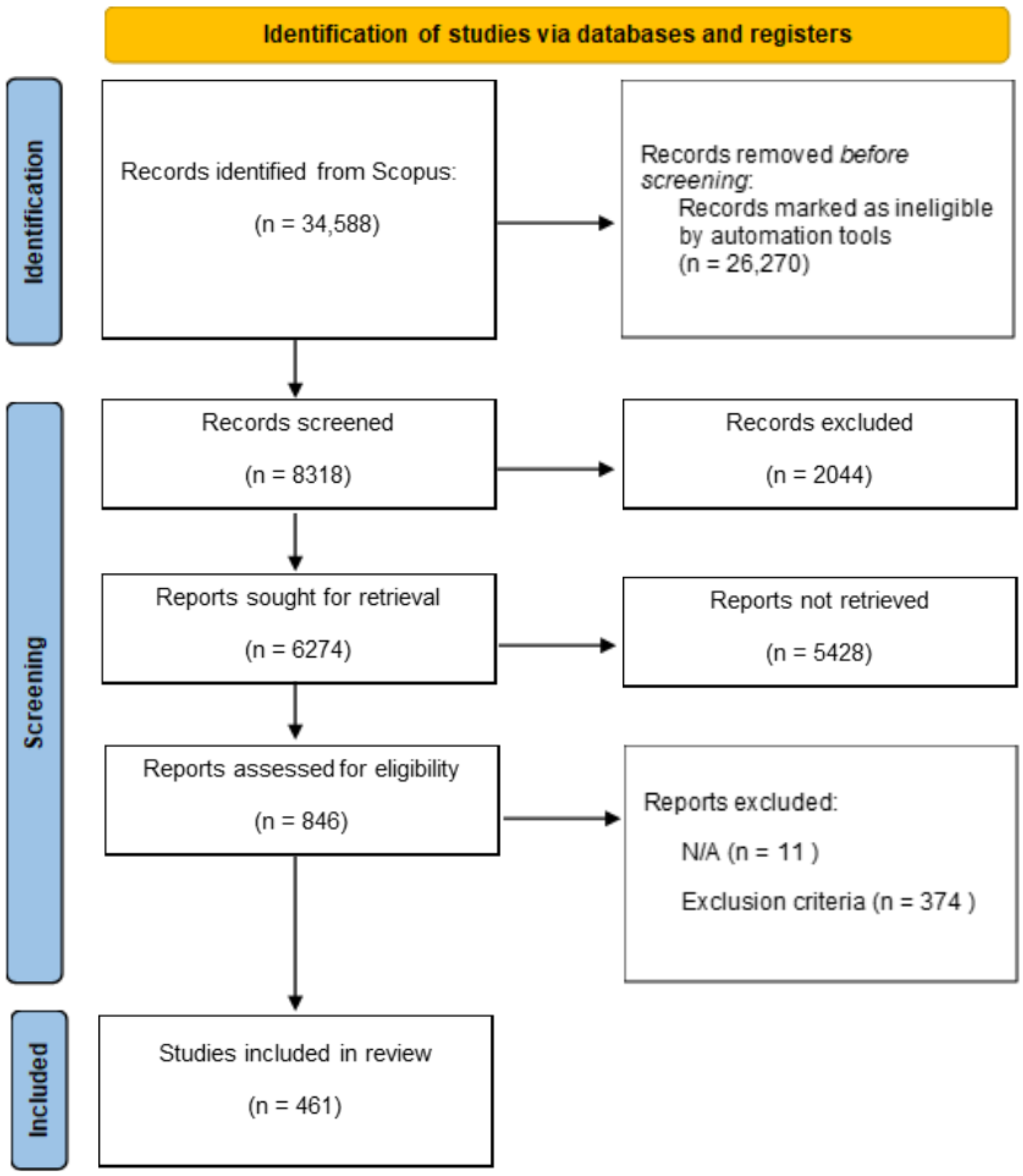
Our empirical study is motivated by the core aspect that underlies the design and implementation of any anomaly detection method, which is effectiveness. In this sense, we pose the following research question: What is the most effective anomaly detection method for sensor data environments? As an example of this type of data, we have chosen the data generated by the vibration (acoustic) sensor mounted on a railway carriage.
5.4. Methods Implementation
In total, 19 methods were used to build the empirical studies. It should be noted that in order to maintain the replicability of the study, where possible, most of the machine learning models were built using a default configuration.
5.4.1. Local Outlier Factor (LOF)
The LOF model is used to detect anomalies by assessing the local density of data points. It calculates the LOF score for each data point based on its density relative to its neighbours. The process starts by defining a neighbourhood around each data point, typically using the k-nearest neighbours algorithm. The LOF score for a point is then calculated by comparing the density of the point’s neighbourhood to the density of its neighbours. If a point has a significantly lower density than its neighbours, it is considered an outlier with a higher LOF score. In this way, LOF identifies anomalies by evaluating the local context of data points, making it effective for detecting outliers in complex datasets with varying densities.
The model was implemented using sklearn.neighbors.LocalOutlierFactor with the following parameters: n_neighbors = 20, algorithm = ‘auto’, leaf_size = 30, metric = ‘minkowski’, p = 2, metric_params = None, contamination = ‘auto’, novelty = True, and n_jobs = None.
5.4.2. Isolation Forest (IF)
The IF is an anomaly detection algorithm that works by isolating anomalies within a data set. It does this by randomly selecting features and splitting values between the minimum and maximum values of those features, creating a binary tree structure through recursive splitting. The core idea of the algorithm is that anomalies that are rare and distant from the majority of data points tend to require fewer splits to isolate. During training, the isolation forest builds many such isolation trees. The final anomaly score for a data point is determined by averaging the path lengths across all trees, with shorter paths indicating a higher likelihood that the point is an anomaly.
The model was implemented using sklearn.ensemble.IsolationForest with the following parameters: n_estimators = 100, max_samples = ‘auto’, contamination = ‘auto’, max_features = 1.0, bootstrap = False, n_jobs = None, random_state = None, verbose = 0, and warm_start = False.
5.4.3. Gaussian Hidden Markov Model (GHMM)
The Gaussian Hidden Markov Model (GHMM) is a statistical model used for anomaly detection. In this context, data are processed by GHMM by first representing it as a sequence of observations over time. Each observation is assumed to be generated from a Gaussian distribution. The GHMM consists of hidden states that capture the underlying dynamics of the data. These states are not directly observable but influence the generation of observations. The model learns transition probabilities between hidden states, reflecting how the data evolve over time. Anomalies are detected by evaluating the likelihood of a given sequence of observations under the GHMM. If a sequence has a significantly low likelihood according to the model, it suggests that the data follow a different pattern than what the GHMM has learned. This deviation from the learned behavior is indicative of an anomaly. GHMMs are particularly useful for time-series data where anomalies may manifest as deviations from the expected temporal patterns.
The model was implemented using hmmlearn.hmm.GaussianHMM with the following parameters: n_components = 2, covariance_type = ‘diag’, min_covar = 0.001, startprob_prior = 1.0, transmat_prior = 1.0, means_prior = 0, means_weight = 0, covars_prior = 0.01, covars_weight = 1, algorithm = ‘viterbi’, random_state = 42, n_iter = 50, tol = 0.01, verbose = False, params = ‘stmc’, init_params = ‘stmc’, and implementation = ‘log’.
5.4.4. Naive Bayes
In the context of anomaly detection, the Naive Bayes model processes data by applying probabilistic reasoning. It assumes that the features in the data are conditionally independent given the class labels, which is why it is called “naive”. To use Naive Bayes for anomaly detection, the model must first be trained on a dataset containing both normal and anomalous instances. During training, it calculates the probability distributions of the features for each class (normal and anomalous). These distributions represent how the features in each class are expected to behave. When it comes to detecting anomalies in new data, Naive Bayes calculates the probability of observing a particular set of feature values, given both the normal and anomalous classes. It then uses Bayes’ theorem to calculate the posterior probability that an instance belongs to the anomaly class. If this posterior probability exceeds a predefined threshold, the instance is classified as an anomaly.
The model was implemented using sklearn.naive_bayes.GaussianNB with the following parameters: priors = None, var_smoothing = .
5.4.5. Support Vector Classification (SVC)
Support Vector Classification (SVC) can be considered as an extension of the traditional Support Vector Machine (SVM), with a primary emphasis on binary classification problems. Like SVM, SVC leverages the fundamental principles of margin maximization and the use of support vectors, but its unique design and tuning make it an ideal choice for handling classification tasks. SVC excels in situations where the goal is to categorize data into two distinct classes, such as anomaly detection.
The model was implemented using sklearn.svm.SVC with the following parameters: C = 1.0, kernel = ‘rbf’, degree = 3, gamma = ‘scale’, coef0 = 0.0, shrinking = True, probability = False, tol = 0.001, cache_size = 200, class_weight = None, verbose = False, max_iter = −1, decision_function_shape = ‘ovr’, break_ties = False, and random_state = None.
5.4.6. Support Vector Regression (SVR)
Support Vector Regression (SVR) finds a valuable application in anomaly detection when considering its capabilities beyond traditional regression tasks. While SVM is primarily associated with classification and SVR with regression, both can be adapted for anomaly detection purposes. In the context of anomaly detection, SVR departs from its traditional regression objectives. Instead of fitting a hyperplane that best captures the data distribution, the goal of SVR is to identify anomalies or outliers that do not fit the expected patterns within the data set. SVR uses the principle of margin maximization to determine the threshold for what constitutes an anomaly. Data points that exceed this threshold are considered anomalies as they represent a significant deviation from the established norm.
The model was implemented using sklearn.svm.SVR with the following parameters: kernel = ‘rbf’, degree = 3, gamma = ‘scale’, coef0 = 0.0, tol = 0.001, C = 1.0, epsilon = 0.1, shrinking = True, cache_size = 200, verbose = False, and max_iter = −1.
5.4.7. One-Class SVM
One-Class SVM is designed for anomaly detection in situations where only one class (the normal class) is represented in the training data. It learns to model the distribution of normal data points and identifies anomalies as data points that deviate significantly from this learned distribution. It is particularly useful when dealing with unbalanced datasets or when there is a lack of labelled anomaly data.
The model was implemented using sklearn.svm.OneClassSVM with the following parameters: kernel = ‘rbf’, degree = 3, gamma = ‘scale’, coef0 = 0.0, tol = 0.001, nu = 0.5, shrinking = True, cache_size = 200, verbose = False, and max_iter = −1.
5.4.8. Logistic Regression
Logistic regression is initially trained on a labelled dataset consisting of both normal and abnormal instances. During this training phase, the model learns to establish a decision boundary that effectively separates the two classes. The goal of the model is to calculate the probability that a given data point belongs to the positive class (anomaly) based on its features. To achieve this, Logistic Regression uses the logistic function (sigmoid) to transform a linear combination of the input features into a value between 0 and 1. This value represents the estimated probability that the instance is an anomaly. Once trained, the logistic regression model can be used for anomaly detection by applying it to new, unlabelled data. For each data point, the model calculates the probability, and if it exceeds a predefined threshold, the point is classified as an anomaly; otherwise, it is classified as normal.
The model was implemented using sklearn.linear_model.LogisticRegression with the following parameters: penalty = ‘l2’, dual = False, tol = 0.0001, C = 1.0, fit_intercept = True, intercept_scaling = 1, class_weight = None, random_state = None, solver = ‘lbfgs’, max_iter = 100, multi_class = ‘auto’, verbose = 0, warm_start = False, n_jobs = None, and l1_ratio = None.
5.4.9. K-Nearest Neighbors (KNN)
The k-Nearest Neighbors (KNN) model for anomaly detection processes data by calculating the Manhattan distances between each data point in the test set and all data points in the training set. It selects the k nearest neighbors for each test data point based on these distances. The labels of these nearest neighbors from the training set are aggregated, and the test data point is classified based on the most frequent label among the neighbors. KNN determines anomalies by considering the consensus of labels among the nearest neighbors.
The KNN model is configured to use k = 2 nearest neighbors and the Manhattan distance metric for anomaly detection.
5.4.10. Decision Tree
The decision tree is trained on a labelled dataset containing examples of both normal and abnormal cases. During training, the model learns to create a tree structure where each internal node represents a decision based on a feature and each leaf node represents a class label, which in this case would be normal or anomalous. The decision tree algorithm aims to construct a tree that effectively divides the data into subsets that are as pure as possible in terms of class labels. In other words, it seeks to minimize impurity or maximise information gain at each node when making decisions about which features to split on. To detect anomalies in new, unlabelled data, the model traverses the tree from the root node down to a leaf node, making decisions based on the feature values of the data point being evaluated. The last leaf node reached determines the classification of the data point, whether it is normal or an anomaly.
The model was implemented using sklearn.tree.DecisionTreeClassifier with the following parameters: criterion = ‘gini’, splitter = ‘best’, max_depth = None, min_samples_split = 2, min_samples_leaf = 1, min_weight_fraction_leaf = 0.0, max_features = None, random_state = None, max_leaf_nodes = None, min_impurity_decrease = 0.0, class_weight = None, and ccp_alpha = 0.0.
5.4.11. Random Forest
In the context of anomaly detection, the Random Forest algorithm processes data through an ensemble of decision trees to identify anomalies within a dataset. Random Forest is initially trained on a labelled dataset containing examples of both normal and anomalous cases. During training, the model creates an ensemble of decision trees, each trained on a subset of the data and a subset of the features. This ensemble approach helps reduce overfitting and improves generalization. Each decision tree within the random forest independently makes predictions based on the input data. When it comes to anomaly detection, the individual decision trees classify data points as either normal or anomalous based on their internal learned rules. To make a final anomaly prediction for a given data point, the Random Forest combines the predictions of all the decision trees in the ensemble. This is done by majority voting, where the class predicted by the majority of trees becomes the final prediction. Anomalies are often detected when a significant proportion of the decision trees in the Random Forest ensemble classify a data point as an anomaly. The idea is that anomalies are less likely to fit the common patterns captured by most of the decision trees, resulting in a consensus among the trees for classifying an anomaly.
The model was implemented using sklearn.ensemble.RandomForestClassifier with the following parameters: n_estimators = 100, criterion = ‘gini’, max_depth = None, min_samples_split = 2, min_samples_leaf = 1, min_weight_fraction_leaf = 0.0, max_features = ‘sqrt’, max_leaf_nodes = None, min_impurity_decrease = 0.0, bootstrap = True, oob_score = False, n_jobs = None, random_state = None, verbose = 0, warm_start = False, class_weight = None, ccp_alpha = 0.0, and max_samples = None.
5.4.12. AdaBoost
In the context of anomaly detection, AdaBoost combines multiple weak classifiers trained on labelled data. It assigns weights to data points, giving more weight to misclassified data points. The algorithm trains weak classifiers iteratively, adjusting weights and focusing on difficult instances. Anomalies are identified when data points with high weights are difficult to classify.
The model was implemented using sklearn.ensemble.AdaBoostClassifier with the following parameters: estimator = None, n_estimators = 50, learning_rate = 1.0, algorithm = ‘SAMME.R’, and random_state = None.
5.4.13. XGBoost
XGBoost processes data using an ensemble of decision trees. it is first trained on a labelled dataset containing normal and anomalous instances. During training, XGBoost creates a collection of decision trees, often flat to avoid overfitting. Each decision tree independently predicts whether a data point is normal or an anomaly based on its learned rules. To make a final prediction, XGBoost combines the outputs of all the decision trees, often by averaging their predictions. Anomalies are identified when a significant proportion of the decision trees in the XGBoost ensemble classify a data point as an anomaly.
The model was implemented using xgboost.XGBClassifier with the default parameters.
5.4.14. CatBoost
In the area of anomaly detection, CatBoost processes data using a gradient boosting algorithm that focuses on improving the performance of decision trees. It begins with supervised training on a labelled dataset containing both normal and anomalous instances. During training, CatBoost constructs an ensemble of decision trees that adapts to the complexity of the data. Each decision tree in the CatBoost ensemble independently evaluates data points, classifying them as normal or anomalous based on learned patterns. These individual tree outputs are then combined to produce a final prediction. Anomalies are identified when a significant proportion of the decision trees within the CatBoost ensemble classifies a data point as an anomaly. The collective agreement between the trees highlights data instances that deviate from expected patterns.
The model was implemented using catboost.CatBoostClassifier with the default parameters.
5.4.15. Artificial Neural Network (ANN)
Artificial Neural Networks (ANNs) are a class of deep learning models inspired by the structure and function of the human brain. In the context of anomaly detection, ANNs are versatile and can be applied to different types of data, including tabular and structured data. They consist of interconnected layers of artificial neurons, with each layer performing specific computations on the input data. ANNs are able to learn complex patterns and relationships within data, making them effective for anomaly detection tasks, especially when the underlying patterns may not be explicitly temporal.
The model starts with an input layer of 8000 neurons using the ReLU activation function. The subsequent layers consist of three hidden layers, each with two neurons and ReLU activation. The final layer of the model is a single neuron with sigmoid activation. The model is trained using stochastic gradient descent ‘sgd’ as the optimizer and ‘binary_crossentropy’ as the loss function.
5.4.16. Multilayer Perceptrons (MLPs)
Multilayer Perceptrons, commonly known as MLPs, are a fundamental class of neural networks widely used for anomaly detection. They use a feedforward architecture with input, hidden, and output layers, with multiple neurons in each layer. This architectural flexibility allows MLPs to capture complex and non-linear relationships between features, making them adaptable to high-dimensional data. They excel at detecting anomalies that do not have a specific temporal sequence but are instead anomalies scattered across different dimensions or features.
The model was implemented using sklearn.neural_network.MLPClassifier with the following parameters: hidden_layer_sizes = (100), activation = ‘relu’, solver = ‘adam’, alpha = 0.0001, batch_size = ‘auto’, learning_rate = ‘constant’, learning_rate_init = 0.001, power_t = 0.5, max_iter = 200, shuffle = True, random_state = None, tol = 0.0001, verbose = False, warm_start = False, momentum = 0.9, nesterovs_momentum = True, early_stopping = True, validation_fraction = 0.1, beta_1 = 0.9, beta_2 = 0.999, epsilon = , n_iter_no_change = 10, and max_fun = 15,000.
5.4.17. Recurrent Neural Networks (RNNs)
Recurrent Neural Networks (RNNs) specialize in processing sequential data, making them valuable for anomaly detection tasks involving temporal patterns. Unlike MLPs, RNNs incorporate recurrent connections, allowing them to maintain a hidden state that preserves information from previous time steps. This property enables RNNs to capture dependencies over time. However, RNNs may face challenges in capturing long-range dependencies as effectively as more advanced models such as LSTMs.
This neural network model is designed for binary classification tasks, featuring a SimpleRNN layer with 50 ReLU-activated neurons, Dense output layer, ‘adam’ optimization, and ‘binary_crossentropy’ loss.
5.4.18. Long Short-Term Memory (LSTM)
Long Short-Term Memory (LSTM) networks are a variant of RNNs specifically designed to address the vanishing gradient problem and capture long-term dependencies in sequential data. LSTMs use memory cells that can store and update information over time, making them exceptionally well suited to modeling complex temporal relationships. This specialization makes LSTMs a powerful choice for detecting anomalies in sequential data with complex temporal dependencies.
The model consists of two LSTM layers of 64 units each, and dropout layers with a dropout rate of 0.2 are inserted after each LSTM layer to prevent overfitting. A RepeatVector layer is included to repeat the LSTM output sequence 26 times to match the input sequence length. The model ends with a TimeDistributed Dense layer. The model uses stochastic gradient descent (‘sgd’) as the optimizer and ‘binary_crossentropy’ as the loss function.
5.4.19. One-Dimensional Convolutional Neural Networks (1D-CNNs)
One-Dimensional Convolutional Neural Networks (1D-CNNs) are tailor-made for processing one-dimensional sequences, such as time series or sequential sensor data. They use convolutional layers to learn local patterns and features within the data. While lacking the explicit temporal modeling capabilities of RNNs and LSTMs, 1D CNNs excel at capturing local features and are particularly effective at detecting anomalies in sequential data characterized by short-term dependencies and local irregularities.
The model has three Conv1D layers. The first layer has 64 filters, a kernel size of 3, and uses the ReLU activation function. The subsequent Conv1D layers have 128 and 256 filters, also using ReLU activation. After each Conv1D layer, a MaxPooling1D layer with a pool size of 2 is applied to downsample the data. After the last MaxPooling1D layer, a Flatten layer is included to transform the output into a one-dimensional vector. The model contains two Dense layers. The first Dense layer consists of 128 neurons with ReLU activation, while the second Dense layer has a single neuron with sigmoid activation. The model uses the ‘adam’ optimizer and the ‘binary_crossentropy’ loss function.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}