1. Introduction
The energy sector constitutes the source of at least two-thirds of greenhouse gas emissions, which means action must be undertaken to reduce energy consumption and the associated greenhouse gas emissions. According to the World Energy Outlook 2016 Report [
1], there will be a 30% rise in global energy demand to 2040. Globally, it is predicted that renewable energy will see by far the fastest growth [
1]. Natural gas, as the cleanest fossil fuel, can be considered as an important adjunct to renewable energy sources [
2]. Therefore, it is expected that gas consumption will increase worldwide, where the potential for demand growth will be significant in Asia, while Japan will fall back as nuclear power is reintroduced [
1,
3].
The European Commission adopted measures aimed at achieving savings of 20% in primary energy consumption until 2020 [
4]. Some of these measures strongly focus on the residential sector, an important target of energy policy where potential energy savings can be achieved [
4,
5,
6]. Residential consumers give preference to natural gas energy for heating, cooking and hot water over other sources of energy, for being environmentally-friendly, easy to use and reliable, in terms of distribution and supply and eventually less expensive compared to other sources. Smart grids play a relevant role in this matter by empowering consumers to make smarter decisions regarding the use of energy in their household.
The emerging smart grid requires distributed intelligence, as well as the development of models based on artificial intelligence, e.g., [
7,
8,
9]. Several studies have been published in the electrical energy field, mostly facilitated by the availability of suitable databases [
10]. Different is the case for research on the analysis of gas demand, especially when it comes to clustering and consumer profiling based on consumption data. These data can provide significant insights for utilities and policy makers regarding typical consumption curves of the different segments of consumers. The effect of energy policy on the different segments of consumers can be studied based on the way these different segments consume this energy source. A substantial amount of effort has been put into the gas demand forecasting [
11,
12,
13,
14,
15,
16] and into the determinant factors of residential gas consumption [
17,
18]. The study of energy savings has been conducted for buildings, as well, mostly inserted in projects for the development of sustainable cities [
19,
20]. The investigation of the weather impact on energy consumption is also addressed in the literature. The gas sector is one of the most sensitive sectors affected by weather risk and time of year [
21,
22,
23,
24,
25], since there is higher gas demand in colder seasons compared to warmer seasons.
Regarding the use of clustering techniques for residential gas consumers’ load profiling, few papers have been published. In a study [
26] from 2009, gas standardized load profiles (SLP) were obtained by using clustering as part of the development of a semiparametric regression model. Consumers were classified according to their classes (household and small and medium commercial), type (household, office, manufacturer, heating plant, etc.) and gas appliances (heating, cooking, hot water and technology). Then, the authors used Ward’s hierarchical clustering (HC) [
27] and the K-means (KM) clustering algorithm [
28] to obtain the clusters of consumers in the population. For the model implementation, the consumers were classified into the resulting segments obtained, where the most suited type of estimated SLP curves was assigned to them. In [
29,
30], a clustering analysis was performed to determine the segmentation of residential gas consumers. In [
29], fuzzy C-means (FCM) [
31], KM algorithms and HC were used to obtain seasonal representative profiles of gas consumers. These were characterized based on the consumption patterns; however, the consumers’ socio-economic and household key features were not considered. In [
30], the segments were characterized based on the consumption patterns and on the consumers’ socio-economic and household key features; however, a single clustering technique was used.
In this paper, we propose a methodology to determine the segmentation of residential natural gas consumers using clustering techniques. This analysis is novel for the case of natural gas profiling for two reasons. The first is because we use more than a clustering algorithm to obtain the segments. The second relies on the fact that we characterize these segments based not only on the representative profiles obtained from clustering, as well as according to information regarding consumers’ socio-economic and household key features. We use three clustering algorithms, namely KM, FCM and Ward’s HC, to define the profiles of consumers. Classical KM is one of the most used clustering algorithms to obtain energy consumption profiles. Both KM and FCM have already been successfully used for the case of smart metering electricity data [
32,
33,
34,
35,
36,
37,
38,
39,
40,
41] and natural gas data [
26,
30]. FCM allows gradual memberships to cluster, which offers the opportunity to deal with data that belong to more than one cluster simultaneously [
31]. Besides partitioning methods, Ward’s method was selected for being an agglomerative hierarchical clustering technique and because it has already been applied to natural gas data [
26,
29]. A logistic regression is performed to link the socio-economic and household key features to the groups of consumers obtained with clustering.
We use clustering validity indices (CVIs), namely silhouette, Davies and Bouldin’s index, Dunn’s validity index, weighted average intra-inter cluster distance index and Xie and Beni’s index, to evaluate the results obtained from the clustering algorithms referred to above. These CVIs were selected because they all focus on maximizing intra-cluster and minimizing inter-cluster similarities. Davies and Bouldin’s and Dunn’s validity indices are well-known measures, frequently used for the task of selecting the best clustering solution [
42]. The weighted average intra-inter cluster distance index was selected because it gives a measure of the overall cluster quality [
43]. Silhouette combines both cohesion and separation, and the average silhouette width provides an evaluation of clustering validity, which can be visually assessed in a graphical representation [
44]. Finally, Xie and Beni’s index proved to be suited for assessing clustering results, particularly for the FCM algorithm [
45].
We analyze the seasonal clusters obtained and draw conclusions regarding the consumption curves and characteristics of each cluster. High frequency smart metering gas consumption data from Ireland [
46] are used. The database is rich since it contains data of approximately one and a half thousand households over one and a half years.
The outline of the paper is as follows. In
Section 2, we present the data preprocessing steps. In
Section 3, we address the clustering techniques and the CVIs. In
Section 4, we evaluate and discuss the clustering results and the specific characteristics of each segment of gas consumers. In
Section 5, we present the conclusions of this research and future work.
2. Data Preprocessing
Smart metering data consist of consumption data recorded in a smart meter device in intervals of an h or less. In order to obtain the profiles of consumers for an easier interpretation and analysis, preprocessing was performed. The data preprocessing adopted in the paper is represented in
Figure 1.
Data collected from smart meters may exhibit missing values, e.g., due to noise. The missing data may be replaced by appropriate values or left as missing. In the paper, missing data were ignored, given that the aggregation task reduced this impact on the overall data quality. The missing data analysis was followed by a process of context filtering, which involved the selection of data representing a specific context such as a temporal window, type of day and location. Regarding the outliers’ analysis, all households with a significant percentage of null consumption measurements were considered outliers and excluded. In the task of data aggregation, the period used (e.g., monthly, weekly) and operator (e.g., sum, median) have to be defined. The operator of summation was used to aggregate consumption data hourly per season for each consumer, as presented in
Figure 2. “Day
A” corresponded to the aggregated hours of a day for a consumer in the respective season. Thus, for
H input features and
N consumers, the feature vector for consumer
k is
where
k = 1:
N,
contained the information in matrix of (
1).
In this paper, the profiles were normalized based on the maximum hourly consumption of all consumers, using the minimum-maximum normalization method:
where
is the normalized version of the feature value
x to be normalized.
and
are the maximum and minimum value of feature
x, respectively. This method is commonly used in engineering and clustering applications to normalize the data due to its linear transforming form [
47].
4. Results and Discussion
4.1. Natural Gas Data Preprocessing
The gas consumption data, as well as the socio-economic features of consumers and household characteristics were provided by the Irish Social Science Data Archive (ISSDA) [
55]. The smart metering gas consumption data (in kWh) were collected from 1 December 2009–30 May 2011 with a frequency of a half an h in each day. Smart metering data from 1493 households were available for preprocessing.
4.1.1. Missing Data Analysis
Six days were missing in the database. We ignored these days, since there was no obvious way to attribute the gas use. We considered that the available data had a significant extent and their absence would not affect the following steps of data preprocessing. Moreover, the aggregation task would reduce this impact on the overall data quality.
4.1.2. Context Filtering
We excluded weekends and holidays from the analysis since they represented atypical periods of consumption. Thus, we used only smart metering data from working days. Then, we extracted the profiles seasonally, by aggregating days for each season of a year. We used data from December of 2009–2010. The way we divided data for each season is presented in
Table 1. The corresponding number of days to be aggregated was 243.
4.1.3. Outliers Analysis
We observed that there were households with low gas use throughout the study period. These may correspond to holidays or renting accommodation households, which were considered exceptions. Therefore, after data analysis, we considered that all consumers with more than 90% of null consumption measurements in the study period should be excluded. With the removal of these outliers, we obtained more defined and compact representative profiles of consumers. With this criterion, we excluded 63 consumers and were left with 1430. An example of a standard and of a low gas use profile in a year is depicted in
Figure 4.
4.1.4. Data Aggregation
We performed an hourly aggregation of all consumption data, obtaining 24 features for each consumer in each season, as presented in
Figure 2 of
Section 2. We used summation as the aggregation operator in order to keep the value of total amount of gas consumption for each consumer. Given
N samples (here,
N = 1430) and
H input features (here,
H = 24), we constructed a matrix for each season, as given in (
1).
4.1.5. Data Normalization
We normalized the profiles of consumers using the minimum-maximum normalization method (
2), based on the maximum hourly consumption of all consumers for each season. By using a normalization, the normalized consumption curves provided more insights related to the patterns of consumption, and the profiles were more defined.
4.2. Seasonal Consumptions
The profile curves of the seasonal mean hourly aggregated consumption of all consumers are depicted in
Figure 5.
As expected, winter, the coldest season, presents the highest mean hourly aggregated consumptions, while summer, the warmer season, presents the lowest. This happens because gas is mainly used for bathing and cooking in the summer, while in the winter, it is also needed for heating. For every season, there are two evident consumption peaks, one in the morning and the other in the evening. Mean hourly aggregated consumptions are low during the night and, in the case of summer, practically null.
4.3. Seasonal Profiles
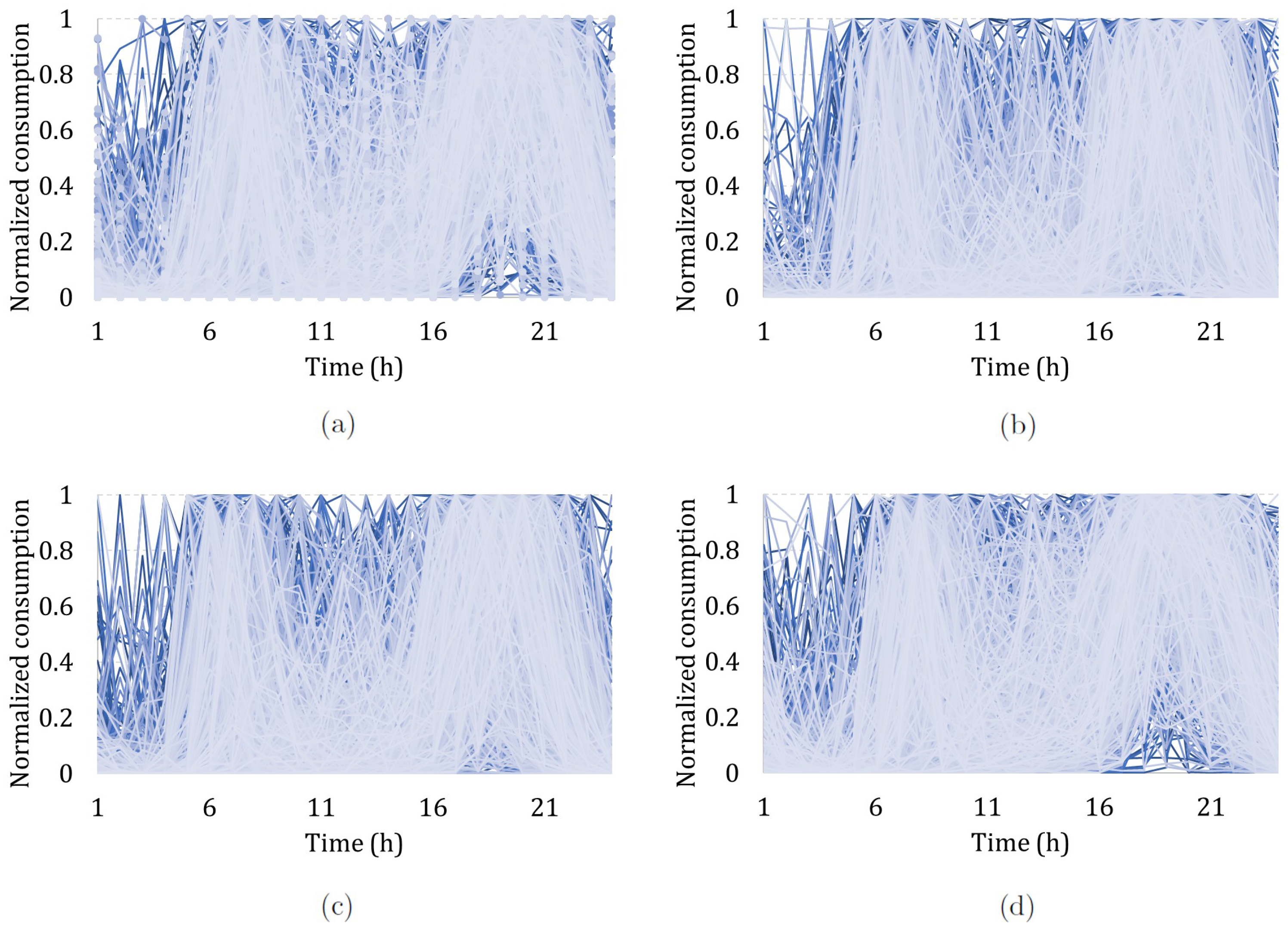
Before performing clustering analysis, we assessed the normalized consumption patterns of consumers for each season and concluded that there was no structure, as it can be seen in
Figure 6. In order to obtain the seasonal profiles, we performed clustering with classical KM and FCM algorithms and Ward’s HC, using MATLAB software. We used the five CVIs presented in
Section 3.2 to assess clustering results. In order to obtain the best clustering configurations, we varied
between two and 10. We considered that the best clustering configuration should present a uniform distribution, minimize intra-cluster distance and maximize inter-cluster distance.
Since the KM algorithm depends on the initialization, we performed ten iterations for each number of clusters () and selected one that presented the best CVI values. For the FCM algorithm, we varied m between 1.25 and two. The best results were achieved with an m of 1.25; therefore, we only present the results obtained with this parameter value.
Clustering results presented in
Table 2 are based on the CVI scores, as well as expert judgment. The criterion to select the algorithm and number of clusters consisted of selecting the algorithm where there was a higher number of CVI agreement on the number of clusters. We provide the results of the CVI scores for each
in
Appendix A.
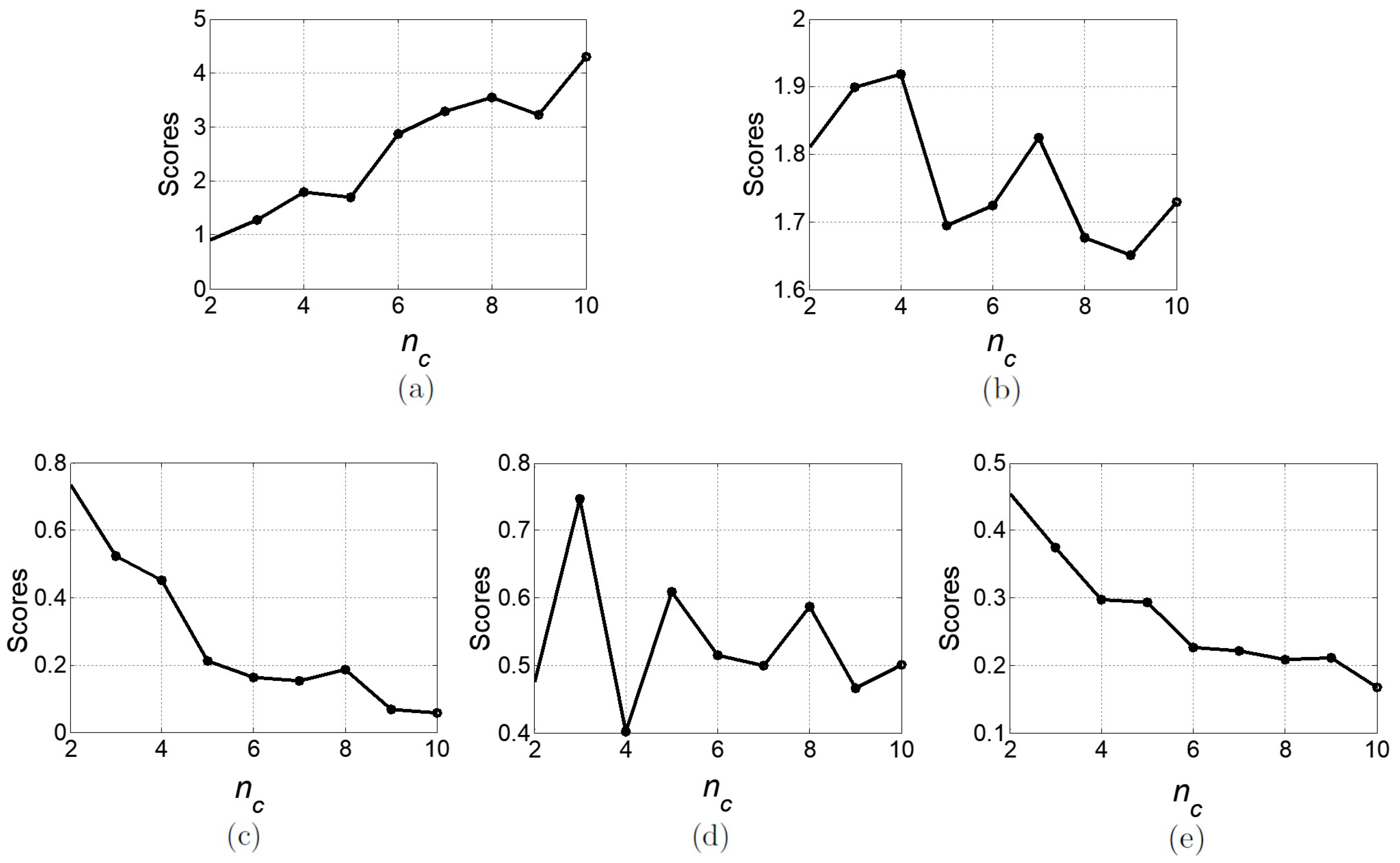
DI consistently indicated two as the best
, as well as Sil, except for two events with HC, as presented in
Table 2. When analyzing the representative profiles obtained with two clusters, we observed that, for all seasons, it consisted of a separation between high and low consumption consumers, as presented in
Appendix B. In this scenario, the majority of the profiles were significantly different from the representative ones. For this reason, we considered that a more interesting analysis regarding the consumption profiles should be performed with a higher
. Thus, the best
obtained for spring and summer was three, with the HC and FCM algorithm, respectively, for autumn was four with HC and for winter was five with the KM algorithm. The selection of algorithms and
for each season was based on the following rationale:
Spring, HC with three clusters: HC was the algorithm where two CVIs agreed regarding the best number of clusters to select;
Summer, FCM with three clusters: Although two CVIs agreed on five clusters for KM and three CVIs agreed on four clusters for HC, for both, one of the clusters was not representative of the population, with a reduced number of consumers. For FCM, two CVIs presented the highest values for five (DB) and three (WI) clusters. Following the elbow method, where an inferior is chosen since adding more clusters does not improve clustering results, three clusters were selected. These clusters were compact, well defined and representative of the population;
Autumn, HC with four clusters: HC was the algorithm where three CVIs agreed regarding the best number of clusters to select;
Winter, KM with five clusters: Both the KM algorithm and HC had three CVIs that agreed on the number of clusters; however KM, presented more compact clusters, which was assessed by visual analysis.
In the following figures illustrating the normalized consumption profiles of the consumers, the x-axis represents the 24 h in a day.
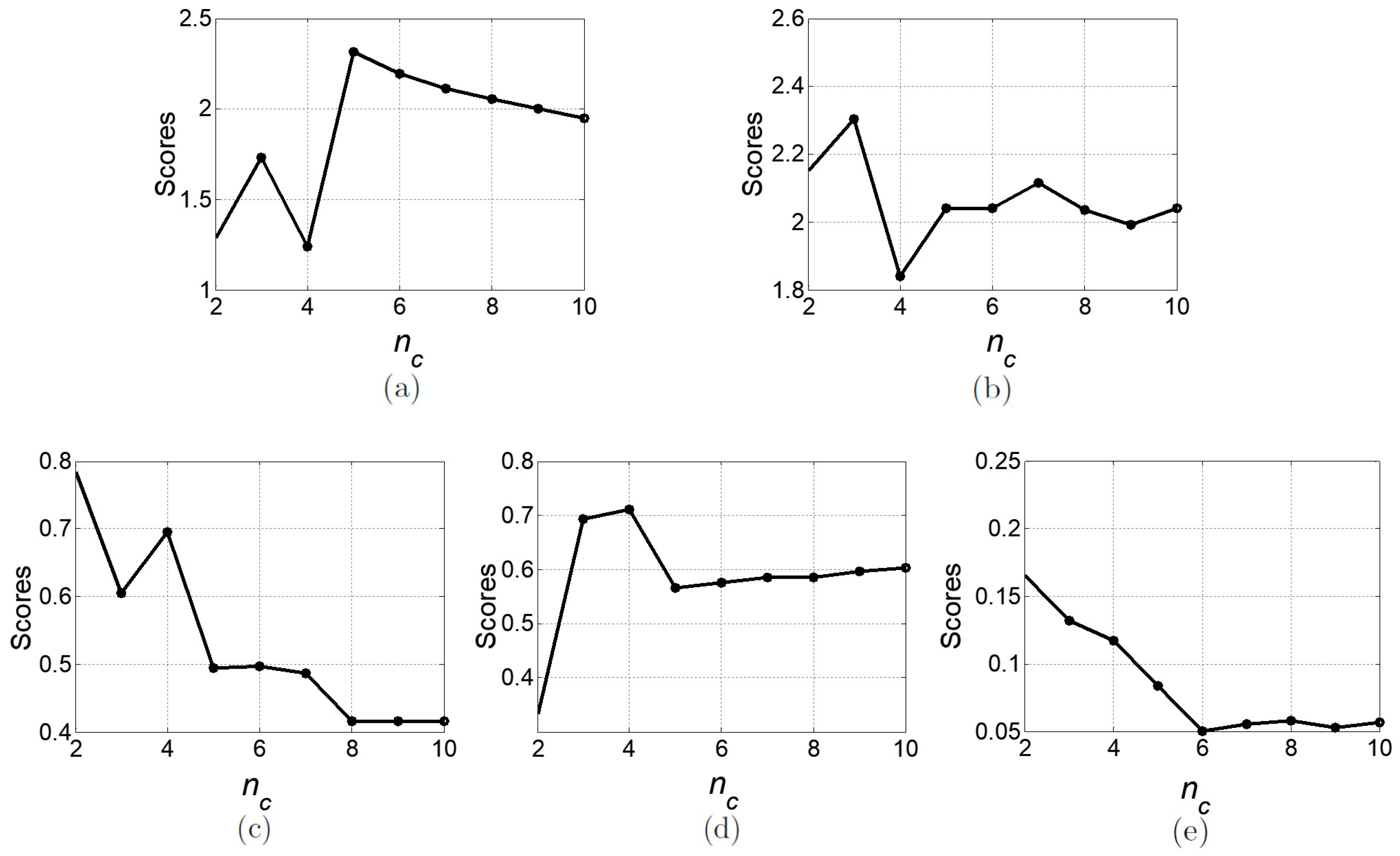
The spring profiles are presented in
Figure 7, where three clusters were obtained using HC. From
Figure 8, it can be observed that WI and XBpresented higher performance with this
. DI and Sil also presented a high value for three clusters, very similar to the ones obtained with two clusters.
The summer profiles are presented in
Figure 9, where three clusters were obtained using the FCM algorithm. This
was mainly indicated by WI, as noticeable in
Figure 10. We considered the higher degree of membership of a consumer to a cluster to turn fuzzy memberships into crisp partitions. With three clusters, higher CVI performance results were achieved with the HC and KM algorithm. However, for both, one of the clusters had a reduced number of consumers. These clusters were not considered representative of the population; therefore, results obtained with FCM algorithm were selected.
The XB index is suited to assess the clustering results of the FCM algorithm; however, this CVI consistently indicated two clusters as the best
, as can be seen in
Table 2. For the case of summer, analyzing the XB index in
Figure 10, there is an elbow point for five clusters. The elbow point consists of the number of clusters with a sharp change of the index values, and it is a method of selecting the best number of clusters. However, between three and five clusters, three were selected, following the principle of the elbow method, where an inferior
is chosen since adding more clusters does not improve clustering results. The three clusters obtained were compact, well defined and representative of the population.
The autumn profiles are presented in
Figure 11, where four clusters were obtained using HC. The clusters obtained with HC were more compact and well defined, compared to the other algorithms, and presented consistent CVIs performance, which can be verified in
Figure 12.
The winter profiles are presented in
Figure 13, where five clusters were obtained using the KM algorithm. For this algorithm, all CVIs indicated five clusters as the best result, except for Sil and DI. Although Sil and DI presented the best result for two clusters, five clusters were the second best result for both, which can be observed in
Figure 14. The clusters obtained with KM were more compact and well defined, compared to HC. For the HC and FCM algorithm, five clusters were selected as the best by at least two CVIs, which can be verified in
Table 2. The higher number of profiles obtained, comparing with the other seasons, is related to a higher use of gas in this season. Consumers’ households are equipped with different heating systems, and depending upon households structural characteristics, as for example the floor area or number of divisions, not to mention socio-economic factors, consumption patterns may substantially vary amongst consumers.
4.4. Normalized Representative Consumption Profiles
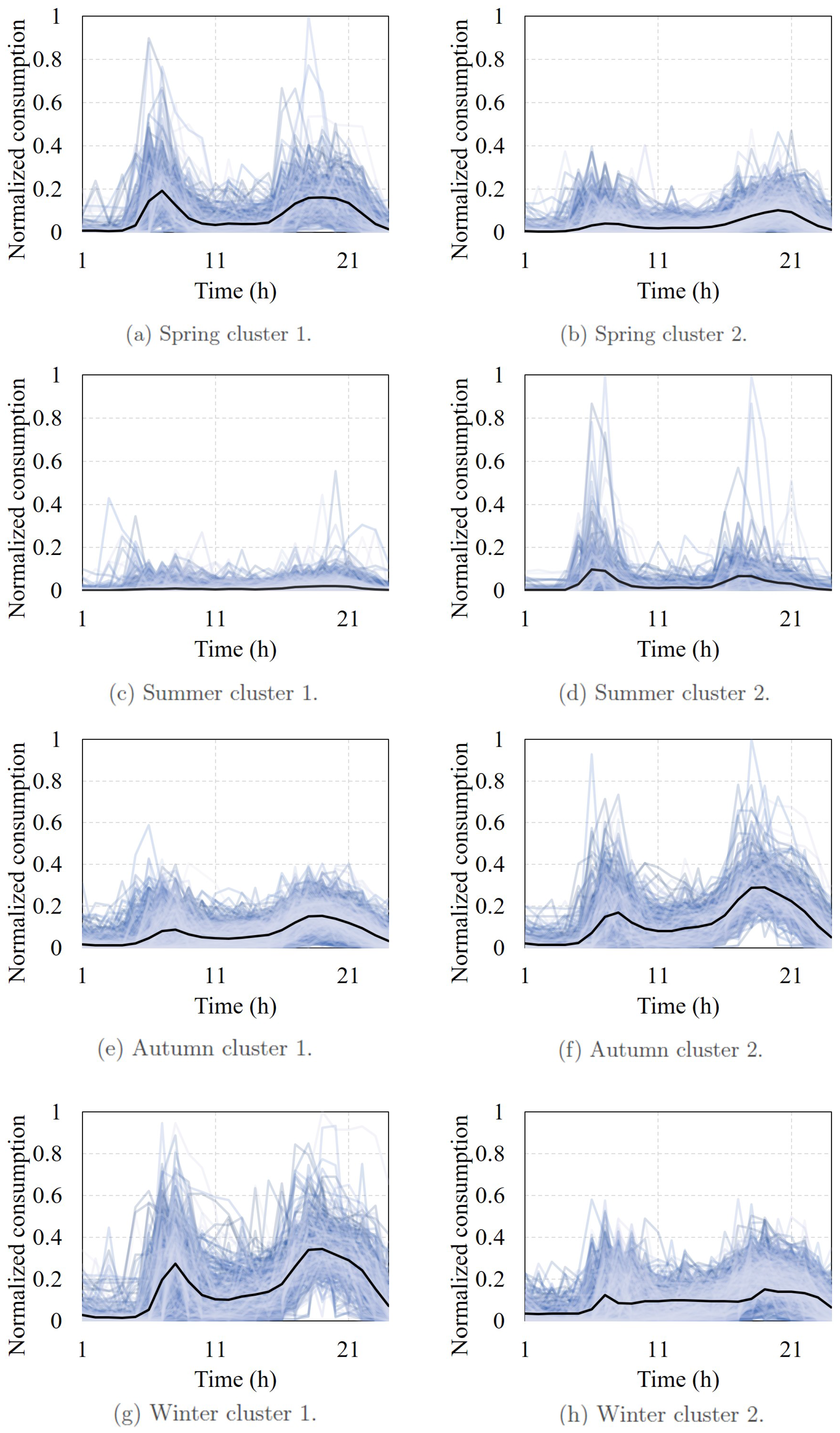
The profiles of the population are represented as normalized load profiles (LP) in
Figure 15 and consist of the clusters’ centers. Cluster 1 corresponds to LP 1, Cluster 2 to LP 2, and the same applies for the other clusters. The population representative profiles are essentially characterized by:
the morning and evening consumption peaks;
the time at which the consumption starts to rise and to decline;
the off-peak consumption.
Except for summer, for each season, there is a normalized LP, which presents the highest peak consumption, compared to the other season LPs. However, despite having the highest peaks, the off-peak consumption of these LPs is not higher than the others of the respective season. In the case of spring, daytime off-peak consumption of LP 1 is higher than the others. Nevertheless, during night, there is another profile (LP 2) with higher off-peak consumption. Summer is the only season where there is a profile with both peaks lower than all the other season profiles’ peaks.
For each season, there is at least one normalized LP that presents an accentuated difference between peaks, as can be verified in
Figure 15; for spring, LP 2 and LP 3, for summer LP 1, for autumn LP 2 and for winter LP 5. The off-peak consumption is significantly lower in spring and summer given that these are colder compared to the other seasons and thus characterized by a higher amount of gas use. Regarding the off-peak consumption hours, colder seasons have a normalized LP (LP 2 for autumn and LP 5 for winter) with consumptions at 12 p.m. approximately equal to those in the morning peak. Despite this fact, the off-peak consumption of winter LPs during night until morning activity starts is relatively low, compared with the consumptions that the LPs present throughout the day.
Each season has at least one normalized LP with a larger peak consumption that may take several hours to rise and decline, which may be related to the heating systems’ programming.
The representative normalized consumption profiles were obtained from data of 1430 consumers. We found that among these, the database contained information regarding socio-economic and household key features of 1246 consumers. After analyzing the normalized profiles obtained and the available features in the database, we found that the most relevant were the ones presented in
Table 3. We aimed at assessing the relationship between LPs and socio-economic and household features for a season and a mid-season, namely summer and spring.
The percentage of the 1246 consumers in each cluster is presented in
Table 4, from
–
, where each cluster is represented by LP 1–LP 5, respectively. We considered that the profiles obtained were representative of the population, with a significant number of consumers in each cluster.
The percentage of consumers in each normalized LP is presented for each categorical feature, considering the consumers of each cluster in
Table 5. The percentages considering the consumers of all clusters (i.e., the total number of consumers) for each normalized LP are presented in
Table 6. The percentage value of the category that best represents the consumers’ profiles, i.e., the one with a higher relative percentage in the population for that key feature, is highlighted in bold text.
The consumers’ normalized representative profiles can be described for each season (see
Table 5):
Spring:
- -
LP 1: those who have the highest morning and evening peak consumption, as well as the highest daytime off-peak consumption and a low one during night. This normalized LP represents the smallest group (8%) of consumers in this season. The majority of consumers belong to upper middle social class AB and receive an income superior to 75 k€. More than a half of the consumers’ households have four bedrooms;
- -
LP 2: those who have a high morning peak consumption and the lowest in the evening, as well as a low daytime off-peak consumption and the highest one during night. The majority of consumers belongs to lower middle social class C1 and use mostly gas and electric cookers as cooking sources;
- -
LP 3: those who have a low off-peak consumption during both day and night, as well as the lowest morning peak consumption and a higher one in the evening. This normalized LP represents the larger group (66%) of consumers in this season. More than a half of the consumers’ households have three bedrooms and are less than 25 years old. About a half of the consumers use an electric cooker as the cooking source, this being reflected in the overall gas consumption, which is the lowest during the day, comparatively with the other normalized LPs.
Summer:
- -
LP 1: those who have the highest morning and evening peak consumption. This normalized LP represents the smallest group (18%) of consumers in this season. The majority of consumers belong to upper middle social class AB and receive an income superior to 75 k€. More than a half of the consumers’ households have four bedrooms;
- -
LP 2: those who have approximately equal morning and evening peak consumption, as well as the highest daytime off-peak consumption. The majority of consumers are between 46 and 55 years old and belong to lower middle and semi-skilled workers social classes C1 and DE, respectively. The majority of the households are less than 50 years old, where the category 26–50 is the most representative in the population for this normalized LP (see
Table 6);
- -
LP 3: those who have a low daytime off-peak consumption and the lowest consumption peaks. This normalized LP represents the larger group (50%) of consumers in this season. The majority of consumers belong to lower middle social class C1 and are between 36 and 45 years old. Almost a half of the consumers use an electric cooker as the cooking source, which is reflected in the overall low gas consumption throughout the day.
4.5. Analysis with Logistic Regression
Logistic regression (LR) models the posterior probabilities (
P) of the classes (correspondent to the representative normalized LPs in this case) via a linear function in
x, while ensuring they sum to one and remain in [0, 1]. We performed an LR for all the N consumers, where N = 1246 and
k = 1:N in (
21)–(
24). We aimed to assess the relationship between the socio-economic and household key features and the different groups of consumption patterns in each season. The drivers of gas consumption could also be ascertained through regression methods such as ordinary least squares (OLS), relating the consumer features to their accumulated consumption. As we aim further with this work to seek the drivers of different consumption dynamics, we wish to understand not only how characteristics relate to high and low consumption, but also how they relate to consumption peaks and other demand curve characteristics at different times of the day. Each cluster of a season displays different curves of normalized consumption, and this is characterized by the morning and evening peak and the off-peak consumptions. Thus, through classification with LR, it is possible to link the gas consumers’ key features with the different consumption groups obtained with clustering, which exhibit different characteristic consumption dynamics.
The clustering analysis resulted in clusters; thus, the classifier linearly separated each one of − 1 clusters into the clusters. The coefficients express the effects of the predictor features on the log odds of being in one cluster or versus the reference cluster .
The equations that describe the LR model for spring are the following:
The equations that describe the LR model for summer are the following:
We assumed a significance level of 0.05, i.e., features were considered statistically significant if their coefficients were associated with
p-values < 0.05 (see
Table 7).
Regarding the household characteristics, the number of bedrooms was significant for the models of both seasons. The coefficients associated with this feature presented the higher values in all equations. The house age was significant in both models, except to discriminate a classification between
and
in summer (
24). The odds of a consumer being in
or
versus
were positively related with both features in spring, while in summer, they were negatively related.
Regarding the consumers’ characteristics, their age was significant for both models, except to discriminate a classification between
and
in summer (
24). The social class was significant only for the summer LR model. The yearly income was significant for both models, except to discriminate a classification between
and
in spring (
21). The odds of a consumer being in
or
versus
was positively related with consumers’ age and yearly income in spring. In summer, the odds of a consumer being in
or
versus
were negatively related to these features, with the exception of consumers’ age in (
24), the coefficient value (0.02) of which was minimum, compared with the others, and not statistically significant. On the contrary, the odds of a consumer being in
or
versus
were negatively related with social class in spring and positively related in summer.
The cooking sources were significant for one of the spring and summer equations, in (
21) and (
24), respectively. The odds of a consumer being in
or
versus
were negatively related with this feature in spring, while in summer, they were positively related.
5. Conclusions
In this paper, we proposed a clustering-based methodology to define the segmentation of residential gas consumers. We tested this methodology by extracting the representative profiles of the population, using smart metering gas consumption data. In order to find the different segments of the population, we used three clustering algorithms and five CVIs, which resulted in a total of 15 normalized representative load profiles reflecting the different consumption patterns. For spring and summer, we obtained three representative profiles, using the HC and FCM algorithm, respectively. For autumn, we obtained four representative profiles using HC. For winter, we obtained five representative profiles using the KM algorithm.
The representative profiles were essentially characterized by two evident consumption peaks, one in the morning and the other in the evening, the off-peak consumption and the time at which the consumption started to rise and to decline. Moreover, we selected two seasons, spring and summer, to analyze the relationship between specific socio-economic and household characteristics and consumers’ normalized representative load profiles. We obtained interesting insights by studying a mid-season and a season displaying different consumption dynamics. Therefore, we found specific characteristics in each cluster, leading to the identification of the different population groups for each season. For both seasons, the smaller representative group of the population presented the highest morning and evening peak consumption. In this group, the majority of consumers belonged to the upper middle social class, received an income superior to 75 k€ and more than a half had four bedrooms in the household. The most representative group of the population was characterized by about a half, in spring, and almost a half, in summer, of the consumers using mainly the electric cooker as the cooking source, which was reflected in the overall low gas consumption throughout the day.
The LR was performed based on the clustering results obtained, so that a relationship between the key features and the consumption profiles could be defined considering the different groups of consumption patterns in each season. We found that the number of bedrooms in the household was a significant feature in the LR models. This was in accordance with the clustering results, where the most representative category of this feature for each cluster had a representative value superior to 46%.
In the future, other clustering algorithms, such as mixed fuzzy clustering, which combines time-variant and time invariant variables, CVIs and similarity measures can be applied in order to further explore the data. The knowledge derived from the proposed methodology can assist energy utilities and policy makers in the development of consumer engagement strategies, demand forecasting tools and in the design of more sophisticated tariff systems.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















