
Conservative Quantization of Covariance Matrices with Applications to Decentralized Information Fusion †


1
Intelligent Sensor-Actuator-Systems Laboratory (ISAS), Institute of Anthropomatics and Robotics (IAR), Karlsruhe Institute of Technology (KIT), 76131 Karlsruhe, Germany
2
Autonomous Multisensor Systems Group (AMS), Institute for Intelligent Cooperating Systems (ICS), Otto von Guericke University Magdeburg (OVGU), 39106 Magdeburg, Germany
*
Author to whom correspondence should be addressed.
†
This paper is an extended version of our paper published in Funk, C.; Noack, B.; Hanebeck, U.D. Conservative Quantization of Fast Covariance Intersection. In proceedings of the 2020 IEEE International Conference on Multisensor Fusion and Integration (MFI 2020), Karlsruhe, Germany, 14–16 September 2020.
Sensors 2021, 21(9), 3059; https://doi.org/10.3390/s21093059
Submission received: 25 March 2021
/
Revised: 21 April 2021
/
Accepted: 22 April 2021
/
Published: 28 April 2021
(This article belongs to the Special Issue Multisensor Fusion and Integration)
{kind=link}
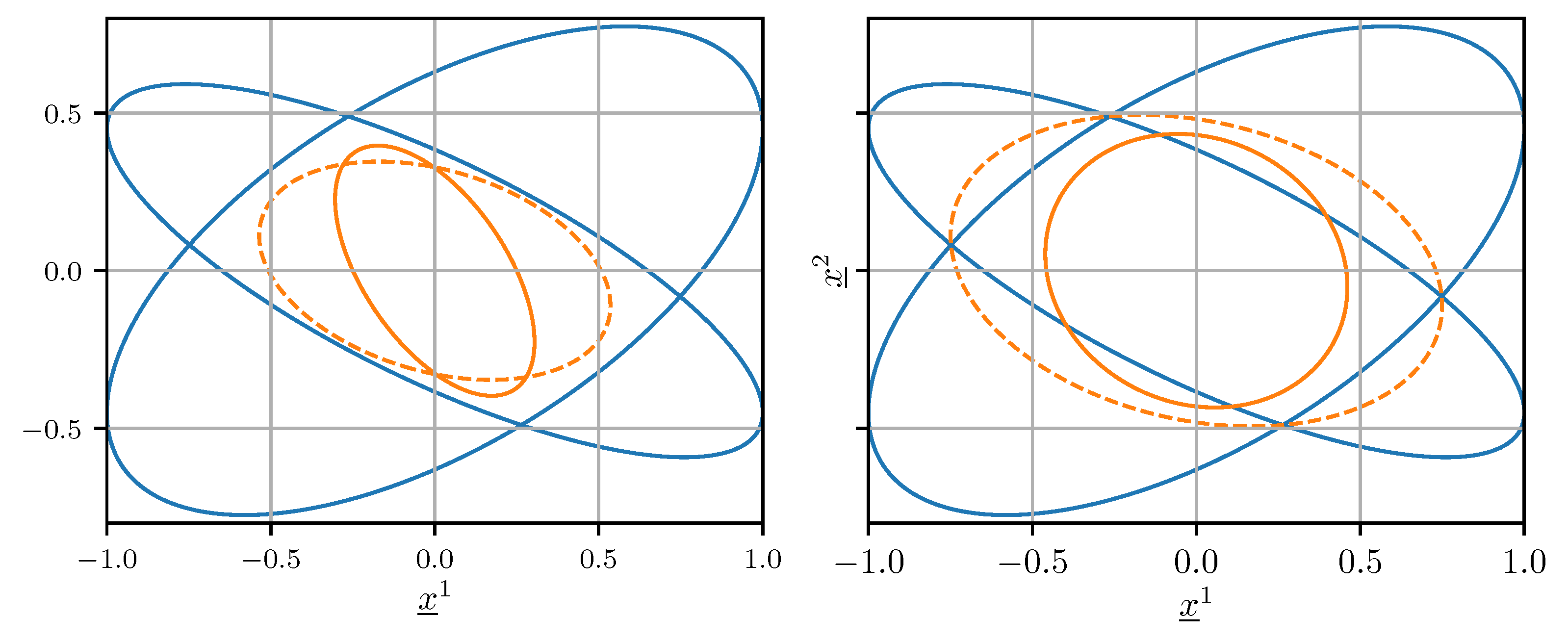{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Information fusion in networked systems poses challenges with respect to both theory and implementation. Limited available bandwidth can become a bottleneck when high-dimensional estimates and associated error covariance matrices need to be transmitted. Compression of estimates and covariance matrices can endanger desirable properties like unbiasedness and may lead to unreliable fusion results. In this work, quantization methods for estimates and covariance matrices are presented and their usage with the optimal fusion formulas and covariance intersection is demonstrated. The proposed quantization methods significantly reduce the bandwidth required for data transmission while retaining unbiasedness and conservativeness of the considered fusion methods. Their performance is evaluated using simulations, showing their effectiveness even in the case of substantial data reduction.
1. Introduction
Interconnected sensor systems can gather more data, are more robust to faults and outliers, and can cover larger regions than a single sensor system. Such networked systems can also benefit from heterogeneous sensing modalities and parameterizations. Typical examples are wireless sensor networks which are used, for instance, in environmental monitoring [1,2,3], building automation [4,5], or moving object tracking [6,7]. A single node in a wireless sensor network often has limited energy, processing, and storage resources, and the wireless transmission of data is the most energy-intensive operation performed by the node while processing sensor data exhibits relatively low energy demands [8]. Even for networked systems that do not use wireless data transmission or that have sufficient energy resources, communication can be a limiting factor when nodes need to transmit large-scale estimates, which may occur in cooperative map building [9], cooperative localization [10,11], or multi-object tracking [12].
From the accruing sensor data, the interconnected devices can compute state estimates locally, e.g., by employing Kalman filter methods. Such estimates are typically supplied with error covariance matrices, which need to be transmitted and stored alongside the estimates, to be able to assess their uncertainty and combine them reliably. Therefore, reducing the amount of transmitted data through prior compression is key to meeting bandwidth limitations when high-dimensional state estimates are exchanged and to ensure long operating times of battery-driven sensor nodes when wireless data transmission is used. A comprehensive survey of lossless and lossy compression methods that are suitable for wireless sensor networks is given in [13]. The surveyed methods include multiple probabilistic quantization-based approaches [14,15,16,17] tailored to estimation problems. However, only scalar estimates are considered and their respective variances are assumed to be known to the receiver. Quantization as a means of data reduction has also been applied to Kalman filtering, a prominent example being the sign of innovations Kalman filter [18,19]. Again, the required covariance matrices are assumed to be known to the receiver. In contrast to the previous works, it is assumed in [20] that the receiver has no prior knowledge of the covariance matrices, which therefore need to be transmitted via the network. The authors develop data reduction methods for covariance matrices based on conservative diagonal approximations and, in [21], they investigate techniques to select subsets of the information to be transmitted. These methods assess how the selected information contributes to the receiver’s estimation quality.
In this paper, similarly to [20], we assume that the receiver has no knowledge about the covariance matrix at the transmitter. Hence, the sender has to prepare both its estimate and covariance matrix for transmission. In general, the covariance matrix will not be diagonal and dominates the amount of data that needs to be transmitted as its number of elements grows quadratically with the dimension of the estimate. The individual quantization of each coefficient constitutes a promising approach to reduce the data. However, such a quantized covariance matrix, in general, does not reliably account for the uncertainty of the estimate and can even violate the positive definiteness of the covariance matrix. For this reason, we study and compare two different approaches to compute a quantized covariance matrix that conservatively bounds the actual error covariance matrix. The first scheme employs a quantization based on diagonal dominance while the second scheme relies on a modified Cholesky decomposition. To further compress the data to be transmitted, we also investigate a quantization of the estimates. As typical fusion algorithms rely on unbiasedness, we employ a quantizer that preserves this property. The proposed quantization schemes yield conservative estimates that reliably assess the estimation error and can be further processed at the receiver.
At the receiver, the estimates are typically fed to a fusion algorithm to combine them with other estimates and to improve the estimation accuracy. Fusion algorithms that strive to minimize the error of the fusion result need access to the covariance matrices of the input estimates. Optimal fusion algorithms [22,23] can be designed if cross-correlations between the estimates are also known. They typically require the transmission of additional information [24] or specific communication strategies [25,26]. In the case where correlations are unknown, conservative fusion algorithms compute a bound on the actual but unknown error covariance matrix of the fusion results. Examples of such algorithms are covariance intersection (CI) [27], fast covariance intersection (FCI) [28,29], and inverse covariance intersection (ICI) [30,31], which are guaranteed to produce results with a conservative uncertainty quantification in the form of a covariance matrix. Other algorithms such as ellipsoidal intersection (EI) [32,33] provide no such guarantee but are typically less conservative. In this paper, we study how the proposed quantization schemes integrate with fusion algorithms and consider both optimal fusion and covariance intersection.
This paper is an extended version of [34], which proposed a quantization technique for covariance intersection. Here, we study the use of quantization in a broader sense to cover different fusion algorithms, and we propose an additional quantization scheme for covariance matrices that provides tighter bounds at the expense of higher computational demand. In total, this paper’s contributions address three different aspects:
- Covariance Quantization. We propose two approaches to the conservative quantization of covariance matrices. The first scheme uses diagonal dominance [34]. As an alternative, we study a modified Cholesky decomposition and compare it to the first approach.
- Fusion of Estimates. We apply the quantization schemes to both an optimal fusion algorithm and covariance intersection in order to demonstrate that reliable estimates are attained.
Implementations of the proposed quantization schemes, written in Python, are provided as supplementary material, the link to which can be found at the end of the paper.
2. Notation
Lower case letters denote scalar quantities and additional underlining indicates n-dimensional vector-valued quantities. The standard basis vectors of are and denotes the n-dimensional zero vector. Bold uppercase letters indicate -matrices such as . The ith coefficient of a vector and the th coefficient of a matrix are and , respectively. In addition, index ranges such as , , and are used to extract subvectors and submatrices. As an example, is the subvector containing the ith to the jth coefficient of and are the first i coefficients of the jth column of . The use of boldface as in and indicates random scalars and random vectors, respectively. Uppercase calligraphic letters indicate sets. In particular, is used to denote the set of symmetric matrices in and to denote the set of symmetric positive semi-definite (PSD) matrices in . For and , the notation signifies that . If then is called an upper bound for . For (conditional) expectations the symbols and are used. The unconditional covariance between two random quantities is designated by or by if the arguments are identical. Similarly, the conditional covariance is denoted by or .
3. Considered Problem
The process of quantization approximates a continuous quantity using a discrete one. In this work, we consider the quantization of covariance matrices and estimates with the goal of reducing the bandwidth and storage requirements on an interconnected sensor system. We demonstrate how optimal fusion and covariance intersection can be applied to quantized data while retaining some of their desirable properties.
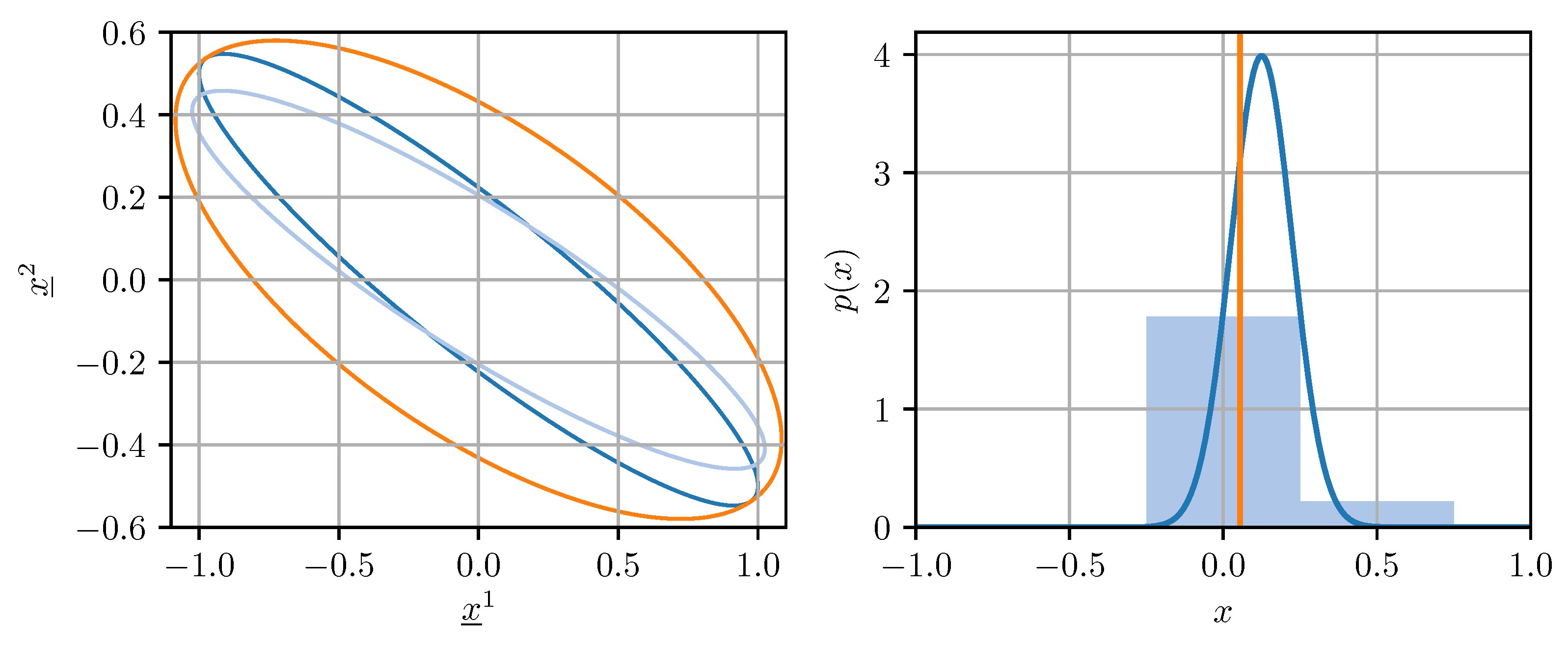
For our purposes, a quantizer is a map , where the domain is a closed, coefficient-wise bounded subset of either or , and the codomain , the so-called codebook, is a finite set. Quantizing covariance matrices for use in fusion methods is not straightforward. Naive coefficient-wise quantization of a covariance matrix can lead to a result that underestimates the uncertainty encoded in the original covariance matrix, or even worse, is not a valid covariance matrix anymore. This can cause divergence in certain estimation algorithms [27]. Ideally, the quantized covariance matrix should be an upper bound on a conservative estimate of the original matrix in the sense that holds. This averts divergence and guarantees that the confidence ellipsoid induced by contains the one induced by [27]. The described situation is illustrated on the left side of Figure 1. Conservative quantization of covariance matrices can be achieved by enforcing certain conditions on the quantization error, as will be discussed in Section 4.
Similarly to quantizing covariance matrices, quantizing estimates for use in fusion methods creates certain challenges. Deterministic quantization of an estimate can introduce bias and additional noise, which (1) biases the results obtained from fusion methods and (2) invalidates the covariance matrix associated with the estimate. This is visualized on the right side of Figure 1. Both of the aforementioned issues can be addressed by using randomized quantizers, which will be discussed in Section 5 in the context of applying fusion methods to quantized data.
4. Conservative Quantization of Covariance Matrices
In the following, conservative quantizers for covariance matrices, i.e., symmetric positive semi-definite (PSD) matrices, are derived. To that end, let be a quantizer that maps PSD matrices from an coefficient-wise bounded and closed set to a finite codebook . The quantizer should satisfy the condition
to ensure that the quantized matrix is an upper bound on the original matrix . With the quantization error defined as , this can also be expressed as
In other words, the quantization error must always be PSD for the quantized matrix to be an upper bound on the original matrix. Ideally, the quantizer should not only produce conservative results but should also minimize the total quantization error . This requires enumerating all elements in in the worst case and is thus not computationally feasible, even for relatively small matrices. Practical quantizers will therefore not be able to minimize the total quantization error exactly. To remain computationally tractable, the quantizers considered in this work operate in two steps: First, the off-diagonal coefficients are individually rounded to the nearest codeword in some off-diagonal codebook . Then, the diagonal coefficients are individually rounded up to a codeword in some diagonal codebook so as to make the quantization error PSD.
4.1. Covariance Quantization Based on Diagonal Dominance
The rounding method for diagonal coefficients considered in this section is based on the notion of diagonal dominance. Diagonal dominance is a simple sufficient condition for a symmetric matrix, such as the quantization error matrix , to be PSD. A symmetric matrix is said to be diagonally dominant if
holds for each row . The connection between diagonal dominance and positive semi-definiteness is obtained immediately by applying the Gershgorin circle theorem [36] to a diagonally dominant matrix to lower bound its eigenvalues.
Theorem 1.
Let be diagonally dominant, then holds.
The approach to conservative quantization of a PSD matrix pursued here is to first quantize the off-diagonal coefficients of using a codebook and to then quantize the diagonal coefficients using a codebook such that (3) is satisfied for the quantization error . This leads to the quantizer
where rounds to the nearest codeword in the off-diagonal codebook and rounds up to the nearest codeword in the diagonal codebook . The codebooks are
where is the maximum off-diagonal codeword, and , are quantization resolutions, with b the number of bits per codeword. This choice enables the following theorem regarding well definedness.
Theorem 2.
The quantizer proposed above is well defined if the coefficients of all matrices are contained in the interval .
Proof.
The quantization error of an off-diagonal coefficient is at most. Therefore
holds for all diagonal coefficients. Since the right hand side equals , rounding up the perturbed diagonal coefficients is always possible, and the claim holds. □
When not stated otherwise, the above conditions for well defined are implicitly assumed to hold. The next theorem confirms that the output of is indeed an upper bound for its input.
Theorem 3.
The quantizer proposed above has PSD quantization error for all and is thus conservative, that is, holds for all .
Proof.
In the following, we omit the dependence of on for brevity. The off-diagonal quantization errors are and the diagonal ones are
By the definition of we have
and the claim follows from Theorem 1. □
Furthermore, the quantizer introduced above is optimal in the sense that, given codebooks , there is no quantizer with symmetric diagonally dominant quantization error that has a smaller total quantization error .
Theorem 4.
Let be defined by (4) with coefficient-wise codebooks and defined by (5) and (6). Given , the quantization error is the minimizer of
where the dependency of on has been omitted for brevity.
Proof.
The problem can be reformulated as a nested minimization, the inner one
being over the diagonal coefficients given the off-diagonal coefficients and the outer one
being over the off-diagonal coefficients given the solutions of the inner optimization. Furthermore, the inner minimization can be split into decoupled minimizations
for . By definition of the operation
are the optimal solutions to these subproblems. They exist because is well defined. The minimum cost of each decoupled problem is thus
which is non-decreasing in each . Using this intermediate result, the outer minimization problem can be seen to attain its minimum by separately minimizing the , as due to the non-decreasing property, is minimal if each is minimal. Thus, the minimum is, by definition of , attained by setting . □
Although the above quantizer minimizes the conservativeness of the quantized matrix in the sense of Theorem 4, the inequalities (3) are only sufficient and not necessary for the quantization error to be PSD. Hence, the results of this method are usually more conservative than necessary. The proposed quantizer has a low computational complexity of because the matrix coefficients are quantized individually.
4.2. Covariance Quantization Based on Modified Cholesky Decomposition
The covariance matrix quantization approach presented in the previous section is computationally efficient but can be overly conservative. An alternative quantizer that is guaranteed to be less conservative at the cost of increased computational expense is presented in this section. The basic approach of first quantizing the off-diagonal coefficients and then finding quantized diagonal coefficients that make the overall quantization result conservative is retained. However, instead of employing diagonal dominance to find the quantized diagonal coefficients, a modified Cholesky factorization adopted from [37] is leveraged. We motivate the proposed method by first introducing the Cholesky decomposition in conjunction with a result relating its existence to positive semi-definiteness [36] (Corollary 7.2.9).
Theorem 5.
Let be a symmetric matrix and a permutation matrix (Permutation matrices are orthogonal matrices that arise by permuting the rows and columns of an identity matrix. Matrix multiplication with a permutation matrix permutes either the rows or the columns of the other matrix, depending on the order of multiplication). Then there is a lower triangular matrix with nonnegative diagonal coefficients such that
holds if and only if is positive semi-definite. The above factorization is called a (pivoted) Cholesky decomposition of with Cholesky factor .
Should not be PSD, a so-called modified Cholesky decomposition can be performed to find a diagonal nonnegative matrix such that a Cholesky decomposition exists [37,38,39]. In the following, the basic recursive approach to simultaneously compute the matrices , , and is introduced, based on the exposition in [37]. The recursion begins by setting . The computations
are then performed for . Each is a permutation matrix swapping two rows and columns such that with determined according to some criterion. For now we will assume so that . The are nonnegative perturbations applied to the kth diagonal coefficient of . The vector is selected to cancel the kth row and column of . This is achieved by letting
and results in the upper-most/left-most rows and columns of being zero. For the recursion to terminate successfully, must either be such that is positive or such that is zero. This is always possible, as can be arbitrarily large. Unraveling the recursion up to and using the fact that gives
This can be written in the more condensed form
by introducing , with , and
It can be shown that is a permutation matrix, is lower triangular with nonnegative diagonal coefficients, and has its diagonal populated with the and is otherwise zero. Hence, (16) is a Cholesky decomposition of and according to Theorem 5, must be positive semi-definite. Note that the above recursion can be computed in-place essentially like an ordinary Cholesky decomposition (see for instance [40] (Algorithm 4.2.2)), the main differences being the diagonal shifts and allowing .
We will now describe how the above approach can be applied to finding quantized diagonal coefficients that make the overall quantization result conservative. For that, first quantize each off-diagonal coefficient of the given PSD matrix by rounding it to the nearest codeword in (see Section 4.1) resulting in the preliminary quantized matrix and preliminary quantization error
Note that in the remainder of this section we will omit the dependence of and on for brevity. Since the diagonal elements of are zero, cannot be PSD unless it is zero, as can be easily verified. Then the modified Cholesky decomposition of is computed, giving a diagonal matrix such that holds. Adding to and rounding the diagonal coefficients up to the nearest codeword in (see Section 4.1) then gives the final quantization result
Assume for the moment that the quantizer defined above is well-defined, i.e., that there always are codewords in that the perturbed diagonal elements can be rounded up to. In that case, the following theorem applies.
Theorem 6.
The quantizer as defined above is conservative.
Proof.
Due to the modified Cholesky decomposition, it holds that . By rounding the diagonal of up, we get where is diagonal and nonnegative and thus . Therefore, or equivalently holds. □
So far, the diagonal perturbations have been assumed to be almost arbitrary. In order to guarantee that the quantizer is well-defined, we adopt the specific choice
described in [37]. This has several advantageous implications as can be seen from Theorem 7 [37] (Theorem 5.1.2) and the subsequent corollaries.
Theorem 7.
If is chosen as in (20) to compute the modified Cholesky decomposition of some , then is positive semi-definite (it can be rank-deficient) and the upper bound
holds for . The result is valid, provided each swaps the kth row and column only with some subsequent row and column.
Applying the above theorem to the quantizer proposed in this section, it is evident that with the given choice of , the diagonal perturbations are always smaller than or equal to the maximum perturbation required by the quantization approach from Section 4.1. Inspecting the proof in [37], it can indeed be deduced that every is smaller than or equal to its corresponding perturbation (after permutation using the ) in the diagonal dominance based approach.
Corollary 1.
The quantizer proposed in this section is well defined if the coefficients of all matrices in are in the interval .
Proof.
By applying Theorem 7 to , it follows that holds for . Comparing to (4), can be seen to be smaller than the maximum amount added to diagonal coefficients by the quantizer from Section 4.1. Hence, following the same argument as for Theorem 2 and using the bound on , the claim follows. □
Corollary 2.
The quantizer proposed in this section has lower or identical total quantization error compared to the quantizer from Section 4.1.
Proof.
By the discussion above, the diagonal perturbations are smaller than or equal to those used by the quantizer based on diagonal dominance. This translates into a reduced absolute deviation from the original diagonal elements, also after rounding up. The off-diagonal quantization errors are identical. Hence, the total quantization error is less than or equal to that of the quantizer based on diagonal dominance. □
The final ingredient in the above quantization approach is the choice of the permutation matrices which, up to now, have been assumed to be identity matrices. We adopt the choice of proposed in [37], which greatly improved performance in our experiments. Each matrix is chosen in order to swap two rows and columns such that with where is a recursively computed vector initialized at using
and recursively updated for each according to
after choosing the respective and . These changes do not affect the theoretical results, as they only pertain to the strategy of choosing . We do not take into account the remaining modifications proposed in [37], as they do not seem to improve performance in our case. Due to the modified Cholesky decomposition, the quantizer introduced in this section has computational complexity of , compared to the complexity of the quantizer from Section 4.1.
5. Applications to Information Fusion
The goal of any fusion algorithm is to combine estimates and of the same random quantity to obtain an, in some sense, improved estimate of . Typically, the estimates and are provided in conjunction with error covariance matrix estimates and and the fusion method uses them to compute an error covariance estimate for the fused estimate .
In the following, two fusion methods from the literature that are unbiased () and conservative () under certain conditions, are introduced and their application with quantized error covariance matrices and estimate vectors is considered. In that context, a quantizer for unbiased estimate vectors is derived, that retains their unbiasedness and provides a conservative estimate of the error covariance matrix of the quantization result. Finally, it is demonstrated how the covariance quantization methods from Section 4 can be applied in conjunction with the unbiased estimate quantizer to retain unbiasedness and conservativeness of the fusion methods.
5.1. Optimal Fusion and Covariance Intersection
In the following, let and be unbiased estimates of some random vector and let
be their joint error covariance matrix. The fused estimate and its associated estimated error covariance matrix will be denoted by and , respectively. Note that need not necessarily be identical to the actual error covariance matrix . In case the cross-covariance is known, the optimal fusion result in the BLUE (best linear unbiased estimator) sense is given by the Bar-Shalom–Campo formulas [22]
The estimated error covariance matrix computed using the Bar-Shalom–Campo formulas is exact, i.e., holds [22]. The cross-covariance required by (25) and (26) can be tracked, e.g., using samples [41] to encode the cross-correlations or by a square-root decomposition [24] of the noise covariance matrices. Both approaches require additional data to be transmitted. If the error covariance matrices and are not known, but upper bounds and are available, applying (25) and (26) using the estimates yields a conservative error covariance matrix estimate [42].
In the common case where the cross-covariance is unknown but not negligible, setting in (25) and (26) generally does not produce a conservative error covariance matrix estimate, i.e., . This means that the confidence ellipsoid induced by does not contain the confidence ellipsoid induced by for any . An example of this behavior is illustrated on the left side of Figure 2.
The covariance intersection (CI) algorithm, originally devised by Julier and Uhlmann [27], enables the conservative and unbiased fusion of the estimates and , regardless of their generally unknown cross-covariance, as long as conservative error covariance matrix estimates and are available. The CI algorithm itself is defined by
where any gives an unbiased estimate and an upper bound on its error covariance matrix . The weight is determined numerically by minimizing either the trace or the determinant of . The right side of Figure 2 shows that using CI, the confidence ellipsoid induced by contains the one induced by .
5.2. Unbiased Conservative Quantization of Estimates
Applying the Bar-Shalom–Campo formulas (25) and (26) and the covariance intersection Equations (27) and (28) to quantized estimate vectors requires some consideration as naively quantizing the unbiased estimate vectors and does not retain their unbiasedness which in turn leads to biased fused estimates . Moreover, quantizing estimate vectors increases their error covariance matrices, which has to be accounted for in order to retain conservativeness of the fusion algorithms. To address these issues we derive a randomized quantizer for unbiased estimate vectors that produces unbiased quantized estimate vectors and provides an upper bound on their error covariance matrices.
We begin by introducing a randomized quantizer with and satisfying , , that has the desired unbiasedness property. The quantizer was proposed for estimating quantization in a different but equivalent form in [15] (see also [35,43]) and is defined by
where is an estimate of a random variable , rounds to the nearest codeword in , and is independently uniformly distributed in the closed interval . The quantizer therefore consists of rounding combined with additive dither [44]. The codebook is given by , where is the maximum codeword, is the increment between adjacent codewords, and b is the number of bits required to represent a codeword. The assumption guarantees a quantization error bounded by . It is shown in [15] that satisfies
that is, it does not add bias and provides an upper bound on the quantization result’s variance. Undesirably, the upper bound is on the variance , not the error variance and the two quantities coincide only when is deterministic.
We propose a randomized quantizer for coefficient-wise bounded estimate vectors of some random vector that is an coefficient-wise version of the one given by (29) [34]. Its domain and codebook are the Cartesian products and . The quantization process can thus be described by
where now denotes coefficient-wise rounding and has independent coefficients uniformly distributed in the closed interval . As an immediate consequence of (30) applied coefficient-wise to , we have the following corollary.
Corollary 3.
Let be as in (31) and , then holds.
Due to rounding and dither, the quantized estimate’s error contains additional noise compared to the original estimate’s error . Consequently, the known error covariance matrix of the original estimate must be adapted to reflect the increased uncertainty. In general, computing the exact covariance matrix of is infeasible without knowledge of the distribution (if the distribution of was known, the approach in [45] could be used to approximate arbitrarily well) of . Therefore, a conservative upper bound for in a similar vein as (30), is determined.
Theorem 8.
Let be as in (31) and let be an estimate of a random vector , then holds.
Proof.
The estimation error covariance matrix after quantization can be expanded into
by adding and subtracting . The cross-terms can be shown to be zero by using the definition of , unbiasedness, and the tower rule to obtain
Due to being unbiased (also conditionally), holds. Since and are independent, we have . Applying these equations to the inner expectation of (32) shows that
as claimed. As is known, it only remains to bound . Since is (conditionally) unbiased and has independent coefficients,
follows for , which by the tower rule and unbiasedness results in
for . Furthermore, it holds that and thus for . Combined, this means that . The claimed upper bound then follows immediately. □
The upper bound given above is fast to compute and does not require any knowledge of the distribution of either or , at the cost of being overly conservative, particularly if a component of is concentrated between two codewords or for large .
5.3. Quantized Optimal Fusion and Covariance Intersection
We are now in the position to formulate a process that allows to apply the Bar-Shalom–Campo formulas or covariance intersection to quantized estimates and covariance matrices while retaining unbiasedness and conservativeness of said fusion methods. The proposed approach is as follows:
- Quantize the estimates and so that the quantization results remain unbiased. Account for the potential increase in uncertainty due to the quantization process. Both goals are achieved by employing the unbiased, conservative estimate quantizer introduced in the previous subsection.
- Quantize the error covariance matrices of the quantized estimates conservatively. This is done using either the quantizer from Section 4.1 or the one from Section 4.2.
- Apply the Bar-Shalom–Campo formulas or covariance intersection to the quantized estimates and quantized error covariance matrices. Since the quantized estimates are unbiased and the quantized error covariance matrices are conservative the fusion result will also be unbiased and conservative.
In the following, the above process using CI in conjunction with either the diagonal dominance (DD)-based quantizer from Section 4.1 or the modified Cholesky (MC) decomposition-based quantizer from Section 4.2 will be referred to as DD-CI and MC-CI, respectively. The methods obtained by replacing CI with the optimal (OPT) fusion formulas in the DD-CI and MC-CI methods will be referred to as DD-OPT and MC-OPT.
6. Results and Discussion
The total quantization errors of the proposed covariance matrix quantizers are evaluated using randomly selected covariance matrices. In addition, the performance of DD-CI/OPT and MC-CI/OPT relative to CI/optimal fusion is evaluated by applying the methods to randomly generated data. Finally, the DD-CI and MC-CI approaches are evaluated in a decentralized 2D target tracking scenario.
6.1. Evaluation of the Covariance Quantizers
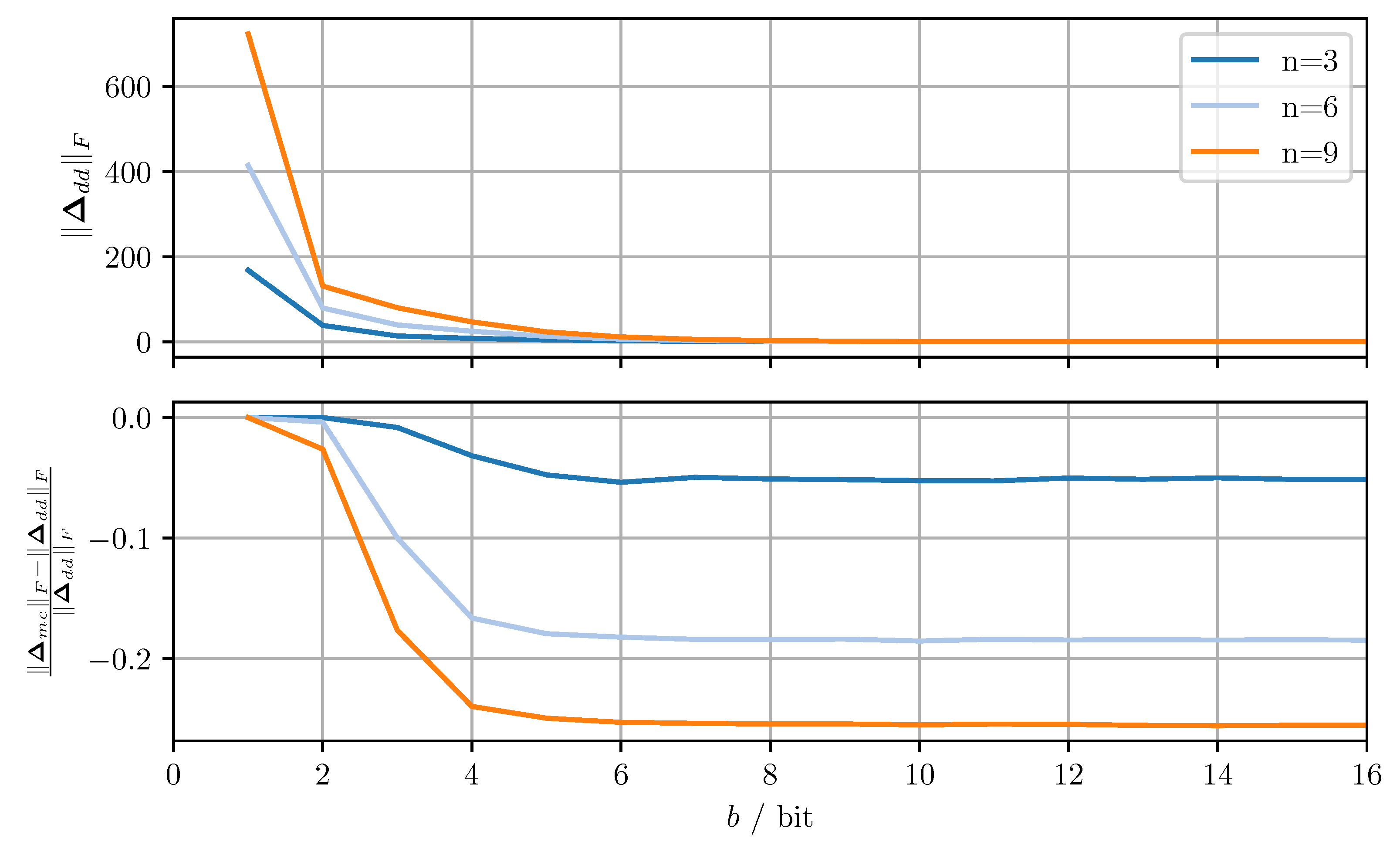
The two proposed covariance matrix quantizers are applied to independent random covariance matrices. The random matrices are generated as where has zero-mean, normally distributed elements with variance one. The Frobenius norms of the resulting quantization error matrices are averaged over all samples. Figure 3 shows the averaged Frobenius norm of the diagonal dominance based quantizer and the relative improvement in average norm achieved by the modified Cholesky decomposition based quantizer for varying numbers of bits per codeword b and matrix dimensions n. For the codebooks, was used and 10,000 samples were included in each average.
The quantization error increases monotonically as b decreases with larger n leading to stronger deterioration of performance. The dependency on b is a result of the quantization resolution decreasing exponentially for decreasing b. The dependency on n is due to the fact that for increasing n the quantization error per element remains roughly the same, whereas the number of matrix elements increases quadratically. Therefore the off-diagonal quantization error increases for increasing n. The shift applied to the diagonal elements to ensure conservativeness must then grow larger with increasing n, thereby increasing the diagonal quantization error. The relative improvement in average norm can be seen to be approximately constant over b, the notable exception being where there is little to no improvement. This behavior can be understood by considering the limiting case of . In said case, each element of the quantized matrix is either zero or the maximum codeword of the respective codebook. Since the off-diagonal elements are identical in both approaches and the diagonal elements are always rounded up, the quantized matrix and thus the quantization error are identical in both approaches.
6.2. Evaluation of Quantized Optimal Fusion and Quantized Covariance Intersection
The test data for this evaluation are generated by first drawing a zero mean Gaussian random vector with covariance matrix . This vector represents the ground truth. Then, a random vector is drawn from a zero mean Gaussian distribution with covariance matrix , where has zero mean Gaussian elements with variance one. Finally, two correlated estimates and of are computed. Optimal fusion, covariance intersection and their quantized versions are applied to the estimates and using their known conditional (cross-)covariance matrices
The mean squared errors , where is the fused estimate with f indicating the fusion approach, are computed by repeatedly generating test data, applying the fusion approaches, and averaging the squared Euclidean norm of the resulting estimate errors. The mean traces of the error covariance estimates , where f indicates the fusion approach, are also computed using averaging. If any quantization operation fails for any of the test data, the computed MSE and averaged trace are discarded.
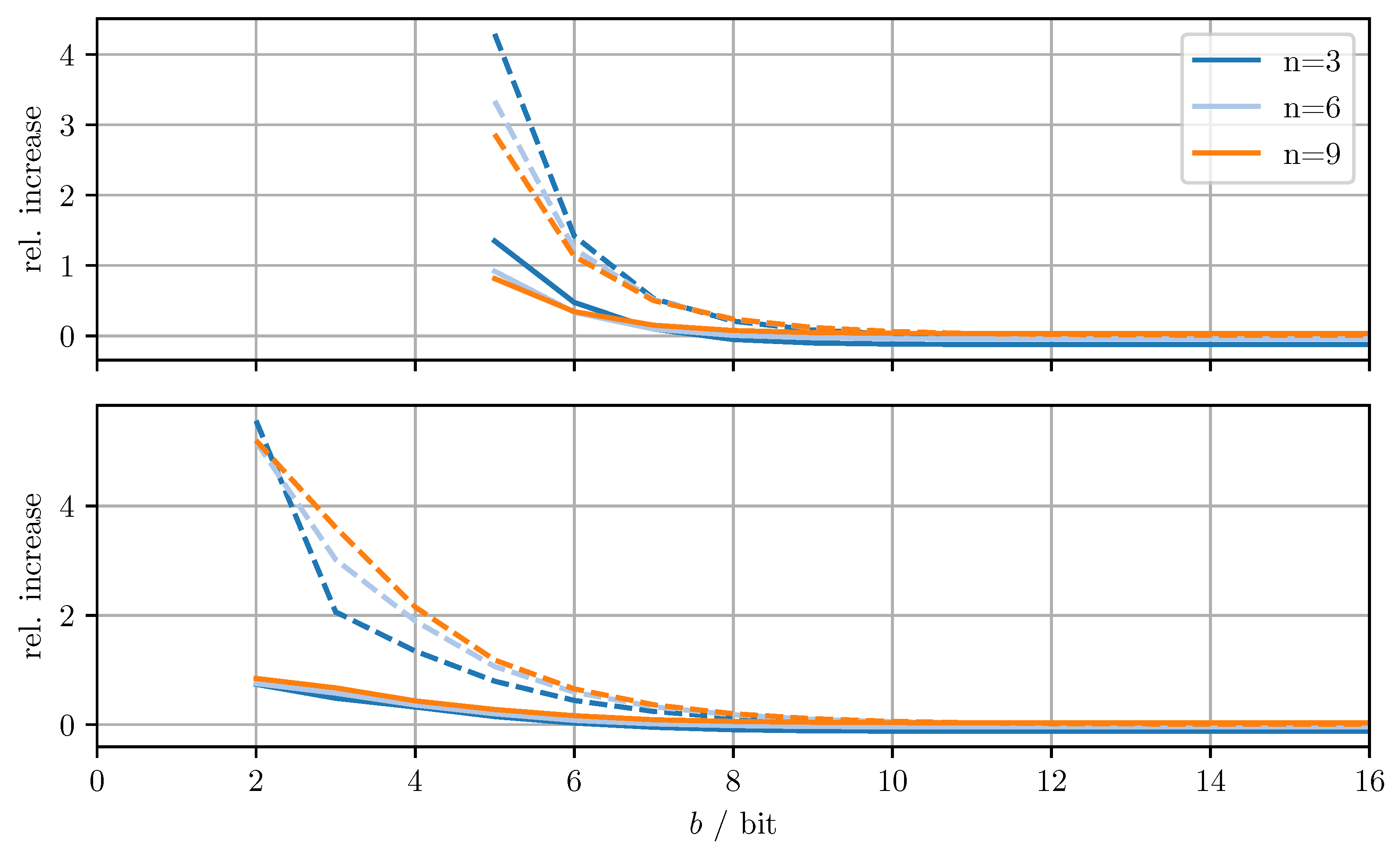
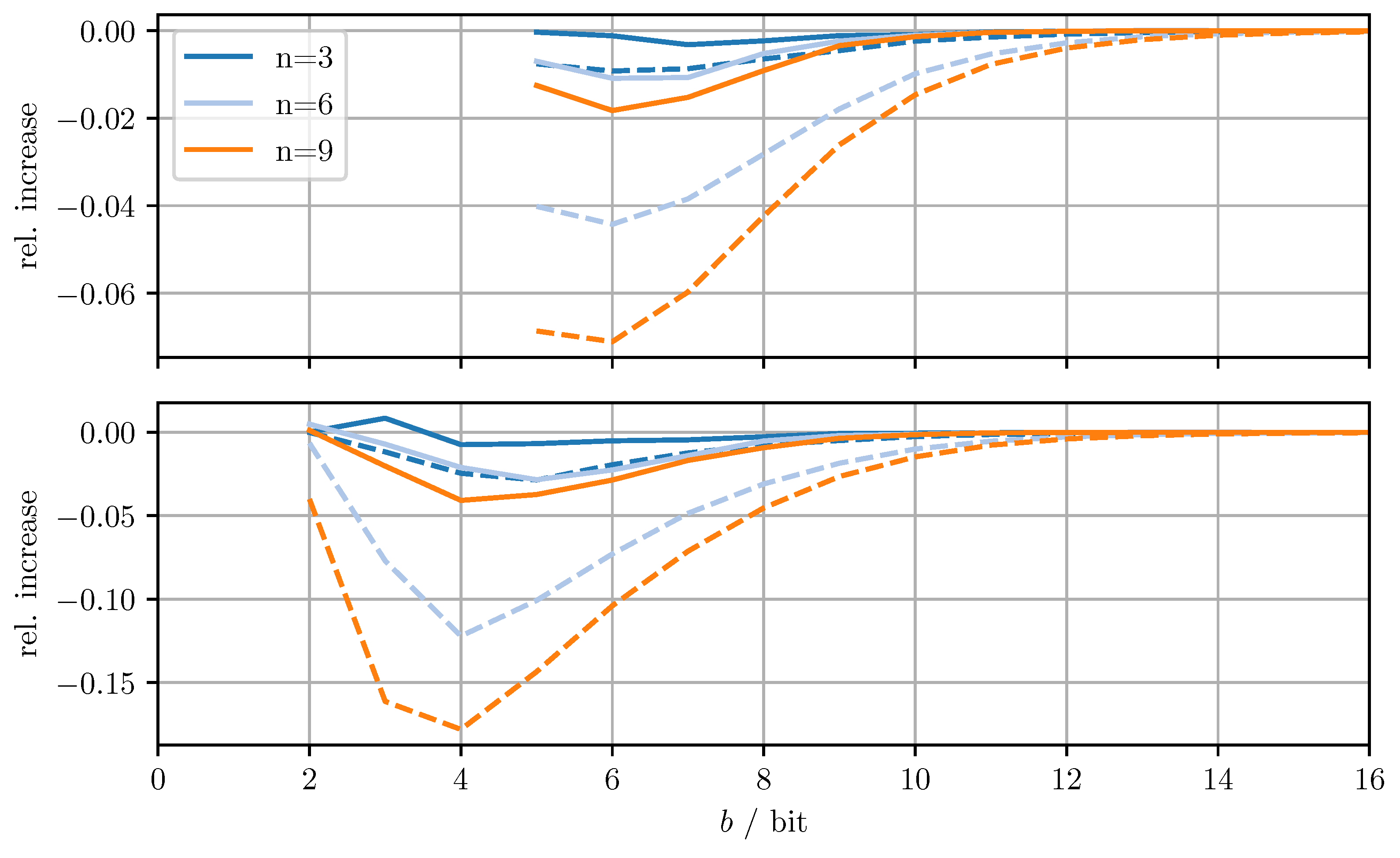
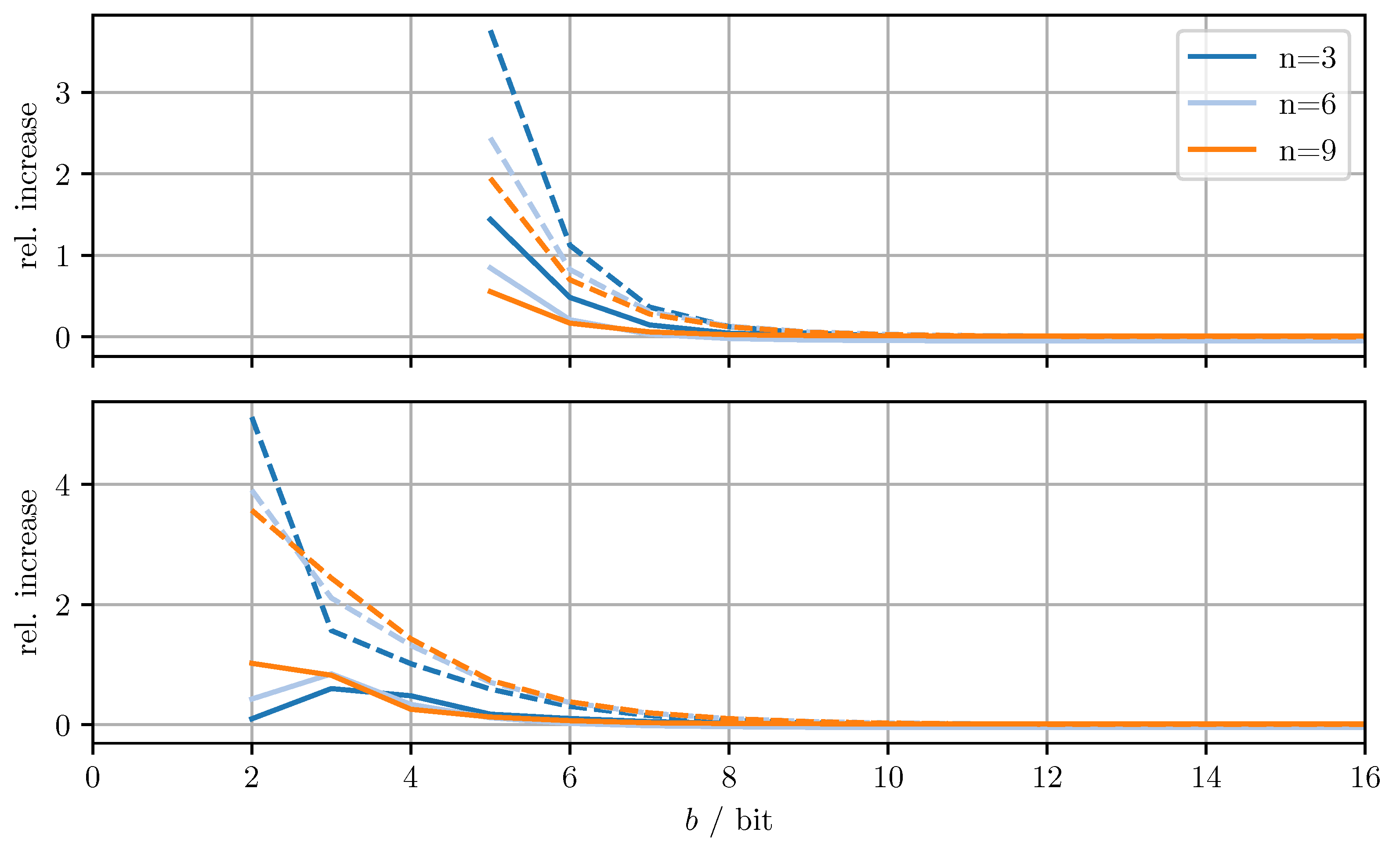
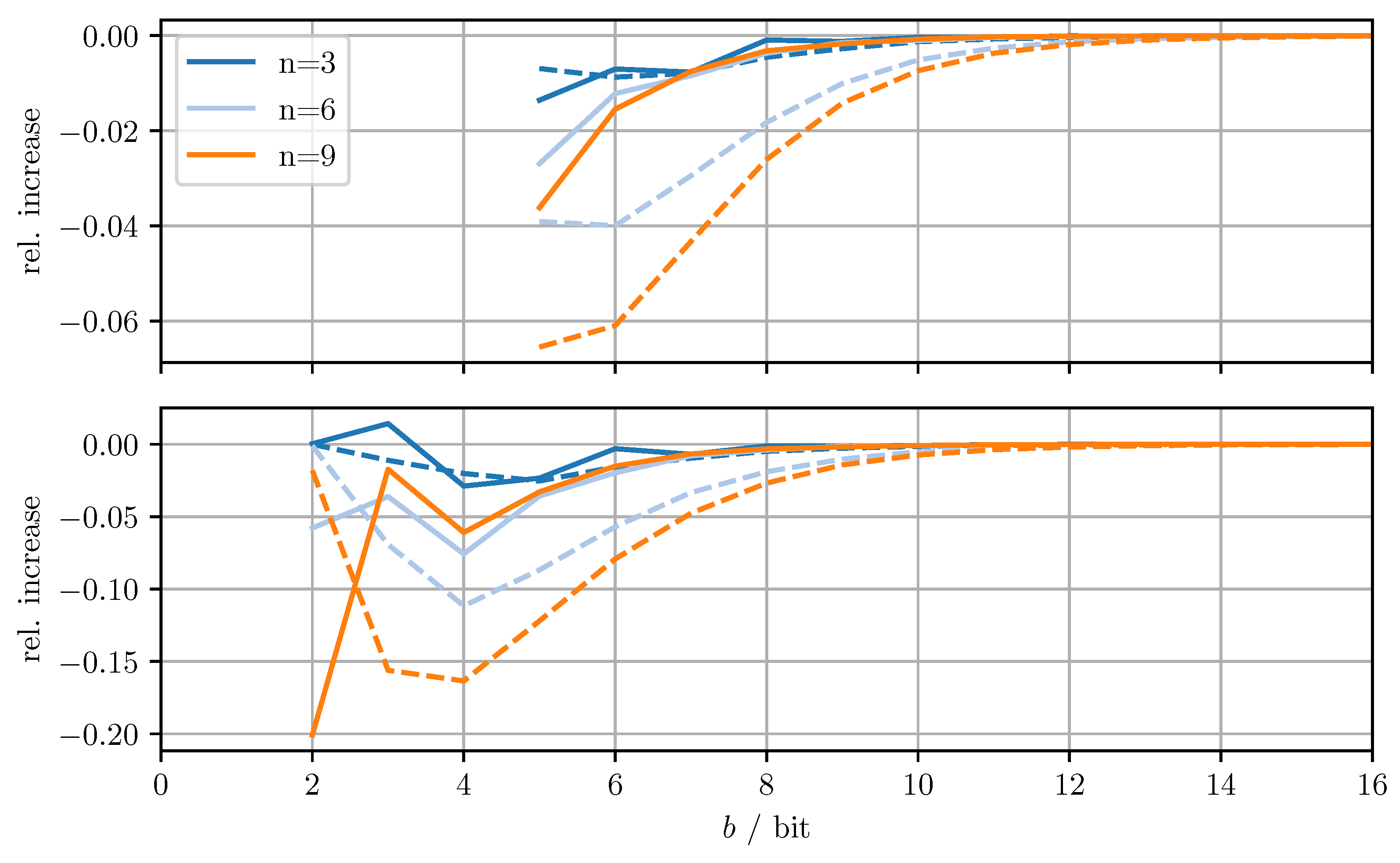
Figure 4 shows the relative increase of the MSE and the relative increase of the averaged trace when using DD-OPT instead of OPT. Figure 5 shows the relative increase of the MSE and the relative increase of the averaged trace , when using MC-OPT instead of DD-OPT. Figure 6 and Figure 7 show the same quantities but compare DD-CI to CI and MC-CI to DD-CI, respectively. In all figures, varying dimensions n and numbers of bits per codeword b are considered both with and without quantizing estimate vectors. The results are obtained by averaging over 1000 independent trials and using for the codebooks , , and .
From Figure 4, it can be seen that for DD-OPT the increase of the estimate MSE and of the averaged trace of the error covariance estimate is moderate except for small b. Moreover, the increase in the averaged trace is larger than the increase in MSE for all n and b. This is to be expected, since the quantization process retains conservativeness. The dimensionality of the test data has varying influence on the performance, depending on b and on whether quantized estimates are being used. Using quantized estimate vectors is seen to adversely affect performance. In fact, when quantizing the estimate vectors the error covariance quantization fails below five bits per codeword, due to the excessively inflated error covariance estimate produced by the estimate quantization. Figure 5 shows that the MC-OPT approach performs better than the DD-OPT approach in terms of the average trace of the error covariance estimate and in most cases also in terms of actual MSE. Larger n leads to larger improvements. The improved performance in terms of average trace is guaranteed by the theoretical results from Section 4.2. Note that there is no guarantee that the actual MSE reduces if the error covariance matrices are quantized more accurately. It can also be seen that there is an optimal number of bits per codeword and that for small b there is little to no improvement. The latter result is due to the phenomenon discussed in Section 6.1. The results for CI, DD-CI, and MC-CI displayed in Figure 6 and Figure 7 exhibit the same general behavior as the results for OPT, DD-OPT, and MC-OPT discussed above, also in terms of theoretical guarantees. One notable difference is the relative improvement of actual MSE. In contrast to optimal fusion, the improvement does not seem to diminish for large n and small b.
6.3. Evaluation of Quantized Covariance Intersection in 2D Tracking Scenario
This evaluation scenario considers two sensor nodes that cooperatively track an object. The object is characterized by a discrete-time (nearly) constant acceleration model
affected by the zero-mean white Gaussian noise term . The six-dimensional state consists of position, velocity, and acceleration in both the - and -direction. The corresponding matrices of the process model are given by
where is the time step [46]. For the Monte Carlo simulation with 1000 runs, the initial states are drawn from
Two sensor nodes a and b are simulated that observe projections of position and velocity according to
with , . The zero-mean white Gaussian measurement noise terms have the covariance matrix
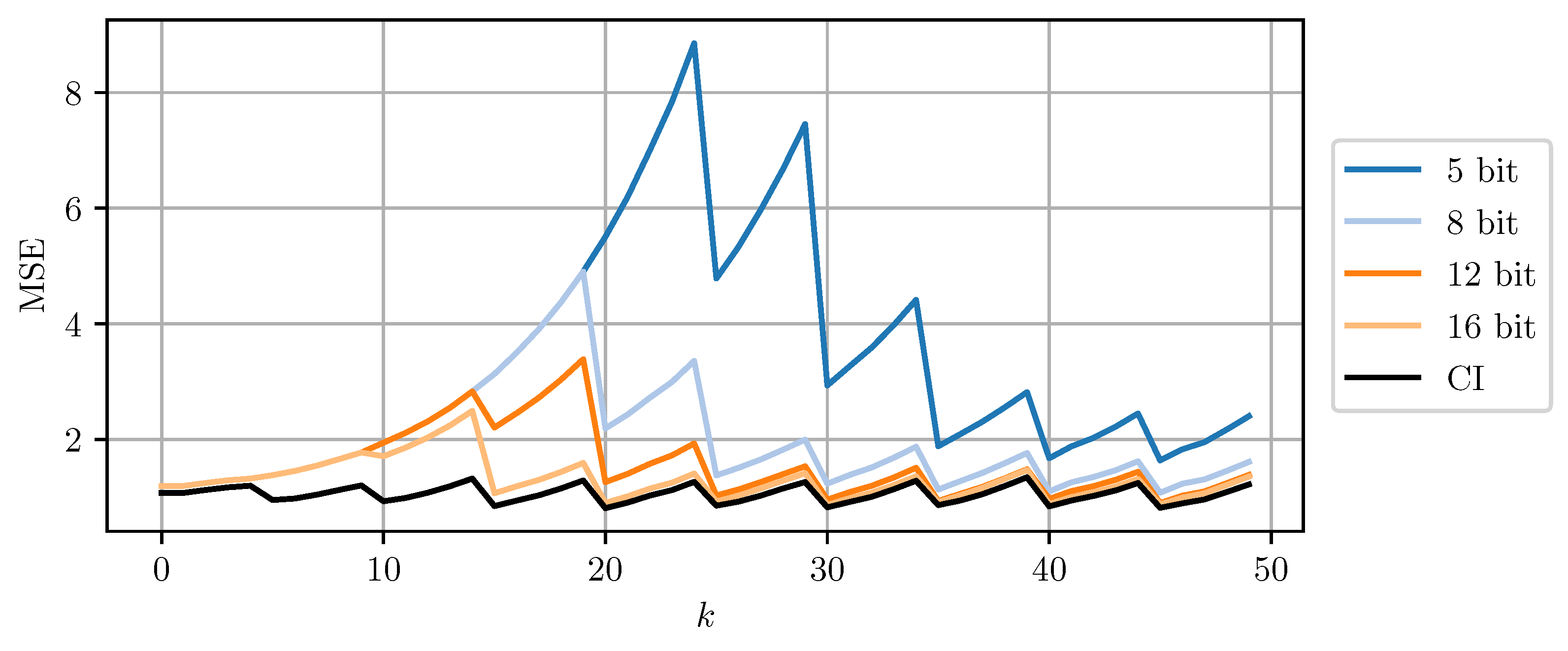
respectively. Each sensor node uses a Kalman filter to compute estimates for 50 time steps. Sensor node a transmits its state and error covariance estimate to sensor node b at every 5th time step. Prior to transmission, it quantizes the estimates with the proposed method and codebook parameter . Node b fuses its own estimate with the received one by employing CI. Every 11th time step, sensor node b quantizes and transmits its state and error covariance estimate to node a, which again fuses it with its own estimate using CI. The receiving node in both cases reinitializes its own estimate with the fusion result.
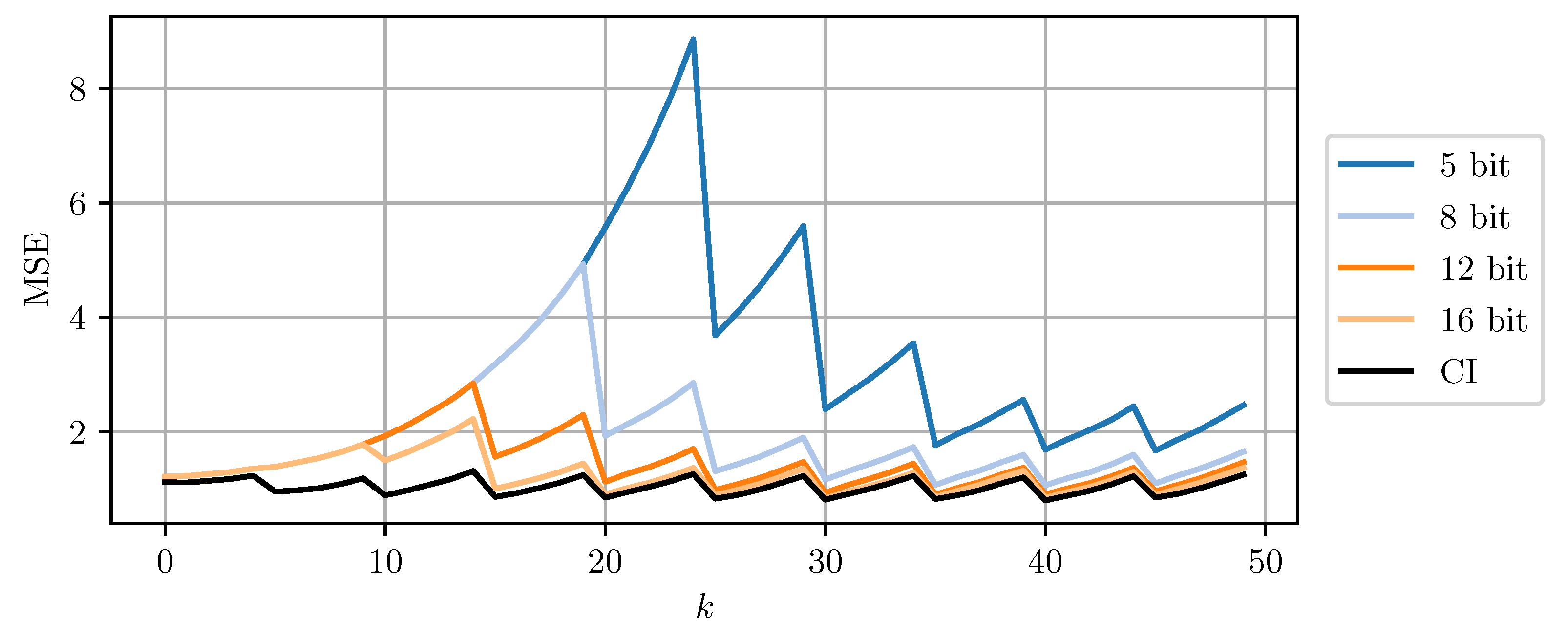
Figure 8 and Figure 9 compare DD-CI and MC-CI using different numbers of bits per codeword, against CI using 64-bit floating point numbers. The results for higher numbers of bits per codeword are close to the estimates obtained through CI with 64-bit floats. However, even a 5-bit quantization still yields reasonable results. Quantization using less than 5 bits per codeword leads to too conservative bounds on the error covariance matrices that cannot be encoded using the given codebook. The estimate MSE exhibits an initial transient peak. It is here, that the improved performance of MC-CI over DD-CI can be observed most clearly.
7. Conclusions
Available bandwidth and energy budget can be limiting factors for the data transmission capabilities of interconnected sensor systems. Algorithms for decentralized information fusion in networks require the exchange of estimates and, in some cases, covariance matrices. If covariance matrices need to be transmitted, they dominate the amount of transmitted data. In this paper, we have proposed two methods for the conservative quantization of covariance matrices, a method for the unbiased conservative quantization of estimates, and have applied them to optimal fusion and covariance intersection. The presented quantization approaches retain unbiasedness and conservativeness of the considered fusion methods while reducing the amount of data that must be transmitted. We have empirically demonstrated the effectiveness of the proposed covariance quantization methods, individually and in conjunction with fusion methods. Further improvements in performance could be achieved by using varying, possibly data-dependent quantization resolutions for subsets of the coefficients of the considered covariance matrices. Moreover, the proposed quantization schemes can also be applied to other sensor fusion algorithms like inverse covariance intersection. For future work, theoretical results concerning the convergence behavior of state and covariance estimates when using quantized data in a decentralized setting are of interest. Conservative vector quantization for covariance matrices is also worth consideration.
Supplementary Materials
The following are available online at https://www.mdpi.com/article/10.3390/s21093059/s1, Python implementations of the quantization approaches.
Author Contributions
Conceptualization, C.F.; methodology, C.F. and B.N.; software, C.F. and B.N.; validation, C.F. and B.N.; formal analysis, C.F.; investigation, C.F. and B.N.; resources, U.D.H.; data curation, C.F. and B.N.; writing—original draft preparation, C.F. and B.N.; writing—review and editing, U.D.H.; visualization, C.F. and B.N.; supervision, U.D.H.; project administration, U.D.H.; funding acquisition, U.D.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
We acknowledge support by the KIT-Publication Fund of the Karlsruhe Institute of Technology.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Tolle, G.; Polastre, J.; Szewczyk, R.; Culler, D.; Turner, N.; Tu, K.; Burgess, S.; Dawson, T.; Buonadonna, P.; Gay, D.; et al. A Macroscope in the Redwoods. In Proceedings of the 3rd International Conference on Embedded Networked Sensor Systems (SenSys ’05), San Diego, CA, USA, 2–4 November 2005; pp. 51–63. [Google Scholar] [CrossRef]
- Werner-Allen, G.; Lorincz, K.; Ruiz, M.; Marcillo, O.; Johnson, J.; Lees, J.; Welsh, M. Deploying a Wireless Sensor Network on an Active Volcano. IEEE Internet Comput. 2006, 10, 18–25. [Google Scholar] [CrossRef]
- Jamil, M.S.; Jamil, M.A.; Mazhar, A.; Ikram, A.; Ahmed, A.; Munawar, U. Smart Environment Monitoring System by Employing Wireless Sensor Networks on Vehicles for Pollution Free Smart Cities. Proc. Eng. 2015, 107, 480–484. [Google Scholar] [CrossRef] [Green Version]
- Osterlind, F.; Pramsten, E.; Roberthson, D.; Eriksson, J.; Finne, N.; Voigt, T. Integrating Building Automation Systems and Wireless Sensor Networks. In Proceedings of the 2007 IEEE Conference on Emerging Technologies and Factory Automation (EFTA 2007), Patras, Greece, 25–28 September 2007; pp. 1376–1379. [Google Scholar] [CrossRef] [Green Version]
- Torfs, T.; Sterken, T.; Brebels, S.; Santana, J.; van den Hoven, R.; Spiering, V.; Bertsch, N.; Trapani, D.; Zonta, D. Low Power Wireless Sensor Network for Building Monitoring. IEEE Sens. J. 2013, 13, 909–915. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.Y.; Peng, W.C.; Tseng, Y.C. Efficient In-Network Moving Object Tracking in Wireless Sensor Networks. IEEE Trans. Mob. Comput. 2006, 5, 1044–1056. [Google Scholar] [CrossRef]
- Tsai, H.W.; Chu, C.P.; Chen, T.S. Mobile Object Tracking in Wireless Sensor Networks. Comput. Commun. 2007, 30, 1811–1825. [Google Scholar] [CrossRef]
- Rault, T.; Bouabdallah, A.; Challal, Y. Energy Efficiency in Wireless Sensor Networks: A Top-Down Survey. Comput. Netw. 2014, 67, 104–122. [Google Scholar] [CrossRef] [Green Version]
- Brink, K.; Sherrill, R.; Godwin, J.; Zhang, J.; Willis, A. Maplets: An Efficient Approach for Cooperative SLAM Map Building Under Communication and Computation Constraints. In Proceedings of the 2020 IEEE/ION Position, Location and Navigation Symposium (PLANS), Portland, OR, USA, 20–23 April 2020. [Google Scholar]
- Ouimet, M.; Iglesias, D.; Ahmed, N.; Martínez, S. Cooperative Robot Localization Using Event-Triggered Estimation. J. Aerosp. Inf. Syst. 2018, 15, 427–449. [Google Scholar] [CrossRef] [Green Version]
- Wu, M.; Ma, H.; Zhang, X. Decentralized Cooperative Localization with Fault Detection and Isolation in Robot Teams. Sensors 2018, 18, 3360. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Günay, M.; Orguner, U.; Demirekler, M. Chernoff Fusion of Gaussian Mixtures for Distributed Maneuvering Target Tracking. In Proceedings of the 18th International Conference on Information Fusion (Fusion 2015), Washington, DC, USA, 6–9 July 2015. [Google Scholar]
- Srisooksai, T.; Keamarungsi, K.; Lamsrichan, P.; Araki, K. Practical Data Compression in Wireless Sensor Networks: A Survey. J. Netw. Comput. Appl. 2012, 35, 37–59. [Google Scholar] [CrossRef]
- Xiao, J.J.; Luo, Z.Q. Decentralized Estimation in an Inhomogeneous Sensing Environment. IEEE Trans. Inf. Theory 2005, 51, 3564–3575. [Google Scholar] [CrossRef]
- Xiao, J.J.; Cui, S.; Luo, Z.Q.; Goldsmith, A. Power Scheduling of Universal Decentralized Estimation in Sensor Networks. IEEE Trans. Signal Process. 2006, 54, 413–422. [Google Scholar] [CrossRef]
- Li, J.; AlRegib, G. Rate-Constrained Distributed Estimation in Wireless Sensor Networks. IEEE Trans. Signal Process. 2007, 55, 1634–1643. [Google Scholar] [CrossRef]
- Li, J.; AlRegib, G. Distributed Estimation in Energy-Constrained Wireless Sensor Networks. IEEE Trans. Signal Process. 2009, 57, 3746–3758. [Google Scholar] [CrossRef]
- Ribeiro, A.; Giannakis, G.B.; Roumeliotis, S.I. SOI-KF: Distributed Kalman Filtering With Low-Cost Communications Using the Sign of Innovations. IEEE Trans. Signal Process. 2006, 54, 4782–4795. [Google Scholar] [CrossRef] [Green Version]
- Msechu, E.J.; Roumeliotis, S.I.; Ribeiro, A.; Giannakis, G.B. Decentralized Quantized Kalman Filtering With Scalable Communication Cost. IEEE Trans. Signal Process. 2008, 56, 3727–3741. [Google Scholar] [CrossRef]
- Forsling, R.; Sjanic, Z.; Gustafsson, F.; Hendeby, G. Consistent Distributed Track Fusion Under Communication Constraints. In Proceedings of the 22nd International Conference on Information Fusion (Fusion 2019), Ottawa, ON, Canada, 2–5 July 2019. [Google Scholar]
- Forsling, R.; Sjanic, Z.; Gustafsson, F.; Hendeby, G. Communication Efficient Decentralized Track Fusion Using Selective Information Extraction. In Proceedings of the IEEE 23rd International Conference on Information Fusion (Fusion 2020), Rustenburg, South Africa, 6–9 July 2020. [Google Scholar] [CrossRef]
- Bar-Shalom, Y.; Campo, L. The Effect of the Common Process Noise on the Two-Sensor Fused-Track Covariance. IEEE Trans. Aerosp. Electron. Syst. 1986, 22, 803–805. [Google Scholar] [CrossRef]
- Sun, S.L.; Deng, Z.L. Multi-Sensor Optimal Information Fusion Kalman Filter. Automatica 2004, 40, 1017–1023. [Google Scholar] [CrossRef]
- Radtke, S.; Noack, B.; Hanebeck, U.D. Fully Decentralized Estimation Using Square-Root Decompositions. In Proceedings of the 23rd International Conference on Information Fusion (Fusion 2020), Rustenburg, South Africa, 6–9 July 2020. [Google Scholar]
- Chong, C.Y. Hierarchical Estimation. In Proceedings of the MIT/ONR Workshop on C3, Monterey, CA, USA, 16–27 July 1979. [Google Scholar]
- Dormann, K.; Noack, B.; Hanebeck, U.D. Optimally Distributed Kalman Filtering with Data-Driven Communication. Sensors 2018, 18, 1034. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Julier, S.J.; Uhlmann, J.K. A Non-divergent Estimation Algorithm in the Presence of Unknown Correlations. In Proceedings of the IEEE American Control Conference (ACC 1997), Albuquerque, NM, USA, 6 June 1997; Volume 4, pp. 2369–2373. [Google Scholar]
- Niehsen, W. Information Fusion based on Fast Covariance Intersection Filtering. In Proceedings of the 5th International Conference on Information Fusion (Fusion 2002), Annapolis, MD, USA, 8–11 July 2002. [Google Scholar]
- Fränken, D.; Hüpper, A. Improved Fast Covariance Intersection for Distributed Data Fusion. In Proceedings of the 8th International Conference on Information Fusion (Fusion 2005), Philadelphia, PA, USA, 25–28 July 2005. [Google Scholar]
- Noack, B.; Sijs, J.; Reinhardt, M.; Hanebeck, U.D. Decentralized Data Fusion with Inverse Covariance Intersection. Automatica 2017, 79, 35–41. [Google Scholar] [CrossRef]
- Noack, B.; Sijs, J.; Hanebeck, U.D. Inverse Covariance Intersection: New Insights and Properties. In Proceedings of the 20th International Conference on Information Fusion (Fusion 2017), Xi’an, China, 10–13 July 2017. [Google Scholar]
- Sijs, J.; Lazar, M.; van den Bosch, P.P.J. State-fusion with Unknown Correlation: Ellipsoidal Intersection. In Proceedings of the 2010 American Control Conference (ACC 2010), Baltimore, MD, USA, 30 June–2 July 2010. [Google Scholar]
- Noack, B.; Sijs, J.; Hanebeck, U.D. Algebraic Analysis of Data Fusion with Ellipsoidal Intersection. In Proceedings of the 2016 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI 2016), Baden-Baden, Germany, 19–21 September 2016. [Google Scholar]
- Funk, C.; Noack, B.; Hanebeck, U.D. Conservative Quantization of Fast Covariance Intersection. In Proceedings of the 2020 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI 2020), Karlsruhe, Germany, 14–16 September 2020. [Google Scholar]
- Hopkins, M.; Mikaitis, M.; Lester, D.R.; Furber, S. Stochastic Rounding and Reduced-Precision Fixed-Point Arithmetic for Solving Neural Ordinary Differential Equations. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2020, 378. [Google Scholar] [CrossRef] [Green Version]
- Horn, R.A.; Johnson, C.R. Matrix Analysis, 2nd ed.; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Schnabel, R.B.; Eskow, E. A New Modified Cholesky Factorization. SIAM J. Sci. Stat. Comput. 1990, 11, 1136–1158. [Google Scholar] [CrossRef]
- Gill, P.E.; Murray, W. Newton-Type Methods for Unconstrained and Linearly Constrained Optimization. Math. Program. 1974, 7, 311–350. [Google Scholar] [CrossRef]
- Schnabel, R.B.; Eskow, E. A Revised Modified Cholesky Factorization Algorithm. SIAM J. Optim. 1999, 9, 1135–1148. [Google Scholar] [CrossRef]
- Golub, G.H.; Van Loan, C.F. Matrix Computations; JHU Press: Baltimore, MD, USA, 2013; Volume 3. [Google Scholar]
- Radtke, S.; Noack, B.; Hanebeck, U.D.; Straka, O. Reconstruction of Cross-Correlations with Constant Number of Deterministic Samples. In Proceedings of the 21st International Conference on Information Fusion (Fusion 2018), Cambridge, UK, 10–13 July 2018. [Google Scholar]
- Chen, L.; Arambel, P.; Mehra, R. Estimation under Unknown Correlation: Covariance Intersection Revisited. IEEE Trans. Autom. Control 2002, 47, 1879–1882. [Google Scholar] [CrossRef] [Green Version]
- Gupta, S.; Agrawal, A.; Gopalakrishnan, K.; Narayanan, P. Deep Learning with Limited Numerical Precision. arXiv 2015, arXiv:1502.02551v1. [Google Scholar]
- Carbone, P.; Petri, D. Effect of Additive Dither on the Resolution of Ideal Quantizers. IEEE Trans. Instrum. Measur. 1994, 43, 389–396. [Google Scholar] [CrossRef]
- Widrow, B.; Kollar, I.; Liu, M.C. Statistical Theory of Quantization. IEEE Trans. Instrum. Measur. 1996, 45, 353–361. [Google Scholar] [CrossRef] [Green Version]
- Li, X.R.; Jilkov, V. Survey of Maneuvering Target Tracking. Part I. Dynamic Models. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1333–1364. [Google Scholar] [CrossRef]
Figure 1.
(Left): Confidence ellipsoids of a covariance matrix (dark blue), its naively quantized version (light blue), and its conservatively quantized version (orange). (Right): Density of a Gaussian random variable (dark blue), histogram (light blue), and mean (orange) of its quantized version.
Figure 1.
(Left): Confidence ellipsoids of a covariance matrix (dark blue), its naively quantized version (light blue), and its conservatively quantized version (orange). (Right): Density of a Gaussian random variable (dark blue), histogram (light blue), and mean (orange) of its quantized version.

Figure 2.
Confidence ellipsoids of and (blue), (orange, solid), and (orange, dashed) when . The result obtained using optimal fusion with the erroneous assumption is shown on the left. The result achieved using CI is shown on the right.
Figure 2.
Confidence ellipsoids of and (blue), (orange, solid), and (orange, dashed) when . The result obtained using optimal fusion with the erroneous assumption is shown on the left. The result achieved using CI is shown on the right.

Figure 3.
Average Frobenius norm of the quantization error matrix of the diagonal dominance-based quantization approach (top), and the relative improvement achieved by the modified Cholesky-based quantization approach (bottom) for varying dimensions n and bits per codeword b.
Figure 3.
Average Frobenius norm of the quantization error matrix of the diagonal dominance-based quantization approach (top), and the relative improvement achieved by the modified Cholesky-based quantization approach (bottom) for varying dimensions n and bits per codeword b.

Figure 4.
Relative increase of actual MSE (solid)/averaged trace (dashed) of DD-OPT with respect to OPT for varying dimensions n and bits per codeword b. Top row with quantized estimate vector and quantized error covariance, bottom row only with quantized error covariance.
Figure 4.
Relative increase of actual MSE (solid)/averaged trace (dashed) of DD-OPT with respect to OPT for varying dimensions n and bits per codeword b. Top row with quantized estimate vector and quantized error covariance, bottom row only with quantized error covariance.

Figure 5.
Relative increase of actual MSE (solid)/averaged trace (dashed) of MC-OPT with respect to DD-OPT for varying dimensions n and bits per codeword b. Top row with quantized estimate vector and quantized error covariance, bottom row only with quantized error covariance.
Figure 5.
Relative increase of actual MSE (solid)/averaged trace (dashed) of MC-OPT with respect to DD-OPT for varying dimensions n and bits per codeword b. Top row with quantized estimate vector and quantized error covariance, bottom row only with quantized error covariance.

Figure 6.
Relative increase of actual MSE (solid)/averaged trace (dashed) of DD-CI with respect to CI for varying dimensions n and bits per codeword b. Top row with quantized estimate vector and quantized error covariance, bottom row only with quantized error covariance.
Figure 6.
Relative increase of actual MSE (solid)/averaged trace (dashed) of DD-CI with respect to CI for varying dimensions n and bits per codeword b. Top row with quantized estimate vector and quantized error covariance, bottom row only with quantized error covariance.

Figure 7.
Relative increase of actual MSE (solid)/averaged trace (dashed) of MC-CI with respect to DD-CI for varying dimensions n and bits per codeword b. Top row with quantized estimate vector and quantized error covariance, bottom row only with quantized error covariance.
Figure 7.
Relative increase of actual MSE (solid)/averaged trace (dashed) of MC-CI with respect to DD-CI for varying dimensions n and bits per codeword b. Top row with quantized estimate vector and quantized error covariance, bottom row only with quantized error covariance.

Figure 8.
The estimate MSE of sensor node b plotted over time step k for varying bits per codeword using DD-CI. ‘CI’ indicates the use of a 64 bit floating point representation for each scalar.
Figure 8.
The estimate MSE of sensor node b plotted over time step k for varying bits per codeword using DD-CI. ‘CI’ indicates the use of a 64 bit floating point representation for each scalar.

Figure 9.
The estimate MSE of sensor node b plotted over time step k for varying bits per codeword using MC-CI. ‘CI’ indicates the use of a 64 bit floating point representation for each scalar.
Figure 9.
The estimate MSE of sensor node b plotted over time step k for varying bits per codeword using MC-CI. ‘CI’ indicates the use of a 64 bit floating point representation for each scalar.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Funk, C.; Noack, B.; Hanebeck, U.D. Conservative Quantization of Covariance Matrices with Applications to Decentralized Information Fusion. Sensors 2021, 21, 3059. https://doi.org/10.3390/s21093059
AMA Style
Funk C, Noack B, Hanebeck UD. Conservative Quantization of Covariance Matrices with Applications to Decentralized Information Fusion. Sensors. 2021; 21(9):3059. https://doi.org/10.3390/s21093059
Chicago/Turabian StyleFunk, Christopher, Benjamin Noack, and Uwe D. Hanebeck. 2021. "Conservative Quantization of Covariance Matrices with Applications to Decentralized Information Fusion" Sensors 21, no. 9: 3059. https://doi.org/10.3390/s21093059
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.