
Pseudo-Labeling Optimization Based Ensemble Semi-Supervised Soft Sensor in the Process Industry


Abstract
:1. Introduction
- (1)
- Probabilistic generative models: This type of method aims to improve the estimation accuracy of the underlying distribution of the input space by introducing abundant unlabeled data. These methods assume that all samples, labeled and unlabeled, are generated from the same underlying model. The main difference among the different generative methods lies in the underlying assumptions. For example, Ge and Song [21] proposed a semi-supervised principal component regression (PCR) model, using a probabilistic method. The method first formulates a generative model structure according to the traditional PCR model. Then, by assuming that both probability density functions of the principal component and the process noise are Gaussian, the optimal parameters with respect to the data distribution are optimized by maximizing a likelihood function using an expectation-maximum algorithm, where supervised and unsupervised objectives are involved. Similarly, a semi-supervised probabilistic partial least squares regression model was developed for soft sensor modeling [22]. However, the assumption of Gaussian distribution is often ill-conditioned for industrial processes with multiple modes, where the process data usually exhibit non-Gaussian characteristics. To tackle this issue, non-Gaussian distribution based assumptions have been introduced to build generative soft sensor models, such as a mixture semi-supervised probabilistic PCR model [23], semi-supervised Gaussian mixture regression [24], semi-supervised Dirichlet process mixture of Gaussians [25], semi-supervised mixture of latent factor analysis models [26], and Student’s-t mixture regression [27]. Overall, the key to building an accurate generative model lies in accurate model assumptions, which are often difficult to determine without sufficient reliable domain knowledge.
- (2)
- Graph based methods: Methods of this type are based on manifold assumptions and require constructing a semi-labeled graph to assure the label smoothness over the graph. To this end, one needs to define a graph where the nodes denote labeled and unlabeled samples, and where the edges connect two nodes if their corresponding samples are highly similar. One typical example of such method is the label propagation method [28], originally proposed for addressing classification problems. As for graph based SSL soft sensors, it is a common practice to embed the graph based regularization into the cost function based on traditional supervised regression techniques. For example, two semi-supervised soft sensors were developed, by integrating the extreme learning machine (ELM) method and the graph Laplacian regularization into a unified modeling framework for industrial Mooney viscosity prediction [29,30]. Similarly, Yan et al. [31] developed a semi-supervised Gaussian process regression (GPR) for quality prediction, by using a semi-supervised covariance function, which was defined by introducing the manifold information into the traditional covariance function. Moreover, to enhance the model performance for handling complex process characteristics, as well as exploiting unlabeled process data, Yao and Ge [32] proposed a semi-supervised deep learning model for soft sensor development. First, it implements unsupervised feature extraction through an autoencoder with a deep network structure. Then, ELM is utilized for regression, by introducing manifold regularization. In addition, Yan et al. [33] proposed a semi-supervised deep neural regression network with manifold embedding for soft sensor modeling.
- (3)
- Representation learning based methods: A general strategy for these methods is to use unlabeled data to assist in extracting abstract latent features of the input data. The most common techniques for this purpose are deep learning methods [34], such as convolutional neural networks, deep belief networks (DBN), long/short-term memory neural networks, and a large variety of autoencoders. Besides its strong representation ability, deep learning is inherently semi-supervised and, thus, can effectively exploit all available process data. As an early attempt, Shang et al. [35] employed a DBN to build soft sensors for estimating the heavy diesel 95% cut-point of a crude distillation unit (CDU). However, traditional representation techniques are mainly implemented in an unsupervised manner, where the output variable information is ignored. To address this issue, several research works have focused on exploring semi-supervised representation learning techniques. For instance, Yan et al. [36] proposed a deep relevant representation learning approach based on a stacked autoencoder, which conducts a mutual information analysis between the representations and the output variable in each layer. Similar research has also been reported in references [37,38,39].
- (4)
- Self-labeled methods [40]: The core of such methods is extending the labeled training set by adding high-confidence pseudo-labeled data. In such a modeling framework, one or more predictive models are first trained with labeled data only, and then refined using the extended labeled set through iterative learning. Two representative examples are self-training [41], and co-training [42], based on which some variants have also been proposed, such as COREG [43], Tri-training [44], Multi-train [45], and CoForest [46]. As an instantiation of self-training, a semi-supervised support vector regression model was proposed and verified using 30 regression datasets and an industrial semiconductor manufacturing dataset [47]. In the method, the label distribution of the unlabeled data is estimated with two probabilistic local reconstruction models, thus providing the labeling confidence. Differently, based on the co-training paradigm, Bao et al. [48] proposed a co-training partial least squares (PLS) method for semi-supervised soft sensor development, by splitting the total process variables into two different parts, serving as two views. Instead of using single-output regression techniques, four semi-supervised multiple-output learning soft sensor models [49] were developed. In addition, by applying a spatial view, a temporal view, and a transformed view together, a multi-view transfer semi-supervised regression was developed, by combining transfer learning and co-training for air quality prediction [50]. Another example is a co-training style semi-supervised artificial neural network model for thermal conductivity prediction based on a disagreement-based semi-supervised learning principle [51]. The core of this method is constructing two artificial neural networks learners with different architectures, to label the unlabeled samples. Despite the simplicity and flexibility of implementation, the success of self-labeled SSL soft sensors heavily depends on the reliable confidence estimation of pseudo-labeled data.
- (1)
- An improved supervised regression model NCLELM was developed and serves as the base learning technique for the proposed EnSSNCLELM modeling framework. Despite the fast training speed, ELM is prone to deliver unstable predictions, due to the random assignments of input weights and biases. By introducing the ensemble strategy of negative correlation learning into ELM, the NCLELM algorithm allows explicitly increasing the diversity among the base ELM models and, thus, enhancing the prediction accuracy and reliability.
- (2)
- A multi-learner pseudo-labeling optimization (MLPLO) approach is proposed to achieve pseudo-label estimation. Differently from traditional self-labeling techniques such as self-training and co-training, the MLPLO method attempts to build an explicit optimization problem with the unknown labels of the unlabeled data as the decision variables. Meanwhile, by exploring the inherent connections between labeled and unlabeled data, the individual and collaborative prediction performance of multiple learners are defined and integrated as the optimization objective. Then, an evolutionary optimization approach is adopted to solve the formulated pseudo-labeling optimization problem (PLOP), so as to obtain high-confidence pseudo-labeled samples for expanding the labeled set. A significant advantage of MLPLO is its strong capability for avoiding the error propagation and accumulation found with commonly used iterative learning.
- (3)
- By effectively combining a MLPLO strategy with ensemble modeling, the proposed EnSSNCLELM soft sensor method allows achieving the complementary advantages of semi-supervised and ensemble learning. On the one hand, semi-supervised learning is helpful for enhancing the accuracy and diversity of ensemble members by providing different high-confidence pseudo-labeled sets. On the other hand, combining multiple semi-supervised models using ensemble methods makes it possible to fully utilize the information of unlabeled data and reduce the modeling uncertainty caused by sub-optimal parameter settings and data selection.
2. Preliminaries
2.1. Extreme Learning Machine
2.2. Negative Correlation Learning
3. Proposed NCLELM and EnSSNCLELM Soft Sensor Methods
3.1. NCLELM
3.2. EnSSNCLELM
3.2.1. Formulating the Pseudo-Labeling Optimization Problem
- (1)
- Individual accuracy using the pseudo-labeled data. It is well known that successful data-driven modeling greatly relies on the assumption that modeling data are independent and identically distributed. That is to say, good prediction performance on unseen samples can be attained only when the test and training data come from the same distribution. This assumption usually applies to developing data-based models for industrial processes. Thus, in the context of semi-supervised modeling, we assume that the labeled and unlabeled data are drawn from the same distribution. Intuitively, this implies that a NCLELM model trained with the pseudo-labeled data can also provide accurate predictions on the labeled set, if the pseudo labels are estimated well enough. Specifically, suppose denote the diverse NCLELM models learned from the pseudo-labeled subsets , respectively. It is obvious that we expect the performance of on to be good if the acquired has high quality. Furthermore, by considering all individual accuracies simultaneously, the overall accuracy is minimized:where represents the predicted label of the labeled sample using , and is the jth actual label.
- (2)
- Individual accuracy improvement after including the pseudo-labeled data. In many self-labeling semi-supervised learning algorithms [48,49,50], the pseudo labels are usually estimated from the already built predictive models. Then, the confidence of these pseudo-labeled data is evaluated according to the prediction accuracy enhancement of the model after adding the target pseudo-labeled data to the original training set. The larger the performance improvement, the higher the confidence of the pseudo-labeled data. Similarly, we also employ this way to evaluate the confidence of the optimized pseudo labels. Suppose are the NCLELM models learned from , respectively. Then, it is desirable to minimize the prediction errors of on the labeled training set:where is the predicted label of the labeled sample using .
- (3)
- Smoothness of labeled and pseudo-labeled data. The objective functions in Equations (18) and (19) focus on evaluating the characteristics of pseudo-labeled subsets, but do not consider the overall confidence of all pseudo labels. According to the smoothness assumption [16,17], similar inputs will lead to similar outputs. Obviously, this assumption should also hold true for the mixed data of labeled and pseudo-labeled data, if we can obtain high-confidence pseudo labels. A popular approach using this idea, is introducing a regularization term to the cost function in semi-supervised learning, e.g., semi-supervised ELM [29] and semi-supervised deep learning [33]. In this way, the information behind the unlabeled data can be utilized in model training, to avoid overfitting. Thus, in our proposed MLPLO approach, we introduce Laplace regularization to ensure the smoothness of the labeled and pseudo-labeled data during the optimization process. After mixing the labeled samples and pseudo-labeled samples , a graph based regularization term, called smoothness objective, is defined and expected to be minimized:where denotes the outputs of the labeled and pseudo-labeled sets, i.e., ], and represents a graph Laplace matrix with dimensions, which can be calculated from . is a diagonal matrix with the elements determined as follows:where represents the connection weight between two nodes and in the graph model. Usually, can be calculated by
- (4)
- Ensemble accuracy of multiple learners using the pseudo-labeled data. In addition to the smoothness objective, the collaborative confidence evaluation can also be achieved through the ensemble prediction performance of NCLELM models . Thus, we expect to minimize the ensemble prediction errors of on the labeled training set:where is the ensemble prediction output of the labeled sample. By ensuring the ensemble prediction accuracy, the confidence of the pseudo labels can be further improved. It should be noted that, although many strategies can be used for achieving this combination, the simple averaging rule was chosen because complex schemes are likely to cause overfitting [71].
3.2.2. Solving the Pseudo-Labeling Optimization Problem
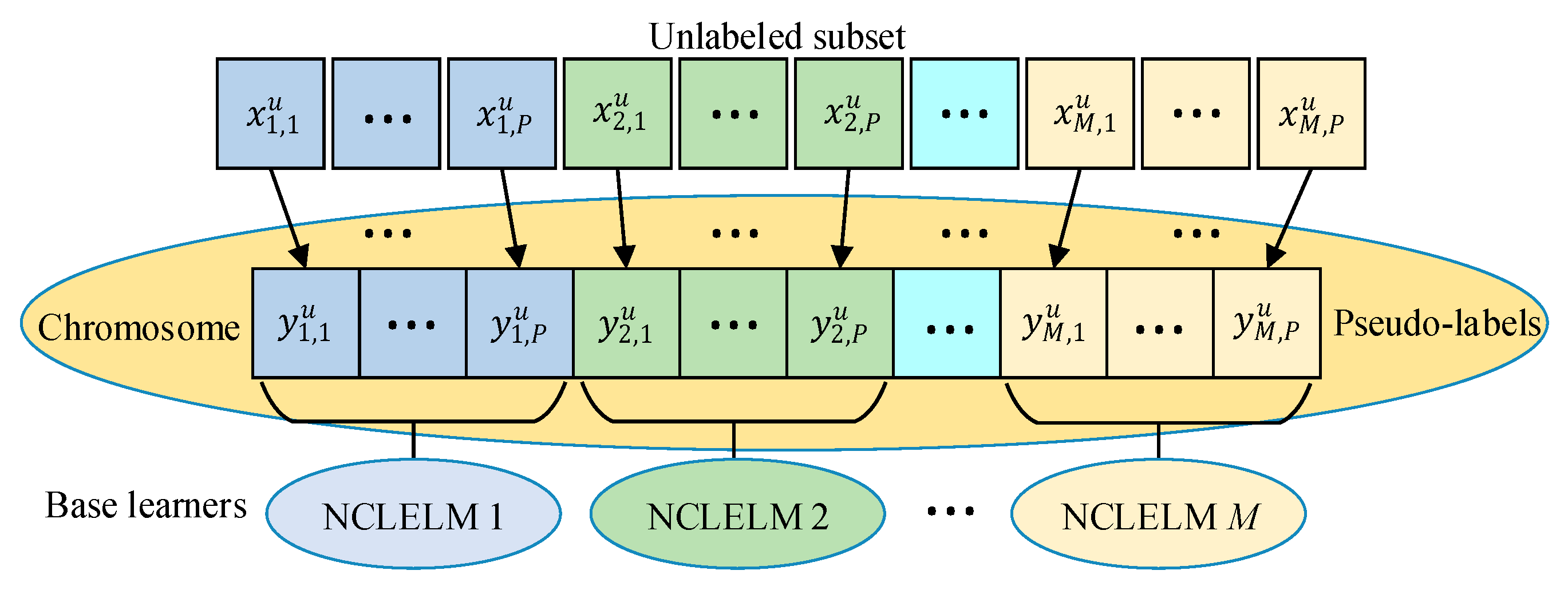
3.2.3. Building Diverse SSNCLEM Base Models
3.2.4. Combining Diverse SSNCLEM Base Models
3.2.5. Implementation Procedure of the EnSSNCLELM Soft Sensor
| Algorithm 1 EnSSNCLELM soft sensor method. |
| INPUT: : labeled set |
| : unlabeled set |
| : validation set |
| : population size for GA optimization |
| : maximum number of iterations |
| : trade-off parameters |
| {}: the number of ELM in each NCLELM, the number of hidden node size of ELM base models, the tradeoff parameter of NCLELM method, respectively |
| : the number of unlabeled data that requires pseudo labeling |
| : the number of NCLELM models for the MLPLO approach |
| PROCESS: |
| 1: Generate diverse combinations of parameters for the MLPLO optimization, where , , and ; |
| %% Building diverse SSNCLELM models |
| 2: for to do |
| %% Estimating the pseudo labels through the MLPLO approach |
| 3: Generate new initial NCLELM models with the hyperparameters by randomly setting the input weights and biases; |
| 4: Select a small-scale unlabeled set by randomly resampling from ; |
| 5: Determine the pseudo labels of as the decision variables with and set the lower and upper bounds for based on GPR regression analysis; |
| 6: Encode the decision variables as real-valued chromosome , and randomly generate an initial population with individuals within the decision boundary; |
| 7: Repeat times: |
| 8: Decode the pseudo labels of from each individual chromosome in the population; |
| 9: Evaluate the fitness of each individual in according to Equation (24); |
| 10: Generate an offspring population by performing selection, crossover, and mutation operations; |
| mutation operations; |
| 11: end of Repeat |
| 12: Select the best individual from the final population; |
| 13: Obtain the best pseudo labels by decoding the chromosome and form the pseudo-labeled set ; |
| %% Building diverse SSNCLELM models for each run |
| 14: Update the initial models using the optimized enlarged labeled set to obtain the semi-supervised models ; |
| 15: end of for |
| %% Ensemble pruning based on performance improvement evaluation |
| 16: Let ; |
| 17: for to do |
| 18: for to do |
| 19: .evaluate(); |
| 20: ; |
| 21: if ; |
| 22: Add to the selected model pool ; |
| 23: end of if |
| 24: end of for |
| 25: end of for |
| 26: Let ; |
| %% Constructing PLS stacking ensemble model |
| 27: Let ; |
| 28: ; |
| 29: Let ; |
| 30: , where is the regression coefficient of PLS; |
| %% Online prediction |
| 31: Given a query sample ; |
| 32: ; |
| 33: The final prediction output of are obtained by Equation (30). |
| OUTPUT: |
4. Case Studies
4.1. Application to Penicillin Fermentation Process
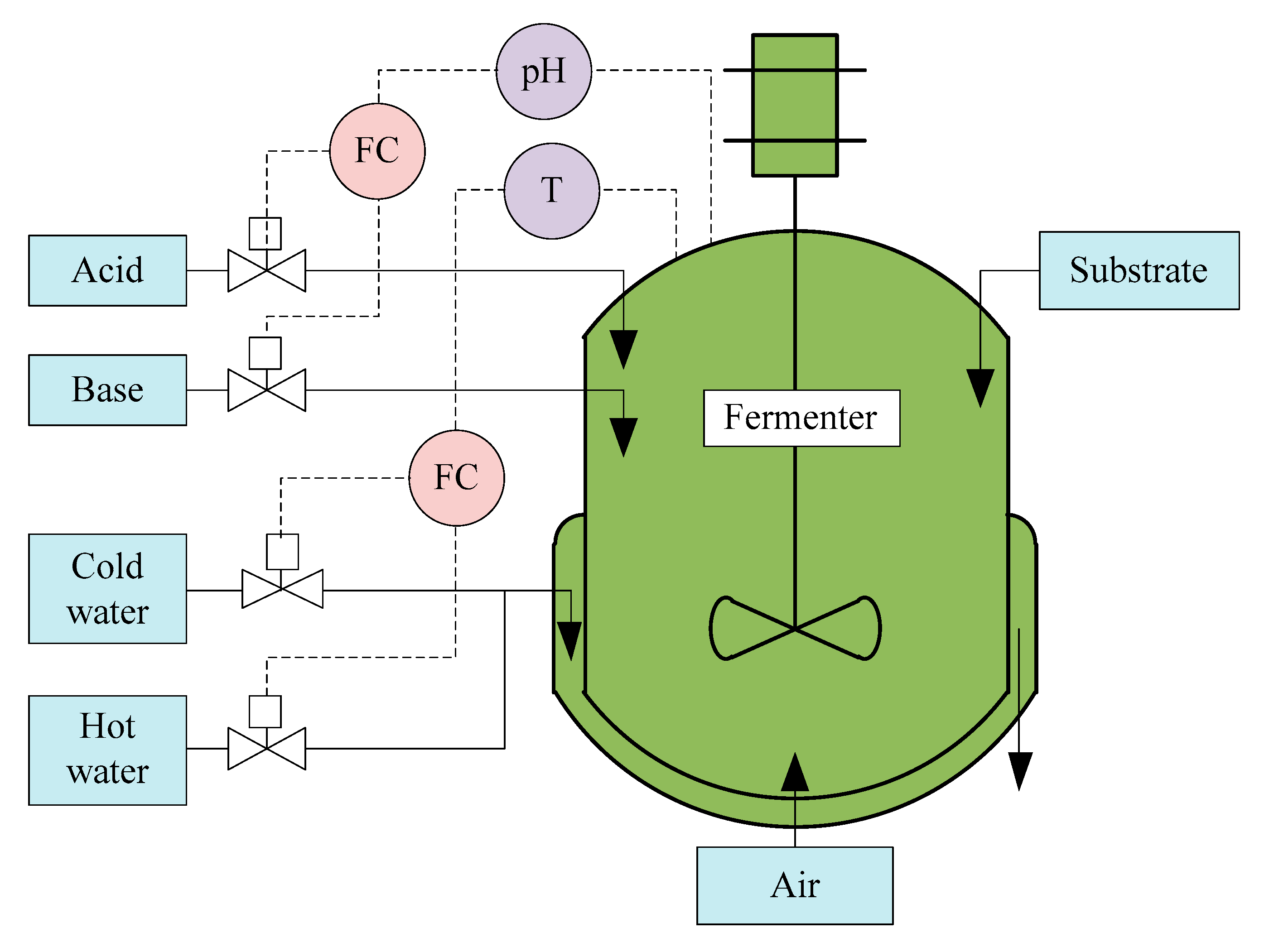
4.1.1. Process Description
4.1.2. Prediction Performance and Discussion of NCLELM
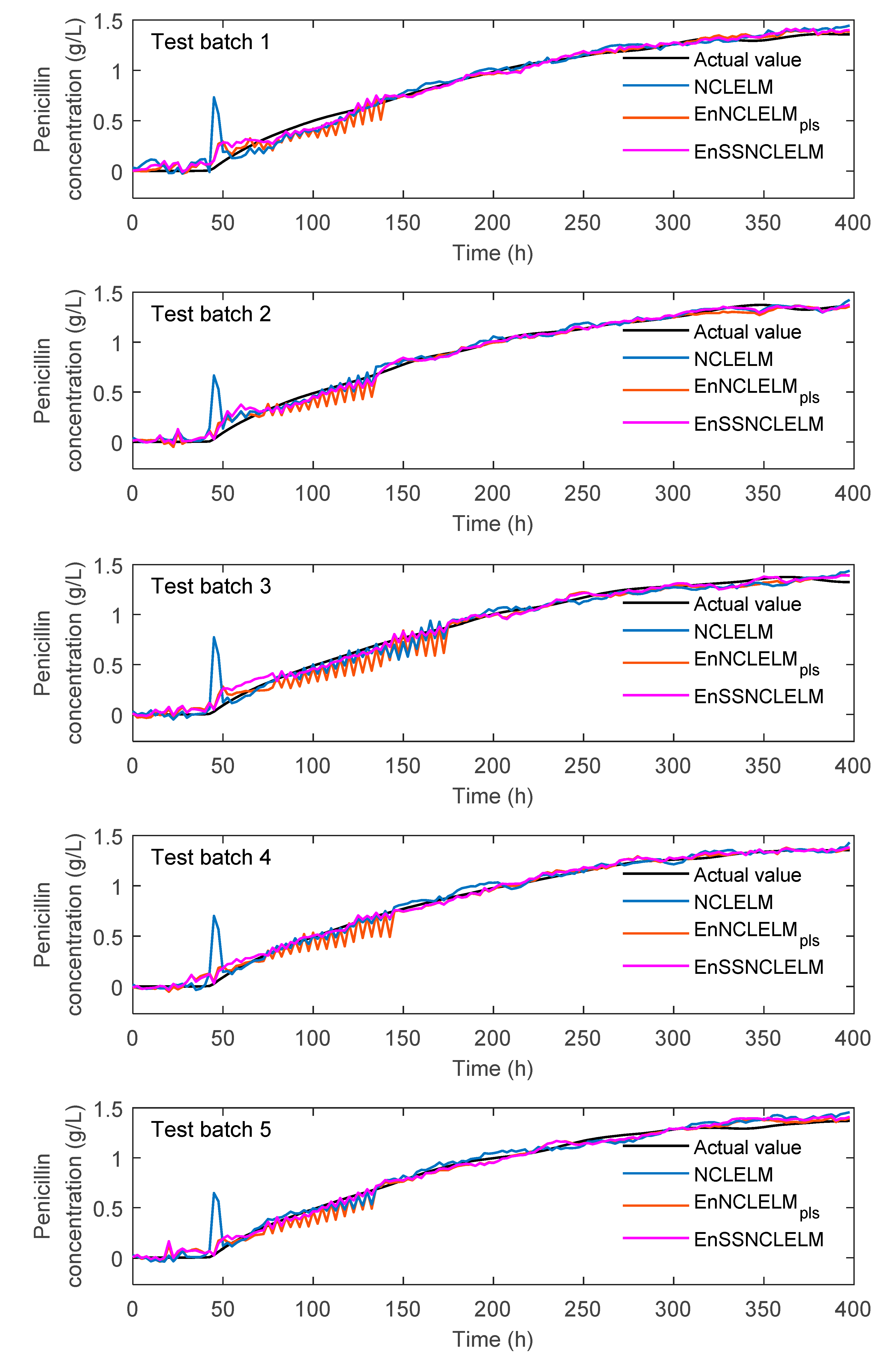
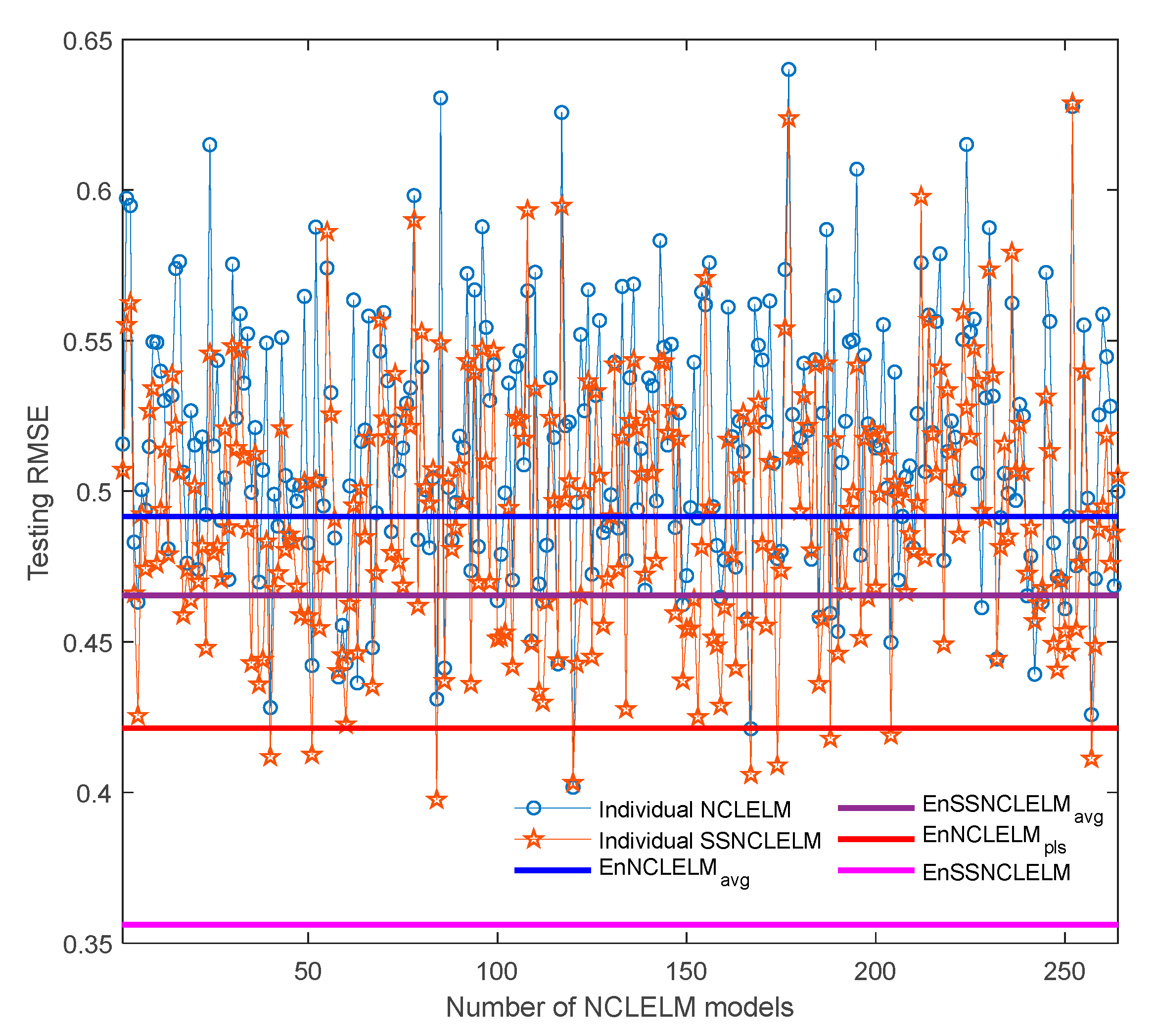
4.1.3. Analysis and Comparison of EnSSNCLELM Prediction Results
4.2. Application to an Industrial Chlortetracycline Fermentation Process
4.2.1. Process Description
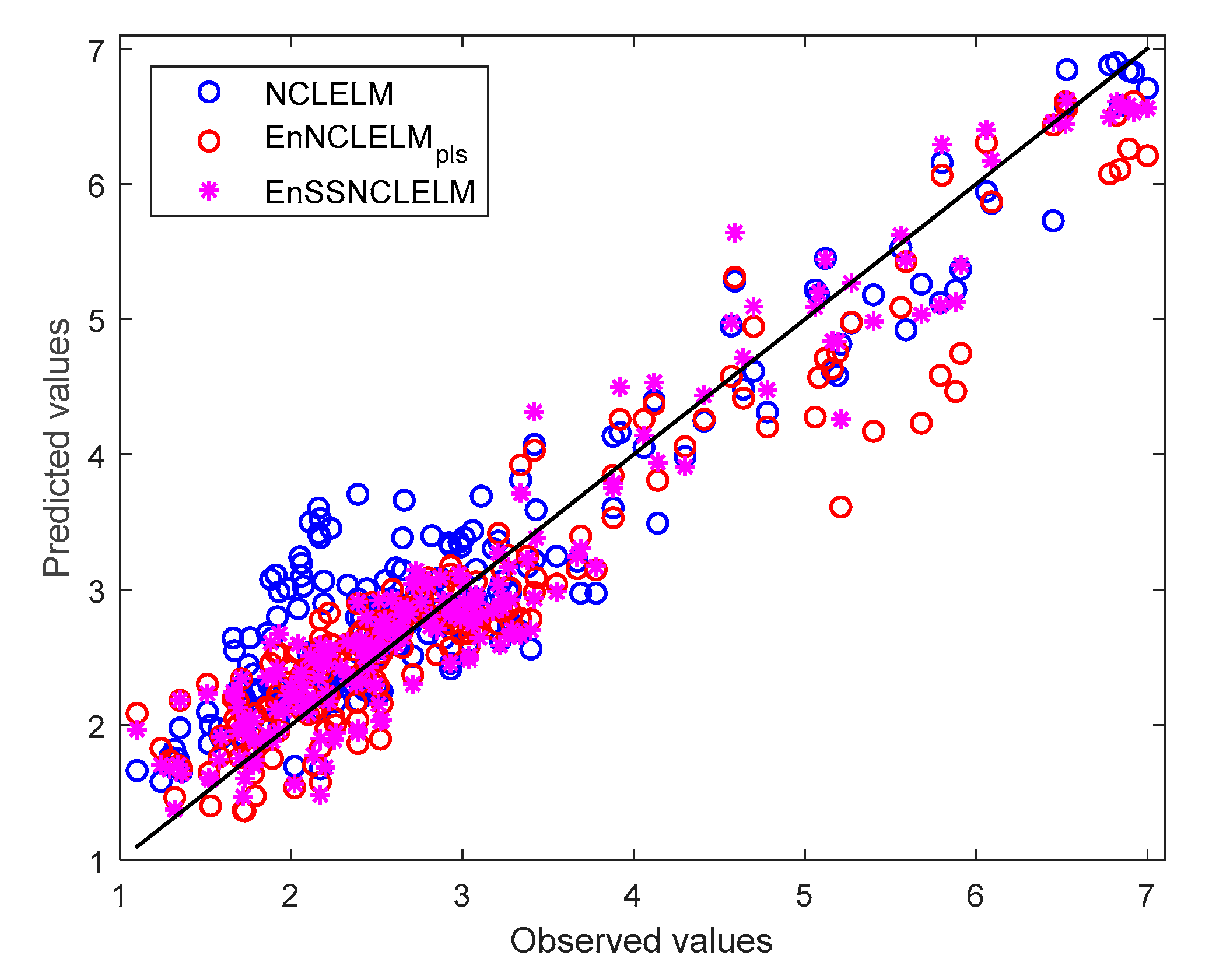
4.2.2. Analysis and Comparison of Prediction Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Weber, R.; Brosilow, C. The use of secondary measurements to improve control. AIChE J. 1972, 18, 614–623. [Google Scholar] [CrossRef]
- Fortuna, L.; Graziani, S.; Rizzo, A.; Xibilia, M.G. Soft Sensors for Monitoring and Control of Industrial Processes; Springer Science & Business Media: Berlin, Germany, 2007. [Google Scholar]
- Kadlec, P.; Gabrys, B.; Strandt, S. Data-driven Soft Sensors in the process industry. Comput. Chem. Eng. 2009, 33, 795–814. [Google Scholar] [CrossRef] [Green Version]
- Ge, Z.; Song, Z.; Gao, F. Review of Recent Research on Data-Based Process Monitoring. Ind. Eng. Chem. Res. 2013, 52, 3543–3562. [Google Scholar] [CrossRef]
- Yin, S.; Li, X.; Gao, H.; Kaynak, O. Data-Based Techniques Focused on Modern Industry: An Overview. IEEE Trans. Ind. Electron. 2015, 62, 657–667. [Google Scholar] [CrossRef]
- Ge, Z. Review on data-driven modeling and monitoring for plant-wide industrial processes. Chemom. Intell. Lab. Syst. 2017, 171, 16–25. [Google Scholar] [CrossRef]
- Qin, S.J.; Chiang, L.H. Advances and opportunities in machine learning for process data analytics. Comput. Chem. Eng. 2019, 126, 465–473. [Google Scholar] [CrossRef]
- Liu, Y.; Xie, M. Rebooting data-driven soft-sensors in process industries: A review of kernel methods. J. Process Control 2020, 89, 58–73. [Google Scholar] [CrossRef]
- Zhu, Q.-X.; Zhang, X.-H.; He, Y.-L. Novel Virtual Sample Generation Based on Locally Linear Embedding for Optimizing the Small Sample Problem: Case of Soft Sensor Applications. Ind. Eng. Chem. Res. 2020, 59, 17977–17986. [Google Scholar] [CrossRef]
- He, Y.-L.; Hua, Q.; Zhu, Q.-X.; Lu, S. Enhanced virtual sample generation based on manifold features: Applications to developing soft sensor using small data. ISA Trans. 2021, in press. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, C.; Liu, K.; Chen, B.; Yao, Y. Domain adaptation transfer learning soft sensor for product quality prediction. Chemom. Intell. Lab. Syst. 2019, 192, 103813. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, C.; Zhang, M.; Dai, Y.; Yao, Y. Development of Adversarial Transfer Learning Soft Sensor for Multi-Grade Processes. Ind. Eng. Chem. Res. 2020, 59, 16330–16345. [Google Scholar] [CrossRef]
- Lyu, Y.; Chen, J.; Song, Z. Synthesizing labeled data to enhance soft sensor performance in data-scarce regions. Control Eng. Pract. 2021, 115, 104903. [Google Scholar] [CrossRef]
- Ge, Z. Active learning strategy for smart soft sensor development under a small number of labeled data samples. J. Process Control 2014, 24, 1454–1461. [Google Scholar] [CrossRef]
- Tang, Q.; Li, D.; Xi, Y. A new active learning strategy for soft sensor modeling based on feature reconstruction and uncertainty evaluation. Chemom. Intell. Lab. Syst. 2018, 172, 43–51. [Google Scholar] [CrossRef]
- Zhu, X.; Goldberg, A.B. Introduction to semi-supervised learning. Synth. Lect. Artif. Intell. Mach. Learn. 2009, 3, 1–130. [Google Scholar] [CrossRef] [Green Version]
- Kostopoulos, G.; Karlos, S.; Kotsiantis, S.; Ragos, O. Semi-supervised regression: A recent review. J. Intell. Fuzzy Syst. 2018, 35, 1483–1500. [Google Scholar] [CrossRef]
- Ge, Z. Semi-supervised data modeling and analytics in the process industry: Current research status and challenges. IFAC J. Syst. Control 2021, 16, 100150. [Google Scholar] [CrossRef]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2019, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]
- Chapelle, O.; Scholkopf, B.; Zien, A. Semi-supervised learning (chapelle, o. et al., eds.; 2006) [book reviews]. IEEE Trans. Neural Netw. 2009, 20, 542. [Google Scholar] [CrossRef]
- Ge, Z.; Song, Z. Semisupervised Bayesian method for soft sensor modeling with unlabeled data samples. AIChE J. 2011, 57, 2109–2119. [Google Scholar] [CrossRef]
- Zheng, J.; Song, Z. Semisupervised learning for probabilistic partial least squares regression model and soft sensor application. J. Process Control 2018, 64, 123–131. [Google Scholar] [CrossRef]
- Sedghi, S.; Sadeghian, A.; Huang, B. Mixture semisupervised probabilistic principal component regression model with missing inputs. Comput. Chem. Eng. 2017, 103, 176–187. [Google Scholar] [CrossRef]
- Shao, W.; Ge, Z.; Song, Z. Soft-Sensor Development for Processes With Multiple Operating Modes Based on Semisupervised Gaussian Mixture Regression. IEEE Trans. Control Syst. Technol. 2019, 27, 2169–2181. [Google Scholar] [CrossRef]
- Shao, W.; Ge, Z.; Song, Z. Quality variable prediction for chemical processes based on semisupervised Dirichlet process mixture of Gaussians. Chem. Eng. Sci. 2019, 193, 394–410. [Google Scholar] [CrossRef]
- Shao, W.; Ge, Z.; Song, Z. Semi-supervised mixture of latent factor analysis models with application to online key variable estimation. Control Eng. Pract. 2019, 84, 32–47. [Google Scholar] [CrossRef]
- Wang, J.; Shao, W.; Zhang, X.; Qian, J.; Song, Z.; Peng, Z. Nonlinear variational Bayesian Student’s-t mixture regression and inferential sensor application with semisupervised data. J. Process Control 2021, 105, 141–159. [Google Scholar] [CrossRef]
- Zhu, X. Learning from Labeled and Unlabeled Data with Label Propagation; Tech Report; Carnegie Mellon University: Pittsburgh, PA, USA, 2002. [Google Scholar]
- Zheng, W.; Gao, X.; Liu, Y.; Wang, L.; Yang, J.; Gao, Z. Industrial Mooney viscosity prediction using fast semi-supervised empirical model. Chemom. Intell. Lab. Syst. 2017, 171, 86–92. [Google Scholar] [CrossRef]
- Zheng, W.; Liu, Y.; Gao, Z.; Yang, J. Just-in-time semi-supervised soft sensor for quality prediction in industrial rubber mixers. Chemom. Intell. Lab. Syst. 2018, 180, 36–41. [Google Scholar] [CrossRef]
- Yan, W.; Guo, P.; Tian, Y.; Gao, J. A Framework and Modeling Method of Data-Driven Soft Sensors Based on Semisupervised Gaussian Regression. Ind. Eng. Chem. Res. 2016, 55, 7394–7401. [Google Scholar] [CrossRef]
- Yao, L.; Ge, Z. Deep Learning of Semisupervised Process Data with Hierarchical Extreme Learning Machine and Soft Sensor Application. IEEE Trans. Ind. Electron. 2017, 65, 1490–1498. [Google Scholar] [CrossRef]
- Yan, W.; Xu, R.; Wang, K.; Di, T.; Jiang, Z. Soft Sensor Modeling Method Based on Semisupervised Deep Learning and Its Application to Wastewater Treatment Plant. Ind. Eng. Chem. Res. 2020, 59, 4589–4601. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT press: Cambridge, MA, USA, 2016. [Google Scholar]
- Shang, C.; Yang, F.; Huang, D.; Lyu, W. Data-driven soft sensor development based on deep learning technique. J. Process Control 2014, 24, 223–233. [Google Scholar] [CrossRef]
- Yan, X.; Wang, J.; Jiang, Q. Deep relevant representation learning for soft sensing. Inf. Sci. 2020, 514, 263–274. [Google Scholar] [CrossRef]
- Yuan, X.; Ou, C.; Wang, Y.; Yang, C.; Gui, W. A novel semi-supervised pre-training strategy for deep networks and its application for quality variable prediction in industrial processes. Chem. Eng. Sci. 2020, 217, 115509. [Google Scholar] [CrossRef]
- Yuan, X.; Ou, C.; Wang, Y.; Yang, C.; Gui, W. Deep quality-related feature extraction for soft sensing modeling: A deep learning approach with hybrid VW-SAE. Neurocomputing 2020, 396, 375–382. [Google Scholar] [CrossRef]
- de Lima, J.M.M.; de Araujo, F.M.U. Ensemble Deep Relevant Learning Framework for Semi-Supervised Soft Sensor Modeling of Industrial Processes. Neurocomputing 2021, 462, 154–168. [Google Scholar] [CrossRef]
- Triguero, I.; García, S.; Herrera, F. Self-labeled techniques for semi-supervised learning: Taxonomy, software and empirical study. Knowl. Inf. Syst. 2015, 42, 245–284. [Google Scholar] [CrossRef]
- Rosenberg, C.; Hebert, M.; Schneiderman, H. Semi-Supervised Self-Training of Object Detection Models. In Proceedings of the 2005 Seventh IEEE Workshops on Applications of Computer Vision (WACV/MOTION’05), Washington, DC, USA, 5–7 January 2005; Volume 1, pp. 29–36. [Google Scholar]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory—COLT’ 98, Association for Computing Machinery, New York, NY, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Zhou, Z.-H.; Li, M. Semi-supervised regression with co-training. In IJCAI; Morgan Kaufmann: Edinburgh, Scotland, 2005; pp. 908–913. [Google Scholar]
- Zhou, Z.-H.; Li, M. Tri-training: Exploiting unlabeled data using three classifiers. IEEE Trans. Knowl. Data Eng. 2005, 17, 1529–1541. [Google Scholar] [CrossRef] [Green Version]
- Gu, S.; Jin, Y. Multi-train: A semi-supervised heterogeneous ensemble classifier. Neurocomputing 2017, 249, 202–211. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Zhou, Z.-H. Improve Computer-Aided Diagnosis With Machine Learning Techniques Using Undiagnosed Samples. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2007, 37, 1088–1098. [Google Scholar] [CrossRef] [Green Version]
- Kang, P.; Kim, D.; Cho, S. Semi-supervised support vector regression based on self-training with label uncertainty: An application to virtual metrology in semiconductor manufacturing. Expert Syst. Appl. 2016, 51, 85–106. [Google Scholar] [CrossRef]
- Bao, L.; Yuan, X.; Ge, Z. Co-training partial least squares model for semi-supervised soft sensor development. Chemom. Intell. Lab. Syst. 2015, 147, 75–85. [Google Scholar] [CrossRef]
- Li, D.; Liu, Y.; Huang, D. Development of semi-supervised multiple-output soft-sensors with Co-training and tri-training MPLS and MRVM. Chemom. Intell. Lab. Syst. 2020, 199, 103970. [Google Scholar] [CrossRef]
- Lv, M.; Li, Y.; Chen, L.; Chen, T. Air quality estimation by exploiting terrain features and multi-view transfer semi-supervised regression. Inf. Sci. 2019, 483, 82–95. [Google Scholar] [CrossRef]
- Liang, Y.; Liu, Z.; Liu, W. A co-training style semi-supervised artificial neural network modeling and its application in thermal conductivity prediction of polymeric composites filled with BN sheets. Energy AI 2021, 4, 100052. [Google Scholar] [CrossRef]
- Kaneko, H.; Funatsu, K. Adaptive soft sensor based on online support vector regression and Bayesian ensemble learning for various states in chemical plants. Chemom. Intell. Lab. Syst. 2014, 137, 57–66. [Google Scholar] [CrossRef] [Green Version]
- Jin, H.; Chen, X.; Wang, L.; Yang, K.; Wu, L. Adaptive Soft Sensor Development Based on Online Ensemble Gaussian Process Regression for Nonlinear Time-Varying Batch Processes. Ind. Eng. Chem. Res. 2015, 54, 7320–7345. [Google Scholar] [CrossRef]
- Liu, Y.; Huang, D.; Liu, B.; Feng, Q.; Cai, B. Adaptive ranking based ensemble learning of Gaussian process regression models for quality-related variable prediction in process industries. Appl. Soft Comput. 2021, 101, 107060. [Google Scholar] [CrossRef]
- Chen, X.; Mao, Z.; Jia, R.; Zhang, S. Ensemble regularized local finite impulse response models and soft sensor application in nonlinear dynamic industrial processes. Appl. Soft Comput. 2019, 85, 105806. [Google Scholar] [CrossRef]
- Zhou, Z.-H. Ensemble Methods: Foundations and Algorithms; Taylor & Francis: Boca Raton, FL, USA, 2012. [Google Scholar]
- Fazakis, N.; Karlos, S.; Kotsiantis, S.; Sgarbas, K. A multi-scheme semi-supervised regression approach. Pattern Recognit. Lett. 2019, 125, 758–765. [Google Scholar] [CrossRef]
- Zhang, M.-L.; Zhou, Z.-H. Exploiting unlabeled data to enhance ensemble diversity. Data Min. Knowl. Discov. 2011, 26, 98–129. [Google Scholar] [CrossRef] [Green Version]
- Sun, Q.; Ge, Z. Deep Learning for Industrial KPI Prediction: When Ensemble Learning Meets Semi-Supervised Data. IEEE Trans. Ind. Inform. 2021, 17, 260–269. [Google Scholar] [CrossRef]
- Shao, W.; Tian, X. Semi-supervised selective ensemble learning based on distance to model for nonlinear soft sensor development. Neurocomputing 2017, 222, 91–104. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, X. Ensemble learning via negative correlation. Neural Netw. 1999, 12, 1399–1404. [Google Scholar] [CrossRef]
- He, Y.-L.; Geng, Z.-Q.; Zhu, Q.-X. Data driven soft sensor development for complex chemical processes using extreme learning machine. Chem. Eng. Res. Des. 2015, 102, 1–11. [Google Scholar] [CrossRef]
- Pan, B.; Jin, H.; Yang, B.; Qian, B.; Zhao, Z. Soft Sensor Development for Nonlinear Industrial Processes Based on Ensemble Just-in-Time Extreme Learning Machine through Triple-Modal Perturbation and Evolutionary Multiobjective Optimization. Ind. Eng. Chem. Res. 2019, 58, 17991–18006. [Google Scholar] [CrossRef]
- Jin, H.; Pan, B.; Chen, X.; Qian, B. Ensemble just-in-time learning framework through evolutionary multi-objective optimization for soft sensor development of nonlinear industrial processes. Chemom. Intell. Lab. Syst. 2019, 184, 153–166. [Google Scholar] [CrossRef]
- Shi, X.; Kang, Q.; An, J.; Zhou, M. Novel L1 Regularized Extreme Learning Machine for Soft-Sensing of an Industrial Process. IEEE Trans. Ind. Inform. 2021, 18, 1009–1017. [Google Scholar] [CrossRef]
- Brown, G.; Wyatt, J.L.; Tino, P.; Bengio, Y. Managing diversity in regression ensembles. J. Mach. Learn. Res. 2005, 6, 1621–1650. [Google Scholar]
- Alhamdoosh, M.; Wang, D. Fast decorrelated neural network ensembles with random weights. Inf. Sci. 2014, 264, 104–117. [Google Scholar] [CrossRef]
- Chen, H.; Jiang, B.; Yao, X. Semisupervised Negative Correlation Learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5366–5379. [Google Scholar] [CrossRef] [PubMed]
- Jin, H.; Li, Z.; Chen, X.; Qian, B.; Yang, B.; Yang, J. Evolutionary optimization based pseudo labeling for semi-supervised soft sensor development of industrial processes. Chem. Eng. Sci. 2021, 237, 116560. [Google Scholar] [CrossRef]
- Zhou, Z.-H.; Wu, J.; Tang, W. Ensembling neural networks: Many could be better than all. Artif. Intell. 2002, 137, 239–263. [Google Scholar] [CrossRef] [Green Version]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning, Print; MIT Press: Cambridge, MA, USA, 2008. [Google Scholar] [CrossRef] [Green Version]
- Bansal, J.C.; Singh, P.K.; Pal, N.R. Evolutionary and Swarm Intelligence Algorithms; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Dasgupta, D.; Michalewicz, Z. Evolutionary Algorithms in Engineering Applications; Springer Science & Business Media: New York, NY, USA, 2013. [Google Scholar]
- Huang, L.; Deng, X.; Bo, Y.; Zhang, Y.; Wang, P. Evolutionary optimization assisted delayed deep cycle reservoir modeling method with its application to ship heave motion prediction. ISA Trans. 2021, in press. [Google Scholar] [CrossRef] [PubMed]
- Ma, M.; Sun, C.; Mao, Z.; Chen, X. Ensemble deep learning with multi-objective optimization for prognosis of rotating machinery. ISA Trans. 2021, 113, 166–174. [Google Scholar] [CrossRef]
- Haidong, S.; Ziyang, D.; Junsheng, C.; Hongkai, J. Intelligent fault diagnosis among different rotating machines using novel stacked transfer auto-encoder optimized by PSO. ISA Trans. 2020, 105, 308–319. [Google Scholar] [CrossRef] [PubMed]
- Jian, J.-R.; Zhan, Z.-H.; Zhang, J. Large-scale evolutionary optimization: A survey and experimental comparative study. Int. J. Mach. Learn. Cybern. 2019, 11, 729–745. [Google Scholar] [CrossRef]
- Shao, W.; Tian, X. Adaptive soft sensor for quality prediction of chemical processes based on selective ensemble of local partial least squares models. Chem. Eng. Res. Des. 2015, 95, 113–132. [Google Scholar] [CrossRef]
- Jin, H.; Shi, L.; Chen, X.; Qian, B.; Yang, B.; Jin, H. Probabilistic wind power forecasting using selective ensemble of finite mixture Gaussian process regression models. Renew. Energy 2021, 174, 1–18. [Google Scholar] [CrossRef]
- Li, Y.-F.; Liang, D.-M. Safe semi-supervised learning: A brief introduction. Front. Comput. Sci. 2019, 13, 669–676. [Google Scholar] [CrossRef]
- Yu, J. Multiway Gaussian Mixture Model Based Adaptive Kernel Partial Least Squares Regression Method for Soft Sensor Estimation and Reliable Quality Prediction of Nonlinear Multiphase Batch Processes. Ind. Eng. Chem. Res. 2012, 51, 13227–13237. [Google Scholar] [CrossRef]
- Jin, H.; Chen, X.; Yang, J.; Zhang, H.; Wang, L.; Wu, L. Multi-model adaptive soft sensor modeling method using local learning and online support vector regression for nonlinear time-variant batch processes. Chem. Eng. Sci. 2015, 131, 282–303. [Google Scholar] [CrossRef]
- Birol, G.; Ündey, C.; Cinar, A. A modular simulation package for fed-batch fermentation: Penicillin production. Comput. Chem. Eng. 2002, 26, 1553–1565. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Variable Description (Unit) |
|---|---|
| 1 | Culture time (h) |
| 2 | Aeration rate (L/h) |
| 3 | Agitator power (W) |
| 4 | Substrate feed rate (L/h) |
| 5 | Substrate feed temperature (K) |
| 6 | Dissolved oxygen concentration (g/L) |
| 7 | Culture volume (L) |
| 8 | Carbon dioxide concentration (g/L) |
| 9 | pH (−) |
| 10 | Fermenter temperature (K) |
| 11 | Generated heat (kcal) |
| 12 | Cooling water flow rate (L/h) |
| Method | RMSE | R2 |
|---|---|---|
| ELM | 0.1044 | 0.9479 |
| NCLELM | 0.0812 | 0.9689 |
| CoELM | 0.0772 | 0.9720 |
| SSELM | 0.1019 | 0.9506 |
| EnNCLELMavg | 0.0778 | 0.9714 |
| EnSSNCLELMavg | 0.0599 | 0.9822 |
| EnNCLELMpls | 0.0627 | 0.9821 |
| EnSSNCLELM | 0.0440 | 0.9908 |
| No. | Variable Description | No. | Variable Description |
|---|---|---|---|
| 1 | Cultivation time (min) | 6 | Volume of air consumption (m3) |
| 2 | Temperature (°C) | 7 | Substrate feed rate (L/h) |
| 3 | pH | 8 | Volume of substrate consumption (L) |
| 4 | Dissolved oxygen concentration (%) | 9 | Volume of ammonia consumption (L) |
| 5 | Air flow rate (m3/h) | 10 | Volume of culture medium (m3) |
| Method | RMSE | R2 |
|---|---|---|
| ELM | 0.5993 | 0.8009 |
| NCLELM | 0.5214 | 0.8527 |
| CoELM | 0.5033 | 0.8614 |
| SSELM | 0.5566 | 0.8303 |
| EnNCLELMavg | 0.4916 | 0.8699 |
| EnSSNCLELMavg | 0.4654 | 0.8834 |
| EnNCLELMpls | 0.4214 | 0.9044 |
| EnSSNCLELM | 0.3561 | 0.9317 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Jin, H.; Dong, S.; Yang, B.; Chen, X. Pseudo-Labeling Optimization Based Ensemble Semi-Supervised Soft Sensor in the Process Industry. Sensors 2021, 21, 8471. https://doi.org/10.3390/s21248471
Li Y, Jin H, Dong S, Yang B, Chen X. Pseudo-Labeling Optimization Based Ensemble Semi-Supervised Soft Sensor in the Process Industry. Sensors. 2021; 21(24):8471. https://doi.org/10.3390/s21248471
Chicago/Turabian StyleLi, Youwei, Huaiping Jin, Shoulong Dong, Biao Yang, and Xiangguang Chen. 2021. "Pseudo-Labeling Optimization Based Ensemble Semi-Supervised Soft Sensor in the Process Industry" Sensors 21, no. 24: 8471. https://doi.org/10.3390/s21248471
APA StyleLi, Y., Jin, H., Dong, S., Yang, B., & Chen, X. (2021). Pseudo-Labeling Optimization Based Ensemble Semi-Supervised Soft Sensor in the Process Industry. Sensors, 21(24), 8471. https://doi.org/10.3390/s21248471