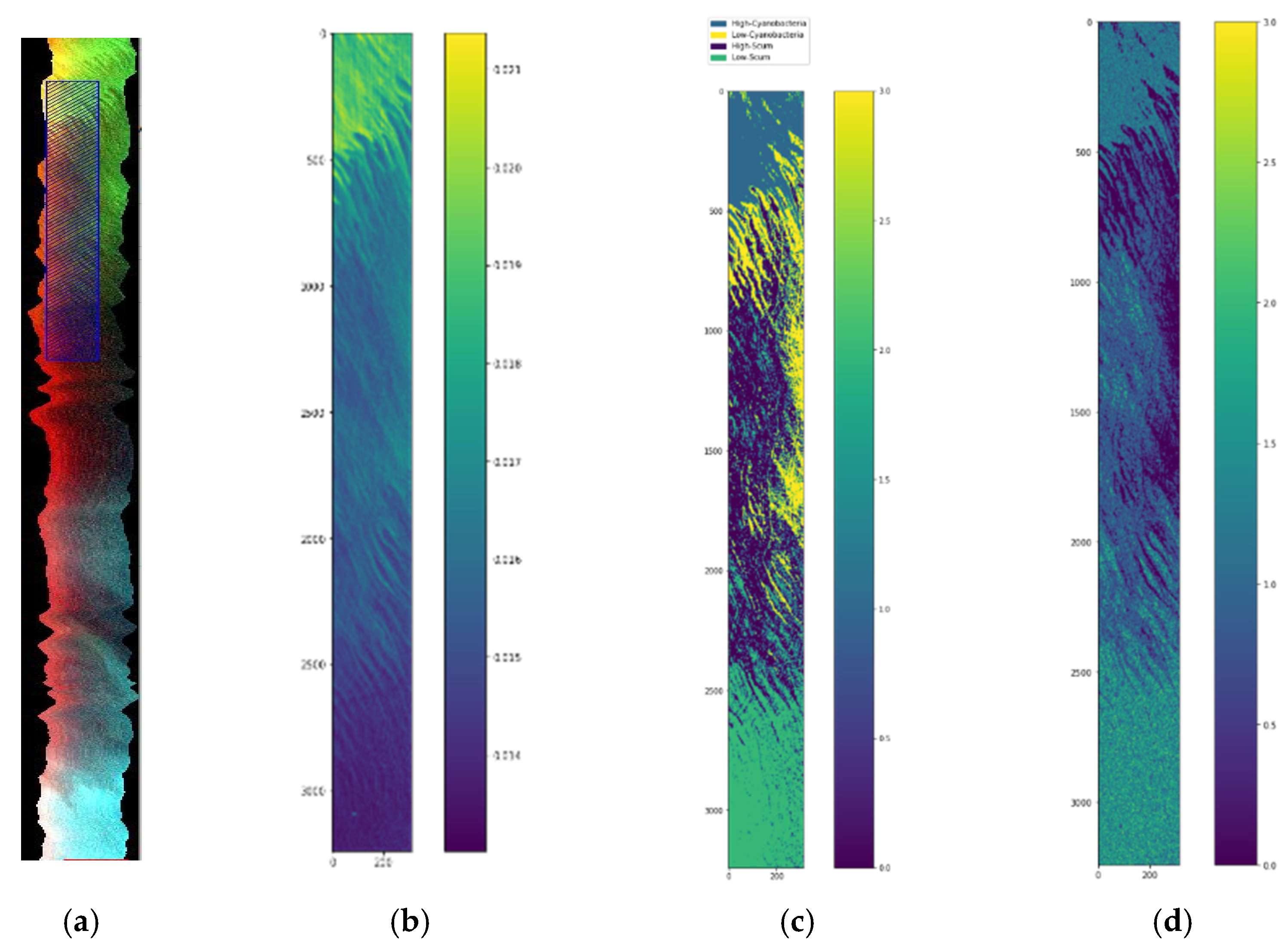
This section describes the images, and the methods used for preprocessing, labeling, and classification of the hyperspectral images. Two types of HSI are used: ones without groundtruth data and another with groundtruth data. The ones without groundtruth data are from airborne HSI sensors flown by NASA Glenn Research Center (GRC).
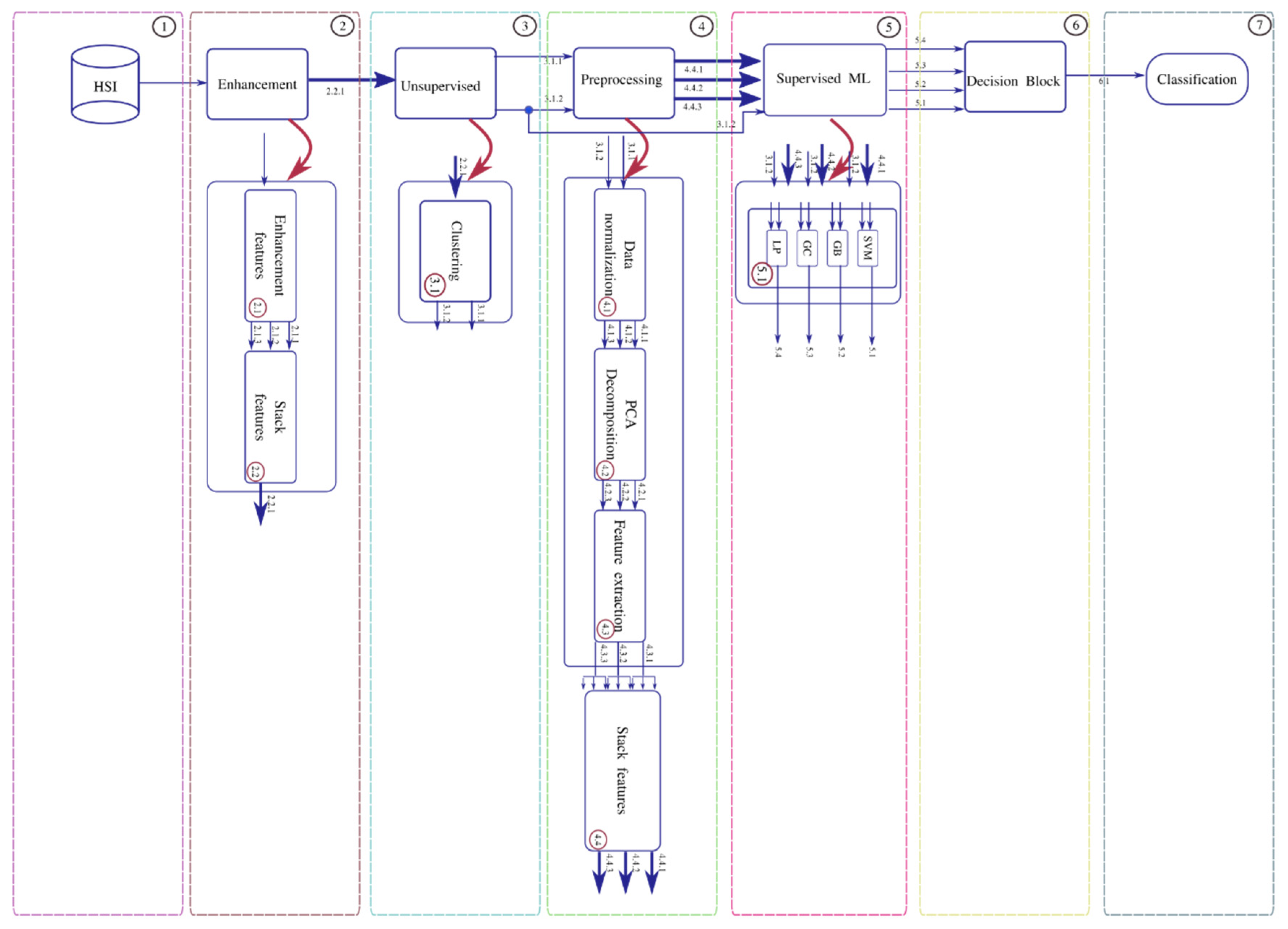
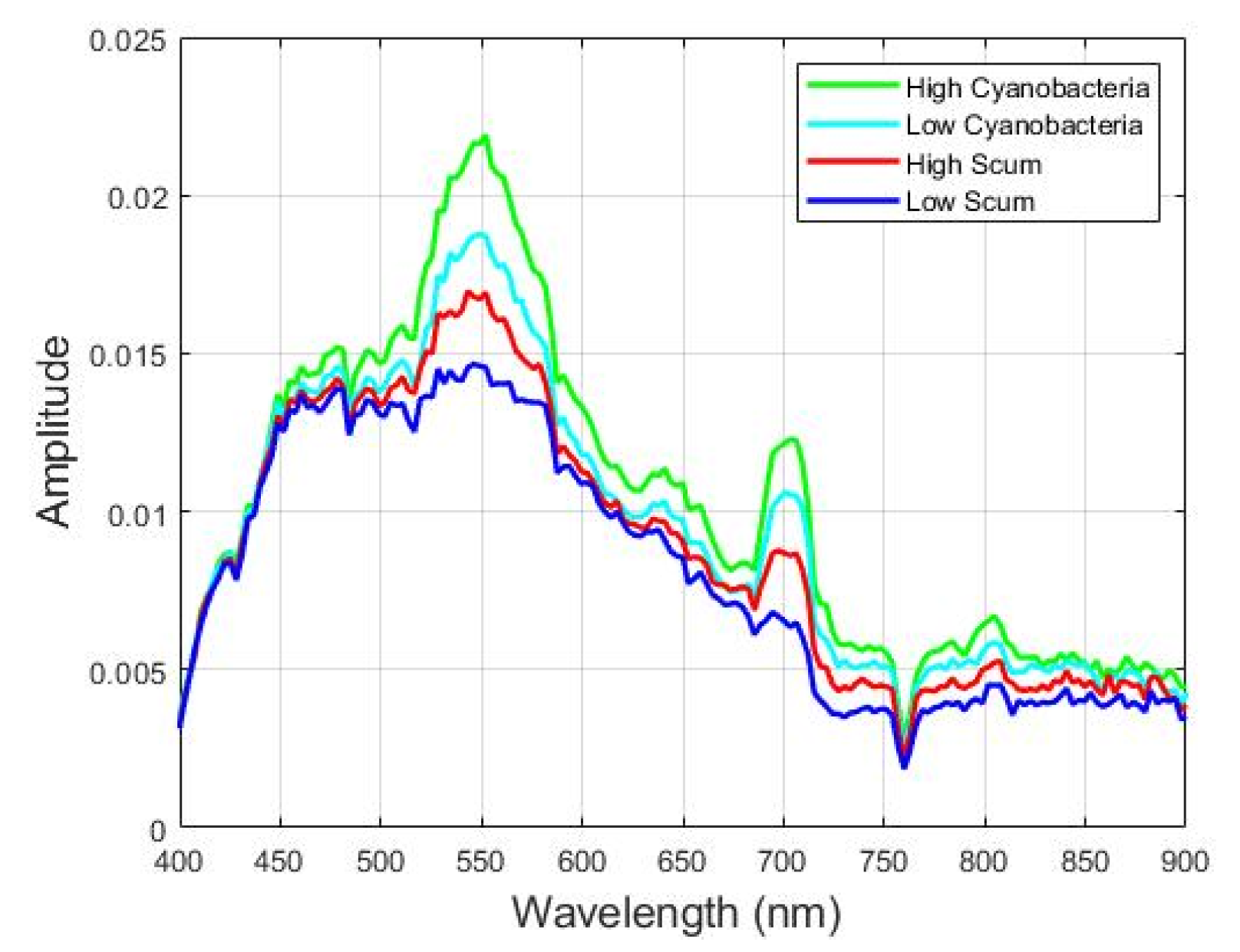
In the 2.2 sub-process, the enhancement vectors are stacked. The 3 arrows indicate the 3 features which are then stacked into one data frame. In the 2.2 sub-process, the stacked vectors are then input to the unsupervised stage. In the 3.1 sub-process, the label assignment is made. The data preparation for this stage requires a 1-D tensor representation of the image. The experiment consists of various trials of cluster numbers, k = 2 to 5, to result in an output image label representation from the original image after the enhancement stage. Once the best label assignment for the Lake Erie image is determined, we have the data and the corresponding labels. Since the images do not have specific groundtruth data, the unsupervised stage produces a label representation of the original image for the best number of clusters. The next is stage 4 processing which includes 4 sub-processes. Sub-process 4.1 is a data normalization process using three different kinds of normalization: normalization scaling (ns), maximum scaling (ms), and scaling (sc). After the data normalization process, sub-process 4.2 is PCA decomposition and selection of 3, 5, or 7 bands. In sub-process 4.3, the feature vectors ft from the enhancement stage are computed. In sub-process 4.4, the resulting vectors are stacked into an array Y and are concatenated with the labels provided by the unsupervised stage. Stacked vectors and the labels are then input to the process 5, supervised Machine Learning (ML) stage.
2.1. Workflow for Supervised Classification of Jasper Image
We have used the Jasper HSI, because it is similar to the Lake Erie image as it has land cover and an inland water body.
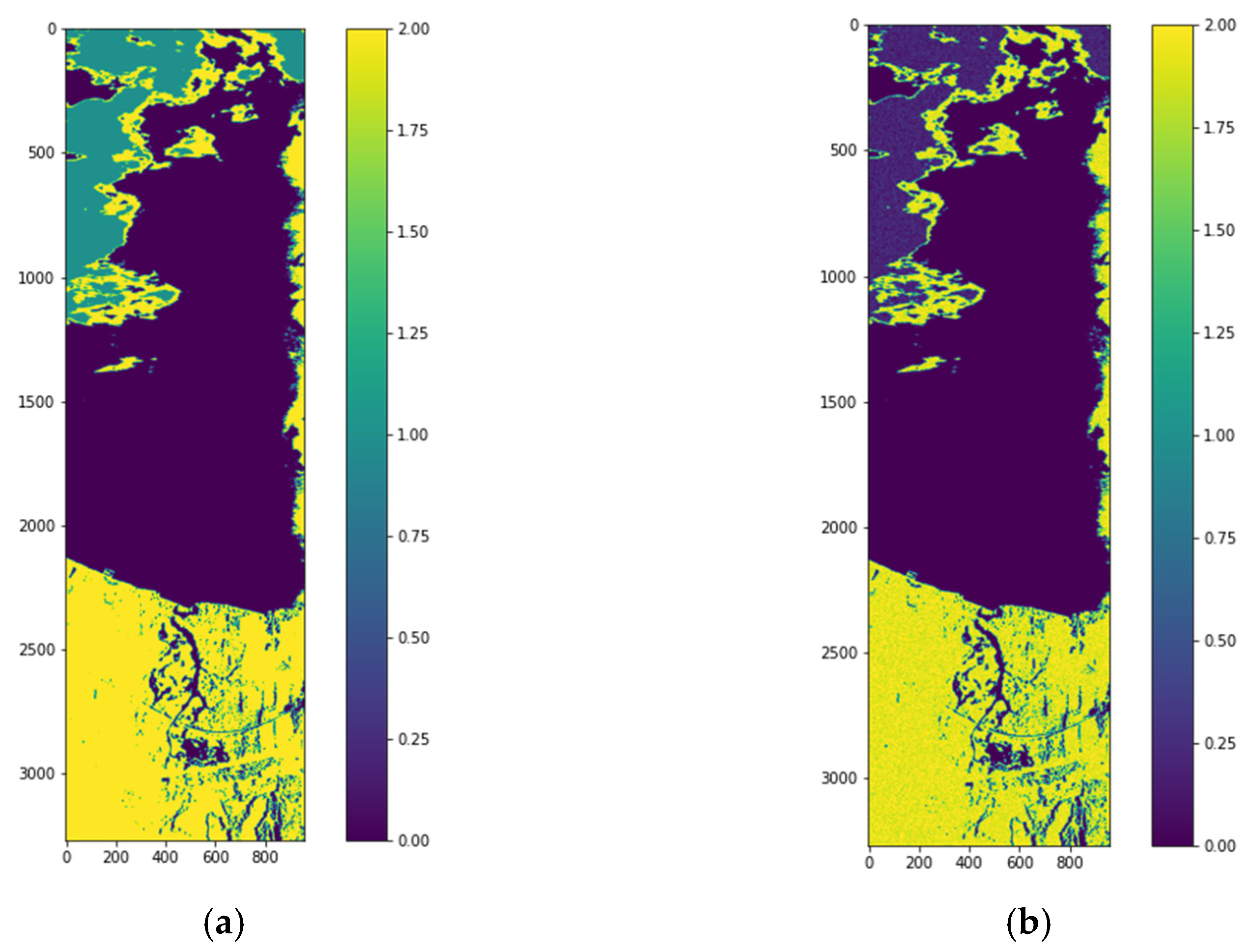
Figure 3 shows the Jasper image along with the groundtruth. The Jasper image has 100 rows, 100 columns, and has 224 bands.
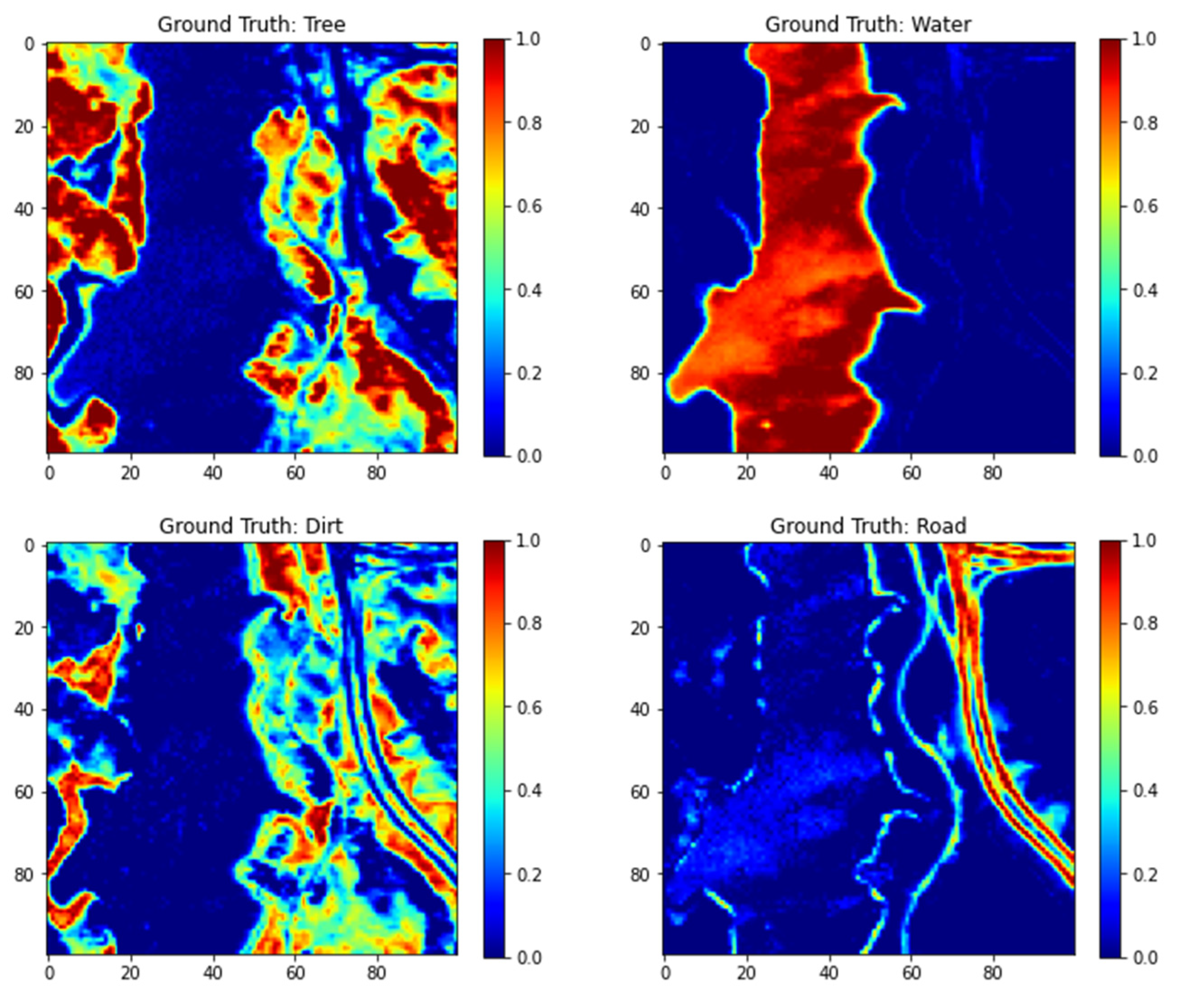
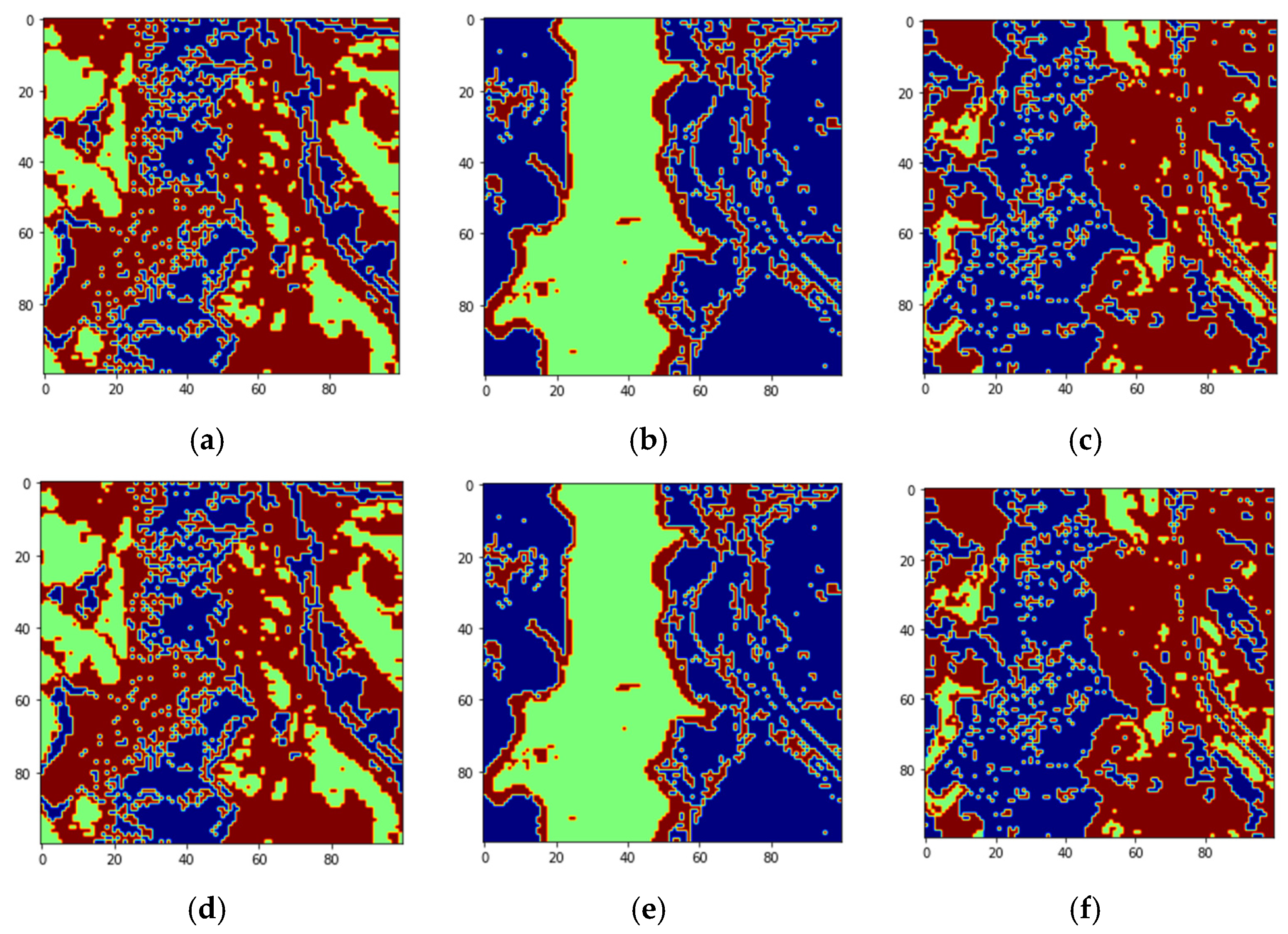
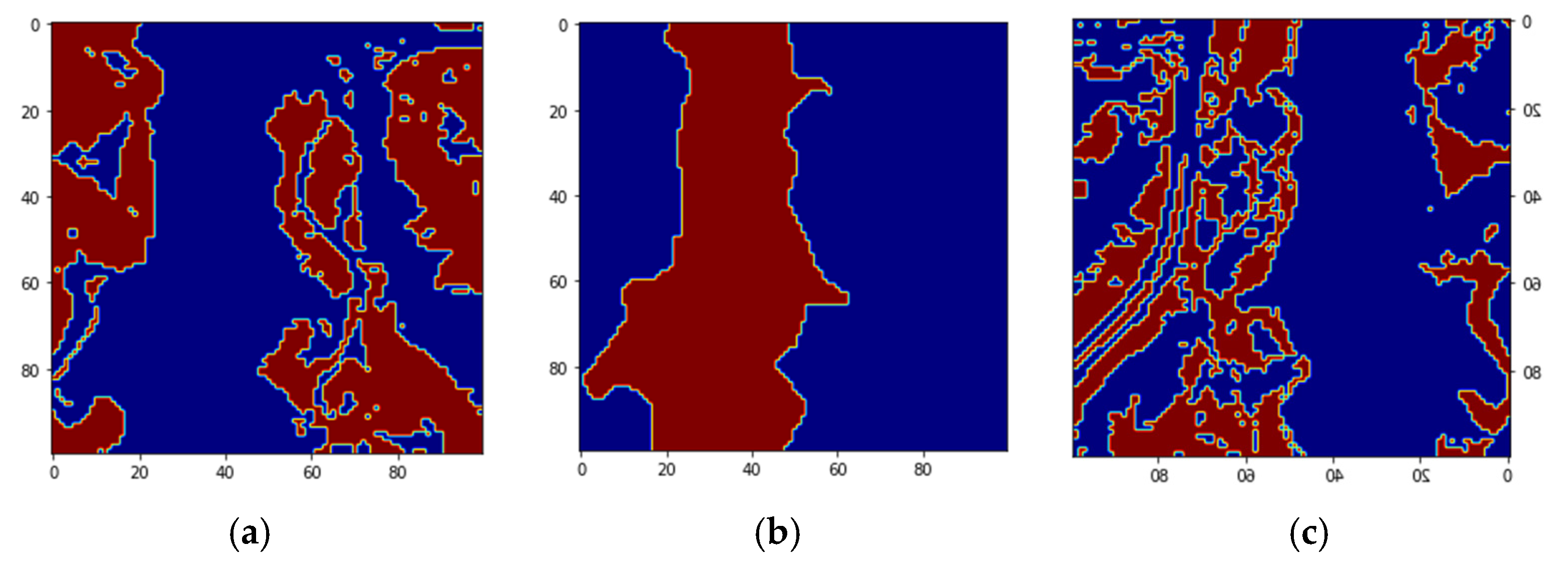
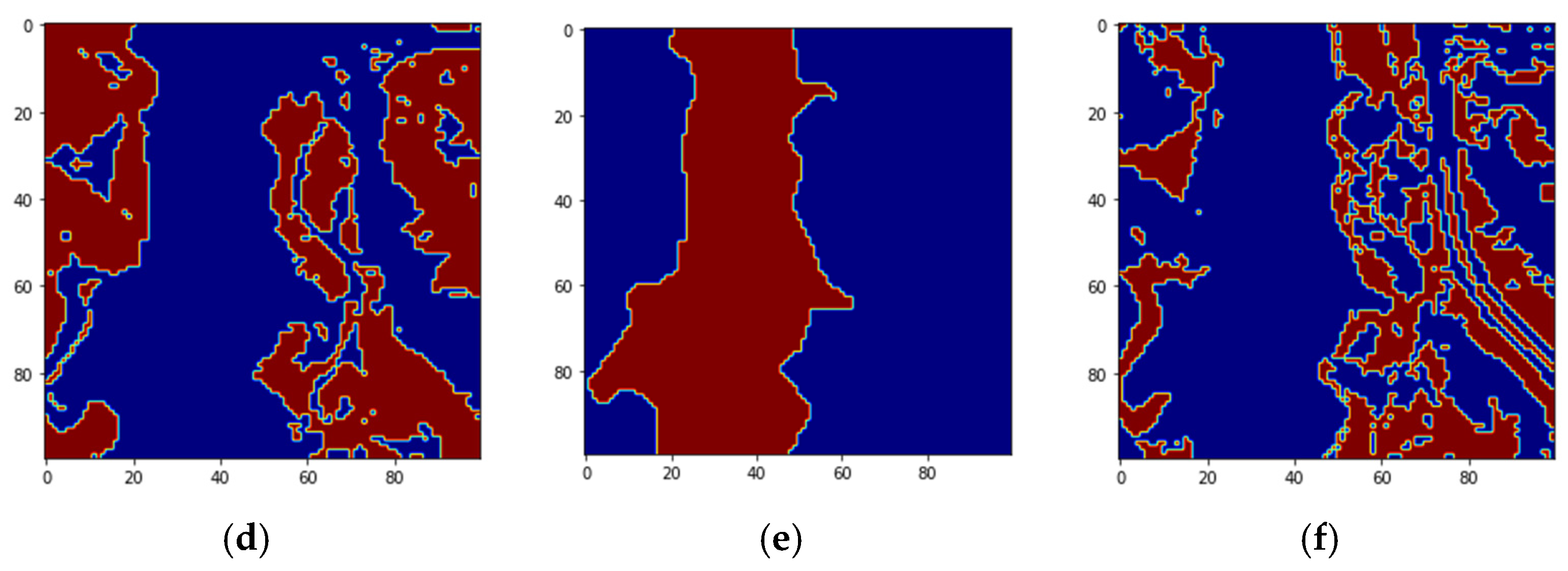
Figure 4 shows the four endmember abundances for the materials present in the Jasper image. The endmembers are road, soil, water, and tree. We did not consider the road class because of an insufficient number of pixels for training. The available groundtruth has endmember abundances for each of the pixels. In [
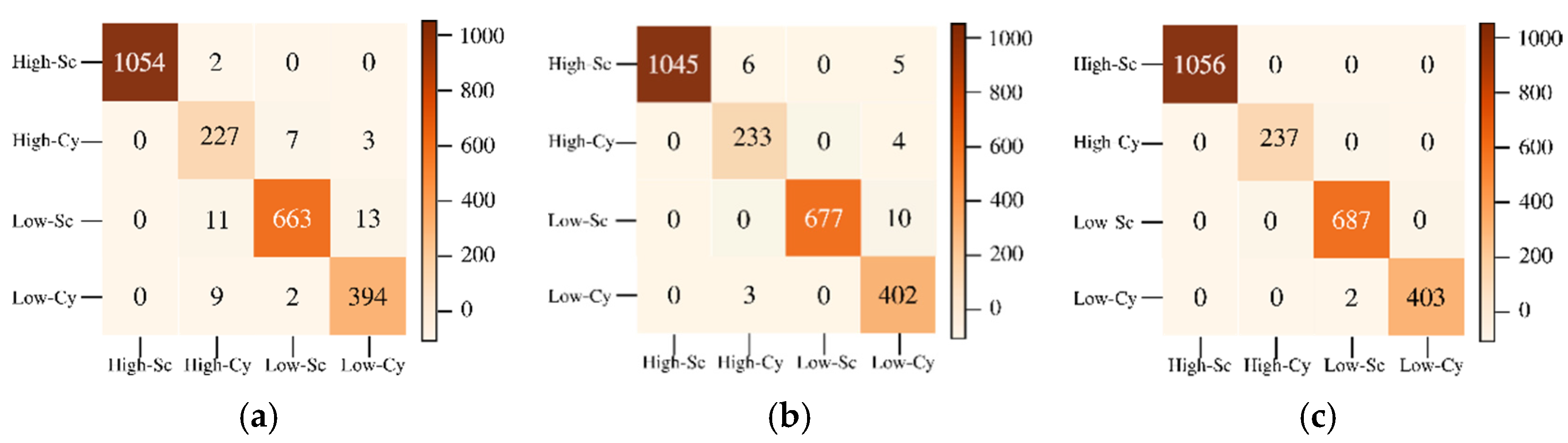
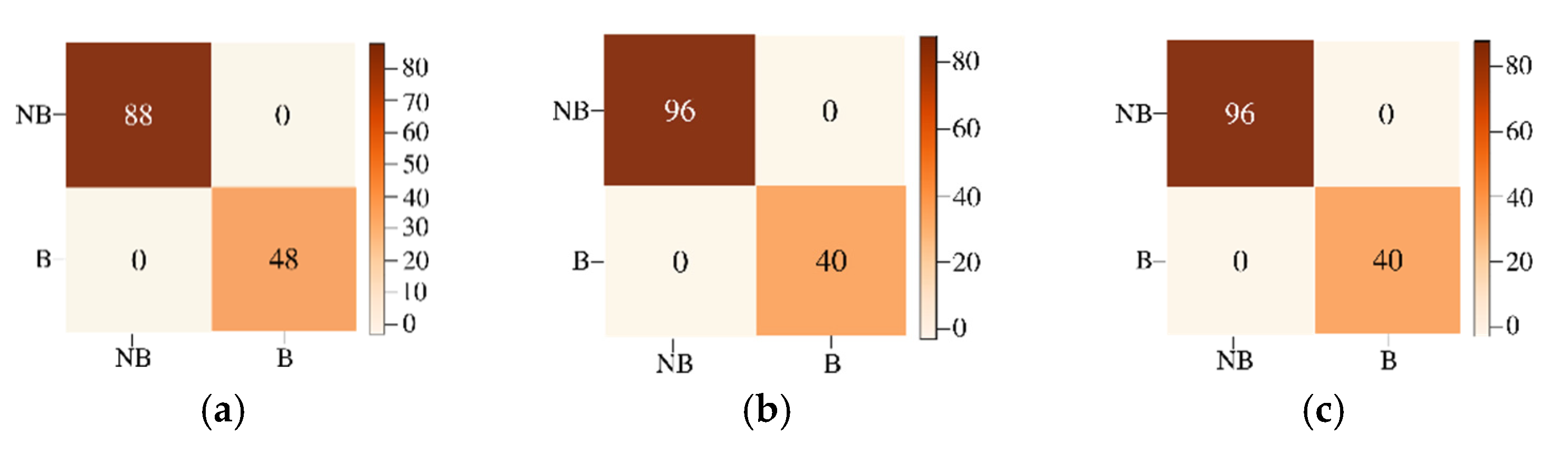
29] random labeling of the HSI pixels is used for creating labels. Here, we conduct two classification experiments by generating labels based on groundtruth endmember abundances. For the first experiment, to perform a fixed classification of each pixel to a particular class, we created three labels for each pixel from the endmember abundances as strongly belong, weakly belong, and does not belong to one of the three original groundtruth classes. If the fractional abundance is greater than 0.8, then the pixel is labeled as strongly belonging to the class. If the fractional abundance is less than 0.8, then the pixel weakly belongs to the class, and if the abundance is 0 the pixel does not belong to the class. All the four machines are trained with training batches for the three groundtruth classes and for the three labels for each of the three groundtruth classes resulting in training of nine classes. We also conduct a second classification experiment with two labels for pixels. The pixel is labeled as strongly belonging to the class if the abundance is less than the groundtruth maximum value for the class and greater than 0.4. If the pixel value is greater than the minimum groundtruth value and less than 0.4, it is labeled as not belonging to the class, resulting in the training of 6 classes. For both the experiments, 10 fold cross-validation is done which results in the training of a total of 90, and 60 models for both experiments, respectively. We have effectively converted an unmixing problem into a classification problem by assigning fixed labels to pixels with fractional abundances by thresholding. The procedure for preprocessing and extraction of batch sizes for training and testing are explained below.
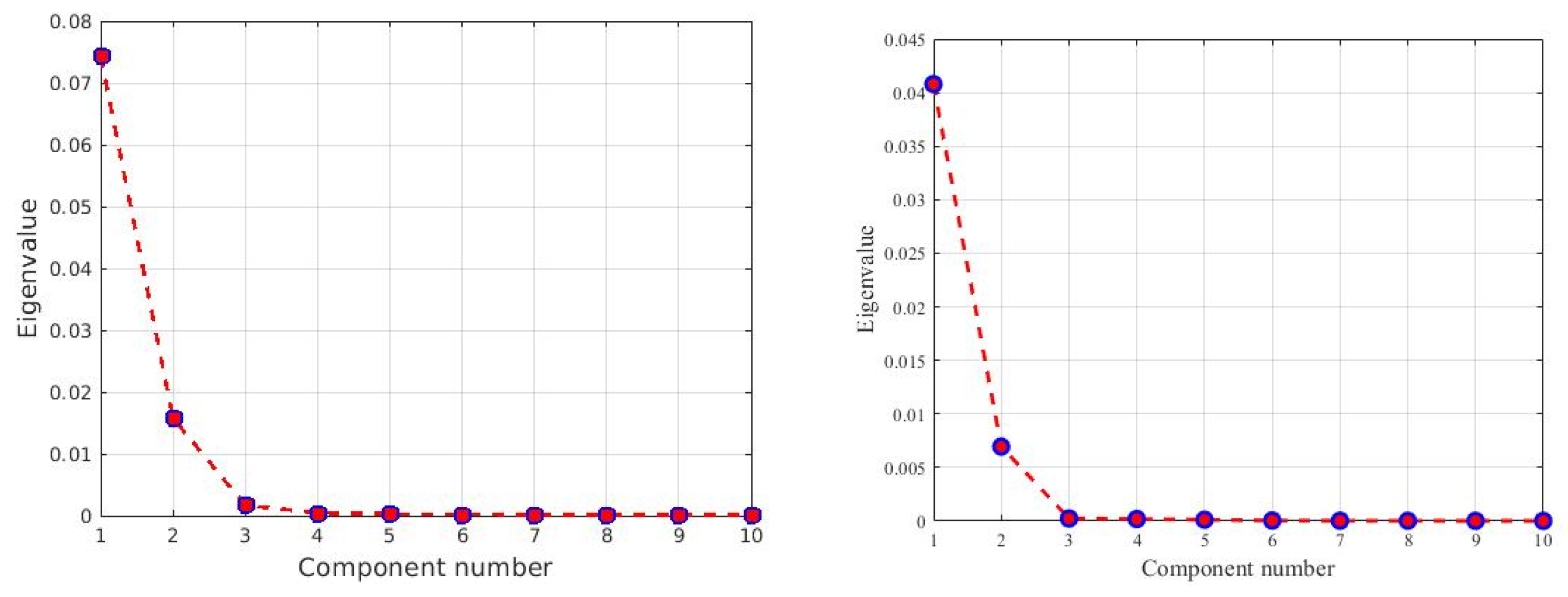
Firstly, PCA is applied to the Jasper image, and three, five, and seven dominant PCA bands are selected. The batch selection process consists of the random extraction of parts of the image by class. The batches are divided into groups for training, testing, and left-over data. Batch sizes for the training data are 820, 1000, and 1500 pixels. The data is split into training data, testing data corresponding to the same selected batch size as training data, and the remaining data not used for training or testing is used only for the image reconstruction. This data is around 400 pixels. The training is done with less than 2% of the pixels of Jasper HSI for each class.
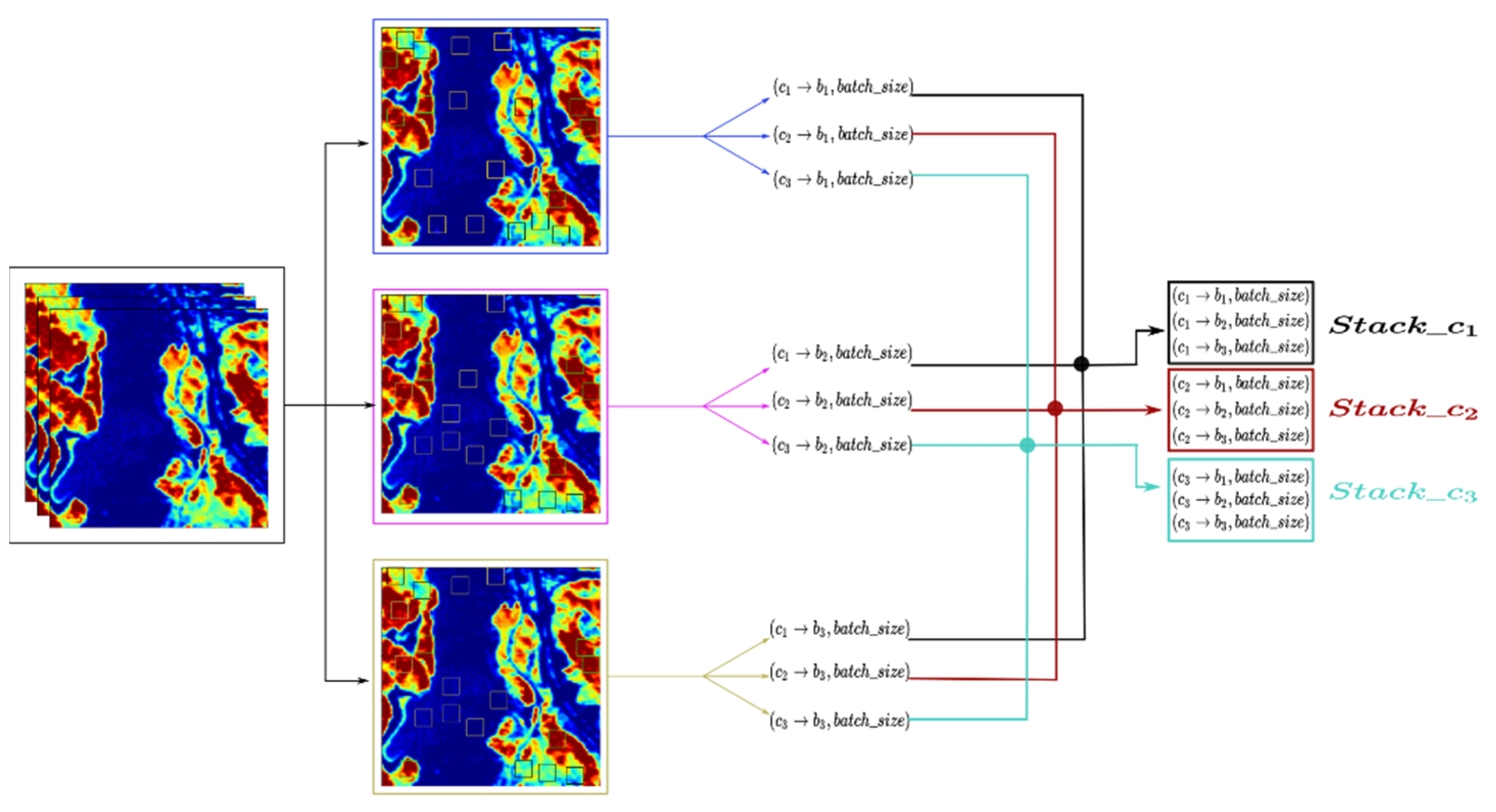
Figure 5 explains the batch size extraction process for three PCA bands with min–max scaling. The experiment is repeated with max-scaling and normalization. Finally, the batches are stacked for training the models. For two labels (strongly belong, and does not belong), the training batch sizes are (6 × 820 pixels), where 6 corresponds to two batches for each of the three PCA bands. The six batches per class are stacked together for training the models for all three classes. The testing batch sizes are (9 × 820 pixels) where 9 corresponds to three batches for each of the three PCA bands which are stacked together for testing for the three classes. There is a remaining 980 pixels of left-over data which is used for image reconstruction. The experiment is repeated for batch sizes of 1000 and 1500 pixels. For three labels (strongly belong, weakly belong, and does not belong), the batch sizes are smaller: 300, 500, and 600 pixels. The training is done on the features extracted from the batches.
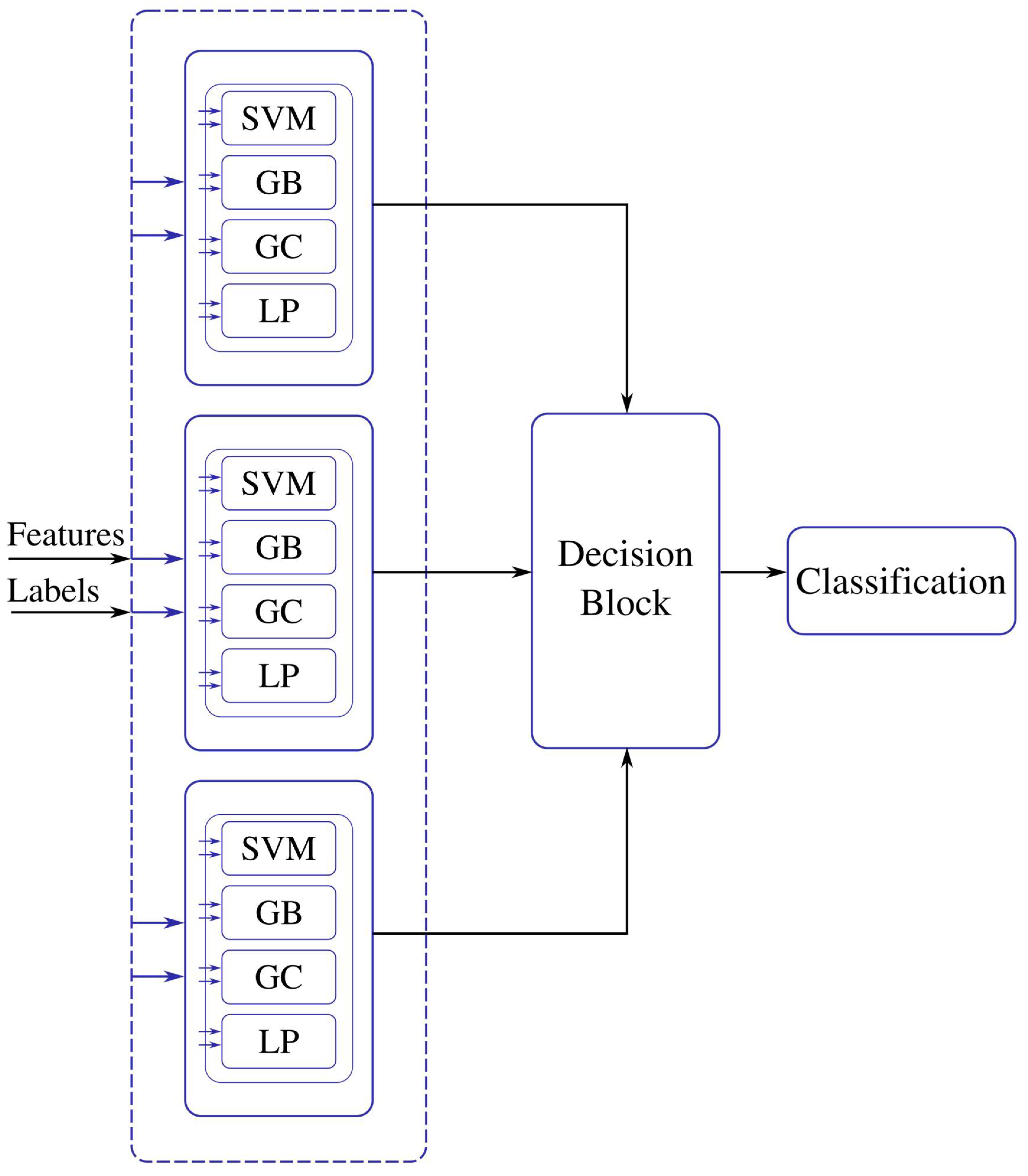
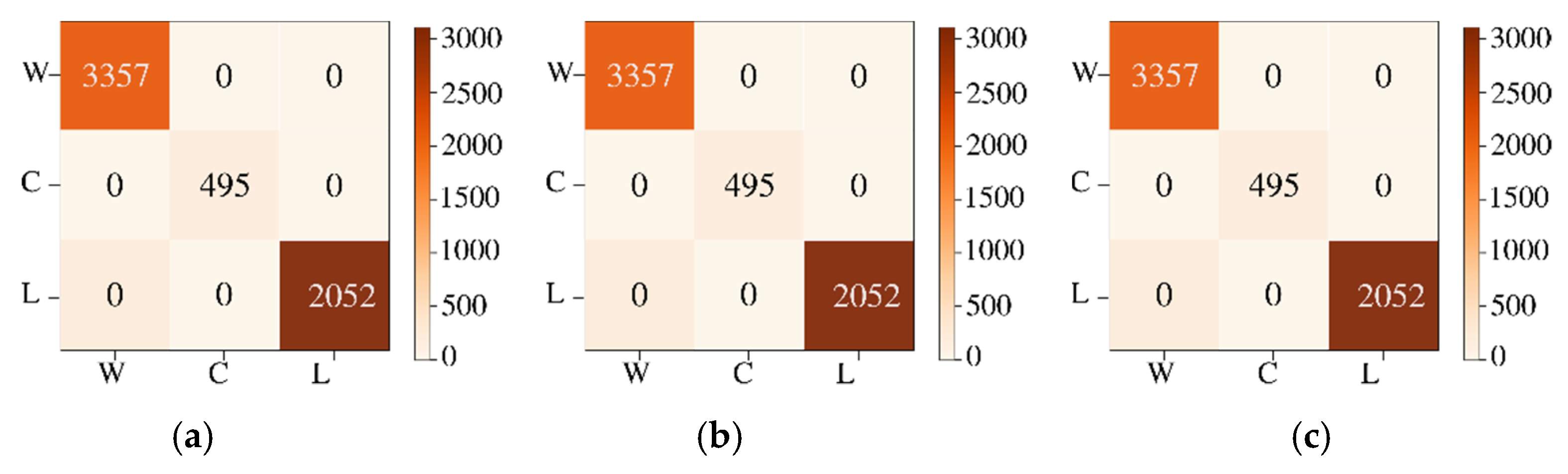
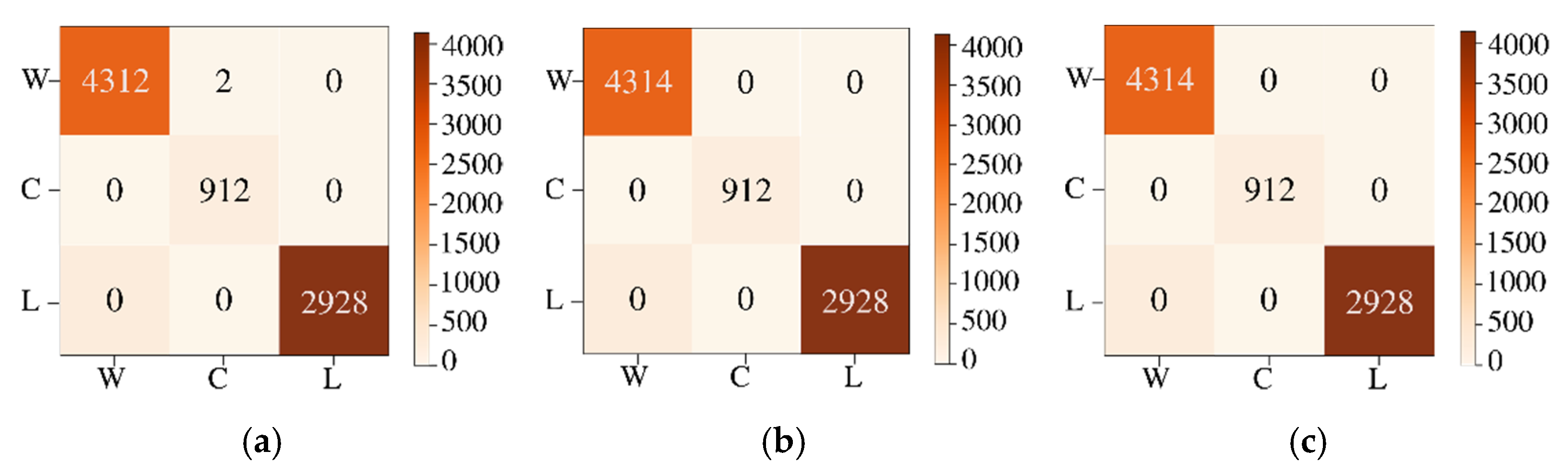
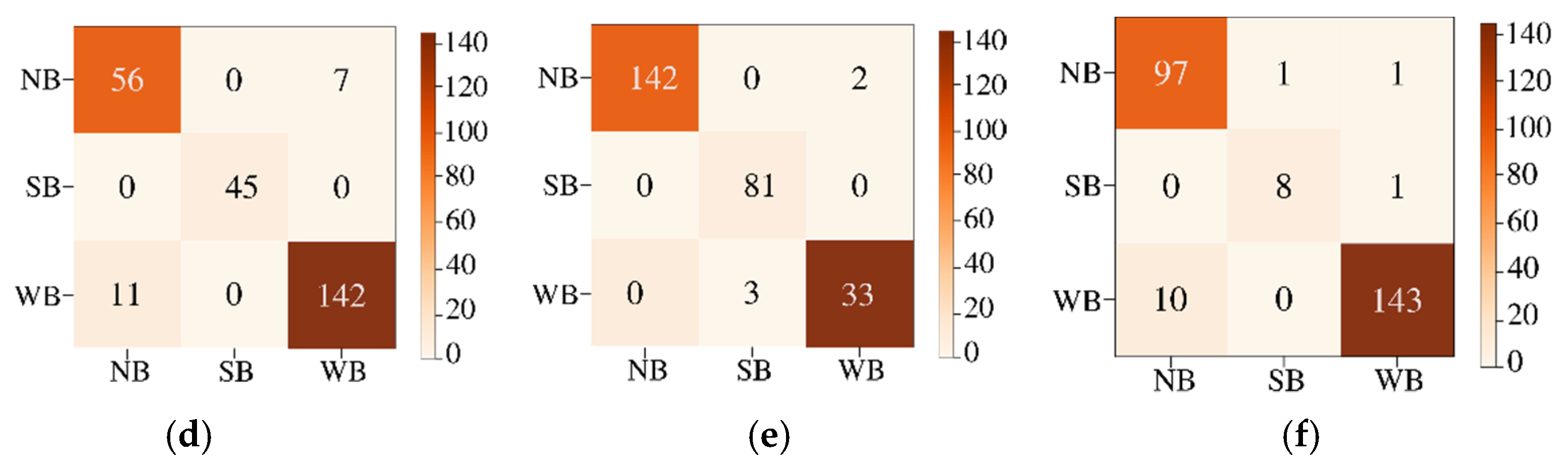
The features are energy, mean, and standard deviation which are calculated on the batches of pixels. The ML models are trained with the computed features. The ensemble model for the training process for the three classes, trees, water, and soil, is shown in
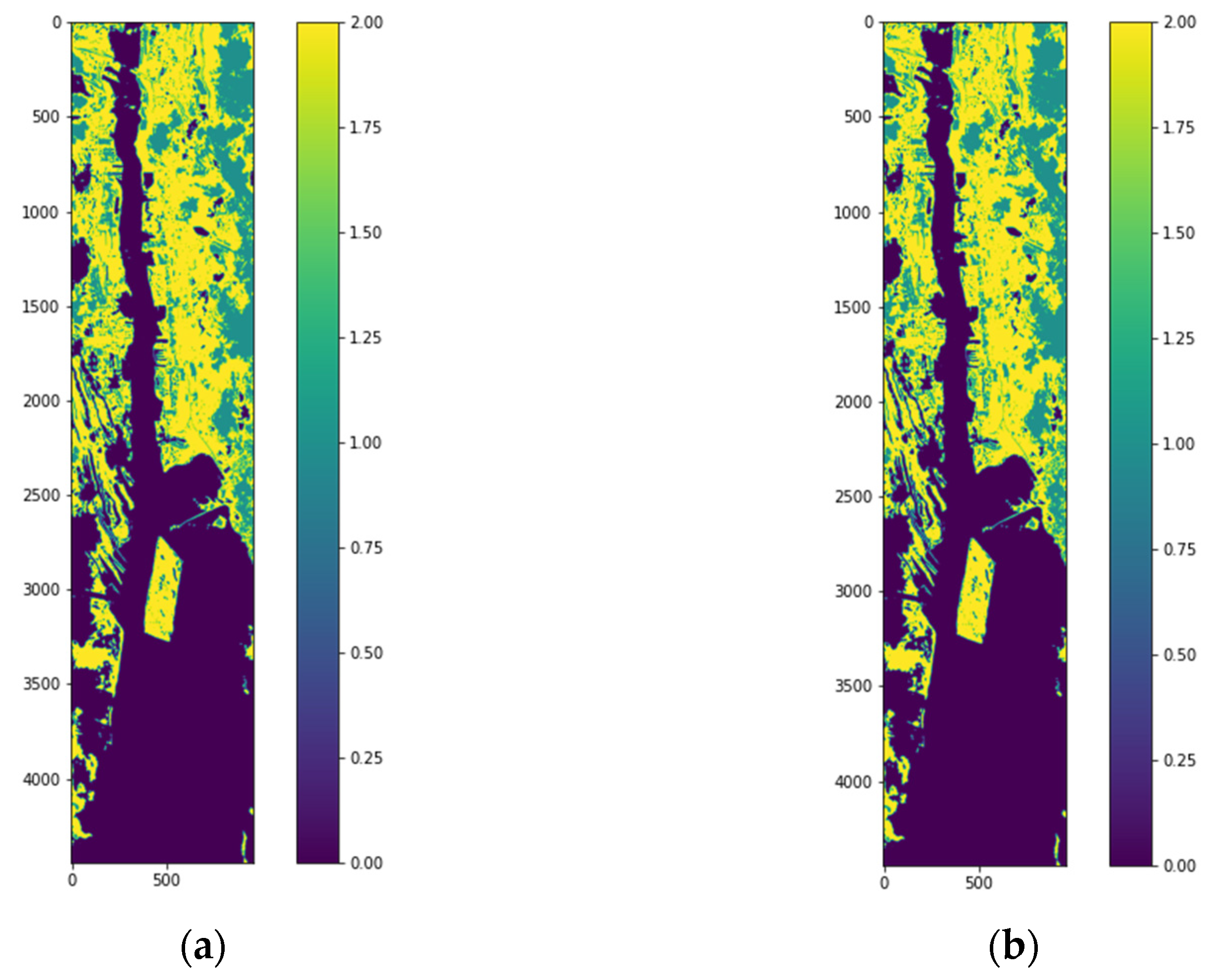
Figure 6. The labeled testing pixels are then used to reconstruct the classified Jasper image with color code for each class.
Pseudocode description of the algorithms for the image enhancement features block, supervised ML block, and decision block are given below.
- A.
Pseudo code feature enhancement block
Input: Hyperspectral Image
Output: Stacked vector Enhancement
Begin:
compute the energy feature using Equation (1)
compute the mean using Equation (2)
compute the standard deviation using Equation (3)
concatenate the energy, mean and standard deviation in to a data frame
Return Stacked enhancement vector
The enhancement features block is applied to obtain the spectral features representation. The input is the 1-D reshaped hyperspectral image vector placed as columns for each of the bands, then the energy, mean, and standard deviation feature are extracted. Finally, the data is stacked in to a data frame.
- B.
Pseudo code supervised machine learning block
Input: dataset train (data), label for dataset train (label), tolerance, kernel, depth, estimators
Output: Models
Begin: Initialize variables for accuracy, F1 score, confusion matrix for the models (metrics)
For 10-fold cross validation of the data
compute SVM Model using data, label, and tolerance
compute GB Model using data, label, estimators, and depth
compute LP Model using data, label, and tolerance
compute GC Model using data, label, and kernel
compute accuracy score for the four models
compute F1 score for the four models
compute confusion matrix score for the four models
save (SVM Model, GB Model, LP Model, GC Model)
append accuracy, F1-score, confusion matrix
Return Models, metrics
The unsupervised machine learning block proposed is composed of four machine learning methods: SVM, GB, GC, LP. The models are trained using a 10-fold cross-validation methodology. Then, the input of the machine learning blocks is the selected training data, the respective labels, and the tuning parameters. The tuning parameters are configured for each machine learning technique as follow:
SVM is set using a linear kernel, and hinge as a loss function and tolerance values of 1 × 10−3. The Gradient Boosting parameter is the depth of the individual regression estimator which is set to 10, the number of boosting stages is 100, and the learning rate for each tree is 1.0. The LP classifier is set to tolerance or stopping criteria of 1 × 10−5. The Gaussian classifier is set with the RBF kernel using L-BFGS quasi-Newton methods as an optimization function.
- C.
Pseudo code decision block
Input: data_test (batch_size, features), label (batch_size), models
Output: Best classifiers
Begin: Initialize dictionary metrics variable (accuracy, F1 score, confusion matrix, training data, predicted labels), maximum accuracy variable
For each folderModels
For each Model
load model
compute accuracy
compute F1 score
compute confusion matrix
append accuracy, F1 score, confusion matrix, model, and variables in dictionary metrics
concatenate dictionary metrics in a pandas data frame
obtain the best model classifier using the accuracy criteria
Return best classifier
The above pseudocode procedure is for the principal blocks of the workflow in
Figure 2 and
Figure 6. The rest of the blocks that include preprocessing methods for scaling, and dimensionality reduction using PCA are straightforward to compute.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}