Improving Empirical Mode Decomposition Using Support Vector Machines for Multifocus Image Fusion


Abstract
:1. Introduction
2. Fusion Principle
2.1. EMD-based multifocus image fusion using the SVM
- 1)
- Treating the original image I as the initial residue I0.
- 2)
- Connecting all the local maxima and minima along rows using constructed smooth cubic splines to get upper envelope uer and lower envelope ler. Similarly, upper envelope uec and lower envelope lec along columns are also obtained. The mean plane ul is defined:Then, the difference between I0 and ul isThis is one iteration of the sifting process. Because the value of ul decreases rapidly for the first several iterations and then decreases slowly, this suggests that the appropriate number of iterations can be used as the stopping criterion. Hence, the appropriate number of iterations to build IMFs is used in this paper. This sifting process is ended until ω1 becomes an IMF. The residue is obtained by:
- 3)
- Treating the residue as the new input dataset. A series of {ωi}1≤i≤J is obtained by repeating 2) untilIJ is a monotonic component (J denotes the decomposition levels). I can be recovered by IEMD:
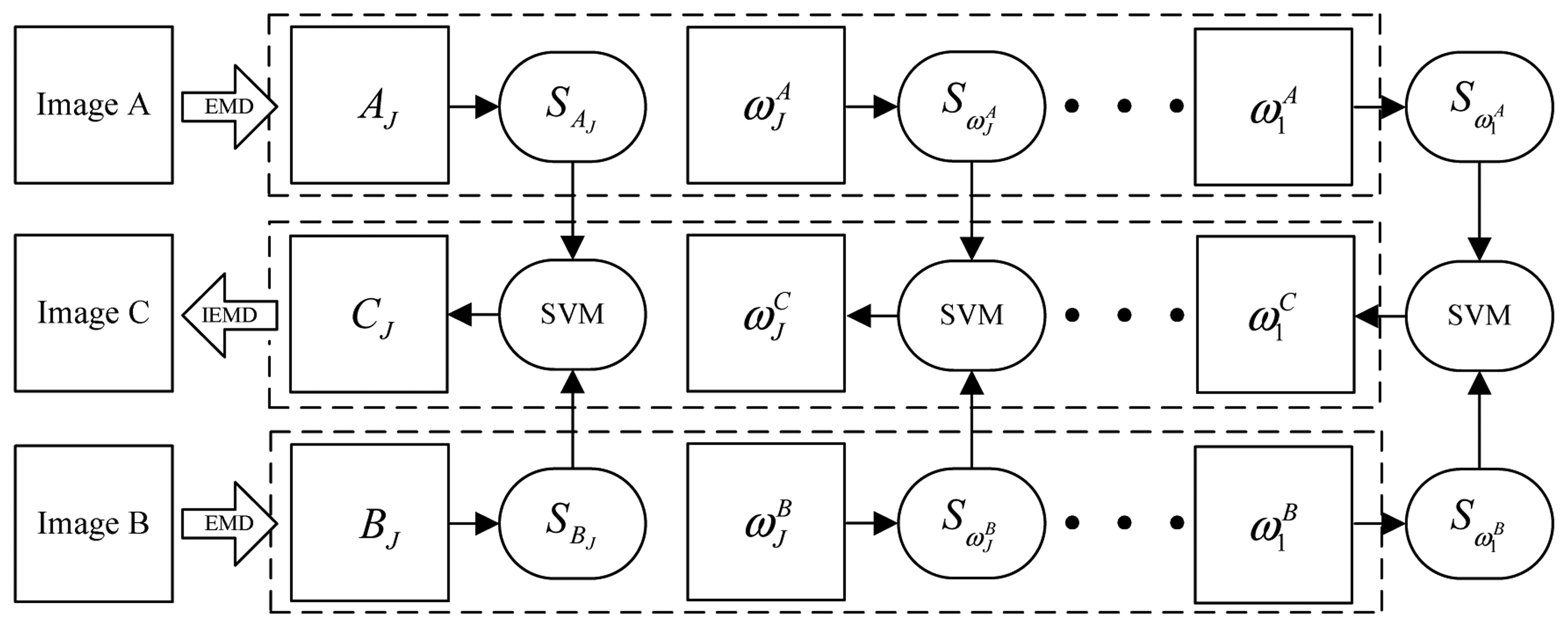
2.2. The procedure of the proposed method
- 1)
- Extract generalized spatial frequency (S) of each pixel of A and B using a small window (W) centered at the current pixel position according to formula (6). In this paper, the W of 3×3 is used. Let I and I(m, n) denote A or B and its gray value at (m, n), respectively. Then SI(m, n) is given by:S is used to measure the overall activity level of a pixel value because it is a manner that gray value switches to its neighbors.
- 2)
- Collect training patterns as follows:where M and N are the dimensions of A and B.
- 3)
- Train a SVM using the training patterns obtained 2). The kernel function used has the following form:where xi and xj denote the training patterns given by equations (7) and (8).
- 4)
- Decompose A and B with EMD along rows and columns to J levels, resulting in a residue and a total of J IMF planes, respectively.
- 5)
- Derive the S value of the EMD coefficients of A and B at each position at each level according to formula (6), denoted by and
- 6)
- Perform the fusion based on the outputs of the SVM. If the SVM output is positive, coefficients for the corresponding position of the fused image will come from A, and vice versa. In other words, the fused coefficient at level j is given by:where and are the outputs of the SVM obtained in 3) by inputting the S value obtained in 5).
- 7)
- Finally, the fused image is recovered by implementing IEMD according to formula (4). In Figure 2, the position (m, n) has been omitted in order to be concise.
3. Experiments
4. Conclusions
Acknowledgments
References
- Wang, W.W.; Shui, P. L.; Song, G.X. Multifocus image fusion in wavelet domain. Proceedings of the 2th International Conference on Machine Learning and Cybernetics 2003, 2887–2890. [Google Scholar]
- Li, S.T.; Kwok, J.T.; Tsang, I.W.; Wang, Y.N. Fusing Images With Different Focuses Using Support Vector Machines. IEEE Transactions on neural networks 2004, 15, 1555–1561. [Google Scholar]
- Huang, W.; Jing, Z.L. Multifocus image fusion using pulse coupled neural network. Pattern Recognition Letters 2007, 28, 1123–1132. [Google Scholar]
- Li, M.; Cai, W.; Tan, Z. A region-based multi-sensor image fusion scheme using pulse-coupled neural network. Sensors 2008, 8, 520–528. [Google Scholar]
- Piella, G. A general framework for multiresolution image fusion: from pixels to regions. Pattern Recognition Letters 2006, 27, 1948–1956. [Google Scholar]
- Li, S.T.; Kwok, J.T.; Wang, Y.N. Multifocus image fusion using artificial neural networks. Pattern Recognition Letters 2002, 23, 985–997. [Google Scholar]
- Li, S.T.; Kwok, J.T.; Wang, Y.N. Combination of images with diverse focuses using the spatial frenquency. Information Fusion 2 2001, 169–176. [Google Scholar]
- Mallat, S.G. A theory for multiresolution signal decomposition: The wavelet representation. IEEE Transactions on Pattern Analysis and Machine Intelligence 1989, 11, 674–693. [Google Scholar]
- Dutilleux, P. An implementation of the ′algorithme à trous′ to compute the wavelet transform. In Wavelets: Time-Frequency Methods and Phase Space.; Combes, J. M., Grossman, A., Tchamitchian, Ph., Eds.; Springer-Verlag: Berlin, Germany, 1989; pp. 298–304. [Google Scholar]
- Huang, N.E.; Shen, Z.; Long, S.R. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. 1998, A 454, 903–995. [Google Scholar]
- Huang, W.; Shen, Z.; Huang, N.E.; Fung, Y.C. Nonlinear indicial response of complex non-stationary oscillations as pulmonary hypertension responding to step hypoxia. Proc. Natl. Acad. Sci. USA 1999, 96, 1834–1839. [Google Scholar]
- Chen, S.H.; Su, H.B.; Zhang, R.H.; Tian, J. Fusing remote sensing images using à trous wavelet transform and empirical mode decomposition. Pattern Recognition letters 2008, 29, 330–342. [Google Scholar]
- Flandrin, P.; Rilling, G.; Goncalves, P. Empirical mode decomposition as a filter bank. IEEE Signal Processing Letters 2004, 2, 112–114. [Google Scholar]
- Yang, Z.H.; Qi, D.X.; Yang, L.H. Signal period analysis based on Hilbert-Huang transform and its application to texture analysis. Proceedings of the third international conference on image and graphics; 2004; pp. 430–433. [Google Scholar]
- Hariharan, H.; Gribok, A.; Abidi, M.A. Image fusion and enhancement via empirical mode decomposition. Journal of Pattern Recognition Research 2006, 1, 16–31. [Google Scholar]
- Zhao, Z.D.; Pan, M.; Chen, Y.Q. Instantaneous frequency estimate for non-stationary signal. Proceedings of the 5thWorld Congress on Intelligent Control andAutomation 2004, 4, 3641–3643. [Google Scholar]
- Nunes, J.C.; Bouaoune, Y.; Delechelle, E.; Niang, O.; Bunel, Ph. Image analysis by bidimensional empirical mode decomposition. Image and Vision Computing 2003, 21, 1019–1026. [Google Scholar]
- Vapnik, V.N. An Overview of Statistical Learning Theory. IEEE Transactions on neural networks 1999, 5, 988–999. [Google Scholar]
- Garzelli, A. Possibilities and Limitations of the Use of Wavelets in Image Fusion. Proceedings of IEEE International Geoscience and Remote Sensing Symposium; 2002; 1, pp. 66–68. [Google Scholar]
- Pal, S.K.; Majumdar, T.J.; Bhattacharya, A.K. ERS-2 SAR and IRS-1C LISS III data fusion: A PCA approach to improve remote sensing based geological interpretation. ISPRS Journal of Photogrammetry & Remote Sensing 2007, 61, 281–297. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AWT | EMD | EVM | |
|---|---|---|---|
| RMSE | 5.2075 | 3.0118 | 2.6166 |
| MI | 2.5338 | 3.8520 | 3.9093 |
| AWT | EMD | EVM | |
|---|---|---|---|
| RMSE | 3.8077 | 3.2249 | 2.7220 |
| MI | 1.7062 | 3.2331 | 3.4211 |
© 2008 by MDPI (http://www.mdpi.org). Reproduction is permitted for noncommercial purposes.
Share and Cite
Chen, S.; Su, H.; Zhang, R.; Tian, J.; Yang, L. Improving Empirical Mode Decomposition Using Support Vector Machines for Multifocus Image Fusion. Sensors 2008, 8, 2500-2508. https://doi.org/10.3390/s8042500
Chen S, Su H, Zhang R, Tian J, Yang L. Improving Empirical Mode Decomposition Using Support Vector Machines for Multifocus Image Fusion. Sensors. 2008; 8(4):2500-2508. https://doi.org/10.3390/s8042500
Chicago/Turabian StyleChen, Shaohui, Hongbo Su, Renhua Zhang, Jing Tian, and Lihu Yang. 2008. "Improving Empirical Mode Decomposition Using Support Vector Machines for Multifocus Image Fusion" Sensors 8, no. 4: 2500-2508. https://doi.org/10.3390/s8042500
APA StyleChen, S., Su, H., Zhang, R., Tian, J., & Yang, L. (2008). Improving Empirical Mode Decomposition Using Support Vector Machines for Multifocus Image Fusion. Sensors, 8(4), 2500-2508. https://doi.org/10.3390/s8042500