Learning-Based Adaptive Imputation Methodwith kNN Algorithm for Missing Power Data

Abstract
:1. Introduction
- A novel feature vector is modeled for representing the patterns of past power data under an NPR-based model for missing power data imputation.
- Through learning, the optimal length of the feature vector and the optimal historical length are decided. Furthermore, the proposed LAI imputes accurate missing power data by using a weighted distance within an optimized historical length.
- The proposed method is extended to improve the accuracy of missing data imputation considering an unexpected variation of power data by adaptively selecting between LI and the proposed LAI.
- From the simulation under various energy consumption profiles, the proposed method is analyzed and validated. Finally, the proposed eLAI achieves about a 74% reduction of average imputation error in an energy system, compared to the existing methods.
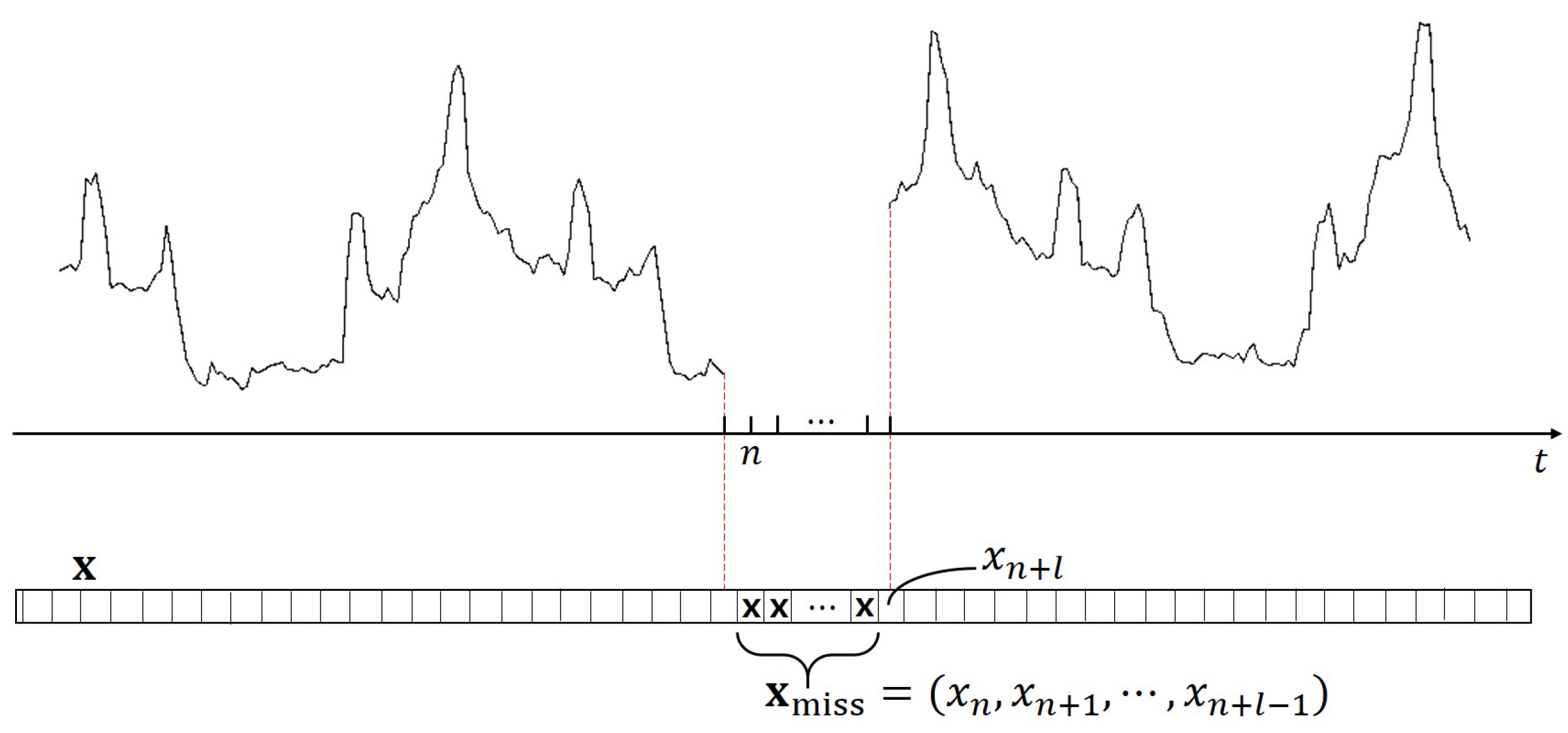
2. Learning-Based Adaptive Imputation Method
2.1. Proposed LAI Method
| Algorithm 1 Learning algorithm for optimal p and selection. |
| INPUT: M = (set of intentional missing situation), P, , initial error, error condition OUTPUT: ,
|
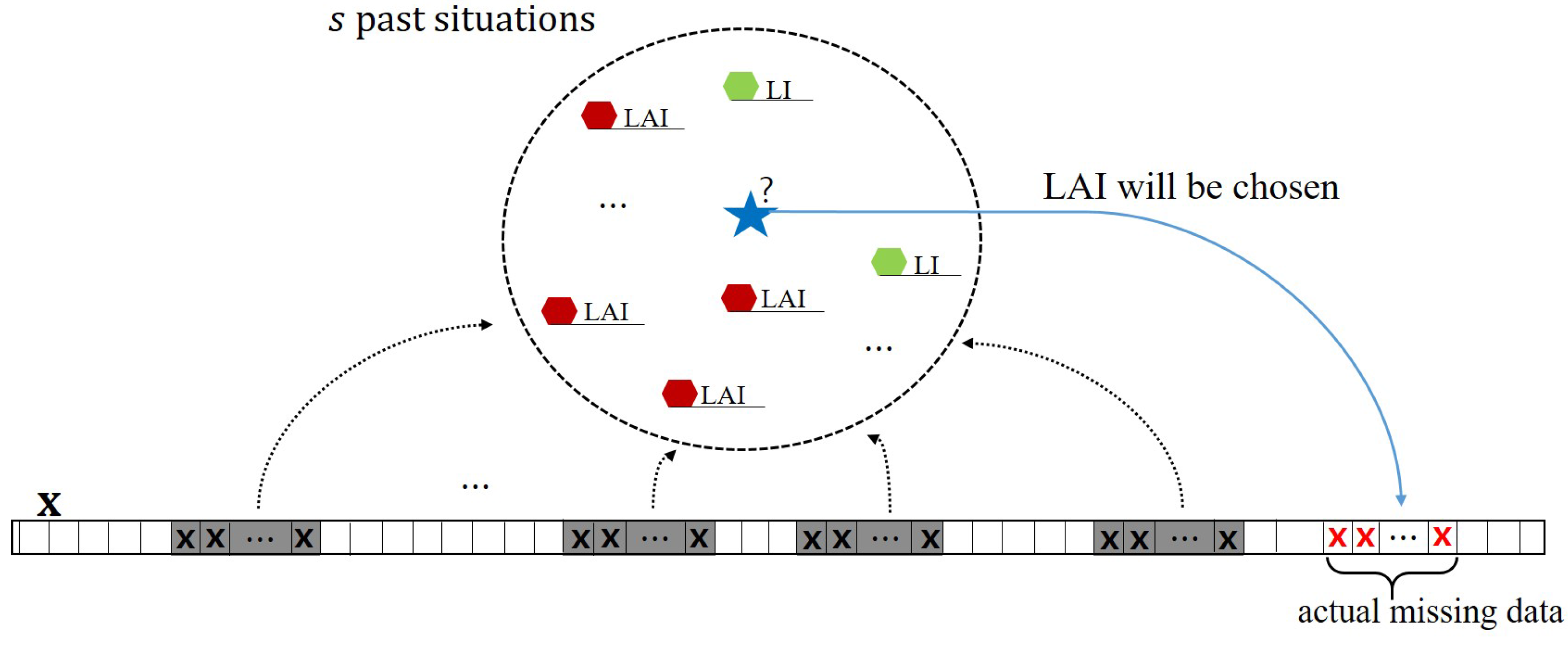
2.2. Extended LAI Method
3. Performance Evaluation
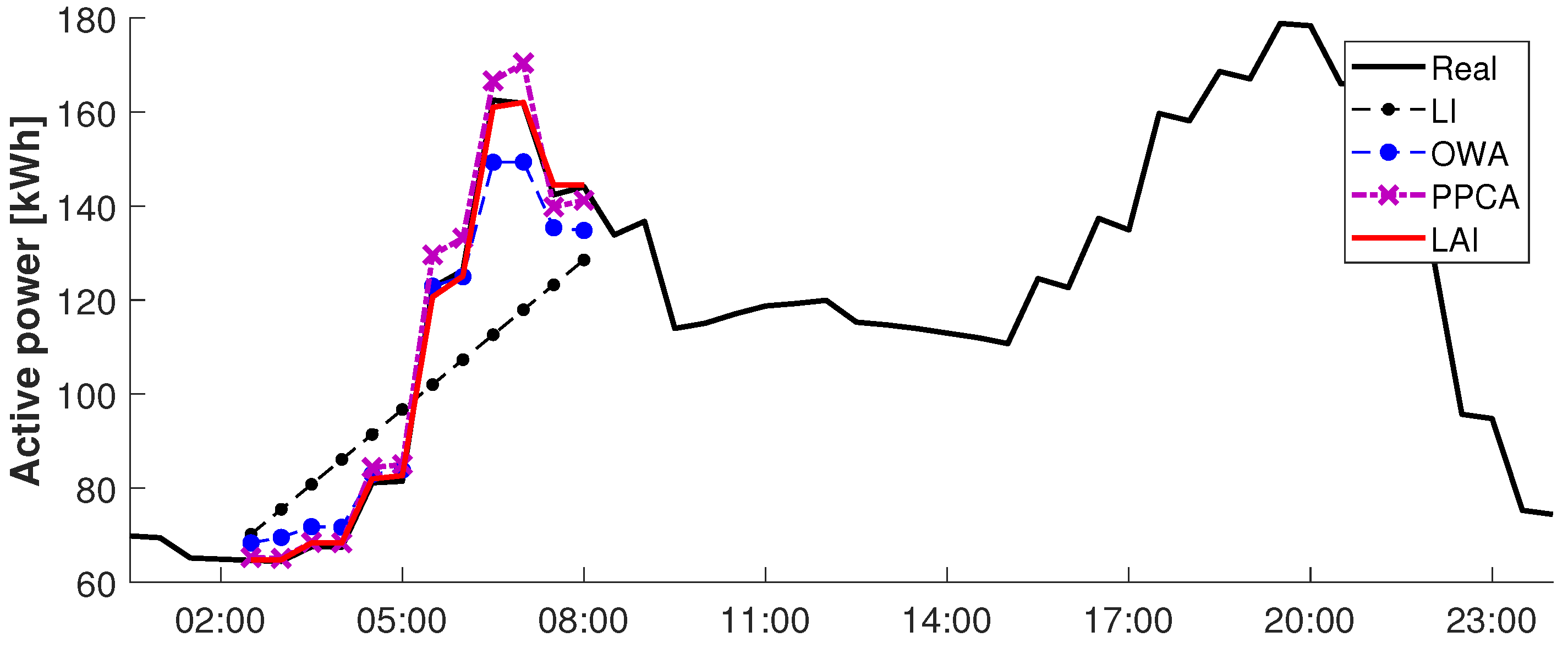
3.1. Comparison Method
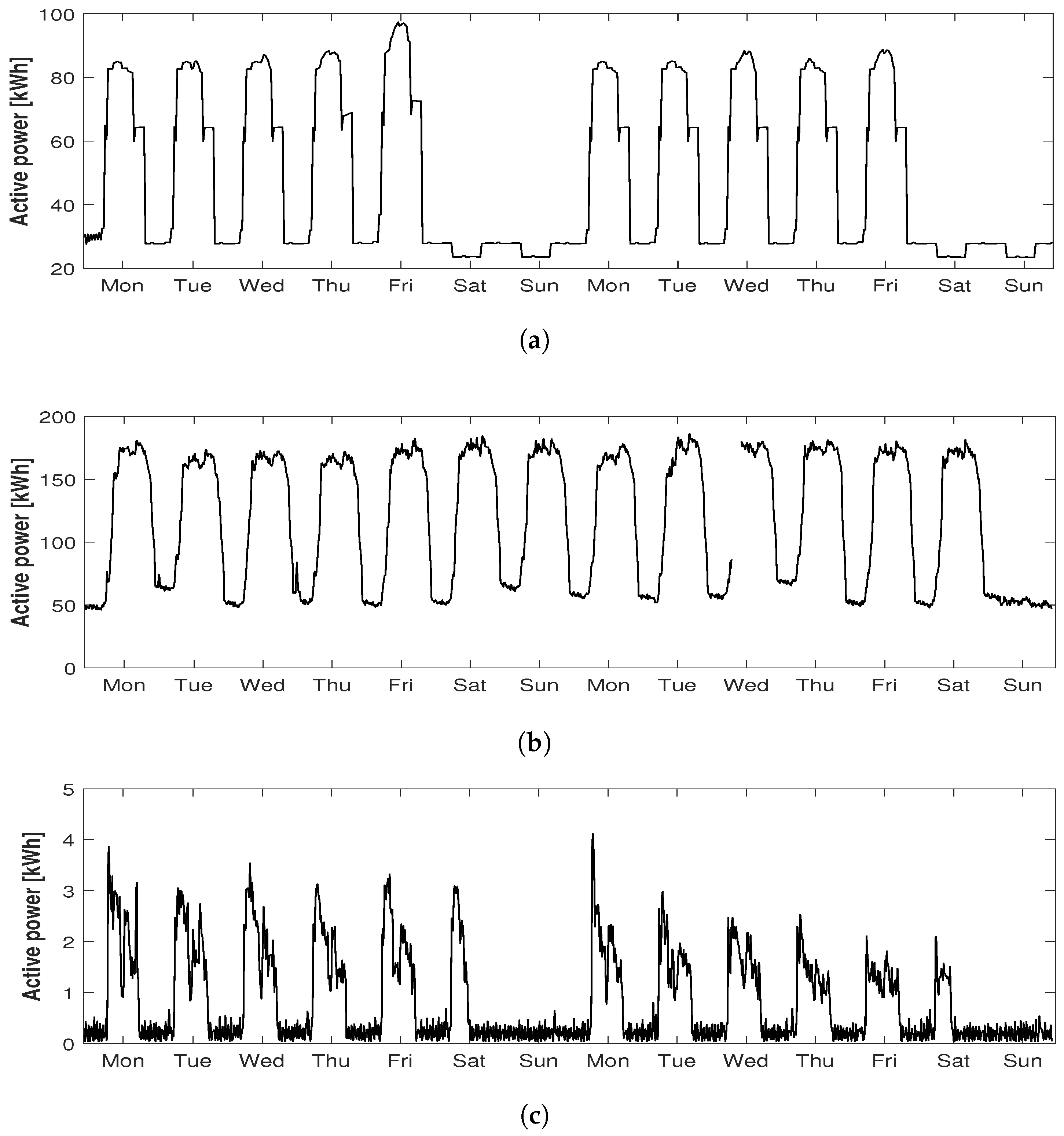
3.2. Data
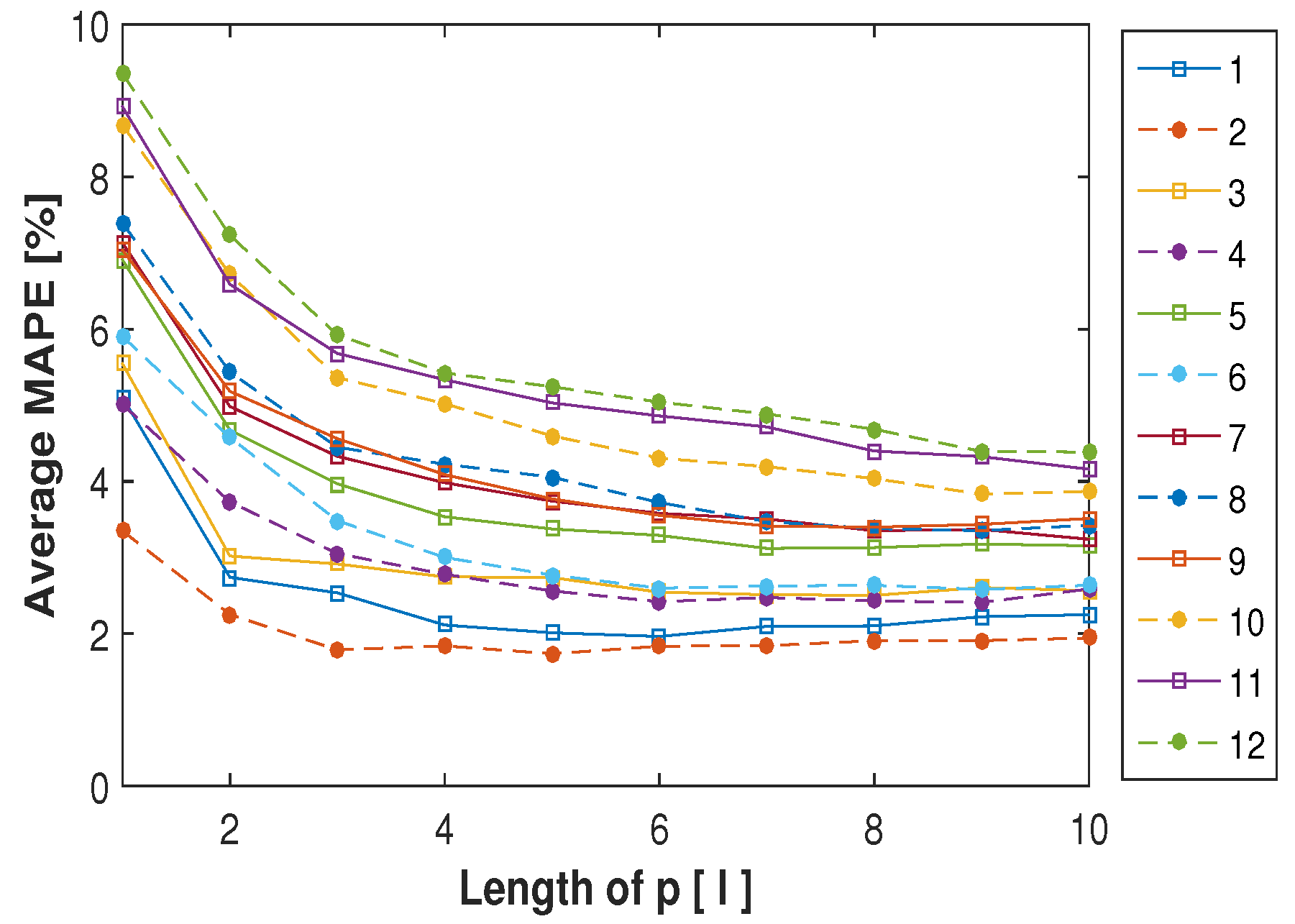
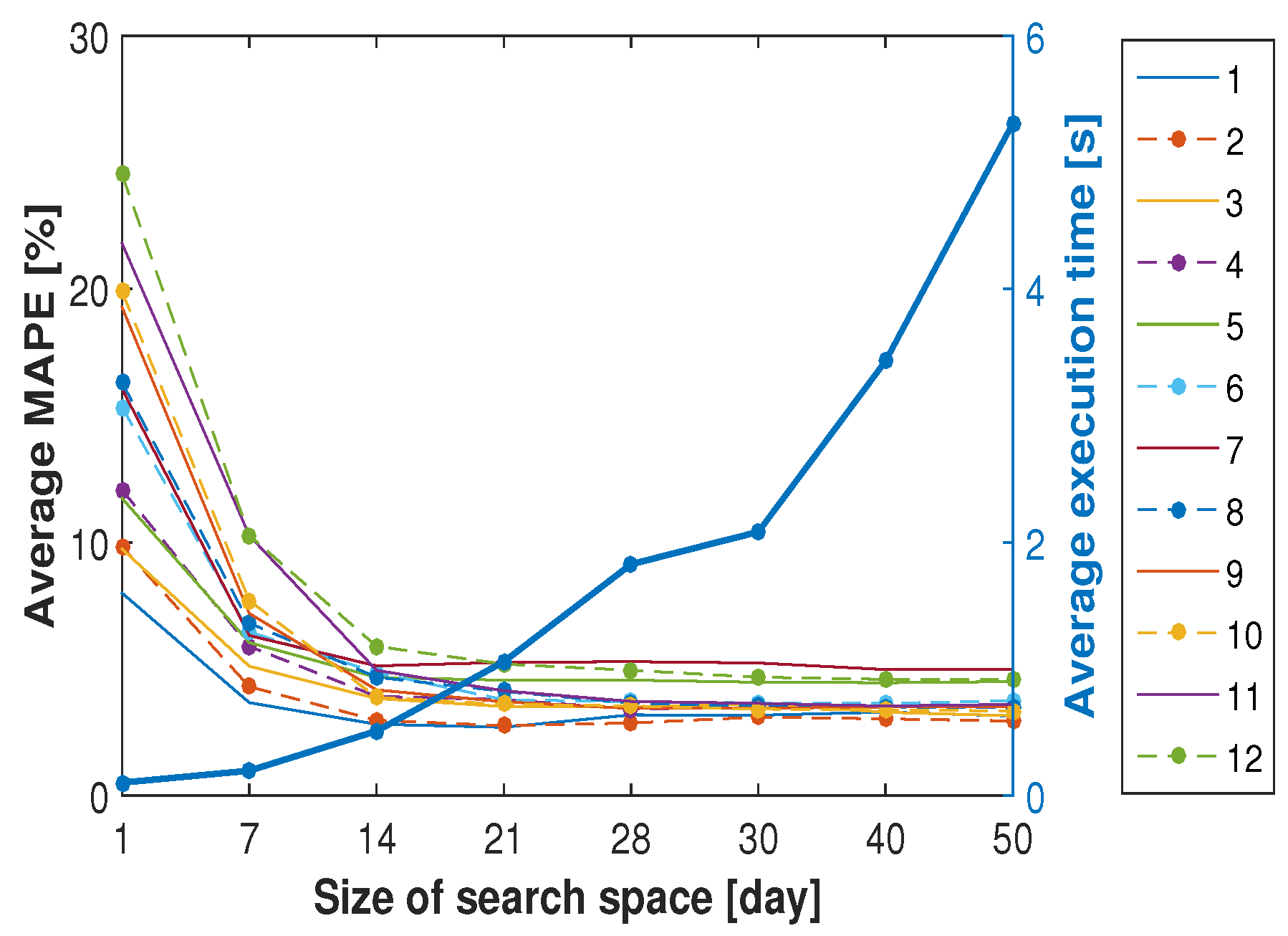
3.3. Parameter Selection
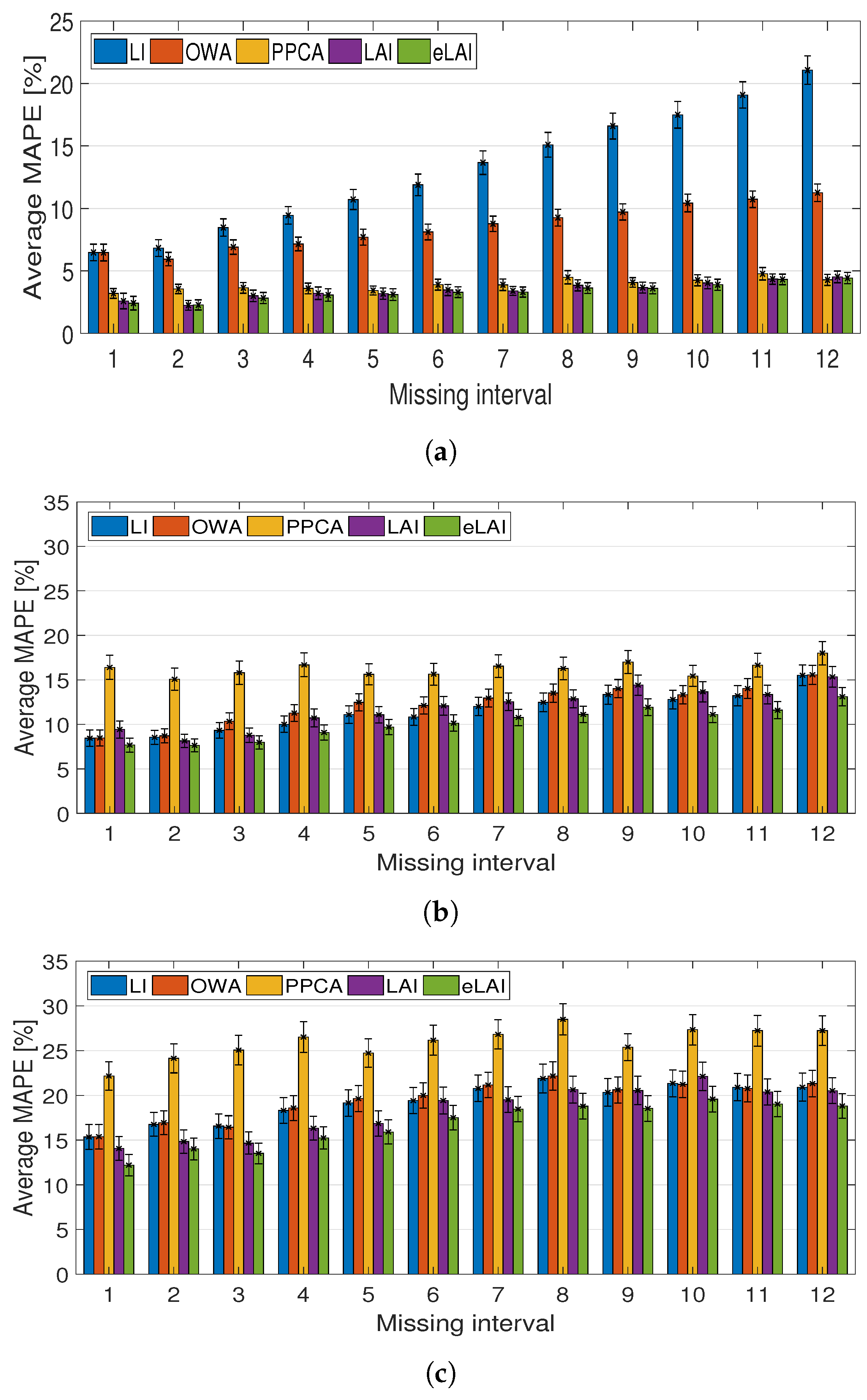
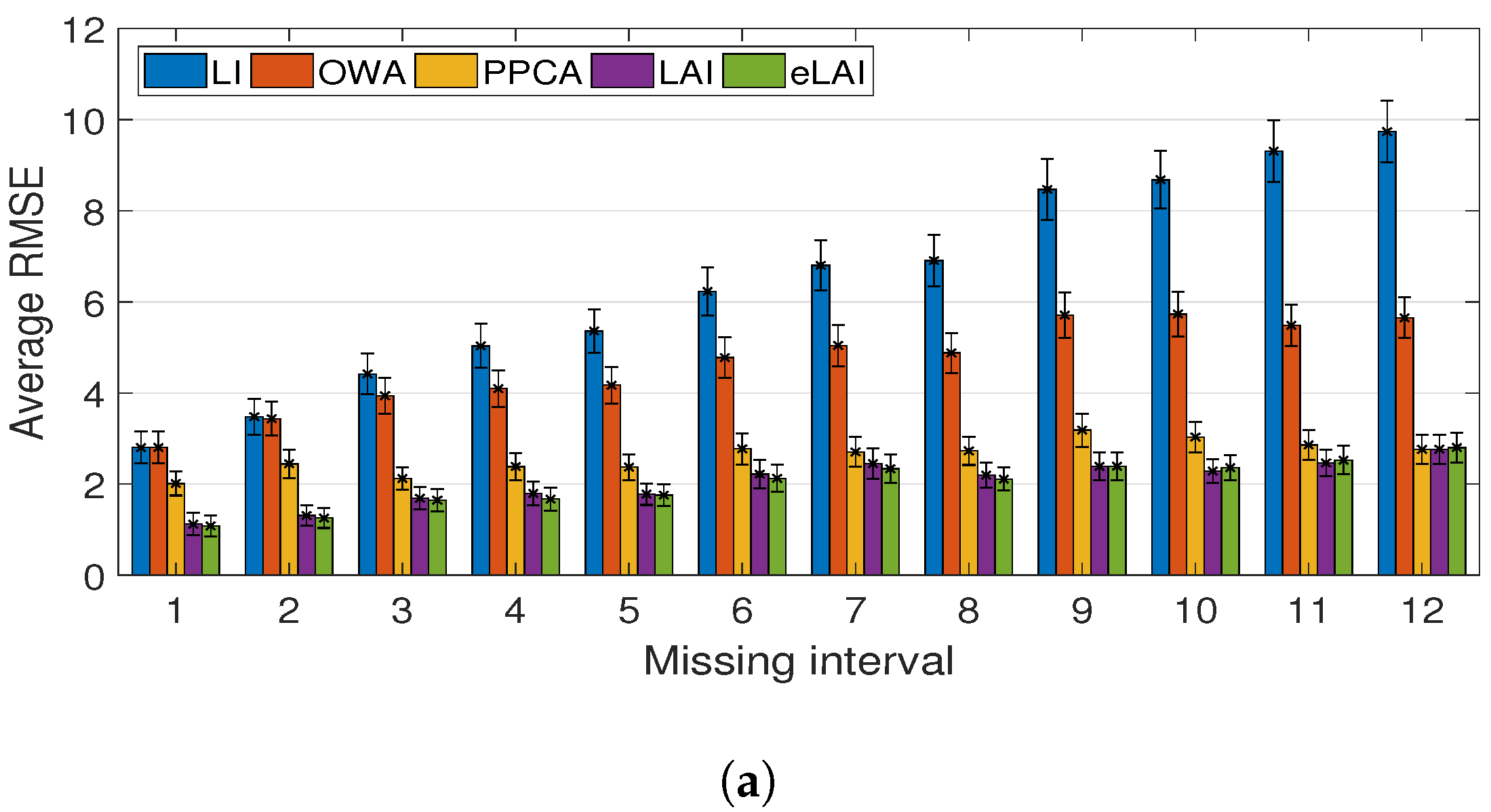
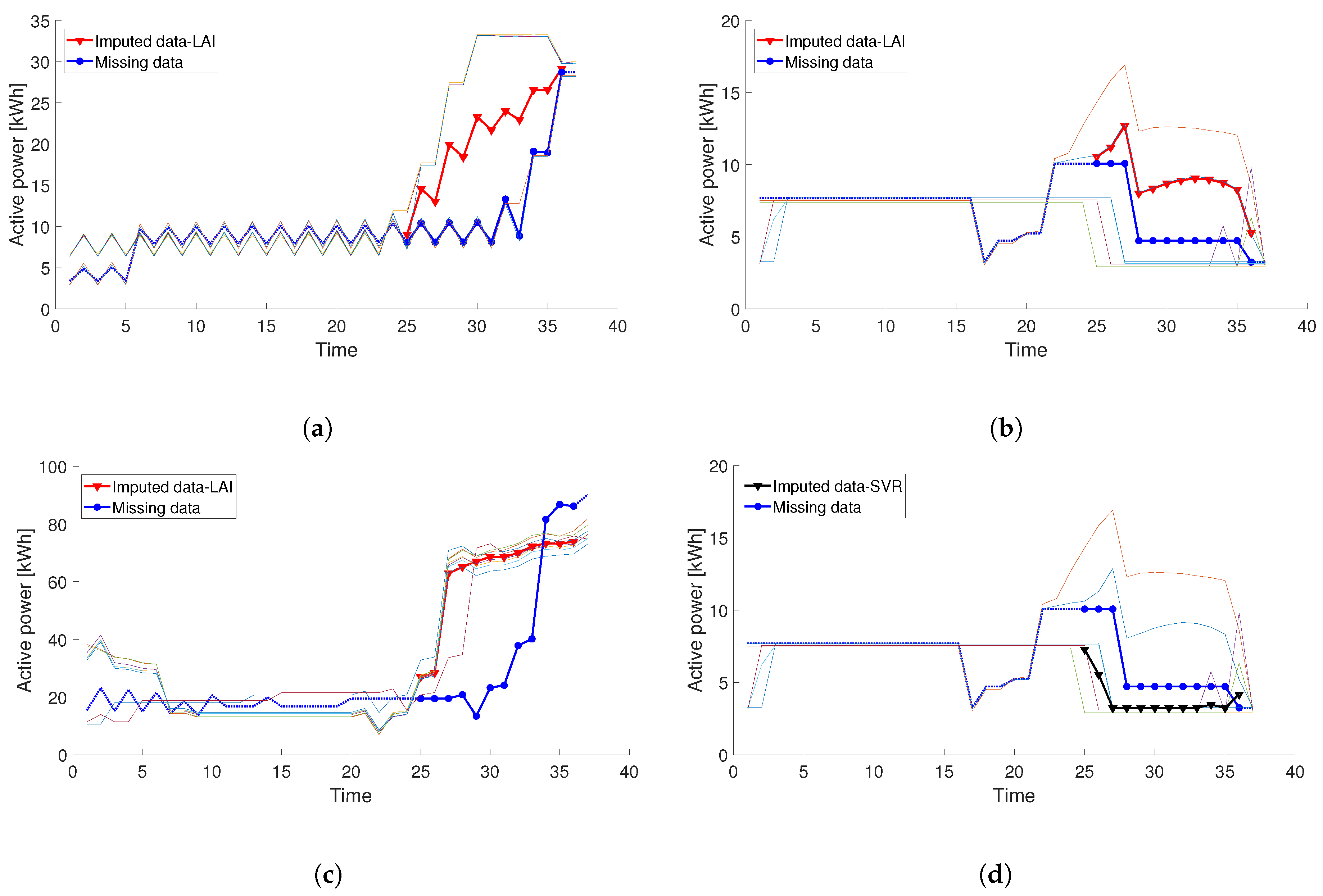
3.4. The Result of the Performance Evaluation
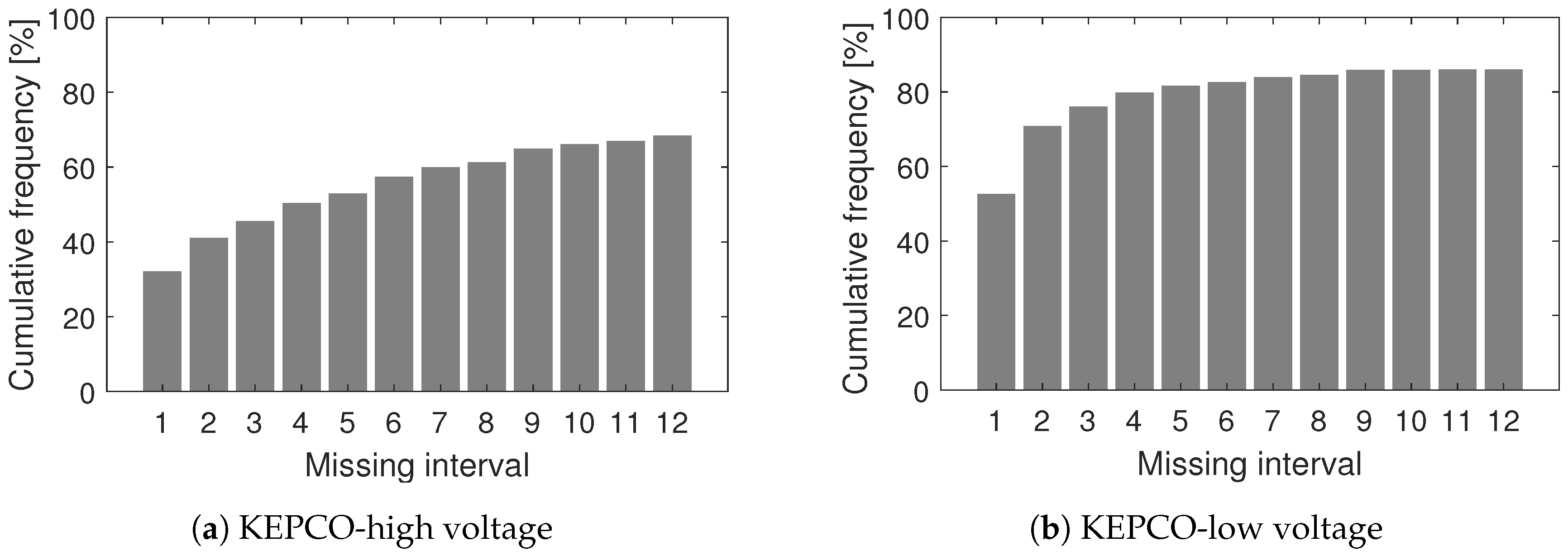
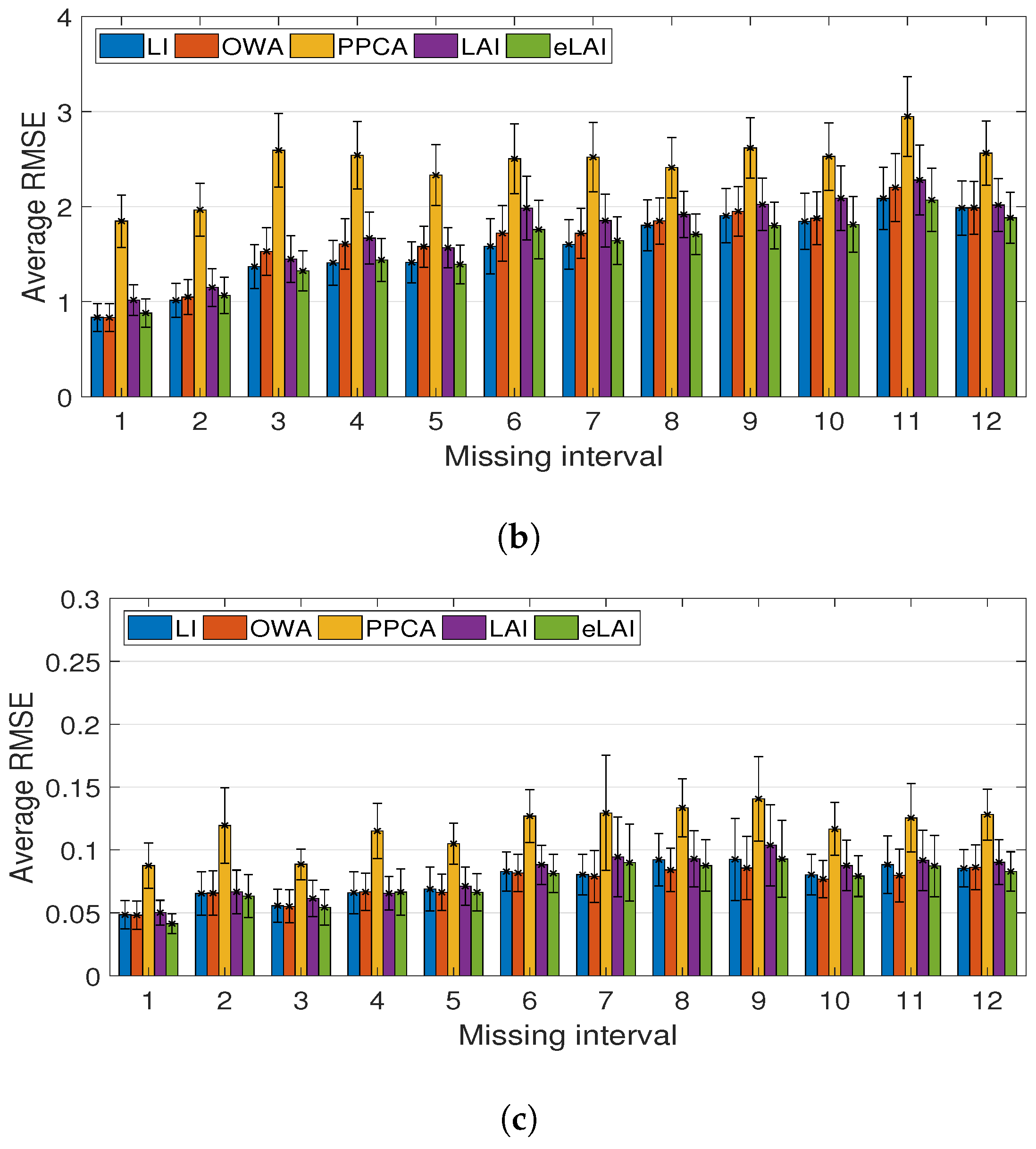
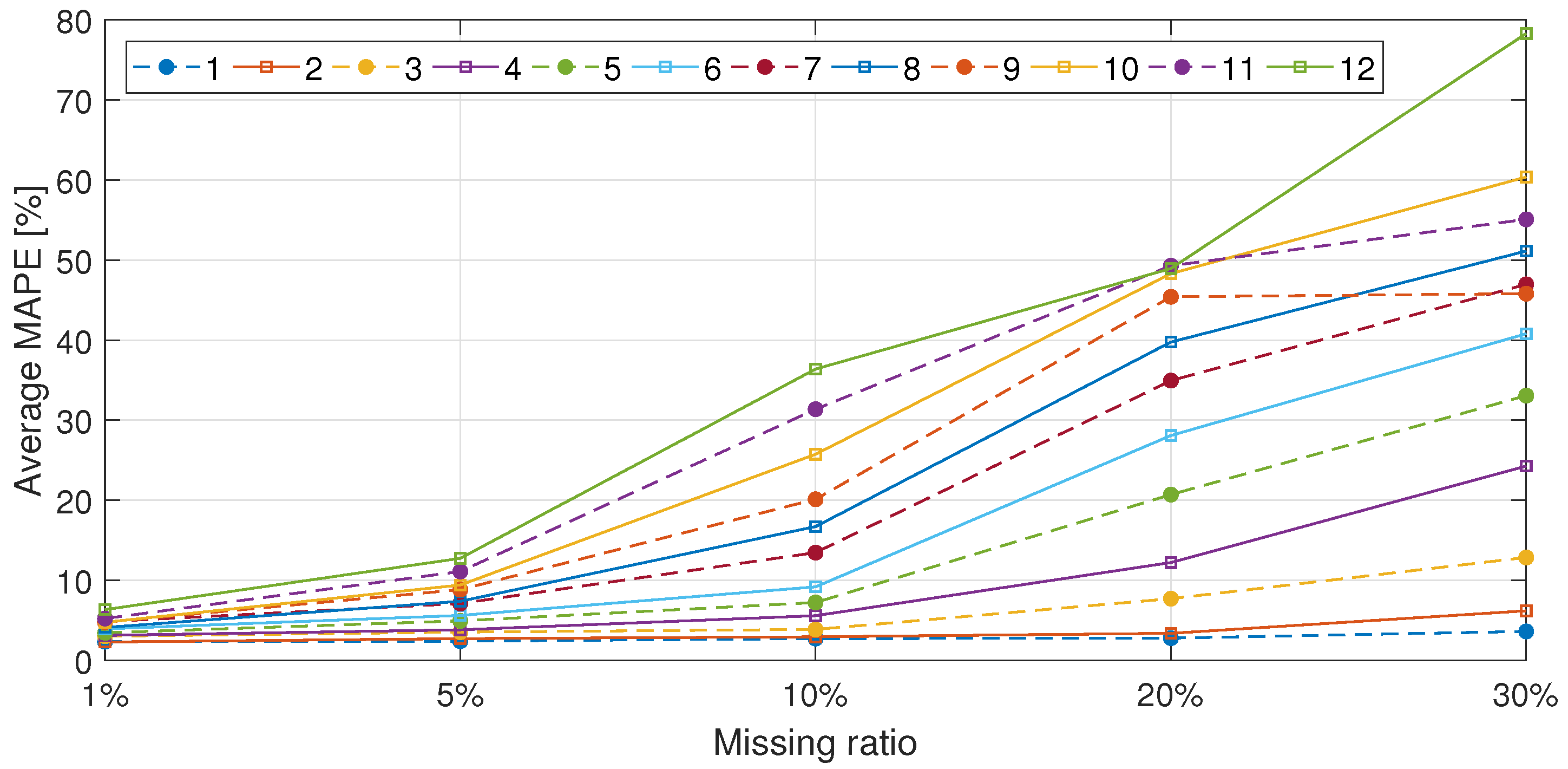
3.5. Performance Evaluation According to the Missing Ratio
4. Discussion and Future Work
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Alahakoon, D.; Yu, X. Smart electricity meter data intelligence for future energy systems: A survey. IEEE Trans. Ind. Inform. 2016, 12, 425–436. [Google Scholar] [CrossRef]
- Pan, E.; Wang, D.; Han, Z. Analyzing big smart metering data towards differentiated user services: A sublinear approach. IEEE Trans. Big Data 2016, 2, 249–261. [Google Scholar] [CrossRef]
- Chen, W.; Zhou, K.; Yang, S.; Wu, C. Data quality of electricity consumption data in a smart grid environment. Renew. Sustain. Energy Rev. 2017, 75, 98–105. [Google Scholar] [CrossRef]
- Karkouch, A.; Mousannif, H.; Moatassime, H.A.; Noel, T. Data quality in internet of things. J. Netw. Comput. Appl. 2016, 73, 57–81. [Google Scholar] [CrossRef]
- Lee, J.; Guo, J.; Choi, J.K.; Zukerman, M. Distributed energy trading in microgrids: A game-theoretic model and its equilibrium analysis. IEEE Trans. Ind. Electron. 2015, 62, 3524–3533. [Google Scholar] [CrossRef]
- Park, S.; Lee, J.; Bae, S.; Hwang, G.; Choi, J.K. Contribution-based energy-trading mechanism in microgrids for future smart grid: A game theoretic approach. IEEE Trans. Ind. Electron. 2016, 63, 4255–4265. [Google Scholar] [CrossRef]
- Mohassel, R.R.; Fung, A.; Mohammadi, F.; Raahemifar, K. A survey on advanced metering infrastructure. Int. J. Electr. Power Energy Syst. 2014, 63, 473–484. [Google Scholar] [CrossRef]
- Quilumba, F.L.; Lee, W.-J.; Huang, H.; Wang, D.Y.; Szabados, R.L. Using smart meter data to improve the accuracy of intraday load forecasting considering customer behavior similarities. IEEE Trans. Smart Grid 2015, 6, 911–918. [Google Scholar] [CrossRef]
- Taieb, S.B.; Huser, R.; Hyndman, R.J.; Genton, M.G. Forecasting uncertainty in electricity smart meter data by boosting additive quantile regression. IEEE Trans. Smart Grid 2016, 7, 2448–2455. [Google Scholar] [CrossRef]
- Liu, L.; Esmalifalak, M.; Ding, Q.; Emesih, V.A.; Han, Z. Detecting false data injection attacks on power grid by sparse optimization. IEEE Trans. Smart Grid 2014, 5, 612–621. [Google Scholar] [CrossRef]
- Huang, Z.; Zhu, T. Real-time data and energy management in microgrids. In Proceedings of the 2016 IEEE Real-Time Systems Symposium (RTSS), Porto, Portugal, 29 November–2 December 2016; pp. 79–88. [Google Scholar] [CrossRef]
- Peppanen, J.; Zhang, X.; Grijalva, S.; Reno, M.J. Handling bad or missing smart meter data through advanced data imputation. In Proceedings of the 2016 IEEE Power & Energy Society, Innovative Smart Grid Technologies Conference (ISGT), Minneapolis, MN, USA, 6–9 September 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Chang, H.; Park, D.; Lee, Y.; Yoon, B. Multiple time period imputation technique for multiple missing traffic variables: Nonparametric regression approach. Can. J. Civ. Eng. 2012, 39, 448–459. [Google Scholar] [CrossRef]
- Interim Mindanao Electricity Market (IMEM). Metering Standards and Procedures Issue 1.0; IMEM: Taguig, Philipines, 2013.
- Elhub. Standard for Validation, Estimation and Editing of AMS Metering Values; Norwegian Electricity Market Project; Elhub: Oslo, Norway, 2014. [Google Scholar]
- Australian Energy Market Operator (AEMO). Metrology Procedure: Part B: Metering Data Validation, Substitution and Estimation Procedure for Metering Types 1–7; AEMO: Melbourne, Australia, 2014. [Google Scholar]
- Fowler, K.M.; Colotelo, A.H.; Downs, J.L.; Ham, K.D.; Henderson, J.W.; Montgomery, S.A.; Vernon, C.R.; Parker, S.A. Simplified Processing Method for Meter Data Analysis; Pacific Northwest National Laboratory (PNNL): Richland, WA, USA, 2015.
- Pacific Gas & Electric Company (PG & E). The Electric ESP Handbook; PG & E: San Francisco, CA, USA, 2017. [Google Scholar]
- Sunila, G. Practical Machine Learning; Packt Publishing Ltd.: Birmingham, UK, 2016; p. 192. [Google Scholar]
- Qu, L.; Li, L.; Zhang, Y.; Hu, J. PPCA-based missing data imputation for traffic flow volume: A systematical approach. IEEE Trans. Intell. Transp. Syst. 2009, 10, 512–522. [Google Scholar]
- Li, L.; Li, Y.; Li, Z. Efficient missing data imputing for traffic flow by considering temporal and spatial dependence. Transp. Res. Part C Emerg. Technol. 2013, 34, 108–120. [Google Scholar] [CrossRef]
- Tipping, M.E.; Bishop, C.M. Probabilistic principal component analysis. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 1999, 61, 611–622. [Google Scholar] [CrossRef]
- Open Energy Information. Available online: http://en.openei.org/datasets/dataset/simulated-load-profiles-17year-doe-commercial-reference-buildings (accessed on 29 August 2017).
- Madhu, G.; Rajinikanth, T.V. A novel index measure imputation algorithm for missing data values: A machine learning approach. In Proceedings of the IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, India, 18–20 December 2012; pp. 1–7. [Google Scholar] [CrossRef]
- Richman, M.B.; Trafalis, T.B.; Adrianto, I. Missing data imputation through machine learning algorithms. In Artificial Intelligence Methods in the Environmental Sciences; Springer: Berlin, Germany, 2009; pp. 153–169. [Google Scholar] [CrossRef]
- Shi, W.; Zhu, Y.; Zhang, J.; Tao, X.; Sheng, G.; Lian, Y.; Wang, G.; Chen, Y. Improving power grid monitoring data quality: An efficient machine learning framework for missing data prediction. In Proceedings of the 2015 IEEE 7th International Symposium on Cyberspace Safety and Security (CSS), 2015 IEEE 12th International Conferen on Embedded Software and Systems (ICESS), 2015 IEEE 17th International Conference on High Performance Computing and Communications (HPCC), New York, NY, USA, 24–26 August 2015; pp. 417–422. [Google Scholar] [CrossRef]
- Gunn, S.R. Support Vector Machines for Classification and Regression; ISIS Technical Report; University of Southampton: Southampton, UK, 1998; Volume 14, pp. 85–86. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Missing Length | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| Optimized k | 1 | 3 | 4 | 4 | 3 | 2 | 4 | 4 | 3 | 2 | 5 | 8 |
| Optimized s | 7 | 11 | 7 | 3 | 11 | 13 | 9 | 3 | 11 | 11 | 11 | 9 |
| MAPE | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | Avg | |
| LAI | 2.59 | 2.25 | 3.00 | 3.22 | 3.18 | 3.48 | 3.40 | 3.85 | 3.67 | 4.04 | 4.35 | 4.53 | 3.46 |
| (0.621) | (0.387) | (0.457) | (0.500) | (0.458) | (0.442) | (0.358) | (0.443) | (0.436) | (0.463) | (0.412) | (0.465) | (0.454) | |
| eLAI | 2.42 | 2.28 | 2.83 | 3.07 | 3.11 | 3.29 | 3.31 | 3.63 | 3.61 | 3.90 | 4.32 | 4.43 | 3.35 |
| (0.549) | (0.402) | (0.440) | (0.499) | (0.465) | (0.430) | (0.410) | (0.426) | (0.434) | (0.444) | (0.416) | (0.450) | (0.447) | |
| RMSE | |||||||||||||
| LAI | 1.75 | 1.59 | 2.21 | 2.46 | 2.23 | 2.76 | 3.13 | 2.78 | 3.56 | 3.26 | 3.66 | 3.77 | 2.76 |
| (0.563) | (0.317) | (0.413) | (0.446) | (0.359) | (0.443) | (0.523) | (0.389) | (0.667) | (0.462) | (0.527) | (0.531) | (0.470) | |
| eLAI | 1.73 | 1.59 | 2.19 | 2.33 | 2.22 | 2.63 | 2.97 | 2.70 | 3.57 | 3.31 | 3.74 | 3.76 | 2.73 |
| (0.562) | (0.370) | (0.423) | (0.440) | (0.374) | (0.423) | (0.501) | (0.381) | (0.665) | (0.469) | (0.550) | (0.520) | (0.473) | |
| MAPE | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | Avg | |
| LAI | 2.77 | 2.45 | 3.12 | 3.28 | 3.26 | 3.52 | 3.53 | 3.82 | 3.59 | 4.03 | 4.28 | 4.36 | 3.50 |
| (0.626) | (0.419) | (0.457) | (0.501) | (0.466) | (0.470) | (0.384) | (0.441) | (0.411) | (0.463) | (0.407) | (0.434) | (0.456) | |
| eLAI | 2.58 | 2.42 | 2.90 | 3.16 | 3.18 | 3.37 | 3.52 | 3.58 | 3.58 | 3.84 | 4.25 | 4.30 | 3.39 |
| (0.556) | (0.414) | (0.430) | (0.450) | (0.469) | (0.454) | (0.442) | (0.422) | (0.416) | (0.438) | (0.407) | (0.414) | (0.447) | |
| RMSE | |||||||||||||
| LAI | 1.80 | 1.82 | 2.38 | 2.62 | 2.37 | 2.82 | 3.30 | 2.83 | 3.61 | 3.30 | 3.66 | 3.73 | 2.85 |
| (0.562) | (0.396) | (0.437) | (0.466) | (0.391) | (0.430) | (0.540) | (0.395) | (0.631) | (0.452) | (0.510) | (0.502) | (0.476) | |
| eLAI | 1.84 | 1.76 | 2.34 | 2.48 | 2.32 | 2.73 | 3.33 | 2.76 | 3.69 | 3.24 | 3.68 | 3.78 | 2.83 |
| (0.582) | (0.392) | (0.445) | (0.459) | (0.387) | (0.420) | (0.553) | (0.390) | (0.635) | (0.443) | (0.512) | (0.511) | (0.4772) | |
| MAPE (%) | RMSE | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| LI | OWA | PPCA | LAI | eLAI | LI | OWA | PPCA | LAI | eLAI | |
| Avg | 13.07 | 8.54 | 3.92 | 3.46 | 3.35 | 9.03 | 6.69 | 3.41 | 2.76 | 2.73 |
| DOE | (0.885) | (0.631) | (0.430) | (0.454) | (0.447) | (1.019) | (0.810) | (0.527) | (0.470) | (0.473) |
| Avg | 11.47 | 12.24 | 16.26 | 11.87 | 10.16 | 4.73 | 6.53 | 7.40 | 3.34 | 3.66 |
| HIGH | (0.990) | (0.976) | (1.275) | (0.999) | (0.878) | (4.726) | (6.528) | (7.400) | (3.337) | (3.662) |
| Avg | 19.47 | 19.52 | 25.94 | 18.32 | 16.80 | 0.96 | 0.43 | 0.12 | 0.08 | 0.07 |
| LOW | (1.471) | (1.432) | (1.649) | (1.427) | (1.341) | (1.927) | (0.782) | (0.024) | (0.020) | (0.019) |
| Missing Ratio of Historical Data (%) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | |
| 1 | 2.33 | 2.39 | 2.72 | 2.78 | 3.61 | 3.94 | 5.25 | 6.87 | 9.95 | 11.96 | 12.17 |
| (0.495) | (0.503) | (0.547) | (0.521) | (0.634) | (0.603) | (0.686) | (0.775) | (0.969) | (1.150) | (2.805) | |
| 2 | 2.29 | 2.71 | 2.94 | 3.38 | 6.19 | 9.66 | 15.15 | 29.73 | 41.10 | 48.62 | - |
| (0.389) | (0.442) | (0.418) | (0.451) | (0.674) | (0.823) | (1.197) | (2.539) | (6.014) | (22.450) | - | |
| 3 | 3.01 | 3.53 | 3.86 | 7.70 | 12.85 | 21.32 | 28.43 | 29.84 | 46.64 | - | - |
| (0.500) | (0.532) | (0.494) | (0.797) | (0.996) | (1.423) | (3.089) | (7.497) | (43.579) | - | - | |
| 4 | 3.12 | 3.81 | 5.58 | 12.22 | 24.27 | 31.43 | 34.16 | 32.52 | - | - | - |
| (0.471) | (0.523) | (0.655) | (1.006) | (1.505) | (3.111) | (8.284) | (16.606) | - | - | - | |
| 5 | 3.44 | 4.93 | 7.22 | 20.71 | 33.07 | 35.80 | 55.13 | - | - | - | - |
| (0.423) | (0.583) | (0.698) | (1.356) | (2.280) | (5.489) | (20.628) | - | - | - | - | |
| 6 | 3.93 | 5.61 | 9.18 | 28.09 | 40.80 | 47.30 | 37.79 | - | - | - | - |
| (0.477) | (0.648) | (0.854) | (1.673) | (3.623) | (9.715) | (12.384) | - | - | - | - | |
| 7 | 4.83 | 7.10 | 13.46 | 34.95 | 46.97 | 45.91 | 64.69 | - | - | - | - |
| (0.593) | (0.737) | (1.118) | (2.068) | (5.869) | (18.011) | (0.969) | - | - | - | - | |
| 8 | 4.11 | 7.38 | 16.71 | 39.77 | 51.13 | 52.98 | - | - | - | - | - |
| (0.416) | (0.720) | (1.267) | (2.631) | (10.450) | (21.932) | - | - | - | - | - | |
| 9 | 4.76 | 8.83 | 20.12 | 45.41 | 45.81 | 53.83 | - | - | - | - | - |
| (0.551) | (0.914) | (1.444) | (3.547) | (8.259) | (82.396) | - | - | - | - | - | |
| 10 | 4.76 | 9.41 | 25.75 | 48.31 | 60.38 | - | - | - | - | - | - |
| (0.510) | (0.903) | (1.681) | (4.677) | (13.452) | - | - | - | - | - | - | |
| 11 | 5.22 | 11.10 | 31.37 | 49.30 | 55.09 | - | - | - | - | - | - |
| (0.560) | (0.993) | (1.831) | (5.211) | (25.101) | - | - | - | - | - | - | |
| 12 | 6.34 | 12.74 | 36.39 | 48.95 | 78.31 | - | - | - | - | - | - |
| (0.668) | (1.058) | (2.028) | (7.129) | (22.444) | - | - | - | - | - | - | |
| DOE | HIGH | LOW | |
|---|---|---|---|
| LAI | 5.65 | 14.73 | 21.03 |
| (1.017) | (1.190) | (1.576) | |
| eLAI | 4.22 | 10.63 | 17.71 |
| (0.590) | (0.916) | (1.393) |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Park, S.; Lee, J.; Joo, Y.; Choi, J.K. Learning-Based Adaptive Imputation Methodwith kNN Algorithm for Missing Power Data. Energies 2017, 10, 1668. https://doi.org/10.3390/en10101668
Kim M, Park S, Lee J, Joo Y, Choi JK. Learning-Based Adaptive Imputation Methodwith kNN Algorithm for Missing Power Data. Energies. 2017; 10(10):1668. https://doi.org/10.3390/en10101668
Chicago/Turabian StyleKim, Minkyung, Sangdon Park, Joohyung Lee, Yongjae Joo, and Jun Kyun Choi. 2017. "Learning-Based Adaptive Imputation Methodwith kNN Algorithm for Missing Power Data" Energies 10, no. 10: 1668. https://doi.org/10.3390/en10101668
APA StyleKim, M., Park, S., Lee, J., Joo, Y., & Choi, J. K. (2017). Learning-Based Adaptive Imputation Methodwith kNN Algorithm for Missing Power Data. Energies, 10(10), 1668. https://doi.org/10.3390/en10101668