
A Transfer Learning Framework with a One-Dimensional Deep Subdomain Adaptation Network for Bearing Fault Diagnosis under Different Working Conditions


Abstract
:1. Introduction
2. Related Works
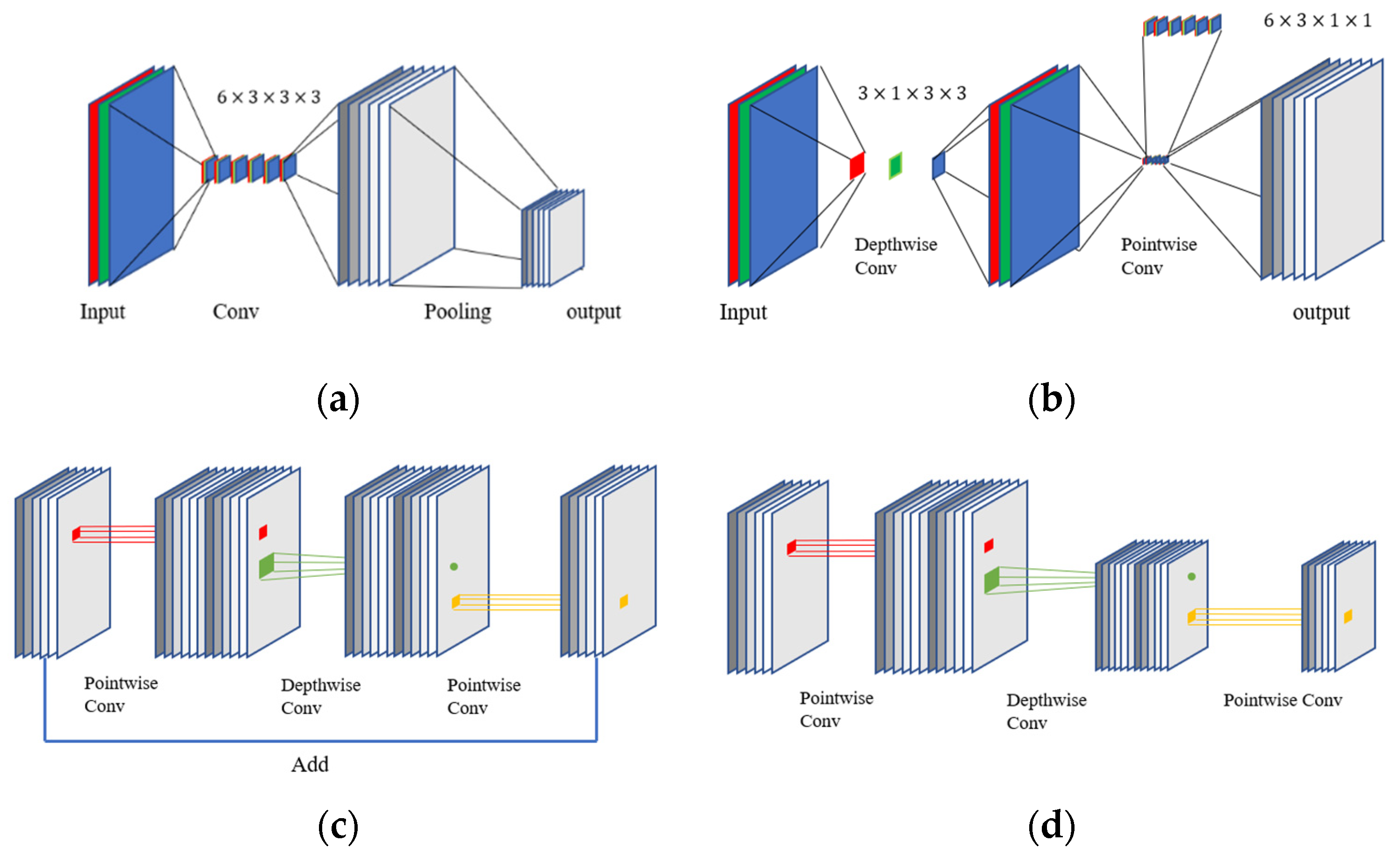
2.1. Convolutional Neural Network
2.2. Domain Adaptation
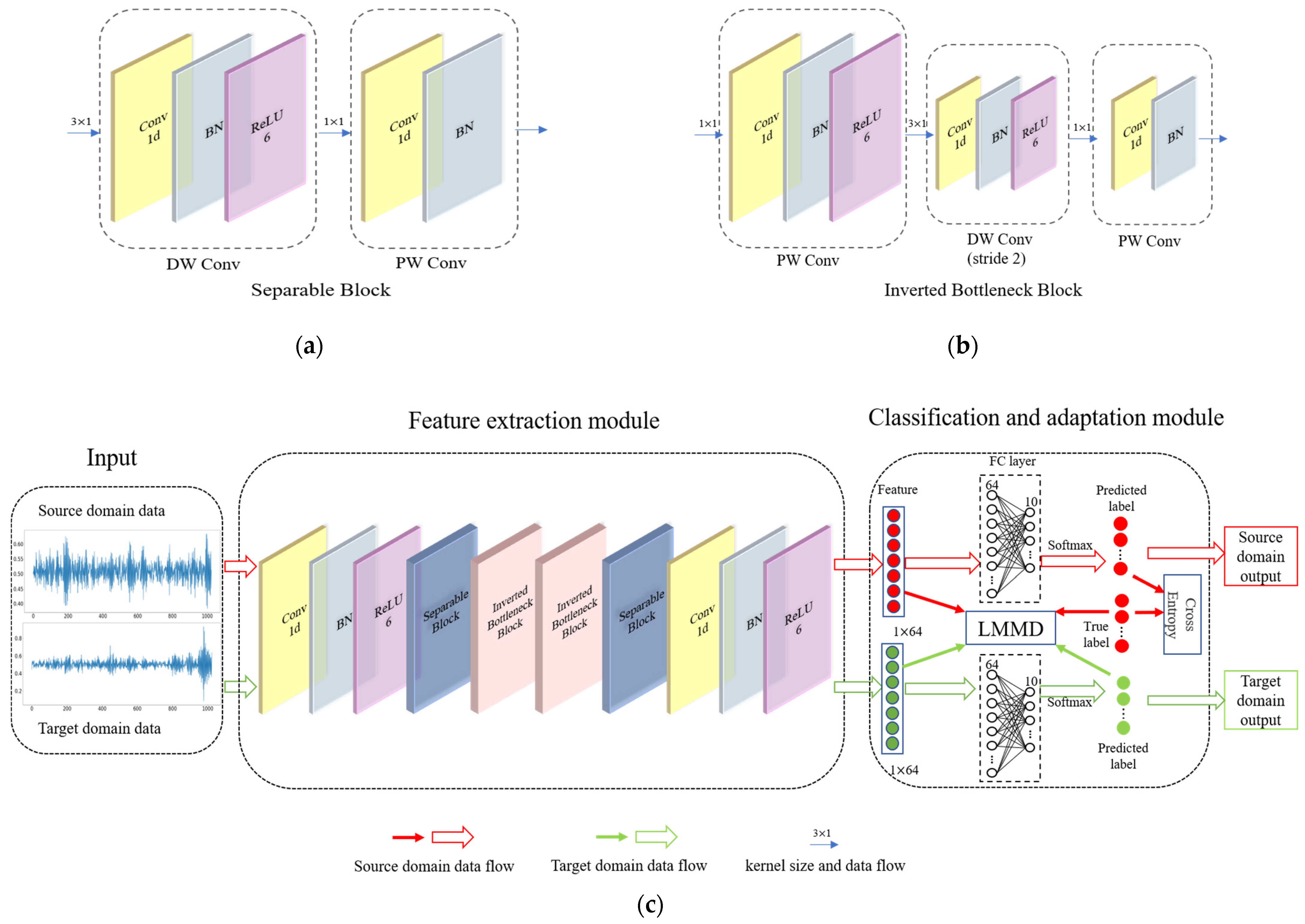
2.3. MobileNet V2
2.4. Local Maximum Mean Discrepancy (LMMD)
3. Materials and Methods
3.1. Framework Structure
3.1.1. Feature Extraction Module
3.1.2. Classification and Adaptation Module
3.2. Optimization Objectives
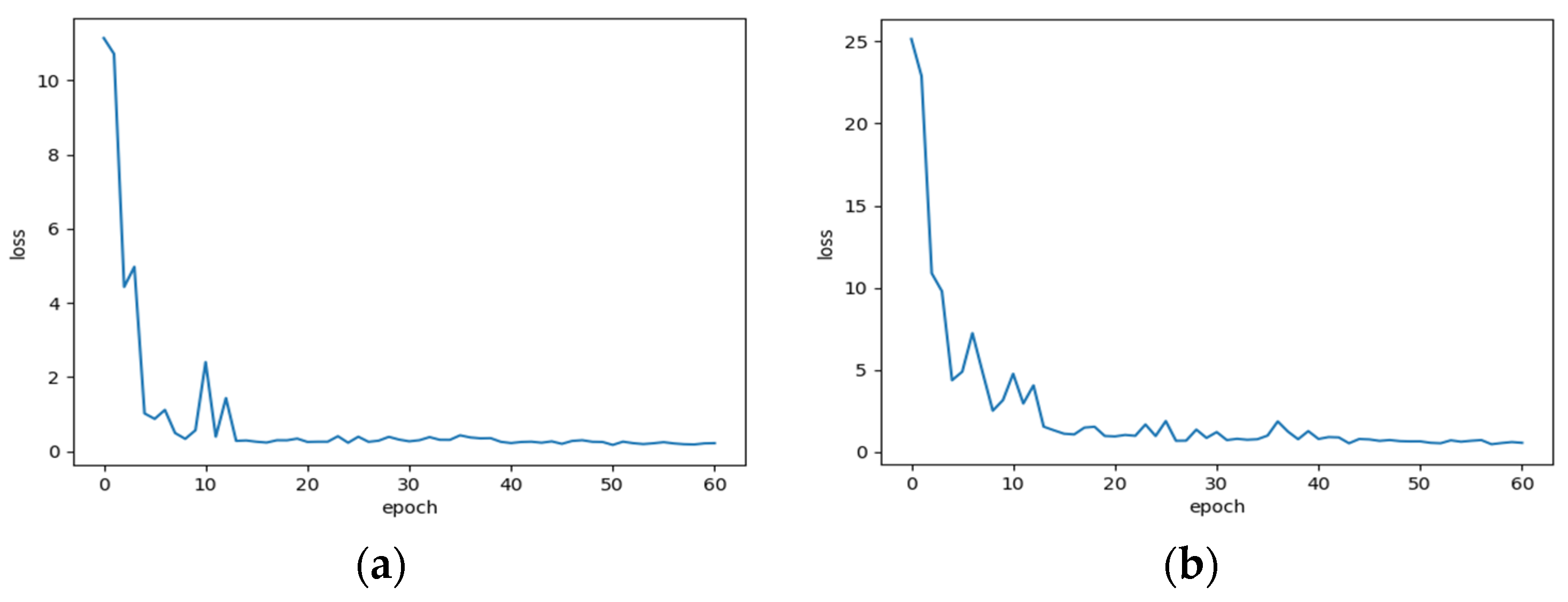
3.3. Network Training Strategy
| Algorithm 1 1D-LDSAN. |
| Input: labeled source domain data and unlabeled target domain data. Output: predicted category of target domain. Begin Step 1: normalize source domain and target domain data Step 2: initial neural network parameters with random values Step 3: input the normalized source domain and target domain data into the neural network to calculate and Step 4: optimize the parameters of neural network using Adam strategy, repeat Step 3 and Step 4 until the specified epoch is reached Step 5: save the model Step 6: diagnose the target domain data using the trained model Step 7: output the classification results End |
4. Experiments
4.1. Dataset Description
4.2. Comparison of Different Signal Lengths
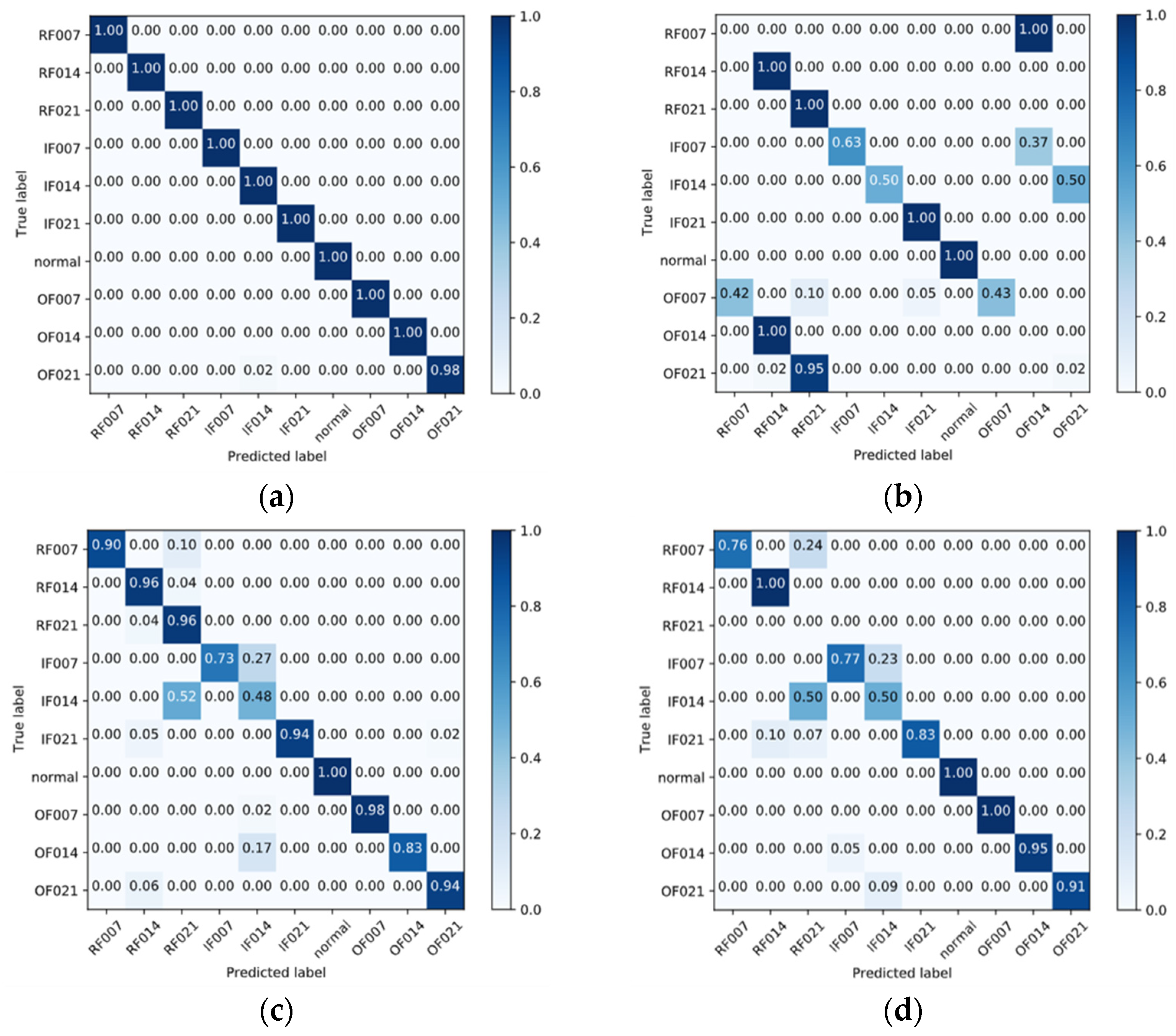
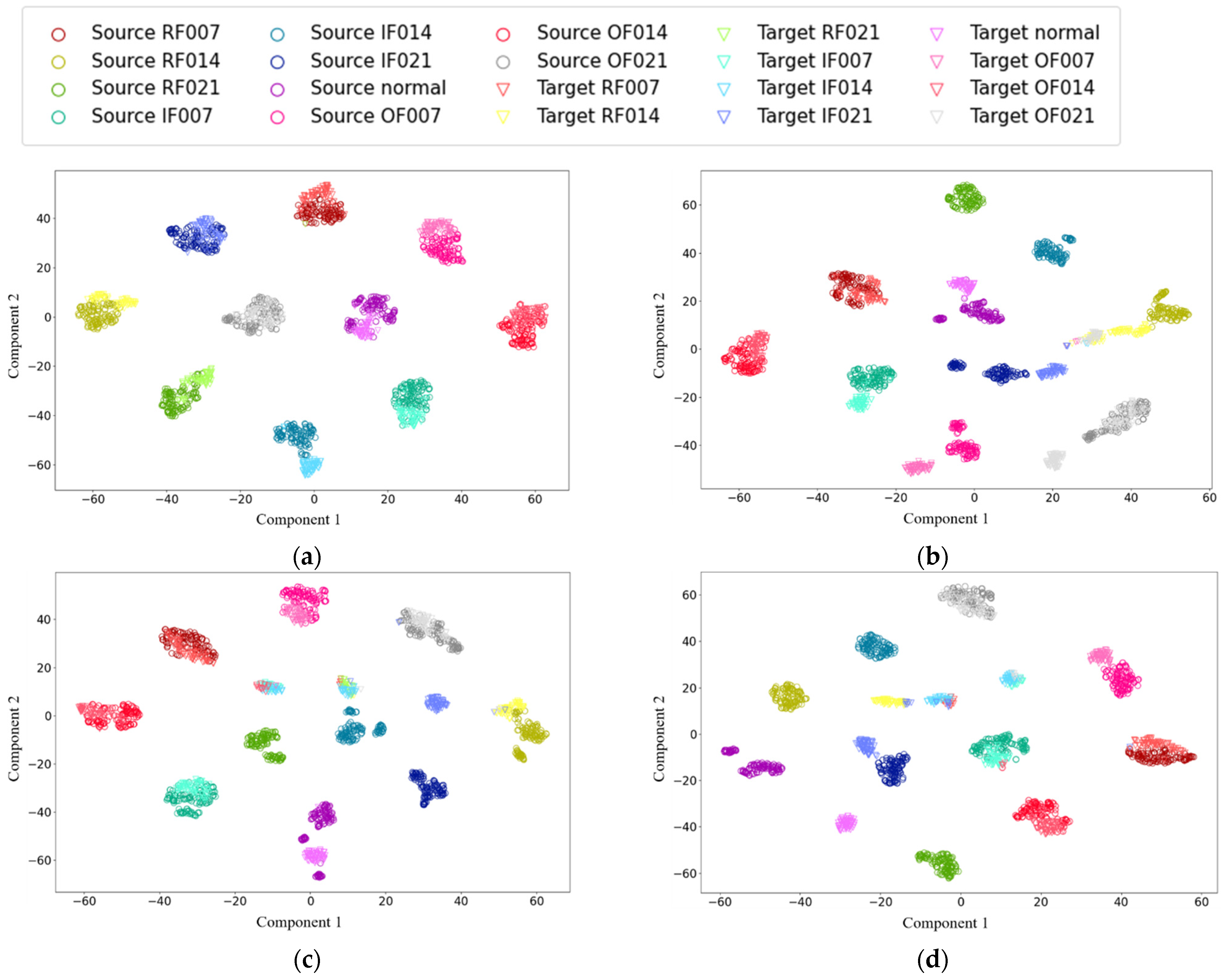
4.3. Comparison with Other Transfer Learning Methods
4.4. Verification with a Small Proportion of the Target Domain Data
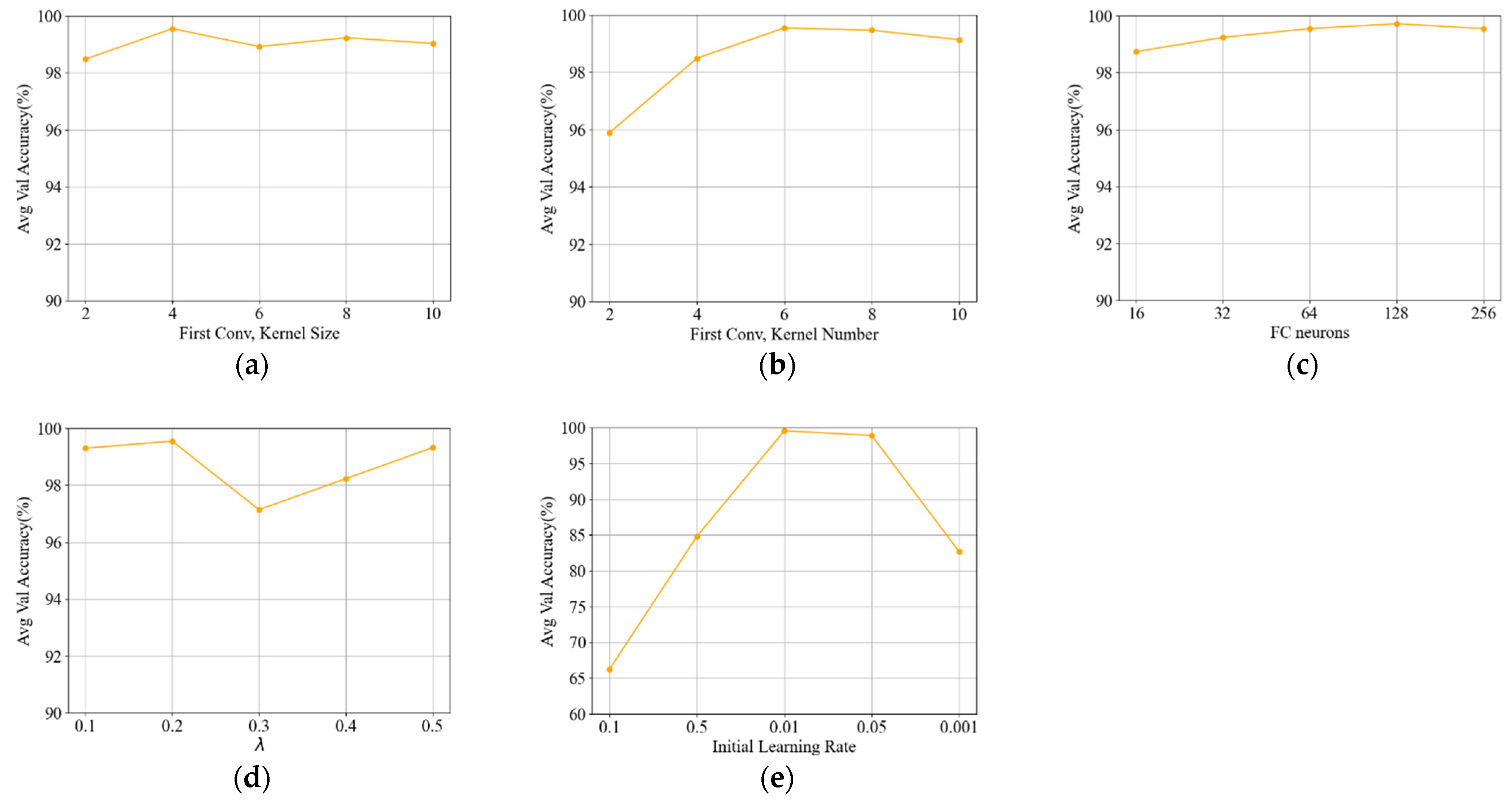
4.5. Parameter Sensitivity Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tang, S.; Yuan, S.; Zhu, Y. Convolutional Neural Network in Intelligent Fault Diagnosis toward Rotatory Machinery. IEEE Access 2020, 8, 86510–86519. [Google Scholar] [CrossRef]
- Lang, X.; Steven, C.; Paolo, P. Rolling element bearing diagnosis based on singular value decomposition and composite squared envelope spectrum. Mech. Syst. Signal Process. 2021, 148, 107174. [Google Scholar]
- Hoang, D.T.; Kang, H.J. A survey on Deep Learning based bearing fault diagnosis. Neurocomputing 2019, 335, 327–335. [Google Scholar] [CrossRef]
- Cerrada, M.; Sanchez, R.V.; Li, C.; Pacheco, F.; Cabrera, D.; Oliveira, J.V.D.; Vasquez, R. A review on data-driven fault severity assessment in rolling bearings. Mech. Syst. Signal Process. 2018, 99, 169–196. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Wang, B.; Thomas, G.H. Deep Learning Algorithms for Bearing Fault Diagnostics—A Comprehensive Review. IEEE Access 2020, 8, 29857–29881. [Google Scholar] [CrossRef]
- Xu, X.; Cao, D.; Zhou, Y.; Gao, J. Application of neural network algorithm in fault diagnosis of mechanical intelligence. Mech. Syst. Signal Process. 2020, 141, 106625. [Google Scholar] [CrossRef]
- Testa, A.; Cinque, M.; Coronato, A.; Pietro, G.D.; Augusto, J.C. Heuristic strategies for assessing wireless sensor network resiliency: An event-based formal approach. J. Heuristics 2015, 21, 145–175. [Google Scholar] [CrossRef] [Green Version]
- Wei, H.; Zhang, Q.; Shang, M.; Gu, Y. Extreme learning Machine-based classifier for fault diagnosis of rotating Machinery using a residual network and continuous wavelet transform. Measurement 2021, 183, 109864. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Ma, H.; Luo, Z.; Li, X. Federated learning for machinery fault diagnosis with dynamic validation and self-supervision. Knowl.-Based Syst. 2021, 213, 106679. [Google Scholar] [CrossRef]
- Neupane, D.; Seok, J. Bearing Fault Detection and Diagnosis Using Case Western Reserve University Dataset with Deep Learning Approaches: A Review. IEEE Access 2020, 8, 93155–93178. [Google Scholar] [CrossRef]
- Song, X.; Zhu, D.; Liang, P.; An, L. A New Bearing Fault Diagnosis Method Using Elastic Net Transfer Learning and LSTM. J. Intell. Fuzzy Syst. 2021, 40, 12361–12369. [Google Scholar] [CrossRef]
- Shen, C.; Xie, J.; Wang, D.; Jiang, X.; Shi, J.; Zhu, Z. Improved Hierarchical Adaptive Deep Belief Network for Bearing Fault Diagnosis. Appl. Sci. 2019, 9, 3374. [Google Scholar] [CrossRef] [Green Version]
- Shao, S.; Yan, R.; Lu, Y.; Wang, P.; Gao, R.X. DCNN-Based Multi-Signal Induction Motor Fault Diagnosis. IEEE Trans. Instrum. Meas. 2020, 6, 2658–2669. [Google Scholar] [CrossRef]
- Jv, A.; Yqc, A.; Jing, W.B. FaultFace: Deep Convolutional Generative Adversarial Network (DCGAN) based Ball-Bearing failure detection method. Inf. Sci. 2021, 542, 195–211. [Google Scholar]
- Ince, T.; Kiranyaz, S.; Eren, L.; Askar, M.; Gabbouj, M. Real-Time Motor Fault Detection by 1-D Convolutional Neural Networks. IEEE Trans. Ind. Electron. 2016, 63, 7067–7075. [Google Scholar] [CrossRef]
- Cheng, C.; Zhou, B.; Ma, G.; Wu, D.; Yuan, Y. Wasserstein distance based deep adversarial transfer learning for intelligent fault diagnosis with unlabeled or insufficient labeled data. Neurocomputing 2020, 409, 35–45. [Google Scholar] [CrossRef]
- Zhang, B.; Li, W.; Li, X.; Ng, S. Intelligent Fault Diagnosis Under Varying Working Conditions Based on Domain Adaptive Convolutional Neural Networks. IEEE Access 2018, 6, 66367–66384. [Google Scholar] [CrossRef]
- Wang, K.; Wei, Z.; Xu, A.; Zeng, P.; Yang, S. One-Dimensional Multi-Scale Domain Adaptive Network for Bearing-Fault Diagnosis under Varying Working Conditions. Sensors 2020, 21, 6039. [Google Scholar] [CrossRef]
- Pan, S.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. arXiv 2014, arXiv:1409.7495. [Google Scholar]
- Yang, B.; Li, Q.; Chen, L.; Shen, C. Bearing Fault Diagnosis Based on Multilayer Domain Adaptation. Shock Vib. 2020, 2020, 8873960. [Google Scholar] [CrossRef]
- Wu, J.; Tang, T.; Chen, M.; Wang, Y.; Wang, K. A study on adaptation lightweight architecture based deep learning models for bearing fault diagnosis under varying working conditions. Expert Syst. Appl. 2020, 160, 113710. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Ma, H.; Luo, Z.; Li, X. Open-Set Domain Adaptation in Machinery Fault Diagnostics Using Instance-Level Weighted Adversarial Learning. IEEE Trans. Ind. Inform. 2021, 17, 7445–7455. [Google Scholar] [CrossRef]
- Jiao, J.; Zhao, M.; Lin, J.; Liang, K. Residual joint adaptation adversarial network for intelligent transfer fault diagnosis. Mech. Syst. Signal Process. 2020, 145, 106962. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhuang, F.; Wang, J.; Ke, G.; Chen, J.; Bian, J.; Xiong, H.; He, Q. Deep Subdomain Adaptation Network for Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1713–1722. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A New Deep Learning Model for Fault Diagnosis with Good Anti-Noise and Domain Adaptation Ability on Raw Vibration Signals. Sensors 2017, 2, 425. [Google Scholar] [CrossRef] [PubMed]
- Yu, D.; Gu, Y. A Machine Learning Method for the Fine-Grained Classification of Green Tea with Geographical Indication Using a MOS-Based Electronic Nose. Foods 2021, 10, 795. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- He, Z.; Shao, H.; Zhong, X.; Zhao, X. Ensemble transfer CNNs driven by multi-channel signals for fault diagnosis of rotating machinery cross working conditions. Knowl.-Based Syst. 2020, 207, 106396. [Google Scholar] [CrossRef]
- Glorot, X.; Antoine, B.; Yoshua, B. Deep Sparse Rectifier Neural Networks. J. Mach. Learn. Res. 2011, 15, 315–323. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.; Henderson, D.; Howard, R.; Hubbard, W.; Jackel, L. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Yu, C.; Wang, J.; Chen, Y.; Huang, M. Transfer Learning with Dynamic Adversarial Adaptation Network. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 778–786. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning transferable features with deep adaptation networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICML’15), Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]
- Zhang, W.; Li, X.; Ma, H.; Luo, Z.; Li, X. Universal Domain Adaptation in Fault Diagnostics with Hybrid Weighted Deep Adversarial Learning. IEEE Trans. Ind. Inform. 2021, 17, 7957–7967. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural net-works for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, CA, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zheng, H.; Gu, Y. EnCNN-UPMWS: Waste Classification by a CNN Ensemble Using the UPM Weighting Strategy. Electronics 2021, 10, 427. [Google Scholar] [CrossRef]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef] [Green Version]
- Boer, P.; Kroese, D.P.; Mannor, S.; Rubinstein, R.A. Tutorial on the Cross-Entropy Method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Li, Q.; Shen, C.; Chen, L.; Zhu, Z. Knowledge mapping-based adversarial domain adaptation: A novel fault diagnosis method with high generalizability under variable working conditions. Mech. Syst. Signal Process. 2021, 147, 107095. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Case Western Reserve University Bearing Dataset. Available online: https://engineering.case.edu/bearingdatacenter (accessed on 21 January 2022).
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep Domain Confusion: Maximizing for Domain Invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Zhang, M.; Wang, D.; Lu, W.; Yang, J.; Li, Z.; Liang, B. A Deep Transfer Model with Wasserstein Distance Guided Multi-Adversarial Networks for Bearing Fault Diagnosis under Different Working Conditions. IEEE Access 2019, 7, 65303–65318. [Google Scholar] [CrossRef]
- Laurens, V.D.M.; Hinton, G. Visualizing data using t-SNE. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block | Layer | Parameters | Output Size |
|---|---|---|---|
| Input | Input | / | 1024 × 1 |
| Regular Conv | ConvBNReLU6 | Kernel size = 6@4 × 1 × 1 stride = 4 | 256 × 6 |
| Separable Block | ConvBNReLU6 | Kernel size = 6@3 × 1 stride = 1 | 256 × 6 |
| ConvBN | Kernel size = 16@1 × 1v4 stride = 1 | 256 × 16 | |
| Inverted Bottleneck Block | ConvBNReLU6 | Kernel size = 96@1 × 1 × 16 stride = 1 | 256 × 96 |
| ConvBNReLU6 | Kernel size = 96@3 × 1 stride = 2 | 128 × 96 | |
| ConvBN | Kernel size = 24@1 × 1 × 96 stride = 1 | 128 × 24 | |
| Inverted Bottleneck Block | ConvBNReLU6 | Kernel size = 144@1 × 1 × 24 stride = 1 | 128 × 144 |
| ConvBNReLU6 | Kernel size = 144@3 × 1 stride = 2 | 64 × 144 | |
| ConvBN | Kernel size = 32@1 × 1 × 144 stride = 1 | 64 × 32 | |
| Separable Block | ConvBNReLU6 | Kernel size = 32@3 × 1 stride = 1 | 64 × 32 |
| ConvBN | Kernel size = 48@1 × 1 × 32 stride = 1 | 64 × 48 | |
| Regular Conv | ConvBNReLU6 | Kernel size = 64@1 × 1 × 48 stride = 1 | 64 × 64 |
| Avg Pooling | / | / | 1 × 64 |
| Domain | Load (HP) | Rotating Speed (r/min) | Number of Samples | Number of Labels |
|---|---|---|---|---|
| A | 0 | 1797 | 1186 | 10 |
| B | 1 | 1772 | 1186 | 10 |
| C | 2 | 1750 | 1185 | 10 |
| D | 3 | 1730 | 1189 | 10 |
| Domain | 256 Points | 512 Points | 1024 Points | 2048 Points |
|---|---|---|---|---|
| A | 4763 | 2379 | 1186 | 591 |
| B | 4762 | 2379 | 1186 | 591 |
| C | 4760 | 2377 | 1185 | 591 |
| D | 4769 | 2383 | 1189 | 592 |
| Task | 256 Points | 512 Points | 1024 Points | 2048 Points |
|---|---|---|---|---|
| A-B | 98.84% | 99.65% | 99.90% | 99.93% |
| A-C | 97.04% | 99.45% | 99.89% | 99.90% |
| A-D | 97.44% | 99.64% | 99.98% | 99.90% |
| B-A | 98.94% | 99.79% | 99.96% | 98.70% |
| B-C | 99.11% | 99.66% | 100.00% | 99.93% |
| B-D | 95.96% | 96.27% | 99.97% | 99.93% |
| C-A | 97.95% | 98.90% | 99.77% | 98.80% |
| C-B | 98.44% | 99.45% | 99.55% | 99.73% |
| C-D | 98.70% | 99.80% | 99.93% | 99.97% |
| D-A | 94.16% | 97.11% | 99.54% | 98.80% |
| D-B | 92.42% | 95.94% | 99.48% | 97.17% |
| D-C | 98.28% | 99.19% | 99.89% | 99.77% |
| AVG | 97.27% | 98.74% | 99.82% | 99.38% |
| Task | 1D-CNN | DDC | DANN | WDMAN [15] | Task | 1D-CNN |
|---|---|---|---|---|---|---|
| A-B | 99.23% | 98.12% | 99.53% | 99.73% | 99.20% | 99.90% |
| A-C | 89.20% | 93.61% | 95.50% | 99.67% | 99.37% | 99.89% |
| A-D | 77.88% | 84.36% | 84.43% | 100.00% | 99.37% | 99.98% |
| B-A | 98.23% | 98.34% | 97.39% | 99.13% | 99.01% | 99.96% |
| B-C | 91.59% | 98.47% | 98.50% | 100.00% | 99.92% | 100.00% |
| B-D | 78.51% | 79.41% | 88.17% | 99.93% | 99.31% | 99.97% |
| C-A | 88.90% | 88.94% | 92.70% | 98.53% | 99.13% | 99.77% |
| C-B | 90.66% | 92.57% | 93.76% | 99.80% | 99.40% | 99.55% |
| C-D | 84.59% | 90.03% | 90.72% | 100.00% | 99.40% | 99.93% |
| D-A | 77.27% | 78.69% | 79.19% | 98.07% | 98.84% | 99.54% |
| D-B | 69.82% | 72.33% | 76.71% | 98.27% | 99.24% | 99.48% |
| D-C | 80.06% | 83.61% | 86.37% | 99.53% | 99.61% | 99.89% |
| AVG | 85.49% | 88.21% | 90.25% | 99.39% | 99.32% | 99.82% |
| Task | 0% | 10% | 20% | 30% | 40% | 50% |
|---|---|---|---|---|---|---|
| A-B | 99.23% | 99.79% | 99.57% | 99.84% | 99.92% | 99.90% |
| A-C | 89.20% | 99.90% | 99.79% | 99.90% | 99.94% | 99.89% |
| A-D | 77.88% | 98.79% | 98.85% | 99.58% | 97.48% | 99.98% |
| B-A | 98.23% | 99.90% | 99.86% | 99.76% | 99.91% | 99.96% |
| B-C | 91.59% | 99.78% | 99.96% | 99.98% | 99.75% | 100.00% |
| B-D | 78.51% | 99.94% | 99.27% | 99.10% | 99.99% | 99.97% |
| C-A | 88.90% | 99.47% | 99.70% | 99.71% | 99.87% | 99.77% |
| C-B | 90.66% | 99.52% | 99.53% | 99.57% | 99.65% | 99.55% |
| C-D | 84.59% | 99.48% | 99.66% | 99.78% | 99.82% | 99.93% |
| D-A | 77.27% | 99.20% | 99.61% | 98.30% | 99.33% | 99.54% |
| D-B | 69.82% | 98.09% | 98.38% | 99.30% | 99.09% | 99.48% |
| D-C | 80.06% | 99.68% | 99.78% | 99.53% | 99.79% | 99.89% |
| AVG | 85.50% | 99.46% | 99.49% | 99.53% | 99.55% | 99.82% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, R.; Gu, Y. A Transfer Learning Framework with a One-Dimensional Deep Subdomain Adaptation Network for Bearing Fault Diagnosis under Different Working Conditions. Sensors 2022, 22, 1624. https://doi.org/10.3390/s22041624
Zhang R, Gu Y. A Transfer Learning Framework with a One-Dimensional Deep Subdomain Adaptation Network for Bearing Fault Diagnosis under Different Working Conditions. Sensors. 2022; 22(4):1624. https://doi.org/10.3390/s22041624
Chicago/Turabian StyleZhang, Ruixin, and Yu Gu. 2022. "A Transfer Learning Framework with a One-Dimensional Deep Subdomain Adaptation Network for Bearing Fault Diagnosis under Different Working Conditions" Sensors 22, no. 4: 1624. https://doi.org/10.3390/s22041624
APA StyleZhang, R., & Gu, Y. (2022). A Transfer Learning Framework with a One-Dimensional Deep Subdomain Adaptation Network for Bearing Fault Diagnosis under Different Working Conditions. Sensors, 22(4), 1624. https://doi.org/10.3390/s22041624