

Violent Video Recognition by Using Sequential Image Collage





Abstract
1. Introduction
- Proposing an MLP-Mixer-driven framework for violence recognition, distinguished by its reduced computational demands vis-à-vis Transformer-centric models.
- Introducing a composite dataset comprising both image collages that capture the space and time relationships between video frames and unmodified video frames. This composite dataset augments the training process, culminating in a spatio-temporal model exhibiting superior action recognition capabilities.
2. Related Work
2.1. Handcrafted Feature-Based Methods
2.2. Deep Learning-Based Methods
2.3. Transformer-Based Methods
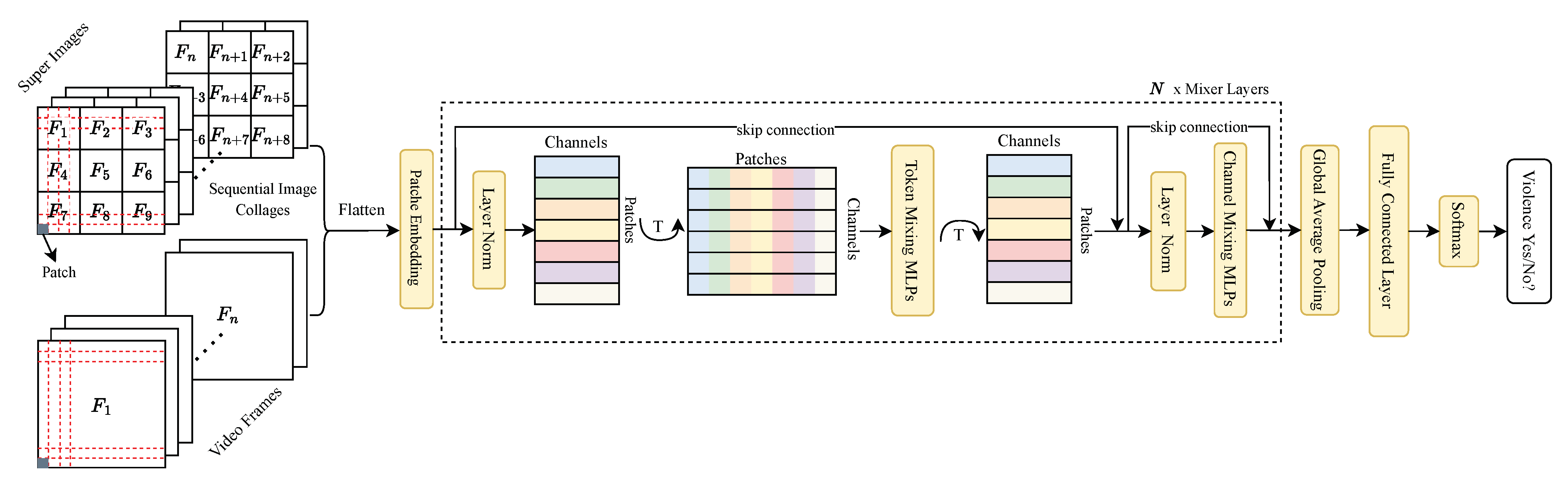
3. Methodology
3.1. Main Architecture
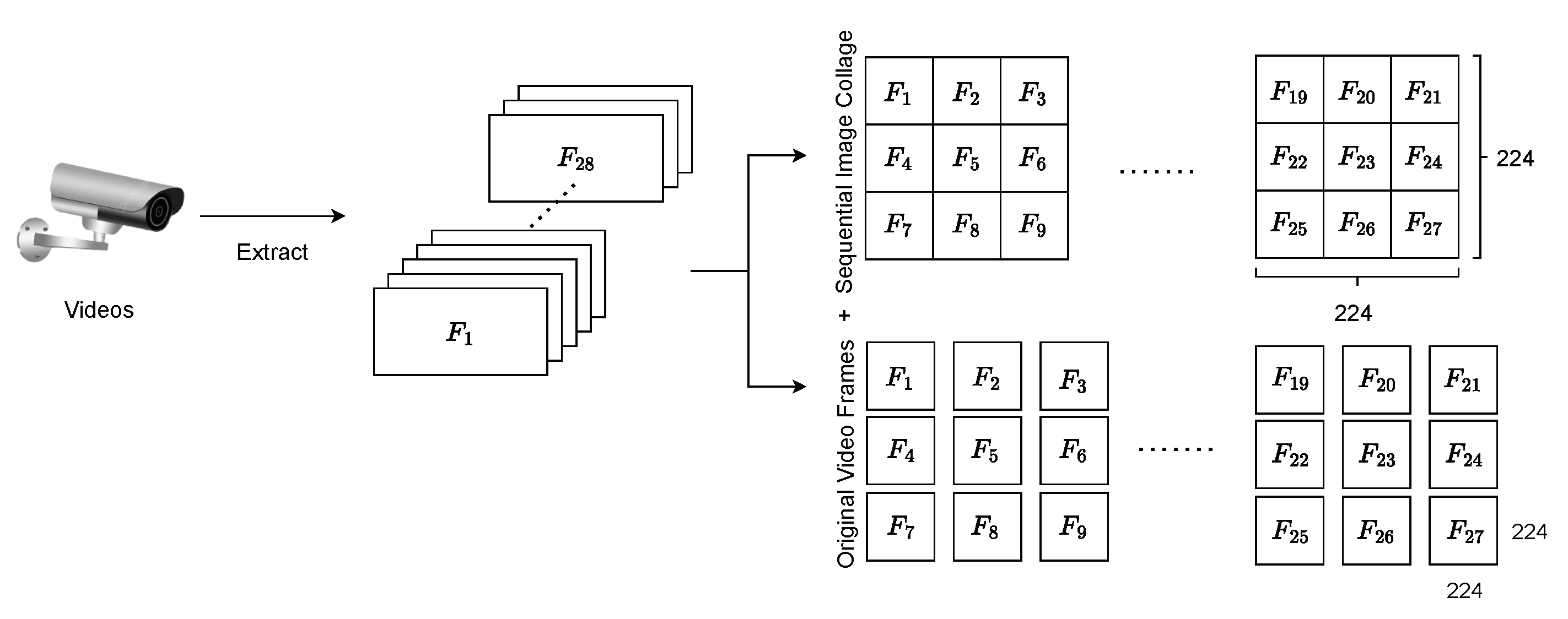
3.2. Dual-form Dataset
3.3. MLP-Mixer
3.4. Sequential Image Collage
4. Experimental Results
4.1. Datasets
- The dataset of smart-city CCTV violence detection (SCVD): The SCVD dataset, as detailed in [56], serves as the primary benchmark. It encompasses three distinct classes: non-violent behavior, violent behavior involving weapons, and violent behavior not involving weapons. The dataset is characterized by varying clip counts across these categories, with 112 clips for weapon violence, 124 for violent behavior, and 248 for non-violent behavior. Notably, during the experimental phase, weapon violence and violent behavior are amalgamated into a singular category. This decision stemmed from the primary objective of discerning the mere presence or absence of violent acts within the imagery.
- The dataset of real-life violence situations (RLVS): This RLVS dataset, introduced in [57], offers a real-world glimpse into violent and non-violent scenarios. It comprises 1000 videos sourced from YouTube, evenly split into violent and non-violent categories. The violent segments predominantly feature actual altercations, such as street skirmishes, while the non-violent segments depict everyday activities—ranging from exercising and eating to walking.
- Hockey fight dataset: The hockey fight dataset, as documented in [17], is tailored specifically for violent behavior recognition within the context of professional ice hockey. It houses 1000 videos, meticulously curated from National Hockey League matches. These videos are evenly distributed, encompassing 500 clips each for violent and non-violent behaviors, providing a specialized lens into the nuances of aggression within a sports setting.
4.2. Hyperparameter Settings
4.3. Results
4.4. Ablation Study
4.4.1. Different Combinations of Super Images
4.4.2. Temporal Shift of Super Image
4.4.3. Different Patch Sizes of SIC
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- Jain, A.; Duin, R.; Mao, J. Statistical pattern recognition: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 4–37. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Laptev, I.; Perez, P. Retrieving actions in movies. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Rahmani, H.; Mian, A.; Shah, M. Learning a Deep Model for Human Action Recognition from Novel Viewpoints. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 667–681. [Google Scholar] [CrossRef]
- Ji, Y.; Yang, Y.; Shen, F.; Shen, H.T.; Zheng, W.S. Arbitrary-View Human Action Recognition: A Varying-View RGB-D Action Dataset. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 289–300. [Google Scholar] [CrossRef]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the International Conference on Pattern Recognition, Cambridge, UK, 26 August 2004; Volume 3, pp. 32–36. [Google Scholar]
- Yang, Q.; Wu, A.; Zheng, W.S. Person Re-identification by Contour Sketch Under Moderate Clothing Change. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2029–2046. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.C.; Hu, M.C.; Cheng, W.H.; Hsieh, Y.H.; Chen, H.M. Human Action Recognition and Retrieval Using Sole Depth Information. In Proceedings of the 20th ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 1053–1056. [Google Scholar]
- Angelini, F.; Fu, Z.; Long, Y.; Shao, L.; Naqvi, S.M. 2D Pose-Based Real-Time Human Action Recognition With Occlusion-Handling. IEEE Trans. Multimed. 2020, 22, 1433–1446. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble methods in machine learning. In Proceedings of the Multiple Classifier Systems, Cagliari, Italy, 21–23 June; Springer: Berlin/H eidelberg, Germany, 2000; pp. 1–15. [Google Scholar]
- Bermejo Nievas, E.; Deniz Suarez, O.; Bueno García, G.; Sukthankar, R. Violence Detection in Video Using Computer Vision Techniques. In Computer Analysis of Images and Patterns; Springer: Seville, Spain; 29–31 August 2011, pp. 332–339.
- Hassner, T.; Itcher, Y.; Kliper-Gross, O. Violent flows: Real-time detection of violent crowd behavior. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 1–6. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. Real-World Anomaly Detection in Surveillance Videos. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Xu, L.; Gong, C.; Yang, J.; Wu, Q.; Yao, L. Violent video detection based on MoSIFT feature and sparse coding. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3538–3542. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Li, J.; Jiang, X.; Sun, T.; Xu, K. Efficient Violence Detection Using 3D Convolutional Neural Networks. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–8. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Ben Mabrouk, A.; Zagrouba, E. Spatio-temporal feature using optical flow based distribution for violence detection. Pattern Recognit. Lett. 2017, 92, 62–67. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, T.; Zhou, J.; Guan, J. Video anomaly detection based on spatio-temporal relationships among objects. Neurocomputing 2023, 532, 141–151. [Google Scholar] [CrossRef]
- Huszár, V.D.; Adhikarla, V.K.; Nágyesi, I.; Krasznay, C. Toward Fast and Accurate Violence Detection for Automated Video Surveillance Applications. IEEE Access 2023, 11, 18772–18793. [Google Scholar] [CrossRef]
- Ravanbakhsh, M.; Nabi, M.; Sangineto, E.; Marcenaro, L.; Regazzoni, C.; Sebe, N. Abnormal event detection in videos using generative adversarial nets. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1577–1581. [Google Scholar]
- Ravanbakhsh, M.; Sangineto, E.; Nabi, M.; Sebe, N. Training Adversarial Discriminators for Cross-Channel Abnormal Event Detection in Crowds. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1896–1904. [Google Scholar]
- Yang, H.; Sun, B.; Li, B.; Yang, C.; Wang, Z.; Chen, J.; Wang, L.; Li, H. Iterative Class Prototype Calibration for Transductive Zero-Shot Learning. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 1236–1246. [Google Scholar] [CrossRef]
- Hu, Z.; Zhang, Y.; Huang, H.; Wen, X.; Agbodike, O.; Chen, J. Reinforcement learning for energy efficiency improvement in UAV-BS access networks: A knowledge transfer scheme. Eng. Appl. Artif. Intell. 2023, 120, 105930. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, ICLR 2021, Virtual, 3–7 May 2021; pp. 1–21. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef]
- Yang, S.; Wang, X.; Li, Y.; Fang, Y.; Fang, J.; Liu, W.; Zhao, X.; Shan, Y. Temporally Efficient Vision Transformer for Video Instance Segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 2875–2885. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. MLP-Mixer: An all-MLP Architecture for Vision. In Proceedings of the 35th Conference on Neural Information Processing Systems, NeurIPS, Virtual, 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Brooklyn, NY, USA, 2021; Volume 34, pp. 24261–24272. [Google Scholar]
- Ojiako, K.; Farrahi, K. MLPs Are All You Need for Human Activity Recognition. Appl. Sci. 2023, 13, 11154. [Google Scholar] [CrossRef]
- Fan, Q.; Chen, C.F.; Panda, R. Can an image classifier suffice for action recognition? In Proceedings of the International Conference on Learning Representations, ICLR, Virtual, 25–29 April 2022; pp. 1–13. [Google Scholar]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Dense trajectories and motion boundary descriptors for action recognition. Int. J. Comput. Vis. 2013, 103, 60–79. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B.; Schmid, C. Human detection using oriented histograms of flow and appearance. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 428–441. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the ACM COLT’92, Fifth Annual ACM Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Lowe, D. Object recognition from local scale-invariant features. In Proceedings of the IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. In Proceedings of the Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K., Eds.; Curran Associates, Inc.: Brooklyn, NY, USA, 2014; Volume 27, pp. 1–9. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Ng, J.Y.H.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016; pp. 20–36. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the 31th Conference on Neural Information Processing Systems, NIPS, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Brooklyn, NY, USA, 2017; pp. 1–11. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. ViViT: A video vision transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 6836–6846. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Goyal, R.; Ebrahimi Kahou, S.; Michalski, V.; Materzynska, J.; Westphal, S.; Kim, H.; Haenel, V.; Fruend, I.; Yianilos, P.; Mueller-Freitag, M.; et al. The “something something” video database for learning and evaluating visual common sense. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5842–5850. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 3202–3211. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. TSM: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7083–7093. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Aremu, T.; Zhiyuan, L.; Alameeri, R.; Saddik, A.E. SIViDet: Salient Image for Efficient Weaponized Violence Detection. arXiv 2023, arXiv:2207.12850. [Google Scholar]
- Soliman, M.M.; Kamal, M.H.; El-Massih Nashed, M.A.; Mostafa, Y.M.; Chawky, B.S.; Khattab, D. Violence Recognition from Videos using Deep Learning Techniques. In Proceedings of the International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 8–10 December 2019; pp. 80–85. [Google Scholar]
- Zhang, H.; Cissé, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. In Proceedings of the International Conference on Learning Representations, ICLR, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–13. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; Bengio, Y., LeCun, Y., Eds.; pp. 1–14. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference On Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Specification | S/16 |
|---|---|
| Patch resolution | 16 × 16 |
| Number of layers | 8 |
| Sequence length S | 196 |
| Hidden size C | 512 |
| MLP dimension | 2048 |
| MLP dimension | 256 |
| Parameters | 18 M |
| Type | Method | Hockey Fight | RLVS | SCVD | |||
|---|---|---|---|---|---|---|---|
| Acc. | R-1 | Acc. | R-1 | Acc. | R-1 | ||
| Transformer-based | ViT/B16 [31] | 97.4 | 97.4 | 96.1 | 96.0 | 90.4 | 89.2 |
| Swin-B [52] | 97.8 | 97.8 | 95.5 | 95.5 | 90.4 | 89.4 | |
| PVTv2 [59] | 97.3 | 97.3 | 97.1 | 97.1 | 90.6 | 89.5 | |
| CNN-based | ResNet50 [60] | 97.1 | 97.1 | 96.9 | 96.9 | 90.1 | 89.0 |
| ResNet101 [60] | 98.2 | 98.2 | 97.1 | 97.0 | 91.0 | 90.0 | |
| VGG16 [61] | 97.2 | 97.2 | 96.0 | 95.9 | 89.2 | 88.2 | |
| InceptionV4 [62] | 97.3 | 97.3 | 97.1 | 97.1 | 90.1 | 89.1 | |
| MLP-Mixer S/16 | MLP-Mixer [34] | 96.0 | 96.0 | 88.4 | 88.4 | 74.0 | 74.0 |
| MLP-Mixer B/16 | MLP-Mixer [34] | 96.9 | 96.9 | 89.6 | 89.6 | 76.5 | 76.5 |
| MLP-based S/16 | SIC (Ours) | 97.5 | 97.5 | 96 | 95.9 | 90.7 | 89.7 |
| Method | Scale | Params | FLOPs |
|---|---|---|---|
| ViT/B16 [31] (ICLR 2021) | 224 × 224 | 85.6 M | 16.86 G |
| Swin-B [52] (ICCV 2021) | 224 × 224 | 86.6 M | 15.16 G |
| Resnet50 [60] (CVPR 2016) | 224 × 224 | 23.5 M | 4.13 G |
| Resnet101 [60] (CVPR 2016) | 224 × 224 | 42.5 M | 7.86 G |
| PVTv2 [59] (Comput. Vis. Media 2022) | 224 × 224 | 24.8 M | 3.89 G |
| VGG-16 [61] (ICLR 2015) | 224 × 224 | 134.26 M | 15.46 G |
| InceptionV4 [62] (AAAI 2017) | 224 × 224 | 41.14 M | 6.15 G |
| MLP-Mixer S/16 [34] (NeurIPS 2021) | 224 × 224 | 18 M | 3.78 G |
| MLP-Mixer B/16 [34] (NeurIPS 2021) | 224 × 224 | 59.88 M | 12.61 G |
| SIC (ours) | 224 × 224 | 18 M | 3.78 G |
| Combination | Hockey Fight | RLVS | SCVD | |||
|---|---|---|---|---|---|---|
| Acc. | R-1 | Acc. | R-1 | Acc. | R-1 | |
| 97.0 | 97.0 | 95.4 | 95.3 | 89.3 | 88.2 | |
| 97.5 | 97.5 | 96.0 | 95.9 | 90.7 | 89.7 | |
| 97.0 | 97.0 | 94.2 | 94.1 | 89.5 | 88.5 | |
| Hockey Fight | RLVS | SCVD | ||||
|---|---|---|---|---|---|---|
| Acc. | R-1 | Acc. | R-1 | Acc. | R-1 | |
| super image | 97.5 | 97.5 | 96.0 | 95.9 | 90.7 | 89.7 |
| shift super image | 97.1 | 97.1 | 95.7 | 95.7 | 89.3 | 88.2 |
| Patch Size | Hockey Fight | RLVS | SCVD | |||
|---|---|---|---|---|---|---|
| Acc. | R-1 | Acc. | R-1 | Acc. | R-1 | |
| 97.5 | 97.5 | 96.0 | 95.9 | 90.7 | 89.7 | |
| 96.9 | 96.9 | 95.6 | 95.6 | 90.3 | 89.2 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tu, Y.-S.; Shen, Y.-S.; Chan, Y.Y.; Wang, L.; Chen, J. Violent Video Recognition by Using Sequential Image Collage. Sensors 2024, 24, 1844. https://doi.org/10.3390/s24061844
Tu Y-S, Shen Y-S, Chan YY, Wang L, Chen J. Violent Video Recognition by Using Sequential Image Collage. Sensors. 2024; 24(6):1844. https://doi.org/10.3390/s24061844
Chicago/Turabian StyleTu, Yueh-Shen, Yu-Shian Shen, Yuk Yii Chan, Lei Wang, and Jenhui Chen. 2024. "Violent Video Recognition by Using Sequential Image Collage" Sensors 24, no. 6: 1844. https://doi.org/10.3390/s24061844
APA StyleTu, Y.-S., Shen, Y.-S., Chan, Y. Y., Wang, L., & Chen, J. (2024). Violent Video Recognition by Using Sequential Image Collage. Sensors, 24(6), 1844. https://doi.org/10.3390/s24061844