Modeling of Scramjet Combustors Based on Model Migration and Process Similarity

1
School of Aeronautics and Astronautics, Zhejiang University, Hangzhou 310027, China
2
College of Aerospace Science and Engineering, National University of Defense Technology, Changsha 410073, China
*
Author to whom correspondence should be addressed.
Energies 2019, 12(13), 2516; https://doi.org/10.3390/en12132516
Submission received: 14 May 2019
/
Revised: 12 June 2019
/
Accepted: 25 June 2019
/
Published: 30 June 2019
(This article belongs to the Special Issue Scramjet and Ramjet Combustion)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Contributed by the low cost, the simulation method is considered an attractive option for the optimization and design of the supersonic combustor. Unfortunately, accurate and satisfactory modeling is time-consuming and cost-consuming because of the complex processes and various working conditions. To address this issue, a mathematical modeling for the combustor on the basis of the clustering algorithm, machine learning algorithm, and model migration strategy is developed in this paper. A general framework for the migration strategy of the combustor model is proposed among the similar combustors, and the base model, which is developed by training the machine learning model with data from the existing combustion processes, is amended to fit the unexampled combustor using the model migration strategy with a few data. The simulation results validate the effectiveness of the development strategy, and the migrated model is proved to be suitable for the new combustor in higher accuracy with less time and calculation.
1. Introduction
Contributed by the key factors of higher speed and no requirement to carry oxygen, scramjets are considered as a promising propulsion for cruise missiles [1,2,3,4,5,6]. As one of the ramjet airbreathing engines [7], the scramjet is made of an inlet, combustor, and nozzle. Among these components, the combustor has a key effect on the working characteristics, including the transient response, fuel efficiency, and levels of emissions [8]. With the continued development of aircraft, there is an increasing need for precision in the propulsion performance of the scramjets, which can be achieved by optimizing the supersonic combustors’ processes [9]. Since experiments are cost-intensive, simulation methods are popularly adopted to model the process of the supersonic combustor.
Currently, modeling of the supersonic combustor is mainly based on the following three types: the experience design method, the method combining CFD with experience, and the method combining CFD with verification experiments [10,11]. Many CFD researchers have adopted the method based on Navier–Stokes equations to analyze the scramjet combustor in detail. Early in the systematic development of scramjets, Billig [12] developed a quasi-one-dimensional model of scramjet combustors based on pressure–area variation. Such a model can give only a rough approximation of the actual flow and combustion processes. A two-dimensional flow model with coaxial injection of hydrogen parallel to the air flow was considered by Tsujikawa and Northam, who also analyzed the effect of active cooling with slush hydrogen, which is a key aspect of their model [13]. Subsequently, aiming at the investigation on combustor mode transition in the combustor, Xiao [14] adopted a fully coupled form of species conservation equations and Reynolds averaged Navier–Stokes equations as a governing equation set for a chemically reacting supersonic viscous flow. A quasi-one-dimensional, inviscid chemical equilibrium model, which was capable of rapidly analyzing the combustor without requiring predefined geometries, was developed by Vanyai [15] to simulate scramjet engines defined by predetermined combustion processes. These methods are accurate in a certain range; however, they are also time-consuming and subject to limitations of turbulence modeling. It is therefore meaningful to develop a method that can quickly predict the overall performance of a scramjet combustor.
At present, researchers have pursued several empirical models to simulate the process of the combustor. These models assume the combustor as a black-box, and just focus on the relationship between the input and output parameters without taking the physical mechanism into consideration. As for the applications of the control, optimization, and analysis of the combustors, these empirical modeling methods have an attractive prospect [16,17,18,19,20,21]. However, a large number of data samples is the premise of accurate and reliable data-driven models [22]. Unfortunately, it is time-consuming and of high cost to obtain experimental data samples from the new combustor. Therefore, developing a precise empirical model with less data and calculation is an attractive problem which is worthy of solving.
One way to remedy the problem mentioned above is the model migration strategy developed by Gao and Lu [23,24,25,26]. The key methodology of the model migration strategy is to revise the base model obtained from the existing processes to fit the new process as long as there are similarities between the existing and new processes. Moreover, a series of model migration strategies for different types of similarity have also been investigated by Gao and Lu [23,24,25]. The key aim of these strategies is to model the new process with less experimental data and get rid of the repetitive training, and the validity has been verified by the injection process [26,27,28].
As far as supersonic combustors are concerned, although they have different structures and sizes for adjusting to different operation conditions, there is the same underlying physic mechanism in the combustors. That also means the input–output mapping relationship among the combustors remains the same or similar [22]. Therefore, in this paper, the model migration strategy is used to simulate the supersonic combustor, and a new rapid simulation method to predict the performances of the combustor on basis of the model migration strategy is proposed. This approach first uses data from the existing combustors to develop a base model, modifies the base model to meet these requirements of the new combustor, and predicts the differences between the real process of the new combustor and the base model through the meaningful information extracted from the existing combustors and a little data obtained from the new combustor. In this method, both overall and local migrations play crucial roles in revising the base model to fit the new combustor. Specifically, some performances of the combustor, namely, the total pressure and the total pressure recovery coefficient, are predicted in the simulation case, and the performances of the real mechanical process of the new combustor are adopted for comparison with the proposed method.
Generally speaking, the modeling method that we built is similar to a migration learning algorithm. A similar study applied to scramjet engines has been conducted for a multi-objective design optimization [11]; this method still requires a CFD model. In contrast, in our model migration method process, a CFD model is not necessary. The common CFD model focuses on solving these governing equations, which is often more difficult and time-consuming. We do not need to be clear about the reason why specific changes occur in the process, and it is sufficient only to record the attribute value. Many steps of model migration are trained by data points to approximately simulate this relationship. Moreover, when the CFD model is difficult to build, it is often modeled by a large amount of data. With the migration modeling method, the amount of data required for data-based modeling can be reduced, which is the significance of our method. The more complex the process is, the more difficult CFD modeling is, and the more data are required for data-based modeling. In this case, the optimization effect of the application of our migration modeling method is more obvious.
2. Process Representation of Supersonic Combustors
Although the structure of supersonic combustors is simple and similar, their internal operation mechanisms are complex. Therefore, there are numerous parameters in the process of operation of a supersonic combustor. This paper divides these parameters into three categories:
- (1)
- Configuration parameters: The combustion chamber is basically composed of an air intake, a nozzle, a combustion chamber, and an ignition device. The sizes of these components, including the blockage ratio, overall length, and cross-section area, influence the performance of the combustor. The parameters that affect the combustor according to the configuration of the supersonic combustor itself are named the configuration parameters. The intrinsic properties of the material of the combustor are also assumed to be configuration parameters.
- (2)
- Inlet parameters: The inlet parameters, such as the equivalence ratio, the total inlet temperature, the flow Maher number, and the inlet total pressure, are the main properties of the inflow fluid when it begins to enter the combustor. The intrinsic properties of the fluid are also defined as inlet parameters.
- (3)
- Outlet parameters: The outlet parameters are the main characteristics of the outflow fluid leaving the combustor. The outlet parameters include the total temperature, Maher number, total pressure of outlet, static pressure, and the static temperature. The outlet parameters are determined after the configuration and inlet parameters are determined.
Regardless of how complicated the process of the combustor is, its properties can be classified into the above three parameters. Therefore, every combustor, P, can be characterized through a series of process properties and the relations among these properties, as shown in Equation (1) [23]:
Here, X is the input variables which could reflect the nature of the combustor, such as the configuration and the inlet parameters; Y is the output variables, including the outlet parameters; and R denotes the relationships between X and Y governed by the physic mechanism of the combustor. Generally, R can be obtained by many modeling methods besides hybrid, data-driven, and first-principles approaches. In this paper, we assume the combustor as a black-box with the ignorance of the internal physics principles, and only take the input–output mapping relationship into consideration. Hence, this paper unitizes the BP (back propagation) neural network to simulate the relationship instead of seeking the specific functions.
Taking the combustor modeling as an instance, any combustors could be characterized through a series of process attributes, including the chamber type, the blockage ratio, the inlet total pressure, the inlet total temperature, the inflow Mach number, the outlet total pressure, the outlet total temperature, and the outflow Mach number. The selected types of the process attributes vary with different modeling needs.
For a particular combustor molding process that operates with an annular chamber, an inflow Mach number of 2, an inlet total pressure of 800 K, an inlet total temperature of 1000 Pa, an outflow Mach number of 3, an outlet total pressure of 3200 Pa, and an outlet total temperature of 1500 K can be described as follows:
3. Model Migration Strategy for Supersonic Combustors
The basic requirement for model migration is process similarity. When the response curves of different processes witness similar behavior while there are varied magnitudes under the identical operating range of an input variable, these processes are assumed to be trend similar. Trend similarity is a type of process similarity [24]. For different supersonic combustors, despite the differences in sizes and inlet parameters, the variation trend of the output parameters is similar because the underling physics principles remain the same. Therefore, the combustor has a trend similarity and satisfies the prerequisite of model migration.
Assuming that the data of the existing combustor can be obtained and that of the new combustor can be accessible, we could develop the new combustor model according to the following steps: development of the base model; performing preliminary experiments of the new combustor; overall migration; local migration; and validity of the new model.
3.1. Development of the Base Model
Based on the above process representation method of the combustor, every existing combustor can be represented as , where xi is the input parameter, yi stands for the corresponding output value, and l represents the amount of training data. These data sets can form a sample as follows:
where n is the amount of data sets.
Although each data set is different, the underling physics principles remain the same. Thus, we assume the combustor as a black-box with the ignorance of the internal physics principles, and only take the input–output mapping relationship into consideration. This black box model is mainly developed using the bagging algorithm [29,30,31] and the BP neural network [29].
We can get a base model F of the new combustor by the following steps: select m training data sets from the training sample D randomly; train the data sets to obtain a model named fi in accordance with the BP neural network; put the training data sets back to the sample D; repeat the above steps K times to obtain K base models: ; and obtain the weighted average of these base models according to Equation (4) and output the weighted average model F.
The foundation of the base model F is the machine learning algorithm. According to the characteristics of machine learning, we know that if the sum of the data set is larger, then the accuracy of the base model will be higher. However, a large calculation burden would be added to the development of the ensemble members if the data pairs contain too much training data. Furthermore, the methodology of improving the accuracy by increasing the training data samples is invalid when the existing combustor is limited, and the data cannot be obtained in large quantities. In this paper, the focus of the modeling method is the migration strategy rather than the data modeling, and the migration strategy does not require high accuracy for the base model, as long as it can inherit some of the characteristics of the existing combustor and maintain similar trends. In fact, a base model trained by approximately 20 sets of data can meet the requirements of the migration strategy [24], as verified in the following simulation.
3.2. Preliminary Experiments of the New Combustor
Although the base model can reflect the general characteristics between the existing combustor and the new combustor, it is difficult to maintain the unique features of the new combustor. Therefore, it is necessary to conduct some sparse experiments to obtain the main features of the new process and take these features into consideration during the modeling process. For reflecting the characteristics of the new process, the preliminary experiments need to be designed at key and influential data-points.
The cluster estimation method could divide the data samples into cluster centers for describing the regions with high data density and each cluster center is considered as the representation of this local region [32,33]. For maintaining the key influence of every factor and nonlinear features of the output space at the same time, the cluster estimation method is adopted for designing experiments of the new combustor. With this cluster method, the process behavior of the existing combustors could be described at little cost. As stated previously, every existing combustor can be represented by a data set . Next, we combine the input data xi with the corresponding y-value to form N input–output data pairs D (xi; yi), where xi denotes the input, y stands for the output, and D denotes the augmented data vector. Every input–output data pair can be regarded as a data point star. The gap among these data point pairs should be consistent with the resolution of parameters so as to ensure these cluster centers could describe the features of the existing combustors in a precise way. Therefore, the characteristics of the new combustor could be captured if we conduct experiments at the same cluster center points. Every data point Di is considered as a potential cluster center according to the cluster estimation method, and then the measure of each possible center could be calculated by Equation (5) [24,34]:
where r denotes the effective radius of a cluster center, defining a neighborhood, N represents the number of data points surrounding the potential center, and Ai stands for the potential of the ith particular data point. Assuming that the potential is hardly affected by these data points which are outside the radius, the measurement of that for a particular data point would be characterized as a function of the gap to the remaining points. When it is neighboring to the candidate data point, this data point would have significant influence on the potential. As the radius of every region of the input–output space is set to be same, the cluster center would have the equal effective ranges on every region.
Adopting the fitting radius of every region, we could get the corresponding amount and position of the cluster center. Additionally, the dimension where the input parameters effectively contribute to the output parameter would have a larger amount of cluster centers for the larger density. Every cluster center can be considered as a typical representation data point maintaining the key features of the existing combustors. Hence, conducting preliminary experiments concluding these cluster centers could contain the main characteristic behavior of the new combustor.
3.3. Overall Migration
The base model can be presented in the form as follows:
where Xbase and Ybase are the input and output, and f is the function relationship between the input and output of the base model.
Comparing the data obtained from the preliminary experiments with the data obtained from the base model, we find that disagreement exists between the types of data. Moreover, shift and scale occur in both the output and input data. The amendment model is then obtained through both the slope/bias correction of the input and that of the output space according to Equation (7) [22,23,24]:
where C1 and B1 denote the re-scaling and shifting in input space, respectively, and C0and B0 represent the re-scale and shift in output space, respectively. In other words, C0 and C1 are the ratio coefficients, and B0 and B1 are the offset coefficients. The aforementioned coefficients are estimated through the optimization of Equations (8) and (9) and the training data obtained from the new combustor [22,23,24]:
where y stands for the data of the new combustor obtained in the preliminary experiments, εi is the predicted error between the experimental and theoretical values, and C0 and C1 are the ratio coefficients, and B0 and B1 are the offset coefficients.
3.4. Local Migration
Even though the amendment model has the higher precision than the base model [23,24,25,26], some disagreements remain in the amendment model because of the nonlinearity of the process of combustors. Therefore, the local model migration approach is used to re-amend the deviation between the amendment model and the new combustor. This approach groups the input space into a series of local deviation compensation models while amending the deviation according to the degrees of deviation in each local interval of the original amendment model. These local deviation compensation models constitute the global deviation compensation model through the fusion algorithm, and the global deviation compensation model is then used to re-amend the amendment model to finally obtain a re-amendment model. As the local model migration method takes full consideration of features of the marginal points, it can compensate for the nonlinear deviation [34].
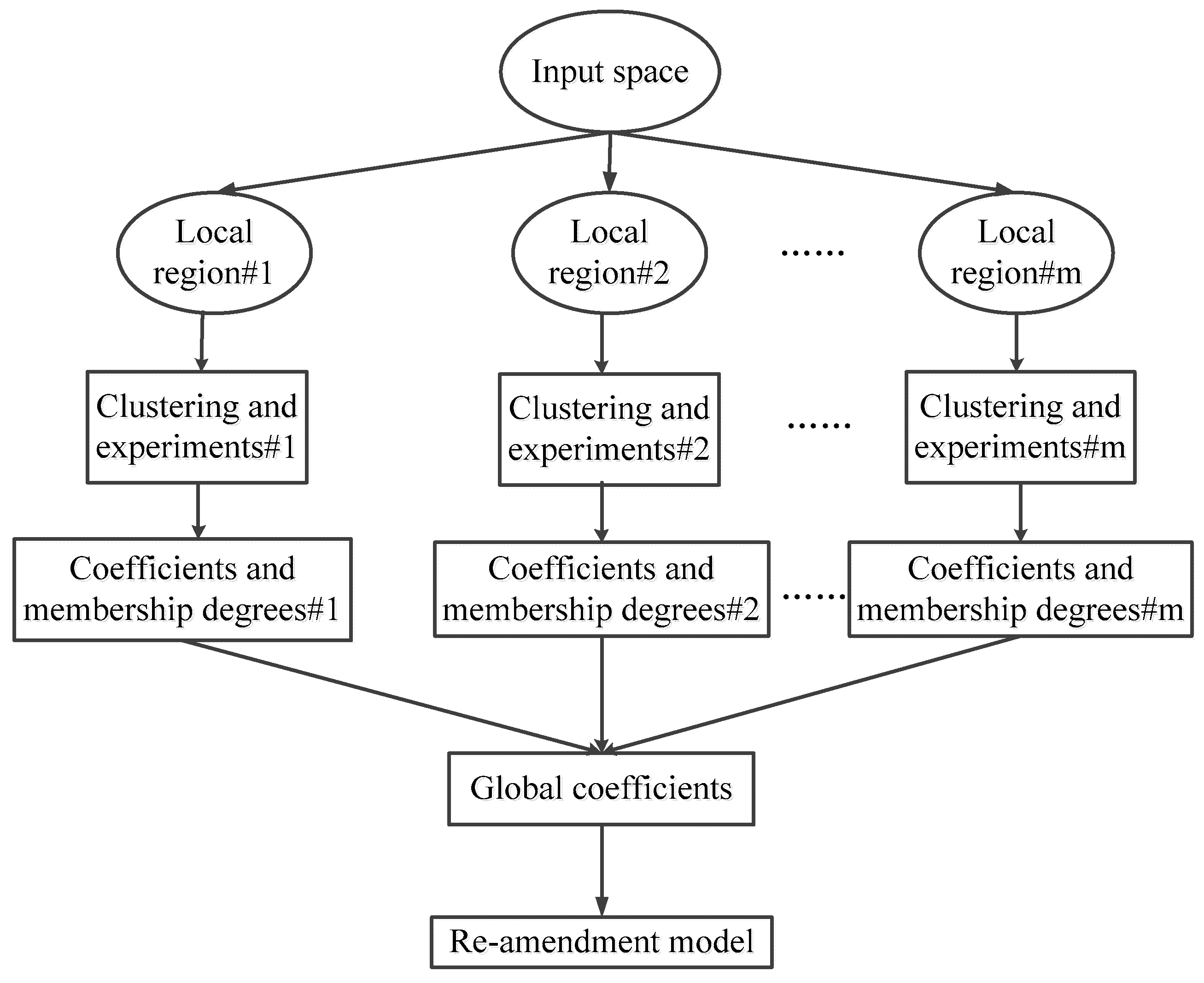
Figure 1 gives a diagram of the local model migration method, and the specific steps [34] are as follows:
- (1)
- Divide the input space into N equal parts, and each part forms a local region. Although the larger the N value, the higher the overall accuracy, it will be accompanied by an increasing burden of the calculation. Therefore, the amount of the local regions had better be moderate (typical 10–30).
- (2)
- Take each local region as a separate sample, and then use the clustering algorithm to generate cluster centers. However, a smaller cluster radius is selected for a deeper level of clustering in the computation of the probability of every data point into the cluster center, as shown in Equation (10) [34]:where rF is the new cluster radius, which is smaller than the previous radius. Moreover, to consider the influence of the edge points and ensure that the new cluster centers are far from the existing cluster centers, Equation (10) is further revised as follows [34]:where K stands for the number of existing cluster centers, M denotes the number of edge points, Ak and Am are the values of probabilities calculated by the Equation (10), and λm denotes the predicted error. The follow-up experiments are approximately the same as that shown in the previous Section 3.2. Next, we can obtain some experimental data. These experimental data consist of the corresponding experimental samples.
- (3)
- Train the coefficients of each region through the experimental data and the predicted value of the amendment model. The calculating process is the same as that shown in Section 3.3. Moreover, the coefficients of each region obtained by Equations (8) and (9) are defined as , and m stands for the amount of local regions.
- (4)
- Calculate the membership degree of each experimental sample to each local space. Thus, the global coefficient, G, is obtained by the weighted average of the membership degree according to the following formula:where is the membership degree between the local space and the experimental data sample.
- (5)
- Re-amend the amendment model with the global coefficient, and then output the re-amendment model calculated by Equation (7).
3.5. Test and Verify the Re-Amendment Model
The re-amendment model established through the overall migration and local migration requires a verification experiment to be performed. We can compare the prediction value with the actual value to validate the precision of the model by using some of the new process data that have not previously been used. If the verification fails, then repeat these previous steps. If the accuracy of the model meets the requirements, then this model is adequate for use.
4. Simulation and Verification
To validate this modeling method, we adopted a case study and compared the prediction values of the developed model with that of a mechanism model.
Limited to our present experimental conditions, the experimental data of the combustor were difficult to obtain, and the cost of the experiments was relatively high. Therefore, we adopted a mechanism model, which has been used by many authors including Billing, Ferri, and Curran, to generate simulation data as the experimental data in the model migration strategy. Meanwhile, the mechanism model can provide simulation validation for the re-amendment model of the new combustor.
The structural representation of existing combustors and the new combustor is shown in Figure 2. The outlet/inlet cross-sectional area ratios of existing combustors were selected to be 1.5, 2.4, and 3.0, and that of the new combustor was 2.0. In this case study, the existing combustors and the new combustor were different merely in two attributes (the outlet/inlet cross-sectional area and the fuel equivalent ratio of the inflow fluid); the other input attributes, such as the Maher number, static temperature, and static pressure, were assumed to be the same. The outlet/inlet cross-sectional area and the fuel equivalent ratio of the inflow fluid were regarded as the input variables. The total pressure of the outflow fluid and the total pressure recovery coefficient were chosen to be the output variables.
In our simulation case, every existing combustor had 200 data pairs and the mechanism model generated 200 data pairs for the new combustor. Overall, 12.5% of the total dataset of the existing combustors was randomly adopted to train the base model; just one data pair obtained from the new combustor was used in the overall migration, 20 data pairs of the new combustor were used in the local migration, and the remaining data pairs of the new combustor was used for validation. The loss function was mean square deviation while the network architecture was the BP (back propagation) neural network. Additionally, the simulation software was MATLAB.
4.1. Export the Total Pressure of the Outflow Fluid
In this simulation process, the total pressure of the outflow fluid is taken as the output variable. Figure 3a shows the three existing combustors.
First, 25 data pairs were randomly sampled from three existing combustors through the bagging algorithm [23,24,25,26]. Next, the base model was obtained through training the black-box model with these data pairs. The cluster estimation method grouped the existing data set into several cluster centers. The preliminary experiments of the new combustor were designed with the guidance of the cluster centers. Finally, we obtained the amendment model using the overall migration and the re-amendment model using the local migration.
Figure 3a shows the three existing combustors. The prediction results from the base model, the amendment model, and the re-amendment model were compared with the mechanism model in Figure 3b. As shown in Figure 3b, it is obvious that there are large differences between the base model and the mechanism model, but the two models have a similar trend. Compared with the base model, the amendment model has a higher precision. However, there are many offset points in the amendment model. The re-amendment model is closest to the mechanism model and has minimum offset points. This result proved that the re-amendment model can achieve very accurate prediction performance and can be used as the final model.
According to the characteristics of machine learning, we know that if the sum of the data set is larger, then the accuracy of the base model is higher. To examine the effect of the amount of the existing data set on the migration modeling process, we took the same simulation steps but used more of the data sets obtained from the existing combustors. Figure 4a shows the three existing combustors, and the simulation results are given in Figure 4b.
Comparing the simulation results in Figure 4b with those in Figure 3b, we find that using more data can reduce the shifting between the base model and the mechanism model but increase the number of edge points. Although using more data sets improves the prediction performance of the base model, the re-amendment model has similar prediction accuracy to that of the re-amendment developed in Figure 3b. However, it is more difficult to correct the edge points than it is to correct the shifting. Therefore, it is more economical to develop a base model with 25 sets of the existing combustor data.
4.2. Export the Total Pressure Recovery Coefficient
4.3. Discussion
By using the total pressure of the inflow fluid and the total pressure recovery coefficient as the input variables for the simulation, the results proved the reliability of the model migration strategy of the combustor, which is also less computation-intensive. Moreover, both the linear and nonlinear processes are valid. Furthermore, by comparing the performance of the models developed with 25 data sets with that of the models developed with 50 data sets, we found that it is more economical to develop a base model with approximately 25 sets of existing combustor data.
In summary, the model migration strategy developed in this paper can be well applied to model combustion processes and provides a more optimized case for the future design of the supersonic combustors. Last, but not least, the application is not limited to these parameters. Regarding more complex processes, they can also be written as data points in a higher dimension coordinate system. As the proposed modeling method only processes data points, the method remains valid for more complex processes. With this modeling method, the amount of data required for data-based modeling can be reduced, which is the significance of the paper. However, when the amount of data is too small to meet the minimum requirement of this modeling method, the methodology would be invalid.
5. Conclusions
Proposing a precise model for the combustor is a tough and high-costing but meaningful project. Therefore, this paper outlined a model migration strategy that makes full use of the data obtained from existing combustors and needs a few experiments. A systematic modeling method, containing the development of a base model, preliminary experiments of the new combustor, overall migration and local migration, was developed. For the simulation case in which the new combustor was a shift and re-scale of the existing combustors, the re-amendment model was developed by the model migration strategy, using less data than that required for developing a traditional data-based model. The results verify this proposed modeling method is valid.
Author Contributions
Conceptualization, T.C.; methodology, Y.O.; writing—original draft preparation, Y.O.
Funding
This research was funded by the National Natural Science Foundation of China (Grant No. 91541106).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Oevermann, M. Numerical investigation of turbulent hydrogen combustion in a scramjet using flamelet modeling. Aerosp. Sci. Technol. 2000, 4, 463–480. [Google Scholar] [CrossRef]
- Dharavath, M.; Manna, P.; Chakraborty, D. Thermochemical exploration of hydrogen combustion in generic scramjet combustor. Aerosp. Sci. Technol. 2013, 24, 264–274. [Google Scholar] [CrossRef]
- Shin, J.; Sung, H.G. Combustion characteristics of hydrogen and cracked kerosene in a dlr scramjet combustor using hybrid rans/les method. Aerosp. Sci. Technol. 2018, 80, 433–444. [Google Scholar] [CrossRef]
- Kim, J.W.; Kwon, O.J. Modeling of incomplete combustion in a scramjet engine. Aerosp. Sci. Technol. 2018, 78, 397–402. [Google Scholar] [CrossRef]
- Rezaeiravesh, S.; Vinuesa, R.; Liefvendahl, M.; Schlatter, P. Assessment of uncertainties in hot-wire anemometry and oil-film interferometry measurements for wall-bounded turbulent flows. Eur. J. Mech. B Fluids 2018, 72, 57–73. [Google Scholar] [CrossRef] [Green Version]
- Vinuesa, R.; Hosseini, S.M.; Hanifi, A.; Henningson, D.S.; Schlatter, P. Pressure-gradient turbulent boundary layers developing around a wing section. Flow Turbul. Combust 2017, 99, 613–641. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Zhu, J.; Sun, M.; Wang, Z. Effect of cavity fueling schemes on the laser-induced plasma ignition process in a scramjet combustor. Aerosp. Sci. Technol. 2018, 78, 197–204. [Google Scholar] [CrossRef]
- Tsujikawa, Y.; Northam, G.B. Effects of hydrogen active cooling on scramjet engine performance. Int. J. Hydrogen Energy 1996, 21, 299–304. [Google Scholar] [CrossRef]
- Choubey, G.; Pandey, K.M. Effect of variation of angle of attack on the performance of two-strut scramjet combustor. Int. J. Hydrogen Energy 2016, 41, 11455–11470. [Google Scholar] [CrossRef]
- Curran, E.T. Scramjet engines: The first forty years. J. Propuls. Power 2001, 17, 1138–1148. [Google Scholar] [CrossRef]
- Ogawa, H.; Capra, B.; Lorain, P. Numerical investigation of upstream fuel injection through porous media for scramjet engines via surrogate-assisted evolutionary algorithms. In Proceedings of the Aiaa Aerospace Sciences Meeting, Kissimmee, FL, USA, 5–9 January 2015. [Google Scholar]
- Billig, F.S. Design of supersonic combustors based on pressure-area fields. Symp. Combust. 1967, 11, 755–769. [Google Scholar] [CrossRef]
- Timothy, F.O.; Brien; Starkey, R.P.; Lewis, M.J. Quasi-one-dimensional high-speed engine model with finite-rate chemistry. J. Propuls. Power 2001, 17, 1366–1374. [Google Scholar]
- Xiao, B.; Xing, J.; Tian, Y.; Wang, X. Experimental and numerical investigations of combustion mode transition in a direct–connect scramjet combustor. Aerosp. Sci. Technol. 2015, 46, 331–338. [Google Scholar] [CrossRef]
- Vanyai, T.; Bricalli, M.; Brieschenk, S.; Boyce, R.R. Scramjet performance for ideal combustion processes. Aerosp. Sci. Technol. 2018, 75, 215–226. [Google Scholar] [CrossRef]
- Sarkar, S.; Chakravarthy, S.R.; Ramanan, V.; Ray, A. Dynamic data-driven prediction of instability in a swirl-stabilized combustor. Int. J. Spray Combust. Dyn. 2016, 8. [Google Scholar] [CrossRef]
- Held, T.; Mueller, M.; Li, S.; Mongia, H. A data-driven model for no(x), co and uhc emissions for a dry low emissions gas turbine combustor. In Proceedings of the Joint Propulsion Conference and Exhibit, San Jose, CA, USA, 15–17 July 2013. [Google Scholar]
- Charles, R.E.; Samuelsen, G.S. An experimental data base for the computational fluid dynamics of combustors. J. Eng. Gas Turbines Power 1989, 111, 11–14. [Google Scholar] [CrossRef]
- Ling, J.; Ruiz, A.; Lacaze, G.; Oefelein, J. Uncertainty analysis and data-driven model advances for a jet-in-crossflow. In Proceedings of the ASME Turbo Expo 2016: Turbomachinery Technical Conference and Exposition, Coex, Seoul, Korea, 13–17 June 2016; p. 05. [Google Scholar]
- Tucki, K.; Mruk, R.; Orynycz, O.; Botwińska, K.; Gola, A.; Bączyk, A. Toxicity of exhaust fumes (co, nox) of the compression-ignition (diesel) engine with the use of simulation. Sustainability 2019, 11, 2188. [Google Scholar] [CrossRef]
- Tucki, K.; Mruk, R.; Orynycz, O.; Wasiak, A.; Botwińska, K.; Gola, A. Simulation of the operation of a spark ignition engine fueled with various biofuels and its contribution to technology management. Sustainability 2019, 11, 2799. [Google Scholar] [CrossRef]
- Chu, F.; Dai, B.; Dai, W.; Jia, R.; Ma, X.; Wang, F. Rapid modeling method for performance prediction of centrifugal compressor based on model migration and svm. IEEE Access 2017, 5, 21488–21496. [Google Scholar] [CrossRef]
- Lu, J.; Yao, K.; Gao, F. Process similarity and developing new process models through migration. Aiche J. 2009, 55, 2318–2328. [Google Scholar] [CrossRef]
- Lu, J.; Gao, F. Process modeling based on process similarity. IFAC Proc. Vol. 2010, 40, 379–384. [Google Scholar] [CrossRef]
- Lu, J.; Gao, F. Model migration with inclusive similarity for development of a new process model. Ind. Eng. Chem. Res. 2008, 47, 9508–9516. [Google Scholar] [CrossRef]
- Lu, J.; Yuan, Y.; Gao, F. Model migration for development of a new process model. Ind. Eng. Chem. Res. 2009, 48, 9603–9610. [Google Scholar] [CrossRef]
- Luo, L.; Yuan, Y.; Gao, F. Iterative improvement of parameter estimation for model migration by means of sequential experiments. Comput. Chem. Eng. 2015, 73, 128–140. [Google Scholar] [CrossRef]
- Luo, L.; Yao, Y.; Gao, F. Cost-effective process modeling and optimization methodology assisted by robust migration techniques. Ind. Eng. Chem. Res. 2015, 54, 150507154215008. [Google Scholar] [CrossRef]
- Zhu, S.; Thool, R.C. Intrusion detection based on bp neural network and bagging method. Comput. Eng. Appl. 2009, 45, 123–124. [Google Scholar]
- Li, F.G.; Fan, J.L.; Wang, L.; Zhang, H.L.; Duan, R. A method based on manifold learning and bagging for text classificatio. In Proceedings of the International Conference on Artificial Intelligence, Management Science and Electronic Commerce, Zhengzhou, China, 8–10 August 2011; pp. 2713–2716. [Google Scholar]
- Li, Y. Ensemble Modeling Method Based on Bagging Algorithm and Gaussian Process; Journal of Southeast University; Southeast University: Nanjing, China, 2011. [Google Scholar]
- Shu-Ying, D. The research on clustering algorithm for large datasets. Comput. Eng. Softw. 2016, 1, 24. [Google Scholar]
- Gong, M.G.; Wang, S.; Meng, M.A.; Yu, C.; Jiao, L.C.; Wen-Ping, M.A. Two-phase clustering algorithm for complex distributed data. J. Softw. 2011, 22, 2760–2772. [Google Scholar] [CrossRef]
- Cheng, F. Process Modeling Based on Migration; Northeastern University: Nanjing, China, 2013. (In Chinese) [Google Scholar]
Figure 1.
Local migration principle diagram.

Figure 2.
Structural representation of the existing combustors and the new combustor.

Figure 3.
Simulation of the total pressure of the outflow fluid with 25 data pairs. (a) existing combustors; (b) simulation of the new combustor.
Figure 3.
Simulation of the total pressure of the outflow fluid with 25 data pairs. (a) existing combustors; (b) simulation of the new combustor.

Figure 4.
Simulation of the total pressure of the outflow fluid with 50 data pairs. (a) existing combustors; (b) simulation of the new combustor.
Figure 4.
Simulation of the total pressure of the outflow fluid with 50 data pairs. (a) existing combustors; (b) simulation of the new combustor.

Figure 5.
Simulation of the total pressure of the total pressure recovery coefficient. (a) existing combustors; (b) simulation of the new combustor.
Figure 5.
Simulation of the total pressure of the total pressure recovery coefficient. (a) existing combustors; (b) simulation of the new combustor.

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Cui, T.; Ou, Y. Modeling of Scramjet Combustors Based on Model Migration and Process Similarity. Energies 2019, 12, 2516. https://doi.org/10.3390/en12132516
AMA Style
Cui T, Ou Y. Modeling of Scramjet Combustors Based on Model Migration and Process Similarity. Energies. 2019; 12(13):2516. https://doi.org/10.3390/en12132516
Chicago/Turabian StyleCui, Tao, and Yang Ou. 2019. "Modeling of Scramjet Combustors Based on Model Migration and Process Similarity" Energies 12, no. 13: 2516. https://doi.org/10.3390/en12132516
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.