
DPSSD: Dual-Path Single-Shot Detector

 , ,
, ,
Abstract
:1. Introduction
- (a)
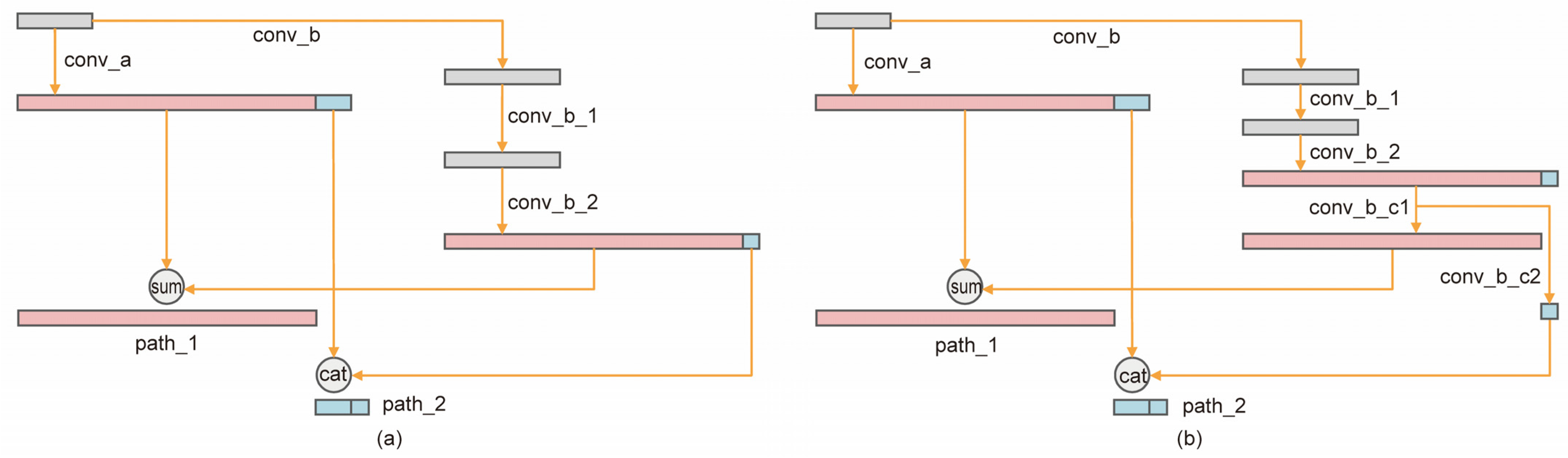
- We first introduced a dual-path network in the single-stage object detector by proposing a paradigm called the “Dual-Path Feature Pyramid”, as shown in Figure 1e. It combines two feature fusion methods, i.e., residual connection and concatenation connection.
- (b)
- After experimental validation, a new feature fusion module was proposed to enhance the fusion of high-level semantic and low-level spatial features to further optimize the multi-scale feature learning problem.
2. Related Work
3. Dual-Path Single-Shot Detector
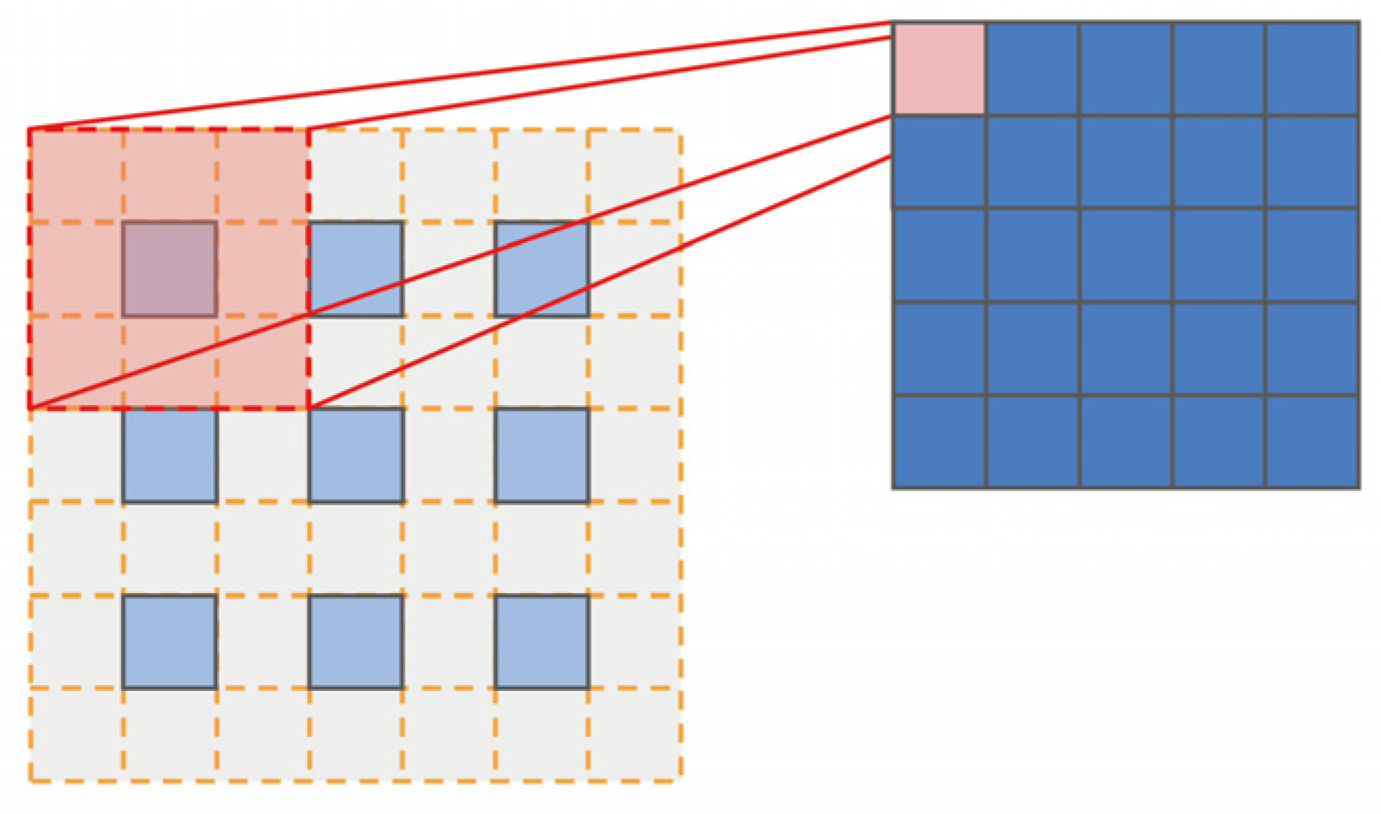
3.1. Convolution Neural Network
3.1.1. Dual-Path Network
3.1.2. Feature Fusion Module
3.1.3. Prediction Module
3.2. Training Model
4. Experiments
4.1. Experiment Consideration
4.2. Experiment on PASCAL VOC
4.3. Ablation Experiment on the PASCAL VOC
4.4. Experiment on the Microsoft COCO
4.5. Experiment on Inference Speed
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, X.W.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Singh, B.; Davis, L.S. An analysis of scale invariance in object detection snip. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3578–3587. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 354–370. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Chen, Y.; Li, J.; Xiao, H.; Jin, X.; Yan, S.; Feng, J. Dual path networks. Adv. Neural Inf. Processing Syst. 2017, 30. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Processing Syst. 2016, 29. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by concatenating feature maps for object detection. arXiv 2017, arXiv:1705.09587. [Google Scholar]
- Zhou, P.; Ni, B.; Geng, C.; Hu, J.; Xu, Y. Scale-transferrable object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 528–537. [Google Scholar]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 9259–9266. [Google Scholar]
- Wu, X.; Sahoo, D.; Zhang, D.; Zhu, J.; Hoi, S.C.H. Single-shot bidirectional pyramid networks for high-quality object detection. Neurocomputing 2020, 401, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Processing Syst. 2019, 32. [Google Scholar]
- Everingham, M.; Van, L.; Christopher, G.; Williams, K.I.; Winn, J.; Zisserman, A.; Everingham, M.; Gool, L.V.; Williams, C.; Winn, J. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance problems in object detection: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3388–3415. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikainen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Parameters | Output | Layers | Parameters | Output | ||||
|---|---|---|---|---|---|---|---|---|---|
| Size/Stride | Groups | Size/Stride | Groups | ||||||
| Conv1_1 | conv | 7 × 7/2 | 1 | 80 × 80 × 64 | Conv5_1 | conv_a | 1 × 1/1 | 1 | 20 × 20 × 1024 20 × 20 × 384 |
| maxpool | 3 × 3/2 | 1 | conv_b | 1 × 1/1 | 1 | ||||
| Conv2_1 | conv_a | 1 × 1/1 | 1 | 80 × 80 × 256 80 × 80 × 48 | conv_b_1 | 3 × 3/1 | 32 | ||
| conv_b | 1 × 1/1 | 1 | conv_b_2 | 1 × 1/1 | 1 | ||||
| conv_b_1 | 3 × 3/1 | 32 | Conv5_2 - Conv5_3 | conv_b | 1 × 1/1 | 1 | 20 × 20 × 1024 20 × 20 × 512(+128) | ||
| conv_b_2 | 1 × 1/1 | 1 | conv_b_1 | 3 × 3/1 | 32 | ||||
| Conv2_2 - Conv2_3 | conv_b | 1 × 1/1 | 1 | 80 × 80 × 256 80 × 80 × 80 | conv_b_2 | 1 × 1/1 | 1 | ||
| conv_b_1 | 3 × 3/1 | 32 | Conv6_1 | conv_a | 1 × 1/2 | 1 | 10 × 10 × 1024 10 × 10 × 384 | ||
| conv_b_2 | 1 × 1/1 | 1 | conv_b | 1 × 1/1 | 1 | ||||
| Conv3_1 | conv_a | 1 × 1/2 | 1 | 40 × 40 × 512 40 × 40 × 96 | conv_b_1 | 3 × 3/2 | 32 | ||
| conv_b | 1 × 1/1 | 1 | conv_b_2 | 1 × 1/1 | 1 | ||||
| conv_b_1 | 3 × 3/2 | 32 | Conv7_1 | conv_a | 1 × 1/2 | 1 | 5 × 5 × 1024 5 × 5 × 384 | ||
| conv_b_2 | 1 × 1/1 | 1 | conv_b | 1 × 1/1 | 1 | ||||
| Conv3_2 - Conv3_4 | conv_b | 1 × 1/1 | 1 | 40 × 40 × 512 40 × 40 × 128(+32) | conv_b_1 | 3 × 3/2 | 32 | ||
| conv_b_1 | 3 × 3/1 | 32 | conv_b_2 | 1 × 1/1 | 1 | ||||
| conv_b_2 | 1 × 1/1 | 1 | Conv8_1 | conv_a | 1 × 1/2 | 1 | 3 × 3 × 1024 3 × 3 × 384 | ||
| Conv4_1 | conv_a | 1 × 1/2 | 1 | 20 × 20 × 1024 20 × 20 × 72 | conv_b | 1 × 1/1 | 1 | ||
| conv_b | 1 × 1/1 | 1 | conv_b_1 | 3 × 3/2 | 32 | ||||
| conv_b_1 | 3 × 3/2 | 32 | conv_b_2 | 1 × 1/1 | 1 | ||||
| conv_b_2 | 1 × 1/1 | 1 | Conv9_1 | conv_a | 1 × 1/2 | 1 | 1 × 1 × 1024 1 × 1 × 384 | ||
| Conv4_2 - Conv4_20 | conv_b | 1 × 1/1 | 1 | 20 × 20 × 1024 20 × 20 × 96(+24) | conv_b | 1 × 1/1 | 1 | ||
| conv_b_1 | 3 × 3/1 | 32 | conv_b_1 | 3 × 3/2 | 32 | ||||
| conv_b_2 | 1 × 1/1 | 1 | conv_b_2 | 1 × 1/1 | 1 | ||||
| Method | mAP | Anchor Boxes | Input Resolution |
|---|---|---|---|
| DPN (a) + PM (a) | 78.9 | 17,080 | 320 × 320 |
| DPN (a) + FFM (a) + PM (a) | 81.2 | 17,080 | 320 × 320 |
| DPN (a) + FFM (b) + PM (a) | 80.6 | 17,080 | 320 × 320 |
| DPN (a) + FFM (c) + PM (a) | 80.8 | 17,080 | 320 × 320 |
| DPN (a) + FFM (d) + PM (a) | 80.5 | 17,080 | 320 × 320 |
| DPN (a) + FFM (a) + PM (b) | 80.9 | 17,080 | 320 × 320 |
| DPN (b) + FFM (a) + PM(a) | 67.1 | 17,080 | 320 × 320 |
| Method | SSD300 [6] | SSD512 [6] | STDN300 [18] | STDN321 [18] | STDN513 [18] | DSSD321 [19] | DSSD513 [19] | DPSSD320 (Ours) | DPSSD512 (Ours) |
|---|---|---|---|---|---|---|---|---|---|
| Network | VGG | VGG | DenseNet-169 | DenseNet-169 | DenseNet-169 | Residual-101 | Residual-101 | DPN | DPN |
| mAP | 77.5 | 79.5 | 78.1 | 79.3 | 80.9 | 78.6 | 81.5 | 81.2 | 82.9 |
| aero | 79.5 | 84.8 | 81.1 | 81.2 | 86.1 | 81.9 | 86.6 | 88.5 | 87.9 |
| bike | 83.9 | 85.1 | 86.9 | 88.3 | 89.3 | 84.9 | 86.2 | 87 | 88 |
| bird | 76 | 81.5 | 76.4 | 78.1 | 79.5 | 80.5 | 82.6 | 82.3 | 87.1 |
| boat | 69.6 | 73 | 69.2 | 72.2 | 74.3 | 68.4 | 74.9 | 76.2 | 79.9 |
| bottle | 50.5 | 57.8 | 52.4 | 54.3 | 61.9 | 53.9 | 62.5 | 56.5 | 66.3 |
| bus | 87 | 87.8 | 87.7 | 87.6 | 88.5 | 85.6 | 89 | 88.7 | 88.5 |
| car | 85.7 | 88.3 | 84.2 | 86.5 | 88.3 | 86.2 | 88.7 | 88.2 | 89 |
| cat | 88.1 | 87.4 | 88.3 | 88.8 | 89.4 | 88.9 | 88.8 | 88.4 | 88.4 |
| chair | 60.3 | 63.5 | 60.2 | 63.5 | 67.4 | 61.1 | 65.2 | 67.4 | 71.2 |
| cow | 81.5 | 85.4 | 81.3 | 83.2 | 86.5 | 83.5 | 87 | 84.6 | 87.3 |
| table | 77 | 73.2 | 77.6 | 79.4 | 79.5 | 78.7 | 78.7 | 77.3 | 79.2 |
| dog | 86.1 | 86.2 | 86.6 | 86.1 | 86.4 | 86.7 | 88.2 | 86.7 | 88 |
| horse | 87.5 | 86.7 | 88.9 | 89.3 | 89.2 | 88.7 | 89 | 89 | 89.1 |
| mbike | 83.9 | 83.9 | 87.8 | 88 | 88.5 | 86.7 | 87.5 | 87.8 | 87.3 |
| person | 79.4 | 82.5 | 76.8 | 77.3 | 79.3 | 79.7 | 83.7 | 80.9 | 85 |
| plant | 52.3 | 55.6 | 51.8 | 52.5 | 53 | 51.7 | 51.1 | 59.5 | 59 |
| sheep | 77.9 | 81.7 | 78.4 | 80.3 | 77.9 | 78 | 86.3 | 84.3 | 86.1 |
| sofa | 79.5 | 79 | 81.3 | 80.8 | 81.4 | 80.9 | 81.6 | 83.7 | 81.9 |
| train | 87.6 | 86.6 | 87.5 | 86.3 | 86.6 | 87.2 | 85.7 | 87 | 86.2 |
| tv | 76.8 | 80 | 77.8 | 82.1 | 85.5 | 79.4 | 83.7 | 80.6 | 82.8 |
| Method | Data | Network | Avg. Precision, IoU: | Avg. Precision, Area: | Avg. Recall, #Dets: | Avg. Recall, Area: | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.5:0.95 | 0.5 | 0.75 | S | M | L | 1 | 10 | 100 | S | M | L | |||
| SSD300 [6] | trainval35k | VGG | 25.1 | 43.1 | 25.8 | 6.6 | 25.9 | 41.4 | 23.7 | 35.1 | 37.2 | 11.2 | 40.4 | 58.4 |
| SSD512 [6] | trainval35k | VGG | 28.8 | 48.5 | 30.3 | 10.9 | 31.8 | 43.5 | 26.1 | 39.5 | 42.0 | 16.5 | 46.6 | 60.8 |
| DSSD321 [19] | trainval35k | Residual-101 | 28.0 | 46.1 | 29.2 | 7.4 | 28.1 | 47.6 | 25.5 | 37.1 | 39.4 | 12.7 | 42.0 | 62.6 |
| DSSD513 [19] | trainval35k | Residual-101 | 33.2 | 53.3 | 35.2 | 13.0 | 35.4 | 51.1 | 28.9 | 43.5 | 46.2 | 21.8 | 49.1 | 66.4 |
| STDN300 [18] | trainval | DenseNet-169 | 28.0 | 45.6 | 29.4 | 7.9 | 29.7 | 45.1 | 24.4 | 36.1 | 38.7 | 12.5 | 42.7 | 60.1 |
| STDN513 [18] | trainval | DenseNet-169 | 31.8 | 51.0 | 33.6 | 14.4 | 36.1 | 43.4 | 27.0 | 40.1 | 41.9 | 18.3 | 48.3 | 57.2 |
| DPSSD320 (ours) | trainval35k | DPN | 30.6 | 50.2 | 32.2 | 10.3 | 32.0 | 47.6 | 26.8 | 39.5 | 41.5 | 16.1 | 44.9 | 62.6 |
| DPSSD512 (ours) | trainval35k | DPN | 33.9 | 53.8 | 36.3 | 14.5 | 37.5 | 48.7 | 28.7 | 43.4 | 45.7 | 20.6 | 51.2 | 64.3 |
| Method | Base Network | mAP | Speed (fps) | Anchor Boxes | GPU | Input Resolution |
|---|---|---|---|---|---|---|
| SSD300 [6] | VGG16 | 77.5 | 46 | 8732 | Titan X | 300 × 300 |
| SSD512 [6] | VGG16 | 79.5 | 19 | 24,564 | Titan X | 512 × 512 |
| SSD300 (copied) | VGG16 | 77.6 | 49 | 8732 | Titan Xp | 300 × 300 |
| SSD512 (copied) | VGG16 | 79.7 | 24 | 24,564 | Titan Xp | 512 × 512 |
| DSSD321 [19] | Residual-101 | 78.6 | 9.5 | 17,080 | Titan X | 321 × 321 |
| DSSD513 [19] | Residual-101 | 81.5 | 5.5 | 43,688 | Titan X | 513 × 513 |
| DSSD321 (copied) | Residual-101 | 78.7 | 12.7 | 17,080 | Titan Xp | 321 × 321 |
| DSSD513 (copied) | Residual-101 | 81.3 | 9.8 | 43,688 | Titan Xp | 513 × 513 |
| STDN300 [18] | DenseNet-169 | 78.1 | 41.5 | 13,888 | Titan Xp | 300 × 300 |
| STDN321 [18] | DenseNet-169 | 79.2 | 40.1 | 17,080 | Titan Xp | 321 × 321 |
| STDN513 [18] | DenseNet-169 | 80.9 | 28.6 | 43,680 | Titan Xp | 513 × 513 |
| DPSSD320 (ours) | DPN | 81.2 | 30.7 | 17,080 | Titan Xp | 320 × 320 |
| DPSSD512 (ours) | DPN | 82.9 | 21.3 | 43,680 | Titan Xp | 512 × 512 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shan, D.; Xu, Y.; Zhang, P.; Wang, X.; He, D.; Zhang, C.; Zhou, M.; Yu, G. DPSSD: Dual-Path Single-Shot Detector. Sensors 2022, 22, 4616. https://doi.org/10.3390/s22124616
Shan D, Xu Y, Zhang P, Wang X, He D, Zhang C, Zhou M, Yu G. DPSSD: Dual-Path Single-Shot Detector. Sensors. 2022; 22(12):4616. https://doi.org/10.3390/s22124616
Chicago/Turabian StyleShan, Dongri, Yalu Xu, Peng Zhang, Xiaofang Wang, Dongmei He, Chenglong Zhang, Maohui Zhou, and Guoqi Yu. 2022. "DPSSD: Dual-Path Single-Shot Detector" Sensors 22, no. 12: 4616. https://doi.org/10.3390/s22124616
APA StyleShan, D., Xu, Y., Zhang, P., Wang, X., He, D., Zhang, C., Zhou, M., & Yu, G. (2022). DPSSD: Dual-Path Single-Shot Detector. Sensors, 22(12), 4616. https://doi.org/10.3390/s22124616