1. Introduction
As the complexity of power systems increases with the demand for electric power, the use of advanced power system equipment is becoming more widespread. Furthermore, power systems have become significantly more complicated following the integration of renewable energy resources, such as solar and wind [
1]; the employment of high-speed operating devices, such as flexible AC transmission systems (FACTS) and high voltage direct current (HVDC) [
2]; and the increasing prevalence of electric vehicles. In addition, although end users have only acted as electricity consumers in previous decades, smart grid environments enable them to take advantage of information technology (IT) and advanced power system facilities to become independent electric power suppliers [
3]. In particular, the adoption of an energy storage system (ESS) provides opportunities for installing a variety of distributed power sources in the grid [
4]. Hence, it is plausible that the complexity of power systems will increase continuously.
Contingency analysis, which is used to assess the effects of power system component failures in advance, is conducted to enable better power system management. Unfortunately, the number of computations required to calculate the power flow increases with the complexity of the power system [
5]. There have been many studies on methods and applications of power flow computations, and the Newton–Raphson (N-R) [
6] and Gauss–Seidel (G-S) [
7] methods have been adopted widely for this purpose. These computations take a long time even though the performance of computing devices is improving continuously. This is because one of the key steps of power flow computation is to solve nonlinear equations.
The computation time increases with the scale and complexity of a power system. In large power systems, many contingencies must be analyzed because the operation of the system is predicted for each possible contingency. Thus, the analysis is extremely time-consuming. Although
contingencies are assumed for power system analysis in general, analyses of
contingencies (several devices failing at the same time) and
contingencies (a sequence of accidents) are also necessary for real power system operation [
8]. In the case of
contingency analysis, we can assume that
k components fail at the same time. In this case, the large number of possible combinations of faults means that many calculations are required. In the case of
contingencies, two devices fail sequentially. Therefore, the number of possible
contingencies is equal to
n multiplied by
.
Many calculations, requiring high performance computing, are necessary for power system analysis [
9]. We can improve the speed of these calculations by applying parallel processing. Various methods for applying parallel processing for power flow computation have been studied previously. The basic concepts of using parallel processing for power flow computations are presented in [
10,
11]. Following the publication of those papers, there have been some studies on parallel power flow computations in high speed computing environments [
12,
13,
14,
15]. In recent years, several studies have analyzed power systems by constructing an environment that physically uses a large number of cores [
16,
17].
The parallelism method of calculation, as an alternative to employing a number of cores, has also been studied extensively. Analysis of a power system requires many calculations related to the matrix and a number of studies have focused on parallel processing of matrix calculations [
18,
19]. In addition, graphics processing units (GPUs) have been used for fast power flow calculations, as an alternative to other machine cores for parallel processing [
20,
21,
22,
23]. Detailed explanations of the parallel processing issues affecting early research are provided in
Section 3.
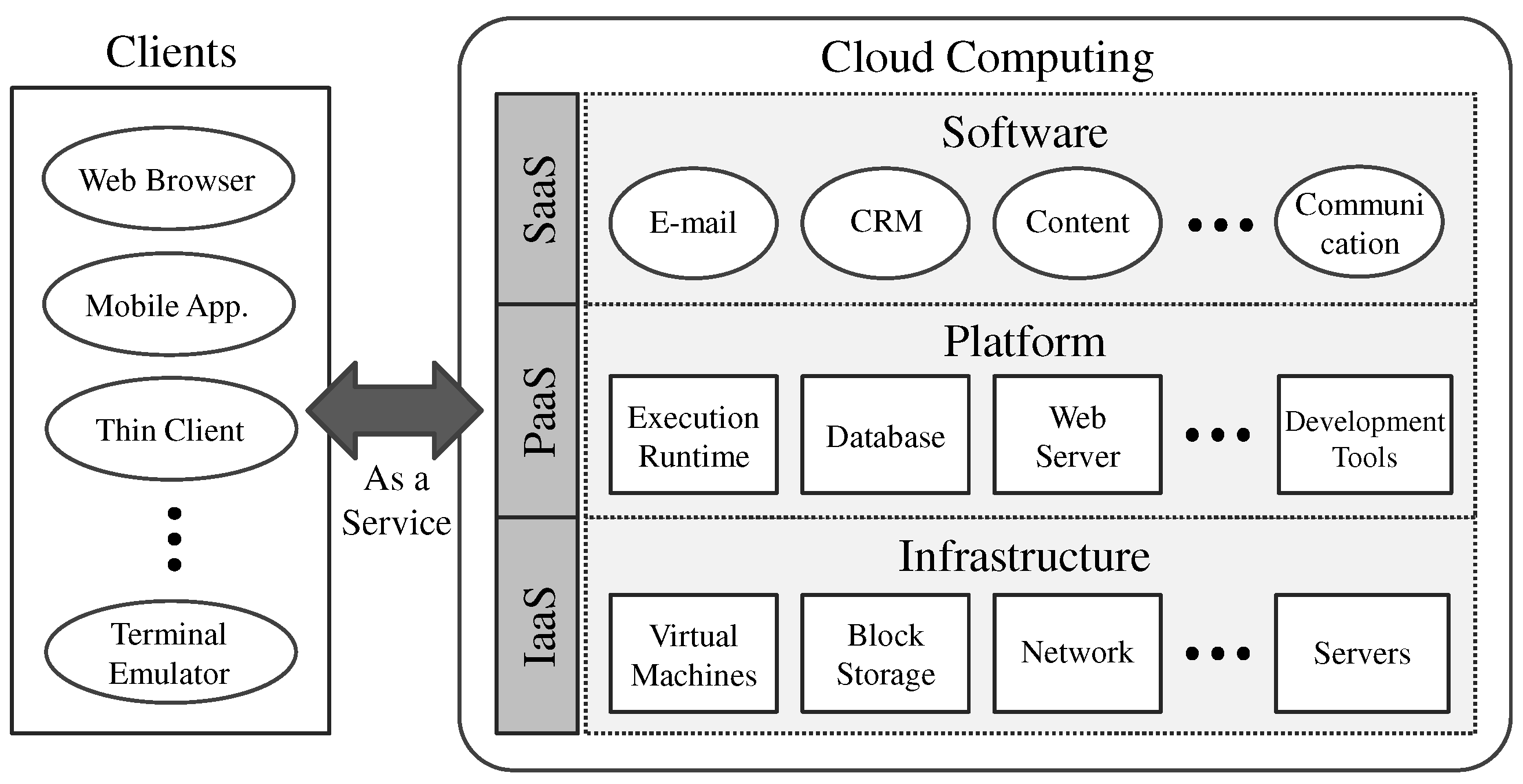
Previous studies have already established that it is better to use parallel processing for analysis of power systems with high computational complexity. For efficient parallel processing, it is necessary to secure resources for calculation; however, physical expansion is limited by cost, and, even if a dedicated system is provided, there is the further disadvantage that the machine is idle when the analysis is not in progress. To overcome these drawbacks, we propose a parallel processing scheme for power system analysis using cloud computing, in which the necessary computing resources can be acquired at the required time. In recent years, technology has advanced to the stage where it is relatively easy to create an environment that enables researchers to take advantage of cloud computing.
Parallel processing can be divided into fine-grained parallelism for allocating parts of the operation and coarse-grained parallelism for parallel processing of the entire operation. Most previous studies on matrix handling have investigated fine-grained parallelism. In this study, we propose a cloud computing-based contingency analysis method that exploits coarse-grained parallelism so that the entire computation is parallel. We obtained a significant performance improvement in the contingency analysis of KEPCO2015 by using a Hadoop-based Amazon EC2 cloud computing system with 1 NameNode and 16 DataNodes.
The experimental results show that our proposed contingency analysis achieved speedups of 8.00×, 17.98×, 27.28×, and 35.32× on 32, 64, 128, and 256 cores, respectively, when adopting task management optimization. We also confirmed that the addition of computing resources can lead to further performance enhancement, even for more contingencies, because the total execution time decreases in proportion to the number of cores used.
In summary, the main contributions of this paper are:
We propose a massive parallel contingency analysis using a cloud computing platform.
We propose a task management optimization to improve performance and scalability of the parallel contingency analysis on a Hadoop-based cloud computing system.
We obtained a 37-fold or greater performance improvement on the Amazon Web Service (AWS) environment.
The rest of the paper is organized as follows: In
Section 2, we describe the background of our study and briefly explain cloud computing, parallelism granularity, and power flow computation. We present related works in
Section 3. In
Section 4, we introduce the overall architecture of our contingency analysis method, the N-R method, and the motivation for this study. In
Section 5, we provide a detailed description of a massive cloud computing-based power flow computation. We evaluate the performance of our method in terms of speedup and present task execution behavior in
Section 6. Finally, conclusions are provided in
Section 7.
3. Related Works
Typically, power system analysis is based on contingency analysis, which is in turn based on the results of power flow computations. As mentioned earlier, the time required to compute power flows increases with the size and complexity of the power system. In addition, the number of contingencies requiring analysis also tends to increase for stable power system operation.
As the performance of computers continues to improve, parallel processing is not necessary when conducting power flow computations for a small number of contingencies. However, when analyzing a large number of contingencies, it is advantageous to adopt parallel processing and thus reduce the computation time. For instance, it would be useful to perform contingency analysis in parallel. The computational complexity of this analysis is very large, so it is appropriate to process the power flow computations in parallel.
The basic concepts related to the application of parallel processing to power flow computation are explained in [
10,
11]. Parallel contingency analysis in high performance computing environments is studied in [
12], where an effective method for conducting contingency analysis using parallel processing is presented. In [
13], a dynamic computational load balancing method is proposed using high performance computing machines for a large number of computations.
There have been attempts to improve the performance of parallel computing using multiple machines. Recently, several large-scale projects using parallel computing have been performed for power system analysis. In [
16], contingency analysis is performed using a commercial program in a massively parallel environment. A total of 4127 contingencies were scaled to 4127 cores and the solution time is reduced significantly. In [
17], a computational platform for dynamic security assessment of a large power system with a commercial analysis tool is presented as a part of the iTesla project; 10,000 cores are used in the case study in this project.
The need for high computing power to analyze a power system and its effects is demonstrated by the results of previous studies. However, there is a physical constraint whereby many large-scale connected computing machines are needed. In this paper, we propose a power system analysis platform using cloud computing as a solution to this limit, without the need for a commercial analysis tool, and we obtain reasonable results without physical constraints by using the cloud computing environment.
There have also been a number of previous studies on how to distribute calculations for parallel processing, and most previous research has focused on applying matrix calculation to parallel computing [
10,
18,
19]. These studies are based on fine-grained parallelism that assigns some of the calculations. Another method for exploiting fine-grained parallelism is to perform power flow computations using GPUs. The GPU-based technique is an example of a parallel processing method that increases the speed of power flow computations. In [
20], the basics of parallel computing using GPUs are established, and a method for utilizing GPUs is presented in [
21]. A detailed implementation of power flow computation parallel processing done using GPUs is provided in [
22,
23], with reasonable results. Using GPUs is an effective method for reducing the time taken for power flow computations, but does not exploit the coarse-grained method of assigning all calculations. In addition, there is a limit to the increase in the speed because the overall effect of the parallel processing depends on the performance of the hardware. To overcome these weaknesses, we herein propose a method to perform power flow computations in a cloud computing environment without specific hardware configurations and exploit coarse-grained parallelism to perform entire computations in parallel.
4. Challenges in Contingency Analysis of Real Power Systems
4.1. Overall Architecture of Contingency Analysis
Algorithm 1 describes the structure of a conventional contingency analysis that performs the power flow computation of a power system for N different contingencies. The inputs of the algorithm are and , which denote a list of contingency data and cluster data of the power system, respectively. The output is , which is a list of convergence results of the power system for all contingencies. indicates the result of applying one contingency to the cluster data and is the result of the i-th power flow computation.
This analysis algorithm mainly consists of the following two procedures. First, it updates the cluster data of a power system using the i-th contingency data, i.e., , at Line 5. Second, it obtains a convergence result of the updated cluster data by performing a power flow computation at Line 7. Since the algorithm repeats the previous two procedures for all contingency data, its execution time linearly increases in proportion to the number of contingencies, i.e., N.
| Algorithm 1 Contingency analysis. |
INPUT: list of contingency data, : cluster data.
OUTPUT: list of convergence results.
- 1:
procedure ContingencyAnalysis(, ) - 2:
i = 0; - 3:
while do - 4:
// Updates cluster data with i-th contingency - 5:
= UpdateClusterData(, ); - 6:
// Performs i-th power flow computation - 7:
= PowerFlowComputation(); - 8:
end while - 9:
end procedure
|
4.2. Newton–Raphson Based Power Flow Computation
The N-R method can be used to determine the magnitude and angle of the voltage at each bus in the power system. A brief description of the N-R method and its application is as follows.
The general form of the nodal equation for a power system network is:
where
is the admittance matrix of the network,
I is a current vector, and
V is a voltage vector. The
ith equation, describing the flow at bus
i, is:
A complex power equation can be expressed as follows:
It is necessary to derive power balance equations before we can solve the power flow problem. The method for deriving power balance equations is discussed in detail in [
38], so we only provide the derived equations. At bus
i, the power balance equations are
The N-R method is an iterative technique for solving a set of nonlinear equations. We can use Equations (
4) and (
5), which are nonlinear power balance equations, to calculate the power flow solutions. The N-R method is described in detail in [
38]. The matrix form of the resulting linear set of equations is:
where
J is the Jacobian. We can obtain the complete formulation of the power mismatch using the power balance equations in Equations (
4) and (
5) and the N-R method from Equation (
6), as follows:
The N-R method converges to the solution after fewer iterations than the G-S method, and is more accurate. In addition, it exhibits better convergence during the computation, and is more efficient in large-scale systems. However, it usually requires more computation per iteration than other power flow computation methods, so the computation time per iteration is slightly longer. To improve the performance and feasible size of the computations by implementing parallel processing, we selected the N-R method for the power flow computations in this study.
4.3. Motivation
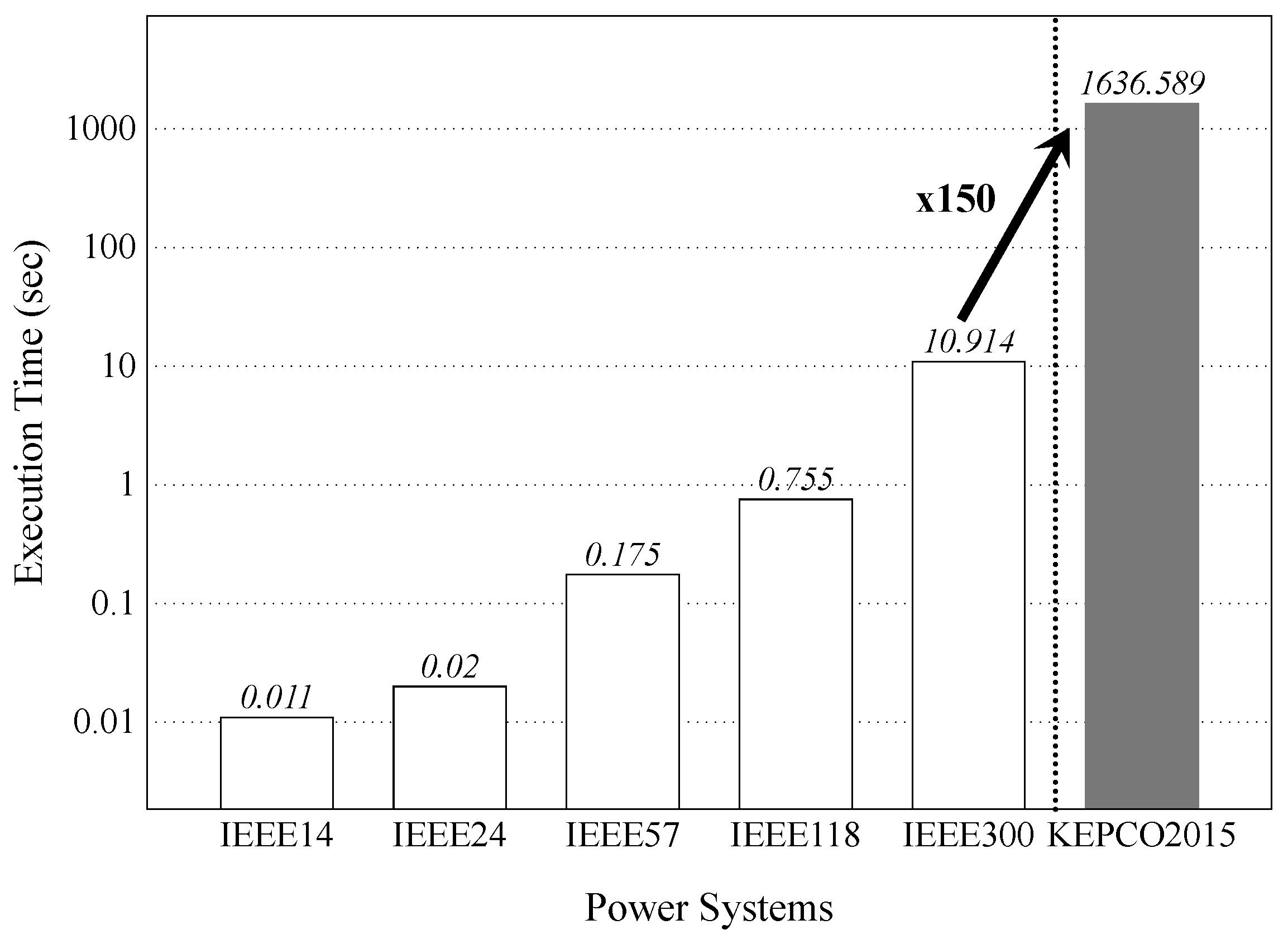
Figure 3 shows the execution time of contingency analysis for a variety of power systems, including a real power system, i.e., KEPCO2015. For each power system, we performed the contingency analysis by applying the contingencies from each branch in turn. In other words, we computed the power flow of a power system with
branches, where
N is the total number of branches of the system. Hence, we employed 17, 32, 64, 170, 306, and 2589 contingencies to evaluate the execution time of contingency analysis for power systems, IEEE14, IEEE24, IEEE57, IEEE118, IEEE300, and KEPCO2015, respectively. The specifications of the power systems are briefly outlined in
Table 1, which describes how many buses, generators, and branches are involved in each system.
These results show that the contingency analysis takes less than 1 s in most of the IEEE systems, except for IEEE300, which requires up to 10.914 s. However, we obtained a completely different result for KEPCO2015, which represents the state of a real power system located in South Korea in 2015. Due to its large-scale cluster data including buses, branches, generators, and so on, the contingency analysis requires a considerably long execution time, i.e., 1636.589 s. Further, if we assume that contingencies from more than two different branches can take place at the same time, the execution time increases significantly because the number of contingencies to be analyzed grows exponentially. The contingency analysis in most real power systems consumes a significantly large amount of execution time, and acceleration of this analysis should be studied.
In this paper, we propose a parallelized contingency analysis using cloud computing by exploiting the coarse-grained parallelism of independent contingencies from each other.
5. Massive Power Flow Computation Using Cloud Computing
In this section, we describe how to perform massive power flow computations using cloud computing. We explain how to obtain coarse-grained parallelism of the power flow computation with the MapReduce framework. In addition, we present a case study that performs parallel contingency analysis on a Hadoop platform [
39].
5.1. Exploiting Coarse-Grained Parallelism with MapReduce
Some previous works on power flow analysis parallelization have obtained fine-grained parallelism by parallelizing a conjugate gradient algorithm for solving a linear system, i.e., a system of the form , which is the most time-consuming part of the power flow analysis. However, performance improvements derived from the fine-grained parallelism are restricted by computing resource limitations if a large power flow analysis, e.g., contingency analysis, is performed. In addition, some other studies have presented to exploit coarse-grained parallelism by independently performing multiple contingency analysis on multi-processors in parallel. Although they employ well-known parallel programming models such as OpenMP (Open Multi-Processing), MPI (Message Passing Interface), and so on, it is still very challenging for users to obtain significant coarse-grained parallelism due to inevitable load imbalance and communication overhead.
We propose to resolve this problem by exploiting coarse-grained parallelism within a MapReduce framework on cloud computing. We can significantly improve the performance of a massive power flow analysis by simultaneously executing multiple independent tasks via the enormous computing capability of cloud computing. In particular, since most of the recent MapReduce-based cloud computing environments also provide GPU-based computing capabilities that make it easy to implement fine-grained parallelism [
40], we were able to maximize the performance of our method by applying it orthogonally to the existing fine-grained parallelism. MapReduce is one of the most prominent programming models used to produce and manipulate large datasets by executing parallel and distributed algorithms on computing clusters. In general, a MapReduce system is designed to be maintained on many distributed servers, to perform multiple tasks in parallel, to manage communication between the different components of the system, and to support redundancy and fault tolerance.
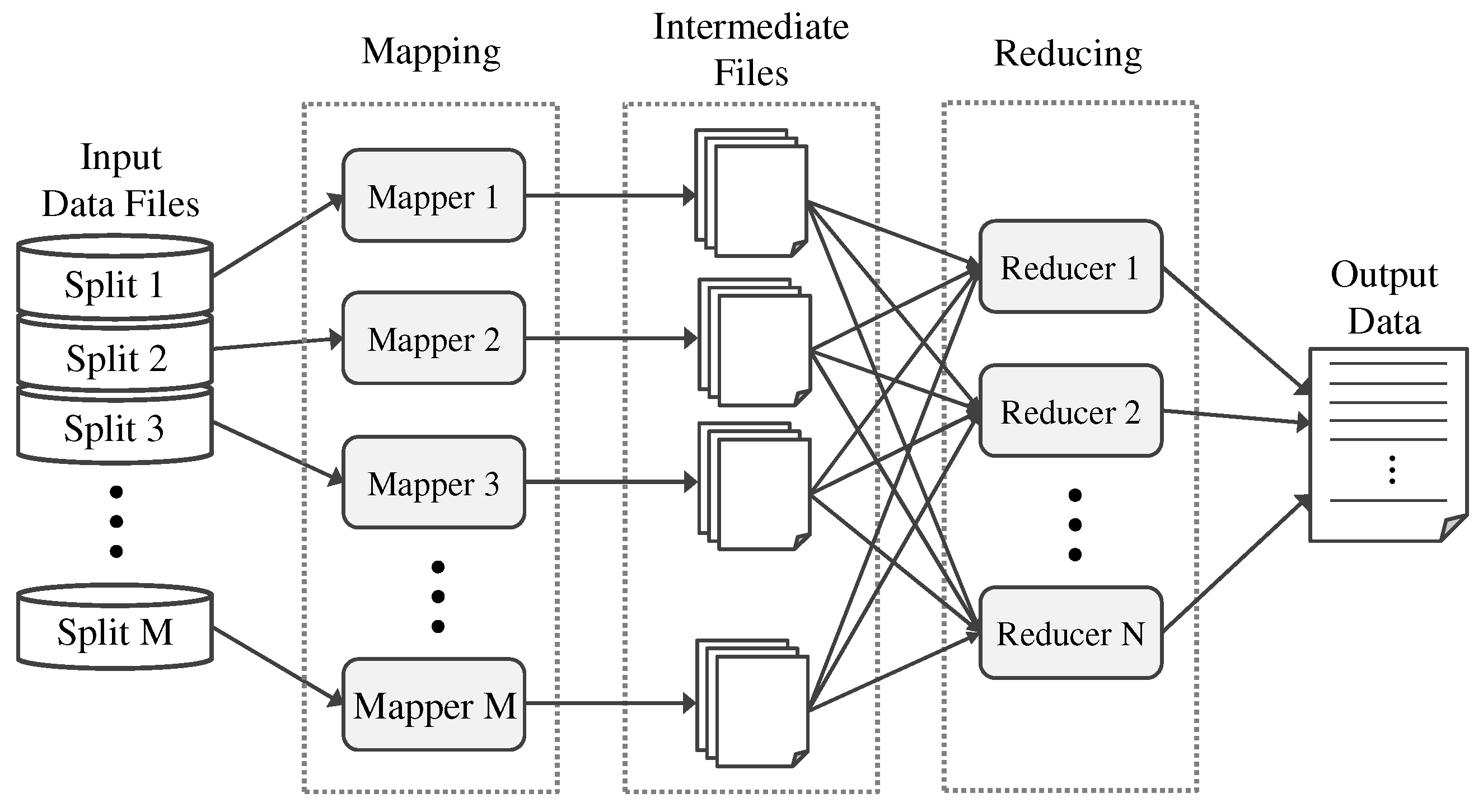
Figure 4 presents a brief overview of a MapReduce program. A MapReduce program principally consists of a map function that filters and sorts the input data, and a reduce function that integrates the intermediate data from the map function into the output data. Each split input item is assigned to a mapper by a task scheduler, and the mapping results are output to intermediate files. The files are shuffled, partitioned, and then input to the reducers, which assemble the output data. To obtain significant coarse-grained parallelism, we need to divide the input data to minimize communication and synchronization overheads so that each of the mappers performs a large number of tasks independent from each other.
5.2. Case Study: Hadoop-Based Parallel Contingency Analysis
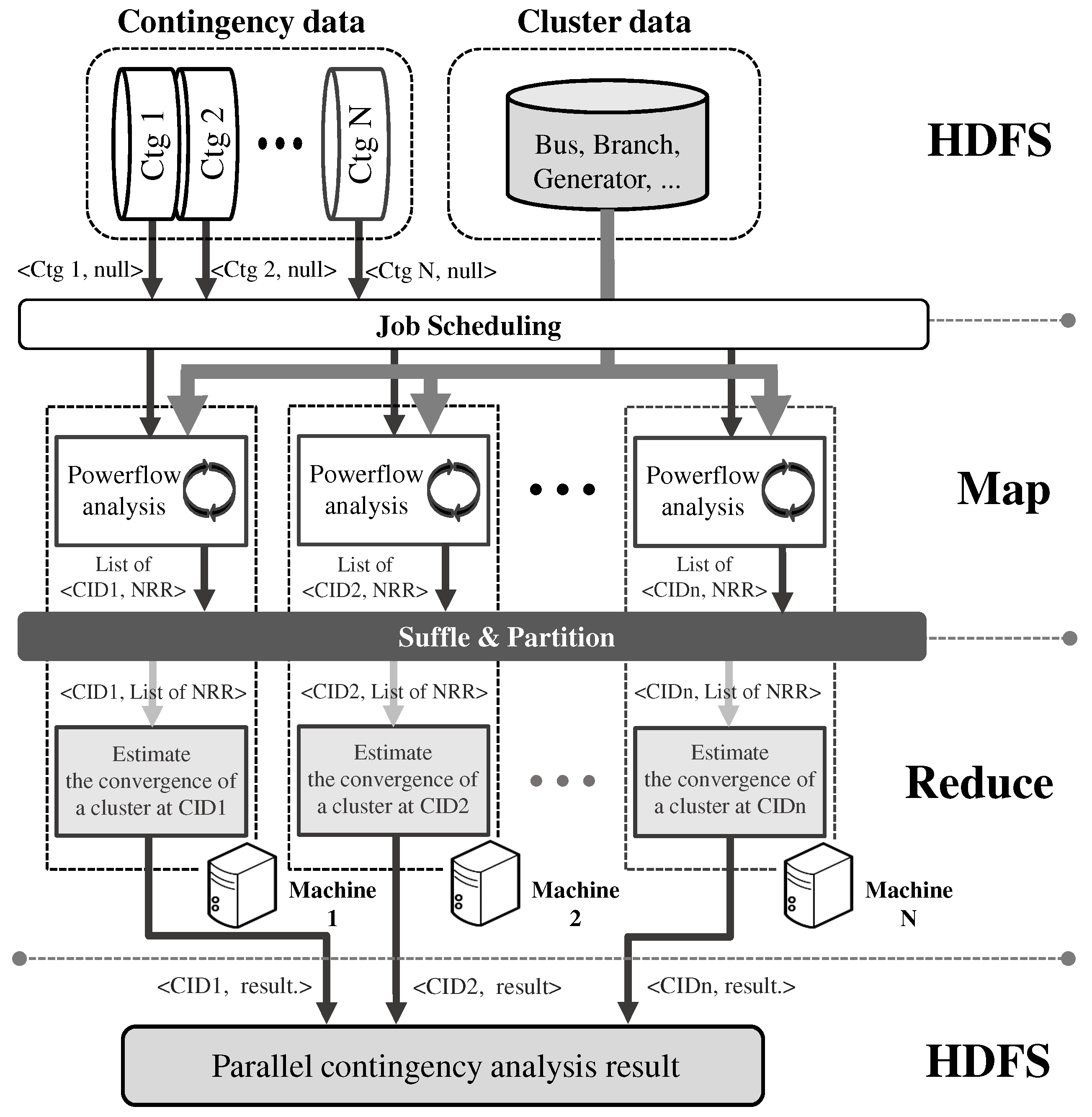
Our parallel contingency analysis program, which uses Hadoop infrastructure to perform massive power flow computations, is outlined schematically in
Figure 5. The input data is stored in a Hadoop distributed file system (HDFS) comprised of the following two types of data: a set of contingency data and a set of cluster data. Each contingency is assigned to a different mapper, but the cluster data are shared by all of the mappers.
First, each mapper updates the cluster data with the given contingency data, and then performs power flow analysis to estimate the convergence of the power system specified by the cluster data. The mapper returns a key and value pair, i.e., a contingency ID (CID) and the maximum mismatch, for each iteration of the N-R algorithm. In our implementation, the N-R algorithm is implemented in C/C++ and is accessed using a Java native interface (JNI) in the mapper, i.e.,the map method. Second, the intermediate results from the mappers are delivered to reducers after being shuffled and partitioned. Then, each reducer takes a pair of key and list values, i.e., a CID and a list of mismatch values, and estimates whether the cluster converges at the contingency that is indicated by the CID. The reducer also returns a key and value pair, i.e., a CID and the result of the convergence analysis result. Finally, the results of the convergence analysis for all contingencies are merged together and written to an output file.
6. Performance Evaluation
In this section, we describe the experimental environment in detail and evaluate the performance of our Hadoop-based parallel contingency analysis.
6.1. Experimental Environment
In
Table 2, we describe the organization of the Hadoop-based cloud computing system that we employed to assess the performance of our proposed parallel contingency analysis. We assembled the Hadoop system using remote computing resources from Amazon Elastic Compute Cloud (EC2), which are provided by AWS. We used Cloudera’s open-source Apache Hadoop distribution, i.e., CDH, which provides an Apache Hadoop framework such as Hadoop YARN, HDFS, and so on.
In detail, the Hadoop system occupies a single NameNode and 16 DataNodes. A NameNode is designed to provide a unified namespace that the HDFS uses to manage access to the data files in the distributed file system. It also supports file system operations, such as open, close, and rename, and maps split data files, i.e., data blocks, to DataNodes. The DataNodes redundantly store the data blocks in their storage, execute read and write operations on the blocks, and implement the map and reduce procedures.
For the evaluation, we designed each of the DataNodes to utilize 2, 4, 8, and 16 cores of an Intel Xeon E5-2686 v4. Hence, we performed the experiments with a large number of cores, i.e., 32, 64, 128, and 256, by using 16 DataNodes together. Further, since we adopted instances of AWS EC2, we expected to use different network bandwidths of 450, 750, 1000, and 2000 Mbps when using 32, 64, 128, and 256 cores, respectively. We performed 16 reduce tasks, which we started after more than 90% of all map tasks were complete.
6.2. Task Management Optimization
As mentioned in
Section 2.2, to maximize the performance improvement from coarse-grained parallelism in parallel contingency analysis, we are required to minimize load imbalance among computing resources while diminishing the overheads of communication and synchronization [
41]. We propose a task management optimization that splits all contingencies into as many chunks as there are available cores in advance, and then assigns each of the chunks to a map task to be executed on a single core. By adopting optimization instead of employing a single map task for each contingency, we can improve the performance degradation caused by task management overhead on a Hadoop platform.
6.3. Experimental Results
Figure 6 shows the performance improvement of our parallel contingency analysis of KEPCO2015 on 32, 64, 128, and 256 cores with respect to conventional contingency analysis. The gray bar represents the speedup when adopting task management optimization and the white bar shows the results with no optimization. Without the optimization, we obtained speedups of 1.78×, 3.26×, 6.62×, and 12.85× on 32, 64, 128, and 256 cores, respectively. The speedup improved by slightly more than a factor of two because the network bandwidth increased from 750 to 1000 Mbps when the number of cores increased from 64 to 128.
Furthermore, the task management optimization strategy significantly enhanced the performance of the parallel contingency analysis. We improved the performance by up to 35.32× on 256 cores and achieved the speedup of 8.00×, 17.98×, and 27.28× on 32, 64, and 128 cores, respectively. These results confirm that our proposed architecture yields significant performance improvements by exploiting the coarse-grained parallelism of contingency analysis using cloud computing. In particular, as the speedup increases proportionally to the number of cores used, we expect that additional computing resources will lead to further performance enhancements.
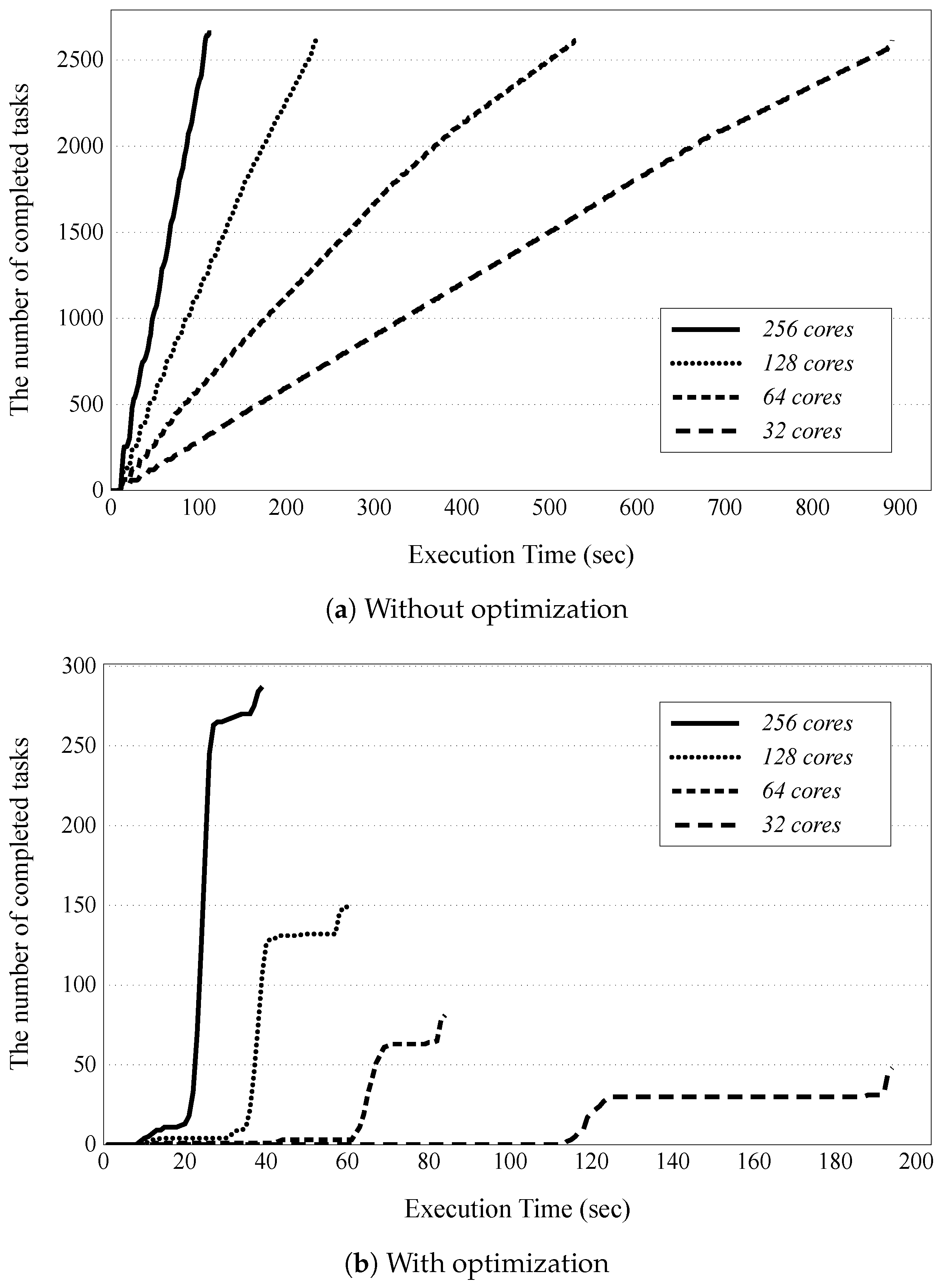
Figure 7 shows the task execution behavior of our parallel contingency analysis of KEPCO2015, both with and without applying the task management optimization. Each line indicates the total completed tasks over time for the different numbers of cores, i.e., 32, 64, 128, and 256 cores. The completed tasks involve both map and reduce tasks. As shown in
Figure 7a, when the optimization was not adopted, the number of completed tasks became identical to the number of contingencies in KEPCO2015, i.e., 2589, and the total execution time decreased in proportion to the number of employed cores, which increased from 32 to 256.
Figure 7b shows that the number of completed tasks becomes equal to the number of occupied cores through task management optimization. This is because we created and executed as many map tasks as the number of cores, as mentioned in
Section 6.2. We can also confirm that the optimization reduced the overall execution time for completing all tasks significantly. When using 256 cores, the number of completed tasks increased relatively sharply in the first round, i.e., between 19 s and 29 s, and then rose gradually over the next few seconds of the second round. In detail, after 90% of all the map tasks were completed in the first round, 16 reduce tasks were created and executed in the second round. Finally, from 33 s onwards, the number of completed tasks started to rise quickly again as the reduce tasks began to finish. Although different numbers of cores were used, similar behaviors are shown in each graph.
7. Conclusions
In this paper, we propose a novel parallel architecture for accelerating contingency analysis in real power systems. To the best of our knowledge, our study is the first to suggest a cloud computing platform for massive power flow computations by exploiting coarse-grained parallelism. We also propose a task management optimization that divides all contingencies into as many chunks as there are available cores in advance, and then assigns each of the chunks to a different core. This optimization allows minimizing load imbalances between computing resources while diminishing the overheads imposed by communication and synchronization.
As a result, we obtained a significant performance improvement in the contingency analysis of a real power system, i.e., KEPCO2015, by using a Hadoop-based cloud computing system with 1 NameNode and 16 DataNodes on Amazon EC2. The experimental results show that our proposed contingency analysis achieved speedups of 8.00×, 17.98×, 27.28×, and 35.32× on 32, 64, 128, and 256 cores, respectively, when adopting task management optimization. Furthermore, from task execution behaviors, we can expect to enhance the performance further by employing additional computing resources, since the total execution time of tasks is decreased in proportion to the number of cores used.
Different from the conventional fine- and coarse-grained parallelization technologies with ultimately limited hardware resources such as GPU, local servers, and so on, our proposed architecture can tremendously accelerate the analysis of large power systems that require massive power flow computations by using unlimited cloud computing.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}