational Agents. In Proceedings of the 2020 IEEE Frontiers in Education Conference (FIE), Uppsala, Sweden, 21–24 October 2020; pp. 1–9. [Google Scholar]
- Paschoal, L.N.; Turci, L.F.; Conte, T.U.; Souza, S.R. Towards a conversational agent to support the software testing education. In Proceedings of the 33th Brazilian Symposium on Software Engineering, Salvador, Brazil, 23–27 September 2019; pp. 57–66. [Google Scholar]
- Graesser, A.C.; Wiemer-Hastings, K.; Wiemer-Hastings, P.; Kreuz, R.; Group, T.R. AutoTutor: A simulation of a human tutor. Cogn. Syst. Res. 1999, 1, 35–51. [Google Scholar] [CrossRef]
- Abdellatif, A.; Badran, K.; Shihab, E. MSRBot: Using bots to answer questions from software repositories. Empir. Softw. Eng. 2020, 25, 1834–1863. [Google Scholar] [CrossRef] [Green Version]
- Hobert, S. Say hello to ‘coding tutor’! design and evaluation of a chatbot-based learning system supporting students to learn to program. In Proceedings of the 40th International Conference on Information Systems, ICIS 2019, Munich, Germany, 15–18 December 2019. [Google Scholar]
- Kloos, C.D.; Catálan, C.; Muñoz-Merino, P.J.; Alario-Hoyos, C. Design of a conversational agent as an educational tool. In Proceedings of the 2018 Learning With MOOCS (LWMOOCS), Madrid, Spain, 26–28 September 2018; pp. 27–30. [Google Scholar]
- Aguirre, C.C.; Kloos, C.D.; Alario-Hoyos, C.; Muñoz-Merino, P.J. Supporting a MOOC through a conversational agent. Design of a first prototype. In Proceedings of the 2018 International Symposium on Computers in Education (SIIE), Cadiz, Spain, 19–21 September 2018; pp. 1–6. [Google Scholar]
- Assistant, G. Google Assistant, Your Own Personal Google. Available online: https://assistant.google.com/ (accessed on 9 December 2021).
- Lin, P.; Van Brummelen, J.; Lukin, G.; Williams, R.; Breazeal, C. Zhorai: Designing a Conversational Agent for Children to Explore Machine Learning Concepts. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13381–13388. [Google Scholar]
- Cai, W.; Grossman, J.; Lin, Z.J.; Sheng, H.; Wei, J.T.Z.; Williams, J.J.; Goel, S. Bandit algorithms to personalize educational chatbots. Mach. Learn. 2021, 110, 1–30. [Google Scholar] [CrossRef]
- Kim, N.Y.; Cha, Y.; Kim, H.S. Future English learning: Chatbots and artificial intelligence. Multimed.-Assist. Lang. Learn. 2019, 22, 32–53. [Google Scholar]
- Maria, A. Got an Alexa? You’ve Got a Polyglot Tutor That Can Teach You a Language. Available online: https://www.fluentu.com/blog/can-alexa-teach-languages/ (accessed on 9 December 2021).
- Pham, X.L.; Pham, T.; Nguyen, Q.M.; Nguyen, T.H.; Cao, T.T.H. Chatbot as an intelligent personal assistant for mobile language learning. In Proceedings of the 2018 2nd International Conference on Education and E-Learning, Bali, Indonesia, 5–7 November 2018; pp. 16–21. [Google Scholar]
- Fei, W.Y.; Petrina, S. Using learning analytics to understand the design of an intelligent language tutor–Chatbot lucy. Ed. Preface 2013, 4, 124–131. [Google Scholar] [CrossRef] [Green Version]
- Hien, H.T.; Pham-Nguyen, C.; Nam, L.N.H.; Dinh, T.L. Intelligent Assistants in Higher-Education Environments: The FIT-EBot, a Chatbot for Administrative and Learning Support. In Proceedings of the 9th International Symposium on Information and Communication Technology, Danang City, Vietnam, 6–7 December 2018; pp. 69–76. [Google Scholar]
- Ranoliya, B.R.; Raghuwanshi, N.; Singh, S. Chatbot for university related FAQs. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Manipal, India, 13–16 September 2017; pp. 1525–1530. [Google Scholar]
- Lee, K.; Jo, J.; Kim, J.; Kang, Y. Can Chatbots Help Reduce the Workload of Administrative Officers?—Implementing and Deploying FAQ Chatbot Service in a University. In Proceedings of the International Conference on Human-Computer Interaction, Orlando, FL, USA, 26–31 July 2019; pp. 348–354. [Google Scholar]
- Feng, D.; Shaw, E.; Kim, J.; Hovy, E. An intelligent discussion-bot for answering student queries in threaded discussions. In Proceedings of the 11th International Conference on Intelligent User Interfaces, Sydney, Australia, 29 January–1 February 2006; pp. 171–177. [Google Scholar]
- LI, X.; Zhong, H.; Zhang, B.; Zhang, J. A General Chinese Chatbot based on Deep Learning and Its’ Application for Children with ASD. Int. J. Mach. Learn. Comput. 2020, 10, 1–10. [Google Scholar] [CrossRef]
- Triantafyllidou, C. Assistive Technologies for Dyslexia: Punctuation and Its Interfaces with Speech. Master’s Thesis, University of Central Florida, Orlando, FL, USA, 2020. [Google Scholar]
- Park, D.E.; Shin, Y.J.; Park, E.; Choi, I.A.; Song, W.Y.; Kim, J. Designing a Voice-Bot to Promote Better Mental Health: UX Design for Digital Therapeutics on ADHD Patients. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems; Extended Abstracts, Honolulu, HI, USA, 25–30 April 2020; pp. 1–8. [Google Scholar]
- Valadão, C.T.; Goulart, C.; Rivera, H.; Caldeira, E.; Bastos Filho, T.F.; Frizera-Neto, A.; Carelli, R. Analysis of the use of a robot to improve social skills in children with autism spectrum disorder. Res. Biomed. Eng. 2016, 32, 161–175. [Google Scholar] [CrossRef] [Green Version]
- Boucenna, S.; Narzisi, A.; Tilmont, E.; Muratori, F.; Pioggia, G.; Cohen, D.; Chetouani, M. Interactive technologies for autistic children: A review. Cogn. Comput. 2014, 6, 722–740. [Google Scholar] [CrossRef] [Green Version]
- Scassellati, B.; Boccanfuso, L.; Huang, C.M.; Mademtzi, M.; Qin, M.; Salomons, N.; Ventola, P.; Shic, F. Improving social skills in children with ASD using a long-term, in-home social robot. Sci. Robot. 2018, 3. [Google Scholar] [CrossRef] [Green Version]
- Costa, A.P.; Charpiot, L.; Lera, F.R.; Ziafati, P.; Nazarikhorram, A.; Van Der Torre, L.; Steffgen, G. More attention and less repetitive and stereotyped behaviors using a robot with children with autism. In Proceedings of the 27th IEEE 27th IEEE International Symposium on Robot and Human Interactive Communication, Nanjing, China, 27–31 August 2018; pp. 534–539. [Google Scholar]
- Vanderborght, B.; Simut, R.; Saldien, J.; Pop, C.; Rusu, A.S.; Pintea, S.; Lefeber, D.; David, D.O. Using the social robot probo as a social story telling agent for children with ASD. Interact. Stud. 2012, 13, 348–372. [Google Scholar] [CrossRef]
- Peca, A.; Tapus, A.; Aly, A.; Pop, C.; Jisa, L.; Pintea, S.; Rusu, A.; David, D. Exploratory study: Children’s with autism awareness of being imitated by NAO Robot. arXiv 2020, arXiv:2003.03528. [Google Scholar]
- Laranjo, L.; Dunn, A.G.; Tong, H.L.; Kocaballi, A.B.; Chen, J.; Bashir, R.; Surian, D.; Gallego, B.; Magrabi, F.; Lau, A.Y.; et al. Conversational agents in healthcare: A systematic review. J. Am. Med. Inform. Assoc. 2018, 25, 1248–1258. [Google Scholar] [CrossRef] [Green Version]
- Car, L.T.; Dhinagaran, D.A.; Kyaw, B.M.; Kowatsch, T.; Rayhan, J.S.; Theng, Y.L.; Atun, R. Conversational agents in health care: Scoping review and conceptual analysis. J. Med. Internet Res. 2020, 22, e17158. [Google Scholar]
- Theresa Schachner, R.; Keller, F.v.W. Artificial Intelligence-Based Conversational Agents for Chronic Conditions: Systematic Literature Review. J. Med. Internet Res. 2020, 22, e20701. [Google Scholar] [CrossRef]
- Montenegro, J.L.Z.; da Costa, C.A.; da Rosa Righi, R. Survey of conversational agents in health. Expert Syst. Appl. 2019, 129, 56–67. [Google Scholar] [CrossRef]
- Fadhil, A.; Wang, Y.; Reiterer, H. Assistive conversational agent for health coaching: A validation study. Methods Inf. Med. 2019, 58, 009–023. [Google Scholar] [CrossRef]
- Neerincx, M.A.; van Vught, W.; Blanson Henkemans, O.; Oleari, E.; Broekens, J.; Peters, R.; Kaptein, F.; Demiris, Y.; Kiefer, B.; Fumagalli, D.; et al. Socio-Cognitive Engineering of a Robotic Partner for Child’s Diabetes Self-Management. Front. Robot. 2019, 6, 118. [Google Scholar] [CrossRef] [Green Version]
- High, R. The Era of Cognitive Systems: An Inside Look at IBM Watson and How It Works; IBM Redbooks: Endicott, NY, USA, 2012; 16p. [Google Scholar]
- Strickland, E. IBM Watson, heal thyself: How IBM overpromised and underdelivered on AI health care. IEEE Spectr. 2019, 56, 24–31. [Google Scholar] [CrossRef]
- Ross, C.; Swetlitz, I. IBM’s Watson supercomputer recommended ‘unsafe and incorrect’ cancer treatments, internal documents show. Stat 2018, 25, 1–10. [Google Scholar]
- Xu, L.; Zhou, Q.; Gong, K.; Liang, X.; Tang, J.; Lin, L. End-to-End Knowledge-routed relational dialogue system for automatic diagnosis. In Proceedings of the Association for the Advance of Artificial Intelligence, Online, 2–9 February 2019; pp. 7346–7353. [Google Scholar]
- Fitzpatrick, K.K.; Darcy, A.; Vierhile, M. Delivering cognitive behavior therapy to young adults with symptoms of depression and anxiety using a fully automated conversational agent (Woebot): A randomized controlled trial. JMIR Mental Health 2017, 4, e19. [Google Scholar] [CrossRef]
- Edwards, R.A.; Bickmore, T.; Jenkins, L.; Foley, M.; Manjourides, J. Use of an interactive computer agent to support breastfeeding. Matern. Child Health J. 2013, 17, 1961–1968. [Google Scholar] [CrossRef]
- Yang, W.; Zeng, G.; Tan, B.; Ju, Z.; Chakravorty, S.; He, X.; Chen, S.; Yang, X.; Wu, Q.; Zhou, Y.; et al. On the generation of medical dialogues for COIVD-19. arXiv 2020, arXiv:2005.05442. [Google Scholar]
- Palanica, A.; Flaschner, P.; Thommandram, A.; Li, M.; Fossat, Y. Physicians’ perceptions of chatbots in health care: Cross-sectional web-based survey. J. Med. Internet Res. 2019, 21, e12887. [Google Scholar] [CrossRef]
- Nadarzynski, T.; Miles, O.; Cowie, A.; Ridge, D. Acceptability of artificial intelligence (AI)-led chatbot services in healthcare: A mixed-methods study. Digit. Health 2019, 5, 2055207619871808. [Google Scholar] [CrossRef]
- Scholten, M.R.; Kelders, S.M.; Van Gemert-Pijnen, J.E. Self-Guided Web-Based Interventions: Scoping Review on User Needs and the Potential of Embodied Conversational Agents to Address Them. J. Med. Internet Res. 2017, 19, e383. [Google Scholar] [CrossRef] [Green Version]
- Dhanda, S. How Chatbots Will Transform the Retail Industry; Juniper Research: Hampshire, UK, 2018; Available online: https://www.brand-news.it/wp-content/uploads/2018/07/How-Chatbots-Will-Transform-The-Retail-Industry-whitepaper.pdf (accessed on 9 December 2021).
- Bavaresco, R.; Silveira, D.; Reis, E.; Barbosa, J.; Righi, R.; Costa, C.; Antunes, R.; Gomes, M.; Gatti, C.; Vanzin, M.; et al. Conversational agents in business: A systematic literature review and future research directions. Comput. Sci. Rev. 2020, 36, 100239. [Google Scholar] [CrossRef]
- Thomas, N. An e-business chatbot using AIML and LSA. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 2740–2742. [Google Scholar]
- Cui, L.; Huang, S.; Wei, F.; Tan, C.; Duan, C.; Zhou, M. Superagent: A customer service chatbot for e-commerce websites. In Proceedings of the ACL 2017, System Demonstrations, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 97–102. [Google Scholar]
- Xu, A.; Liu, Z.; Guo, Y.; Sinha, V.; Akkiraju, R. A new chatbot for customer service on social media. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 3506–3510. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Yan, Z.; Duan, N.; Chen, P.; Zhou, M.; Zhou, J.; Li, Z. Building task-oriented dialogue systems for online shopping. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Pradana, A.; Sing, G.O.; Kumar, Y. Sambot-intelligent conversational bot for interactive marketing with consumer-centric approach. Int. J. Comput. Inf. Syst. Ind. Manag. Appl. 2017, 6, 265–275. [Google Scholar]
- Kaghyan, S.; Sarpal, S.; Zorilescu, A.; Akopian, D. Review of Interactive Communication Systems for Business-to-Business (B2B) Services. Electron. Imaging 2018, 2018, 1–11. [Google Scholar] [CrossRef]
- Lewis, M.; Yarats, D.; Dauphin, Y.N.; Parikh, D.; Batra, D. Deal or No Deal? End-to-End Learning for Negotiation Dialogues, 2017. arXiv 2017, arXiv:1706.05125. [Google Scholar]
- Luo, X.; Tong, S.; Fang, Z.; Qu, Z. Frontiers: Machines vs. humans: The impact of artificial intelligence chatbot disclosure on customer purchases. Mark. Sci. 2019, 38, 937–947. [Google Scholar] [CrossRef]
- Følstad, A.; Nordheim, C.B.; Bjørkli, C.A. What makes users trust a chatbot for customer service? An exploratory interview study. In Proceedings of the International Conference on Internet Science, St. Petersburg, Russia, 24–26 October 2018; pp. 194–208. [Google Scholar]
- Li, C.H.; Yeh, S.F.; Chang, T.J.; Tsai, M.H.; Chen, K.; Chang, Y.J. A Conversation Analysis of Non-Progress and Coping Strategies with a Banking Task-Oriented Chatbot. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 26 April 2020; pp. 1–12. [Google Scholar]
- Agarwal, A. How to Write a Twitter Bot in 5 Minutes. Available online: https://www.labnol.org/internet/write-twitter-bot/27902/ (accessed on 9 December 2021).
- Peterschmidt, D. How to Make a Twitter Bot in Under an Hour Even If You Don’t Code That Often. Available online: https://medium.com/science-friday-footnotes/how-to-make-a-twitter-bot-in-under-an-hour-259597558acf (accessed on 9 December 2021).
- Adams, T. AI-Powered Social Bots. arXiv 2017, arXiv:1706.05143. [Google Scholar]
- Assenmacher, D.; Clever, L.; Frischlichy, L. Demystifying Social Bots: On the Intelligence of Automated Social Media Actors. Soc. Media Soc. 2020, 1–14. [Google Scholar] [CrossRef]
- Kollanyi, B. Automation, Algorithms, and Politics| Where Do Bots Come From? An Analysis of Bot Codes Shared on GitHub. Int. J. Commun. 2016, 10, 20. [Google Scholar]
- Ferrara, E.; Varol, Q.; Davis, C.; Menczer, F.; Flammini, A. The rise of social bots. Commun. ACM 2016, 37, 81–88. [Google Scholar] [CrossRef] [Green Version]
- Varol, O.; Ferrara, E.; Davis, C.; Menczer, F.; Flammini, A. Online human-bot interactions: Detection, estimation, and characterization. In Proceedings of the International AAAI Conference on Web and Social Media, Montréal, QC, Canada, 15–18 May 2017; pp. 280–289. [Google Scholar]
- Subrahmanian, V.S.; Azaria, A.; Durst, S.; Kagan, V.; Galstyan, A.; Lerman, K.; Zhu, L.; Ferrara, E.; Flammini, A.; Menczer, F. The DARPA Twitter bot challenge. IEEE Comput. Mag. 2016, 49, 38–46. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.; Eoff, B.; Caverlee, J. Seven months with the devils: A long-term study of content polluters on twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Cambridge, MA, USA, 8–11 July 2011. [Google Scholar]
- Deriu, J.; Rodrigo, A.; Otegi, A.; Echegoyen, G.; Rosset, S.; Agirre, E.; Cieliebak, M. Survey on evaluation methods for dialogue systems. Artif. Intell. Rev. 2021, 54, 755–810. [Google Scholar] [CrossRef]
- Griol, D.; Carbó, J.; Molina, J.M. An automatic dialog simulation technique to develop and evaluate interactive conversational agents. Appl. Artif. Intell. 2013, 27, 759–780. [Google Scholar] [CrossRef] [Green Version]
- Papineni, K.A.; Roukos, S.; Ward, T.; Zhu, W. Understanding Affective Experiences with BLEU: A method for automatic evaluation of machine translation. In Proceedings of the Association of Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002. [Google Scholar]
- Lin, C.Y. Rouge: A Package for Automatic Evaluation of Summaries. Available online: https://aclanthology.org/W04-1013.pdf (accessed on 9 December 2021).
- Banerjee, S.; Lavie, A. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Liu, C.W.; Lowe, R.; Serban, I.V.; Noseworthy, M.; Charlin, L.; Pineau, J. How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation. arXiv 2016, arXiv:1603.08023. [Google Scholar]
- Lowe, R.; Noseworthy, M.; Serban, I.V.; Angelard-Gontier, N.; Bengio, Y.; Pineau, J. Towards an automatic turing test: Learning to evaluate dialogue responses. arXiv 2017, arXiv:1708.07149. [Google Scholar]
- Tao, C.; Mou, L.; Zhao, D.; Yan, R. Ruber: An unsupervised method for automatic evaluation of open-domain dialog systems. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Guo, F.; Metallinou, A.; Khatri, C.; Raju, A.; Venkatesh, A.; Ram, A. Topic-based evaluation for conversational bots. arXiv 2018, arXiv:1801.03622. [Google Scholar]
- Serban, I.V.; Lowe, R.; Henderson, P.; Charlin, L.; Pineau, J. A Survey of Available Corpora for Building Data-Driven Dialogue Systems. arXiv 2017, arXiv:1512.05742. [Google Scholar]
- Keneshloo, Y.; Shi, T.; Ramakrishnan, N.; Reddy, C.K. Deep Reinforcement Learning For Sequence to Sequence Models. arXiv 2018, arXiv:1805.09461. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Su, H.; Shen, X.; Li, W.; Cao, Z.; Niu, S. DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset. In Proceedings of the Eighth International Joint Conference on Natural Language Processing; Long Papers, Taipei, Taiwan, 27 November–1 December 2017; Volume 1. [Google Scholar]
- Ameixa, D.; Coheur, L.; Redol, R.A. From Subtitles to Human Interactions: Introducing The Subtle Corpus. Technical Report. Available online: https://www.inesc-id.pt/ficheiros/publicacoes/10062.pdf (accessed on 9 December 2021).
- Lison, P.; Tiedemann, J. OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. In Proceedings of the International Conference on Language Resources and Evaluation, Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Tiedemann, J. News from OPUS-A collection of multilingual parallel corpora with tools and interfaces. In Proceedings of the International Conference on Recent Advances in Natural Language Processing, Online, 1–3 September 2021; pp. 237–248. [Google Scholar]
- Dodge, J.; Gane, A.; Zhang, X.; Bordes, A.; Chopra, S.; Miller, A.H.; Szlam, A.; Weston, J. Evaluating Prerequisite Qualities for Learning End-to-End Dialog Systems. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Danescu-Niculescu-Mizil, C.; Lee, L. Chameleons in imagined conversations: A new approach to understanding coordination of linguistic style in dialogs. arXiv 2011, arXiv:1106.3077. [Google Scholar]
- Li, J.; Galley, M.; Brockett, C.; Spithourakis, G.P.; Gao, J.; Dolan, B. A Persona-Based Neural Conversation Model. arXiv 2016, arXiv:1603.06155. [Google Scholar]
- Ritter, A.; Cherry, C.; Dolan, B. Unsupervised Modeling of Twitter Conversations. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; pp. 172–180. [Google Scholar]
- Schrading, N.; Ovesdotter Alm, C.; Ptucha, R.; Homan, C. An Analysis of Domestic Abuse Discourse on Reddit. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September; pp. 2577–2583.
- Zhang, Y.; Sun, S.; Galley, M.; Chen, Y.C.; Brockett, C.; Gao, X.; Gao, J.; Liu, J.; Dolan, B. DIALOGPT: Large-Scale Generative Pre-training for Conversational Response Generation. arXiv 2019, arXiv:1911.00536. [Google Scholar]
- Bao, S.; He, H.; Wang, F.; Wu, H.; Wang, H. PLATO: Pre-trained Dialogue Generation Model with Discrete Latent Variable. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 85–96. [Google Scholar]
- Lowe, R.; Pow, N.; Serban, I.; Pineau, J. The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems. arXiv 2017, arXiv:1506.08909. [Google Scholar]
- Alizadeh, K. Limitations of Twitter Data Issues to be Aware of When Using Twitter Text Data. Available online: https://towardsdatascience.com/limitations-of-twitter-data-94954850cacf (accessed on 9 December 2021).
- Zeng, C.; Li, S.; Li, Q.; Hu, J.; Hu, J. A Survey on Machine Reading Comprehension—Tasks, Evaluation Metrics and Benchmark Datasets. Appl. Sci. 2020, 10, 7640. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. Squad: 100,000+ questions for machine comprehension of text. arXiv 2016, arXiv:1606.05250. [Google Scholar]
- Rajpurkar, P.; Jia, R.; Liang, P. Know What You Don’t Know: Unanswerable Questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics; Short Papers, Melbourne, Australia, 15–20 July 2018; Volume 2, pp. 784–789. [Google Scholar] [CrossRef] [Green Version]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching Machines to Read and Comprehend. Adv. Neural Inf. Process. Syst. 2015, 28, 1693–1701. [Google Scholar]
- Kwiatkowski, T.; Palomaki, J.; Redfield, O.; Collins, M.; Parikh, A.; Alberti, C.; Epstein, D.; Polosukhin, I.; Devlin, J.; Lee, K.; et al. Natural questions: A benchmark for question answering research. Trans. Assoc. Comput. Linguist. 2019, 7, 453–466. [Google Scholar] [CrossRef]
- Joshi, M.; Choi, E.; Weld, D.; Zettlemoyer, L. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics; Long Papers, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1601–1611. [Google Scholar] [CrossRef]
- Rastogi, A.; Zang, X.; Sunkara, S.; Gupta, R.; Khaitan, P. Towards Scalable Multidomain Conversational Agents: The Schema-Guided Dialogue Dataset. arXiv 2020, arXiv:1909.05855. [Google Scholar]
- Budzianowski, P.; Wen, T.H.; Tseng, B.H.; Casanueva, I.; Ultes, S.; Ramadan, O.; Gašić, M. MultiWOZ—A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Byrne, B.; Krishnamoorthi, K.; Sankar, C.; Neelakantan, A.; Duckworth, D.; Yavuz, S.; Goodrich, B.; Dubey, A.; Cedilnik, A.; Kim, K.Y. Taskmaster-1: Toward a Realistic and Diverse Dialog Dataset. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Peskov, D.; Clarke, N.; Krone, J.; Fodor, B. Multi-Domain Goal-Oriented Dialogues (MultiDoGO): Strategies toward Curating and Annotating Large Scale Dialogue Data. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4526–4536. [Google Scholar]
- Zeng, G.; Yang, W.; Ju, Z.; Yang, Y.; Wang, S.; Zhang, R.; Zhou, M.; Zeng, J.; Dong, X.; Zhang, R.; et al. MedDialog: Large-scale Medical Dialogue Datasets. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 9241–9250. [Google Scholar] [CrossRef]
- Sharma, A.; Lin, I.W.; Miner, A.S.; Atkins, D.C.; Althoff, T. Towards facilitating empathic conversations in online mental health support: A reinforcement learning approach. arXiv 2021, arXiv:2101.07714. [Google Scholar]
- Rashkin, H.; Smith, E.M.; Li, M.; Boureau, Y.L. Towards Empathetic Open-domain Conversation Models: A New Benchmark and Dataset. arXiv 2019, arXiv:1811.00207. [Google Scholar]
- McKeown, G.; Valstar, M.F.; Cowie, R.; Pantic, M. The SEMAINE corpus of emotionally coloured character interactions. In Proceedings of the 2010 IEEE International Conference on Multimedia and Expo, ICME, Singapore, 19–23 July 2010; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Allouch, M.; Azaria, A.; Azoulay, R. Detecting sentences that may be harmful to children with special needs. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 1209–1213. [Google Scholar]
- Chai, Y.; Liu, G.; Jin, Z.; Sun, D. How to Keep an Online Learning Chatbot From Being Corrupted. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Yu, Y.; Eshghi, A.; Mills, G.; Lemon, O. The BURCHAK corpus: A challenge data set for interactive learning of visually grounded word meanings. In Proceedings of the 6th Workshop on Vision and Language, Valencia, Spain, 4 April 2017; pp. 1–10. [Google Scholar]
- Wolska, M.; Vo, Q.B.; Tsovaltzi, D.; Kruijff-Korbayová, I.; Karagjosova, E.; Horacek, H.; Fiedler, A.; Benzmüller, C. An Annotated Corpus of Tutorial Dialogs on Mathematical Theorem Proving. In Proceedings of the International Conference on Language Resources and Evaluation ( LREC), Lisbon, Portugal, 26–28 May 2004; pp. 1007–1010. [Google Scholar]
- Hutzler, D.; David, E.; Avigal, M.; Azoulay, R. Learning methods for rating the difficulty of reading comprehension questions. In Proceedings of the 2014 IEEE International Conference on Software Science, Technology and Engineering, Ramat Gan, Israel, 11–12 June 2014; pp. 54–62. [Google Scholar]
- Bloom, B.S.; Engelhart, M.D.; Furst, E.J.; Hill, W.H.; Krathwohl, D.R. Taxonomy of Educational Objetives: The Classification of Educational Goals: Handbook I: Cognitive Domain; Technical Report; Longmans, Green and Company: New York, NY, USA, 1956. [Google Scholar]
- Stasaski, K.; Kao, K.; Hearst, M.A. CIMA: A Large Open Access Dialogue Dataset for Tutoring. In Proceedings of the 15th Workshop on Innovative Use of NLP for Building Educational Applications, Seattle, WA, USA, 10 July 2020; pp. 52–64. [Google Scholar] [CrossRef]
- Arabshahi, F.; Lee, J.; Gawarecki, M.; Mazaitis, K.; Azaria, A.; Mitchell, T. Conversational neuro-symbolic commonsense reasoning. arXiv 2021, arXiv:2006.10022. [Google Scholar]
- Chkroun, M.; Azaria, A. A Safe Collaborative Chatbot for Smart Home Assistants. Sensors 2021, 21, 6641. [Google Scholar] [CrossRef]
- Chkroun, M.; Azaria, A. Lia: A virtual assistant that can be taught new commands by speech. Int. J.-Hum.-Comput. Interact. 2019, 35, 1596–1607. [Google Scholar] [CrossRef]
- Došilović, F.K.; Brčić, M.; Hlupić, N. Explainable artificial intelligence: A survey. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 0210–0215. [Google Scholar]
- Rosenfeld, A.; Richardson, A. Explainability in human–agent systems. Auton. Agents -Multi-Agent Syst. 2019, 33, 673–705. [Google Scholar] [CrossRef] [Green Version]
- Bird, E.; Fox-Skelly, J.; Jenner, N.; Larbey, R.; Weitkamp, E.; Winfield, A. The Ethics of Artificial Intelligence: Issues And Initiatives; Technical Report; European Parliamentary Research Service: Strasbourg, France, 2020. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Personal Assistants and Open-Domain CAs | |||
|---|---|---|---|
| CA | Short Description | Main Technology | Evaluation Method |
| ALICE [48] | a general-purpose chatbot | AIML, | the most human computer |
| pattern matching | winner, 2000, 2001, 2004 | ||
| LSA-bot [50] | ad-hoc implementation | Latent Semantic Analysis | - |
| of the LSA framework | (LSA) | ||
| IRIS [51] | example-based | vector space model | success and |
| chatbot | cosine similarity metric | failure examples | |
| DeepProbe [129] | an open-domain chatbot | seq-2-seq | AUC scores |
| chatbot | |||
| RubyStar [130] | an open-domain chatbot | seq-2-seq, topic detection, | human evaluation |
| engagement monitoring, | by the Alexa Prize | ||
| context tracking | evaluation | ||
| Siri [1] | Apple’s | CNN, | commercial |
| virtual assistant | LSTM | application | |
| Cortana [3] | voice-controlled assistant | NLP, Tellme Networks, | commercial |
| for Microsoft windows | Semantic search database | application | |
| Alexa [23] | Amazon voice assistant | NLP, LSTM | commercial |
| application | |||
| KBot [135] | knowledge | SVM + analytical | F-score, precision, |
| chatbot | queries engine | recall, intent classification | |
| MILABOT [74] | speech/text CA | DRL | Amazon Alexa |
| Prize competition | |||
| Discussion-Bot [154] | question-answering | semantically related | human judges classified |
| chatbot | matching, TF-IDF metric | the answers quality | |
| Goal-Oriented CAs | |||
| CA | Short Description | Main Technology | Evaluation Method |
| SUGILITE [133] | Programming-by-demonstration | frame-based | a lab study: |
| system | dialogue management | task completion time | |
| Safebot [134] | collaborative chatbot | parser+Word2Vec | users’ engagement |
| LIA [55] | learning by | uses combinatory categorial | speed of task |
| instructions agent | grammar (CCG) parser | completeness | |
| CAs for Social Support | |||
| CA | Short Description | Main Technology | Evaluation Method |
| ELIZA [19] | the first CA: | pattern matching | people experience |
| emulates a psychologist | |||
| XiaoIce [107] | a popular social CA | IQ + EQ + Personality | human rating |
| Meena [2] | a sensible chatbot | generative chatbot | human evaluation metric |
| trained end-to-end on | called Sensibleness and | ||
| social media conversations | Specificity Average (SSA) | ||
| Educational CAs | |||
|---|---|---|---|
| CA | Short Description | Main Technology | Evaluation Method |
| Sara [125] | student’s assistant | scaffolding strategy | pretest and posttest |
| scores of learners | |||
| pro-survey and post-survey | |||
| AutoTutor [139] | computer tutor | LSA, pattern-matching | learning gain |
| speech act classification | |||
| MSRbot [140] | sofware related Q&A | Dialogflow | effectiveness, efficience |
| Zhorai [145] | CA for children | NLTK package | accuracy, child’s level |
| to explore ML concepts | Website visualizer | of engagement | |
| MathBot [146] | math teaching chatbot | rule based | crowd worker preferences |
| English Practice [149] | Personal Assistant for | Dialogflow | statistics about |
| Mobile Language Learning | platform | real users | |
| Lucy [150] | embodied on-line virtual agent for | ALICE offshoot | demonstrative examples |
| language learning | |||
| FIT-EBot [151] | administrative chatbot | DialogFlow | students reports |
| QTrobot [161] | social robot to assist | bodied humanoid robot | interviews with |
| children with ASD | the users | ||
| Probo [162] | social robot | compliant actuation systems | children performance |
| for children with ASD | |||
| Healthcare CAs | |||
| CA | Short Description | Main Technology | Evaluation Method |
| CoachAI [168] | patient’s support | task-oriented finite state | user’s engagement, system |
| chatbot | machine (FSM) architecture | accaptance and rating. | |
| Woebot [174] | therapist CA | AI, NLP, empathy engine | users’ reports |
| Mandy [126] | a primary care CA | NLU, NLG, word2vec | accuracy |
| Tanya [175] | graphically embodied female | increased | |
| agent that supports breastfeeding | breastfeeding success | ||
| KR-DS [173] | diagnosis chatbot | Bi-LSTM, Deep Q-network | diagnosis accuracy |
| Commercial CAs | |||
| CA | Short Description | Main Technology | Evaluation Method |
| SuperAgent [183] | customer-service chatbot | AIML + LSA | 2 customer reviews |
| SamBot [187] | question-answering CA | AIML | Loebner Prize Competition |
| + user interaction | |||
| General-Purpose Datasets | ||||
|---|---|---|---|---|
| Dataset | Source | Description | Size | Used for |
| DailyDialog [213] | hand written, | daily interactions | 13,118 dialogs, | general |
| manualy labeled | .9 turns | purpose | ||
| [216] | subtitles | interaction–response | purpose | |
| pairs | ||||
| Movie dialogue dataset | movie metadata | OMDb, MovieLens, | 3.1 M simulated | Movies QA and |
| [217] | as knowledge triples | and Reddit | QA pairs | recommendation |
| Cornell Movie Dialogues | Short conversations | movie metadata | 220 K | understanding |
| Corpus [218] | from film scripts | conversations | linguistic style | |
| Ubuntu dialogue | Ubuntu chat stream | human–human chat | 930 K | response |
| corpus [224] | conversations | generation | ||
| Question-Answering Datasets | ||||
| Squad Version 1.1 | questions and answers | 00 K questions | 100 K q&a | machine reading |
| [227] | on Wikipedia articles | on Wikipedia articles | comprehension | |
| Squad Version 2 | questions and answers | Squad 1.1 + | 100 K Q&A + | machine reading |
| [228] | and additional questions | 50 k questions | 50 k questions | comprehension |
| with no answers | with no answers | |||
| CNN/Daily Mail | queries from the CNN | cont.–query–answer | M stories+ | machine reading |
| comprehension [229] | and Daily Mail websites | triples | associated queries | training dataset |
| Natural Questions | Google search queries+ | Google question+ | 307,372 | training & |
| dataset [230] | Wikipedia answers | long answer+ | training examples | evaluation of |
| by crowd workers | short answers | answ. systems | ||
| TriviaQA | crowdworkers | question-answer- | 95 K quest.-ans. | reading |
| [231] | questions | evidence triples | pairs + 6 evidence | comprehension |
| doc. per quest. | ||||
| Datasets for Goal Oriented CAs | ||||
|---|---|---|---|---|
| Schema Guided | dialogue simulator+ | multi-domain, | 20 k | intent prediction, |
| Dialogue [232] | paid | task-oriented | conversations | lang. generation, |
| crowd-workers | human-agent convev. | dialogue tracking | ||
| MultiWOZ | turkers working | human-human | 10 k dialogues | Task-oriented |
| [233] | conversations | dialogue modelling | ||
| Taskmaster-1 | crowd workers | spoken & written | 5507 spoken & | dialogue systems |
| [234] | users and | technical | 7708 written | research, dev. |
| center operators | dialogs | dialogs | and design | |
| MultiDoGo | crowd workers | human to human, | 1 K dialogues | virtual assistants |
| [235] | paired with | services dialogues | across 6 domains, | development |
| trained annotators | ||||
| Datasts for Supporting CAs | ||||
| COVID-19 dialogue | online healthcare | conversations between | 603 Eng. + | medical dialogue |
| dataset [176] | platform | doctors and | 1088 Chinese | system |
| patients | consultations | systems | ||
| MedDialog | medical dialogue | doctors–patients | 1.1 M Chinese + | medical dialogue |
| [236] | platform | conversations | 0.3 M English | systems |
| dialogues | ||||
| SEMAINE | human–human | emotionally coloured | 25 recordings, | eliciting non-verbal |
| [239] | conversation | conversations video | 0 min | signals in |
| experiment | recordings | long | human-computer | |
| interactions | ||||
| EmpatheticDialogues | 810 crowd workers | conversations | 25 k conversations | recognizing |
| [238] | select an emotion | grounded in | human’s feelings | |
| and talk about it | emotional situations | |||
| Offensive response | input–response | input–response | 110 K | improve CA |
| dataset [241] | records from SimSimi | pairs and | chat pairs | abilities |
| offensivity annotated | their annotation | |||
| by crowd workers | ||||
| BURCHAK dataset | dialogues of | chat outputs of | 177 dialogues | learning |
| [242] | pairs of participants, | dialogues | 2454 turns | visually grounded |
| discussing visual | word meanings | |||
| attributes of 9 objects | in a foreign language | |||
| The CIMA collection | conversations between | tutoring interactions | 2970 tutor | tutoring conversation |
| [246] | crowd workers playing | and accompanying | responses | based on |
| as students and tutors. | responses | to 350 exercises. | a provided strategy. | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Allouch, M.; Azaria, A.; Azoulay, R. Conversational Agents: Goals, Technologies, Vision and Challenges. Sensors 2021, 21, 8448. https://doi.org/10.3390/s21248448
Allouch M, Azaria A, Azoulay R. Conversational Agents: Goals, Technologies, Vision and Challenges. Sensors. 2021; 21(24):8448. https://doi.org/10.3390/s21248448
Chicago/Turabian StyleAllouch, Merav, Amos Azaria, and Rina Azoulay. 2021. "Conversational Agents: Goals, Technologies, Vision and Challenges" Sensors 21, no. 24: 8448. https://doi.org/10.3390/s21248448
APA StyleAllouch, M., Azaria, A., & Azoulay, R. (2021). Conversational Agents: Goals, Technologies, Vision and Challenges. Sensors, 21(24), 8448. https://doi.org/10.3390/s21248448