New Insights in Computational Methods for Pharmacovigilance: E-Synthesis, a Bayesian Framework for Causal Assessment


Abstract
:1. Introduction
2. State of the Art
2.1. Aggregation of Spontaneous Reports
2.2. Aggregation of Human and Animal Data
2.3. Bayesian Aggregation of Safety Trial Data
2.4. Data Mining and Fusion Methods
2.5. Semantic (Web) Methods
3. E-Synthesis: A Bayesian Epistemology-Driven Framework for Pharmacovigilance
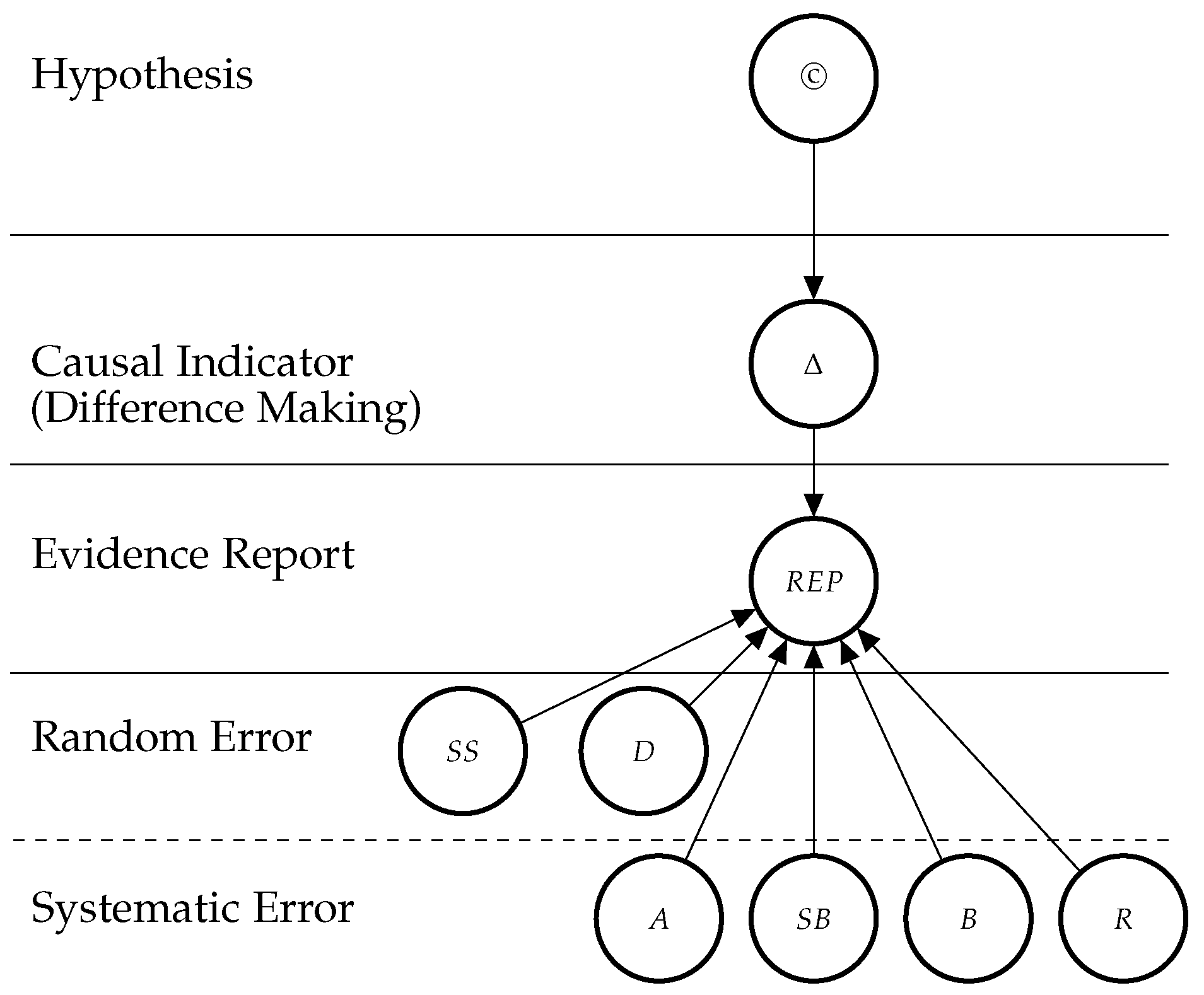
3.1. Bayesian Network Model
3.2. Theoretical Entities
3.2.1. The Causal Hypothesis (©)
3.2.2. Indicators of Causation
“None of my nine viewpoints can bring indisputable evidence for or against the cause-and-effect hypothesis and none can be required as a sine qua non. What they can do, with greater or less strength, is to help us make up our minds in the fundamental question—is there any other way of explaining the set of facts before us, is there any other equally, or more, likely than cause and effect?” (Bradford Hill both refers to explanatory power and likelihood as reliable grounds to justify causal judgements, and presents the respective criteria as opposed to tests of significance: “No formal tests of significance can answer those questions. Such tests can, and should, remind us of the effects that the play of chance can create, and they will instruct us on the likely magnitude of those effects. Beyond that, they contribute nothing to the proof of our hypothesis.” [55])
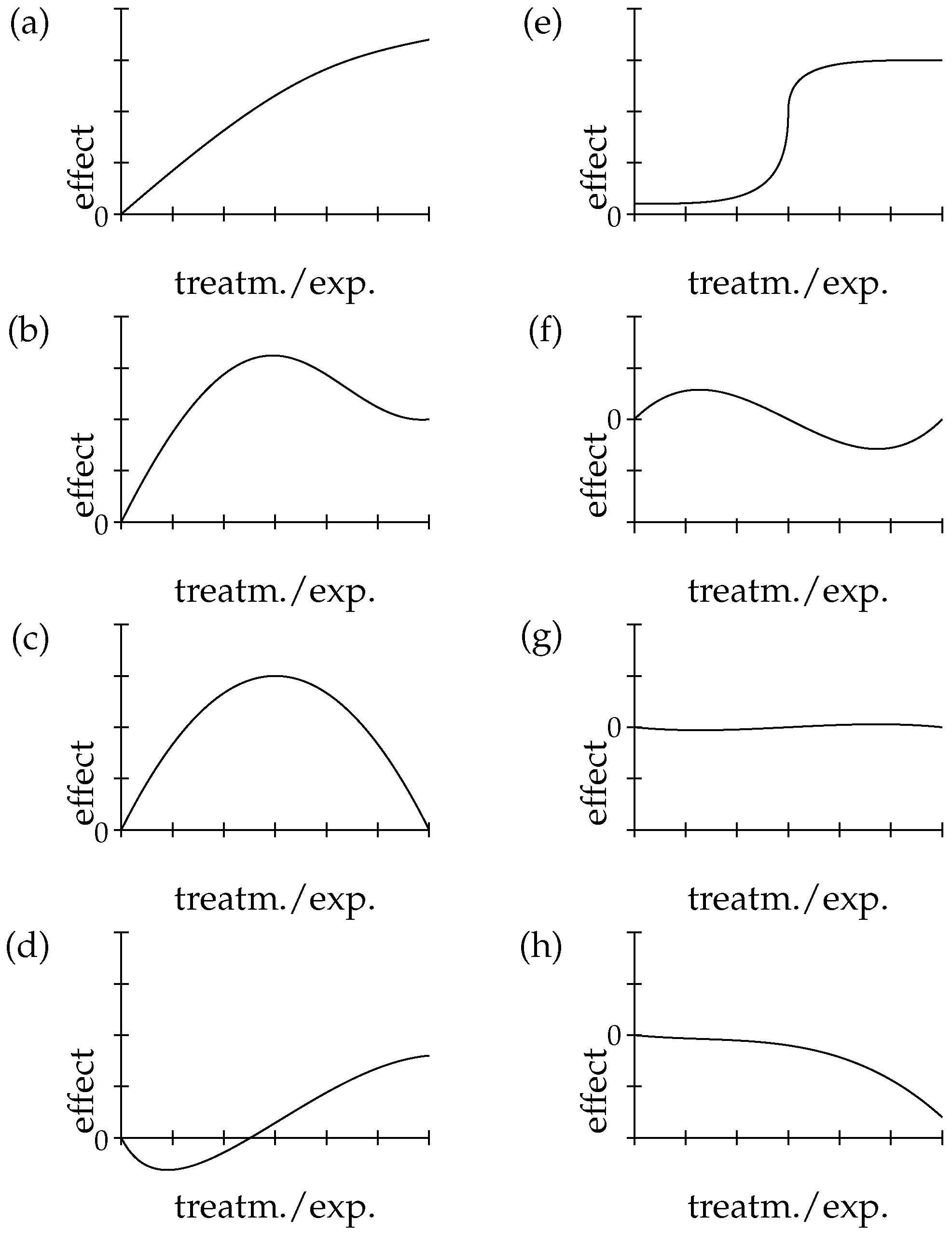
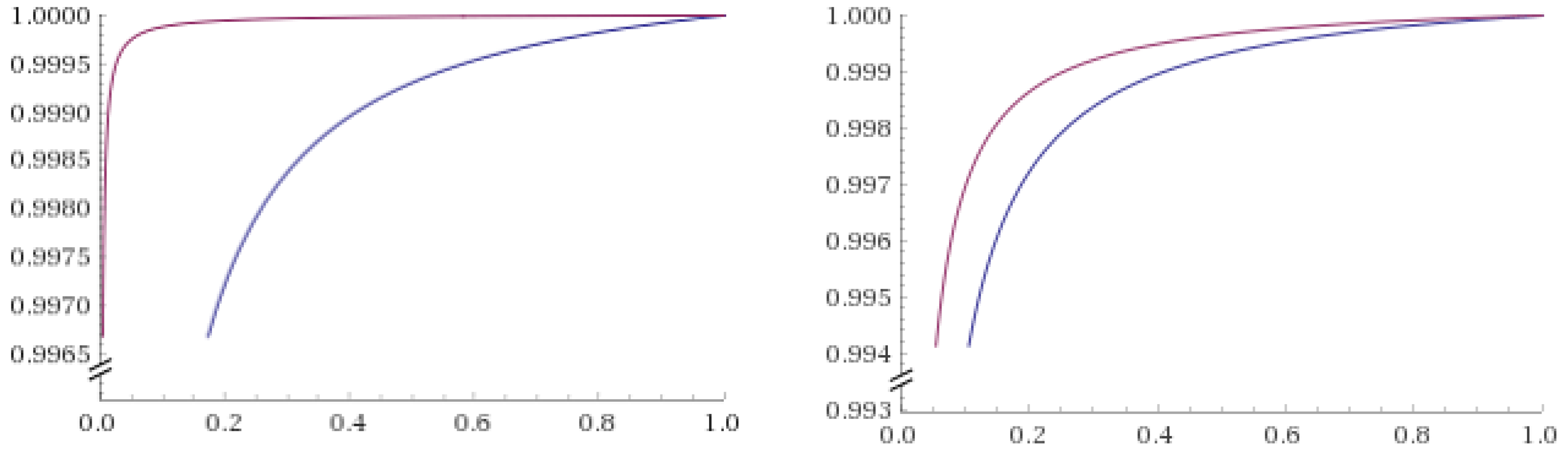
4. Zooming in E-Synthesis: Processing Evidence for Dose-Response
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| A | Adjustment for Confounders |
| ADR | Adverse drug reaction |
| AIC | Akaike information criterion |
| B | Blinding |
| BIC | Bayesian information criterion |
| D | Duration |
| DR | Dose-response Relationship |
| ECETOC | European Centre for Ecotoxicology and Toxicology of Chemicals |
| ES | Effect Size |
| EUDRAVIGILANCE | European Union Drug Regulating Authorities Pharmacovigilance |
| FAERS | FDA Adverse Event Reporting System |
| FDA | Food and Drug Administration (US) |
| IC | Information Component |
| M | Mechanistic Knowledge |
| MCP-Mod | Multiple Comparison Procedures and Modeling algorithm |
| MGPS | Multi-item Gamma Poisson Shrinker |
| PD | Probabilistic Dependence |
| PRR | Proportional Reporting Ratio |
| R | Randomisation |
| RCT | Randomized controlled trial |
| REP | Report Variable |
| RoG | Rate of Growth |
| ROR | Reporting Odds Ratio |
| SB | Sponsorship Bias |
| SS | Sample Size |
| T | Temporal Precedence |
| WHO | World Health Organization |
| © | Hypothesis of Causation |
| Δ | Difference Making |
| Available Evidence | |
| Σ | Set of statistical Indicators: PD, DR and RoG |
References
- Stausberg, J.; Hasford, J. Drug-related admissions and hospital-acquired adverse drug events in Germany: A longitudinal analysis from 2003 to 2007 of ICD-10-coded routine data. BMC Health Serv. Res. 2011, 11, 134. [Google Scholar] [CrossRef] [PubMed]
- Wu, T.Y.; Jen, M.H.; Bottle, A.; Molokhia, M.; Aylin, P.; Bell, D.; Majeed, A. Ten-year trends in hospital admissions for adverse drug reactions in England 1999–2009. J. R. Soc. Med. 2010, 103, 239–250. [Google Scholar] [CrossRef] [PubMed]
- Brvar, M.; Fokter, N.; Bunc, M.; Mozina, M. The frequency of adverse drug reaction related admissions according to method of detection, admission urgency and medical department specialty. BMC Clin. Pharmacol. 2009, 9, 8. [Google Scholar] [CrossRef] [PubMed]
- van der Hooft, C.S.; Dieleman, J.P.; Siemes, C.; Aarnoudse, A.J.L.; Verhamme, K.M.; Stricker, B.H.; Sturkenboom, M.C. Adverse drug reaction-related hospitalisations: A population-based cohort study. Pharmacoepidemiol. Drug Saf. 2008, 17, 365–371. [Google Scholar] [CrossRef] [PubMed]
- Kongkaew, C.; Noyce, P.R.; Ashcroft, D.M. Hospital admissions associated with adverse drug reactions: A systematic review of prospective observational studies. Ann. Pharmacother. 2008, 42, 1017–1025. [Google Scholar] [CrossRef] [PubMed]
- Aktionbündnis Patientensicherheit. Agenda Patientensicherheit 2007. Available online: http://www.aps-ev.de/wp-content/uploads/2016/10/Agenda_2007_mit_Titelblatt.pdf (accessed on 2 April 2019).
- EMA. Better Vigilance for Public Health Protection. Overview of the New European Union Pharmacovigilance Legislation. Available online: https://www.ema.europa.eu/en/documents/leaflet/better-vigilance-health-protection-innovation_en.pdf (accessed on 2 April 2019).
- Mokdad, A.H.; Marks, J.S.; Stroup, D.F.; Gerberding, J.L. Actualcauses of death in the United States, 2000. JAMA 2004, 291, 1238–1245. [Google Scholar] [CrossRef] [PubMed]
- Wysowski, D.K.; Swartz, L. Adverse drug event surveillance and drug withdrawals in the United States, 1969–2002: The importance of reporting suspected reactions. Arch. Intern. Med. 2005, 165, 1363–1369. [Google Scholar] [CrossRef] [PubMed]
- Pirmohamed, M.; James, S.; Meakin, S.; Green, C.; Scott, A.K.; Walley, T.J.; Farrar, K.; Park, B.K.; Breckenridge, A.M. Adverse drug reactions as cause of admission to hospital: prospective analysis of 18,820 patients. BMJ 2004, 329, 15–19. [Google Scholar] [CrossRef] [PubMed]
- Schneeweiss, S.; Hasford, J.; Göttler, M.; Hoffmann, A.; Riethling, A.K.; Avorn, J. Admissions caused by adverse drug events to internal medicine and emergency departments in hospitals: A longitudinal population-based study. Eur. J. Clin. Pharmacol. 2002, 58, 285–291. [Google Scholar] [CrossRef]
- Hay, M.; Thomas, D.W.; Craighead, J.L.; Economides, C.; Rosenthal, J. Clinical development success rates for investigational drugs. Nat. Biotechnol. 2014, 32, 40. [Google Scholar] [CrossRef]
- Goldman, M. Reflections on the innovative medicines initiative. Nat. Rev. Drug Discov. 2011, 10, 321. [Google Scholar] [CrossRef] [PubMed]
- Goldman, M. The innovative medicines initiative: A European response to the innovation challenge. Clin. Pharmacol. Ther. 2012, 91, 418–425. [Google Scholar] [CrossRef] [PubMed]
- Lundkvist, J.; Jönsson, B. Pharmacoeconomics of adverse drug reactions. Fundam. Clin. Pharmacol. 2004, 18, 275–280. [Google Scholar] [CrossRef] [PubMed]
- Cooper, N.; Coyle, D.; Abrams, K.; Mugford, M.; Sutton, A. Use of evidence in decision models: An appraisal of health technology assessments in the UK since 1997. J. Health Serv. Res. Policy 2005, 10, 245–250. [Google Scholar] [CrossRef] [PubMed]
- Herxheimer, A. Pharmacovigilance on the turn? Adverse reactions methods in 2012. Br. J. Gen. Pract. 2012, 62, 400–401. [Google Scholar] [CrossRef] [PubMed]
- Anjum, R.L.; Copeland, S.; Rocca, E. Medical scientists and philosophers worldwide appeal to EBM to expand the notion “of evidence”. BMJ Evid.-Based Med. 2018. [Google Scholar] [CrossRef] [PubMed]
- Amrhein, V.; Greenland, S.; McShane, B. Scientists rise up against statistical significance. Nature 2019, 567, 305–307. [Google Scholar] [CrossRef] [Green Version]
- Landes, J.; Osimani, B.; Poellinger, R. Epistemology of causal inference in pharmacology. Towards a framework for the assessment of harms. Eur. J. Philos. Sci. 2018, 8, 3. [Google Scholar] [CrossRef]
- De Pretis, F.; Landes, J.; Osimani, B. E-Synthesis: A Bayesian framework for causal assessment in pharmacosurveillance. Front. Pharmacol. 2019, Submitted. [Google Scholar]
- Bretz, F.; Pinheiro, J.C.; Branson, M. Combining multiple comparisons and modeling techniques in dose-response studies. Biometrics 2005, 61, 738–748. [Google Scholar] [CrossRef]
- Pinheiro, J.; Bornkamp, B.; Glimm, E.; Bretz, F. Model-based dose finding under model uncertainty using general parametric models. Stat. Med. 2014, 33, 1646–1661. [Google Scholar] [CrossRef] [PubMed]
- Schorning, K.; Bornkamp, B.; Bretz, F.; Dette, H. Model selection versus model averaging in dose finding studies. Stat. Med. 2016, 35, 4021–4040. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bornkamp, B.; Ohlssen, D.; Magnusson, B.P.; Schmidli, H. Model averaging for treatment effect estimation in subgroups. Pharm. Stat. 2017, 16, 133–142. [Google Scholar] [CrossRef] [PubMed]
- Gutjahr, G.; Bornkamp, B. Likelihood ratio tests for a dose-response effect using multiple nonlinear regression models. Biometrics 2017, 73, 197–205. [Google Scholar] [CrossRef] [PubMed]
- Shao, K.; Shapiro, A.J. A web-based system for Bayesian benchmark dose estimation. Environ. Health Perspect. 2018, 126, 017002. [Google Scholar] [CrossRef]
- Watson, S.; Chandler, R.E.; Taavola, H.; Härmark, L.; Grundmark, B.; Zekarias, A.; Star, K.; van Hunsel, F. Safety concerns reported by patients identified in a collaborative signal detection workshop using vigibase: Results and reflections from Lareb and Uppsala Monitoring Centre. Drug Saf. 2018, 41, 203–212. [Google Scholar] [CrossRef] [PubMed]
- Caster, O.; Sandberg, L.; Bergvall, T.; Watson, S.; Norén, G.N. vigiRank for statistical signal detection in pharmacovigilance: First results from prospective real-world use. Pharmacoepidemiol. Drug Saf. 2017, 26, 1006–1010. [Google Scholar] [CrossRef] [Green Version]
- Bergvall, T.; Norén, G.N.M. vigiGrade: A tool to identify well-documented individual case reports and highlight systematic data quality issues. Drug Saf. 2014, 37, 65–77. [Google Scholar] [CrossRef]
- Tregunno, P.M.; Fink, D.B.; Fernandez-Fernandez, C.; Lázaro-Bengoa, E.; Norén, G.N. Performance of probabilistic method to detect duplicate individual case safety reports. Drug Saf. 2014, 37, 249–258. [Google Scholar] [CrossRef]
- Shanks, N.; Greek, R.; Greek, J. Are animal models predictive for humans? Philos. Ethics Humanit. Med. 2009, 4, 2. [Google Scholar] [CrossRef]
- ECETOC. Framework for the Integration of Human and Animal Data in Chemical Risk Assessment. Available online: http://www.ecetoc.org/wp-content/uploads/2014/08/ECETOC-TR-104.pdf (accessed on 25 March 2019).
- Price, K.L.; Amy Xia, H.; Lakshminarayanan, M.; Madigan, D.; Manner, D.; Scott, J.; Stamey, J.D.; Thompson, L. Bayesian methods for design and analysis of safety trials. Pharm. Stat. 2014, 13, 13–24. [Google Scholar] [CrossRef] [PubMed]
- Spiegelhalter, D.J.; Freedman, L.S.; Parmar, M.K.B. Bayesian approaches to randomized trials. J. R. Stat. Soc. Ser. A Stat. Soc. 1994, 157, 357–387. [Google Scholar] [CrossRef]
- Thorlund, K.; Golchi, S.; Mills, E. Bayesian adaptive clinical trials of combination treatments. Contemp. Clin. Trials Commun. 2017, 8, 227–233. [Google Scholar] [CrossRef] [PubMed]
- Berry, D.A. Bayesian clinical trials. Nat. Rev. Drug Discov. 2006, 5, 27, Review Article. [Google Scholar] [CrossRef]
- Spiegelhalter, D.J. Bayesian Approaches to Clinical Trials and Health Care Evaluation; Spiegelhalter, D.J., Abrams, K.R., Myles, J.P., Eds.; Statistics in Practice; Wiley: Chichester, UK, 2006. [Google Scholar]
- Berry, S.M.; Carlin, B.P.; Lee, J.J.; Muller, P. Bayesian Adaptive Methods for Clinical Trials; Bioscience, Mathematics & Statistics; Taylor & Francis: Boca Raton, FL, USA, 2010. [Google Scholar]
- Emmanuel Lesaffre, A.B.L. Bayesian Biostatistics; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Poluzzi, E.; Raschi, E.; Piccinni, C.; De Ponti, F. Data mining techniques in pharmacovigilance: Analysis of the publicly accessible FDA adverse event reporting system (AERS). In Data Mining Applications in Engineering and Medicine; Karahoca, A., Ed.; IntechOpen: London, UK, 2012; pp. 201–213. [Google Scholar]
- Subeesh, V.; Maheswari, E.; Saraswathy, G.R.; Swaroop, A.M.; Minnikanti, S.S. A comparative study of data mining algorithms used for signal detection in FDA AERS database. J. Young Pharm. 2018, 10, 444–449. [Google Scholar] [CrossRef]
- Candore, G.; Juhlin, K.; Manlik, K.; Thakrar, B.; Quarcoo, N.; Seabroke, S.; Wisniewski, A.; Slattery, J. Comparison of statistical signal detection methods within and across spontaneous reporting databases. Drug Saf. 2015, 38, 577–587. [Google Scholar] [CrossRef] [PubMed]
- Hauben, M.; Zhou, X. Quantitative methods in pharmacovigilance. Focus on signal detection. Drug Saf. 2003, 26, 159. [Google Scholar] [CrossRef] [PubMed]
- Hauben, M.; Madigan, D.; Gerrits, C.M.; Walsh, L.; Van Puijenbroek, E.P. The role of data mining in pharmacovigilance. Exp. Opin. Drug Saf. 2005, 4, 929–948. [Google Scholar] [CrossRef] [PubMed]
- Hauben, M.; Patadia, V.; Gerrits, C.; Walsh, L.; Reich, L. Data mining in pharmacovigilance. The need for a balanced perspective. Drug Saf. 2005, 28, 835–842. [Google Scholar] [CrossRef] [PubMed]
- Klepper, M.J.; Cobert, B. Drug Safety Data: How to Analyze, Summarize and Interpret to Determine Risk; Jones & Bartlett Learning: Burlington, MA, USA, 2011. [Google Scholar]
- Edwards, I.R.; Lindquist, M. Pharmacovigilance. Critique and Ways Forward; ADIS: Zurich, Switzerland, 2017. [Google Scholar]
- Haghighat, M.; Abdel-Mottaleb, M.; Alhalabi, W. Discriminant correlation analysis: Real-time feature level fusion for multimodal biometric recognition. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1984–1996. [Google Scholar] [CrossRef]
- Jönsson, A.K.; Lövborg, H.; Lohr, W.; Ekman, B.; Rocklöv, J. Increased risk of drug-induced hyponatremia during high temperatures. Int. J. Environ. Res. Public Health 2017, 14, 827. [Google Scholar] [CrossRef] [PubMed]
- Streit, R.; Silver, J. Data fusion aspects of pharmacovigilance. In Proceedings of the 14th International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011; pp. 1522–1528. [Google Scholar]
- Shibata, A.; Hauben, M. Pharmacovigilance, signal detection and signal intelligence overview. In Proceedings of the 14th International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011; pp. 1515–1521. [Google Scholar]
- Koutkias, V.G.; Jaulent, M.C. Computational approaches for pharmacovigilance signal detection: Toward integrated and semantically-enriched frameworks. Drug Saf. 2015, 38, 219. [Google Scholar] [CrossRef] [PubMed]
- Piccinni, C.; Poluzzi, E.; Orsini, M.; Bergamaschi, S. PV-OWL—Pharmacovigilance surveillance through semantic web-based platform for continuous and integrated monitoring of drug-related adverse effects in open data sources and social media. In Proceedings of the 2017 IEEE 3rd International Forum on Research and Technologies for Society and Industry (RTSI), Modena, Italy, 11–13 September 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Hill, A.B. The environment and disease: Association or causation? Proc. R. Soc. Med. 1965, 58, 295–300. [Google Scholar] [CrossRef] [PubMed]
- Pearl, J. Causality: Models, Reasoning, and Inference, 1 ed.; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Poellinger, R. Analogy-based inference patterns in pharmacological research. In Uncertainty in Pharmacology: Epistemology, Methods, and Decisions; La Caze, A., Osimani, B., Eds.; Boston Studies in Philosophy of Science; Springer: Berlin, Germany, 2018; forthcoming. [Google Scholar]
- Bovens, L.; Hartmann, S. Bayesian Epistemology; Oxford University Press: Oxford, UK, 2003. [Google Scholar]
- Howson, C.; Urbach, P. Scientific Reasoning, 3rd ed.; Open Court Publishing: Chicago, IL, USA, 2006. [Google Scholar]
- Talbott, W. Bayesian epistemology. In Stanford Encyclopedia of Philosophy, Summer 2011 ed.; Zalta, E.N., Ed.; Metaphysics Research Lab, Stanford University: Stanford, CA, USA, 2011; Available online: http://plato.stanford.edu/archives/sum2011/entries/epistemology-bayesian (accessed on 25 March 2019).
- Lindley, D.V. The philosophy of statistics. J. R. Stat. Soc. Ser. D Stat. 2000, 49, 293–337. [Google Scholar] [CrossRef]
- Woodward, J. Making Things Happen: A Theory of Causal Explanation; Oxford Studies in the Philosophy of Science; Oxford University Press: Oxford, UK, 2003. [Google Scholar]
- Reichenbach, H. The Direction of Time; University of California Press: Berkeley, CA, USA, 1956. [Google Scholar]
- Cartwright, N. What is wrong with Bayes nets? Monist 2001, 84, 242–264. [Google Scholar] [CrossRef]
- Naranjo, C.A.; Busto, U.; Sellers, E.M.; Sandor, P.; Ruiz, I.; Roberts, E.; Janecek, E.; Domecq, C.; Greenblatt, D. A method for estimating the probability of adverse drug reactions. Clin. Pharm. Ther. 1981, 30, 239–245. [Google Scholar] [CrossRef]
- Karch, F.E.; Lasagna, L. Toward the operational identification of adverse drug reactions. Clin. Pharm. Ther. 1977, 21, 247–254. [Google Scholar] [CrossRef]
- Varallo, F.R.; Planeta, C.S.; Herdeiro, M.T.; de Carvalho Mastroianni, P. Imputation of adverse drug reactions: Causality assessment in hospitals. PLoS ONE 2017, 12, e0171470. [Google Scholar] [CrossRef]
- Phillips, E.J. Classifying ADRs—Does dose matter? Br. J. Clin. Pharmacol. 2016, 81, 10–12. [Google Scholar] [CrossRef]
- Aronson, J.K.; Ferner, R.E. The law of mass action and the pharmacological concentration-effect curve: Resolving the paradox of apparently non-dose-related adverse drug reactions. Br. J. Clin. Pharmacol. 2016, 81, 56–61. [Google Scholar] [CrossRef]
- Barr, R.G.; Wentowski, C.C.; Curhan, G.C.; Somers, S.C.; Stampfer, M.J.; Schwartz, J.; Speizer, F.E.; Carlos, A.; Camargo, J. Prospective study of acetaminophen use and newly diagnosed asthma among women. Am. J. Respir Crit. Care Med. 2004, 169, 836–841. [Google Scholar] [CrossRef] [PubMed]
- Patino, C.M.; Ferreira, J.C. Test for trend: Evaluating dose-response effects in association studies. J. Bras. Pneumol. 2016, 42, 240. [Google Scholar] [CrossRef] [PubMed]
- Vittinghoff, E.; Glidden, D.V.; Shiboski, S.C.; McCulloch, C.E. Regression Methods in Biostatistics: Linear, Logistic, Survival, and Repeated Measures Models; Springer: New York, NY, USA, 2005; p. 340. [Google Scholar]
- Hothorn, L.A. Trend tests in epidemiology: P-values or confidence intervals? Biometr. J. 1999, 41, 817–825. [Google Scholar] [CrossRef]
- Liu, S.; Johnson, V.E. A robust Bayesian dose-finding design for phase I/II clinical trials. Biostatistics 2016, 17, 249–263. [Google Scholar] [CrossRef] [PubMed]
- Takeda, K.; Morita, S. Bayesian dose-finding phase I trial design incorporating historical data from a preceding trial. Pharm. Stat. 2018, 17, 372–382. [Google Scholar] [CrossRef]
- Toumazi, A.; Comets, E.; Alberti, C.; Friede, T.; Lentz, F.; Stallard, N.; Zohar, S.; Ursino, M. dfpk: An R-package for Bayesian dose-finding designs using pharmacokinetics (PK) for phase I clinical trials. Comput. Methods Programs Biomed. 2018, 157, 163–177. [Google Scholar] [CrossRef] [PubMed]
- Mu, R.; Xu, J. A new Bayesian dose-finding design for drug combination trials. Stat. Biopharm. Res. 2017, 9, 384–389. [Google Scholar] [CrossRef]
- De Pretis, F. New mathematical perspectives to understand the Information Society: the statistical mechanics approach to model and analyze big-data. In Proceedings of the International Conference of Young Scientists and Specialists “Information Society as Contemporary System of Defense and Attack”, Baku, Azerbaijan, 27–28 November 2014; Mütercim Publishing House: Baku, Azerbaijan, 2016; pp. 3–10. [Google Scholar]
- Gelman, A.; Hennig, C. Beyond subjective and objective in statistics. J. R. Stat. Soc. Ser. A Stat. Soc. 2017, 180, 967–1033, with comments. [Google Scholar] [CrossRef] [Green Version]
- Hawthorne, J. Degree-of-Belief and Degree-of-Support: Why Bayesians Need Both Notions. Mind 2005, 114, 277–320. [Google Scholar] [CrossRef]
- Dawid, A.P. On individual risk. Synthese 2017, 194, 3445–3474. [Google Scholar] [CrossRef]
- Sprenger, J. The objectivity of Subjective Bayesianism. Eur. J. Philos. Sci. 2019. [Google Scholar] [CrossRef]
- Longino, H.E. Science as Social Knowledge: Values and Objectivity in Scientific Inquiry; Princeton University Press: Princeton, NJ, USA, 1990. [Google Scholar]
- Edwards, W.; Lindman, H.; Savage, L.J. Bayesian statistical inference for psychological research. Psychol. Rev. 1963, 70, 193. [Google Scholar] [CrossRef]
- Senn, S.S. Statistical Issues in Drug Development; John Wiley & Sons: Hoboken, NJ, USA, 2008; Volume 69. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| di | ni | yi | ri |
|---|---|---|---|
| 0 | 137,568 | 108 | 7.85 × 10−4 |
| 10 | 99,922 | 112 | 1.12 × 10−3 |
| 31.67 | 32,077 | 41 | 1.28 × 10−3 |
| 60 | 10,656 | 16 | 1.50 × 10−3 |
| 86.67 | 17,059 | 22 | 1.29 × 10−3 |
| Model | θ | Specification of f(di|θ) | AIC | BIC | R2 | Adjusted R2 |
|---|---|---|---|---|---|---|
| exponential | (α, β) | αexp(βdi) | −66.29 | −67.46 | 0.98 | 0.97 |
| linear | (α, β) | βdi + α | −66.79 | −67.96 | 0.56 | 0.41 |
| quadratic | (α, β, γ) | γdi2 + βdi + α | −74.57 | −76.13 | 0.95 | 0.90 |
| cubic | (α, β, γ, δ) | δdi3 + γdi2 + βdi + α | −70.10 | −72.06 | 0.95 | 0.80 |
| 1.01 × 10−3 |
| 1.06 × 10−3 |
| 1.16 × 10−3 |
| 1.30 × 10−3 |
| 1.46 × 10−3 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
De Pretis, F.; Osimani, B. New Insights in Computational Methods for Pharmacovigilance: E-Synthesis, a Bayesian Framework for Causal Assessment. Int. J. Environ. Res. Public Health 2019, 16, 2221. https://doi.org/10.3390/ijerph16122221
De Pretis F, Osimani B. New Insights in Computational Methods for Pharmacovigilance: E-Synthesis, a Bayesian Framework for Causal Assessment. International Journal of Environmental Research and Public Health. 2019; 16(12):2221. https://doi.org/10.3390/ijerph16122221
Chicago/Turabian StyleDe Pretis, Francesco, and Barbara Osimani. 2019. "New Insights in Computational Methods for Pharmacovigilance: E-Synthesis, a Bayesian Framework for Causal Assessment" International Journal of Environmental Research and Public Health 16, no. 12: 2221. https://doi.org/10.3390/ijerph16122221