Data-Driven Prediction of Load Curtailment in Incentive-Based Demand Response System


Abstract
:1. Introduction
- The reduced amount of energy in demand response is predicted. This research issue is not seriously considered because the uncertain load curtailment problem is a new upcoming issue in the liberalized energy market. This paper can be a starting point in the prediction of demand response.
- Two difficulties, data sparsity and each customer’s individual characteristics, are alleviated with the proposed ensemble method. It is also verified that a single prediction algorithm cannot cover each customer’s unique response characteristics.
- In the experiment, the real data in a currently operating demand response system are used in order to increase the credibility. The proposed method provided an increased performance compared to other baseline methods with real data.
2. Proposed Prediction Model
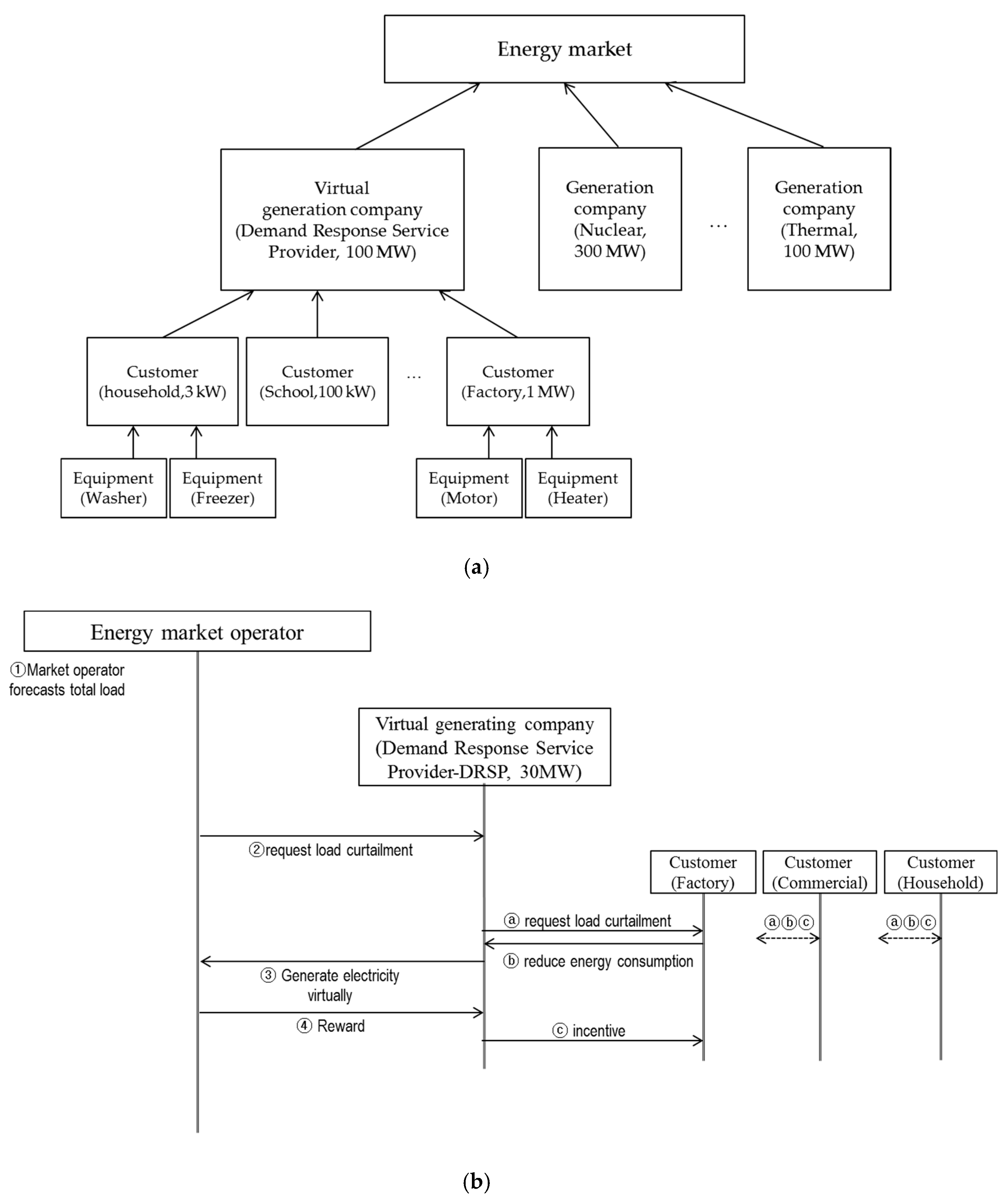
2.1. Prediction Target
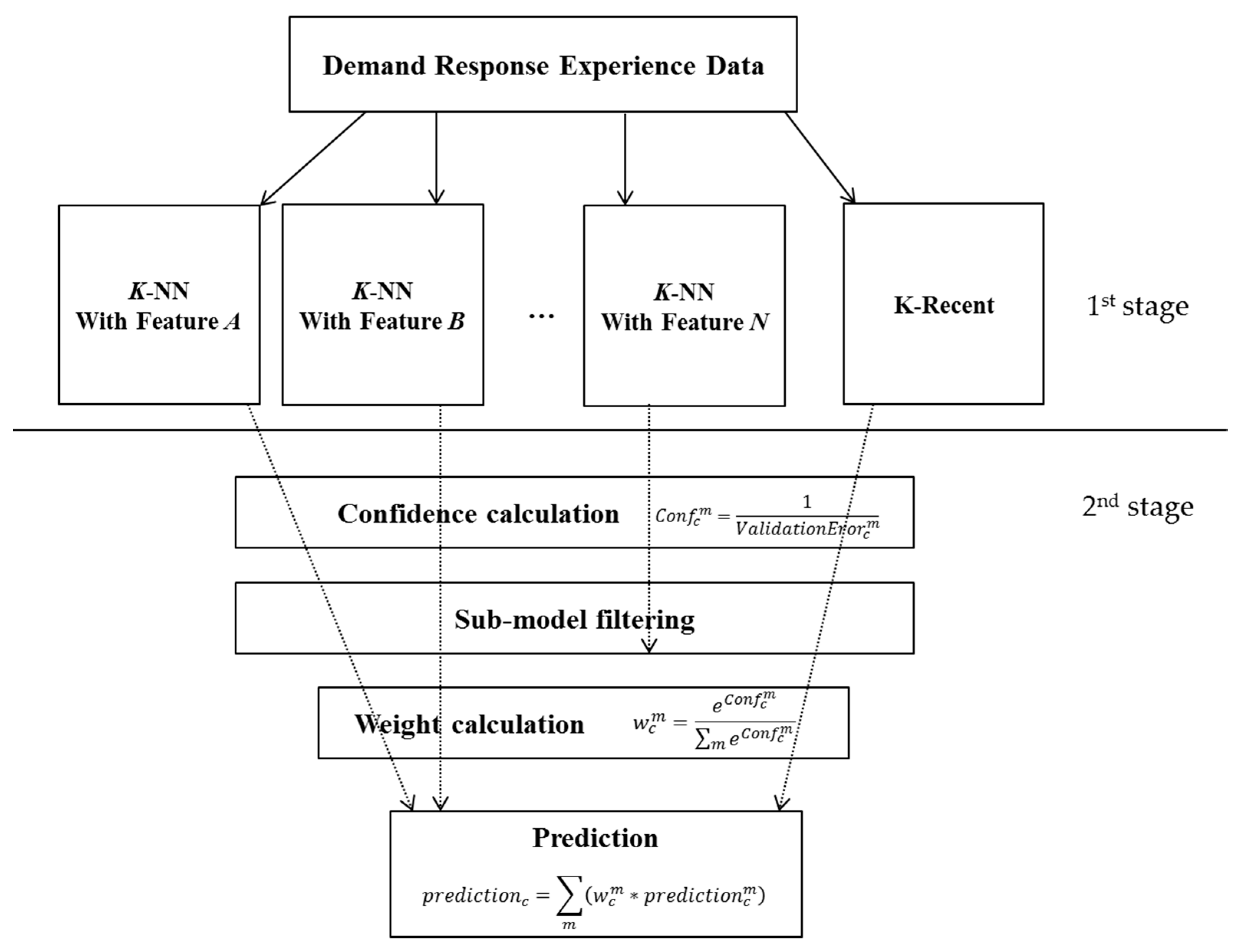
2.2. Prediction Model
3. Experiment
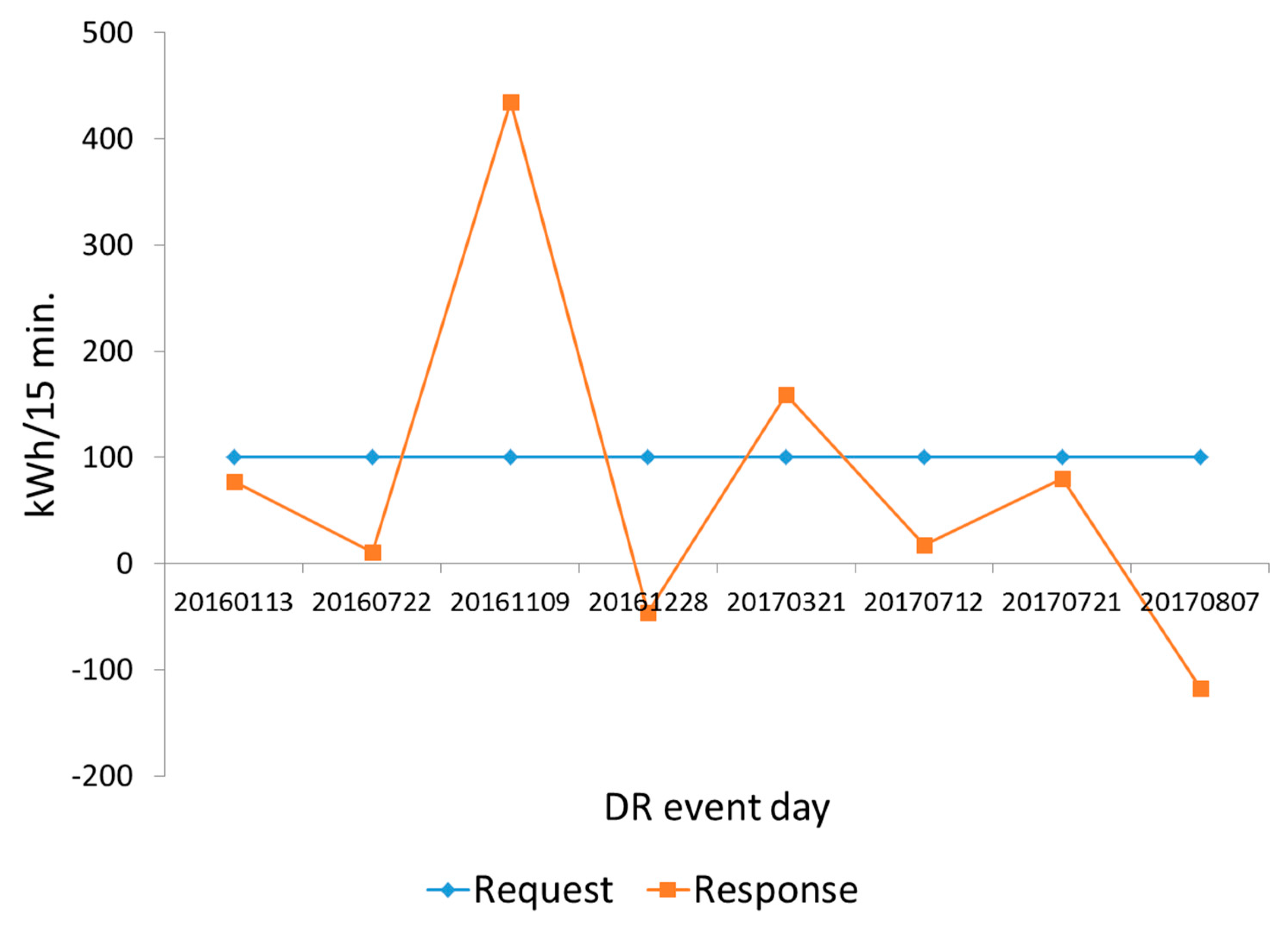
3.1. Data Description
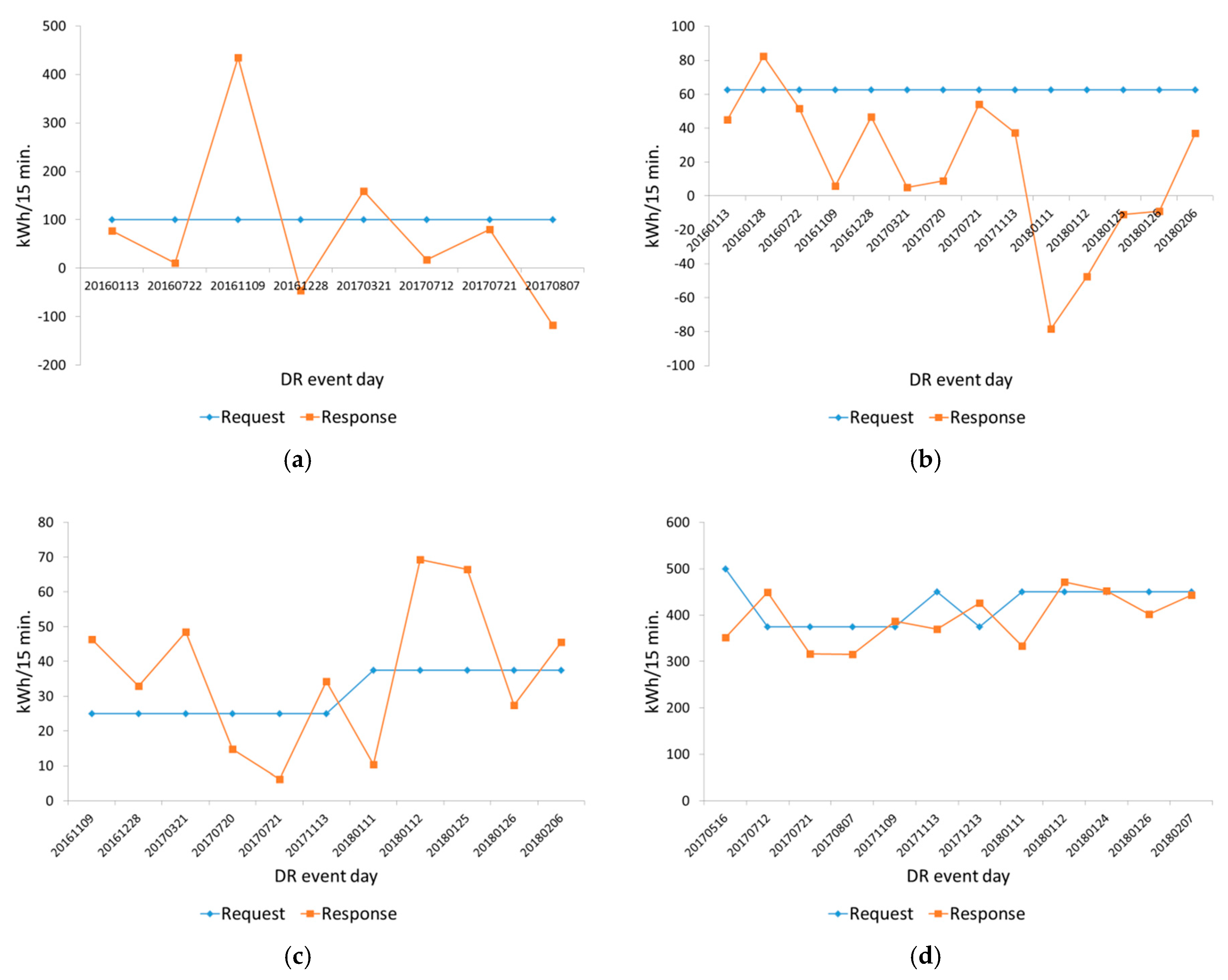
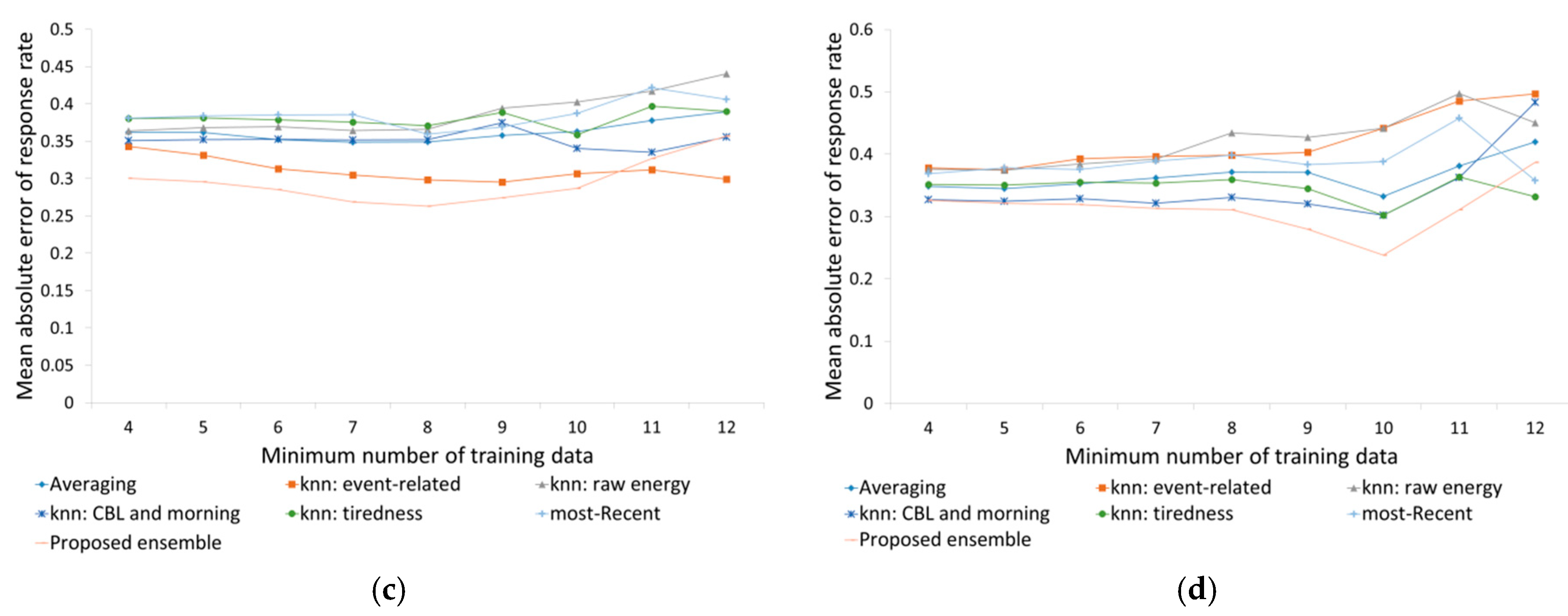
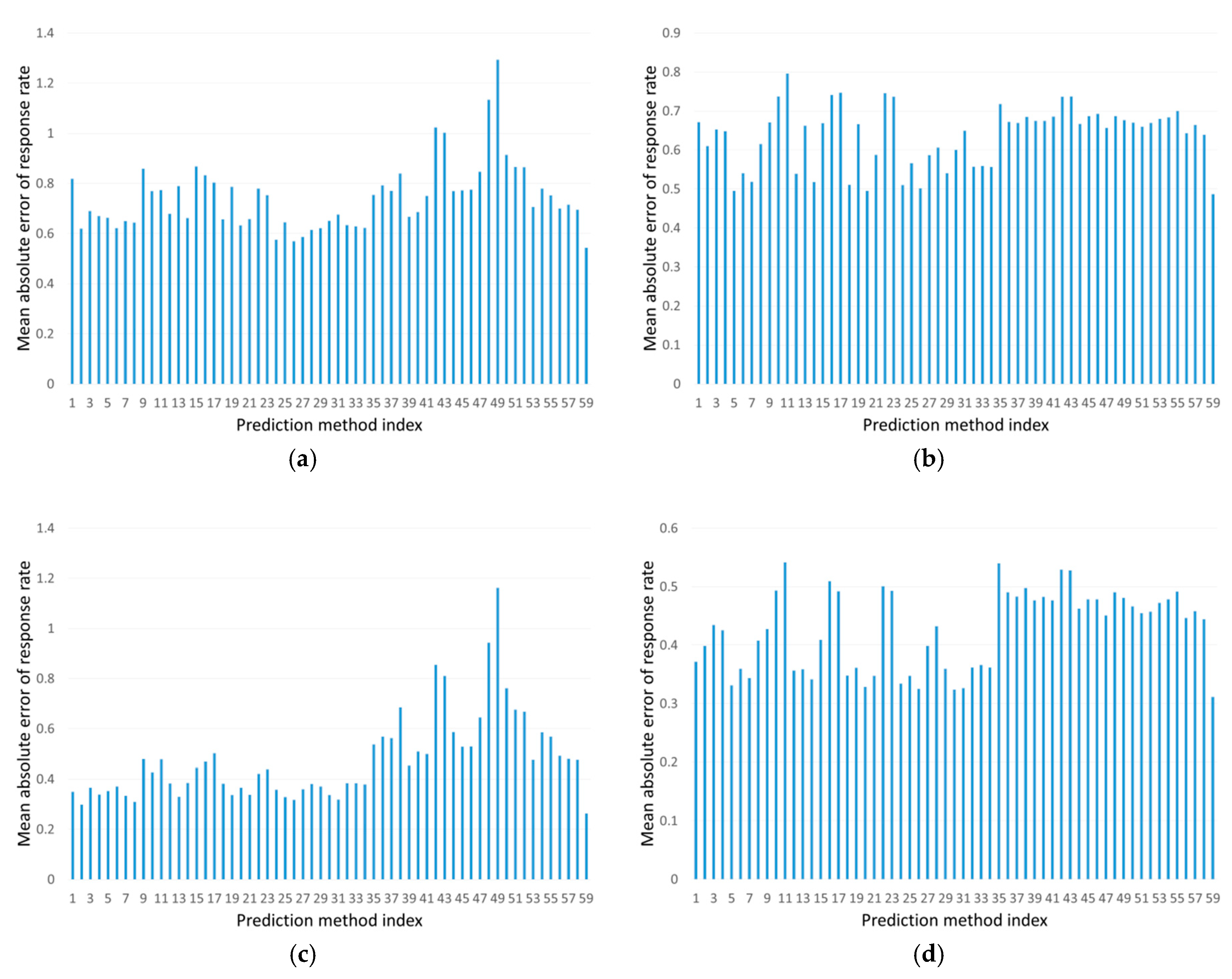
3.2. Experiment Result
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- US Department of Energy. Benefits of Demand Response in Electricity Markets and Recommendations for Achieving Them; US Department of Energy: Washington, DC, USA, 2006.
- Agency, I.E. The Power to Choose: Demand Response in Liberalised Electricity Markets; OECD Publishing: Paris, France, 2003. [Google Scholar]
- Albadi, M.H.; El-Saadany, E.F. A summary of demand response in electricity markets. Electr. Power Syst. Res. 2008, 78, 1989–1996. [Google Scholar] [CrossRef]
- Kang, J.; Lee, J.-H. Data-Driven Optimization of Incentive-based Demand Response System with Uncertain Responses of Customers. Energies 2017, 10, 1537. [Google Scholar] [CrossRef]
- Korea Energy Market Operation Protocol. Available online: http://www.kpx.or.kr (accessed on 18 September 2017). (In Korean).
- Atkinson, S.E. Responsiveness to time-of-day electricity pricing: First empirical results. J. Econom. 1979, 9, 79–95. [Google Scholar] [CrossRef]
- Herter, K. Residential implementation of critical-peak pricing of electricity. Energy Policy 2007, 35, 2121–2130. [Google Scholar] [CrossRef] [Green Version]
- Taylor, T.N.; Schwarz, P.M.; Cochell, J.E. 24/7 hourly response to electricity real-time pricing with up to eight summers of experience. J. Regul. Econ. 2005, 27, 235–262. [Google Scholar] [CrossRef]
- Ghazvini, M.A.F.; Faria, P.; Ramos, S.; Morais, H.; Vale, Z. Incentive-based demand response programs designed by asset-light retail electricity providers for the day-ahead market. Energy 2015, 82, 786–799. [Google Scholar] [CrossRef]
- Aman, S.; Frincu, M.; Chelmis, C.; Noor, M.; Simmhan, Y.; Prasanna, V.K. Prediction models for dynamic demand response: Requirements, challenges, and insights. In Proceedings of the 2015 IEEE International Conference on Smart Grid Communications (SmartGridComm), Miami, FL, USA, 2–5 November 2015; pp. 338–343. [Google Scholar]
- Chelmis, C.; Aman, S.; Saeed, M.R.; Frincu, M.; Prasanna, V.K. Estimating Reduced Consumption for Dynamic Demand Response. In Proceedings of the AAAI Workshop on Computational Sustainability, Austin, TX, USA, 25–26 January 2015. [Google Scholar]
- Aman, S.; Chelmis, C.; Prasanna, V.K. Learning to REDUCE: A Reduced Electricity Consumption Prediction Ensemble. In Proceedings of the AAAI Workshop: AI for Smart Grids and Smart Buildings, Phoenix, AZ, USA, 12–13 February 2016. [Google Scholar]
- Ninagawa, C.; Kondo, S.; Morikawa, J. Prediction of aggregated power curtailment of smart grid demand response of a large number of building air-conditioners. In Proceedings of the 2016 International Conference on Industrial Informatics and Computer Systems (CIICS), Sharjah, UAE, 13–16 March 2016; pp. 1–4. [Google Scholar]
- Barakat, E.H.; Al-Qassim, J.M.; Al Rashed, S.A. New model for peak demand forecasting applied to highly complex load characteristics of a fast developing area. IEE Proc. C Gener. Transm. Distrib. 1992, 139, 136–140. [Google Scholar] [CrossRef]
- Fan, J.Y.; McDonald, J.D. A real-time implementation of short-term load forecasting for distribution power systems. IEEE Trans. Power Syst. 1994, 9, 988–994. [Google Scholar] [CrossRef]
- Chen, J.-F.; Wang, W.-M.; Huang, C.-M. Analysis of an adaptive time-series autoregressive moving-average (ARMA) model for short-term load forecasting. Electr. Power Syst. Res. 1995, 34, 187–196. [Google Scholar] [CrossRef]
- Huang, S.R. Short-term load forecasting using threshold autoregressive models. IEE Proc. C Gener. Transm. Distrib. 1997, 144, 477–481. [Google Scholar] [CrossRef]
- Moghram, I.; Rahman, S. Analysis and evaluation of five short-term load forecasting techniques. IEEE Trans. Power Syst. 1989, 4, 1484–1491. [Google Scholar] [CrossRef]
- Hyde, O.; Hodnett, P.F. An adaptable automated procedure for short-term electricity load forecasting. IEEE Trans. Power Syst. 1997, 12, 84–94. [Google Scholar] [CrossRef]
- Al-Garni, A.Z.; Zubair, S.M.; Nizami, J.S. A regression model for electric-energy-consumption forecasting in Eastern Saudi Arabia. Energy 1994, 19, 1043–1049. [Google Scholar] [CrossRef]
- Infield, D.G.; Hill, D.C. Optimal smoothing for trend removal in short term electricity demand forecasting. IEEE Trans. Power Syst. 1998, 13, 1115–1120. [Google Scholar] [CrossRef]
- Djukanovic, M.; Babic, B.; Sobajic, D.J.; Pao, Y.-H. Unsupervised/supervised learning concept for 24-hour load forecasting. IEE Proc. C Gener. Transm. Distrib. 1993, 140, 311–318. [Google Scholar] [CrossRef]
- Beccali, M.; Cellura, M.; Brano, V.L.; Marvuglia, A. Forecasting daily urban electric load profiles using artificial neural networks. Energy Convers. Manag. 2004, 45, 2879–2900. [Google Scholar] [CrossRef]
- Kim, K.-H.; Park, J.-K.; Hwang, K.-J.; Kim, S.-H. Implementation of hybrid short-term load forecasting system using artificial neural networks and fuzzy expert systems. IEEE Trans. Power Syst. 1995, 10, 1534–1539. [Google Scholar]
- Brown, R.E.; Hanson, A.P.; Hagan, D.L. Long range spatial load forecasting using non-uniform areas. In Proceedings of the 1999 IEEE Transmission and Distribution Conference, New Orleans, LA, USA, 11–16 April 1999; Volume 1, pp. 369–373. [Google Scholar]
- Mori, H.; Kobayashi, H. Optimal fuzzy inference for short-term load forecasting. In Proceedings of the 1995 IEEE Power Industry Computer Application Conference, Salt Lake City, UT, USA, 7–12 May 1995; pp. 312–318. [Google Scholar]
- Raza, M.Q.; Khosravi, A. A review on artificial intelligence based load demand forecasting techniques for smart grid and buildings. Renew. Sustain. Energy Rev. 2015, 50, 1352–1372. [Google Scholar] [CrossRef]
- Khan, A.R.; Mahmood, A.; Safdar, A.; Khan, Z.A.; Khan, N.A. Load forecasting, dynamic pricing and DSM in smart grid: A review. Renew. Sustain. Energy Rev. 2016, 54, 1311–1322. [Google Scholar] [CrossRef]
- Chao, H. Demand response in wholesale electricity markets: The choice of customer baseline. J. Regul. Econ. 2011, 39, 68–88. [Google Scholar] [CrossRef]
- Mathieu, J.L.; Callaway, D.S.; Kiliccote, S. Variability in automated responses of commercial buildings and industrial facilities to dynamic electricity prices. Energy Build. 2011, 43, 3322–3330. [Google Scholar] [CrossRef] [Green Version]
- Coughlin, K.; Piette, M.A.; Goldman, C.; Kiliccote, S. Statistical analysis of baseline load models for non-residential buildings. Energy Build. 2009, 41, 374–381. [Google Scholar] [CrossRef] [Green Version]
- Chelmis, C.; Aman, S.; Saeed, M.R.; Frincu, M.; Prasanna, V.K. Predicting reduced electricity consumption during dynamic demand response. In Proceedings of the AAAI Workshop on Computational Sustainability, Austin, TX, USA, 25–26 January 2015. [Google Scholar]
- Ziekow, H.; Goebel, C.; Struker, J.; Jacobsen, H.-A. The potential of smart home sensors in forecasting household electricity demand. In Proceedings of the 2013 IEEE International Conference on Smart Grid Communications (SmartGridComm), Vancouver, BC, Canada, 21–24 October 2013; pp. 229–234. [Google Scholar]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef] [Green Version]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Weka 3—Data Mining with Open Source Machine Learning Software in Java. Available online: https://www.cs.waikato.ac.nz/ml/weka/ (accessed on 27 August 2018).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description |
|---|---|
| Raw energy consumption | Daily energy consumption pattern. It is the average of all normal days and consists of 96 dimensions. |
| Demand response (DR) event-related data | Information related to DR events. It consists of start time, duration, day of week, and day in year. |
| Customer baseline load | Customer baseline load in the DR event duration. For its calculation, refer to Section 3.1. |
| Tiredness | The index that presents the tiredness of a customer. Previous tiredness is divided by the interval between the latest DR event and the upcoming event day. If the interval is less than seven days, tiredness is increased. |
| Morning energy consumption | The energy consumption in the morning (8:00~9:00 a.m.) of a DR event day. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, J.; Lee, S. Data-Driven Prediction of Load Curtailment in Incentive-Based Demand Response System. Energies 2018, 11, 2905. https://doi.org/10.3390/en11112905
Kang J, Lee S. Data-Driven Prediction of Load Curtailment in Incentive-Based Demand Response System. Energies. 2018; 11(11):2905. https://doi.org/10.3390/en11112905
Chicago/Turabian StyleKang, Jimyung, and Soonwoo Lee. 2018. "Data-Driven Prediction of Load Curtailment in Incentive-Based Demand Response System" Energies 11, no. 11: 2905. https://doi.org/10.3390/en11112905
APA StyleKang, J., & Lee, S. (2018). Data-Driven Prediction of Load Curtailment in Incentive-Based Demand Response System. Energies, 11(11), 2905. https://doi.org/10.3390/en11112905