Appendix A.1. Variables
In the following it is explained which variables provided by the SOEP were used. Each variable can be linked via its unique identifier to the data file containing it. The SOEP provides an online search-engine which allows for further information on the variables to be easily obtained by searching for the unique identifier:
https://paneldata.org/soep-core (last access: 5 September 2019).
For the dependent variable, the Mental Component Scale (MCS) scores, contained in variable
MCS, from the
HEALTH file were used. The MSC scale of the SF-12v2 provide self-rated measurements of specific aspects of mental health. Using instruments based on self-reports are suited to measure aspects of health, since mental and physical health are facets of the health-related quality of life, which is a subjective matter [
90]. Self-rated measurements are a standard tool in health research, and experience growing importance [
37]. They may reveal insights that might not be gained with objective measurements—for example, according to Bährer-Kohler and Carod-Artal [
91], many people state that they suffer from poor mental health even though they may not reach thresholds for official diagnoses. An observation’s score is computed as a weighted average of the answers given on six questions. The weights are constructed with the help of factor loadings resulting from a factor analysis. The MCS scores provided by the SOEP are based on a four-factor model. Information on the algorithm for their computation is provided by Nübling et al. [
64] and Andersen et al. [
63]. The four factors provided by the SOEP are labelled as mental health (two items), role emotional (two items), social functioning (one item), and vitality (one item) [
64]. Test-theoretical properties of the MCS scale are mentioned in
Section 2 (p. 3).
In some parts, the same explanatory variables as used by Silbersdorff et al. [
27] were incorporated. The authors used variables that are standard in the field of (physical) health research, such as annual net equivalised household income, age, education, marital status, a variable indicating whether an individual is a German national (or not), and a variable indicating whether an individuals lives in former West or East Germany. These variables are also frequently used in mental health research [
14,
34,
37,
92] and are in line with current academic textbooks ([
93], pp. 76–77).
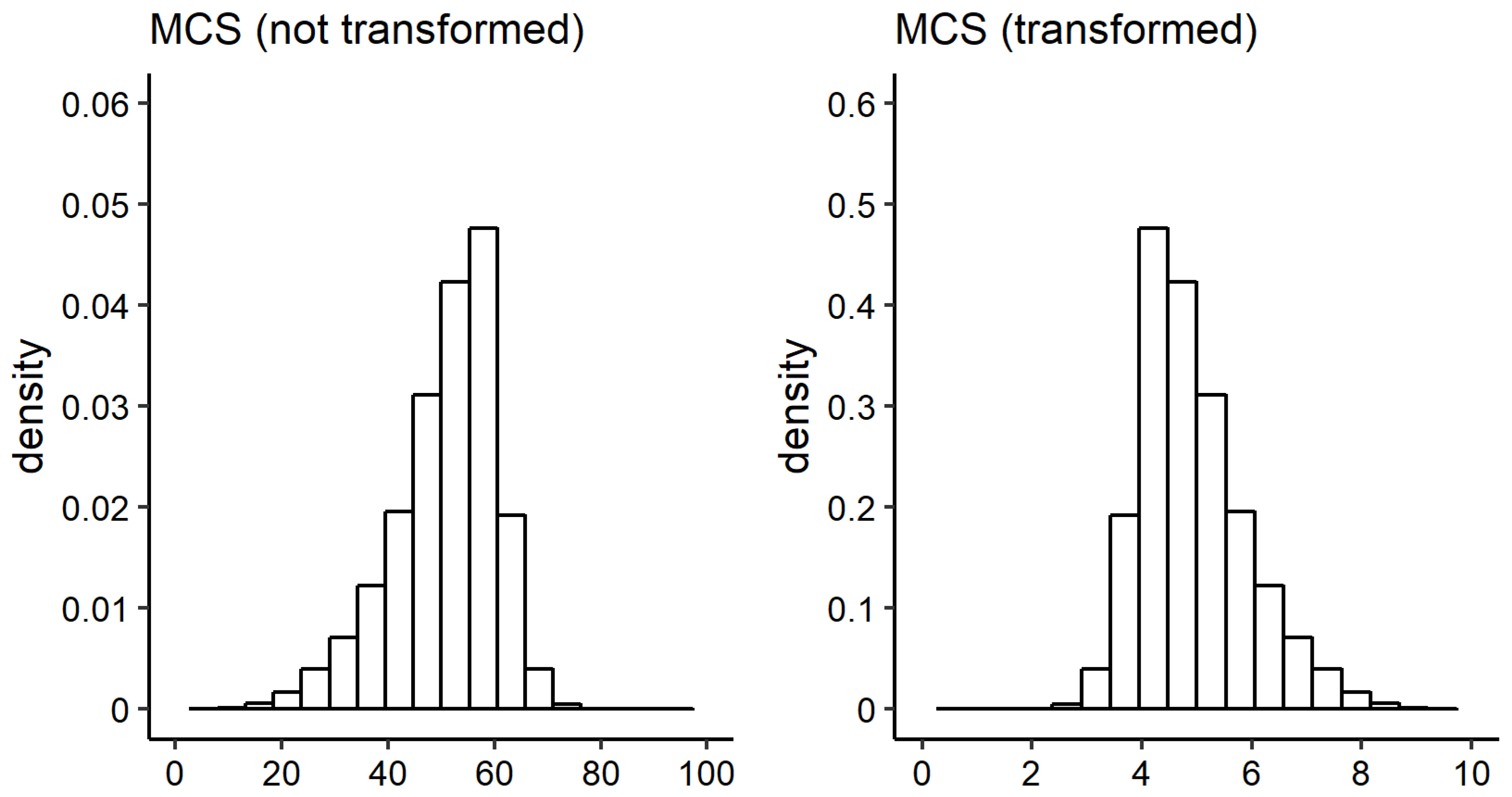
An individual’s income is operationalised as the annual net equivalised household income. The annual net household income is given by
i1110215. The variable is provided in the
bfpequiv file, from the survey of year 2015. It is a backdating question, and therefore refers to the income of 2014. The annual net household income is adjusted with the help of Modified OECD Equivalence Weights to account for the number of individuals living in the household, as well as the children/adults ratio [
94]. The formula for the computation recommended by the SOEP is used ([
95], p. 38). In order to equivalise, the variables “Number of persons in household” (
d1110614) and “Number of children in household aged 0–13” (
h1110114) are used. Both variables are taken from the
bepequiv file. Following Silbersdorff et al. [
27] a log transformation (natural logarithm) on income is used. For simplification, within this publication, the term
is used to refer to the variable.
While income is the main variable of interest, all other variables included in the models are used to statistically control for their effects:
The variable age (
) is provided by
d1110114 in the
bepequiv file. Based on simple descriptive analysis, (mean) PCS scores seem to decrease with increasing age, whereas (mean) MCS scores seem to stay approximately equal ([
8], pp. 815–816, Table 8.4). Westerhof and Keyes [
50] disentangled the effect of age on mental health (positive aspects) and mental illness with the help of four linear regression models with differing dependent variables. The authors found negative significant effects for age and age squared on mental illness, yet the effect of age squared vanished when control variables (e.g., age, educational status, employment status, gender, income, migration) were introduced. For age and age squared, positive significant effects were found on emotional well-being. Additionally, age—but not age squared—was found to have positive significant effect on psychological well-being. On the other hand, no effects were found for social well-being.
Following Silbersdorff et al. [
27], the individuals’ educational attainment was measured with the International Standard Classification of Education—ISCED97 [
82]. The variable can be found in the
bepgen file with the identifier
isced97_14. The original six categories were reduced to four categories:
includes all individuals with ISCED levels 0, 1, and 2, representing pre-primary, primary, and lower secondary education;
includes all observations, with ISCED level 3 representing upper secondary education;
includes all observations with ISCED levels 4 and 5;
includes all observations with ISCED level 6. Related to Germany this means, that the first education level (
) contains the educational attainment of finishing Kindergarten and/or Haupt-, Realschule, Gymnasium (ohne Oberstufe). The second education level (
) contains the educational attainment of finishing Berufsschule, Gymnasium (Oberstufe) or equivalent schooling-levels. The third education level (
) contains the educational attainment of being awarded a Bachelor’s or Master’s degree. The fourth education level (
) contains the educational attainment of being awarded a doctorate or a habilitation.
As a dummy variable indicating whether an individual is a German national, the variable bep129 from the bep file was used.
For the marital status, the six categories of bep127 from the bep file were reduced to four categories. The four categories are: , containing individuals who are married and are living together or who are in a same-sex partnership and living with their partner; contains all individuals being married but living separately, who are divorced or having a dissolved registered partnership, or those who have a registered same-sex partnership but are living separately; contains all individuals who are single; contains all individuals who are widowed.
As a variable indicating whether an individual lives in former West or East Germany, a dummy variable is built with the help of the variable state of residence (
l1110114) from the
bepequiv file. Differences in the prevalence of mental disorders between former West and East Germany were present in the past [
96], but seem to have vanished nowadays [
34].
To account for the well-known effects of being unemployed on mental health, a dummy variable with two levels is used:
. Therefore, the variable
bep09 from the
bep file is used. Meta analyses on the evidence of negative effects of being unemployed on mental illness [
58], as well as evidence of positive effects of being employed on mental health exist [
61].
Differences in mental health when comparing individuals living in rural and and urban areas are well-known. Mental health tend to be worse for individuals living in urban areas compared to individuals living in rural areas [
34,
57,
59,
62]. Many different operationalisations of the degree of rurality/urbanity in research exist—for example, self ratings [
59], number of inhabitants [
62], and the degree of concentration of inhabitants [
60]. In part, these effects may be grounded in special physical characteristics of urban areas such as traffic, pollution, noise, artificial light at night, availability of green areas, presence of crime, availability of drugs, and many more. In order to operationalise this concept, the variable
beh57 (from the
beh file) is dichotomised to the variable
, indicating whether an individual lives closer than ten kilometres to the nearest metropolis (reference group) or not.
Only those individuals with full information on all variables are used. Individuals who reported that their income is zero were removed from the analysis since the log-transformation could not be applied (0.0008% of the sample). The sample for the analysis yields 22,678 individuals: 10,387 males and 12,291 females. 80% of the data was used as training data (and therefore 20% was used as test data).
Appendix A.2. Choosing a Distribution for the Conditional Health Distribution
Table A1 lists all used distributions tested as response distributions within this publication. Columns
,
,
,
indicate the used link functions, if the parameter is present in the respective distribution. Rigby et al. [
97] provide a publication in which all distributions available in the
gamlss package are described.
Table A1.
Distributions used for the analysis.
Table A1.
Distributions used for the analysis.
| Distribution | gamlss Name | | | | | Page |
| Box–Cox power exponential (BCPE) | BCPE | ident. | log | ident. | log | p. 291 |
| Box-Cox-Cole-Green (BCCG) | BCCG | ident. | log | ident. | - | p. 282 |
| Box–Cox-t (BCT) | BCT | ident. | log | ident. | log | p. 290 |
| Dagum (Da) | GB2 | log | log | log | = 1 | p. 294 |
| Gamma (Ga) | GA | log | log | - | - | p. 271 |
| Generalised Beta type 2 (GB2) | GB2 | log | log | log | log | p. 293 |
| Generalised Gamma (GG) | GG | log | log | ident. | - | p. 285 |
| Generalised Inverse Gaussian (GIG) | GIG | log | log | ident. | - | p. 287 |
| Log Normal (LOGNo) | LOGNO | ident. | log | - | - | p. 275 |
| Normal (No) | NO | ident. | log | - | - | p. 232 |
| Pearson-Type-VI (PtVI) | GB2 | log | = 1 | log | log | p. 293 |
| Singh-Maddala (SM) | GB2 | log | log | = 1 | log | p. 293 |
| Weibull (WEI3) | WEI3 | log | log | - | - | p. 280 |
The column named
page of
Table A1 gives the page of the publication on which the distribution is described. The probability density function, cumulative density function and, if defined, the expectation, variance, skewness, and kurtosis are provided. The publication can be accessed at:
https://www.gamlss.com/distributions/; last access: 26 August 2019.
Table A2 and
Table A3 display information criteria of the models for the male and female sample. Both tables are sorted by the
in ascending order. The smallest five values in each column are marked by a dagger symbol (†). The notation can be understood as follows: BCT (
= 🗸,
= 🗸,
= 🗸,
= –) indicates that a model with BCT distribution as a response distribution is fitted. The BCT distribution is fully described by four parameters, where the check symbols (🗸) indicate that only the first three have been linked to the regression predictor, while
is modelled only by an intercept.
Unfortunately, estimation routines fail when a GG distribution is used and all three parameters are linked to the regression predictor. As a consequence, GG ( = 🗸, = 🗸, = 🗸) does not occur in the respective tables.
Table A2.
Information criteria of estimated models with the male sample.
Table A2.
Information criteria of estimated models with the male sample.
| Model (Male) | AIC | BIC | GAIC () | TGDEV a |
|---|
| GB2 ( = 🗸, = 🗸, = 🗸, = ) | 20,734 † | 21,128 | 20,846 † | 5166 † |
| GB2 ( = 🗸, = 🗸, = –, = –) | 20,760 † | 20,971 † | 20,820 † | 5185 † |
| GB2 ( = 🗸, = 🗸, = 🗸, = –) | 20,763 † | 21,066 | 20,849 † | 5188 |
| Da ( = 🗸, = 🗸, = –) | 20,769 † | 20,973 † | 20,827 † | 5189 |
| BCT ( = 🗸, = 🗸, = 🗸, = –) | 20,777 † | 21,079 | 20,863 | 5184 † |
| Da ( = 🗸, = 🗸, = ) | 20,781 | 21,076 | 20,865 | 5189 |
| BCT ( = 🗸, = 🗸, = 🗸, = ) | 20,781 | 21,175 | 20,893 | 5187 |
| BCCG ( = 🗸, = 🗸, = ) | 20,783 | 21,078 | 20,867 | 5181 † |
| BCPE ( = 🗸, = 🗸, = 🗸, = –) | 20,784 | 21,086 | 20,870 | 5182 † |
| BCPE ( = 🗸, = 🗸, = 🗸, = ) | 20,786 | 21,179 | 20,898 | 5187 |
| BCT ( = 🗸, = 🗸, = –, = –) | 20,799 | 21,010 † | 20,859 † | 5197 |
| GG ( = 🗸, = 🗸, = –) | 20,809 | 21,012 † | 20,867 | 5190 |
| BCCG ( = 🗸, = 🗸, = –) | 20,810 | 21,013 † | 20,868 | 5192 |
| BCPE ( = 🗸, = 🗸, = –, = –) | 20,810 | 21,021 | 20,870 | 5195 |
| SM ( = 🗸, = 🗸, = –) | 20,848 | 21,052 | 20,906 | 5221 |
| SM ( = 🗸, = 🗸, = ) | 20,851 | 21,146 | 20,935 | 5220 |
| GIG ( = 🗸, = 🗸, = ) | 20,879 | 21,174 | 20,963 | 5233 |
| PtVI ( = 🗸, = 🗸, = ) | 20,903 | 21,198 | 20,987 | 5240 |
| GB2 ( = 🗸, = –, = –, = –) | 20,915 | 21,034 | 20,949 | 5242 |
| Da ( = 🗸, = –, = –) | 20,918 | 21,031 | 20,950 | 5244 |
| GIG ( = 🗸, = 🗸, = –) | 20,919 | 21,123 | 20,977 | 5248 |
| PtVI ( = 🗸, = 🗸, = –) | 20,929 | 21,133 | 20,987 | 5248 |
| BCT ( = 🗸, = –, = –, = –) | 20,938 | 21,058 | 20,972 | 5249 |
| BCPE ( = 🗸, = –, = –, = –) | 20,952 | 21,072 | 20,986 | 5250 |
| BCCG ( = 🗸, = –, = –) | 20,956 | 21,069 | 20,988 | 5246 |
| GG ( = 🗸, = –, = –) | 20,958 | 21,070 | 20,990 | 5246 |
| SM ( = 🗸, = –, = –) | 20,979 | 21,092 | 21,011 | 5267 |
| GIG ( = 🗸, = –, = –) | 21,006 | 21,119 | 21,038 | 5277 |
| LOGNo ( = 🗸, = ) | 21,020 | 21,216 | 21,076 | 5281 |
| PtVI ( = 🗸, = –, = –) | 21,028 | 21,141 | 21,060 | 5286 |
| LOGNo ( = 🗸, = –) | 21,146 | 21,251 | 21,176 | 5328 |
| Ga ( = 🗸, = ) | 21,267 | 21,464 | 21,323 | 5357 |
| Ga ( = 🗸, = –) | 21,381 | 21,486 | 21,411 | 5400 |
| No ( = 🗸, = ) | 22,040 | 22,237 | 22,096 | 5574 |
| No ( = 🗸, = –) | 22,148 | 22,253 | 22,178 | 5613 |
| WEI3 ( = 🗸, = ) | 23,305 | 23,501 | 23,361 | 5894 |
| WEI3 ( = 🗸, = –) | 23,341 | 23,447 | 23,371 | 5909 |
Table A3.
Information criteria of estimated models with the female sample.
Table A3.
Information criteria of estimated models with the female sample.
| Model (Male) | AIC | BIC | GAIC () | TGDEV a |
|---|
| BCPE ( = 🗸, = 🗸, = 🗸, = ) | 26,475 † | 26,878 | 26,587 † | 6617 |
| BCPE ( = 🗸, = 🗸, = 🗸, = –) | 26,487 † | 26,796 † | 26,573 † | 6603 † |
| GB2 ( = 🗸, = 🗸, = 🗸, = ) | 26,547 † | 26,950 | 26,659 | 6622 |
| BCCG ( = 🗸, = 🗸, = ) | 26,555 † | 26,857 | 26,639 † | 6612 † |
| BCT ( = 🗸, = 🗸, = 🗸, = –) | 26,557 † | 26,866 | 26,643 † | 6612 † |
| BCPE ( = 🗸, = 🗸, = –, = –) | 26,569 | 26,785 † | 26,629 † | 6623 |
| BCT ( = 🗸, = 🗸, = 🗸, = ) | 26,576 | 26,979 | 26,688 | 6612 † |
| GB2 ( = 🗸, = 🗸, = 🗸, = –) | 26,595 | 26,904 | 26,681 | 6613 † |
| GB2 ( = 🗸, = 🗸, = –, = –) | 26,605 | 26,821 † | 26,665 | 6624 |
| GG ( = 🗸, = 🗸, = –) | 26,615 | 26,824 † | 26,673 | 6627 |
| BCCG ( = 🗸, = 🗸, = –) | 26,621 | 26,829 † | 26,679 | 6629 |
| BCT ( = 🗸, = 🗸, = –, = –) | 26,623 | 26,839 | 26,683 | 6629 |
| GIG ( = 🗸, = 🗸, = ) | 26,626 | 26,928 | 26,710 | 6634 |
| PtVI ( = 🗸, = 🗸, = ) | 26,658 | 26,960 | 26,742 | 6639 |
| PtVI ( = 🗸, = 🗸, = –) | 26,659 | 26,867 | 26,717 | 6643 |
| GIG ( = 🗸, = 🗸, = –) | 26,668 | 26,877 | 26,726 | 6634 |
| LOGNo ( = 🗸, = ) | 26,723 | 26,924 | 26,779 | 6658 |
| Da ( = 🗸, = 🗸, = ) | 26,753 | 27,056 | 26,837 | 6643 |
| Da ( = 🗸, = 🗸, = –) | 26,764 | 26,973 | 26,822 | 6652 |
| BCPE ( = 🗸, = –, = –, = –) | 26,800 | 26,922 | 26,834 | 6650 |
| GG ( = 🗸, = –, = –) | 26,824 | 26,939 | 26,856 | 6651 |
| BCCG ( = 🗸, = –, = –) | 26,827 | 26,942 | 26,859 | 6653 |
| GIG ( = 🗸, = –, = –) | 26,828 | 26,943 | 26,860 | 6653 |
| BCT ( = 🗸, = –, = –, = –) | 26,829 | 26,952 | 26,863 | 6653 |
| GB2 ( = 🗸, = –, = –, = –) | 26,837 | 26,960 | 26,871 | 6651 |
| PtVI ( = 🗸, = –, = –) | 26,847 | 26,962 | 26,879 | 6659 |
| LOGNo ( = 🗸, = –) | 26,902 | 27,009 | 26,932 | 6676 |
| SM ( = 🗸, = 🗸, = ) | 26,903 | 27,205 | 26,987 | 6684 |
| Ga ( = 🗸, = ) | 26,921 | 27,123 | 26,977 | 6712 |
| SM ( = 🗸, = 🗸, = –) | 26,941 | 27,150 | 26,999 | 6694 |
| Da ( = 🗸, = –, = –) | 26,980 | 27,095 | 27,012 | 6674 |
| Ga ( = 🗸, = –) | 27,077 | 27,185 | 27,107 | 6727 |
| SM ( = 🗸, = –, = –) | 27,122 | 27,237 | 27,154 | 6711 |
| No ( = 🗸, = ) | 27,637 | 27,838 | 27,693 | 6902 |
| No ( = 🗸, = –) | 27,799 | 27,907 | 27,829 | 6920 |
| WEI3 ( = 🗸, = ) | 28,755 | 28,957 | 28,811 | 7190 |
| WEI3 ( = 🗸, = –) | 28,798 | 28,906 | 28,828 | 7198 |
Appendix A.3. Residual Diagnostics
Stasinopoulos et al. [
81] (pp. 417–422) recommend to use diagnostic plots of normalised quantile residuals to assess the adequacy of estimated models. According to Stasinopoulos et al. [
81] (p. 418), the “[...] main advantage of normalized (randomized) quantile residuals is that, whatever the distribution of the response variable, the true residuals always have standard normal distribution when the assumed model is correct”. Hereafter, we refer to normalised quantile residuals simply as residuals.
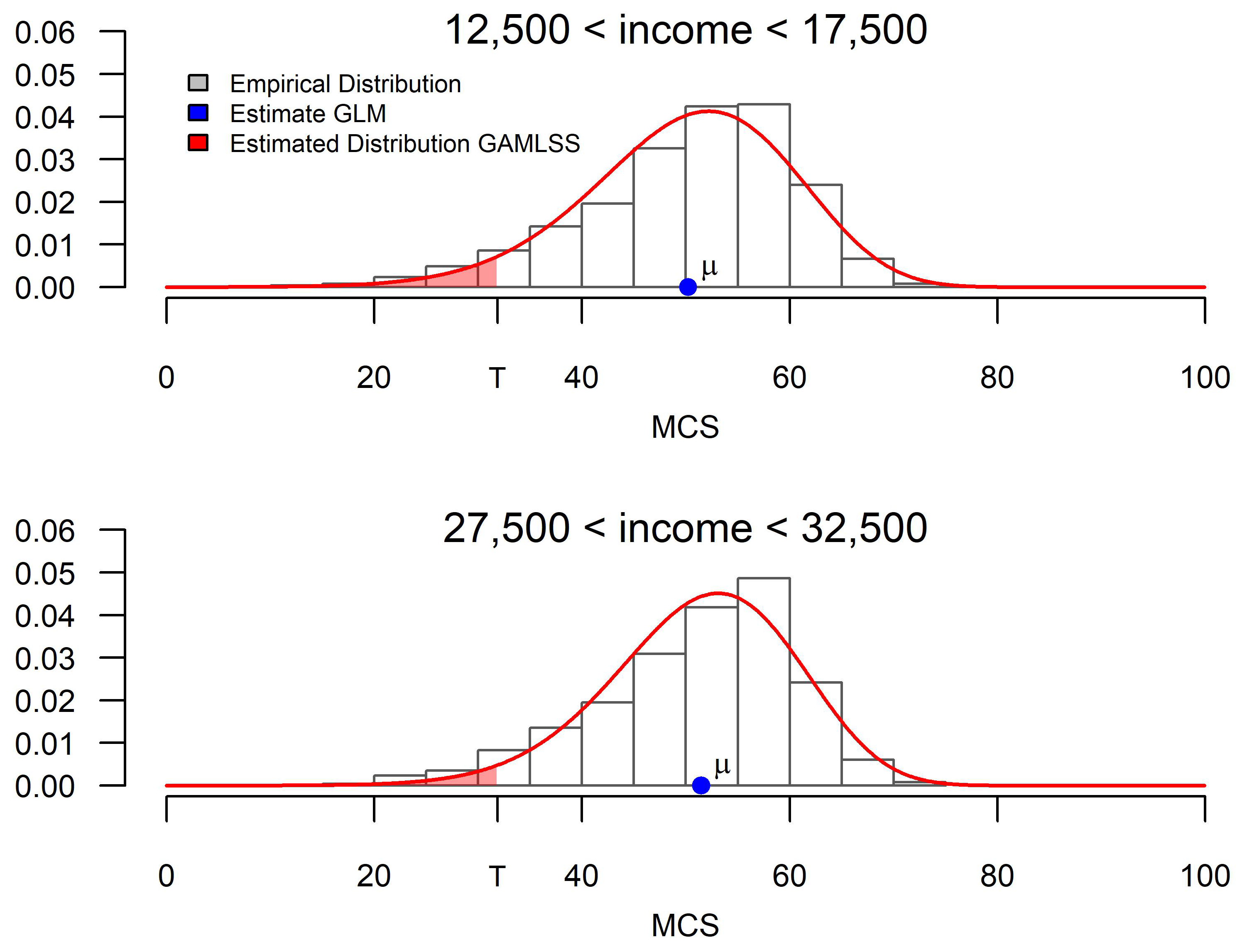
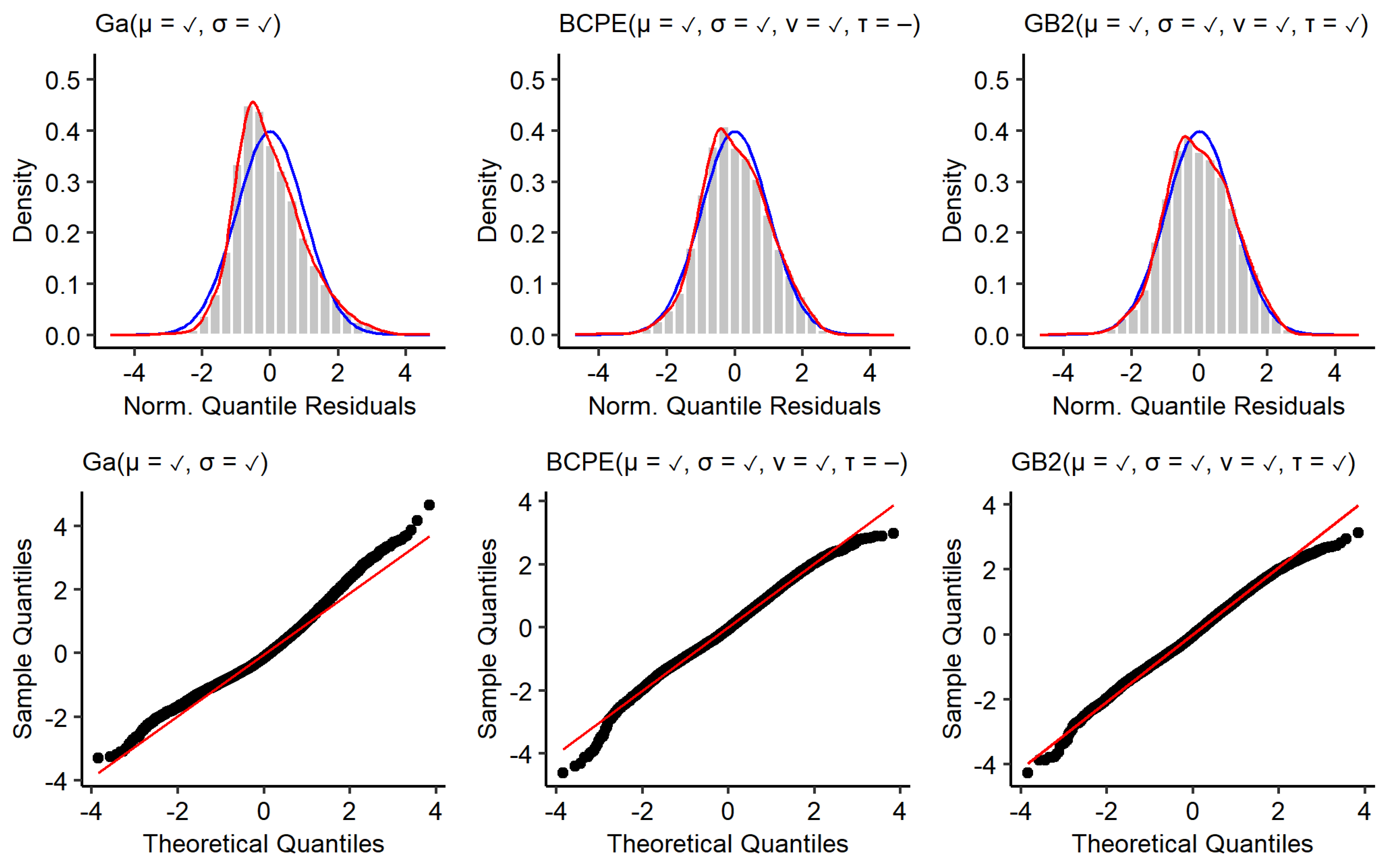
The top row of
Figure A1 shows kernel density estimates of the residuals from the models estimated with the male training data (red), as well as a standard normal distribution (blue). The bottom row shows corresponding quantile–quantile plots. The residuals of the GA model deviate most from a standard normal distribution. The residuals are positively skewed (
) and the kernel density estimate reveals a tail too thin for small residuals and a tail too fat for large residuals. Additionally, the distribution of residuals is leptokurtic
(the curtosis of a standard normal distribution is 3). This is also resembled by deviations from the red diagonal shown in the quantile–quantile plots. Using BCPE and GB2 distributions led to residuals with a skewness close to 0 (
,
). Furthermore, the distribution of residuals is less leptokurtic for the BCPE model (
) and slightly platykurtic for the GB2 model (
). Even though the tails of the kernel density estimates for the BCPE and GB2 model look close to optimal, the quantile–quantile plots show that there is a remaining deviation from a standard normal distribution in the tails.
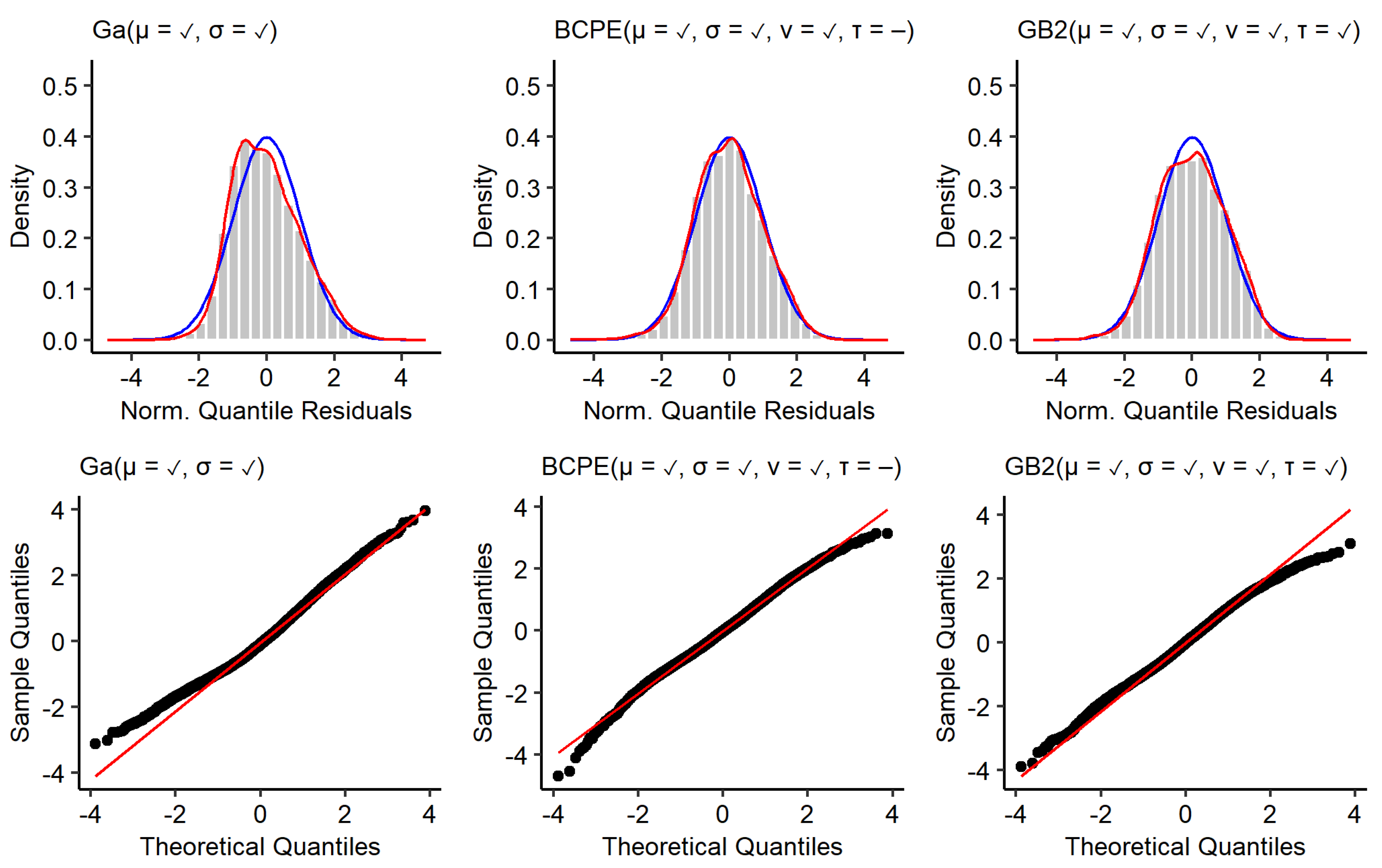
Figure A2 shows the same type of plot for models estimated with the female training data. The general observable patterns are comparable to the models estimated with the male training data. The residuals resulting from the GA model are positively skewed (
) and slightly platykurtic (
). The quantile–quantile plots reveal that there are deviations from the optimal in the lower tail. Using a BCPE or GB2 distribution instead again leads to distributions of residuals with a skewness close to 0 (
,
). While the curtosis of the residuals of the BCPE model is very close to its ideal value of three (
), the residuals of the GB2 model are platykurtic (
). Again, the tails of the kernel density estimates for the BCPE and GB2 model look close to optimal. Yet, the quantile–quantile plots show that there is a remaining deviation from a standard normal distribution in the tails. As a conclusion, it can be said that none of the used response distributions leads to residuals that clearly outperform the other. For all models, it holds that deviations of the distribution of residuals from a standard normal distribution are not of such magnitude that the models must be discarded.
Figure A1.
Residuals of models estimated with the male training data. Top: Histogram and kernel density estimate of normalised quantile residuals with standard normal distribution (blue). Bottom: Quantile–quantile plots.
Figure A1.
Residuals of models estimated with the male training data. Top: Histogram and kernel density estimate of normalised quantile residuals with standard normal distribution (blue). Bottom: Quantile–quantile plots.
Figure A2.
Residuals of models estimated with the female training data. Top: histogram and kernel density estimate of normalised quantile residuals with standard normal distribution (blue). Bottom: Quantile–quantile plots.
Figure A2.
Residuals of models estimated with the female training data. Top: histogram and kernel density estimate of normalised quantile residuals with standard normal distribution (blue). Bottom: Quantile–quantile plots.
Appendix A.5. Bootstrap Confidence Intervals
Bootstrap 0.95 confidence intervals (CI) were calculated within this publication in the following manner: Let be the estimate for which a 95%-bootstrap CI should be obtained. may be any kind of distributional measure, that is, the expectation or a risk measure, obtained from a prediction based on an estimated GAMLSS model with the training data. Let the training data have N observations.
Create a bootstrap sample: Sample with replacement N observations from the training data.
Estimate a GAMLSS model with the bootstrap sample.
Calculate .
Repeat steps one to three 2500 times to obtain estimates.
Calculate the empirical 2.5% and 97.5% quantiles from the distribution of resulting from the 2500 bootstrap samples.
One important quantity to discuss is the chosen number of bootstrap samples,
B. In general, it holds that the larger the number of bootstrap samples, the more certain one can be to find stable boundaries. The term
stable hereby means that the boundaries of the confidence intervals do not change remarkably when the number of bootstrap samples is further increased.
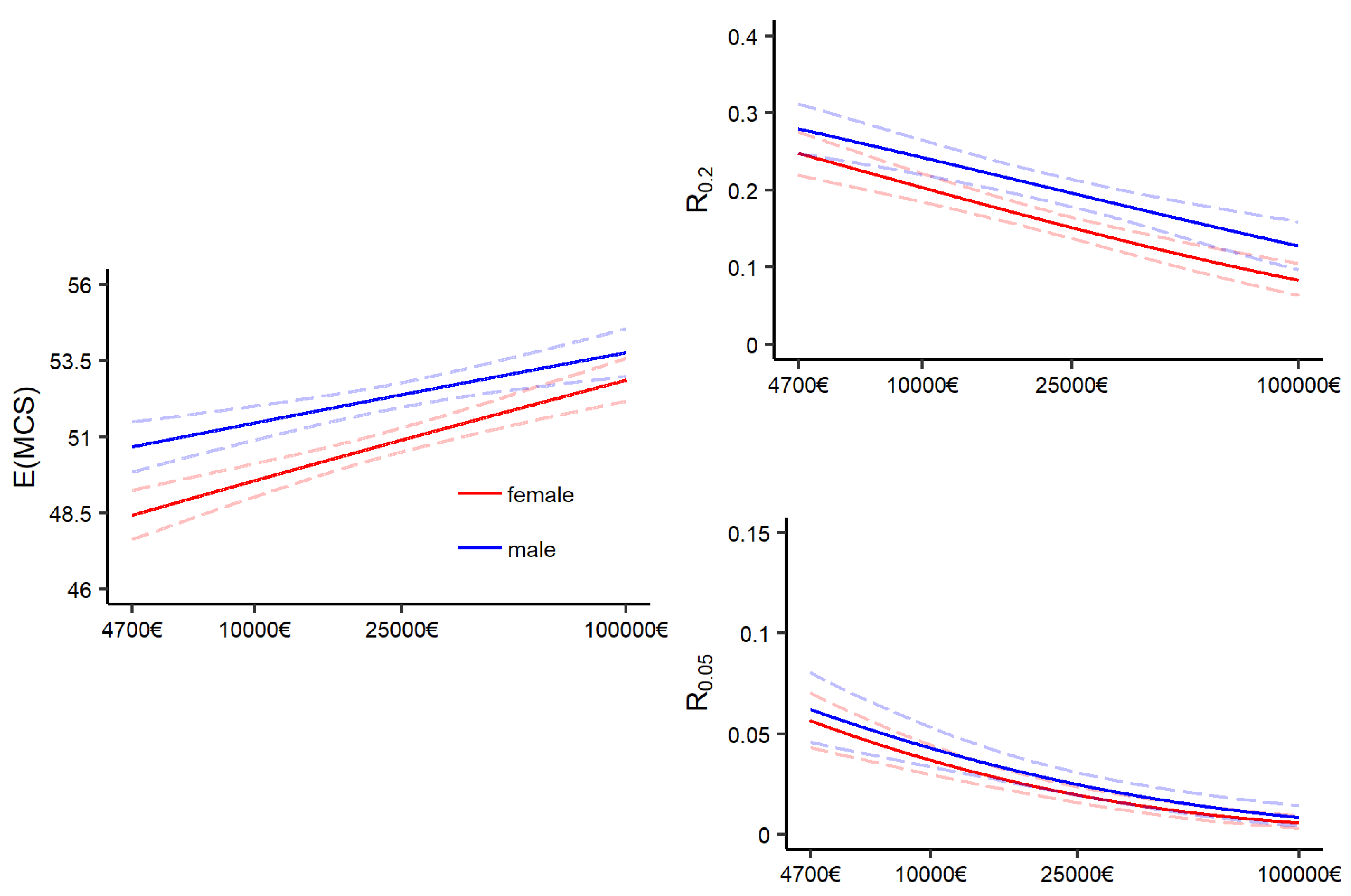
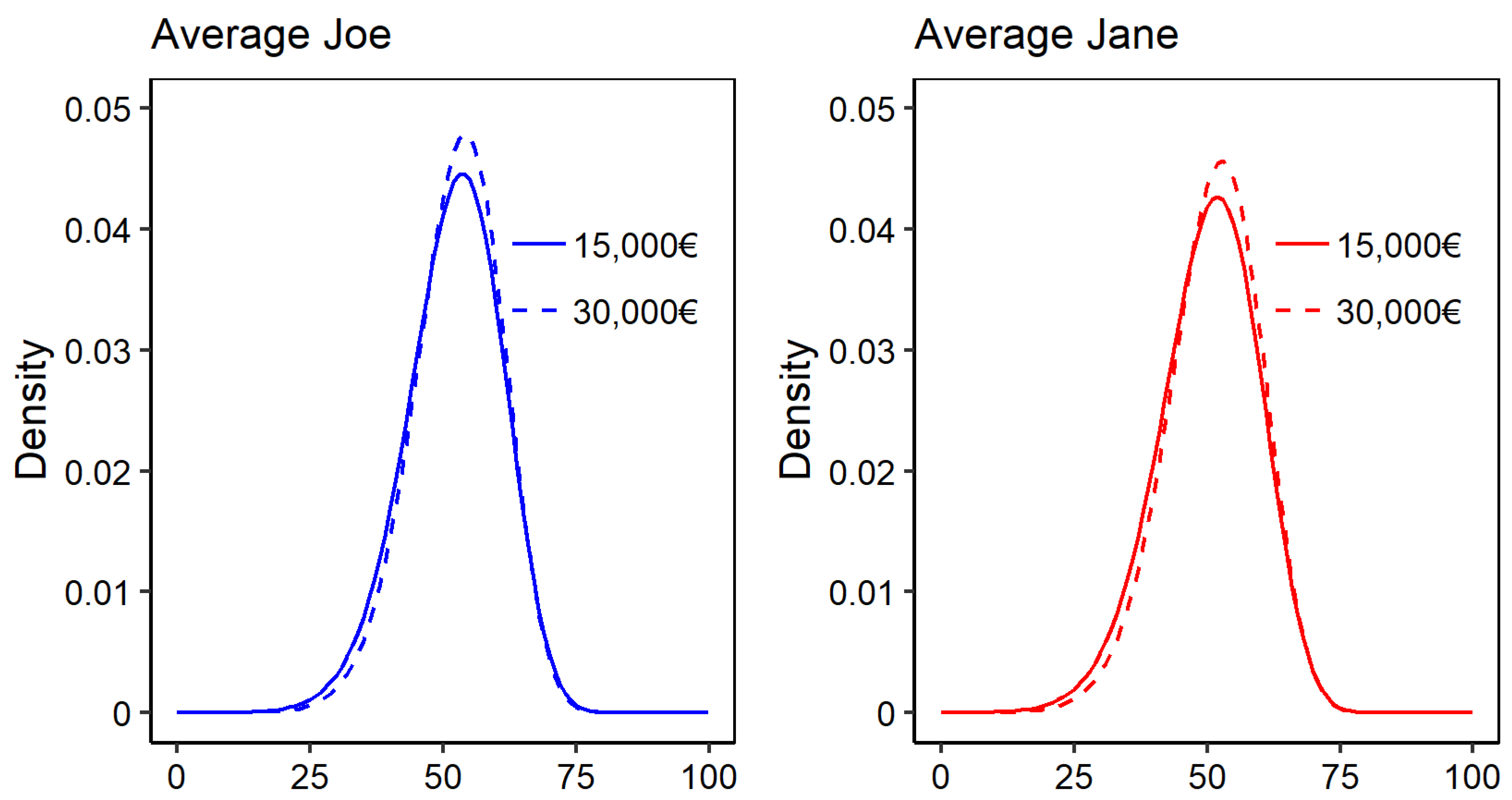
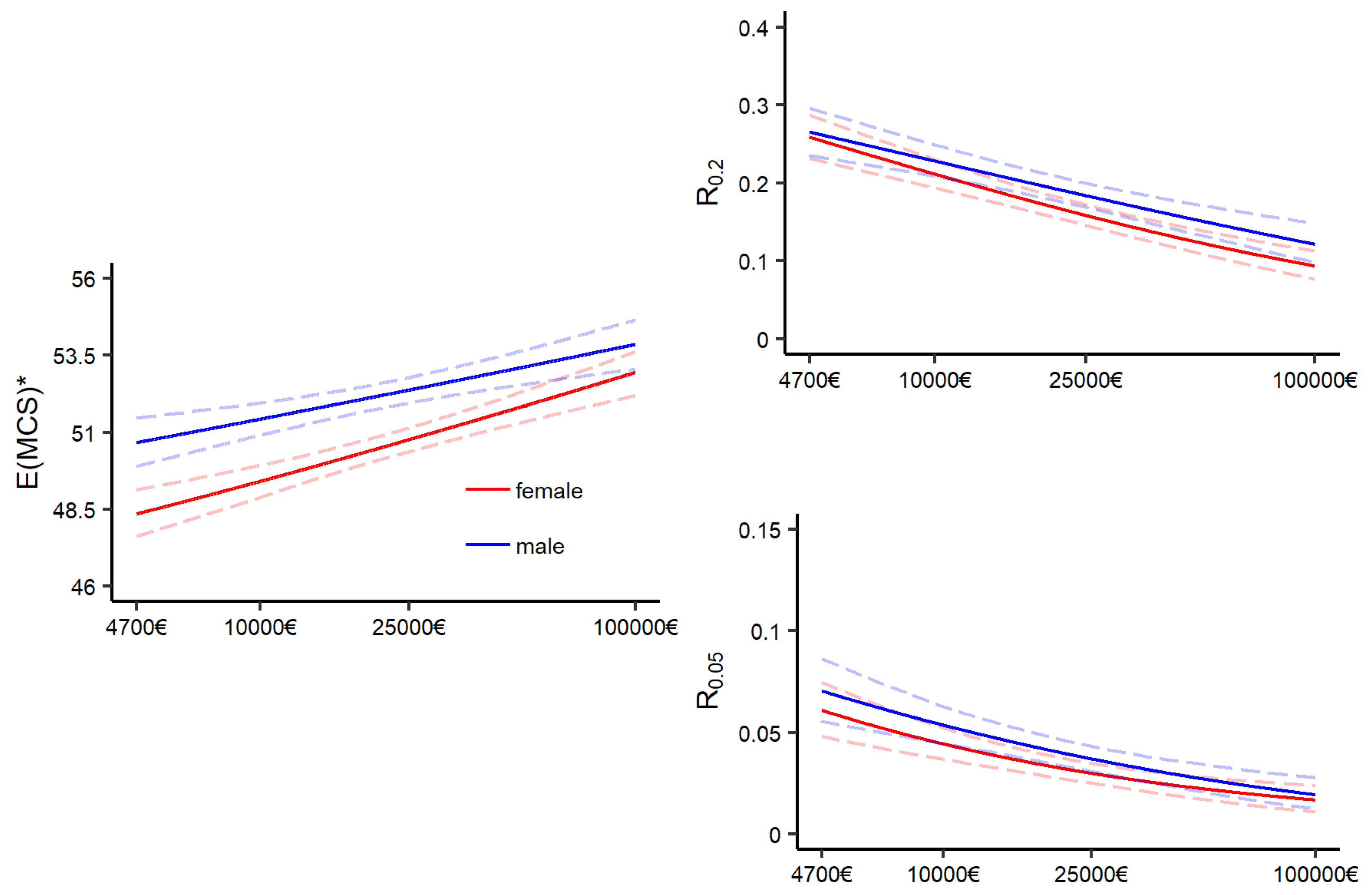
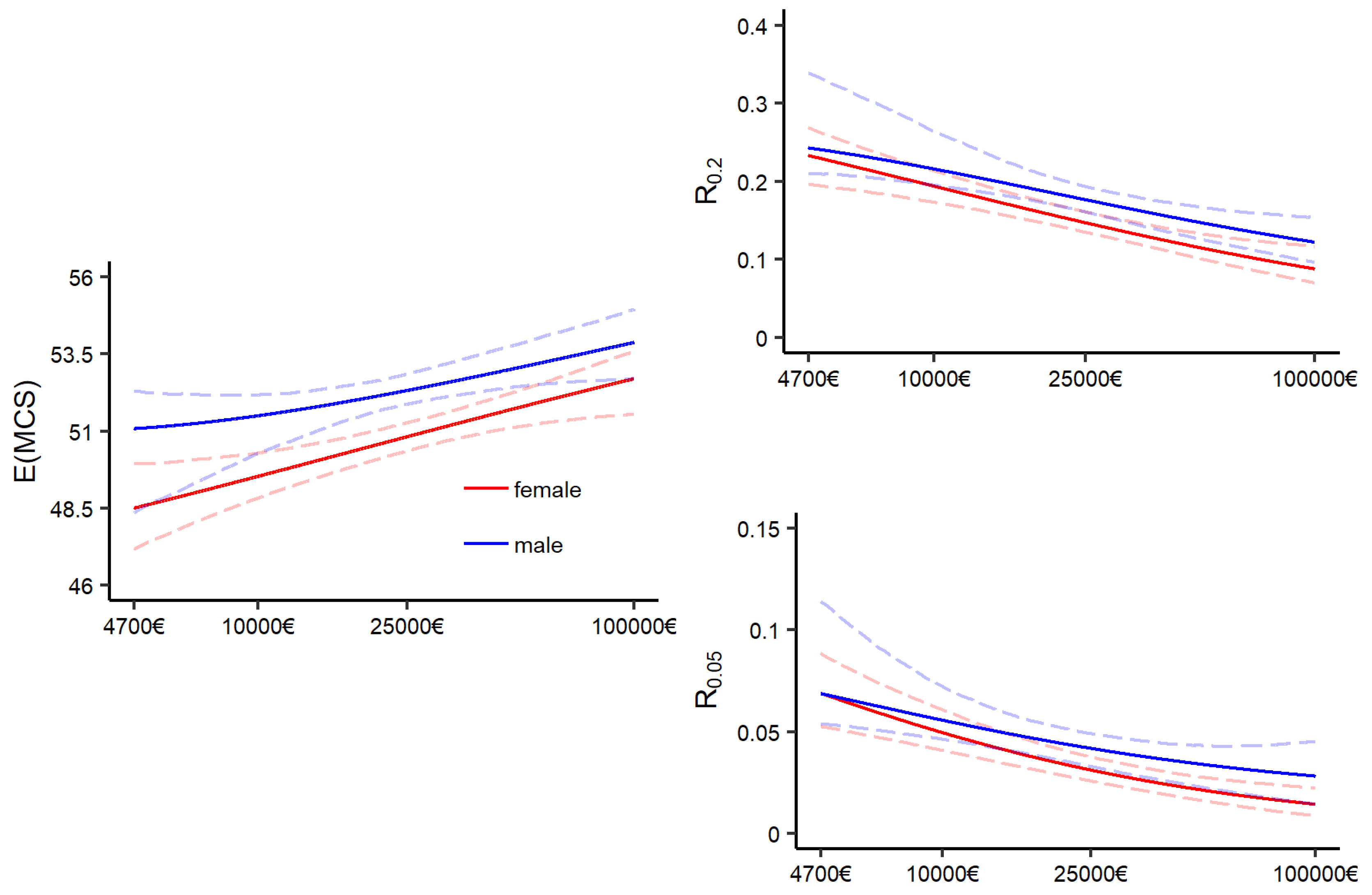
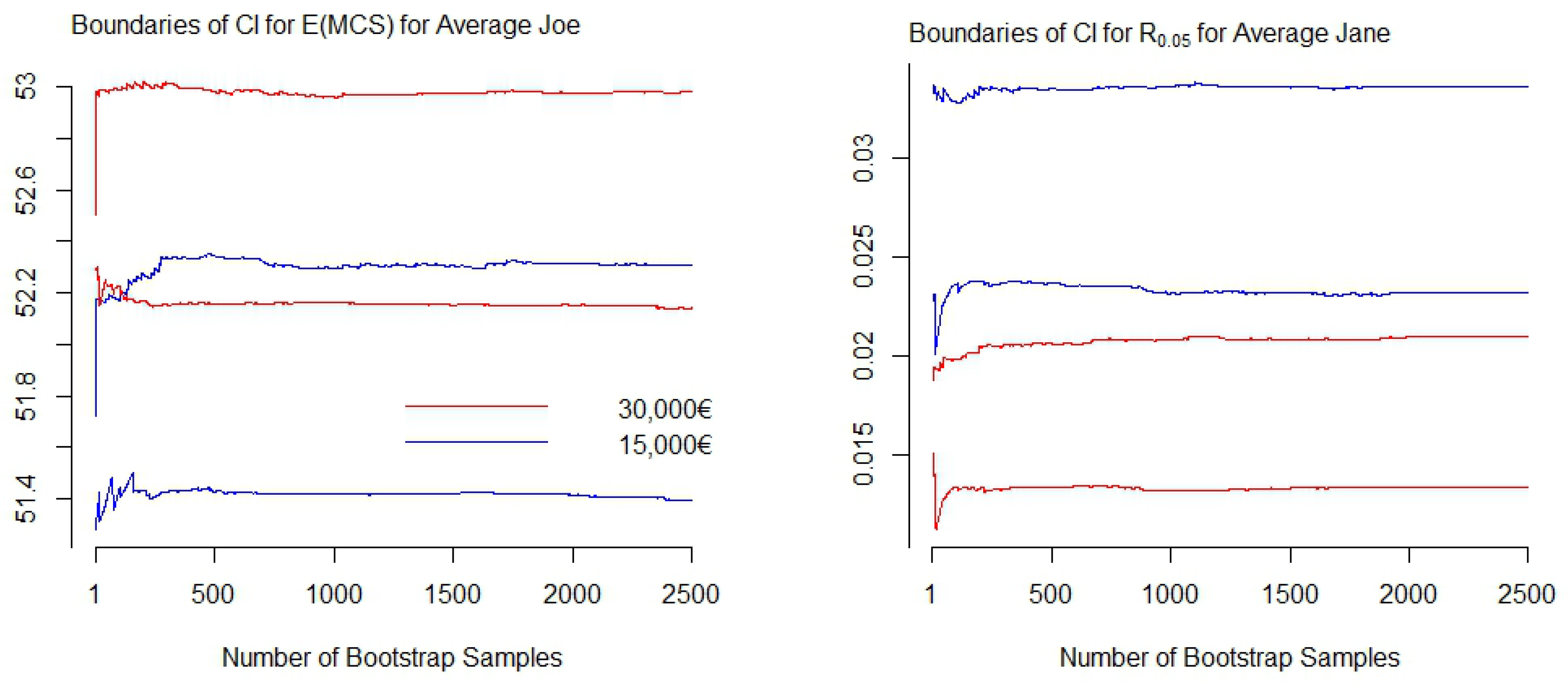
Figure A5 displays the boundaries of the confidence intervals in dependence of the number of generated bootstrap samples for two exemplarily selected distributional measures resulting from GA models. The graphs on the left of
Figure A5 display the boundaries of the confidence intervals for the conditional expectation of average Joe with an annual household net income of 15,000€ (blue) and 30,000€ (red). The graphs on the right display pendants for the risk measure
for average Jane. One can observe that with
the boundaries have stabilized, and therefore may be sufficient. As a recommendation,
may serve as rough indication for the minimum amount of bootstrap samples to start with. Since a suitable choice of
B is unique to each estimate—and the data and model by which the estimate is produced—bootstrap diagnostics should be applied.
Figure A5.
Boundaries of bootstrap confidence intervals for two distributional measures resulting from the GA model with an increasing number of bootstrap samples. Right: Expectation of MCS scores; left: Risk measure .
Figure A5.
Boundaries of bootstrap confidence intervals for two distributional measures resulting from the GA model with an increasing number of bootstrap samples. Right: Expectation of MCS scores; left: Risk measure .



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








